展开查看详情
1 .是 Spark Streaming, Structured
Streaming
正如在之前的那篇⽂文章中 Spark Streaming 设计原理理 中说到 Spark 团队之后对 Spark Streaming 的
维护可能越来越少,Spark 2.4 版本的 Release Note ⾥里里⾯面果然⼀一个 Spark Streaming 相关的 ticket 都
没有。相⽐比之下,Structured Streaming 有将近⼗十个 ticket 说明。所以各位同学,是时候舍弃 Spark
Streaming 转向 Structured Streaming 了了,当然理理由并不不⽌止于此。我们这篇⽂文章就来分析⼀一下 Spark
Streaming 的不不⾜足,以及Structured Streaming 的设计初衷和思想是怎么样的。⽂文章主要参考今年年
(2018 年年)sigmod 上⾯面的这篇论⽂文:Structured Streaming: A Declarative API for Real-Time
Applications in Apache Spark 。
⾸首先可以注意到的了了论⽂文标题中的 Declarative API,中⽂文⼀一般叫做声明式编程 API。⼀一般直接看到这
个词可能不不知道什什么意思,但是当我们列列出他的对⽴立单词:Imperative API,中⽂文⼀一般叫命令式编程
API,仿佛⼀一切都明了了了了。是的,没错,Declarative 只是表达出我们想要什什么,⽽而 Imperative 则是
说为了了得到什什么我们需要做哪些东⻄西⼀一个个说明。举个例例⼦子,我们要⼀一个糕点,去糕点店直接去定做
告诉店员我们要什什么样式的糕点,然后店员去给我们做出来,这就是 Declarative。⽽而 Imperative 对
应的就是⾯面粉店了了。
0. Spark Streaming 不不
在开始正式介绍 Structured Streaming 之前有⼀一个问题还需要说清楚,就是 Spark Streaming 存在
哪些不不⾜足?总结⼀一下主要有下⾯面⼏几点:
Processing Time Event Time。⾸首先解释⼀一下,Processing Time 是数据到达 Spark 被
处理理的时间,⽽而 Event Time 是数据⾃自带的属性,⼀一般表示数据产⽣生于数据源的时间。⽐比如 IoT 中,
传感器器在 12:00:00 产⽣生⼀一条数据,然后在 12:00:05 数据传送到 Spark,那么 Event Time 就是
12:00:00,⽽而 Processing Time 就是 12:00:05。我们知道 Spark Streaming 是基于 DStream 模型的
micro-batch 模式,简单来说就是将⼀一个微⼩小时间段,⽐比如说 1s,的流数据当前批数据来处理理。如果
我们要统计某个时间段的⼀一些数据统计,毫⽆无疑问应该使⽤用 Event Time,但是因为 Spark Streaming
的数据切割是基于 Processing Time,这样就导致使⽤用 Event Time 特别的困难。
Complex, low-level api。这点⽐比较好理理解,DStream (Spark Streaming 的数据模型)提供的 API
类似 RDD 的 API 的,⾮非常的 low level。当我们编写 Spark Streaming 程序的时候,本质上就是要去
构造 RDD 的 DAG 执⾏行行图,然后通过 Spark Engine 运⾏行行。这样导致⼀一个问题是,DAG 可能会因为开
发者的⽔水平参差不不⻬齐⽽而导致执⾏行行效率上的天壤之别。这样导致开发者的体验⾮非常不不好,也是任何⼀一个
基础框架不不想看到的(基础框架的⼝口号⼀一般都是:你们专注于⾃自⼰己的业务逻辑就好,其他的交给
我)。这也是很多基础系统强调 Declarative 的⼀一个原因。
reason about end-to-end application。这⾥里里的 end-to-end 指的是直接 input 到 out,⽐比如 Kafka
接⼊入 Spark Streaming 然后再导出到 HDFS 中。DStream 只能保证⾃自⼰己的⼀一致性语义是 exactly-
once 的,⽽而 input 接⼊入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要⽤用户⾃自
⼰己来保证。⽽而这个语义保证写起来也是⾮非常有挑战性,⽐比如为了了保证 output 的语义是 exactly-once
语义需要 output 的存储系统具有幂等的特性,或者⽀支持事务性写⼊入,这个对于开发者来说都不不是⼀一
件容易易的事情。
�
2 . 。尽管批流本是两套系统,但是这两套系统统⼀一起来确实很有必要,我们有时候确实
需要将我们的流处理理逻辑运⾏行行到批数据上⾯面。关于这⼀一点,最早在 2014 年年 Google 提出 Dataflow 计
算服务的时候就批判了了 streaming/batch 这种叫法,⽽而是提出了了 unbounded/bounded data 的说
法。DStream 尽管是对 RDD 的封装,但是我们要将 DStream 代码完全转换成 RDD 还是有⼀一点⼯工作
量量的,更更何况现在 Spark 的批处理理都⽤用 DataSet/DataFrame API 了了。
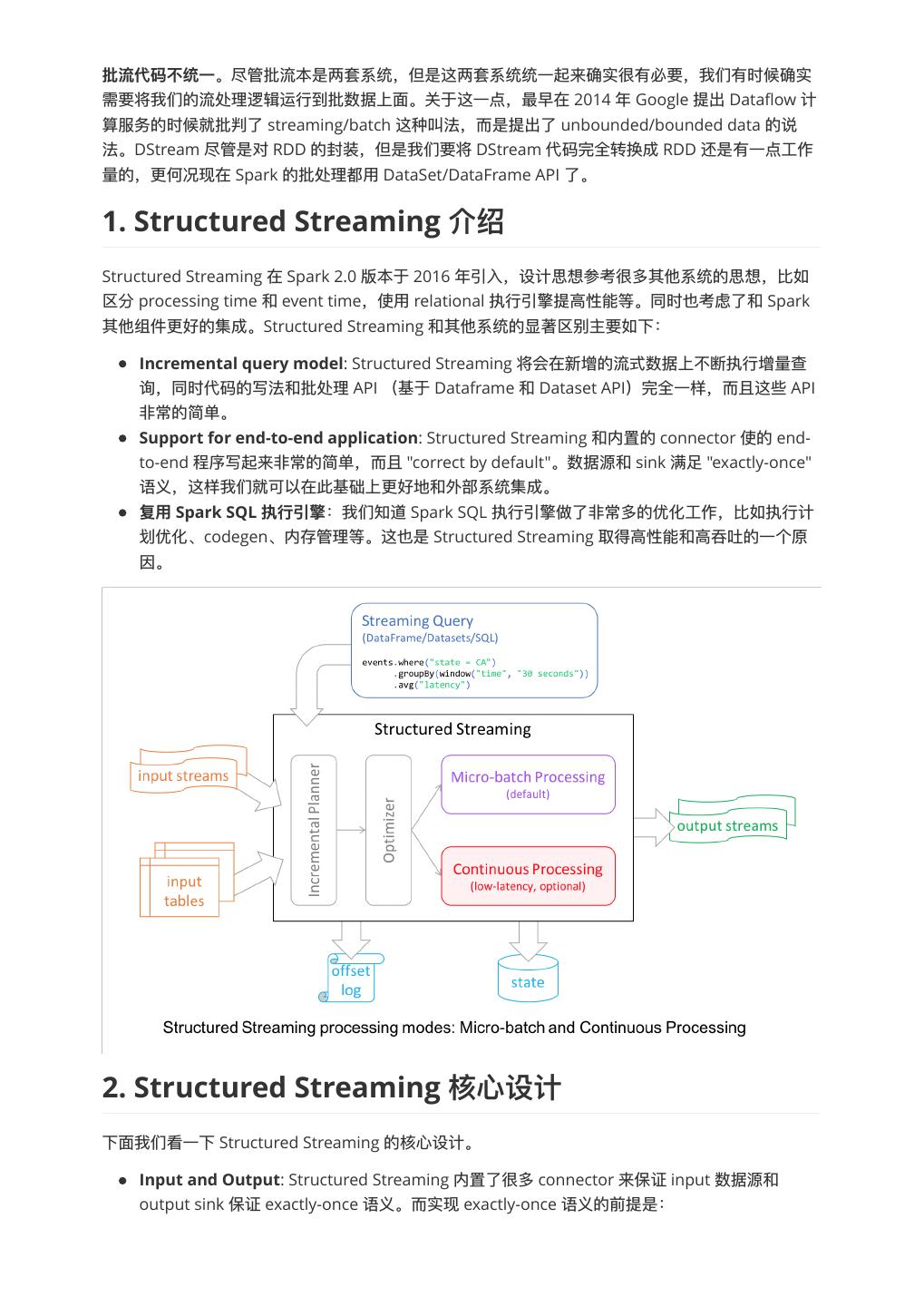
1. Structured Streaming
Structured Streaming 在 Spark 2.0 版本于 2016 年年引⼊入,设计思想参考很多其他系统的思想,⽐比如
区分 processing time 和 event time,使⽤用 relational 执⾏行行引擎提⾼高性能等。同时也考虑了了和 Spark
其他组件更更好的集成。Structured Streaming 和其他系统的显著区别主要如下:
Incremental query model: Structured Streaming 将会在新增的流式数据上不不断执⾏行行增量量查
询,同时代码的写法和批处理理 API (基于 Dataframe 和 Dataset API)完全⼀一样,⽽而且这些 API
⾮非常的简单。
Support for end-to-end application: Structured Streaming 和内置的 connector 使的 end-
to-end 程序写起来⾮非常的简单,⽽而且 "correct by default"。数据源和 sink 满⾜足 "exactly-once"
语义,这样我们就可以在此基础上更更好地和外部系统集成。
Spark SQL :我们知道 Spark SQL 执⾏行行引擎做了了⾮非常多的优化⼯工作,⽐比如执⾏行行计
划优化、codegen、内存管理理等。这也是 Structured Streaming 取得⾼高性能和⾼高吞吐的⼀一个原
因。
2. Structured Streaming
下⾯面我们看⼀一下 Structured Streaming 的核⼼心设计。
Input and Output: Structured Streaming 内置了了很多 connector 来保证 input 数据源和
output sink 保证 exactly-once 语义。⽽而实现 exactly-once 语义的前提是:
�
3 . Input 数据源必须是可以 replay 的,⽐比如 Kafka,这样节点 crash 的时候就可以重新读取
input 数据。常⻅见的数据源包括 Amazon Kinesis, Apache Kafka 和⽂文件系统。
Output sink 必须要⽀支持写⼊入是幂等的。这个很好理理解,如果 output 不不⽀支持幂等写⼊入,那
么⼀一致性语义就是 at-least-once 了了。另外对于某些 sink, Structured Streaming 还提供了了
原⼦子写⼊入来保证 exactly-once 语义。
API: Structured Streaming 代码编写完全复⽤用 Spark SQL 的 batch API,也就是对⼀一个或者多
个 stream 或者 table 进⾏行行 query。query 的结果是 result table,可以以多种不不同的模式
(append, update, complete)输出到外部存储中。另外,Structured Streaming 还提供了了⼀一
些 Streaming 处理理特有的 API:Trigger, watermark, stateful operator。
Execution: 复⽤用 Spark SQL 的执⾏行行引擎。Structured Streaming 默认使⽤用类似 Spark
Streaming 的 micro-batch 模式,有很多好处,⽐比如动态负载均衡、再扩展、错误恢复以及
straggler (straggler 指的是哪些执⾏行行明显慢于其他 task 的 task)重试。除了了 micro-batch 模
式,Structured Streaming 还提供了了基于传统的 long-running operator 的 continuous 处理理模
式。
Operational Features: 利利⽤用 wal 和状态存储,开发者可以做到集中形式的 rollback 和错误恢
复。还有⼀一些其他 Operational 上的 feature,这⾥里里就不不细说了了。
3. Structured Streaming
可能是受到 Google Dataflow 的批流统⼀一的思想的影响,Structured Streaming 将流式数据当成⼀一个
不不断增⻓长的 table,然后使⽤用和批处理理同⼀一套 API,都是基于 DataSet/DataFrame 的。如下图所示,
通过将流式数据理理解成⼀一张不不断增⻓长的表,从⽽而就可以像操作批的静态数据⼀一样来操作流数据了了。
在这个模型中,主要存在下⾯面⼏几个组成部分:
Input Unbounded Table: 流式数据的抽象表示
Query: 对 input table 的增量量式查询
Result Table: Query 产⽣生的结果表
Output: Result Table 的输出
�
4 .下⾯面举⼀一个具体的例例⼦子,NetworkWordCount,代码如下:
1 // Create DataFrame representing the stream of input lines from
connection to localhost:9999
2 val lines = spark.readStream
3 .format("socket")
4 .option("host", "localhost")
5 .option("port", 9999)
6 .load()
7
8 // Split the lines into words
9 val words = lines.as[String].flatMap(_.split(" "))
10
11 // Generate running word count
12 val wordCounts = words.groupBy("value").count()
13
14 // Start running the query that prints the running counts to the
console
15 val query = wordCounts.writeStream
16 .outputMode("complete")
17 .format("console")
18 .start()
代码实际执⾏行行流程可以⽤用下图来表示。把流式数据当成⼀一张不不断增⻓长的 table,也就是图中的
Unbounded table of all input。然后每秒 trigger ⼀一次,在 trigger 的时候将 query 应⽤用到 input
table 中新增的数据上,有时候还需要和之前的静态数据⼀一起组合成结果。query 产⽣生的结果成为
Result Table,我们可以选择将 Result Table 输出到外部存储。输出模式有三种:
Complete mode: Result Table 全量量输出
�
5 . Append mode (default): 只有 Result Table 中新增的⾏行行才会被输出,所谓新增是指⾃自上⼀一次
trigger 的时候。因为只是输出新增的⾏行行,所以如果⽼老老数据有改动就不不适合使⽤用这种模式。
Update mode: 只要更更新的 Row 都会被输出,相当于 Append mode 的加强版。
和 batch 模式相⽐比,streaming 模式还提供了了⼀一些特有的算⼦子操作,⽐比如 window, watermark,
statefaul oprator 等。
window,下图是⼀一个基于 event-time 统计 window 内事件的例例⼦子。
1 import spark.implicits._
2
3 val words = ... // streaming DataFrame of schema { timestamp: Timestamp,
word: String }
4
5 // Group the data by window and word and compute the count of each group
6 val windowedCounts = words.groupBy(
7 window("eventTime", "10 minutes", "5 minutes"),
8 $"word"
9 ).count()
如下图所示,窗⼝口⼤大⼩小为 10 分钟,每 5 分钟 trigger ⼀一次。在 12:11 时候收到了了⼀一条 12:04 的数据,
也就是 late data (什什么叫 late data 呢?就是 Processing Time ⽐比 Event Time 要晚),然后去更更新
其对应的 Result Table 的记录。
�
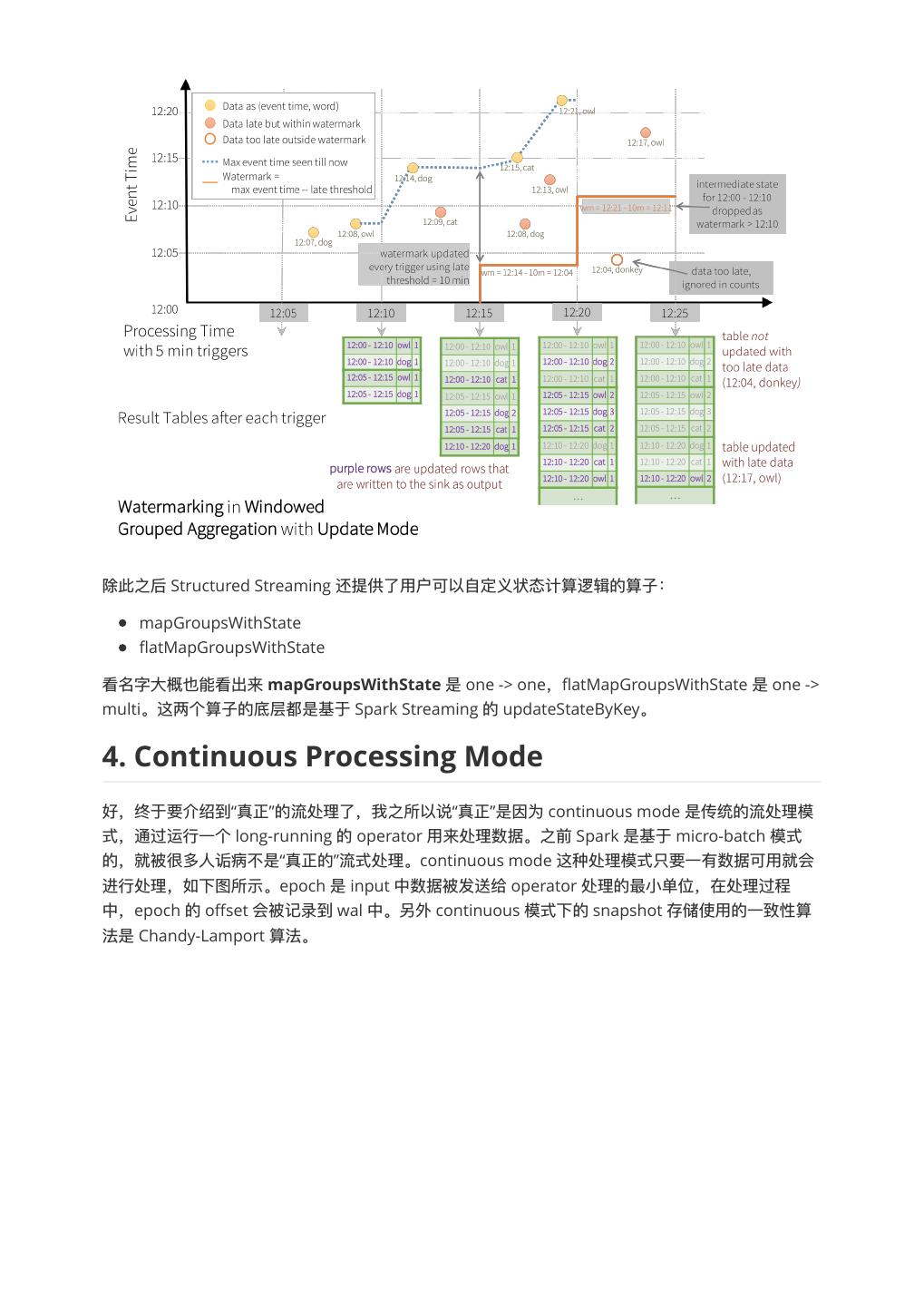
6 .watermark,是也为了了处理理 ,很多情况下对于这种 late data 的时效数据并没有必要⼀一直保留留太久。
⽐比如说,数据晚了了 10 分钟或者还有点有,但是晚了了 1 个⼩小时就没有⽤用了了,另外这样设计还有⼀一个好
处就是中间状态没有必要维护那么多。watermark 的形式化定义为 max(eventTime) - threshold,早
于 watermark 的数据直接丢弃。
1 import spark.implicits._
2
3 val words = ... // streaming DataFrame of schema { timestamp:
Timestamp, word: String }
4
5 // Group the data by window and word and compute the count of each
group
6 val windowedCounts = words
7 .withWatermark("eventTime", "10 minutes")
8 .groupBy(
9 window("eventTime", "10 minutes", "5 minutes"),
10 $"word")
11 .count()
⽤用下图表示更更加形象。在 12:15 trigger 时 watermark 为 12:14 - 10m = 12:04,所以 late date
(12:08, dog; 12:13, owl) 都被接收了了。在 12:20 trigger 时 watermark 为 12:21 - 10m = 12:11,所以
late data (12:04, donkey) 都丢弃了了。
�
7 .除此之后 Structured Streaming 还提供了了⽤用户可以⾃自定义状态计算逻辑的算⼦子:
mapGroupsWithState
flatMapGroupsWithState
看名字⼤大概也能看出来 mapGroupsWithState 是 one -> one,flatMapGroupsWithState 是 one ->
multi。这两个算⼦子的底层都是基于 Spark Streaming 的 updateStateByKey。
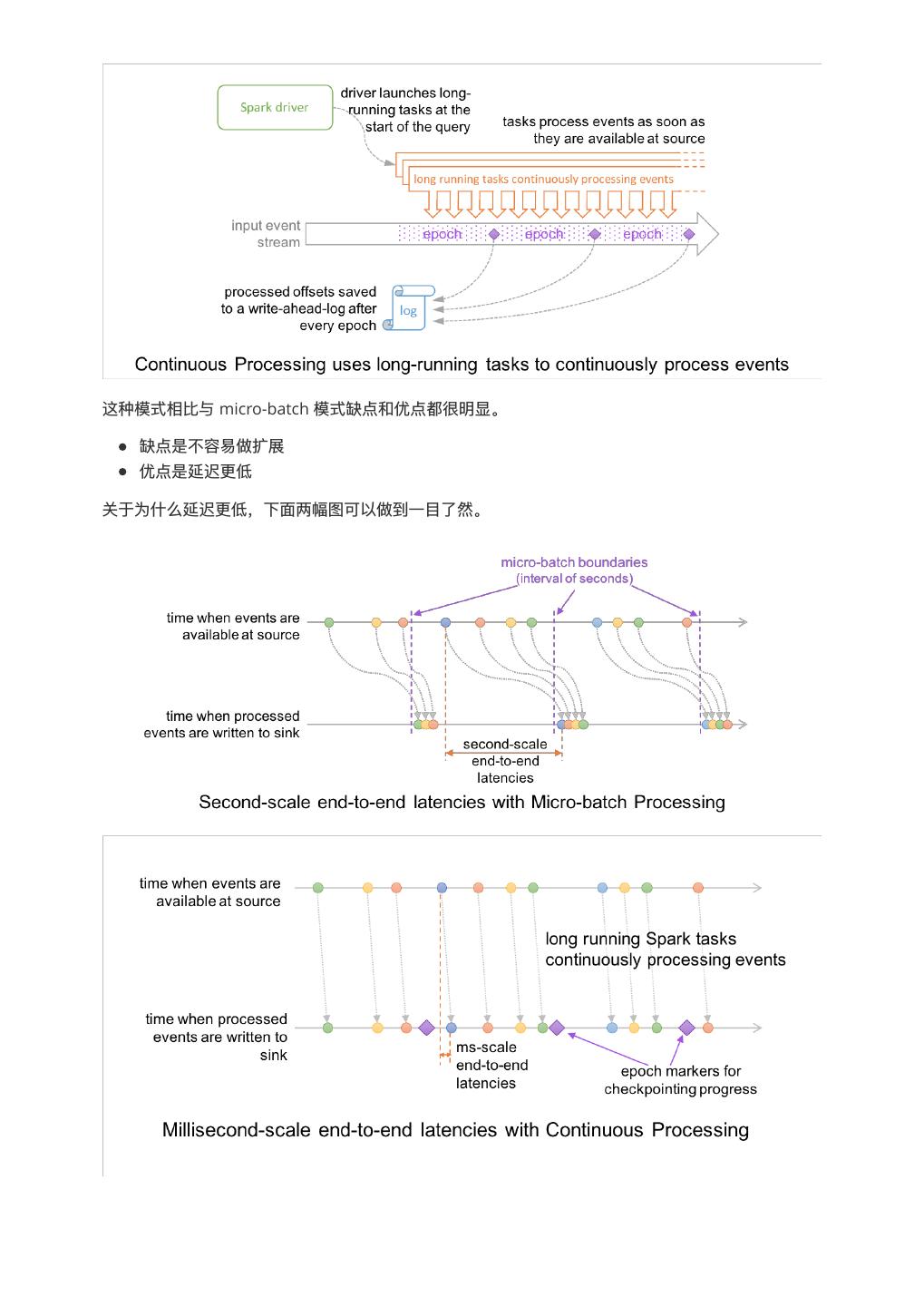
4. Continuous Processing Mode
好,终于要介绍到“真正”的流处理理了了,我之所以说“真正”是因为 continuous mode 是传统的流处理理模
式,通过运⾏行行⼀一个 long-running 的 operator ⽤用来处理理数据。之前 Spark 是基于 micro-batch 模式
的,就被很多⼈人诟病不不是“真正的”流式处理理。continuous mode 这种处理理模式只要⼀一有数据可⽤用就会
进⾏行行处理理,如下图所示。epoch 是 input 中数据被发送给 operator 处理理的最⼩小单位,在处理理过程
中,epoch 的 offset 会被记录到 wal 中。另外 continuous 模式下的 snapshot 存储使⽤用的⼀一致性算
法是 Chandy-Lamport 算法。
�
8 .这种模式相⽐比与 micro-batch 模式缺点和优点都很明显。
缺点是不不容易易做扩展
优点是延迟更更低
关于为什什么延迟更更低,下⾯面两幅图可以做到⼀一⽬目了了然。
5. ⼀一
�
9 .5. ⼀一
对于 Structured Streaming 来说,因为有两种模式,所以我们分开讨论。
micro-batch 模式可以提供 end-to-end 的 exactly-once 语义。原因是因为在 input 端和 output 端
都做了了很多⼯工作来进⾏行行保证,⽐比如 input 端 replayable + wal,output 端写⼊入幂等。
continuous mode 只能提供 at-least-once 语义。关于 continuous mode 的官⽅方讨论的实在太少,
甚⾄至只是提了了⼀一下。在和 @李李呈祥 讨论之后觉得应该还是 continuous mode 由于要尽可能保证低延
迟,所以在 sink 端没有做⼀一致性保证。
6. Benchmark
Structured Streming 的官⽅方论⽂文⾥里里⾯面给出了了 Yahoo! Streaming Benchmark 的结果,Structured
Streaming 的 throughput ⼤大概是 Flink 的 2 倍和 Kafka Streaming 的 90 多倍。
7.
总结⼀一下,Structured Streaming 通过提供⼀一套 high-level 的 declarative api 使得流式计算的编写相
⽐比 Spark Streaming 简单容易易不不少,同时通过提供 end-to-end 的 exactly-once 语义
8.
最后,闲扯⼀一点别的。Spark 在 5 年年推出基于 micro-batch 模式的 Spark Streaming 必然是基于当时
Spark Engine 最快的⽅方式,尽管不不是真正的流处理理,但是在吞吐量量更更重要的年年代,还是尝尽了了甜头。
⽽而 Spark 的真正基于 continuous 处理理模式的 Structured Streaming 直到 Spark 2.3 版本才真正推
出,从⽽而导致近两年年让 Flink 尝尽了了甜头(当然和 Flink 的优秀的语义模型存在很⼤大的关系)。在实时
计算领域,由 Spark 的卓越核⼼心 SQL Engine 助⼒力力的 Structured Streaming,还是⻛风头正劲的 Flink,
亦或是其他流处理理引擎,究竟谁将占领统治地位,还是值得期待⼀一下的。
Ps: 本⼈人本周⼆二在由阿⾥里里巴巴 EMR 团队主导的 Apache Spark 社群钉钉群做了了⼀一场 《从 Spark
Streaming 到 Structured Streaming》的直播,直播 ppt 可以在 slidetalk ⽹网站上⾯面查看,地址:htt
ps://www.slidestalk.com/s/FromSparkStreamingtoStructuredStreaming58639 ,Apache Spark
钉钉社群定期会有技术分享并可以观看直播回放,感兴趣的可以⼀一起来学习,钉钉群⼆二维码如下,使
⽤用钉钉扫码即可加⼊入。
�
10 .9. Reference
1. Zaharia M, Das T, Li H, et al. Discretized streams: Fault-tolerant streaming computation at
scale[C]//Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems
Principles. ACM, 2013: 423-438.
2. Akidau T, Bradshaw R, Chambers C, et al. The dataflow model: a practical approach to
balancing correctness, latency, and cost in massive-scale, unbounded, out-of-order data
�
11 . processing[J]. Proceedings of the VLDB Endowment, 2015, 8(12): 1792-1803.
3. Armbrust M, Das T, Torres J, et al. Structured Streaming: A Declarative API for Real-Time
Applications in Apache Spark[C]//Proceedings of the 2018 International Conference on
Management of Data. ACM, 2018: 601-613.
4. The world beyond batch: Streaming 101
5. The world beyond batch: Streaming 102
6. Streaming Systems
7. https://databricks.com/blog/2018/03/20/low-latency-continuous-processing-mode-in-struc
tured-streaming-in-apache-spark-2-3-0.html
8. https://en.wikipedia.org/wiki/Chandy-Lamport_algorithm
9. A Deep Dive Into Structured Streaming: https://databricks.com/session/a-deep-dive-into-st
ructured-streaming
10. Continuous Applications: Evolving Streaming in Apache Spark 2.0: https://databricks.com/b
log/2016/07/28/continuous-applications-evolving-streaming-in-apache-spark-2-0.html
11. Spark Structured Streaming:A new high-level API for streaming: https://databricks.com/blo
g/2016/07/28/structured-streaming-in-apache-spark.html
12. Event-time Aggregation and Watermarking in Apache Spark’s Structured Streaming: https:/
/databricks.com/blog/2017/05/08/event-time-aggregation-watermarking-apache-sparks-str
uctured-streaming.html
13. http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
14. Benchmarking Structured Streaming on Databricks Runtime Against State-of-the-Art
Streaming Systems: https://databricks.com/blog/2017/10/11/benchmarking-structured-str
eaming-on-databricks-runtime-against-state-of-the-art-streaming-systems.html
�