JuiceFS:打造下一代云原生大数据存储系统
分享
点赞
19
收藏
8
下载 31
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
 献良
献良
/
发布于
/
10154
人观看
传统的云原生(Cloud Native)大数据处理,,从数据的一致性到元数据的管理,面临着各种性能和编程上挑战。HDFS虽然有着不错的性能,和扩展性,但是在使用成本和运维成本上也面临诸多顾虑。JuiceFS是下一代的基于云原生的分布式文件系统,利用OSS/S3/HDFS等公有云存储,在元数据管理上做到弹性管理,极大提升了云原生应用的数据处理效率,支持Spark/Impala/TensorFlow/Hive/HBase等数据处理引擎。
展开查看详情
1 .JuiceFS
Juicedata
2018.11.18
�
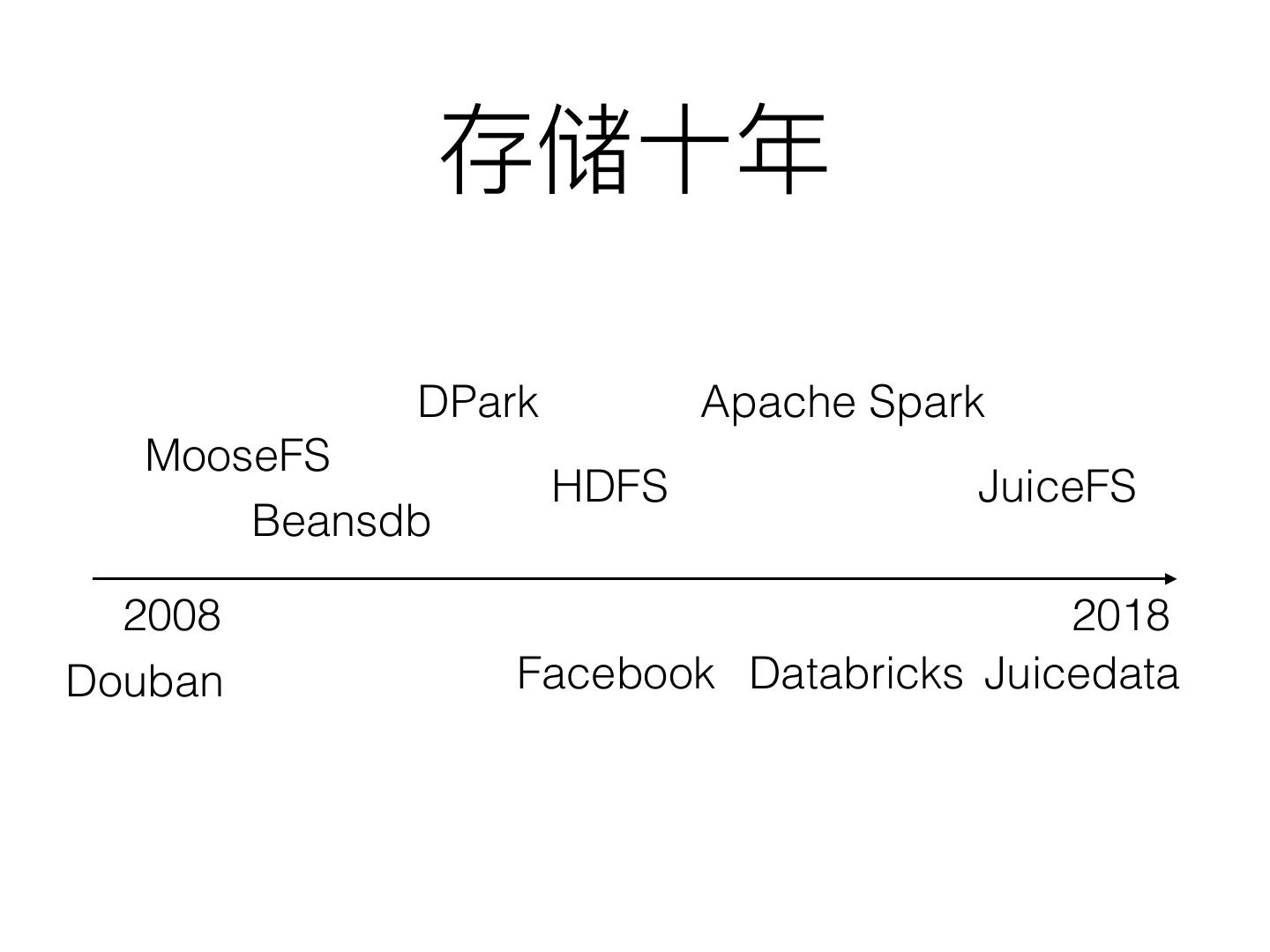
2 . DPark Apache Spark
MooseFS
HDFS JuiceFS
Beansdb
2008 2018
Douban Facebook Databricks Juicedata
�
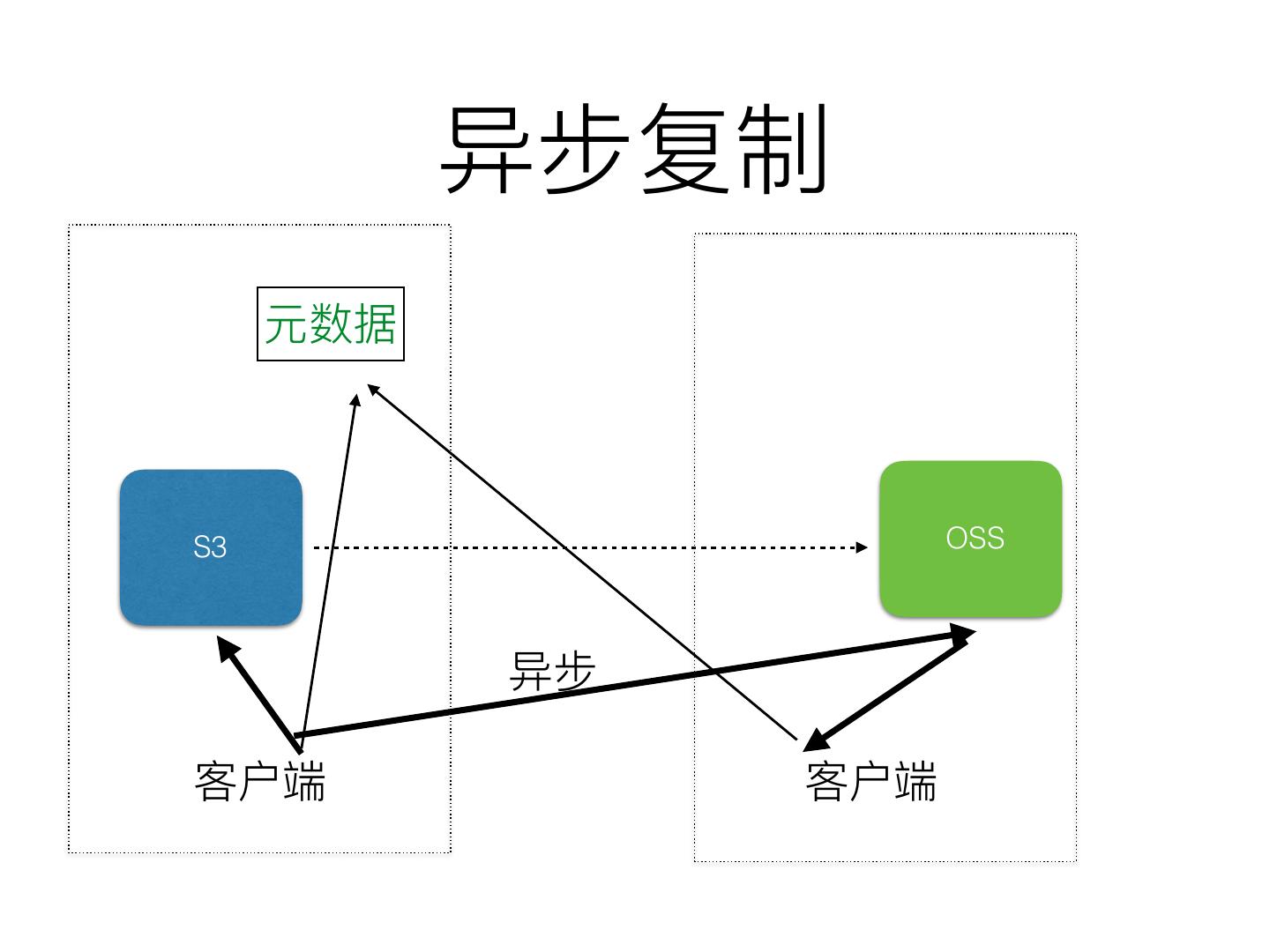
5 . (S3)
• API
• Restful
•
•
�
6 . (S3)
•
•
• FileNotFoundException
•
•
• : FileAlreadyExistsException
•
�
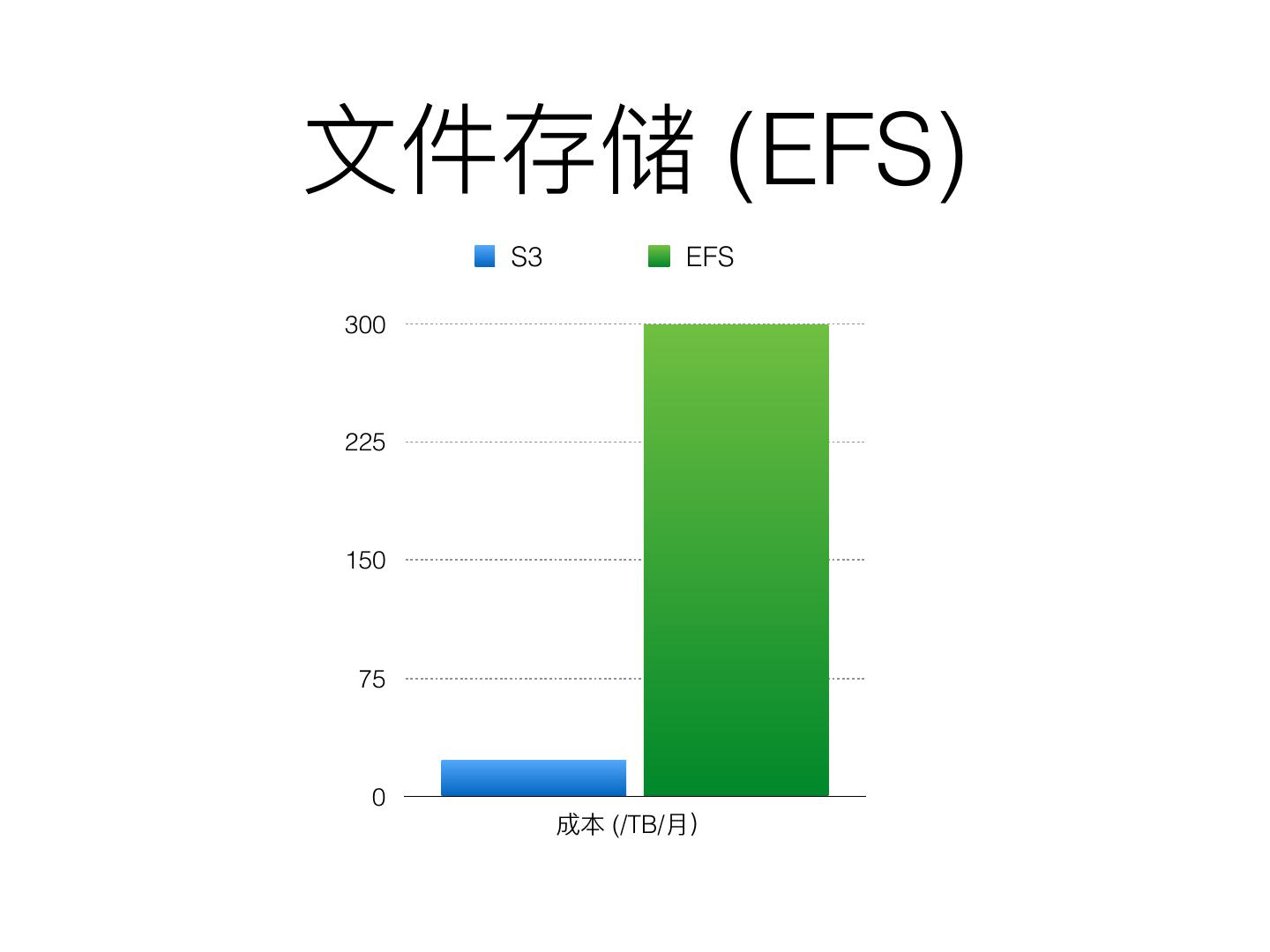
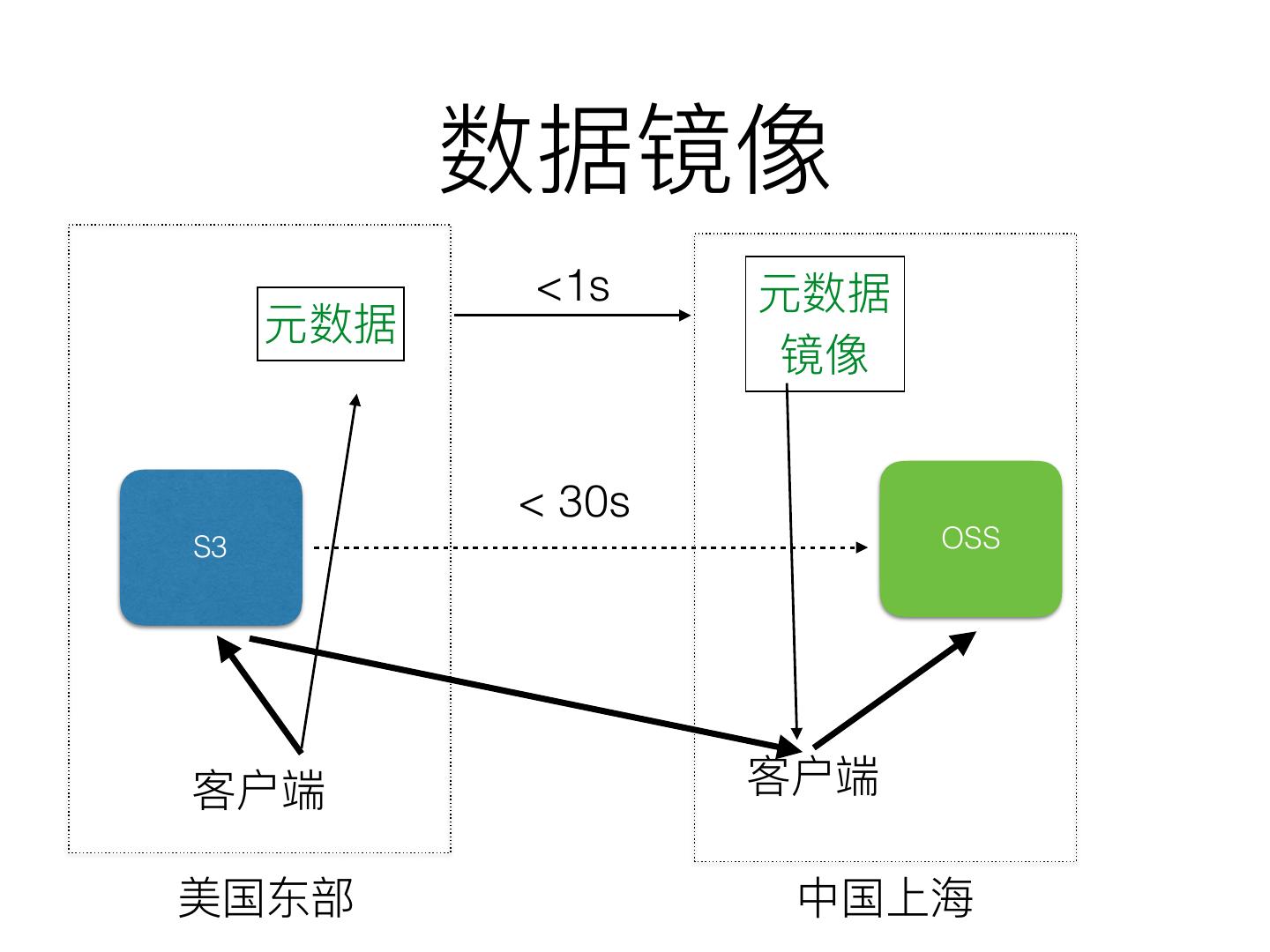
7 . (EFS)
S3 EFS
300
225
150
75
0
(/TB/
�
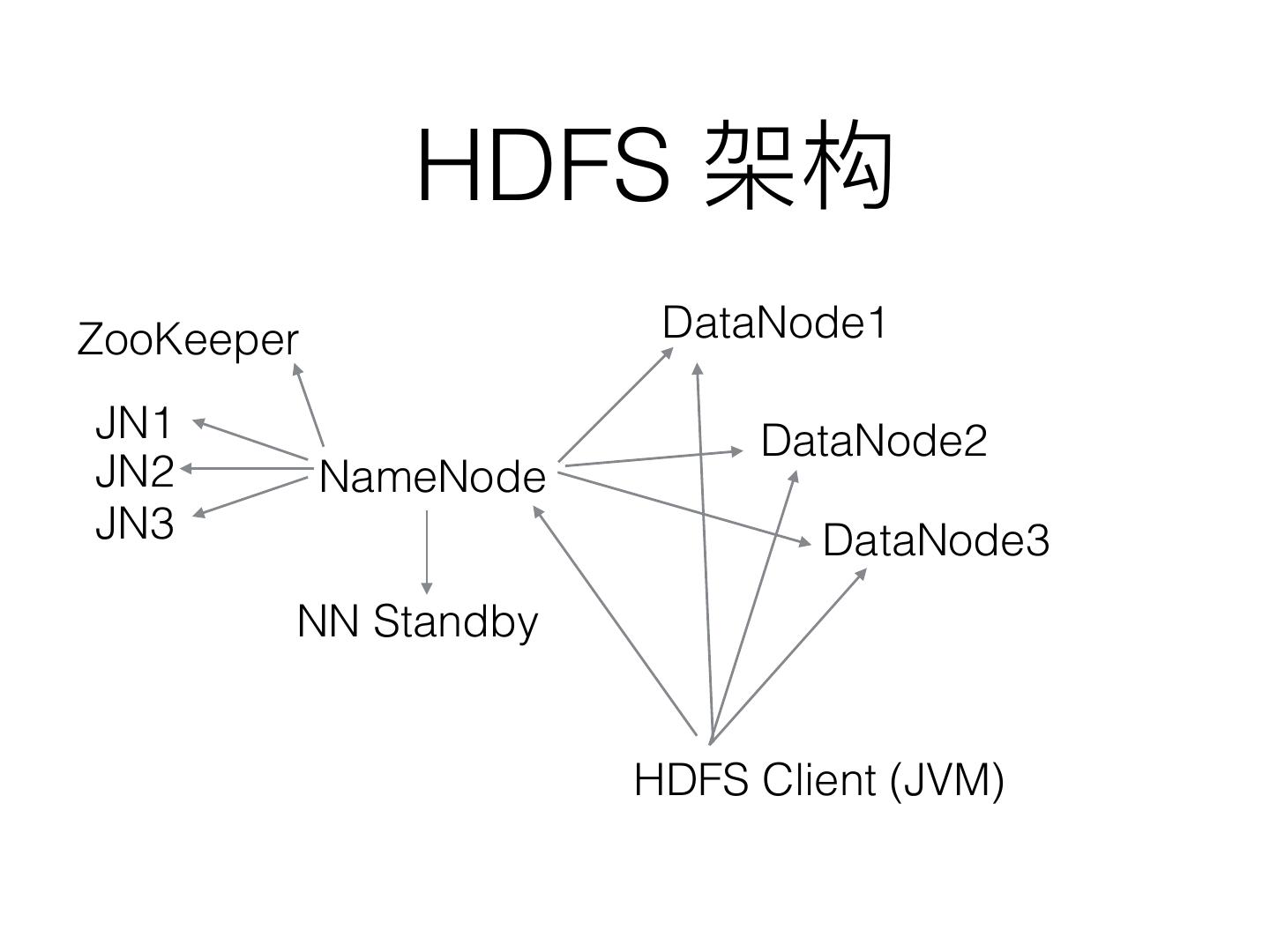
11 . HDFS
ZooKeeper DataNode1
JN1 DataNode2
JN2 NameNode
JN3 DataNode3
NN Standby
HDFS Client (JVM)
�
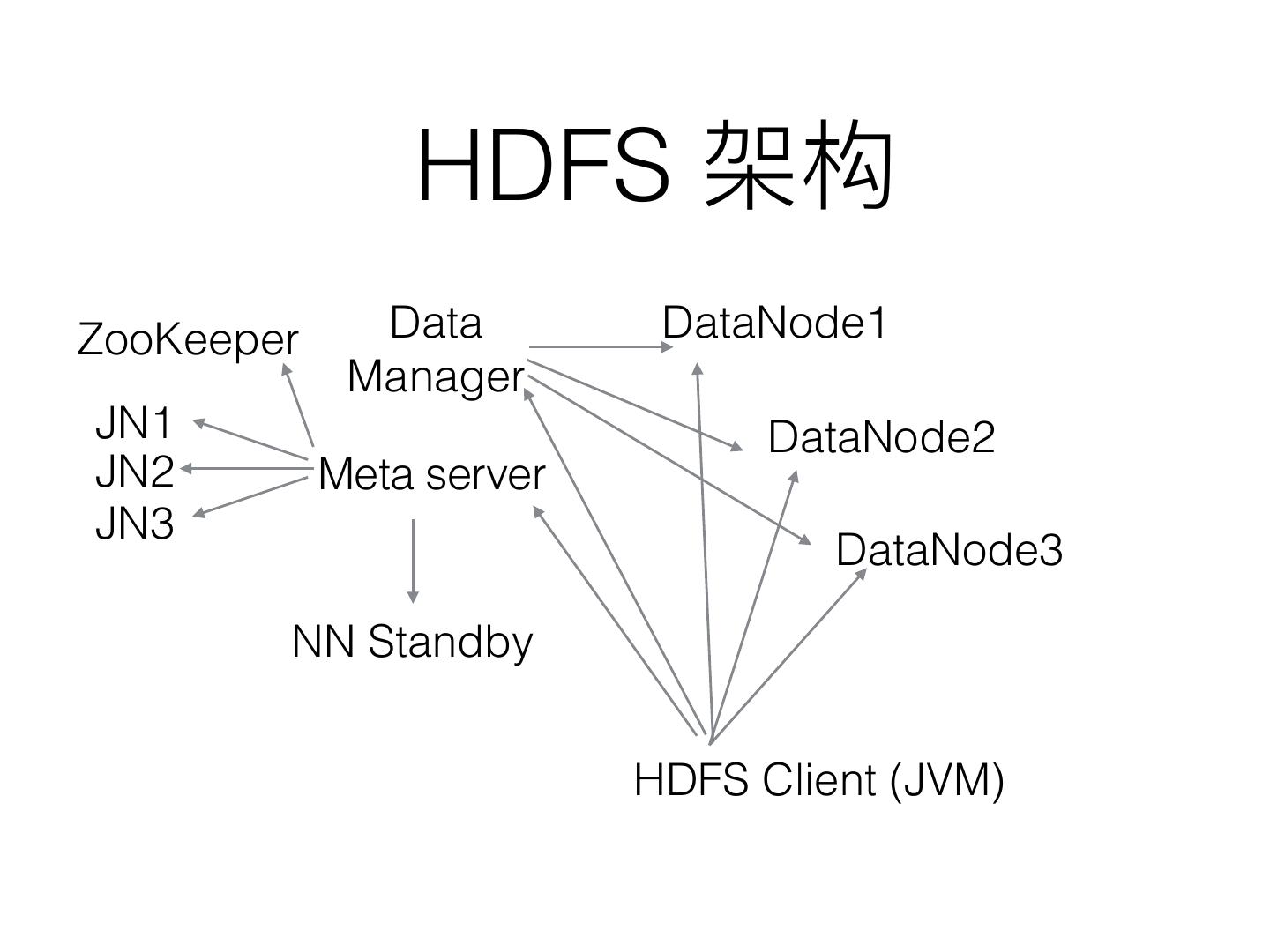
12 . HDFS
ZooKeeper Data DataNode1
Manager
JN1 DataNode2
JN2 Meta server
JN3
DataNode3
NN Standby
HDFS Client (JVM)
�
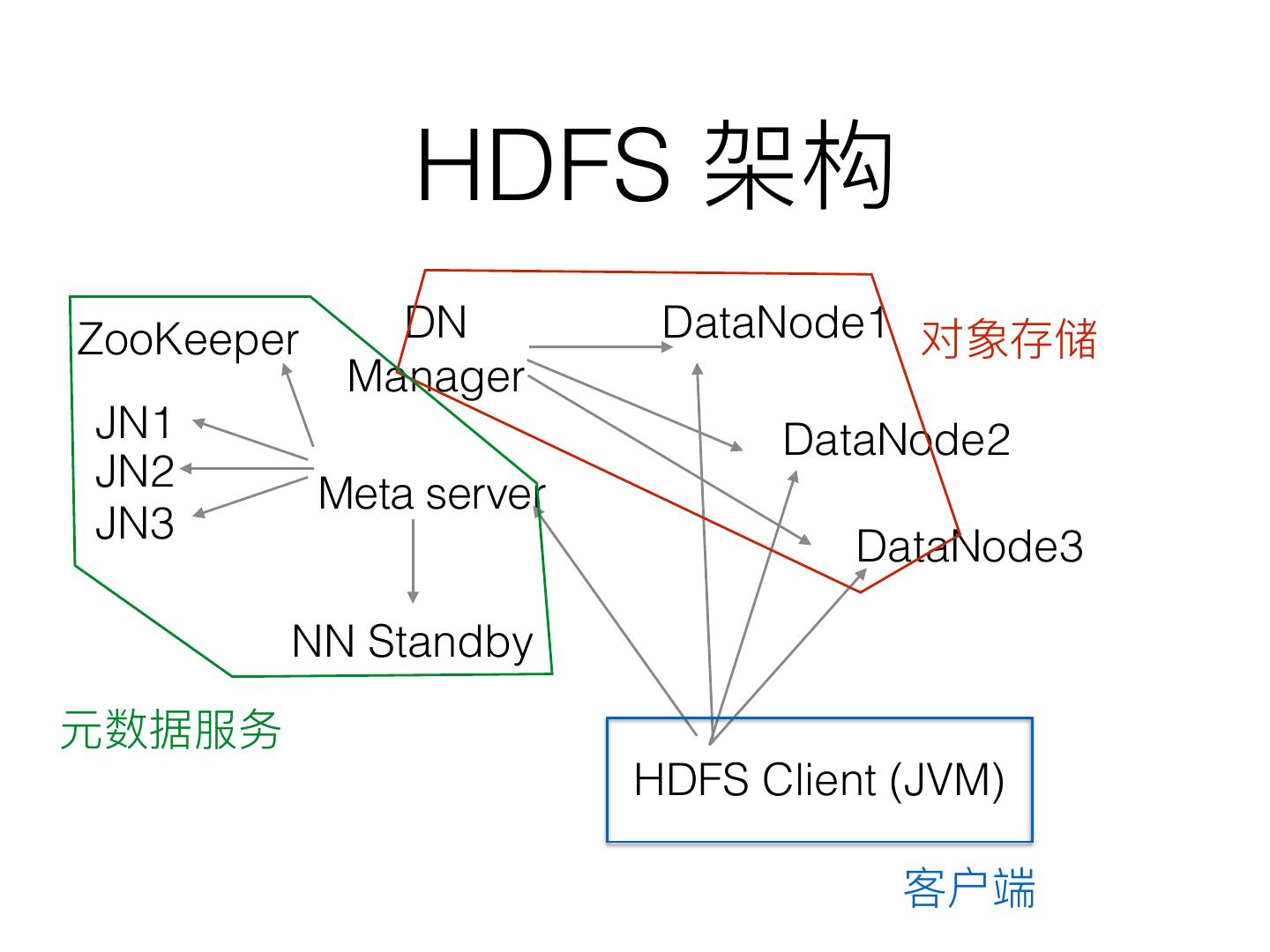
13 . HDFS
ZooKeeper DN DataNode1
Manager
JN1 DataNode2
JN2 Meta server
JN3 DataNode3
NN Standby
HDFS Client (JVM)
�
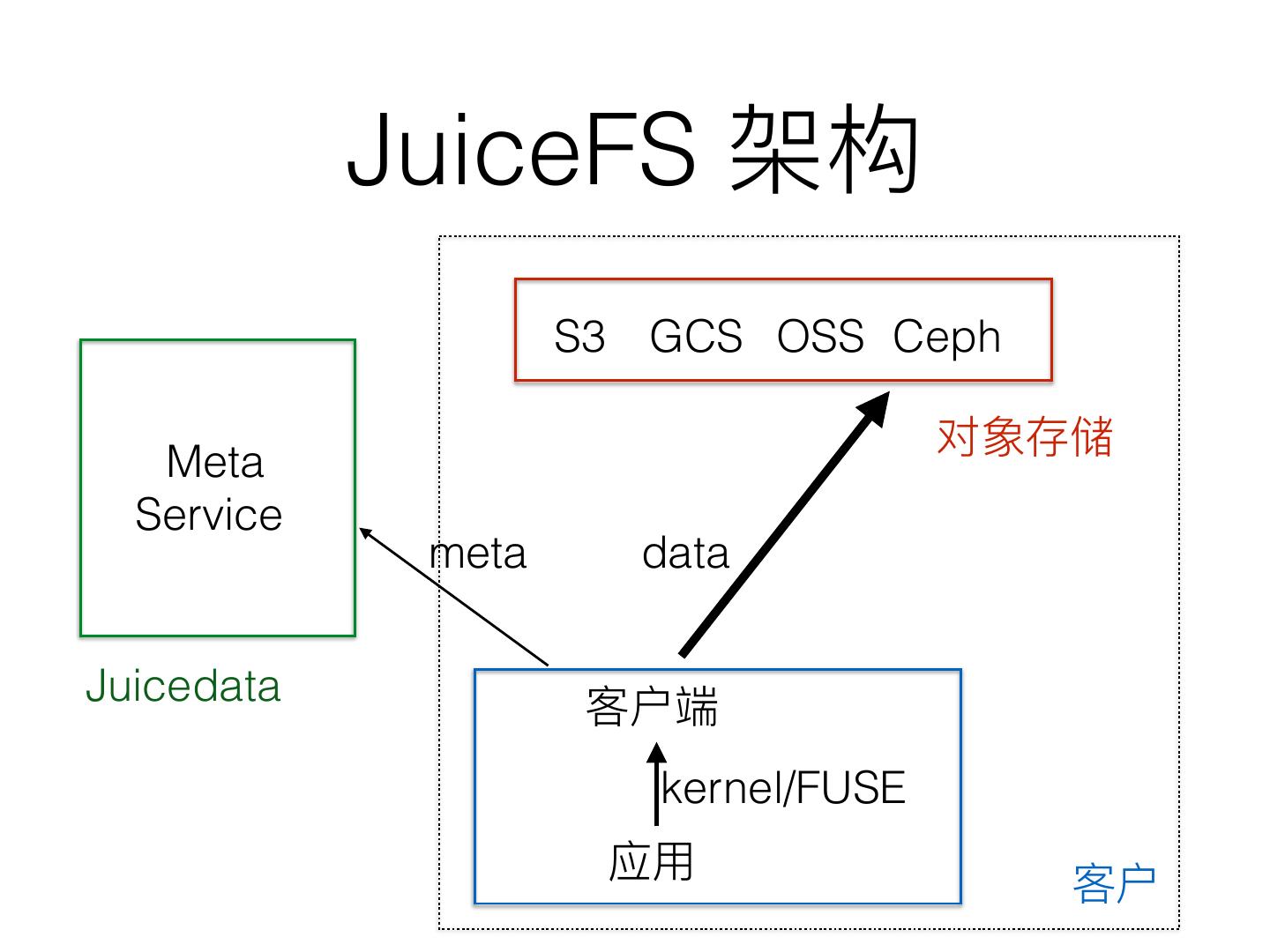
14 . JuiceFS
S3 GCS OSS Ceph
Meta
Service
meta data
Juicedata
kernel/FUSE
�
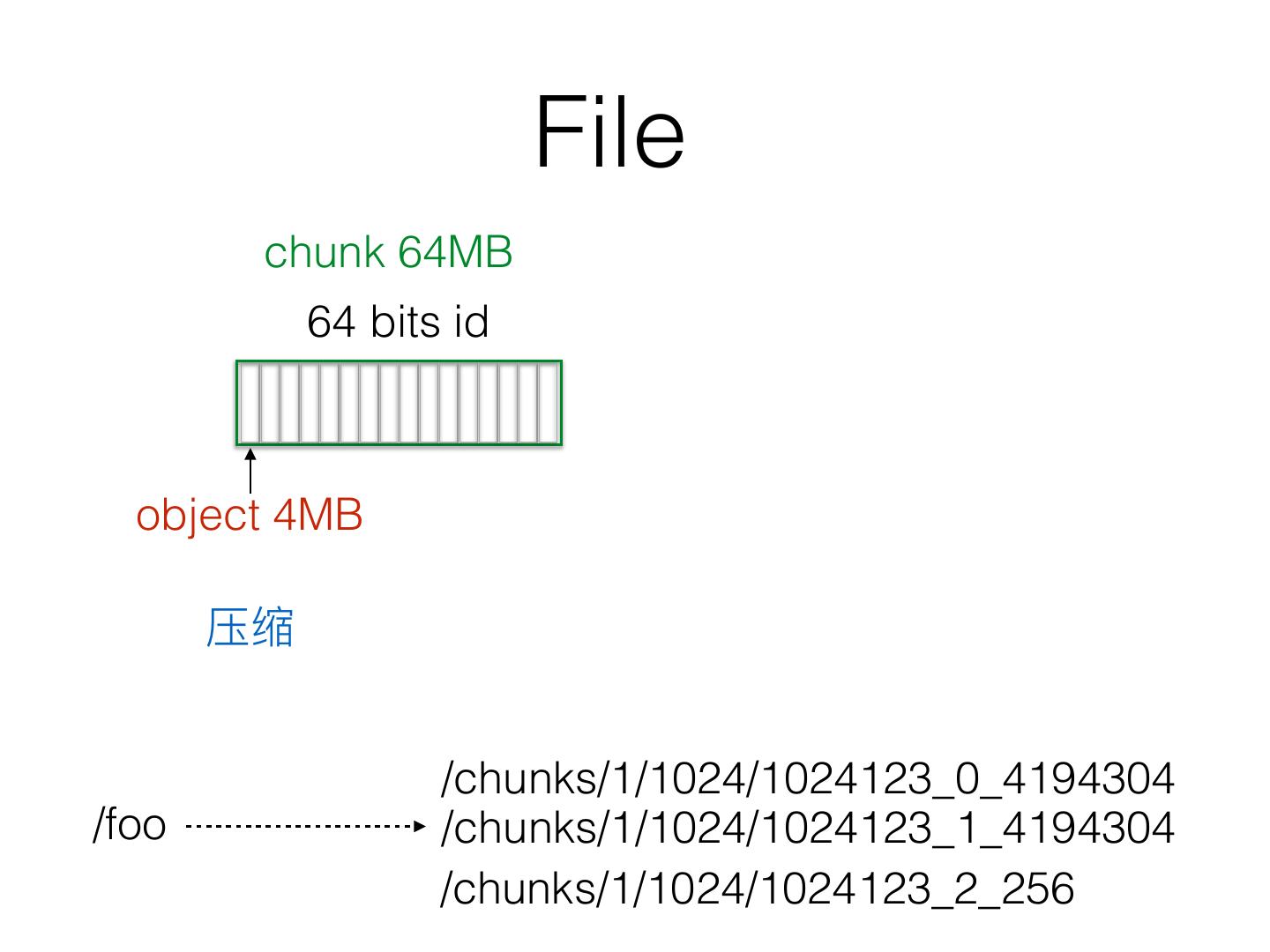
15 . File
chunk 64MB
64 bits id
object 4MB
/chunks/1/1024/1024123_0_4194304
/foo /chunks/1/1024/1024123_1_4194304
/chunks/1/1024/1024123_2_256
�
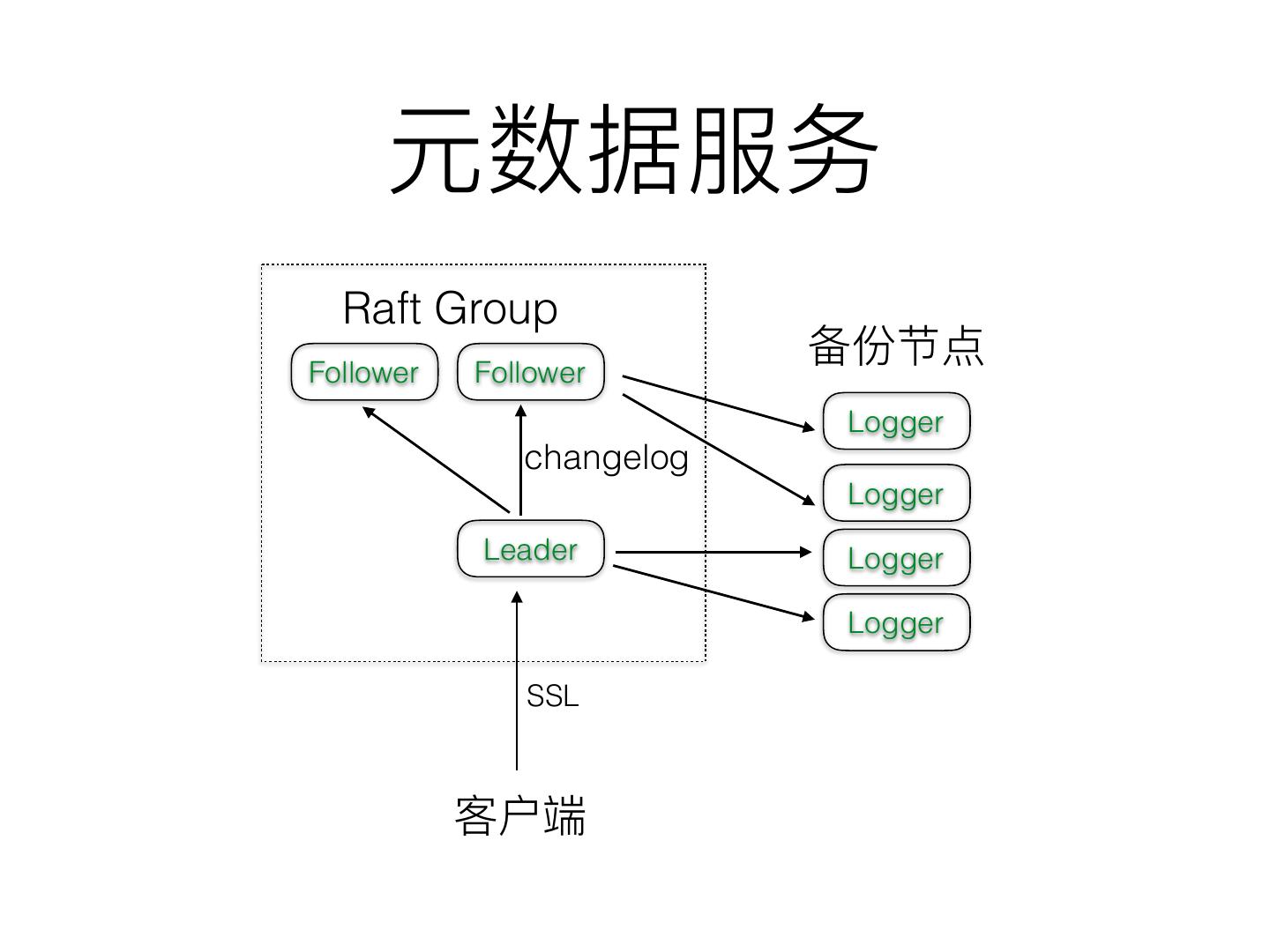
16 . Raft Group
Follower Follower
Logger
changelog
Logger
Leader Logger
Logger
SSL
�
17 . JuiceFS
•
• Raft
•
• key
�
18 . JuiceFS
• •
• •
• •
• •
�
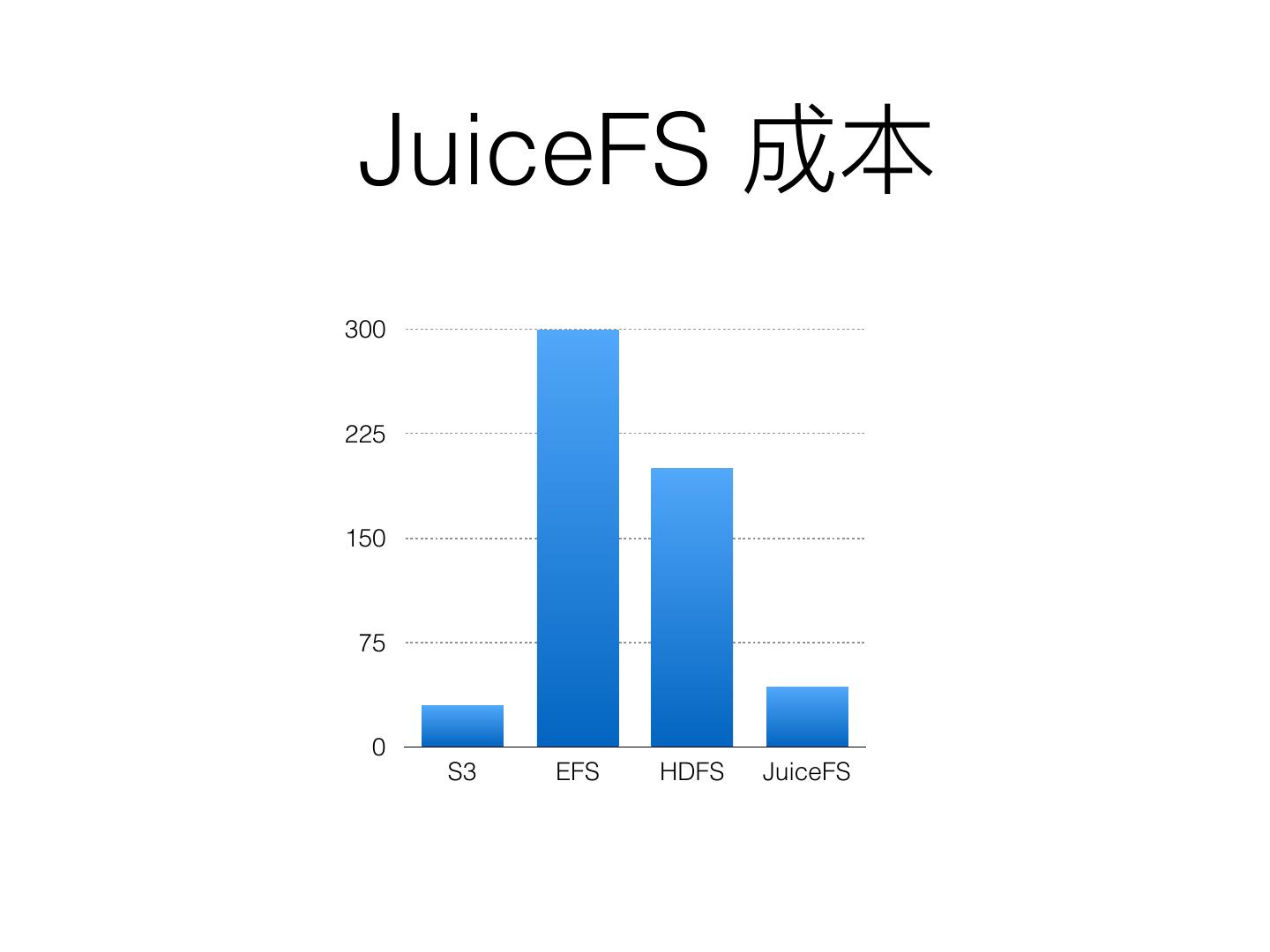
19 . JuiceFS
300
225
150
75
0
S3 EFS HDFS JuiceFS
�
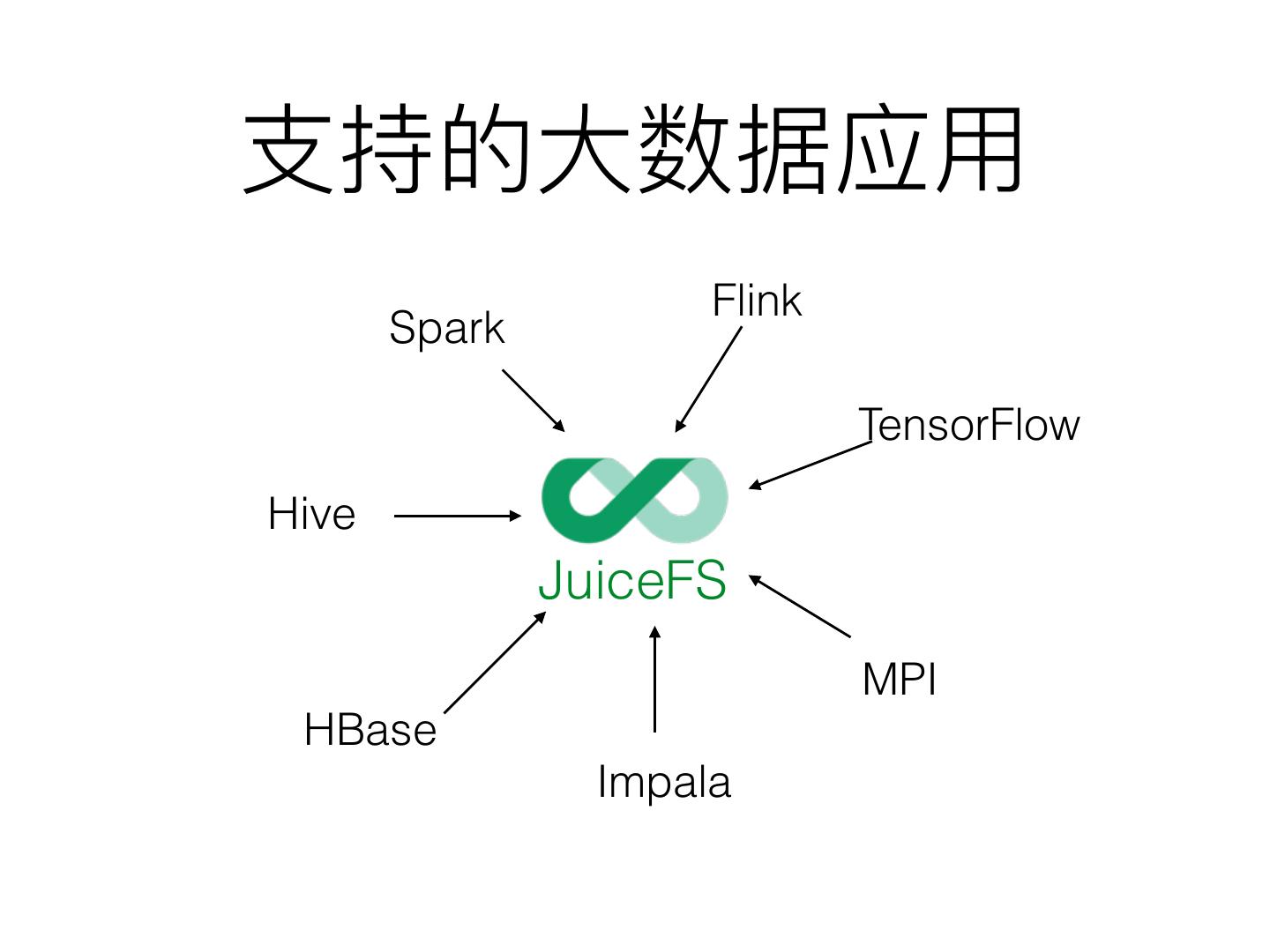
24 . Flink
Spark
TensorFlow
Hive
JuiceFS
MPI
HBase
Impala
�
25 . Thanks
Q&A
davies@juicedata.io
�