展开查看详情
1 .Alluxio 在 携程大数据平台中的实践 郭建华 携程大数据平台研发工程师
2 .个人简介 研究生期间有两年的 Spark 研究经验 两年的大数据平台离线相关系统的研发 目前主要专注于 Spark Sql 的 Bug fix 和调优
3 .提 纲 携 程大数据平台介绍 存在的问题 Alluxio 作为解决方案 踩过的 坑
5 .携 程大数据平台 - 总体架构 资源部署和运维监控 自动运维系统 大数 据 框架设施监控 大数 据业务监控 实时框架 开发平台 Zeus 查询平台 ART 机器学习 算法平台 ( 基 于 Spark MLlib ) 实时数据平台 Muise JStorm Spark Streaming Flink Hermes Kafka Hadoop Hive Spark HBase Presto Kylin Alluxio 调度系统 主数据系统 传输系统 数据质量系统 报 表系统 Adhoc 查询
6 .携 程大数据平台 - 平台规模 1600+ 节点 5 万作业 30 万 Application/ 天 90PB / 100PB 元数 据 :ns1: 7 亿 ns2: 1.5 亿 日增 200TB 440 账户, 1000+ 开发人员 Spark:hive 1:2 13+ 集群 JStorm : 150+ 节点 350+ Application Spark Streaming: 50+ 节点 150+ Application Flink : 10+ 节点 20+ Application 离线计算 实时 计算
8 .存 在的问题 1. 主 机 群与 Spark Streaming 互相影响 ● NameNode 和 RM 增加功能或者调整配置 , 需要停机维护 ● NameNode 晚上 10 点清理 Trash 数据 , 半小时基本上不工作 ● Spark Streaming 长时间占用资源 , 影响用户队列的资源使用 ● 高峰期 Spark Streaming 重启获取不到资源 措施 : 为 Spark Streaming 搭建一套独立集群
9 .存 在的问题 2. 跨集群访问 ● 首先保证 Kerberos 认证同 KDC ● 跨集群读写有两种方式 : read( hdfs ://ns/xxx) 、 save( hdfs ://ns/xxx): RDD 和 DStream spark.sql (“insert tableName ”)
10 .存 在的问题 2.1 read 、 save() ● Spark 配置 : spark.yarn.access.namenodes or spark.yarn.access.hadoopFileSystems ● 客户端对 ns-prod 和 ns 进行 配置 , 分别指向主集群和实时集群 ● ResourceManager 也需要添加两个集群的 ns 信息
11 .存 在的问题 2.2 spark.sql (“hive insert into or overwrite sql ”) ● 各个集群都是使用 ns 来作为 namespace 名称 , Hive 表的 namespace 是固定的 ns 1. 修改客户端 hdfs-site.xml , 主集群使用 ns, 而实时改成其他名称 2. spark- defaults.conf 中相关的配置也需要进行修改 3. fs.defaultFS 也要修改 ,yarn 、 spark 根据这个配置来创建很多临时路径 技术上可行 , 但是配置乱 , 而且很麻烦
12 .存 在的问题 3.NameNode 压力过大 ● metadata 压力过大 ● RPC 压力过大
13 .存 在的问题 3.1 metaData 压力过大 ● Federation, 将 yarn, Spark 的日志和中间结果都保存到了 ns2 ● 开发 merge 小 文件程序 (6.7 亿文件 ) , Hive 设置分区 ttl , 清理 过期的分区 (77PB) ● 监控 tmp 表的最近读写,删除长时间未读写的表 (50 万 ) 仍然存在大量不受监控小文件 :
14 .存 在的问题 3.1 metaData 压力过 大 ● 再深入的分析 , 发现里面存在大量的 Spark streaming 落地的文件 Streaming 落地的文件两大特点 : 1. 单个文件容量小 , 文件数多 2. 落地的文件或者文件夹时间上很有规律并且密度很高 . Streaming 作业落地文件数多且分散 , 不好监管
15 .存 在的问题 3.2 RPC 压力过大 ● 我们将 yarn app log 、 jobhistory 、 yarn-staging- dir 、 spark.yarn.stagingDir 、 spark.history.fs.logDirectory spark.eventLog.dir 、 spark.yarn.archive 迁移到 ns2 来减少 ns1 的 RPC 压力 ● Mover 、 Balancer 中的所有 RPC 请求迁移到了 Standby 节点 ● 还能做的很多
16 .存 在的问题 总 结 Spark 跨集群读写可行,但配置乱且麻烦 Streaming 产生的大量小文件,不容易监控 NN RPC 压力 大,还 能优化的工作很多
18 .引入 Alluxio 流程架构 图 RT HDFS Prod HDFS Alluxio Spark SQL Spark Streaming Kafka hermes qmq mysql 、 ES etl 、 report
19 .Alluxio 如何解决问题 1. 跨集群访问问题 ● Alluxio 提供 unified namespace 功能 , 只需要通过简单的 mount 命令 , 实现 mount 多个集群 ● Spark 通过 Alluxio 来读取数据 , 不用关心数据源来自哪个集群 ● 引入 alluxio client jar, 配置 fs.alluxio.impl 指定到 alluxio 的 FileSystem a lluxio :// master:port / data1 data2 adhoc report art Hdfs ://ns2/ art admin admin Hdfs ://ns1/ adhoc report mount mount
20 .Alluxio 如何解决问题 2. Streaming 小文件问题 ● Alluxio 提供 TTL 功能,及时 清理 Streaming 生成的文件 ,减少元 数据 ● Alluxio 不使用 HDFS 的 Super 用户 ● 在 HDFS 上创建一个 777 路径 , mount 该路径 , 所有需要落地到 HDFS 的 Streaming 作业 , 都必须写到该路径 , 小文件监管容易 .
21 .Alluxio 如何解决问题 3. NameNode RPC 压力 ● Cache 部分热点数据,多作业从 Alluxio 读数据 , 缓解 NameNode RPC 压力 ● 同时 , Alluxio 能够提升 Spark Sql 的执行效率 工具 : hive- testbench ( https:// github.com/gjhkael/hive-testbench) 环境 : Spark2.2.0 on yarn, 5 台 nodemanager , hive 表 :20GB 数据 运行实例 : spark.executor.memory 8g spark.executor.cores 4 spark.executor.instances 5
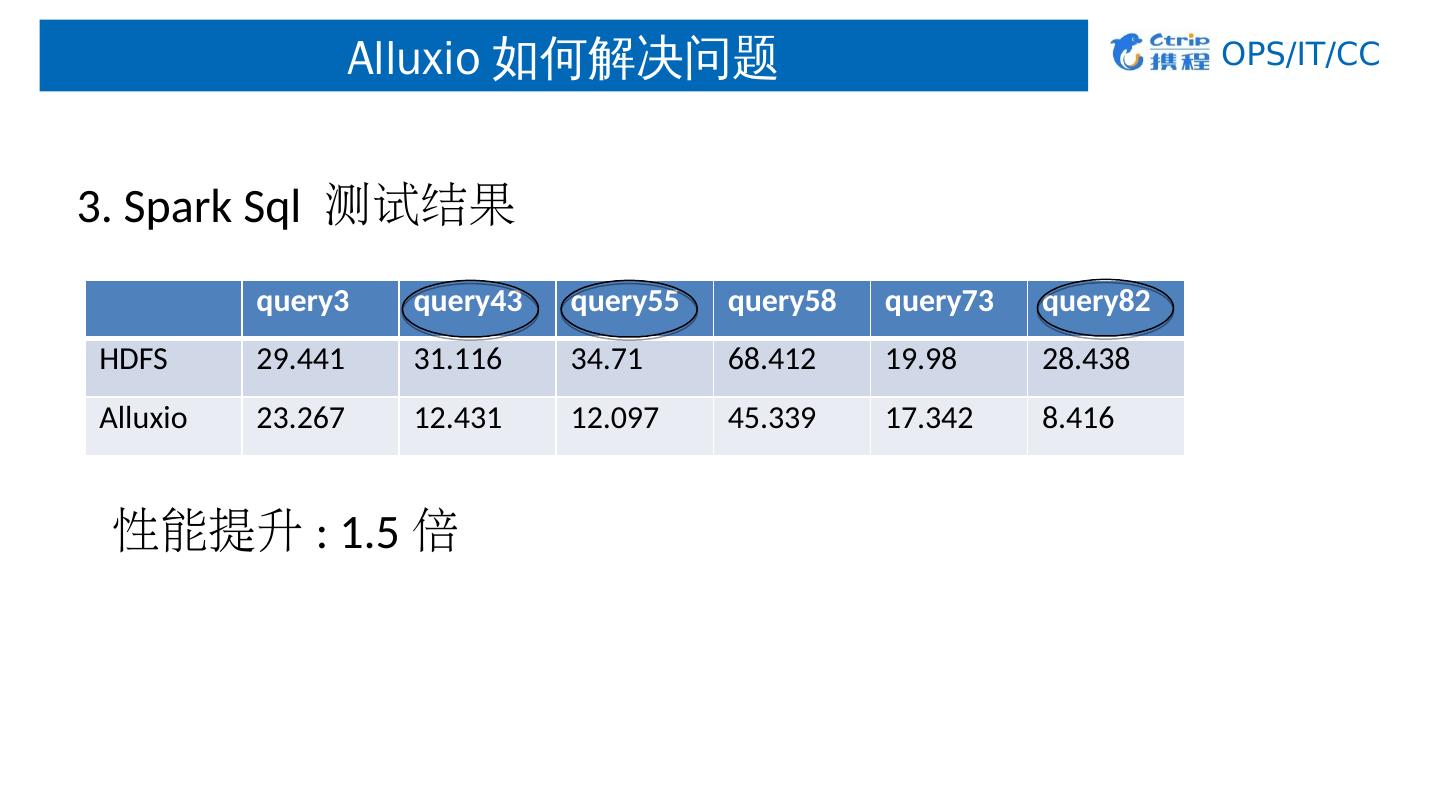
22 .Alluxio 如何解决问题 3. Spark Sql 测试结果 性能提升 : 1.5 倍 query3 query43 query55 query58 query73 query82 HDFS 29 .441 31.116 34.71 68.412 19.98 28.438 Alluxio 23.267 12.431 12.097 45.339 17.342 8.416
23 .Alluxio 使用情况 Alluxio1.4 规模 : 2 master + 4Worker 400GB Mem 800GB HDD
25 .踩 过的坑 1. 安全隐患问题 ● Alluxio1.4 读写数据没有实现 impersonate, 所以需要 HDFS 的 Super 权限 ● alluxio.security.login.username 指定用户 措施: ● Alluxio 使用普通 HDFS 用户 ● 手动建立一个权限为 777 的 HDFS 路径, mount 该路径来作为持久化路径
26 .踩 过的坑 2. TTL 不完善、不支持 Free 策 略 ● 1.4 版本的 Alluxio 只支持指定文件设置 TTL ● 大部 分 Streaming 作业只需要保留近几天的数据 , 需要支持文件夹设置 TTL ● 有些作业只处理近几天数据 , 但是数据需要长时间持久化 , 过期的数据可以 Free 掉 措施: ● 开发基于 Path 的 TTL 支持 , 并贡献给社区 ● 添加 Free 的删除策略功能 , 并贡献给社区 TtlAction DELETE, FREE ; CreateFileOptions SetAttributeOptions
27 .踩 过的坑 3. 数据不一致问题 ● Alluxio 本身不会检测底层文件系统的文件状态 ● 当 HDFS 数据已经 Load 到 Alluxio 后,对 HDFS 文 件进行了修改 措施 : ● 开发 makeConsistency 脚本 , 对不一致数据进行修复 , 并贡献给社区 比较策略:文件名、文件大小、修改时间
28 .后 续展望 整合 Presto ,加快 Adhoc 和报表系统的响应时间。 继续参与社区的发展