









































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
MPI并行编程入门
并行计算概述,MPI并行算法概述以及MPI并行程序设计基础。
展开查看详情
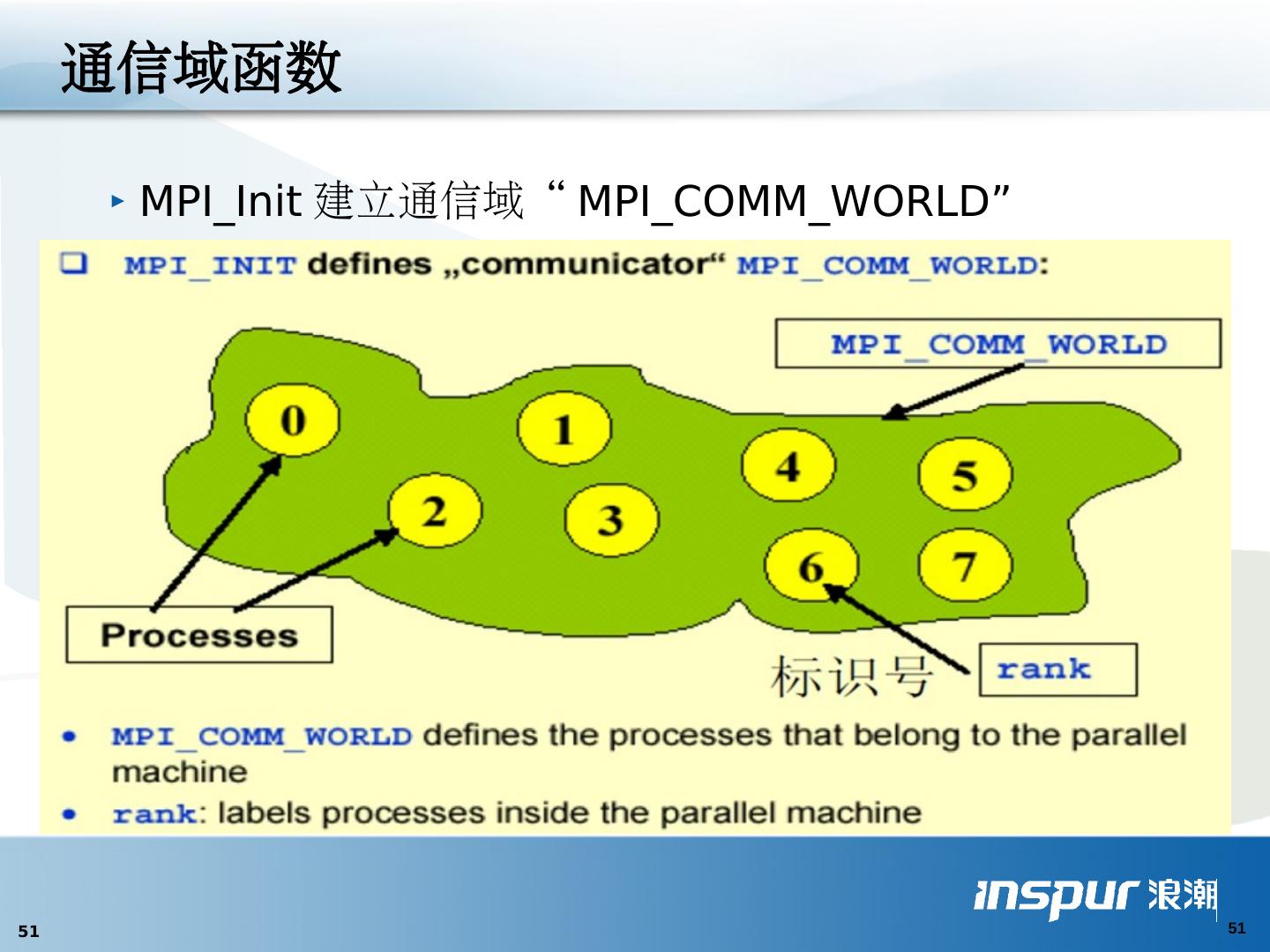
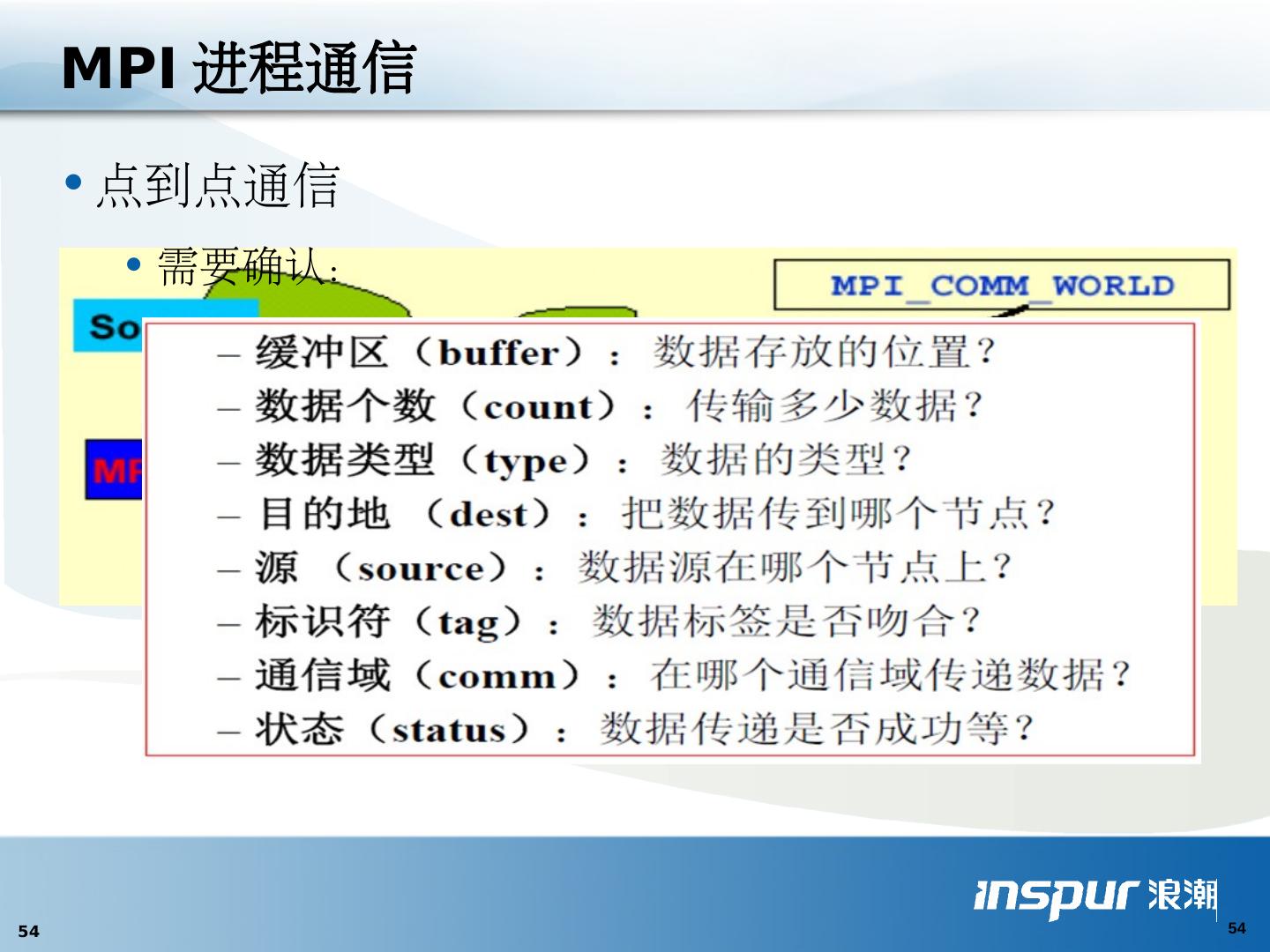
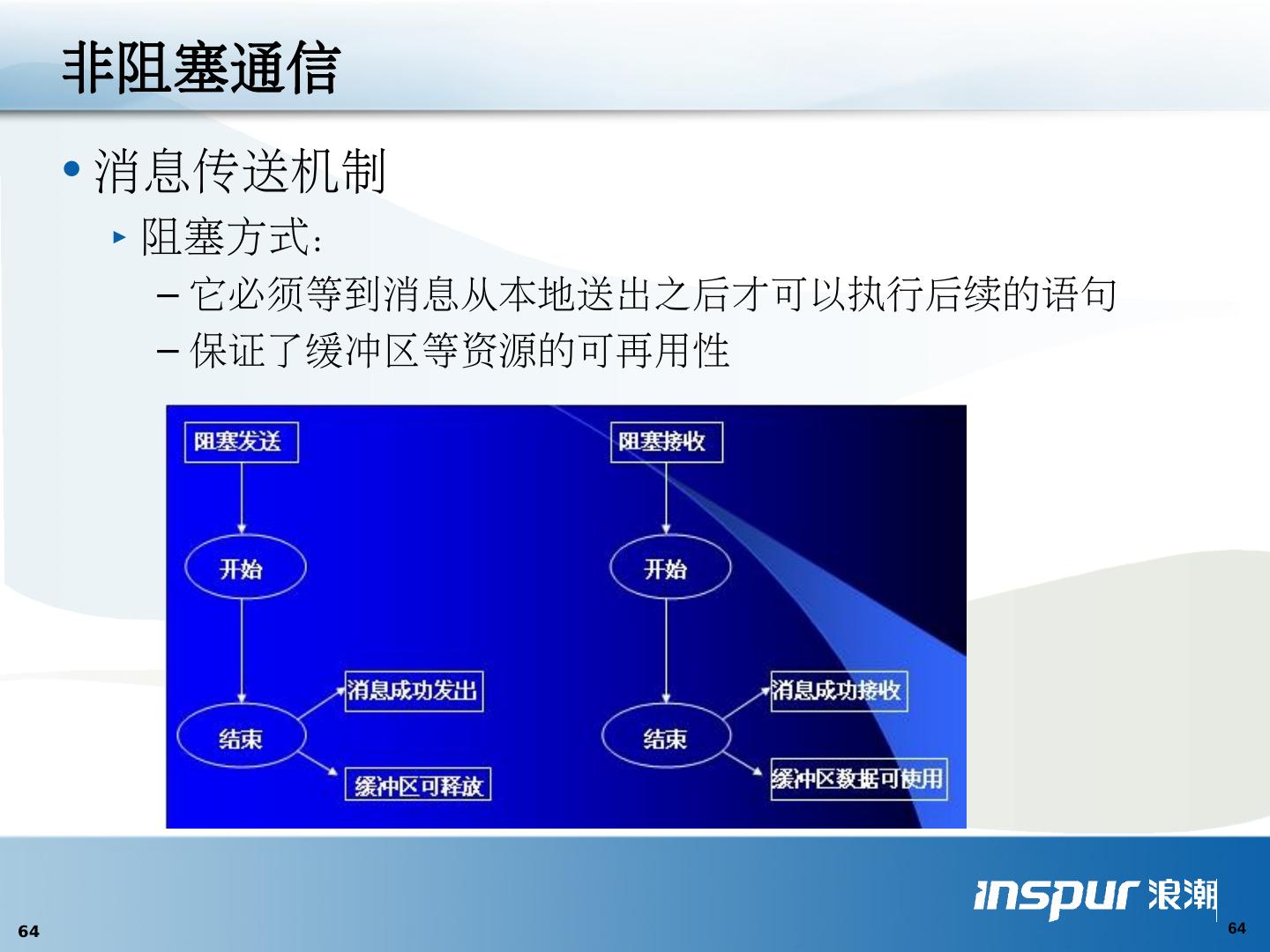
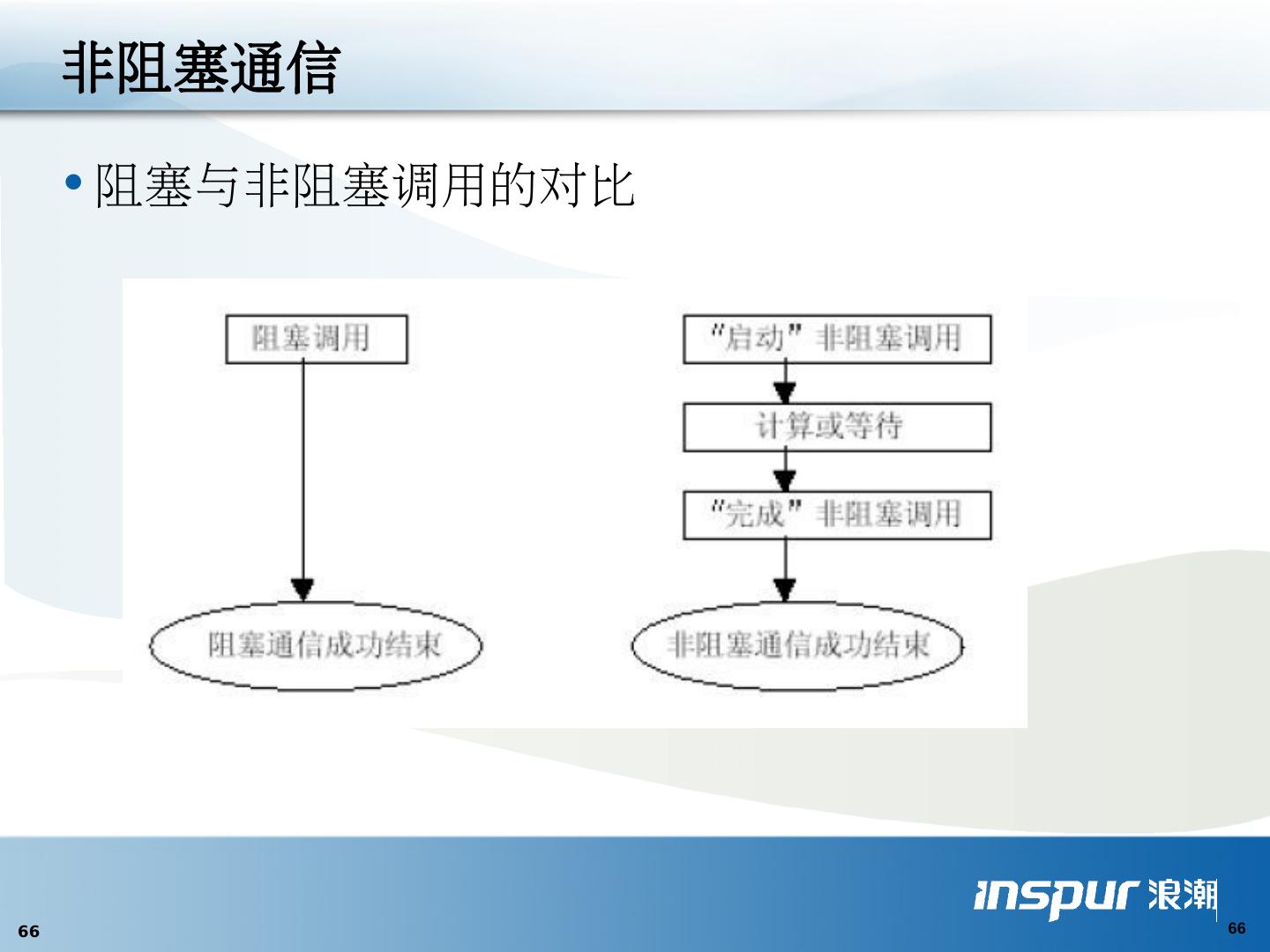
1 .MPI 并行编程入门
2 .主要内容 并行计算概述 MPI 并行算法概述 MPI 并行程序设计基础
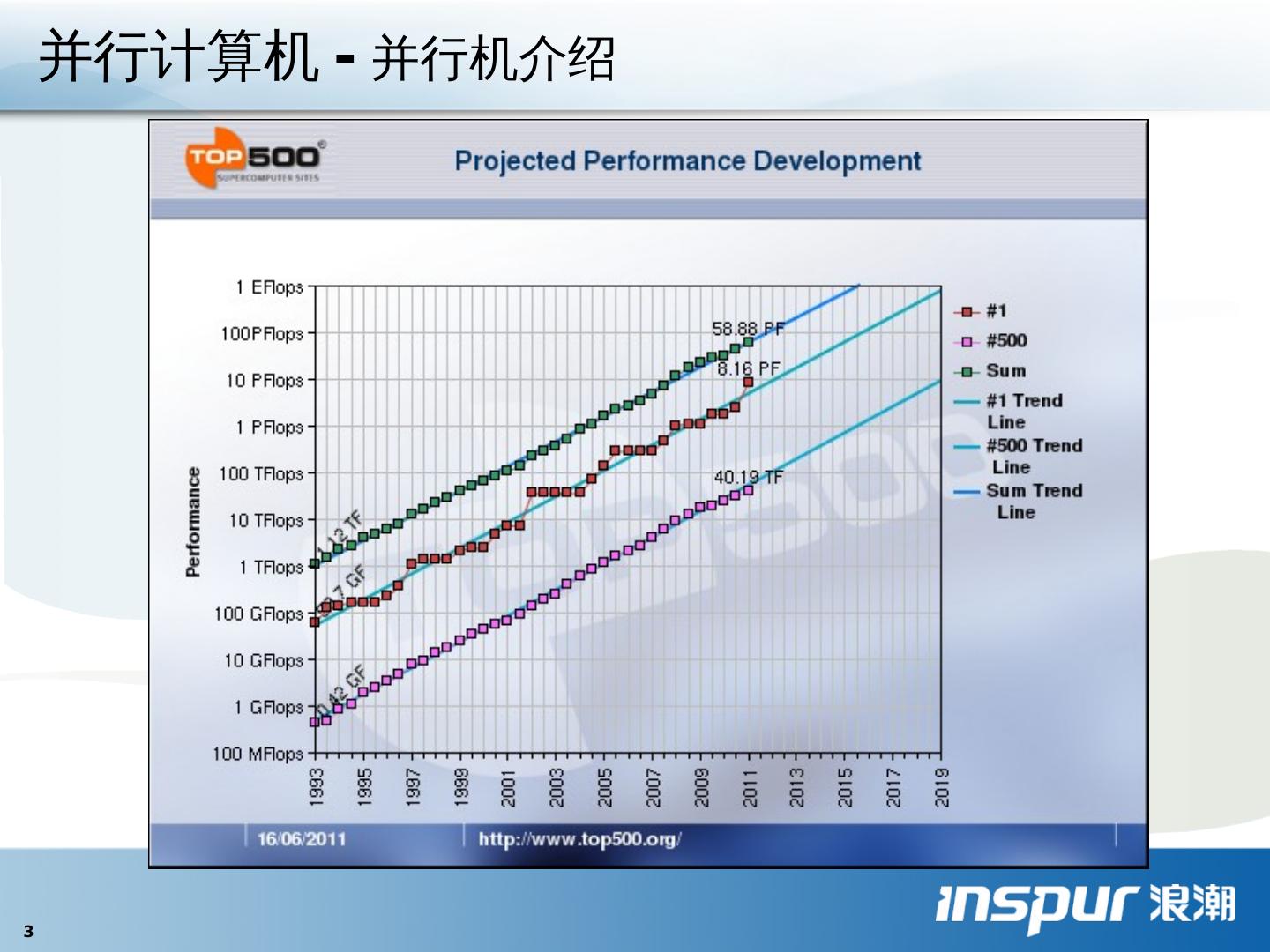
3 .并行计算机 - 并行机介绍
4 .
5 .Will this program still work? #include < stdio.h > int main(void) { printf ("Hello, world!
6 .并行计算机 - 并行机 结构 并行计算机 结构模型 根据指令流和数据流的不同,通常把计算机系统分为: 单指令单数据流 (SISD) 单指令多数据流 (SIMD) 多指令单数据流 (MISD) 多指令多数据流 (MIMD) 并行计算机系统多大部分为 MIMD 系统,包括: 对 称多处理机( SMP ) 分 布式共享存储多处理机( DSM ) 大规模并行处理机( MPP ) 机群( Cluster ) S M 指令个数 I 数据个数 D M S SIMD MISD SISD MIMD
7 .多个 CPU 连接于统一的内存总线 内存地址统一编址,单一操作系统映像 可扩展性较差,一般 CPU 个数少于 32 个 目前商用服务器多采用这种架构 Chipset Memory NIC System CPUs CPUs CPUs CPUs I/O Bus Memory Bus >4 CPUs may require switching Local Area Network SMP- Symmetric MultiProcessing
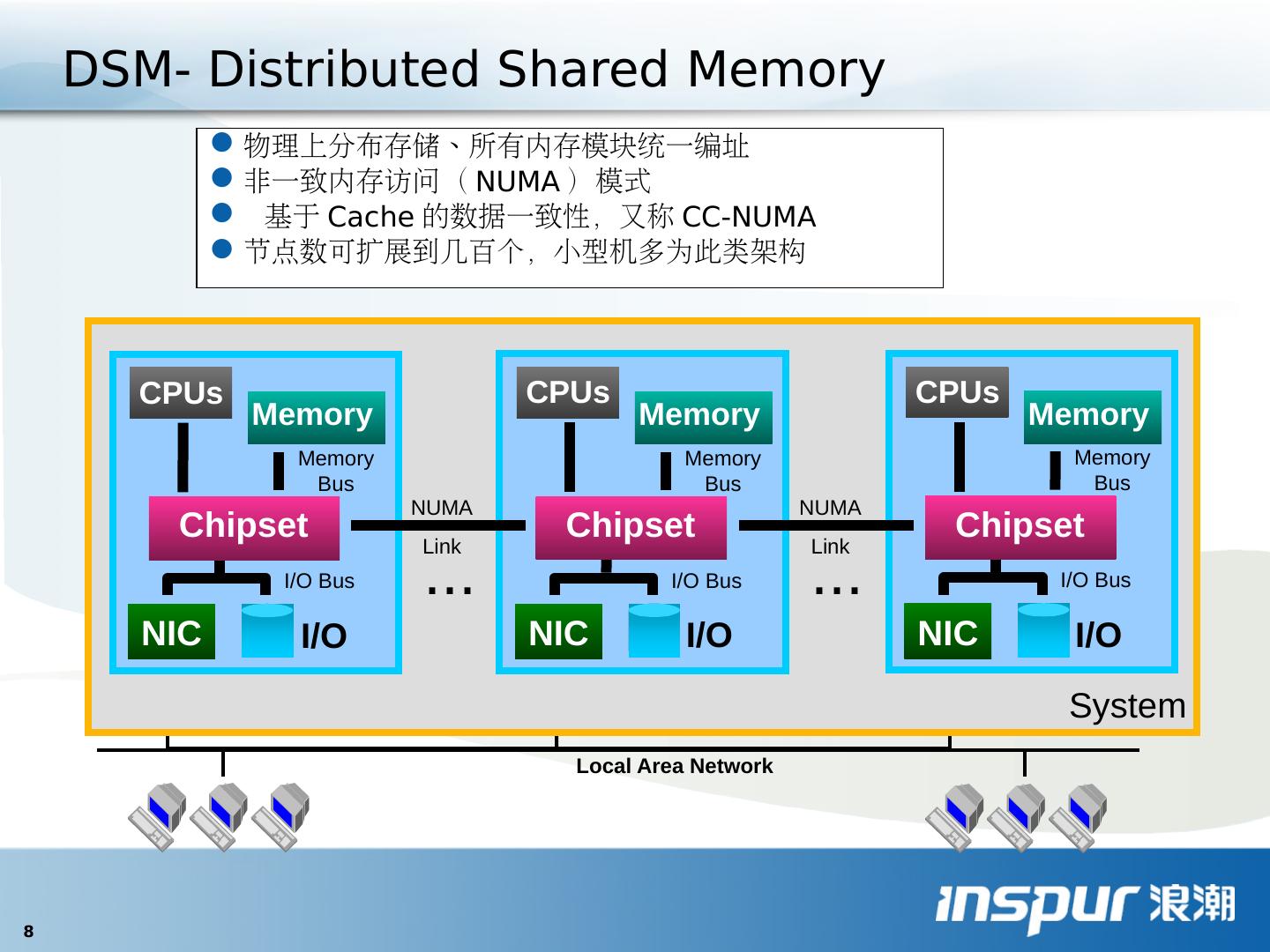
8 .物理上分布存储、所有内存模块统一编址 非一致内存访问( NUMA )模式 基于 Cache 的数据一致性,又称 CC-NUMA 节点数可扩展到几百个,小型机多为此类架构 Local Area Network ... System ... NIC Memory CPUs Chipset I/O Bus Memory Bus I/O NIC Memory CPUs Chipset I/O Bus Memory Bus I/O NIC Memory CPUs Chipset I/O Bus Memory Bus I/O NUMA Link NUMA Link DSM- Distributed Shared Memory
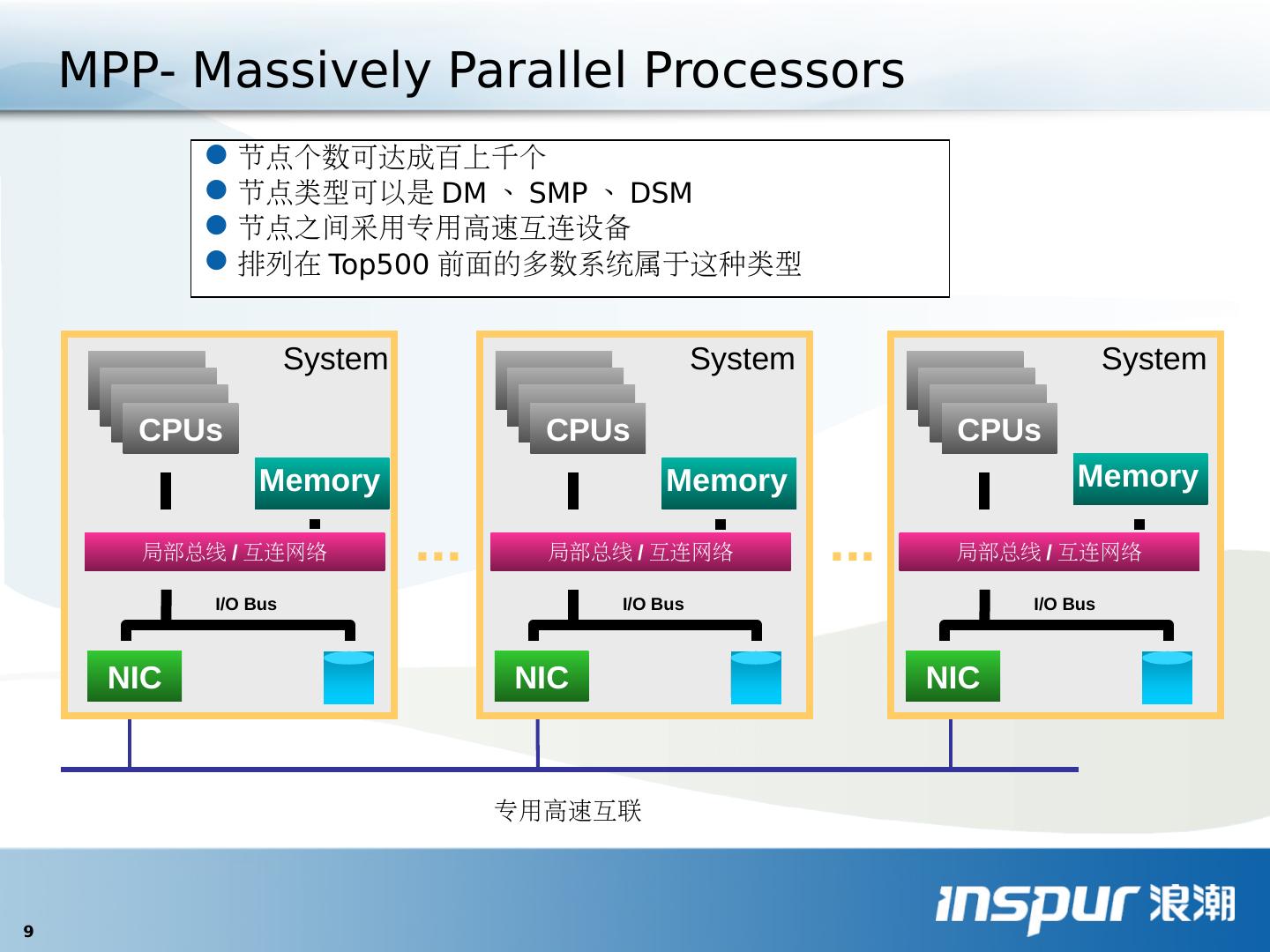
9 .节点个数可达成百上千个 节点类型可以是 DM 、 SMP 、 DSM 节点之间采用专用高速互连设备 排列在 Top500 前面的多数系统属于这种类型 ... ... 专用高速互联 NIC Memory I/O Bus System 局部总线 / 互连网络 CPUs NIC Memory I/O Bus System CPUs 局部总线 / 互连网络 NIC Memory I/O Bus System CPUs 局部总线 / 互连网络 MPP- Massively Parallel Processors
10 .独立的节点、商品化网络连接 开放的硬件设备、操作系统、应用编程接口 节点数可达几百个,性能已接近超级计算机系统 近年来发展很快,已广泛应用到高性能科学计算领域 ... ... System Area Network Local Area Network LAN Memory I/O Bus Memory Bus System Chipset SAN CPUs LAN Memory I/O Bus Memory Bus System Chipset SAN CPUs LAN Memory I/O Bus Memory Bus System Chipset SAN CPUs Cluster
11 .各种架构对比 SMP 瓶颈在访存带宽,限制了可扩展性(性能会严重下降),通过增大 Cache 来缓解,又有数据一致性的问题。 DSM 具有较好的可扩展性,且具有与 SMP 相同的编程模式。共享存储的机器可以运行各种编程模式的程序,包括串行程序、共享存储并行程序和消息传递并行程序。 共享存储的机器首先可以看作是一个内存扩充了的串行机器,可以运行数据量极大的串行程序,如大数据量的数据库应用。利用多个处理器的并行处理性能,自动并行(靠编译器)作用有限,需要其他编程方式的应用,如 OpenMP 。
12 .各种架构对比(续) 分布式存储体系结构 无共享的机器, MPP 和 Cluster ,具有最好的可扩展性,采用消息传递编程,可编程性不如 OpenMP ,也可以通过 DSM 软件的方式来模拟实现共享存储(其实还是通过消息传递,只不过对上层透明),性能受到影响,但可以运行 OpenMP 应用程序。 MPP/PVP 在构造大规模系统,应用饱和性能方面具有优势,资金充足的依然会选择; Cluster 由于无可比拟的性价比优势占据主流位置。 系统的高可用性 更高的计算能力 良好的可扩展性 更高的性价比
13 .各种架构对比(续) 分布式存储体系结构 无共享的机器, MPP 和 Cluster ,具有最好的可扩展性,采用消息传递编程,可编程性不如 OpenMP ,也可以通过 DSM 软件的方式来模拟实现共享存储(其实还是通过消息传递,只不过对上层透明),性能受到影响,但可以运行 OpenMP 应用程序。 MPP/PVP 在构造大规模系统,应用饱和性能方面具有优势,资金充足的依然会选择; Cluster 由于无可比拟的性价比优势占据主流位置。 系统的高可用性 更高的计算能力 良好的可扩展性 更高的性价比
14 .并行算法 并行计算的相关基本概念 并行化分解及通信方法 并行编程风范 并行算法 设计 基本原则和分类 数值计算并行算法
15 .并行算法 并行算法设计:将一个任务分解为多个可同时执行的子任务,这些子任务分别运行在不同的处理器上,通过相互之间的数据交换完成同一个任务。 与并行计算有关的概念: 粒度 :两次并行或交互操作 之间所 执行的计算 负载 并行度:同时执行的分进程数 加速比: 效率: 性能: 并行度与并行粒度大小常互为倒数 : 增大 粒度会减小并行度 . 增加并行度会增加系统 ( 同步 ) 开销
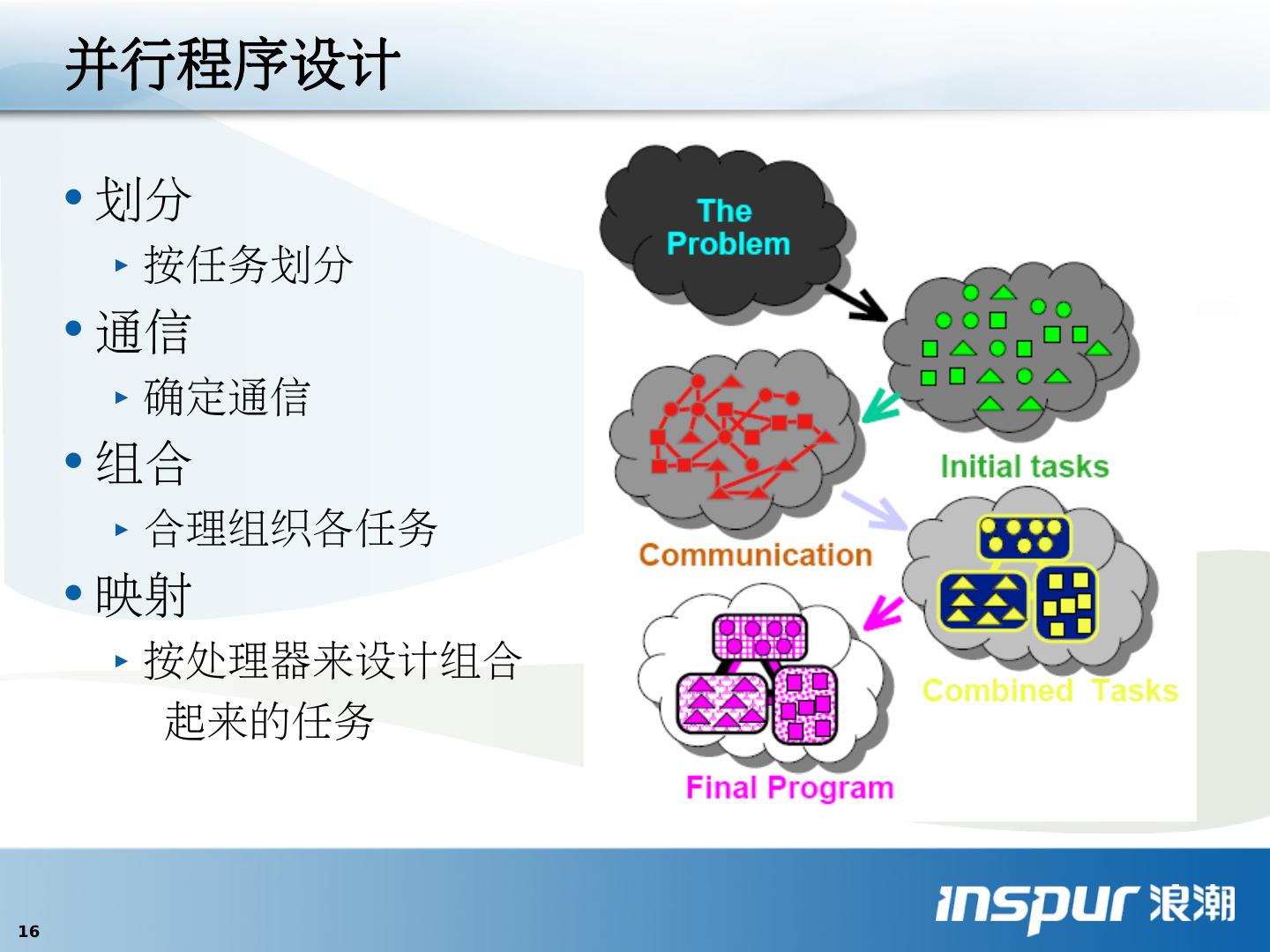
16 .并行程序设计 划分 按任务划分 通信 确定通信 组合 合理组织各任务 映射 按处理器来设计组合 起来的任务
17 .原则 : 使系统大部分时间忙于计算 , 而不是闲置或忙于交互 ; 同时不牺牲并行性 ( 度 ). 划分 : 切割数据和工作负载 分配: 将划分好的数据和工作负载映射到计算结点 ( 处理器 ) 上 分配 方式: 显式分配 : 由用户指定数据和负载如何加载 隐式分配:由编译器和运行时支持系统决定 就近分配原则: 进程所需的数据靠近使用它的进程代码 并行化的基本思想 — 任务划分
18 .区域分解法: 分解被执行的数据 非重叠的区域分解,这种分解将离散化后的方程化成一些独立的小规模问题和一个与每个小问题关联的全局问题,此种分解给出的方法是子结构方法。 带重叠的区域分解 并行化分解方法
19 .功能分解法: 功能分解是将不同功能组成的问题,按照其功能进行分解的一种手段,其目的是逐一解决不同功能的问题,从而获得整个问题的解。 例如:使用 Newton 法求解非线性方程 F(x) = 0 在求解方程的过程中,需要用到函数值和导数值。因此,如果一部分处理机负责计算函数值,另一部分处理机负责计算导数值,就可以得到一种并行计算方法。 这时候计算是按照功能进行分配的,也既是所谓的功能分解。 并行化分解方法
20 .流水线技术: 流水线技术是并行计算中一个非常有效的、常用的手段,在并行计算中起着非常重要的作用。 以求解一簇递推问题为例加以说明: 上述计算中,沿 j 方向的计算是互相独立的,而沿 i 方向的计算则存在着向前依赖关系 ( 递推关系 ) ,无法独立进行。 不失一般性,我们假设数据划分仅沿 i 方向进行,即假设在有 3 个处理器的分布式系统上, ai,j 被分成 3 段 , 如图所示,相同颜色的部分是可以并行计算的。 并行化分解方法 流水线计算示意图
21 .分而治之方法: 以一个简单的求和问题为例,说明什么是分而治之方法。假设在 q = 2*2*2 个处理机上计算: 可以将计算依次分解为两个小的求和问题,用下图简单的描述(图中给出的是处理机号)。在图中,从上至下是分解的过程,从下至上是求部分和的过程。这就是有分有治的一个简单过程,也既是一种分而治之方法。 并行化分解方法 分而治之计算示意图
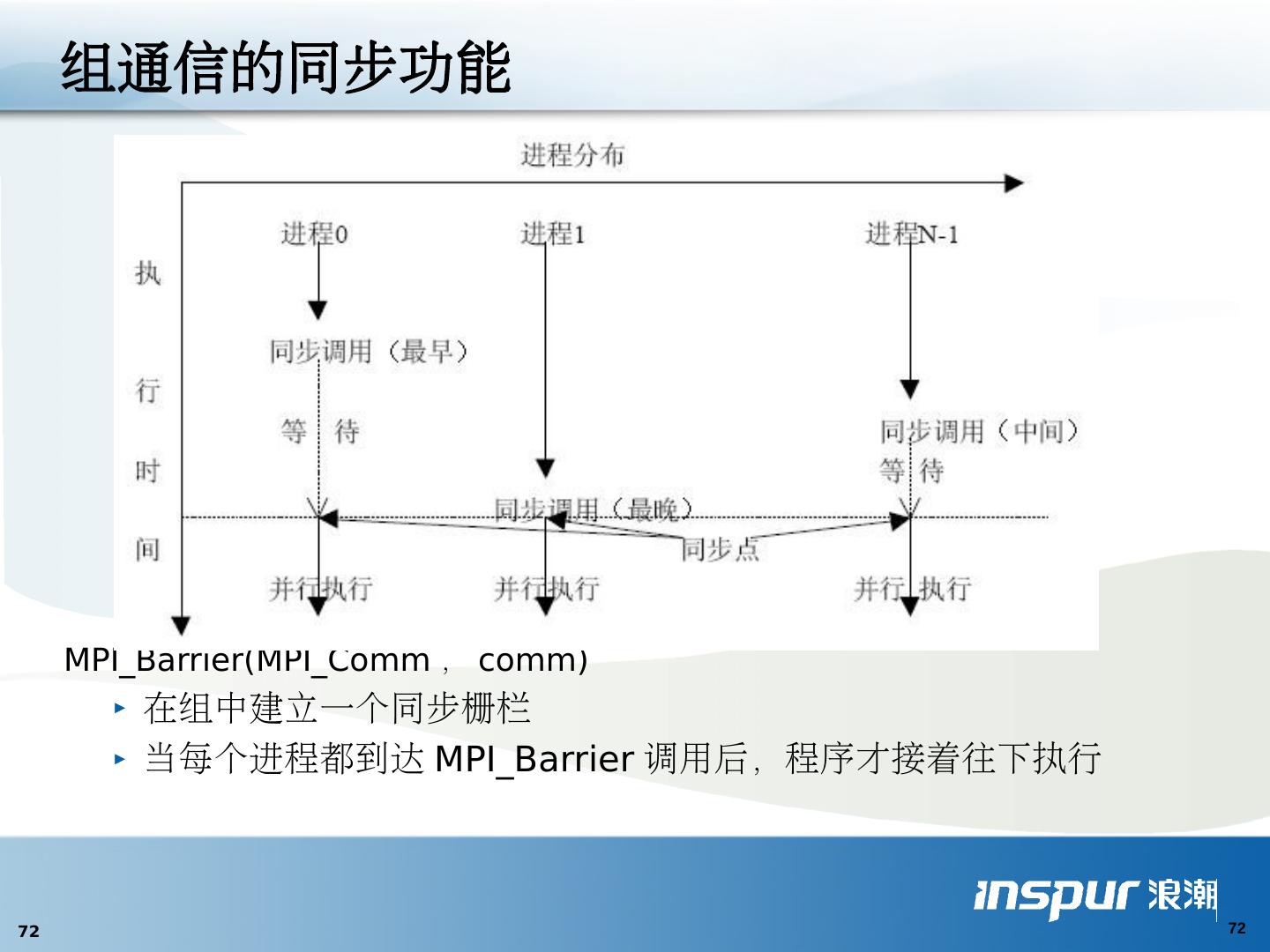
22 .并行化的基石 — 通信 通信方式 共享变量 父进程传给子进程 ( 参数传递方式 ) 消息传递 同步: 导致进程间相互等待或继续执行的 操作 原子同步 控制同步 ( 路障 , 临界区 ) 数据同步 ( 锁 , 条件临界区 , 监控程序 , 事件 ) 聚集: 用一串超步将各分进程计算所得的部分结果合并为一个完整的结果 , 每个超步包含一个短的计算和一个简单的通信或 / 和同步 . 聚集方式 : 归约 扫描
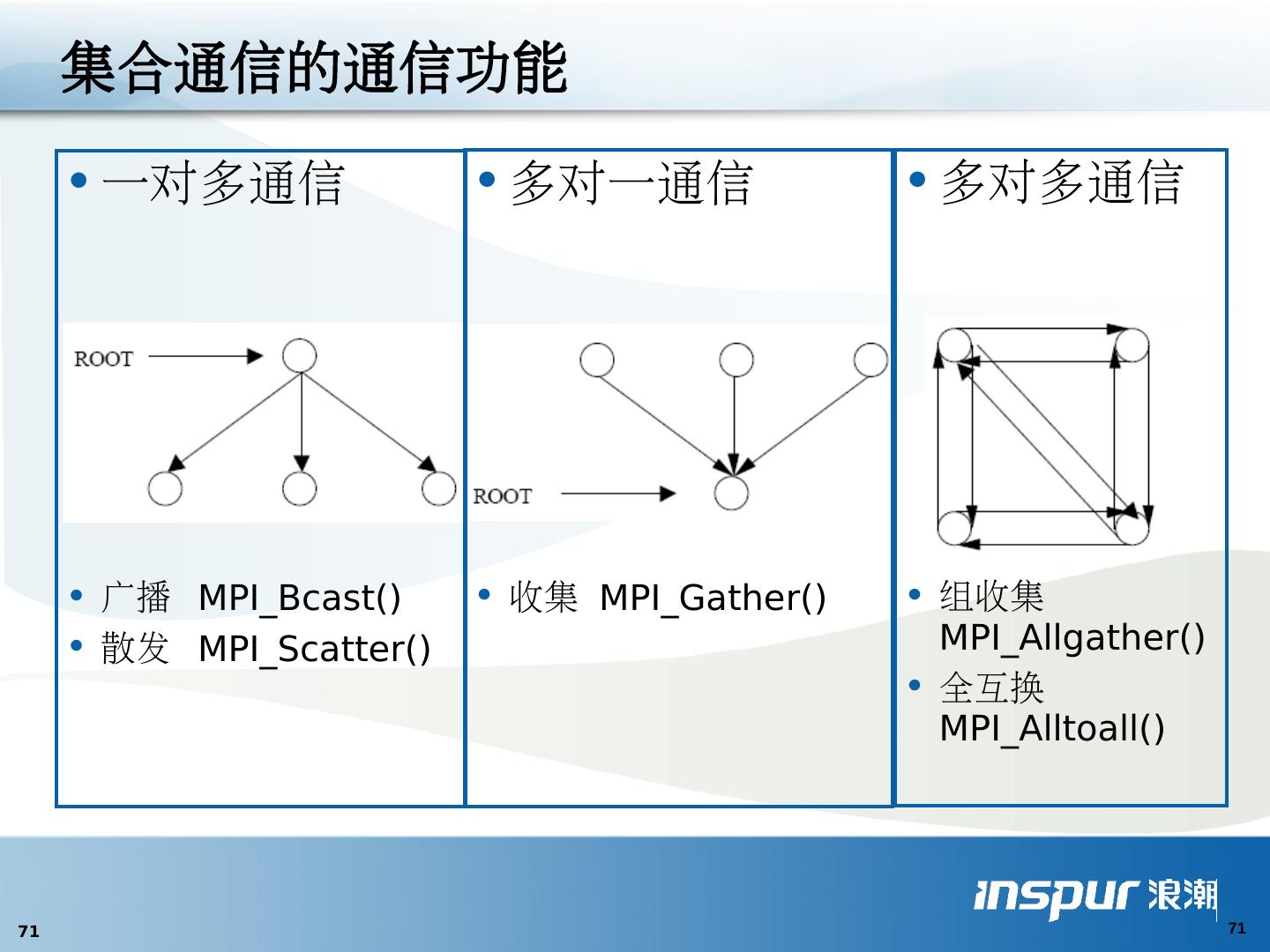
23 .通信 模式 一对一 : 点到点 (point to point) 一对多 : 广播 (broadcast), 播撒 (scatter) 多对一 : 收集 (gather), 归约 (reduce) 多对多 : 全交换 ( Tatal Exchange), 扫描 (scan) , 置换 / 移位 (permutation/shift)
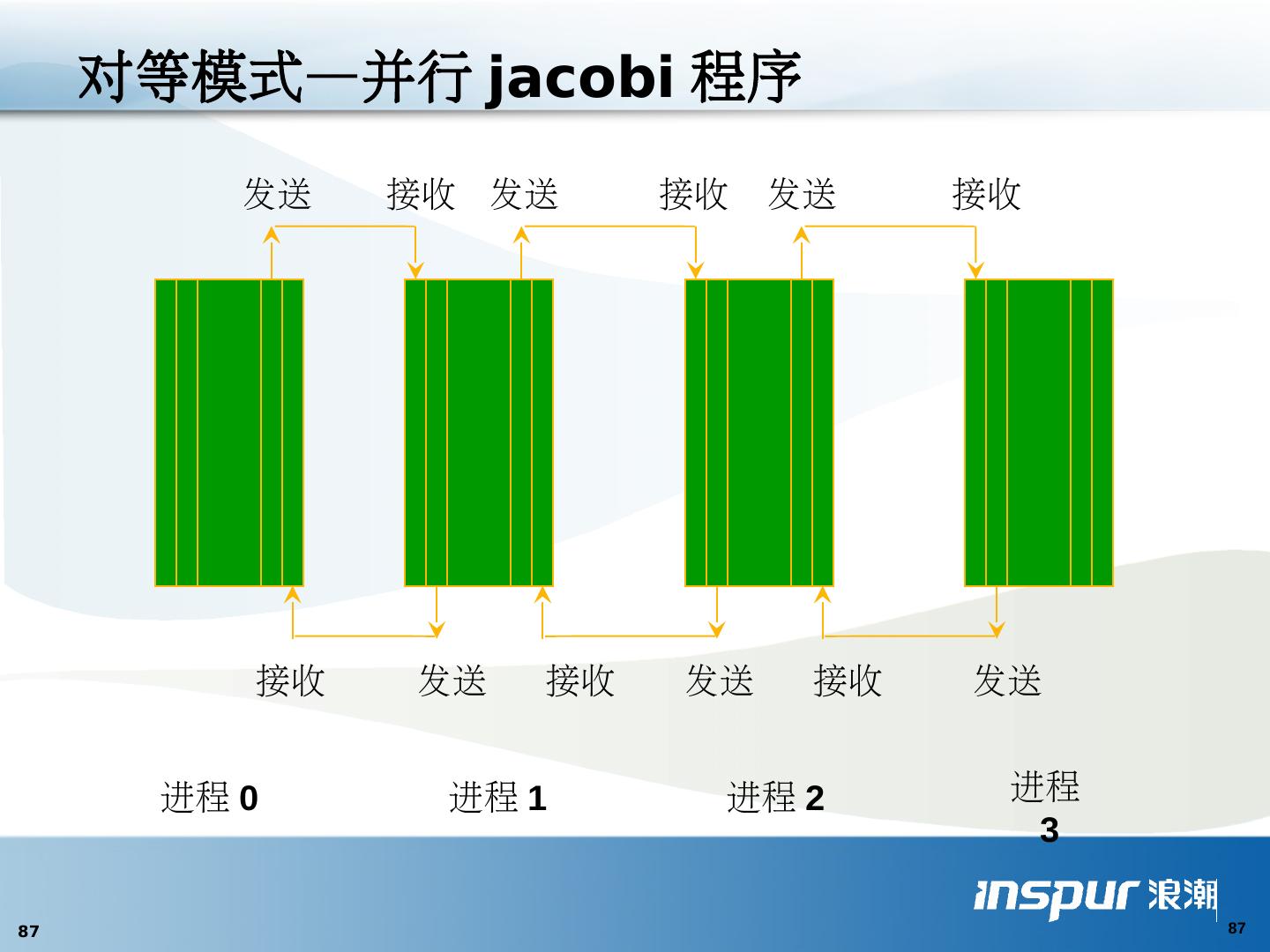
24 .五种并行编程风范 相并行( Phase Parallel ) 主从并行( Master-Slave Parallel ) 分 治并行( Divide and Conquer Parallel ) 流水线并行( Pipeline Parallel ) 工作池并行( Work Pool Parallel )
25 .相并行( Phase Parallel ) 一组超级步(相) 步内各自计算 步间通信、同步 BSP 方便差错和性能分析 计算和通信不能重叠 C C C Synchronous Interaction ...... C C C Synchronous Interaction ......
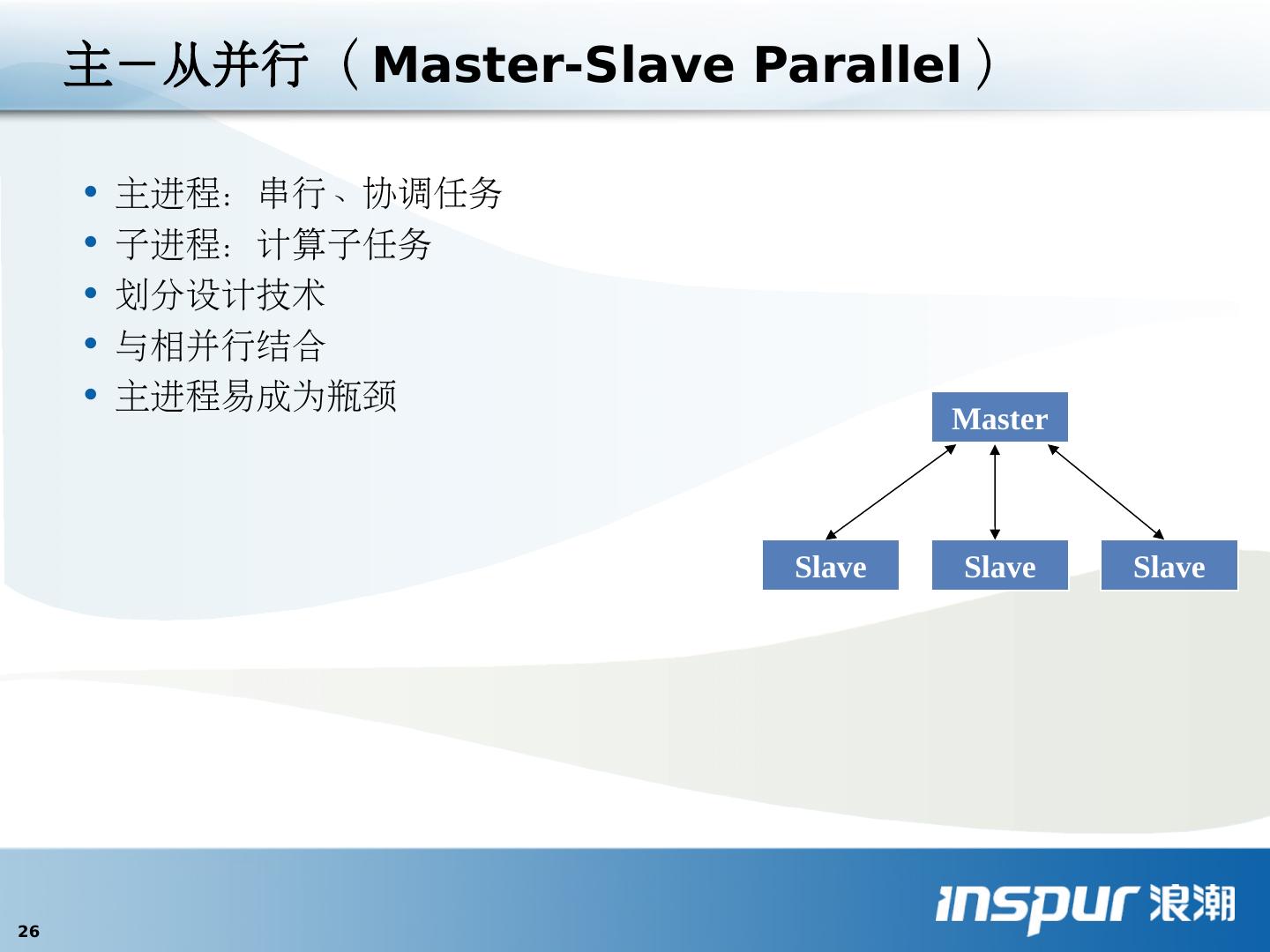
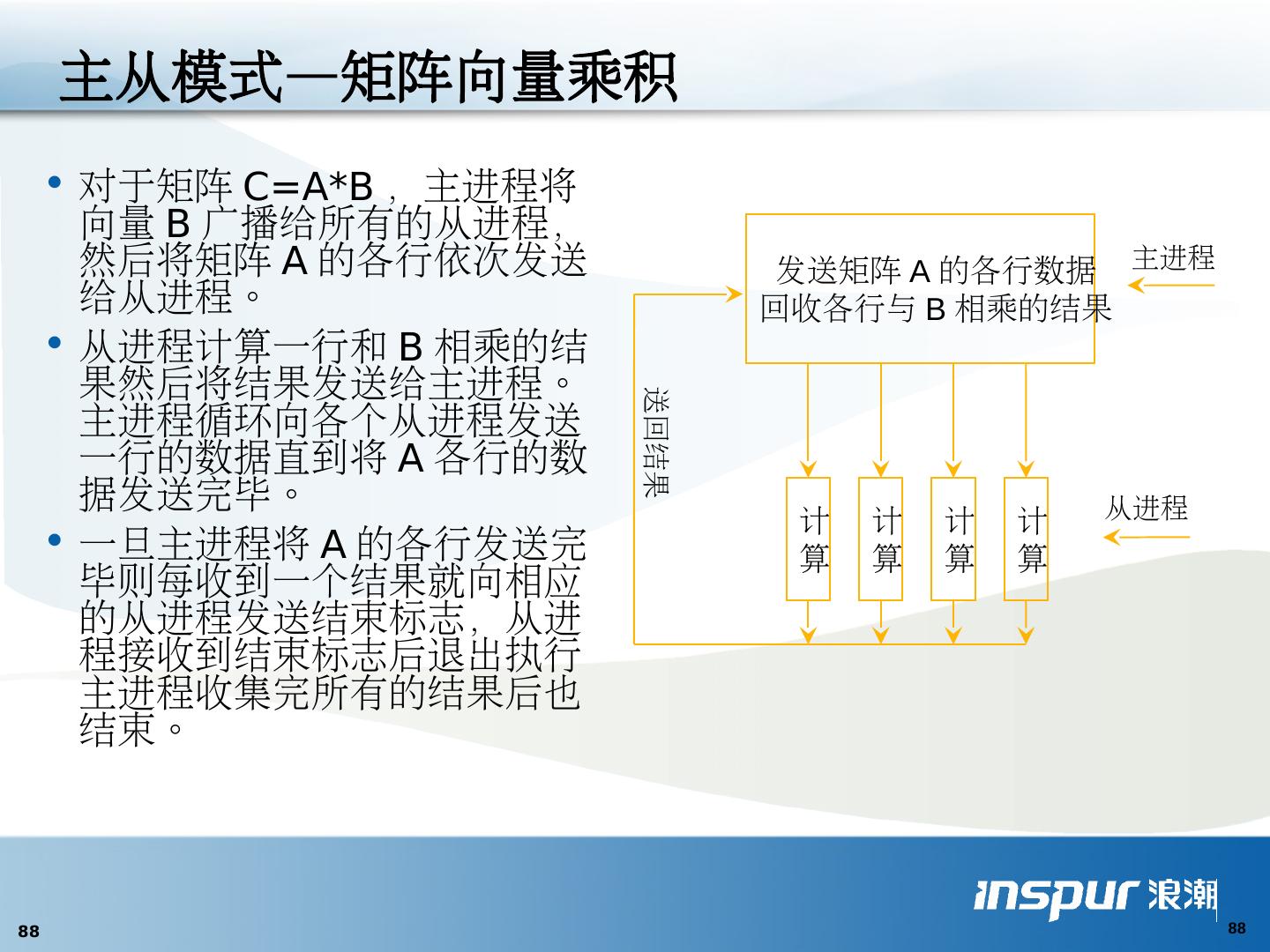
26 .主-从并行( Master-Slave Parallel ) 主进程:串行、协调任务 子进程:计算子任务 划分设计技 术 与相并行结合 主进程易成为瓶颈 Master Slave Slave Slave
27 .分治并行( Divide and Conquer Parallel ) 父进程把负载分割并指派给子进程 递归 重点在于归并 分治设计技 术 难以负载平衡
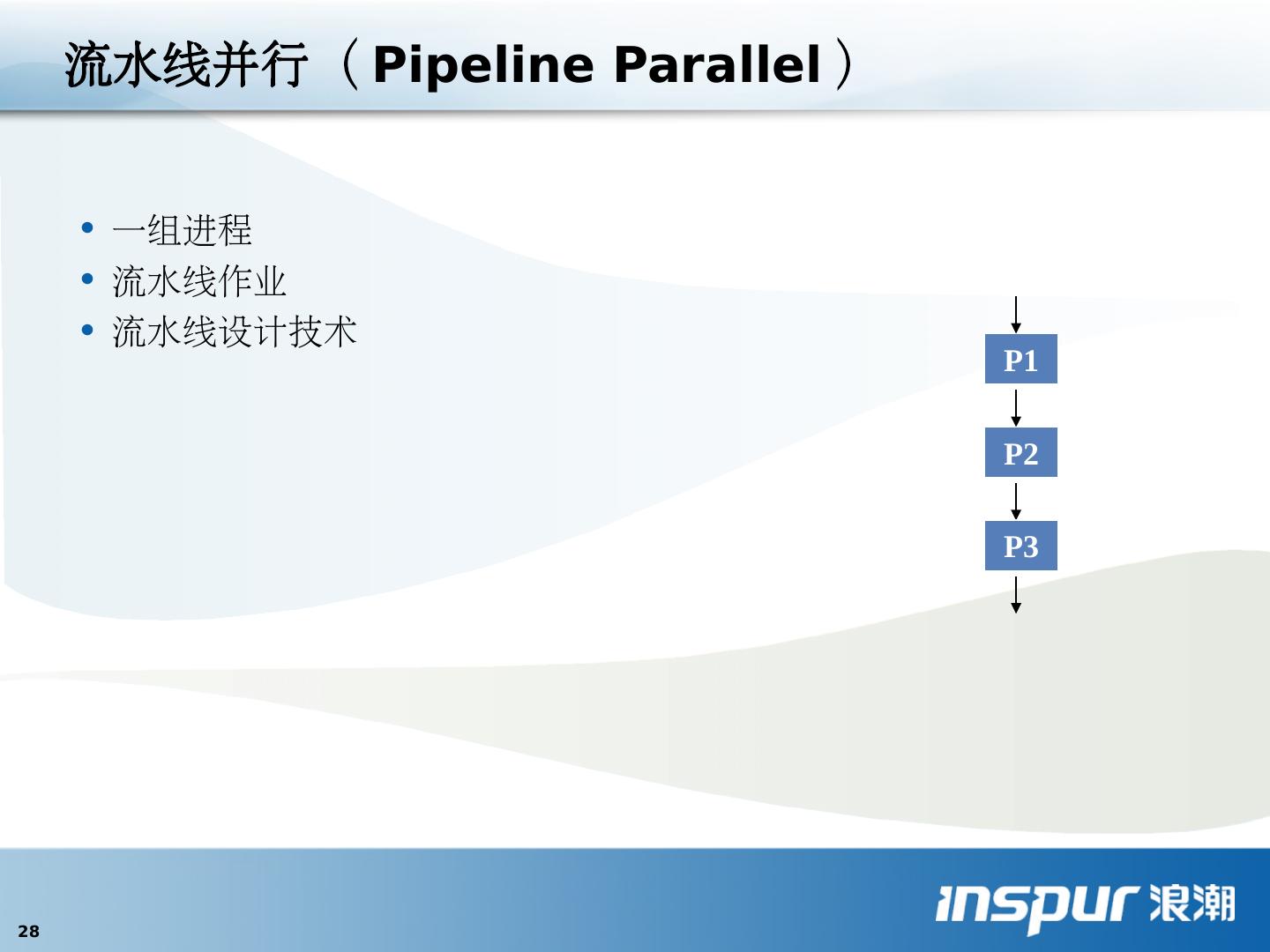
28 .流水线并行( Pipeline Parallel ) 一组进程 流水线作业 流水线设计技 术 P1 P2 P3
29 .工作池并行( Work Pool Parallel ) 初始状态:一件工作 进程从池中取任务执行 可产生新任务放回池中 直至任务池为空 易与负载平衡 临界区问题(尤其消息传递) Work Pool P1 P2 P3
相关推荐
3秒后跳转登录页面
去登陆

