















































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Google Go 编程规范
本系列的 Go ⻛格指南和相关⽂档整理了当前,最佳的⼀个编写易读和惯⽤⽅式的 Go 写法。 遵守⻛格指南并不是绝对的,这份⽂件也永远不会详尽⽆遗。我们的⽬的是尽量减少编写可读 Go 代码的猜测,以便该语⾔的新⼿可以避免常⻅的错误。此⻛格指南也⽤于统⼀ Google 内 Go 代码 review 者的⻛格指南。
展开查看详情
1 . 让 rehpoG Google Go 编程规范 从 这 ⾥ 开 始 编 码 规 范 G o C N 翻译⼩组
2 .Google Go 编程规范 《Google Go 编程规范》采⽤ Hugo 发布。欢迎⼤家通过 issue 提供建议,也可以通过 pull requests 来共同参与 贡献。 安装完 hugo 之后,需要先同步主题⽂件 git submodule update --init --recursive 同步完成后,可在根⽬录执⾏以下指令来测试⽹站: hugo server ⽂档在 content/zh/docs ⽬录下,修改后可以通过 pull requests 提交。 ⽬录 1. 概述 2. ⻛格指南 3. ⻛格决策 4. 最佳实践 授权 The articles in 《Google Go 编程规范》 are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. 贡献者 Xiaomin Fivezh 朱亚光 784909593 刘思家 Sijing233 Zheng ⼩超⼈ Yu ZHANG
3 .概述 原⽂:https://google.github.io/styleguide/go 概述 | ⻛格指南 | ⻛格决策 | 最佳实践 关于 本系列的 Go ⻛格指南和相关⽂档整理了当前,最佳的⼀个编写易读和惯⽤⽅式的 Go 写法。 遵守⻛格指南 并不是绝对的,这份⽂件也永远不会详尽⽆遗。我们的⽬的是尽量减少编写可读 Go 代码的猜测,以便该语 ⾔的新⼿可以避免常⻅的错误。此⻛格指南也⽤于统⼀ Google 内 Go 代码 review 者的⻛格指南。 ⽂档 链接 主要受众 视为标准 视为规范 (Normative) (Canonical) ⻛格指南 https:// 所有⼈ Yes Yes gocn.github.io/ styleguide/docs/ 02-guide/ ⻛格决策 https:// 可读性导师 Yes No gocn.github.io/ styleguide/docs/ 03-decisions/ 最佳实践 https:// 任何有兴趣的⼈ No No gocn.github.io/ styleguide/docs/ 04-best- practices/ ⽂档说明 ⻛格指南 (Style Guide) (https://gocn.github.io/styleguide/docs/02-guide/) 概述了 Google Go ⻛格 的基础。本⽂档为定义名词性质的⽂件,⽤作⻛格决策和最佳实践中建议的基础。 ⻛格决策 (Style Decisions) (https://gocn.github.io/styleguide/docs/03-decisions/) 是⼀份更详细的 ⽂档,它总结了特定场景下⻛格的决策理由,并在适当的时候讨论了决策背后的原因。 这些决定可能偶尔会根据新数据、新语⾔特性、新代码库或新出现的模式⽽改变,但不期望 Google 的 Go 程序员能及时了解本⽂档的更新。 最佳实践 (Best Practices) (https://gocn.github.io/styleguide/docs/04-best-practices/) 描述了⼀些 随时间演变的模式,这些模式可以解决通⽤问题,可读性强,并且对代码可维护的需要有很好的健壮 性。 这些最佳实践并不规范,但⿎励 Google 的 Go 程序员尽可能使⽤它们,以保持代码库的统⼀和⼀致。 这些⽂件旨在: 就权衡备选⻛格的⼀套原则达成⼀致 整理最终的 Go 编码⻛格
4 . 记录并提供 Go 编码惯⽤法的典型示例 记录各种⻛格决策的利弊 帮助减少在 Go 可读性 review 时的意外 帮助可读性导师使⽤⼀致的术语和指导 本⽂档⽆意于: 成为在可读性审查时的详尽的意⻅清单 列出所有的规则,期望每个⼈在任何时候都能记住并遵守 在语⾔特型和⻛格的使⽤上取代良好的判断⼒ 为了消除⻛格差异,证明⼤规模的改变是合理的 不同 Go 程序员之间以及不同团队的代码库之间总会存在差异。然⽽,我们的代码库尽可能保持⼀致符合 Google 和 Alphabet 的最⼤利益。 (有关⼀致性的更多信息,请参阅 指南。)为此,您可以随意进⾏⻛格 改进,但不需要挑剔你发现的每⼀个违反⻛格指南的⾏为。特别是,这些⽂档可能会随着时间的推移⽽改 变,这不是导致现有代码库做出额外改动的理由; 使⽤最新的最佳实践编写新代码,并随着时间的推移解决 上下⽂或者关联到的代码的问题就⾜够了。 重要的是要认识到⻛格问题本质上是个⼈的,并且总是带有特定的权衡。这些⽂档中的⼤部分指南都是主观 的,但就像 gofmt ⼀样,它提供的⼀致性具有重要价值。 因此,⻛格建议不会在未经适当讨论的情况下改 变,Google 的 Go 程序员被⿎励遵循⻛格指南,即使他们可能不同意。 定义 ⻛格⽂档中使⽤的以下词语定义如下: 规范 (Canonical) 制定规定性和持久性规则 在这些⽂档中,“规范”⽤于描述被认为是所有代码(旧的和新的)都应该遵循的标准,并且预计不会随 着时间的推移⽽发⽣重⼤变化。规范⽂档中的原则应该被作者和审稿⼈理解,因此规范⽂档中包含的所 有内容都必须达到⾼标准。 如此⼀来,与⾮规范⽂档相⽐,规范⽂档通常更短并且规定的⻛格元素更 少。 标准 (Normative) 旨在建⽴⼀致性 在这些⽂档中,“规范”⽤于描述 Go 代码审查者使⽤的⼀致同意的⻛格元素,以便建议、术语和理由保 持⼀致。 这些元素可能会随着时间的推移⽽发⽣变化,本⽂涉及的这些⽂件将反映出这些变化,以便审 阅者可以保持⼀致和及时更新。 Go 代码编写者不被要求熟悉此⽂档,但这些⽂档将经常被审阅者⽤作 可读性审查的参考。 惯⽤写法 (Idiomatic) 常⻅且熟悉 在这些⽂档中,“惯⽤写法”指在 Go 代码中普遍存在的东⻄,并已成为⼀种易于识别的常⻅写法。⼀般 来说,如果两者在上下⽂中服务于相同的⽬的,那么惯⽤写法应该优先于⾮惯⽤写法,因为这将是读者 最熟悉的写法。
5 .附加参考 本指南假定读者熟悉 Effective Go,因为它为整个 Go 社区的 Go 代码提供了⼀个通⽤基线。 下⾯是⼀些额外的资源,供那些希望⾃学 Go ⻛格的⼈和希望在他们的评审中附上可链接的评审依据的代码 审阅者。 不期望 Go 可读性过程的参与者熟悉这些资源,但它们可能作为可读性审阅的相关依据出现。 外部参考 Go 语⾔规范 Go FAQ Go 内存模型 Go 数据结构 Go 接⼝ Go 谚语 Go 技巧 - 敬请期待 ⻢桶测试 (Testing-on-the-Toilet) 相关⽂档 厕所⾥的测试(⼜称 TotT)是测试⼩组最明显的成就。从 2006 年开始,TotT 从⼀个会议上的玩笑开始, 已经成为⼀个真正的⾕歌机构,并且是在公司内部传播想法、产⽣讨论和推动新的内部⼯具采⽤的最有效 的⽅式之⼀。TotT TotT: 标识命令 TotT: 测试状态与 vs Testing Interactions TotT: 有效测试 TotT: ⻛险驱动测试 TotT: 变化检测器测试被认为是有害的 额外的外部⽂档 Go 与 教条 少即是成倍的多 Esmerelda 的想象⼒ ⽤于解析的正则表达式 Gofmt 的⻛格没有⼈喜欢,但 Gofmt 却是每个⼈的最爱 (YouTube)
6 .Go ⻛格指南 原⽂:https://google.github.io/styleguide/go 概述 | ⻛格指南 | ⻛格决策 | 最佳实践 ⻛格原则 以下⼏条总体原则总结了如何编写可读的 Go 代码。以下为具有可读性的代码特征,按重要性排序: 清晰:代码的⽬的和设计原理对读者来说是清楚的。 简约:代码以最简单的⽅式来完成它的⽬的。 简洁:代码具有很⾼的信噪⽐,即写出来的代码是有意义的,⾮可有可⽆的。 可维护性:代码可以很容易地被维护。 ⼀致:代码与更⼴泛的 Google 代码库⼀致。 清晰 可读性的核⼼⽬标是写出对读者来说很清晰的代码。 清晰性主要是通过有效的命名、有⽤的注释和有效的代码组织来实现的。 清晰性要从读者的⻆度来看,⽽不是从代码的作者的⻆度来看,代码的易读性⽐易写性更重要。代码的清晰 性有两个不同的⽅⾯: 该代码实际上在做什么? 为什么代码会这么做? 该代码实际上在做什么 Go 被设计得应该是可以⽐较直接地看到代码在做什么。在不确定的情况下或者读者可能需要先验知识才能 理解代码的情况下,我们值得投⼊时间以使代码的⽬的对未来的读者更加明确。例如,它可能有助于: 使⽤更具描述性的变量名称 添加额外的评论 使⽤空⽩与注释来划分代码 将代码重构为独⽴的函数 / ⽅法,使其更加模块化 这⾥没有⼀个放之四海⽽皆准的⽅法,但在开发 Go 代码时,优先考虑清晰性是很重要的。 为什么代码会这么做 代码的基本原理通常由变量、函数、⽅法或包的名称充分传达。如果不是这样,添加注释是很重要的。当代 码中包含读者可能不熟悉的细节时,“为什么?”就显得尤为重要,例如: 编程语⾔中的细微差别,例如,⼀个闭包将捕获⼀个循环变量,但闭包在许多⾏之外 业务逻辑的细微差别,例如,需要区分实际⽤户和虚假⽤户的访问控制检查
7 .⼀个 API 可能需要⼩⼼翼翼才能正确使⽤。例如,由于性能原因,⼀段代码可能错综复杂,难以理解,或者 ⼀连串复杂的数学运算可能以⼀种意想不到的⽅式使⽤类型转换。在这些以及更多的情况下,附带的注释和 ⽂档对这些⽅⾯进⾏解释是很重要的,这样未来的维护者就不会犯错,读者也可以理解代码⽽不需要进⾏逆 向⼯程。 同样重要的是,我们要意识到,⼀些基于清晰性考虑的尝试(如添加额外的注释),实际上会通过增加杂乱 ⽆章的内容、重述代码已经说过的内容、与代码相⽭盾或增加维护负担来保持注释的最新性,以此来掩盖代 码的⽬的。让代码⾃⼰说话(例如,通过代码中的名称本身进⾏描述),⽽不是添加多余的注释。通常情况 下,注释最好是解释为什么要做某事,⽽不是解释代码在做什么。 Google 的代码库基本上是统⼀和⼀致的。通常情况下,那些⽐较突⺎的代码(例如,应⽤⼀个不熟悉的模 式)是基于充分的理由,通常是为了性能。保持这种特性很重要,可以让读者在阅读⼀段新的代码时清楚地 知道他们应该把注意⼒放在哪⾥。 标准库中包含了许多这⼀原则发挥作⽤的例⼦。例如: 在 package sort 中的维护者注释 好的同⼀软件包中可运⾏的例⼦,这对⽤户(他们会查看 godoc)和维护者(他们作为测试的⼀部分运 ⾏)都有利 strings.Cut 只有四⾏代码,但它们提⾼了 callsites 的清晰性和正确性 简约 你的 Go 代码对于使⽤、阅读和维护它的⼈来说应该是简单的。 Go 代码应该以最简单的⽅式编写,在⾏为和性能⽅⾯都能实现其⽬标。在 Google Go 代码库中,简单的代 码: 从头⾄尾都易于阅读 不预设你已经知道它在做什么 不预设你能记住前⾯所有的代码 不含⾮必要的抽象层次 不含过于通⽤的命名 让读者清楚地了解到传值与决定的传播情况 有注释,解释为什么,⽽不是代码正在做什么,以避免未来的歧义 有独⽴的⽂档 包含有效的错误与失败⽤例测试 往往不是看起来“聪明”的代码 在代码的简单性和 API 使⽤的简单性之间可能会需要权衡。例如,让代码更复杂可能是值得的,这样 API 的 终端⽤户可以更容易地正确调⽤ API。相反,把⼀些额外的⼯作留给 API 的终端⽤户也是值得的,这样代码 就会保持简单和容易理解。 当代码需要复杂性时,应该有意地增加复杂性。如果需要额外的性能,或者⼀个特定的库或服务有多个不同 的客户,这通常是必要的。复杂性可能是合理的,但它应该有相应的⽂档,以便客户和未来的维护者能够理 解和驾驭这种复杂性。这应该⽤测试和例⼦来补充,以证明其正确的⽤法,特别是如果同时有⼀个“简单”和 “复杂”的⽅法来使⽤代码。
8 .这⼀原则并不意味着复杂的代码不能或不应该⽤ Go 编写,也不意味着 Go 代码不允许复杂。我们努⼒使代 码库避免不必要的复杂性,因此当复杂性出现时,它表明有关的代码需要仔细理解和维护。理想情况下,应 该有相应的注释来解释其中的道理,并指出应该注意的地⽅。在优化代码以提⾼性能时,经常会出现这种情 况;这样做往往需要更复杂的⽅法,⽐如预先分配⼀个缓冲区并在整个 goroutine ⽣命周期内重复使⽤它。 当维护者看到这种情况时,应该是⼀个线索,说明相关的代码是基于性能的关键考虑,这应该影响到未来修 改时的谨慎。另⼀⽅⾯,如果不必要地使⽤,这种复杂性会给那些需要在未来阅读或修改代码的⼈带来负 担。 如果代码⾮常复杂,但其⽬的应该是简单的,这往往是⼀个我们可以重新审视代码实现的信号,看看是否有 更简单的⽅法来完成同样的事情。 最⼩化机制 如果有⼏种⽅法来表达同⼀个想法,最好选择使⽤最标准⼯具的⽅法。复杂的机制经常存在,但不应该⽆缘 ⽆故地使⽤。根据需要增加代码的复杂性是很容易的,⽽在发现没有必要的情况下删除现有的复杂性则要难 得多。 当⾜以满⾜你的使⽤情况时,争取使⽤⼀个核⼼语⾔结构(例如通道、切⽚、地图、循环或结构) 如果没有,就在标准库中寻找⼀个⼯具(如 HTTP 客户端或模板引擎) 最后,在引⼊新的依赖或创建⾃⼰的依赖之前,考虑 Google 代码库中是否有⼀个能够满⾜的核⼼库 例如,考虑⽣产代码包含⼀个绑定在变量上的标志,它的默认值必须在测试中被覆盖。除⾮打算测试程序的 命令⾏界⾯本身(例如,⽤ os/exec ),否则直接覆盖绑定的值⽐使⽤ flag.Set 更简单,因此更可取。 同样,如果⼀段代码需要检查集合成员的资格,⼀个布尔值的映射(例如, map[string]bool )通常就⾜ 够了。只有在需要更复杂的操作,不能使⽤ map 或过于复杂时,才应使⽤提供类似集合类型和功能的库。 简洁 简洁的 Go 代码具有很⾼的信噪⽐。它很容易分辨出相关的细节,⽽命名和结构则引导读者了解这些细节。 ⽽有很多东⻄会常常会阻碍这些最突出的细节: 重复代码 外来的语法 含义不明的名称 不必要的抽象 空⽩ 重复代码尤其容易掩盖每个相似代码之间的差异,需要读者直观地⽐较相似的代码⾏来发现变化。表驱动测 试是⼀个很好的例⼦,这种机制可以简明地从每个重复的重要细节中找出共同的代码,但是选择哪些部分囊 括在表中,会对表格的易懂程度产⽣影响。 在考虑多种结构代码的⽅式时,值得考虑哪种⽅式能使重要的细节最显著。 理解和使⽤常⻅的代码结构和规范对于保持⾼信噪⽐也很重要。例如,下⾯的代码块在错误处理中⾮常常 ⻅,读者可以很快理解这个代码块的⽬的。
9 .// Good: if err := doSomething(); err != nil { // ... } 如果代码看起来⾮常相似但却有细微的不同,读者可能不会注意到这种变化。在这样的情况下,值得故意 “提⾼”错误检查的信号,增加⼀个注释以引起关注。 // Good: if err := doSomething(); err == nil { // if NO error // ... } 可维护性 代码被编辑的次数⽐它写它的次数多得多。可读的代码不仅对试图了解其⼯作原理的读者有意义,⽽且对需 要改写它的程序员也有意义,清晰性很关键。 可维护的代码: 容易让未来的程序员正确进⾏修改 拥有结构化的 API,使其能够优雅地增加 清楚代码预设条件,并选择映射到问题结构⽽不是代码结构的抽象 避免不必要的耦合,不包括不使⽤的功能 有⼀个全⾯的测试套件,以确保预期⾏为可控、重要逻辑正确,并且测试在失败的情况下提供清晰、可 操作的诊断 当使⽤像接⼝和类型这样的抽象时,根据定义,它们会从使⽤的上下⽂中移除信息,因此必须确保它们提供 ⾜够的好处。当使⽤具体类型时,编辑器和 IDE 可以直接连接到⽅法定义并显示相应的⽂档,但在其他情况 下只能参考接⼝定义。接⼝是⼀个强⼤的⼯具,但也是有代价的,因为维护者可能需要了解底层实现的具体 细节才能正确使⽤接⼝,这必须在接⼝⽂档中或在调⽤现场进⾏解释。 可维护的代码还可以避免在容易忽视的地⽅隐藏重要的细节。例如,在下⾯的每⼀⾏代码中,是否有 : 字 符对于理解这⼀⾏⾄关重要。 // Bad: // 使⽤ = ⽽不是 := 可以完全改变这⼀⾏的含义 if user, err = db.UserByID(userID); err != nil { // ... } // Bad: // 这⾏中间的 ! 很容易错过 leap := (year%4 == 0) && (!(year%100 == 0) || (year%400 == 0)) 这两种写法不能说错误,但都可以写得更明确,或者可以有⼀个附带的评论,提醒注意重要的⾏为。
10 .// Good: u, err := db.UserByID(userID) if err != nil { return fmt.Errorf("invalid origin user: %s", err) } user = u // Good: // 公历闰年不仅仅是 year%4 == 0 // 查看 https://en.wikipedia.org/wiki/Leap_year#Algorithm. var ( leap4 = year%4 == 0 leap100 = year%100 == 0 leap400 = year%400 == 0 ) leap := leap4 && (!leap100 || leap400) 同样地,⼀个隐藏了关键逻辑或重要边界情况的辅助函数,可能会使未来的变化很容易地被误解。 易联想的名字是可维护代码的另⼀个特点。⼀个包的⽤户或⼀段代码的维护者应该能够联想到⼀个变量、⽅ 法或函数在特定情况下的名称。相同概念的函数参数和接收器名称通常应该共享相同的名称,这既是为了保 持⽂档的可理解性,也是为了⽅便以最⼩的开销重构代码。 可维护的代码尽量减少其依赖性(包括隐性和显性)。对更少包的依赖意味着更少的代码⾏可以影响其⾏ 为。避免对内部或未记录的⾏为的依赖,使得代码在未来这些⾏为发⽣变化时,不太容易造成维护负担。 在考虑如何构造或编写代码时,值得花时间去思考代码可能随着时间的推移⽽演变的⽅式。如果⼀个给定的 ⽅法更有利于未来更容易和更安全的变化,这往往是⼀个很好的权衡,即使它意味着⼀个稍微复杂的设计。 ⼀致 ⼀致性的代码是指在更⼴泛的代码库中,在⼀个团队或包的范围内,甚⾄在⼀个⽂件中,看起来、感觉和⾏ 为都是类似的代码。 ⼀致性的问题并不凌驾于上述的任何原则之上,但如果必须有所取舍,那往往有利于⼀致性的实现。 ⼀个包内的⼀致性通常是最直接重要的⼀致性⽔平。如果同⼀个问题在⼀个包⾥有多种处理⽅式,或者同⼀ 个概念在⼀个⽂件⾥有很多名字,那就会⾮常不优雅。然⽽,即使这样,也不应该凌驾于⽂件的⻛格原则或 全局⼀致性之上。 核⼼准则 这些准则收集了所有 Go 代码都应遵循的 Go ⻛格的最重要⽅⾯。我们希望这些原则在你被保障可读性的时 候就已经学会并遵循了。这些不会经常改变,新增加内容也有较⾼准⼊⻔槛。 下⾯的准则是对 Effective Go 中建议的扩展,它为整个社区的 Go 代码提供了⼀个共同的基准线。 格式化
11 .所有 Go 源⽂件必须符合 gofmt ⼯具所输出的格式。这个格式是由 Google 代码库中的预提交检查强制执⾏ 的。⽣成的代码通常也应该被格式化(例如,通过使⽤ format.Source ),因为它也可以在代码搜索中浏 览。 ⼤⼩写混合 Go 源代码在编写包含多个字的名称时使⽤ MixedCaps 或 mixedCaps (驼峰⼤写)⽽不是下划线(蛇形⼤ 写)。 即使在其他语⾔中打破惯例,这也适⽤。例如,⼀个常量如果被导出,则为 MaxLength (⽽不是 MAX_LENGTH ),如果未被导出,则为 maxLength (⽽不是 max_length )。 基于初始化⼤⼩写的考量,局部变量被认为是 不可导出的。 ⾏⻓度 Go 源代码没有固定的⾏⻓度。如果觉得某⼀⾏太⻓,就应该对其进⾏重构⽽不是破坏。如果它已经很短 了,那么就应该允许它继续增加。 不要在以下情况进⾏分⾏: 在缩进变化之前 (例如,函数声明、条件) 要使⼀个⻓的字符串(例如,⼀个 URL)适合于多个较短的⾏ 命名 命名是艺术⽽不是科学。在 Go 中,名字往往⽐许多其他语⾔的名字短⼀些,但同样的⼀般准则也适⽤,名 称应: 使⽤时不感到重复 将上下⽂考虑在内 不重复已经明确的概念 你可以在决定中找到关于命名的更具体的指导。 本地化⼀致性 如果⻛格指南对某⼀特定的⻛格点没有说明,作者可以⾃由选择他们喜欢的⻛格,除⾮相近的代码(通常在 同⼀个⽂件或包内,但有时在⼀个团队或项⽬⽬录内)对这个问题采取了⼀致的⽴场。 有效的本地⻛格化考虑例⼦: 使⽤ %s or %v 来打印错误 使⽤缓冲通道来代替 mutexes ⽆效的本地化⻛格化考虑例⼦: 代码⾏⻓度的限制 使⽤基于断⾔的测试库
12 .如果本地化⻛格与⻛格指南不⼀致,但对可读性的影响仅限于⼀个⽂件,它通常会在代码审查中浮出⽔⾯, ⽽⼀致的修复将超出有关 CL 的范围。在这⼀点上,提交⼀个 bug 来跟踪修复是合适的。 如果⼀个改变会使现有的⻛格偏差变⼤,在更多的 API 表⾯暴露出来,扩⼤存在偏差的⽂件数量,或者引⼊ ⼀个实际的错误,那么局部⼀致性就不再是违反新代码⻛格指南的有效理由。在这些情况下,作者应该在同 ⼀ CL 中清理现有的代码库,在当前 CL 之前进⾏重构,或者找到⼀个⾄少不会使本地化问题恶化的替代⽅ 案。
13 .Go ⻛格决策 原⽂:https://google.github.io/styleguide/go 概述 | ⻛格指南 | ⻛格决策 | 最佳实践 注意: 本⽂是 Google Go ⻛格 系列⽂档的⼀部分。本⽂档是 规范性 (normative) 但不是强制规范 (canonical),并且从属于 Google ⻛格指南。请参阅概述获取更多详细信息。 关于 本⽂包含旨在统⼀和为 Go 可读性导师给出的建议提供标准指导、解释和示例的⻛格决策。 本⽂档并不详尽,且会随着时间的推移⽽增加。如果⻛格指南 与此处给出的建议相⽭盾,⻛格指南优先,并 且本⽂档应相应更新。 参⻅ 关于 获取 Go ⻛格的全套⽂档。 以下部分已从样式决策移⾄指南的⼀部分: 混合⼤写字⺟ MixedCaps: 参⻅ https://gocn.github.io/styleguide/docs/02-guide/#⼤⼩写混合 格式化 Formatting: 参⻅ https://gocn.github.io/styleguide/docs/02-guide/#格式化 ⾏⻓度 Line Length: 参⻅ https://gocn.github.io/styleguide/docs/02-guide/#⾏⻓度 命名 Naming 有关命名的总体指导,请参阅核⼼⻛格指南 中的命名部分,以下部分对命名中的特定区域提供进⼀步的说 明。 下划线 Underscores Go 中的命名通常不应包含下划线。这个原则有三个例外: 仅由⽣成代码导⼊的包名称可能包含下划线。有关如何选择多词包名称的更多详细信息,请参阅包名 称。 *_test.go ⽂件中的测试、基准和示例函数名称可能包含下划线。 与操作系统或 cgo 互操作的低级库可能会重⽤标识符,如 syscall 中所做的那样。在⼤多数代码库 中,这预计是⾮常罕⻅的。 包名称 Package names Go 包名称应该简短并且只包含⼩写字⺟。由多个单词组成的包名称应全部⼩写。例如,包 tabwriter 不 应该命名为 tabWriter 、 TabWriter 或 tab_writer 。 避免选择可能被常⽤局部变量遮蔽覆盖 的包名称。例如, usercount 是⽐ count 更好的包名,因为 count 是常⽤变量名。 Go 包名称不应该有下划线。如果你需要导⼊名称中确实有⼀个包(通常来⾃⽣成的或第三⽅代码),则必 须在导⼊时将其重命名为适合在 Go 代码中使⽤的名称。
14 .⼀个例外是仅由⽣成的代码导⼊的包名称可能包含下划线。具体例⼦包括: 对外部测试包使⽤ _test 后缀,例如集成测试 使⽤ _test 后缀作为 包级⽂档示例 避免使⽤⽆意义的包名称,例如 util 、 utility 、 common 、 helper 等。查看更多关于所谓的“实⽤程 序包”。 当导⼊的包被重命名时(例如 import foob "path/to/foo_go_proto" ),包的本地名称必须符合上述 规则,因为本地名称决定了包中的符号在⽂件中的引⽤⽅式.如果给定的导⼊在多个⽂件中重命名,特别是在 相同或附近的包中,则应尽可能使⽤相同的本地名称以保持⼀致性。 另请参阅:https://go.dev/blog/package-names 接收者命名 Receiver names 接收者 变量名必须满⾜: 短(通常是⼀两个字⺟的⻓度) 类型本身的缩写 始终如⼀地应⽤于该类型的每个接收者 ⻓名称 更好命名 func (tray Tray) func (t Tray) func (info *ResearchInfo) func (ri *ResearchInfo) func (this *ReportWriter) func (w *ReportWriter) func (self *Scanner) func (s *Scanner) 常量命名 Constant names 常量名称必须像 Go 中的所有其他名称⼀样使⽤ 混合⼤写字⺟ MixedCaps。(导出 常量以⼤写字⺟开头, ⽽未导出的常量以⼩写字⺟开头。)即使打破了其他语⾔的约定,这也是适⽤的。常量名称不应是其值的派 ⽣词,⽽应该解释值所表示的含义。 // Good: const MaxPacketSize = 512 const ( ExecuteBit = 1 << iota WriteBit ReadBit ) 不要使⽤⾮混合⼤写常量名称或带有 K 前缀的常量。
15 .// Bad: const MAX_PACKET_SIZE = 512 const kMaxBufferSize = 1024 const KMaxUsersPergroup = 500 根据它们的⻆⾊⽽不是它们的值来命名常量。如果⼀个常量除了它的值之外没有其他作⽤,那么就没有必要 将它定义为⼀个常量。 // Bad: const Twelve = 12 const ( UserNameColumn = "username" GroupColumn = "group" ) 缩写词 Initialisms 名称中的⾸字⺟缩略词或单独的⾸字⺟缩略词(例如,“URL”和“NATO”)应该具有相同的⼤⼩写。 URL 应 显示为 URL 或 url (如 urlPony 或 URLPony ),绝不能显示为 Url 。这也适⽤于 ID 是“identifier” 的缩写; 写 appID ⽽不是 appId 。 在具有多个⾸字⺟缩写的名称中(例如 XMLAPI 因为它包含 XML 和 API ),给定⾸字⺟缩写中的每 个字⺟都应该具有相同的⼤⼩写,但名称中的每个⾸字⺟缩写不需要具有相同的⼤⼩写。 在带有包含⼩写字⺟的⾸字⺟缩写的名称中(例如 DDoS 、 iOS 、 gRPC ),⾸字⺟缩写应该像在标准 中⼀样出现,除⾮你需要为了满⾜ 导出 ⽽更改第⼀个字⺟。在这些情况下,整个缩写词应该是相同的情 况(例如 ddos 、 IOS 、 GRPC )。 缩写词 范围 正确 错误 XML API Exported XMLAPI XmlApi , XMLApi , XmlAPI , XMLapi XML API Unexported xmlAPI xmlapi , xmlApi iOS Exported IOS Ios , IoS iOS Unexported iOS ios gRPC Exported GRPC Grpc gRPC Unexported gRPC grpc DDoS Exported DDoS DDOS , Ddos DDoS Unexported ddos dDoS , dDOS Get ⽅法 Getters 函数和⽅法名称不应使⽤ Get 或 get 前缀,除⾮底层概念使⽤单词“get”(例如 HTTP GET)。此时,更 应该直接以名词开头的名称,例如使⽤ Counts ⽽不是 GetCounts 。
16 .如果该函数涉及执⾏复杂的计算或执⾏远程调⽤,则可以使⽤ Compute 或 Fetch 等不同的词代替 Get , 以使读者清楚函数调⽤可能需要时间,并有可能会阻塞或失败。 变量名 Variable names ⼀般的经验法则是,名称的⻓度应与其范围的⼤⼩成正⽐,并与其在该范围内使⽤的次数成反⽐。在⽂件范 围内创建的变量可能需要多个单词,⽽单个内部块作⽤域内的变量可能是单个单词甚⾄只是⼀两个字符,以 保持代码清晰并避免⽆关信息。 这是⼀条粗略的基础原则。这些数字准则不是严格的规则。要根据上下⽂、清晰 和[简洁](https:// gocn.github.io/styleguide/docs/02-guide/#简洁)来进⾏判断。 ⼩范围是执⾏⼀两个⼩操作的范围,⽐如 1-7 ⾏。 中等范围是⼀些⼩的或⼀个⼤的操作,⽐如 8-15 ⾏。 ⼤范围是⼀个或⼏个⼤操作,⽐如 15-25 ⾏。 ⾮常⼤的范围是指超过⼀⻚(例如,超过 25 ⾏)的任何内容。 在⼩范围内可能⾮常清楚的名称(例如, c 表示计数器)在较⼤范围内可能不够⽤,并且需要澄清以提示 进⼀步了解其在代码中的⽤途。⼀个作⽤域中有很多变量,或者表示相似值或概念的变量,那就可能需要⽐ 作⽤域建议的采⽤更⻓的变量名称。 概念的特殊性也有助于保持变量名称的简洁。例如,假设只有⼀个数据库在使⽤,像 db 这样的短变量名通 常可能保留给⾮常⼩的范围,即使范围⾮常⼤,也可能保持完全清晰。在这种情况下,根据范围的⼤⼩,单 个词 database 可能是可接受的,但不是必需的,因为 db 是该词的⼀种⾮常常⻅的缩写,⼏乎没有其他解 释。 局部变量的名称应该反映它包含的内容以及它在当前上下⽂中的使⽤⽅式,⽽不是值的来源。例如,通常情 况下最佳局部变量名称与结构或协议缓冲区字段名称不同。 ⼀般来说: 像 count 或 options 这样的单字名称是⼀个很好的起点。 可以添加其他词来消除相似名称的歧义,例如 userCount 和 projectCount 。 不要简单地省略字⺟来节省打字时间。例如, Sandbox 优于 Sbx ,特别是对于导出的名称。 ⼤多数变量名可省略 类型和类似类型的词 对于数字, userCount 是⽐ numUsers 或 usersInt 更好的名称。 对于切⽚, users 是⼀个⽐ userSlice 更好的名字。 如果范围内有两个版本的值,则包含类似类型的限定符是可以接受的,例如,你可能将输⼊存储在 ageString 中,并使⽤ age 作为解析值。 省略上下⽂ 中清楚的单词。例如,在 UserCount ⽅法的实现中,名为 userCount 的局部变量可能是多 余的; count 、 users 甚⾄ c 都具有可读性。 单字⺟变量名 Single-letter variable names # 单字⺟变量名是可以减少重复 的有⽤⼯具,但也可能使代码变得不透明。将它们的使⽤限制在完整单词很明 显以及它会重复出现以代替单字⺟变量的情况。 ⼀般来说: 对于⽅法接收者变量,最好使⽤⼀个字⺟或两个字⺟的名称。
17 . 对常⻅类型使⽤熟悉的变量名通常很有帮助: r ⽤于 io.Reader 或 *http.Request w ⽤于 io.Writer 或 http.ResponseWriter 单字⺟标识符作为整数循环变量是可接受的,特别是对于索引(例如, i )和坐标(例如, x 和 y )。 当范围很短时,循环标识符使⽤缩写是可接受的,例如 for _, n := range nodes { ... } 。 重复 Repetition ⼀段 Go 源代码应该避免不必要的重复。⼀个常⻅的情形是重复名称,其中通常包含不必要的单词或重复其 上下⽂或类型。如果相同或相似的代码段在很近的地⽅多次出现,代码本身也可能是不必要的重复。 重复命名可以有多种形式,包括: 包名 vs 可导出符号名 Package vs. exported symbol name # 当命名导出的符号时,包的名称始终在包外可⻅,因此应减少或消除两者之间的冗余信息。如果⼀个包如果 需要仅导出⼀种类型并且以包本身命名,则构造函数的规范名称是 New (如果需要的话)。 实例: 重复的名称 -> 更好的名称 widget.NewWidget -> widget.New widget.NewWidgetWithName -> widget.NewWithName db.LoadFromDatabase -> db.Load goatteleportutil.CountGoatsTeleported -> gtutil.CountGoatsTeleported or goatteleport.Count myteampb.MyTeamMethodRequest -> mtpb.MyTeamMethodRequest or myteampb.MethodRequest 变量名 vs 类型 Variable name vs. type # 编译器总是知道变量的类型,并且在⼤多数情况下,阅读者也可以通过变量的使⽤⽅式清楚地知道变量是什 么类型。只有当⼀个变量的值在同⼀范围内出现两次时,才有需要明确变量的类型。 重复的名称 更好的名称 var numUsers int var users int var nameString string var name string var primaryProject *Project var primary *Project 如果该值以多种形式出现,这可以通过额外的词(如 raw 和 parsed )或底层表示来澄清: // Good: limitStr := r.FormValue("limit") limit, err := strconv.Atoi(limitStr) // Good: limitRaw := r.FormValue("limit") limit, err := strconv.Atoi(limitRaw)
18 .外部上下⽂ vs 本地名称 External context vs. local names # 包含来⾃周围上下⽂信息的名称通常会产⽣额外的噪⾳,⽽没有任何好处。包名、⽅法名、类型名、函数 名、导⼊路径,包含来⾃其上下⽂信息的名称。 Names that include information from their surrounding context often create extra noise without benefit. The package name, method name, type name, function name, import path, and even filename can all provide context that automatically qualifies all names within. // Bad: // In package "ads/targeting/revenue/reporting" type AdsTargetingRevenueReport struct{} func (p *Project) ProjectName() string // Good: // In package "ads/targeting/revenue/reporting" type Report struct{} func (p *Project) Name() string // Bad: // In package "sqldb" type DBConnection struct{} // Good: // In package "sqldb" type Connection struct{} // Bad: // In package "ads/targeting" func Process(in *pb.FooProto) *Report { adsTargetingID := in.GetAdsTargetingID() } // Good: // In package "ads/targeting" func Process(in *pb.FooProto) *Report { id := in.GetAdsTargetingID() } 重复通常应该在符号使⽤者的上下⽂中进⾏评估,⽽不是孤⽴地进⾏评估。例如,下⾯的代码有很多名称, 在某些情况下可能没问题,但在上下⽂中是多余的: // Bad: func (db *DB) UserCount() (userCount int, err error) { var userCountInt64 int64 if dbLoadError := db.LoadFromDatabase("count(distinct users)", &userCountInt64); dbLoadError != nil { return 0, fmt.Errorf("failed to load user count: %s", dbLoadError) } userCount = int(userCountInt64) return userCount, nil } 相反,在上下⽂和使⽤上信息是清楚的情况下,常常可以忽略:
19 .// Good: func (db *DB) UserCount() (int, error) { var count int64 if err := db.Load("count(distinct users)", &count); err != nil { return 0, fmt.Errorf("failed to load user count: %s", err) } return int(count), nil } 评论 Commentary 关于评论的约定(包括评论什么、使⽤什么⻛格、如何提供可运⾏的示例等)旨在⽀持阅读公共 API ⽂档的 体验。有关详细信息,请参阅 Effective Go。 最佳实践⽂档关于 ⽂档约定 的部分进⼀步讨论了这⼀点。 **最佳实践:**在开发和代码审查期间使⽤⽂档预览 查看⽂档和可运⾏示例是否有⽤并以你期望的⽅式呈 现。 提示: Godoc 使⽤很少的特殊格式; 列表和代码⽚段通常应该缩进以避免换⾏。除缩进外,通常应避免装 饰。 注释⾏⻓度 Comment line length 确保注释在即使在较窄的屏幕上的可读性。 当评论变得太⻓时,建议将其包装成多个单⾏评论。在可能的情况下,争取在 80 列宽的终端上阅读良好的 注释,但这并不是硬性限制; Go 中的注释没有固定的⾏⻓度限制。例如,标准库经常选择根据标点符号来 打断注释,这有时会使个别⾏更接近 60-70 个字符标记。 有很多现有代码的注释⻓度超过 80 个字符。本指南不应作为更改此类代码作为可读性审查的⼀部分的理由 (请参阅⼀致),但⿎励团队作为其他重构的⼀部分,有机会时更新注释以遵循此指南。本指南的主要⽬标 是确保所有 Go 可读性导师在提出建议时以及是否提出相同的建议。 有关评论的更多信息,请参阅此 来⾃ The Go Blog 的帖⼦。 # Good: // This is a comment paragraph. // The length of individual lines doesn't matter in Godoc; // but the choice of wrapping makes it easy to read on narrow screens. // // Don't worry too much about the long URL: // https://supercalifragilisticexpialidocious.example.com:8080/Animalia/Chordata/ Mammalia/Rodentia/Geomyoidea/Geomyidae/ // // Similarly, if you have other information that is made awkward // by too many line breaks, use your judgment and include a long line // if it helps rather than hinders. 避免注释在⼩屏幕上重复换⾏,这是⼀种糟糕的阅读体验。
20 .# Bad: // This is a comment paragraph. The length of individual lines doesn't matter in Godoc; // but the choice of wrapping causes jagged lines on narrow screens or in Critique, // which can be annoying, especially when in a comment block that will wrap repeatedly. // // Don't worry too much about the long URL: // https://supercalifragilisticexpialidocious.example.com:8080/Animalia/Chordata/ Mammalia/Rodentia/Geomyoidea/Geomyidae/ ⽂档注释 Doc comments 所有顶级导出名称都必须有⽂档注释,具有不明显⾏为或含义的未导出类型或函数声明也应如此。这些注释 应该是完整句⼦,以所描述对象的名称开头。冠词(“a”、“an”、“the”)可以放在名字前⾯,使其读起来更 ⾃然。 // Good: // A Request represents a request to run a command. type Request struct { ... // Encode writes the JSON encoding of req to w. func Encode(w io.Writer, req *Request) { ... ⽂档注释出现在 Godoc 中,并通过 IDE 显示,因此应该为使⽤该包的任何⼈编写⽂档注释。 如果出现在结构中,⽂档注释适⽤于以下符号或字段组: // Good: // Options configure the group management service. type Options struct { // General setup: Name string Group *FooGroup // Dependencies: DB *sql.DB // Customization: LargeGroupThreshold int // optional; default: 10 MinimumMembers int // optional; default: 2 } **最佳实践:**如果你对未导出的代码有⽂档注释,请遵循与导出代码相同的习惯(即,以未导出的名称开 始注释)。这使得以后导出它变得容易,只需在注释和代码中⽤新导出的名称替换未导出的名称即可。 注释语句 Comment sentences 完整的注释应该像标准英语句⼦⼀样包含⼤写和标点符号。(作为⼀个例外,如果在其他⽅⾯很清楚,可以 以⾮⼤写的标识符名称开始⼀个句⼦。这种情况最好只在段落的开头进⾏。)
21 .作为句⼦⽚段的注释对标点符号或⼤⼩写没有此类要求。 ⽂档注释 应始终是完整的句⼦,因此应始终⼤写和标点符号。简单的⾏尾注释(特别是对于结构字段)可以 为假设字段名称是主语的简单短语。 // Good: // A Server handles serving quotes from the collected works of Shakespeare. type Server struct { // BaseDir points to the base directory under which Shakespeare's works are stored. // // The directory structure is expected to be the following: // {BaseDir}/manifest.json // {BaseDir}/{name}/{name}-part{number}.txt BaseDir string WelcomeMessage string // displayed when user logs in ProtocolVersion string // checked against incoming requests PageLength int // lines per page when printing (optional; default: 20) } 示例 Examples 包应该清楚地记录它们的预期⽤途。尝试提供⼀个可运⾏的例⼦; 示例出现在 Godoc 中。可运⾏示例属于 测试⽂件,⽽不是⽣产源⽂件。请参阅此示例(Godoc,[source](https://cs.opensource.google/go/go/+/ HEAD:src/time /example_test.go))。 如果⽆法提供可运⾏的示例,可以在代码注释中提供示例代码。与注释中的其他代码和命令⾏⽚段⼀样,它 应该遵循标准格式约定。 命名的结果参数 Named result parameters 当有命名参数时,请考虑函数签名在 Godoc 中的显示⽅式。函数本身的名称和结果参数的类型通常要⾜够 清楚。 // Good: func (n *Node) Parent1() *Node func (n *Node) Parent2() (*Node, error) 如果⼀个函数返回两个或多个相同类型的参数,添加名称会很有⽤。 // Good: func (n *Node) Children() (left, right *Node, err error) 如果调⽤者必须对特定的结果参数采取⾏动,命名它们可以帮助暗示⾏动是什么:
22 .// Good: // WithTimeout returns a context that will be canceled no later than d duration // from now. // // The caller must arrange for the returned cancel function to be called when // the context is no longer needed to prevent a resource leak. func WithTimeout(parent Context, d time.Duration) (ctx Context, cancel func()) 在上⾯的代码中,取消是调⽤者必须执⾏的特定操作。但是,如果将结果参数单独写为 (Context, func()) ,“取消函数”的含义就不清楚了。 当名称产⽣ 不必要的重复 时,不要使⽤命名结果参数。 // Bad: func (n *Node) Parent1() (node *Node) func (n *Node) Parent2() (node *Node, err error) 不要为了避免在函数内声明变量⽽使⽤命名结果参数。这种做法会导致不必要的冗⻓ API,但收益只是微⼩ 的简洁性。 裸返回 仅在⼩函数中是可接受的。⼀旦它是⼀个中等⼤⼩的函数,就需要明确你的返回值。同样,不要仅仅 因为可以裸返回就使⽤命名结果参数。清晰 总是⽐在你的函数中节省⼏⾏更重要。 如果必须在延迟闭包中更改结果参数的值,则命名结果参数始终是可以接受的。 提示: 类型通常⽐函数签名中的名称更清晰。GoTip #38:作为命名类型的函数 演示了这⼀点。 在上⾯的 WithTimeout 中,代码使⽤了⼀个 CancelFunc ⽽不是结果参数列表中的原始 func() ,并 且⼏乎不需要做任何记录⼯作。 包注释 包注释必须出现在包内语句的上⽅,注释和包名称之间没有空⾏。例⼦: // Good: // Package math provides basic constants and mathematical functions. // // This package does not guarantee bit-identical results across architectures. package math 每个包必须有⼀个包注释。如果⼀个包由多个⽂件组成,那么其中⼀个⽂件应该有包注释。 main 包的注释形式略有不同,其中 BUILD ⽂件中的 go_binary 规则的名称代替了包名。 // Good: // The seed_generator command is a utility that generates a Finch seed file // from a set of JSON study configs. package main 只要⼆进制⽂件的名称与 BUILD ⽂件中所写的完全⼀致,其他⻛格的注释也是可以了。当⼆进制名称是第 ⼀个单词时,即使它与命令⾏调⽤的拼写不严格匹配,也需要将其⼤写。
23 .// Good: // Binary seed_generator ... // Command seed_generator ... // Program seed_generator ... // The seed_generator command ... // The seed_generator program ... // Seed_generator ... 提示: 命令⾏调⽤示例和 API ⽤法可以是有⽤的⽂档。对于 Godoc 格式,缩进包含代码的注释⾏。 如果没有明显的 main ⽂件或者包注释特别⻓,可以将⽂档注释放在名为 doc.go 的⽂件中,只有注释和 包⼦句。 可以使⽤多⾏注释代替多个单⾏注释。如果⽂档包含可能对从源⽂件复制和粘贴有⽤的部分,如示例命 令⾏(⽤于⼆进制⽂件)和模板示例,这将⾮常有⽤。 // Good: /* The seed_generator command is a utility that generates a Finch seed file from a set of JSON study configs. seed_generator *.json | base64 > finch-seed.base64 */ package template 供维护者使⽤且适⽤于整个⽂件的注释通常放在导⼊声明之后。这些不会出现在 Godoc 中,也不受上述 包注释规则的约束。 导⼊ 导⼊重命名 只有在为了避免与其他导⼊的名称冲突时,才使⽤重命名导⼊。(由此推论,好的包名称 不需要重命名。) 如果发⽣名称冲突,最好重命名 最本地或特定于项⽬的导⼊。包的本地别名必须遵循包命名指南,包括禁⽌ 使⽤下划线和⼤写字⺟。 ⽣成的 protocol buffer 包必须重命名以从其名称中删除下划线,并且它们的别名必须具有 pb 后缀。有关 详细信息,请参阅 proto 和 stub 最佳实践。 // Good: import ( fspb "path/to/package/foo_service_go_proto" ) 导⼊的包名称没有有⽤的识别信息时(例如 package v1 ),应该重命名以包括以前的路径组件。重命名 必须与导⼊相同包的其他本地⽂件⼀致,并且可以包括版本号。 注意: 最好重命名包以符合 好的包命名规则,但在 vendor ⽬录下的包通常是不可⾏的。
24 .// Good: import ( core "github.com/kubernetes/api/core/v1" meta "github.com/kubernetes/apimachinery/pkg/apis/meta/v1beta1" ) 如果你需要导⼊⼀个名称与你要使⽤的公共局部变量名称(例如 url 、 ssh )冲突的包,并且你希望重命 名该包,⾸选⽅法是使⽤ pkg 后缀(例如 urlpkg )。请注意,可以使⽤局部变量隐藏包; 仅当此类变量 在范围内时仍需要使⽤此包时,才需要重命名。 导⼊分组 导⼊应分为两组: 标准库包 其他(项⽬和 vendor)包 // Good: package main import ( "fmt" "hash/adler32" "os" "github.com/dsnet/compress/flate" "golang.org/x/text/encoding" "google.golang.org/protobuf/proto" foopb "myproj/foo/proto/proto" _ "myproj/rpc/protocols/dial" _ "myproj/security/auth/authhooks" ) 将导⼊项分成多个组是可以接受的,例如,如果你想要⼀个单独的组来重命名、导⼊仅为了特殊效果 或另⼀ 个特殊的导⼊组。
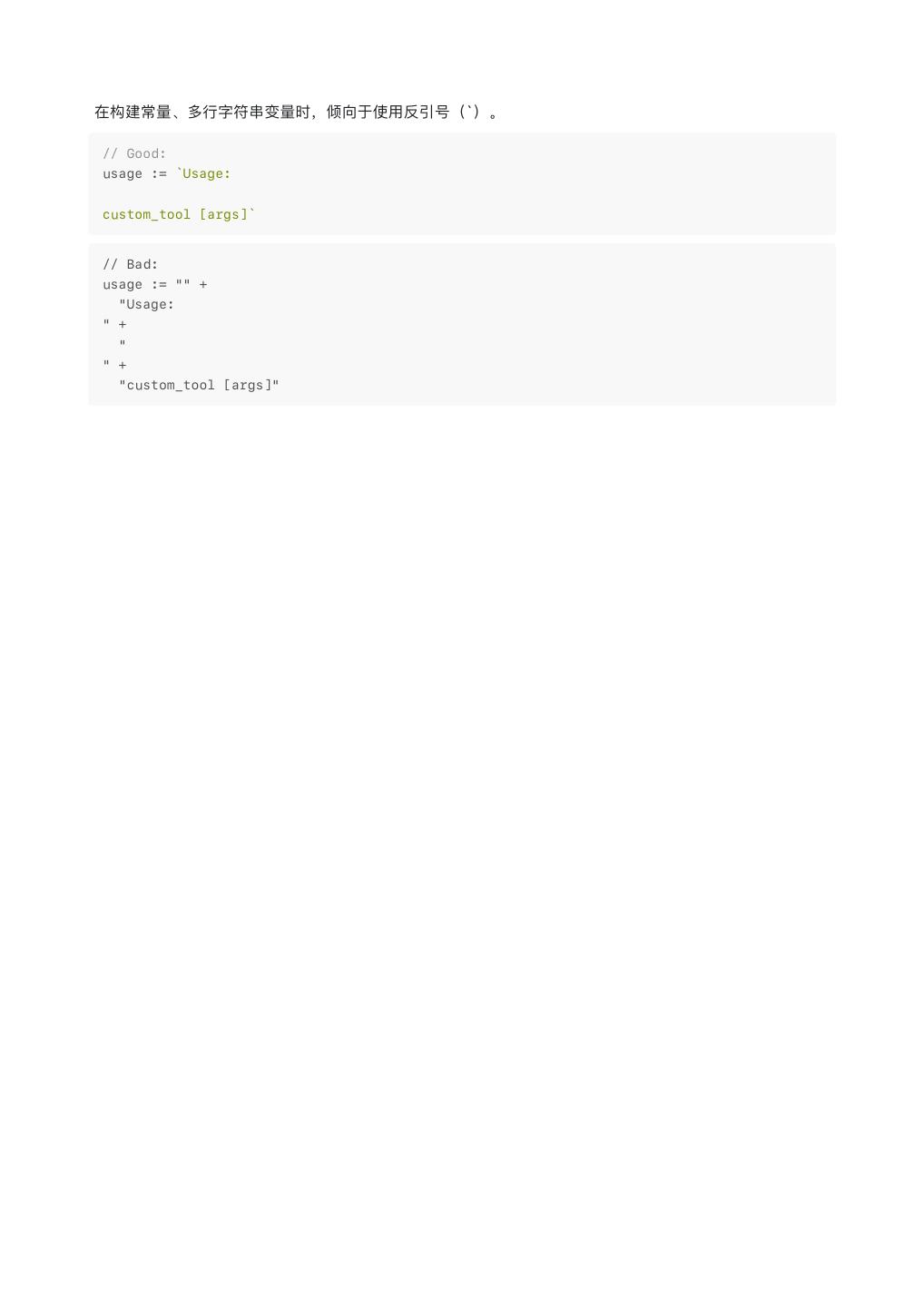
25 .// Good: package main import ( "fmt" "hash/adler32" "os" "github.com/dsnet/compress/flate" "golang.org/x/text/encoding" "google.golang.org/protobuf/proto" foopb "myproj/foo/proto/proto" _ "myproj/rpc/protocols/dial" _ "myproj/security/auth/authhooks" ) 注意: goimports 不⽀持维护可选组 - 超出标准库和 Google 导⼊之间强制分离所需的拆分。为了保持符合 状态,额外的导⼊⼦组需要作者和审阅⼈的注意。 Google 程序有时也是 AppEngine 应⽤程序,应该有⼀个单独的组⽤于 AppEngine 导⼊。 Gofmt 负责按导⼊路径对每个组进⾏排序。但是,它不会⾃动将导⼊分成组。流⾏的 goimports ⼯具结合 了 Gofmt 和导⼊管理,根据上述规则将导⼊进⾏分组。通过 goimports 来管理导⼊顺序是可⾏的,但随着 ⽂件的修改,其导⼊列表必须保持内部⼀致。 导⼊"空" ( import _ ) 使⽤语法 import _ "package" 导⼊的包,称为副作⽤导⼊,只能在主包或需要它们的测试中导⼊。 此类软件包的⼀些示例包括: time/tzdata image/jpeg 在图像处理中的代码 避免在⼯具包中导⼊空⽩,即使⼯具包间接依赖于它们。将副作⽤导⼊限制到主包有助于控制依赖性,并使 得编写依赖于不同导⼊的测试成为可能,⽽不会发⽣冲突或浪费构建成本。 以下是此规则的唯⼀例外情况: 你可以使⽤空⽩导⼊来绕过 nogo 静态检查器 中对不允许导⼊的检查。 你可以在使⽤ //go:embed 编译器指令的源⽂件中使⽤ embed 包的空⽩导⼊。 **提示:**如果⽣产环境中你创建的⼯具包间接依赖于副作⽤导⼊,请记录这⾥的预期⽤途。 导⼊ “.” ( import . ) import . 形式是⼀种语⾔特性,它允许将从另⼀个包导出的标识符⽆条件地带到当前包中。有关更多信 息,请参阅语⾔规范。 不要在 Google 代码库中使⽤此功能; 这使得更难判断功能来⾃何处。
26 .// Bad: package foo_test import ( "bar/testutil" // also imports "foo" . "foo" ) var myThing = Bar() // Bar defined in package foo; no qualification needed. // Good: package foo_test import ( "bar/testutil" // also imports "foo" "foo" ) var myThing = foo.Bar() 错误 返回错误 使⽤ error 表示函数可能会失败。按照惯例, error 是最后⼀个结果参数。 // Good: func Good() error { /* ... */ } 返回 nil 错误是表示操作成功的惯⽤⽅式,否则表示可能会失败。如果函数返回错误,除⾮另有明确说 明,否则调⽤者必须将所有⾮错误返回值视为未确定。通常来说,⾮错误返回值是它们的零值,但也不能直 接这么假设。 // Good: func GoodLookup() (*Result, error) { // ... if err != nil { return nil, err } return res, nil } 返回错误的导出函数应使⽤ error 类型返回它们。具体的错误类型容易受到细微错误的影响:⼀个 nil 指 针可以包装到接⼝中,从⽽就变成⾮ nil 值(参⻅ 关于该主题的 Go FAQ 条⽬)。 // Bad: func Bad() *os.PathError { /*...*/ } 提示:采⽤ context.Context 参数的函数通常应返回 error ,以便调⽤者可以确定上下⽂是否在函数运 ⾏时被取消。
27 .错误字符串 错误字符串不应⼤写(除⾮以导出名称、专有名词或⾸字⺟缩写词开头)并且不应以标点符号结尾。这是因 为错误字符串通常在打印给⽤户之前出现在其他上下⽂中。 // Bad: err := fmt.Errorf("Something bad happened.") // Good: err := fmt.Errorf("something bad happened") 另⼀⽅⾯,完整显示消息(⽇志记录、测试失败、API 响应或其他 UI)的样式视情况⽽定,但通常应⼤写⾸ 字⺟。 // Good: log.Infof("Operation aborted: %v", err) log.Errorf("Operation aborted: %v", err) t.Errorf("Op(%q) failed unexpectedly; err=%v", args, err) 错误处理 遇到错误的代码应该慎重选择如何处理它。使⽤ _ 变量丢弃错误通常是不合适的。如果函数返回错误,请执 ⾏以下操作之⼀: ⽴即处理并解决错误 将错误返回给调⽤者 在特殊情况下,调⽤ log.Fatal 或(如绝对有必要)则调⽤ panic 注意: log.Fatalf 不是标准库⽇志。参⻅ [#logging]。 在极少数情况下适合忽略或丢弃错误(例如调⽤ (*bytes.Buffer).Write 被记录为永远不会失败),随 附的注释应该解释为什么这是安全的。 // Good: var b *bytes.Buffer n, _ := b.Write(p) // never returns a non-nil error 关于错误处理的更多讨论和例⼦,请参⻅ Effective Go 和最佳实践。 In-band 错误 在 C 和类似语⾔中,函数通常会返回-1、null 或空字符串等值,以示错误或丢失结果。这就是所谓的 In- band 处理。 // Bad: // Lookup returns the value for key or -1 if there is no mapping for key. func Lookup(key string) int 未能检查 In-band 错误值会导致错误,并可能将 error 归于错误的功能。
28 .// Bad: // The following line returns an error that Parse failed for the input value, // whereas the failure was that there is no mapping for missingKey. return Parse(Lookup(missingKey)) Go 对多重返回值的⽀持提供了⼀个更好的解决⽅案(⻅ Effective Go 关于多重返回的部分)。与其要求调⽤ ⽅检查 In-band 的错误值,函数更应该返回⼀个额外的值来表明返回值是否有效。这个返回值可以是⼀个 错误,或者在不需要解释时是⼀个布尔值,并且应该是最终的返回值。 // Good: // Lookup returns the value for key or ok=false if there is no mapping for key. func Lookup(key string) (value string, ok bool) 这个 API 可以防⽌调⽤者错误地编写 Parse(Lookup(key)) ,从⽽导致编译时错误,因为 Lookup(key) 有两个返回值。 以这种⽅式返回错误,来构筑更强⼤和明确的错误处理。 // Good: value, ok := Lookup(key) if !ok { return fmt.Errorf("no value for %q", key) } return Parse(value) ⼀些标准库函数,如包 strings 中的函数,返回 In-band 错误值。这⼤⼤简化了字符串处理的代码,但 代价是要求程序员更加勤奋。⼀般来说,Google 代码库中的 Go 代码应该为错误返回额外的值 缩进错误流程 在继续代码的其余部分之前处理错误。这提⾼了代码的可读性,使读者能够快速找到正常路径。这个逻辑同 样适⽤于任何测试条件并以终端条件结束的代码块(例如, return 、 panic 、 log.Fatal )。 如果终⽌条件没有得到满⾜,运⾏的代码应该出现在 if 块之后,⽽不应该缩进到 else ⼦句中。 // Good: if err != nil { // error handling return // or continue, etc. } // normal code // Bad: if err != nil { // error handling } else { // normal code that looks abnormal due to indentation } 提示:如果你使⽤⼀个变量超过⼏⾏代码,通常不值得使⽤ 带有初始化的 if ⻛格。在这种情况下,通常 最好将声明移出,使⽤标准的 if 语句。
29 . // Good: x, err := f() if err != nil { // error handling return } // lots of code that uses x // across multiple lines // Bad: if x, err := f(); err != nil { // error handling return } else { // lots of code that uses x // across multiple lines } 更多细节⻅ Go Tip #1:视线和 TotT:通过减少嵌套降低代码的复杂性。 语⾔ 字⾯格式化 Go 有⼀个⾮常强⼤的复合字⾯语法,⽤它可以在⼀个表达式中表达深度嵌套的复杂值。在可能的情况下, 应该使⽤这种字⾯语法,⽽不是逐字段建值。字⾯意义的 gofmt 格式⼀般都很好,但有⼀些额外的规则可 以使这些字⾯意义保持可读和可维护。 字段名称 # 对于在当前包之外定义的类型,结构体字⾯量通常应该指定字段名。 包括来⾃其他包的类型的字段名。 // Good: good := otherpkg.Type{A: 42} 结构中字段的位置和字段的完整集合(当字段名被省略时,这两者都是有必要搞清楚的)通常不被认为 是结构的公共 API 的⼀部分;需要指定字段名以避免不必要的耦合。 // Bad: // https://pkg.go.dev/encoding/csv#Reader r := csv.Reader{',', '#', 4, false, false, false, false} 在⼩型、简单的结构中可以省略字段名,这些结构的组成和顺序都有⽂档证明是稳定的。 // Good: okay := image.Point{42, 54} also := image.Point{X: 42, Y: 54} 对于包内类型,字段名是可选的。
3秒后跳转登录页面
去登陆

