展开查看详情
1 .Kubernetes
SIG Big Data
�
2 .Landscape
Introduce SIG Big Data
Apache Airflow
Apache Spark
Future of this SIG
Audience Dialogue
�
3 . SIG Mission1
Serve as a community resource for advising big data and data science
related software projects on techniques and best practices for integrating
with Kubernetes.
Represent the concerns of users from big data communities to Kubernetes
for the purposes of driving new features and other enhancements, based
on big data use cases.
1: https://github.com/kubernetes/community/pull/2988
�
4 .Chairs
Anirudh Ramanathan (Rockset)
Erik Erlandson (Red Hat)
Yinan Li (Google)
�
5 . Provenance
Winter 2017: Revived as part of the process of creating a
community platform for prototyping development of a
Kubernetes scheduler backend for Apache Spark.
�
6 . Software Projects
Kubernetes scheduler backend for Apache Spark
HDFS deployments for Kubernetes
Apache Airflow operator and executor for Kubernetes
�
7 .Participating Organizations
Bloomberg
Google
Lightbend
Palantir
Pepperdata
Red Hat
�
8 .Apache Airflow
Task
Dependencies
Task B Task D
Task A Task F
Task C Task E
Execution
�
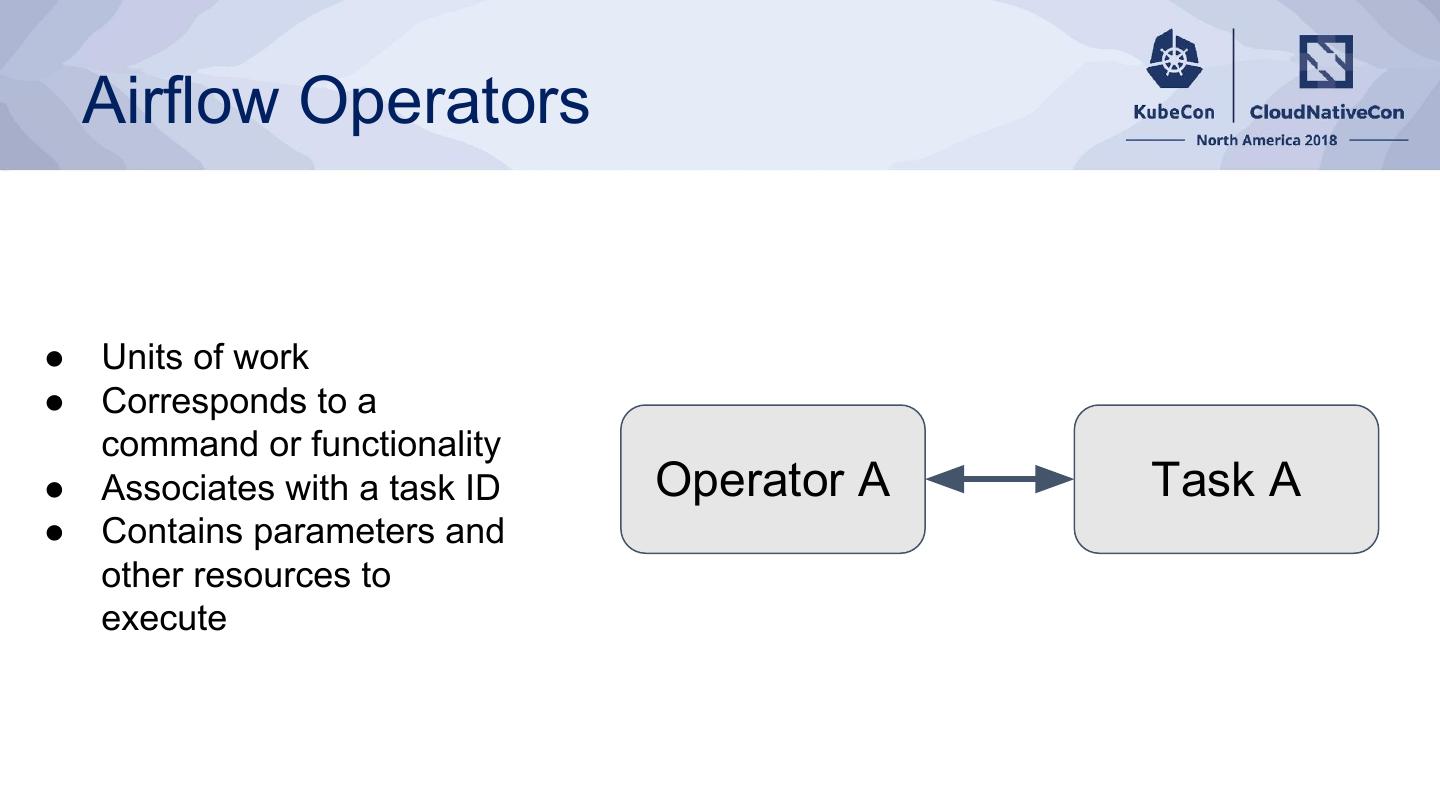
9 . Airflow Operators
● Units of work
● Corresponds to a
command or functionality
● Associates with a task ID Operator A Task A
● Contains parameters and
other resources to
execute
�
10 .Operator Flavors
Run a bash command
Invoke a python function
Send an HTTP request
Execute a SQL query
�
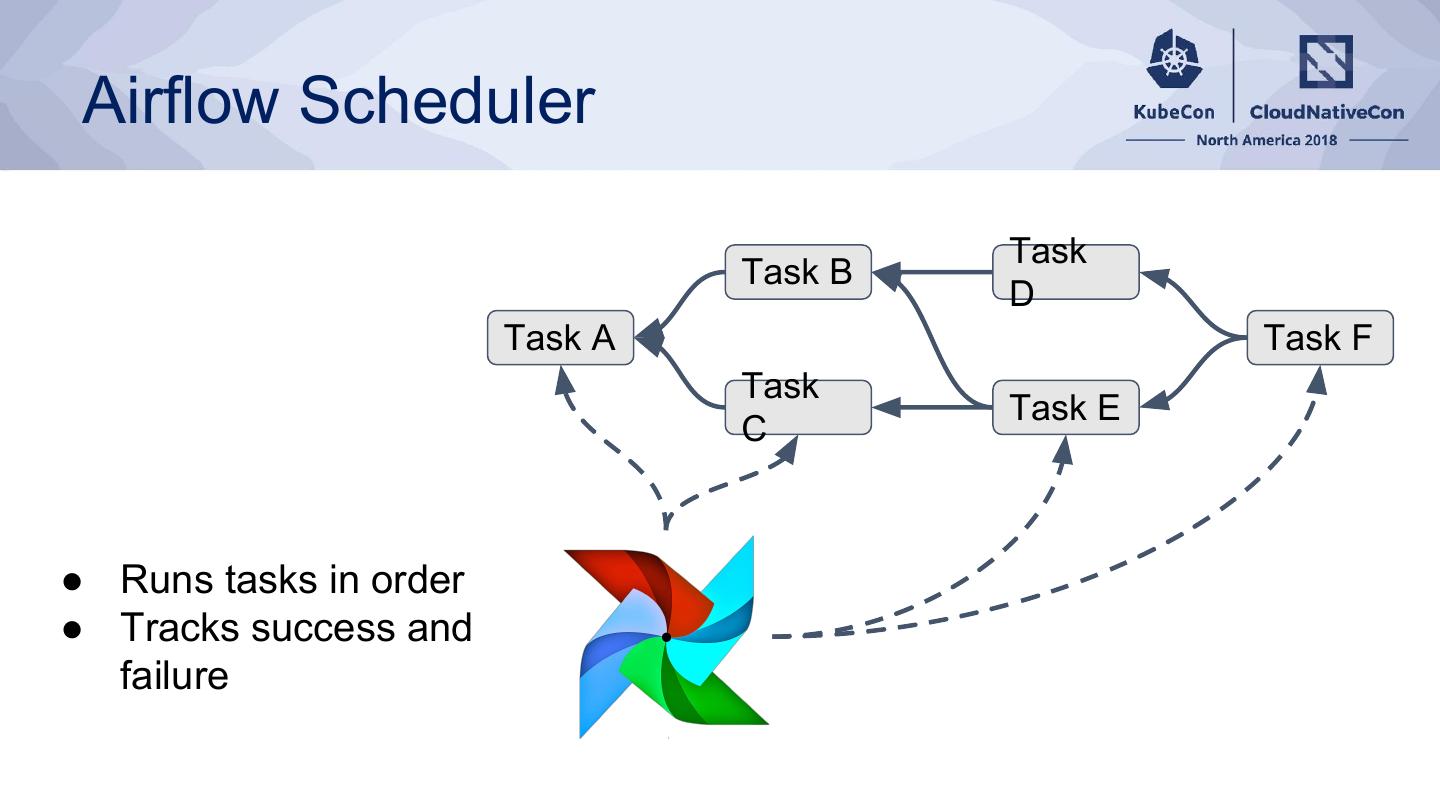
11 . Airflow Scheduler
Task
Task B
D
Task A Task F
Task
Task E
C
● Runs tasks in order
● Tracks success and
failure
�
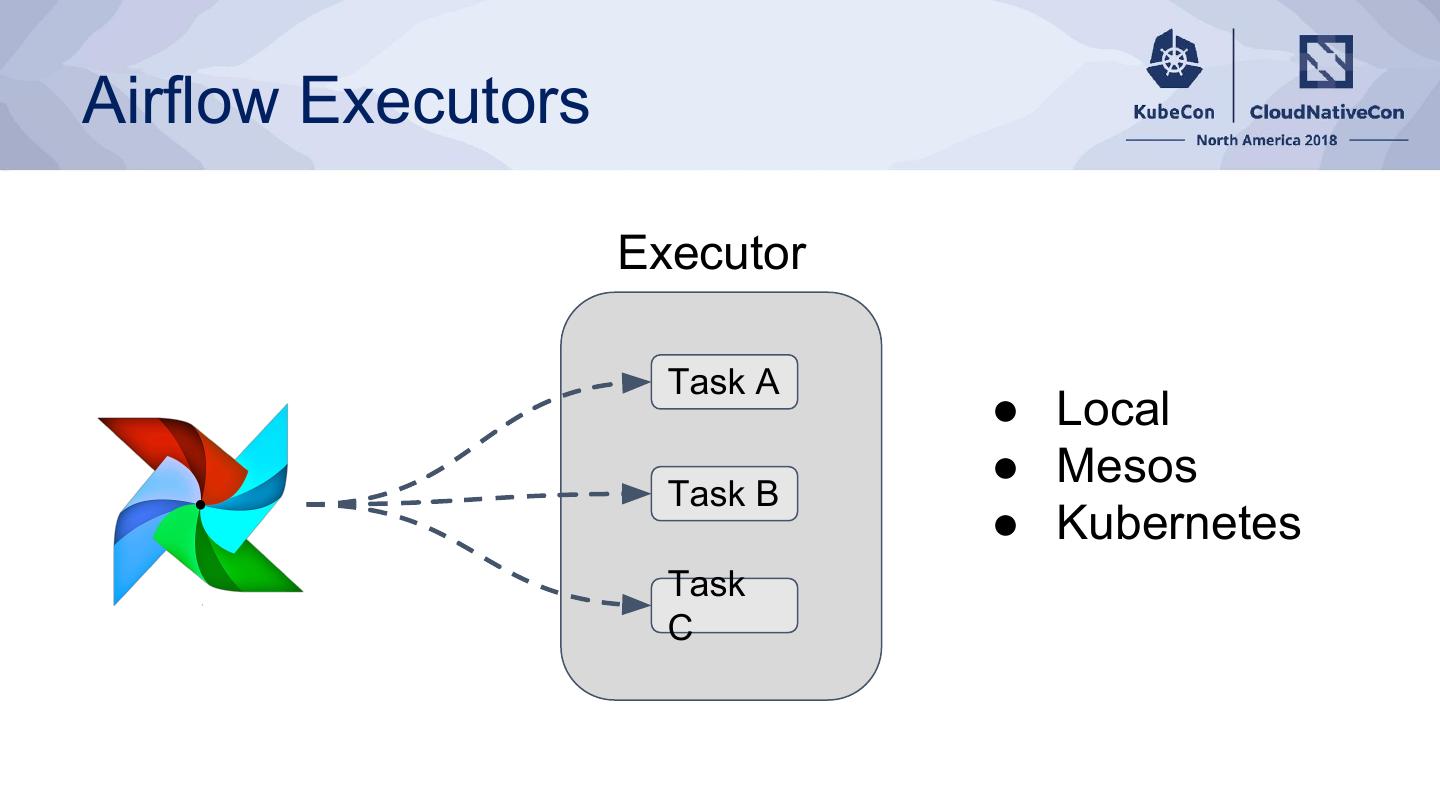
12 .Airflow Executors
Executor
Task A
● Local
● Mesos
Task B
● Kubernetes
Task
C
�
13 . Kubernetes Operator
op = KubernetesPodOperator(
name="example", container image
task_id="Task-A",
namespace='default',
image=[container_image_name],
cmds=["bash", "-cx"],
arguments=["echo", "K8S!"],
labels={"label": "value"},
secrets=[secret_file,secret_env]
volume=[volume],
command to run
volume_mounts=[volume_mount]
affinity=affinity,
is_delete_operator_pod=True,
hostnetwork=False,
tolerations=tolerations)
�
14 .Airflow On Kubernetes
Kubernetes
Task
Task B
D
Task A Task F
Task
Task E
C
DAG & Task
State
�
15 .Airflow DAG Provisioning
GitHub
NFS
EFS
Cinder
[Extend via hooks ...]
�
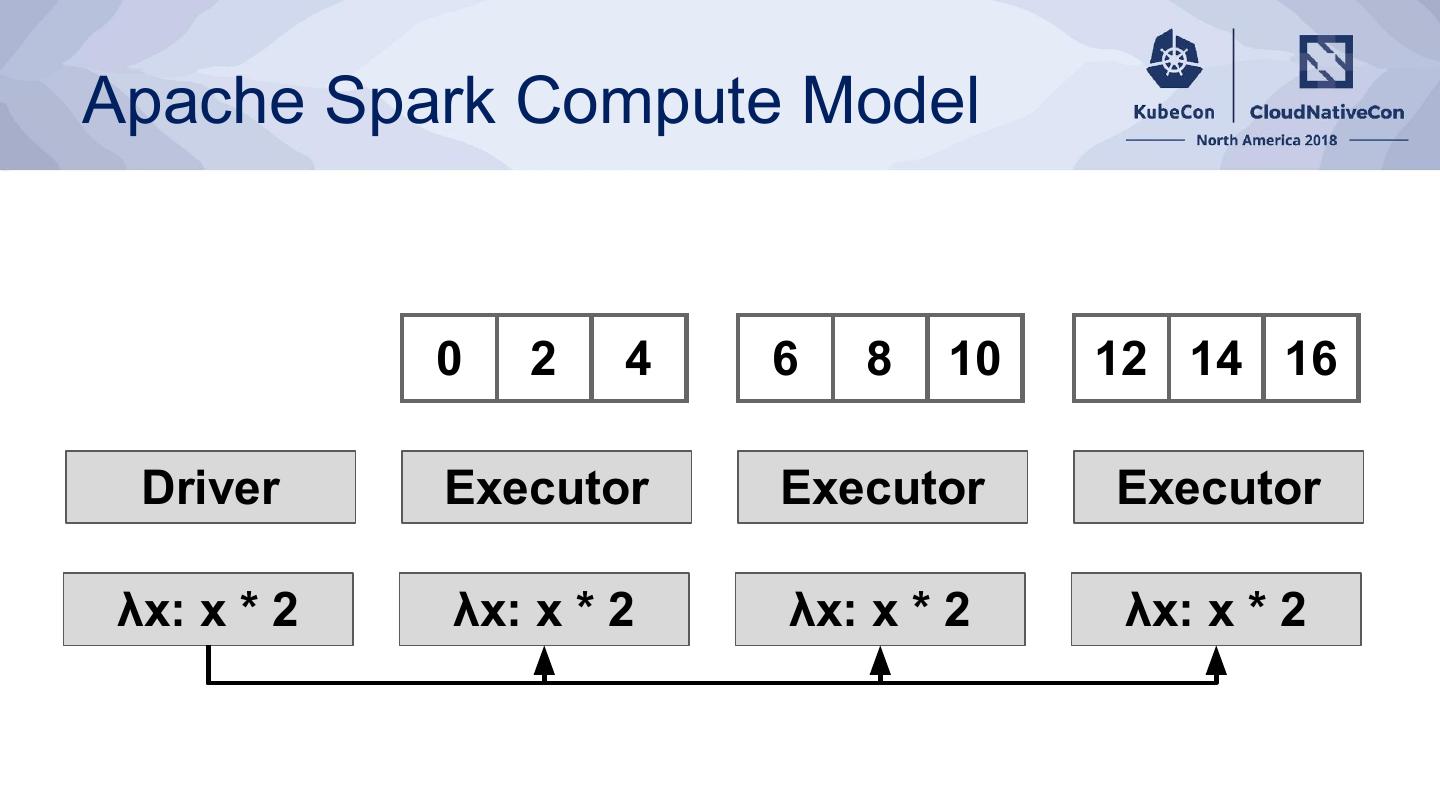
16 .Apache Spark Compute Model
Logical View
App 0 1 2 3 4 5 6 7 8
Physical View
0 1 2 3 4 5 6 7 8
Driver Executor Executor Executor
�
17 .Apache Spark Compute Model
0 2 4 6 8 10 12 14 16
Driver Executor Executor Executor
λx: x * 2 λx: x * 2 λx: x * 2 λx: x * 2
�
18 .Spark on Kubernetes
Driver Pod Executor Pod Executor Pod Executor Pod
0 2 4 6 8 10 12 14 16
Driver Executor Executor Executor
λx: x * 2 λx: x * 2 λx: x * 2 λx: x * 2
�
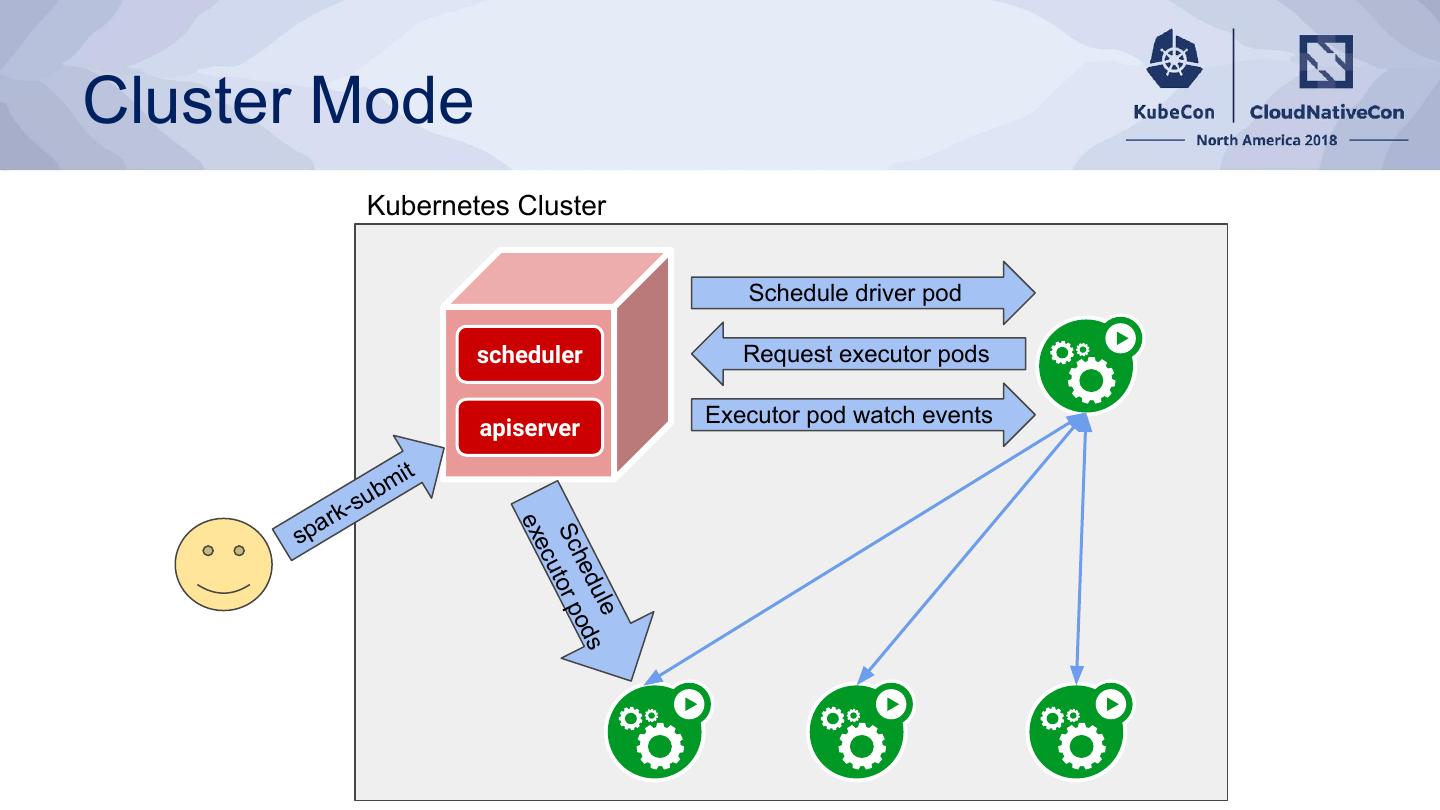
19 .Cluster Mode
Kubernetes Cluster
Schedule driver pod
scheduler Request executor pods
Executor pod watch events
apiserver
mit
- sub
ar k exe
sp
Sc tor p
cu
he
du ods
le
�
20 .K8S Scheduler Backend for Spark
What we have done so far
• Initial release in Spark 2.3.0 with support for cluster mode, Java/Scala,
remote dependencies, and limited pod customization.
• More features in release 2.4.0: Python, R, and limited client mode
support.
• New features in upcoming Spark 3.0: Kerberos support and support
for pod customization using a pod template.
�
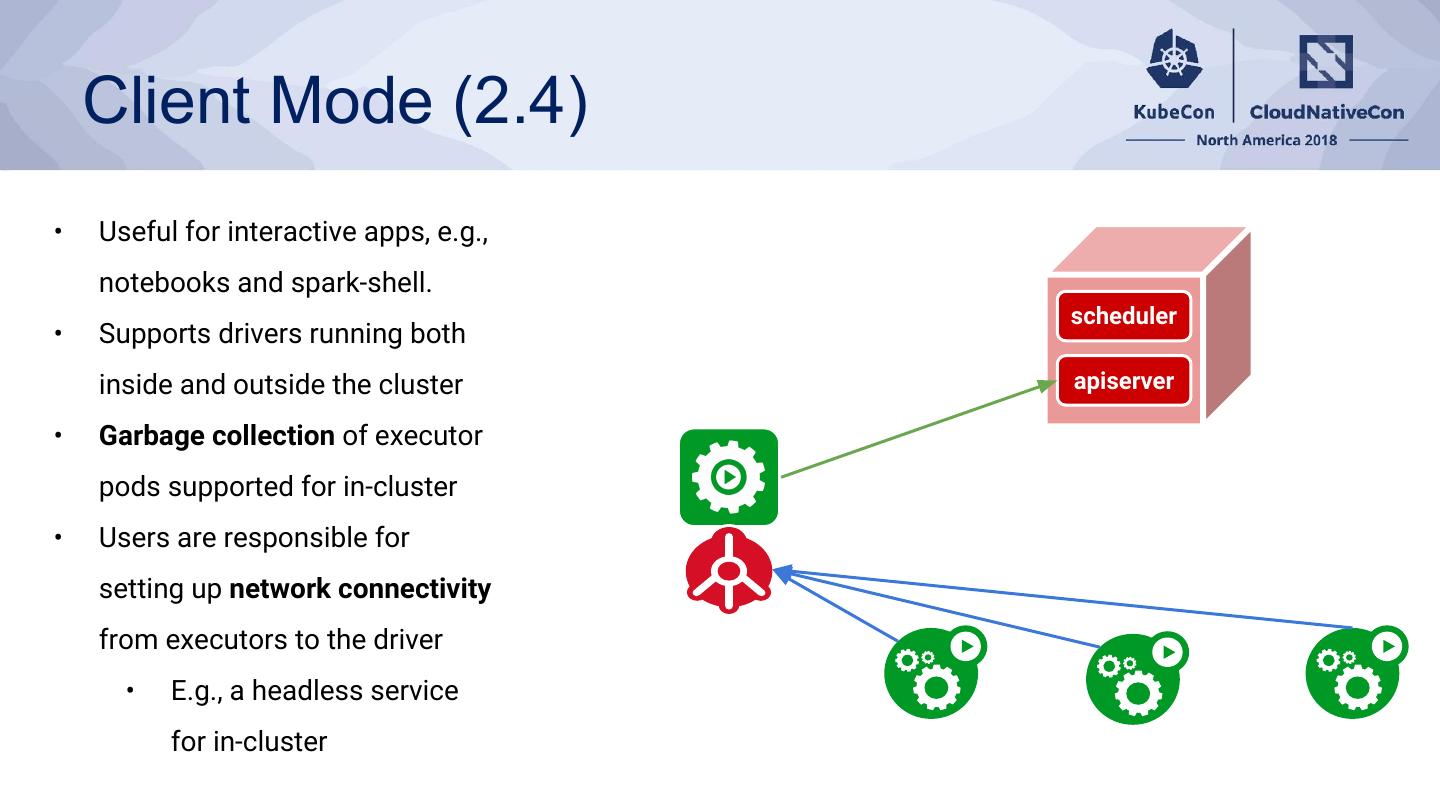
21 . Client Mode (2.4)
• Useful for interactive apps, e.g.,
notebooks and spark-shell.
scheduler
• Supports drivers running both
inside and outside the cluster apiserver
• Garbage collection of executor
pods supported for in-cluster
• Users are responsible for
setting up network connectivity
from executors to the driver
• E.g., a headless service
for in-cluster
�
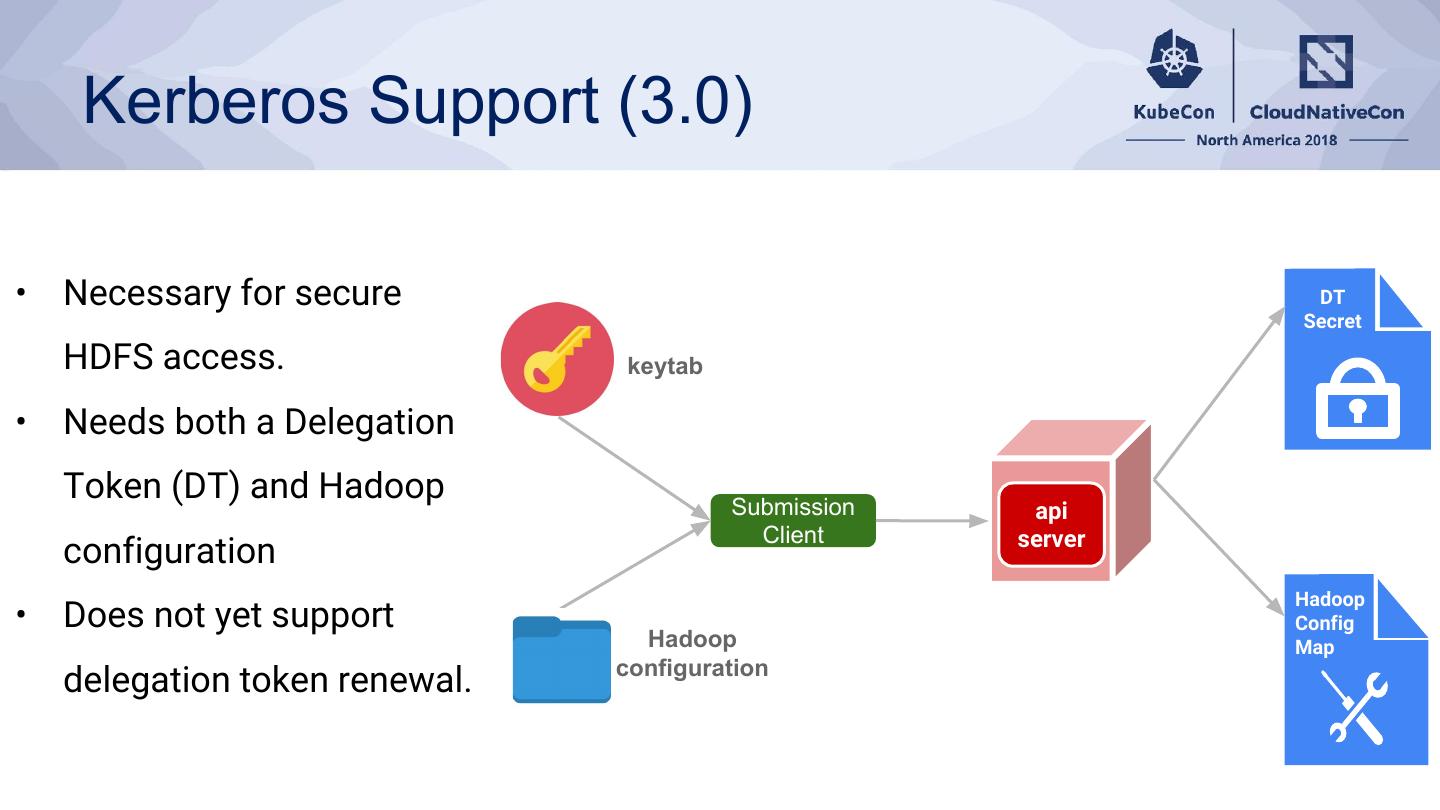
22 . Kerberos Support (3.0)
• Necessary for secure DT
Secret
HDFS access. keytab
• Needs both a Delegation
Token (DT) and Hadoop Submission api
Client server
configuration
Hadoop
• Does not yet support Config
Hadoop Map
configuration
delegation token renewal.
�
23 . Kubernetes Operator for Spark
apiVersion: "sparkoperator.k8s.io/v1alpha1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
• Kubernetes CRD + custom controller mainClass: org.apache.spark.examples.SparkPi
• Supports extensive pod customization through a mutating mainApplicationFile: "..."
driver:
admission webhook memory: "512m"
serviceAccount: spark
• Native Cron support for running scheduled applications executor:
instances: 1
• Automatic application restart with a configurable restart policy memory: "512m"
monitoring:
• Supports exporting application-level metrics and driver/executor exposeDriverMetrics: true
metrics to Prometheus exposeExecutorMetrics: true
prometheus:
• Supports installation with Helm port: 8090
restartPolicy: Never
• Comes with a command-line tool sparkctl
�
24 . Roadmap (3.0 and Beyond)
• Support for using a pod template to customize the driver and executor pods.
• No more new configuration properties
• Dynamic resource allocation and external shuffle service.
• New shuffle service work in progress
• Better support for local application dependencies on client machines.
• Driver resilience for Spark Streaming applications.
• Better scheduling support.
�
25 .Getting Involved
• github.com/apache/spark: code under resource-managers/kubernetes
• Documentation: http://spark.apache.org/docs/latest/running-on-kubernetes.html
• Spark user & dev mailing lists
• Jira (use Kubernetes for Component)
• Slack sig-big-data: https://kubernetes.slack.com/messages/sig-big-data
�
26 .Trajectory: “Graduating” Projects
Apache Spark K8S Backend
Project upstream
channels
Apache Airflow
�
27 .Trajectory: Reaching Out To New
Communities
Flink Operator Demo
Hazelcast (IMDG & Jet)
�
28 . SIG Big Data Charter
Charter currently submitted for consideration
https://github.com/kubernetes/community/pull/2988
Kubernetes Definition of a SIG: Owns some
component, subsystem or other body of Kubernetes
code.
�
29 .Future Directions
Acquire ownership of Kubernetes code
Working Group
SIG sub-project
User Community
�