























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark SQL Adaptive Execution 自适应执行
Adaptive Execution @ Spark + AI Summit Europe 2018
Video @ https://databricks.com/session/spark-sql-adaptive-execution-unleashes-the-power-of-cluster-in-large-scale-2
展开查看详情
1 .Spark SQL Adaptive Execution Unleashes the Power of Cluster in Large Scale Carson Wang(Intel) Chenzhao Guo(Intel) carson.wang@intel.com chenzhao.guo@intel.com #SAISEco12 #SAISEco12
2 .About me • Chenzhao Guo • Big Data Engineer at Intel • Contributor of Spark*, OAP and HiBench • Github:gczsjdy *Other names and brands may be claimed as the property of others. #SAISEco12 2
3 .Agenda • Challenges • Adaptive Execution • Performance #SAISEco12 3
4 .Agenda • Challenges • Adaptive Execution • Performance #SAISEco12 4
5 . Parallelism on reduce side • Influence performance but hard to tune • Manual efforts • Too small -> Spill, OOM • Too big -> Scheduling overhead, I/O requests • Single spark.sql.shuffle.partitions doesn’t fit all stages within an application #SAISEco12 5
6 .Join Strategy Selection • Spark* chooses Join implementation(influences performance) based on data size estimation • BroadcastHashJoin(when 1 side < broadcastThreshold) • SortMergeJoin • ShuffledHashJoin • Problem: output data size of an intermediate operator can’t be accurately anticipated while planning • The most efficient Join operator may not be employed *Other names and brands may be claimed as the property of others. #SAISEco12 6
7 .Data Skew in Join task 0 execution time task 1 • Some partitions data >> the others’ task 2 • Poor load balancing slows down the whole • Common ways to resolve it, but with limitation: • Increase spark.sql.shuffle.partitions • Increase BroadcastJoin threshold • Add prefix to the skewed keys #SAISEco12 7
8 .Spark SQL* Execution Diagram *Other names and brands may be claimed as the property of others. #SAISEco12 8
9 .Agenda • Challenges • Adaptive Execution • Performance #SAISEco12 9
10 .Core Idea • Transfer control (dicisions of physical plan & parallelism) from users and static to framework & runtime #SAISEco12 10
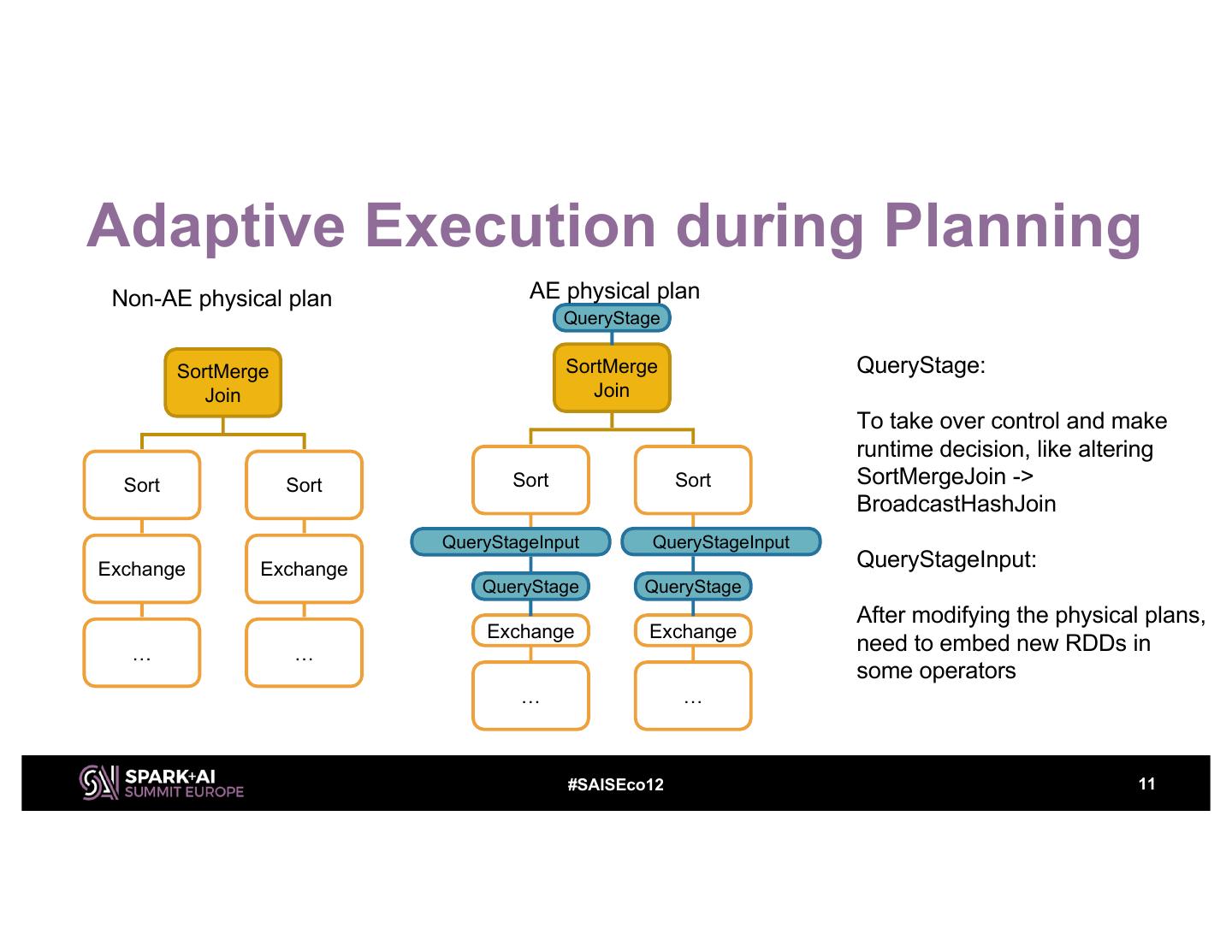
11 .Adaptive Execution during Planning Non-AE physical plan AE physical plan QueryStage SortMerge SortMerge QueryStage: Join Join To take over control and make runtime decision, like altering Sort Sort Sort Sort SortMergeJoin -> BroadcastHashJoin QueryStageInput QueryStageInput Exchange Exchange QueryStageInput: QueryStage QueryStage After modifying the physical plans, Exchange Exchange … … need to embed new RDDs in some operators … … #SAISEco12 11
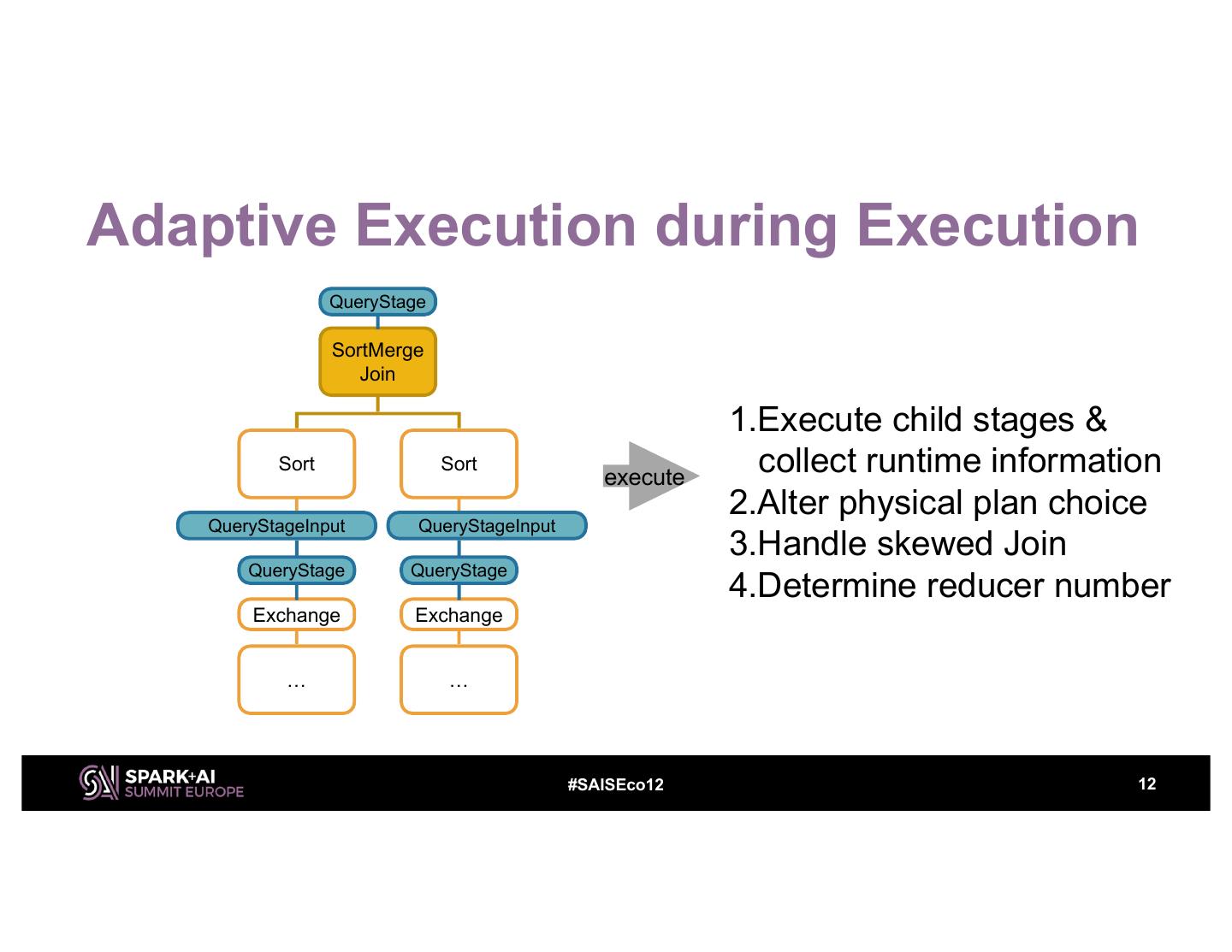
12 .Adaptive Execution during Execution QueryStage SortMerge Join 1.Execute child stages & Sort Sort execute collect runtime information 2.Alter physical plan choice QueryStageInput QueryStageInput 3.Handle skewed Join QueryStage QueryStage 4.Determine reducer number Exchange Exchange … … #SAISEco12 12
13 .Adaptively Determine Number of Reducers • Enable the feature • spark.sql.adaptive.enabled -> true • Configurations • Target input size for a reducer • Min/Max reducer number #SAISEco12 13
14 .Adaptively Determine Number of Reducers • Target input size for reducer -> 64MB • Min-max reducer number -> 1-5 partition merging better load balancing reduced I/O… map side reduce side #SAISEco12 14
15 .Alter Join Implementation at Runtime QueryStage QueryStage SortMerge Broadcast Join HashJoin Reduced shuffle runtime altering Broadcast Sort Sort Exchange QueryStageInput only 5M ! QueryStageInput QueryStageInput only 5M ! QueryStageInput … … … … #SAISEco12 15
16 .Handle Skewed Join at Runtime • Enable the feature • spark.sql.adaptive.skewedJoin.enabled -> true • Configuration • skewed factor F, skewed size S, skewed rowcount R • A partition is considered skewed iff • its size is larger than median partition size * F and also larger than S or • its rowcount is larger than median partition rowcount * F and also larger than R #SAISEco12 16
17 .Handle Skewed Join at Runtime left table right table left table right table Partition 0 Partition 0 partition 0 from Jo Jo mapper 0 in in runtime translation Partition 0 partition 0 from Union mapper 1 partition 0 from mapper 2 Partition 1 better load balancing Partition 2 #SAISEco12 17
18 .Agenda • Challenges • Adaptive Execution • Performance #SAISEco12 18
19 .Performance in Baidu* • Performance boost: 50% ~ 200% • Certain BI scenario hitting SMJ ->BHJ rule • Long running application & use Spark as a service • GraphFrame *Other names and brands may be claimed as the property of others. #SAISEco12 19
20 .Performance in Alibaba* Cloud • TPC-DS* 1TB • 1 master (32 Cores, 64GB RAM) + 6 slave(d1, 32 Cores, 64GB RAM) • Overall performance boost: 1.38x, and max performance boost: 3x • Already incorporated Adaptive Execution in their cloud service product *Other names and brands may be claimed as the property of others. #SAISEco12 20
21 .Summary • Adaptively determine reducer number • Alter Join strategy selection at runtime • Handle skewed Join at runtime • More potential opportunies since Adaptive Execution provides a runtime optimization framework • https://github.com/Intel-bigdata/spark-adaptive #SAISEco12 21
22 .Thank you! #SAISEco12 22
23 .Legal Disclaimer No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps. The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm. Intel does not control or audit third-party benchmark data or the web sites referenced in this document. You should visit the referenced web site and confirm whether referenced data are accurate. Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others Copyright ©2018 Intel Corporation. #SAISEco12
3秒后跳转登录页面
去登陆

