






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
From Spark Streaming to Structured Streaming
Spark 流式有两套系统:Spark Streaming 和 Structured Streaming。那么这两套系统的区别在哪里呢?以及为什么 Spark 有了 Spark Streaming 还有做 Structured Streaming 呢?我们应该如何去选择呢?
展开查看详情
1 .2018/12/4 From Spark Streaming to Structured Streaming From Spark Streaming to Structured Streaming @E-MapReduce http://localhost:3999/xxx.slide#1 1/44
2 .2018/12/4 From Spark Streaming to Structured Streaming Outline Spark Streaming Google Data ow Structured Streaming Reference http://localhost:3999/xxx.slide#1 2/44
3 .2018/12/4 From Spark Streaming to Structured Streaming 1. Spark Streaming http://localhost:3999/xxx.slide#1 3/44
4 .2018/12/4 From Spark Streaming to Structured Streaming 1.1 Overview http://localhost:3999/xxx.slide#1 4/44
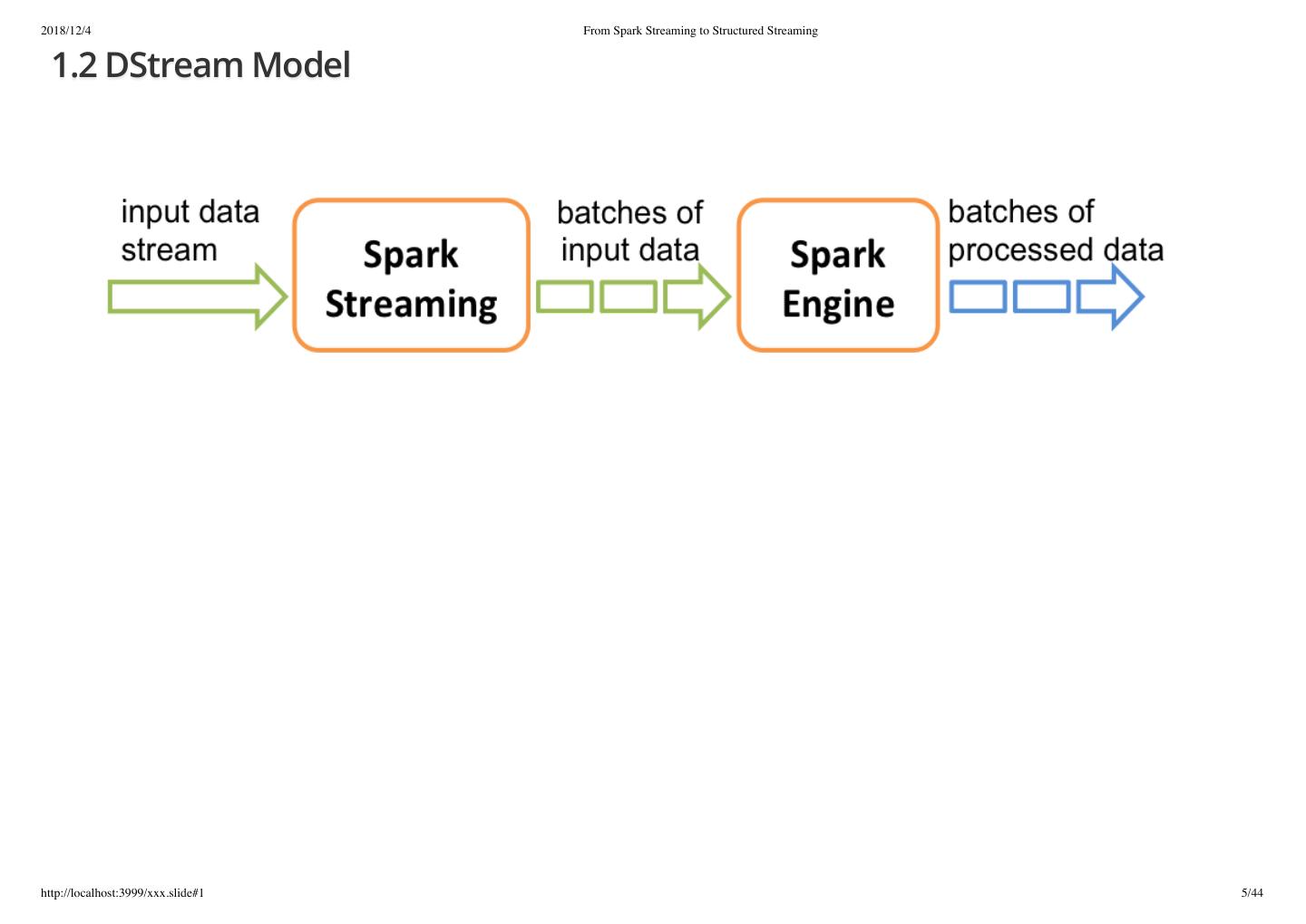
5 .2018/12/4 From Spark Streaming to Structured Streaming 1.2 DStream Model http://localhost:3999/xxx.slide#1 5/44
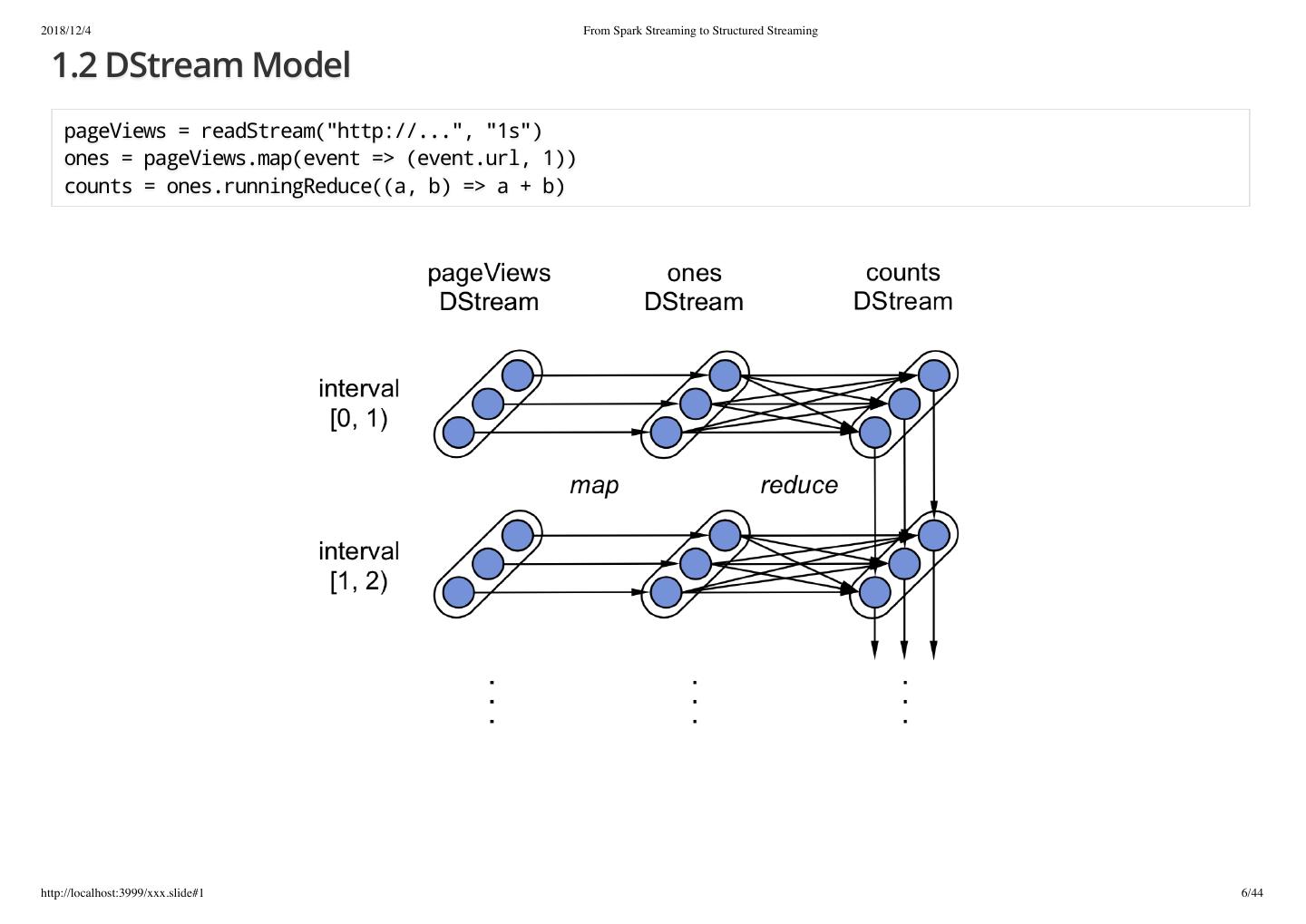
6 .2018/12/4 From Spark Streaming to Structured Streaming 1.2 DStream Model pageViews = readStream("http://...", "1s") ones = pageViews.map(event => (event.url, 1)) counts = ones.runningReduce((a, b) => a + b) http://localhost:3999/xxx.slide#1 6/44
7 .2018/12/4 From Spark Streaming to Structured Streaming 1.3 Failure Recovery Parallel Recovery Straggler http://localhost:3999/xxx.slide#1 7/44
8 .2018/12/4 From Spark Streaming to Structured Streaming 1.4 Consistency Semantics Input -> That Depends DStream -> Exactly Once Output -> At-least-once(default) http://localhost:3999/xxx.slide#1 8/44
9 .2018/12/4 From Spark Streaming to Structured Streaming 1.5 DStream API Transformations on DStreams Output Operations on DStreams http://localhost:3999/xxx.slide#1 9/44
10 .2018/12/4 From Spark Streaming to Structured Streaming 1.6 Evaluation Linear Scalability High Throuphput High Performance http://localhost:3999/xxx.slide#1 10/44
11 .2018/12/4 From Spark Streaming to Structured Streaming 2. Google Data ow http://localhost:3999/xxx.slide#1 11/44
12 .2018/12/4 From Spark Streaming to Structured Streaming 2.1 Overview http://localhost:3999/xxx.slide#1 12/44
13 .2018/12/4 From Spark Streaming to Structured Streaming 2.2 Points Unbounded/Bounded vs Streaming/Batch Window Time Domain: Processing Time vs Event Time http://localhost:3999/xxx.slide#1 13/44
14 .2018/12/4 From Spark Streaming to Structured Streaming 2.3 More The world beyond batch: Streaming 101 The world beyond batch: Streaming 102 Streaming Systems http://localhost:3999/xxx.slide#1 14/44
15 .2018/12/4 From Spark Streaming to Structured Streaming 3. Structured Streaming http://localhost:3999/xxx.slide#1 15/44
16 .2018/12/4 From Spark Streaming to Structured Streaming 3.1 DStream Pains using processing time, not event time complex, low-level api reason about end-to-end guarantees http://localhost:3999/xxx.slide#1 16/44
17 .2018/12/4 From Spark Streaming to Structured Streaming 3.2 Structured Streaming Overview http://localhost:3999/xxx.slide#1 17/44
18 .2018/12/4 From Spark Streaming to Structured Streaming 3.2 Structured Streaming Overview Incremental query model Support for end-to-end applications Spark SQL engine reuse: optimizer and runtime code generator. http://localhost:3999/xxx.slide#1 18/44
19 .2018/12/4 From Spark Streaming to Structured Streaming 3.3 Program Model http://localhost:3999/xxx.slide#1 19/44
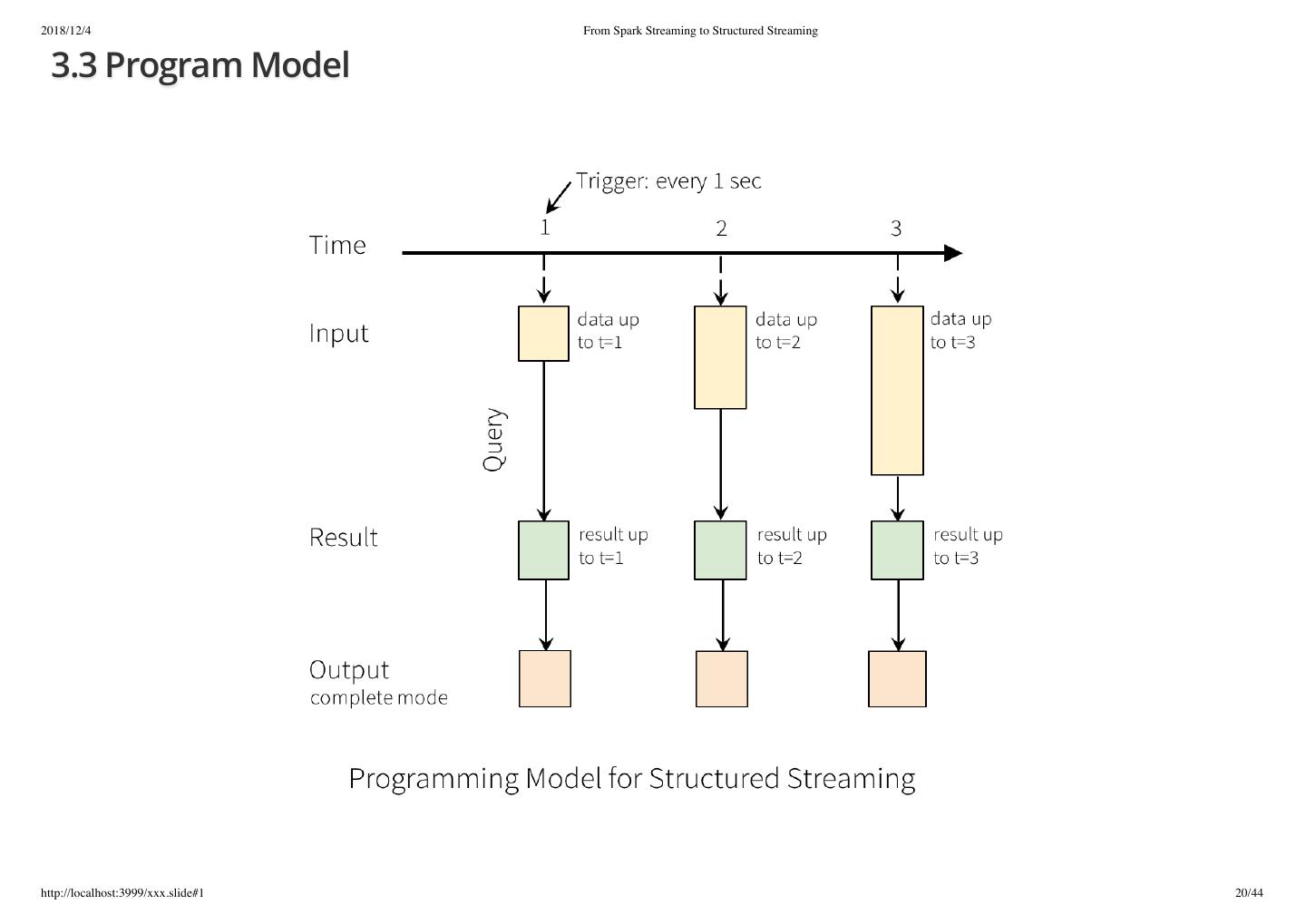
20 .2018/12/4 From Spark Streaming to Structured Streaming 3.3 Program Model http://localhost:3999/xxx.slide#1 20/44
21 .2018/12/4 From Spark Streaming to Structured Streaming 3.3 Program Model WordCount Example // Create DataFrame representing the stream of input lines from connection to localhost:9999 val lines = spark.readStream .format("socket") .option("host", "localhost") .option("port", 9999) .load() // Split the lines into words val words = lines.as[String].flatMap(_.split(" ")) // Generate running word count val wordCounts = words.groupBy("value").count() http://localhost:3999/xxx.slide#1 21/44
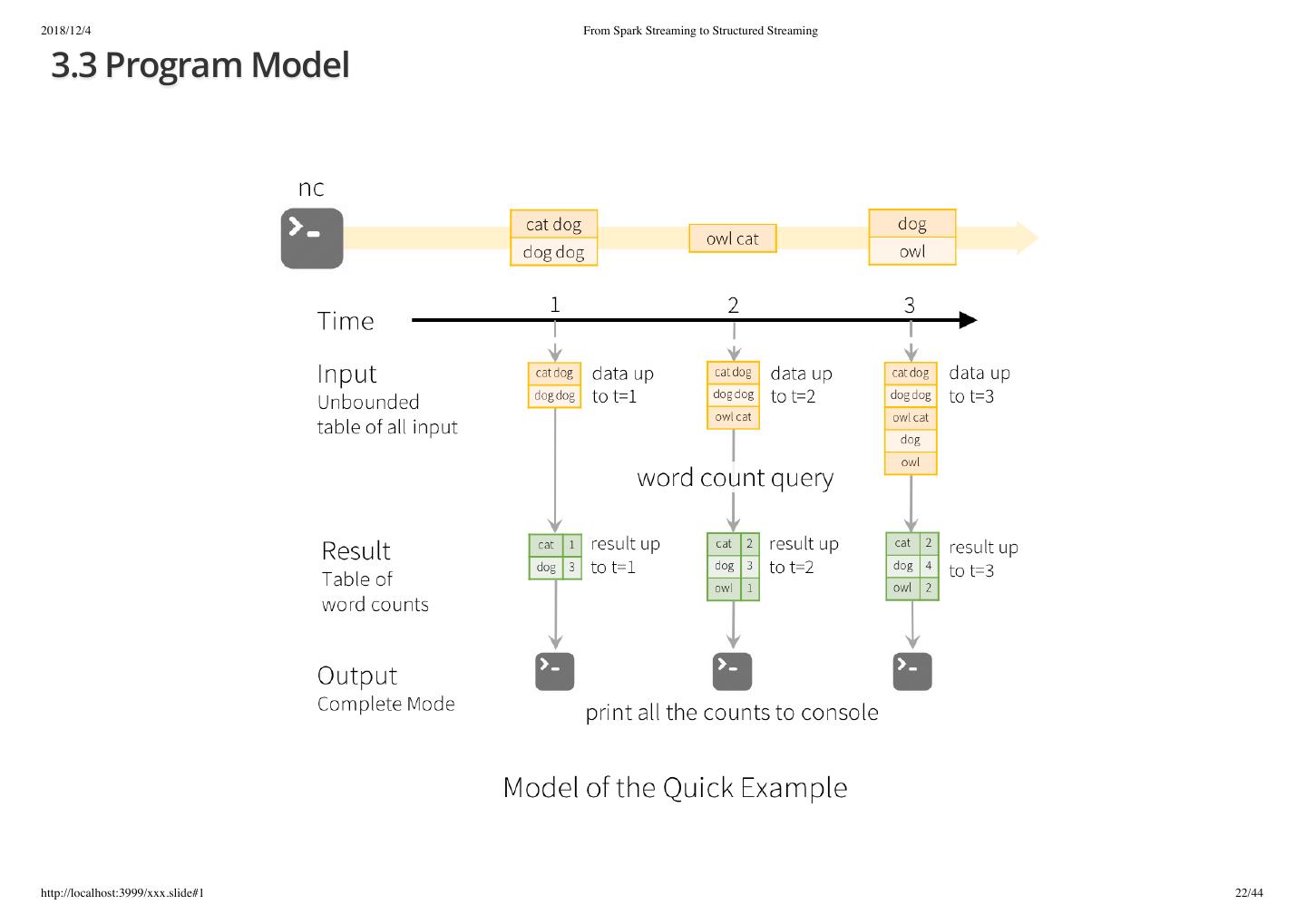
22 .2018/12/4 From Spark Streaming to Structured Streaming 3.3 Program Model http://localhost:3999/xxx.slide#1 22/44
23 .2018/12/4 From Spark Streaming to Structured Streaming 3.4 Output Mode Append mode (default) Complete mode Update mode http://localhost:3999/xxx.slide#1 23/44
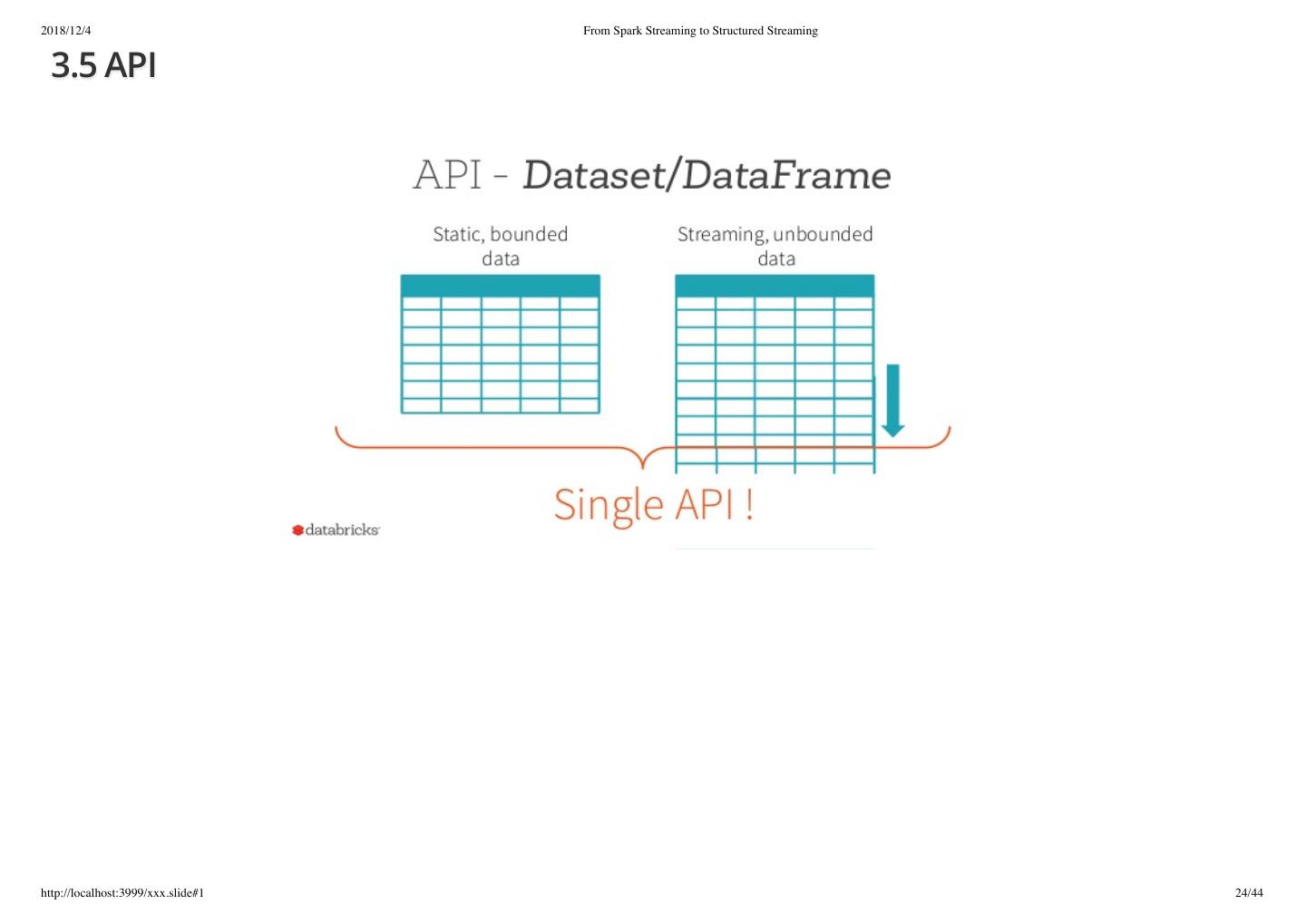
24 .2018/12/4 From Spark Streaming to Structured Streaming 3.5 API http://localhost:3999/xxx.slide#1 24/44
25 .2018/12/4 From Spark Streaming to Structured Streaming 3.5 API Static-typing and runtime type-safety High-level abstraction and custom view into data Ease-of-use of APIs with structure Performance and Optimization http://localhost:3999/xxx.slide#1 25/44
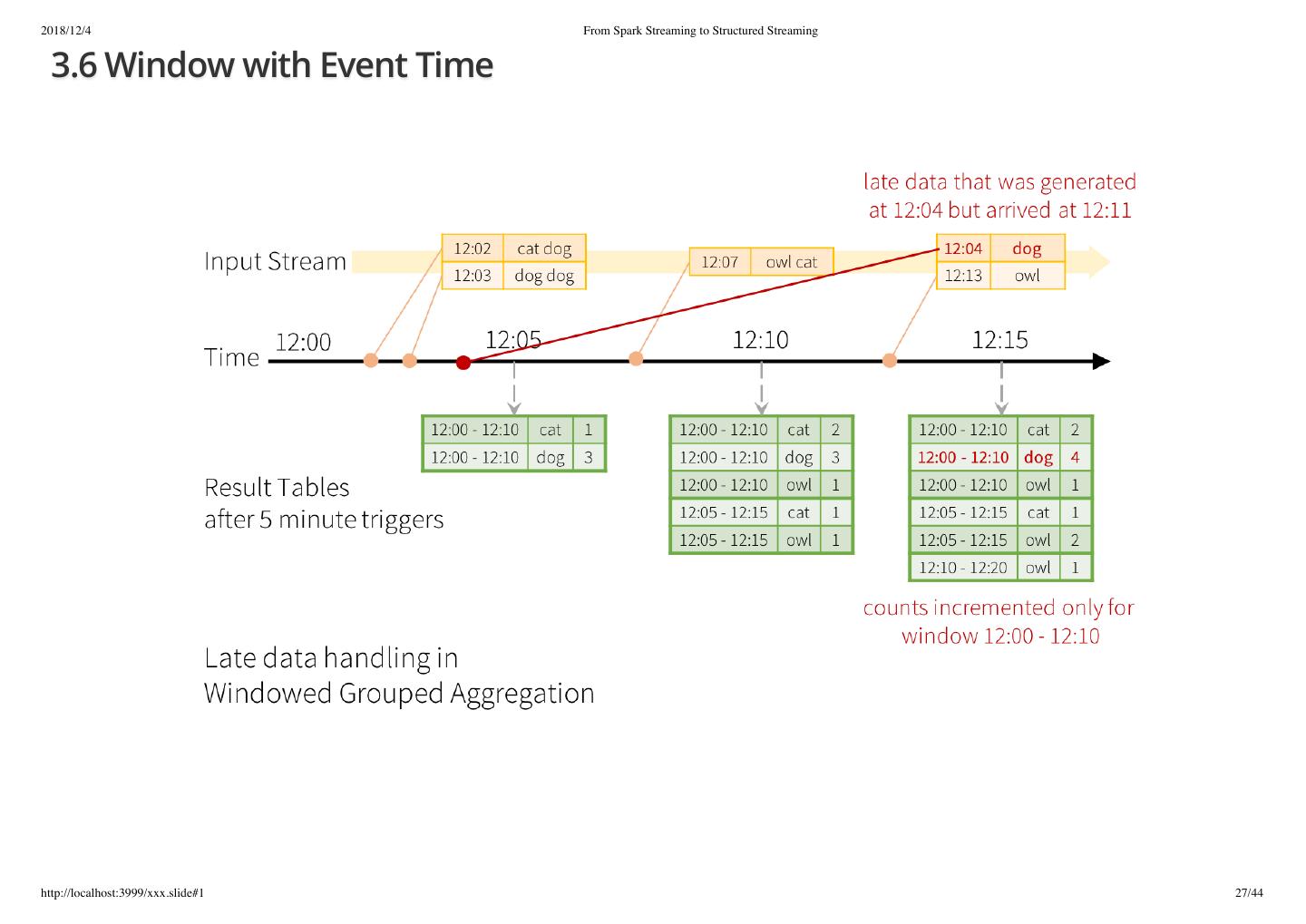
26 .2018/12/4 From Spark Streaming to Structured Streaming 3.6 Window with Event Time import spark.implicits._ val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String } // Group the data by window and word and compute the count of each group val windowedCounts = words.groupBy( window("eventTime", "10 minutes", "5 minutes"), $"word" ).count() http://localhost:3999/xxx.slide#1 26/44
27 .2018/12/4 From Spark Streaming to Structured Streaming 3.6 Window with Event Time http://localhost:3999/xxx.slide#1 27/44
28 .2018/12/4 From Spark Streaming to Structured Streaming 3.7 EventTime Watermark import spark.implicits._ val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String } // Group the data by window and word and compute the count of each group val windowedCounts = words .withWatermark("eventTime", "10 minutes") .groupBy( window("eventTime", "10 minutes", "5 minutes"), $"word") .count() http://localhost:3999/xxx.slide#1 28/44
29 .2018/12/4 From Spark Streaming to Structured Streaming 3.7 EventTime Watermark http://localhost:3999/xxx.slide#1 29/44
3秒后跳转登录页面
去登陆

