






- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Data-Report-Martin-Inline-Graphics-R8-1
在过去两年中,我们与数百位创始人,公司数据负责人和其他专家进行了交流,包括采访了他们当前数据栈中的20多名专业从业人员,希望可以整理出新兴的数据基础设施的最佳实践,并围绕数据基础设施制定通用的词汇表。
通过此高清图表分享我们的调研结果,并向各位技术读者们展示推动数据行业向前发展的技术架构。
展开查看详情
1 . A Unified Data Infrastructure Architecture Query and Processing Ingestion and Sources Transformation Storage Historical Predictive Output Connectors Data Warehouse Dashboards OLTP Databases (Looker, Superset, (Fivetran, Stitch, via CDC Matillion) (Snowflake, BigQuery, Redshift) Mode, Tableau) Applications/ERP Embedded (Oracle, Salesforce, Data Modeling Analytics Netsuite, ...) (dbt, LookML) (Sisense, Looker, cube.js) Event Collectors Workflow Data Science Platform (Segment, Snowplow) Manager (Databricks, Domino, Sagemaker, Dataiku, Augmented (Airflow, Dagster, DataRobot, Anaconda, ...) Analytics Prefect) (Thoughtspot, Outlier, Anodot, Sisu) Logs Data Science and ML Libraries (Pandas, Numpy, R, Dask, Ray, Spark, ... Spark Platform Data Lake Scikit-learn, Pytorch, TensorFlow, Spark ML, XGBoost, ...) App Frameworks 3rd Party APIs (Databricks, EMR) (Plotly Dash, Streamlit) (e.g., Stripe) Databricks/ Delta Lake, Iceberg, Ad Hoc Query Python Libs Hudi, Hive Acid (Pandas, Boto, Engine File and Object Dask, Ray, ...) (Presto, Dremio/ Custom Apps Storage Drill, Impala) Parquet, Batch Query ORC, Avro Engine Real-time (Hive) Analytics (Imply/Druid, Altinity/ S3, GCS, Clickhouse, Rockset) ABS, HDFS Event Streaming (Confluent/Kafka, Pulsar, AWS Kinesis) Stream Processing (Databricks/Spark, Confluent/Kafka, Flink) Metadata Management Quality and Testing Entitlements Observability and Security (Unravel, Accel Data, (Collibra, Alation, Hive, (Great Expectations) (Privacera, Immuta) Fiddler) Metastore, DataHub, ...)
2 . Interpreting the Architecture Query and Processing Ingestion and Sources Transformation Storage Historical Predictive Output Generate relevant Extract data from Store data in a Present results of Provide an interface for analysts and data scientists business and operational systems format accessible to data analysis to to derive insights (query) operational data (E) query & processing internal and systems external users Execute queries and data models against stored Deliver to storage, data, often using distributed compute (processing) aligning schemas Optimize for low Embed data models between source cost, scalability, and into operational and destination (L) analytic workloads systems and (e.g., column store) applications Transform data to a structure ready for In some cases, analysis (T) provide additional data structures or guarantees Describe what Predict what will happened in the happen in the future past (including very recent past) Build data-driven/ ML applications Coordinate the flow of data and the execution of computations across the full lifecycle Ensure proper data quality, performance, and governance of all systems and datasets
3 . Three Common Blueprints Analytic 1 Modern Business Intelligence Systems 2 Multimodal Data Processing Operational 3 AI and ML Systems
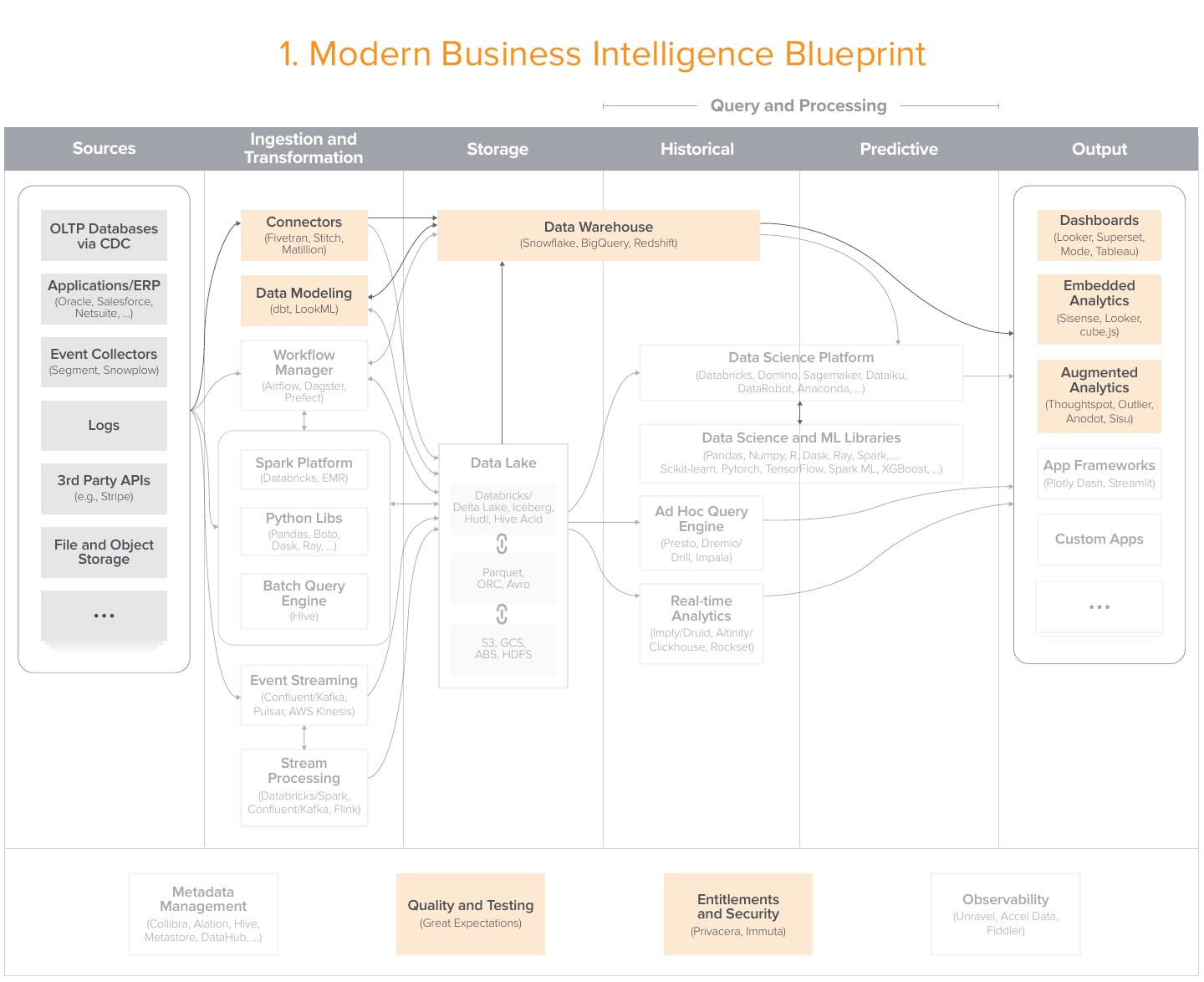
4 . 1. Modern Business Intelligence Blueprint Query and Processing Ingestion and Sources Transformation Storage Historical Predictive Output Connectors Data Warehouse Dashboards OLTP Databases (Looker, Superset, (Fivetran, Stitch, via CDC Matillion) (Snowflake, BigQuery, Redshift) Mode, Tableau) Applications/ERP Embedded (Oracle, Salesforce, Data Modeling Analytics Netsuite, ...) (dbt, LookML) (Sisense, Looker, cube.js) Event Collectors Workflow Data Science Platform (Segment, Snowplow) Manager (Databricks, Domino, Sagemaker, Dataiku, Augmented (Airflow, Dagster, DataRobot, Anaconda, ...) Analytics Prefect) (Thoughtspot, Outlier, Anodot, Sisu) Logs Data Science and ML Libraries (Pandas, Numpy, R, Dask, Ray, Spark, ... Spark Platform Data Lake Scikit-learn, Pytorch, TensorFlow, Spark ML, XGBoost, ...) App Frameworks 3rd Party APIs (Databricks, EMR) (Plotly Dash, Streamlit) (e.g., Stripe) Databricks/ Delta Lake, Iceberg, Ad Hoc Query Python Libs Hudi, Hive Acid (Pandas, Boto, Engine File and Object Dask, Ray, ...) (Presto, Dremio/ Custom Apps Storage Drill, Impala) Parquet, Batch Query ORC, Avro Engine Real-time (Hive) Analytics (Imply/Druid, Altinity/ S3, GCS, Clickhouse, Rockset) ABS, HDFS Event Streaming (Confluent/Kafka, Pulsar, AWS Kinesis) Stream Processing (Databricks/Spark, Confluent/Kafka, Flink) Metadata Management Quality and Testing Entitlements Observability and Security (Unravel, Accel Data, (Collibra, Alation, Hive, (Great Expectations) (Privacera, Immuta) Fiddler) Metastore, DataHub, ...)
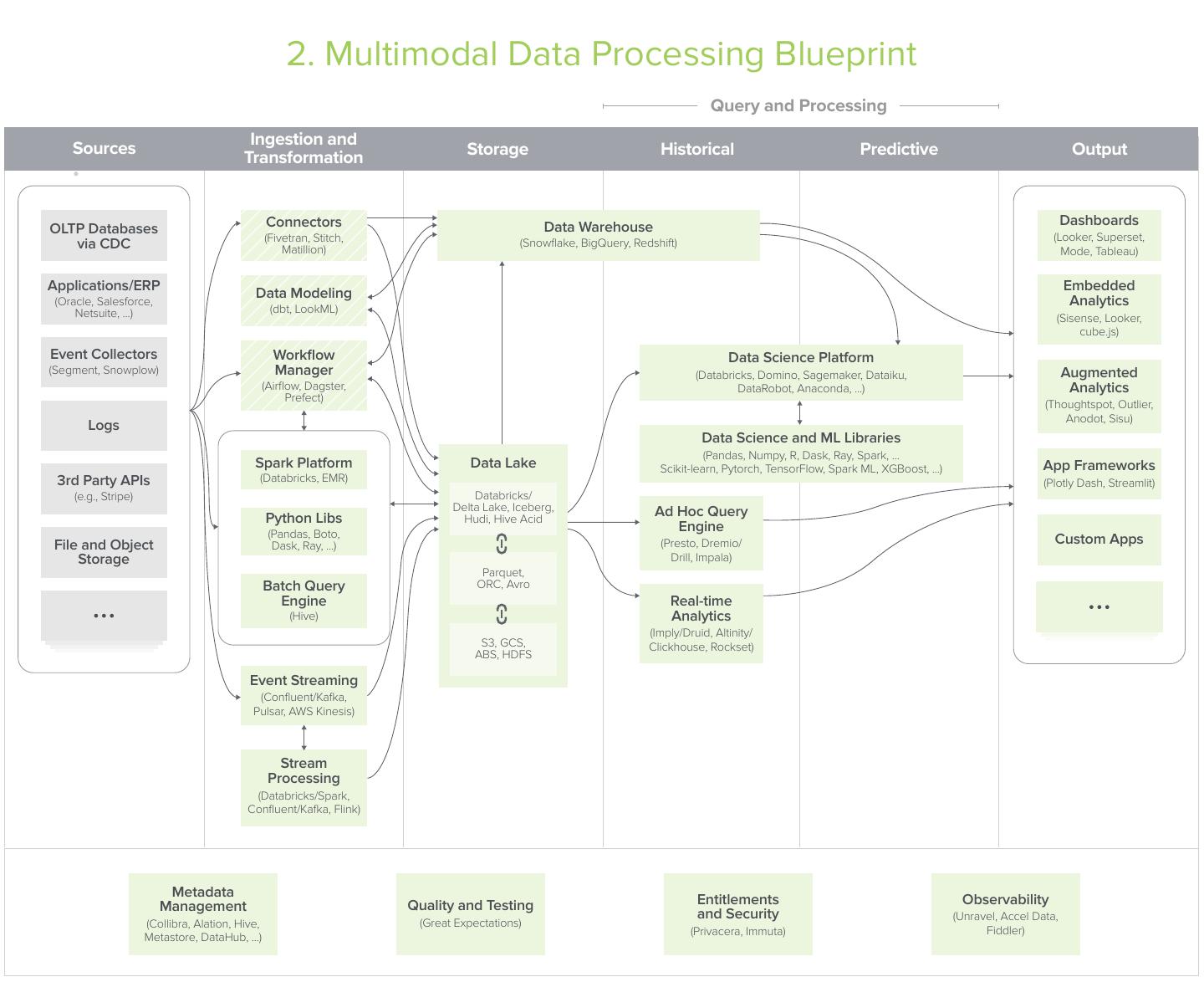
5 . 2. Multimodal Data Processing Blueprint Query and Processing Ingestion and Sources Transformation Storage Historical Predictive Output Connectors Data Warehouse Dashboards OLTP Databases (Looker, Superset, (Fivetran, Stitch, via CDC Matillion) (Snowflake, BigQuery, Redshift) Mode, Tableau) Applications/ERP Embedded (Oracle, Salesforce, Data Modeling Analytics Netsuite, ...) (dbt, LookML) (Sisense, Looker, cube.js) Event Collectors Workflow Data Science Platform (Segment, Snowplow) Manager (Databricks, Domino, Sagemaker, Dataiku, Augmented (Airflow, Dagster, DataRobot, Anaconda, ...) Analytics Prefect) (Thoughtspot, Outlier, Anodot, Sisu) Logs Data Science and ML Libraries (Pandas, Numpy, R, Dask, Ray, Spark, ... Spark Platform Data Lake Scikit-learn, Pytorch, TensorFlow, Spark ML, XGBoost, ...) App Frameworks 3rd Party APIs (Databricks, EMR) (Plotly Dash, Streamlit) (e.g., Stripe) Databricks/ Delta Lake, Iceberg, Ad Hoc Query Python Libs Hudi, Hive Acid (Pandas, Boto, Engine File and Object Dask, Ray, ...) (Presto, Dremio/ Custom Apps Storage Drill, Impala) Parquet, Batch Query ORC, Avro Engine Real-time (Hive) Analytics (Imply/Druid, Altinity/ S3, GCS, Clickhouse, Rockset) ABS, HDFS Event Streaming (Confluent/Kafka, Pulsar, AWS Kinesis) Stream Processing (Databricks/Spark, Confluent/Kafka, Flink) Metadata Management Quality and Testing Entitlements Observability and Security (Unravel, Accel Data, (Collibra, Alation, Hive, (Great Expectations) (Privacera, Immuta) Fiddler) Metastore, DataHub, ...)
6 . 3. AI and ML Blueprint Data Transformation Model Training and Development Model Inference Data Labeling (Labelbox, Snorkel, Scale, Sagemaker) Data Sources (Data lake + Dataflow Automation data warehouse + (Airflow, Pachyderm, Elementl, Prefect, Tecton, Kubeflow) streaming engine) Query Engines Feature Store Feature Server (Presto, Hive) (Tecton) (Tecton, Cassandra) Data Science Libraries (Spark, Pandas, NumPy, Dask) Data Science Platform Model Batch Predictor (Jupyter, Databricks, Domino, Sagemaker, DataRobot, Registry (Spark) H2O, Colab, Deepnote, Noteable) (Algorithmia, MLflow, Sagemaker) Online Model Clients Server Experiment ML (TF Serving, Ray Tracking Framework Compiler Serve, Seldon) (Weights and (Scikit-learn, (TVM) Biases, Comet, XGBoost, MLlib) MLflow) Model DL Monitoring Visualization Framework (Fiddler, Arthur, (Tensorboard, (TensorFlow, Keras, Arize) Fiddler) PyTorch, H2O, Hugging Face) Model Tuning (Sigopt, hyperopt, RL Libraries Ray Tune) (Gym, Dopamine, RLlib, Coach) Distributed Processing (Spark, Ray, Dask, Distributed TF, Kubeflow, Horovod)
3秒后跳转登录页面
去登陆

