展开查看详情
1 .Scaling ride
hailing with
Md Jawad
Data Scientist
GOJEK
�
3 .Our Scale Thailand
Vietnam
Singapore
Operating in 4 countries
and more than 70 cities
Indonesia
80m
app downloads
+250k
merchants
4
countries
1m+
drivers
100m+
monthly bookings
�
5 .Mobility Data Science Team
�
6 .Mobility Data Science Team
■ Matchmaking
■ Surge pricing
�
8 .Agenda
1. Matchmaking model
a. Background
b. Challenges
c. Desired state
2. MLflow
3. Solution
�
9 . Choosing best driver for the job
Selected
driver
Heading to
home area
Customer
Lowest ETA
High rating
�
10 .Matchmaking: First Cut
Prod
Raw Data How can we get models into production asap? Serving
�
11 .Matchmaking: First Cut
Process
Raw Data
Data
Airflow
Airflow DAG
�
12 .Matchmaking: First Cut
Prod
Deploy
Serving
Gitlab for CI/CD
�
13 .Matchmaking: First Cut
Process How are we going Prod
Raw Data Deploy
Data to train models? Serving
Airflow
�
14 .Matchmaking: First Cut
Trigger: Daily Schedule Trigger: API Call Helm deploy to Kubernetes
Build, Test, Deploy Prod
Raw Data Process Data, Train Model
Application Serving
Airflow
�
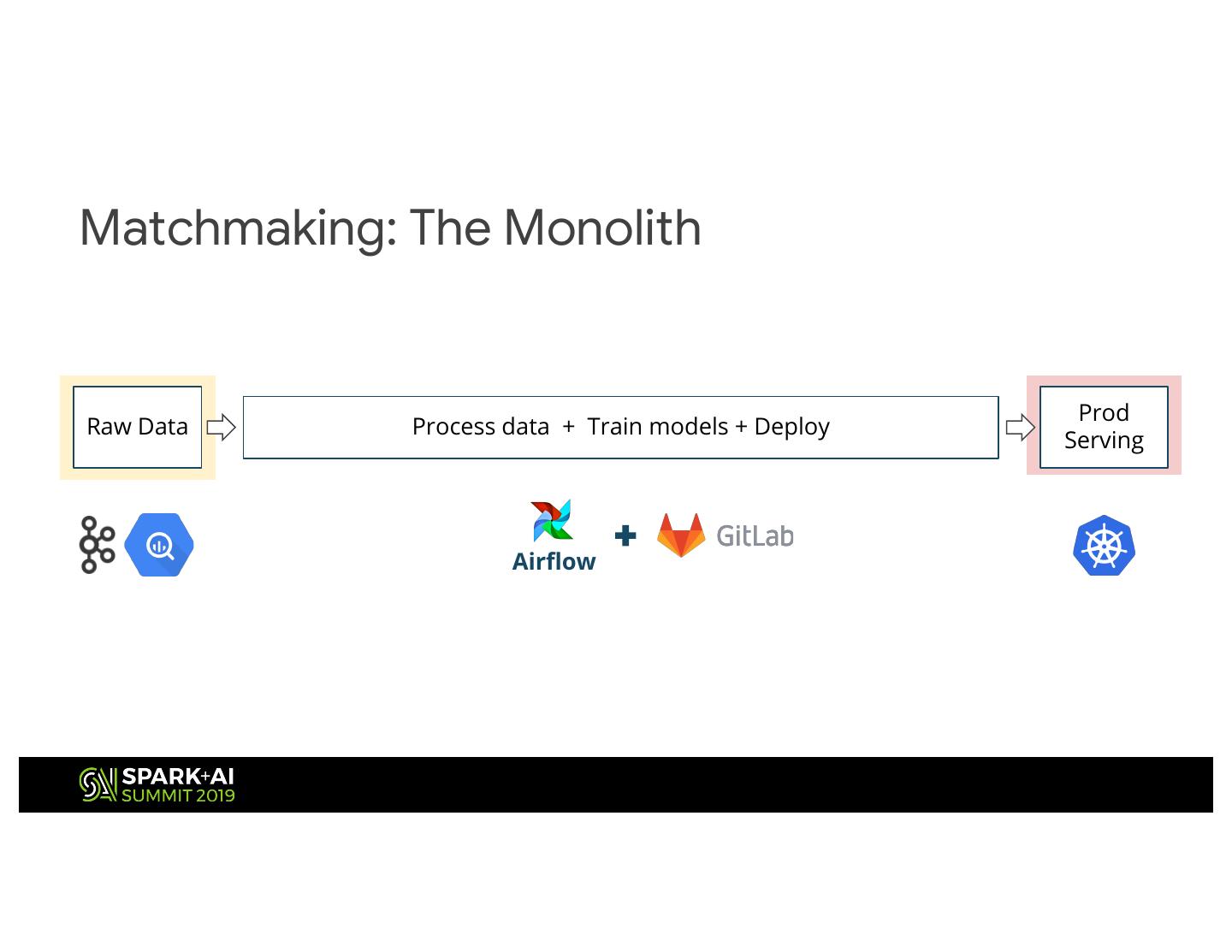
15 .Matchmaking: The Monolith
Prod
Raw Data Process data + Train models + Deploy
Serving
Airflow
�
16 .Challenges with this approach
● Inefficient
○ Need to wait hours for pipeline to run before deploying models
○ Can’t deploy serving without trigger from Airflow
�
17 .Challenges with this approach
● Inefficient
● Hard to experiment
○ Do we fork the codebase for each small change?
○ Do we fan-in and fan-out a single pipeline?
○ Tracking model performance over time
�
18 .Challenges with this approach
● Inefficient
● Hard to experiment
● Versioning is broken
Model tracking
by timestamp?
�
19 .Challenges with this approach
● Inefficient
● Hard to experiment
● Versioning is broken
● Low reproducibility
○ Pipelines have non-deterministic side inputs (API calls,
fetching data, reading configuration)
○ No standardized way to track artifacts or processes
�
20 .Challenges with this approach
● Inefficient
● Hard to experiment
● Versioning is broken
● Low reproducibility Features? Models? Parameters? Metrics?
● No visibility
�
21 .Challenges with this approach
● Inefficient
● Hard to experiment How do we scale to 1000s
● Versioning is broken models and new markets?
● Low reproducibility
● Low visibility
● Hard to scale
Hardcoded
deployments
Airflow trains model, targets
triggers new deploy
through GitLab
�
22 .Challenges with this approach
● Inefficient
● Hard to experiment
● Versioning is broken
● Low reproducibility
● Low visibility
● Hard to scale
● No separation of roles Responsibility of
Data Engineers,
Software Engineers,
Data Scientists
Prod
Raw Data Process data + Train models + Deploy
Serving
�
23 .Desired state
● Easy to experiment
● Easy to reproduce results
● Easy to deploy models
● Easy to evaluate performance of features and models
● Capable of scaling to 1000s of models in many regions
�
24 . μ
λθ Tuning
Scale
An open source platform for the Data Prep
machine learning lifecycle
μ
λθ Tuning
Delta Raw Data Training
Scale
Scale
Model
Deploy Exchange
Governance
Scale
�
25 .MLflow Components
Tracking Projects Models
Record and query Packaging format General model format
experiments: code, for reproducible runs that supports diverse
data, config, results on any platform deployment tools
�
26 .Key Concepts in Tracking
• Parameters: key-value
inputs to your code
• Metrics: numeric values
(can update over time)
• Artifacts: arbitrary files,
including models
• Source: which version
of code ran?
�
27 .Legacy ML workflow
Prod
Raw Data Process data + Train models + Deploy
Serving
Airflow
�
28 .Approach
1. Decouple based on concerns
Process Train Prod
Raw Data ??? ??? Deploy
Data Models Serving
Airflow
�
29 .Approach
1. Decouple based on concerns
2. Implement ML pipeline solution
Process Train Prod
Raw Data ??? ??? Deploy
Data Models Serving
Airflow
�