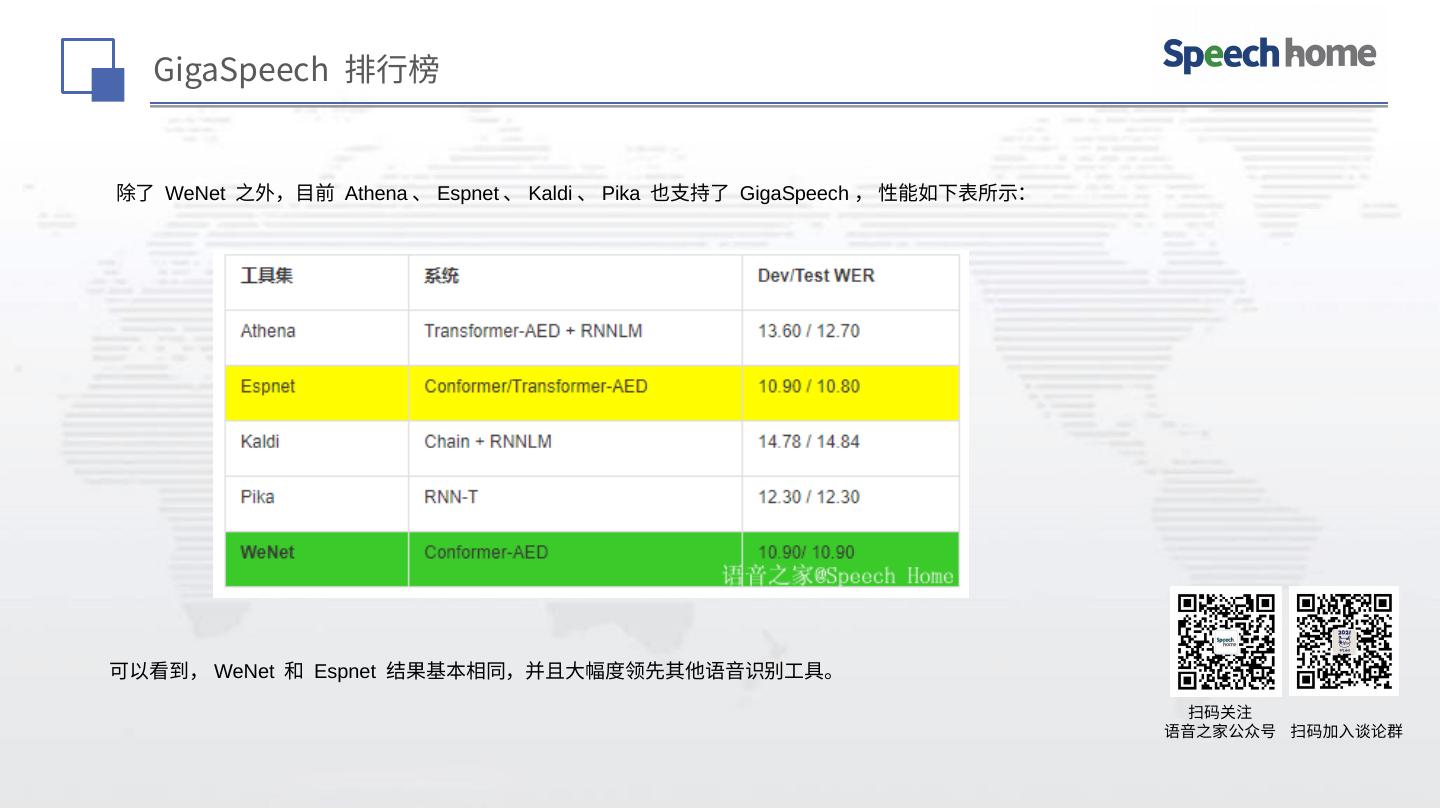
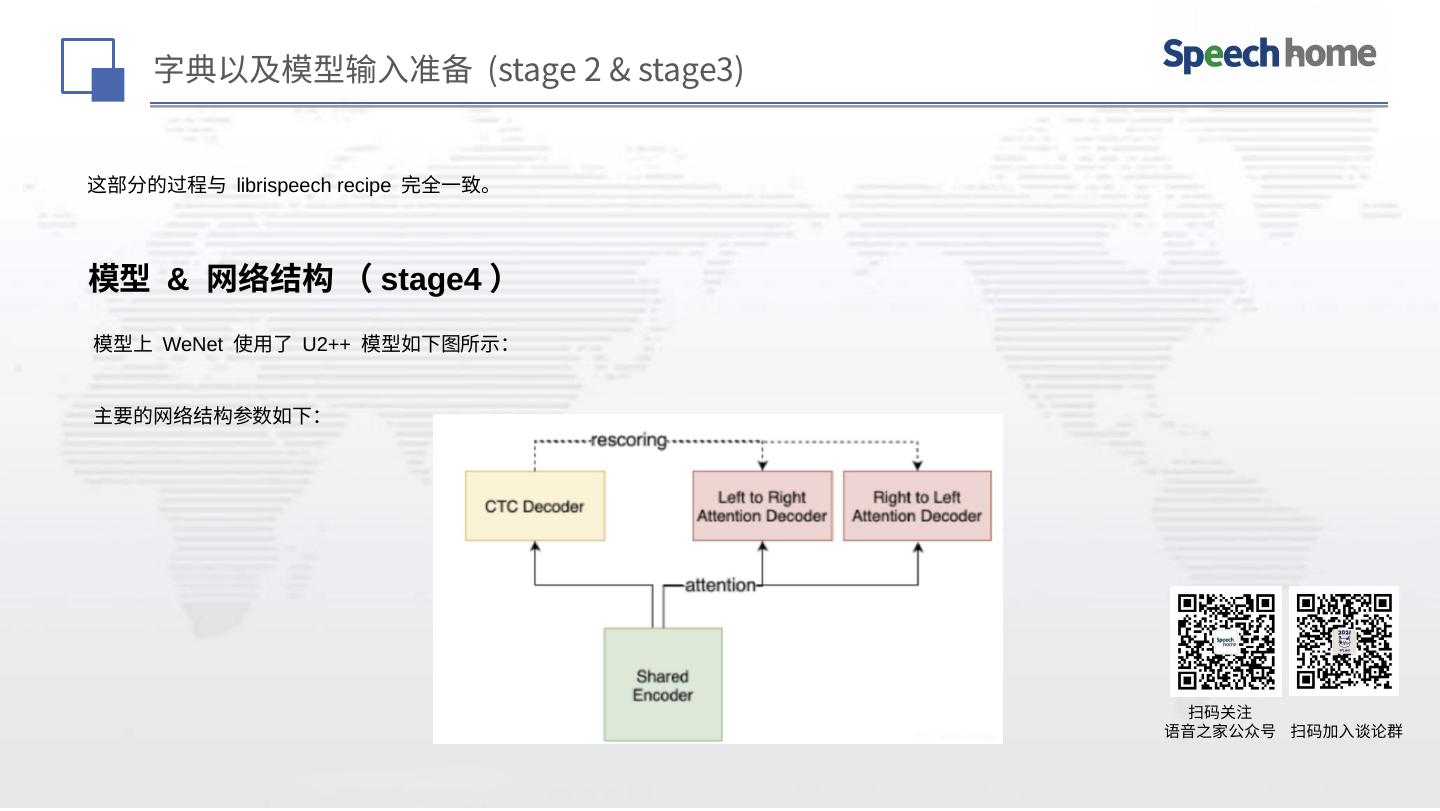
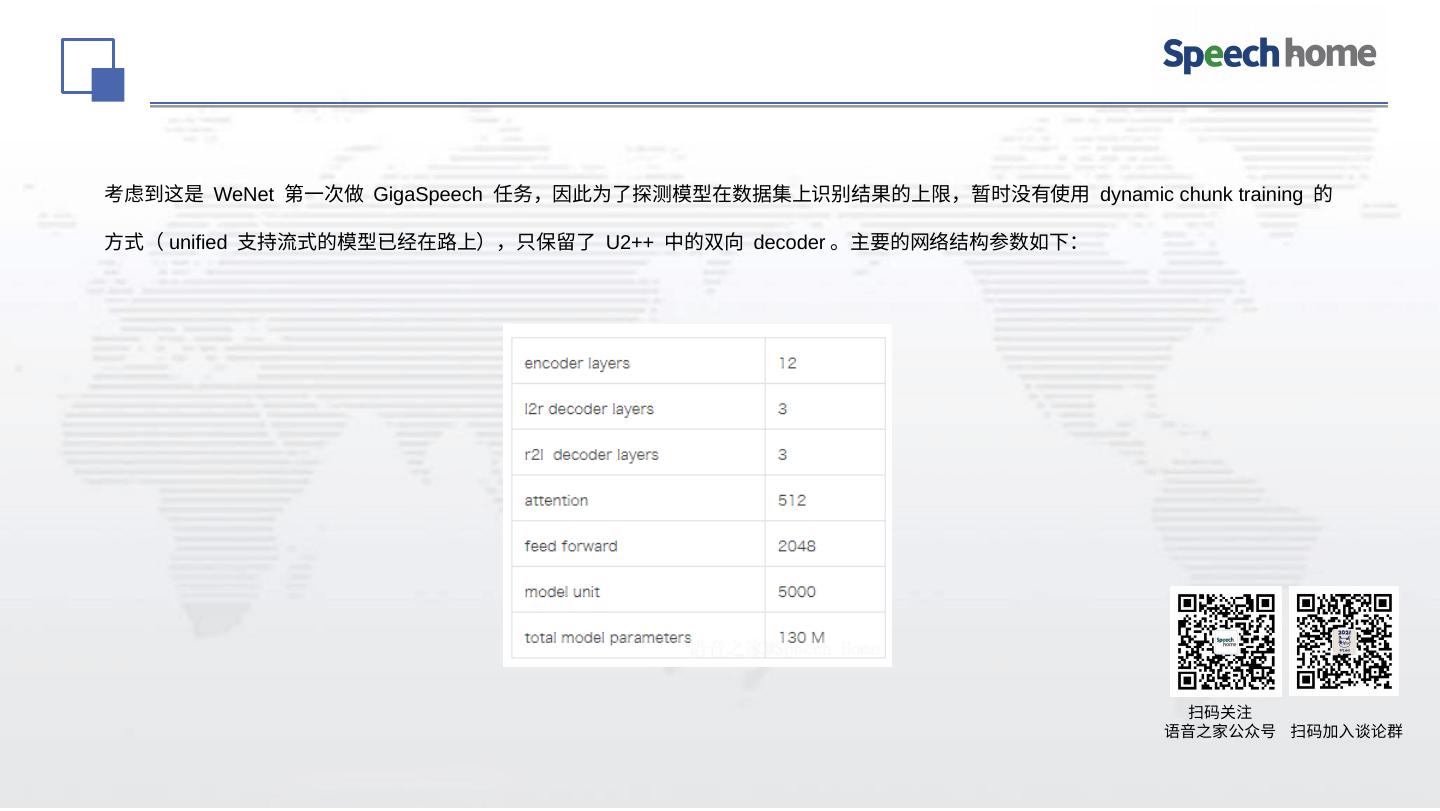
GigaSpeech 拥有10000小时的高质量标注音频数据和33000小时的总音频,是有史以来标注数据量最大、覆盖场景和主题最多的开源语音识别数据集。感谢果果、家宇和卫强老师的奠基性的工作,相信 GigaSpeech 一定能进一步推动语音识别技术在学术界和工业界的发展。
1 .
2 .
3 .
4 .
5 .
6 .
7 .
8 .
确定删除吗?