




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
JanusGraph - Distributed Graph Database with HBase
介绍了TalkingData基于HBase实现的图计算引擎框架。
展开查看详情
1 . hosted by HBaseConAsia2018 JanusGraph — Distributed graph database with HBase XueMin Zhang @ TalkingData
2 . hosted by Content 01 About Us 02 Something about Graph 03 Introduction to JanusGraph 04 JanusGraph with HBase
3 . hosted by Content 01 About Us 02 Something about Graph 03 Introduction to JanusGraph 04 JanusGraph with HBase
4 . hosted by About us About me • Seven years of practical experience in technical research and development(R&D),focusing on distributed storage, distributed computing, real-time computing, etc. • Successively worked in Sina Weibo and TalkingData, and served as the big data Team Leader of Sina r&d center. • Technical speechers on the platforms of China Hadoop, Strata Hadoop/Data Conference and DTCC. About TalkingData • Founded in 2011, TalkingData is China’s leading third-party big data platform. With SmartDP as the core of its data intelligence application ecosystem, TalkingData empowers enterprises and helps them achieve a data-driven digital transformation. • From the beginning, TalkingData’s vision of using “big data for smarter business decisions and a better world” has allowed it to gradually become China’s leading data intelligence solution provider. TalkingData creates value for clients and serves as their “performance partner,” helping modern enterprises achieve data-driven transformation and accelerating the digitization of clients from various industries. Using data-generated insights to change how people see the world and themselves, TalkingData hopes to ultimately improve people’s lives.
5 . hosted by Content 01 About Us 02 Something about Graph 03 Introduction to JanusGraph 04 JanusGraph with HBase
6 . hosted by Something about Graph What is a Graph Database As name suggests, it is a database. Uses graph structures for semantic queries with nodes, edges and properties to represent and store data. Allow data in the store to be linked together directly. compare with traditional relational databases Hybrid relations. Handy in finding connections between entities.
7 . hosted by Something about Graph Graph Structures - Vertices Vertices are the nodes or points in a graph structure Every vertex may contain a unique ID.
8 . hosted by Something about Graph Graph Structures - Vertices Vertices are the nodes or points in a graph structure Every vertex may contain a unique ID. Vertices can be associated with a set of properties (key- value pairs)
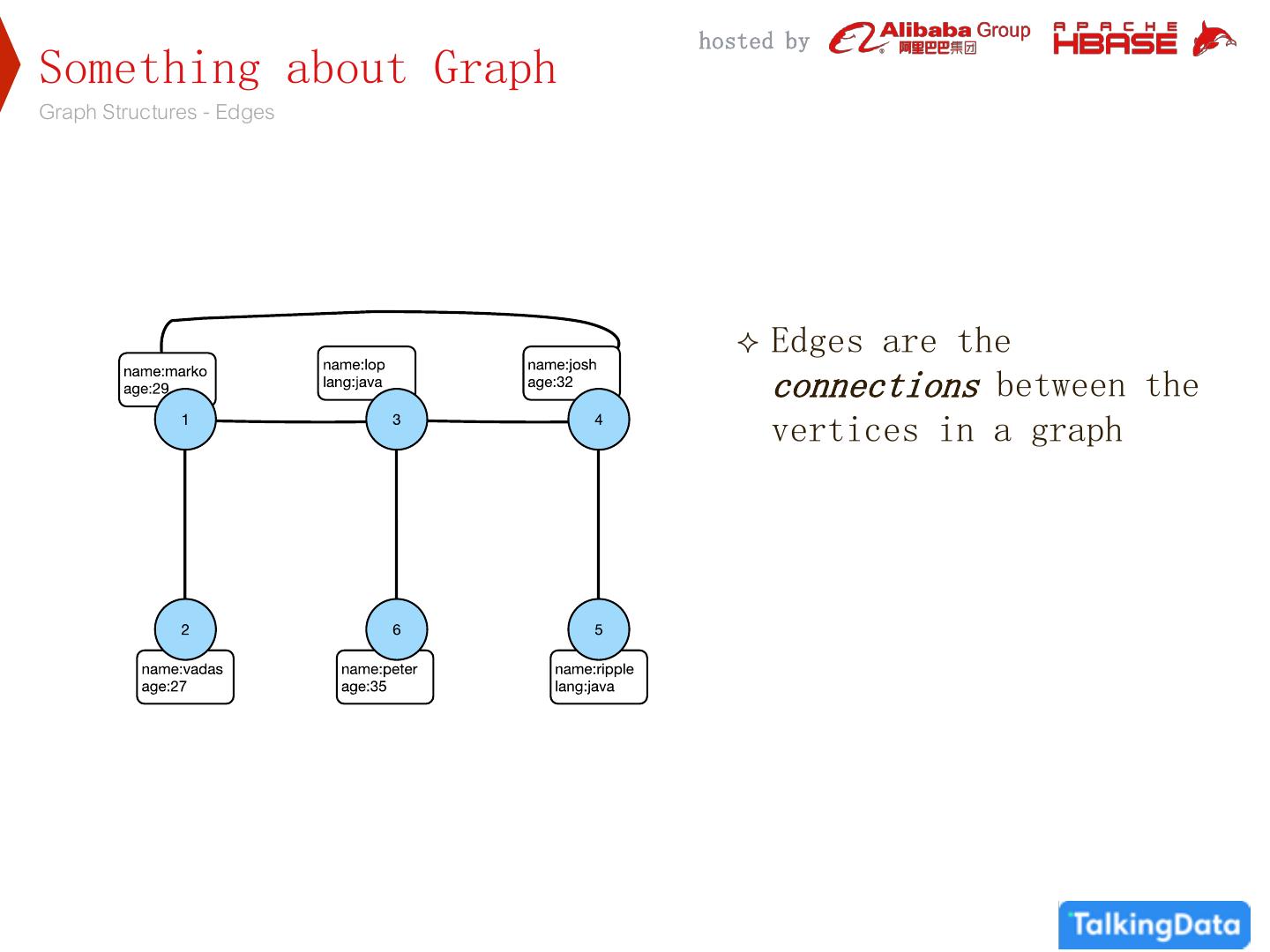
9 . hosted by Something about Graph Graph Structures - Edges Edges are the connections between the vertices in a graph
10 . hosted by Something about Graph Graph Structures - Edges Edges are the connections between the vertices in a graph Edges can be nondirectional, directional, or bidirectional
11 . hosted by Something about Graph Graph Structures - Edges Edges are the connections between the vertices in a graph Edges can be nondirectional, directional, or bidirectional Edges like vertices can have properties and id
12 . hosted by Something about Graph Graph Structures - Graph G = (V, E) The graph is the collection of vertices, edges, and associated properties Vertices and edges can use label classification
13 . hosted by Something about Graph Graph Storage Model - Adjacency Matrix G.vertices = 1 2 3 4 5 6 1 2 3 4 50 61 G.edges = 1 1 1 0 0 2 1 0 0 0 0 0 3 1 0 0 1 0 0 4 1 0 1 0 1 0 5 0 0 0 1 0 0 6 0 0 1 0 0 0
14 . hosted by Something about Graph Graph Storage Model - Adjacency Lists 1 2 3 4 Λ 2 1 Λ 3 1 4 6 Λ 4 1 3 5 Λ 5 4 Λ 6 3 Λ
15 . hosted by Content 01 About Us 02 Something about Graph 03 Introduction to JanusGraph 04 JanusGraph with HBase
16 . hosted by Introduction to JanusGraph Scalable graph database distribute on multi-maching clusters with pluggable storage and indexing. Fully compliant with Apache TinkerPop graph computing framework. Optimized for storing/querying billions of vertices and edges. Supports thousands of concurrent users. Can execute local queries (OLTP) or cross-cluster distributed queries (OLAP). Sponsored by the Linux Foundation. Apache License 2.0
17 . hosted by Introduction to JanusGraph Architecture
18 . hosted by Introduction to JanusGraph Apache Tinkerpop & Gremlin A graph computing framework for both graph databases (OLTP) and graph analytic systems (OLAP) Gremlin graph traversal language
19 . hosted by Introduction to JanusGraph Schema and Data Modeling Consist of edge labels, property keys, vertex labels ,index Explicit or Implicit Can evolve over time without database downtime
20 . hosted by Introduction to JanusGraph Schema - Edge Label Multiplicity MULTI: Multiple edges of the same label between vertices SIMPLE: One edge with that label (unique per label) MANY2ONE: One outgoing edge with that label ONE2MANY: One incoming edge with that label ONE2ONE: One incoming, one outgoing edge with that label
21 . hosted by Introduction to JanusGraph Schema - Property Key Data Types
22 . hosted by Introduction to JanusGraph Schema - Property Key Cardinality SINGLE: At most one value per element. LIST: Arbitrary number of values per element. Allows duplicates. SET: Multiple values, but no duplicates.
23 . hosted by Introduction to JanusGraph Storage Model
24 . hosted by Introduction to JanusGraph What is Graph Partitioning? When the JanusGraph cluster consists of multiple storage backend instances, the graph must be partitioned across those machines. Stores graph in an adjacency list , ssignment of vertices to machines determines the partitioning. Different ways to partition a graph Random Graph Partitioning Explicit Graph Partitioning
25 . hosted by Introduction to JanusGraph Random Graph Partitioning Pros Very efficient Requires no configuration Results in balanced partitions Cons Less efficient query processing as the cluster grows Requires more cross-instance communication to retrieve the desired
26 . hosted by Introduction to JanusGraph Explicit Graph Partitioning Pros Ensures strongly connected subgraphs are stored on the same instance Reduces the communication overhead significantly Easy to setup Cons Only enabled against storage backends that support ordered key Hotspot issue
27 . hosted by Introduction to JanusGraph Edge Cut & Vertex Cut Edge Cut Vertices are hosted on separate machines. Optimization aims to reduce the cross communication and thereby improve query execution. Vertex Cut (by label) A vertex label can be defined as partitioned which means that all vertices of that label will be partitiond across the cluster. In other words, Storing a subset of that vertex’s adjacency list on each partition . Address the hotspot issue caused by vertices with a large number of incident edges.
28 . hosted by Introduction to JanusGraph What is Graph Index? graph indexes : efficient retrieval of vertices or edges by their properties Composite Index (supported through the primary storage backend) Mixed Index (supported through external indexing backend) vertex-centric indexes : effectively address query performance for large degree vertices
29 . hosted by Content 01 About Us 02 Something about Graph 03 Introduction to JanusGraph 04 JanusGraph with HBase
3秒后跳转登录页面
去登陆

