展开查看详情
1 .使用 Byzer-LLM
十分钟手搓大模型
祝海林 @Byzer-LLM @Byzer @Kyligence
�
2 .面对的挑战和思考
Finetune / Deploy 大模型
连接业务数据 繁琐的数据处理 GPU / C PU 资源管理和调度
我们需要能够连接各种业务数据 我们需要join多种数据源,并且将 你需要能够管理和调度你的
库,文件存储,云存储等等 数据转化为模型能够接受的格式, GPU/CPU 资源
这在 Finetune 和 Infer 都是需要
的
高并发的支持 模型的应用场景集成
你需要处理Web服务中遇到的问题,为了维护较高的并 我们可能需要在 ETL 任务,数据分析,流式诸如风控中
发或者吞吐,你需要有大量的工作 使用我们的模型,还可能直接对业务提供 HTTP API。
这里会有大量客户端工作。
�
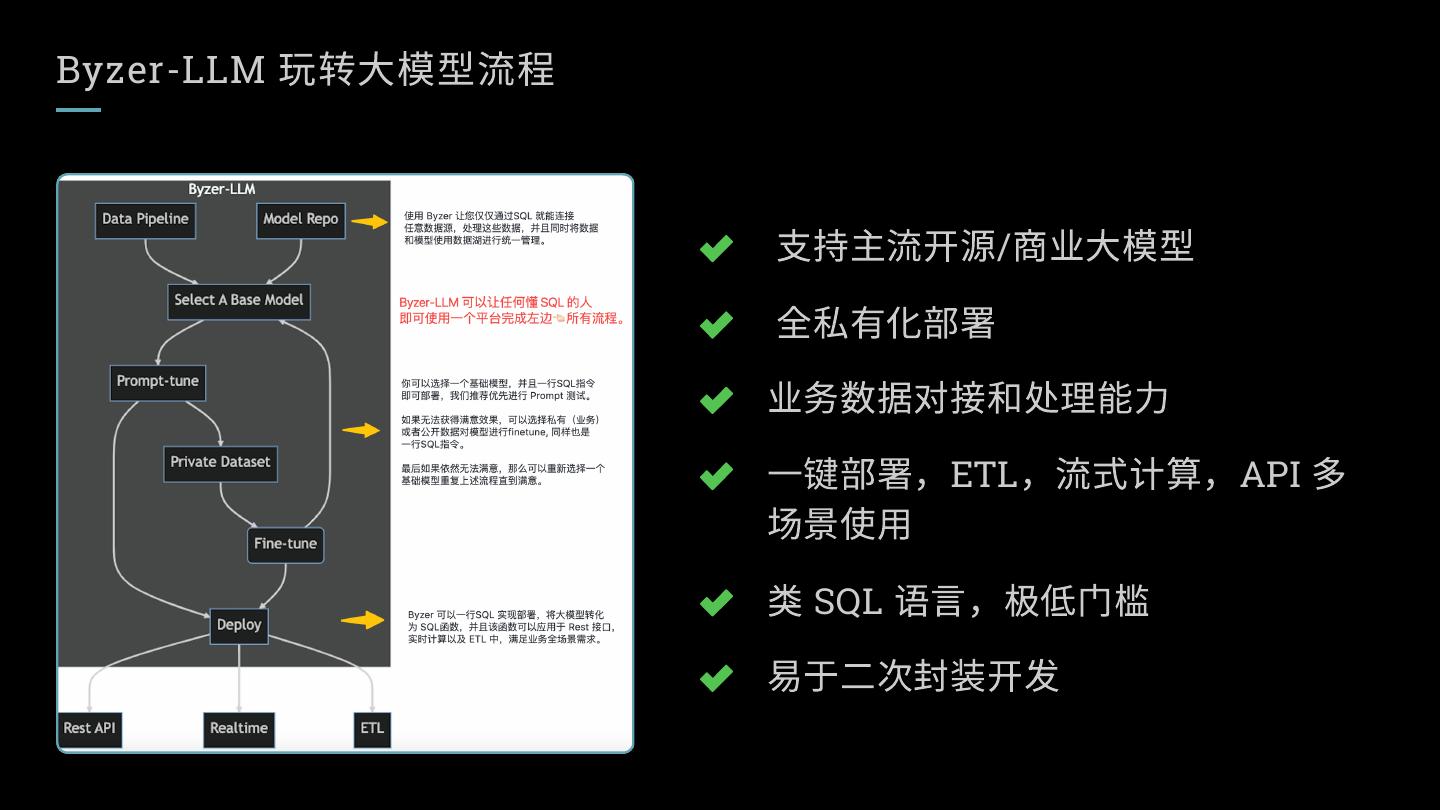
3 .Byzer-LLM 玩转大模型流程
支持主流开源/商业大模型
全私有化部署
业务数据对接和处理能力
一键部署,ETL,流式计算,API 多
场景使用
类 SQL 语言,极低门槛
易于二次封装开发
�
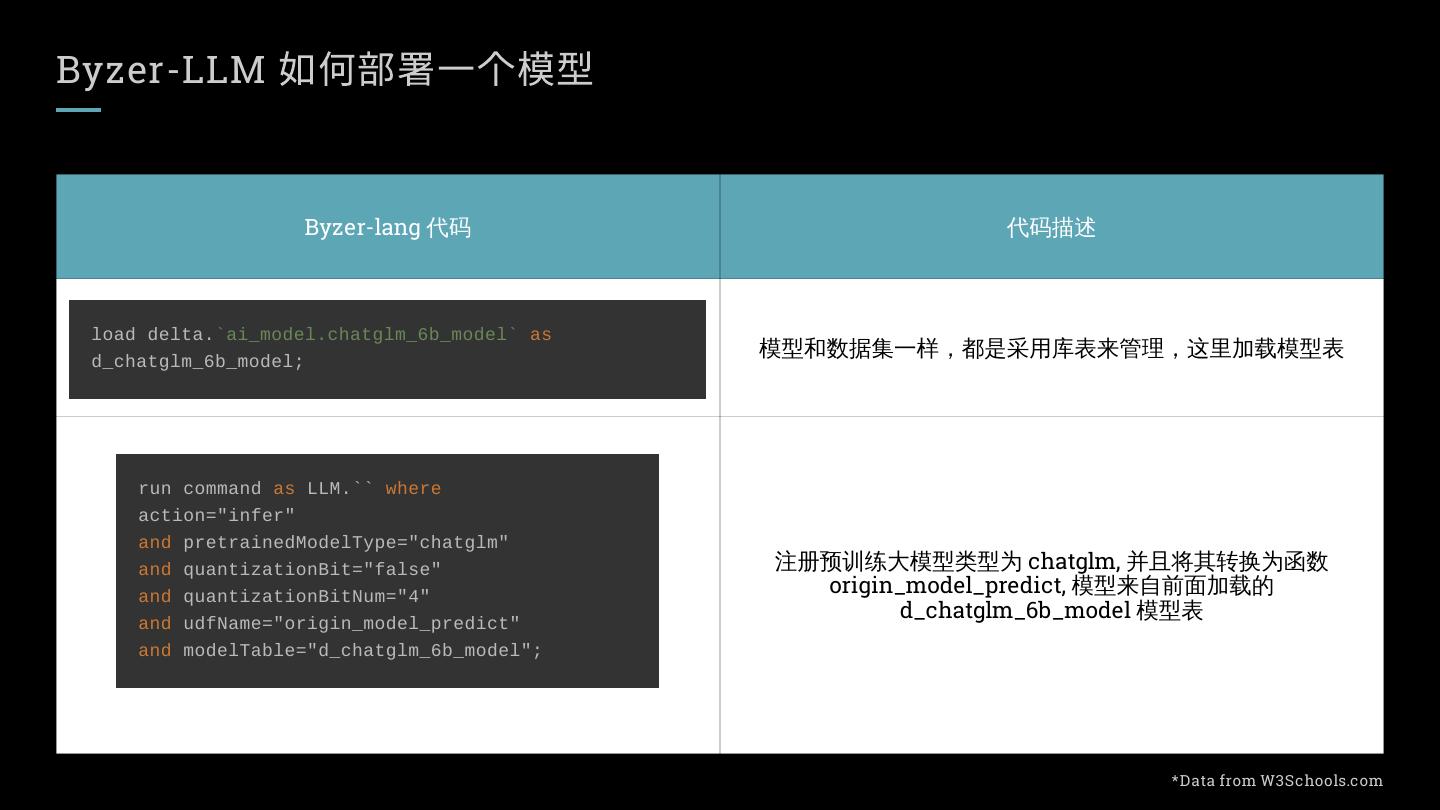
4 .Byzer-LLM 如何部署一个模型
Byzer-lang 代码 代码描述
load delta.`ai_model.chatglm_6b_model` as
模型和数据集一样,都是采用库表来管理,这里加载模型表
d_chatglm_6b_model;
run command as LLM.`` where
action="infer"
and pretrainedModelType="chatglm"
and quantizationBit="false" 注册预训练大模型类型为 chatglm, 并且将其转换为函数
and quantizationBitNum="4"
origin_model_predict, 模型来自前面加载的
d_chatglm_6b_model 模型表
and udfName="origin_model_predict"
and modelTable="d_chatglm_6b_model";
*Data from W3Schools.com
�
5 . Byzer-LLM 如何使用模型
Byzer-lang 代码 代码描述
set prompt='''我给定你一段文本,你需要扩充这段文本,字数大概在100字,
描述的内容尽量要吸引女性用户。下面是我给你的文本: ''';
在 ETL、流式计算中作为一个普通 UDF 函数来使
select '{"instruction":"${prompt} 类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿
用
裤"}'
as value as testData;
select finetune_model_predict(array(value)) as r from testData as result;
set q = '''"{\"instruction\":\"类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔
腿裤\",\"output\":\"NAN\"}"''';
Byzer-LLM 提供了 model/predict endpoint 支持
!sh curl -XPOST 'http://127.0.0.1:9003/model/predict' -d HTTP API调用
'sessionPerUser=true&owner=william&dataType=string&sql=select
finetune_model_predict(array(feature)) as a &data=[${q}]';
*Data from W3Schools.com
�
6 . Byzer-LLM 的并发,资源控制
控制模型单实例 GPU 资源 控制模型的部署实例数 资源池管理
部署前执行:!python conf 部署前执行:!python conf 部署前执行: !python conf
"num_gpus=0.4"; "maxConcurrency=10"; "rayAddress=127.0.0.1:10001";
系统会完成自动调度 表示可以同时支持10个并发请求 表示会连接特定的一个资源池,从而
得到诸如 GPU/CPU等资源
BYZER 使用 HYBRIDRUNTIME, 使用 RAY 来完成 GPU/CPU资源的管理和调度
�
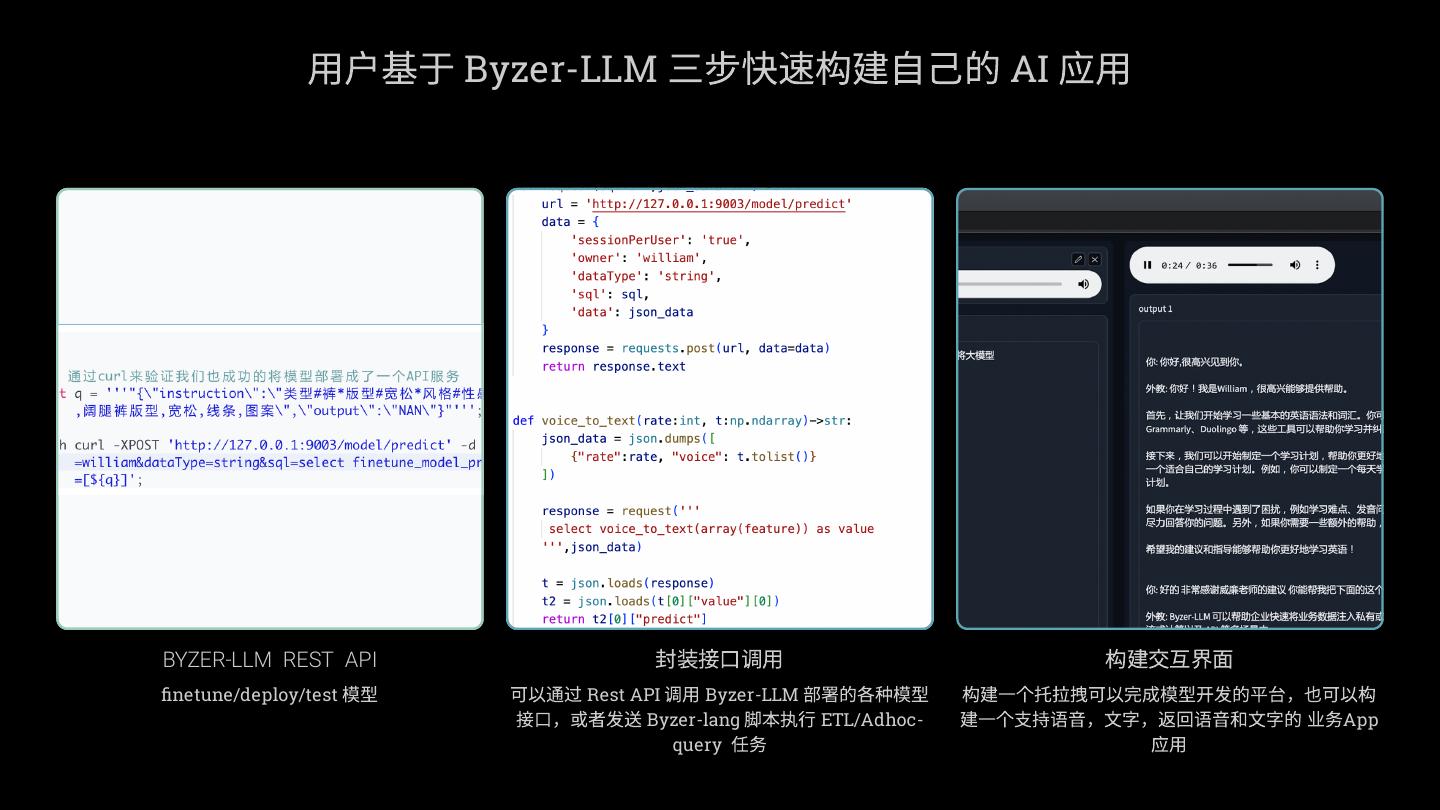
7 . 用户基于 Byzer-LLM 三步快速构建自己的 AI 应用
BYZER-LLM REST API 封装接口调用 构建交互界面
finetune/deploy/test 模型 可以通过 Rest API 调用 Byzer-LLM 部署的各种模型 构建一个托拉拽可以完成模型开发的平台,也可以构
接口,或者发送 Byzer-lang 脚本执行 ETL/Adhoc- 建一个支持语音,文字,返回语音和文字的 业务App
query 任务 应用
�
8 . Byzer-LLM 如何Finetune一个模型
Byzer-lang 代码 代码描述
load jdbc.`business.tunningData`
where url="jdbc:mysql://127.0.0.1:3306/business"
and driver="com.mysql.jdbc.Driver"
and user="root"
and password="${PASSWORD}"
从 MySQL 加载业务数据库,并且修改字段名称
as tunningData;
select content as instruction,"" as input,summary as output
from tunningData as formatTunningData;
load delta.`ai_model.chatglm_6b_model` as d_chatglm_6b_model;
run command as LLM.`` where
pretrainedModelType="chatglm"
and finetuneType="lora" 加载模型,然后对模型使用 Lora 进行 fintune, 最后得到的
and model="d_chatglm_6b_model" 模型重新保存到数据湖里
and inputTable="formatTunningData"
and outputTable="tunnignModel300";
*Data from W3Schools.com
�
9 .Byzer-LLM 架构预览
BY Z E R-LLM 扩展 其他扩展
BY Z E R 接口层 (RE S T / J D BC )
BY Z E R 解释器
BY Z E R
(D ATA+AI
基础设施 ) H Y BRID RU N T IME (S PARK+RAY )
硬件资源( GP U / C P U / 服务器)
BY Z E R-LLM 是 BY Z E R 的一个扩展。 BY Z E R 是面向 D ATA + AI 基础设施
*}
�
10 .PPT is cheap , Show YOU the DEMO
让我们来玩转几个大模型
�
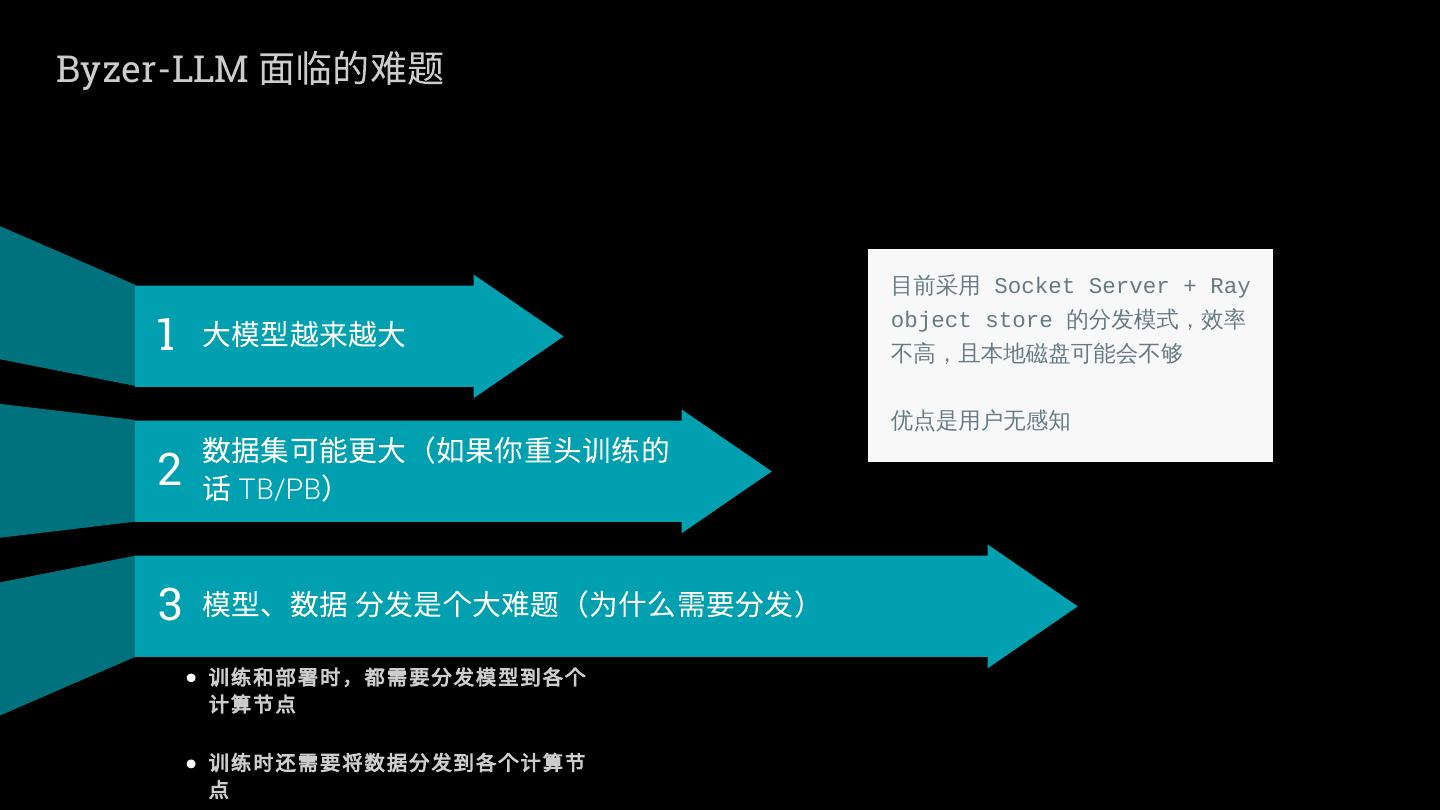
11 .Byzer-LLM 面临的难题
目前采用 Socket Server + Ray
1 大模型越来越大 object store 的分发模式,效率
不高,且本地磁盘可能会不够
数据集可能更大(如果你重头训练的
优点是用户无感知
2 话 TB/PB)
3 模型、数据 分发是个大难题(为什么需要分发)
训练和部署时,都需要分发模型到各个
计算节点
训练时还需要将数据分发到各个计算节
点
�
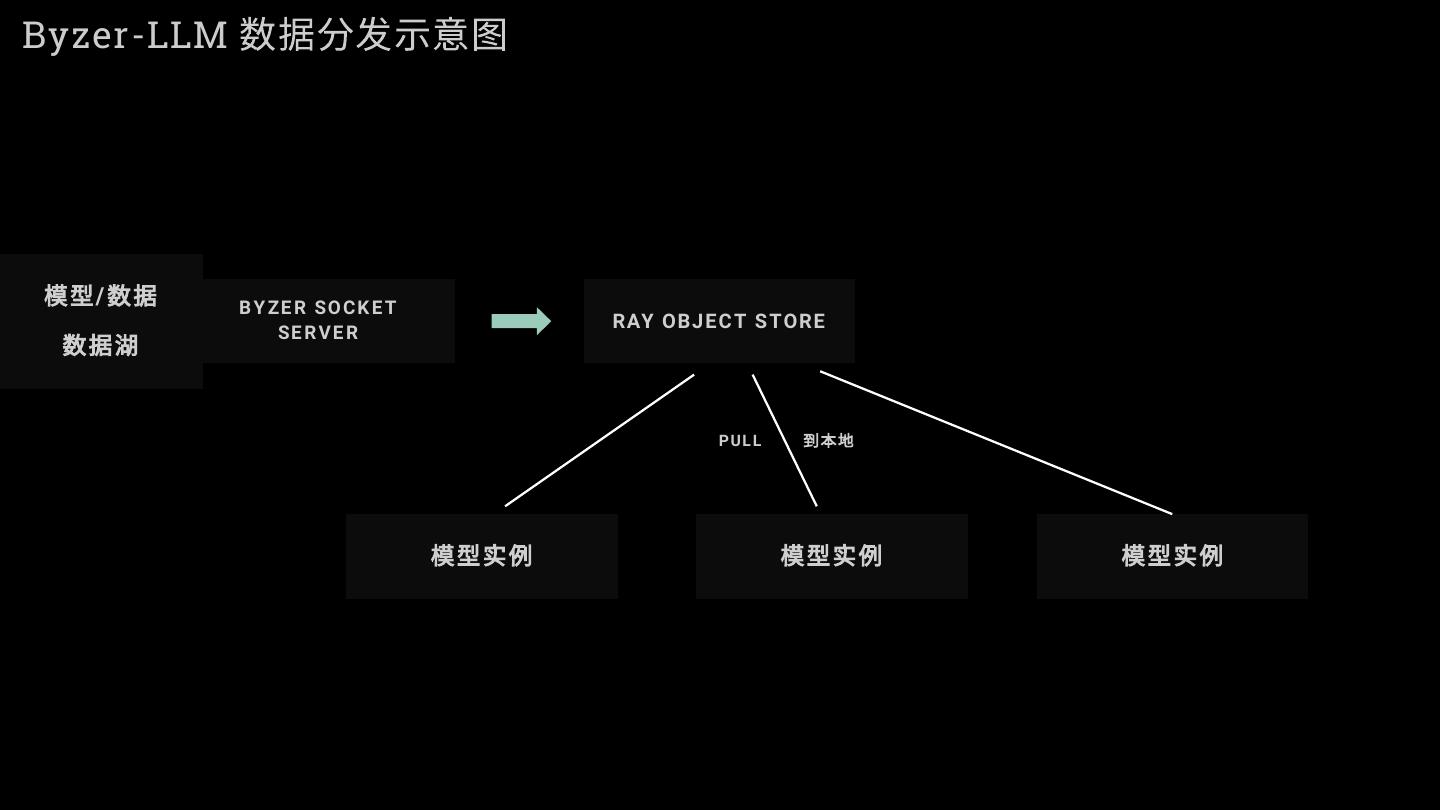
12 .Byzer-LLM 数据分发示意图
模型 / 数据 B Y ZE R SO C K E T
数据湖
RAY OBJ EC T S TORE
SE R V E R
PUL L 到本地
模型实例 模型实例 模型实例
�
13 .使用 JuiceFS 数据分发示意图
模型实例 模型实例 模型实例
J U IC E F S P O S IX
模型 / 数据 IN 数据湖
对象存储 / H D F S 等
�
14 .JuiceFS 解决分发问题优势
一次存储,到处访问 存储成本可控 加速,稳定
其优秀的Posix文件系统兼容性是AI非常需要 支持各种对象存储,包括云或者私有部署 JuiceFS 有多种元数据系统可选可根据需要平
的 衡性能和稳定。同时缓存加速可以很好的利用
加速模型和数据的加载
BY Z E R 数据湖统一管理了模型和数据,通过 J U IC E F S 可以很好的在计算节点被挂载
�
15 .祝海林
在我的GITHUB上查看更多工作并了解更多关于个人项目的内
容,或者更好的是,加我微信,我们可以面谈。
https://byzer.org/
https://twitter.com/allwefantasy
https://github.com/allwefantasy
�