Introduction to Spark
分享
点赞
7
收藏
4
下载 1
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
 深度递归
深度递归
/
发布于
/
3665
人观看
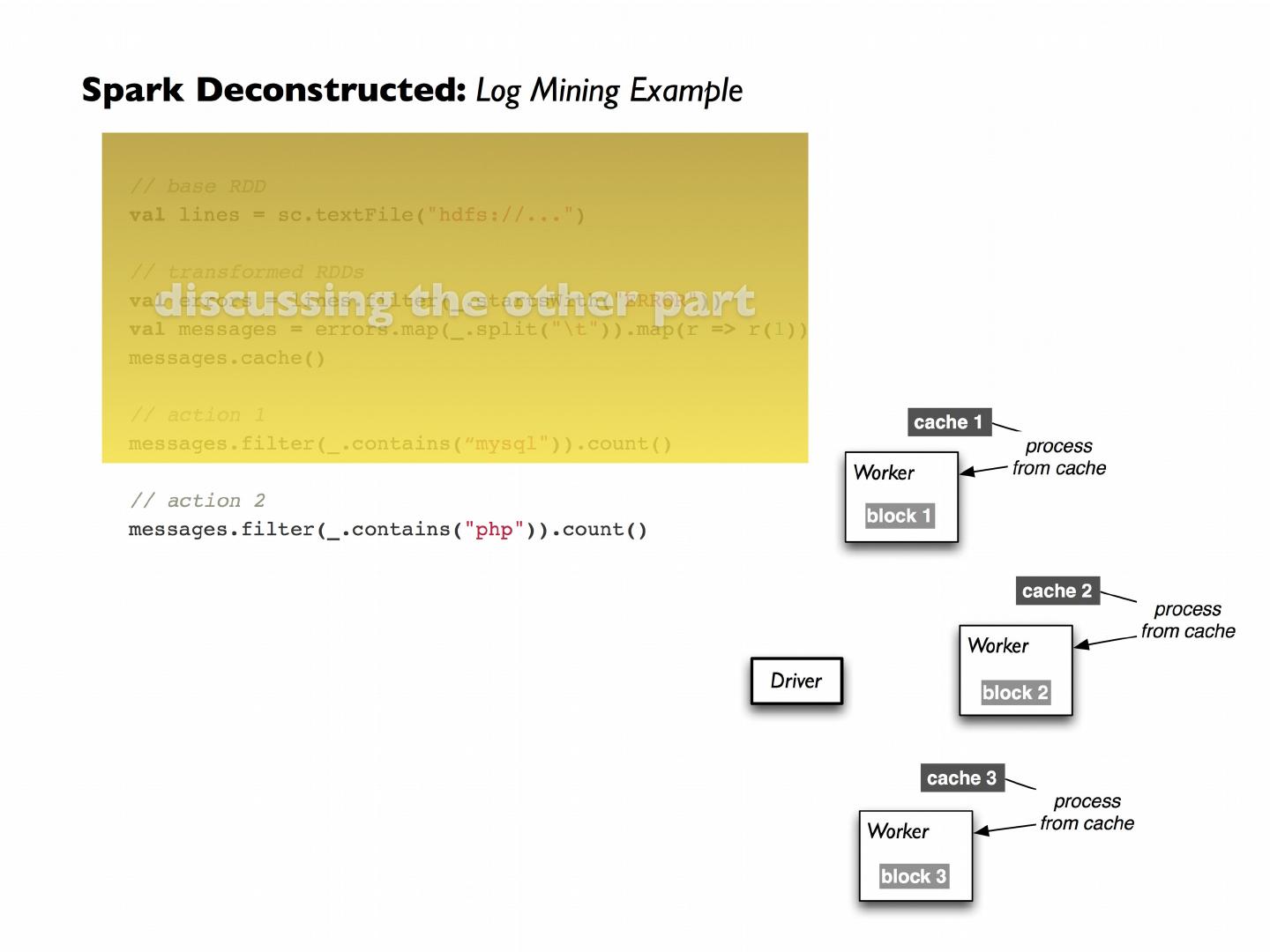
Spark’s goal was to generalize MapReduce to support new applications within the same engine
Two additions:
Fast data sharing
General DAGs (directed acyclic graphs)
Best of both worlds: easy to program & more efficient engine in general
展开查看详情
1 .Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks )
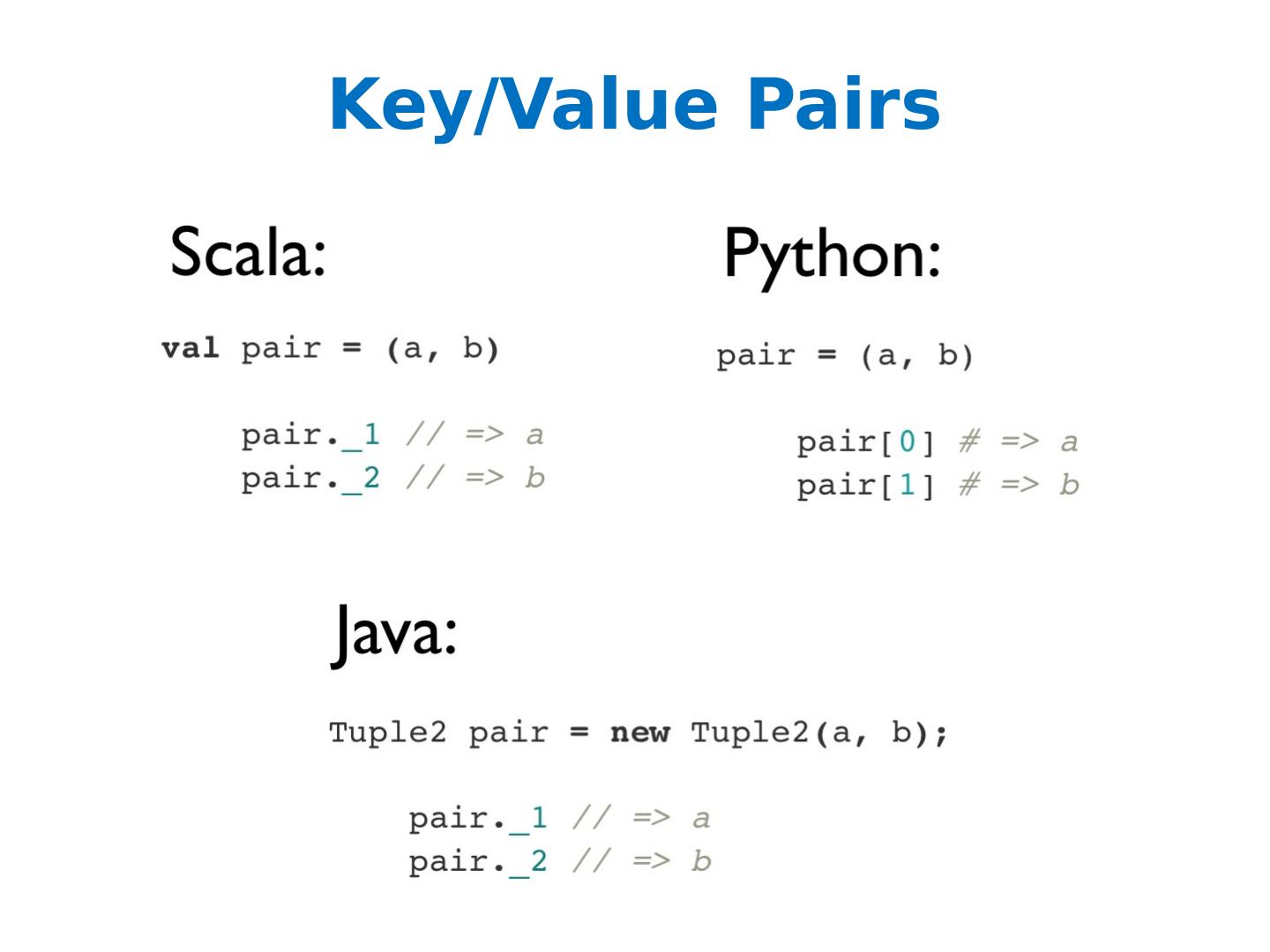
4 .API Hooks Scala / Java All Java libraries *.jar http://www.scala-lang.org Python Anaconda: https://store.continuum.io/cshop/anaconda /
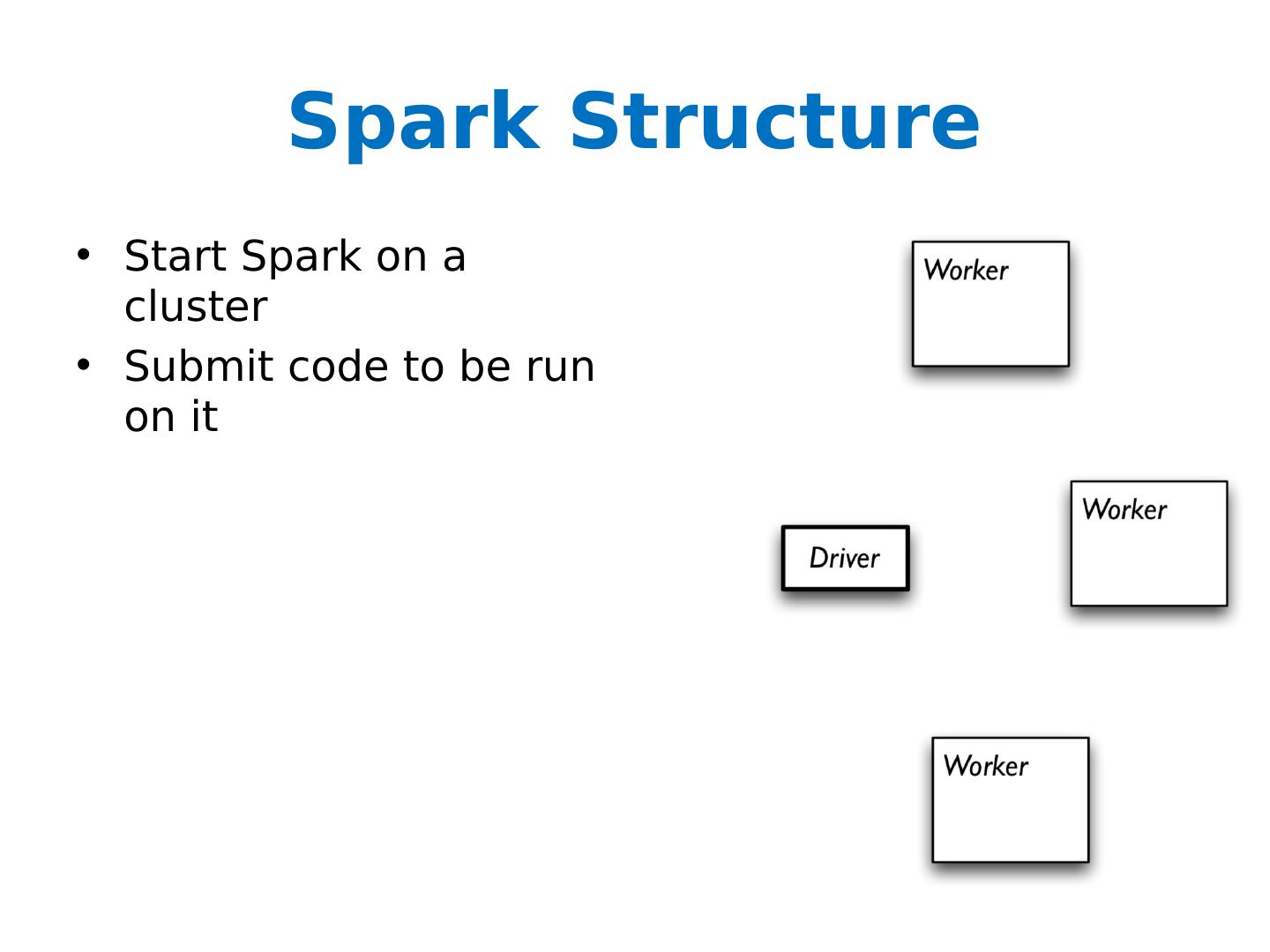
6 .Spark Structure Start Spark on a cluster Submit code to be run on it
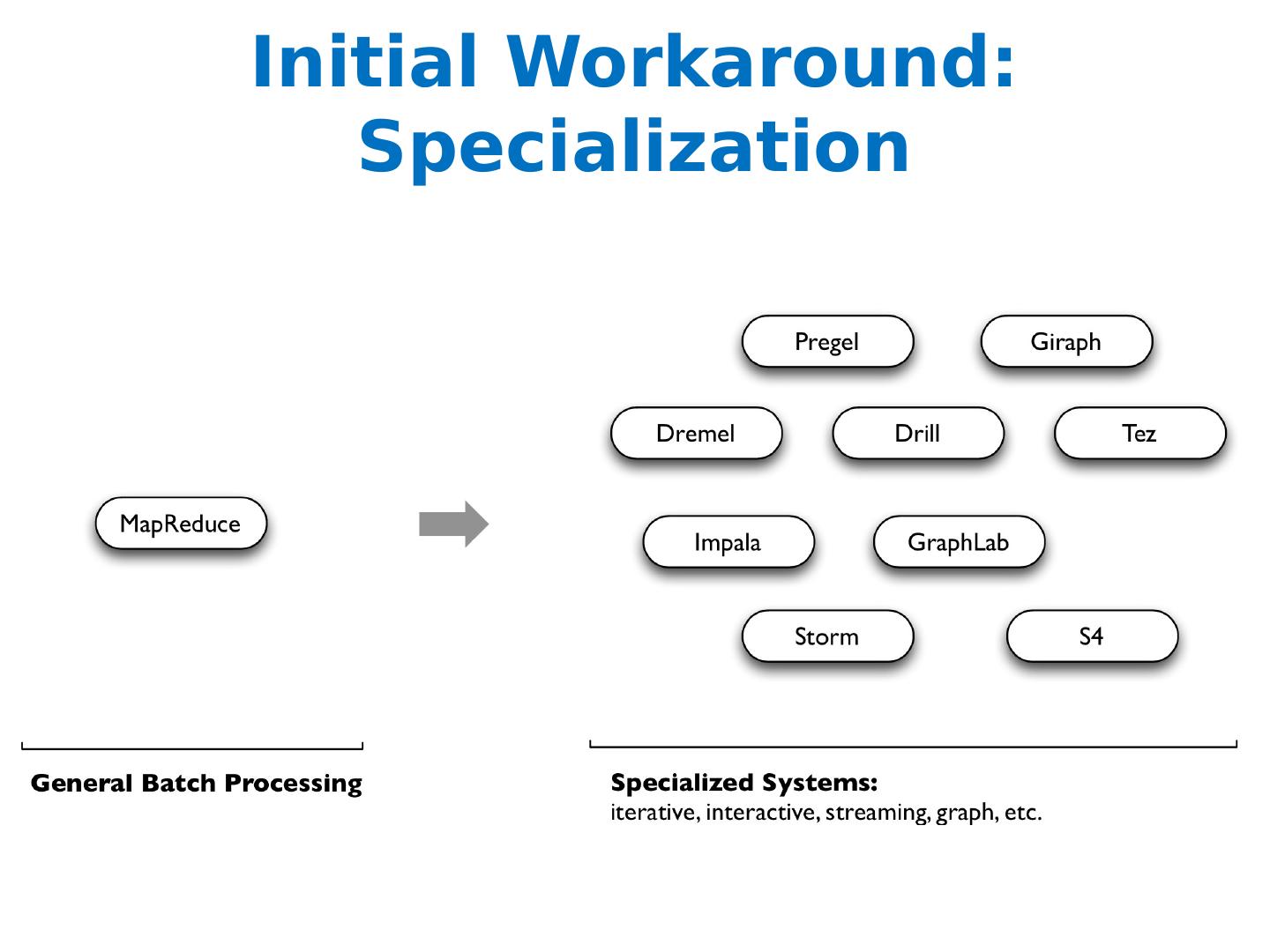
22 .Limitations of MapReduce Performance bottlenecks—not all jobs can be cast as batch processes Graphs? Programming in Hadoop is hard Boilerplate boilerplate everywhere
23 .Initial Workaround: Specialization
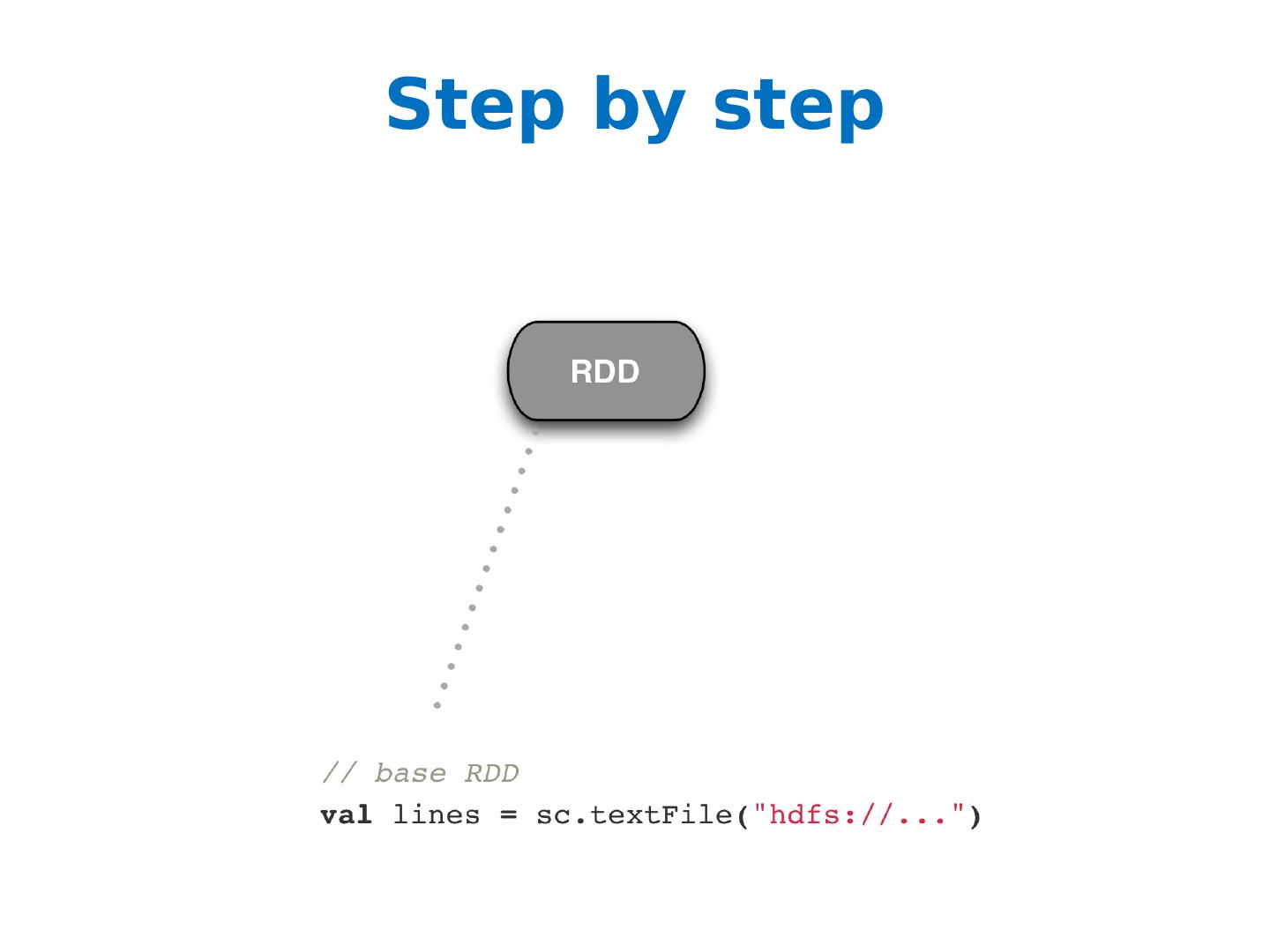
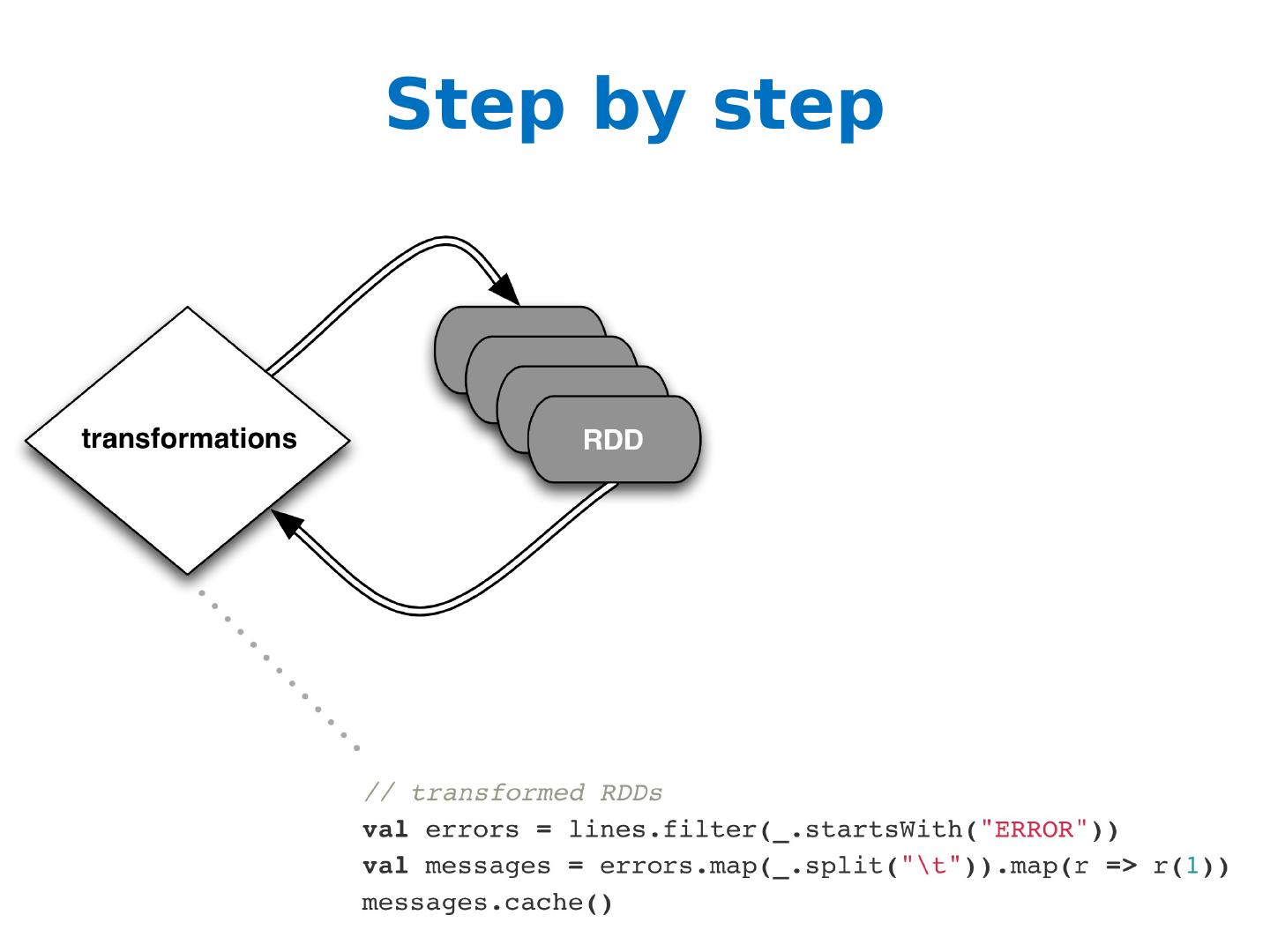
24 .Along Came Spark Spark’s goal was to generalize MapReduce to support new applications within the same engine Two additions: Fast data sharing General DAGs (directed acyclic graphs) Best of both worlds: easy to program & more efficient engine in general
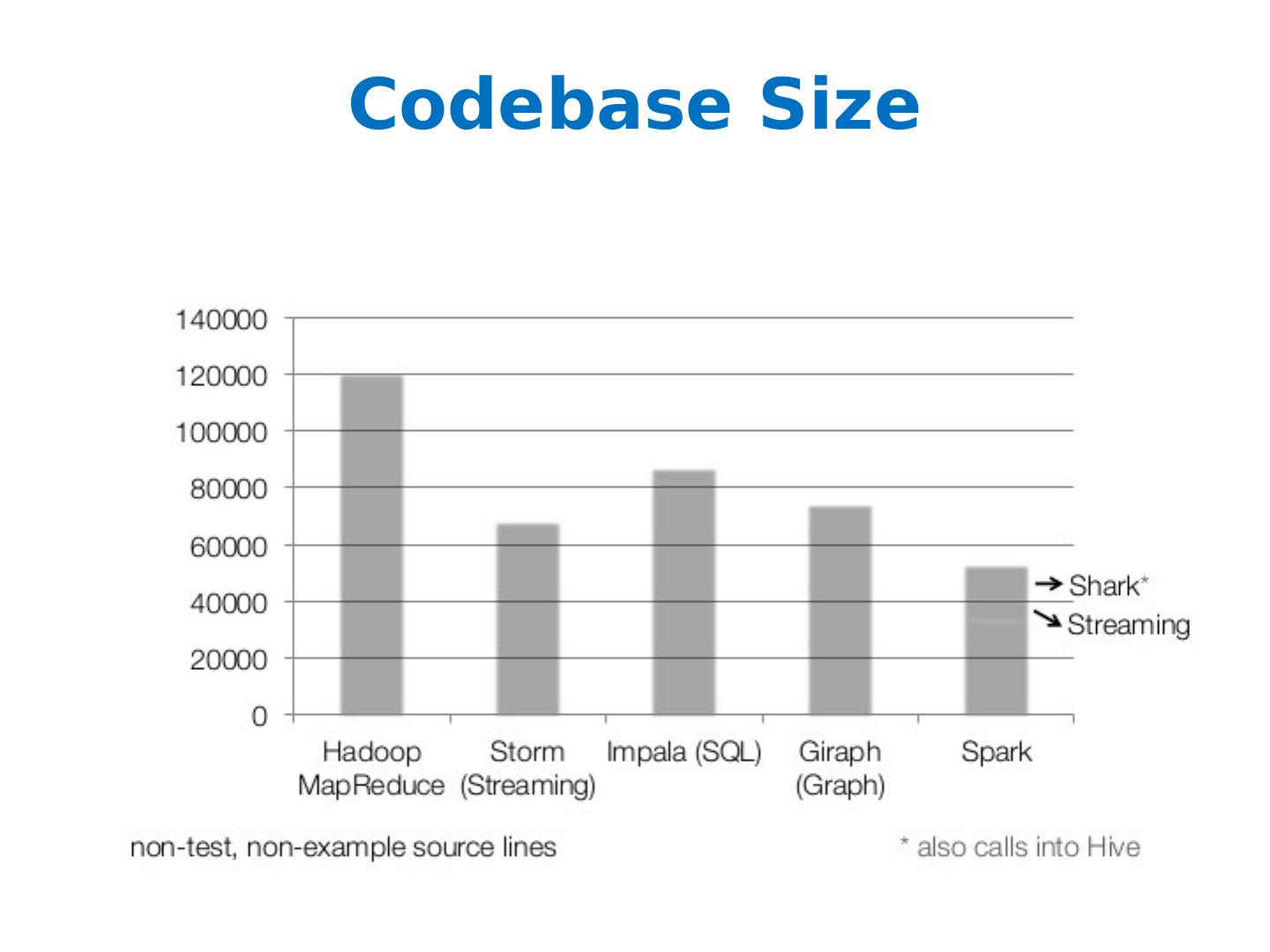
26 .More on Spark More general Supports map/reduce paradigm Supports vertex-based paradigm General compute engine (DAG) More API hooks Scala , Java, and Python More interfaces Batch ( Hadoop ), real-time (Storm), and interactive (???)
27 .Interactive Shells Spark creates a SparkContext object (cluster information) For either shell: sc External programs use a static constructor to instantiate the context
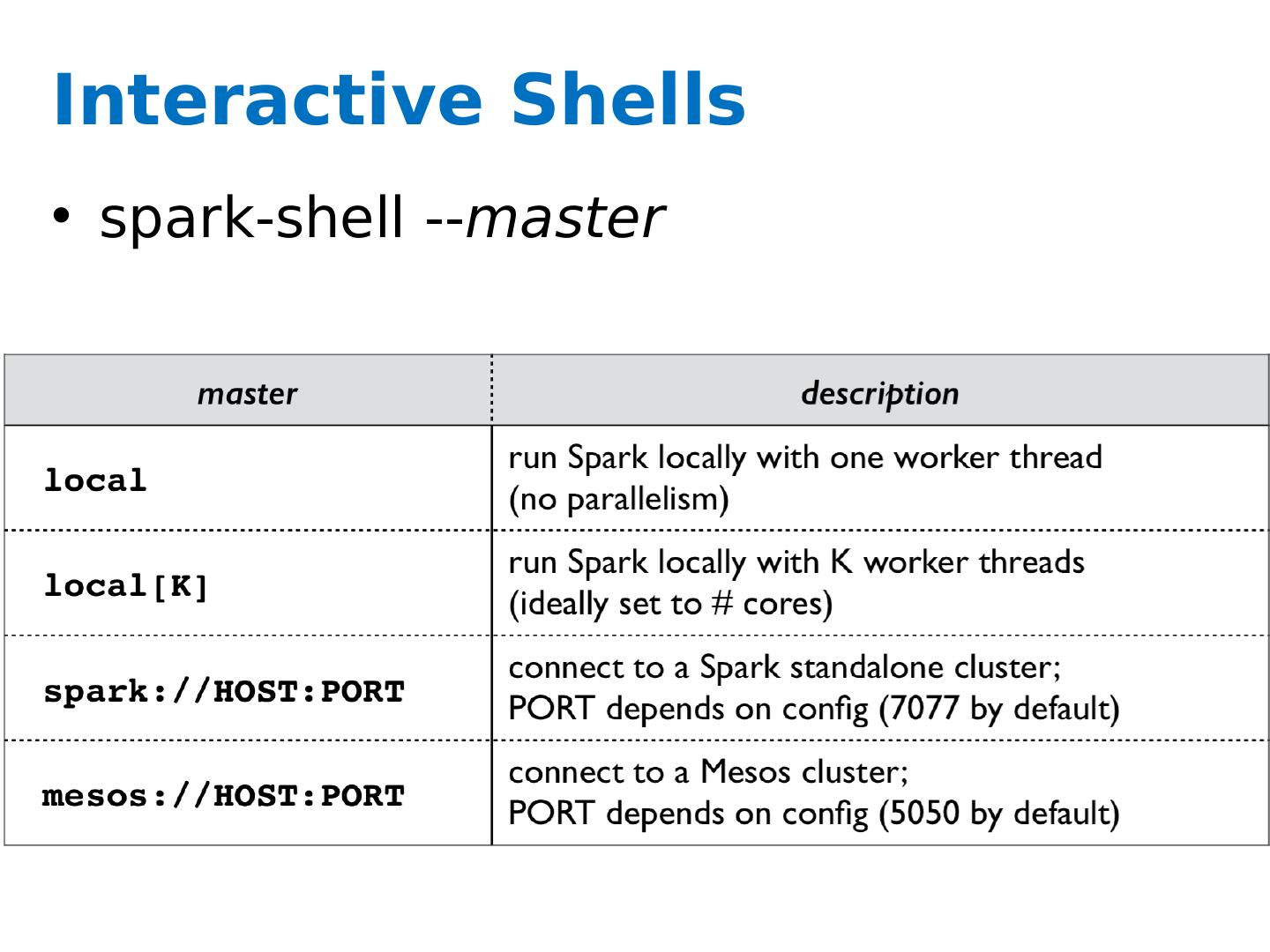
28 .Interactive Shells spark-shell -- master
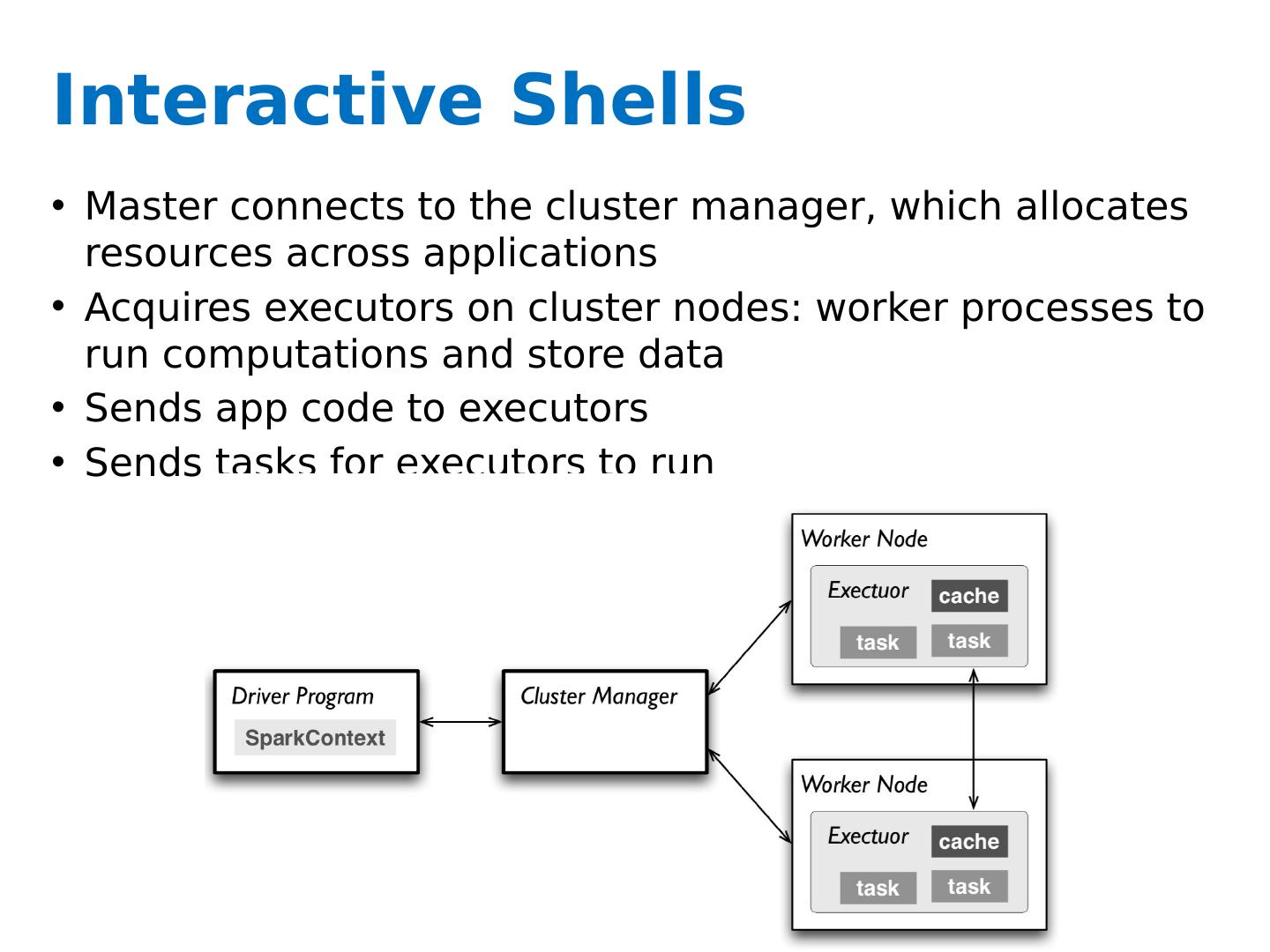
29 .Interactive Shells Master connects to the cluster manager, which allocates resources across applications Acquires executors on cluster nodes: worker processes to run computations and store data Sends app code to executors Sends tasks for executors to run