








































































































































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
自然语言处理基础
自然语言处理的总体介绍及其主要的任务,传统机器学习方法和深度学习方法分析,以及涉及到的NLP前沿研究进展。
展开查看详情
1 .自然语言处理 基础 (Natural Language Processing, NLP) 孙栩 北京大学 xusun@pku.edu.cn http://xusun.org
2 .NLP 的总体介绍 简介、研究范式 NLP 的传统 机器学习方法 简单分类、序列标注问题 NLP 的深度 学习方法 语义表示、反向传播、机器翻译、句法分析、文档分类 NLP 的典型 任务简介 问答系统 、 情感分析 、 自然语言生成 NLP 的前沿 研究进展:自然语言生成面对的主要挑战 内容安排 2 /300
3 .NLP 的总体介绍 简介、研究范式 NLP 的传统 机器学习方法 简单分类、序列标注问题 NLP 的深度 学习方法 语义表示、反向传播、机器翻译、句法分析、文档分类 NLP 的典型 任务简介 问答系统 、 情感分析 、 自然语言生成 NLP 的前沿 研究进展:自然语言生成面对的主要挑战 内容安排 3 /300
4 .NLP 的总体介绍 简介 研究范式
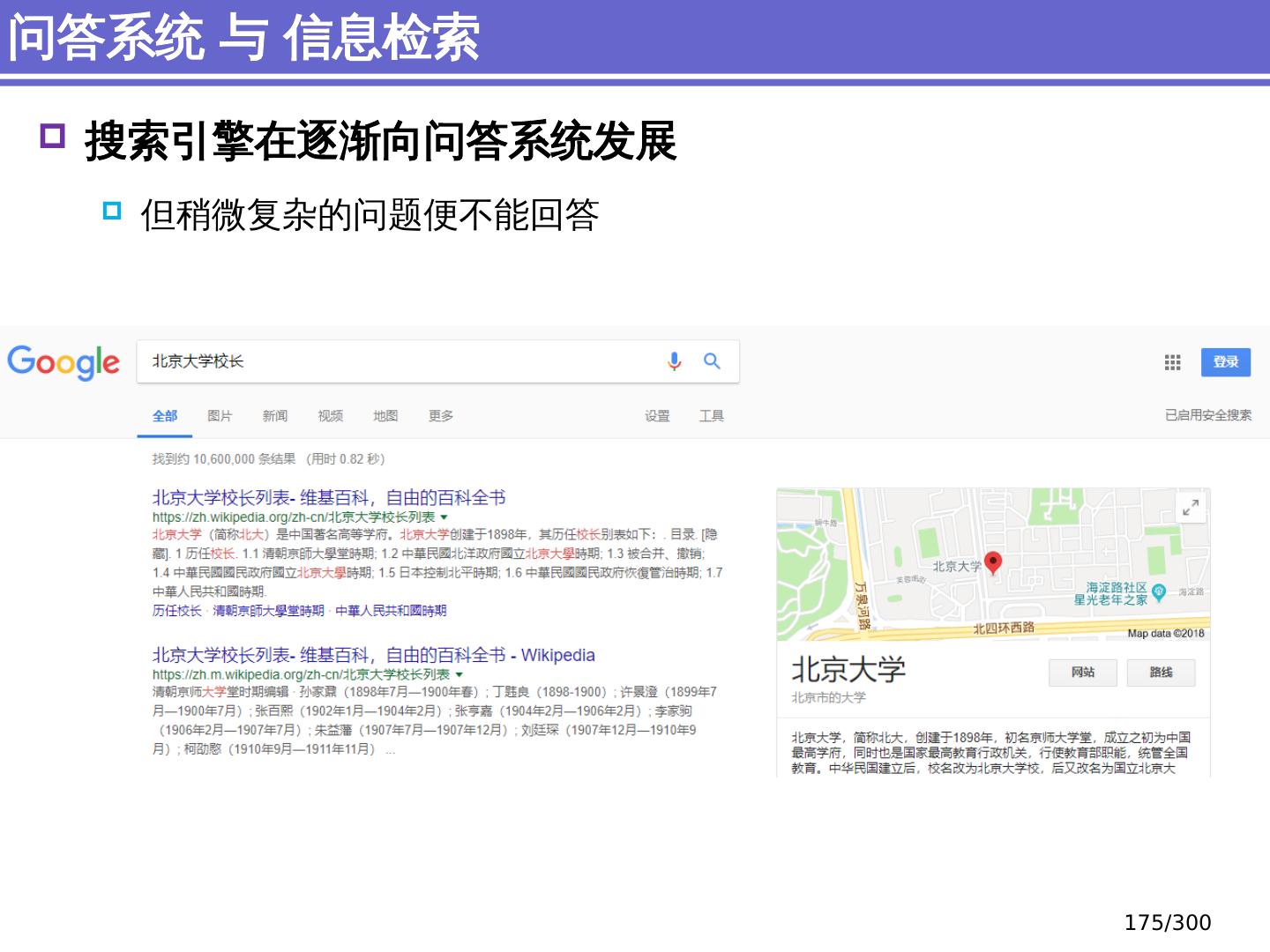
5 .自然语言处理是通过建立形式化的计算模型来分析、理解和处理自然语言 什么是自然语言: 指人类使用的语言,如汉语、英语 等 语言是思维的载体,是人际交流的 工具 语言的两种属性-文字和声音 人类 历史上以语言文字形式记载和流传的 知识 占知识总量的 80 %以上 其它术语 计算语言学 (Computational Linguistics) 自然语言理解 (Natural Language Understanding) 人类语言技术 (Human Language Technology) 自然语言处理是什么? 5 /300
6 .自然语言处理( natural language processing , NLP ) 或 称自然语言理解 (natural language understanding) 是 人工智能研究的重要 内容 自然语言处理就是 利用计算机为工具对人类特有的书面 形式和 口头形式的自然语言的信息进行各种类型处理和 加工 的技术。 - 冯志伟 《 自然语言的计算机处理 》 自然语言处理是什么? 人工智能( AI ) 机器学习、模式识别 机器视觉,等等 自然语言处理 (机器对人类语言的理解) 6 /300
7 .终极目标 强 人工智能 强自然语言处理 使计算机能理解并生成人类语言(人工智能的最高境界) 当前目标 弱人工智能 弱自然语言处理 研制具有一定人类语言能力的计算机文本或语音处理系统(目前阶段切实可行的做法) 研究目标 7 /300
8 .强人工智能、 弱人工智能 ? 如何 判断计算机系统的智能? 计算机系统的表现 (act) 如何? 反应 (react) 如何? 相互作用 (interact ) 如何? 与有意识个体(人)比较如何? 自然语言处理是什么? 8 /300
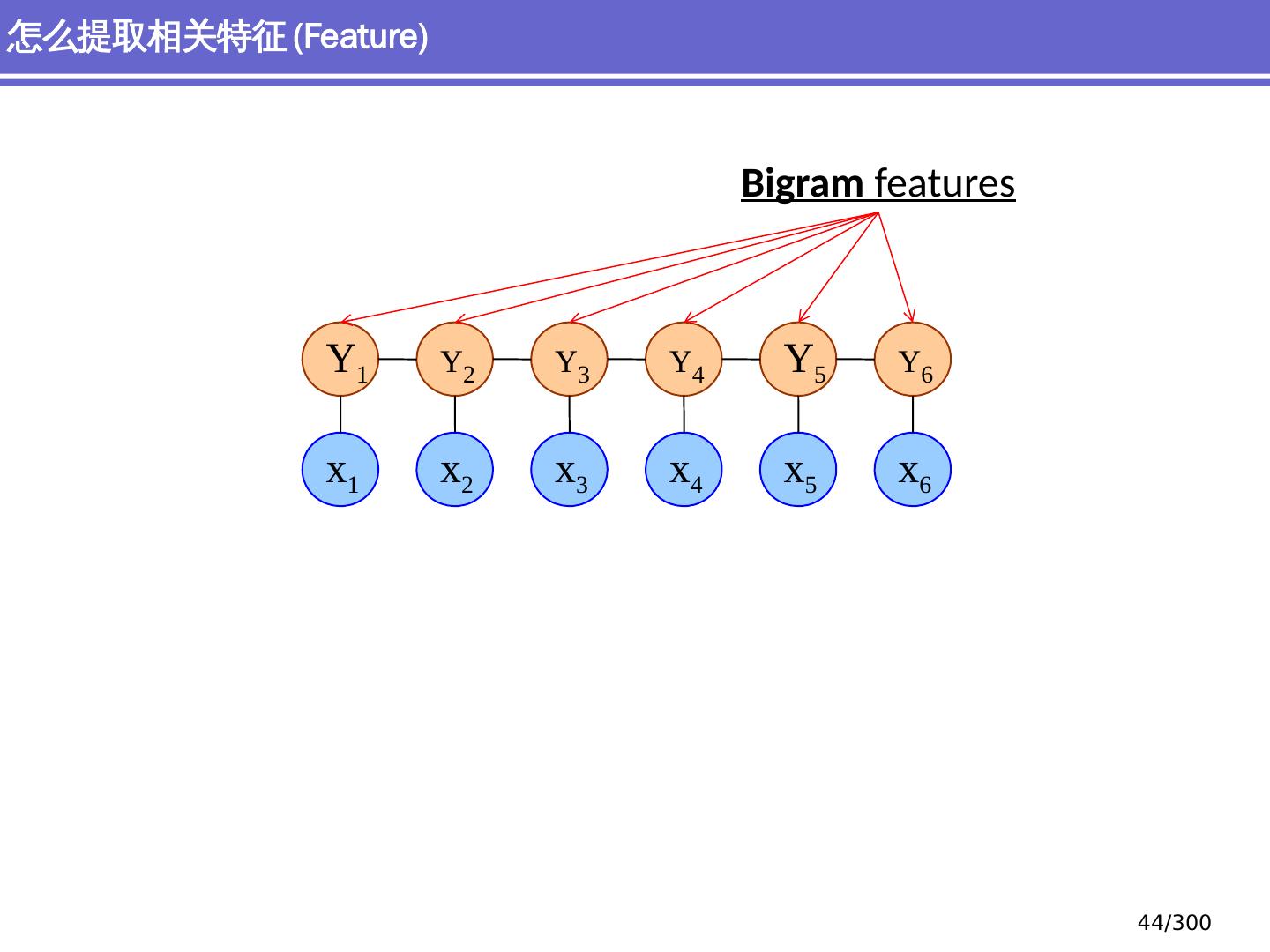
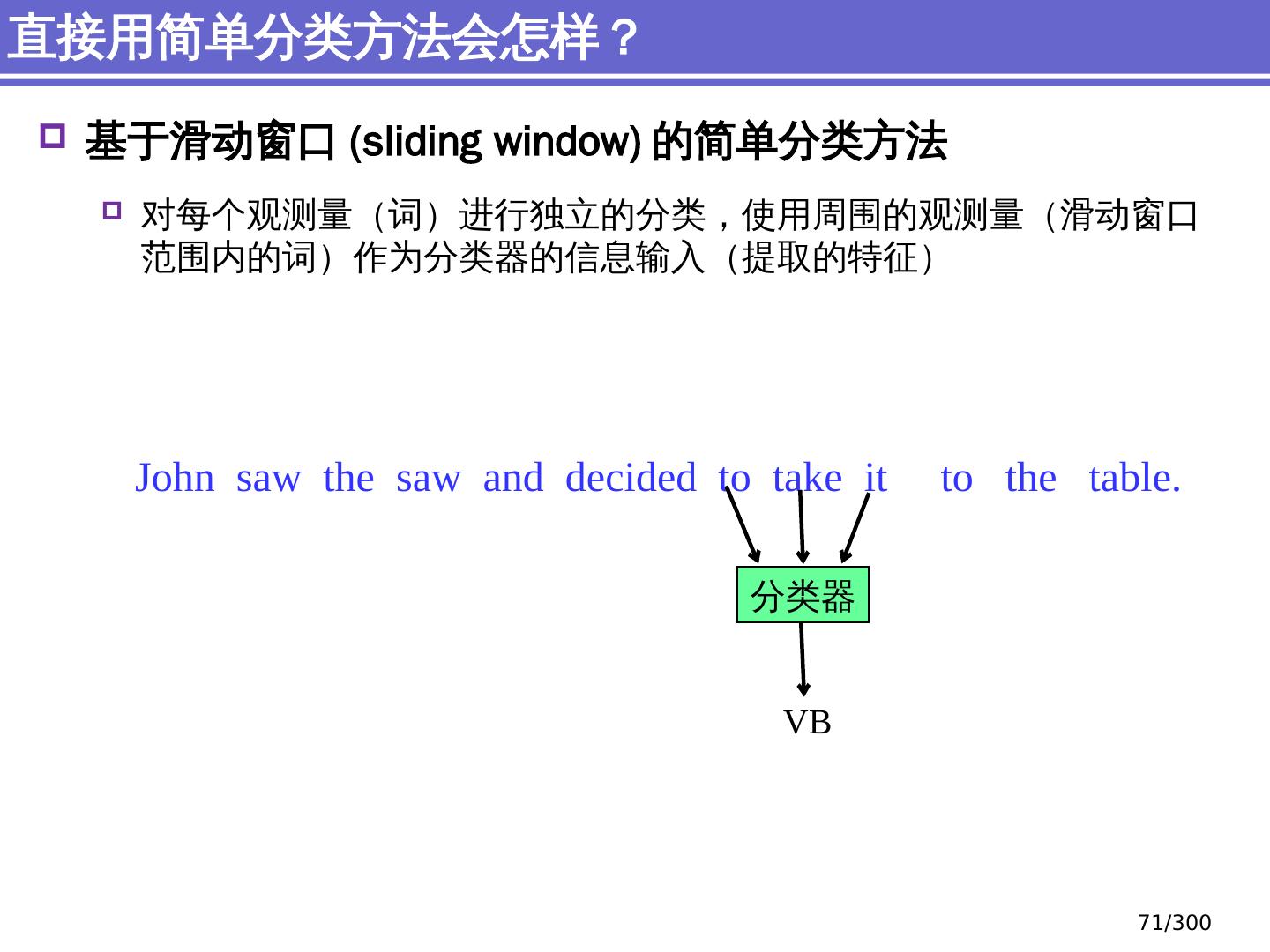
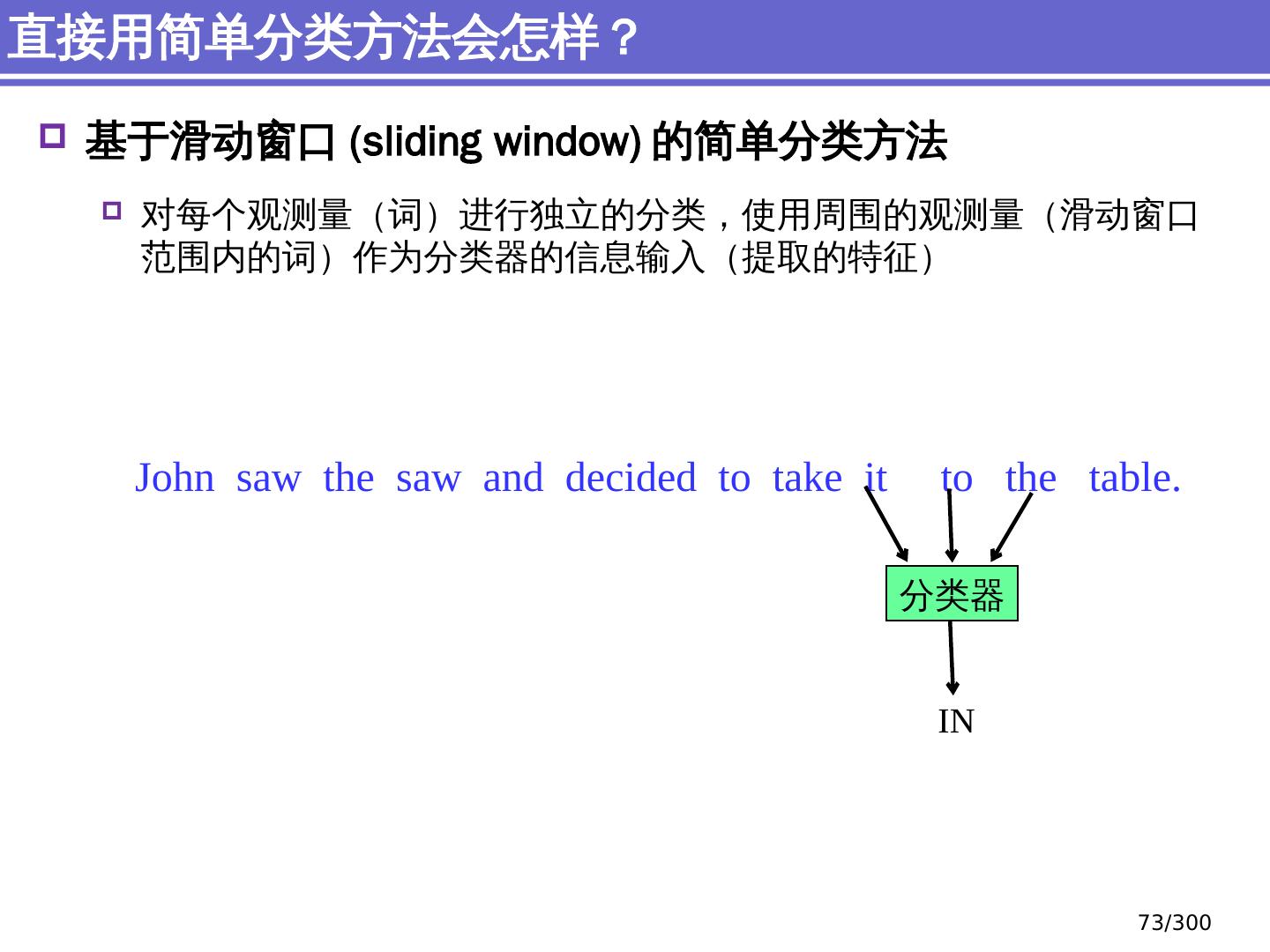
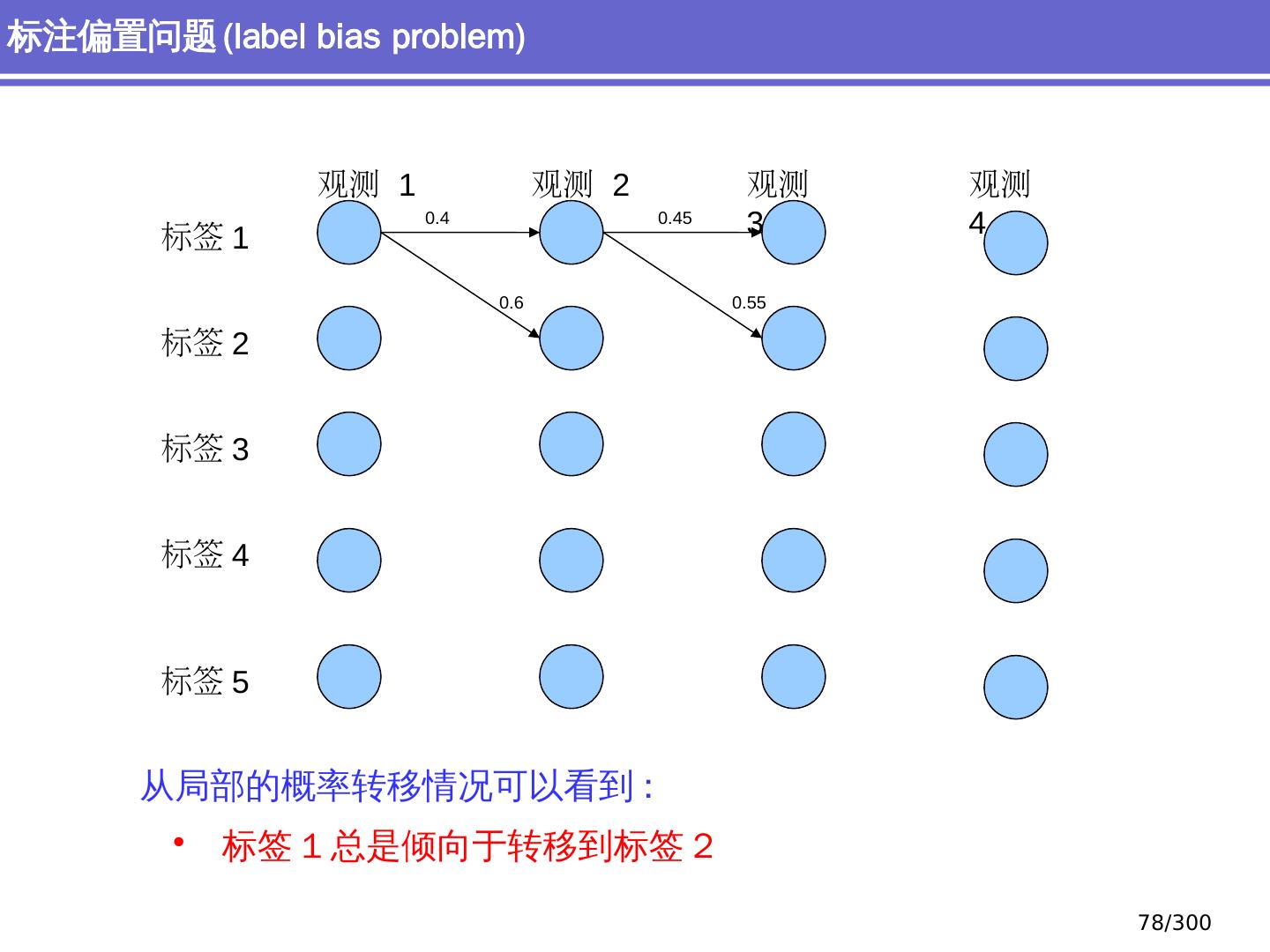
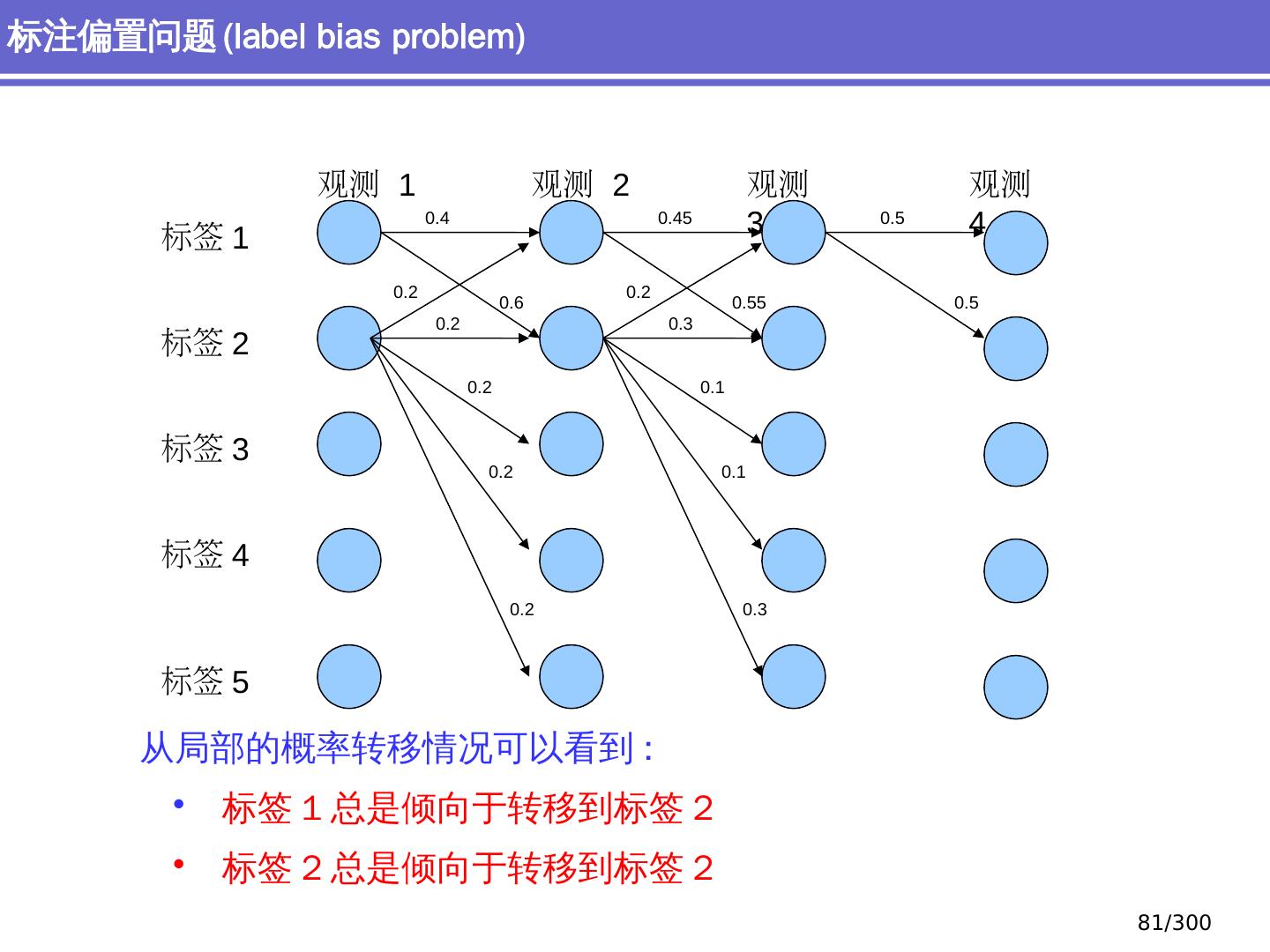
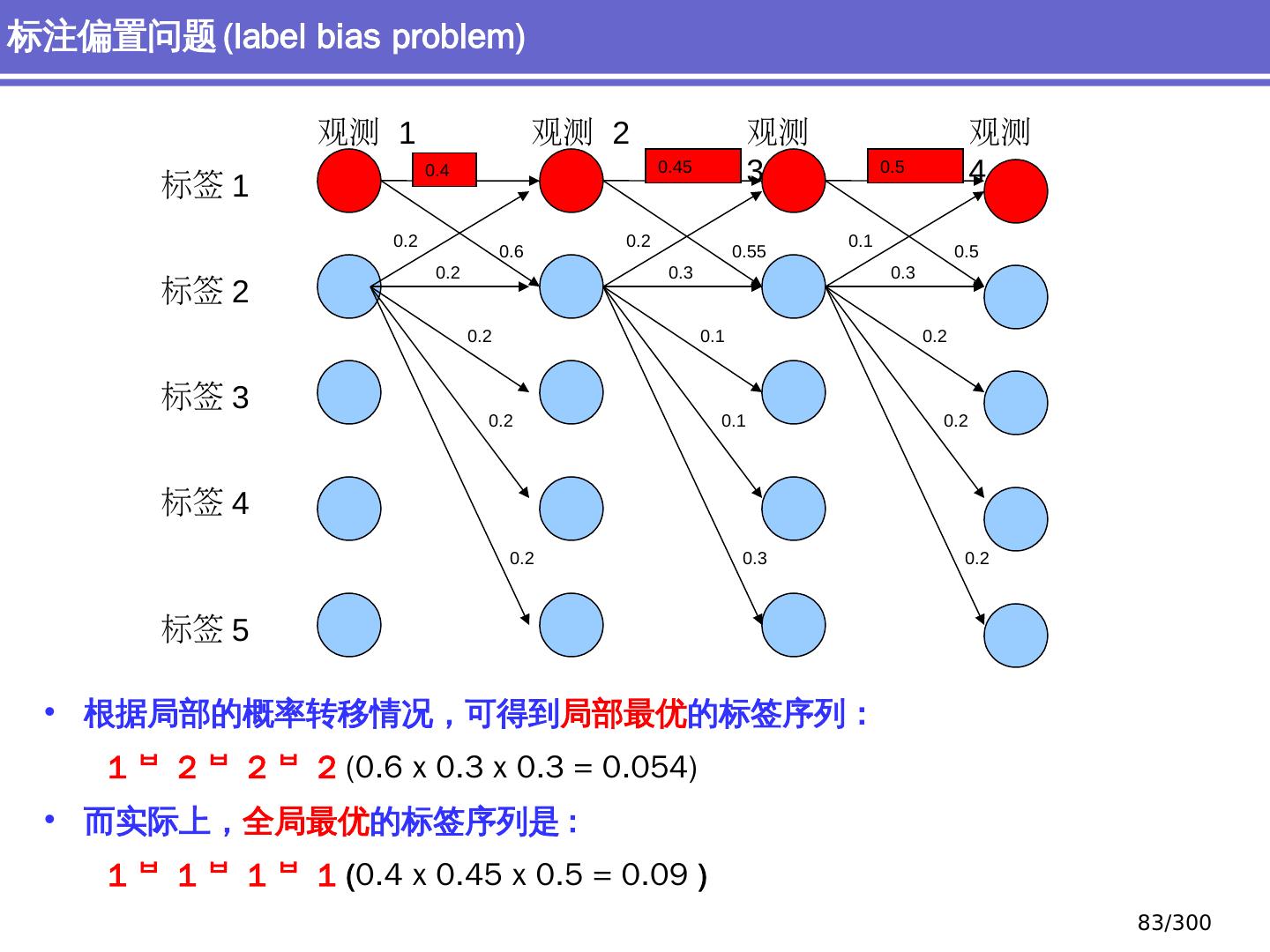
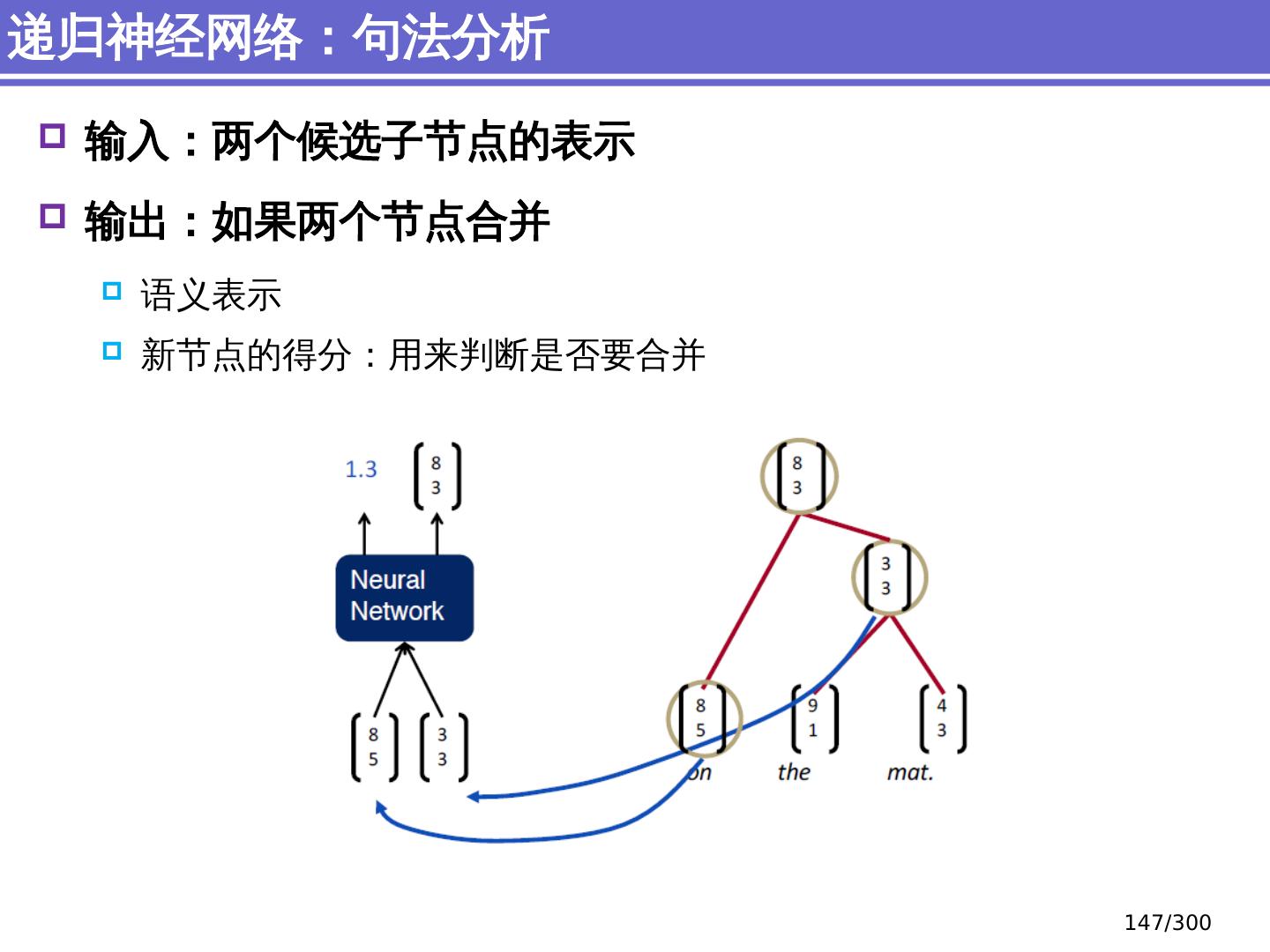
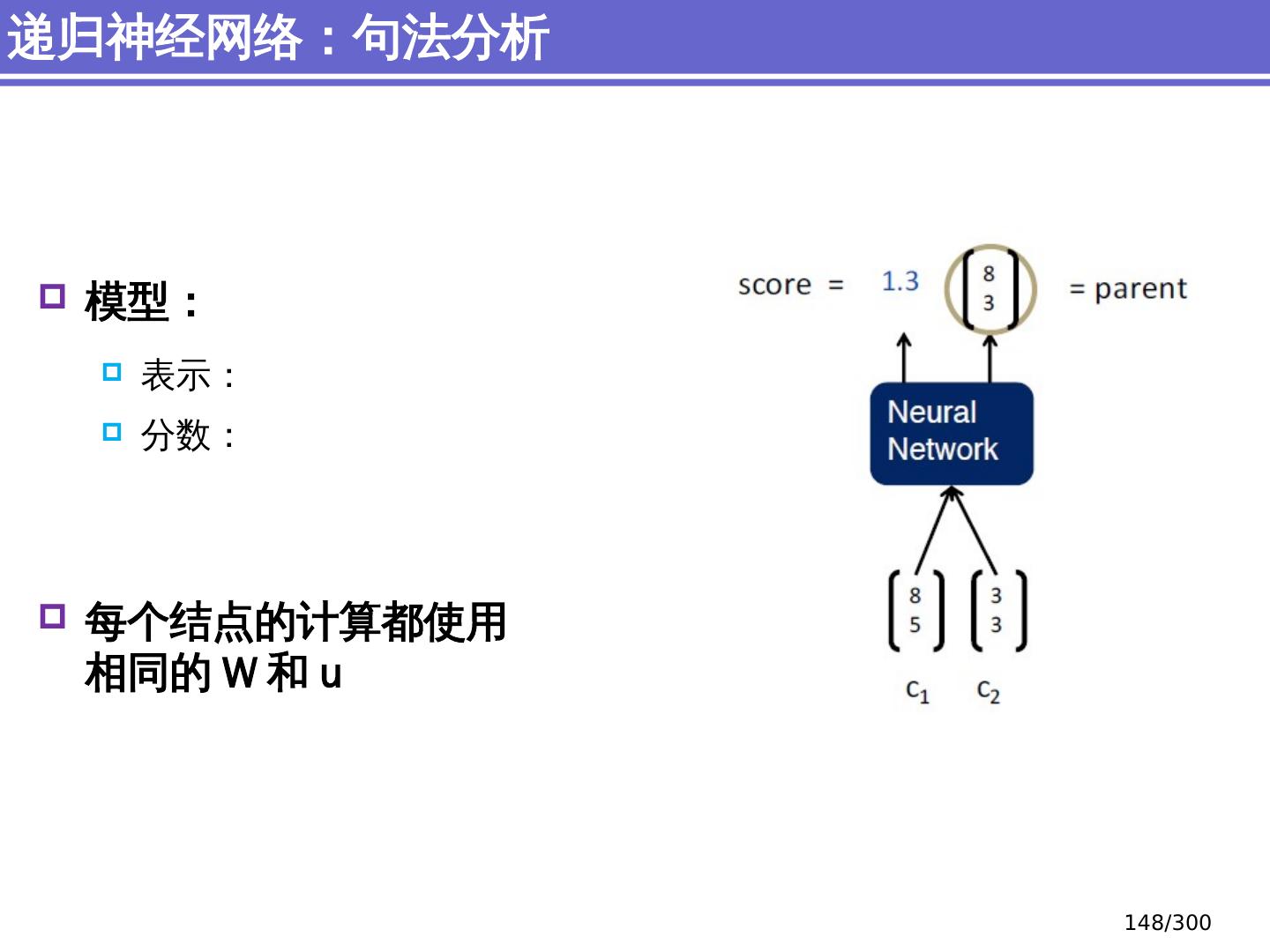
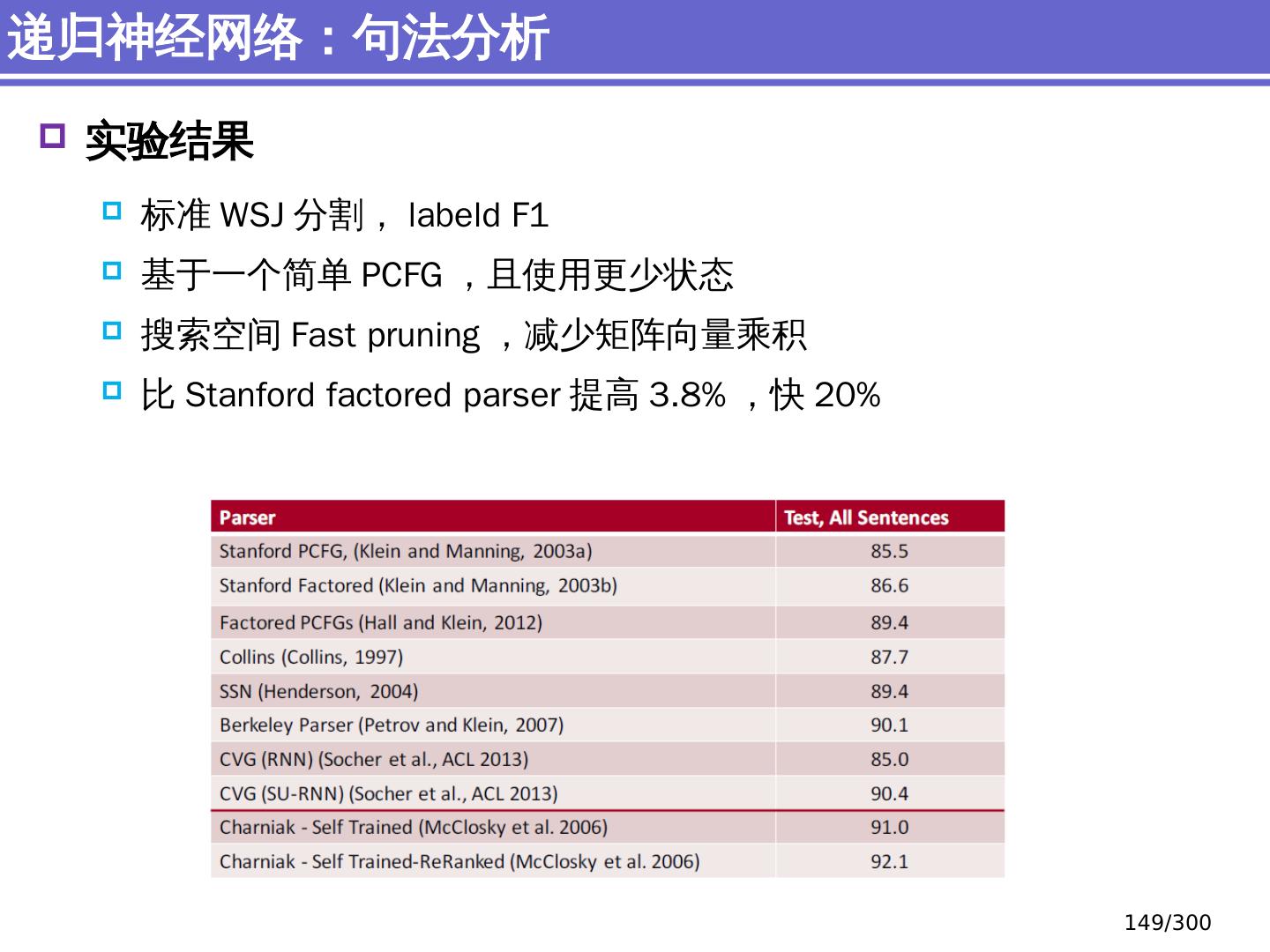
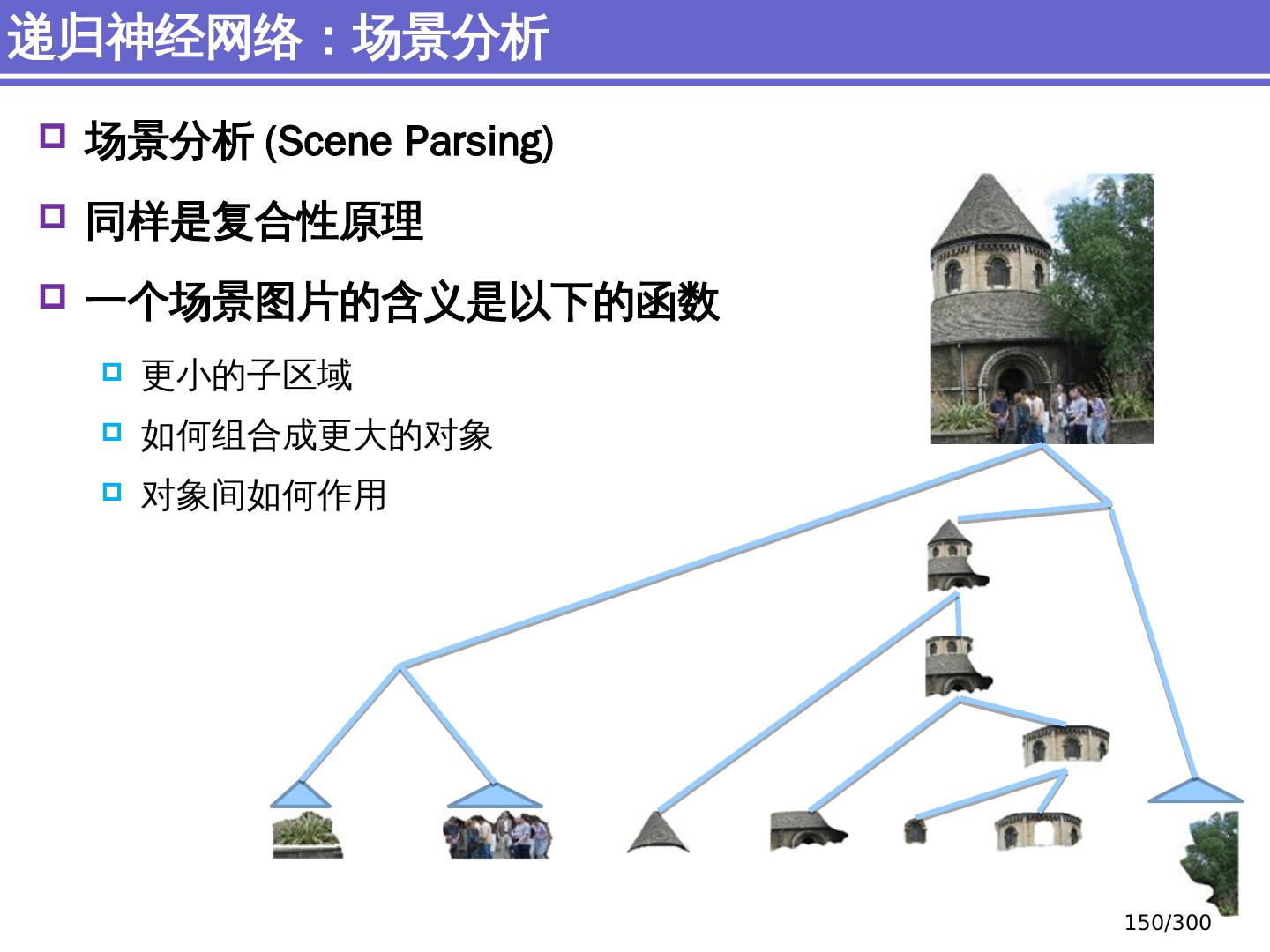
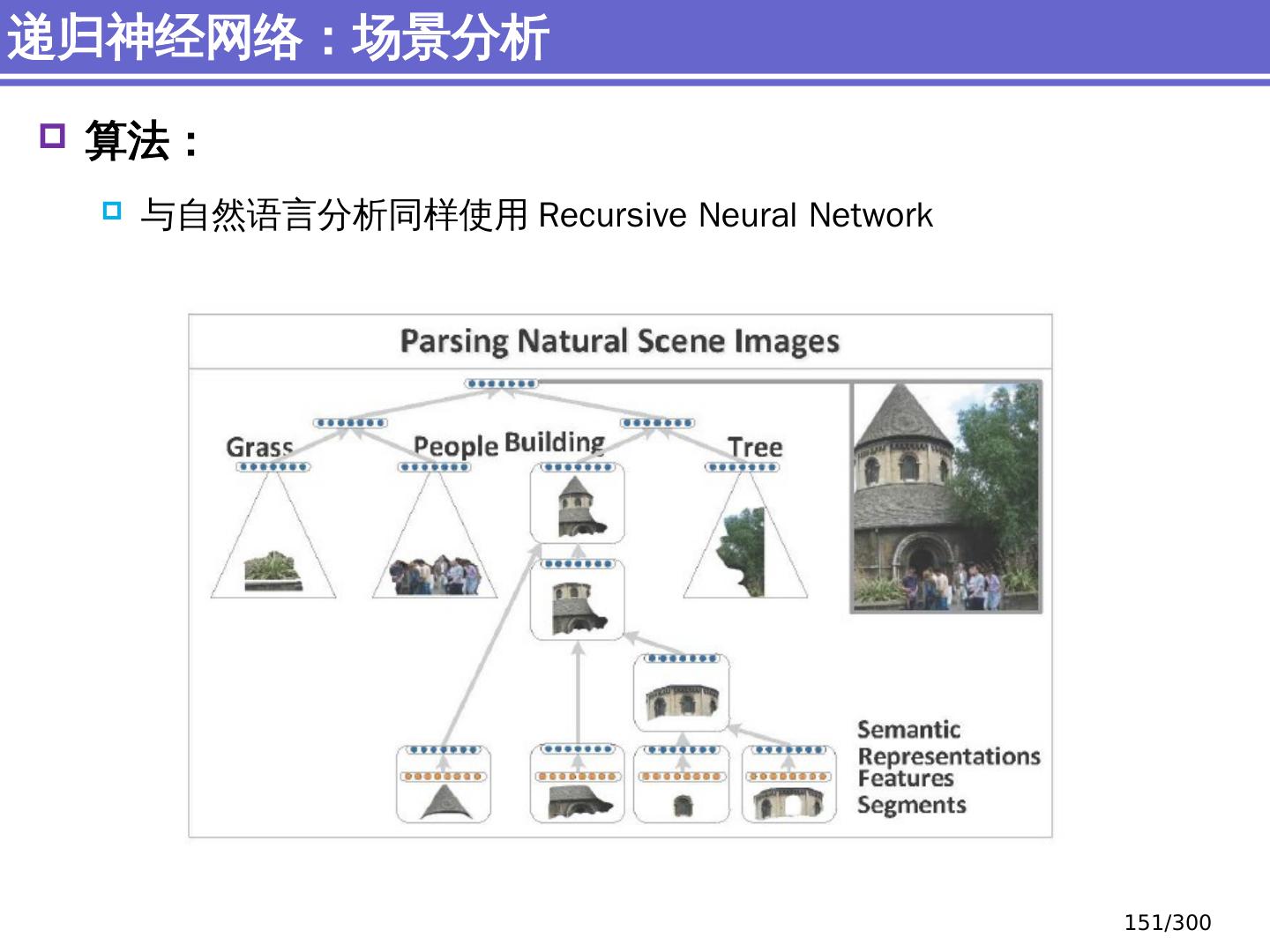
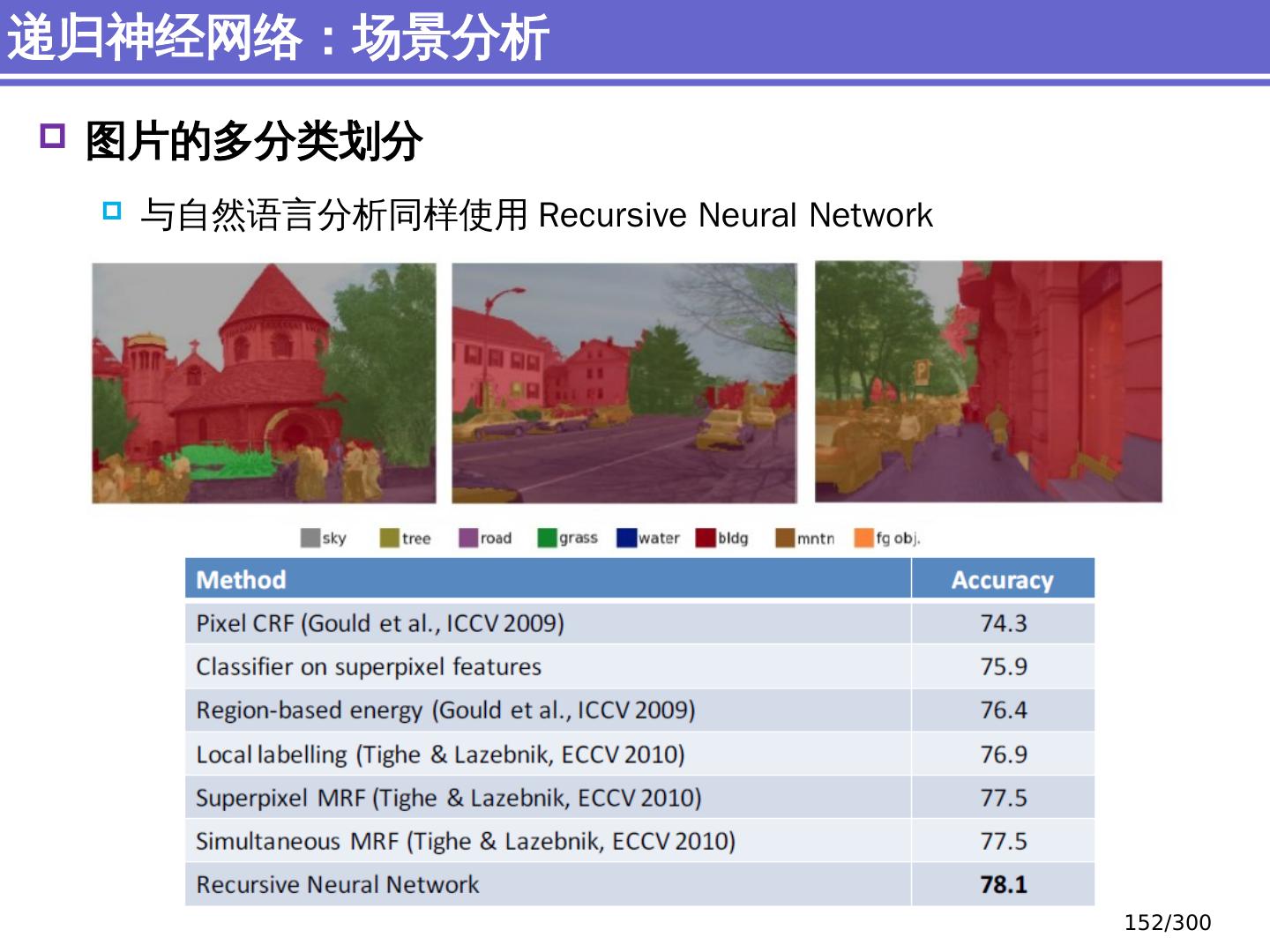
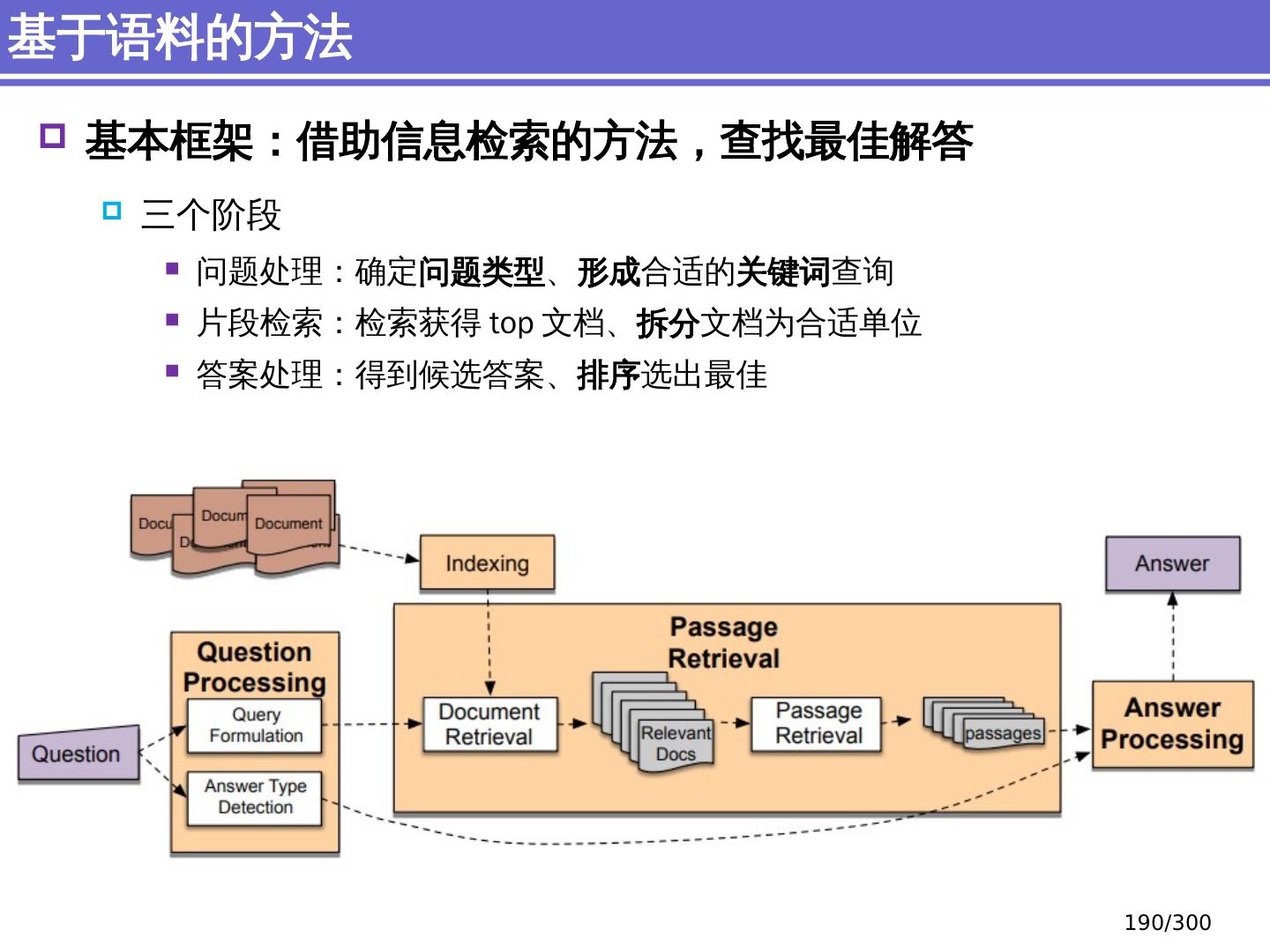
9 .NLP 的 传统 统计机器学习方法 序列标注问题 链 状 结构 典型问题:分词、 词性标注、实体识别 典型模型 :HMM,结构化感知器 句法分析 树状结构 上下文无关句法、 PCFG 模型 依存句法、依存 句法分析 模型 研究方向 S NP VP John V NP liked the dog in the pen 9 /300
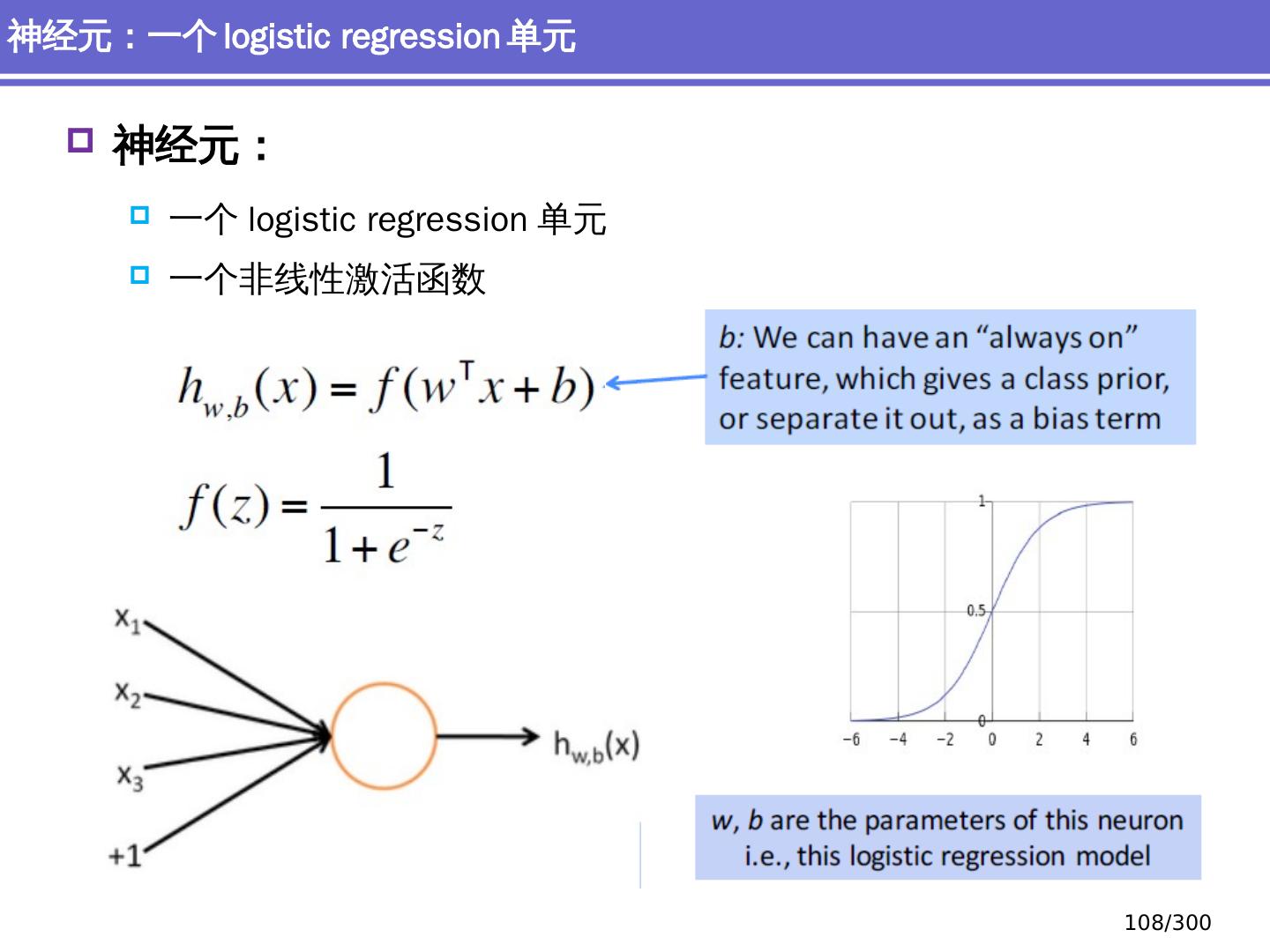
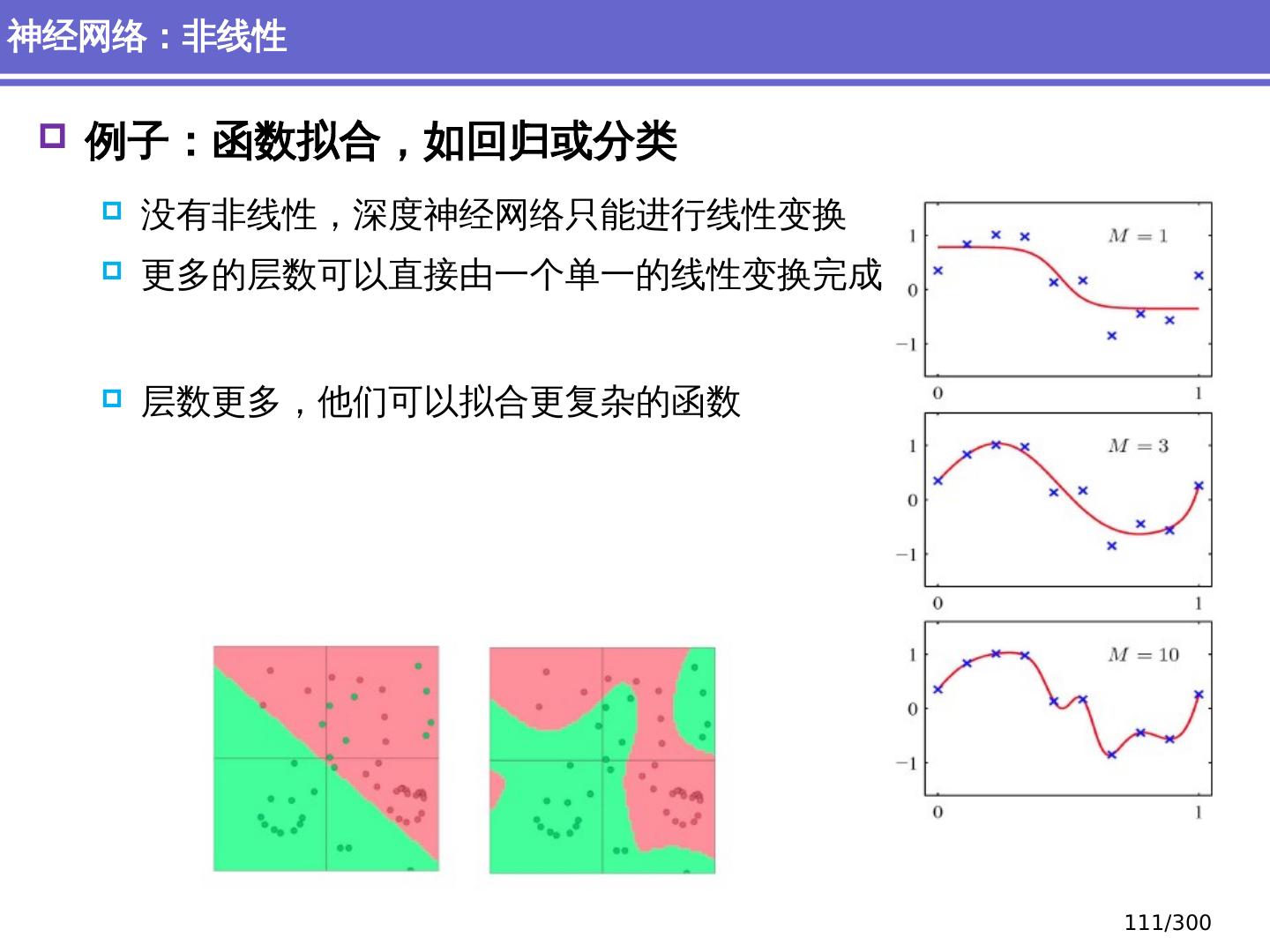
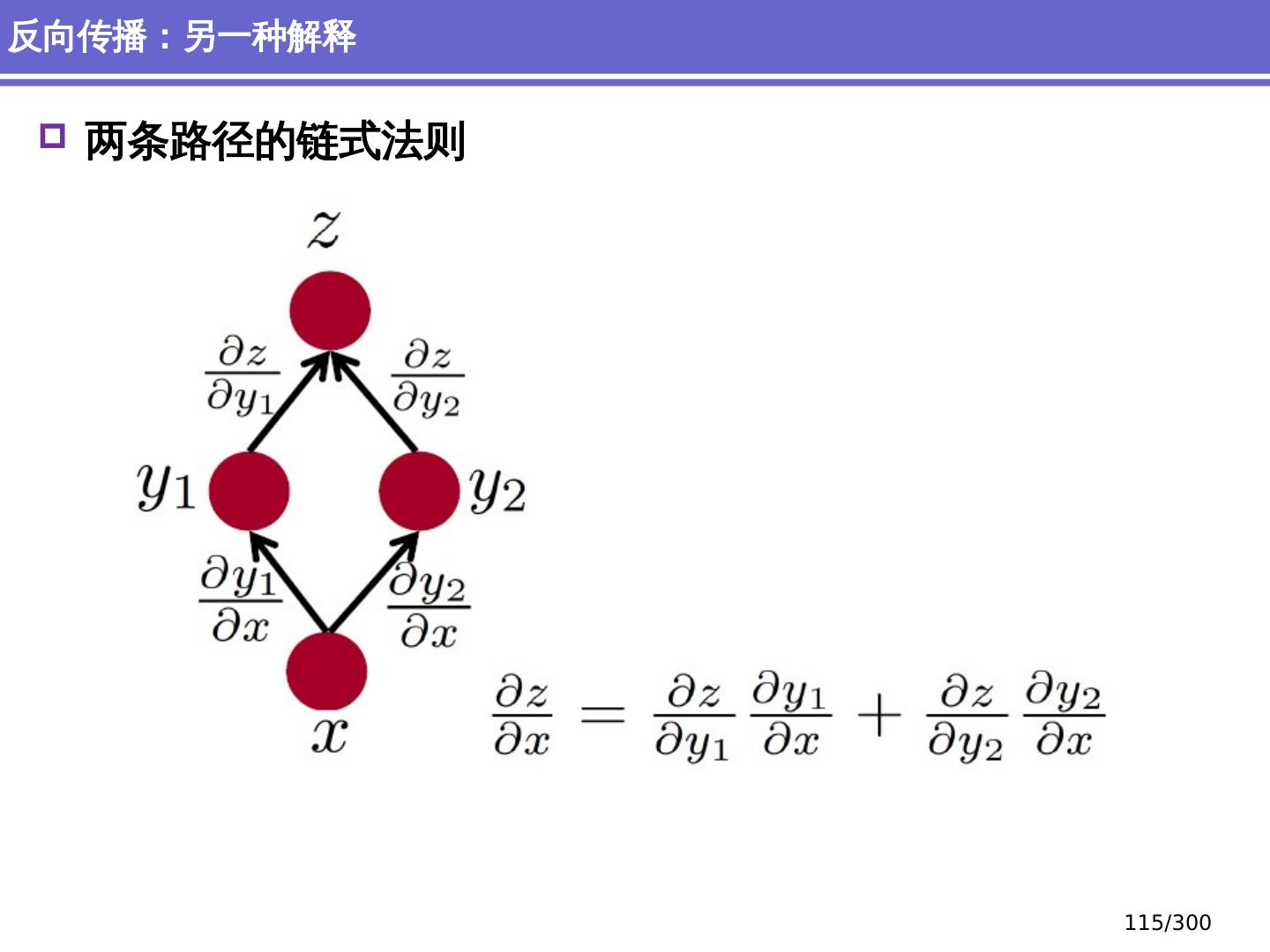
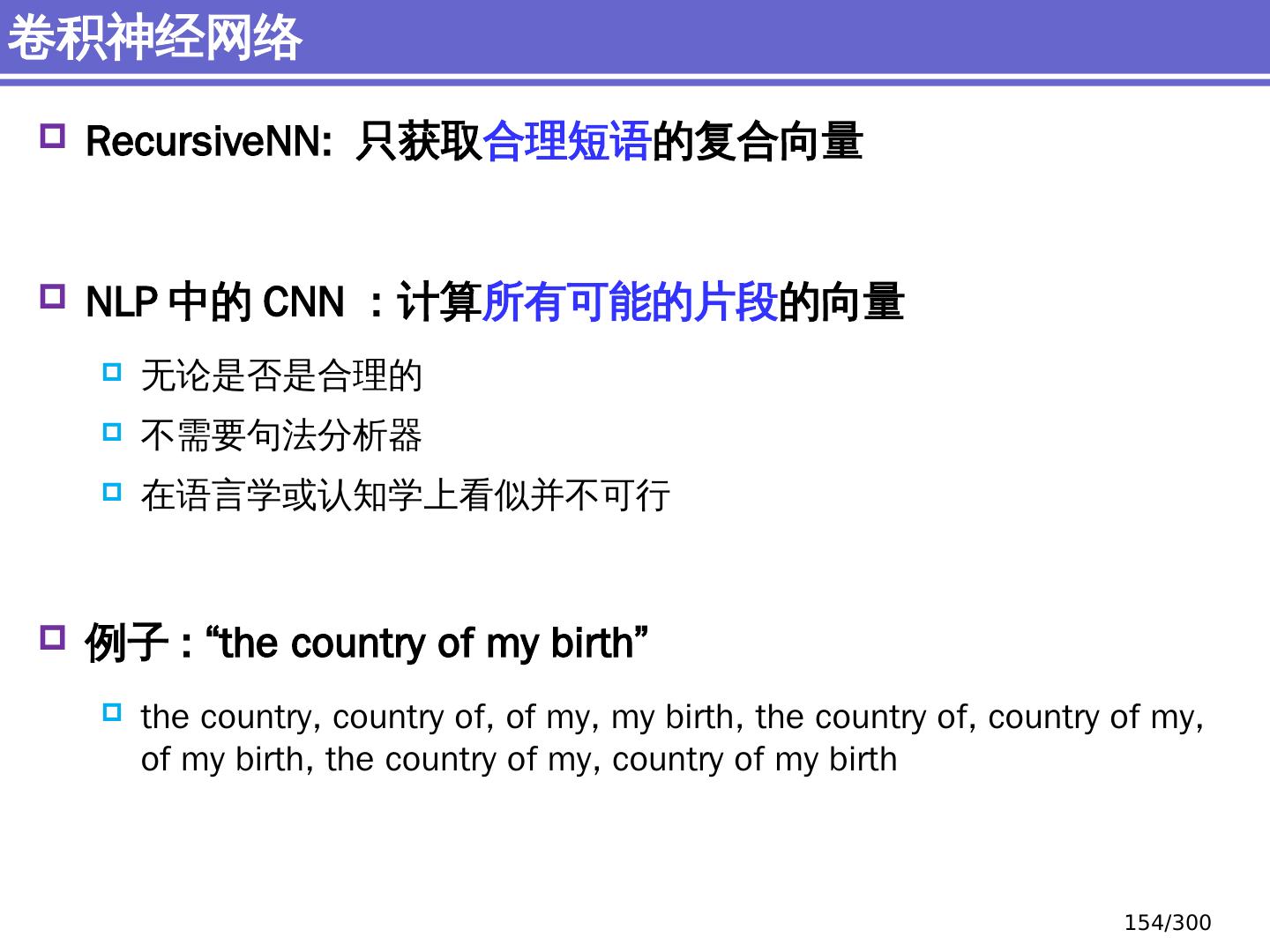
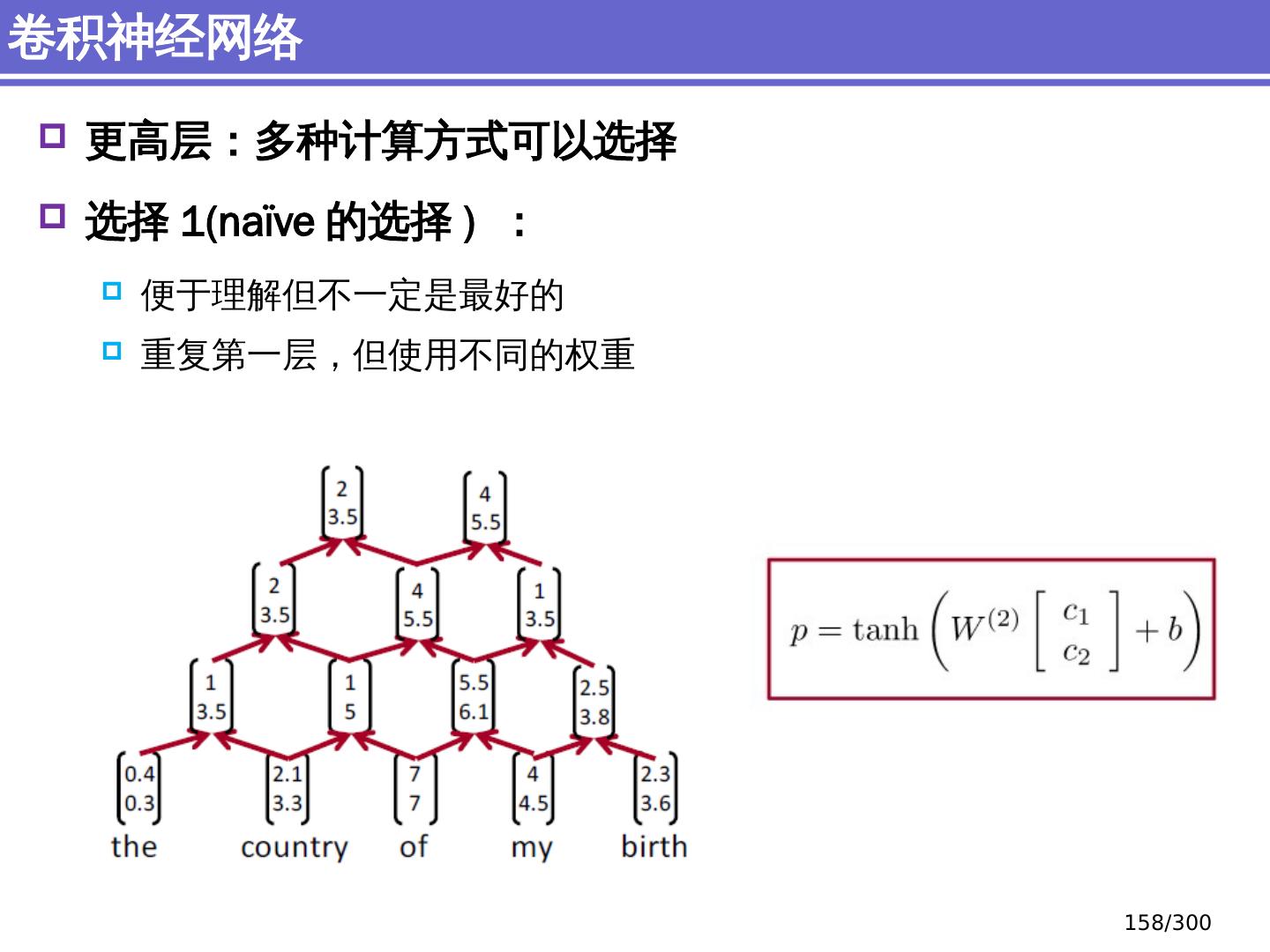
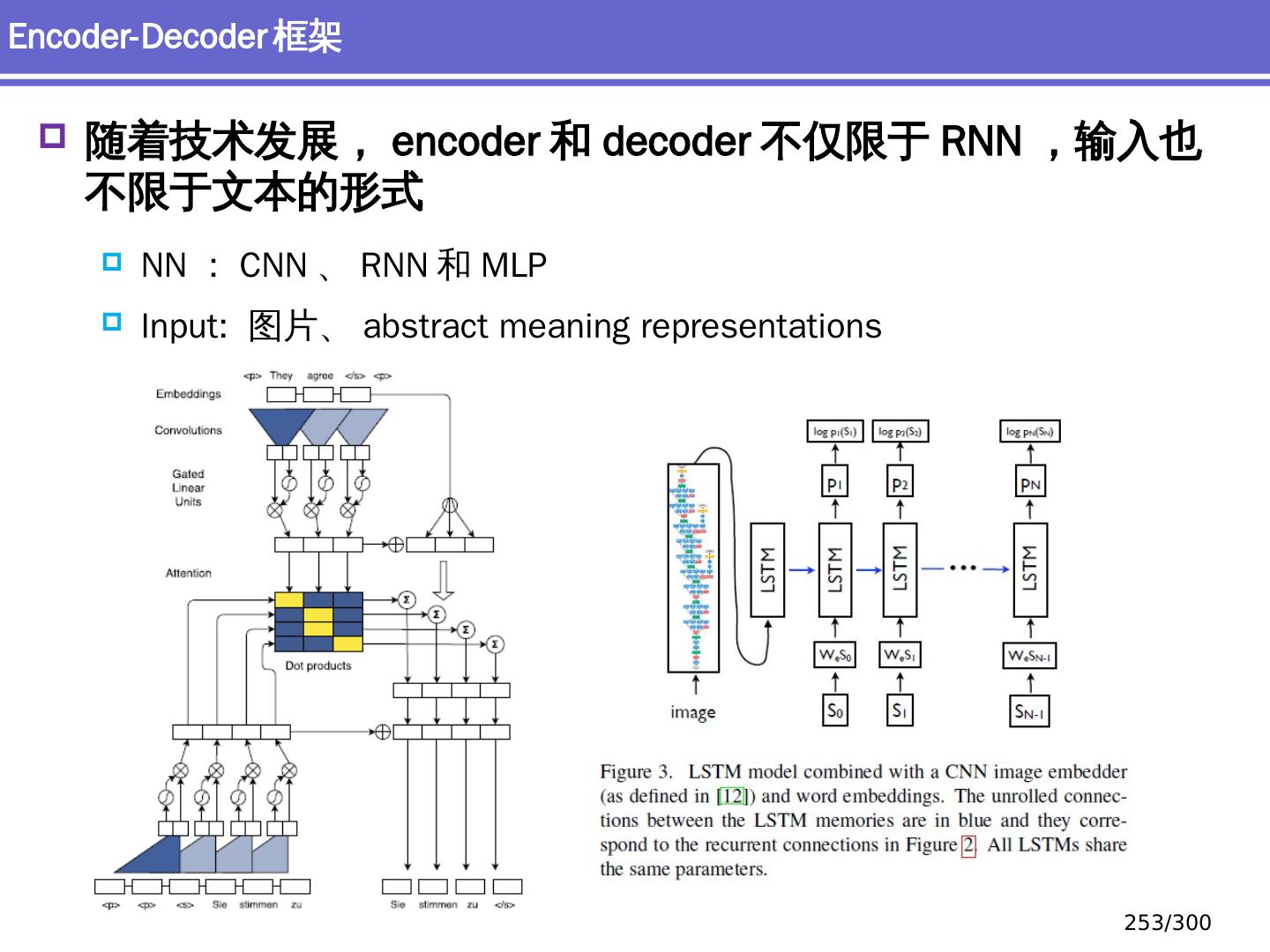
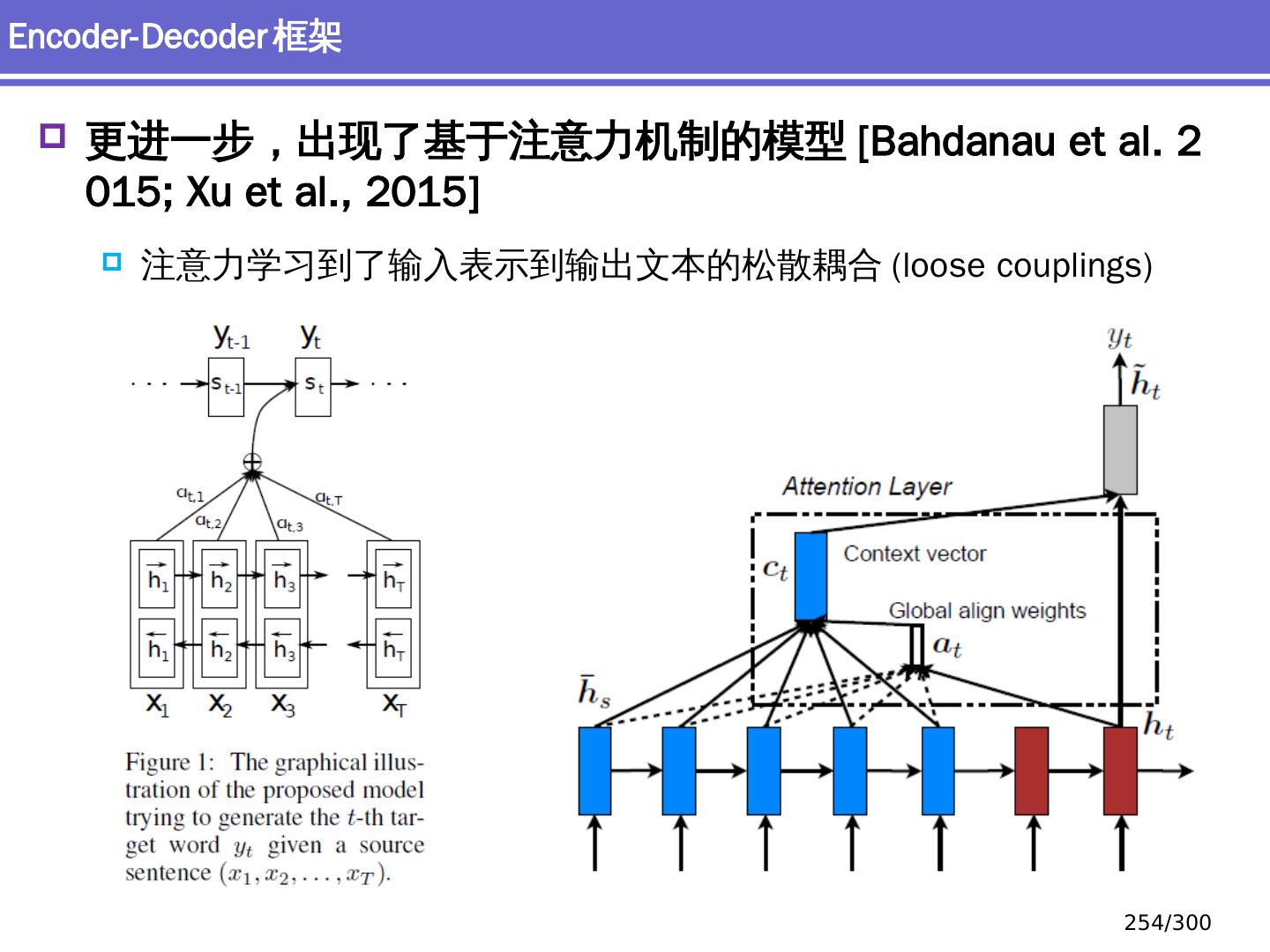
10 .NLP 的深度学习方法 前馈神经网络 词向量 基于窗口的分类 卷积 神经网络 捕捉局部结构信息 NER 、情感 分析 递归 神经网络 循环神经网络 捕捉时序信息 LSTM, GRU 序列到序列模型 Attention 研究方向 10 /300
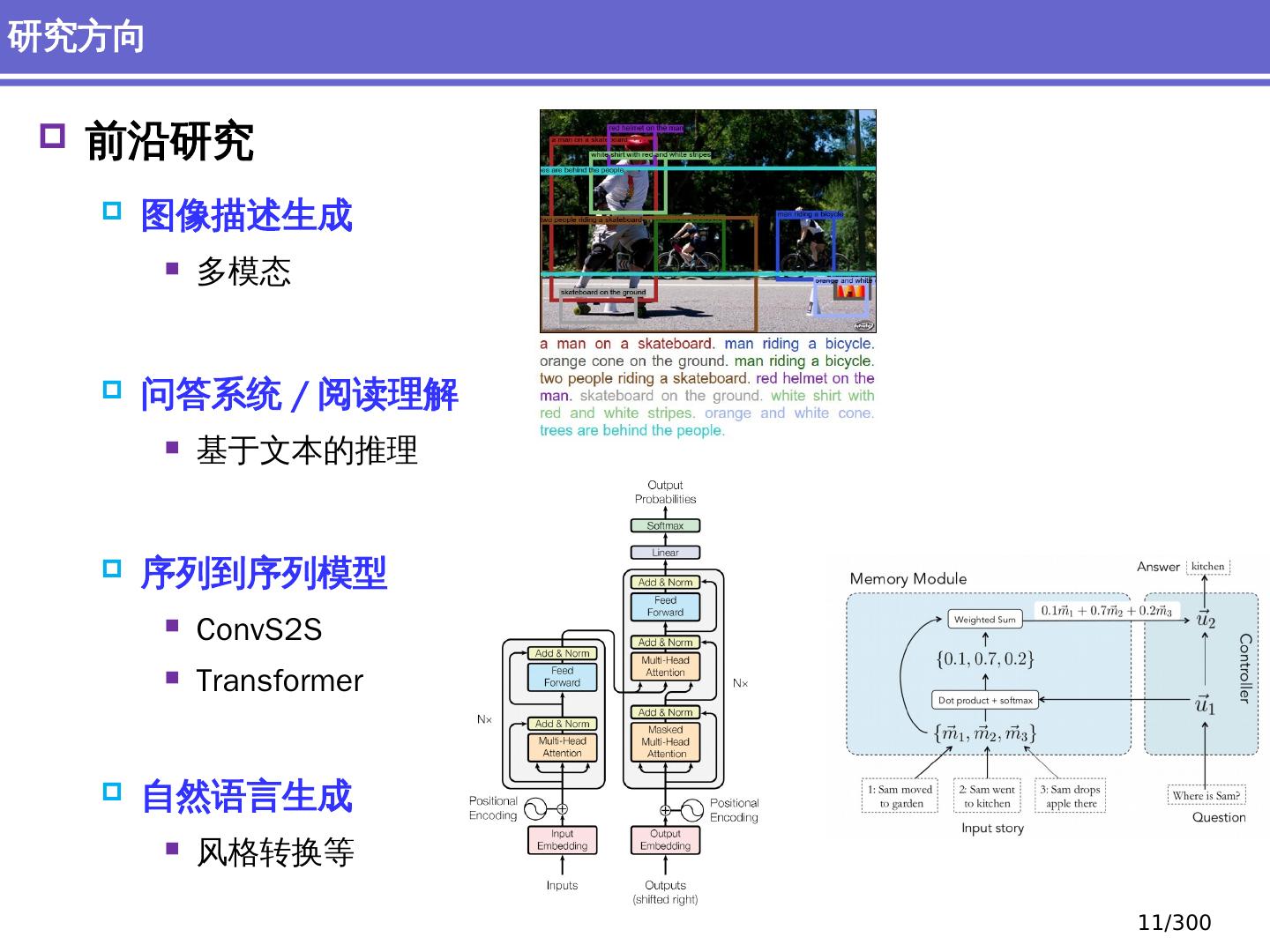
11 .前沿研究 图像描述生成 多模态 问答系统 / 阅读理解 基于文本的推理 序列到序列 模型 ConvS2S Transformer 自然语言生成 风格转换等 研究方向 11 /300
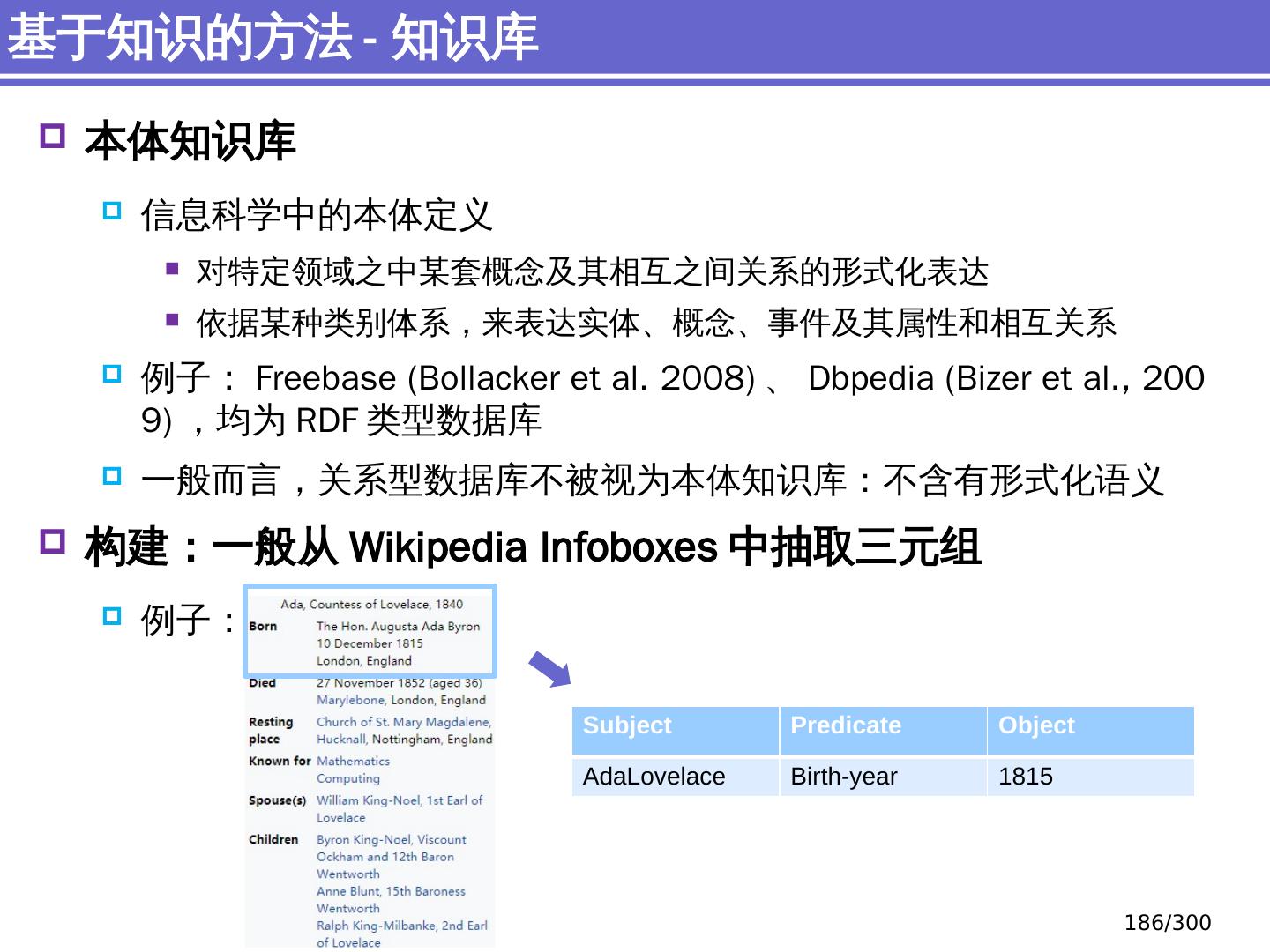
12 .机器翻译 人机对话 信息检索 、信息提取 情感分析、 舆论分析、知识 发现 自动抽取知识库 具体的自然语言处理任务简介 12 /300
13 .搜索 在线广告 / 推荐 自动 / 辅助翻译 语音识别 讯飞 Siri Cortana Alexa 聊天机器人 自动客户服务 控制设备 小冰 自然语言处理与 产业 13 /300
14 .表象原因:自然语言中有大量的歧义现象 无法象处理人工语言那样,写出一个完备的、有限的规则系统来进行定义和描述。自然语言的规则很少没有例外 此外,还有大量的噪音甚至错误表达 歧义举例: The boy saw the girl with a telescope. 本质原因:知识体系的缺乏 自然语言的理解不仅和语言本身的规律有关,还和语言之外的知识(例如常识)有关 语言处理涉及的常是海量知识,知识库的建造维护难以进行 场景 / 背景的建立问题 两个原因的 联系 : 歧义 是知识缺乏的表现形式 自然语言处理的难点是什么? 14 /300
15 .表象原因:自然语言中有大量的歧义现象 无法象处理人工语言那样,写出一个完备的、有限的规则系统来进行定义和描述。自然语言的规则很少没有例外 此外,还有大量的噪音甚至错误表达 歧义举例: The boy saw the girl with a telescope. 本质原因:知识体系的缺乏 自然语言的理解不仅和语言本身的规律有关,还和语言之外的知识(例如常识)有关 语言处理涉及的常是海量知识,知识库的建造维护难以进行 场景 / 背景的建立问题 两个原因的 联系 : 歧义 是知识缺乏的表现形式 自然语言处理的难点是什么? 14 /300
16 .用 规则分析 句子“ the boy saw the girl with a telescope” 具体方法 16 /300
17 .All grammar leak (Sapir 1921) 对于自然语言而言,不大可能写出一部完备的规则集,语言规则有很强的伸缩性。 规则系统的普遍问题 不完备 规则本身的歧义 理论不够严谨 (ad-hoc) 规则调整和更新很复杂 维护困难 具体方法 17 /300
18 .目前, 数据驱动的方法是主流 1992: 24% 1994: 35% 1996: 39% 1999: 60% 2001: 87% 2010 : >90% 效果评测 ? 自然语言 歧义多、关于语言处理方法和系统的评测也需要解决相关的歧义问题 1 ,规避语言学争议、制定标准测试集 2 ,看应用效果 具体方法 18 /300
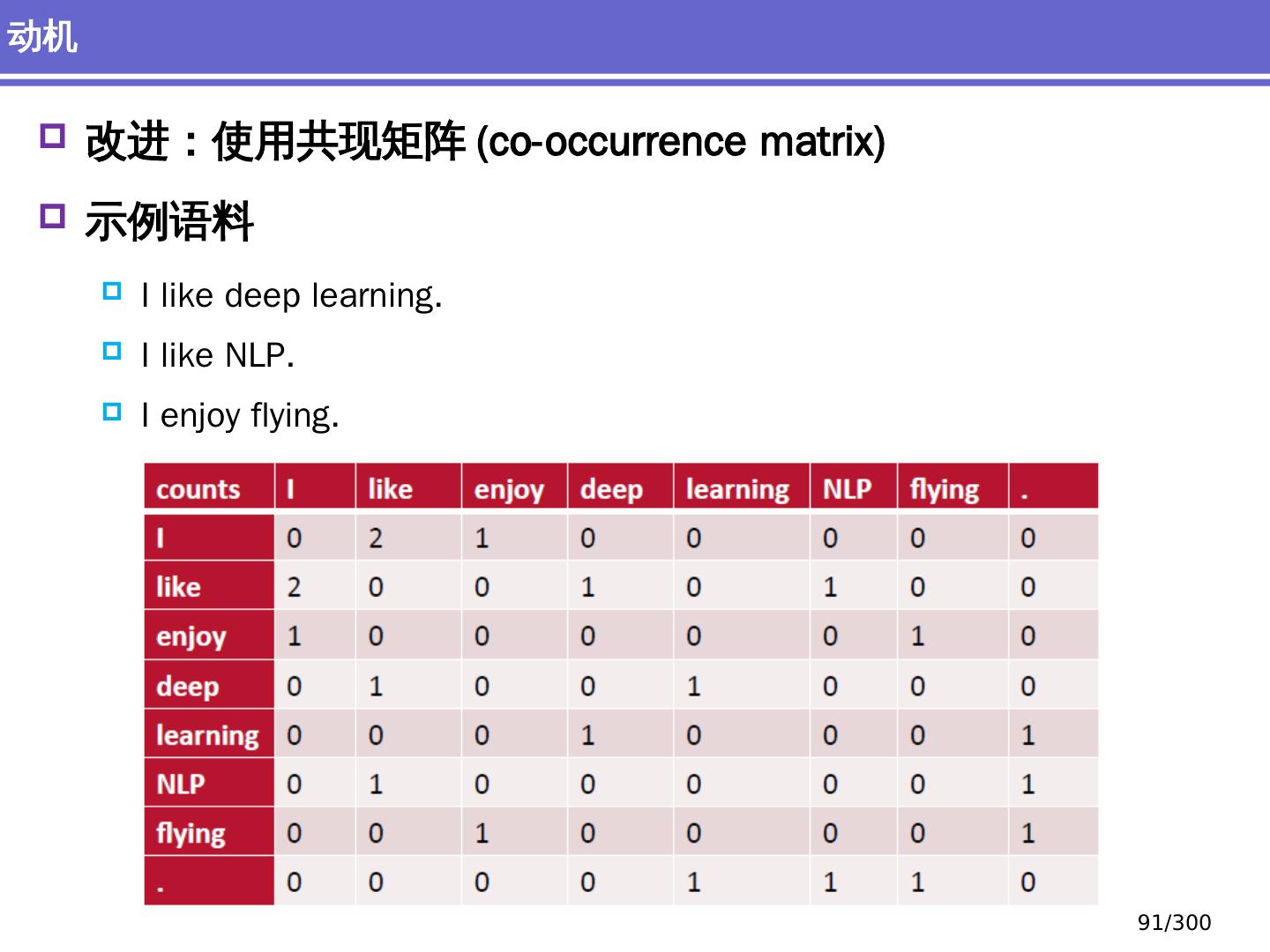
19 .Morphology 词汇学 / 形态学 传统 词素 / 语素 (morphemes) 深度学习 向量表示 神经网络结合 深度 学习方法:词汇学 19 /300
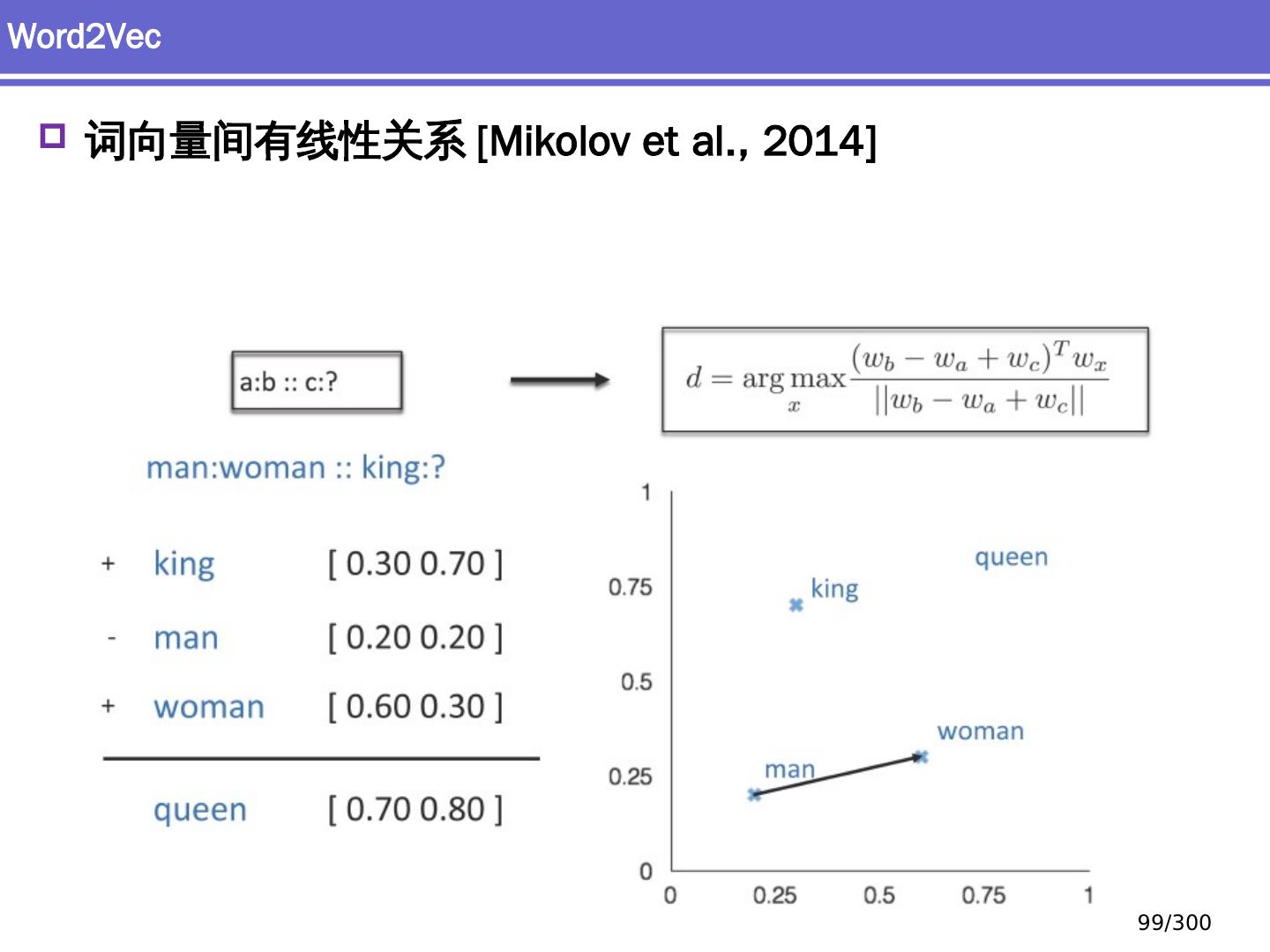
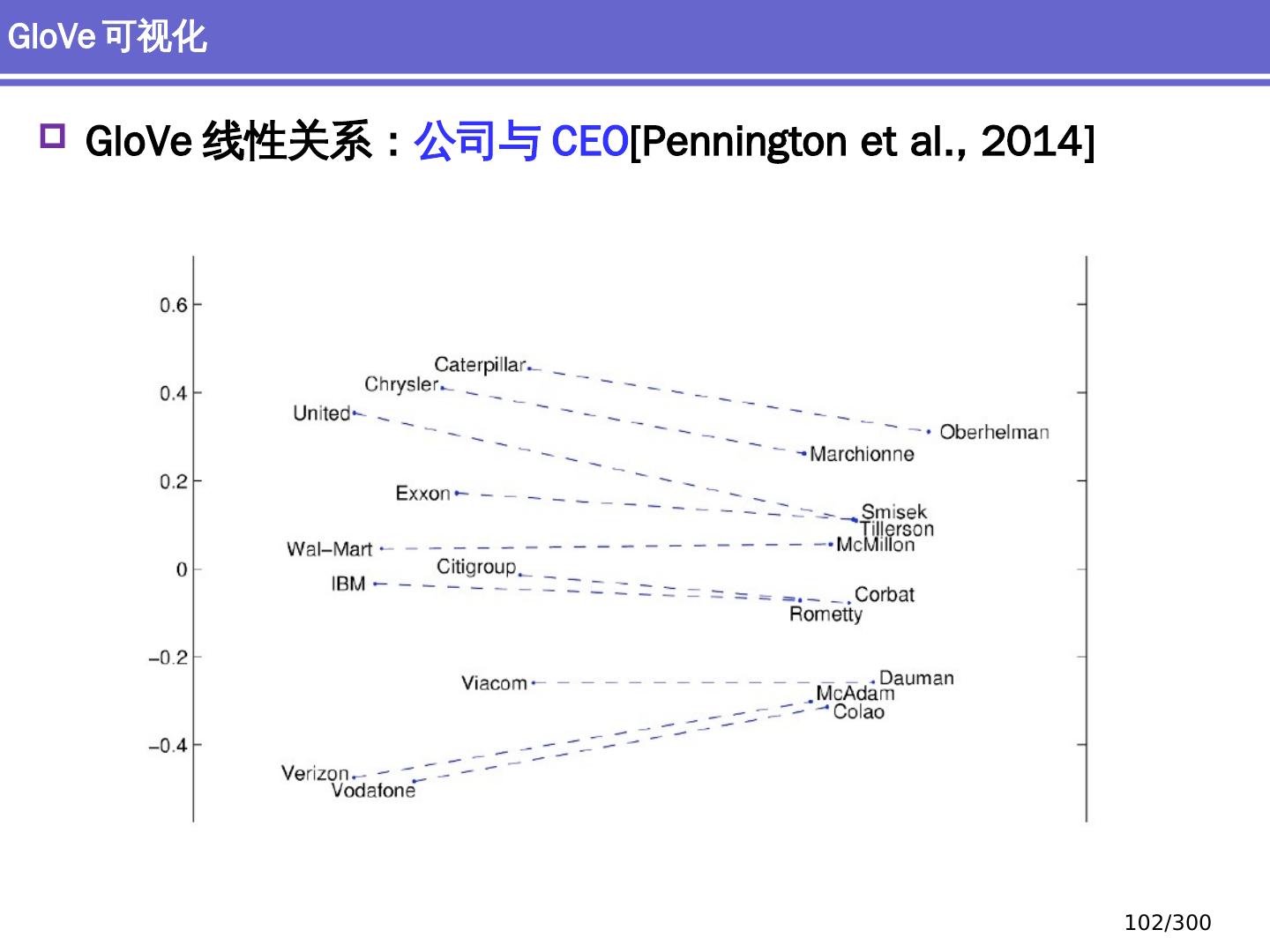
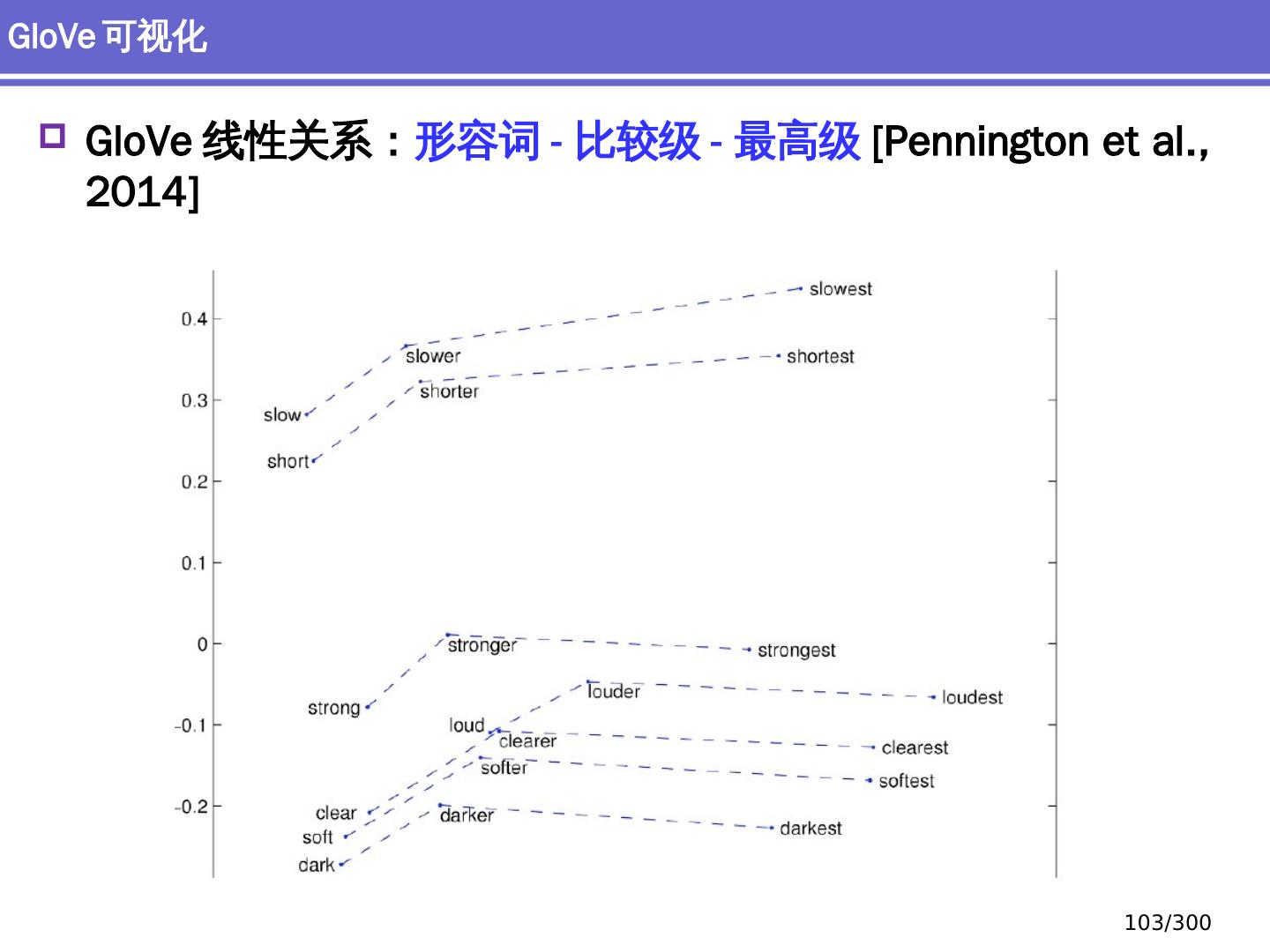
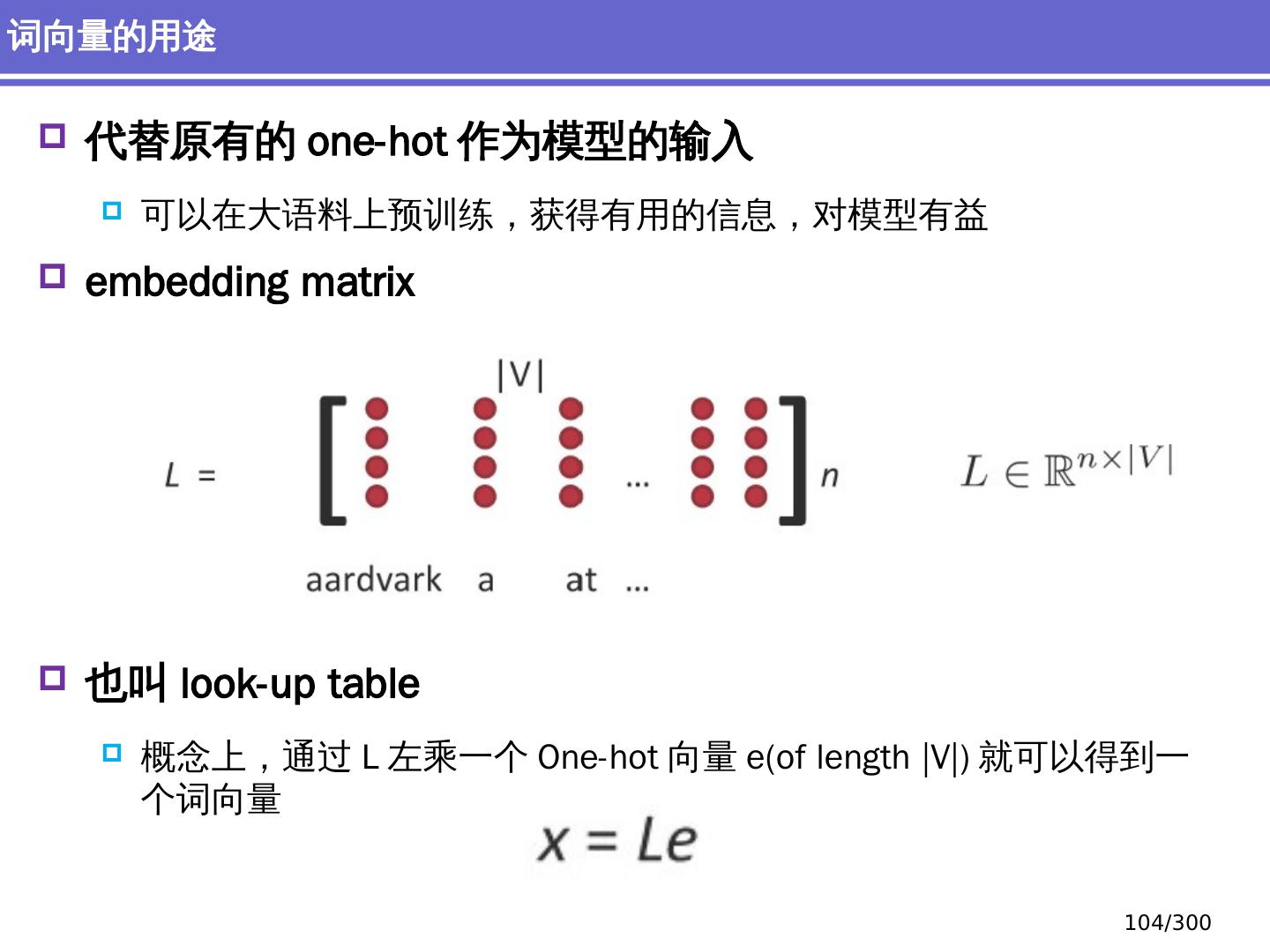
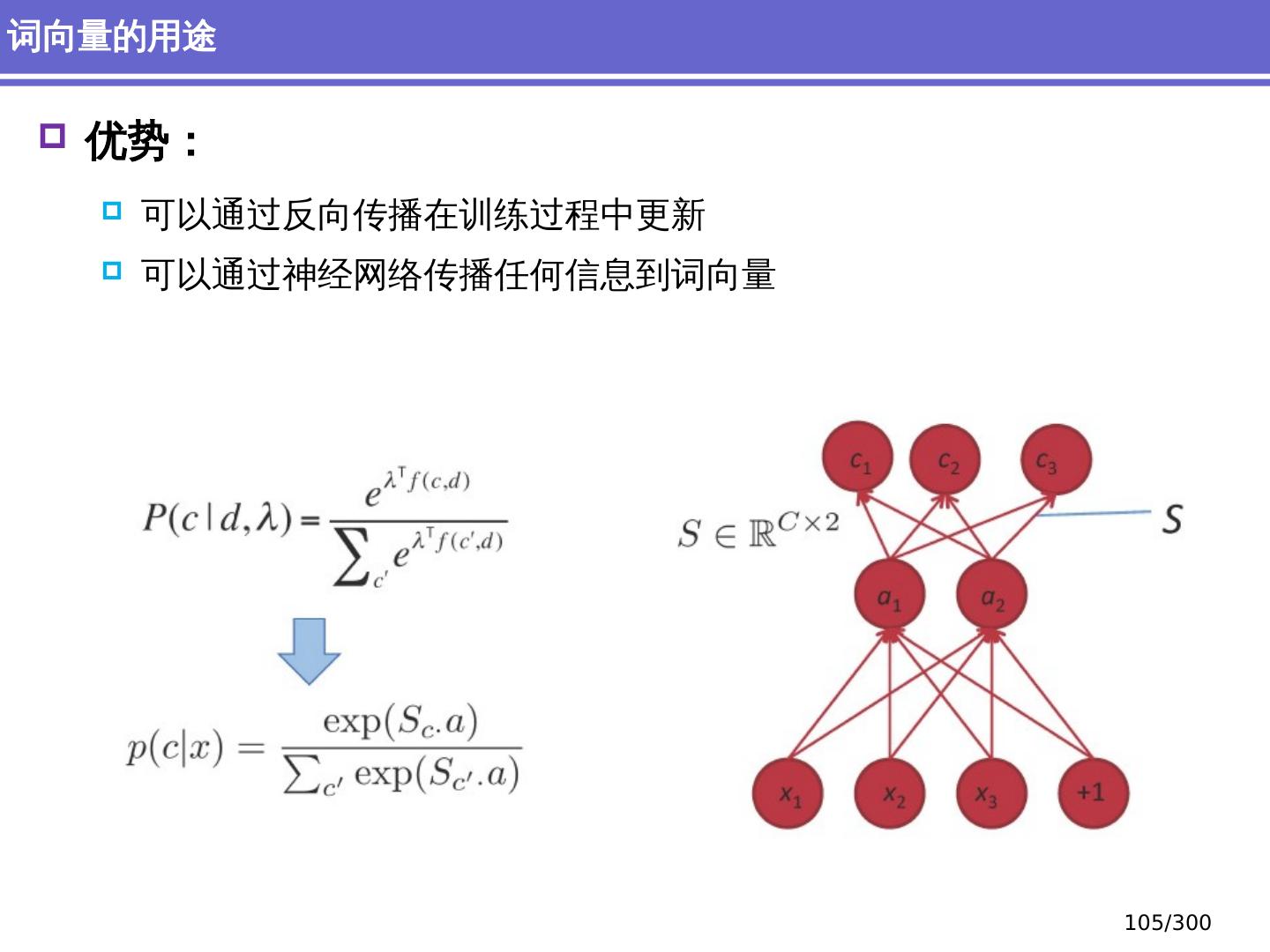
20 .词向量 Word vectors Embedding 深度学习方法:词汇学 20 /300
21 .Syntax 语法 / 句法 传统 短语 离散的类别, NP , VP 深度学习 向量表示 神经网络结合 深度 学习方法:句法 21 /300
22 .Semantics 语 义 传统 : 精心设计的函数系统 没有相似性和模糊性的概念 深度学习 向量表示 神经网络 结合 深度 学习方法:语义 22 /300
23 .情感分析 传统 情感词词典, 词 袋 否定特征 深度学习 递归网络 深度 学习方法:情感分析 23 /300
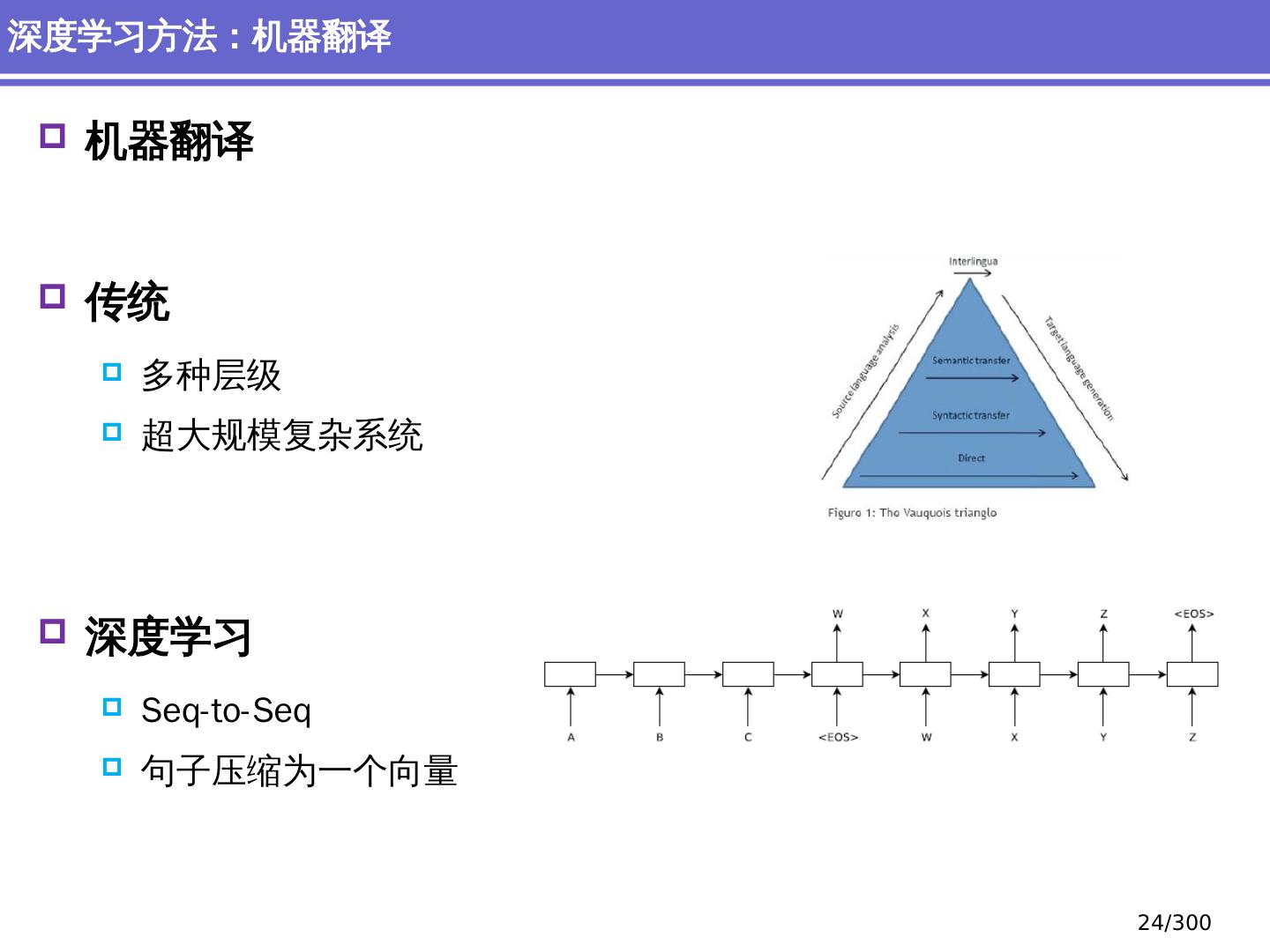
24 .机器翻译 传统 多种层级 超 大规模复杂系统 深度学习 Seq-to-Seq 句子压缩为一个向量 深度 学习方法:机器翻译 24 /300
25 .向量 :一切的表示,表示一切 词素、词、短语、句子 都可以表示为 向量 描述语汇间的复杂关系 多维、连续 相似性 模糊性 深度学习方法 25 /300
26 .NLP 的总体介绍 简介、研究范式 NLP 的传统 机器学习方法 简单分类、序列标注问题 NLP 的深度 学习方法 语义表示、反向传播、机器翻译、句法分析、文档分类 NLP 的典型 任务简介 问答系统 、 情感分析 、 自然语言生成 NLP 的前沿 研究进展:自然语言生成面对的主要挑战 内容安排 26 /300
27 .NLP 的传统机器学习方法 简单分类:机器学习基础 结构化分类:序列标注问题
28 .NLP 的传统机器学习方法 简单分类:机器学习基础 结构化分类:序列标注问题
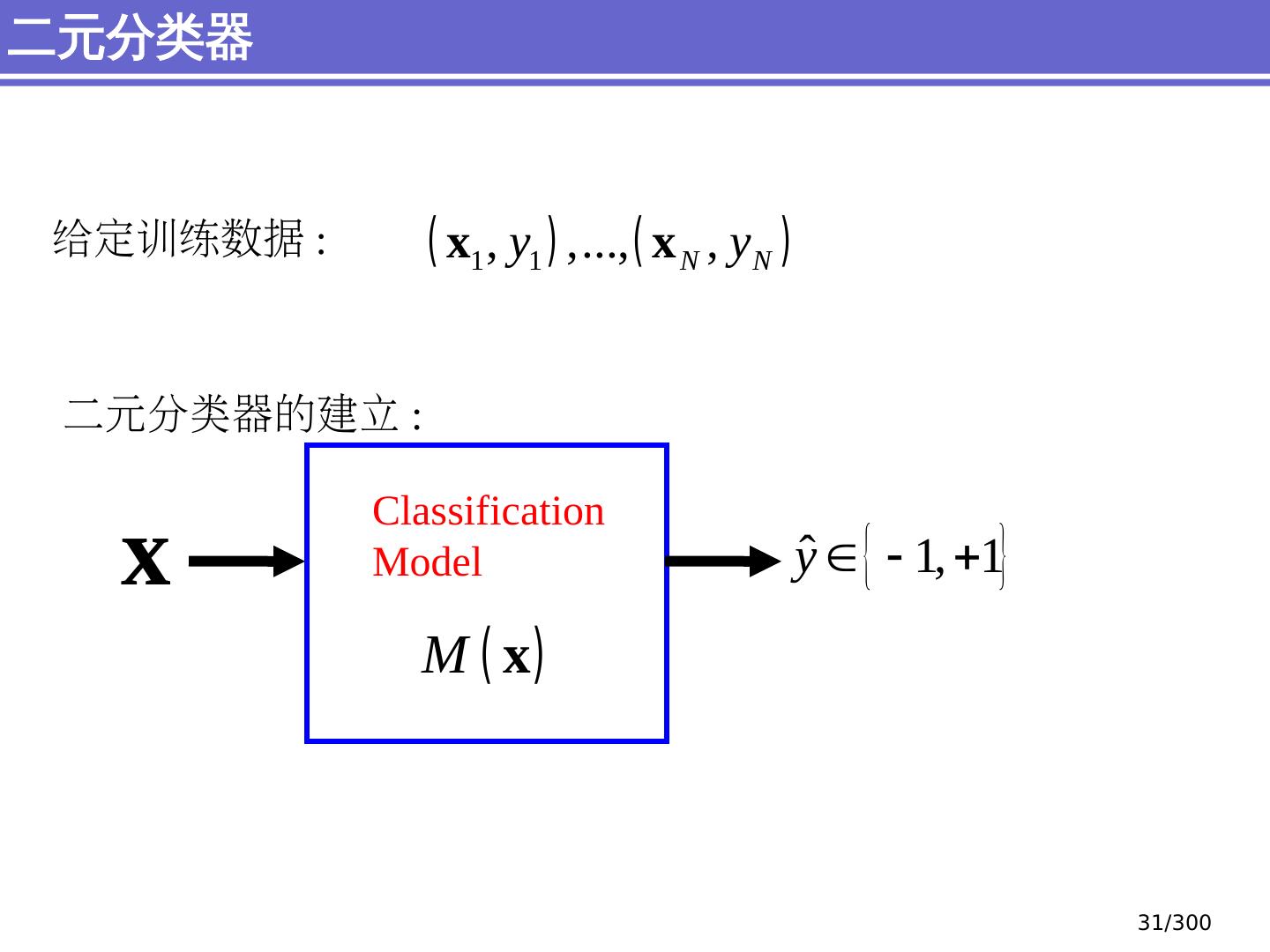
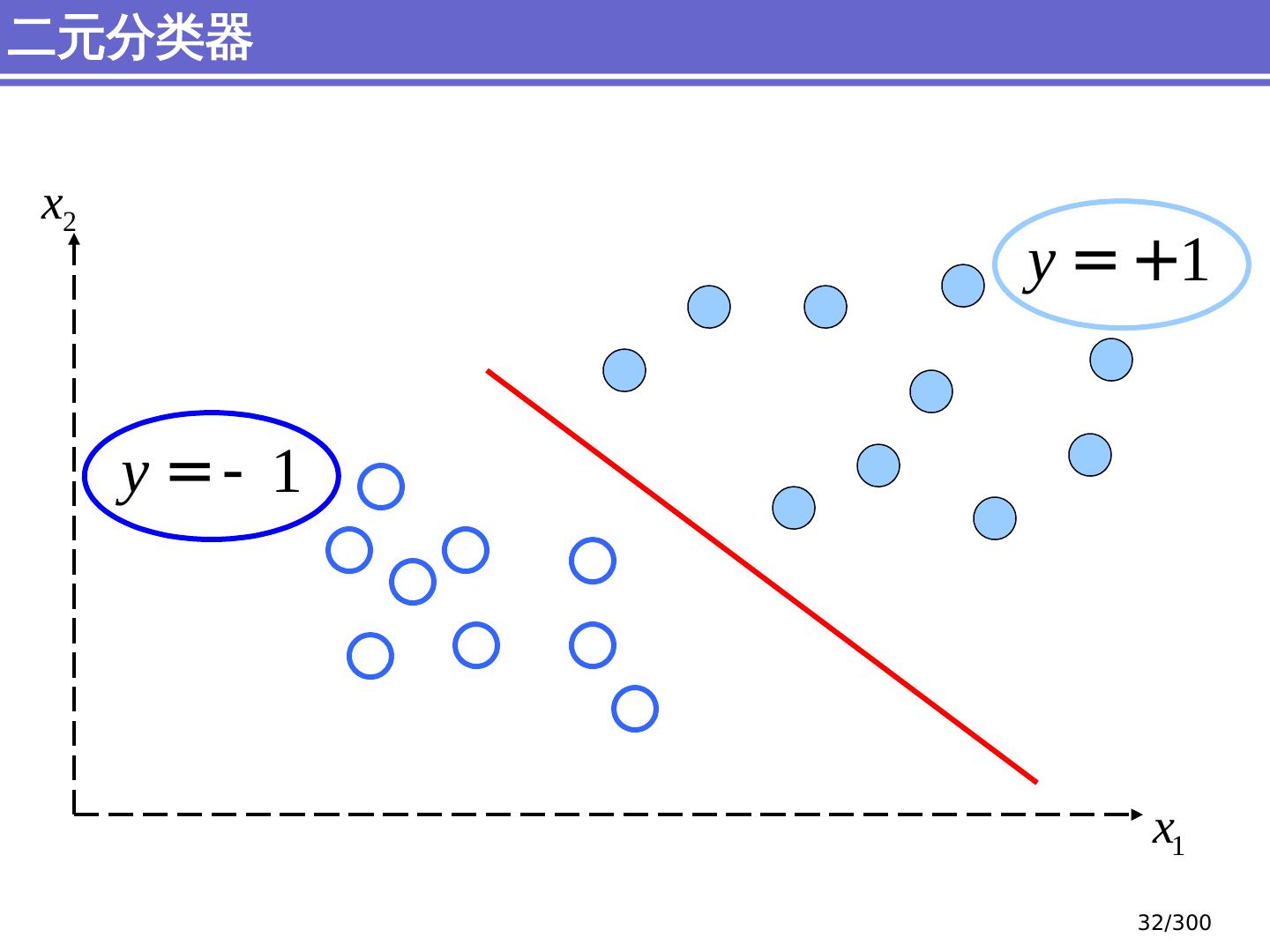
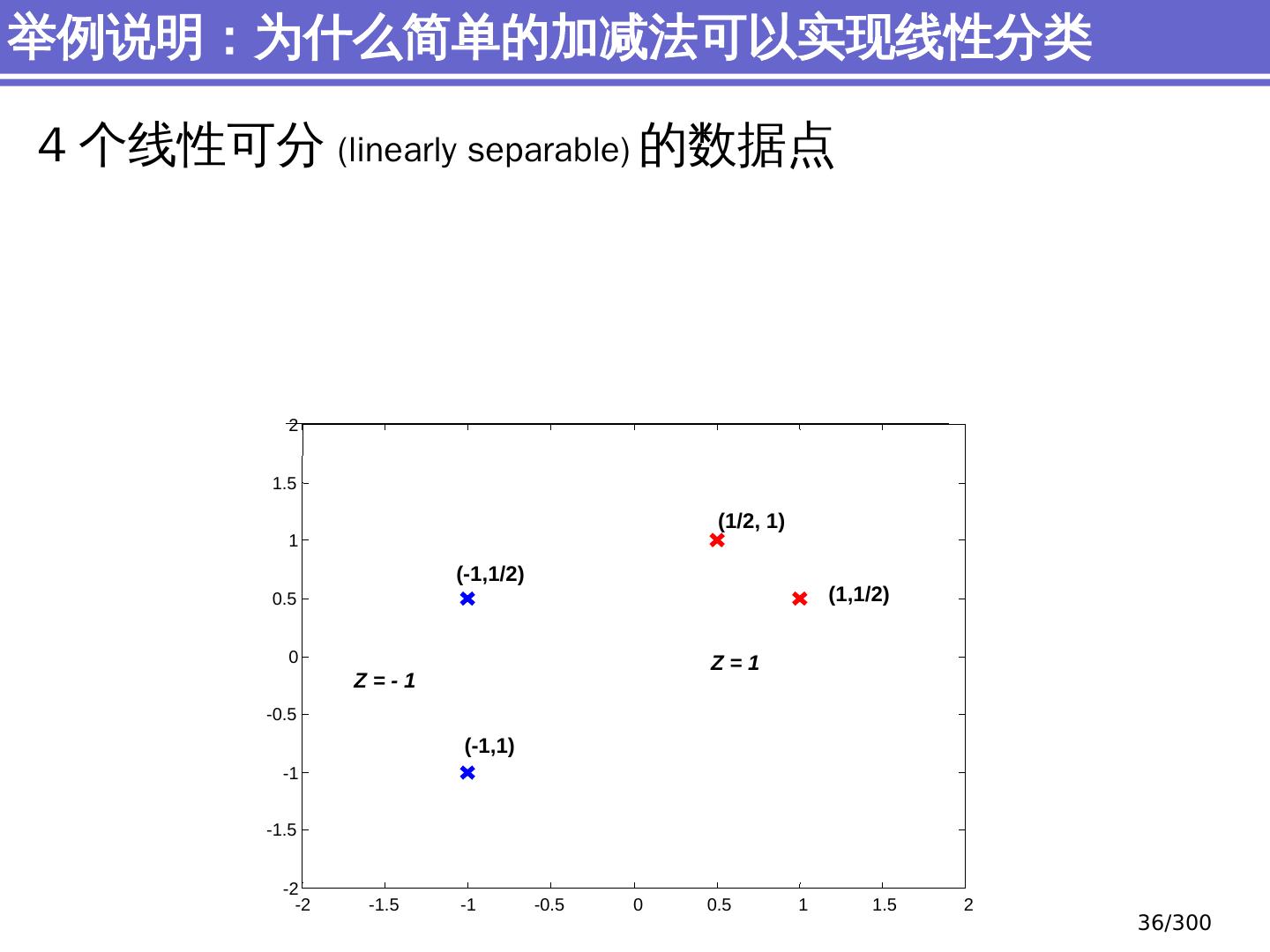
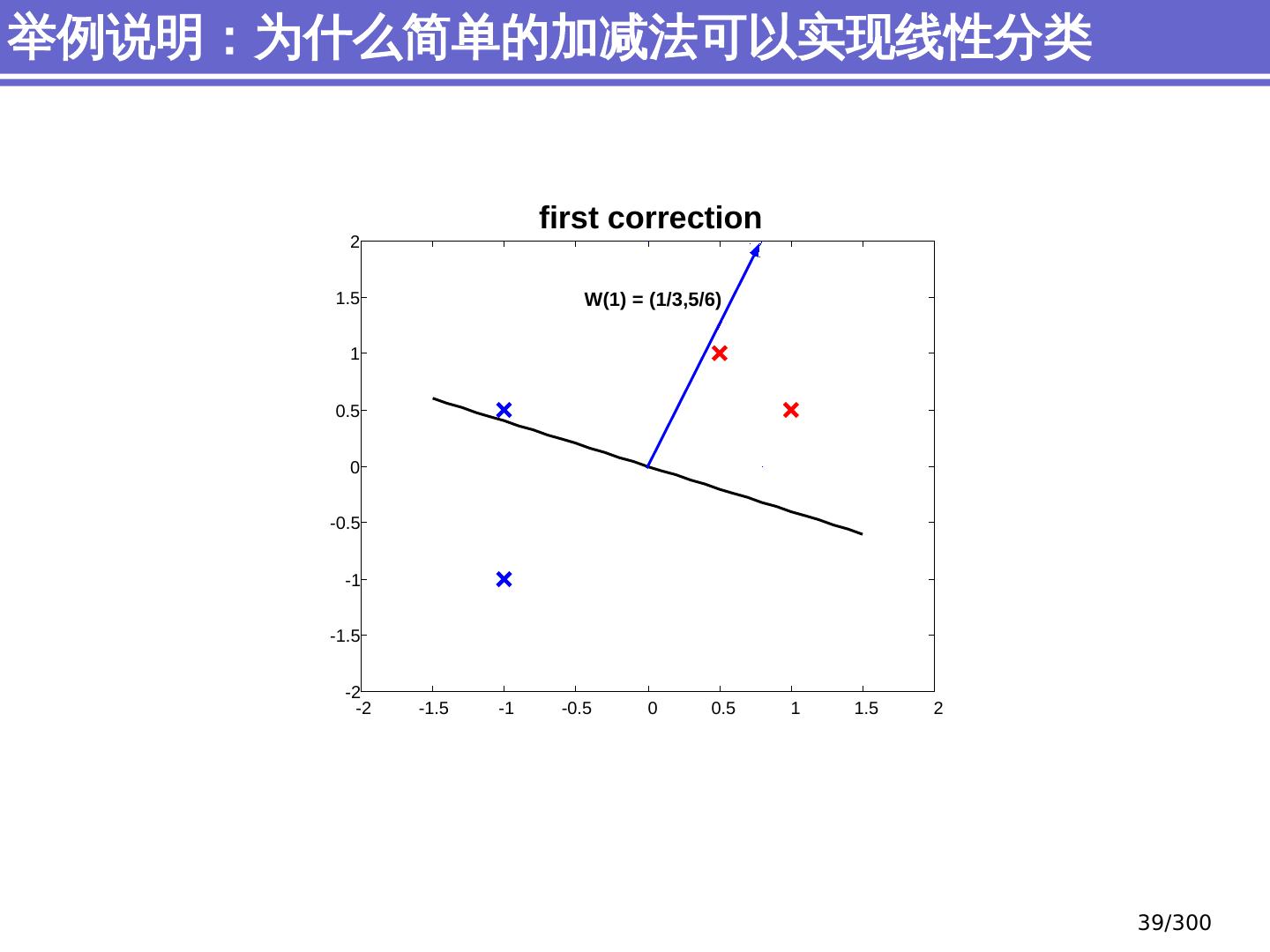
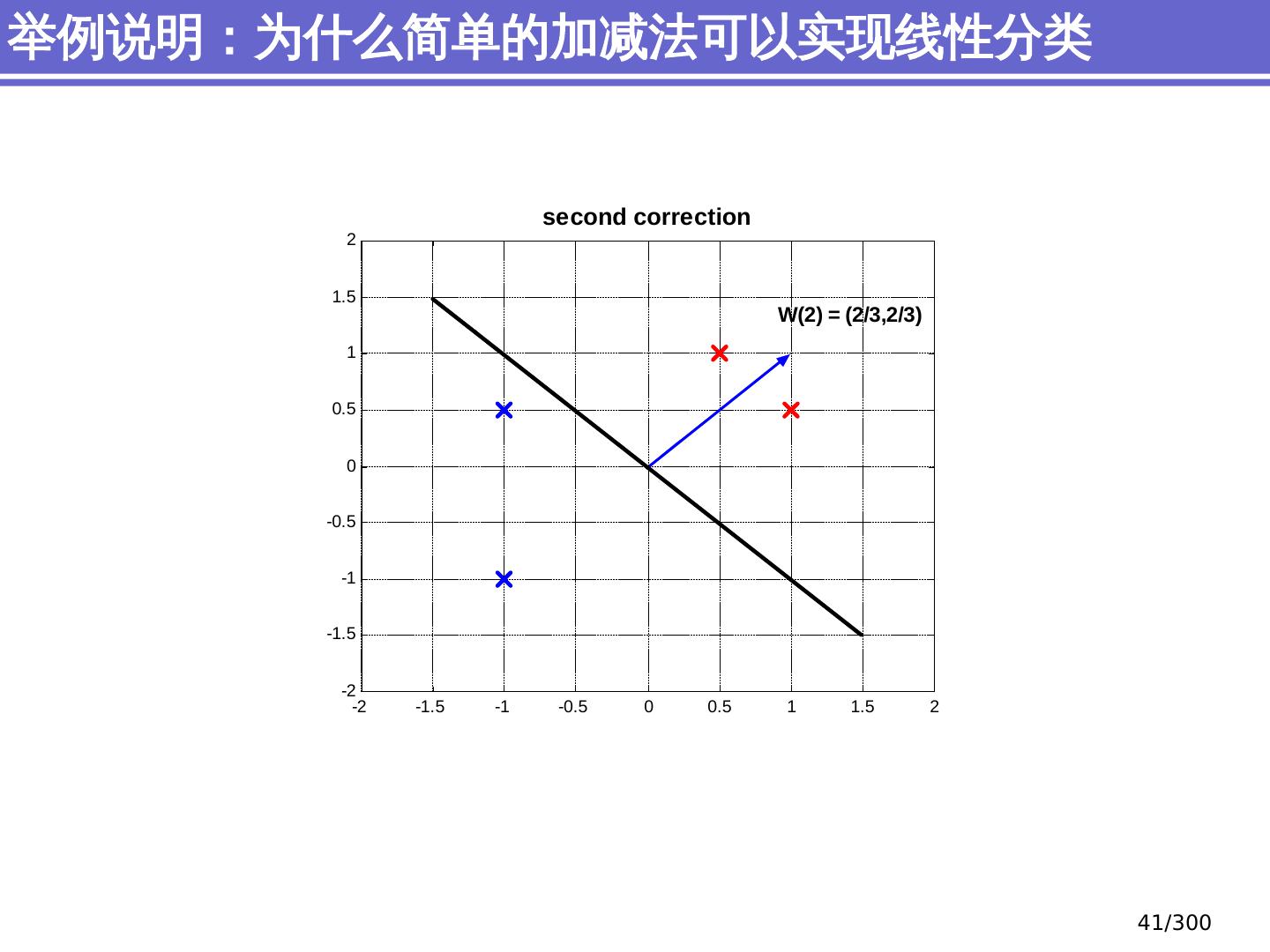
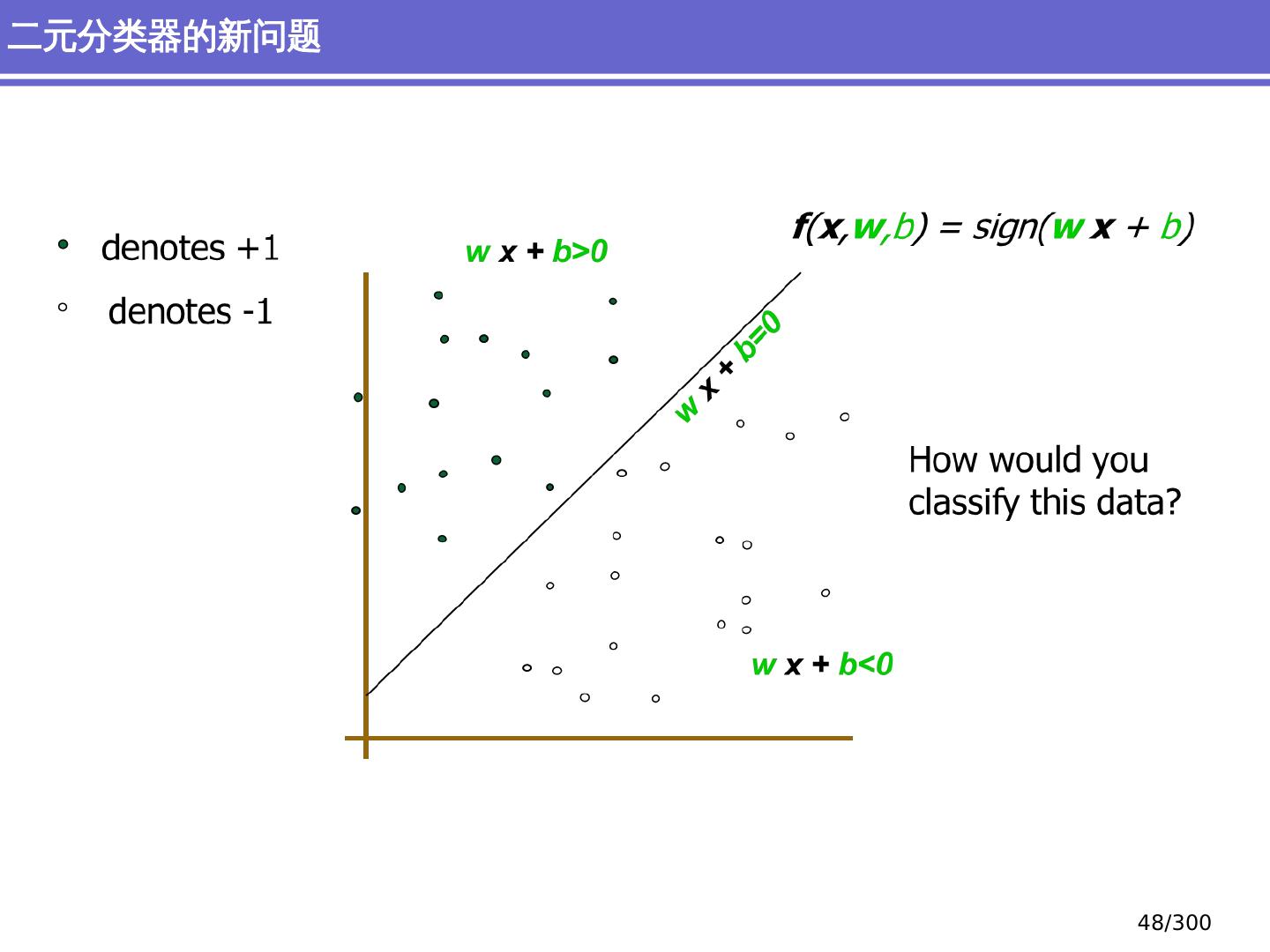
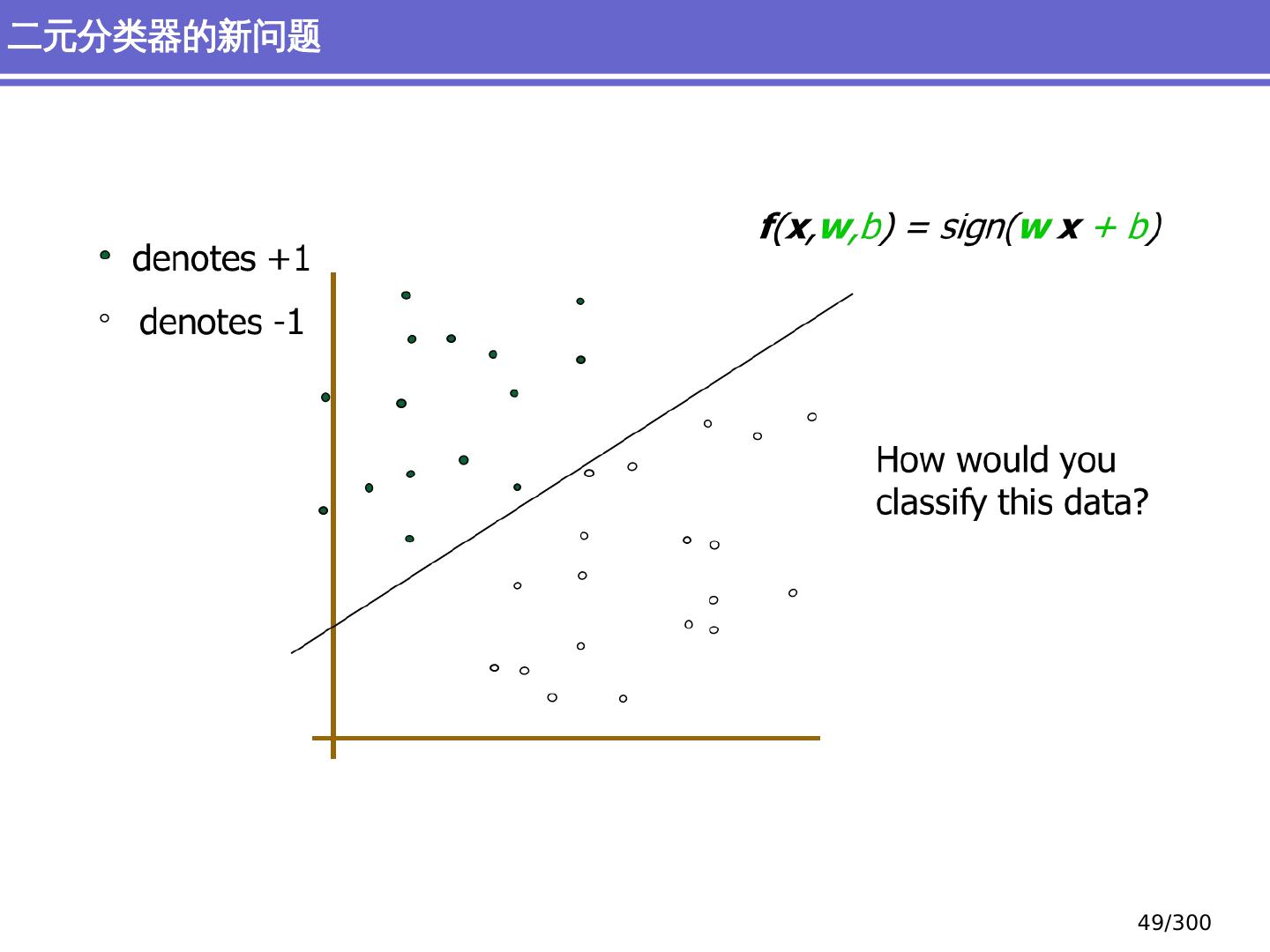
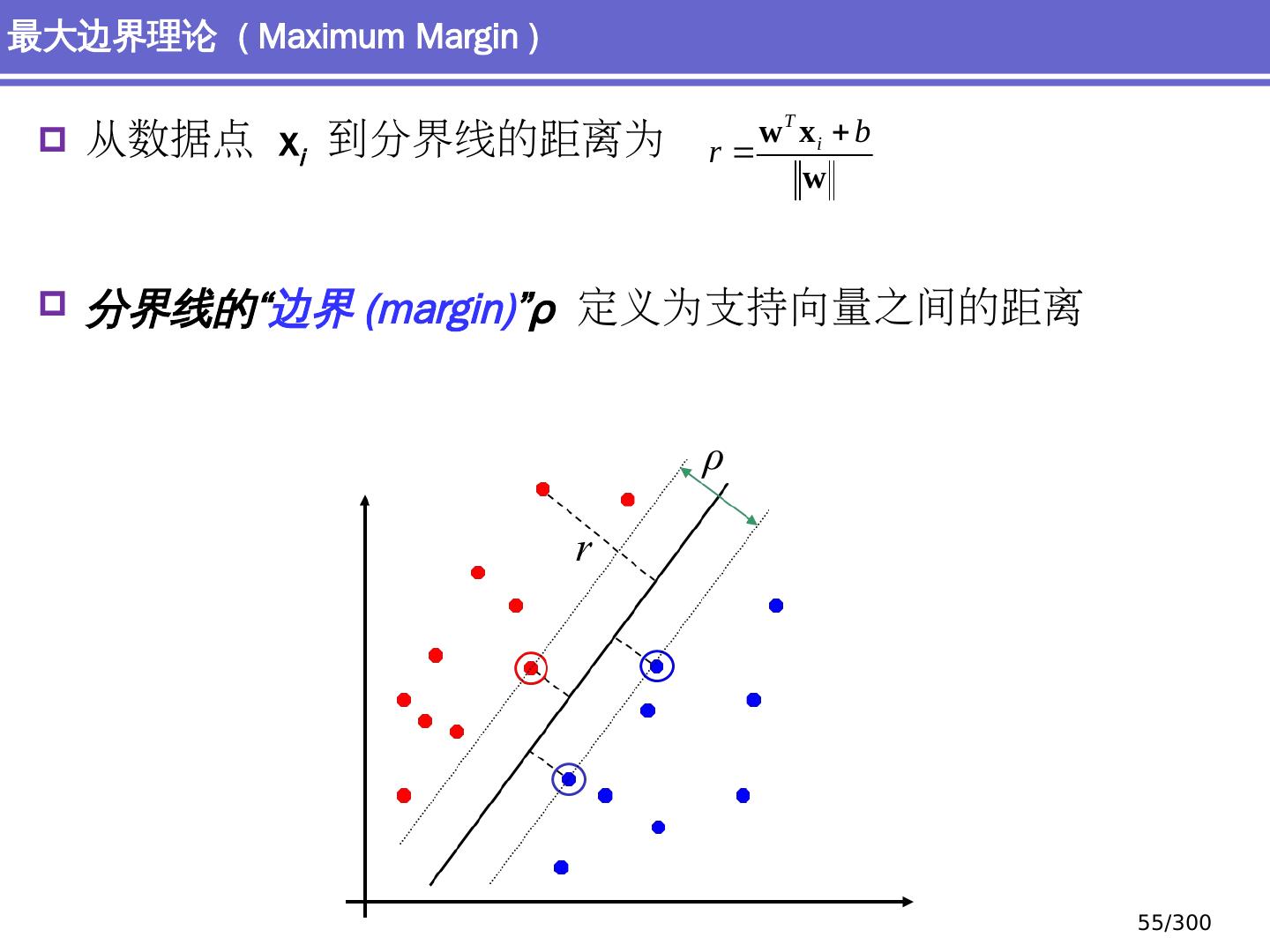
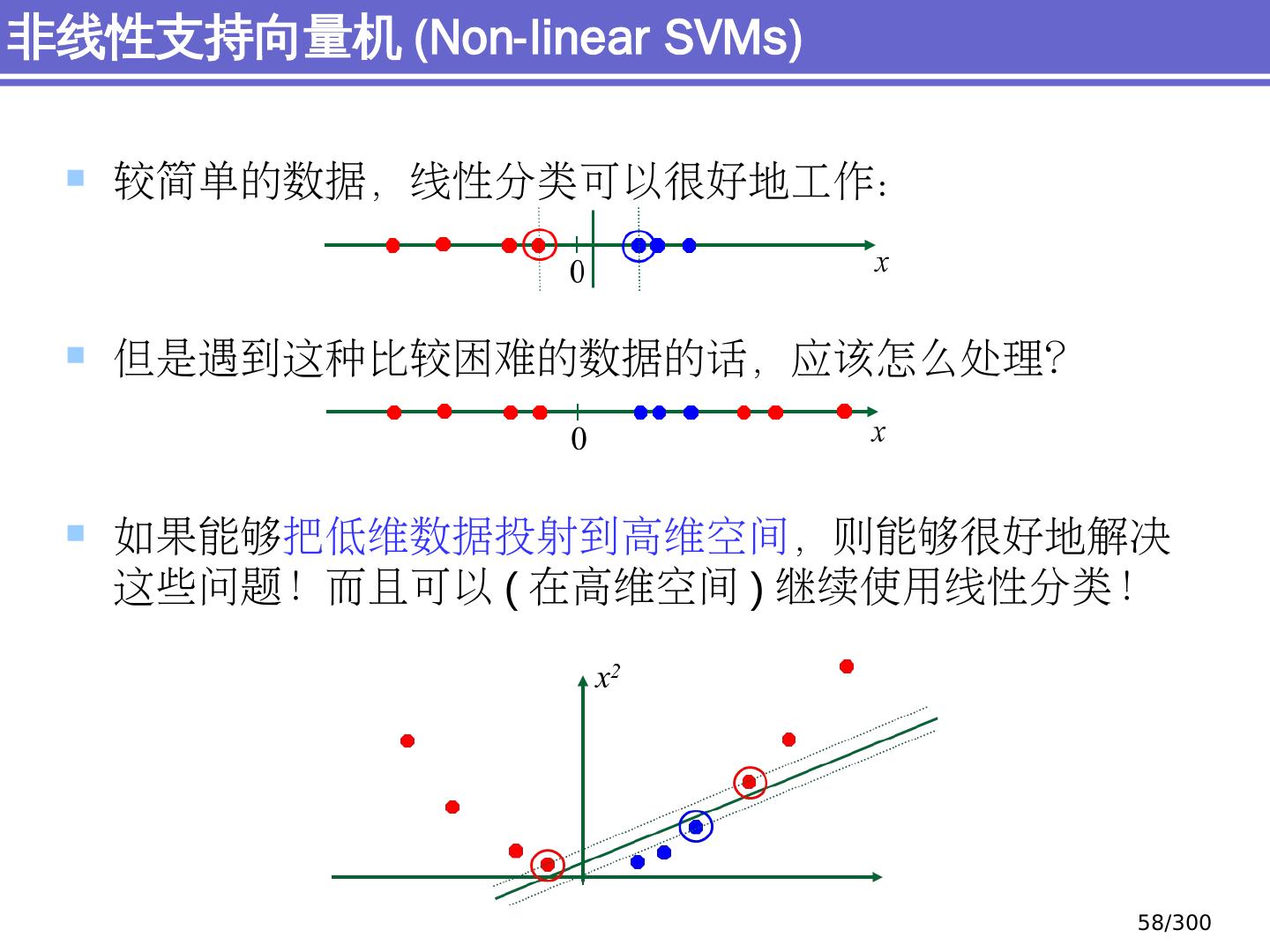
29 .简单分类问题 感知器模型 (perceptron) 支持向量机模型 (support vector machine, SVM) 大纲 29 /300
相关推荐
3秒后跳转登录页面
去登陆

