





































































































































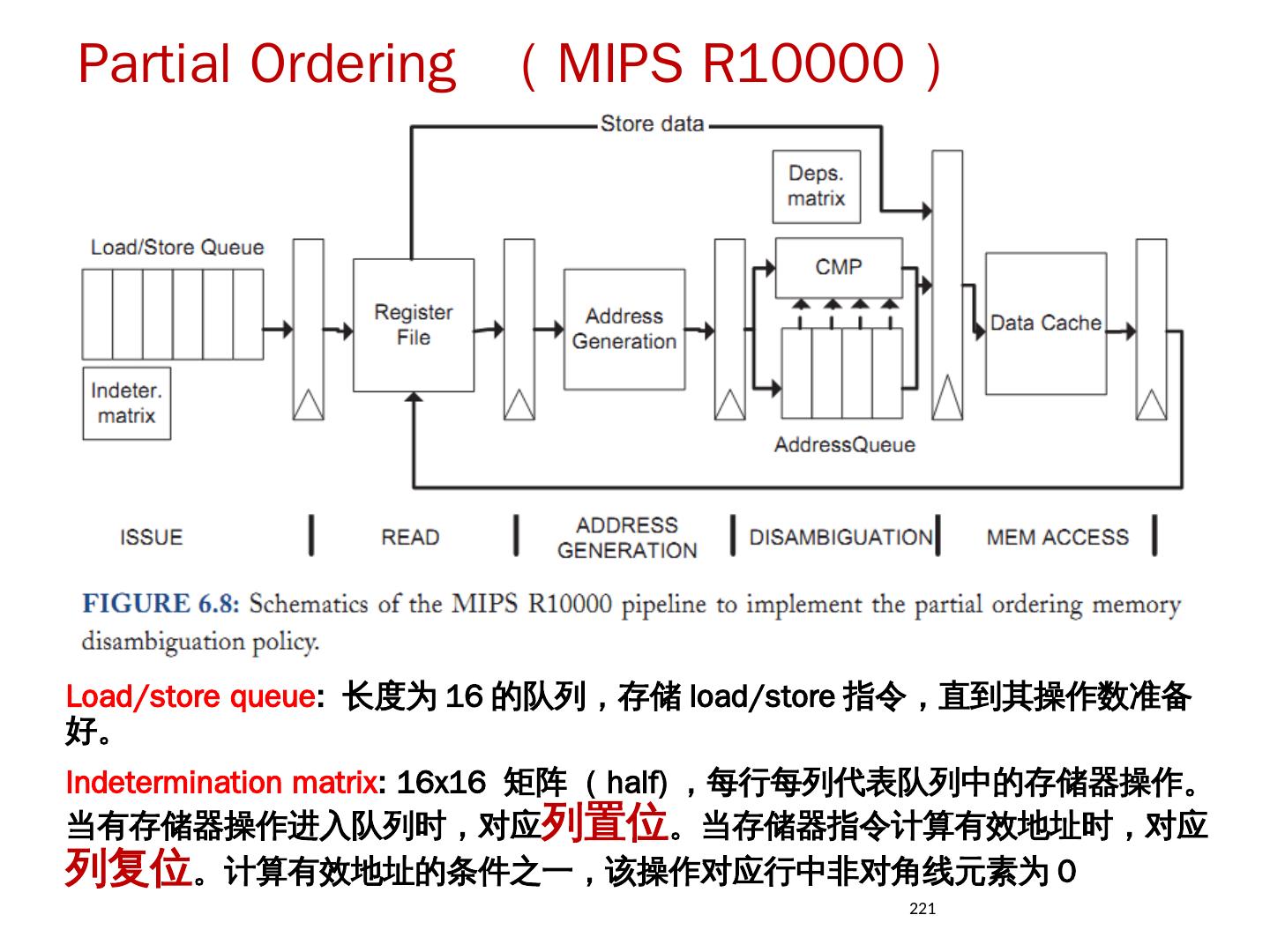

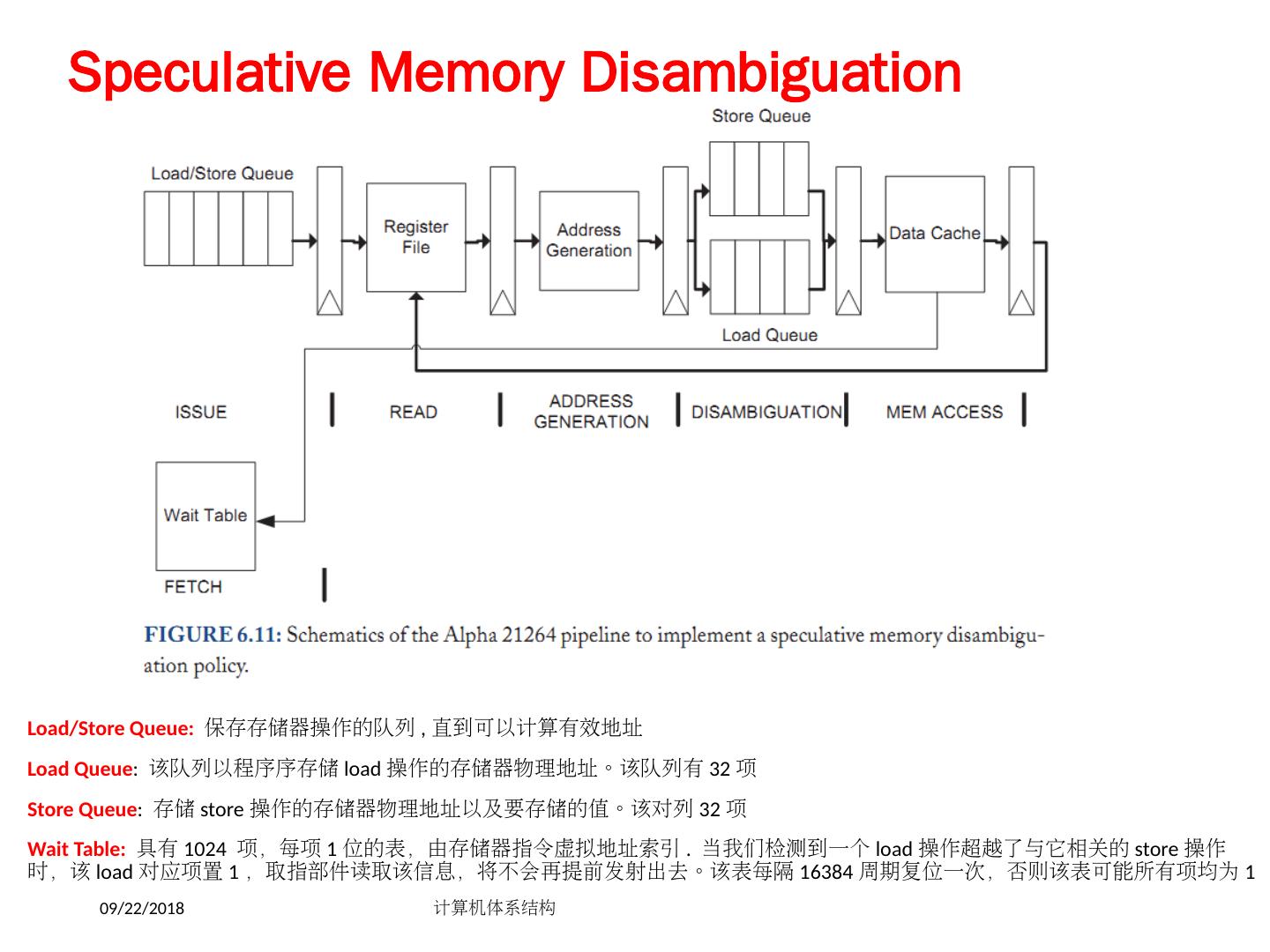
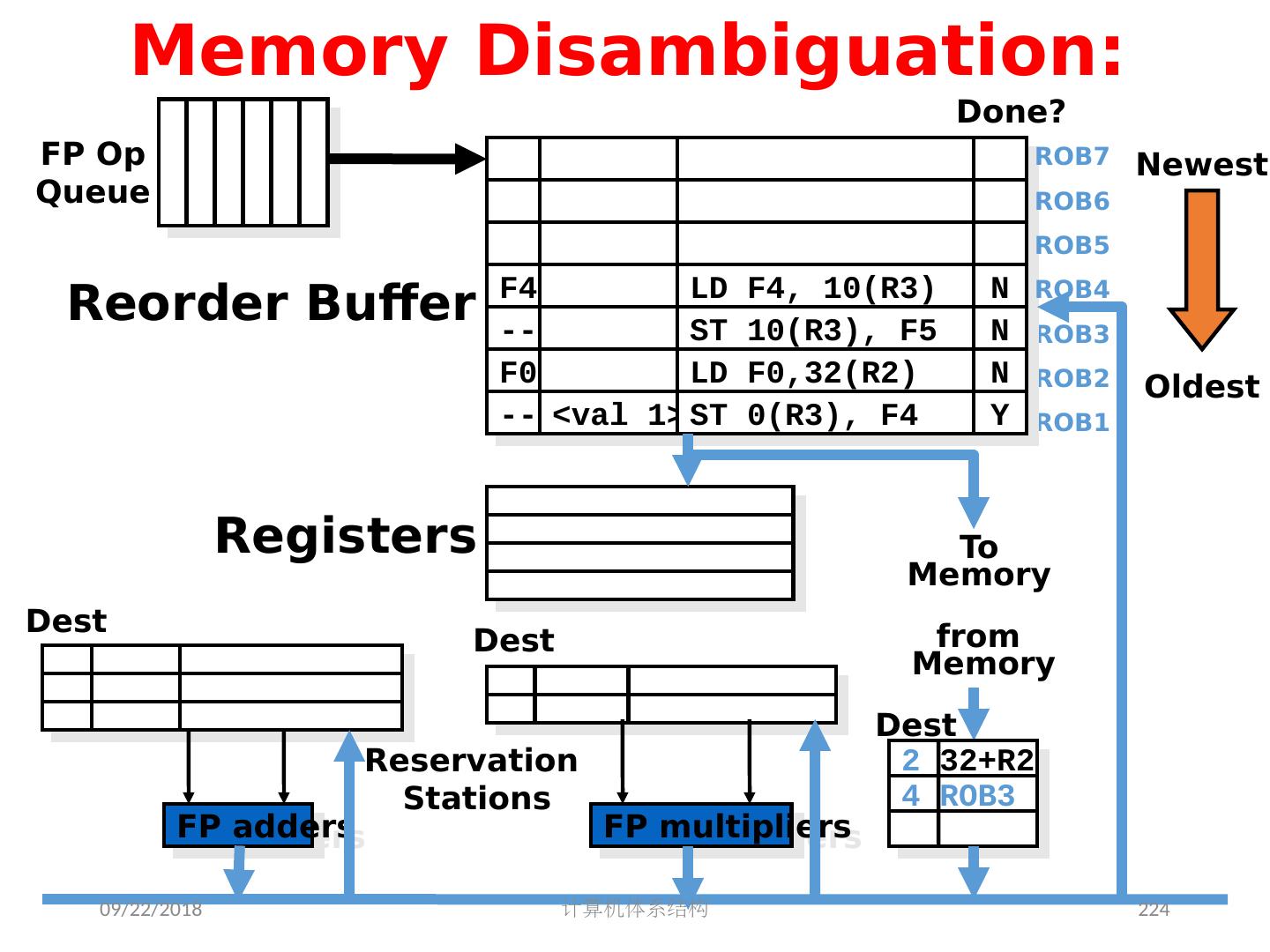





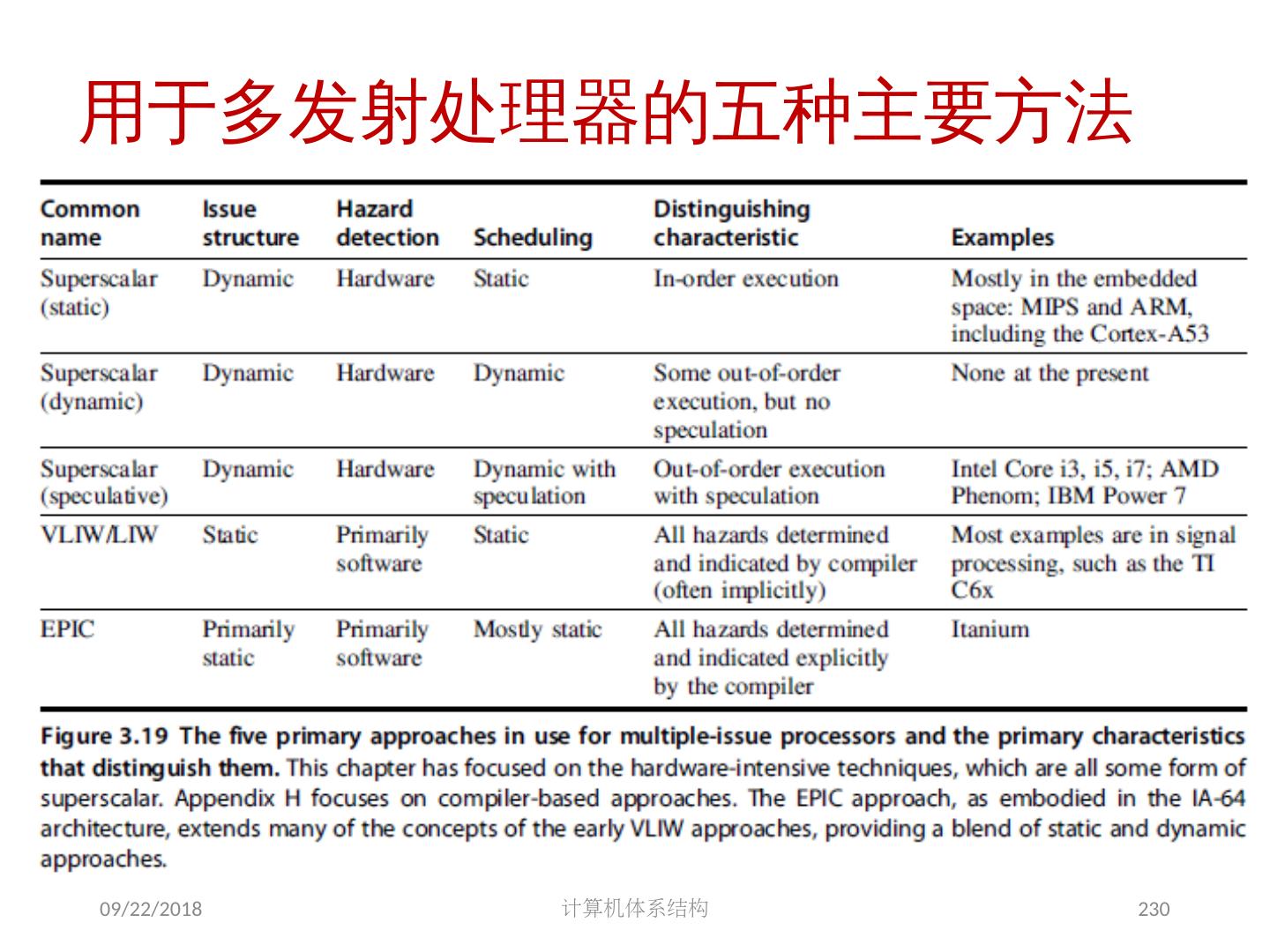





































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
05 计算机体系结构--指令级并行
这一节是中国科学技术大学周学海教授所讲授的计算机体系结构中的指令级并行部分。这一节的主要内容有:指令集并行的基本概念及挑战;软件方法挖掘指令集并行;基本块内的指令集并行;硬件方法挖掘指令集并行;Scoreboard;Tomasulo;跨越基本块的指令集并行;基于硬件的推测执行;以多发射和静态调度来挖掘指令集并行;以动态调度、多发射和推测执行来挖掘指令集并行。
展开查看详情
1 .计算机体系结构 周学海 xhzhou@ustc.edu.cn 0551-63606864 中国科学技术大学
2 .04/16-review 存储器组织 存储系统结构 2018/5/14 计算机体系结构 2 参考文献 Davis, B. T. (2001). Modern dram architectures, University of Michigan : 221. Jacob, B. (2009). The Memory System , Morgan & Claypool.
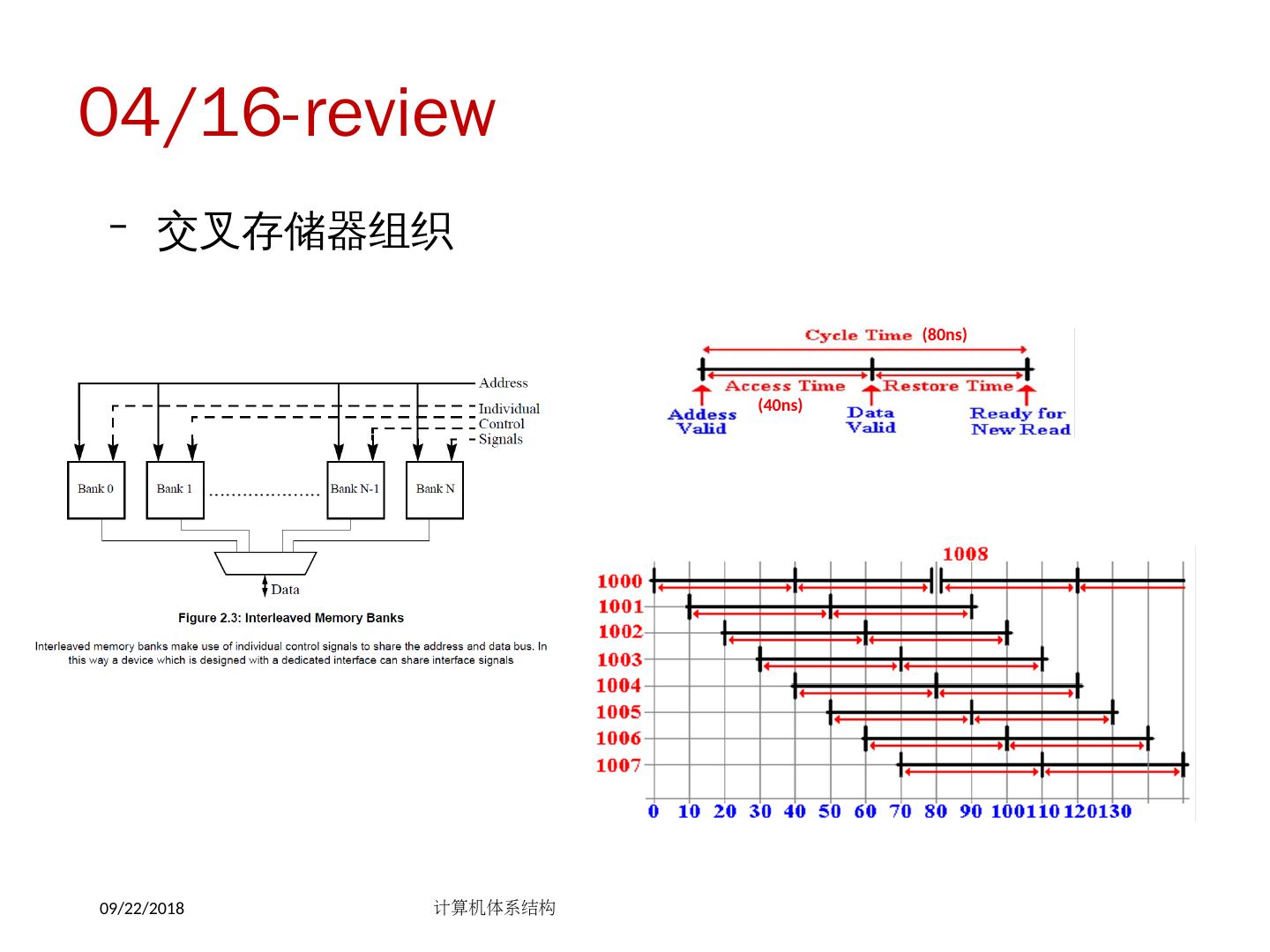
3 .04/16-review 交叉存储器组织 2018/5/14 计算机体系结构 (80ns) (40ns)
4 .04/16-review 虚拟存储 解决的问题: 4Q 映象规则:由于失效开销很大,一般选择低失效率方法,即全相联映射 查找算法-用附加数据结构( VPN -> PPN ) 固定页大小-用页表 可变长段 -段表 替换规则: LRU 写策略:总是用写回法,因为访问硬盘速度很慢。 2018/5/14 计算机体系结构 4
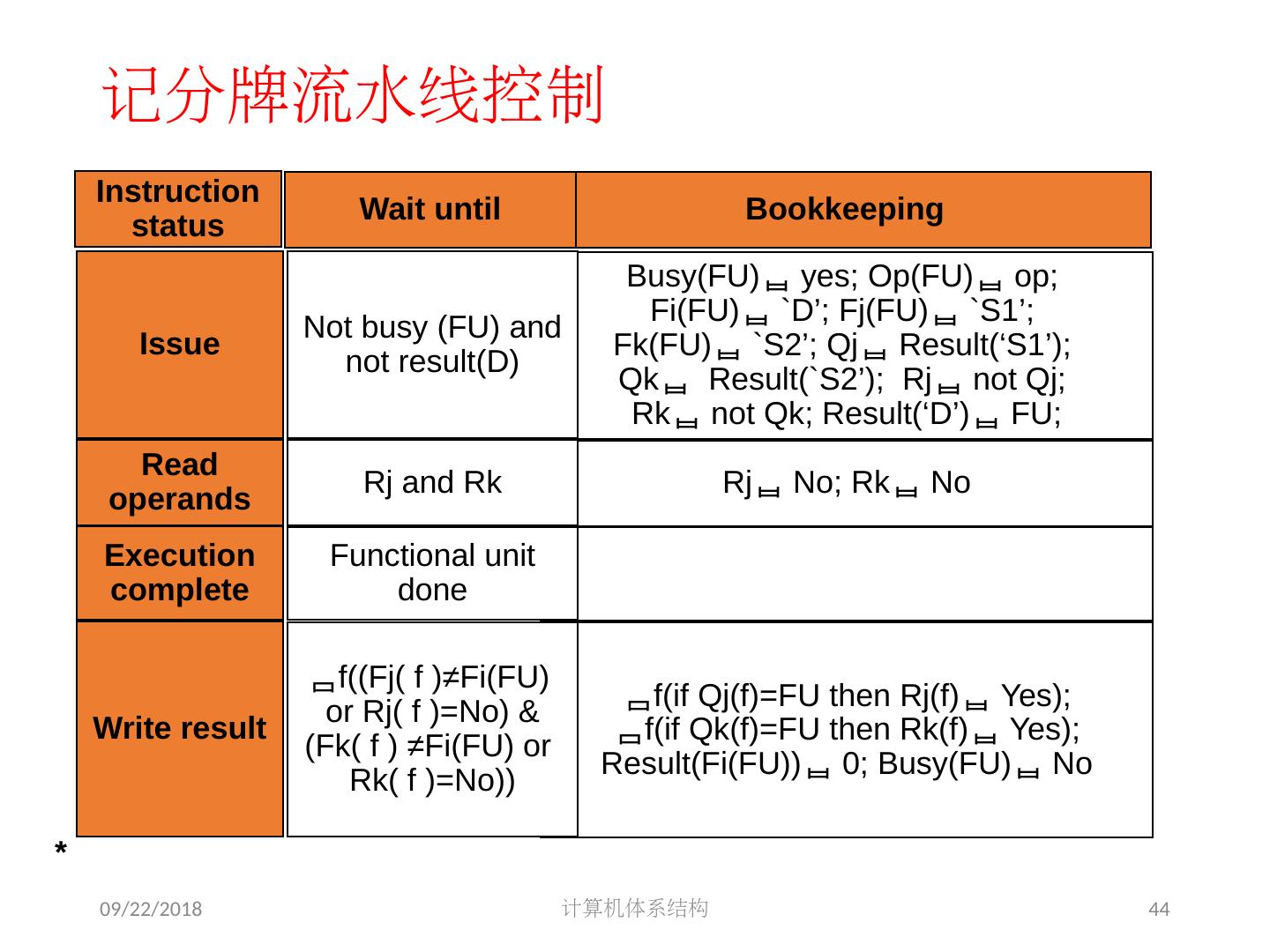
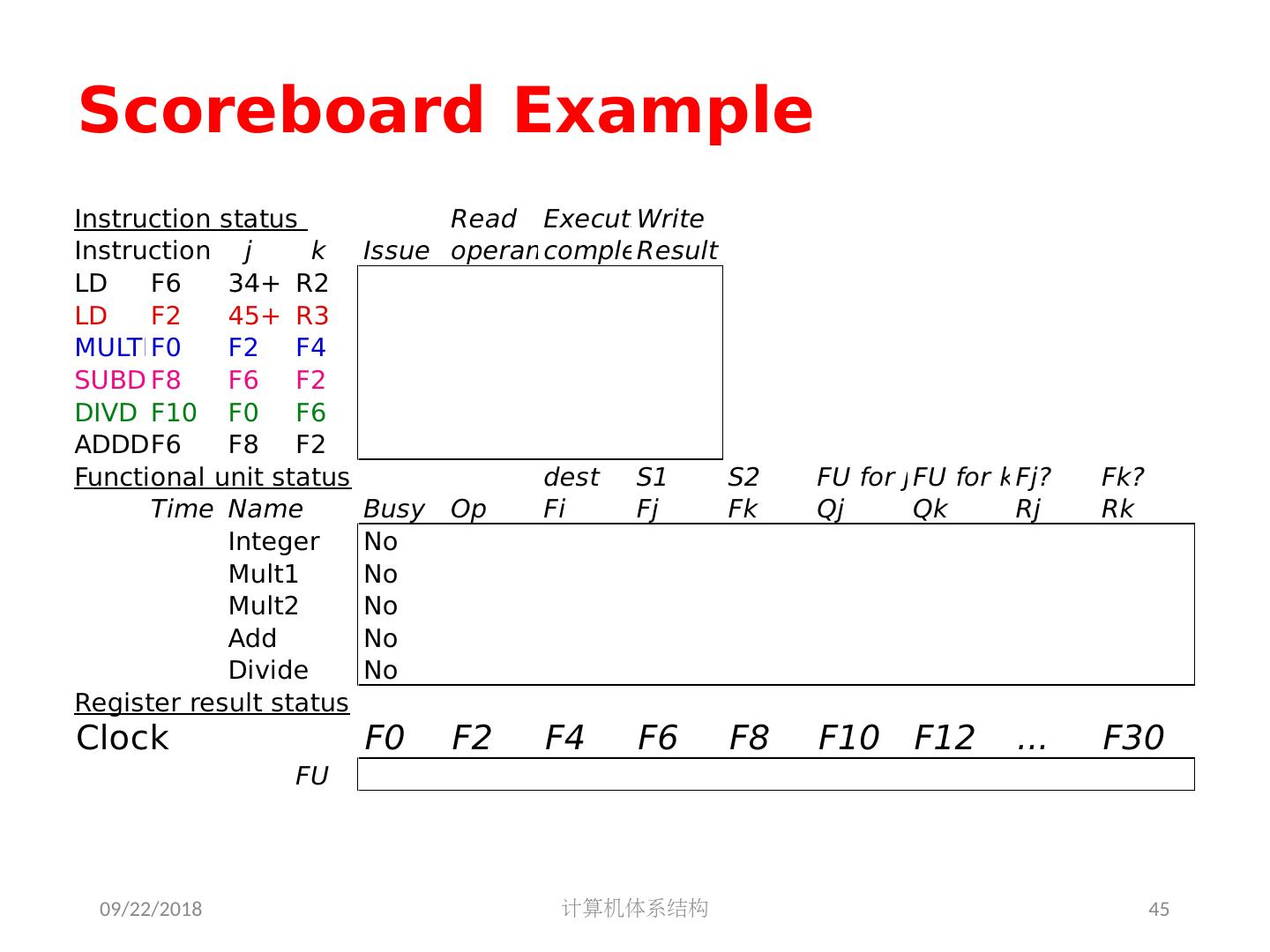
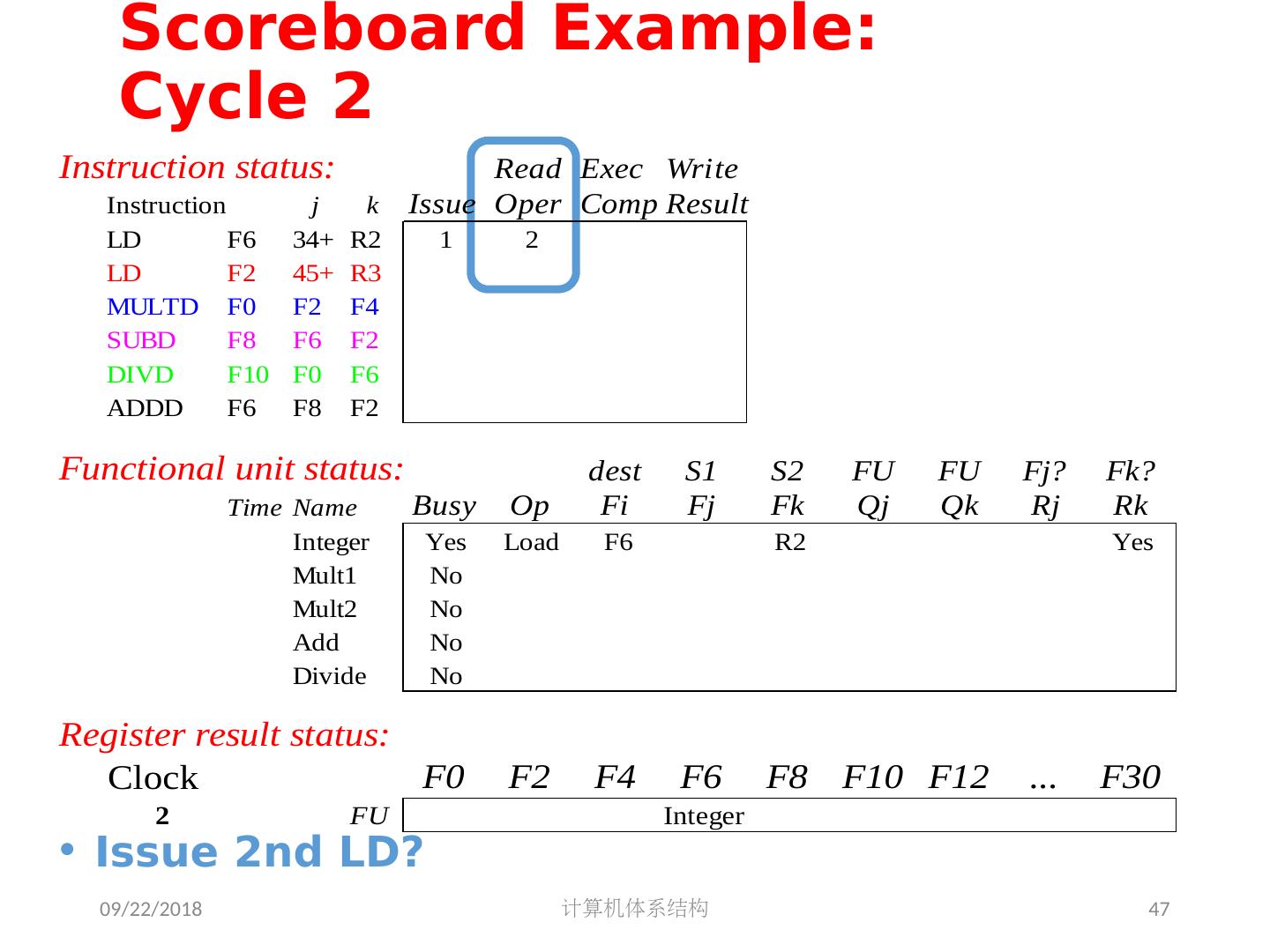
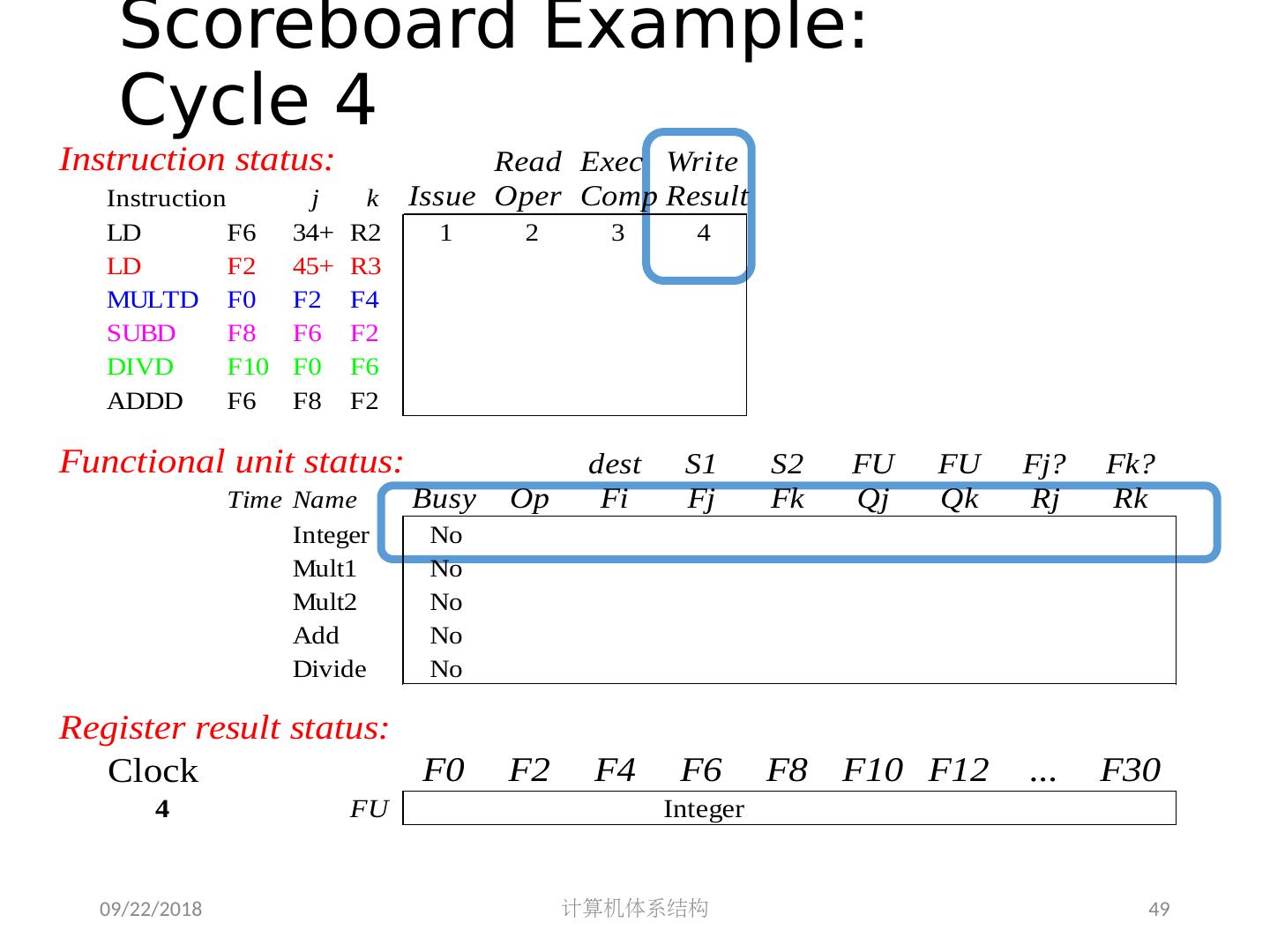
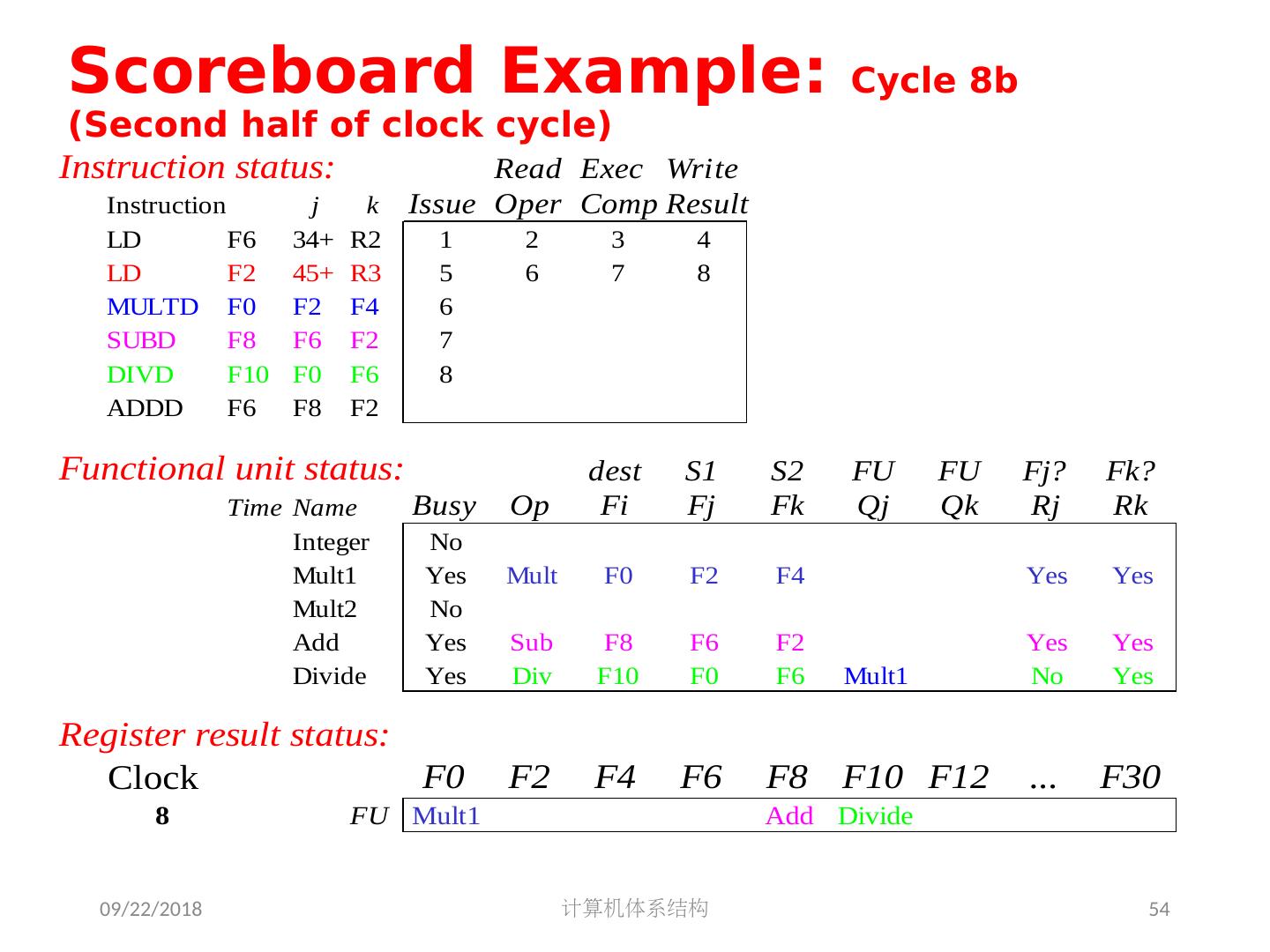
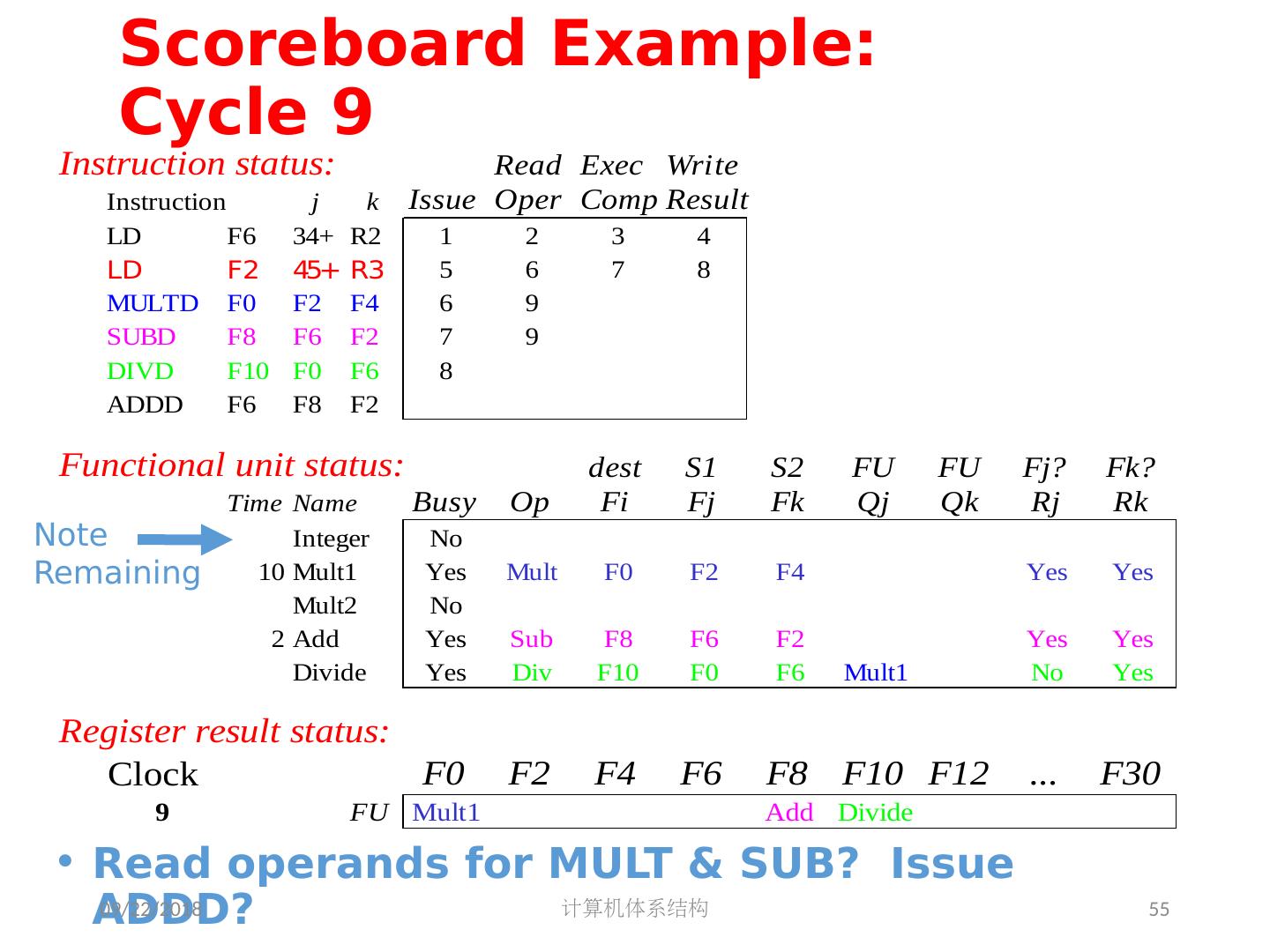
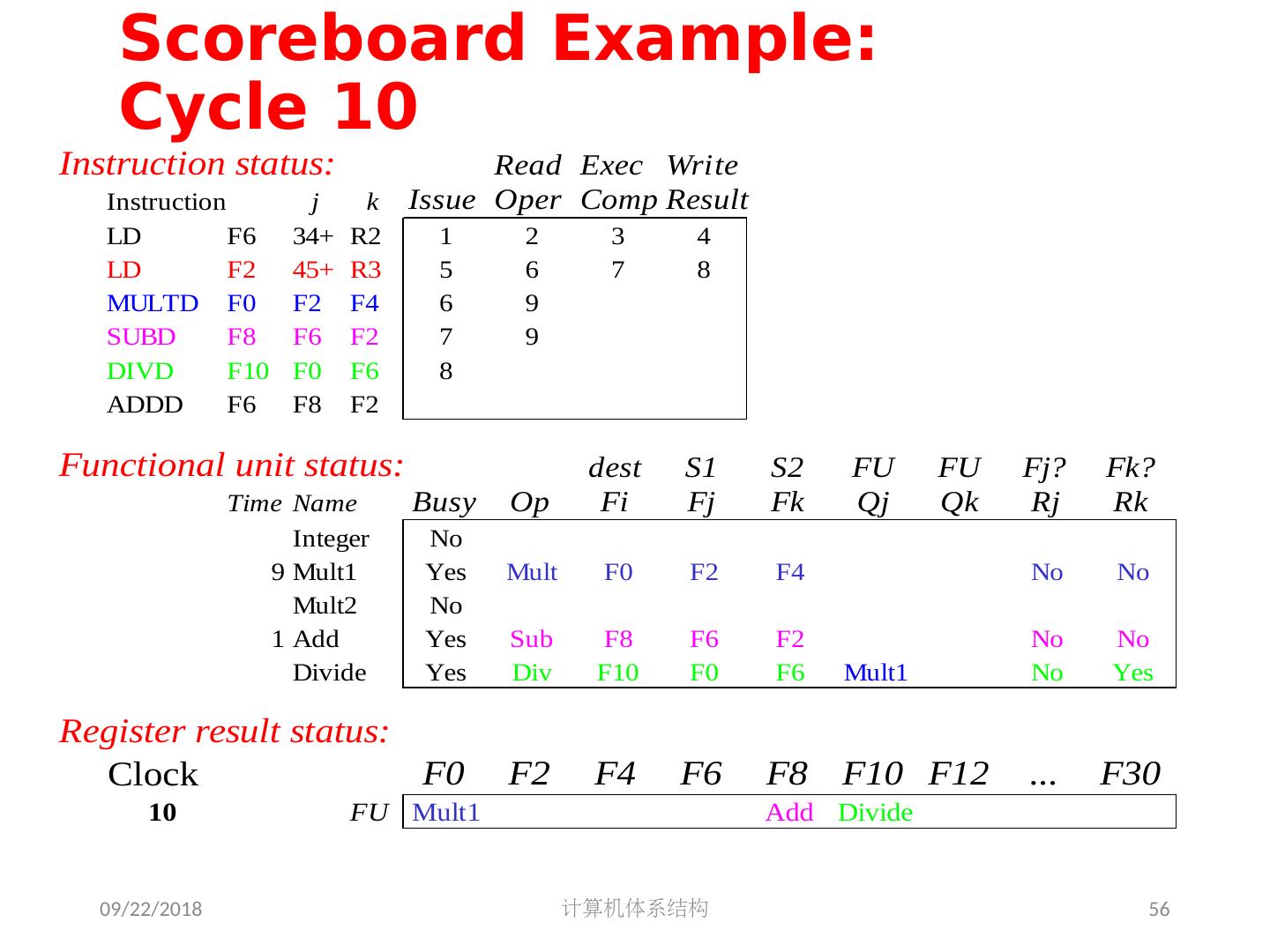
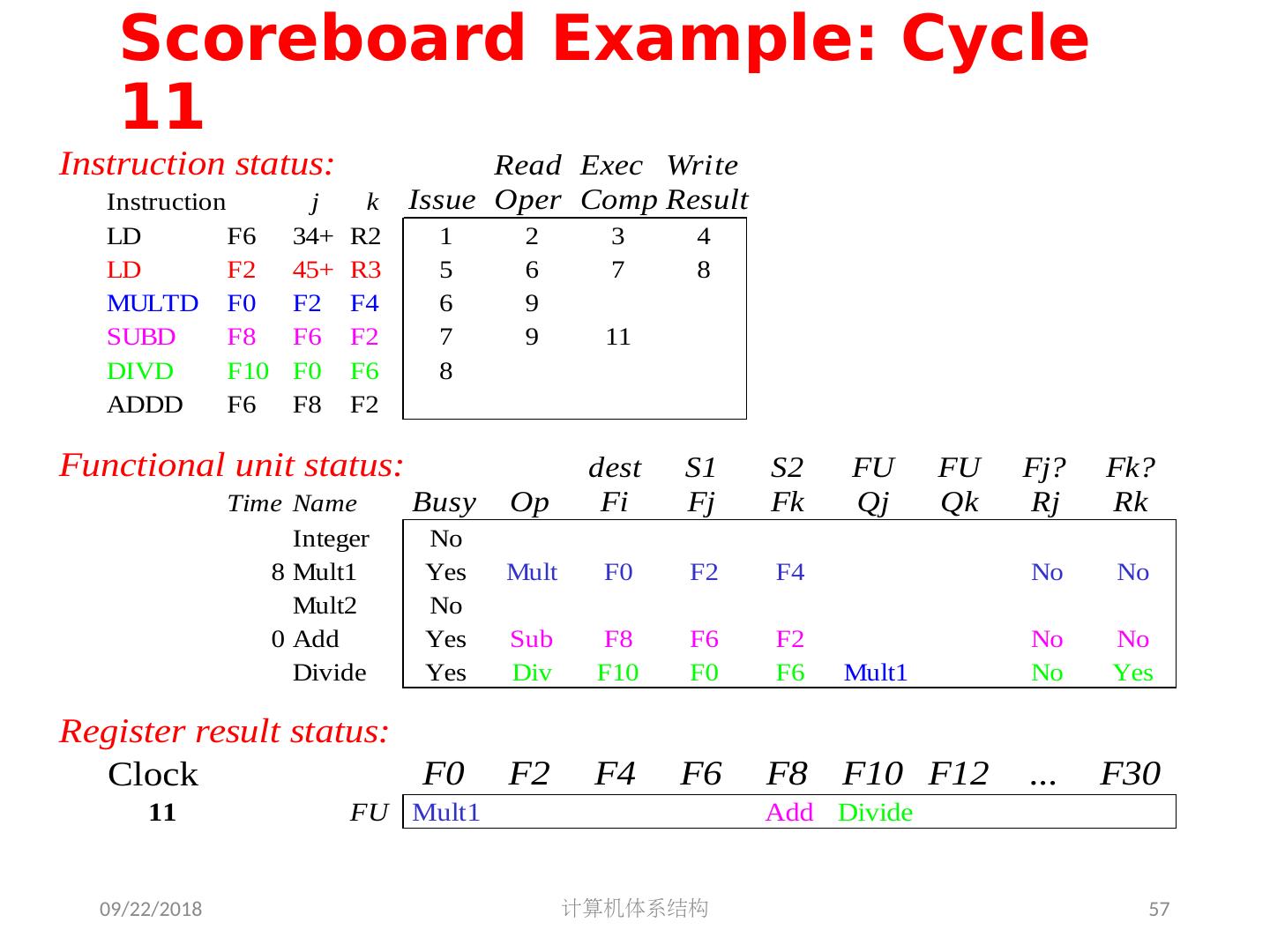
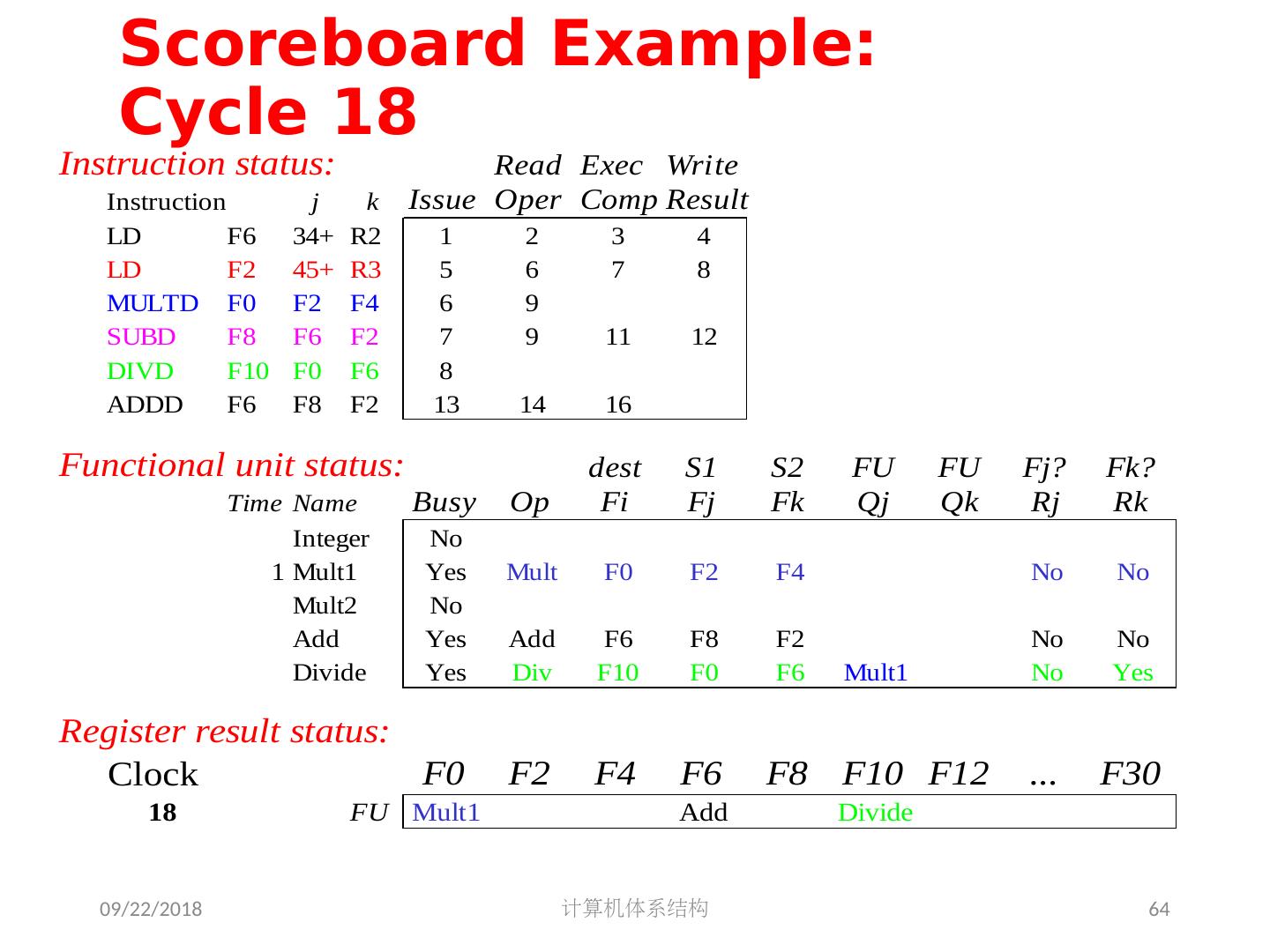
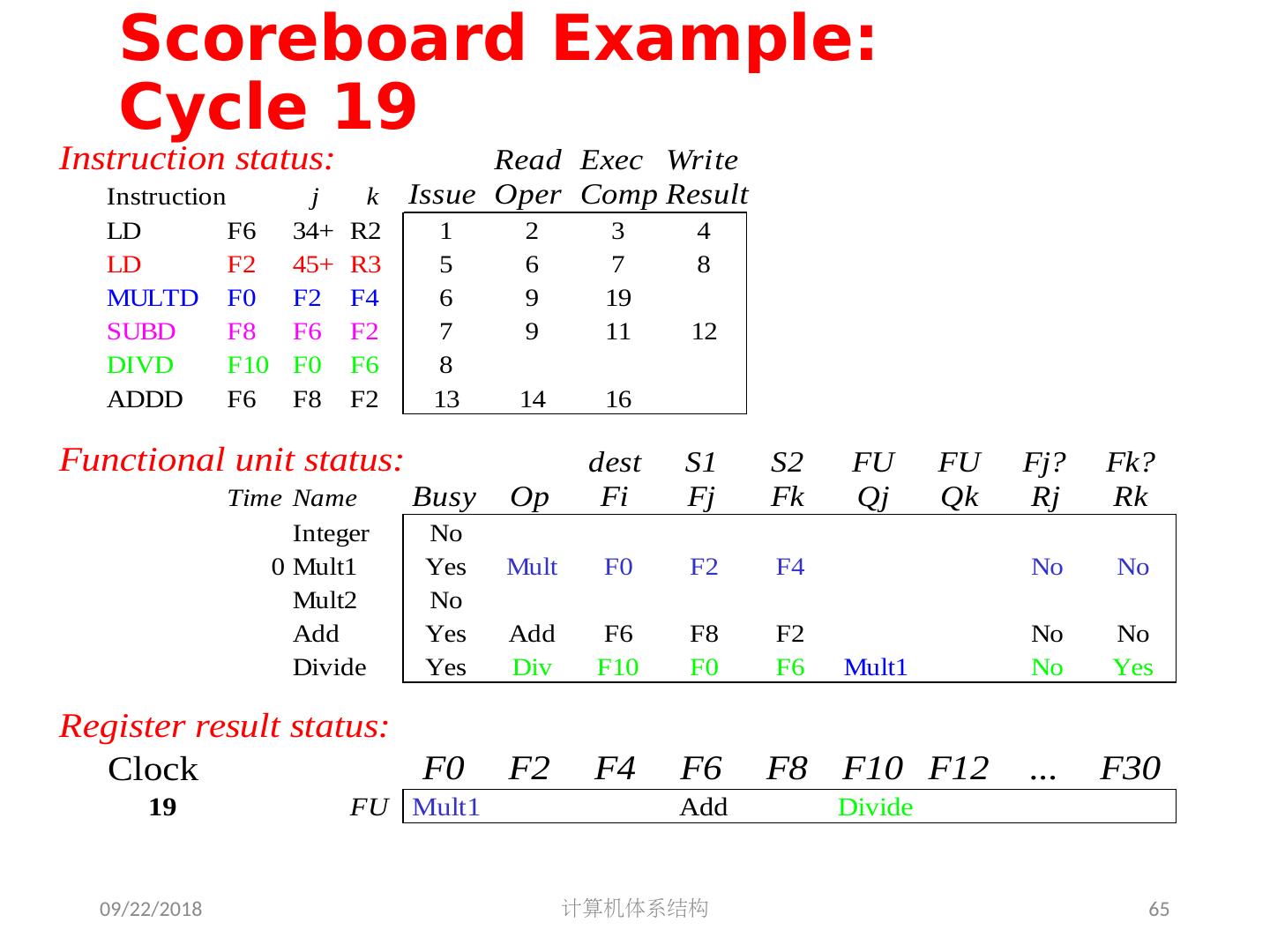
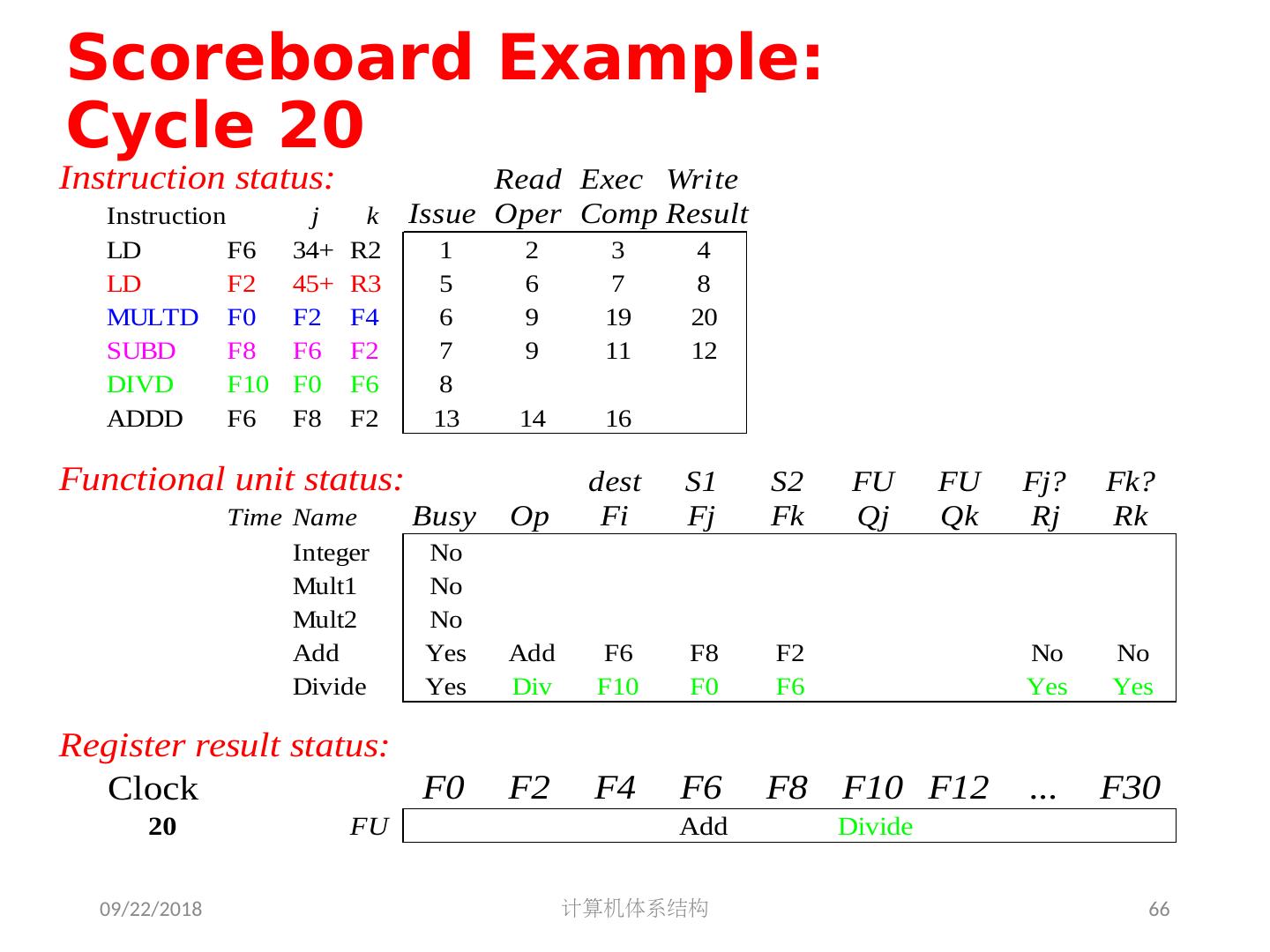
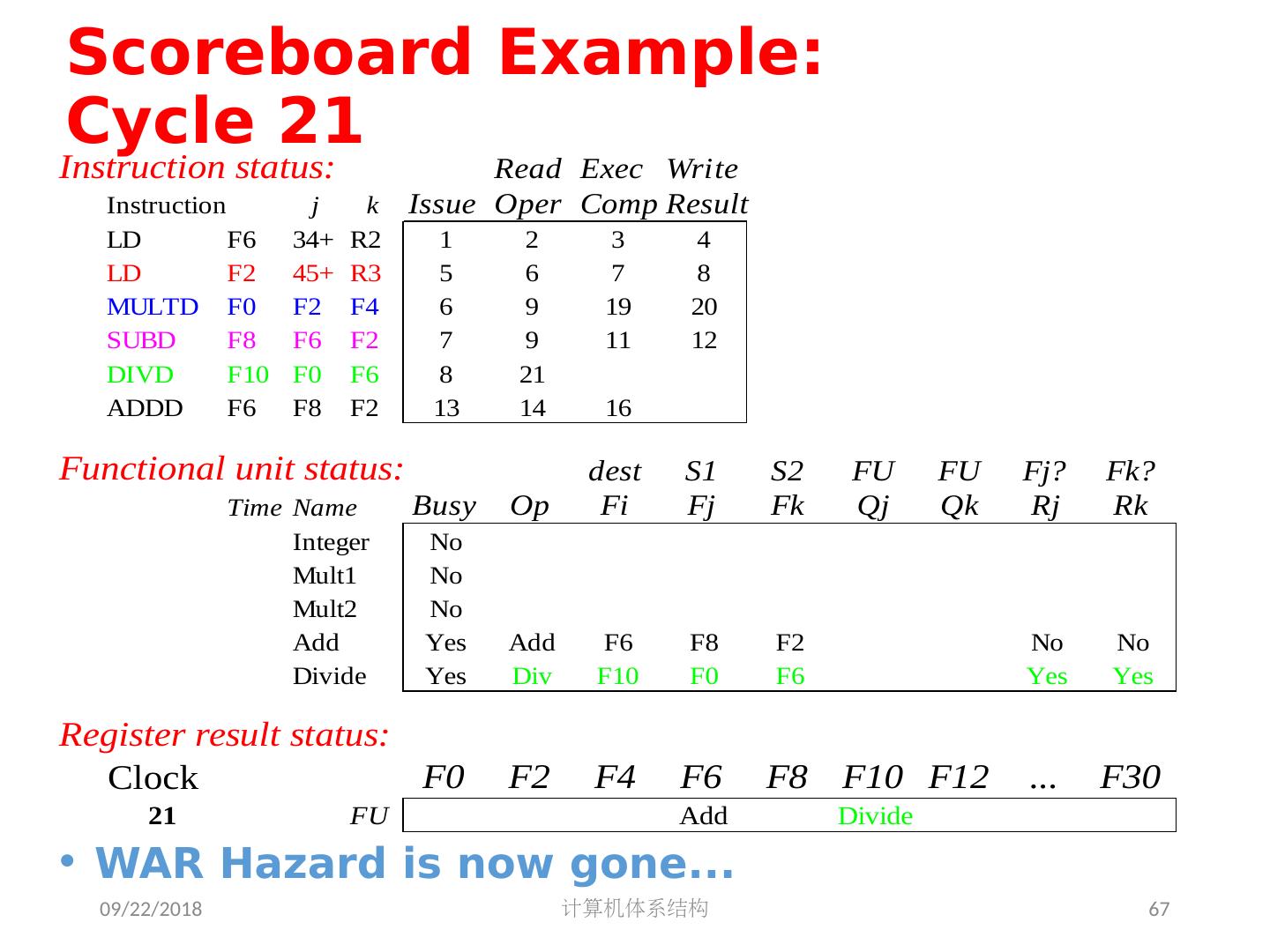
5 .2018/5/14 计算机体系结构 5 第 5 章 指令级并行 指令集并行的基本概念及挑战 软件方法挖掘指令集并行 基本块内的指令集并行 硬件方法挖掘指令集并行 Scoreboard Tomasulo 跨越基本块的指令集并行 基于硬件的推测执行 以多发射和静态调度来挖掘指令集并行 以动态调度、多发射和推测执行来挖掘指令集并行
6 .系统结构的 Flynn 分类 (1966) SISD: Single instruction stream, single data stream 单处理器模式 SIMD: Single instruction stream, multiple data streams 相同的指令作用在不同的数据 可用来挖掘数据级并行 (Data Level Parallelism) 如: Vector processors, SIMD instructions, and Graphics processing units MISD: Multiple instruction streams, single data stream No commercial implementation MIMD: Multiple instruction streams, multiple data streams 通用性最强的一种结构,可用来挖掘线程级并行、数据级并行 ….. 组织方式可以是松耦合方式也可以是紧耦合方式 2018/5/14 计算机体系结构 6
7 .Levels of Parallelism 请求级并行 多个任务可被分配到多个计算机上并行执行 进程级并行 进程可被调度到不同的处理器上并行执行 线程级并行 任务被组织成多个线程,多个线程共享一个进程的地址空间 每个线程有自己独立的程序计数器和寄存器文件 数据级并行 单线程(逻辑上)中并行处理多个数据 (SIMD/Vector execution) 一个程序计数器 , 多个执行部件 指令级并行 针对单一指令流,多个执行部件并行执行不同的指令 2018/5/14 计算机体系结构 7
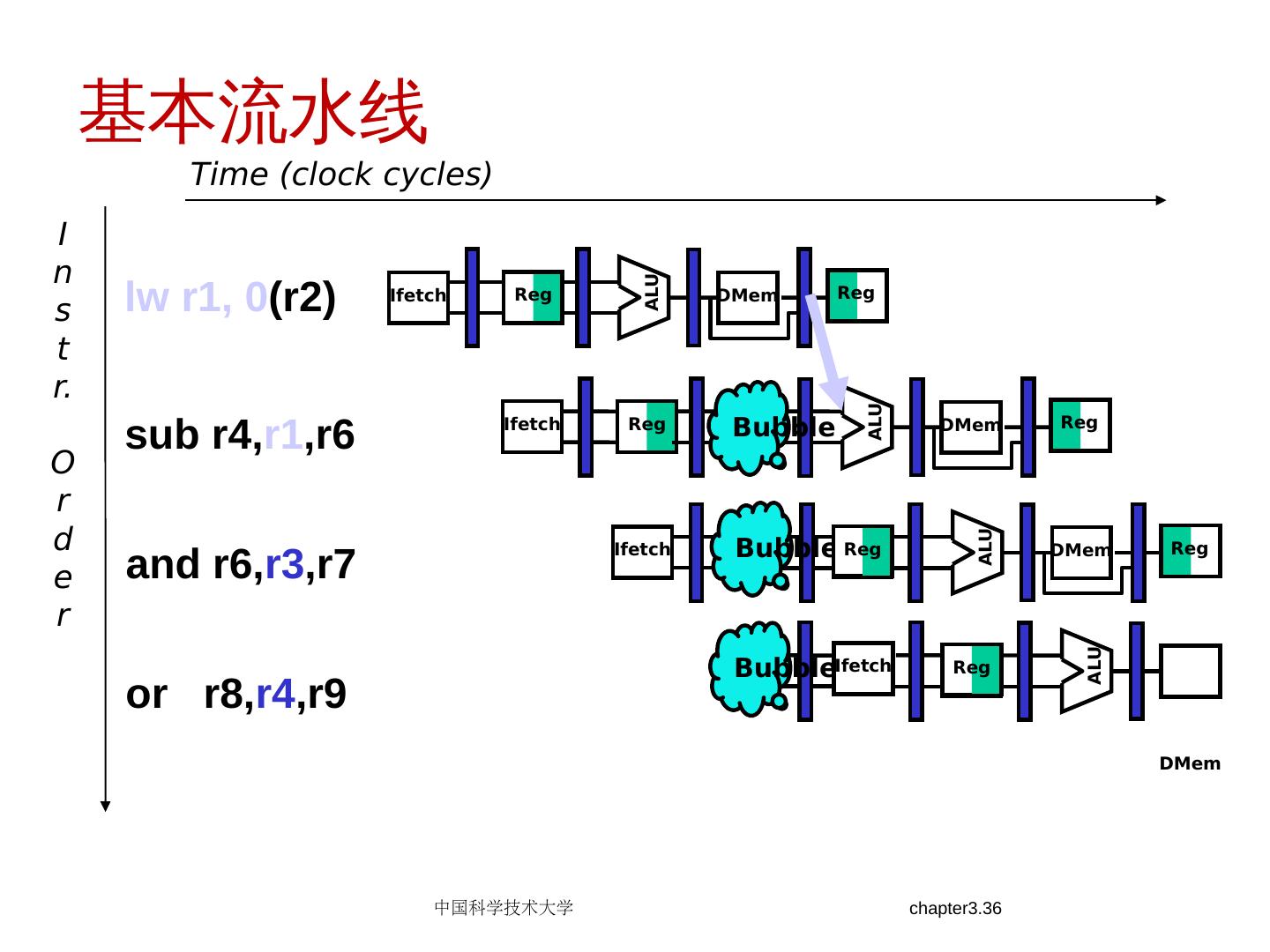
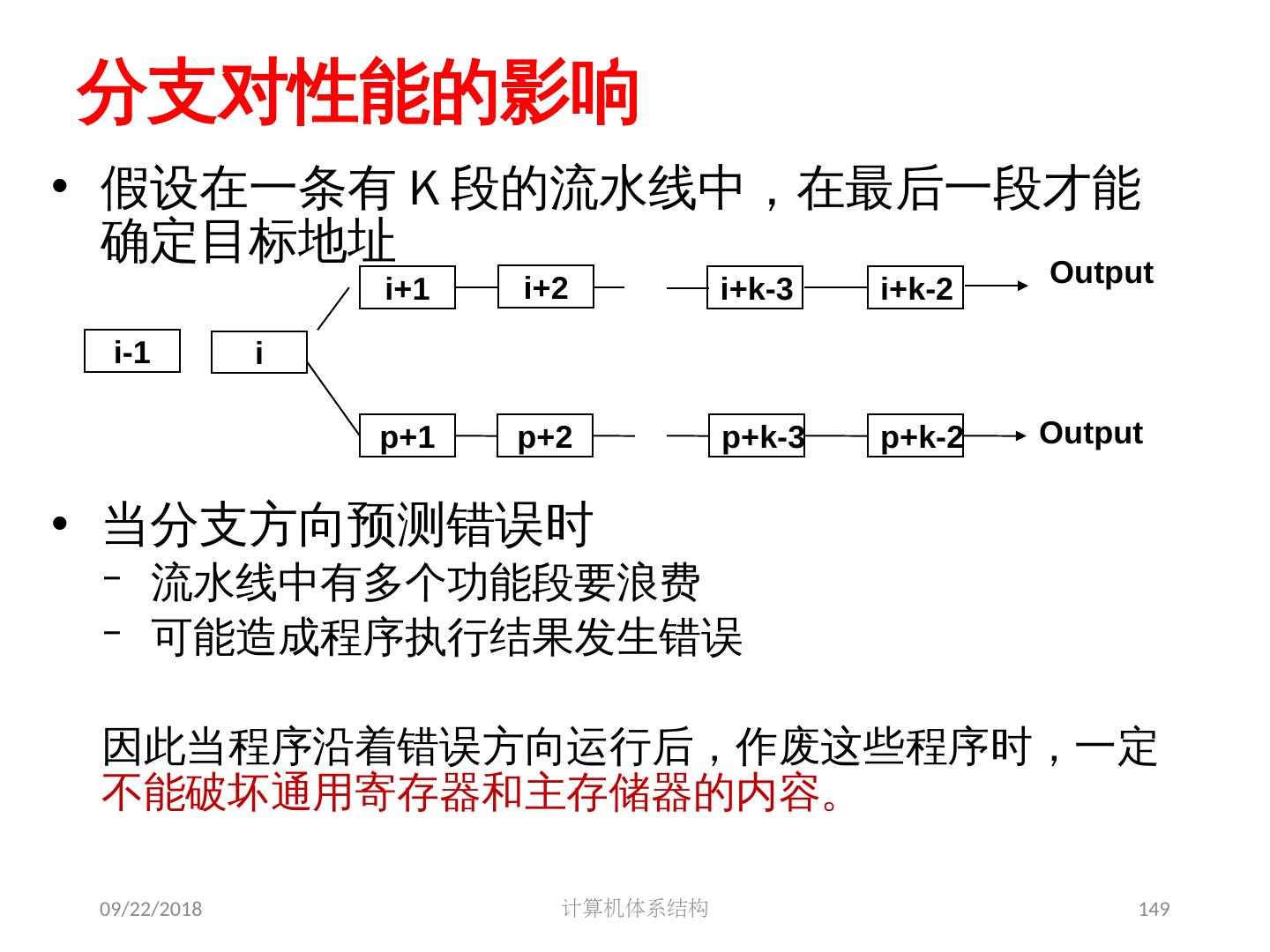
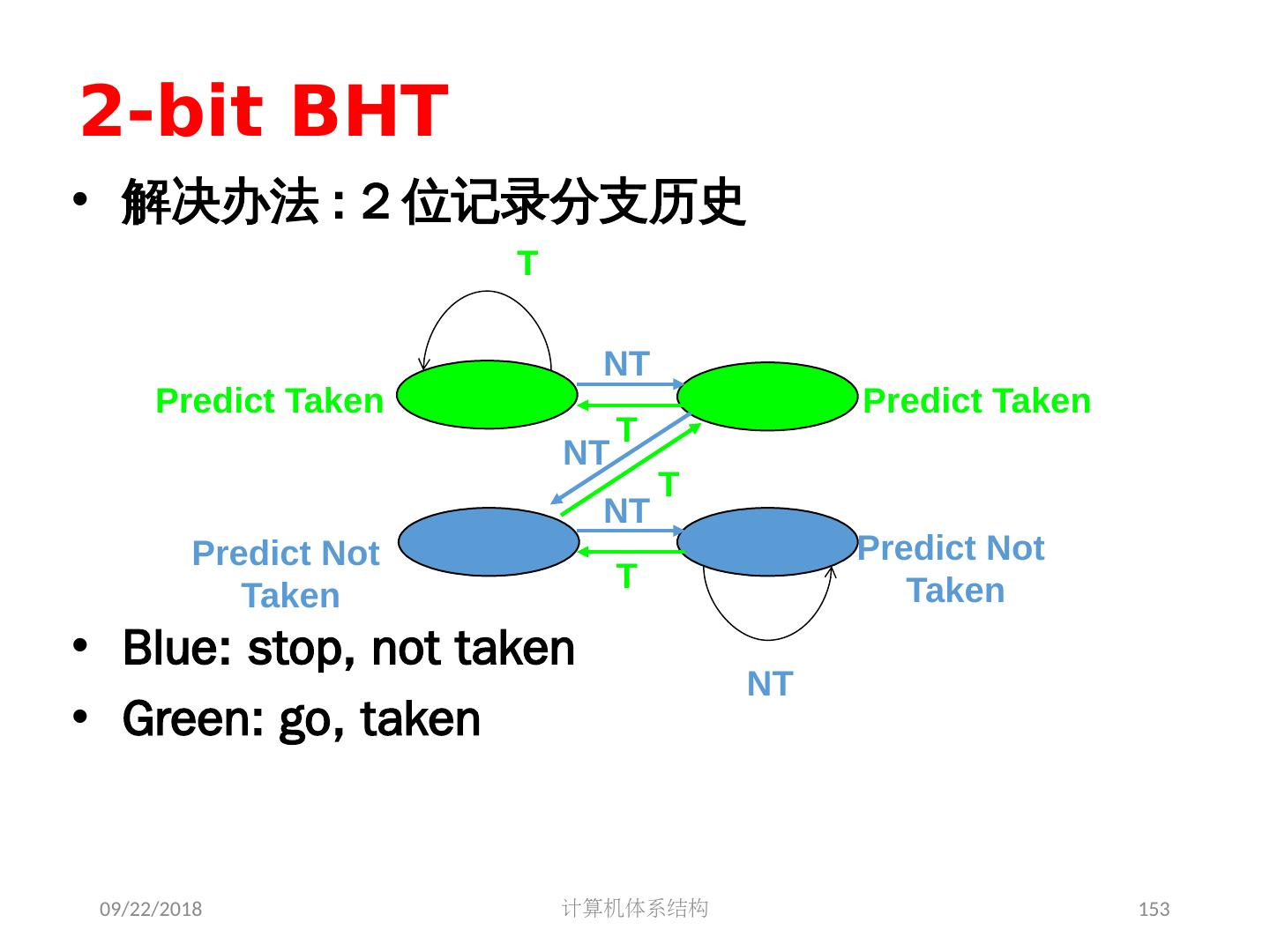
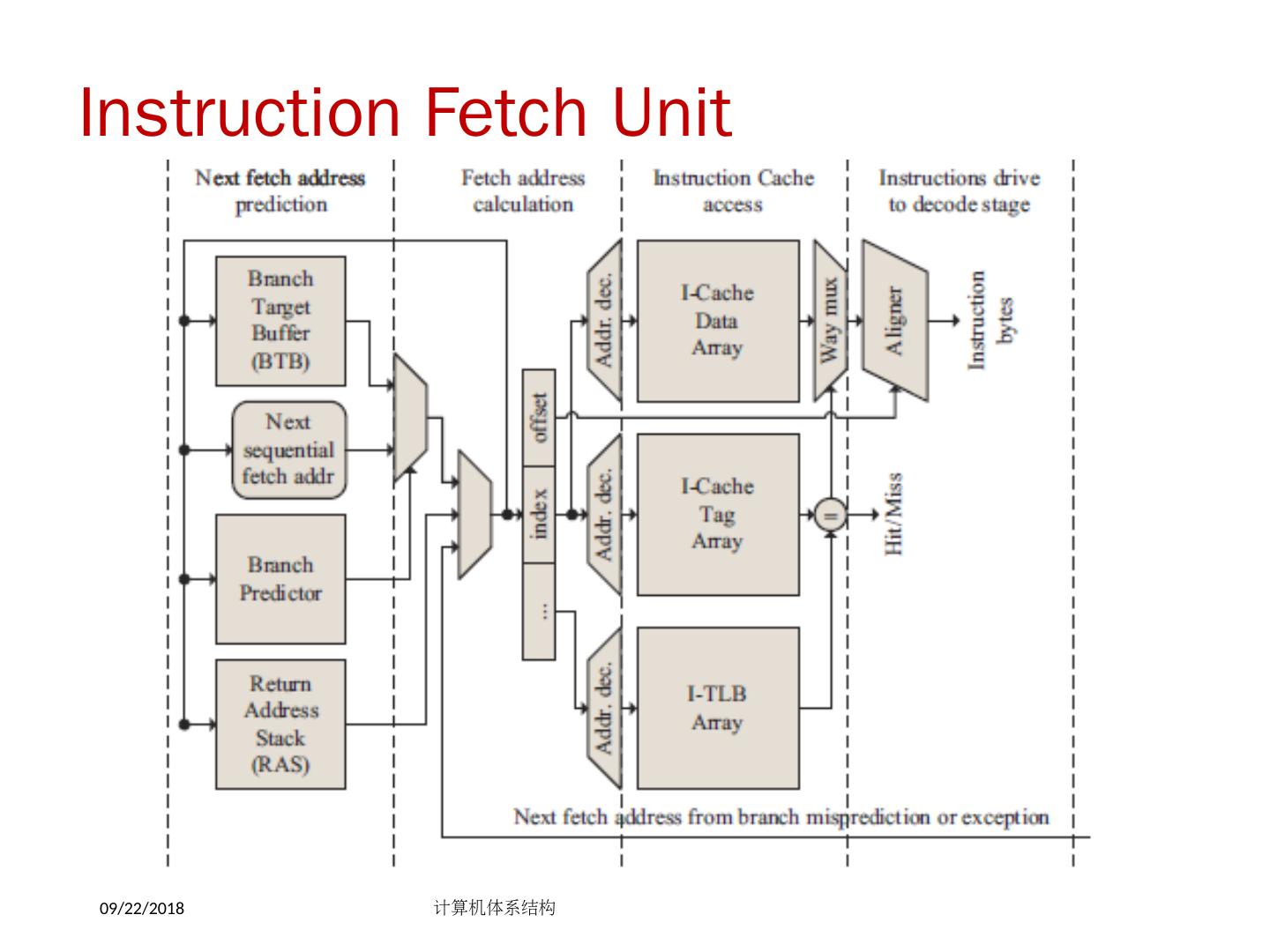
8 .2018/5/14 计算机体系结构 8 Review: 基本流水线 流水线提高的是指令带宽(吞吐率),而不是单条指令的执行速度 相关限制了流水线性能的发挥 结构相关:需要更多的硬件资源 数据相关:需要定向,编译器调度 控制相关:尽早检测条件,计算目标地址,延迟转移,预测 增加流水线的级数会增加相关产生的可能性 异常,浮点运算使得流水线控制更加复杂 编译器可降低数据相关和控制相关的开销 Load 延迟槽 Branch 延迟槽 Branch 预测
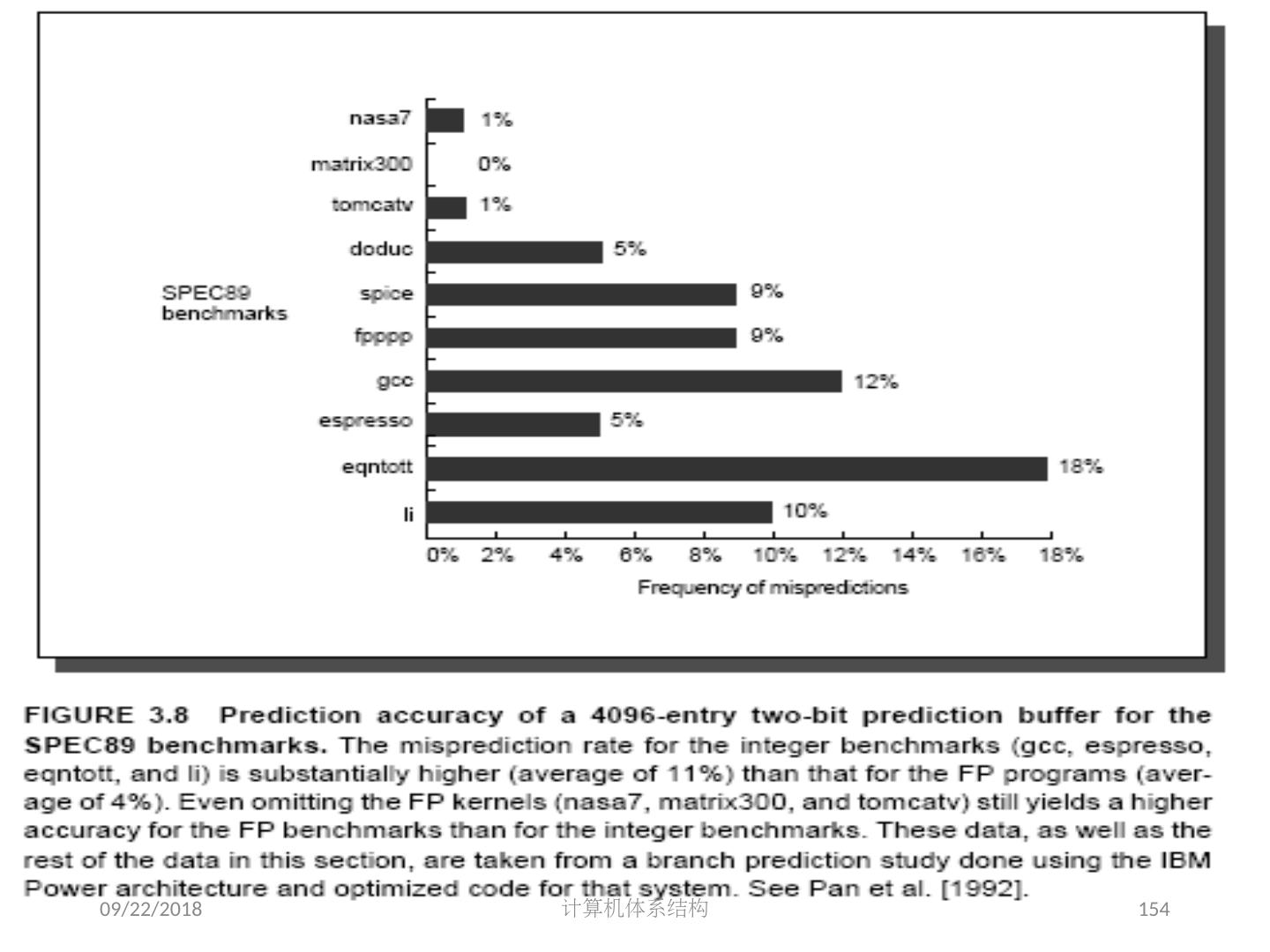
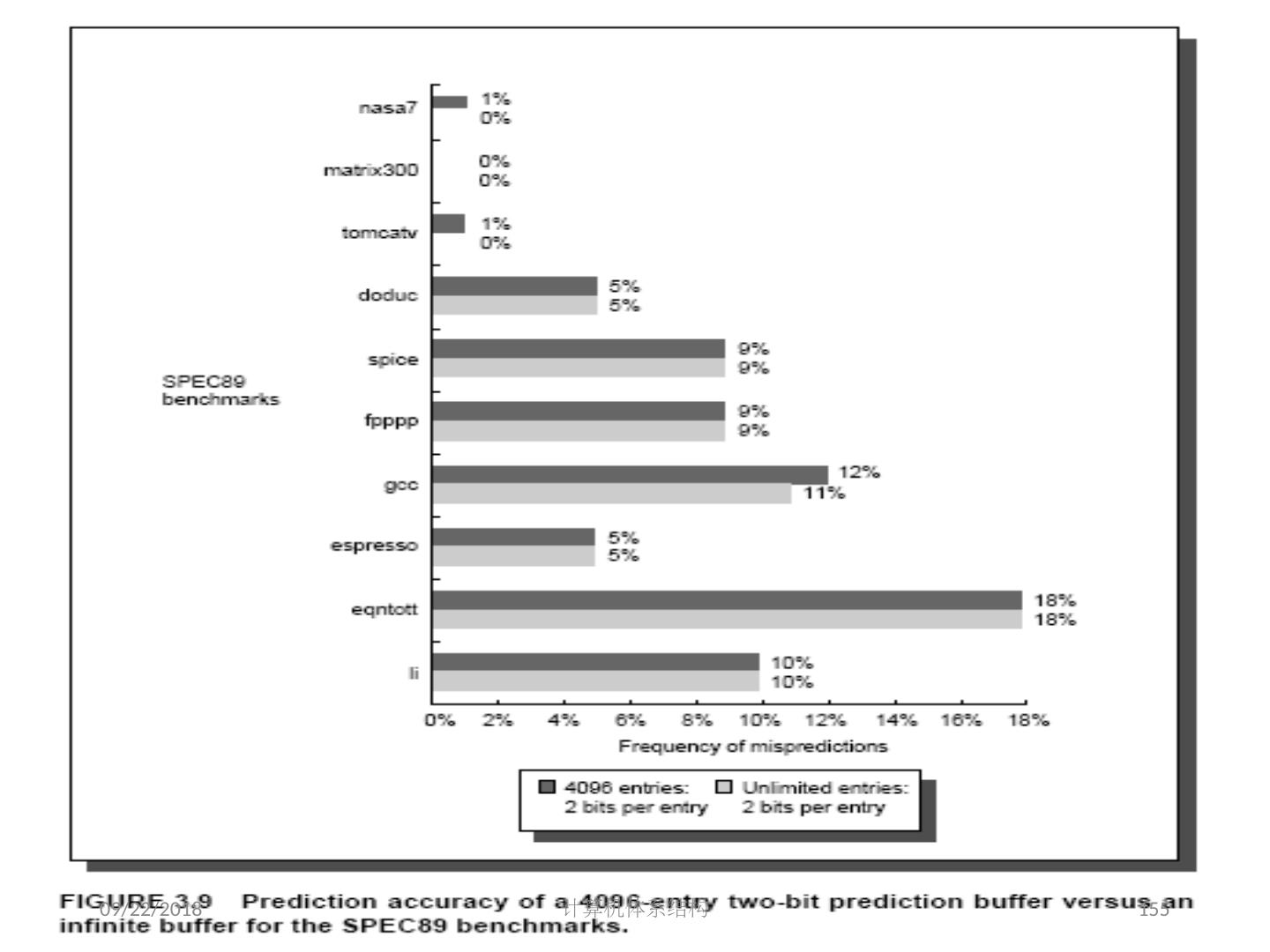
9 .2018/5/14 计算机体系结构 9 5 .1 指令级并行的基本概念及挑战 ILP: 无关的指令重叠执行 流水线的平均 CPI Pipeline CPI = Ideal Pipeline CPI + Struct Stalls + RAW Stalls + WAR Stalls + WAW Stalls + Control Stalls + Memory Stalls 本章研究:减少停顿( stalls) 数的方法和技术 基本途径 软件方法: Gcc : 17% 控制类指令,5 instructions + 1 branch ; 在基本块上,得到更多的并行性 挖掘循环级并行 硬件方法 动态调度方法 以 MIPS 的浮点数操作为例
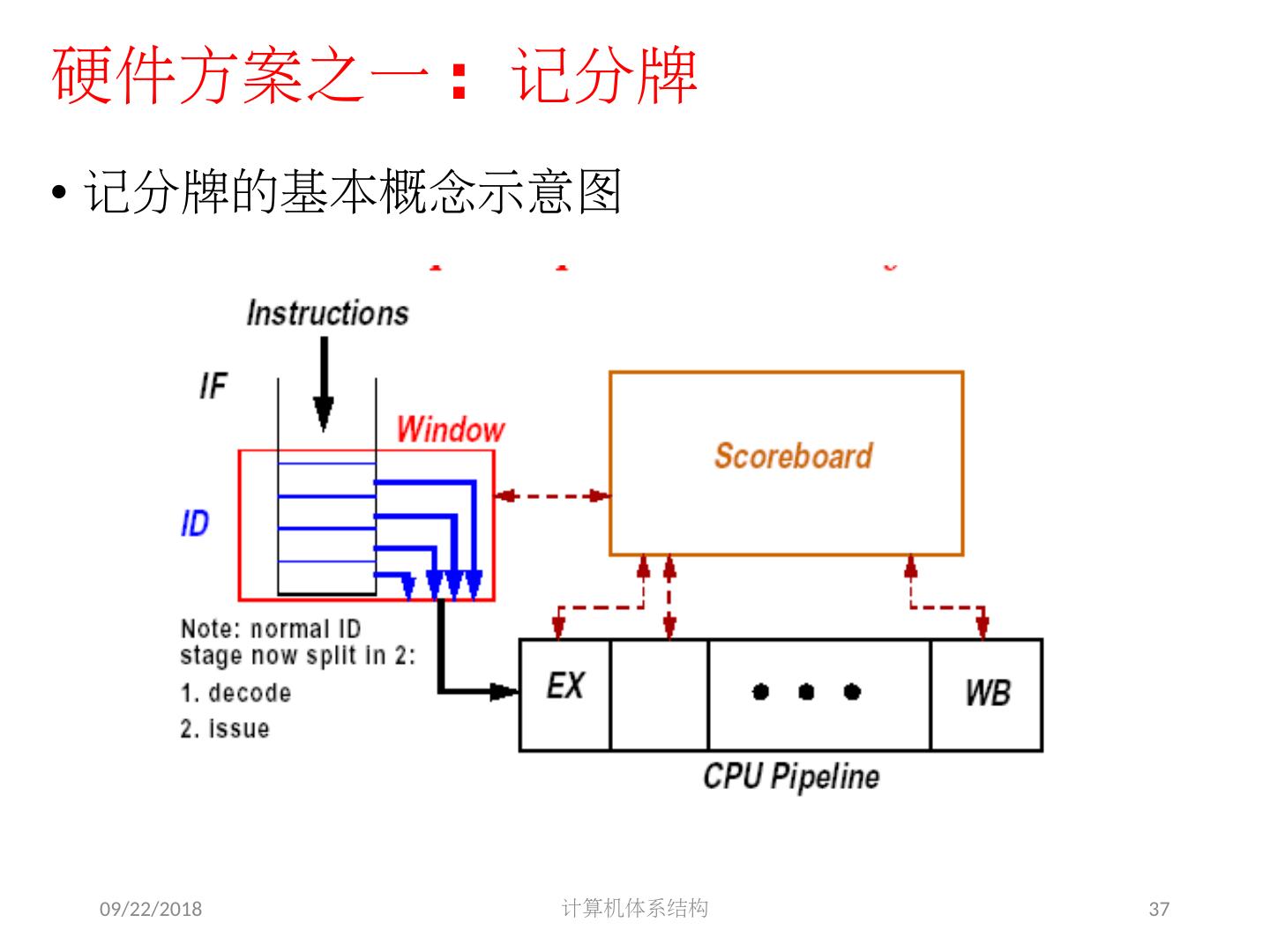
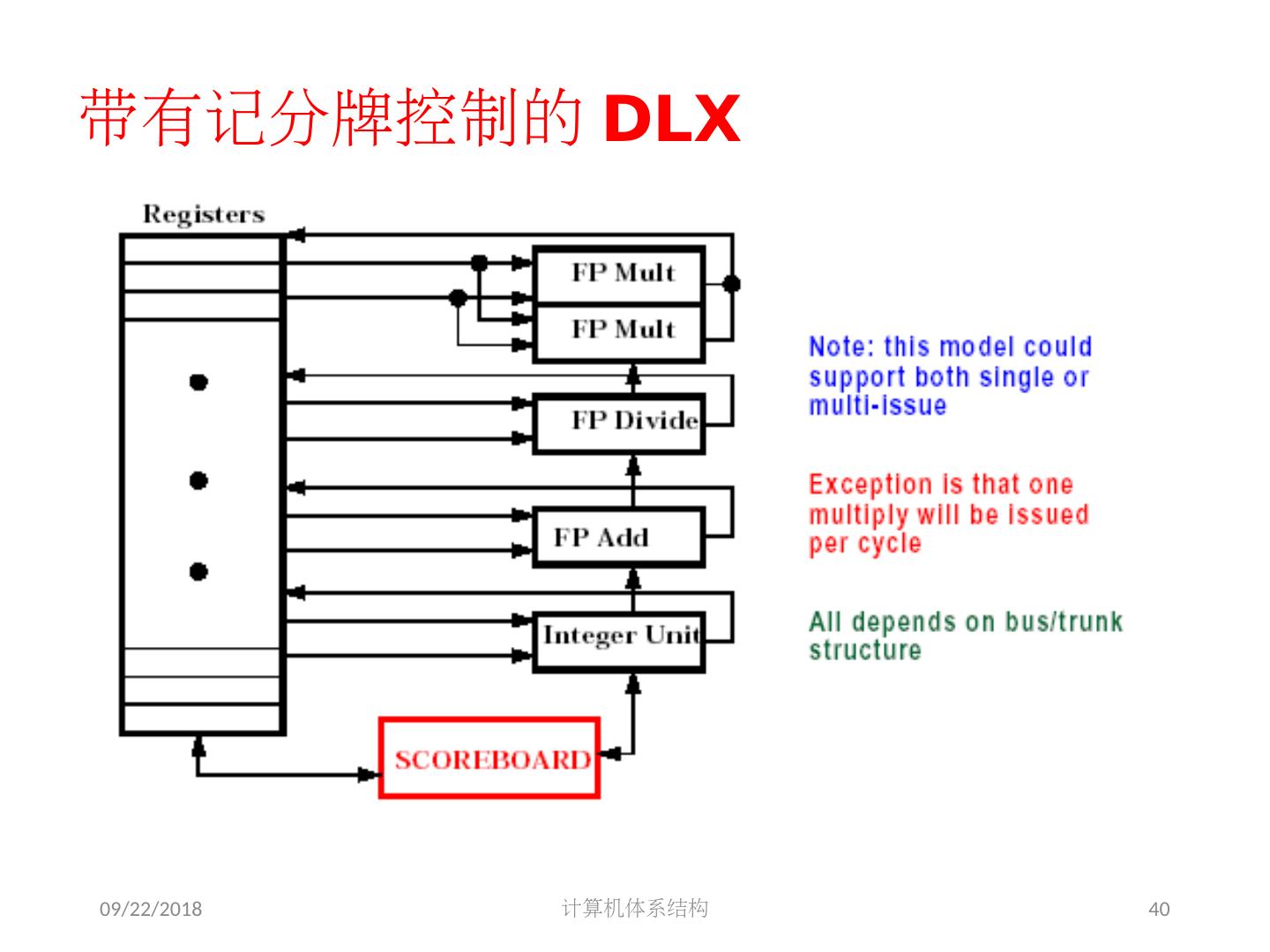
10 .2018/5/14 计算机体系结构 10 采用的基本技术
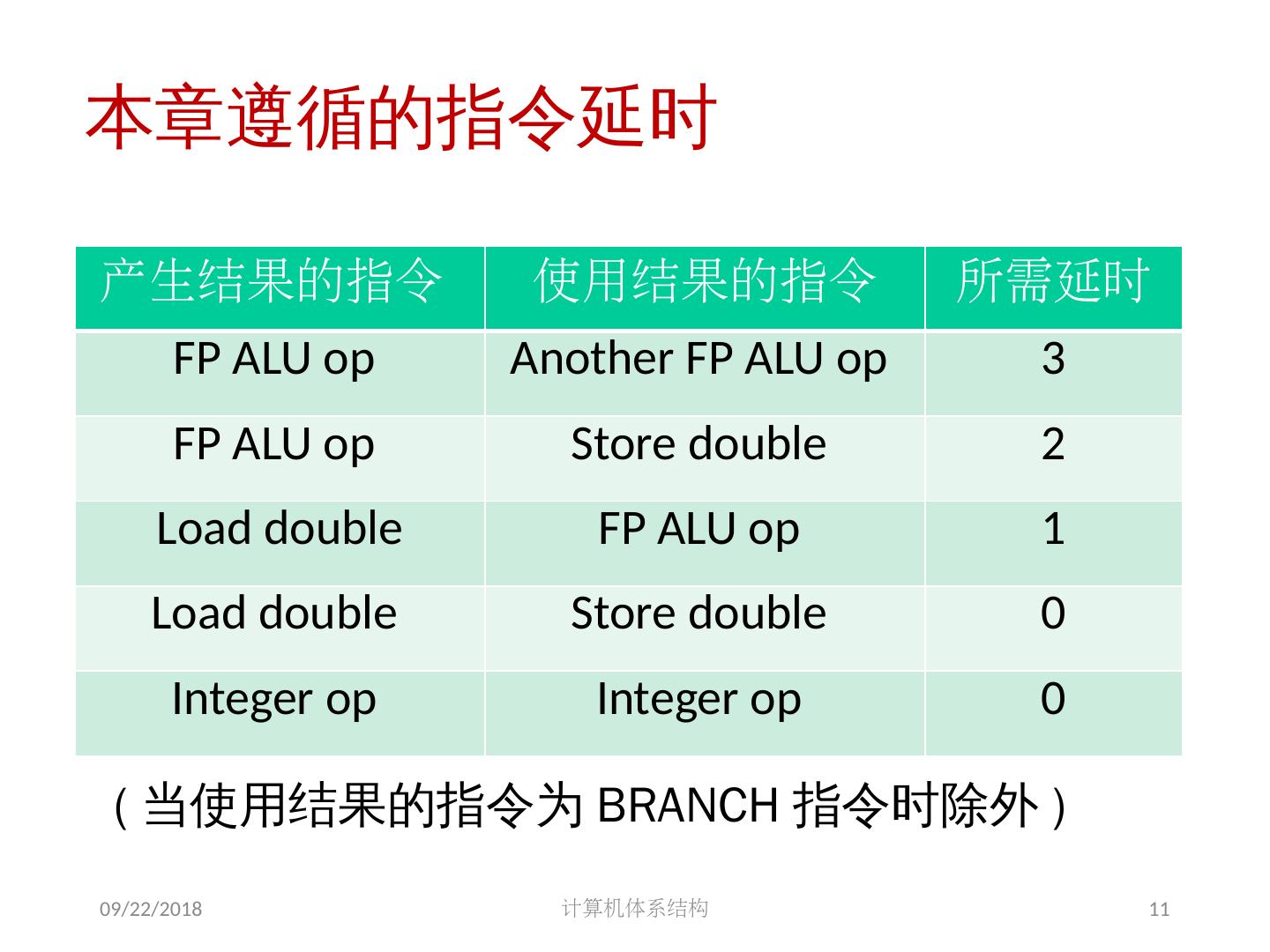
11 .2018/5/14 计算机体系结构 11 本章遵循的指令延时 ( 当使用结果的指令为 BRANCH 指令时除外 ) 产生结果的指令 使用结果的指令 所需延时 FP ALU op Another FP ALU op 3 FP ALU op Store double 2 Load double FP ALU op 1 Load double Store double 0 Integer op Integer op 0
12 .2018/5/14 计算机体系结构 12 5.2 基本块内的指令级并行 基本块的定义: 直线型代码,无分支;单入口;程序由分支语句连接基本块构成 循环级并行 for ( i = 1; i <= 1000; i ++) x( i ) = x( i ) + s; 计算 x( i ) 时没有 数据 相关;可以并行产生1000个数据; 问题:在生成代码时会有 Branch 指令-控制相关 预测比较容易,但我们必须有预测方案 向量处理机模型 load vectors x and y (up to some machine dependent max) then do result- vec = xvec + yvec in a single instruction
13 .2018/5/14 计算机体系结构 13 简单循环及其对应的汇编程序 for (i=1; i<=1000; i++) x(i) = x(i) + s; Loop : LD F0,0(R1) ;F0=vector element ADDD F4,F0,F2 ;add scalar from F2 SD 0(R1),F4 ;store result SUBI R1,R1,8 ;decrement pointer 8B (DW) BNEZ R1,Loop ;branch R1!=zero NOP ;delayed branch slot
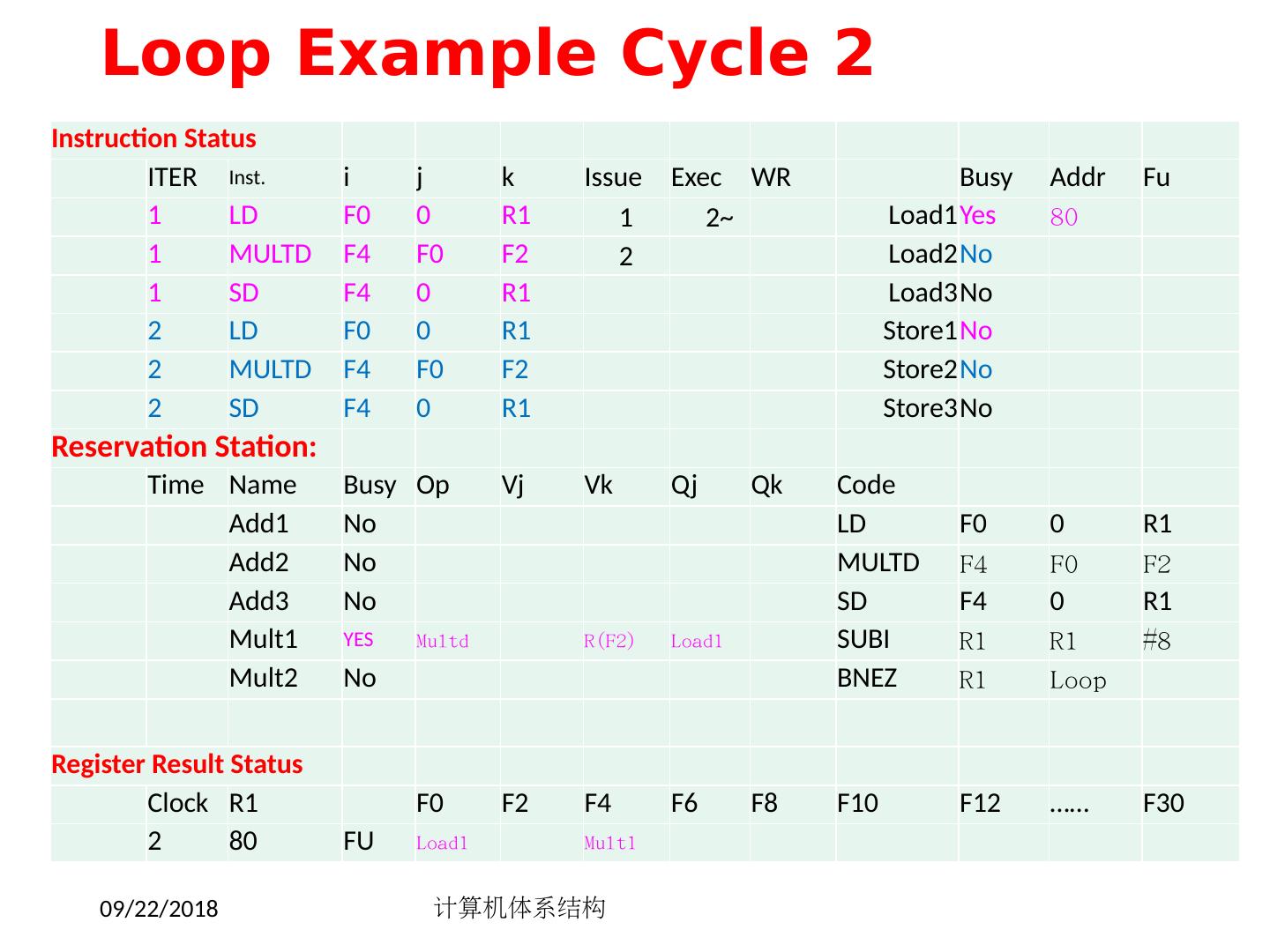
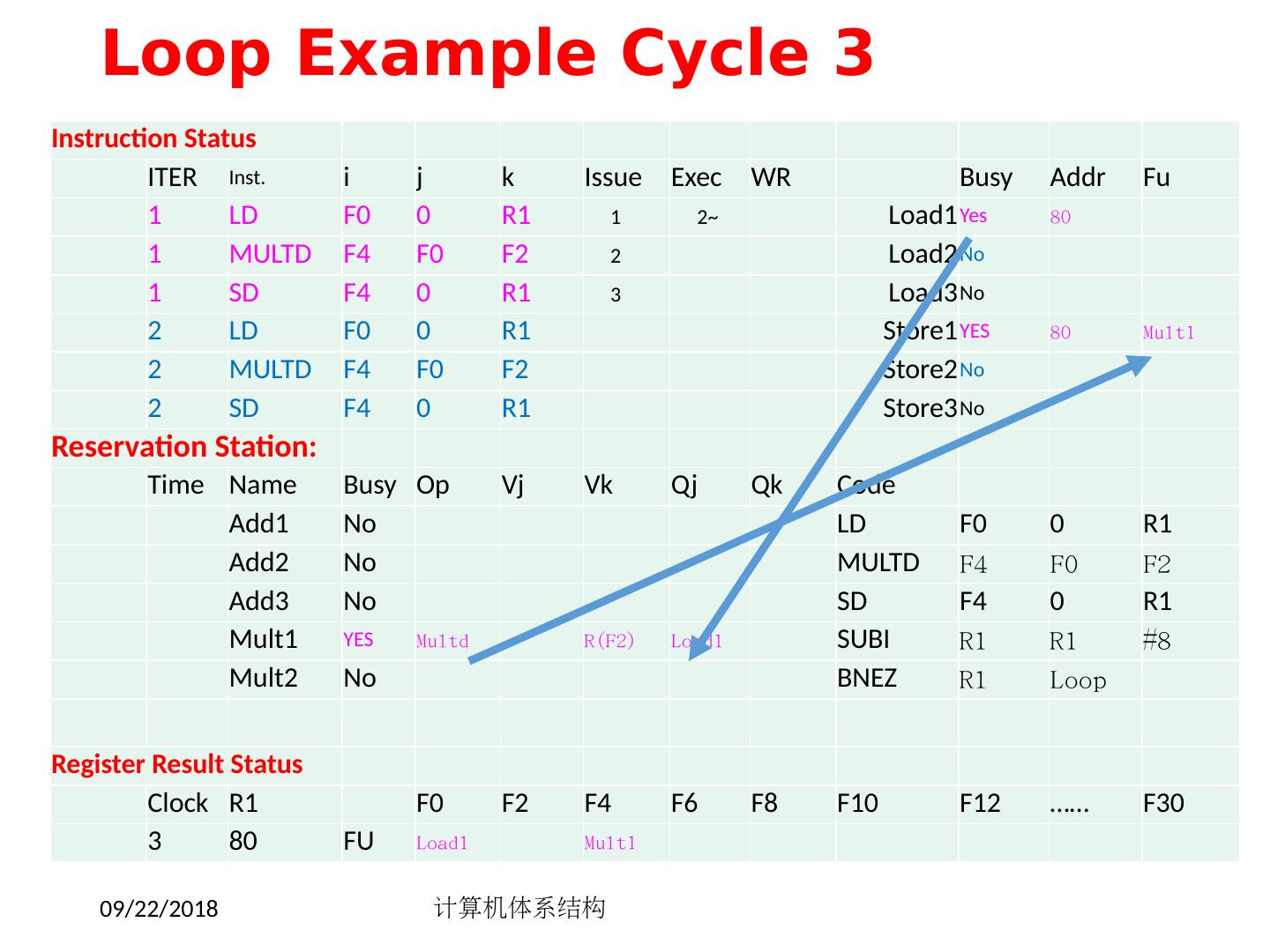
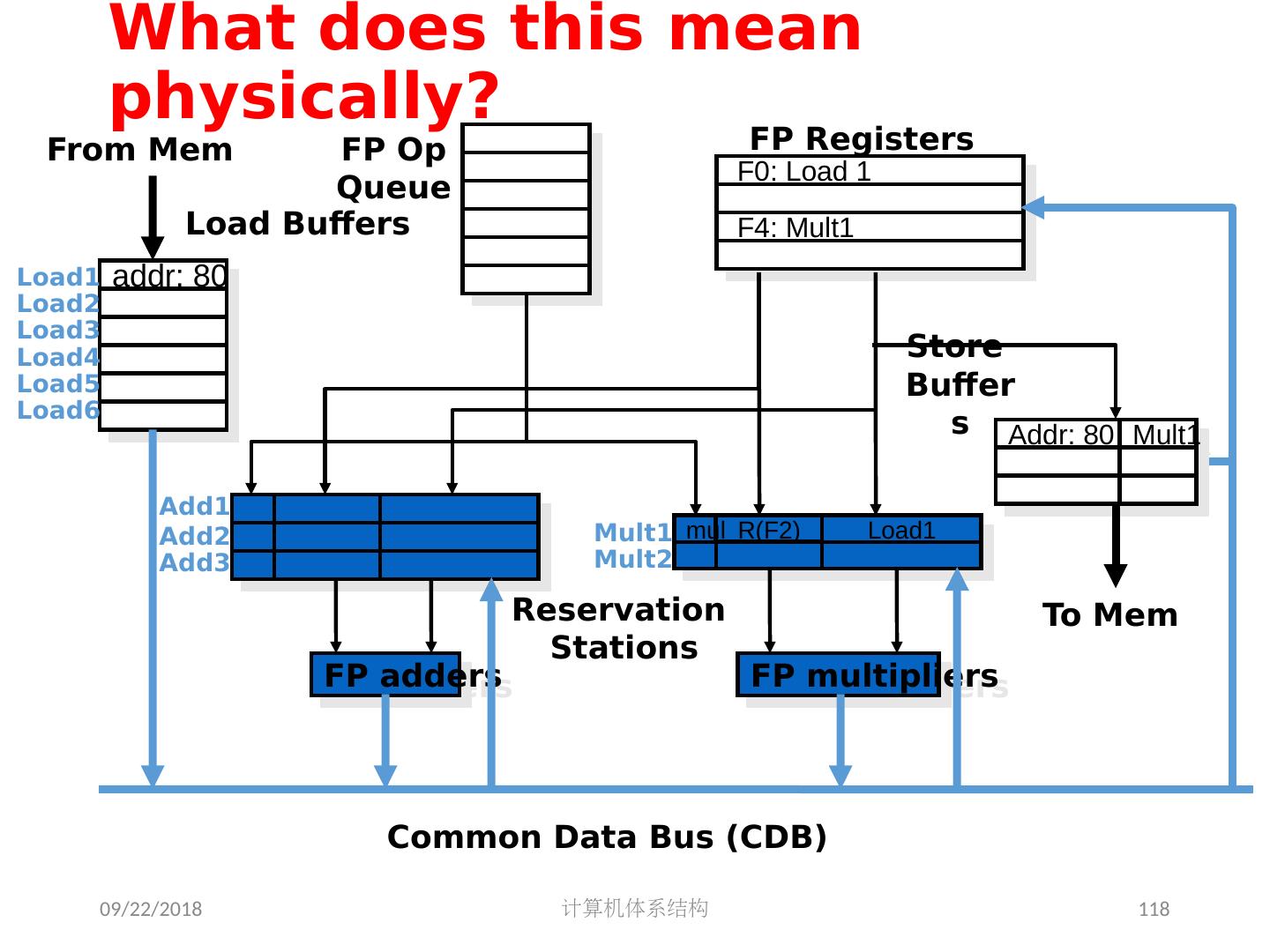
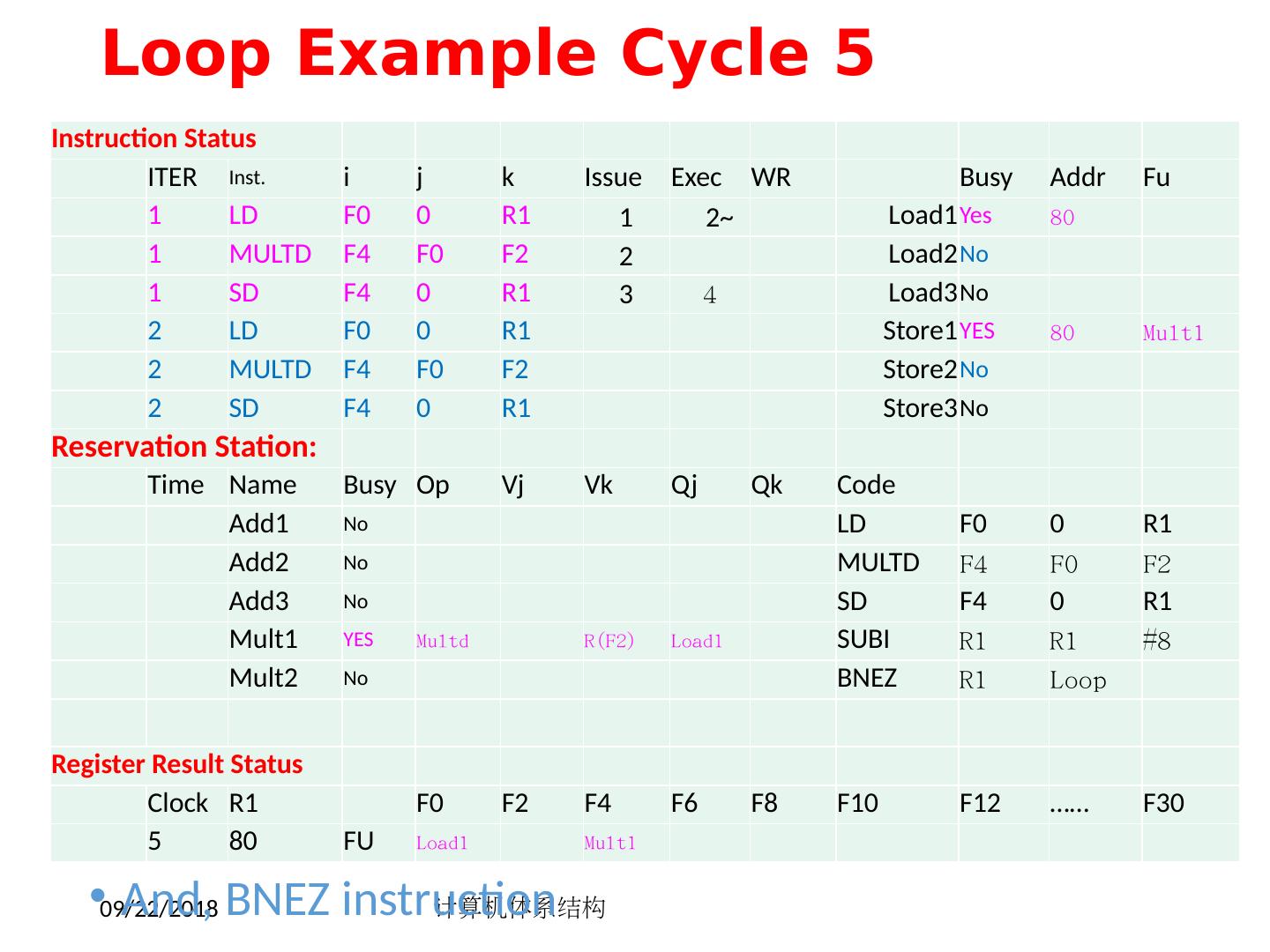
14 .FP 循环中的相关 Loop: LD F0 ,0(R1) ;F0=vector element ADDD F4 , F0 ,F2 ;add scalar in F2 SD 0(R1), F4 ;store result SUBI R1 ,R1,8 ;decrement pointer 8B (DW) BNEZ R1 ,Loop ;branch R1!=zero NOP ;delayed branch slot 产生结果的指令 使用结果的指令 所需的延时 FP ALU op Another FP ALU op 3 FP ALU op Store double 2 Load double FP ALU op 1 Load double Store double 0 Integer op Integer op 0 2018/5/14 计算机体系结构 14
15 .FP 循环中的最少 Stalls 数 6 clocks: 通过循环展开4次是否可以提高性能 ? 1 Loop: LD F0 ,0(R1) 2 SUBI R1 ,R1,8 3 ADDD F4 , F0 ,F2 4 stall 5 BNEZ R1 ,Loop ;delayed branch 6 SD 8 (R1), F4 ;altered when move past SUBI Swap BNEZ and SD by changing address of SD 2018/5/14 计算机体系结构 15
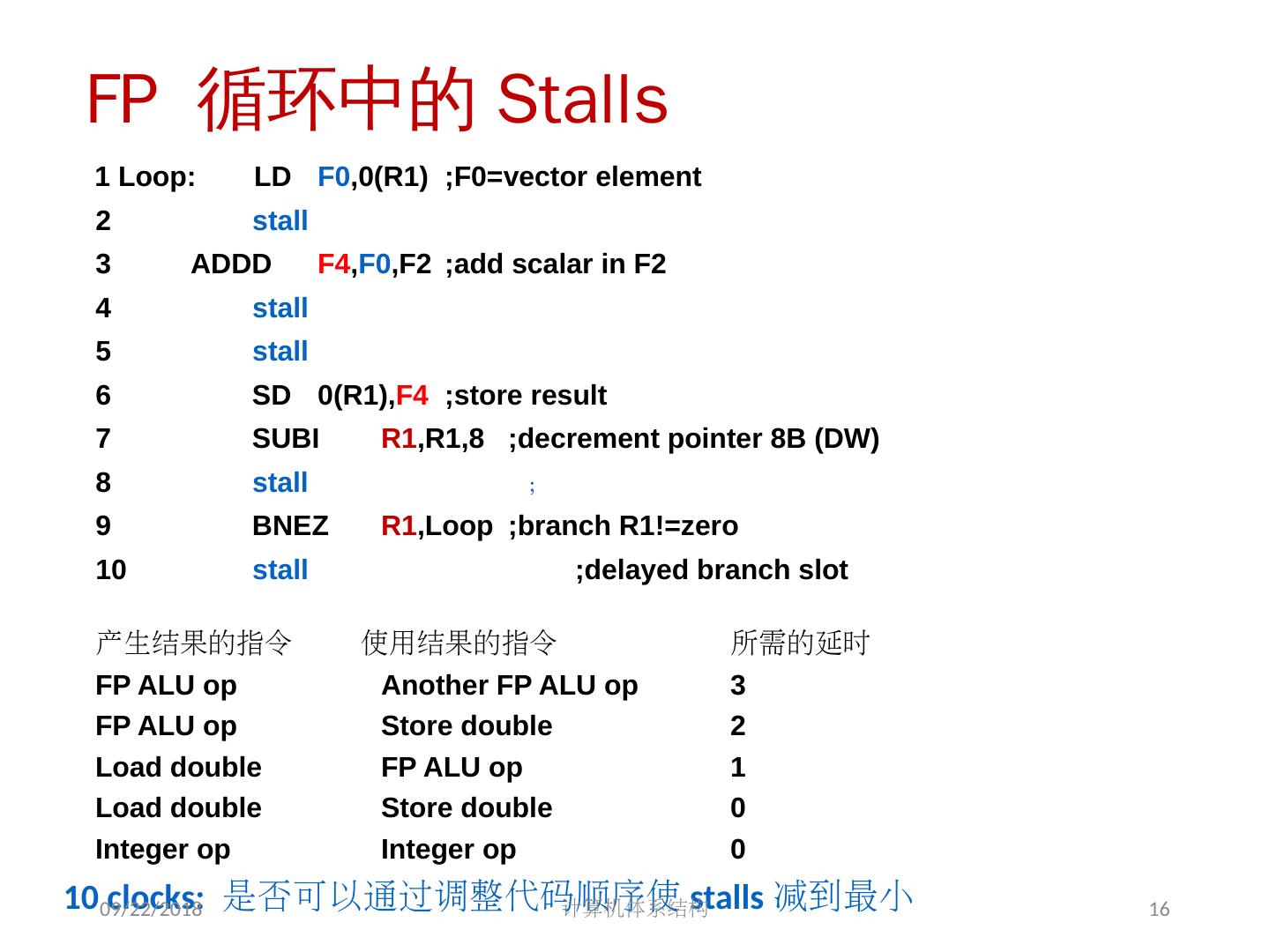
16 .FP 循环中的 Stalls 10 clocks: 是否可以通过调整代码顺序使 stalls 减到最小 1 Loop: LD F0 ,0(R1) ;F0=vector element 2 stall 3 ADDD F4 , F0 ,F2 ;add scalar in F2 4 stall 5 stall 6 SD 0(R1), F4 ;store result 7 SUBI R1 ,R1,8 ;decrement pointer 8B (DW) 8 stall ; 9 BNEZ R1 ,Loop ;branch R1!=zero 10 stall ;delayed branch slot 产生结果的指令 使用结果的指令 所需的延时 FP ALU op Another FP ALU op 3 FP ALU op Store double 2 Load double FP ALU op 1 Load double Store double 0 Integer op Integer op 0 2018/5/14 计算机体系结构 16
17 .循环展开4次 (straight forward way) Rewrite loop to minimize stalls? 1 Loop: LD F0,0(R1) stall 2 ADDD F4,F0,F2 stall stall 3 SD 0(R1),F4 ;drop SUBI & BNEZ 4 LD F6, -8 (R1) stall 5 ADDD F8,F6,F2 stall stall 6 SD -8 (R1),F8 ;drop SUBI & BNEZ 7 LD F10, -16 (R1) stall 8 ADDD F12,F10,F2 stall stall 9 SD -16 (R1),F12 ;drop SUBI & BNEZ 10 LD F14, -24 (R1) stall 11 ADDD F16,F14,F2 stall stall 12 SD -24 (R1),F16 13 SUBI R1,R1, #32 stall ;alter to 4*8 14 BNEZ R1,LOOP 15 NOP 15 + 4 x (1+2) + 1 = 28 cycles, or 7 per iteration Assumes R1 is multiple of 4 2018/5/14 计算机体系结构 17
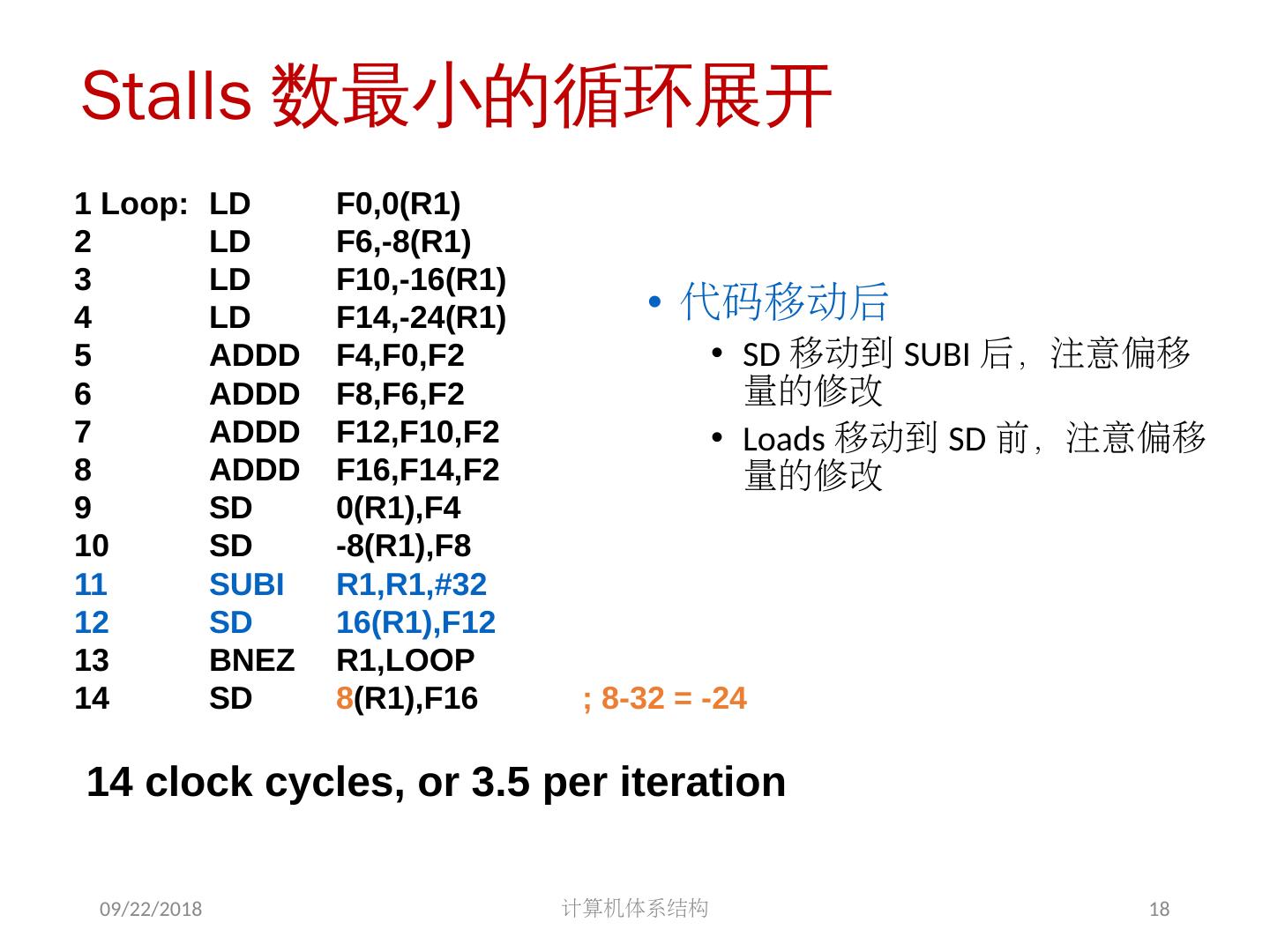
18 .Stalls 数最小的循环展开 代码移动后 SD 移动到 SUBI 后,注意偏移量的修改 Loads 移动到 SD 前,注意偏移量的修改 1 Loop: LD F0,0(R1) 2 LD F6,-8(R1) 3 LD F10,-16(R1) 4 LD F14,-24(R1) 5 ADDD F4,F0,F2 6 ADDD F8,F6,F2 7 ADDD F12,F10,F2 8 ADDD F16,F14,F2 9 SD 0(R1),F4 10 SD -8(R1),F8 11 SUBI R1,R1,#32 12 SD 16(R1),F12 13 BNEZ R1,LOOP 14 SD 8 (R1),F16 ; 8-32 = -24 14 clock cycles, or 3.5 per iteration 2018/5/14 计算机体系结构 18
19 .2018/5/14 计算机体系结构 19 循环展开示例小结 循环展开对循环间无关的程序是有效降低 stalls 的手段(对循环级并行) . 指令调度,必须保证程序运行的结果不变 注意循环展开中的 Load 和 Store, 不同次循环的 Load 和 Store 是相互独立的。需要分析对存储器的引用,保证他们没有引用同一地址 . 不同次的循环,使用不同的寄存器 删除不必要的测试和分支后,需调整循环步长等控制循环的代码 . 移动 SD 到 SUBI 和 BNEZ 后,需要调整 SD 中的偏移
20 .2018/5/14 计算机体系结构 20 -Review 指令级并行 (ILP) : 流水线的平均 CPI Pipeline CPI = Ideal Pipeline CPI + Struct Stalls + RAW Stalls + WAR Stalls + WAW Stalls + Control Stalls +…… 提高指令级并行的方法 软件方法:指令流调度,循环展开,软件流水线, trace scheduling 硬件方法 软件方法:指令流调度 - 循环展开 指令调度,必须保证程序运行的结果不变 偏移量的修改 寄存器的重命名 循环步长的调整
21 .2018/5/14 计算机体系结构 21 从编译器角度看代码移动(1/ 4 ) 编译器分析程序的相关性依赖于给定的流水线 编译器进行指令调度来消除相关 (True) 数据相关( Data dependencies) 对于指令 i 和 j, 如果 指令 j 使用指令 i 产生的结果 , 或 指令 j 与 指令 k 相关, 并且 指令 k 与 指令 i 有数据相关. 如果相关, 不能并行执行 对于寄存器比较容易确定 (fixed names) 但对 memory 的引用,比较难确定 : 100(R4) = 20(R6)? 在不同次的循环中, 20(R6) = 20(R6)?
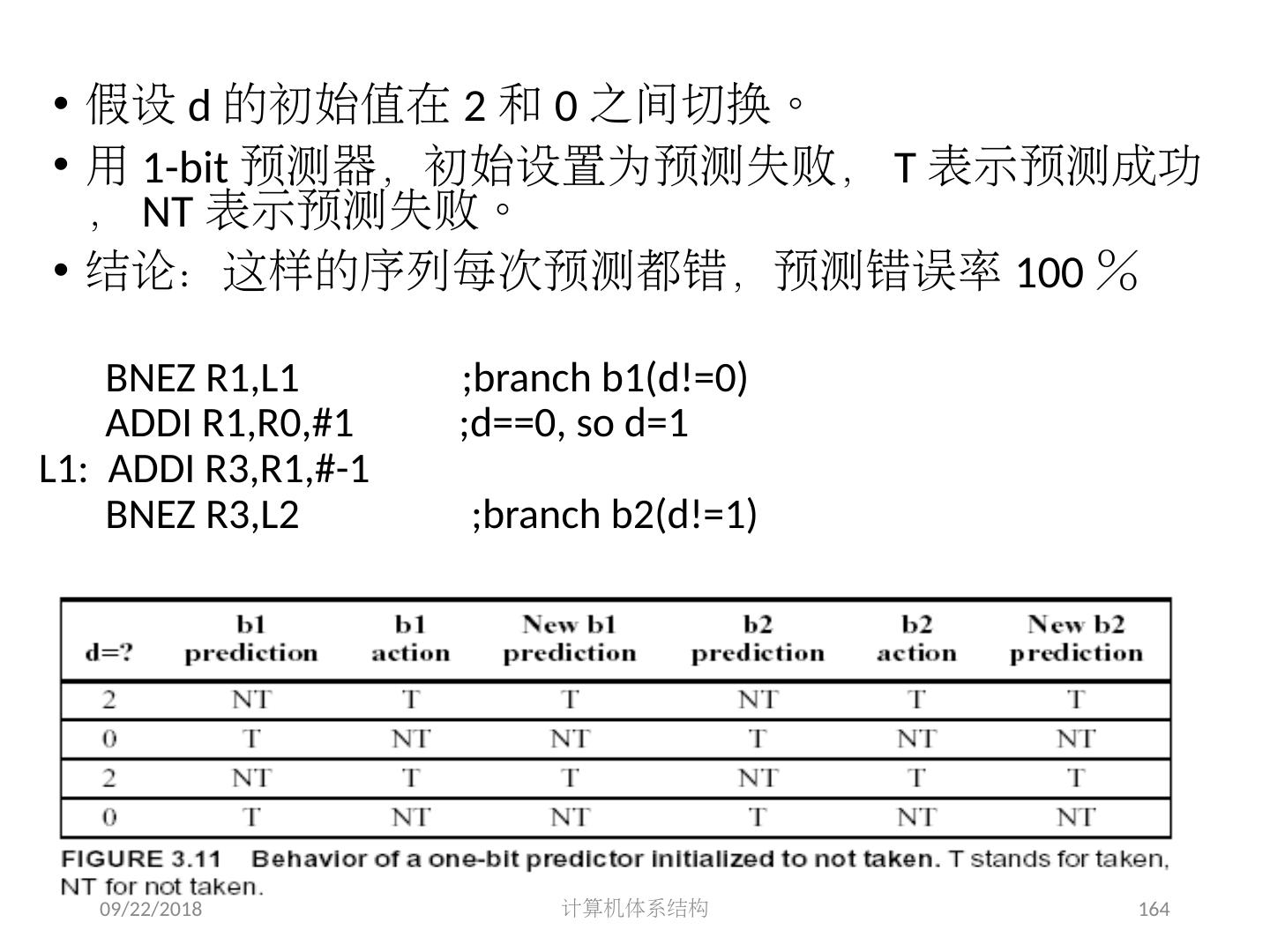
22 .2018/5/14 计算机体系结构 22 下列程序哪里有数据相关 ? 1 Loop: LD F0,0(R1) 2 ADDD F4,F0,F2 3 SUBI R1,R1,8 4 BNEZ R1,Loop ; delayed branch 5 SD 8(R1),F4 ; altered when move past SUBI
23 .2018/5/14 计算机体系结构 23 从编译器角度看代码移动(2/ 4 ) 另一种相关称为名相关( name dependence): 两条指令使用同名参数 (register or memory location) 但不交换数据 反相关( Antidependence) (WAR if a hazard for HW) Instruction j 所写的寄存器或存储单元,与 instruction i 所读的寄存器或存储单元相同,注 instruction i 是先执行 输出相关( Output dependence) (WAW if a hazard for HW) Instruction i 和 instruction j 对同一寄存器或存储单元进行写操作,必须保证两条指令的写顺序
24 .下列是否有名相关 ? 1 Loop: LD F0 ,0(R1) 2 ADDD F4 ,F0,F2 3 SD 0(R1),F4 ;drop SUBI & BNEZ 4 LD F0 , -8 (R1) 5 ADDD F4,F0,F2 6 SD -8 (R1),F4 ;drop SUBI & BNEZ 7 LD F0 , -16 (R1) 8 ADDD F4,F0,F2 9 SD -16 (R1),F4 ;drop SUBI & BNEZ 10 LD F0, -24 (R1) 11 ADDD F4,F0,F2 12 SD -24 (R1),F4 13 SUBI R1,R1, #32 ;alter to 4*8 14 BNEZ R1,LOOP 15 NOP 如何消除名相关? 2018/5/14 计算机体系结构 24
25 .下列是否存在名相关 ? 1 Loop:LD F0,0(R1) 2 ADDD F4,F0,F2 3 SD 0(R1),F4 ;drop SUBI & BNEZ 4 LD F6, -8 (R1) 5 ADDD F8,F6,F2 6 SD -8 (R1),F8 ;drop SUBI & BNEZ 7 LD F10, -16 (R1) 8 ADDD F12,F10,F2 9 SD -16 (R1),F12 ;drop SUBI & BNEZ 10 LD F14, -24 (R1) 11 ADDD F16,F14,F2 12 SD -24 (R1),F16 13 SUBI R1,R1, #32 ;alter to 4*8 14 BNEZ R1,LOOP 15 NOP 这种方法称为寄存器重命名 ( register renaming ) 2018/5/14 计算机体系结构 25
26 .2018/5/14 计算机体系结构 26 从编译器角度看代码移动(3/ 4 ) 访问存储单元时,很难判断名相关 100(R4) = 20(R6)? 不同次的循环, 20(R6) = 20(R6)? 我们给出的示例要求编译器知道假设 R1 不变,因此 : 0(R1) ≠ -8(R1) ≠ -16(R1) ≠ -24(R1) 因此 loads 和 stores 之间相互无关可以移动
27 .2018/5/14 计算机体系结构 27 从编译器角度看代码移动(4/ 4 ) 最后一种相关称为控制相关( control dependence) Example if p1 {S1;}; if p2 {S2;}; S1 依赖于 P1 的测试结果, S2 依赖于 P2 的测试。 处理控制相关的原则: 受分支指令控制的指令,不能移到控制指令之前,以免该指令的执行不在分支指令的控制范围 . 不受分支指令控制的指令,不能移到控制指令之后,以免该指令的执行受分支指令的控制 . 减少控制相关可以提高指令的并行性
28 .下列程序段的控制相关 1 Loop: LD F0,0(R1) 2 ADDD F4,F0,F2 3 SD 0(R1),F4 4 SUBI R1,R1,8 5 BEQZ R1,exit 6 LD F0,0(R1) 7 ADDD F4,F0,F2 8 SD 0(R1),F4 9 SUBI R1,R1,8 10 BEQZ R1,exit 11 LD F0,0(R1) 12 ADDD F4,F0,F2 13 SD 0(R1),F4 14 SUBI R1,R1,8 15 BEQZ R1,exit .... 2018/5/14 计算机体系结构 28
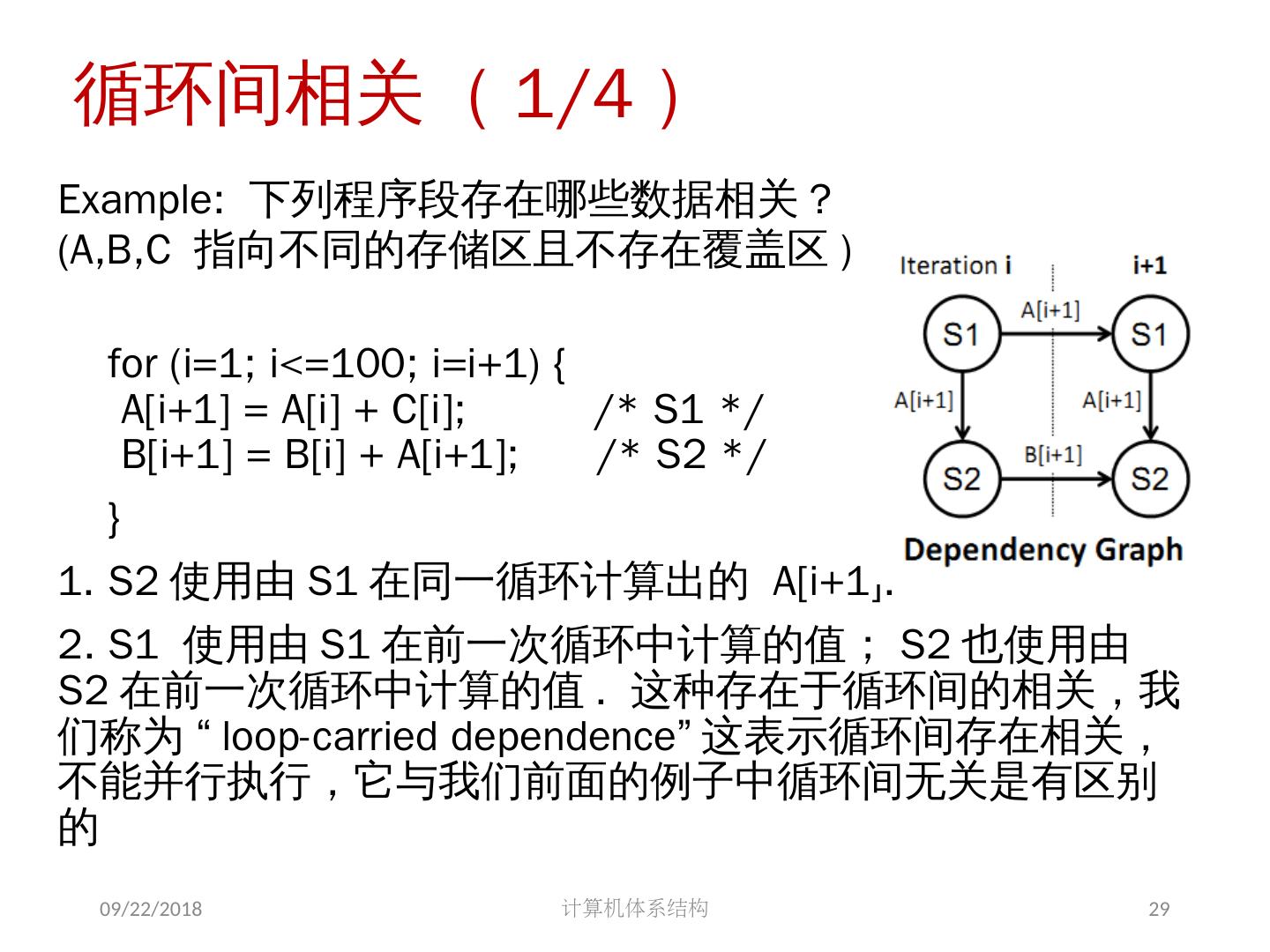
29 .2018/5/14 计算机体系结构 29 循环间相关( 1/4 ) Example: 下列程序段存在哪些数据相关 ? (A,B,C 指向不同的存储区且不存在覆盖区 ) for (i=1; i<=100; i=i+1) { A[i+1] = A[i] + C[i]; /* S1 */ B[i+1] = B[i] + A[i+1]; /* S2 */ } 1. S2 使用由 S1 在同一循环计算出的 A[i+1]. 2. S1 使用由 S1 在前一次循环中计算的值; S2 也使用由 S2 在前一次循环中计算的值 . 这种存在于循环间的相关,我们称为 “ loop-carried dependence” 这表示循环间存在相关,不能并行执行,它与我们前面的例子中循环间无关是有区别的
3秒后跳转登录页面
去登陆

