





















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
流式数据处理
流式数据处理的应用场景,包括基本概念和处理方式;也介绍了流式处理系统常见的编程模型和框架,最后介绍了流式数据处理的一些优化方法。
展开查看详情
1 . Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de | bbdc.berlin | rabl@tu-berlin.de 1 © 2013 Berlin Big Data Center • All Rights Reserved © DIMA 2017
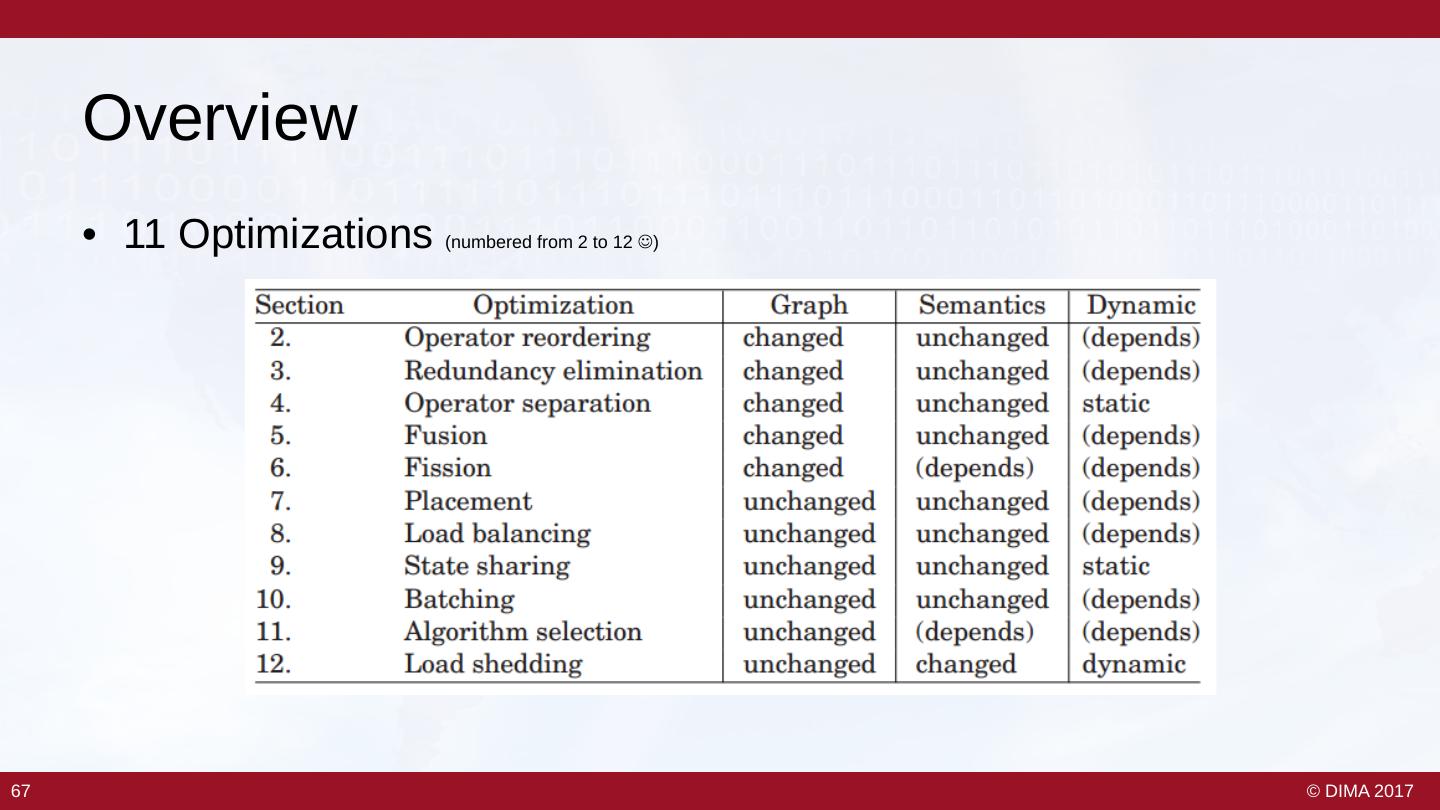
2 . Agenda Introduction to Streams • Use cases • Stream Processing 101 Stream Processing Systems • Ingredients of a stream processing system • Some examples • More details on Storm, Spark, Flink • Maybe a demo (!) Stream Processing Optimizations (if we have time) • How to optimize With slides from Data Artisans, Volker Markl, Asterios Katsifodimos, Jonas Traub 2 2 © DIMA 2017
3 . Big Fast Data • Data is growing and can be evaluated – Tweets, social networks (statuses, check- ins, shared content), blogs, click streams, various logs, … – Facebook: > 845M active users, > 8B messages/day – Twitter: > 140M active users, > 340M tweets/day • Everyone is interested! Image: Michael Carey 3 3 © DIMA 2017
4 . But there is so much more… • Autonomous Driving – Requires rich navigation info – Rich data sensor readings – 1GB data per minute per car (all sensors)1 • Traffic Monitoring – High event rates: millions events / sec – High query rates: thousands queries / sec – Queries: filtering, notifications, analytical Source: http://theroadtochangeindia.wordpress.com/2011/01/13/better-roads/ • Pre-processing of sensor data – CERN experiments generate ~1PB of measurements per second. – Unfeasible to store or process directly, fast preprocessing is a must. 1Cobb: http://www.hybridcars.com/tech-experts-put-the-brakes-on-autonomous-cars/ 4 4 © DIMA 2017
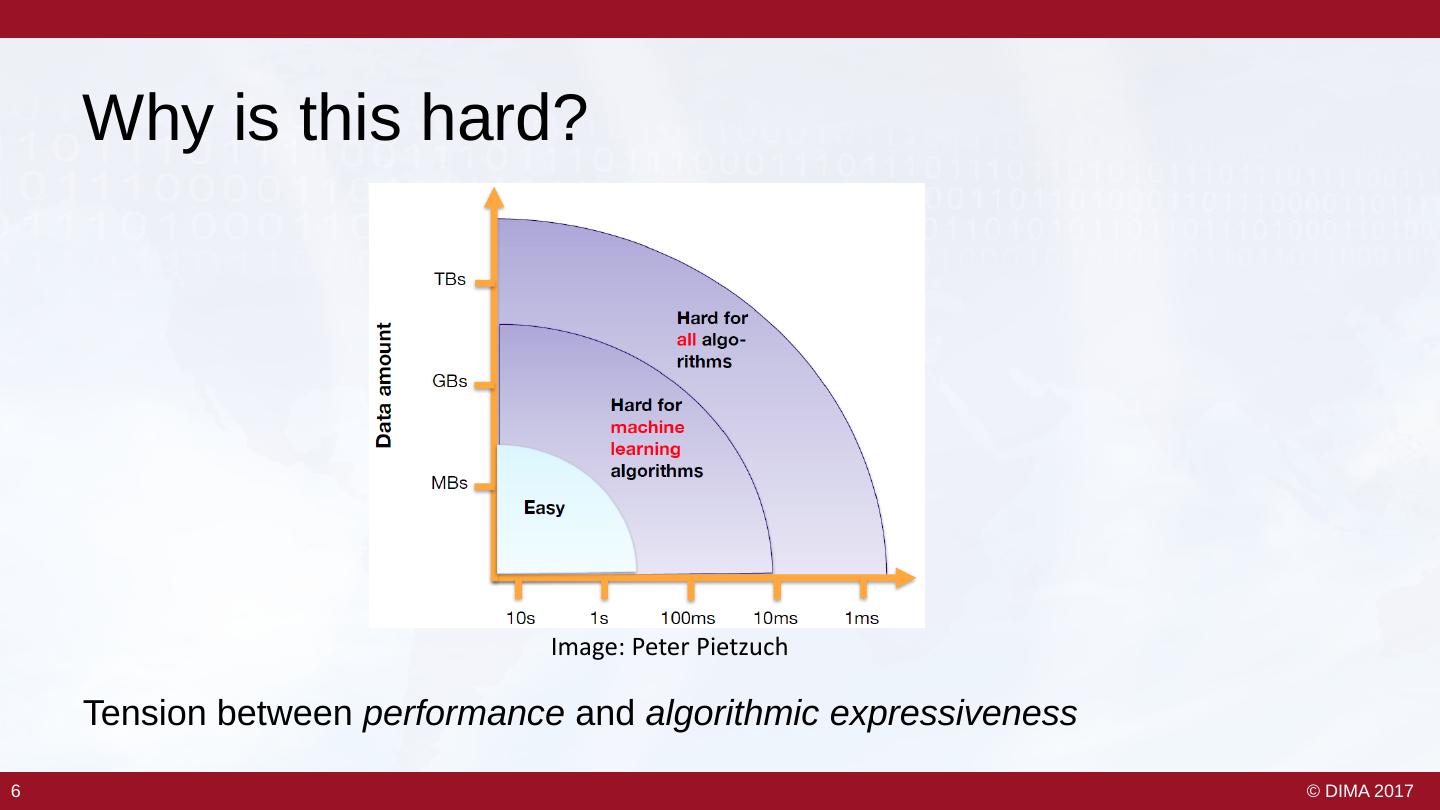
5 . Why is this hard? Image: Peter Pietzuch Tension between performance and algorithmic expressiveness 6 6 © DIMA 2017
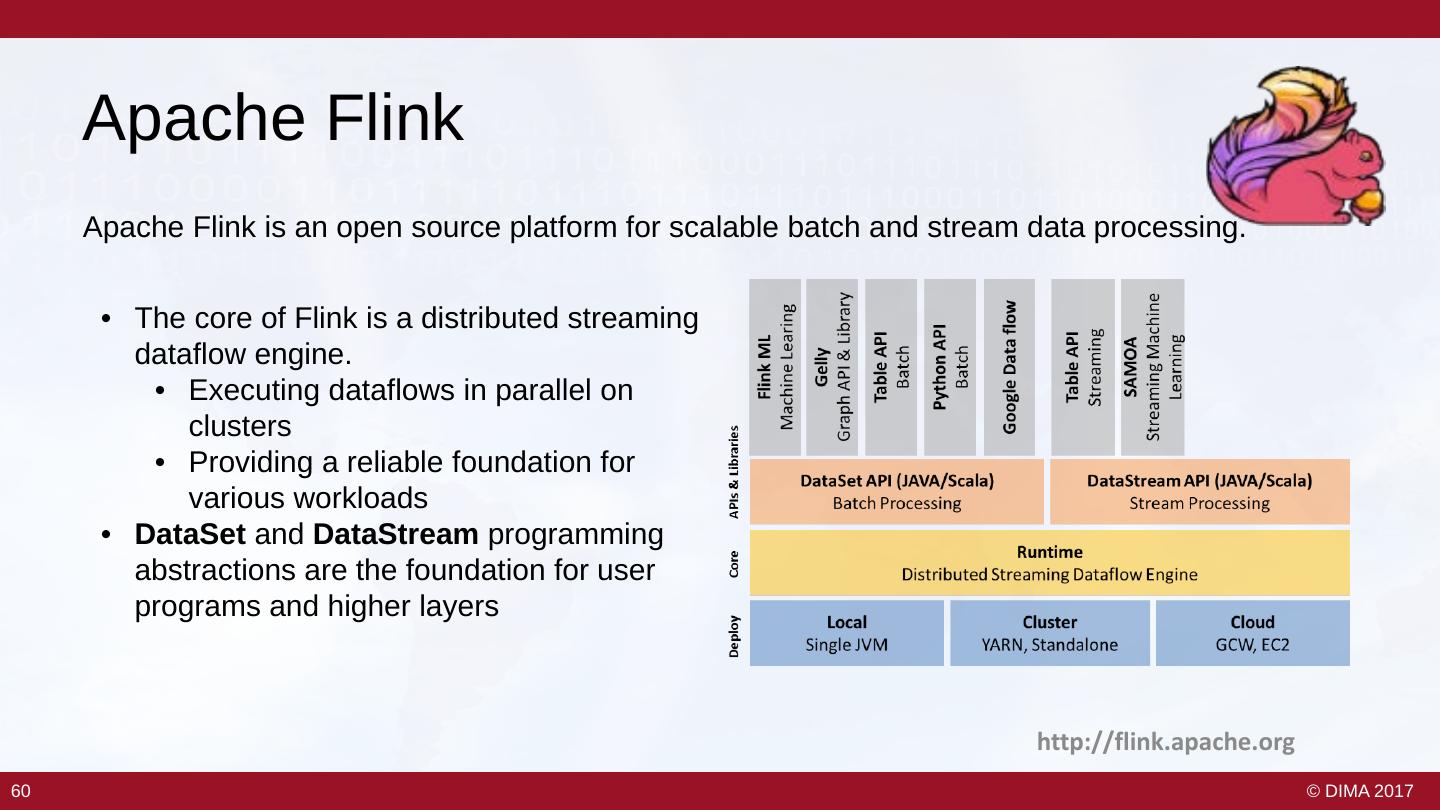
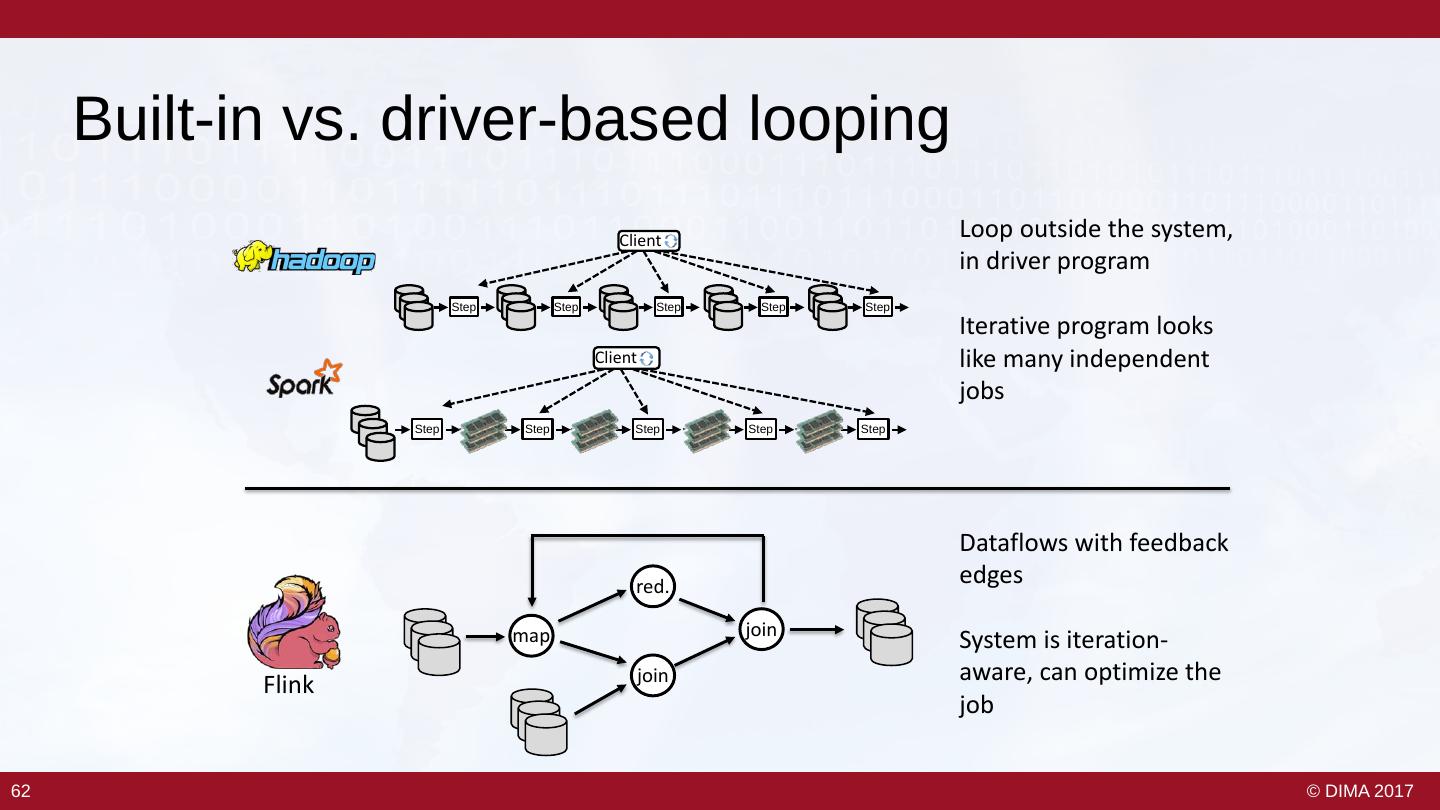
6 . Stream Processing 101 With some Flink Examples Based on the Data Flow Model 7 © DIMA 2017
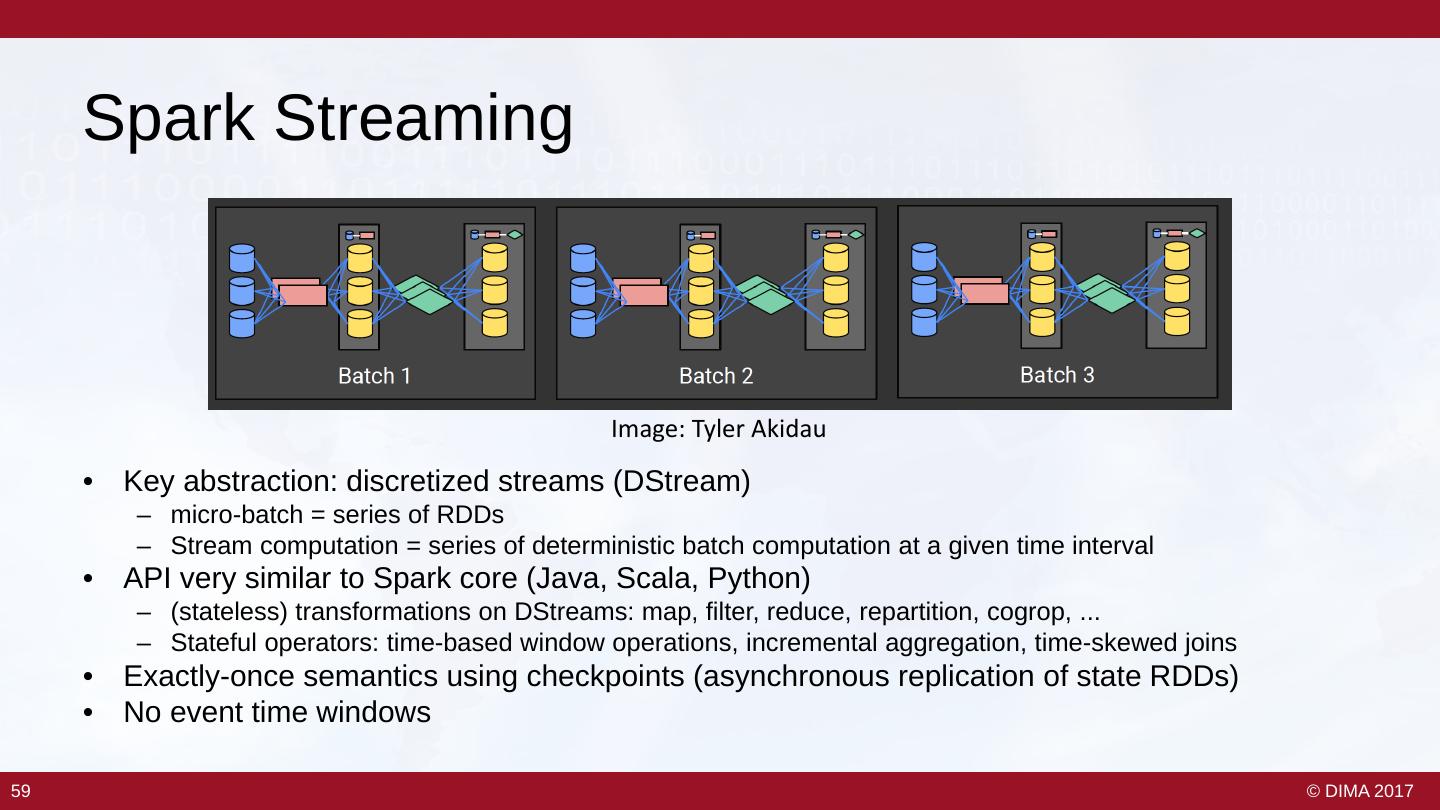
7 . What is a Stream? • Unbounded data – Conceptually infinite, ever growing set of data items / events – Practically continuous stream of data, which needs to be processed / analyzed • Push model – Data production and procession is controlled by the source – Publish / subscribe model • Concept of time – Often need to reason about when data is produced and when processed data should be output – Time agnostic, processing time, ingestion time, event time This part is largely based on Tyler Akidau‘s great blog on streaming - https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101 8 8 © DIMA 2017
8 . Stream Models S = si, si+1, … si = <data item, timestamp> • Turnstile – Elements can come and go – Underlying model is a vector of elements (domain) – si is an update (increment or decrement) to a vector element – Traditional database model – Flexible model for algorithms • Cash register – Similar to turnstile, but elements cannot leave • Time series – si is is a new vector entry – Vector is increasing – This is what all big stream processing engines use 9 9 © DIMA 2017
9 . Event Time • Event time – Data item production time • Ingestion time – System time when data item is received • Processing time – System time when data item is processed • Typically, these do not match! • In practice, streams are unordered! Image: Tyler Akidau 10 10 © DIMA 2017
10 . Time Agnostic Processing Image: Tyler Akidau • Filtering – Stateless – Can be done per data item – Implementations: hash table or bloom filter 11 11 © DIMA 2017
11 . Time Agnostic Processing II Image: Tyler Akidau • Inner join – Only current elements – Stateful – E.g., hash join • What about other joins (e.g., outer join)? 12 12 © DIMA 2017
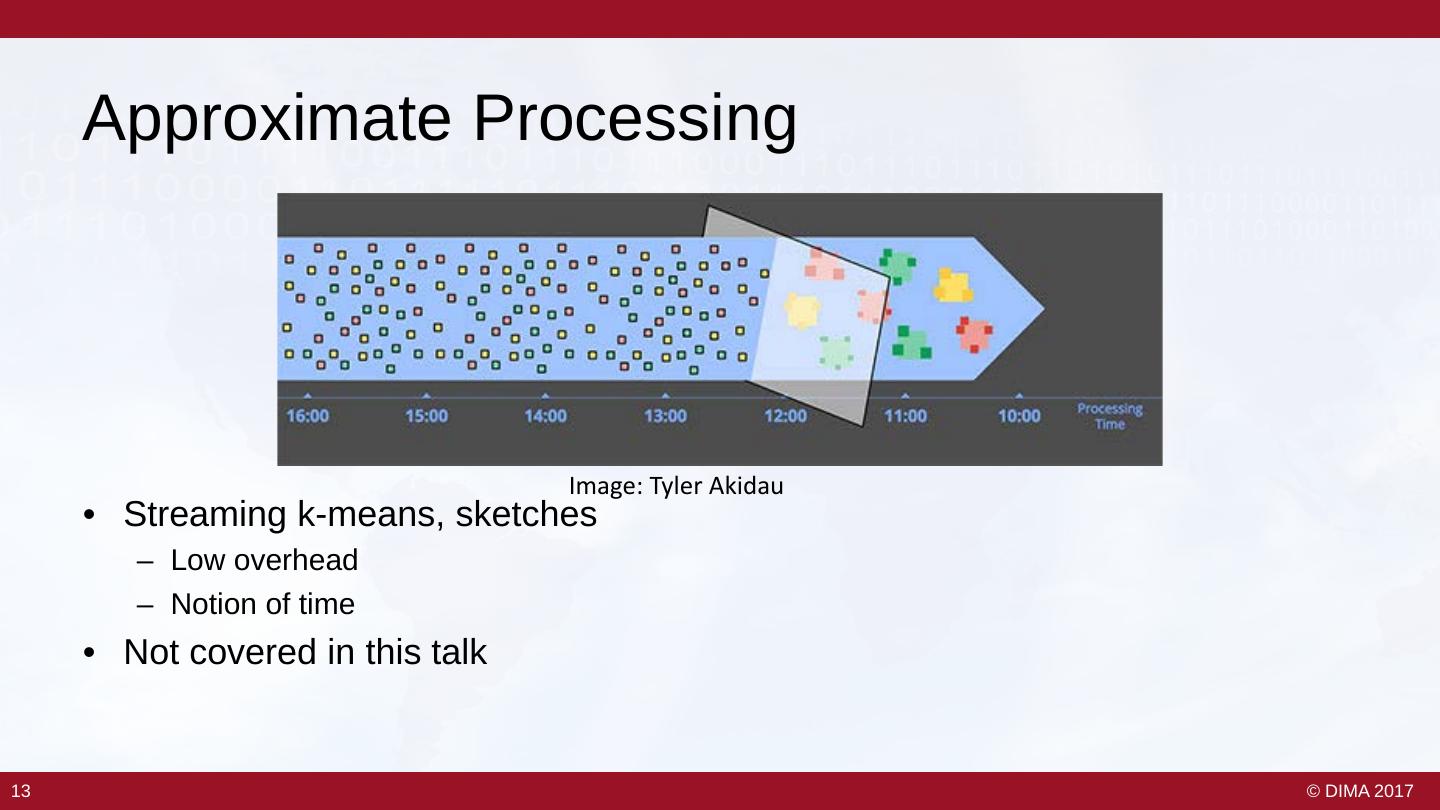
12 . Approximate Processing Image: Tyler Akidau • Streaming k-means, sketches – Low overhead – Notion of time • Not covered in this talk 13 13 © DIMA 2017
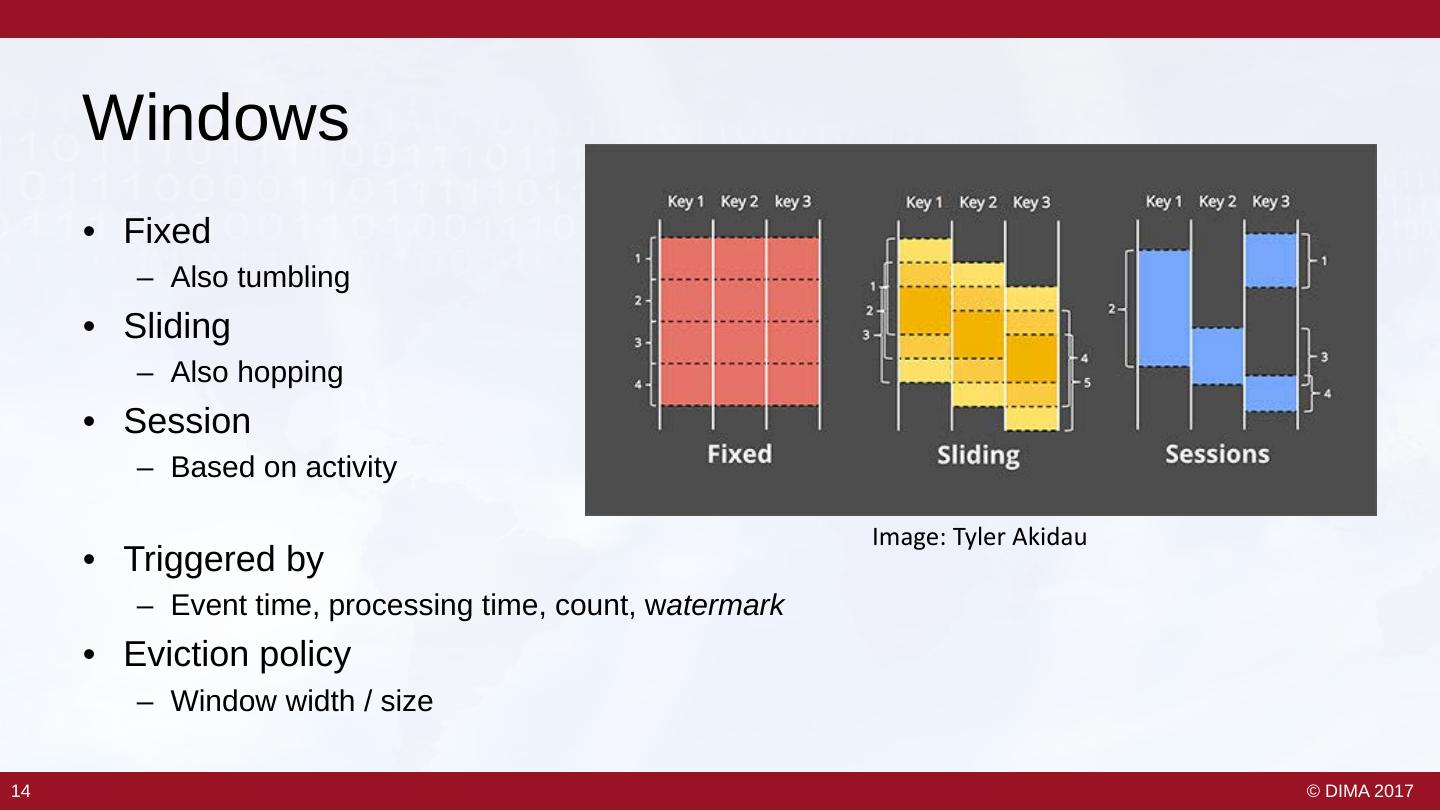
13 . Windows • Fixed – Also tumbling • Sliding – Also hopping • Session – Based on activity Image: Tyler Akidau • Triggered by – Event time, processing time, count, watermark • Eviction policy – Window width / size 14 14 © DIMA 2017
14 . Processing Time Windows Image: Tyler Akidau • System waits for x time units – System decides on stream partitioning – Simple, easy to implement – Ignores any time information in the stream -> any aggregation can be arbitrary • Similar: Counting Windows 15 15 © DIMA 2017
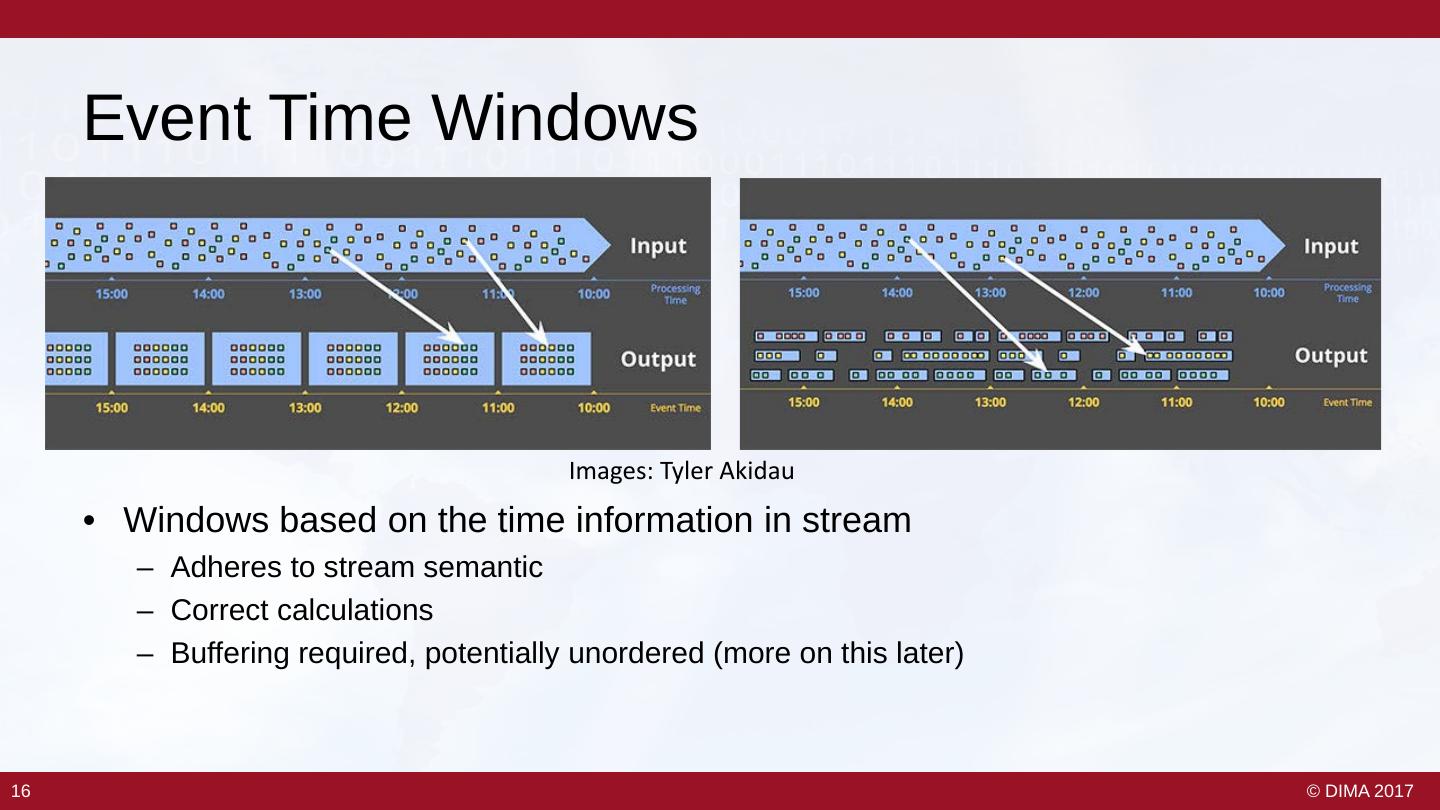
15 . Event Time Windows Images: Tyler Akidau • Windows based on the time information in stream – Adheres to stream semantic – Correct calculations – Buffering required, potentially unordered (more on this later) 16 16 © DIMA 2017
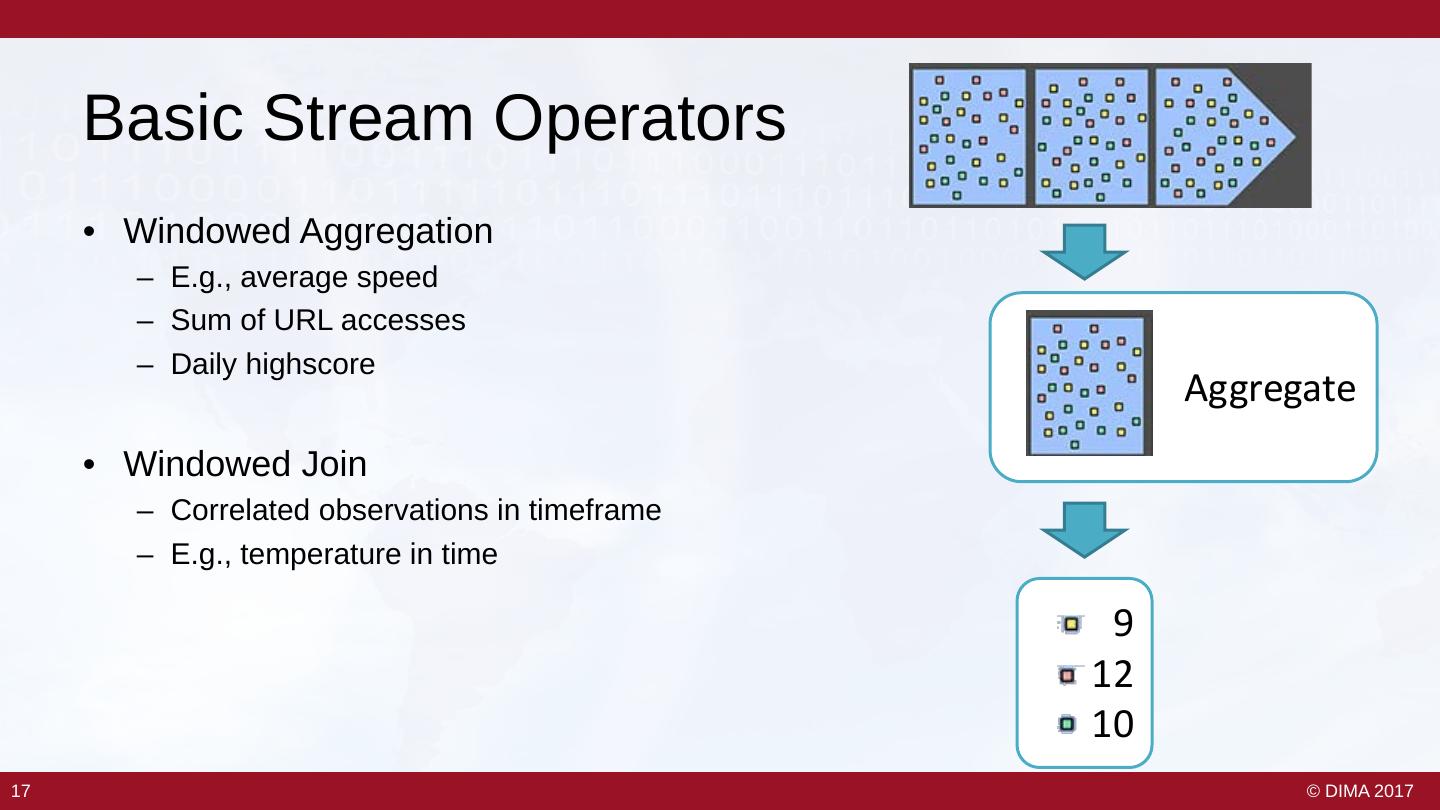
16 . Basic Stream Operators • Windowed Aggregation – E.g., average speed – Sum of URL accesses – Daily highscore Aggregate • Windowed Join – Correlated observations in timeframe – E.g., temperature in time 9 12 10 17 17 © DIMA 2017
17 . Flink’s Windowing • Windows can be any combination of (multiple) triggers & evictions – Arbitrary tumbling, sliding, session, etc. windows can be constructed. • Common triggers/evictions part of the API – Time (processing vs. event time), Count • Even more flexibility: define your own UDF trigger/eviction • Examples: dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))); 18 18 © DIMA 2017
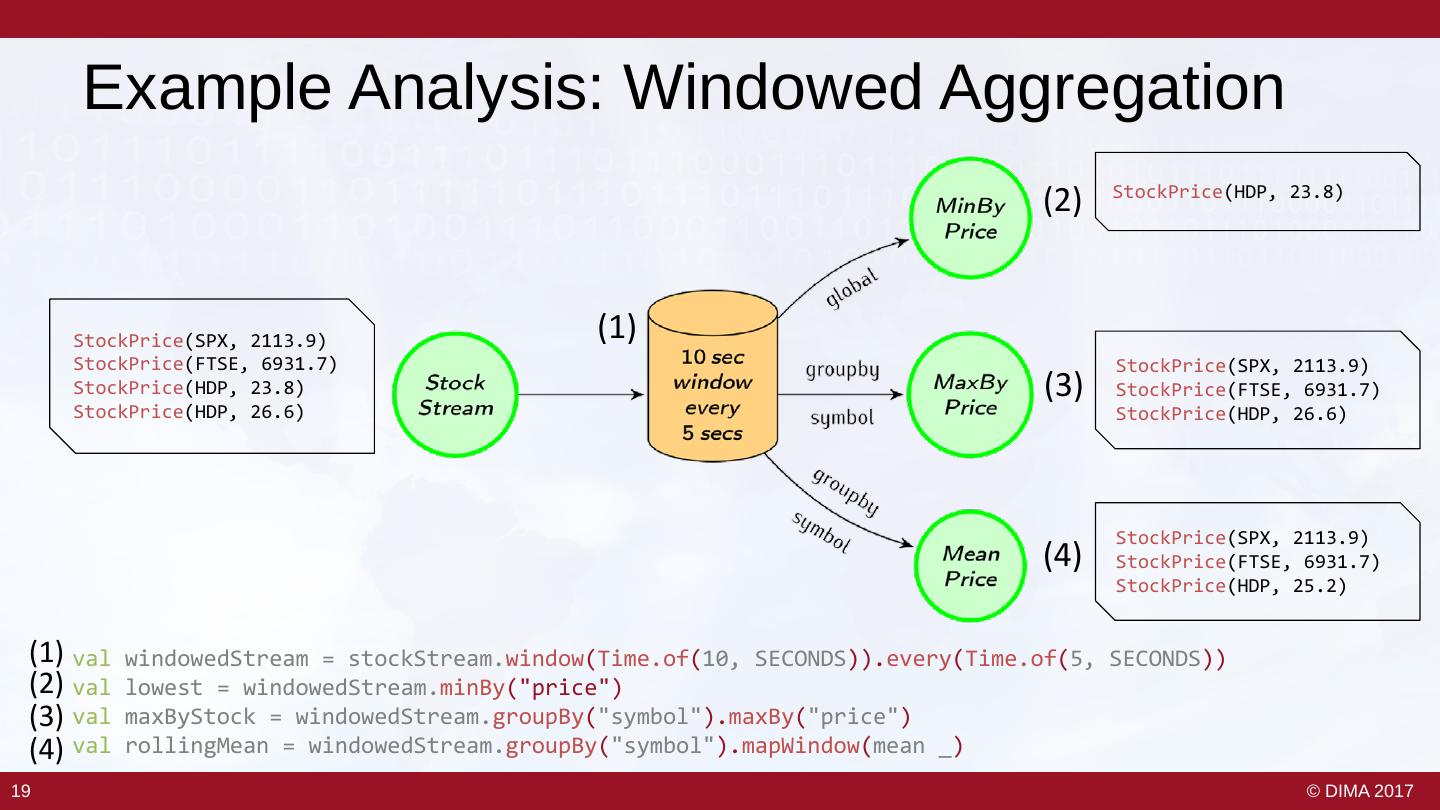
18 . Example Analysis: Windowed Aggregation (2) StockPrice(HDP, 23.8) StockPrice(SPX, 2113.9) (1) StockPrice(FTSE, 6931.7) StockPrice(SPX, 2113.9) StockPrice(HDP, 23.8) (3) StockPrice(FTSE, 6931.7) StockPrice(HDP, 26.6) StockPrice(HDP, 26.6) StockPrice(SPX, 2113.9) (4) StockPrice(FTSE, 6931.7) StockPrice(HDP, 25.2) (1) val windowedStream = stockStream.window(Time.of(10, SECONDS)).every(Time.of(5, SECONDS)) (2) val lowest = windowedStream.minBy("price") (3) val maxByStock = windowedStream.groupBy("symbol").maxBy("price") (4) val rollingMean = windowedStream.groupBy("symbol").mapWindow(mean _) 19 © DIMA 2017
19 . Complex Event Processing • Detecting patterns in a stream • Complex event = sequence of events • Defined using logical and temporal conditions – Logical: data values and combinations – Temporal: within a given period of time Slide by Kai-Uwe Sattler 20 20 © DIMA 2017
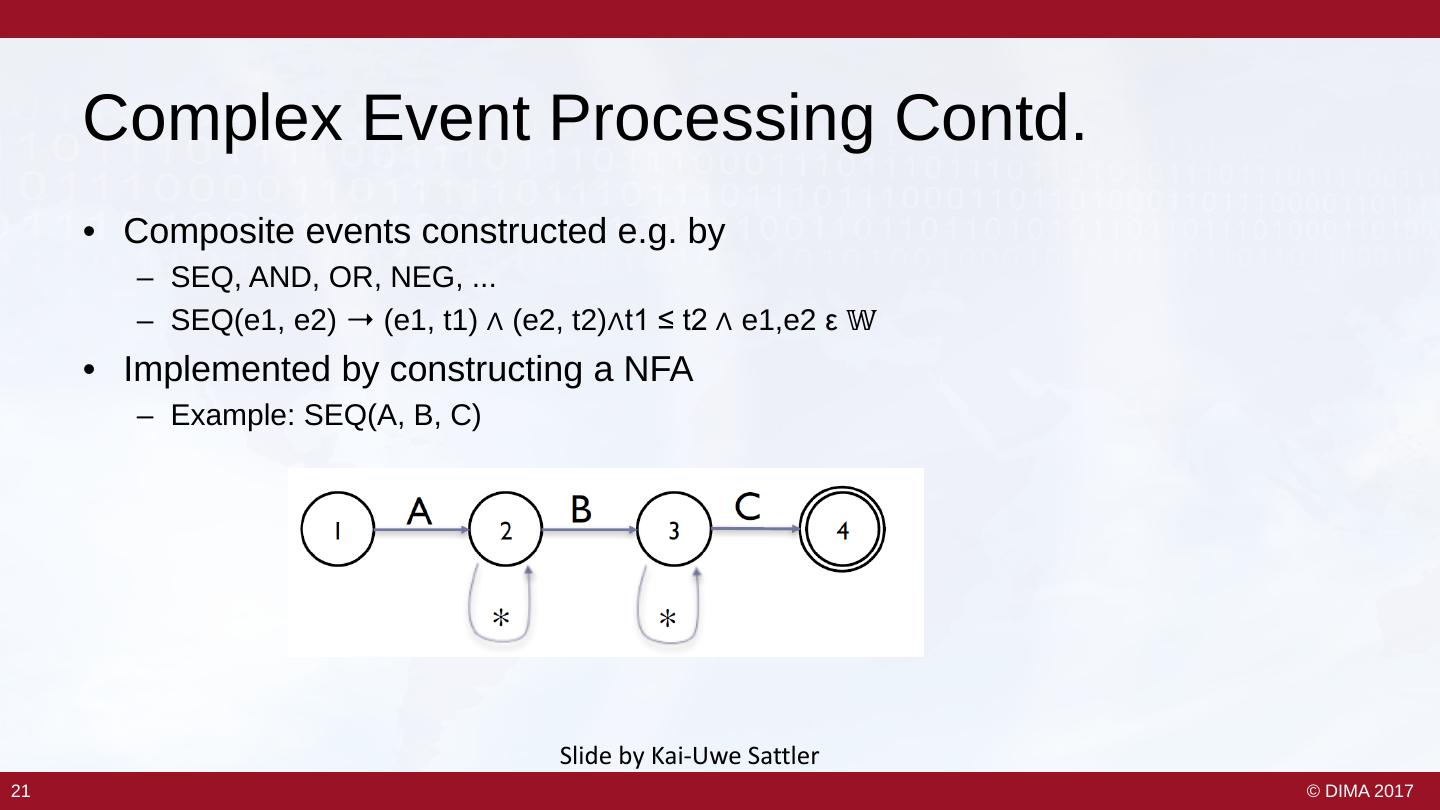
20 . Complex Event Processing Contd. • Composite events constructed e.g. by – SEQ, AND, OR, NEG, ... – SEQ(e1, e2) ➝ (e1, t1) ∧ (e2, t2)∧t1 ≤ t2 ∧ e1,e2 ε 𝕎𝕎 • Implemented by constructing a NFA – Example: SEQ(A, B, C) Slide by Kai-Uwe Sattler 21 21 © DIMA 2017
21 . Stream Processing Systems What makes a system a stream processing system? 22 © DIMA 2017
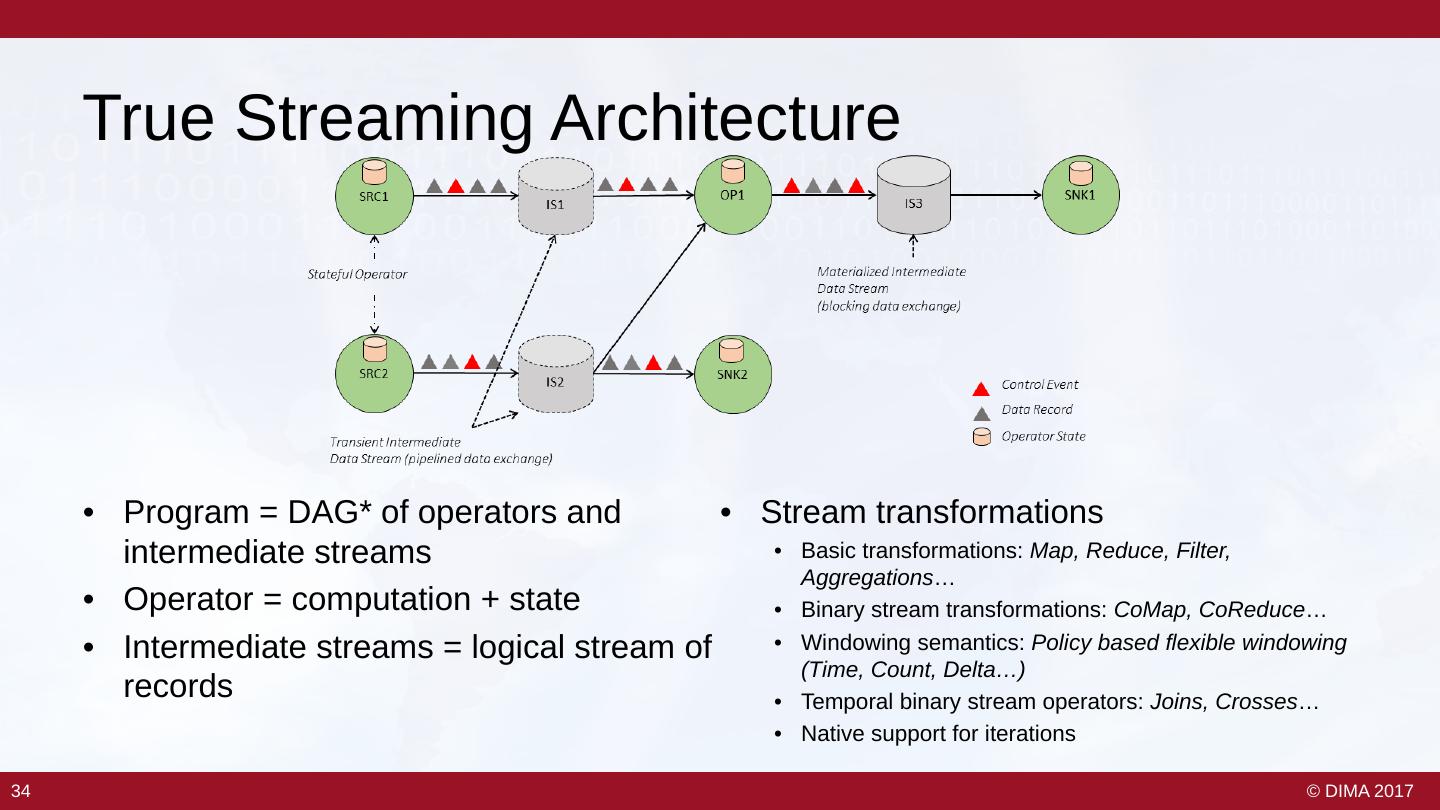
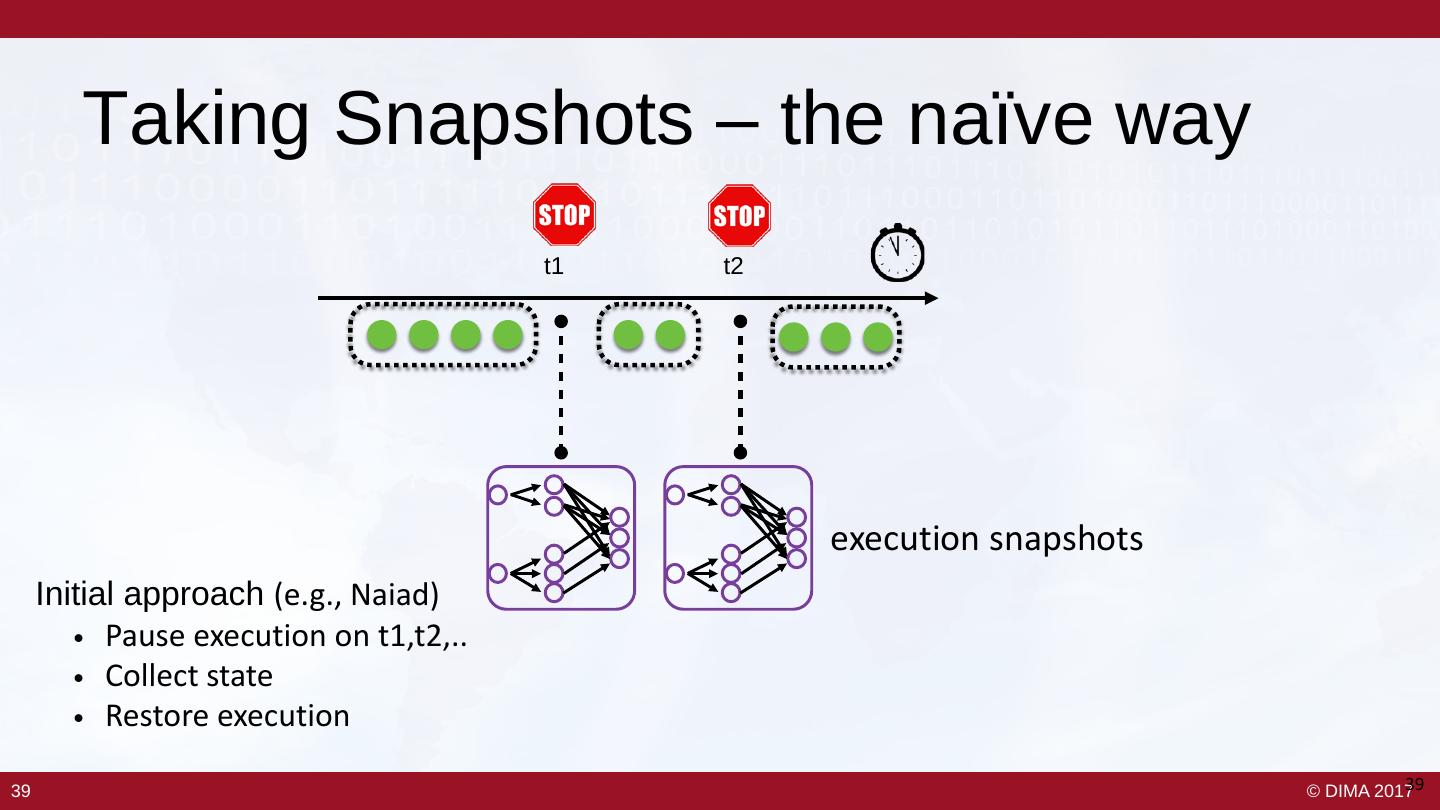
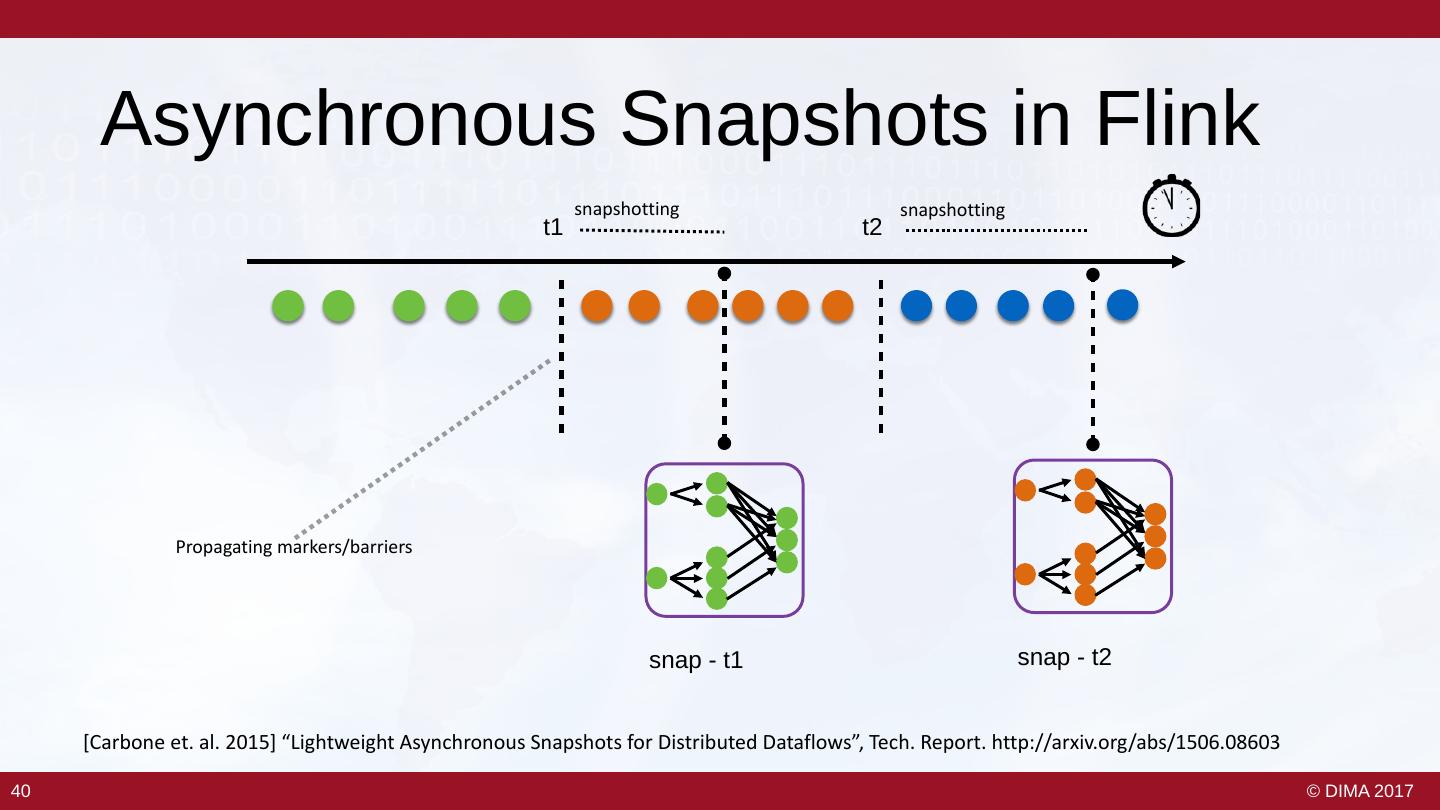
22 . 8 Requirements of Big Streaming • Keep the data moving • Integrate stored and streaming data – Streaming architecture – Hybrid stream and batch • Declarative access • Data safety and availability – E.g. StreamSQL, CQL – Fault tolerance, durable state • Handle imperfections • Automatic partitioning and scaling – Late, missing, unordered items – Distributed processing • Predictable outcomes • Instantaneous processing and – Consistency, event time response The 8 Requirements of Real-Time Stream Processing – Stonebraker et al. 2005 23 23 © DIMA 2017
23 . 8 Requirements of Big Streaming • Keep the data moving • Integrate stored and streaming data – Streaming architecture – Hybrid stream and batch • Declarative access • Data safety and availability – E.g. StreamSQL, CQL – Fault tolerance, durable state • Handle imperfections • Automatic partitioning and scaling – Late, missing, unordered items – Distributed processing • Predictable outcomes • Instantaneous processing and – Consistency, event time response The 8 Requirements of Real-Time Stream Processing – Stonebraker et al. 2005 24 24 © DIMA 2017
24 . Big Data Processing • Databases can process very large data since forever (see VLDB) – Why not use those? • Big data is not (fully) structured – No good for database • We want to learn more from data than just – Select, project, join • First solution: MapReduce 25 25 © DIMA 2017
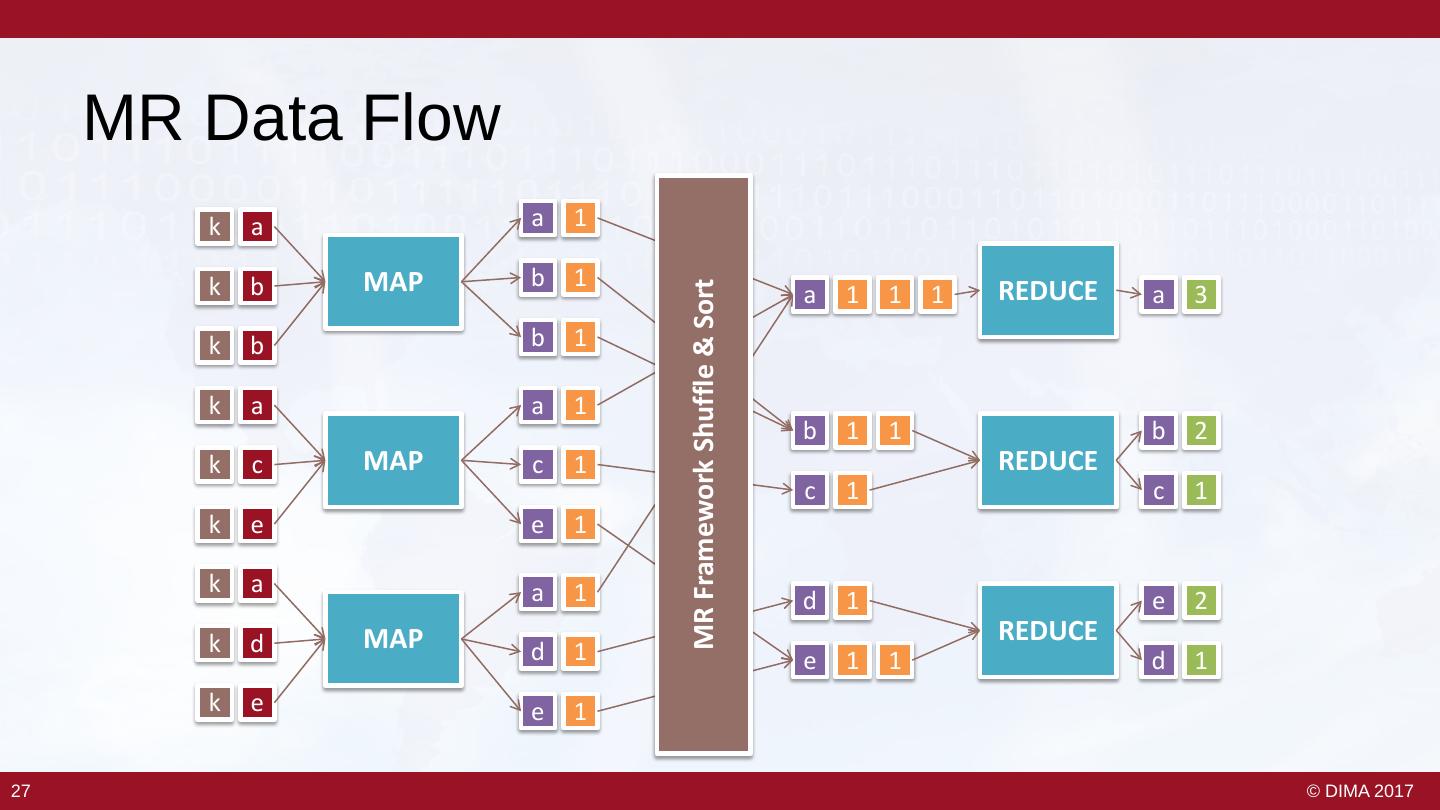
25 . Map Reduce • Framework / programming model by Google – Presented 2004 at OSDI'04 • Inspired by map and reduce functions in functional languages / MPI – Second order functions • Simple parallelization model for shared nothing architectures (“commodity hardware”) • Apache Hadoop – Open-source implementation – Initiated at Yahoo Map: Computation Reduce: Aggregation For each input create list of output values Combine all intermediate values for one key Example: Example: For each word in a sentence emit a k/v pair Sum up all values for the same key indicating one occurrence of the word (“Hello”,(“1”, “1”, “1”, “1”)) -> (“Hello”,(“4”)) (key, “hello world”) -> (“hello”,”1”), (“world”,”1”) Signature Signature reduce (key, list(value)) -> list(value’) map (key, value) -> list(key’, value’) 26 26 © DIMA 2017
26 . MR Data Flow k a a 1 k b MAP b 1 a 1 1 1 REDUCE a 3 MR Framework Shuffle & Sort k b b 1 k a a 1 b 1 1 b 2 k c MAP c 1 REDUCE c 1 c 1 k e e 1 k a a 1 d 1 e 2 k d MAP REDUCE d 1 e 1 1 d 1 k e e 1 27 27 © DIMA 2017
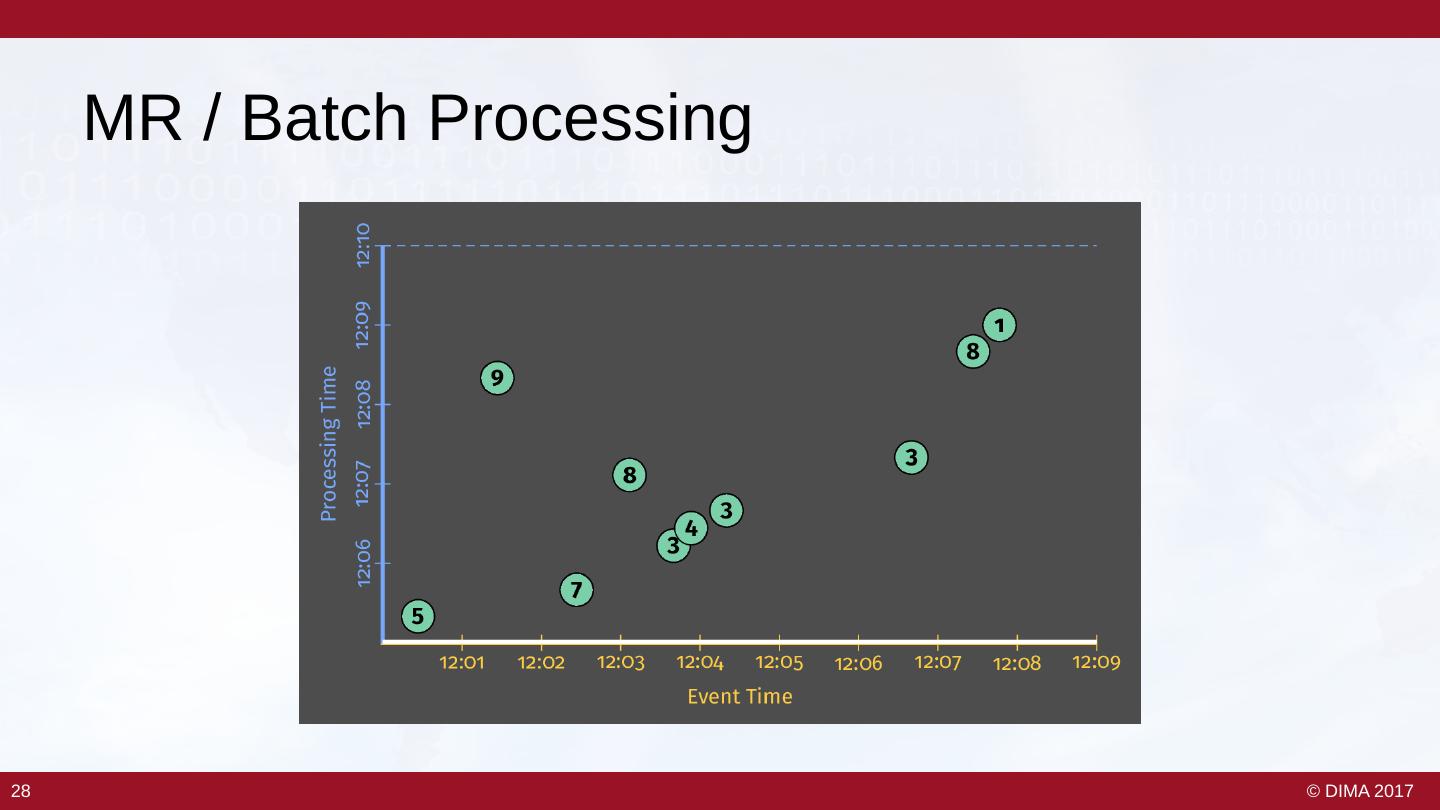
27 . MR / Batch Processing 28 28 © DIMA 2017
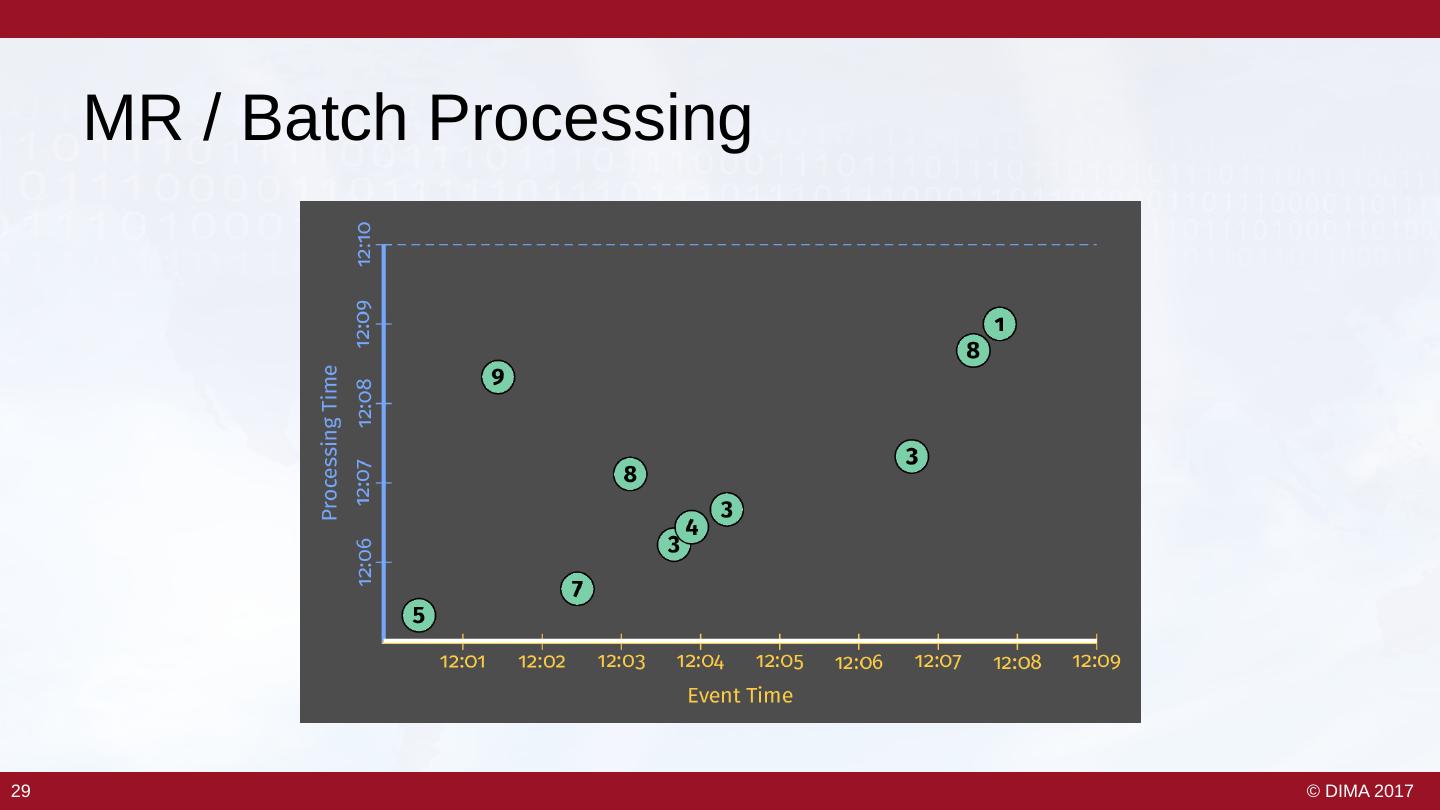
28 . MR / Batch Processing 29 29 © DIMA 2017
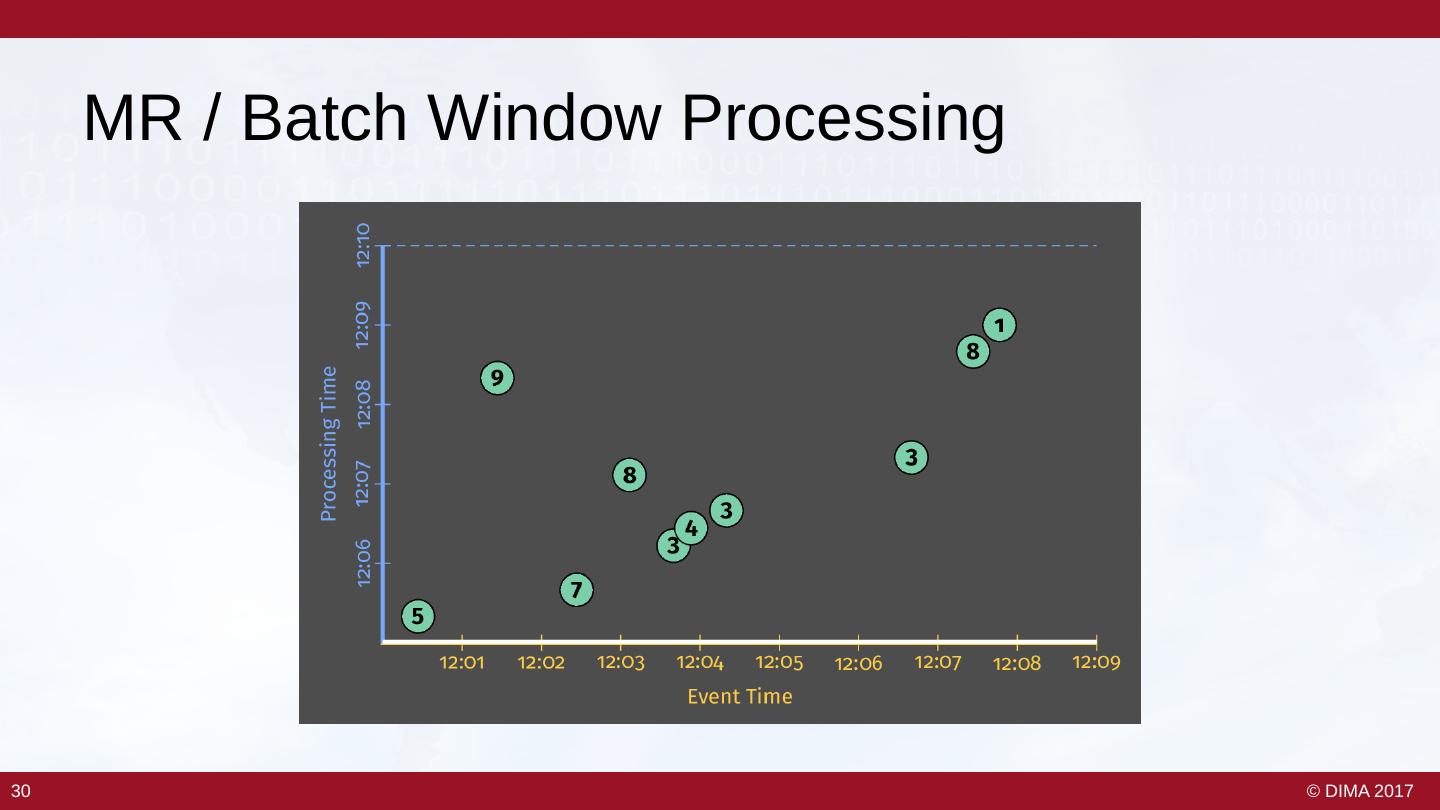
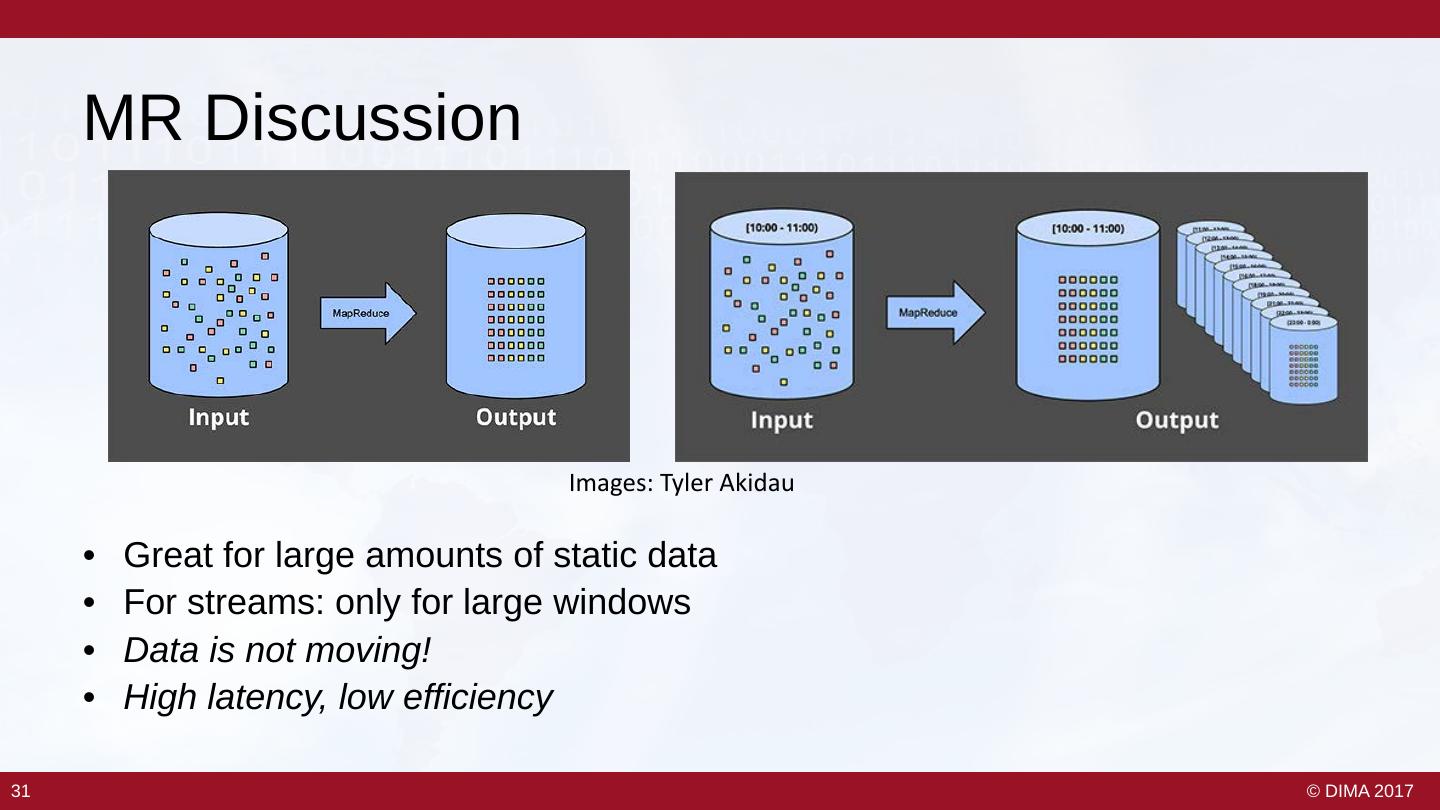
29 . MR / Batch Window Processing 30 30 © DIMA 2017
相关推荐
3秒后跳转登录页面
去登陆

