展开查看详情
2 .提纲 1 Spark 简介 2 Spark 功能 与架构 3 Spark 生态圈介绍 4 Spark 编程
3 .是什么 Spark 系统是 分布式批处理系统 和 分析挖掘引擎 ; AMP LAB 贡献到 Apache 社区的开源项目,是 AMP 大数据栈的基础组件; 做什么 数据处理 ( Data Processing ): 可以用来快速处理数据,兼具容错性和可扩展性。 迭代计算 ( Iterative Computation ):支持迭代计算,有效应对多步的数据处理逻辑。 数据 挖掘 ( Data Mining ):在海量数据基础上进行复杂的挖掘分析,可支持各种数据挖掘和 机器学习 算法。 Spark 简介
4 .轻: Spark 核心代码有 3 万行 。 Scala 语言的简洁和丰富 表达力 巧妙 利用了 Hadoop 和 Mesos 的基础 设施 快 : Spark 对小数据集可达到亚秒级的延迟,对大数据集的迭代机器学习、即席查询、图计算等应用 , Spark 版本比基于 MR 、 Hive 和 Pregel 的实现快 。 内存 计算、数据本地性和传输优化、调度 优化 灵 : Spark 提供了不同层面的灵活性 。 Scala trait 动态混入策略(如可更换的集群调度器、序列化库) ; 允许 扩展新的数据算子、新的数据源、新的 language bindings ( Java 和 Python ) ; Spark 支持内存计算、多迭代批量处理、即席查询、流处理和图计算等多种范式 。 巧 :巧妙借力现有大数据组件 。 Spark 借 Hadoop 之势,与 Hadoop 无缝结合 ; Shark 借了 Hive 的势 ; Spark 特点
5 .Hadoop (MapReduce) 极大的简化了大数据分析,广泛地用作大规模的数据分析 。但是 ,随着大数据需求和使用模式的扩大,用户的需求也越来越多: 更 复杂的 多重处理 需求(比如迭代计算 , ML, Graph ) 低 延迟的 交互式查询 需求(比如 ad-hoc query ) MapReduce 作业结果需要到固化到硬盘上,由此产生数据备份、磁盘 I/O 和序列化等操作产生了大量的开销,也由于这一缺点, MapReduce 计算模型的架构不适合于上述场景 当年 MapReduce 框架设计的目的为整合廉价的商用计算机的计算能力而设计的,但随着近 10 年来硬件的快速发展,硬件成本的降低,内存容量和 CPU 速度已经不再成为问题, 内存计算的时代已经 到来 为什么需要内存计算?
6 .一 种解决思路 MapReduce Impala Pregel Dremel GraphLab Storm Giraph Drill Tez S4 批处理系统 实时计算,流处理,图计算框架 BSP
7 . 不是 一款修改过的 Hadoop ! 是 一款独立的,高速的,开源的分布式计算引擎: >> 内存计算模式 >> Resilient Distributed Datasets( 弹性分布式数据集 ) >> 比 Hadoop 快 40 倍 以上 另一种解决思路
11 .Spark 数据共享机制( 1/2 ) iter . 1 iter . 2 . . . Input HDFS read HDFS write HDFS read HDFS write Input query 1 query 2 query 3 result 1 result 2 result 3 . . . HDFS read 太慢,冗余读写、序列化、磁盘 IO Data Sharing in MapReduce
12 .Spark 数据共享机制 ( 2/2 ) Data Sharing in Spark 10-100x 快于网络和磁盘 iter . 1 iter . 2 . . . Input Distributed memory Input query 1 query 2 query 3 . . . one-time processing
13 .弹性分布式数据集( Resilient Distributed Datasets ) A distributed memory abstraction that lets programmers perform in-memory computations on large clusters 只读 的,可分区 的分布式数据集 只能 直接通过操作符来创建和处理 支持 容错处理 RDD 操作: Transformation & Action Spark 核心概念 -- RDDs
14 .Transformation & Action RDD 操作
15 .每个 RDD 都有一些用来描述 RDD 的元数据信息: 一 组 RDD 分区 (partition) 信息 每个 RDD 都会分成若干个分区,在为 RDD 分配 task 时,都是以分区为基本单位的。 对 父 RDD 的一组依赖,这些依赖描述了 RDD 的 Lineage 窄依赖 (Narrow Dependencies) :子 RDD 的每一个分区依赖于常数个父 RDD 的分区 宽依赖 (Wide Dependencies) :子 RDD 的分区依赖于父 RDD 的所有 分区 Spark RDDs
16 .流水线操作 窄依赖允许在一个集群节点上以流水线的方式( pipeline )计算所有父分区。例如,逐个元素地执行 map 、然后 filter 操作 宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行数据混合,这与 MapReduce 类似。 容错 机制的处理 窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失 RDD 分区的父分区,而且不同节点之间可以并行计算 对于一个宽依赖关系的 Lineage ,单个节点失效可能导致这个 RDD 的所有祖先丢失部分分区,因而需要整体重新计算 。 窄 依赖与宽依赖的区别
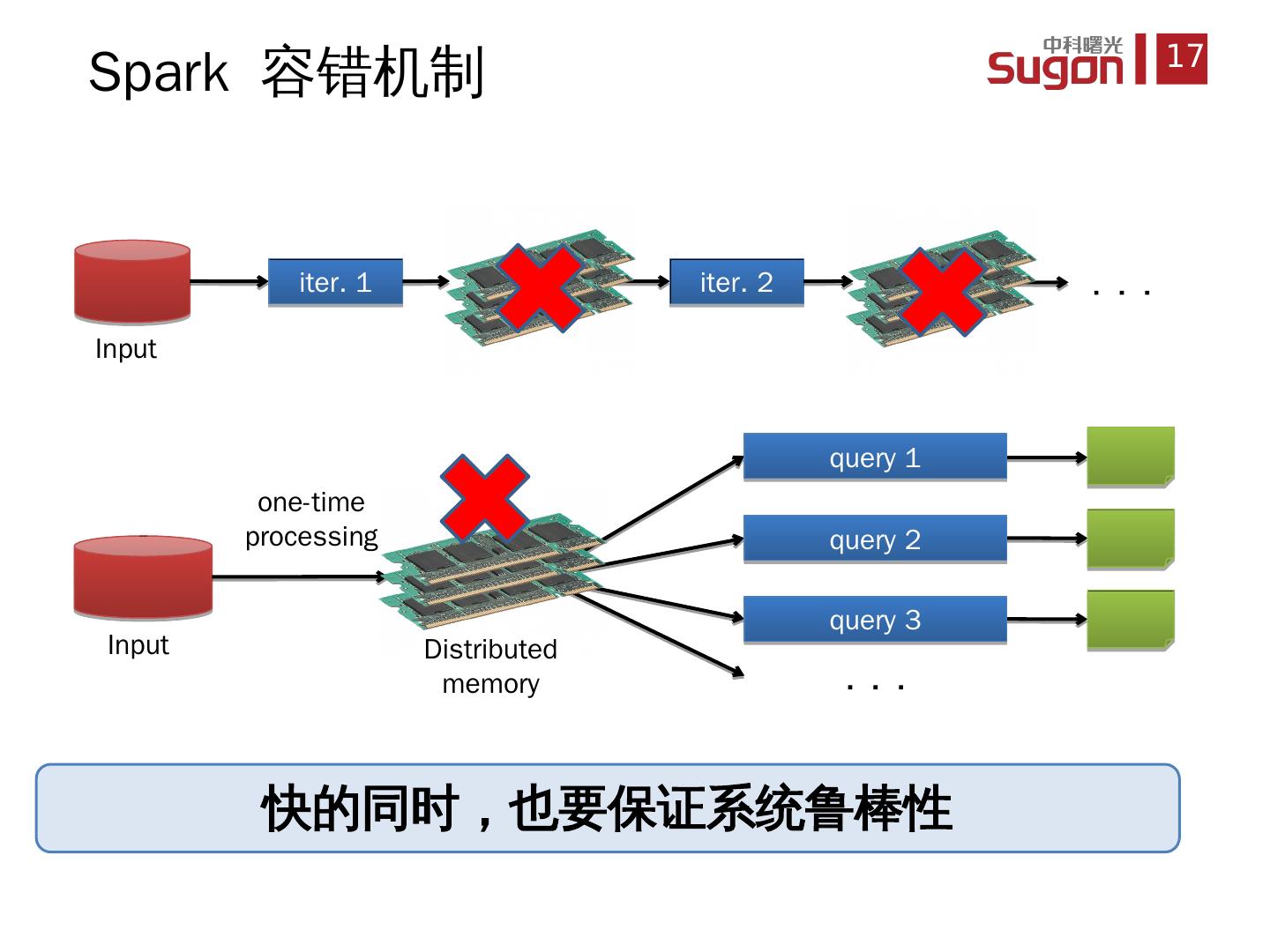
17 .Spark 容错机制 iter . 1 iter . 2 . . . Input Distributed memory Input query 1 query 2 query 3 . . . one-time processing 快的同时,也要保证系统鲁棒性
18 .血统关系 (Lineage) :记录 RDD 是如何从其它 RDD 中演变过来的一系列操作 当 这个 RDD 的部分分区数据丢失时,它可以通过 Lineage 获取足够的信息来重新运算和恢复丢失的数据分区 采用 粗颗粒 的数据模型,性能的 提升 Spark 容错机制
19 .Spark 例子 lines = spark.textFile(“hdfs ://...”) errors = lines. filter ( _.startsWith(“ERROR ”) ) cachedMsgs = errors . cache () Block 1 Block 2 Block 3 Worker Worker Worker Driver cachedMsgs. filter ( _.contains(“M ySQL ”) ). count cachedMsgs. filter ( _.contains(“HDFS”) ). count . . . tasks results Cache 1 Cache 2 Cache 3 Base RDD Transformed RDD Action Result: full-text search of Wikipedia in <1 sec ( vs 20 sec for on-disk data) Result: scaled to 1 TB data in 5-7 sec ( vs 170 sec for on-disk data) 例子 : 假定 有一个大型网站出错,操作员想要检查 Hadoop 文件系统( HDFS )中的日志文件( TB 级大小)来找出原因。通过使用 Spark ,操作员只需将日志中的错误信息装载到一组节点的 RAM 中,然后执行交互式查询 。
20 .Spark 任务调度 (1/2) RDD Objects DAGScheduler TaskScheduler Worker rdd1. join (rdd2) . groupBy (…) . filter (…) build operator DAG split graph into stages of tasks submit each stage as ready launch tasks via cluster manager retry failed or straggling tasks execute tasks store and serve blocks DAG TaskSet Cluster manager Block manager Threads Task
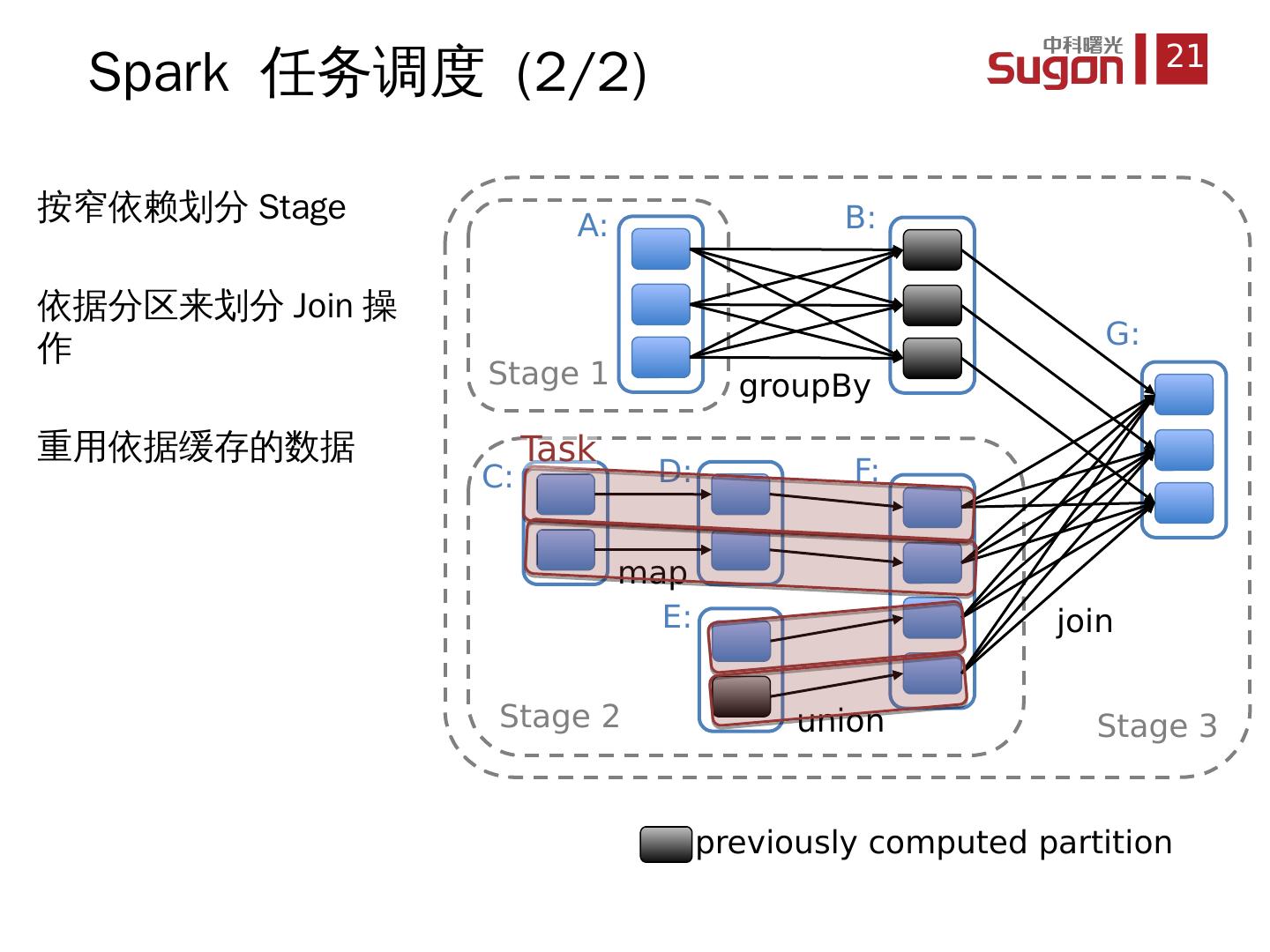
21 .按窄依赖划分 Stage 依据分区来划分 Join 操作 重用 依据缓存的数据 Spark 任务调度 (2/2) join union groupBy map Stage 3 Stage 1 Stage 2 A: B: C: D: E: F: G: = previously computed partition Task
22 .按窄依赖划分 Stage 依据分区来划分 Join 操作 重用 依据缓存的数据 Spark 任务调度 (2/2) join union groupBy map Stage 3 Stage 1 Stage 2 A: B: C: D: E: F: G: = previously computed partition Task
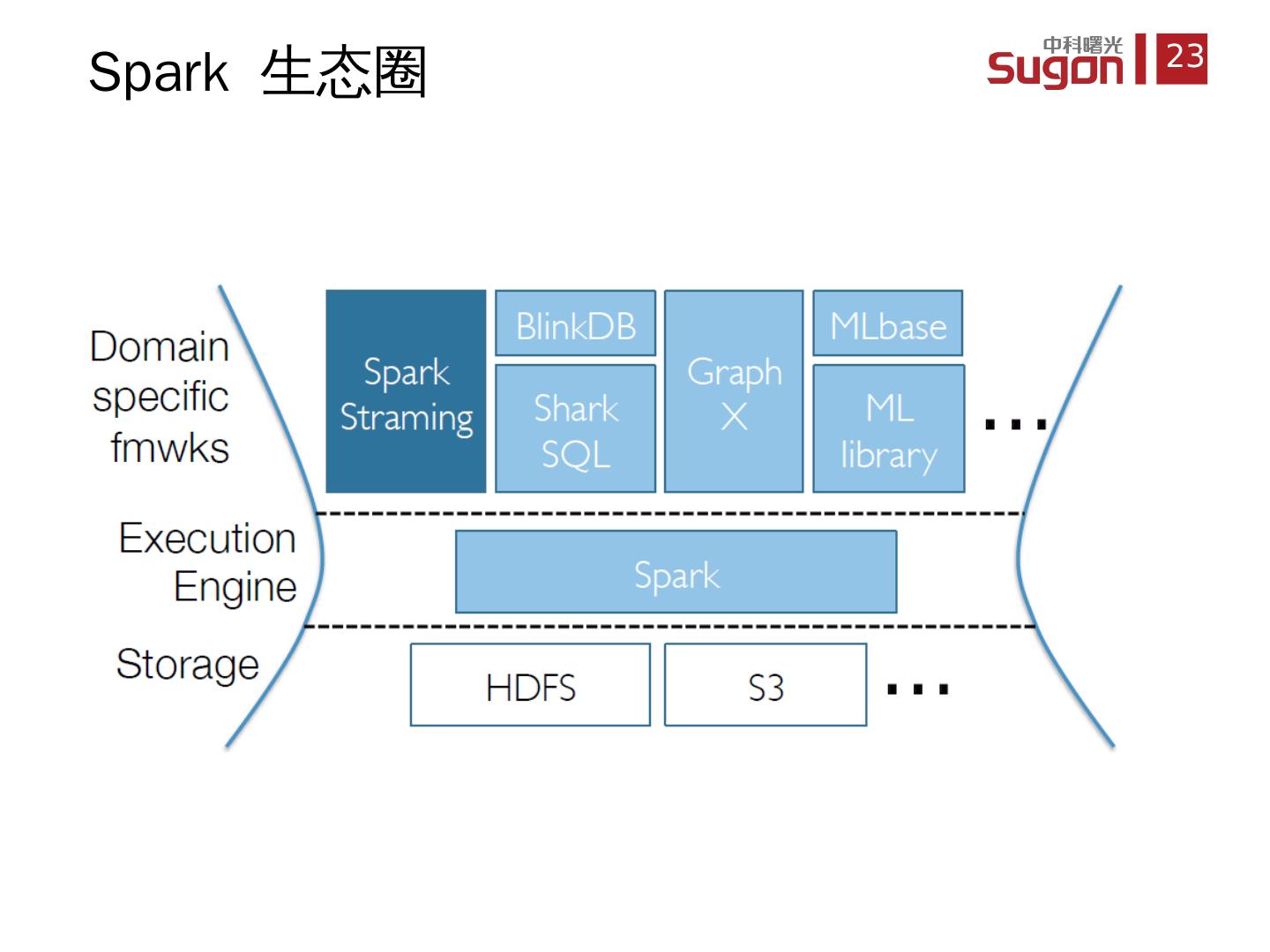
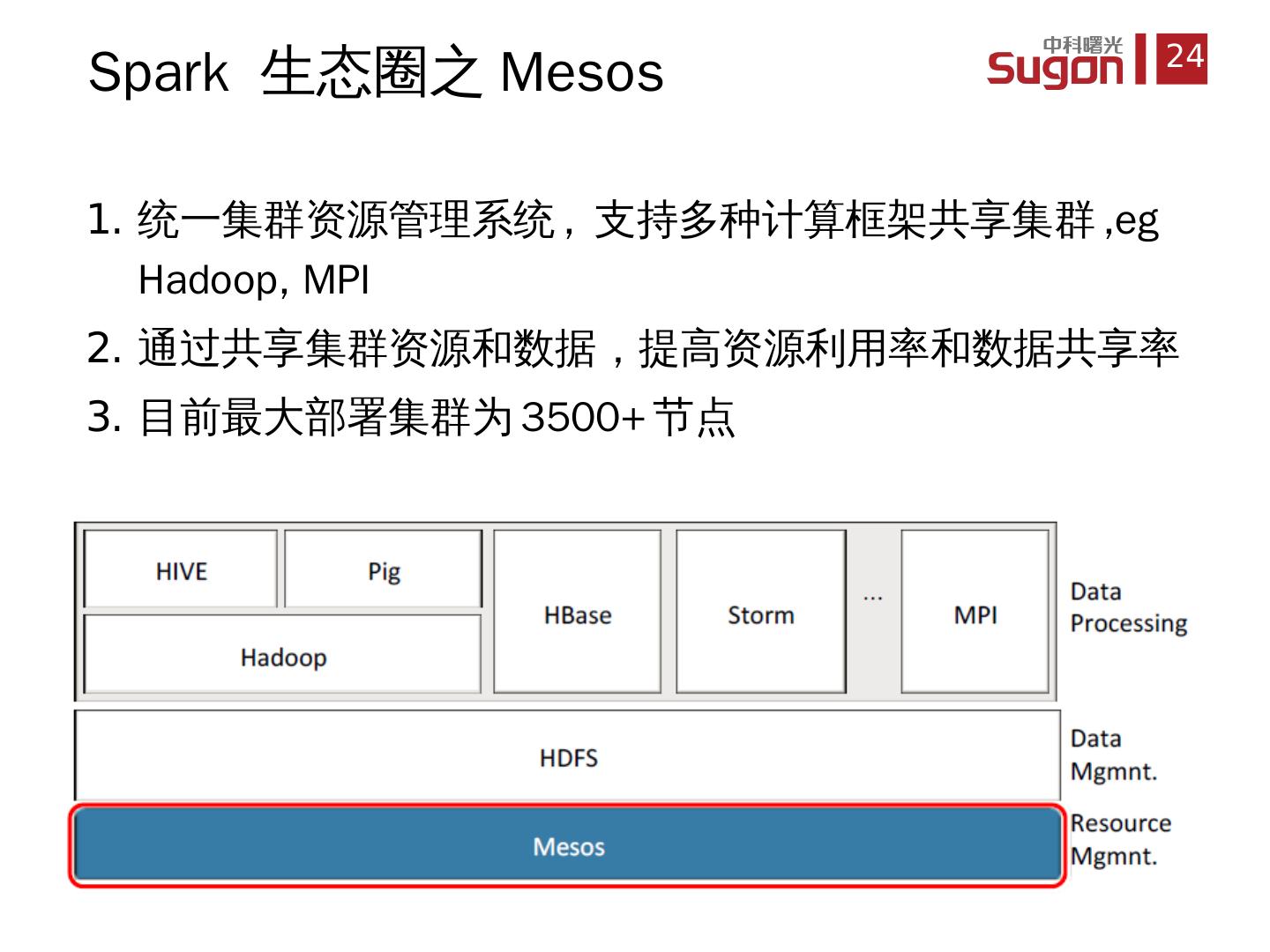
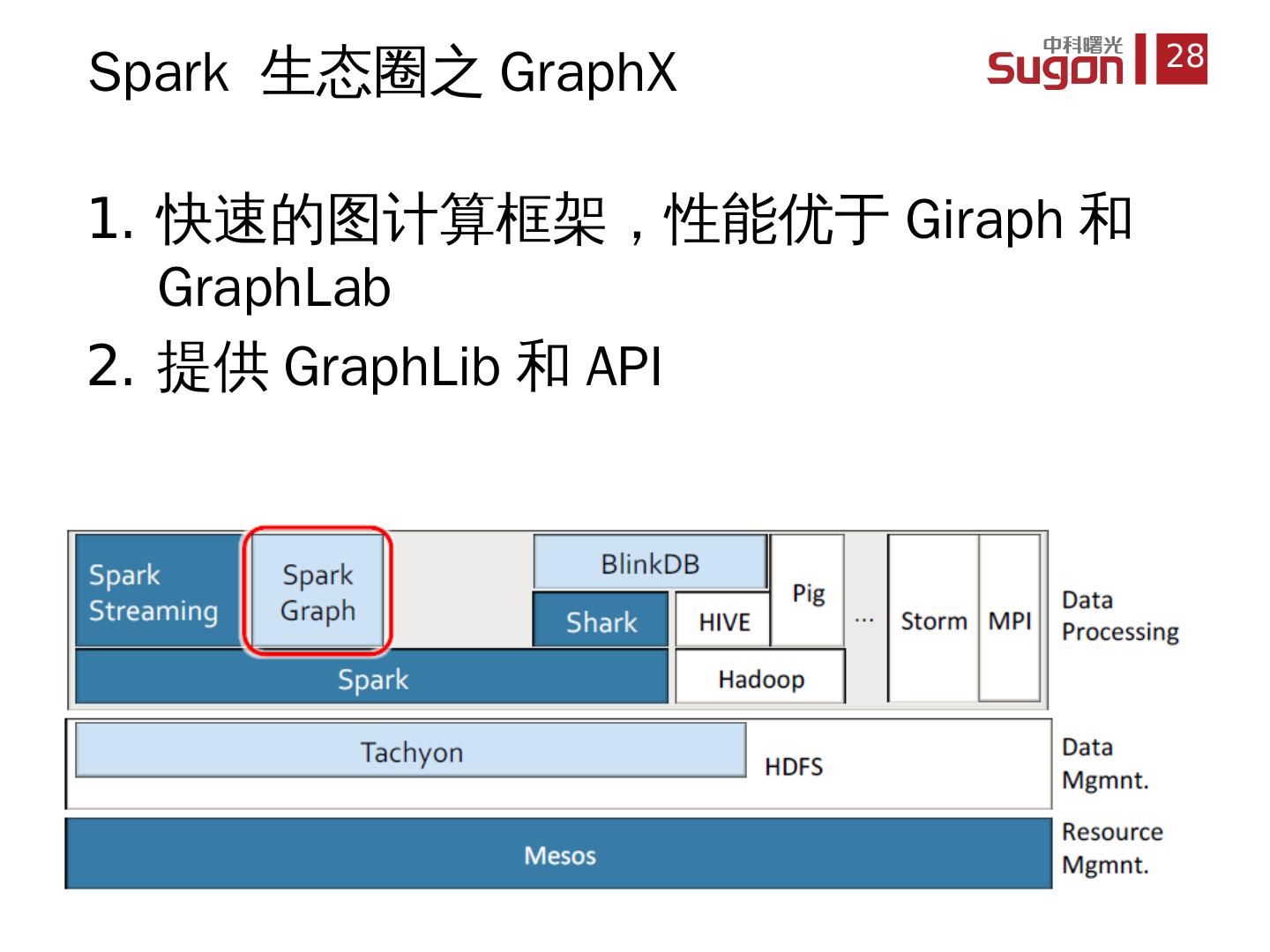
24 .统一 集群资源管理系统 , 支持多种计算框架共享集群 , eg Hadoop , MPI 通过 共享集群资源和数据,提高资源利用率和数据共享率 目前 最大部署集群为 3500+ 节点 Spark 生态圈之 Mesos
25 .支持 大规模流式计算,吞吐量高于 Storm 基于 Spark 单一框架,完善 Spark 批处理、交互式处理和流式处理模式 将 流式计算分解成一系列小而确定的批处理作业 Spark 生态圈之 Spark Streaming
26 .Hive on Spark, 提供 SQL 访问 Spark 内的 RDDs 比 Hive 性能高 40-100 倍 SparkSQL 抛弃 Hive, 直接 SQL on Spark Shark 项目已经停止,目前是单独的 SparkSQL , Hive 现在在做 Hive on Spark Spark 生态圈之 SparkSQL (Shark)
27 .大规模 的模糊查询引擎 允许 用户在准确率和响应时间作出权衡 主要 是 facebook 在使用和维护,最新消息 BlinkDB 加入 Databricks Spark 生态圈之 BlinkDB
28 .快速的图计算框架,性能优于 Giraph 和 GraphLab 提供 GraphLib 和 API Spark 生态圈 之 GraphX
29 .基于 Spark 的机器学习算法包 支持可扩展的机器学习算法 Spark 生态圈之 MLBase ( MLlib )