















































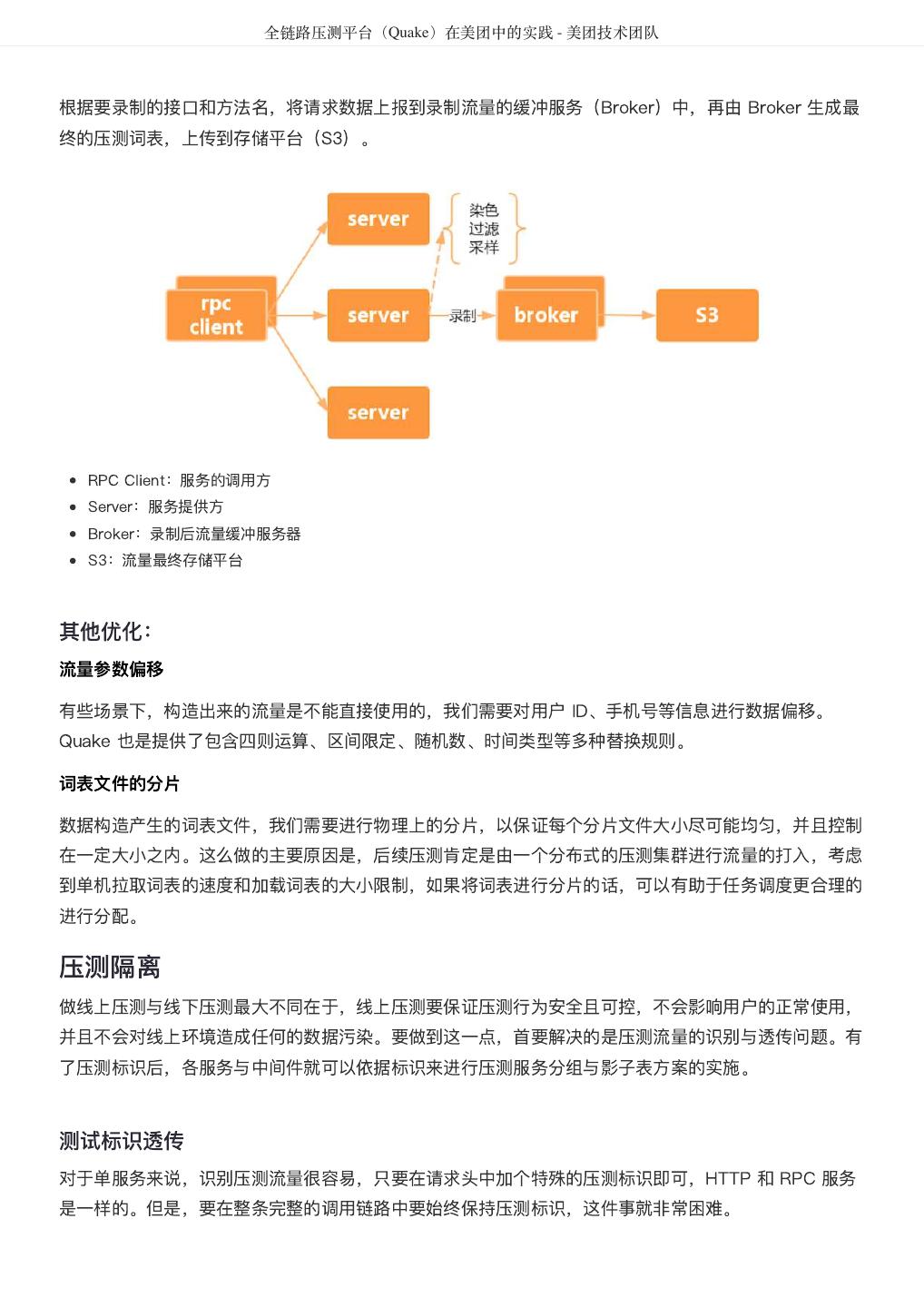
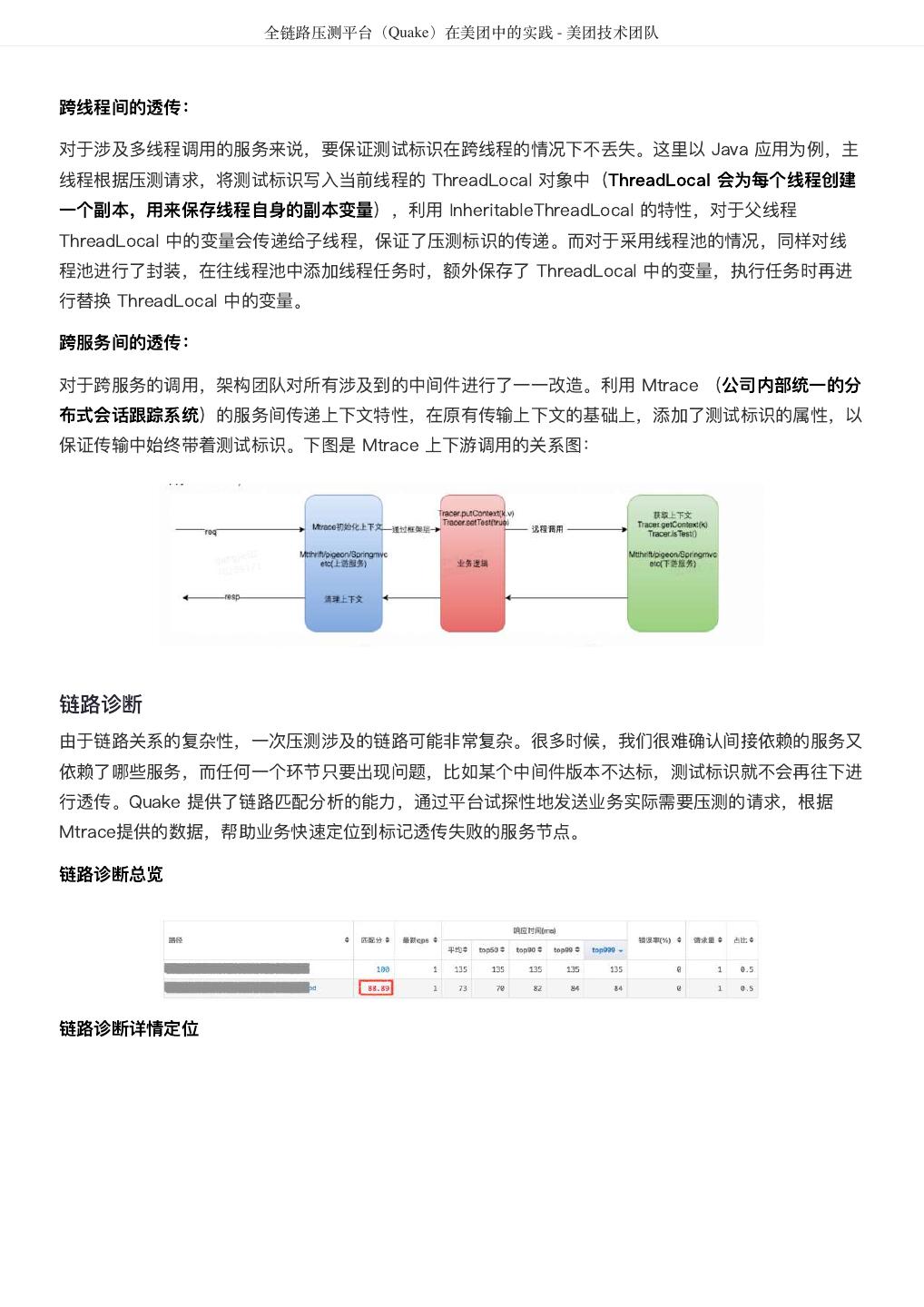
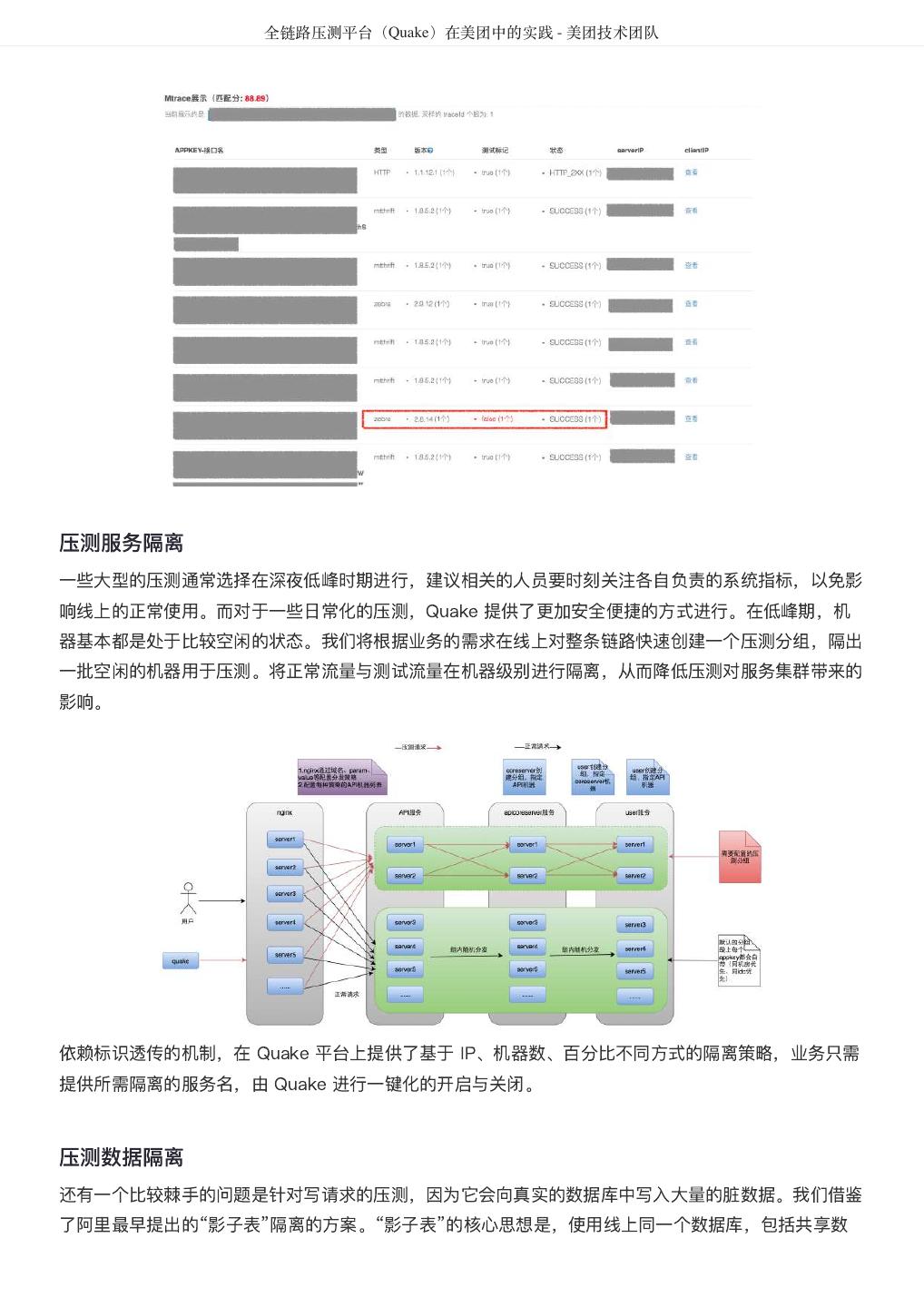
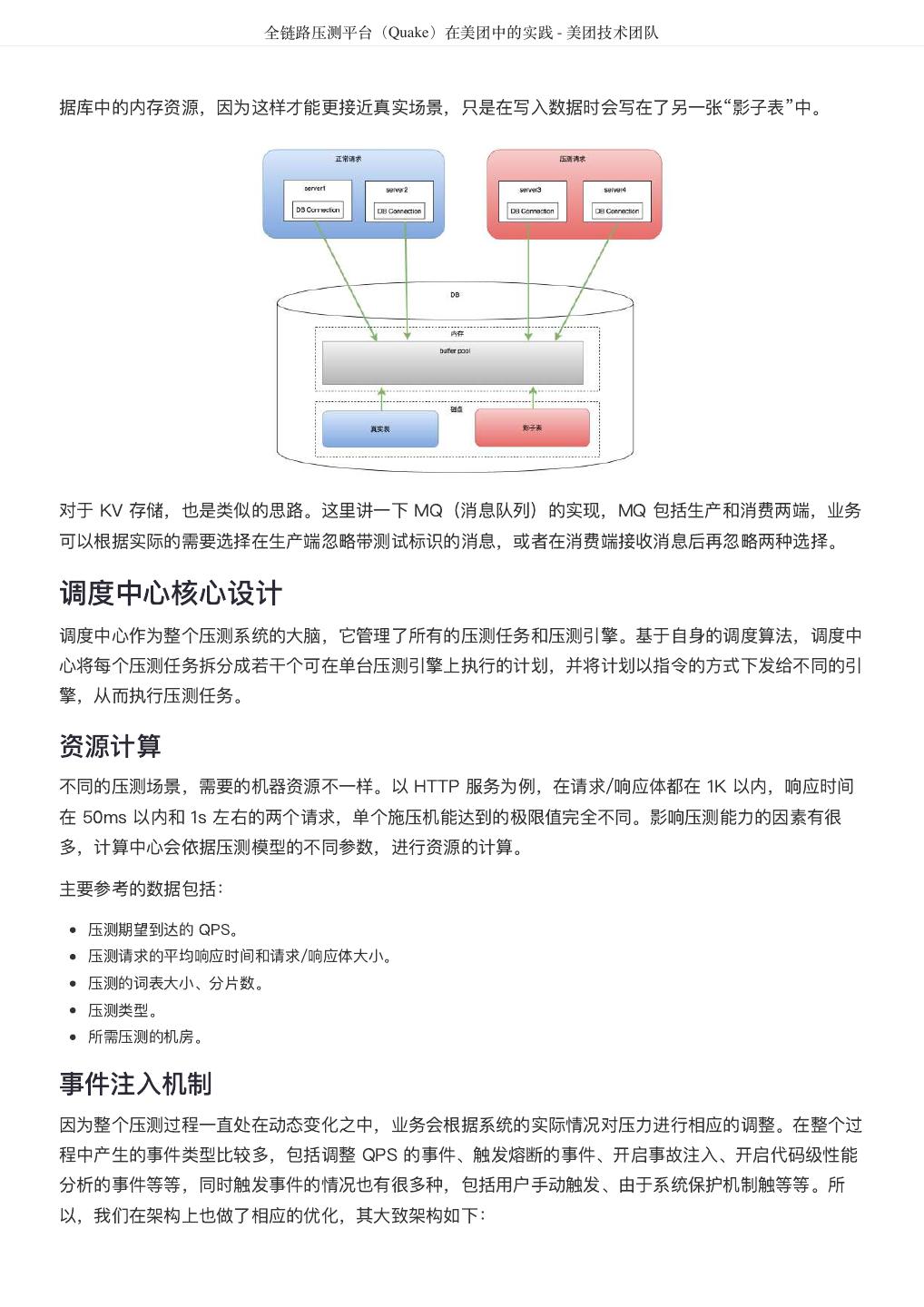

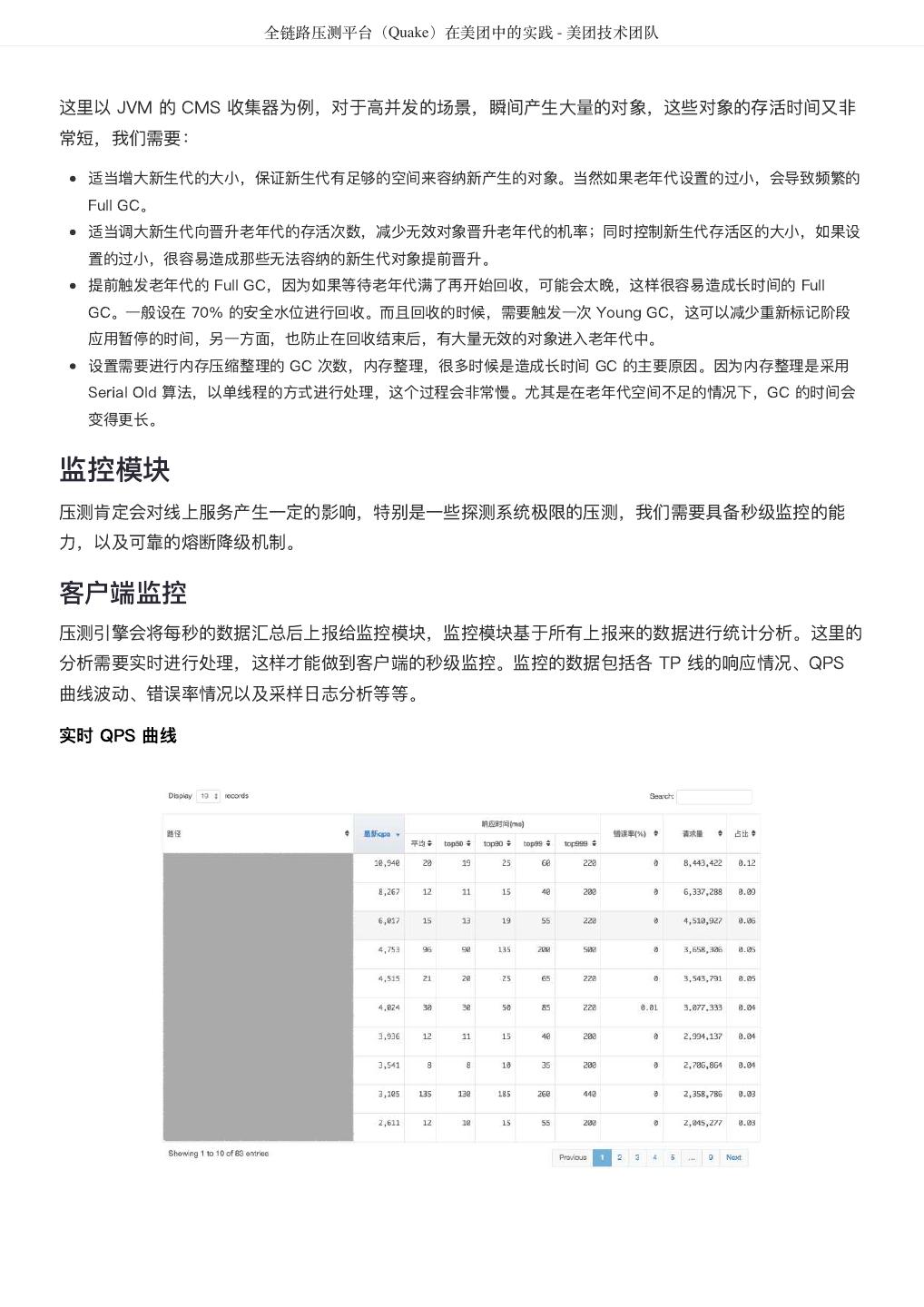


























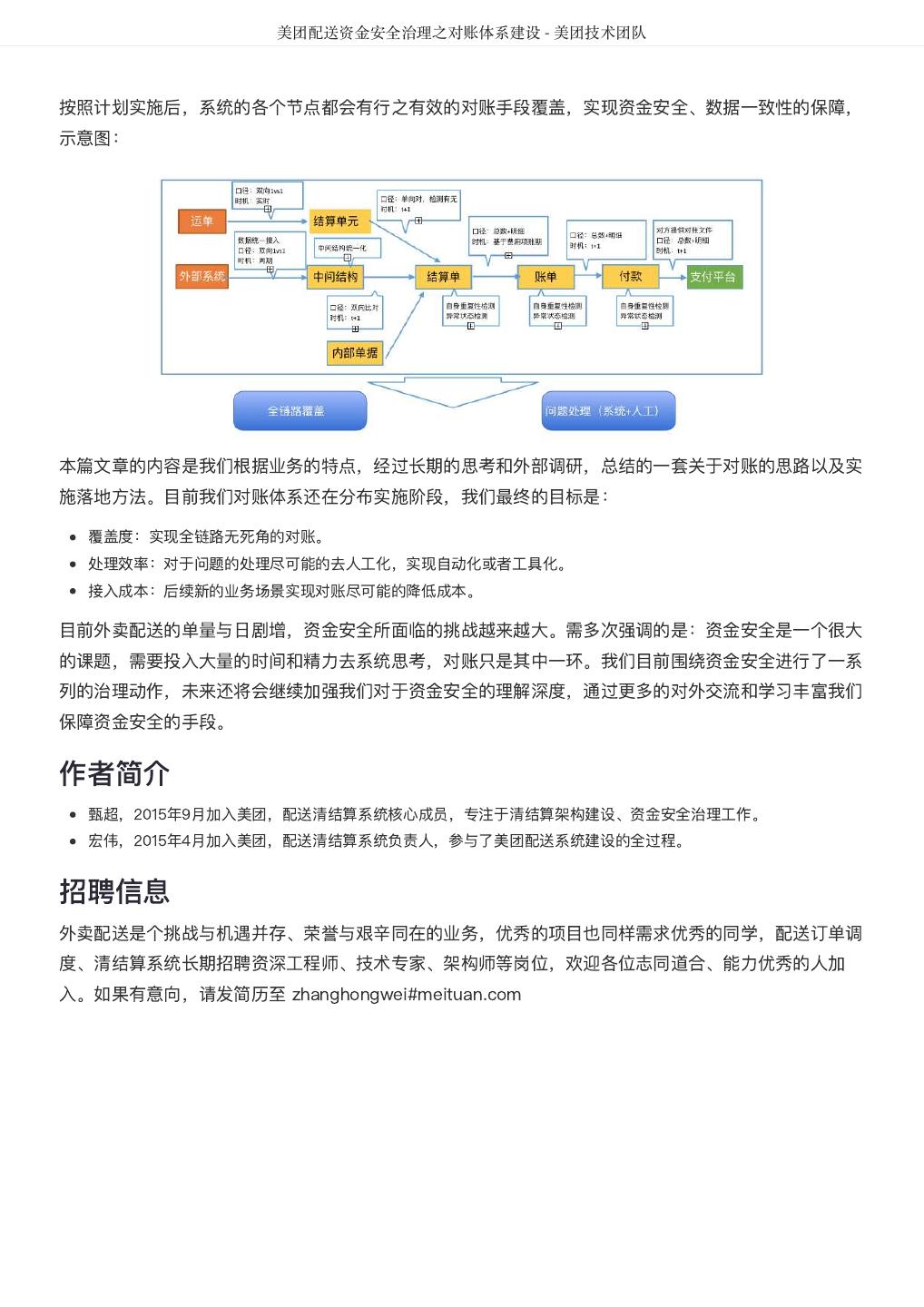

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2018美团技术—系统系列
2018美团技术—系统系列
展开查看详情
1 .
2 . 序 春节已近,年味渐浓。 又到了我们献上技术年货的时候。 不久前,我们已经给大家分享了技术沙龙大套餐,汇集了过去一年我们线上线下技术沙龙 99位讲师,85 个演讲,70+小时 分享。 今天出场的,同样重磅——技术博客全年大合集。 2018年,是美团技术团队官方博客第5个年头, 博客网站 全年独立访问用户累计超过300万,微信公众 号(meituantech)的关注数也超过了15万。 由衷地感谢大家一直以来对我们的鼓励和陪伴! 在2019年春节到来之际,我们再次精选了114篇技术干货,制作成一本厚达1200多页的电子书呈送给大 家。 这本电子书主要包括前端、后台、系统、算法、测试、运维、工程师成长等7个板块。疑义相与析,大家 在阅读中如果发现Bug、问题,欢迎扫描文末二维码,通过微信公众号与我们交流。 也欢迎大家转给有相同兴趣的同事、朋友,一起切磋,共同成长。 最后祝大家,新春快乐,阖家幸福。
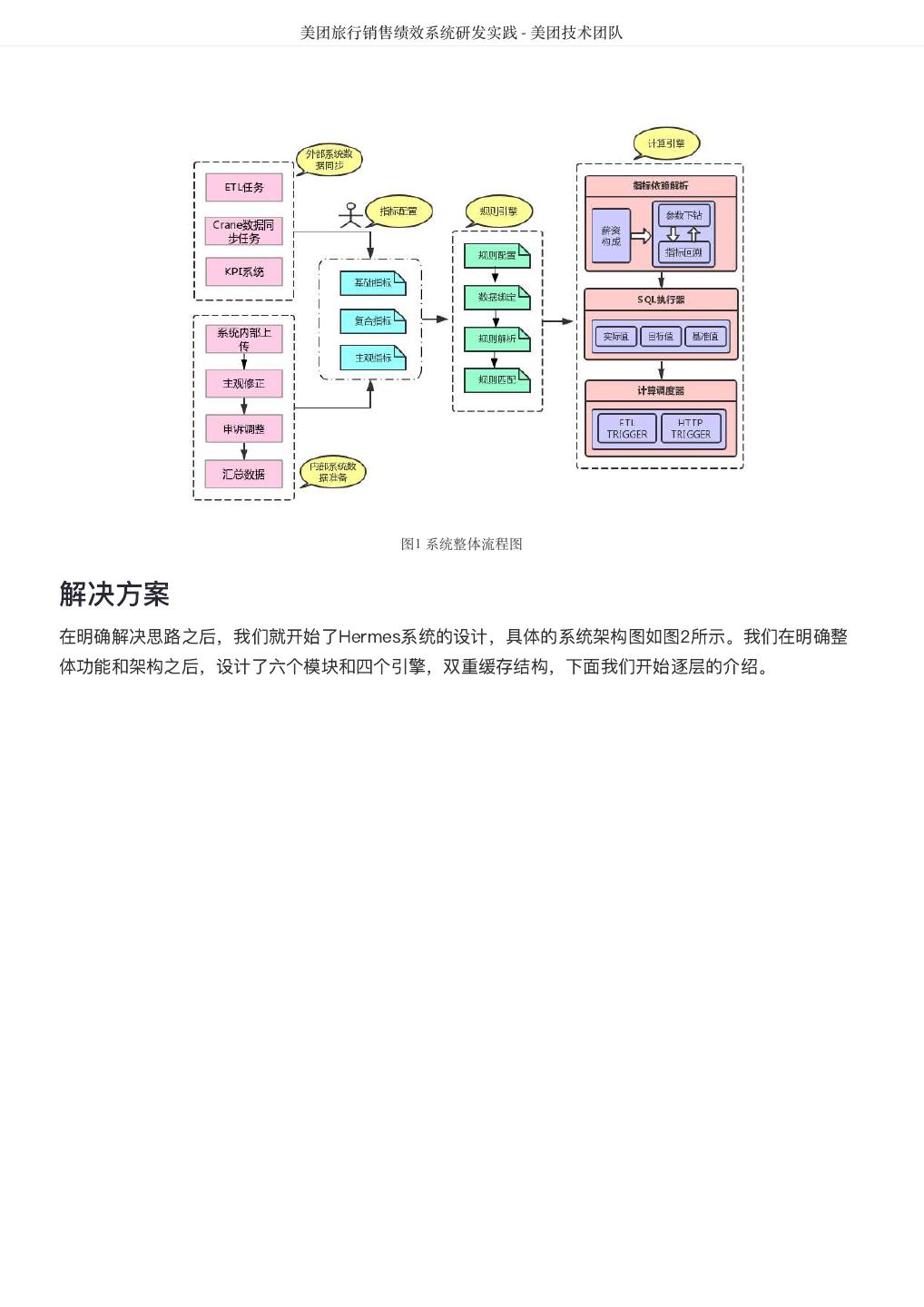
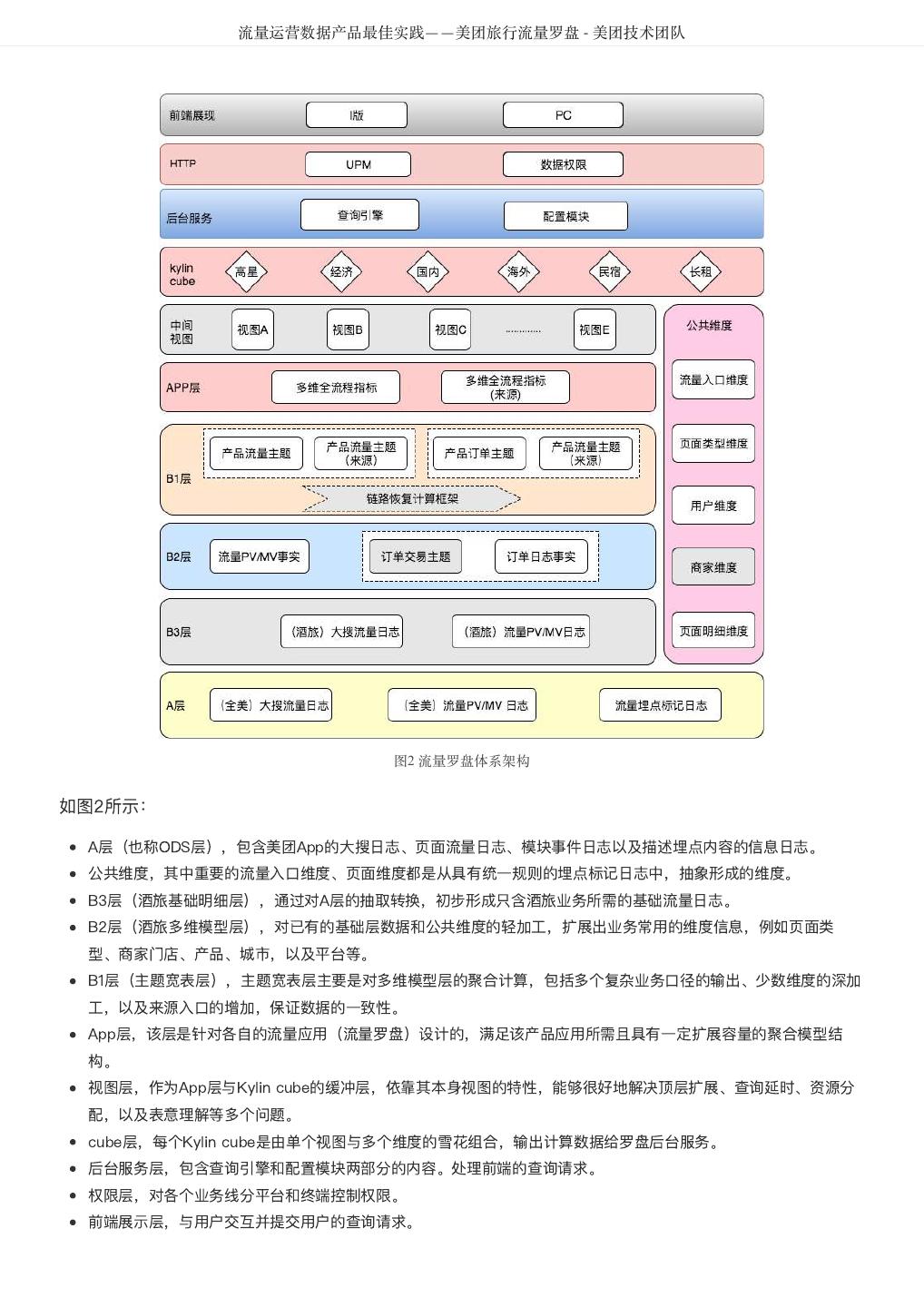
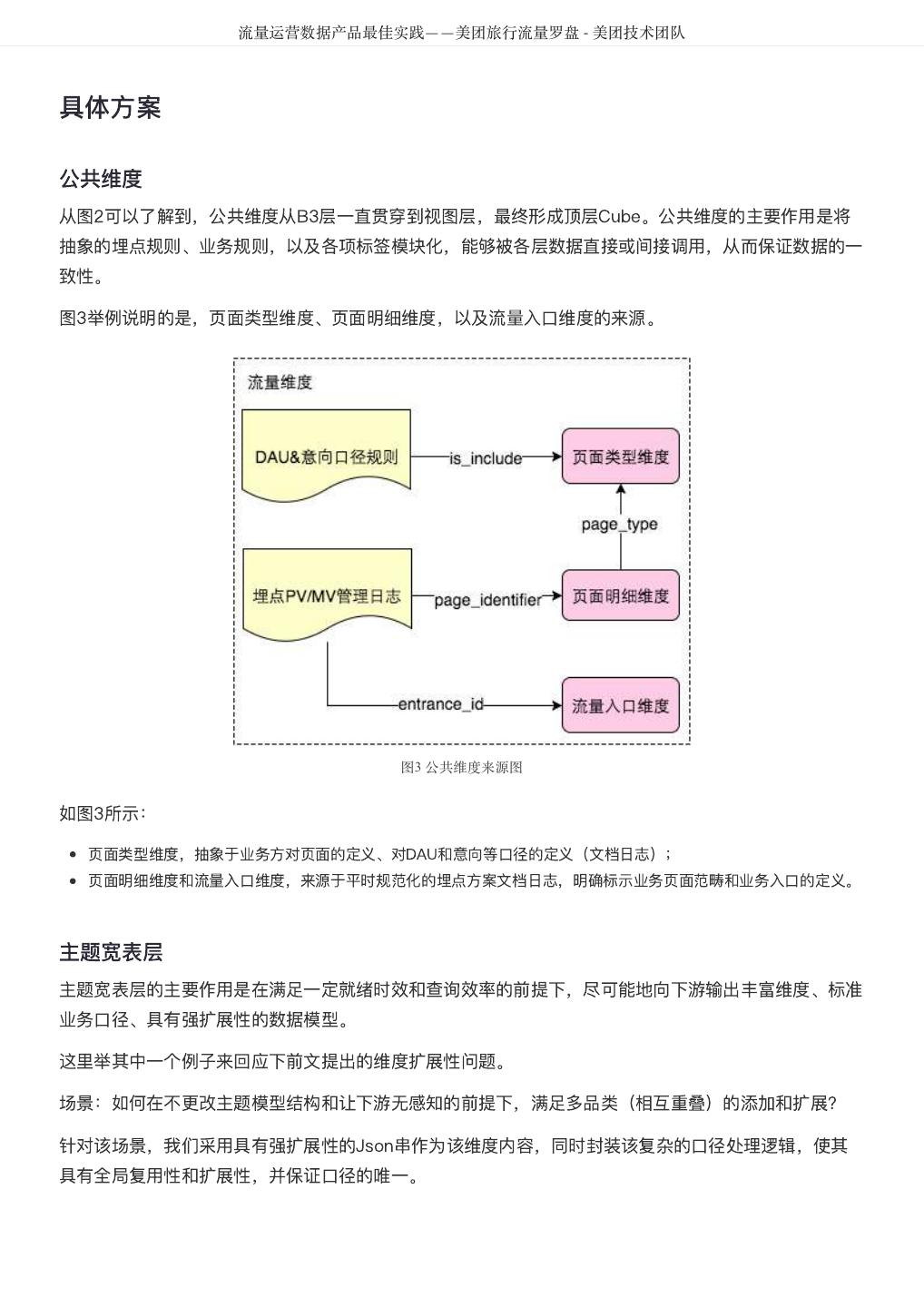
3 . 目录 - 系统篇 DataMan-美团旅行数据质量监管平台实践 ...................................................................... 4 美团 R 语言数据运营实战 ...................................................................... 16 聊聊MyBatis缓存机制 ...................................................................... 24 使用TensorFlow训练WDL模型性能问题定位与调优 ...................................................................... 42 美团点评基于 Flink 的实时数仓建设实践 ...................................................................... 51 美团点评基于Storm的实时数据处理实践 ...................................................................... 59 全链路压测平台(Quake)在美团中的实践 ...................................................................... 65 美团配送系统架构演进实践 ...................................................................... 81 美团旅行销售绩效系统研发实践 ...................................................................... 91 美团酒旅实时数据规则引擎应用实践 ...................................................................... 102 美团配送资金安全治理之对账体系建设 ...................................................................... 111 美团酒旅起源数据治理平台的建设与实践 ...................................................................... 120 高性能平台设计—美团旅行结算平台实践 ...................................................................... 135 实时数据产品实践——美团大交通战场沙盘 ...................................................................... 147 流量运营数据产品最佳实践——美团旅行流量罗盘 ...................................................................... 155
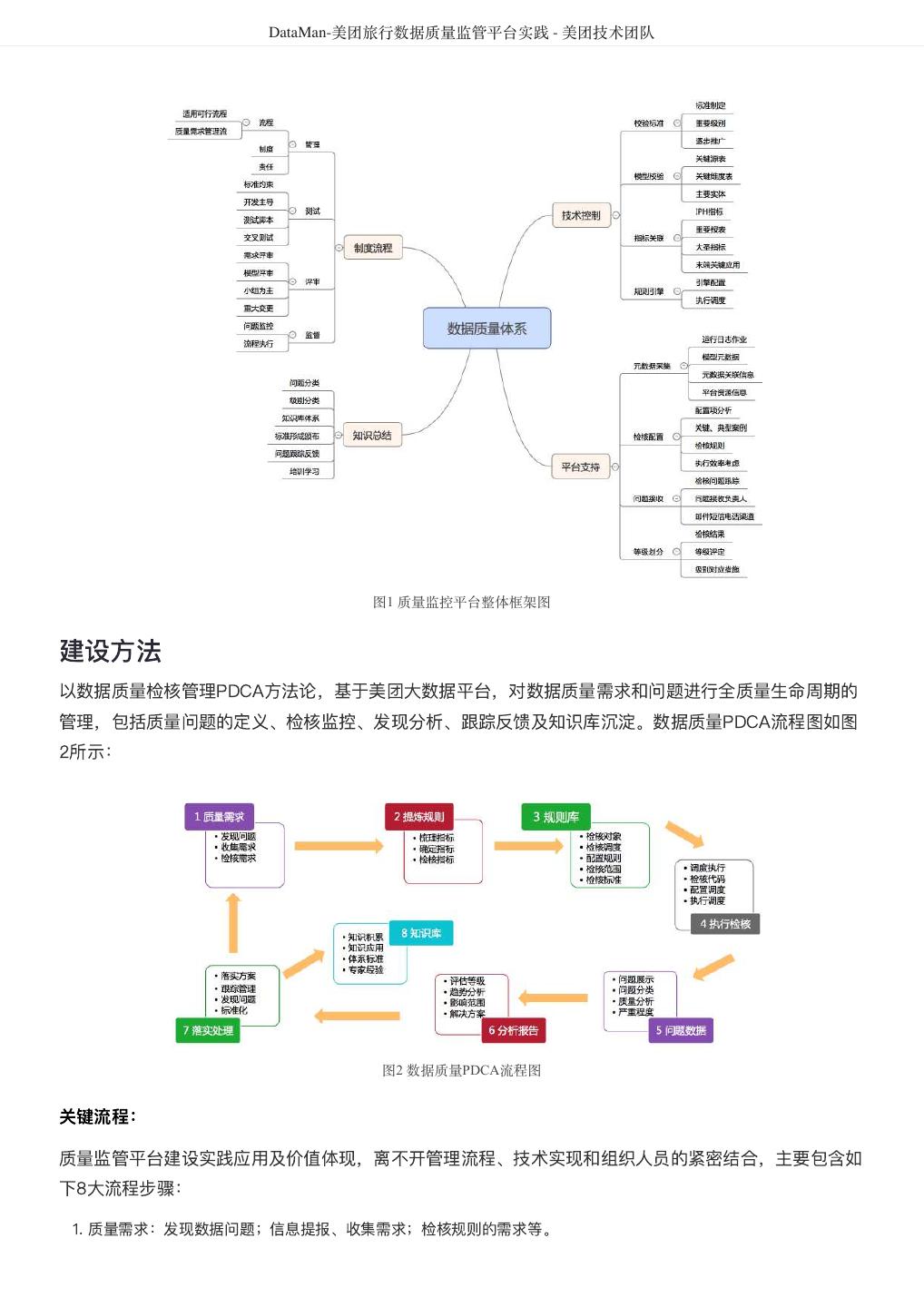
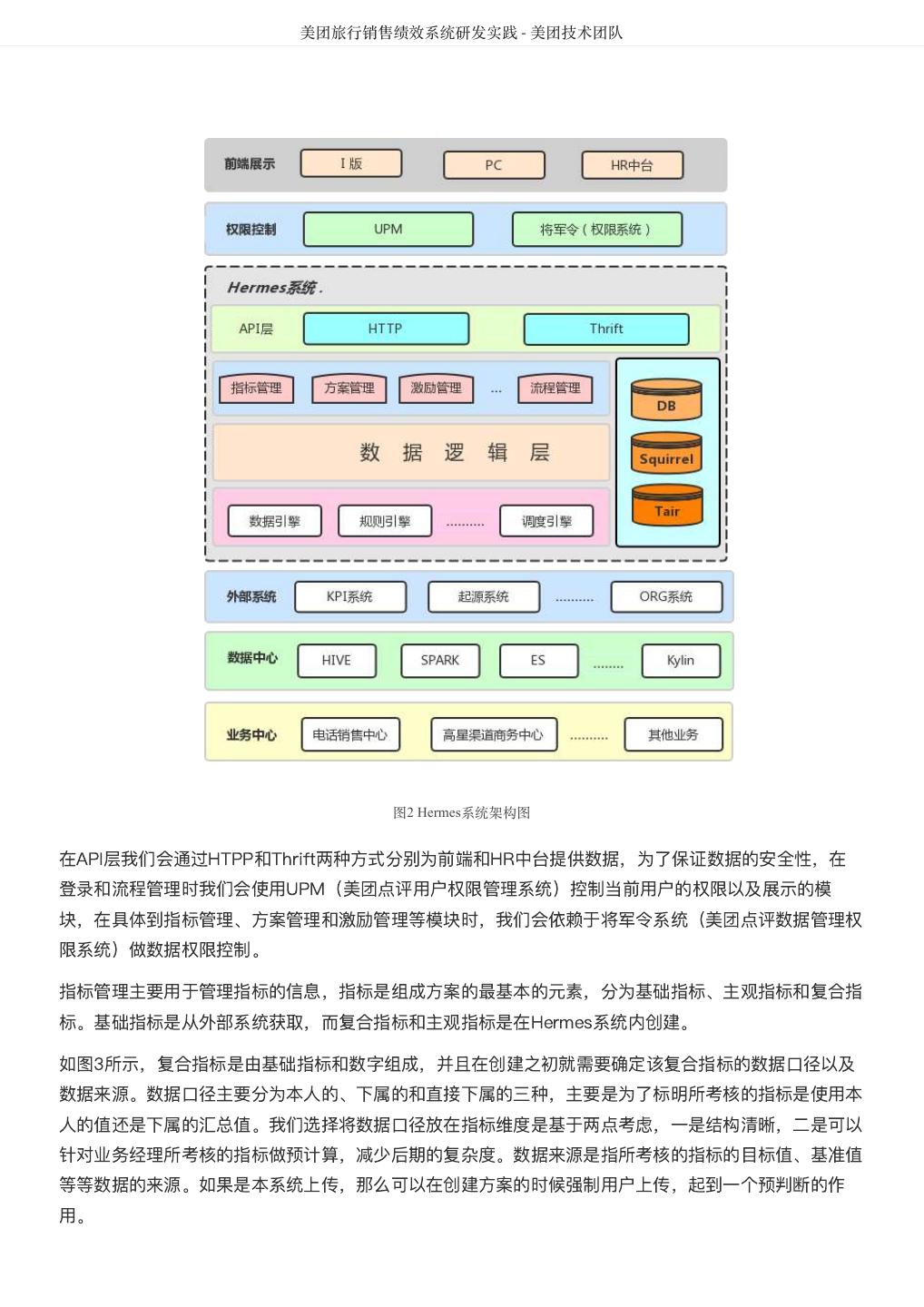
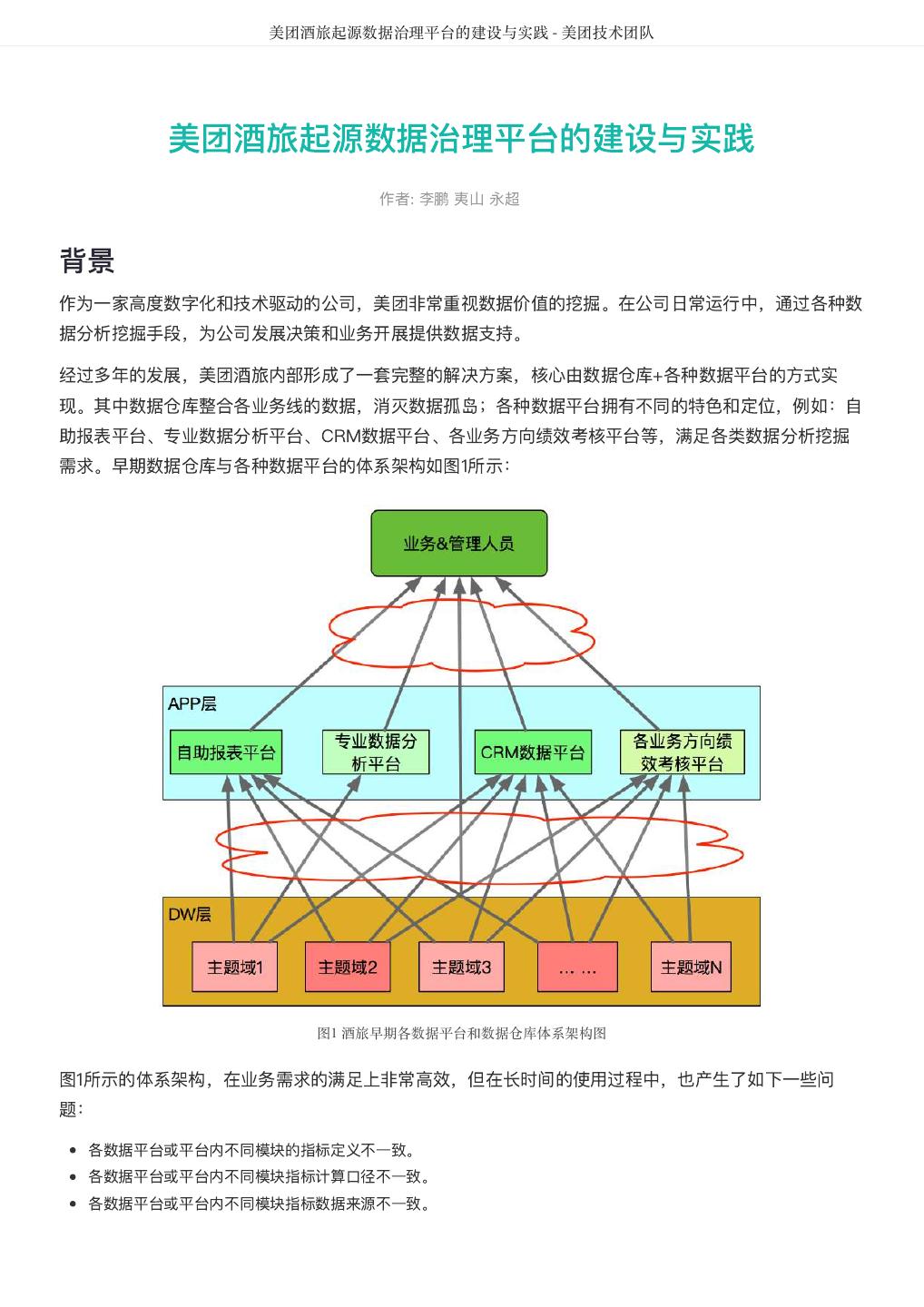
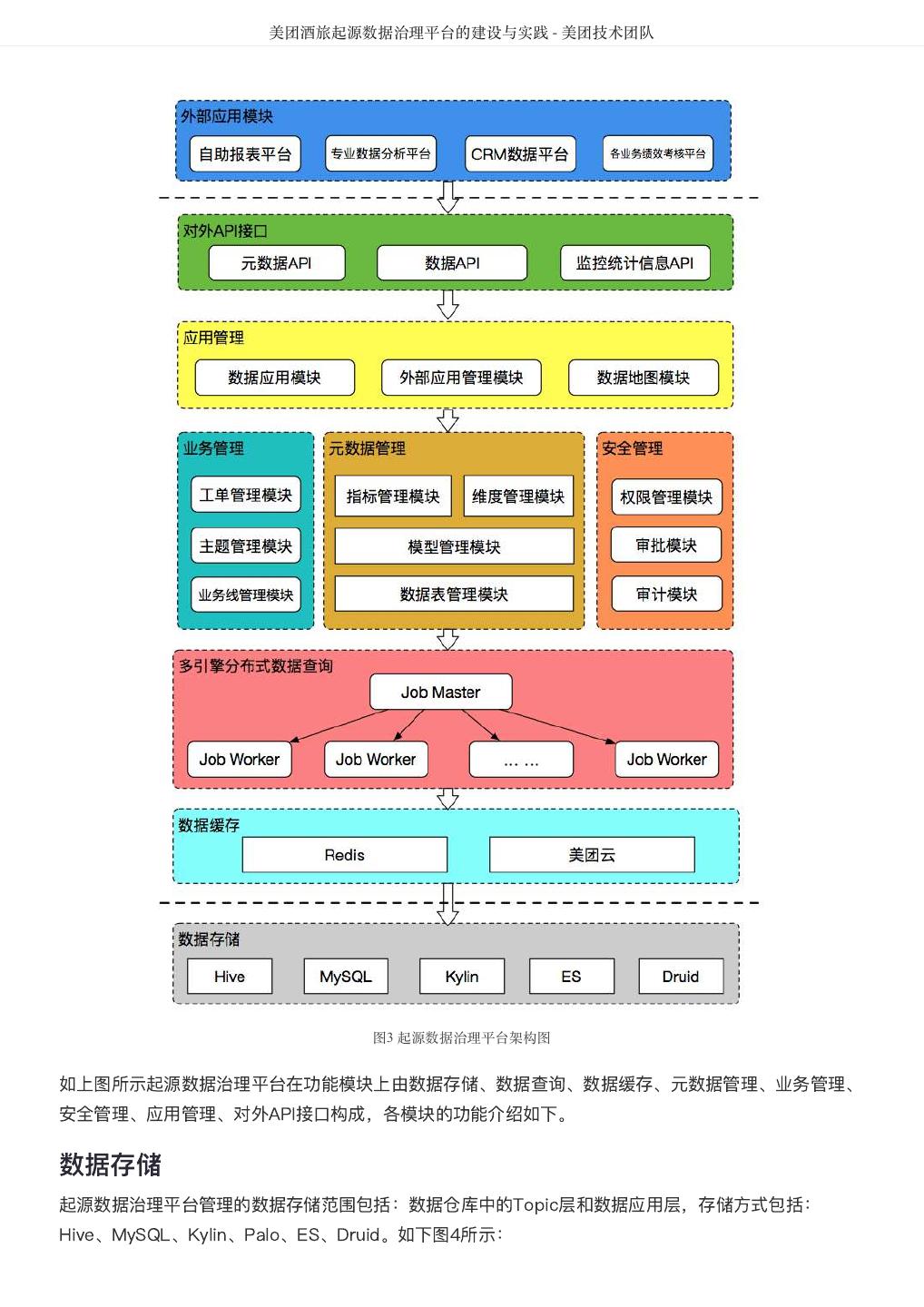
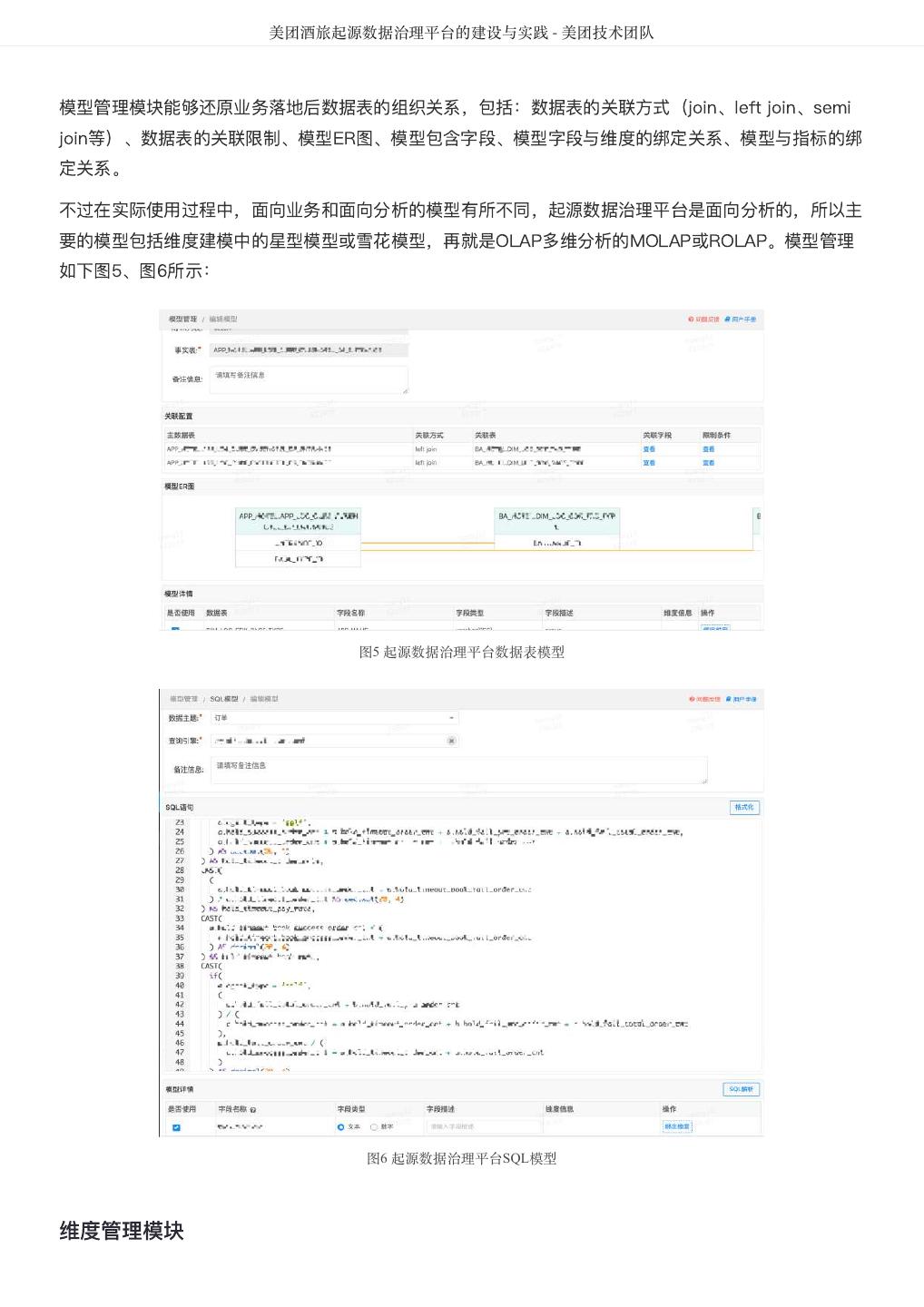
4 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 DataMan-美团旅行数据质量监管平台实践 作者: 德晓 背景 数据,已经成为互联网企业非常依赖的新型重要资产。数据质量的好坏直接关系到信息的精准度,也影响 到企业的生存和竞争力。Michael Hammer(《Reengineering the Corporation》一书的作者)曾说 过,看起来不起眼的数据质量问题,实际上是拆散业务流程的重要标志。 数据质量管理是测度、提高和 验证质量,以及整合组织数据的方法等一套处理准则,而体量大、速度快和多样性的特点,决定了大数据 质量所需的处理,有别于传统信息治理计划的质量管理方式。 本文将基于美团点评大数据平台,通过对数据流转过程中各阶段数据质量检测结果的采集分析、规则引 擎、评估反馈和再监测的闭环管理过程出发,从面临挑战、建设思路、技术方案、呈现效果及总结等方 面,介绍美团平台酒旅事业群(以下简称美旅)数据质量监管平台DataMan的搭建思路和建设实践。 挑战 美旅数据中心日均处理的离线和实时作业高达数万量级, 如何更加合理、高效的监控每类作业的运行状 态,并将原本分散、孤岛式的监控日志信息通过规则引擎集中共享、关联、处理;洞察关键信息,形成事 前预判、事中监控、事后跟踪的质量管理闭环流程;沉淀故障问题,搭建解决方案的知识库体系。在数据 质量监管平台的规划建设中,面临如下挑战: 缺乏统一监控视图,离线和实时作业监控分散,影响性、关联性不足。 数据质量的衡量标准缺失,数据校验滞后,数据口径不统一。 问题故障处理流程未闭环,“点”式解决现象常在;缺乏统一归档,没有形成体系的知识库。 数据模型质量监控缺失,模型重复,基础模型与应用模型的关联度不足,形成信息孤岛。 数据存储资源增长过快,不能监控细粒度资源内容。 DataMan质量监管平台研发正基于此,以下为具体建设方案。 解决思路 整体框架 构建美旅大数据质量监控平台,从可实践运用的视角出发,整合平台资源、技术流程核心要点,重点着力 平台支持、技术控制、流程制度、知识体系形成等方向建设,确保质量监控平台敏捷推进落地的可行性。 数据质量监控平台整体框架如图1所示:
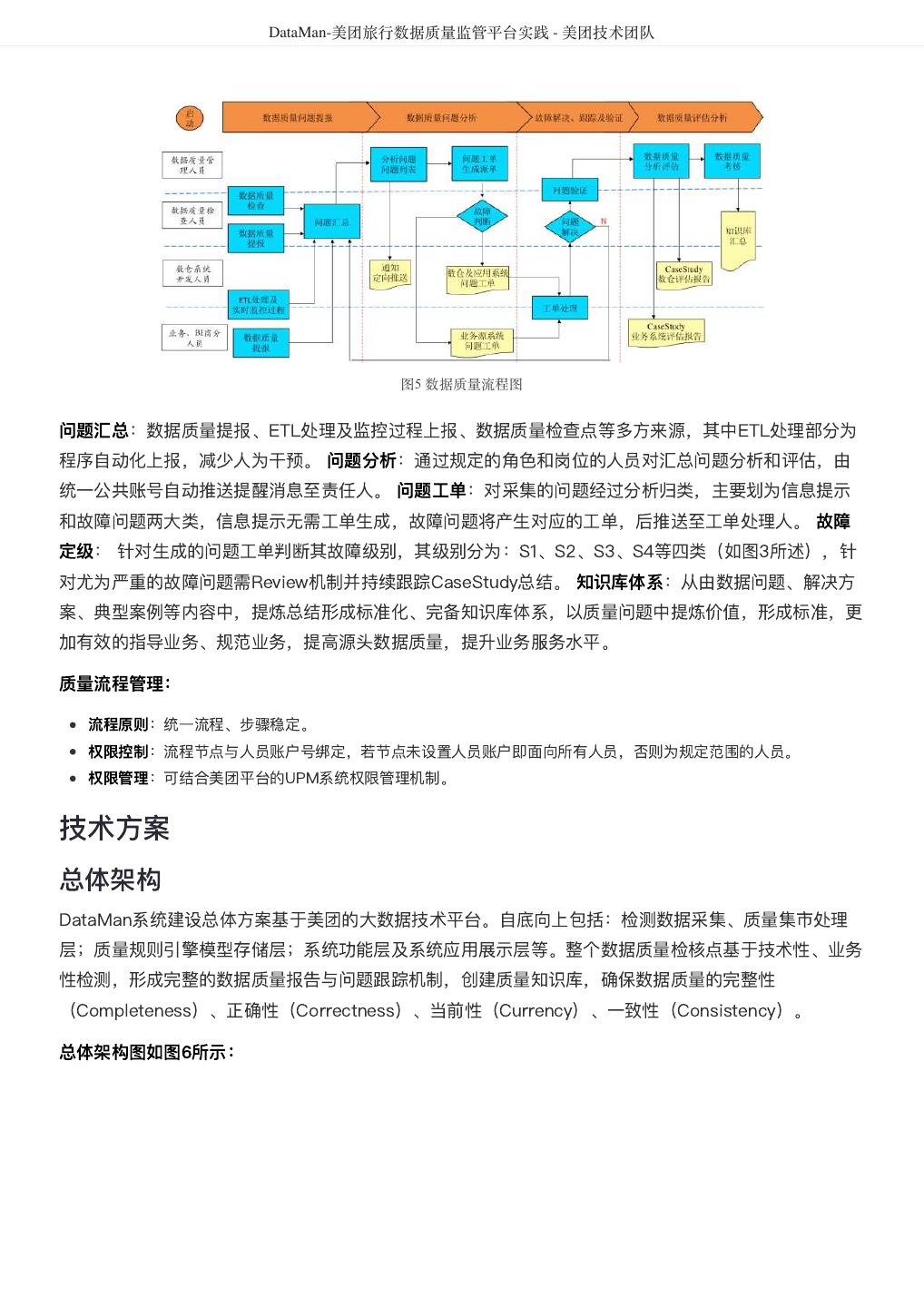
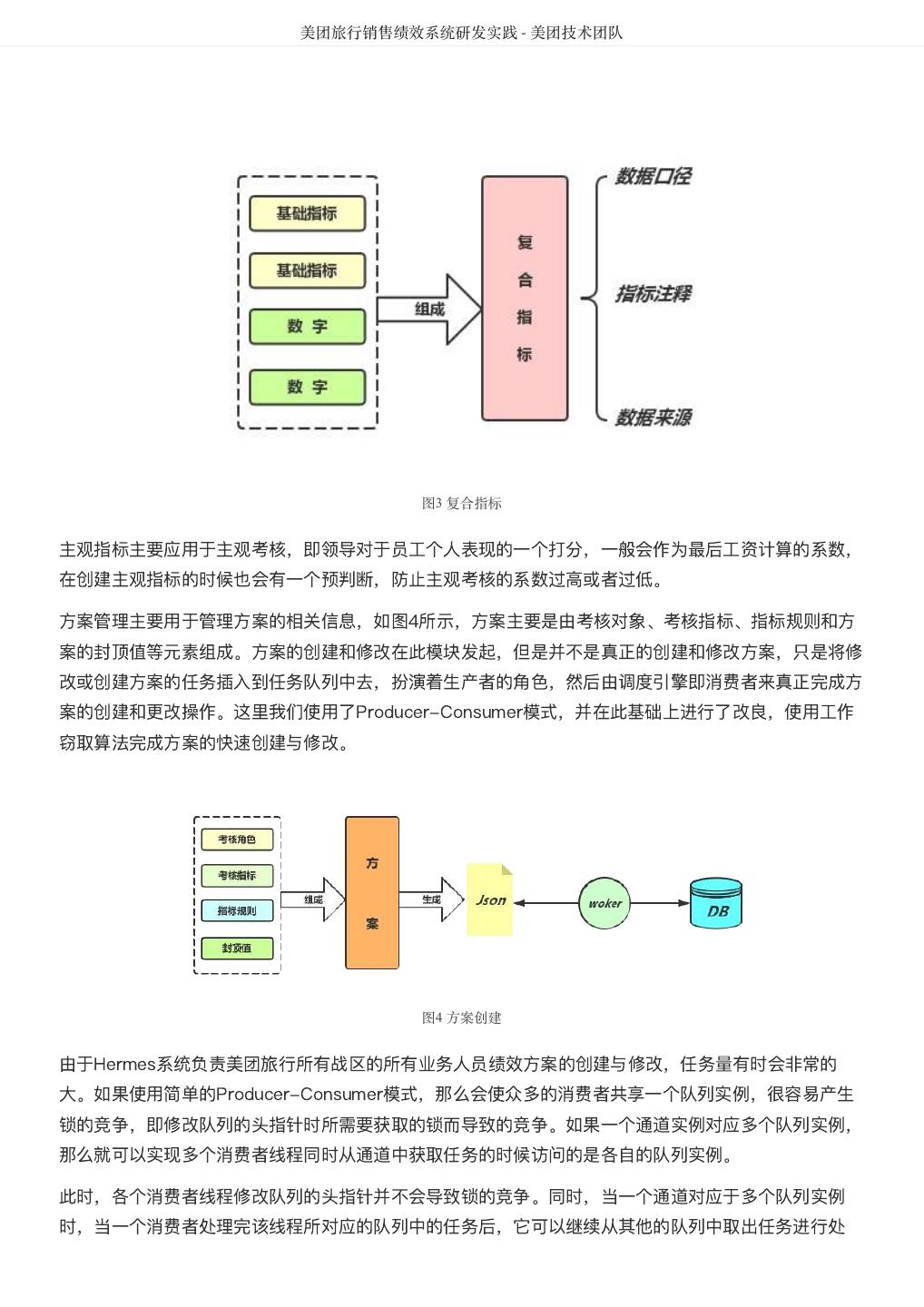
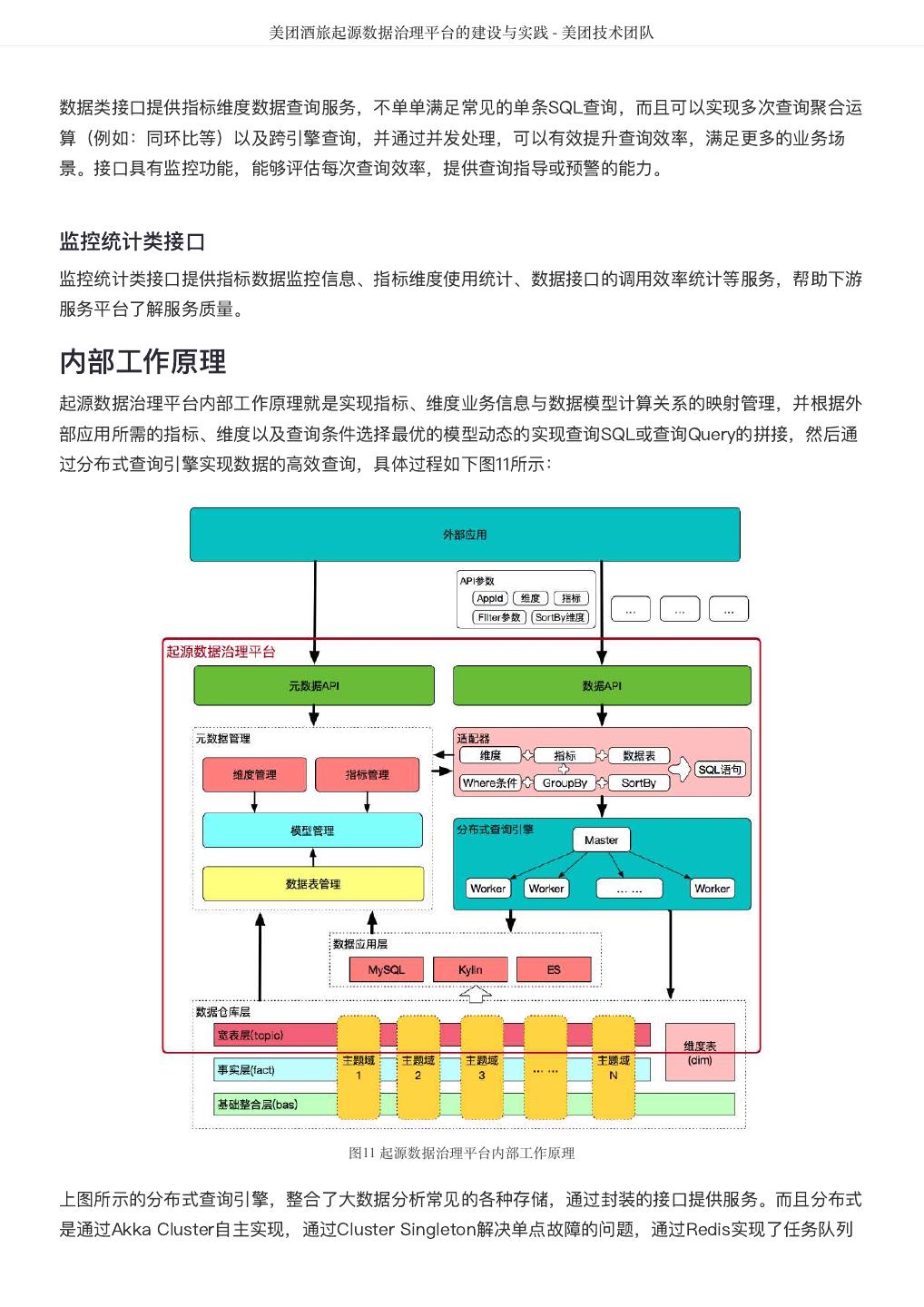
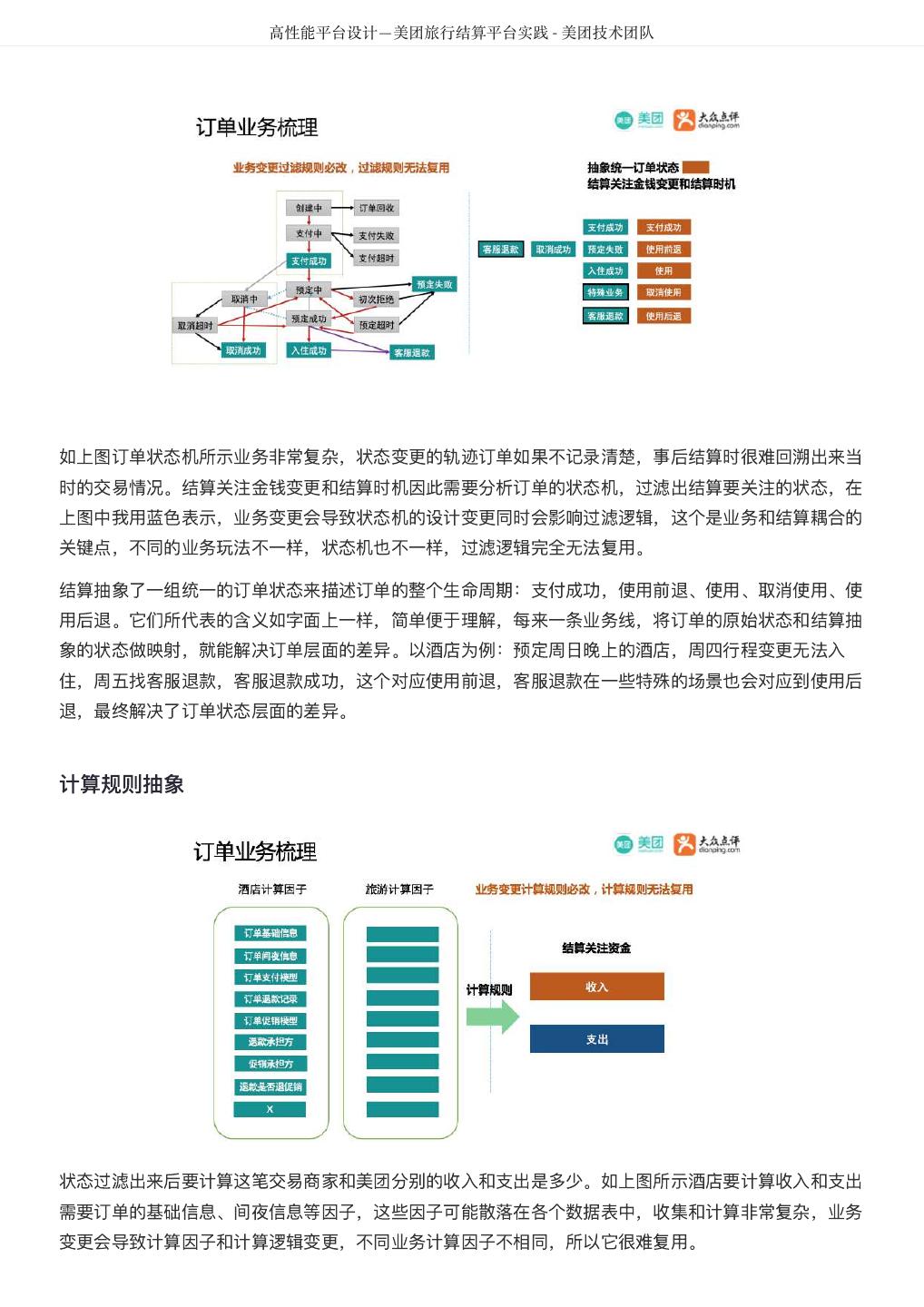
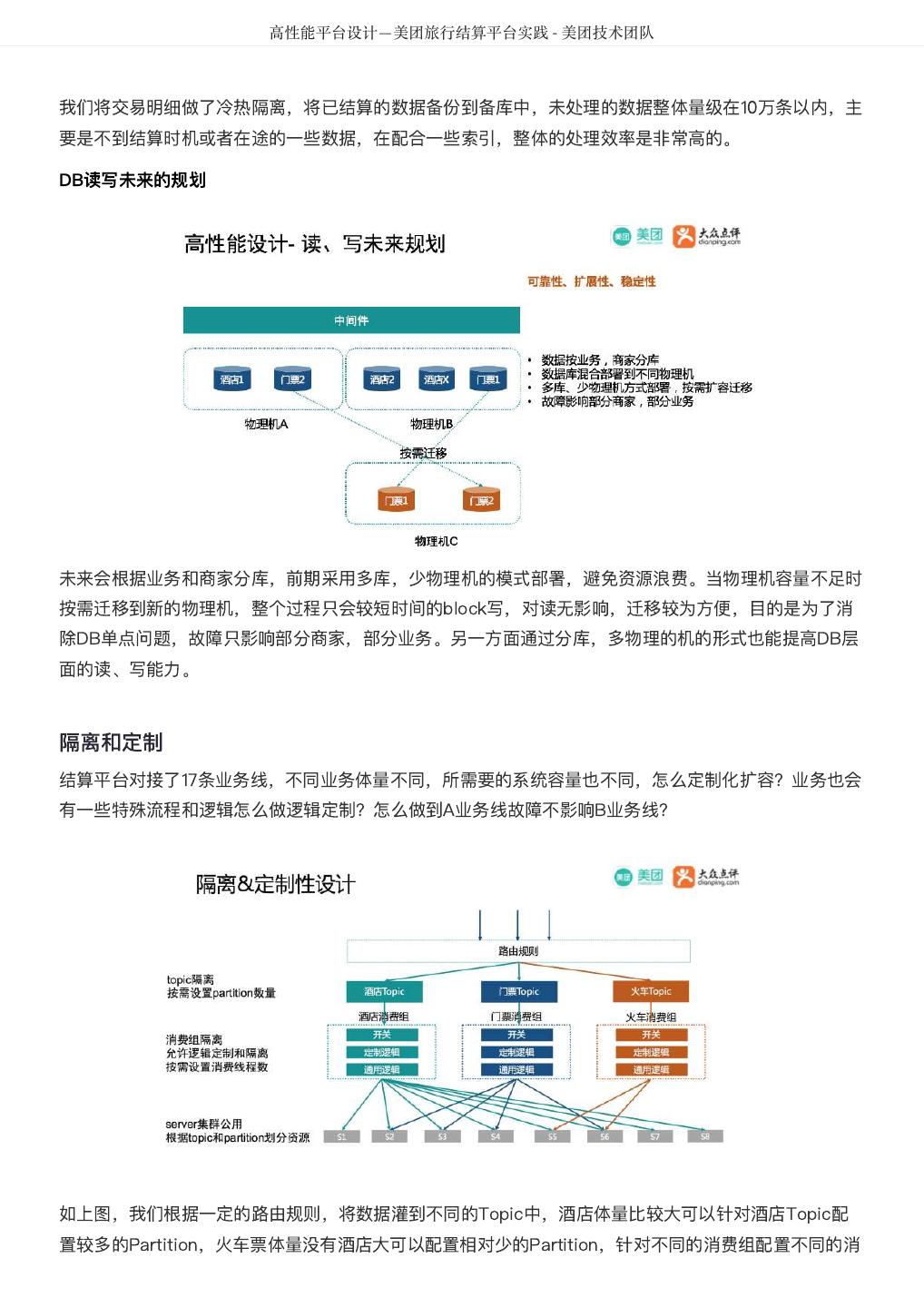
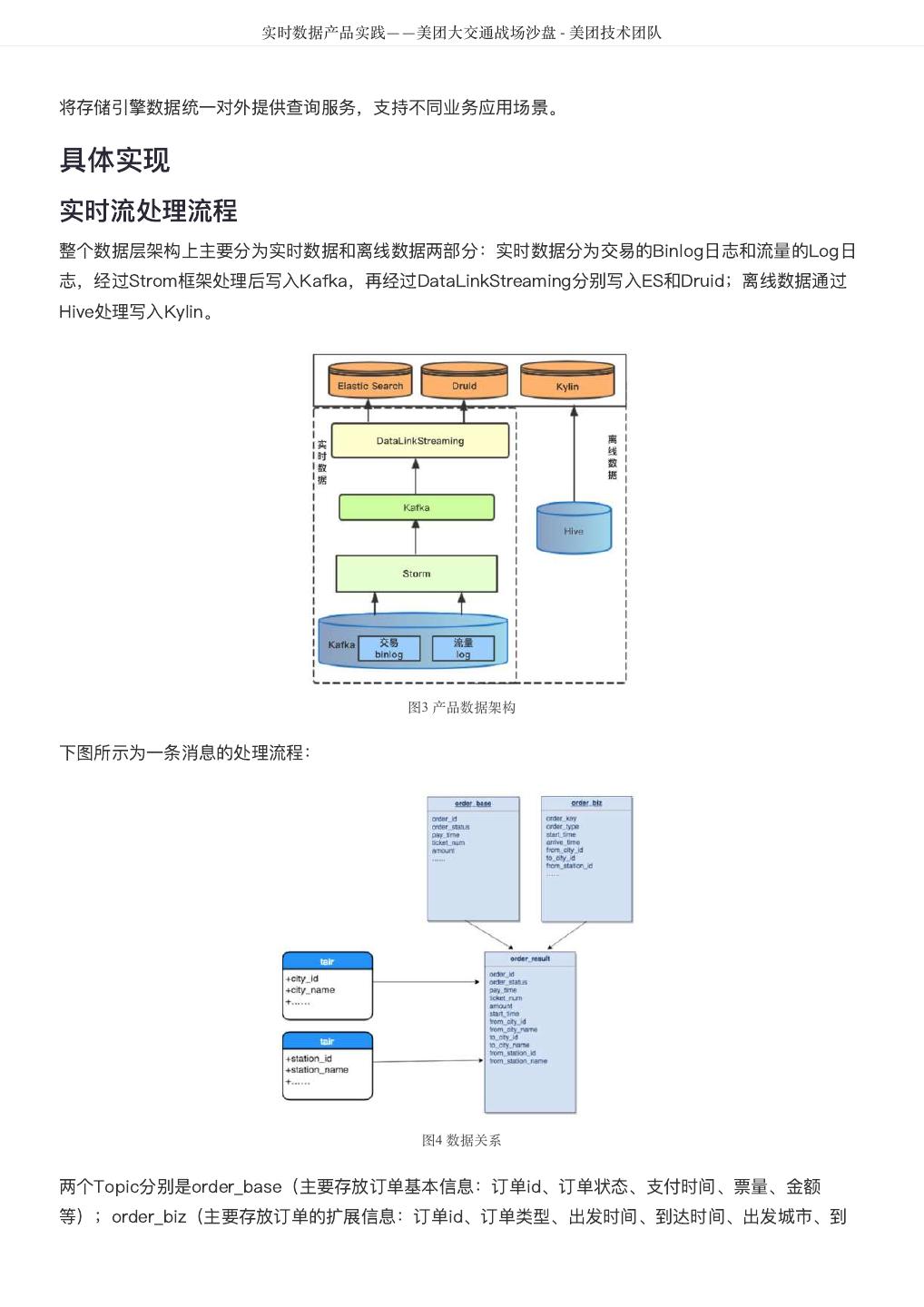
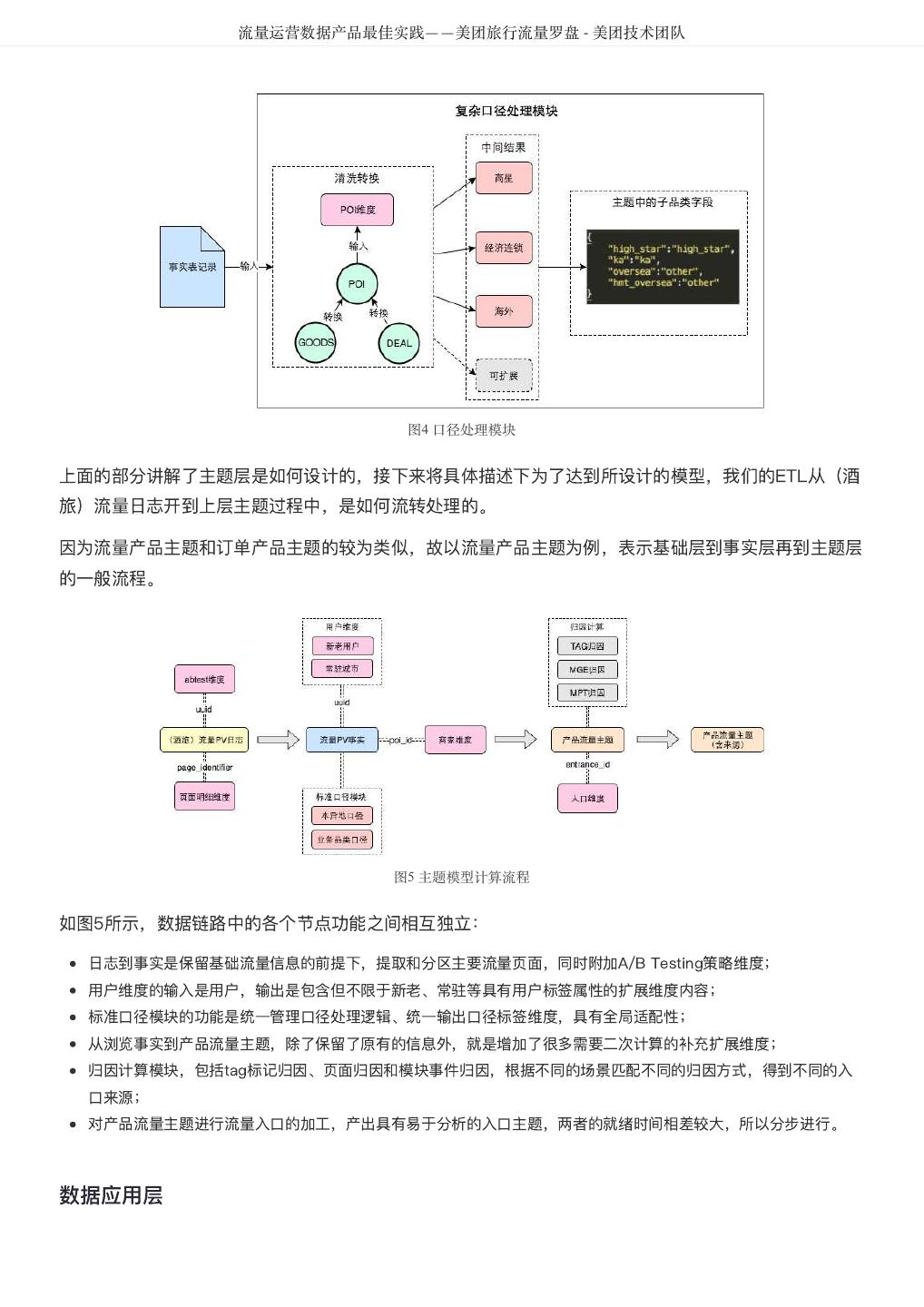
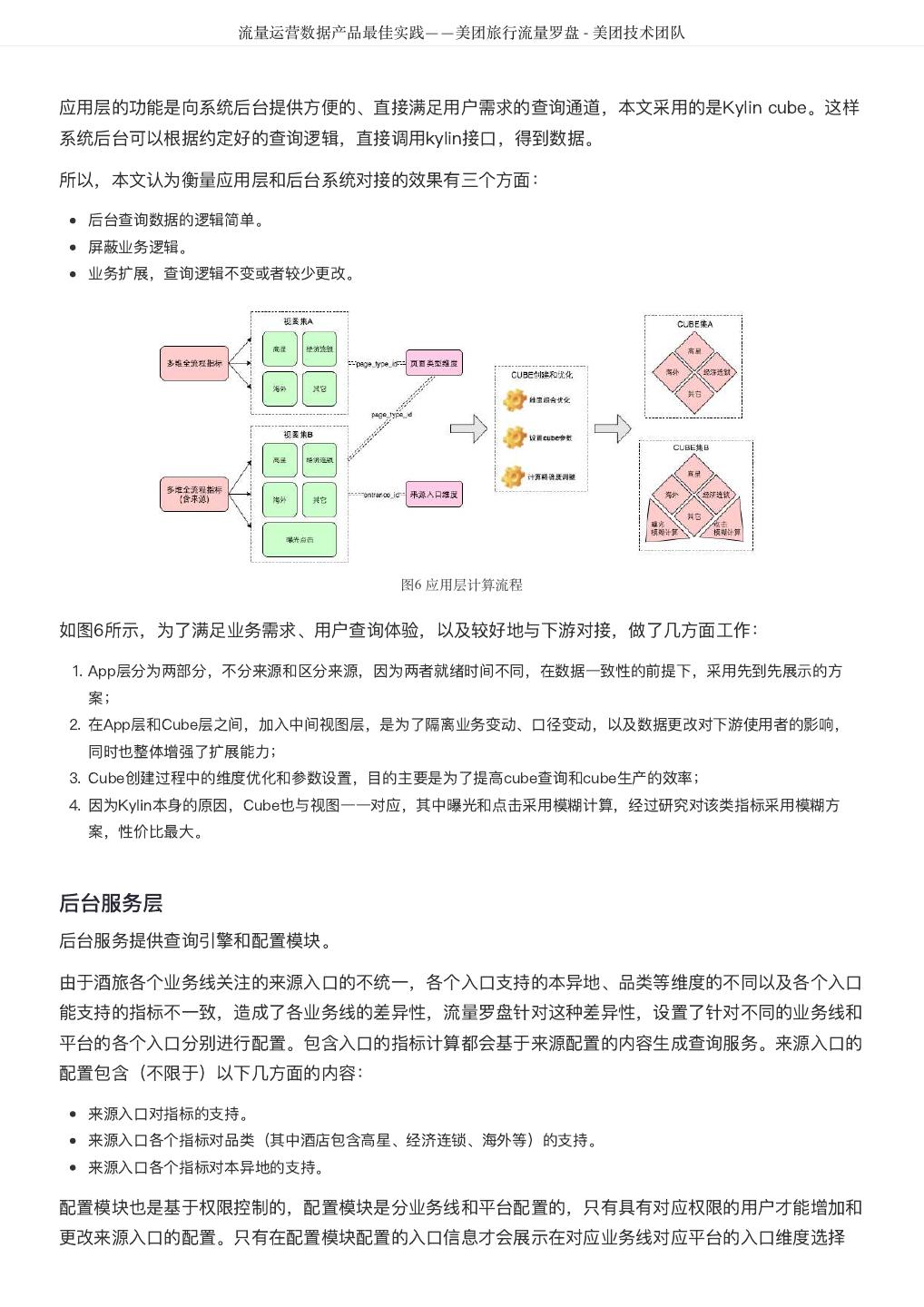
5 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 图1 质量监控平台整体框架图 建设方法 以数据质量检核管理PDCA方法论,基于美团大数据平台,对数据质量需求和问题进行全质量生命周期的 管理,包括质量问题的定义、检核监控、发现分析、跟踪反馈及知识库沉淀。数据质量PDCA流程图如图 2所示: 图2 数据质量PDCA流程图 关键流程: 质量监管平台建设实践应用及价值体现,离不开管理流程、技术实现和组织人员的紧密结合,主要包含如 下8大流程步骤: 1. 质量需求:发现数据问题;信息提报、收集需求;检核规则的需求等。
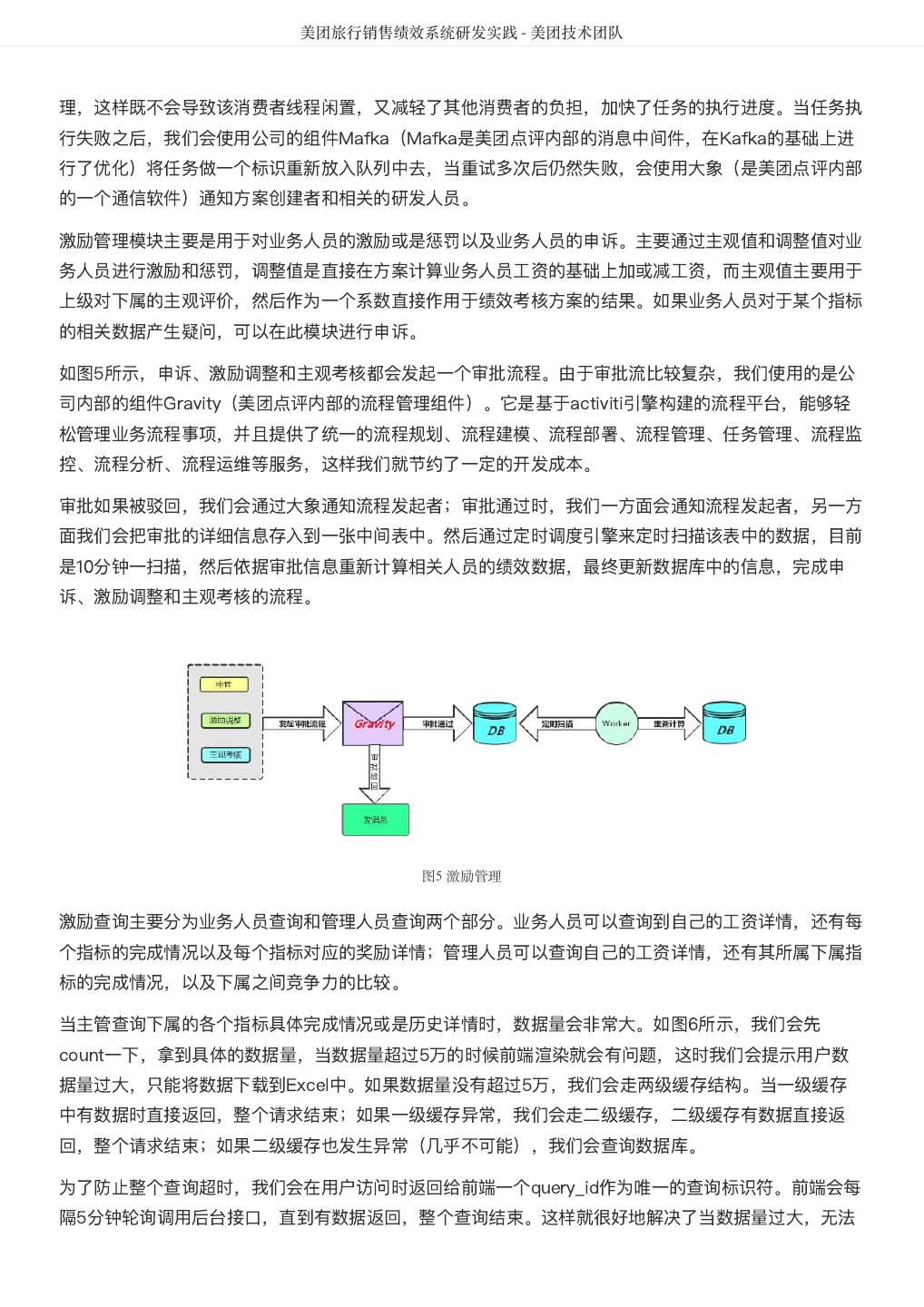
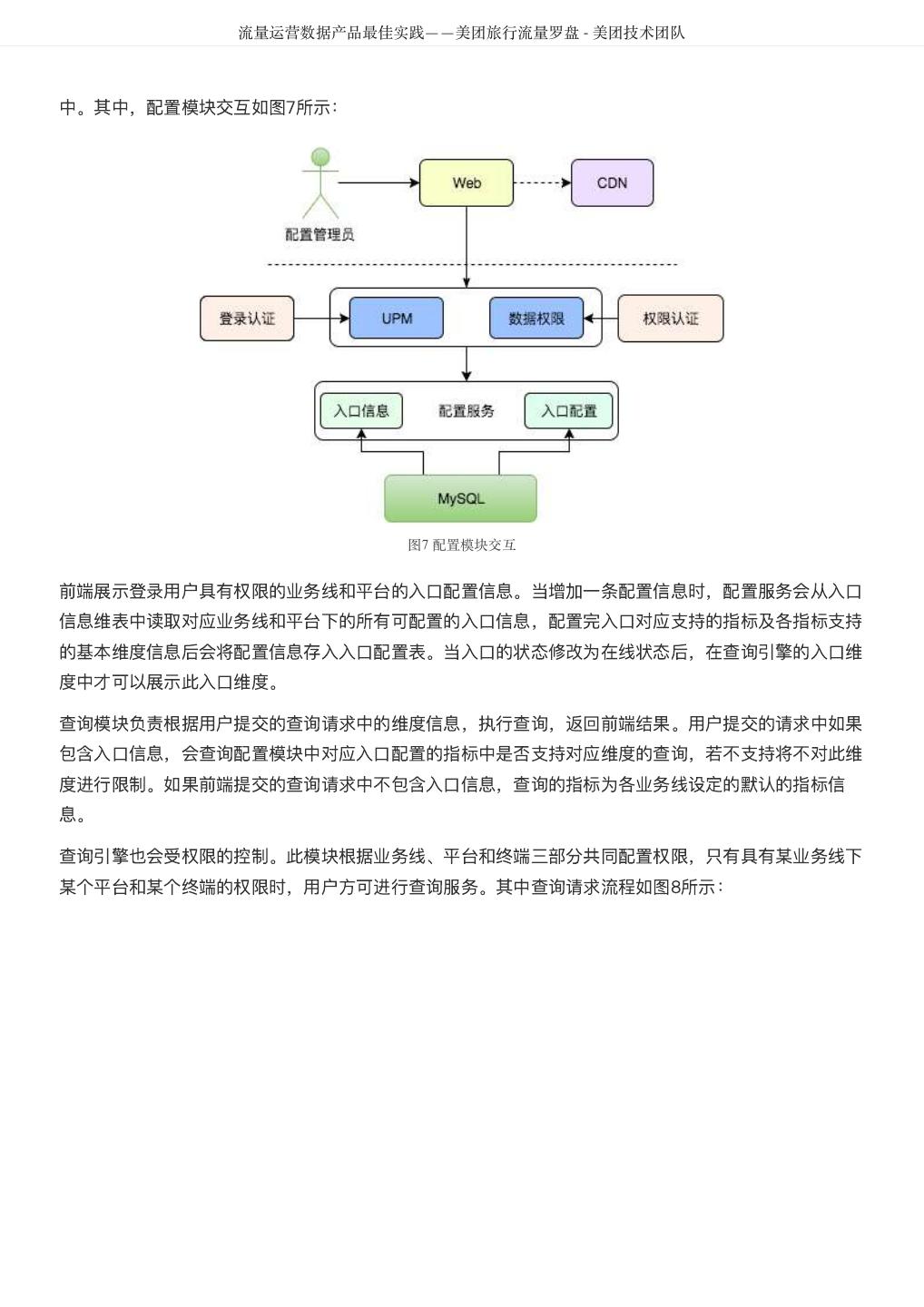
6 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 2. 提炼规则:梳理规则指标、确定有效指标、检核指标准确度和衡量标准。 3. 规则库构建:检核对象配置、调度配置、规则配置、检核范围确认、检核标准确定等。 4. 执行检核:调度配置、调度执行、检核代码。 5. 问题检核:检核问题展示、分类、质量分析、质量严重等级分类等。 6. 分析报告:数据质量报告、质量问题趋势分析,影响度分析,解决方案达成共识。 7. 落实处理:方案落实执行、跟踪管理、解决方案Review及标准化提炼。 8. 知识库体系形成:知识经验总结、标准方案沉淀、知识库体系建设。 质量检核标准 完整性:主要包括实体缺失、属性缺失、记录缺失和字段值缺失四个方面; 准确性:一个数据值与设定为准确的值之间的一致程度,或与可接受程度之间的差异; 合理性:主要包括格式、类型、值域和业务规则的合理有效; 一致性:系统之间的数据差异和相互矛盾的一致性,业务指标统一定义,数据逻辑加工结果一致性; 及时性:数据仓库ETL、应用展现的及时和快速性,Jobs运行耗时、运行质量、依赖运行及时性。 大数据平台下的质量检核标准更需考虑到大数据的快变化、多维度、定制化及资源量大等特性,如数仓及 应用BI系统的质量故障等级分类、数据模型热度标准定义、作业运行耗时标准分类等和数仓模型逻辑分层 及主题划分组合如下图3所示。 图3 质量检核标准图 美旅数仓划分为客服、流量、运营、订单、门店、产品、参与人、风控、结算和公用等十大主题,按 Base、Fact、Topic、App逻辑分层,形成体系化的物理模型。从数据价值量化、存储资源优化等指标评 估,划分物理模型为热、温、冷、冰等四类标准,结合应用自定义其具体标准范围,实现其灵活性配置; 作业运行耗时分为:优、良、一般、关注、耗时等,每类耗时定义的标准范围既符合大数据的特性又可满 足具体分析需要,且作业耗时与数仓主题和逻辑分层深度整合,实现多角度质量洞察评估;针对数万的作 业信息从数据时效性、作业运行等级、服务对象范围等视角,将其故障等级分为: S1:严重度极高; S2:严重度高; S3:严重度中;
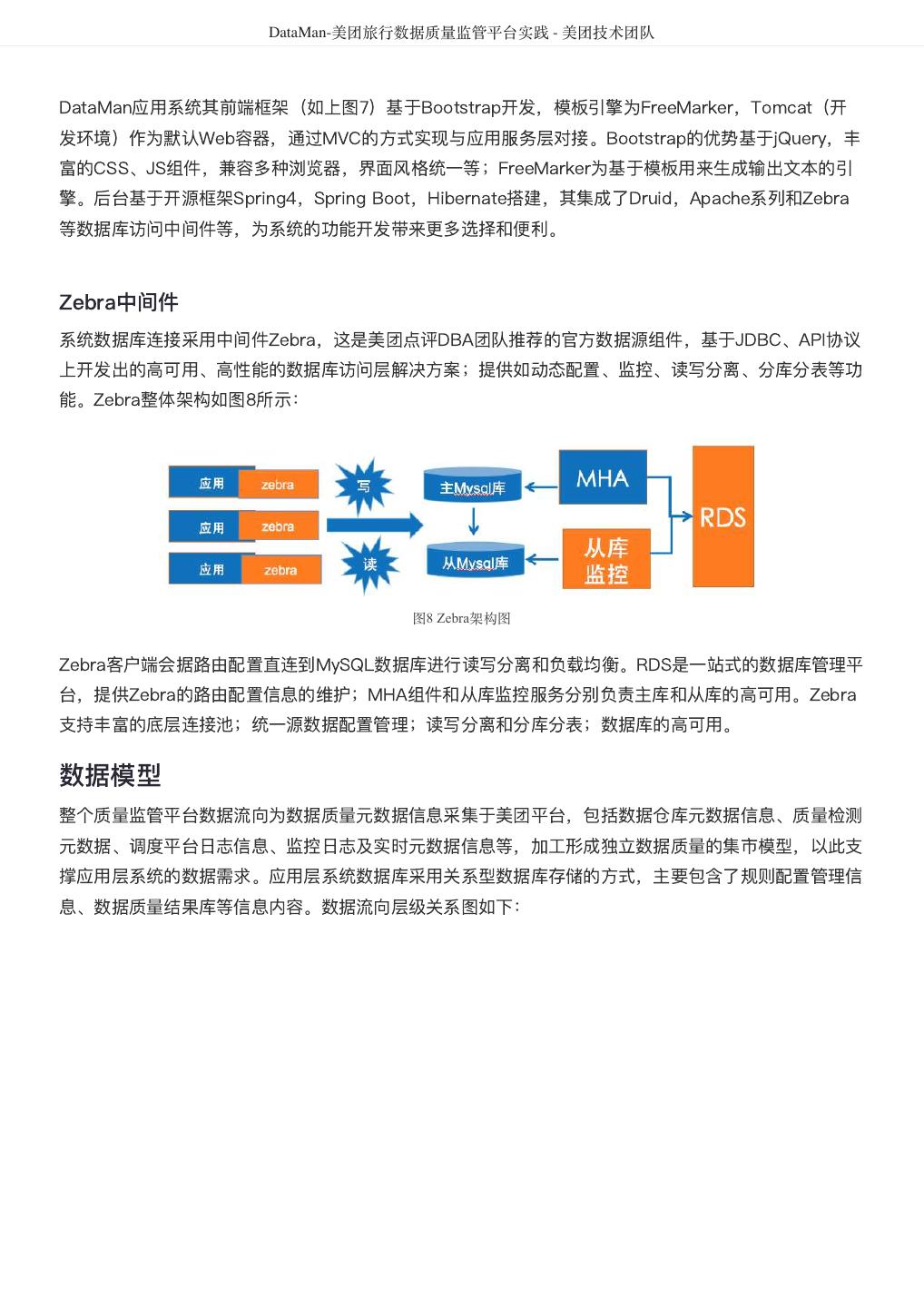
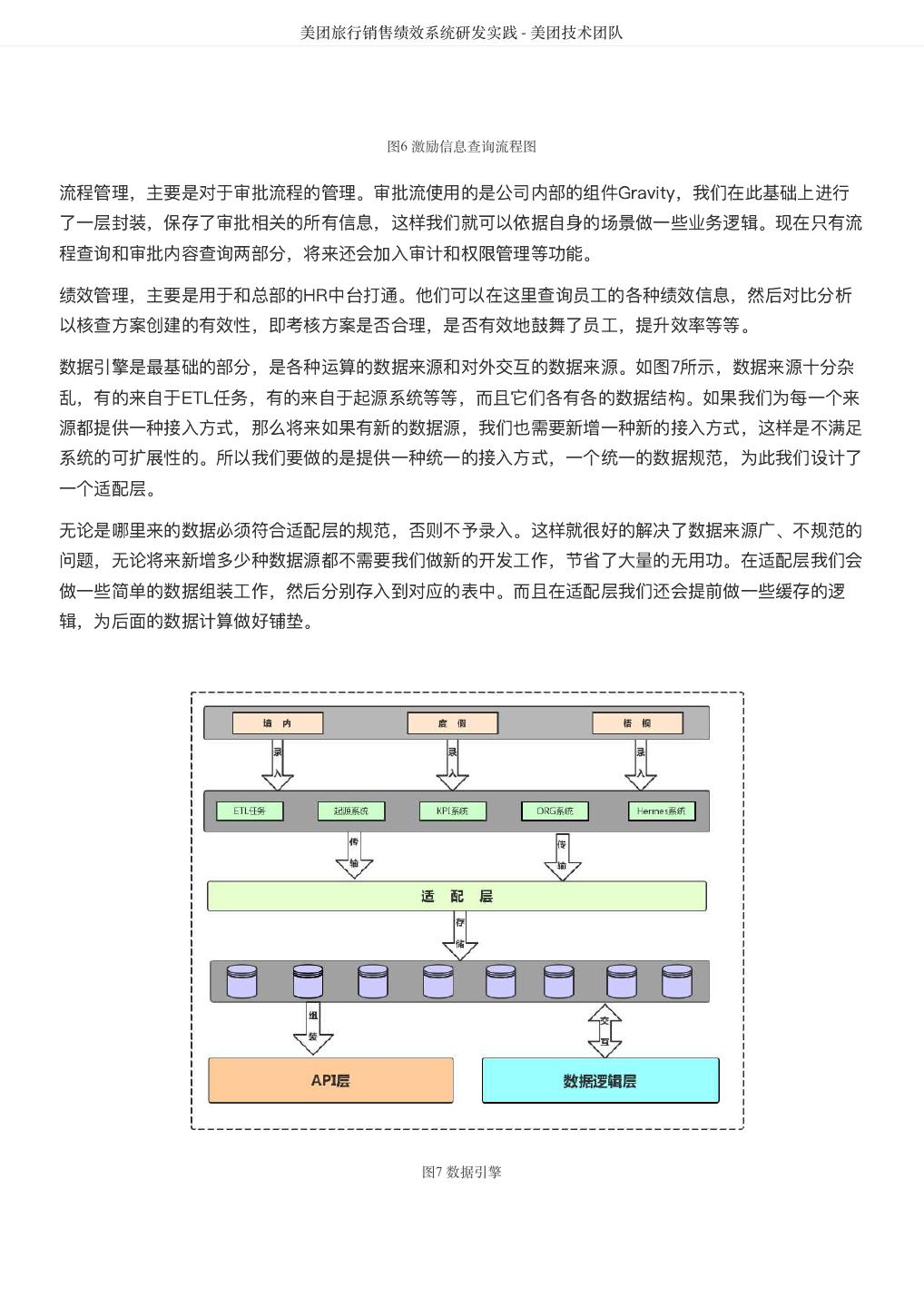
7 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 S4:严重度低等四项标准。 各项均对应具体的实施策略。整体数据质量的检核对象包括离线数仓和实时数据。 监管核心点 图4 数据质量监管功能图 数据质量功能模块设计的主要功能如上图4所示,包括:监控对象管理、检核指标管理、数据质量过程监 控、问题跟踪管理、推荐优化管理、知识库管理及系统管理等。其中过程监控包括离线数据监控、实时数 据监控;问题跟踪处理由问题发现(支持自动检核、人工录入)、问题提报、任务推送、故障定级、故障 处理、知识库沉淀等形成闭环流程。 管理流程 流程化管理是推进数据问题从发现、跟踪、解决到总结提炼的合理有效工具。质量管理流程包括:数据质 量问题提报、数据质量问题分析、故障跟踪、解决验证、数据质量评估分析等主要环节步骤;从干系人员 的角度分析包括数据质量管理人员、数据质量检查人员、数据平台开发人员、业务及BI商分人员等,从流 程步骤到管理人员形成职责和角色的矩阵图。如图5所示:
8 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 图5 数据质量流程图 问题汇总:数据质量提报、ETL处理及监控过程上报、数据质量检查点等多方来源,其中ETL处理部分为 程序自动化上报,减少人为干预。 问题分析:通过规定的角色和岗位的人员对汇总问题分析和评估,由 统一公共账号自动推送提醒消息至责任人。 问题工单:对采集的问题经过分析归类,主要划为信息提示 和故障问题两大类,信息提示无需工单生成,故障问题将产生对应的工单,后推送至工单处理人。 故障 定级: 针对生成的问题工单判断其故障级别,其级别分为:S1、S2、S3、S4等四类(如图3所述),针 对尤为严重的故障问题需Review机制并持续跟踪CaseStudy总结。 知识库体系:从由数据问题、解决方 案、典型案例等内容中,提炼总结形成标准化、完备知识库体系,以质量问题中提炼价值,形成标准,更 加有效的指导业务、规范业务,提高源头数据质量,提升业务服务水平。 质量流程管理: 流程原则:统一流程、步骤稳定。 权限控制:流程节点与人员账户号绑定,若节点未设置人员账户即面向所有人员,否则为规定范围的人员。 权限管理:可结合美团平台的UPM系统权限管理机制。 技术方案 总体架构 DataMan系统建设总体方案基于美团的大数据技术平台。自底向上包括:检测数据采集、质量集市处理 层;质量规则引擎模型存储层;系统功能层及系统应用展示层等。整个数据质量检核点基于技术性、业务 性检测,形成完整的数据质量报告与问题跟踪机制,创建质量知识库,确保数据质量的完整性 (Completeness)、正确性(Correctness)、当前性(Currency)、一致性(Consistency)。 总体架构图如图6所示:
9 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 图6 质量监管DataMan总体架构图 数据源及集市层:首先采集数据平台质量相关的元数据信息、监控日志信息、实时日志、检测配置中心日志、作业日 志及调度平台日志等关键的质量元数据;经数据质量集市的模型设计、监控对象的分类,加工形成完整、紧关联、多 维度、易分析的数据质量基础数据模型,为上层质量应用分析奠定数据基础。数据来源自大数据平台、实时数仓、调 度平台等,涉及到Hive、 Spark、Storm、 Kafka、MySQL及BI应用等相关平台数据源; 存储模型层:主要功能包括规则引擎数据配置、质量模型结果存储;以数据质量监控、影响关联、全方位监控等目标 规则引擎的推动方式,将加工结果数据存储至关系型数据库中,构成精简高质数据层; 系统功能层:包括配置管理、过程监控、问题跟踪、故障流程管理、实时数据监控、知识库体系的创建等;处理的对 象包括日志运行作业、物理监控模型、业务监控模型等主要实体; 系统展示层:通过界面化方式管理、展示数据质量状态,包括质量监控界面、推荐优化模块、质量分析、信息展示、 问题提报、故障跟踪及测量定级、系统权限管理等功能。 技术框架 前后端技术 图7 技术架构图
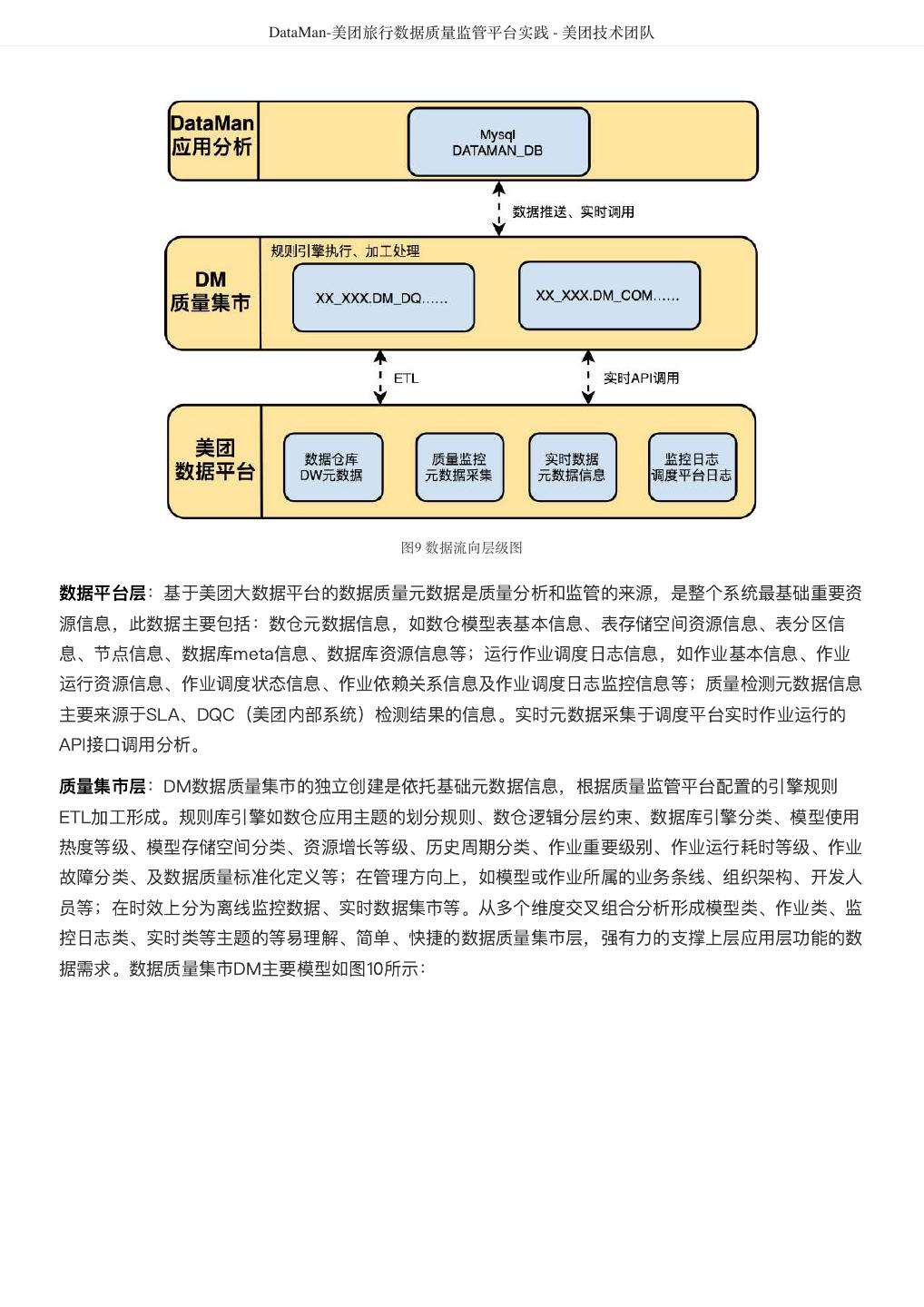
10 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 DataMan应用系统其前端框架(如上图7)基于Bootstrap开发,模板引擎为FreeMarker,Tomcat(开 发环境)作为默认Web容器,通过MVC的方式实现与应用服务层对接。Bootstrap的优势基于jQuery,丰 富的CSS、JS组件,兼容多种浏览器,界面风格统一等;FreeMarker为基于模板用来生成输出文本的引 擎。后台基于开源框架Spring4,Spring Boot,Hibernate搭建,其集成了Druid,Apache系列和Zebra 等数据库访问中间件等,为系统的功能开发带来更多选择和便利。 Zebra中间件 系统数据库连接采用中间件Zebra,这是美团点评DBA团队推荐的官方数据源组件,基于JDBC、API协议 上开发出的高可用、高性能的数据库访问层解决方案;提供如动态配置、监控、读写分离、分库分表等功 能。Zebra整体架构如图8所示: 图8 Zebra架构图 Zebra客户端会据路由配置直连到MySQL数据库进行读写分离和负载均衡。RDS是一站式的数据库管理平 台,提供Zebra的路由配置信息的维护;MHA组件和从库监控服务分别负责主库和从库的高可用。Zebra 支持丰富的底层连接池;统一源数据配置管理;读写分离和分库分表;数据库的高可用。 数据模型 整个质量监管平台数据流向为数据质量元数据信息采集于美团平台,包括数据仓库元数据信息、质量检测 元数据、调度平台日志信息、监控日志及实时元数据信息等,加工形成独立数据质量的集市模型,以此支 撑应用层系统的数据需求。应用层系统数据库采用关系型数据库存储的方式,主要包含了规则配置管理信 息、数据质量结果库等信息内容。数据流向层级关系图如下:
11 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 图9 数据流向层级图 数据平台层:基于美团大数据平台的数据质量元数据是质量分析和监管的来源,是整个系统最基础重要资 源信息,此数据主要包括:数仓元数据信息,如数仓模型表基本信息、表存储空间资源信息、表分区信 息、节点信息、数据库meta信息、数据库资源信息等;运行作业调度日志信息,如作业基本信息、作业 运行资源信息、作业调度状态信息、作业依赖关系信息及作业调度日志监控信息等;质量检测元数据信息 主要来源于SLA、DQC(美团内部系统)检测结果的信息。实时元数据采集于调度平台实时作业运行的 API接口调用分析。 质量集市层:DM数据质量集市的独立创建是依托基础元数据信息,根据质量监管平台配置的引擎规则 ETL加工形成。规则库引擎如数仓应用主题的划分规则、数仓逻辑分层约束、数据库引擎分类、模型使用 热度等级、模型存储空间分类、资源增长等级、历史周期分类、作业重要级别、作业运行耗时等级、作业 故障分类、及数据质量标准化定义等;在管理方向上,如模型或作业所属的业务条线、组织架构、开发人 员等;在时效上分为离线监控数据、实时数据集市等。从多个维度交叉组合分析形成模型类、作业类、监 控日志类、实时类等主题的等易理解、简单、快捷的数据质量集市层,强有力的支撑上层应用层功能的数 据需求。数据质量集市DM主要模型如图10所示:
12 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 图10 数据质量集市模型图 模型设计:“统一规范、简单快捷、快速迭代、保障质量”,基于美团平台元数据、平台日志、实时数据接口等来源, 通过制定的规则、标准,形成可衡量、可评估的数据质量集市层,主要包含公共维度类、模型分析类、作业监控类、 平台监控类等主要内容; 实时数据:针对实时作业的监控通过API接口调用,后落地数据,实时监控作业运行日志状态; 数据加工:基于美团平台离线Hive、Spark引擎执行调度,以数仓模型分层、数仓十大主题规则和数据质量规则库等 为约束条件,加工形成独立的数据集市层。 应用分析层:应用层系统数据采用关系型数据库(MySQL)存储的方式,主要包含了规则配置管理信 息、数据质量分析结果、实时API落地数据、故障问题数据、知识库信息、流程管理及系统管理类等信息 内容,直接面对前端界面的展示和管理。 系统展示 数据质量DataMan监控系统一期建设主要实现的功能包括:个人工作台、信息监控、推荐信息、信息提 报、故障管理、配置管理及权限系统管理等。系统效果如图11所示:
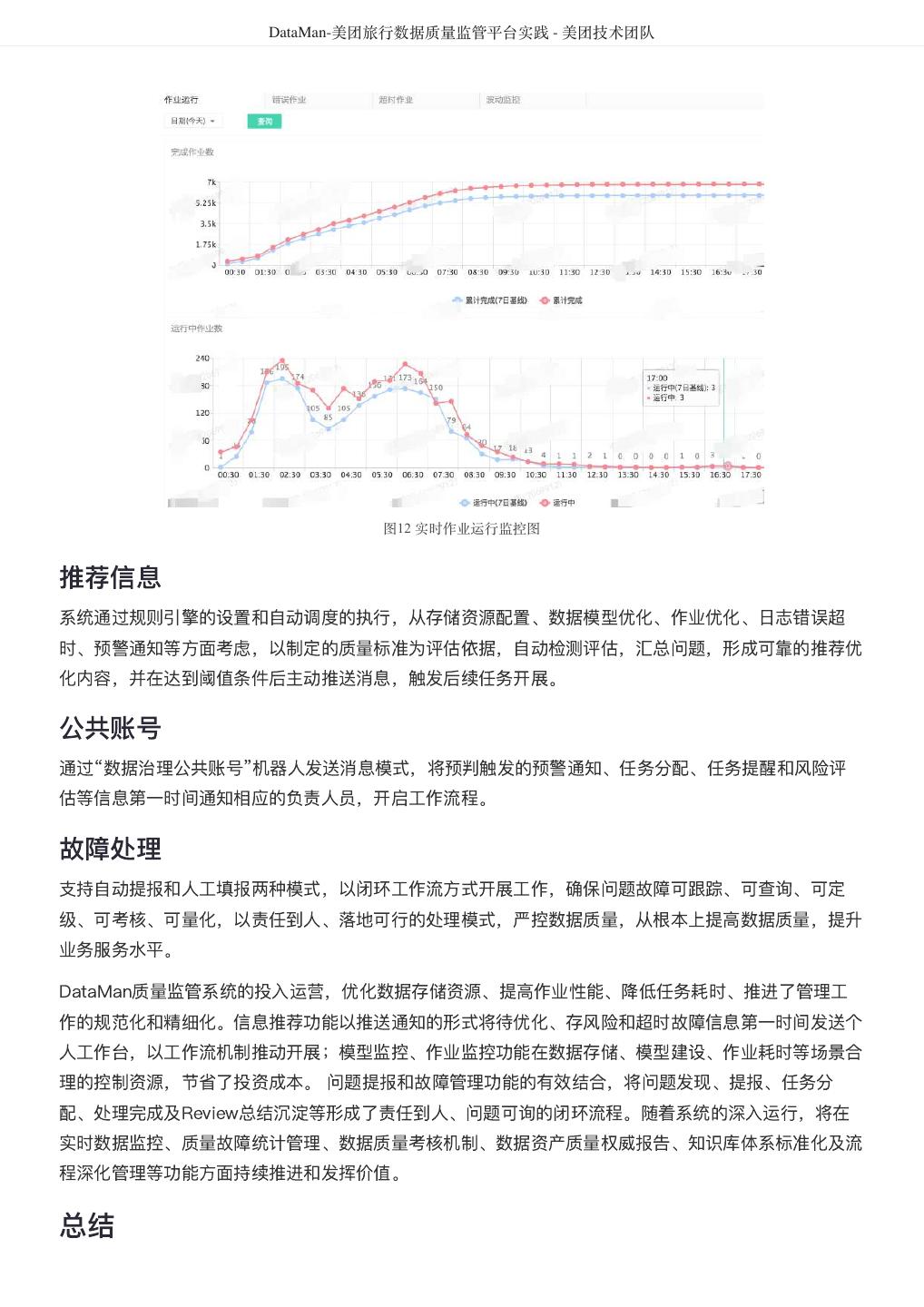
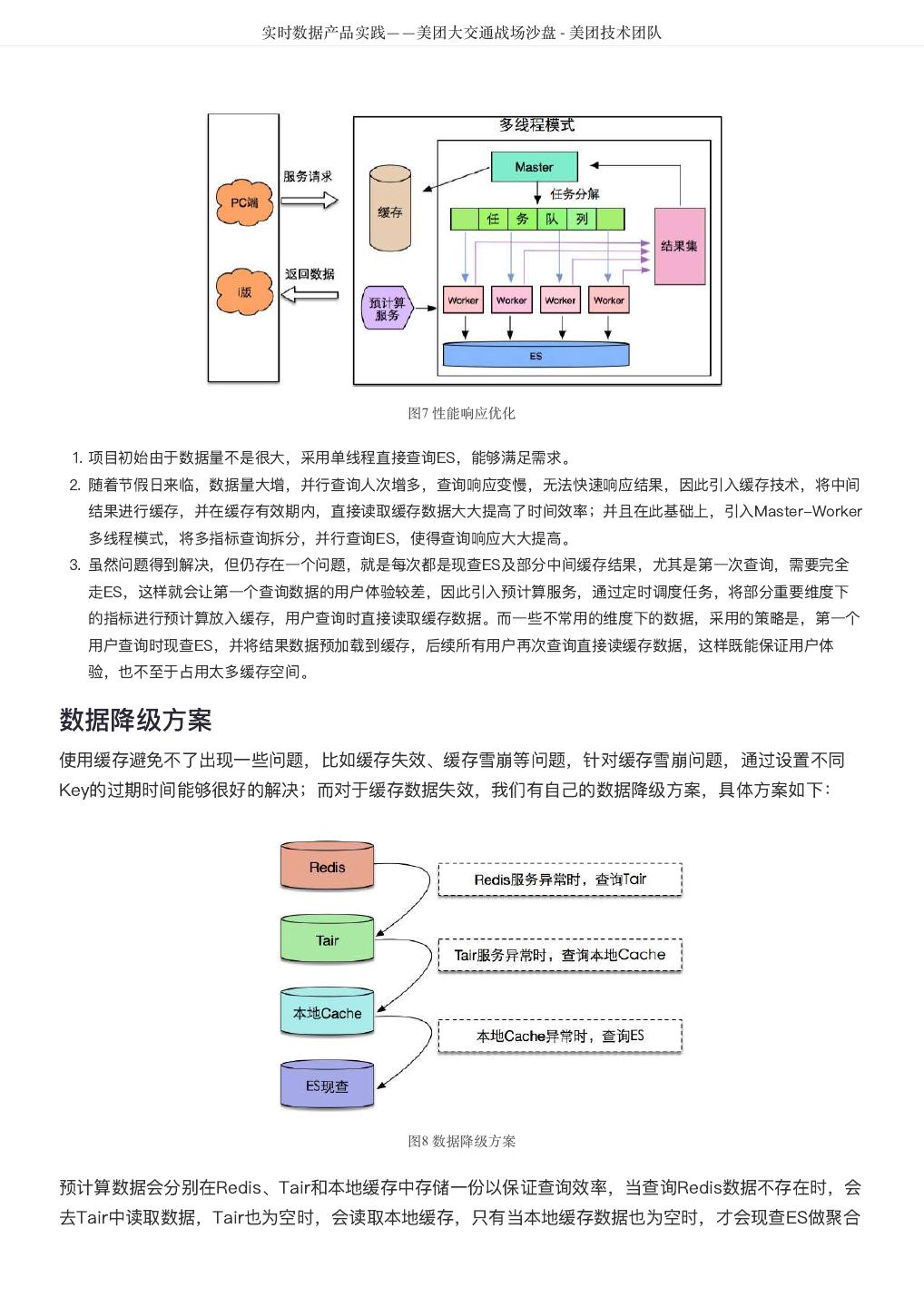
13 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 图11 系统效果图 个人工作台 在系统中将个人待关注、待处理、待优化、待总结等与个人相关的问题和任务形成统一的工作平台入口, 通过公共账号推送的方式,第一时间提醒个人,通知反馈问题的提出者,保障问题可跟踪,进度可查询, 责任到人的工作流程机制。 离线监控 系统可定时执行模型监控、作业监控、平台日志监控等元数据质量规则引擎,开展数据仓库主题模型、逻 辑层级作业、存储资源空间、作业耗时、CPU及内存资源等细化深度分析和洞察;按照质量分析模型, 以时间、增长趋势、同环比、历史基线点等多维度、全面整合打造统一监控平台。 实时监控 从应用角度将作业按照业务条线、数仓分层、数仓主题、组织结构和人员等维度划分,结合作业基线信 息,实时监控正在运行的作业质量,并与作业基线形成对比参照,预警不符合标准的指标信息,第一时间 通知责任人。实时作业运行与基线对比监控效果如图12所示:
14 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 图12 实时作业运行监控图 推荐信息 系统通过规则引擎的设置和自动调度的执行,从存储资源配置、数据模型优化、作业优化、日志错误超 时、预警通知等方面考虑,以制定的质量标准为评估依据,自动检测评估,汇总问题,形成可靠的推荐优 化内容,并在达到阈值条件后主动推送消息,触发后续任务开展。 公共账号 通过“数据治理公共账号”机器人发送消息模式,将预判触发的预警通知、任务分配、任务提醒和风险评 估等信息第一时间通知相应的负责人员,开启工作流程。 故障处理 支持自动提报和人工填报两种模式,以闭环工作流方式开展工作,确保问题故障可跟踪、可查询、可定 级、可考核、可量化,以责任到人、落地可行的处理模式,严控数据质量,从根本上提高数据质量,提升 业务服务水平。 DataMan质量监管系统的投入运营,优化数据存储资源、提高作业性能、降低任务耗时、推进了管理工 作的规范化和精细化。信息推荐功能以推送通知的形式将待优化、存风险和超时故障信息第一时间发送个 人工作台,以工作流机制推动开展;模型监控、作业监控功能在数据存储、模型建设、作业耗时等场景合 理的控制资源,节省了投资成本。 问题提报和故障管理功能的有效结合,将问题发现、提报、任务分 配、处理完成及Review总结沉淀等形成了责任到人、问题可询的闭环流程。随着系统的深入运行,将在 实时数据监控、质量故障统计管理、数据质量考核机制、数据资产质量权威报告、知识库体系标准化及流 程深化管理等功能方面持续推进和发挥价值。 总结
15 . DataMan-美团旅行数据质量监管平台实践 - 美团技术团队 数据质量是数据治理建设的重要一环,与元数据管理、数据标准化及数据服务管理等共同构建了数据治理 的体系框架。建设一个完整DataMan质量监管平台,将从监控、标准、流程制度等方面提升信息管理能 力,优先解决所面临的数据质量和数据服务问题,其效果体现以下几个方面: 监控数据资产质量状态,为优化数据平台和数据仓库性能、合理配置数据存储资源提供决策支持; 持续推动数据质量监控优化预警、实时监控的机制; 重点优先监控关键核心数据资产,管控优化20%核心资源,可提升80%需求应用性能; 规范了问题故障的跟踪、Review、优化方案。从数据中提炼价值,从方案中形成标准化的知识体系; 由技术检测到业务监督,形成闭环工作流机制,提高整体数据质量,全面提升服务业务水平。 数据质量是数据仓库建设、数据应用建设和决策支持的关键因素,可通过完善组织架构和管理流程,加强 部门间衔接和协调,严格按照标准或考核指标执行落地,确保数据质量方能将数据的商业价值最大化,进 而提升企业的核心竞争力和保持企业的可持续发展。 招聘 最后插播一个招聘广告,我们是一群擅长大数据领域数据建设、数仓建设、数据治理及数据BI应用建设的 工程师,期待更多能手加入,有兴趣的同学可以发邮件给yangguang09#meituan.com, zhangdexiao#meituan.com。 作者简介 德晓,美团点评数仓专家、大数据高级工程师,长期从事数据仓库、数据建模、数据治理、大数据方向系统实践建设 等,现为美团点评大交通数据仓库建设负责人。
16 . 美团 R 语言数据运营实战 - 美团技术团队 美团 R 语言数据运营实战 作者: 喻灿 刘强 一、引言 近年来,随着分布式数据处理技术的不断革新,Hive、Spark、Kylin、Impala、Presto 等工具不断推陈 出新,对大数据集合的计算和存储成为现实,数据仓库/商业分析部门日益成为各类企业和机构的标配。 在这种背景下,是否能探索和挖掘数据价值,具备精细化数据运营的能力,就成为判定一个数据团队成功 与否的关键。 在数据从后台走向前台的过程中,数据展示是最后一步关键环节。与冰冷的表格展示相比,将数据转化成 图表并进行适当的内容组织,往往能更快速、更直观的传递信息,进而更好的提供决策支持。从结构化数 据到最终的展示,需要通过一系列的探索和分析过程去完成产品思路的沉淀,这个过程也伴随着大量的数 据二次处理。 上述这些场合 R 语言有着独特的优势。本文将基于美团到店餐饮技术部的精细化数据运营实践,介绍 R 在数据分析与可视化方面的工程能力,希望能够抛砖引玉,也欢迎业界同行给我们提供更多的建议。 二、数据运营产品分类与 R 的优势 2.1 数据运营产品分类 在企业数据运营过程中,考虑使用场景、产品特点、实施角色以及可利用的工具,大致可以将数据运营需 求分为四类,如下表所示,数据运营需求分类: 产品 应用场景 产品特点 实施 工具 角色 分析报告 对模式不固定的数据进行探 基于人对数据的解读;需求发散 数据分 Excel、 索、组织与解释,形成一次 析师、 SQL、R、 性数据分析报告并提供决策 数据工 Tableau 等 支持 程师 报表型产品 通过拖拽式或简单代码方式 开发效率高,开发门槛低;报表表达 数据分 报表工具 进行开发,对模式固定的数 能力差 析师 据组装和报表展现 定制式分析型产品 对固定模式的数据和分析方 开发效率较高,支持对数据的深度应 数据分 Python、 法,形成可重复式的数据分 用,开发过程可复用、可扩展,对有 析师、 R、 析产品并提供决策支持 一定编程能力的开发者开发门槛较 数据工 Tableau 等 低;产品交互能力较弱 程师
17 . 美团 R 语言数据运营实战 - 美团技术团队 定制式展示型产品 对固定模式的数据进行产品 展现样式丰富、交互能力强;仅适合 前端工 ECharts、 的高度定制,通过强化交互 有前端能力的开发者,开发效率较 程师 Highcharts 和用户体验,满足个性化的 低,数据二次处理能力较差 等 数据展示需求 2.2 R 在数据运营上的优势 如上节所述,在精细化数据运营过程中,经常需要使用高度定制的数据处理、可视化、分析等手段,这些 过程 Excel、Tableau、企业级报表工具都无法面面俱到,而恰好是 R 的强项。一般来说,R 具备的如下 特征,让其有了“数据分析领域的瑞士军刀”的名号: 免费、开源、可扩展:截至到 2018-08-02,“The CRAN package repository features 12858 available packages. ”,CRAN 上的软件包涉及贝叶斯分析、运筹学、金融、基因分析、遗传学等方方面面,并在持续新增 和迭代。 可编程:R 本身是一门解释型语言,可以通过代码控制执行过程,并能通过 rPython、rJava 等软件包实现和 Python、Java 语言的互相调用。 强大的数据操控能力: 数据源接入:通过 RMySQL、SparkR、elastic 等软件包,可以实现从 MySQL、Spark、Elasticsearch 等外部 数据引擎获取数据。 数据处理:内置 vector、list、matrix、data.frame 等数据结构,并能通过 sqldf、tidyr、dplyr、reshape2 等 软件包实现对数据的二次加工。 数据可视化:ggplot2、plotly、dygraph 等可视化包可以实现高度定制化的图表渲染。 数据分析与挖掘:R 本身是一门由统计学家发起的面向统计分析的语言,通过自行编程实现或者第三方软件包调 用,可以轻松实现线性回归、方差分析、主成分分析等分析与挖掘功能。 初具雏形的服务框架: Web 编程框架:例如不精通前端和系统开发的同学,通过 shiny 软件包开发自己的数据应用。 服务化能力:例如通过 rserve 包,可以实现 R 和其他语言通信的 C/S 架构服务。 对于以数据为中心的应用来说,Python 和 R 都是不错的选择,两门语言在发展过程中也互有借鉴。“越 接近统计研究与数据分析,越倾向 R;越接近工程开发工程环境的人,越倾向 Python”,Python 是一个 全能型“运动员”,R 则更像是一个统计分析领域的“剑客”,“Python 并未建立起一个能与 CRAN 媲美的 巨大的代码库,R 在这方面具有绝对领先优势。统计学并不是 Python 的核心使命”。各技术网站上有大 量“Python VS R ”的讨论,感兴趣的读者可以自行了解和作出选择。 三、R 的数据处理、可视化、可重复性数据分析能力 对于具备编程能力的分析师或者具备分析能力的开发人员来说,在进行一系列长期的数据分析工程时,使 用 R 既可以满足“一次开发,终身受用”,又可以满足“调整灵活,图形丰富”的要求。下文将分别介绍 R 的数据处理能力、可视化能力和可重复性数据分析能力。 3.1 数据处理 在企业级数据系统中,数据清洗、计算和整合工作会通过数据仓库、Hive、Spark、Kylin 等工具完成。 对于数据运营项目,虽然 R 操作的是结果数据集,但也不能避免需要在查询层进行二次数据处理。
18 . 美团 R 语言数据运营实战 - 美团技术团队 在数据查询层,R 生态现成就存在众多的组件支持,例如可以通过 RMySQL 包进行 MySQL 库表的查 询,可以使用 Elastic 包对 Elasticsearch 索引文档进行搜索。对于 Kylin 等新技术,在 R 生态的组件支 持没有跟上时,可以通过使用 Python、Java 等系统语言进行查询接口封装,在 R 内部使用 rPython、 rJava 组件进行第三方查询接口调用。通过查询组件获取的数据一般以 data.frame、list 等类型对象存 在。 另外 R 本身也拥有比较完备的二次数据处理能力。例如可以通过 sqldf 使用 sql 对 data.frame 对象进行 数据处理,可以使用 reshape2 进行宽格式和窄格式的转化,可以使用 stringr 完成各种字符串处理,其 他如排序、分组处理、缺失值填充等功能,也都具备完善的语言本身和生态的支持。 3.2 数据可视化 数据可视化是数据探索过程和结果呈现的关键环节,而 “ R is a free software environment for statistical computing and graphics. ”,绘图(可视化)系统也是 R 的最大优势之一。 目前 R 主流支持的有三套可视化系统: 内置系统:包括有 base、grid 和 lattice 三个内置发行包,支持以相对比较朴素的方式完成图形绘制。 ggplot2:由 RStudio 的首席科学家 Hadley Wickham 开发,ggplot2 通过一套图形语法支持,支持通过图层叠加以 组合的方式支持高度定制的可视化。这一理念也逐步影响了包括 Plotly、阿里 AntV 等国内外数据可视化解决方案。 截至到 2018-08-02,CRAN 已经落地了 40 个 ggplot2 扩展包,参考链接 。 htmlwidgets for R:这一系统是在 RStudio 支持下于 2016 年开始逐步发展壮大,提供基于 JavaScript 可视化的 R 接口。htmlwidgets for R 作为前端可视化(for 前端工程师)和数据分析可视化(for 数据工程师)的桥梁,发挥了 两套技术领域之间的组合优势。截至到 2018-08-02,经过两年多的发展,目前 CRAN 上已经有 101 个基于 htmlwidgets 开发的第三方包,参考链接 。 实际数据运营分析过程中,可以固化常规的图表展现和可视化分析过程,实现代码复用,提高开发效率。 下图是美团到店餐饮技术部数据团队积累的部分可视化组件示例:
19 . 美团 R 语言数据运营实战 - 美团技术团队 图1 可视化组件示例 基于可视化组件库,一个可视化过程只需要一行代码即可完成,能极大提升开发效率。上图中最后的四象 限矩阵分析示例图的代码如下: vis_4quadrant(iris, 'Sepal.Length', 'Petal.Length', label = 'Species', tooltip = 'tooltip', title = '', xtitle = ' 萼片长度', yt 花瓣长度 itle = ' ', pointSize = 1, annotationSize = 1) 茲再附四象限矩阵分析可视化组件的函数声明: vis_4quadrant <- function(df, x, y, label = '', tooltip = '', title = '', xtitle = '', ytitle = '', showLegend = T, jitter = T, centerType = 'mean', pointShape = 19, pointSize = 5, pointColors = collocatcolors2, lineSize = 0.4, lineType = 'dashed', lineColor = 'black', annotationFace = 'sans serif', annotationSize = 5, annotationColor = 'black', annotationDeviationRatio = 15, gridAnnotationFace = 'sans serif', gridAnnotationSize = 6, gridAnnotationColor = 'black', gridAnnotationAlpha = 0.6, titleFace = 'sans serif', titleSize = 12, titleColor = 'black', xyTitleFace = 'sans serif', xyTitleSize = 8, xyTitleColor = 'black', gridDesc = c('A 区 ', 'B区 ', 'C 区 ', 'D区 数据不完整 '), dataMissingInfo = ' ', renderType = 'widget') { # 绘制分组散点图 # # Args: # df: 数据框;必要字段;需要进行图形绘制的数据,至少应该有三列
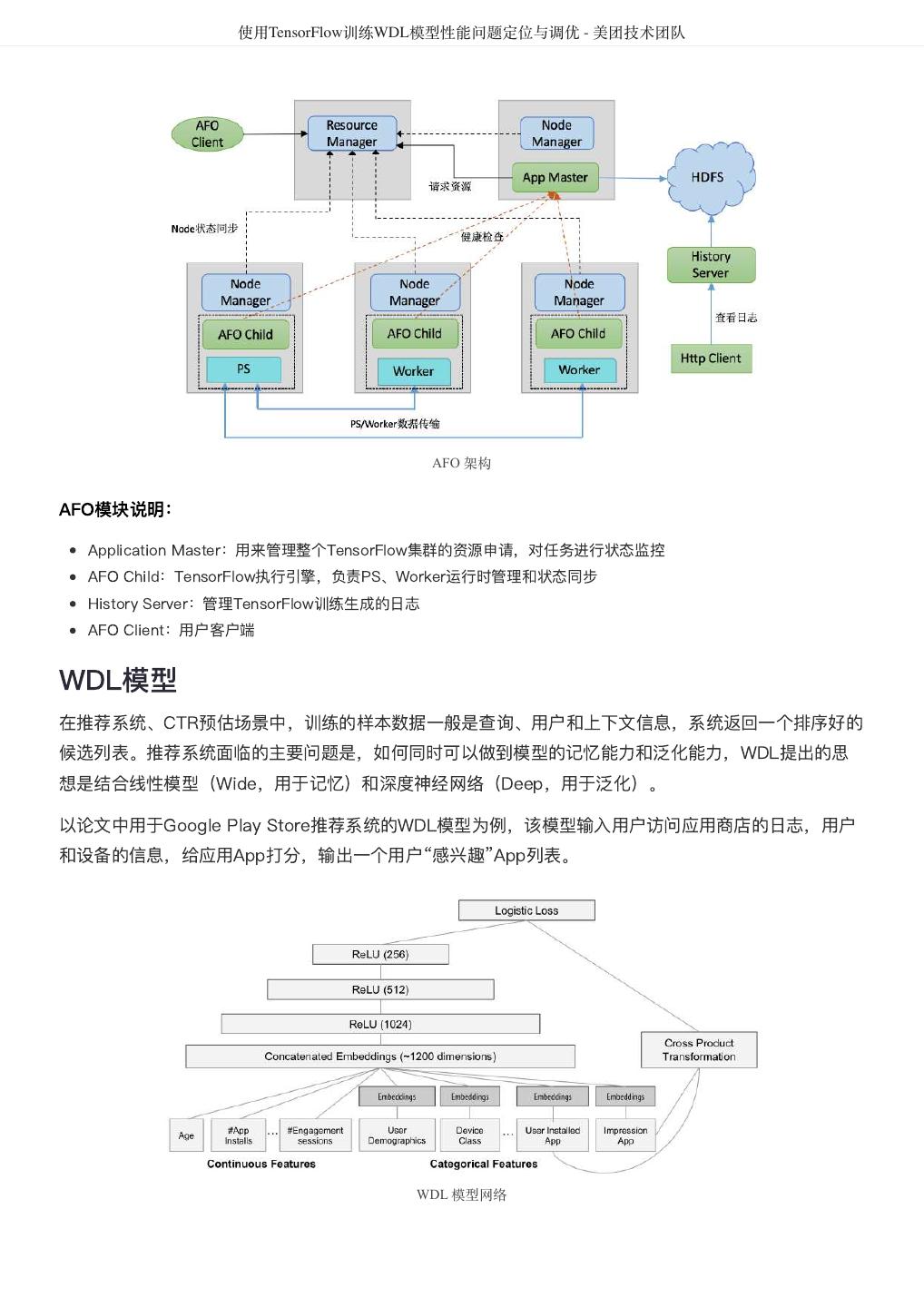
20 . 美团 R 语言数据运营实战 - 美团技术团队 # x:字符串;必要字段;映射到 轴的列名,对应 df 的某一列,此列必须是数值类型或日期类型 X # y:字符串;必要字段;映射到 轴的列名,对应 df 的某一列 Y # 字符串;映射到点上的文字注释 label: # 字符串;映射到点上的悬浮信息 tooltip: # 字符串;标题 title: # 字符串; 轴标题 xtitle: X # 字符串; 轴标题 ytitle: Y # ;定义分区图例是否展示 showLegend: bool # ;定义是否扰动 jitter: bool # 字符串;定义中心点类型,mean 代表平均值,median 代表中位数 centerType: # 整形;定义点型 pointShape: # 数值;定义点大小 pointSize: # 数值;定义线宽 lineSize: # 字符串;定义线型 lineType: # 字符串;定义线色 lineColor: # 字符串;定义注释字体 annotationFace: # 数值;定义注释字体大小 annotationSize: # 字符串;定义注释字体颜色 annotationColor: # 数值;定义注释文本向上偏移系数 annotationDeviationRatio: # 字符串;定义网格注释字体 gridAnnotationFace: # 数值;定义网格注释字体大小 gridAnnotationSize: # 字符串;定义网格注释字体颜色 gridAnnotationColor: # 数值;定义网格注释文本透明度 gridAnnotationAlpha: # 字符串;定义标题字体 titleFace: # 数值;定义标题字体大小 titleSize: # 字符串;定义标题字体颜色 titleColor: # 字符串;定义 、 轴标题字体 xyTitleFace: X Y # 数值;定义 、 轴标题字体大小 xyTitleSize: X Y # 字符串;定义 、 轴标题字体颜色 xyTitleColor: X Y # 长度为 的字符串向量 gridDesc: 4 # 字符串;数据问题提示文本 dataMissingInfo: # 字符串;定义渲染结果类型,widget 对应 htmlwidget 组件,html 对应 html 内容 renderType: # 代码实现略 } 3.3 可重复性数据分析 数据运营分析往往是一个重复性的、重人工参与的过程,最终会落地一套数据分析框架,这套数据分析框 架适配具体的数据,用于支持企业数据决策。 RStudio 通过 rmarkdown + knitr 的方式提供了一套基于文学编程的数据分析报告产出方案,开发者可 以将 R 代码嵌入 Markdown 文档中执行并得到渲染结果(渲染结果可以是 HTML、PDF、Word 文档格 式),实际数据分析过程中,开发者最终能形成一套数据分析模版,每次适配不同的数据,就能产出一份 新的数据分析报告。 rmarkdown 本身具备简单的页面布局能力并可以使用 flexdashboard 进行扩展,因此这套方案不仅能实 现重复性分析过程,还能实现分析结果的高度定制化展示,可以使用 HTML、CSS、JavaScript 前端三 大件对数据分析报告进行展示和交互的细节调整。最终实现人力的节省和数据分析结果的快速、高效产 出。 四、R 服务化改造 4.1 R 服务化框架 R 本身既是一门语言、也是一个跨平台的操作环境,具备强大的数据处理、数据分析、和数据可视化能 力。除了在个人电脑的 Windows/MacOS 环境中上充当个人统计分析工具外,也可以运行在 Linux 服务 环境中,因此可以将 R 作为分析展现引擎,外围通过 Java 等系统开发语言完成缓存、安全检查、权限 控制等功能,开发企业报表系统或数据分析(挖掘)框架,而不仅仅只是将 R 作为一个桌面软件。 企业报表系统或数据分析(挖掘)框架设计方案如下图所示:
21 . 美团 R 语言数据运营实战 - 美团技术团队 图2 R 服务化框架 4.2 foreach + doParallel 多核并行方案 作为一门统计学家开发的解释性语言,R 运行的是 CPU 单核上的单线程程序、并且需要将全部数据加载 到内存进行处理,因此和 Java、Python 等系统语言相比,计算性能是 R 的软肋。对于大数据集合的计 算场景,需要尽量将数据计算部分通过 Hive、Kylin 等分布式计算引擎完成,尽量让 R 只处理结果数据 集;另外也可以通过 doParallel + foreach 方案,通过多核并行提升计算效率,代码示例如下: library(doParallel) library(foreach) registerDoParallel(cores = detectCores()) vis_process1 <- function() { # 可视化过程1 ... } vis_process2 <- function() { # 可视化过程2 ... } data_process1 <- function() { # 数据处理过程1 ... } data_process2 <- function() { # 数据处理过程2 ... } processes <- c('vis_process1', 'vis_process2', 'data_process1', 'data_process2') process_res <- foreach(i = 1:length(process), .packages = c('magrittr')) %dopar% { do.call(processes[i], list()) } vis_process1_res <- process_res[[1]] vis_process2_res <- process_res[[2]] data_process1_res <- process_res[[3]] data_process2_res <- process_res[[4]] 4.3 图形化数据报告渲染性能
22 . 美团 R 语言数据运营实战 - 美团技术团队 在数据分析过程中,R 最重要的是充当图形引擎的角色,因此有必要了解其图形渲染性能。针对主流的基 于 rmarkdown + flexdashboard 的数据分析报告渲染方案,其性能测试结果如下: 系统环境: * 4 核 CPU,8 G 内存,2.20GHz 主频。 * Linux version 3.10.0-123.el7.x86_64。 测试方法: 测试在不同并发度下、不同复杂度的渲染模式下,重复渲染 100 次的耗时。 测试结果(数据分析报告渲染性能测试): 渲染模式 并发度 1 并发度 2 并发度 3 并发度 4 并发度 5 并发度 6 rmarkdown + 1m14.087s 0m39.192s 0m28.299s 0m20.795s 0m21.471s 0m19.755s flexdashboard rmarkdown + 1m48.771s 0m52.716s 0m39.051s 0m27.012s 0m30.224s 0m28.948s flexdashboard + dygraphs rmarkdown + 2m6.840s 1m1.529s 0m42.351s 0m31.596s 0m35.546s 0m34.992s flexdashboard + ggplot2 rmarkdown + 2m30.586s 1m16.696s 0m51.277s 0m40.651s 0m41.406s 0m41.288s flexdashboard + ggplot2 + dygraph 根据测试结果可知: 单应用平均渲染时长在 0.74s 以上,具体的渲染时长视计算复杂度而定(可以通过上节介绍的“foreach + doParallel 多核并行方案 ”加快处理过程)。根据经验,大部分应用能在秒级完成渲染。 由于单核单线程模式所限,当并发请求超过 CPU 核数时,渲染吞吐量并不会相应提升。需要根据实际业务场景匹配 对应的服务端机器配置,并在请求转发时设置并发执行上限。对于内部运营性质的数据系统,单台 4 核 8 G 机器基 本能满足要求。 五、R 在美团数据产品中的落地实践 美团到店餐饮数据团队从 2015 年开始逐步将 R 作为数据产品的辅助开发语言,截至 2018 年 8 月,已 经成功应用在面向管理层的日周月数据报告、面向数据仓库治理的分析工具、面向内部运营与分析师的数 据 Dashboard、面向大客户销售的品牌商家数据分析系统等多个项目中。目前所有的面向部门内部的定 制式分析型产品,都首选使用 R 进行开发。 另外我们也在逐步沉淀 R 可视化与分析组件、开发基于 R 引擎的配置化 BI 产品开发框架,以期进一步 降低 R 的使用门槛、提升 R 的普及范围。 下图是美团到店餐饮数据团队在数据治理过程中,使用 R 开发的 ETL 间依赖关系可视化工具:
23 . 美团 R 语言数据运营实战 - 美团技术团队 图3 ETL 间依赖关系可视化工具 六、结语 综上所述,R 可以在企业数据运营实践中扮演关键技术杠杆,但作为一门面向统计分析的领域语言,在很 长一段时间,R 的发展主要由统计学家驱动。随着近年的数据爆发式增长与应用浪潮,R 得到越来越多工 业界的支持,譬如微软收购基于 R 的企业级数据解决方案提供商 Revolution Analytics、在 SQL Server 2016 集成 R、并从 Visual Studio 2015 开始正式通过 RTVS 集成了 R 开发环境,一系列事件标志着微 软在数据分析领域对 R 的高度重视。 在国内,由 统计之都 发起的 中国 R 会议 ,从 2008 年起已举办了 11 届,推动了 R 用户在国内的发 展壮大。截至 2018 年 8 月,美团的 R 开发者大致在 200 人左右。但相比 Java/Python 等系统语言, R 的用户和应用面仍相对狭窄。作者撰写本文的目的,也是希望给从事数据相关工作的同学们一个新的、 更具优势的可选项。 关于作者 喻灿,美团到店餐饮技术部数据系统与数据产品团队负责人,2015 年加入美团,长期从事数据平台、数据仓库、数 据应用方面的开发工作。从 2013 年开始接触 R,在利用 R 快速满足业务需求和节省研发成本上,有一些心得和产 出。同时也在美团研发和商业分析团队中积极推动 R 的发展。 招聘信息 对数据工程和将数据通过服务业务释放价值感兴趣的同学,可以发送简历到yucan@meituan.com。我们 在数据仓库、数据治理、数据产品开发框架、数据可视化、面向销售和商家侧的数据型创新产品层面,都 有很多未知但有意义的领域等你来开拓。
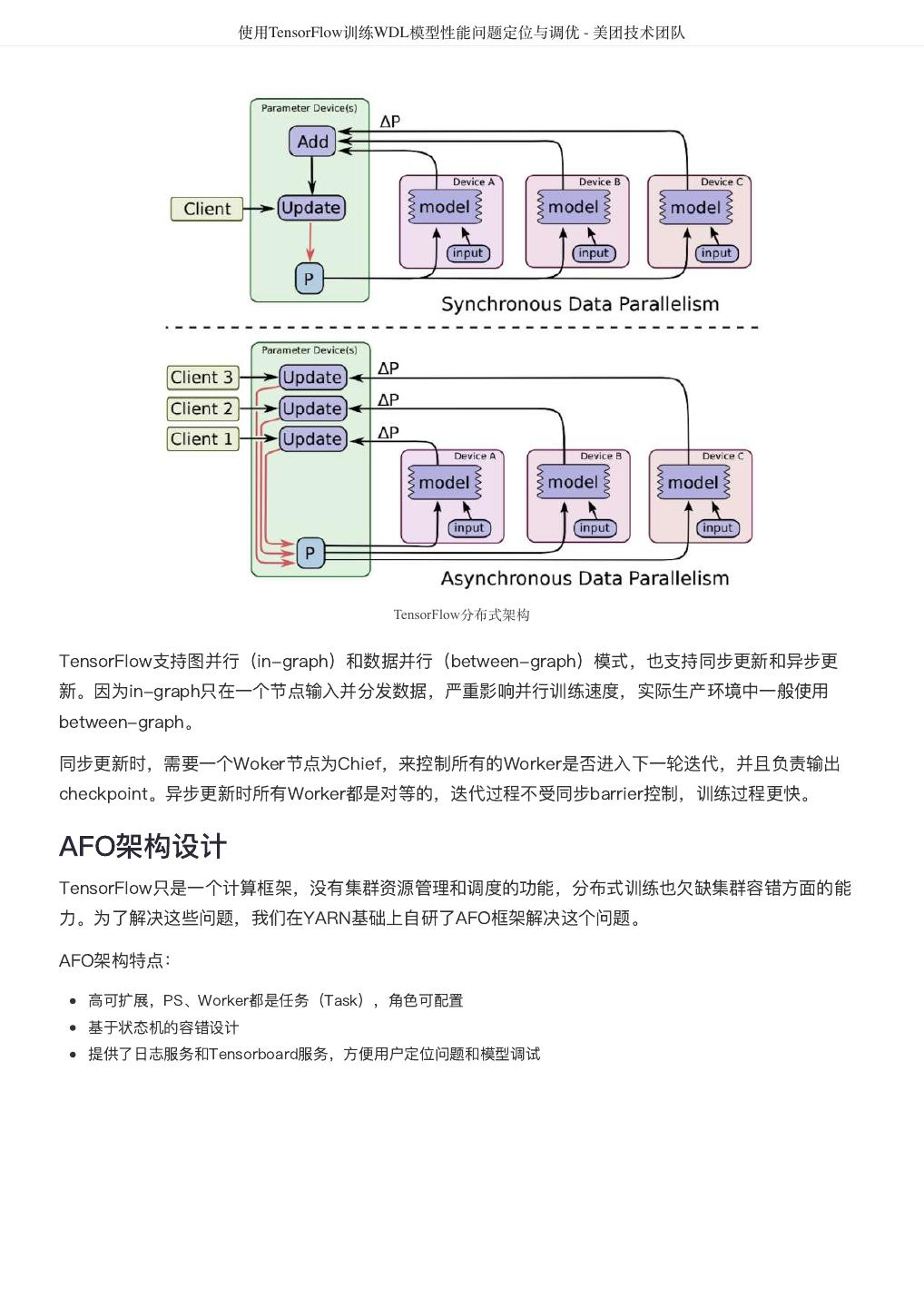
24 . 聊聊MyBatis缓存机制 - 美团技术团队 聊聊MyBatis缓存机制 作者: 凯伦 前言 MyBatis是常见的Java数据库访问层框架。在日常工作中,开发人员多数情况下是使用MyBatis的默认缓 存配置,但是MyBatis缓存机制有一些不足之处,在使用中容易引起脏数据,形成一些潜在的隐患。个人 在业务开发中也处理过一些由于MyBatis缓存引发的开发问题,带着个人的兴趣,希望从应用及源码的角 度为读者梳理MyBatis缓存机制。 本次分析中涉及到的代码和数据库表均放在GitHub上,地址: mybatis-cache-demo 。 目录 本文按照以下顺序展开。 一级缓存介绍及相关配置。 一级缓存工作流程及源码分析。 一级缓存总结。 二级缓存介绍及相关配置。 二级缓存源码分析。 二级缓存总结。 全文总结。 一级缓存 一级缓存介绍 在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供 了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进 行查询,提高性能。具体执行过程如下图所示。
25 . 聊聊MyBatis缓存机制 - 美团技术团队 每个SqlSession中持有了Executor,每个Executor中有一个LocalCache。当用户发起查询时,MyBatis 根据当前执行的语句生成 MappedStatement ,在Local Cache进行查询,如果缓存命中的话,直接返回 结果给用户,如果缓存没有命中的话,查询数据库,结果写入 Local Cache ,最后返回结果给用户。具 体实现类的类关系图如下图所示。 一级缓存配置 我们来看看如何使用MyBatis一级缓存。开发者只需在MyBatis的配置文件中,添加如下语句,就可以使 用一级缓存。共有两个选项, SESSION 或者 STATEMENT ,默认是 SESSION 级别,即在一个MyBatis会 话中执行的所有语句,都会共享这一个缓存。一种是 STATEMENT 级别,可以理解为缓存只对当前执行的 这一个 Statement 有效。 <setting name="localCacheScope" value="SESSION"/> 一级缓存实验 接下来通过实验,了解MyBatis一级缓存的效果,每个单元测试后都请恢复被修改的数据。 首先是创建示例表student,创建对应的POJO类和增改的方法,具体可以在entity包和mapper包中查 看。 CREATE TABLE `student` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(200) COLLATE utf8_bin DEFAULT NULL, `age` tinyint(3) unsigned DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; 在以下实验中,id为1的学生名称是凯伦。 实验1 开启一级缓存,范围为会话级别,调用三次 getStudentById ,代码如下所示:
26 . 聊聊MyBatis缓存机制 - 美团技术团队 public void getStudentById() throws Exception { SqlSession sqlSession = factory.openSession(true); // 自动提交事务 StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class); System.out.println(studentMapper.getStudentById(1)); System.out.println(studentMapper.getStudentById(1)); System.out.println(studentMapper.getStudentById(1)); } 执行结果: 我们可以看到,只有第一次真正查询了数据库,后续的查询使用了一级缓存。 实验2 增加了对数据库的修改操作,验证在一次数据库会话中,如果对数据库发生了修改操作,一级缓存是否会 失效。 @Test public void addStudent() throws Exception { SqlSession sqlSession = factory.openSession(true); // 自动提交事务 StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class); System.out.println(studentMapper.getStudentById(1)); 增加了 System.out.println(" " + studentMapper.addStudent(buildStudent()) + " 个学生"); System.out.println(studentMapper.getStudentById(1)); sqlSession.close(); } 执行结果: 我们可以看到,在修改操作后执行的相同查询,查询了数据库,一级缓存失效。 实验3 开启两个 SqlSession ,在 sqlSession1 中查询数据,使一级缓存生效,在 sqlSession2 中更新数据 库,验证一级缓存只在数据库会话内部共享。 @Test public void testLocalCacheScope() throws Exception { SqlSession sqlSession1 = factory.openSession(true); SqlSession sqlSession2 = factory.openSession(true);
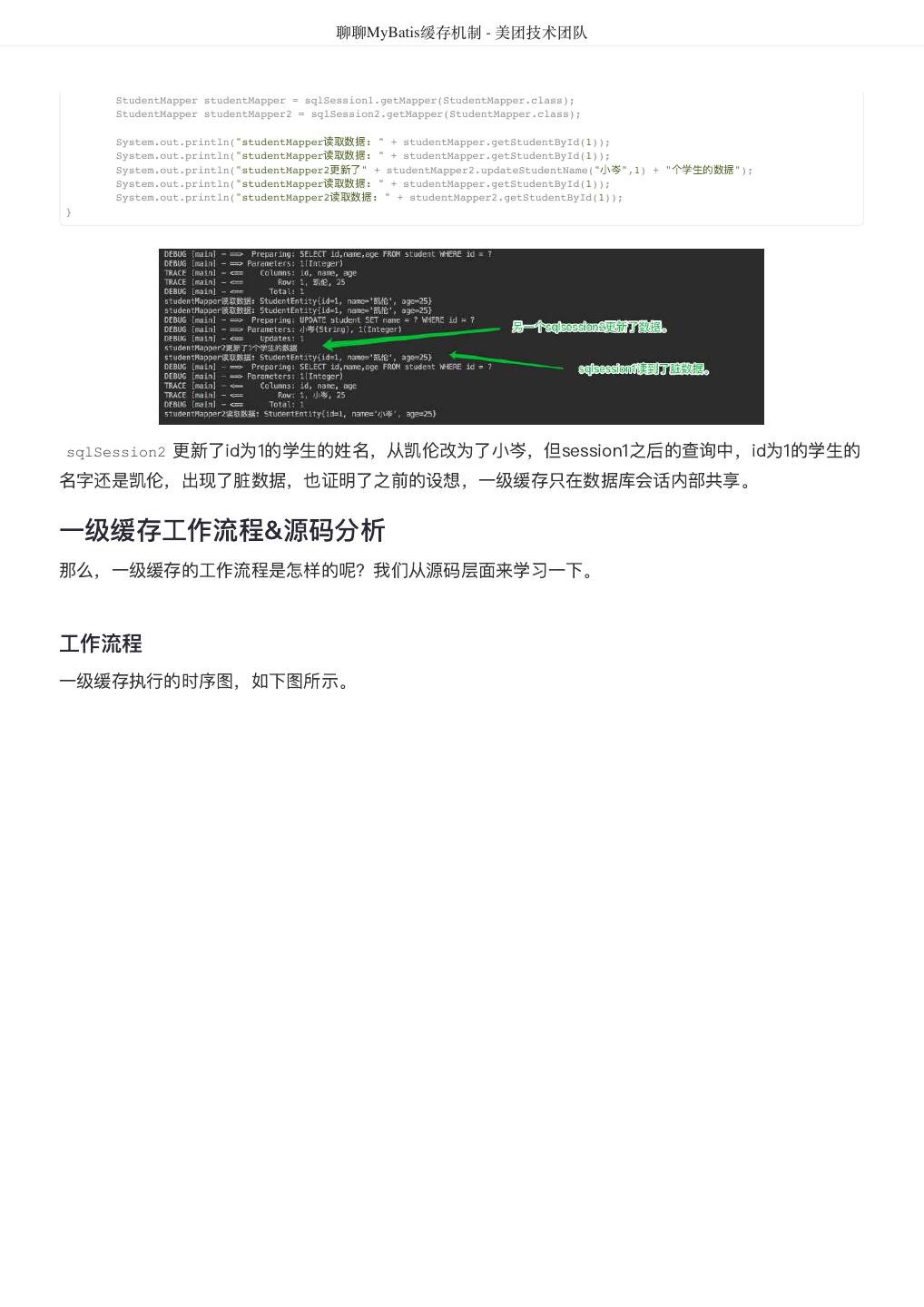
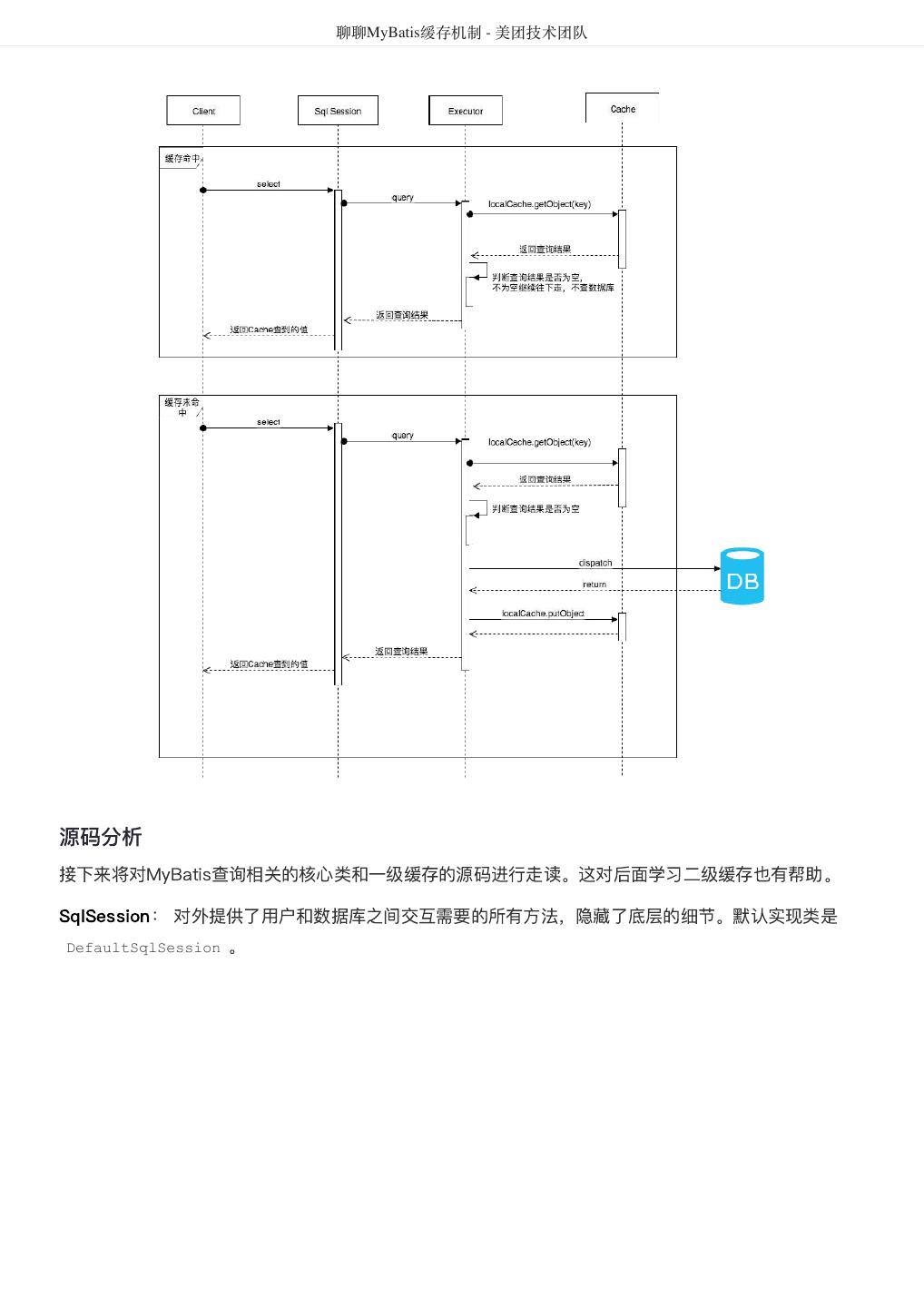
27 . 聊聊MyBatis缓存机制 - 美团技术团队 StudentMapper studentMapper = sqlSession1.getMapper(StudentMapper.class); StudentMapper studentMapper2 = sqlSession2.getMapper(StudentMapper.class); System.out.println("studentMapper读取数据: " + studentMapper.getStudentById(1)); System.out.println("studentMapper读取数据: " + studentMapper.getStudentById(1)); System.out.println("studentMapper2更新了" + studentMapper2.updateStudentName("小岑",1) + " 个学生的数据"); System.out.println("studentMapper读取数据: " + studentMapper.getStudentById(1)); System.out.println("studentMapper2读取数据: " + studentMapper2.getStudentById(1)); } 更新了id为1的学生的姓名,从凯伦改为了小岑,但session1之后的查询中,id为1的学生的 sqlSession2 名字还是凯伦,出现了脏数据,也证明了之前的设想,一级缓存只在数据库会话内部共享。 一级缓存工作流程&源码分析 那么,一级缓存的工作流程是怎样的呢?我们从源码层面来学习一下。 工作流程 一级缓存执行的时序图,如下图所示。
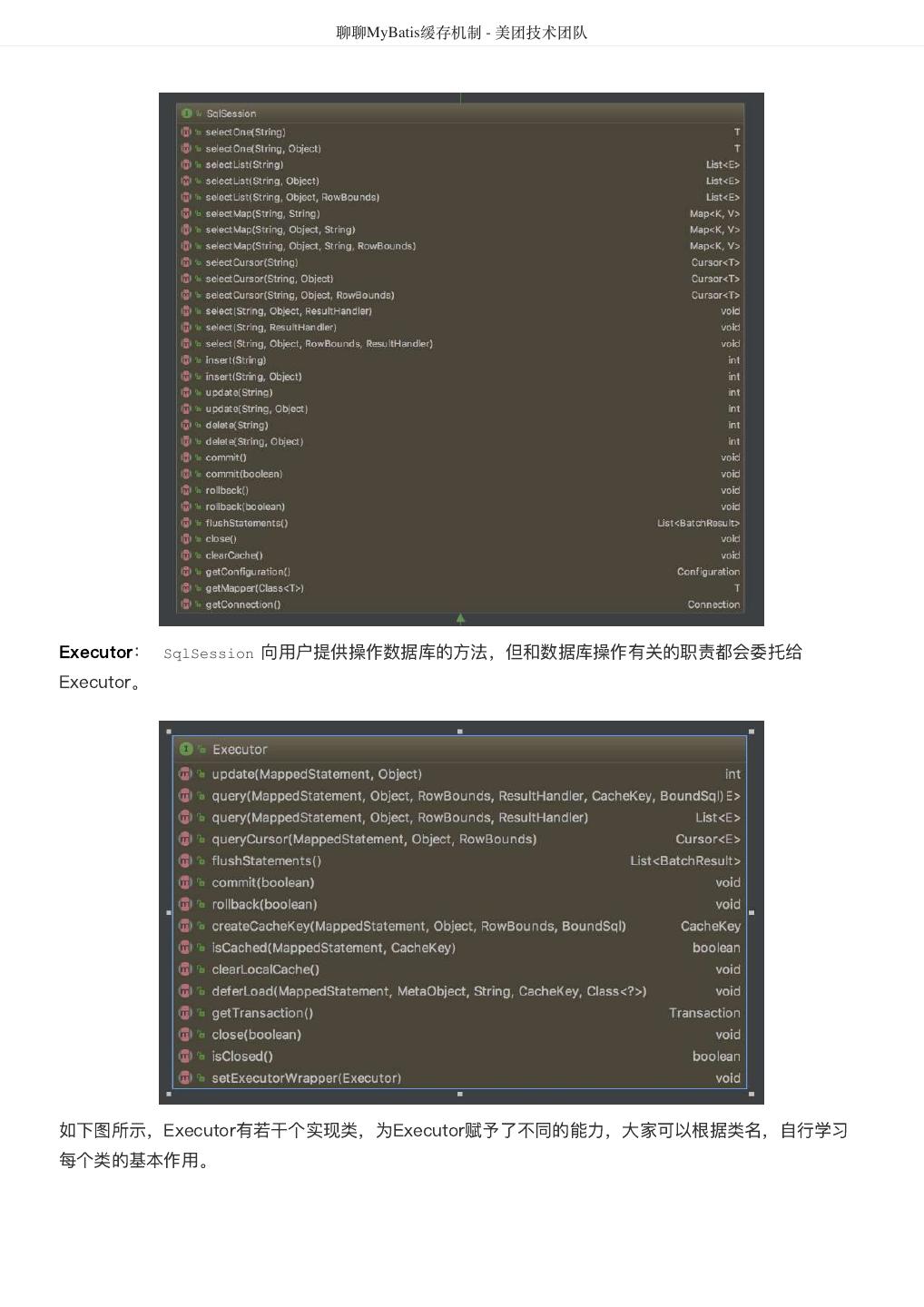
28 . 聊聊MyBatis缓存机制 - 美团技术团队 源码分析 接下来将对MyBatis查询相关的核心类和一级缓存的源码进行走读。这对后面学习二级缓存也有帮助。 SqlSession: 对外提供了用户和数据库之间交互需要的所有方法,隐藏了底层的细节。默认实现类是 DefaultSqlSession 。
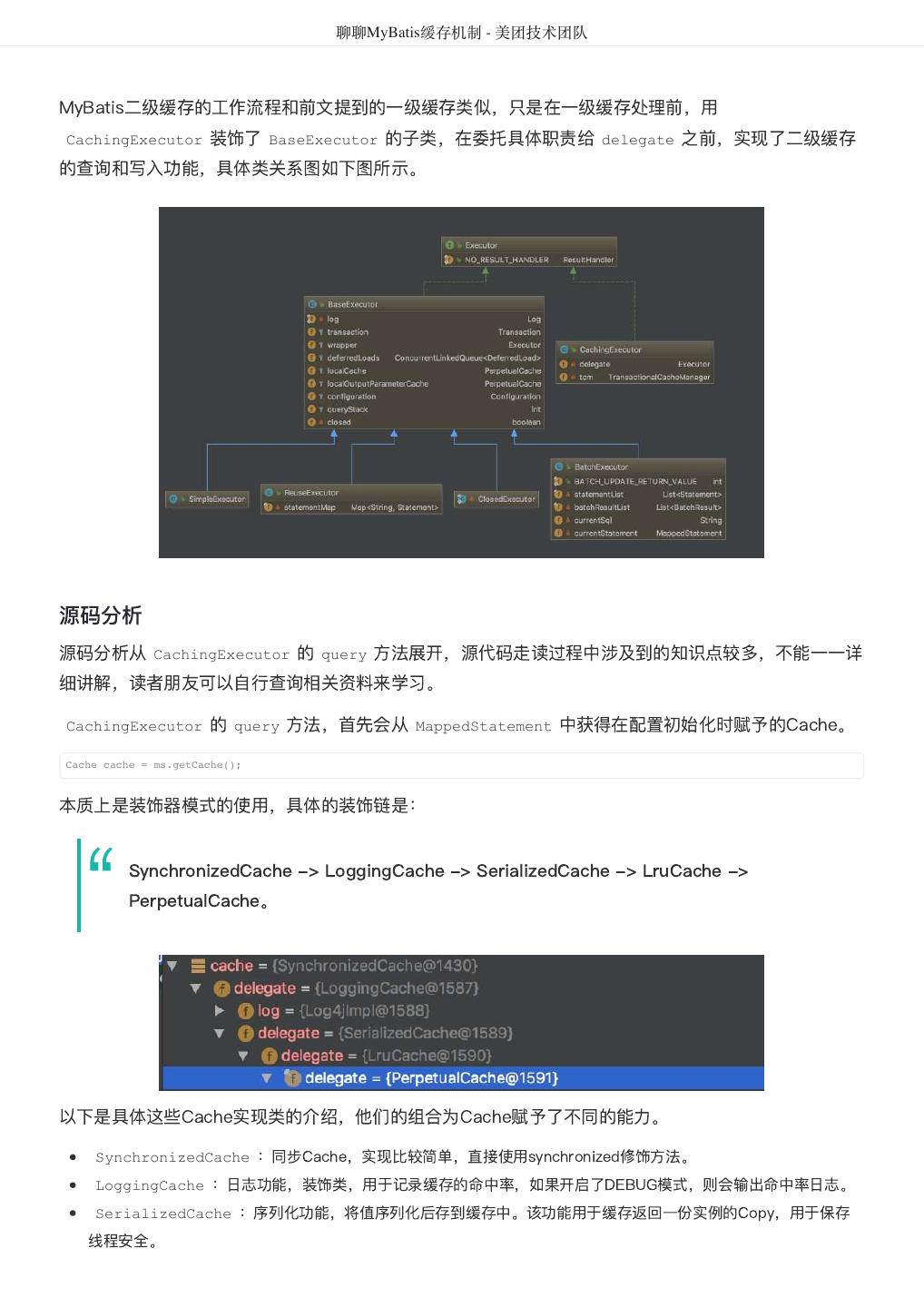
29 . 聊聊MyBatis缓存机制 - 美团技术团队 Executor: SqlSession 向用户提供操作数据库的方法,但和数据库操作有关的职责都会委托给 Executor。 如下图所示,Executor有若干个实现类,为Executor赋予了不同的能力,大家可以根据类名,自行学习 每个类的基本作用。
相关推荐

加关注
3秒后跳转登录页面
去登陆

