


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/FlinkChina/Columnar_Execution_for_Apache_Flink_Batch?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
【分五02-石春晖】Columnar Execution for Apache Flink Batch
点赞
16
收藏
5
下载 5
Columnar Execution for Apache Flink Batch
Content
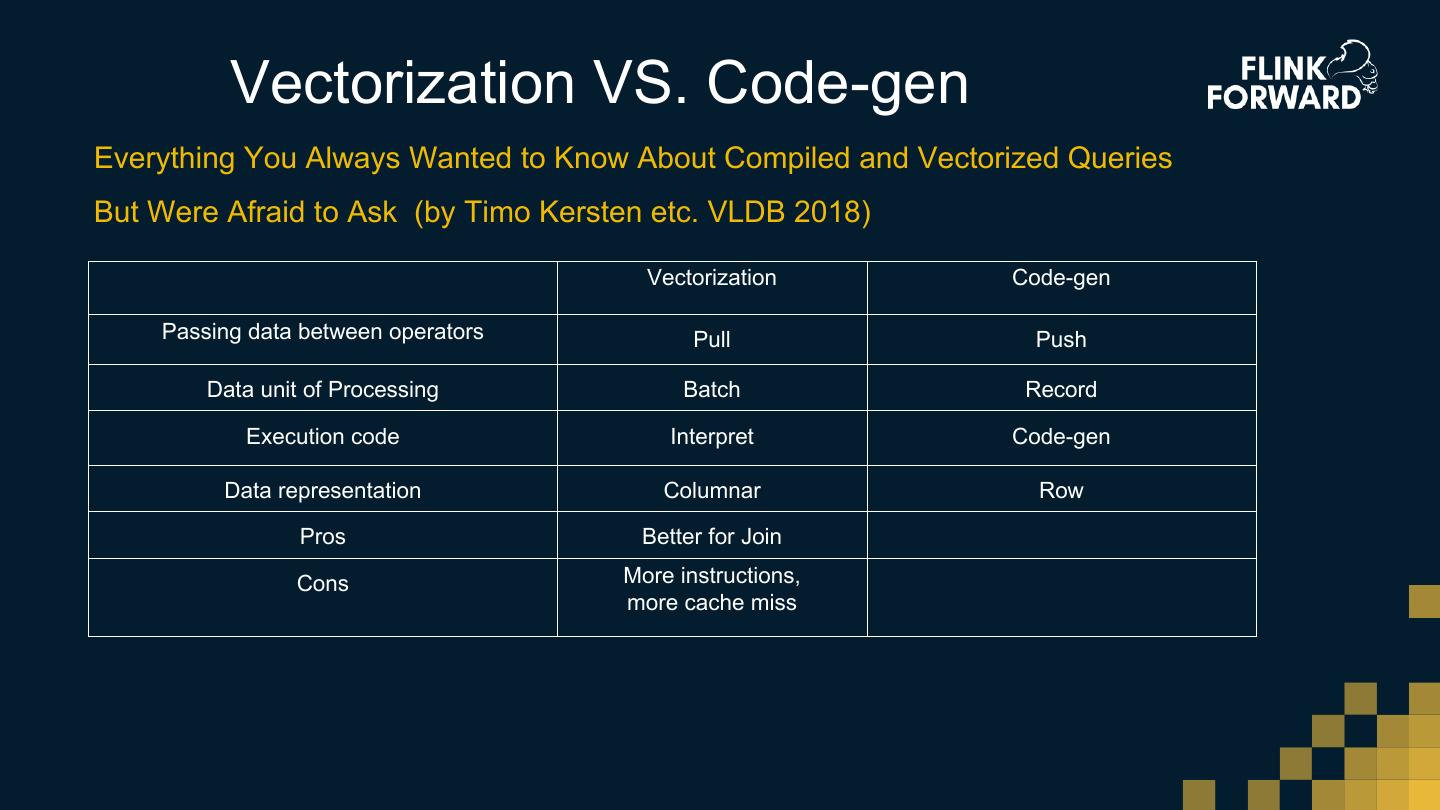
- Background and Literature of vectorization 列式执行
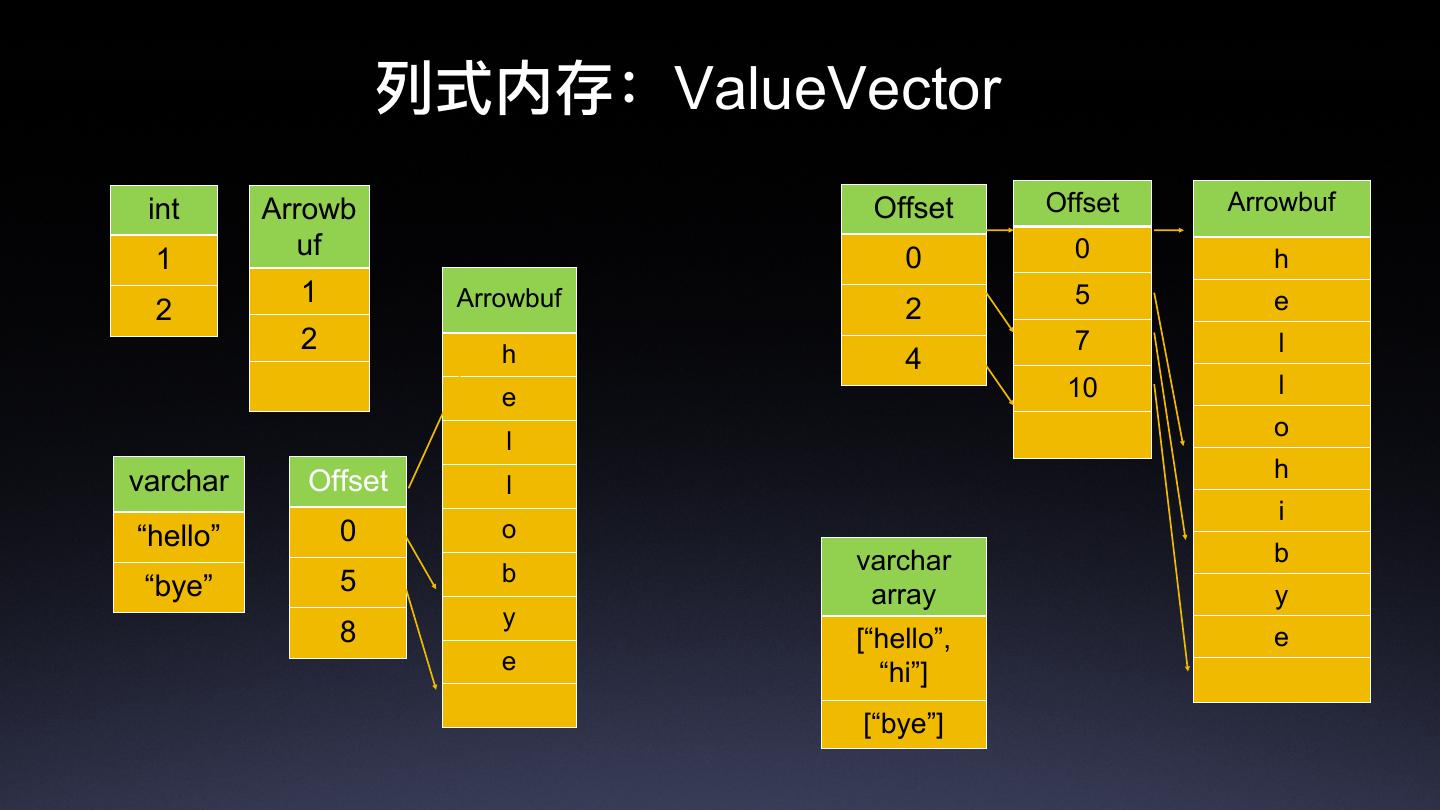
- Vectorized Data Format 列式数据
- Results and Future 展望未来
相关推荐

Apache DolphinScheduler 在唯品富邦消费金融生产应用实践
DolphinScheduler社区

Apache DolphinScheduler 补数功能讲解
DolphinScheduler社区

Apache DolphinScheduler 远程日志存储机制分享
SeaTunnel

Apache SeaTunnel V2 架构剖析与 Apache Paimon 集成
SeaTunnel

金红叶集团在 Apache SeaTunnel 实践探索
SeaTunnel

Apache Kylin 5.0 新版本揭秘
SeaTunnel
测试视频存储
哄哄22

Byzer-LLM 介绍
MLSQL开源社区

