




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase介绍及案例分析
1、HBase基础知识介绍, 2、车联网、物联网、分析、用户画像等典型场景架构分析。
展开查看详情
1 . HBase基本知识介绍及典型案例分析 阿里云 吴阳平(明惠) 阿里云HBase业务架构师 过往记忆博主 中国 HBase 技术社区网站:http://hbase.group
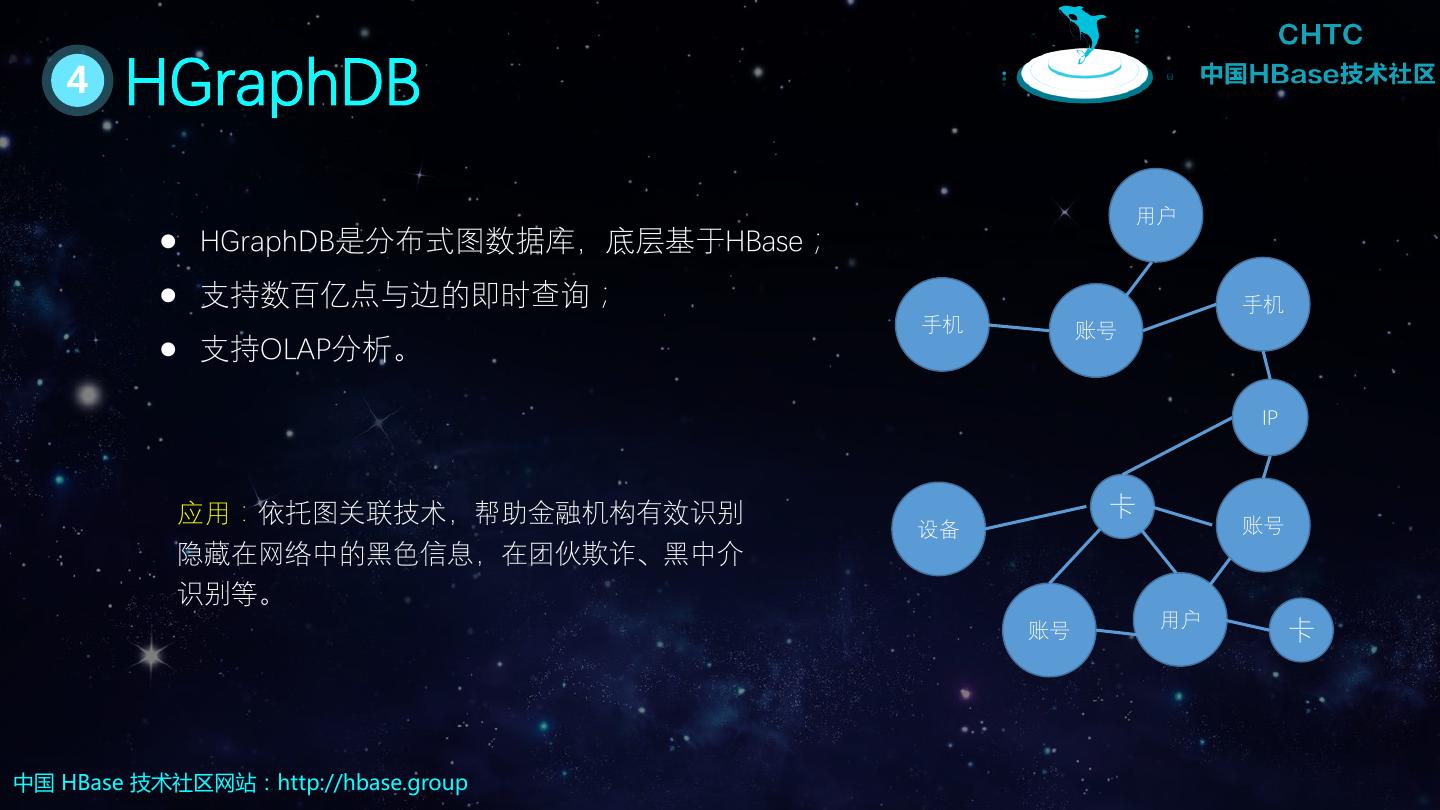
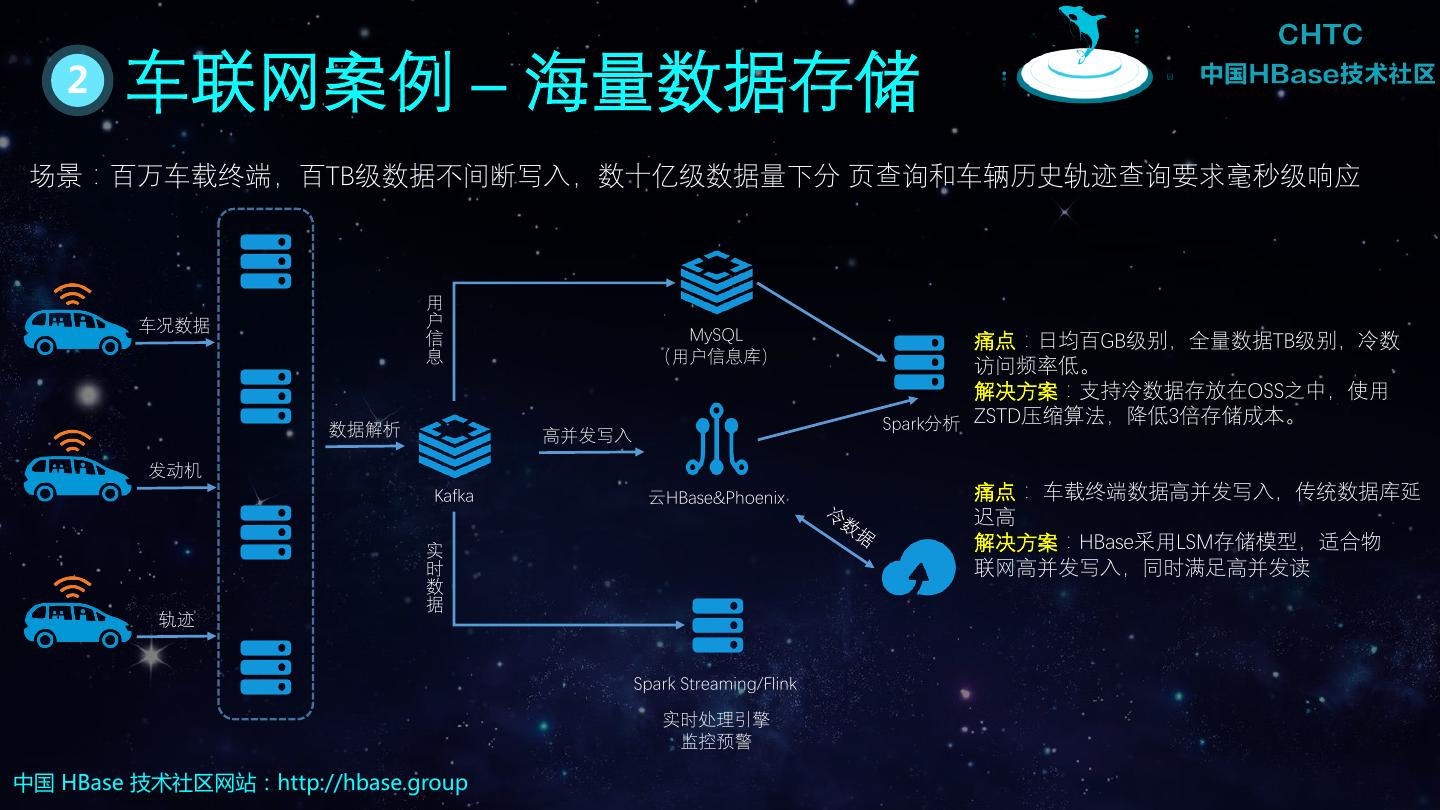
2 . 目录 / Contents 01 HBase基本知识 02 HBase读写流程 03 RowKey设计要点 04 HBase生态介绍 05 HBase典型案例分析 中国 HBase 技术社区网站:http://hbase.group
3 . 01 HBase基本知识 中国 HBase 技术社区网站:http://hbase.group
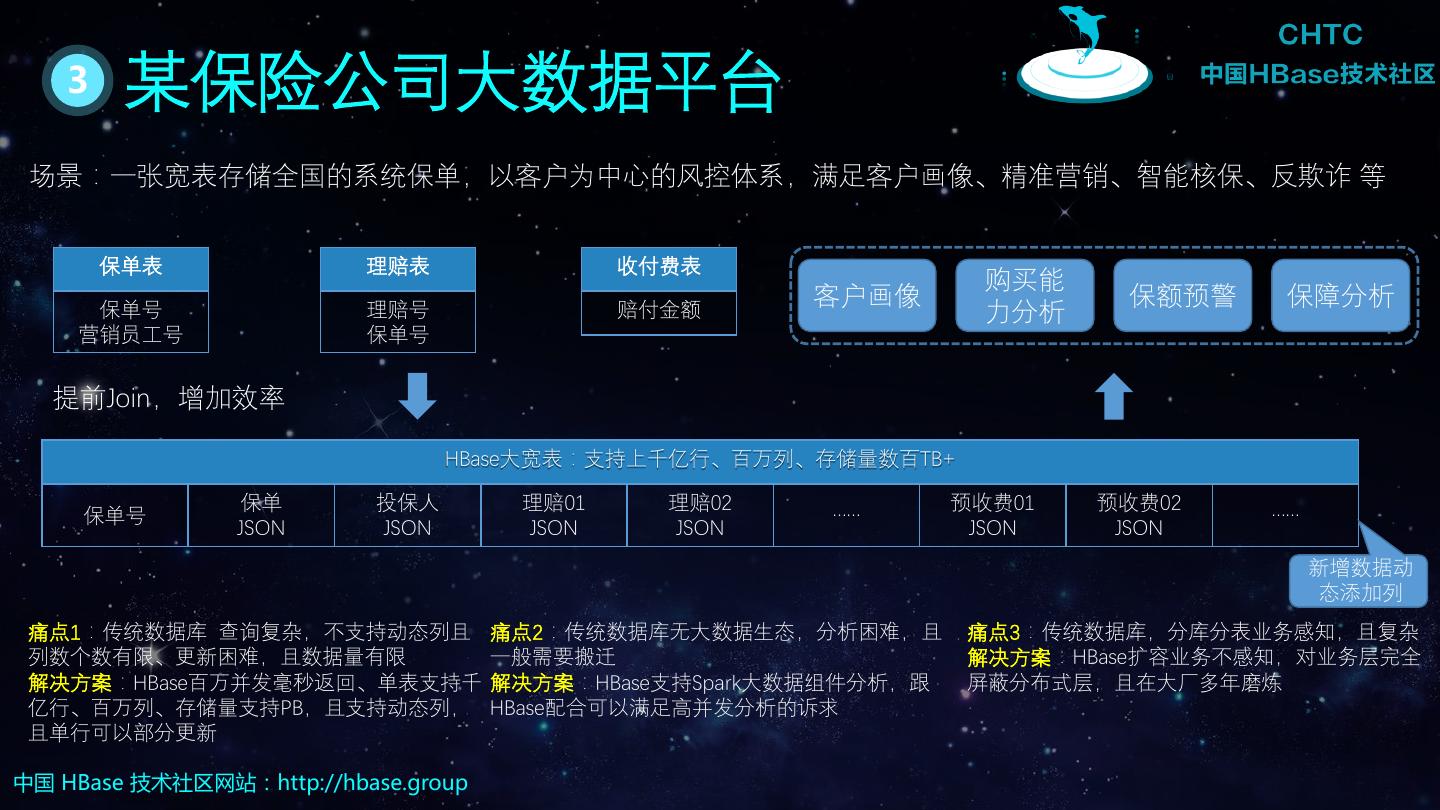
4 . 1 HBase简介 分布式、多版本、面向列的开源数据库; 支持上亿行、百万列; 强一致性、高扩展、高可用。 中国 HBase 技术社区网站:http://hbase.group
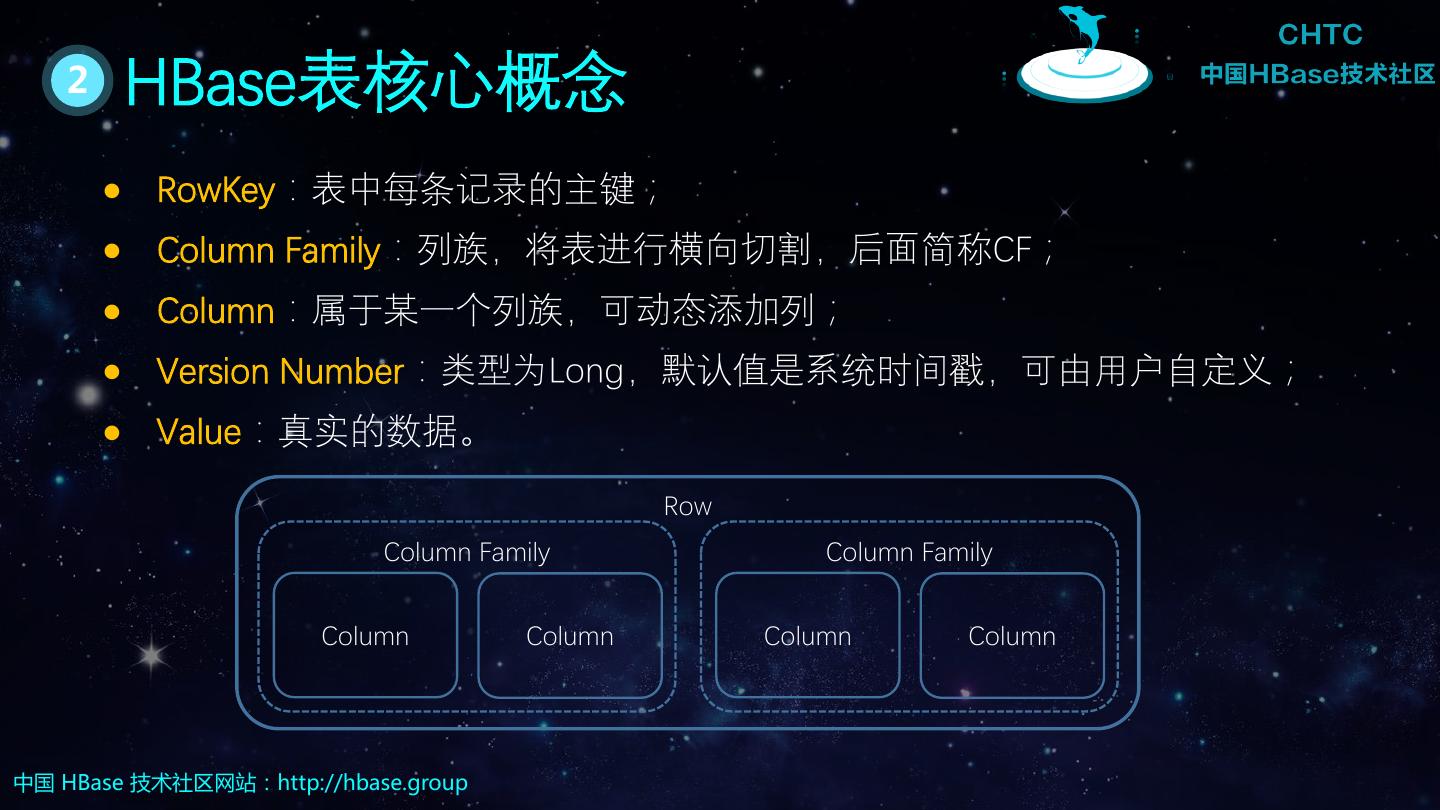
5 . 2 HBase表核心概念 RowKey:表中每条记录的主键; Column Family:列族,将表进行横向切割,后面简称CF; Column:属于某一个列族,可动态添加列; Version Number:类型为Long,默认值是系统时间戳,可由用户自定义; Value:真实的数据。 Row Column Family Column Family Column Column Column Column 中国 HBase 技术社区网站:http://hbase.group
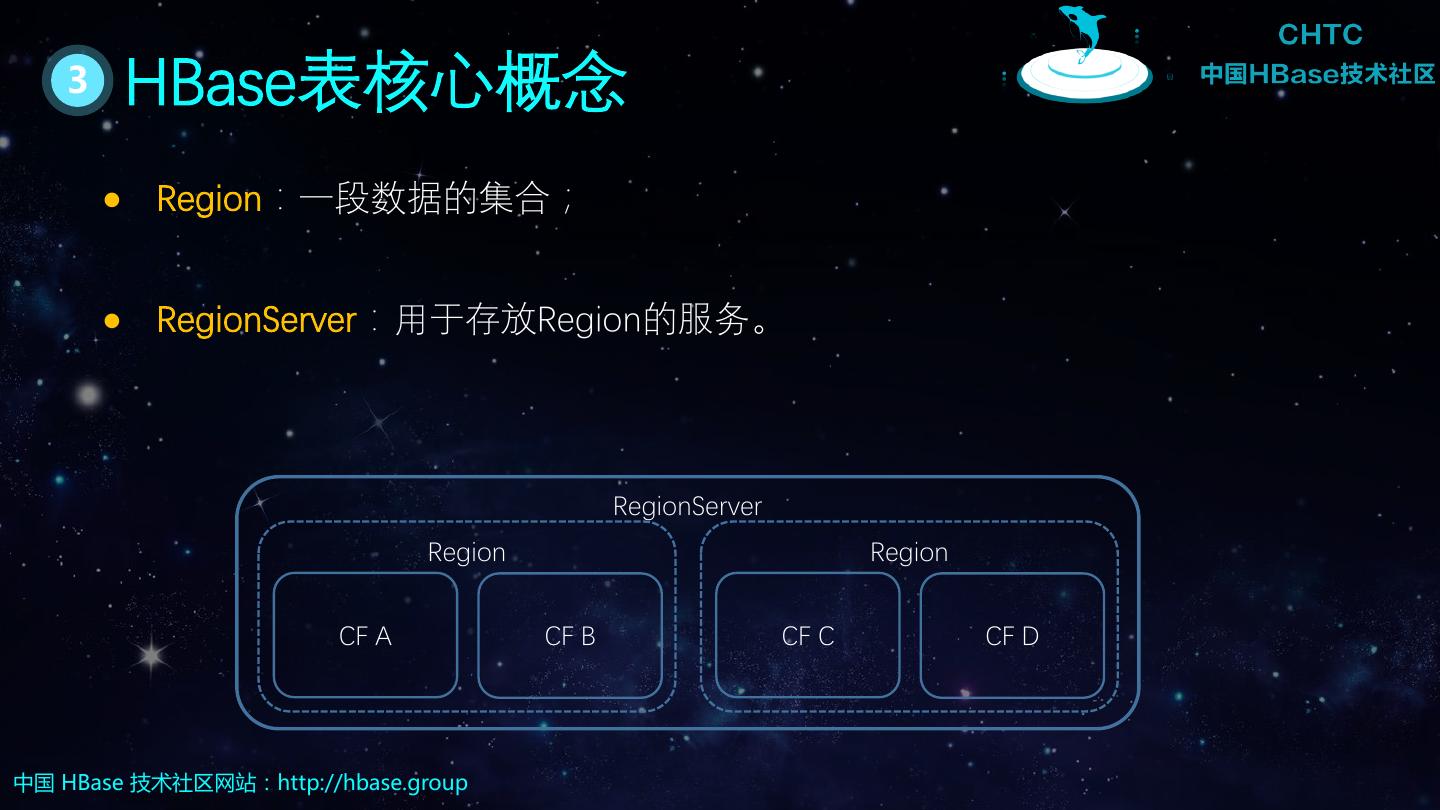
6 . 3 HBase表核心概念 Region:一段数据的集合; RegionServer:用于存放Region的服务。 RegionServer Region Region CF A CF B CF C CF D 中国 HBase 技术社区网站:http://hbase.group
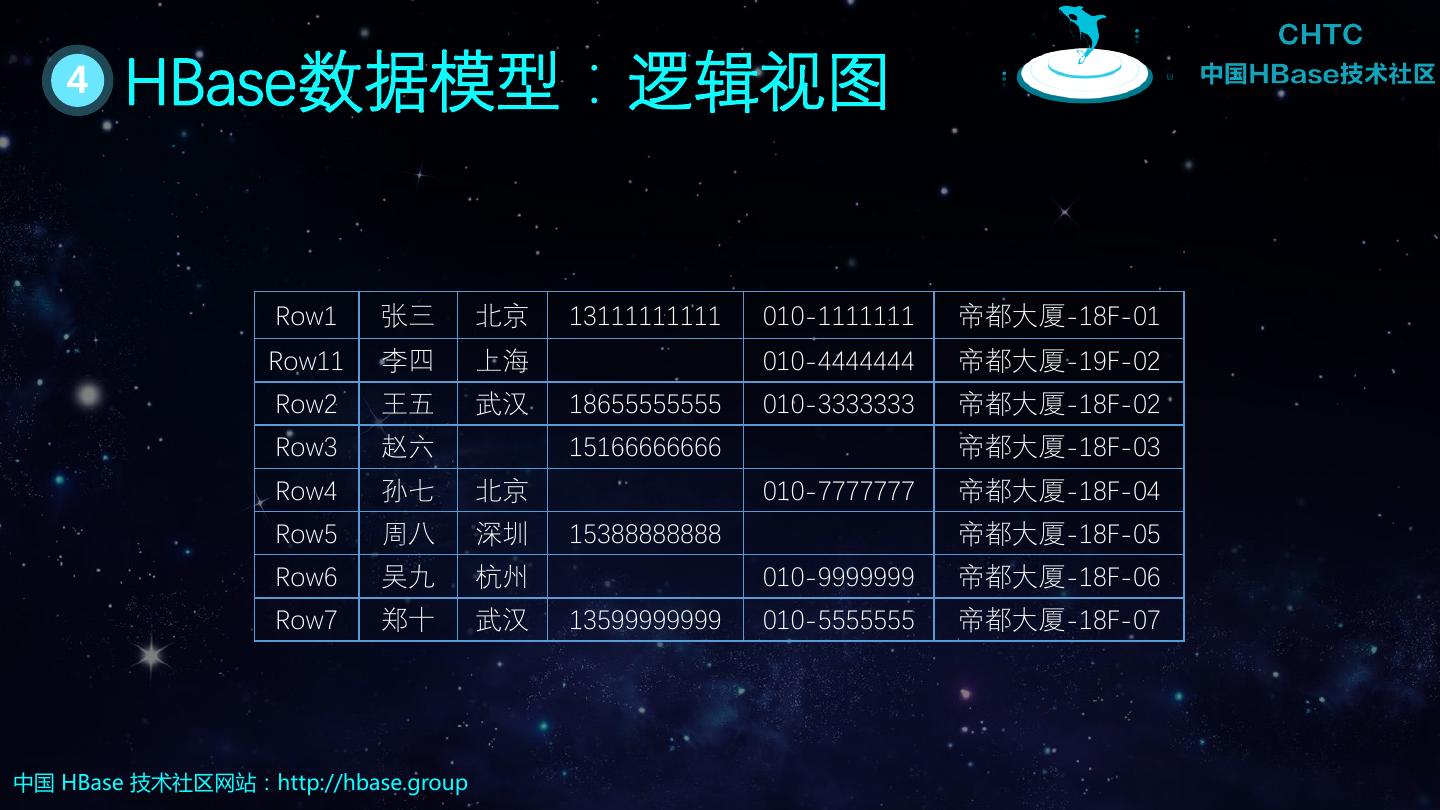
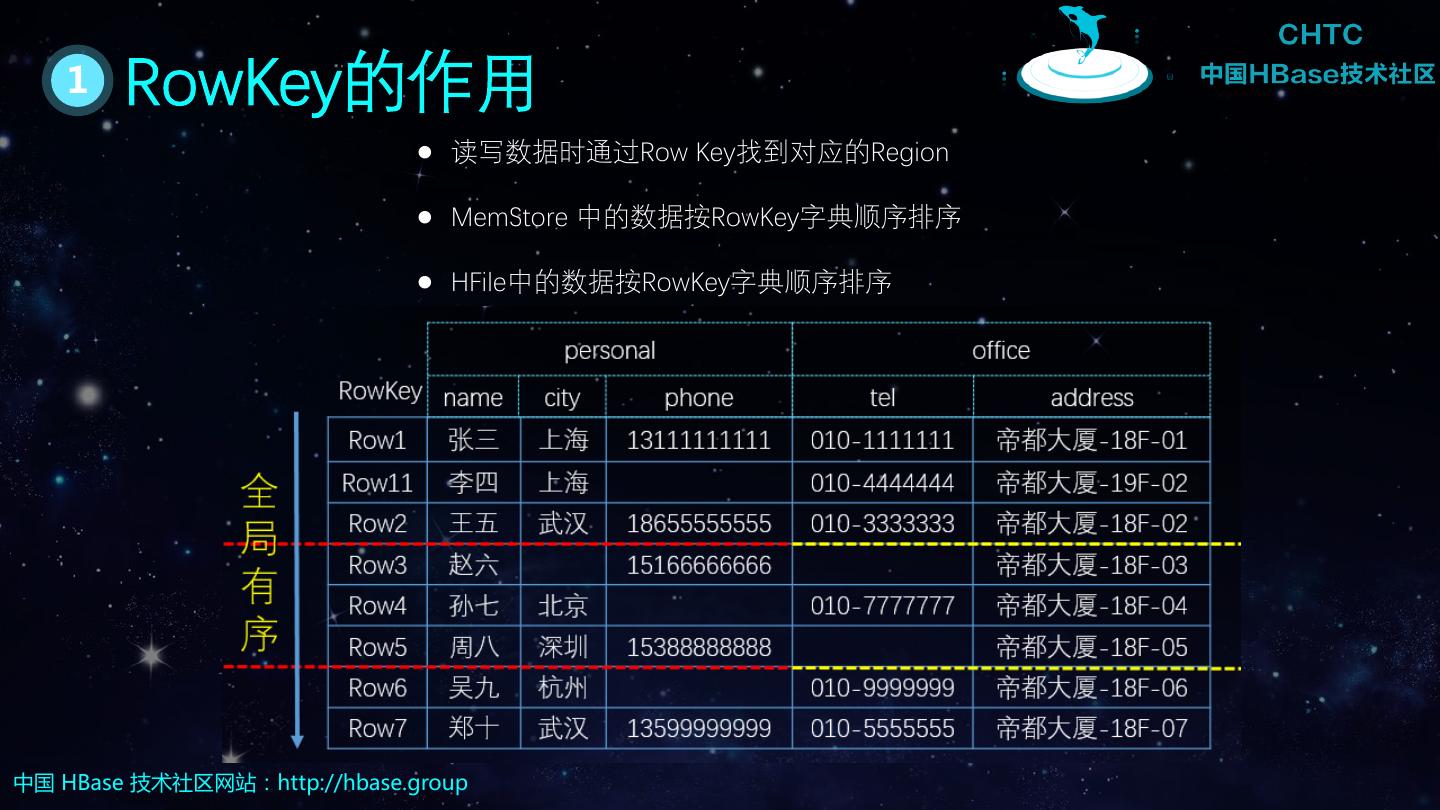
7 . 4 HBase数据模型:逻辑视图 Row1 张三 北京 13111111111 010-1111111 帝都大厦-18F-01 Row11 李四 上海 010-4444444 帝都大厦-19F-02 Row2 王五 武汉 18655555555 010-3333333 帝都大厦-18F-02 Row3 赵六 15166666666 帝都大厦-18F-03 Row4 孙七 北京 010-7777777 帝都大厦-18F-04 Row5 周八 深圳 15388888888 帝都大厦-18F-05 Row6 吴九 杭州 010-9999999 帝都大厦-18F-06 Row7 郑十 武汉 13599999999 010-5555555 帝都大厦-18F-07 中国 HBase 技术社区网站:http://hbase.group
8 . 4 HBase数据模型:逻辑视图 列簇 列 Cell personal office RowKey name city phone tel address Row1 张三 北京 13111111111 010-1111111 帝都大厦-18F-01 Region1 Row11 李四 上海 010-4444444 帝都大厦-19F-02 Region4 Row2 王五 武汉 18655555555 010-3333333 帝都大厦-18F-02 Row3 赵六 15166666666 帝都大厦-18F-03 Region2 Row4 孙七 北京 010-7777777 帝都大厦-18F-04 Region5 Row5 周八 深圳 15388888888 帝都大厦-18F-05 Row6 吴九 杭州 010-9999999 帝都大厦-18F-06 Region3 Region6 Row7 郑十 武汉 13599999999 010-5555555 帝都大厦-18F-07 整个表示按照RowKey字典顺序排序的 中国 HBase 技术社区网站:http://hbase.group
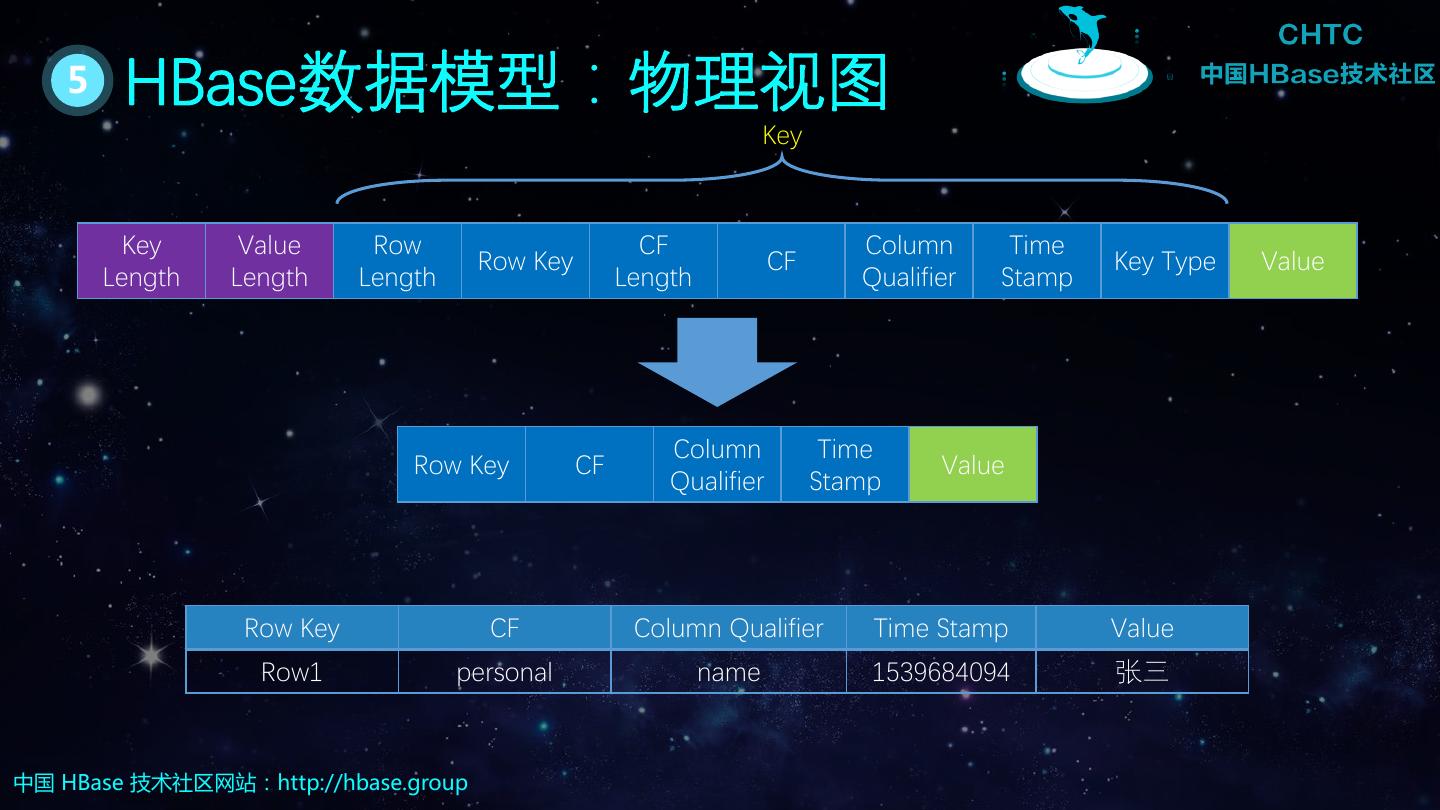
9 . 5 HBase数据模型:物理视图 Key Key Value Row CF Column Time Row Key CF Key Type Value Length Length Length Length Qualifier Stamp Column Time Row Key CF Value Qualifier Stamp Row Key CF Column Qualifier Time Stamp Value Row1 personal name 1539684094 张三 中国 HBase 技术社区网站:http://hbase.group
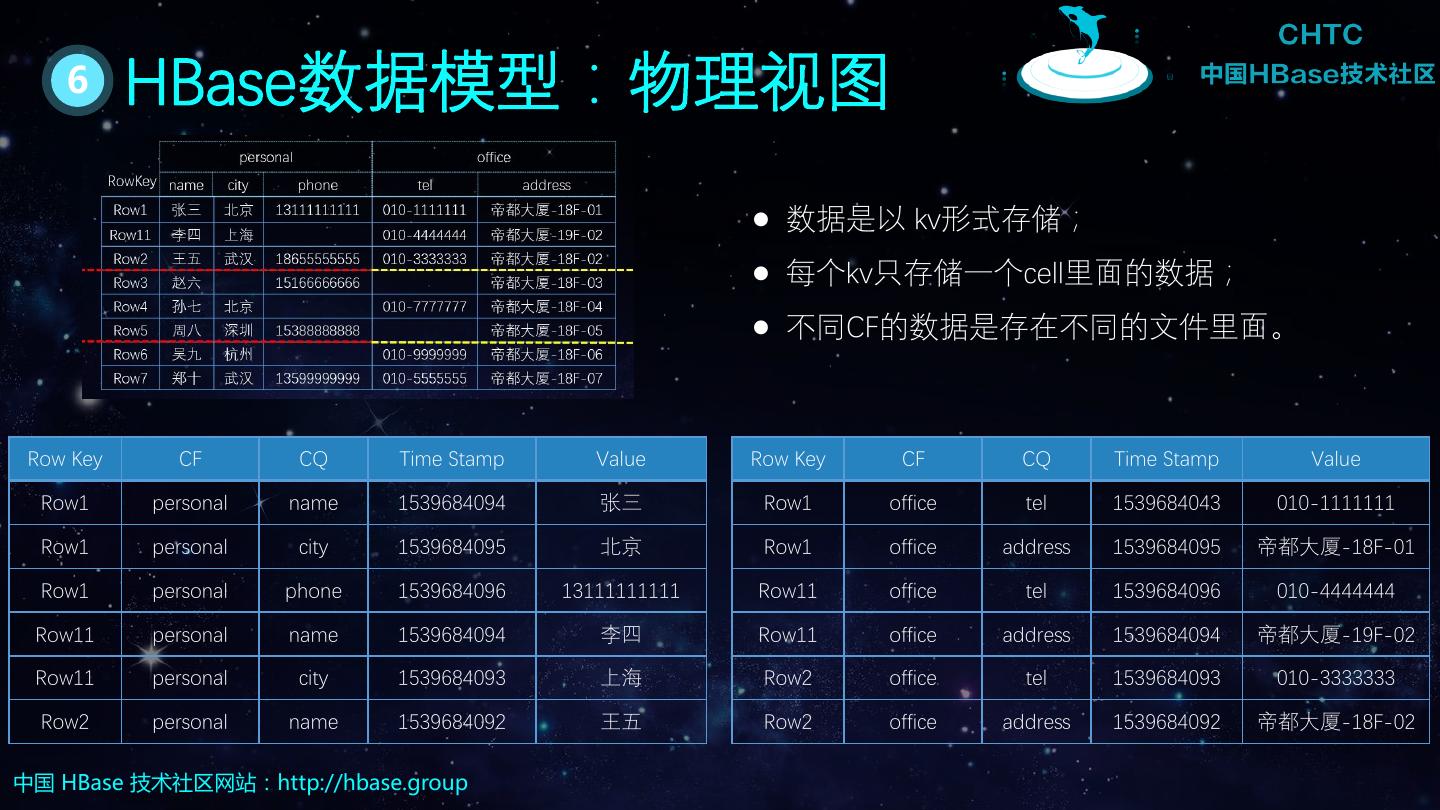
10 . 6 HBase数据模型:物理视图 数据是以 kv形式存储; 每个kv只存储一个cell里面的数据; 不同CF的数据是存在不同的文件里面。 Row Key CF CQ Time Stamp Value Row Key CF CQ Time Stamp Value Row1 personal name 1539684094 张三 Row1 office tel 1539684043 010-1111111 Row1 personal city 1539684095 北京 Row1 office address 1539684095 帝都大厦-18F-01 Row1 personal phone 1539684096 13111111111 Row11 office tel 1539684096 010-4444444 Row11 personal name 1539684094 李四 Row11 office address 1539684094 帝都大厦-19F-02 Row11 personal city 1539684093 上海 Row2 office tel 1539684093 010-3333333 Row2 personal name 1539684092 王五 Row2 office address 1539684092 帝都大厦-18F-02 中国 HBase 技术社区网站:http://hbase.group
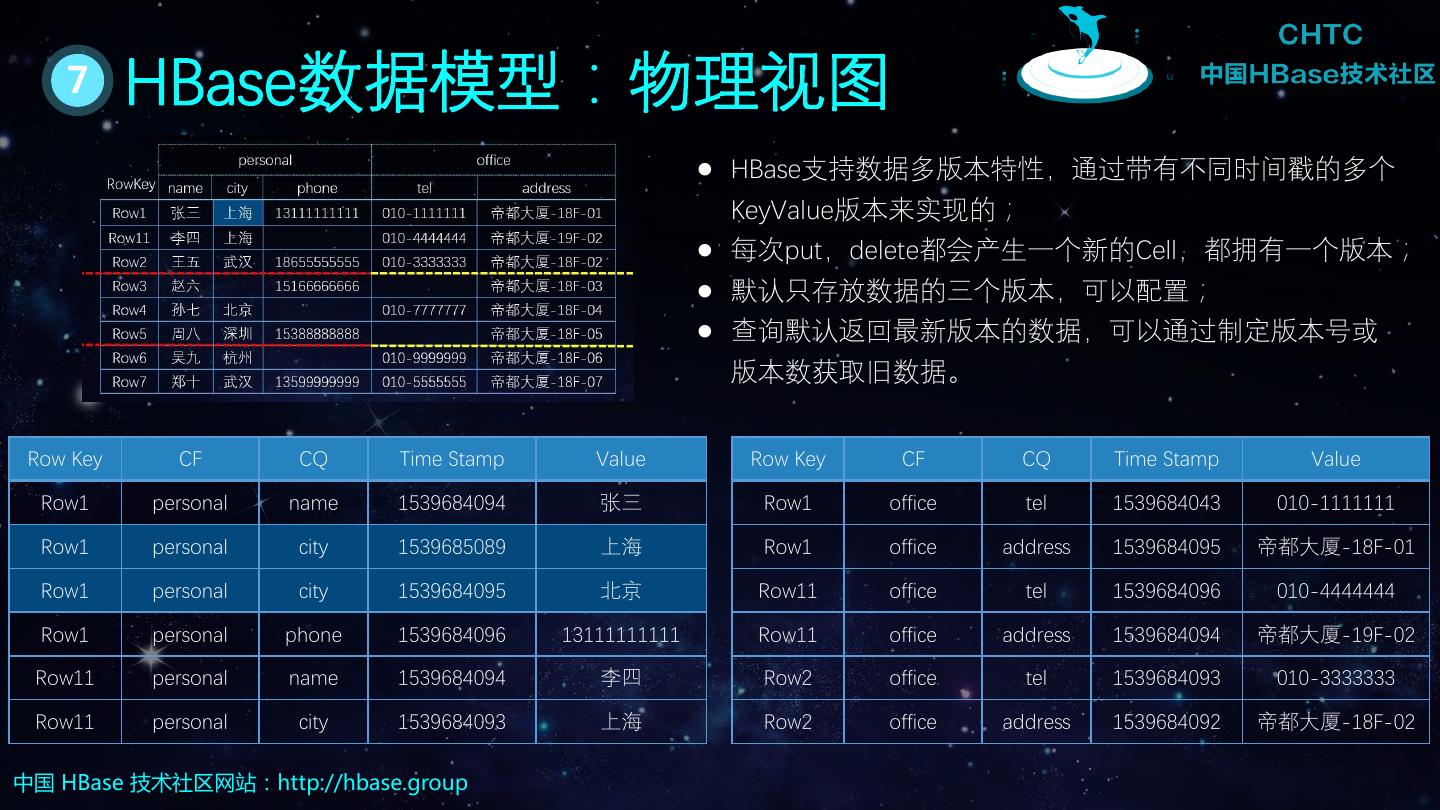
11 . 7 HBase数据模型:物理视图 HBase支持数据多版本特性,通过带有不同时间戳的多个 KeyValue版本来实现的; 每次put,delete都会产生一个新的Cell,都拥有一个版本; 默认只存放数据的三个版本,可以配置; 查询默认返回最新版本的数据,可以通过制定版本号或 版本数获取旧数据。 Row Key CF CQ Time Stamp Value Row Key CF CQ Time Stamp Value Row1 personal name 1539684094 张三 Row1 office tel 1539684043 010-1111111 Row1 personal city 1539685089 上海 Row1 office address 1539684095 帝都大厦-18F-01 Row1 personal city 1539684095 北京 Row11 office tel 1539684096 010-4444444 Row1 personal phone 1539684096 13111111111 Row11 office address 1539684094 帝都大厦-19F-02 Row11 personal name 1539684094 李四 Row2 office tel 1539684093 010-3333333 Row11 personal city 1539684093 上海 Row2 office address 1539684092 帝都大厦-18F-02 中国 HBase 技术社区网站:http://hbase.group
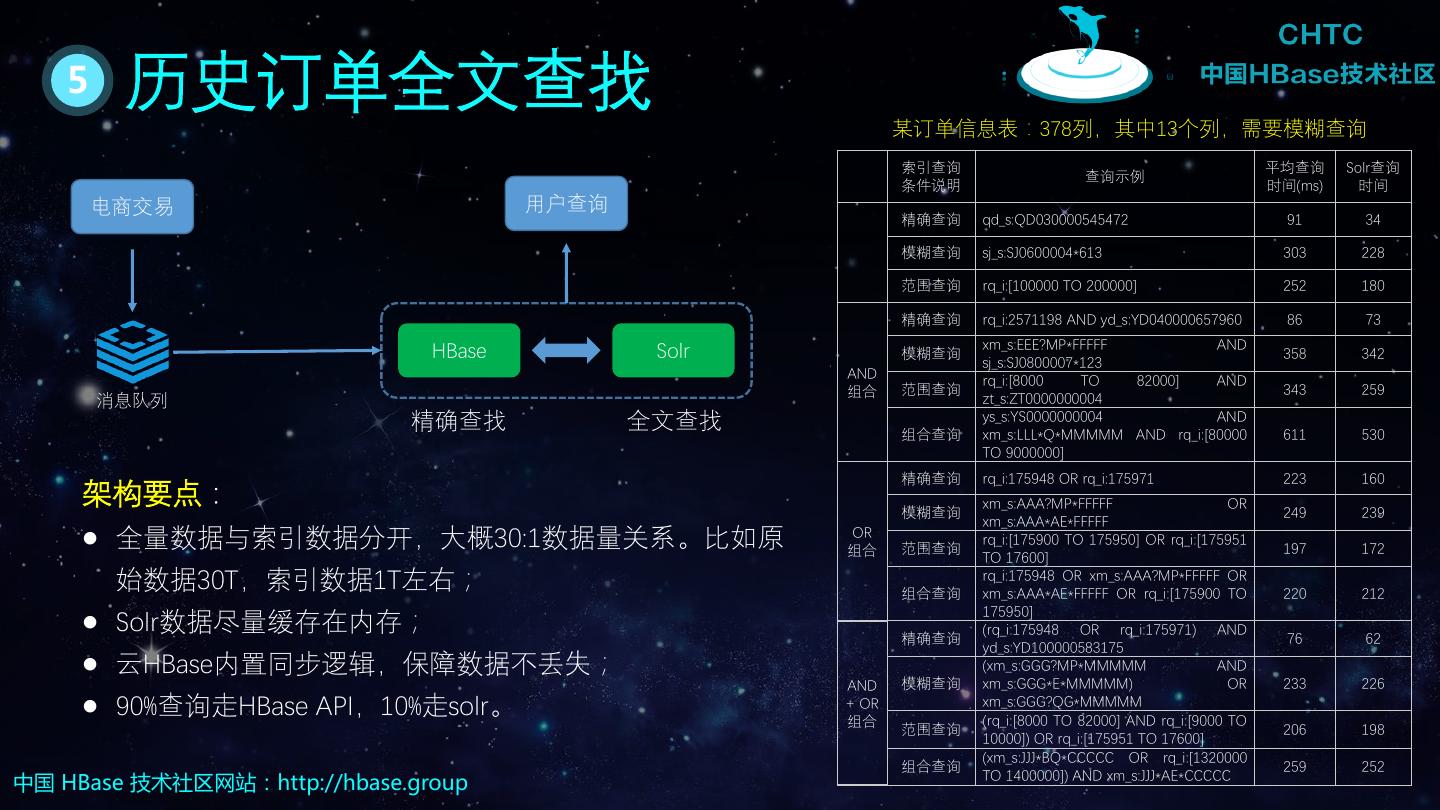
12 . 02 HBase读写流程 中国 HBase 技术社区网站:http://hbase.group
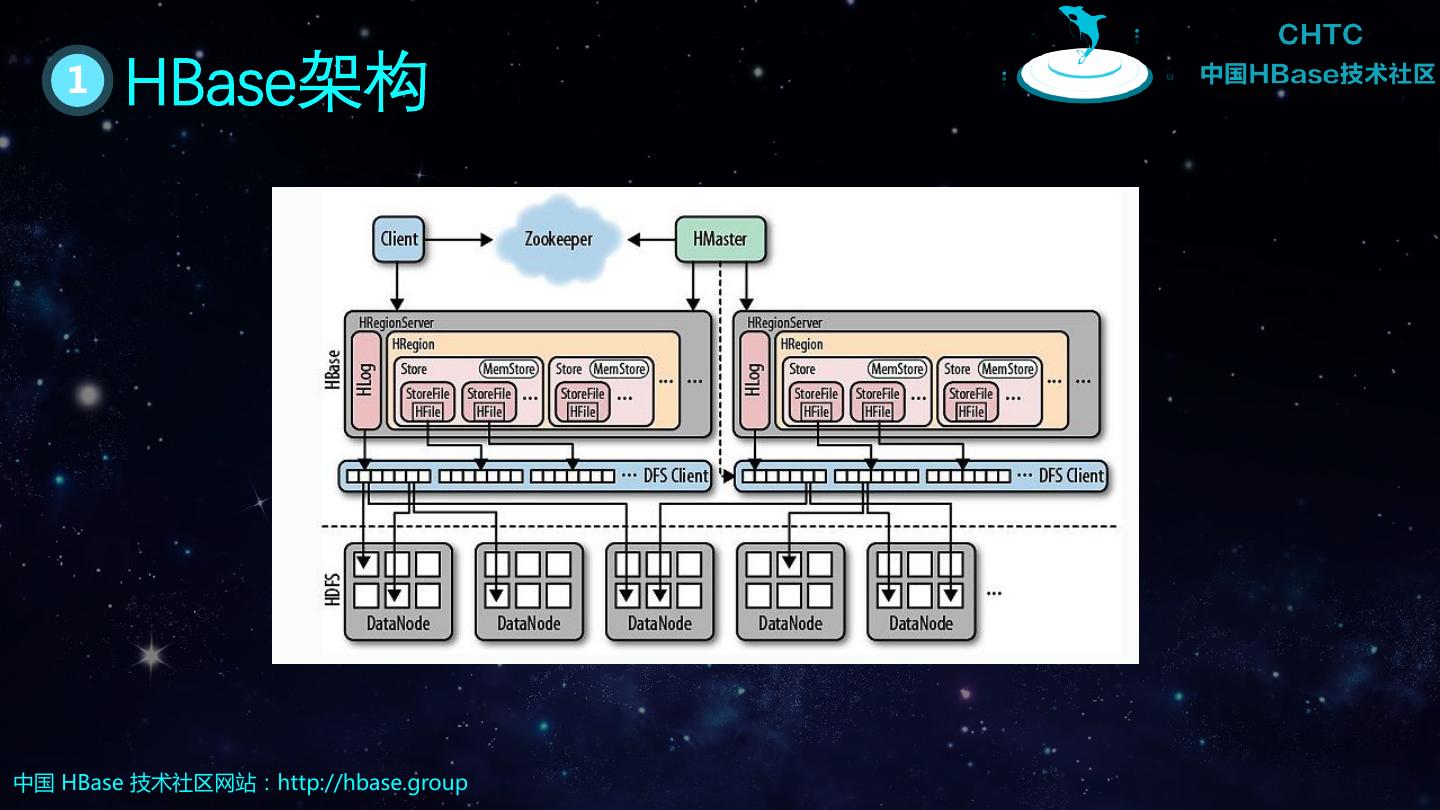
13 . 1 HBase架构 中国 HBase 技术社区网站:http://hbase.group
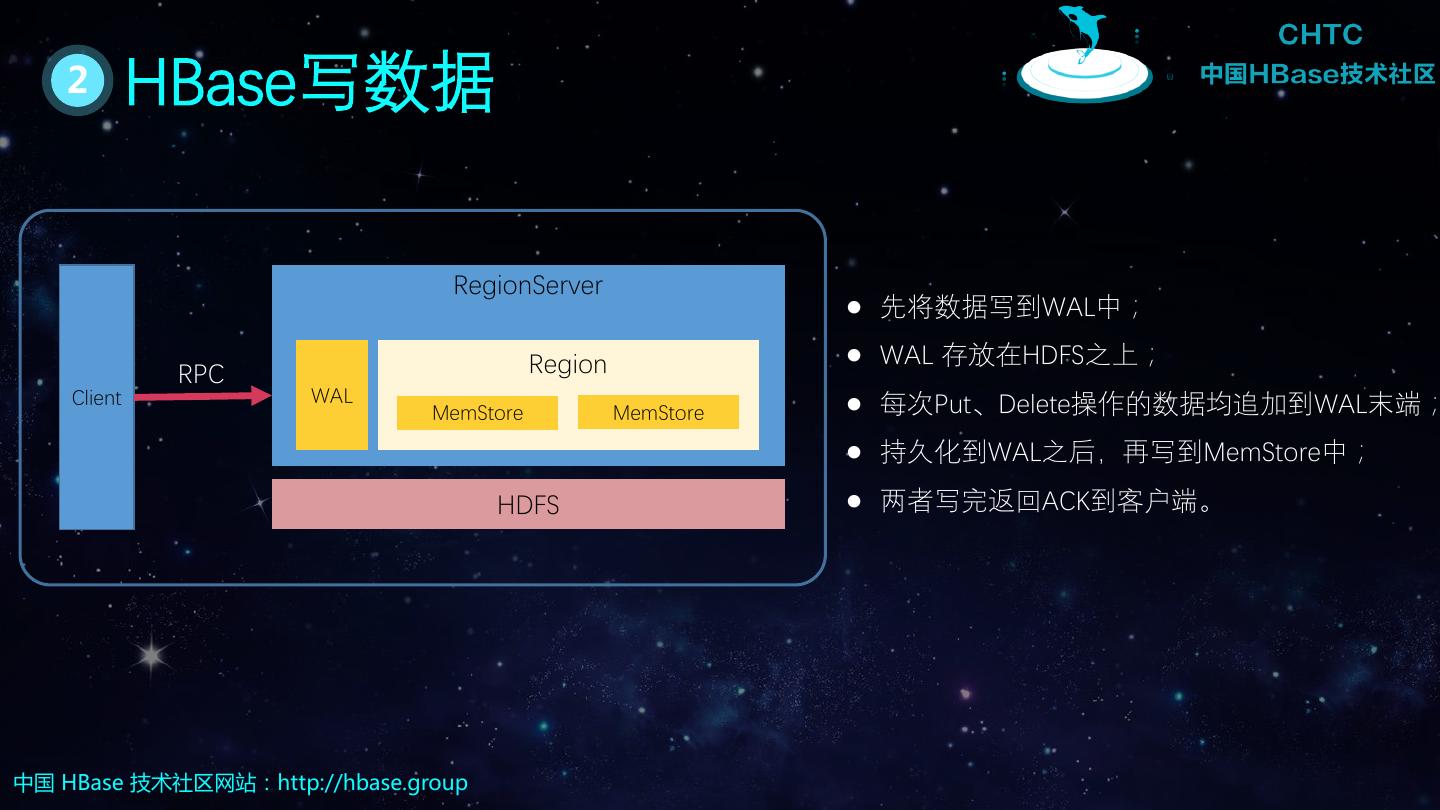
14 . 2 HBase写数据 RegionServer 先将数据写到WAL中; Region WAL 存放在HDFS之上; RPC Client WAL 每次Put、Delete操作的数据均追加到WAL末端; MemStore MemStore 持久化到WAL之后,再写到MemStore中; HDFS 两者写完返回ACK到客户端。 中国 HBase 技术社区网站:http://hbase.group
15 . 3 HBase MemStore Region MemStore MemStore 一个Column Family 对应一个MemStore Key Value Row Key CF CQ Time Stamp Value Row Key CF CQ Time Stamp Value Row1 personal name v1 张三 Row1 office tel v1 010-1111111 Row1 personal city v2 上海 Row1 office address v1 帝都大厦-18F-01 Row1 personal city v1 北京 Row11 office tel v1 010-4444444 Row11 personal name v1 李四 Row11 office address v1 帝都大厦-19F-02 Row11 personal city v1 上海 Row2 office tel v1 010-3333333 Row2 personal name v1 王五 Row2 office address v1 帝都大厦-18F-02 中国 HBase 技术社区网站:http://hbase.group
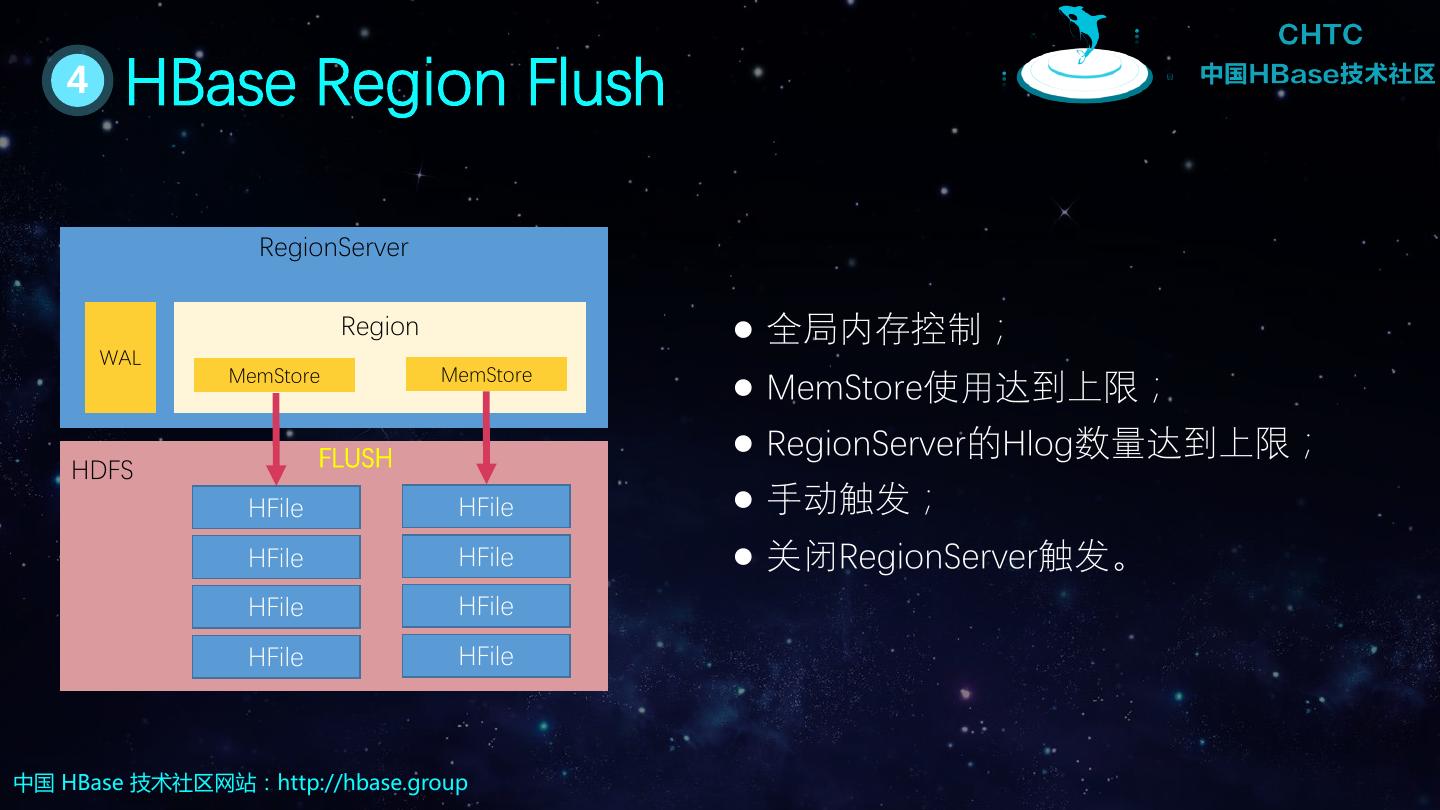
16 . 4 HBase Region Flush RegionServer Region 全局内存控制; WAL MemStore MemStore MemStore使用达到上限; FLUSH RegionServer的Hlog数量达到上限; HDFS HFile HFile 手动触发; HFile HFile 关闭RegionServer触发。 HFile HFile HFile HFile 中国 HBase 技术社区网站:http://hbase.group
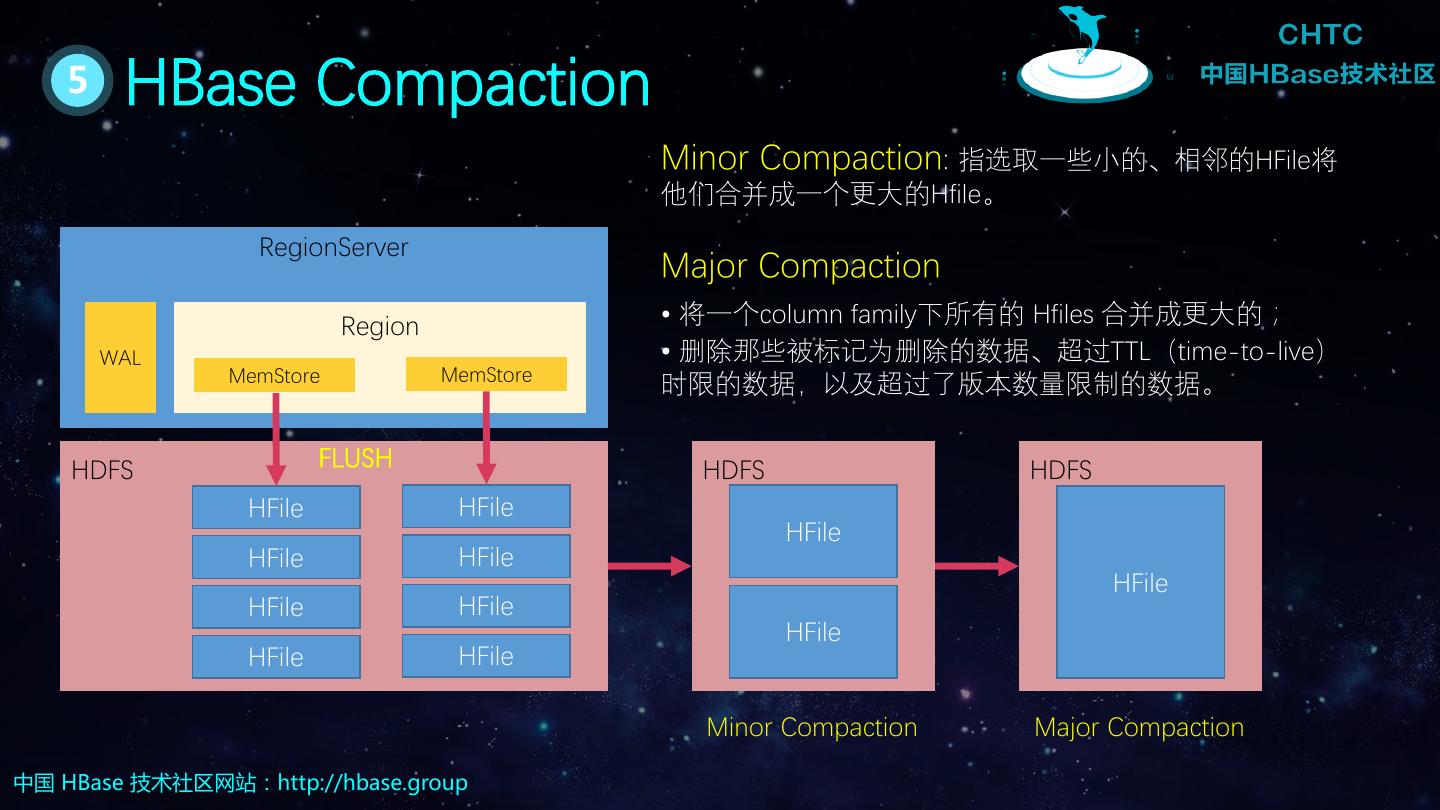
17 . 5 HBase Compaction Minor Compaction: 指选取一些小的、相邻的HFile将 他们合并成一个更大的Hfile。 RegionServer Major Compaction Region • 将一个column family下所有的 Hfiles 合并成更大的; WAL • 删除那些被标记为删除的数据、超过TTL(time-to-live) MemStore MemStore 时限的数据,以及超过了版本数量限制的数据。 HDFS FLUSH HDFS HDFS HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile Minor Compaction Major Compaction 中国 HBase 技术社区网站:http://hbase.group
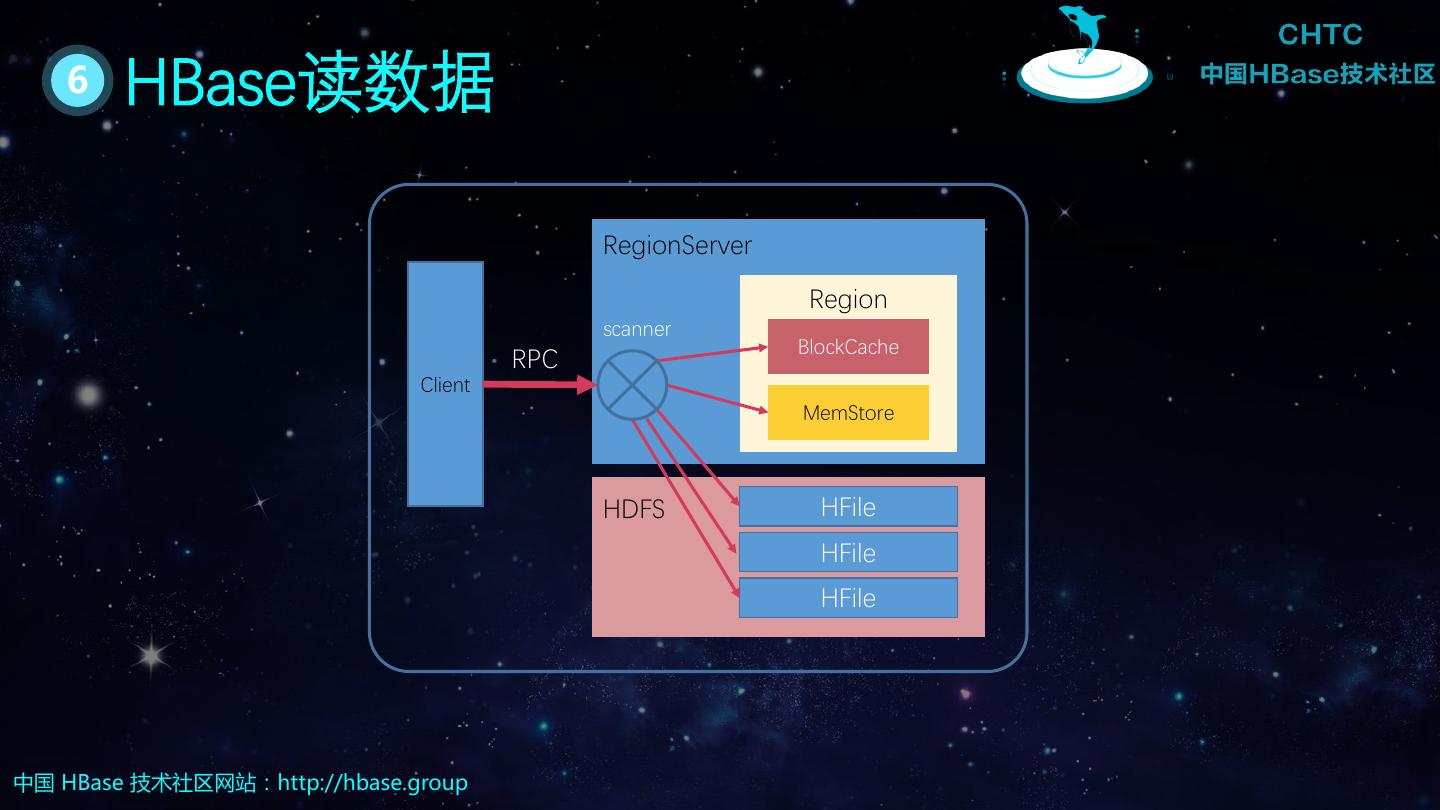
18 . 6 HBase读数据 RegionServer Region scanner BlockCache RPC Client MemStore HDFS HFile HFile HFile 中国 HBase 技术社区网站:http://hbase.group
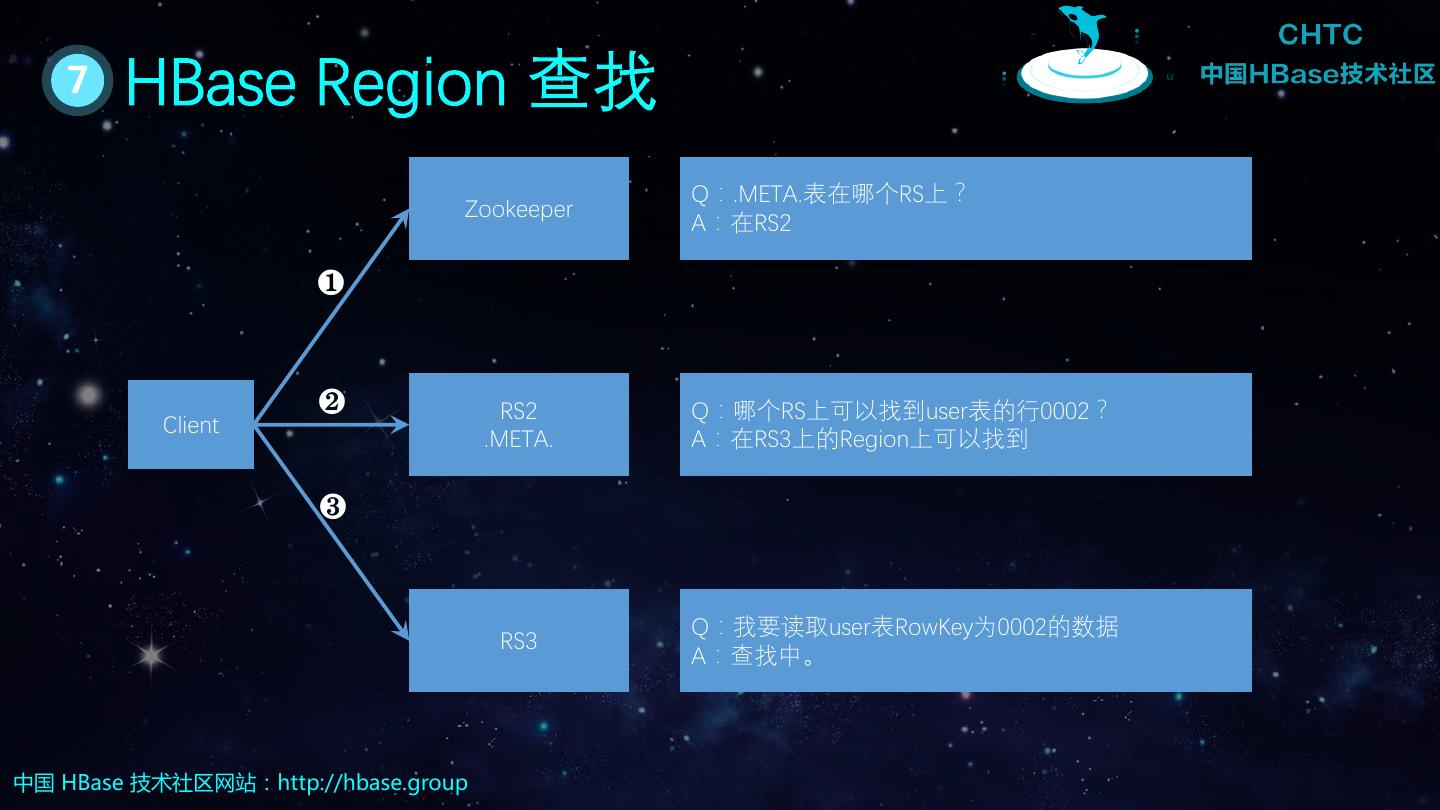
19 . 7 HBase Region 查找 Q:.META.表在哪个RS上? Zookeeper A:在RS2 ❶ ❷ RS2 Q:哪个RS上可以找到user表的行0002? Client .META. A:在RS3上的Region上可以找到 ❸ Q:我要读取user表RowKey为0002的数据 RS3 A:查找中。 中国 HBase 技术社区网站:http://hbase.group
20 . 03 RowKey设计要点 中国 HBase 技术社区网站:http://hbase.group
21 . 1 RowKey的作用 读写数据时通过Row Key找到对应的Region MemStore 中的数据按RowKey字典顺序排序 HFile中的数据按RowKey字典顺序排序 中国 HBase 技术社区网站:http://hbase.group
22 . 2 RowKey的设计原则 Region Region Region 结合业务的特点,并考虑高频查询,尽可能的将数据打散到整个集群。 中国 HBase 技术社区网站:http://hbase.group
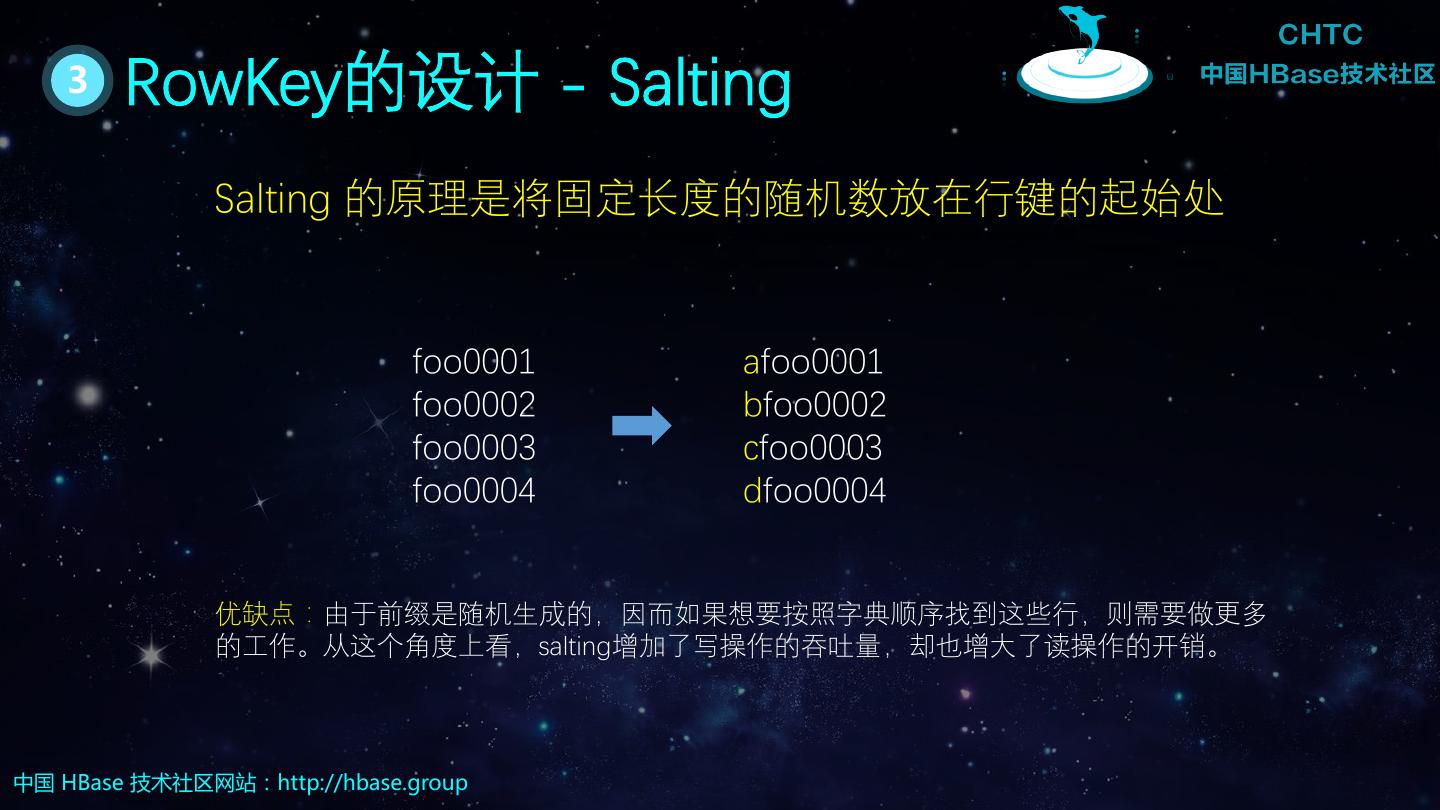
23 . 3 RowKey的设计 - Salting Salting 的原理是将固定长度的随机数放在行键的起始处 foo0001 afoo0001 foo0002 bfoo0002 foo0003 cfoo0003 foo0004 dfoo0004 优缺点:由于前缀是随机生成的,因而如果想要按照字典顺序找到这些行,则需要做更多 的工作。从这个角度上看,salting增加了写操作的吞吐量,却也增大了读操作的开销。 中国 HBase 技术社区网站:http://hbase.group
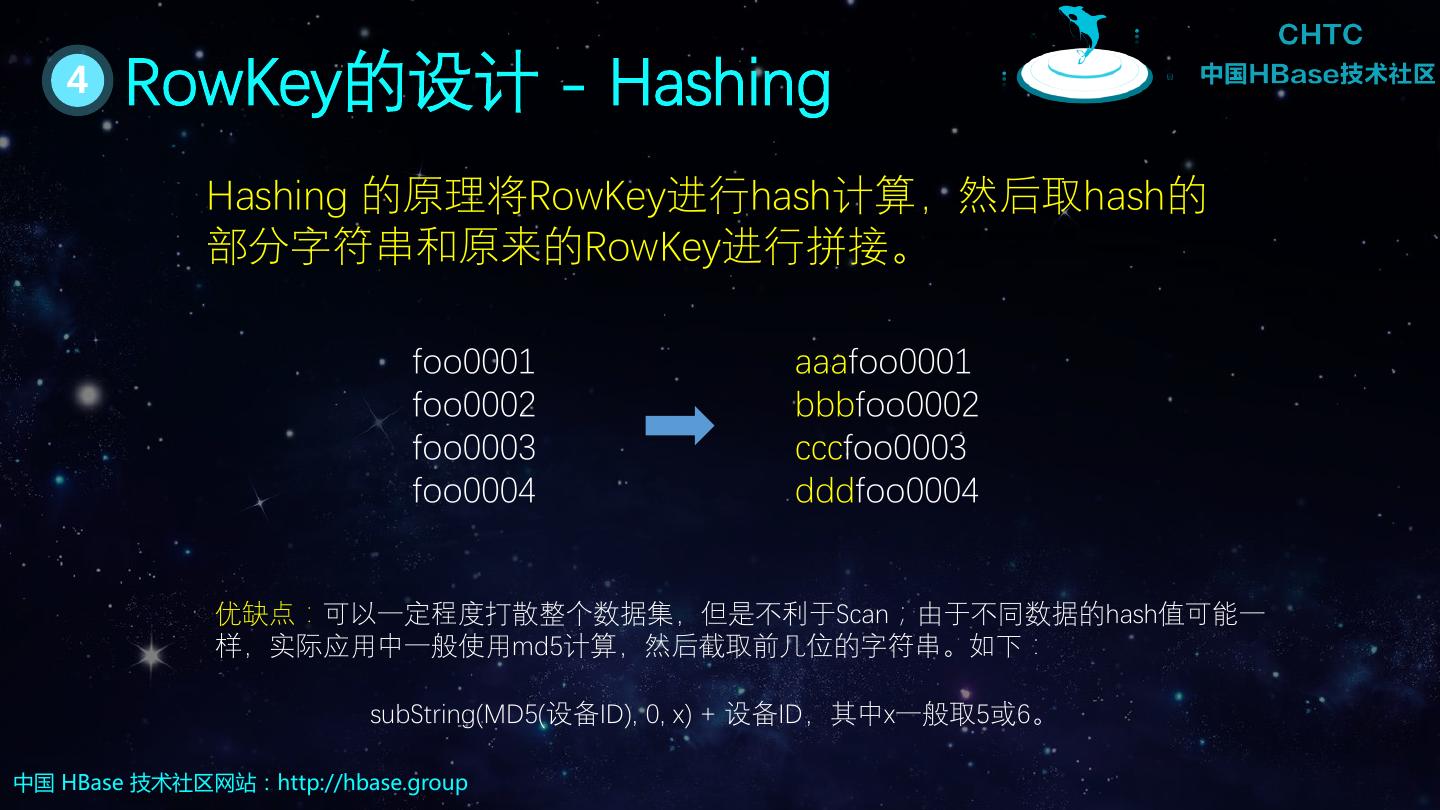
24 . 4 RowKey的设计 - Hashing Hashing 的原理将RowKey进行hash计算,然后取hash的 部分字符串和原来的RowKey进行拼接。 foo0001 aaafoo0001 foo0002 bbbfoo0002 foo0003 cccfoo0003 foo0004 dddfoo0004 优缺点:可以一定程度打散整个数据集,但是不利于Scan;由于不同数据的hash值可能一 样,实际应用中一般使用md5计算,然后截取前几位的字符串。如下: subString(MD5(设备ID), 0, x) + 设备ID,其中x一般取5或6。 中国 HBase 技术社区网站:http://hbase.group
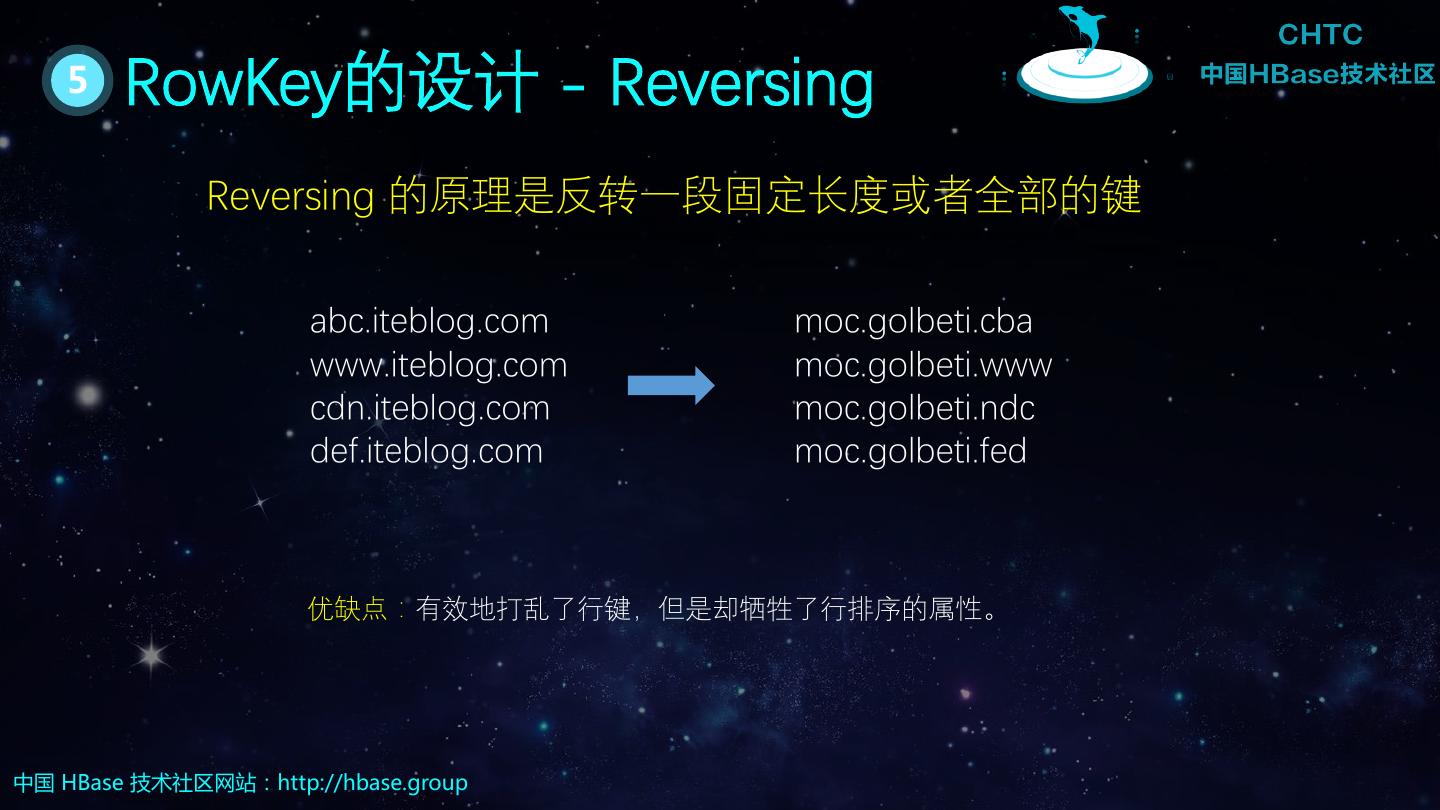
25 . 5 RowKey的设计 - Reversing Reversing 的原理是反转一段固定长度或者全部的键 abc.iteblog.com moc.golbeti.cba www.iteblog.com moc.golbeti.www cdn.iteblog.com moc.golbeti.ndc def.iteblog.com moc.golbeti.fed 优缺点:有效地打乱了行键,但是却牺牲了行排序的属性。 中国 HBase 技术社区网站:http://hbase.group
26 . 04 HBase生态介绍 中国 HBase 技术社区网站:http://hbase.group
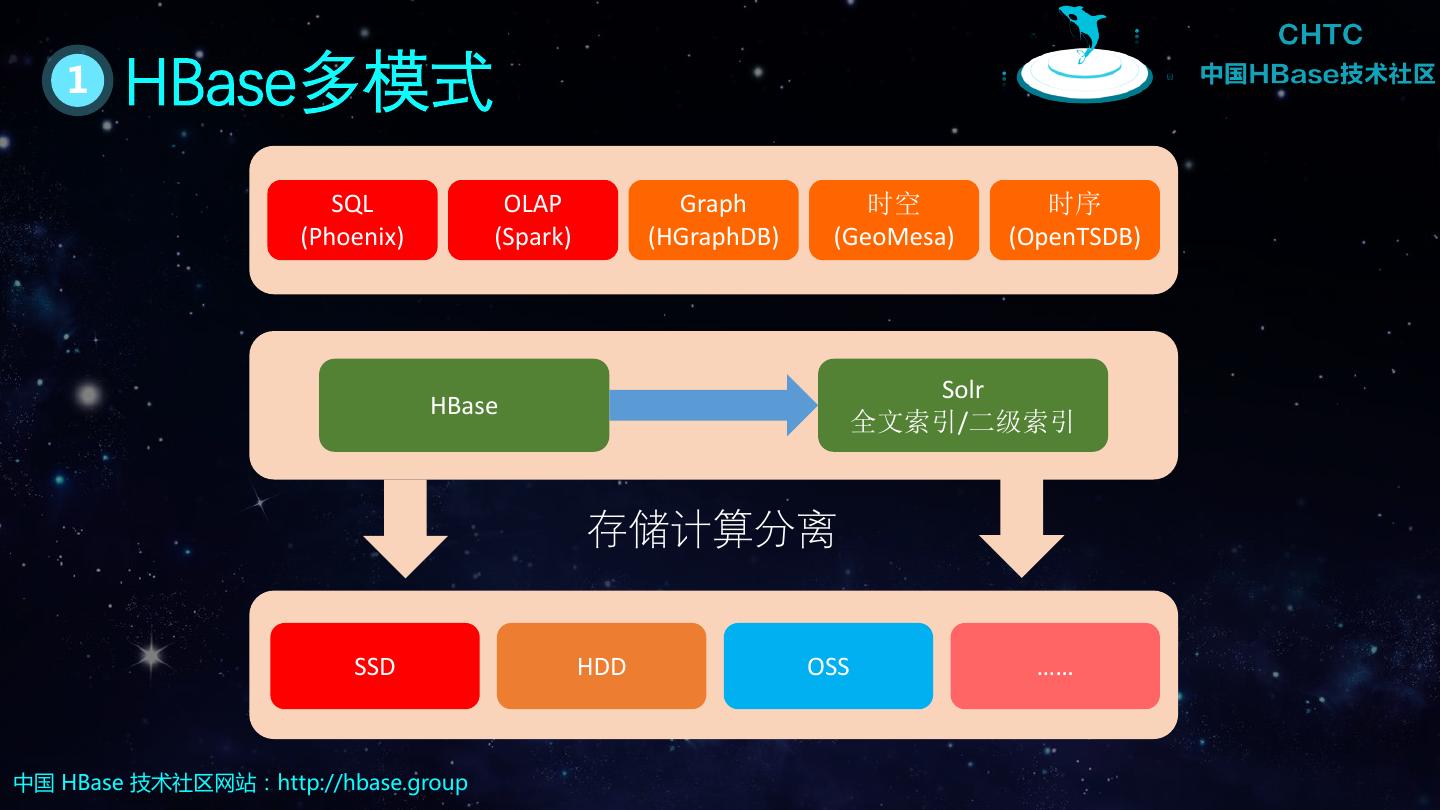
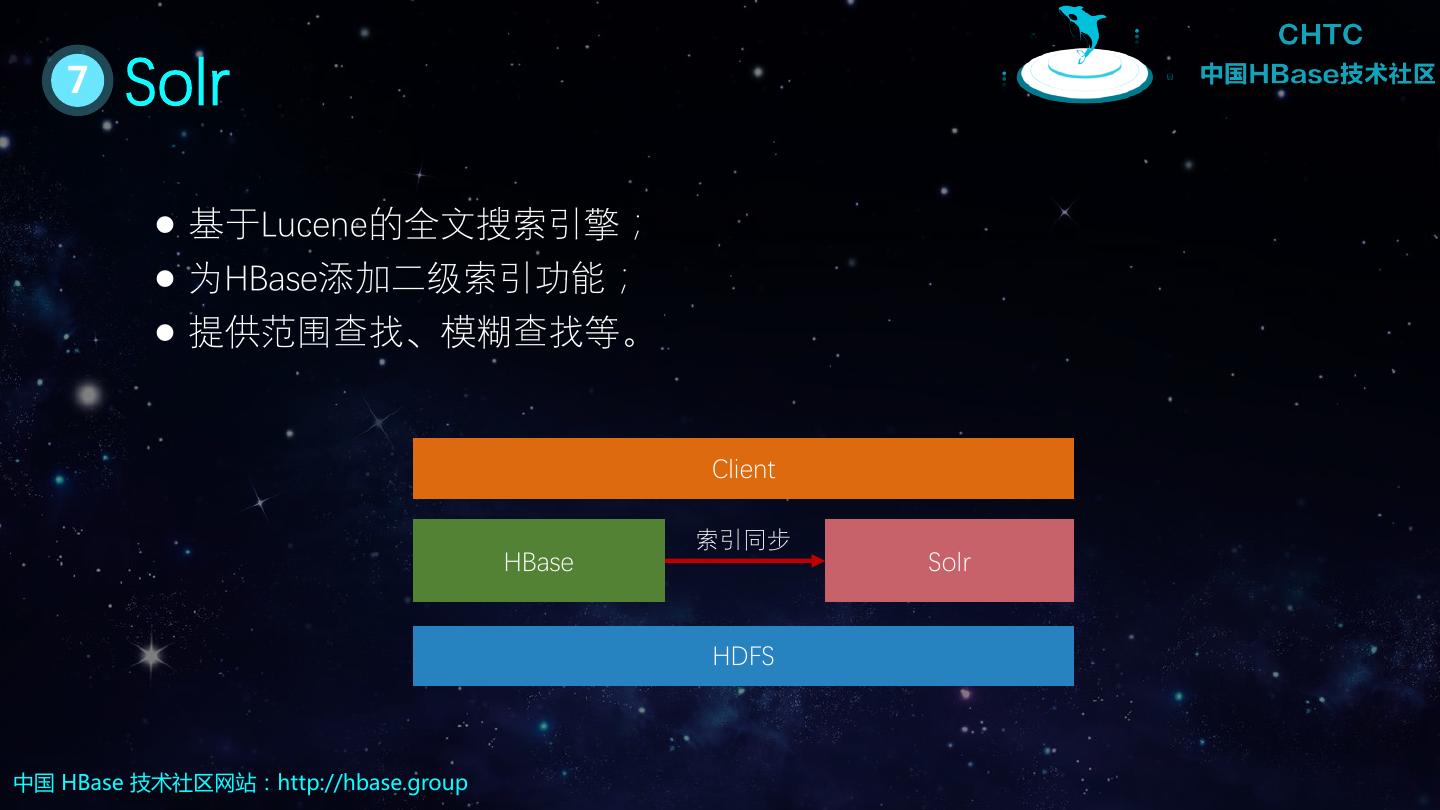
27 . 1 HBase多模式 SQL OLAP Graph 时空 时序 (Phoenix) (Spark) (HGraphDB) (GeoMesa) (OpenTSDB) Solr HBase 全文索引/二级索引 存储计算分离 SSD HDD OSS …… 中国 HBase 技术社区网站:http://hbase.group
28 . 2 Phoenix 构建在HBase之上的关系型数据库层,支持使用SQL进行HBase数据的查询; 将用户编写的sql查询编译为一系列的scan操作,直接使用HBase的API。 结合协处理器和自定义的过滤器的话,小范围的查询在毫秒级响应,千万数据的话响应 速度为秒级。 CREATE TABLE IF NOT EXISTS us_population ( SELECT state as "State",count(city) as "City state CHAR(2) NOT NULL, Count",sum(population) as "Population Sum" city VARCHAR NOT NULL, FROM us_population population BIGINT GROUP BY state CONSTRAINT my_pk PRIMARY KEY (state, city) ORDER BY sum(population) DESC; ); 中国 HBase 技术社区网站:http://hbase.group
29 . 3 Spark OLAP; 利用Spark-SQL查询一些比较复杂的分析; 利用Spark Streaming进行实时流分析,结果存入HBase; 直接读取Hfile。 中国 HBase 技术社区网站:http://hbase.group
3秒后跳转登录页面
去登陆

