

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Alluxio+AVA:让深度训练数据上云
七牛云 Atlab 实验室专注于机器视觉方向的深度学习研究。我们团队针对深度学习训练打造了高效的训练平台 AVA,深度整合了存储和计算资源。为了提高算法工程师训练模型的效率,我们使用 Alluxio 加速训练任务读取海量视频、图片等样本文件,并针对我们的应用场景,从元数据管理和读写分离等方向入手对 Alluxio 进行改造,实现了文件读写性能 50% 以上的提升,同时显著降低了存储系统的成本和容量风险。
展开查看详情
1 .Alluxio & AVA - Deep learning in cloud Qiniu AI Technical Director lichaoguang@qiniu.com (李李朝光)
2 .Agenda ✦ Brief introduction to AVA deep learning platform ✦ Evolution of AVA storage sub-system ✦ Time for Alluxio ✦ Performance boost with Alluxio in cloud ✦ Roadmap of Alluxio in AVA ✦ Contribute to Alluxio
3 .AVA Image, Video service platform Classify Face Text Detection Image Search Track Query Dataset Label Model Training Schedule Inference
4 .AVA architecture Label Dataset Training Model AVA deep learning platform Distributed Storage Distributed Compute Distributed caching Distributed Schedule Object Block GPU mgt Training Virtualization, orchestration, docker Hardware, switch
5 .Agenda ✦ Brief introduction to AVA deep learning platform ✦ Evolution of AVA storage sub-system ✦ Time for Alluxio ✦ Performance boost with Alluxio in cloud ✦ Running Alluxio ✦ Contribute to Alluxio ✦ Roadmap of Alluxio in AVA
6 .Data at present CEPH Storage 200T+ Alluxio RAM/SSD tier 3T/100T+ Training data 50B+ Bucket files 10M+ Image file size 100KB Video file size 500MB Images /day/training 300K+ Image files for model 20M+ KODO new added images /day 100M+
7 .AVA Storage sub-system Qiniu Object Qiniu Object Qiniu Object Poor performance Not shareable Performance + + bad scale Op hell / scale scale + ease
8 .Agenda ✦ Brief introduction to AVA deep learning platform ✦ Evolution of AVA storage sub-system ✦ Time for Alluxio ✦ Performance boost with Alluxio in cloud ✦ Running Alluxio ✦ Contribute to Alluxio ✦ Roadmap of Alluxio in AVA
9 .Alluxio in AVA Application Application Application /a1 /a2 /b1 /b2 /c1 /c2 Bucket Bucket Bucket Bucket Bucket Bucket FUSE FUSE FUSE 3 1 FUSE Adapter (on host) KODO KODO 1 RAM RAM 2 2 3 Worker Worker Worker Worker Worker Worker
10 .Deployment ✦ Cluster: ✦ Master ✦ N+ ✦ 128G (major) RAM or 64G ✦ Zookeeper: 3 node for HA ✦ 3 replicas ✦ Dockerized service ✦ Journal on CEPH FS ✦ One major cluster ✦ G1GC ✦ Other: video, classification, etc ✦ Supported inode: 40M (128G) *** ✦ Ethernet: 10000M * 2 ✦ Inode cache feature ** ✦ Read Worker ✦ Client ✦ 2 tiers: 1.8T SSD * 4, 64G RAM ✦ Write tier: SSD ✦ JVM mem: 16G ✦ Async through ✦ Cache poliicy ✦ Fuse cache *** ✦ Write worker ✦ Separated read/write host *** ✦ 10T CEPH RBD (FS first) ✦ Flush control *** ✦ Async through ✦ Short circuit *** ✦ Persist rate control ***
11 .Why Alluxio on AVA? ✦ Qiniu: cloud vender with object storage ✦ + 2Billions images/videos every day ✦ Multiple vendor support (gateway) ✦ CEPH is not satisfied ✦Shared, scalable, FS inode, performance ✦ Keep training code unchanged ✦ Memory speed ✦ Beautiful code ✦ Good community support ✦ Cache, Cache, Cache !!!
12 .Agenda ✦ Brief introduction to AVA deep learning platform ✦ Evolution of AVA storage sub-system ✦ Time for Alluxio ✦ Performance boost with Alluxio in cloud ✦ Roadmap of Alluxio in AVA ✦ Contribute to Alluxio
13 . Performance boost with Alluxio ✦ Benefit: ✦ Memory cluster: 10GB for short circuit Object storage (KODO) ✦ Short term: pre-warm Master ✦ Long term: LRU evict Network: 1-10M/S ✦ImageNet, 50K images (proper pre-warm) Training POD Tier0: 1GB/S ✦20% faster than CEPH ✦5 times as fast as Object Storage Short Circuit: 8-10GB/S Tier1: 500MB/S ✦Same as CEPH for compute-heavy training Worker (local) Worker (remote) ✦4x fast with short-circuit for IO-heavy training
14 .Caching (1) - Objects/Files cache Object Storage Billions of objects 50% faster than CEPH (pre-warm) Training 5x faster than from cloud Ethernet: 1-10MB/S Alluxio Worker Millions of objects Caching/Persist RAM Tier: 1G-10GB/S Promote/evict SSD Tier: 200-500MB/S Promote/evict SATA Tier: 1-100MB/S Discard
15 .Caching (2) - FUSE meta cache LRU getStatus() Meta Cache open() Client read() Master Client First Access Master …() About N round-trip per file access Every access takes 2-3ms 3x performance boost for small file
16 .Caching (3) - Master safety guarantee Or performance down 10x due to heavy GC! Possibily OOM Inode/Block Evict Persist Master Persist/Evict Worker Worker Monitor Meta Server
17 .Short circuit & Cache Policy GPU 8-10G/S, Short Circuit POD Master Worker 1G/S, Ethernet Possible issues: • Compete with training program Worker • RAM rushing Worker CACHE POLICY • Tier eviction stuck 10M/S, Ethernet 10x storage access / 2x+ samples/sec
18 .Agenda ✦ Brief introduction to AVA deep learning platform ✦ Evolution of AVA storage sub-system ✦ Time for Alluxio ✦ Performance boost with Alluxio in cloud ✦ Roadmap of Alluxio in AVA ✦ Contribute to Alluxio
19 .Plan ✦ Cache Policy ✦ POD schedule ✦ Short Circuit / temp worker ✦ Master inode improvement ✦ Quota/large bucket ✦ off-heap/KV ✦ Reduce lock contention ✦ Write enhancement (retry, etc) ✦ Evict manager ✦ Standalone service
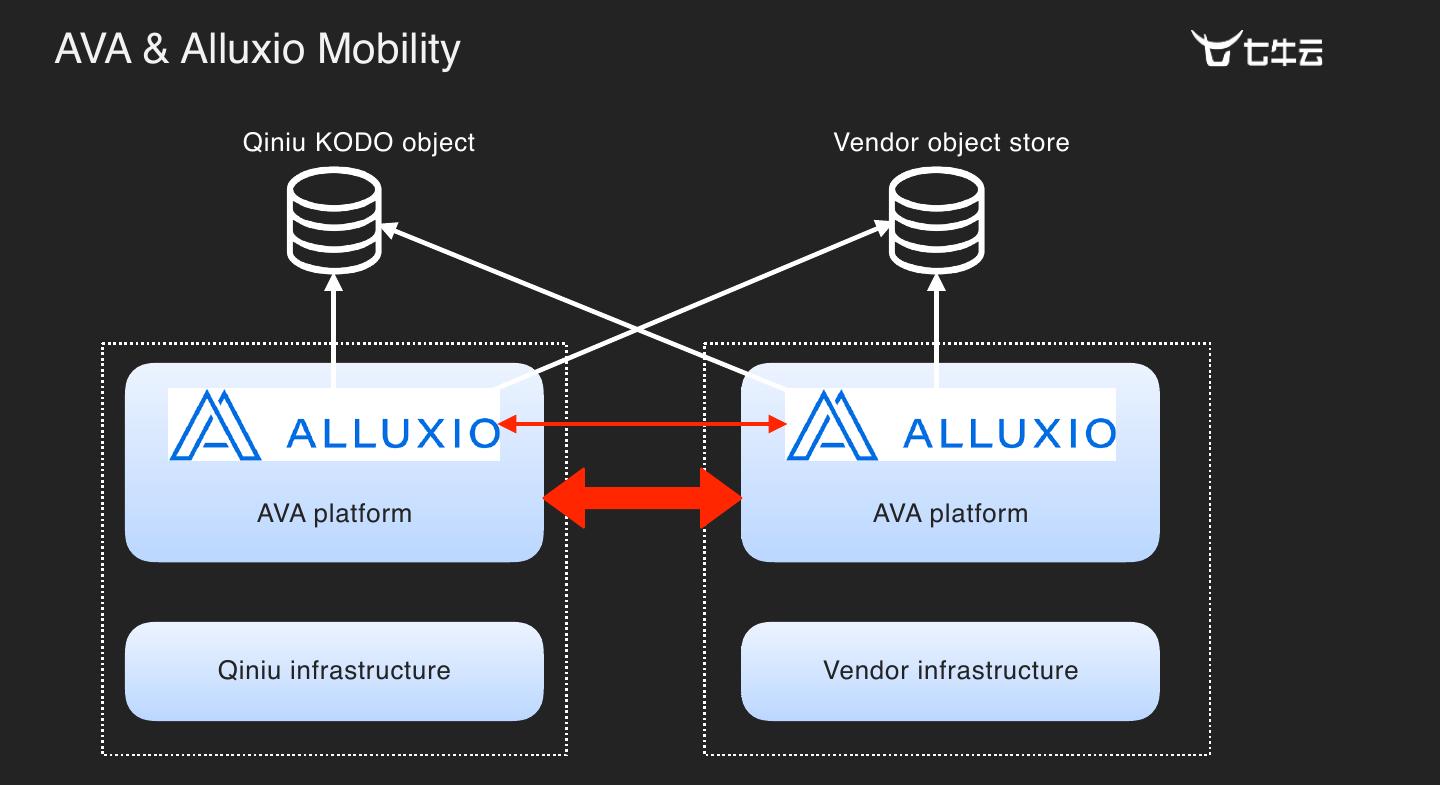
20 .AVA & Alluxio Mobility Qiniu KODO object Vendor object store AVA platform AVA platform Qiniu infrastructure Vendor infrastructure
21 .Edge storage & Edge compute & Alluxio & AVA Edge Object Store Object Store Edge Storage Edge Storage Alluxio Alluxio Edge Compute AVA Alluxio Edge Compute AVA AVA Customer IDC Cloud, etc, Qiniu
22 .Agenda ✦ Brief introduction to AVA deep learning platform ✦ Evolution of AVA storage sub-system ✦ Time for Alluxio ✦ Performance boost with Alluxio in cloud ✦ Roadmap of Alluxio in AVA ✦ Contribute to Alluxio
23 .Community contribution ✦ More to come ✦ Large file upload ✦ FUSE cache ✦ Bucket mount conflict ✦ Selective read/write worker ✦ Lock improvement ✦ Master Inode mem shrink ✦ Quota ✦……
24 .Thanks!
3秒后跳转登录页面
去登陆

