展开查看详情
1 .饿了么监控体系的演进
演讲人:黄杰
全球敏捷运维峰会 广州站
�
2 .自我介绍
• 2015 年加入饿了么,负责饿了么监控平台构建及周边工具链建设
• 曾在携程框架部,负责 Logging/Tracing/Metrics
全球敏捷运维峰会 广州站
�
3 .目录
• 背景
• 遇到的问题
• 场景化
• 系统设计
全球敏捷运维峰会 广州站
�
4 .背景
1.0 2.0 3.0
1. Statsd/Graphite/Grafana 1. Statsd/Graphite/Grafana 1. EMonitor/LinDB
2. ETrace 2. ETrace/LinDB 2. SLS
3. Zabbix 3. ESM/InfluxDB/Grafana
4. ELog 4. ELK
单IDC 异地多活
全球敏捷运维峰会 广州站
�
5 .现状
1. 覆盖了饿了么所有的监控 (业务监控,全链路监控,PaaS,IaaS等)
2. 覆盖所有应用及服务器
3. 每天采集原始数据 800T
4. 高峰计算事件 7000W/s
全球敏捷运维峰会 广州站
�
6 .目录
• 背景
• 遇到的问题
• 场景化
• 系统设计
全球敏捷运维峰会 广州站
�
7 .遇到的问题
1. 多套监控系统,包括收集,可视化及报警等
2. 各种上下文切换
3. 适合熟练工,不适合新同学
1. 快速发现问题
核心问题
2. 快速定位问题
E-Monitor
1. GOC
核心用户
2. 开发人员
全球敏捷运维峰会 广州站
�
8 .如何解决
业务
1. 各层面向的用户及其视角是不一样的 (订单/运单)
2. 做好业务侧监控,并能联动
应用
3. 标准化应用/PaaS/IaaS各层监控 Tracing/Logging
(Exception/SOA/DB/Redis/Q)
4. 需要一个纽带来把各层串联起来
5. 端对端监控 PaaS
中间件
6. 与其他系统集成 (ES/DAL/Redis/Q/Job/SLB)
IaaS
(CPU/MEM/Network/TCP)
全球敏捷运维峰会 广州站
�
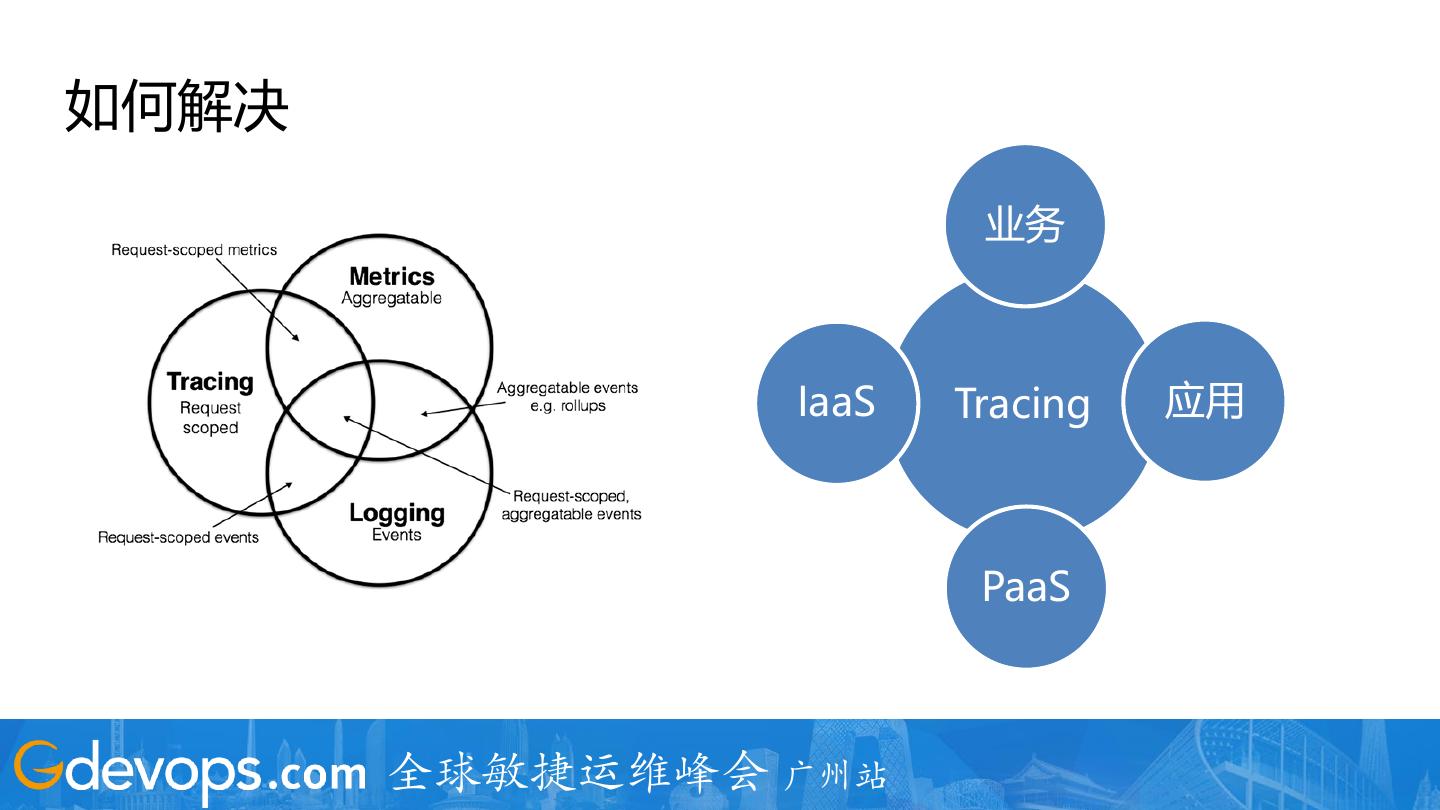
9 .如何解决
业务
IaaS Tracing 应用
PaaS
全球敏捷运维峰会 广州站
�
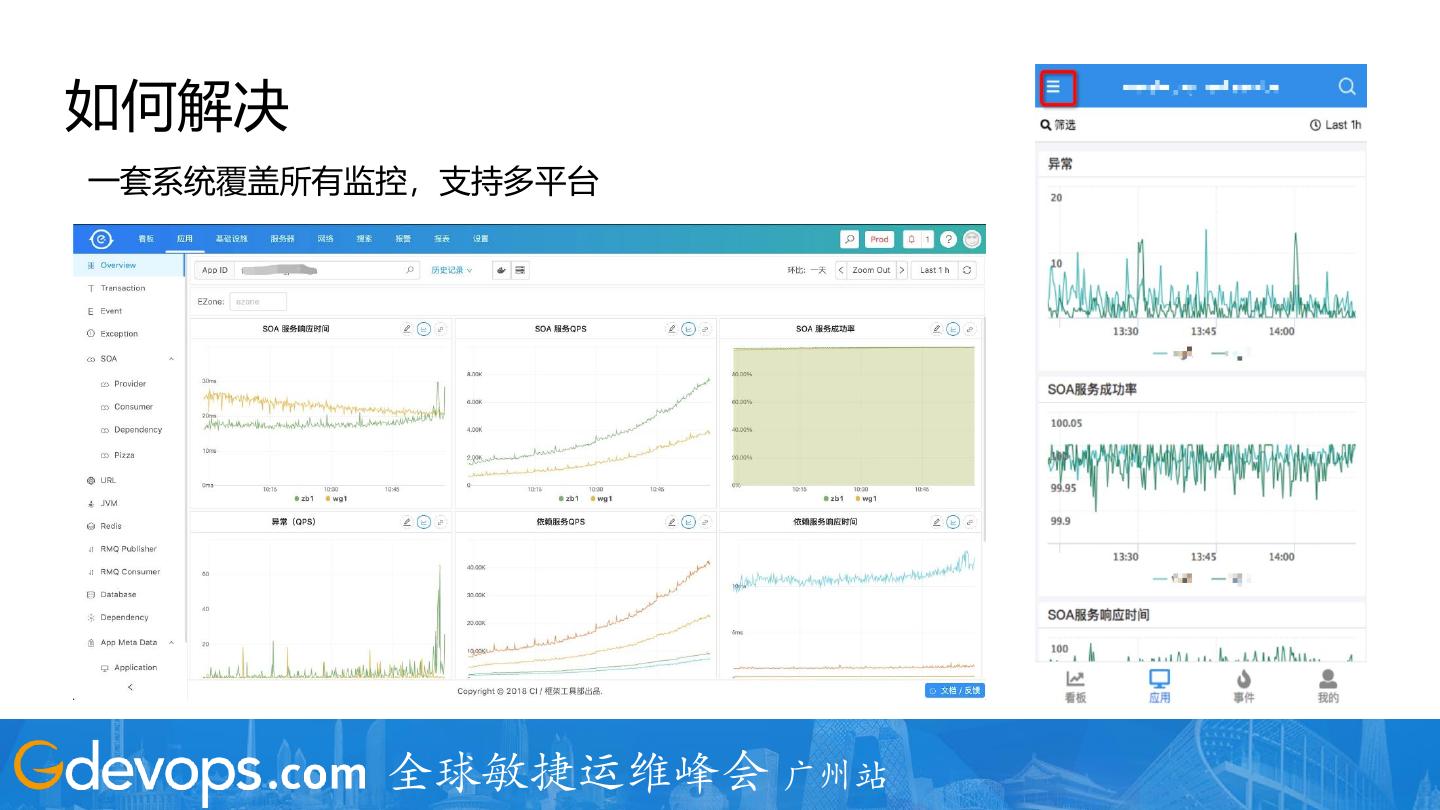
10 .如何解决
一套系统覆盖所有监控,支持多平台
全球敏捷运维峰会 广州站
�
11 .目录
• 背景
• 遇到的问题
• 场景化
• 系统设计
全球敏捷运维峰会 广州站
�
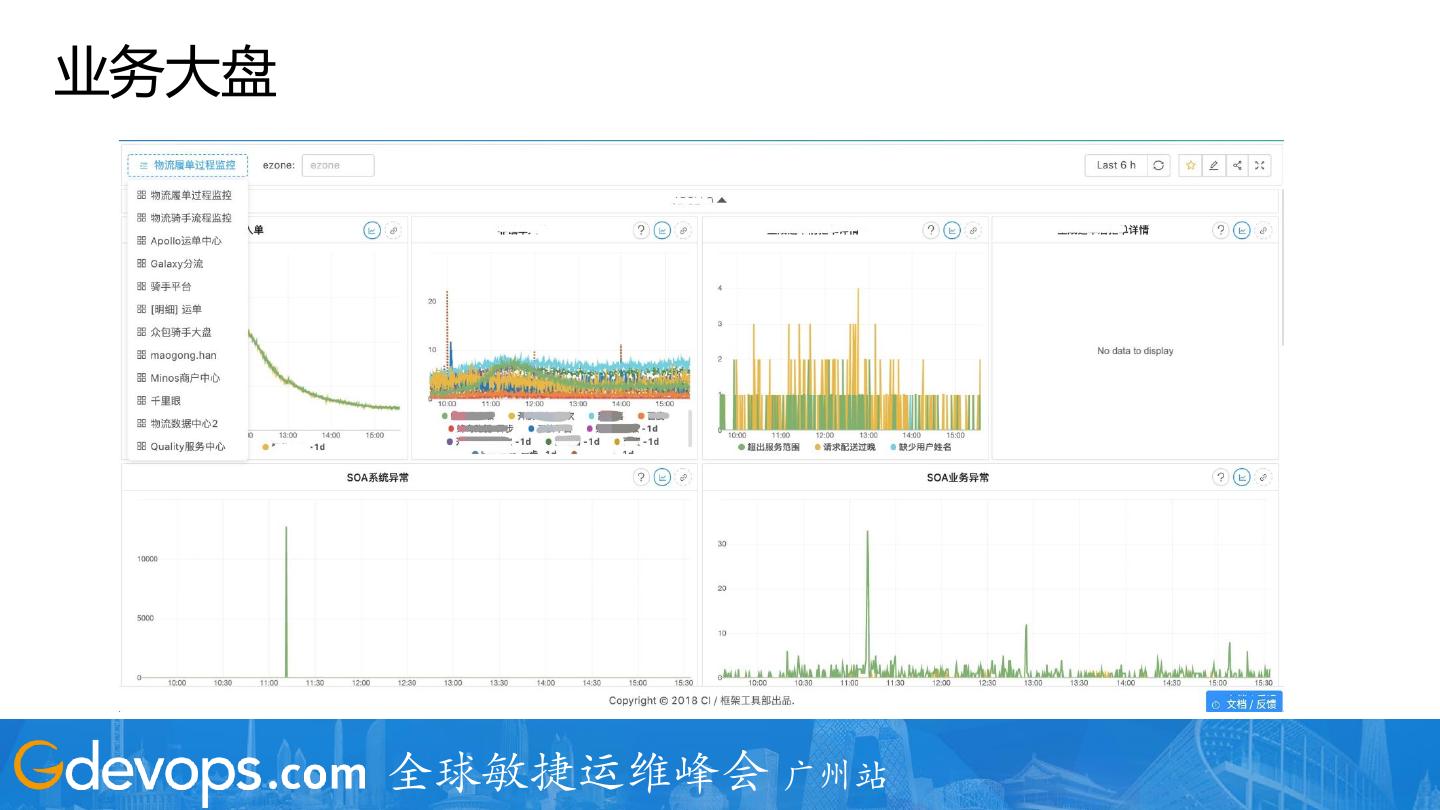
12 . 业务大盘
VS Grafana
1. 与业务更贴合
2. Dashboard App
3. Chart Repo
4. Drill Down
5. 小工具
全球敏捷运维峰会 广州站
�
15 .应用监控 – Exception
全球敏捷运维峰会 广州站
�
16 .应用监控 - SOA
全球敏捷运维峰会 广州站
�
17 .应用监控 - SOA
全球敏捷运维峰会 广州站
�
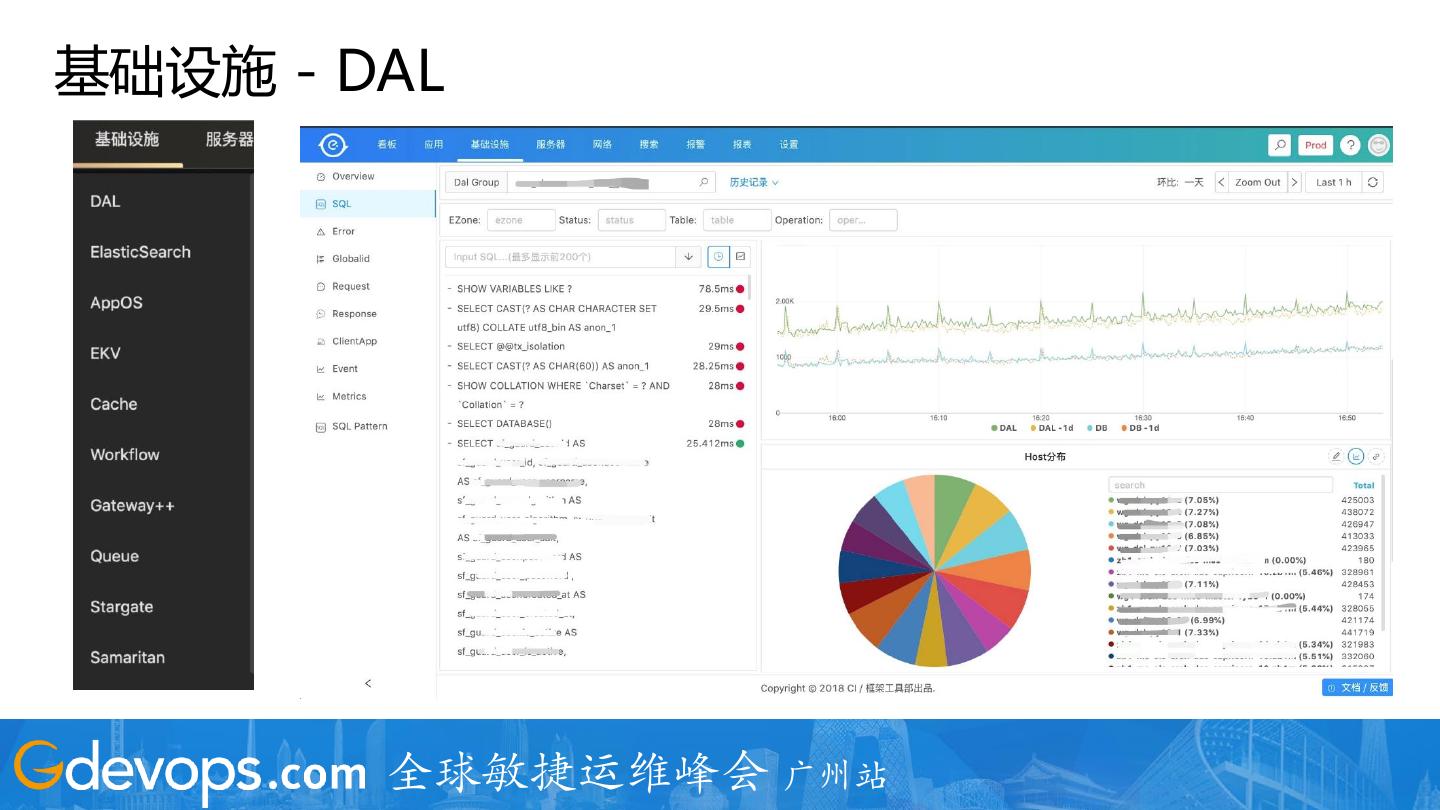
18 .基础设施 - DAL
全球敏捷运维峰会 广州站
�
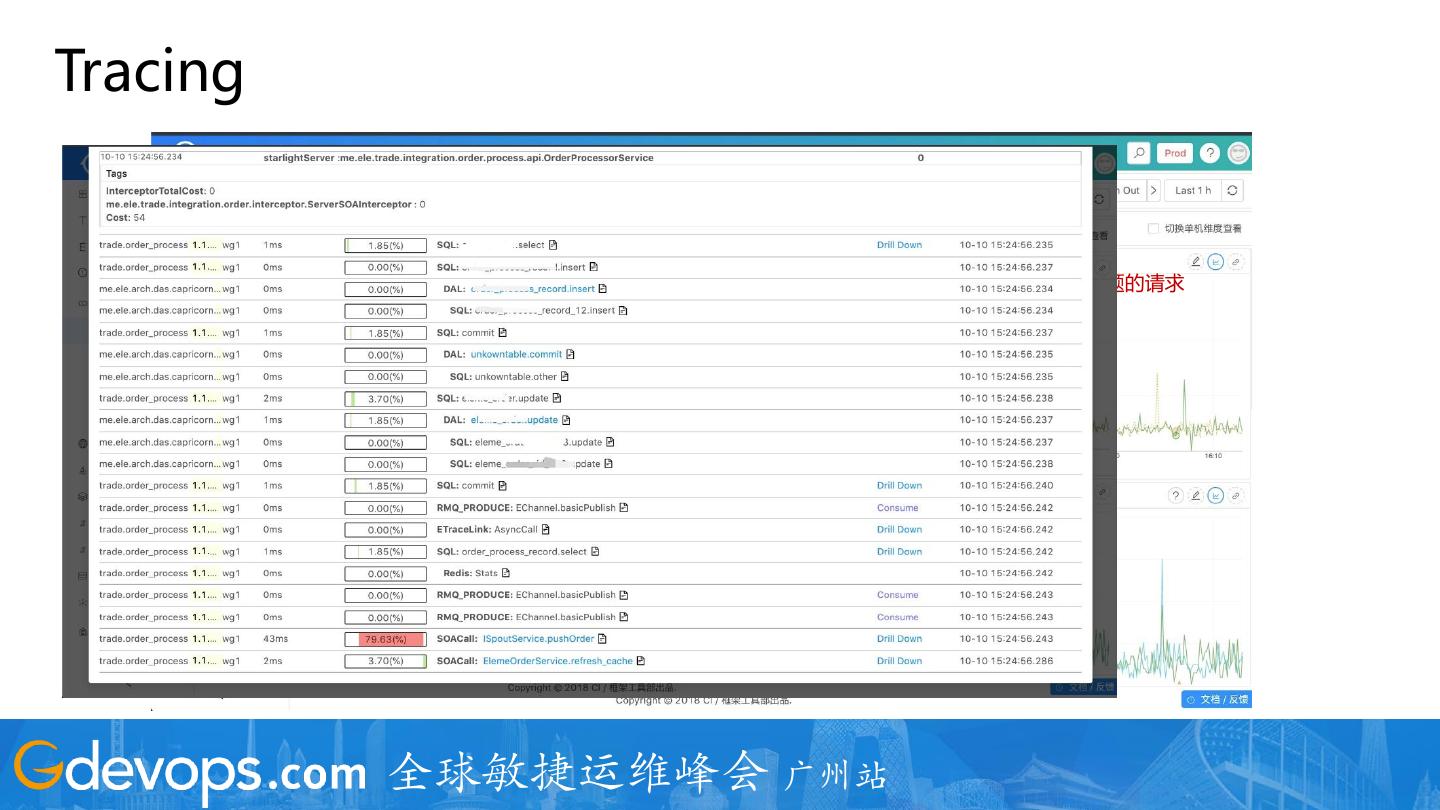
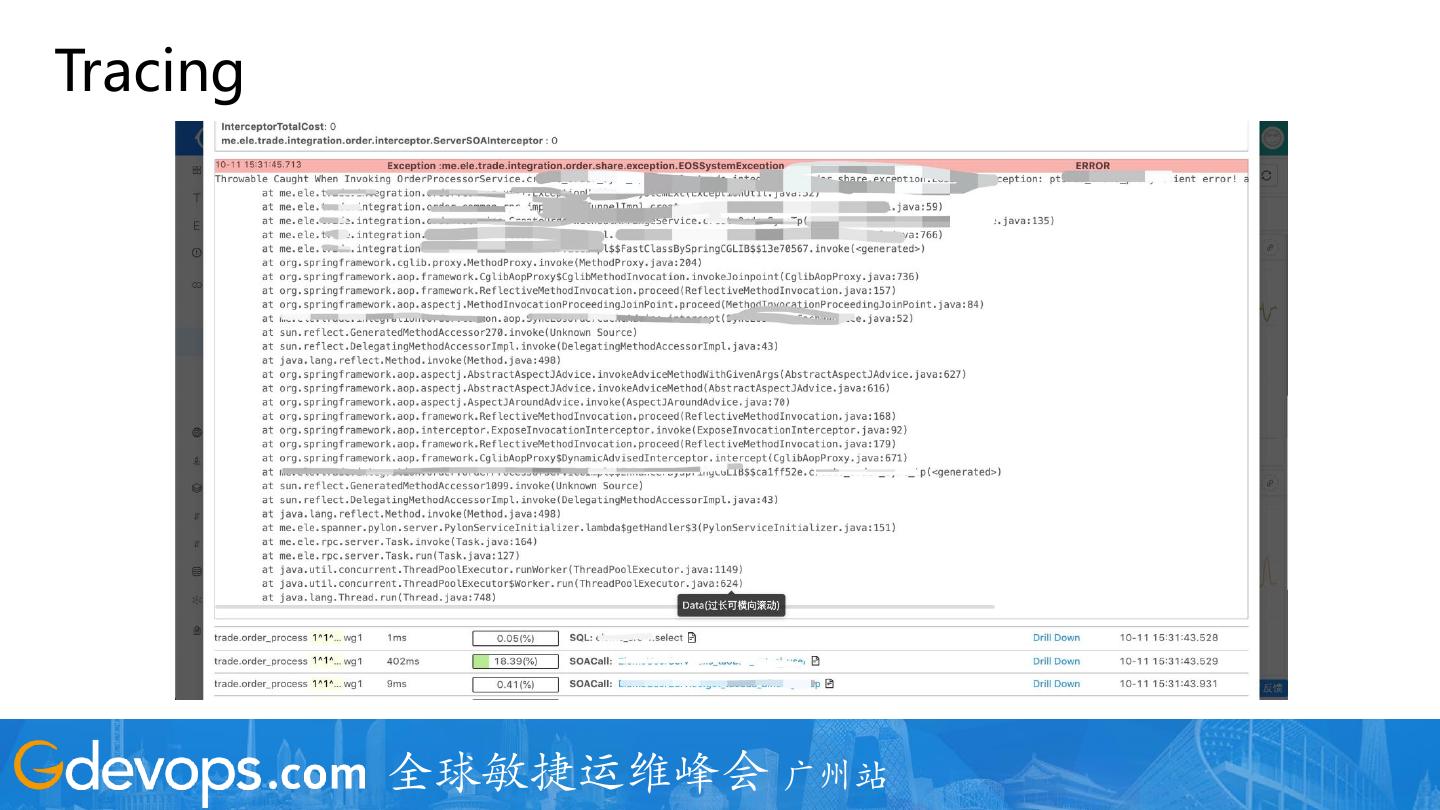
20 .Tracing
采样10s内有问题的请求
全球敏捷运维峰会 广州站
�
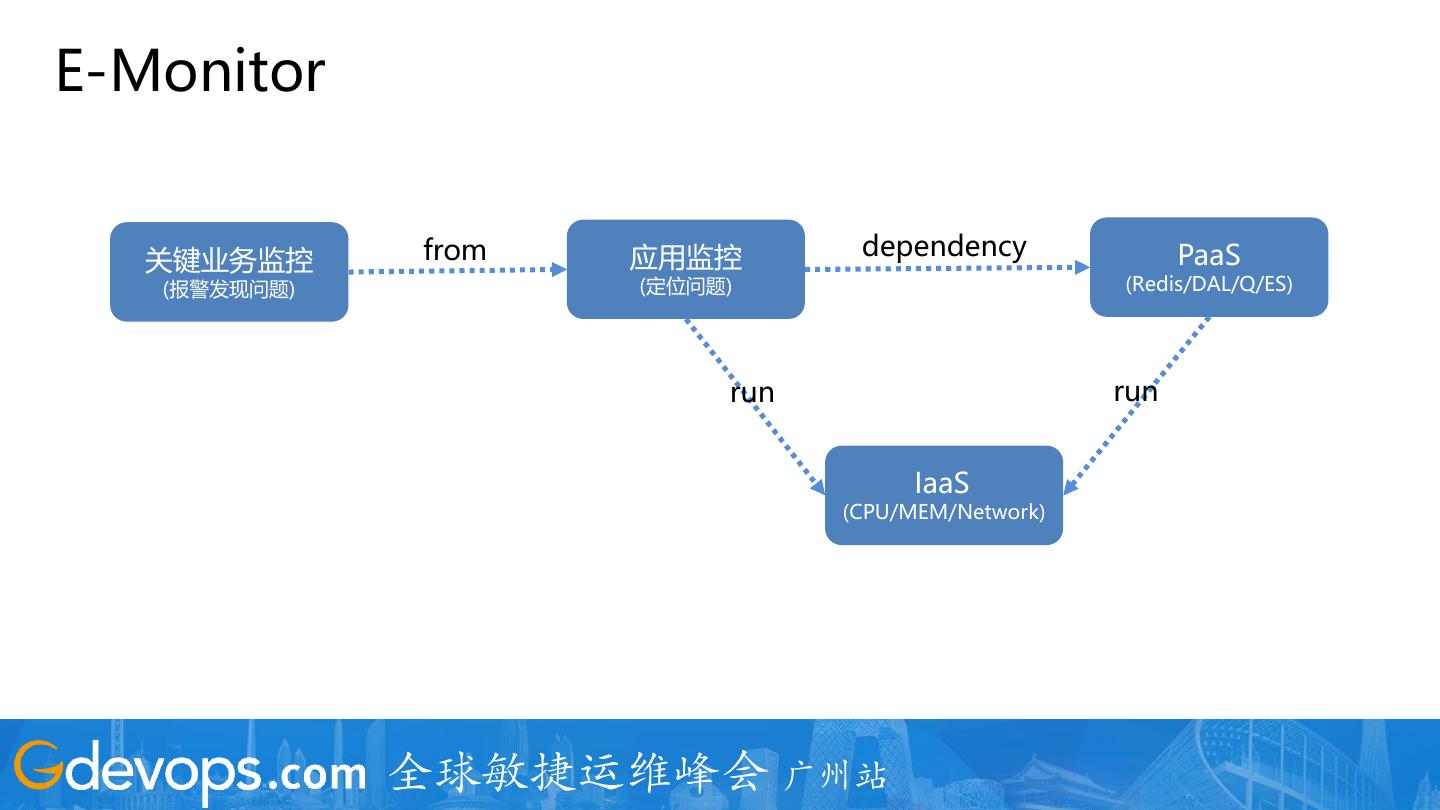
22 .E-Monitor
关键业务监控 from 应用监控 dependency PaaS
(报警发现问题) (定位问题) (Redis/DAL/Q/ES)
run run
IaaS
(CPU/MEM/Network)
全球敏捷运维峰会 广州站
�
23 .目录
• 背景
• 遇到的问题
• 场景化
• 系统设计
全球敏捷运维峰会 广州站
�
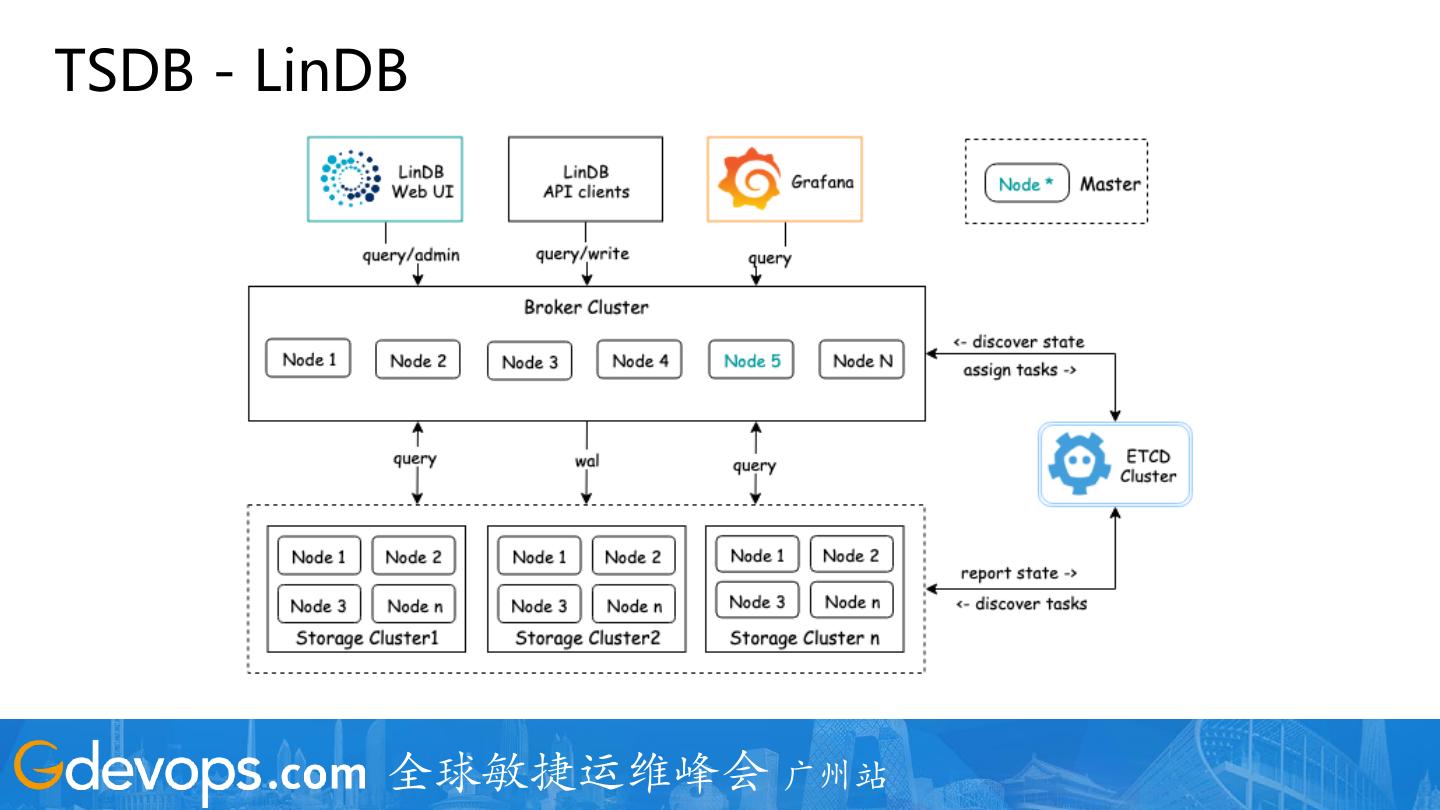
24 .整体架构
1. Pipeline -> Lambda
2. 支持多IDC
3. 全量日志,通过指标+采样的方式
4. 支持 Java/Golang/Python/PHP/C++/Node.js
5. 所有监控数据计算窗口为 10S
5. 自研 + 开源组件构建了整套系统
全球敏捷运维峰会 广州站
�
26 .踩过的坑
1. Kafka broker 节点 IO Hang 住,导致所有 Producer 线程全部 Hang 住,流量掉底
2. HBase 上构建了索引,导致 HBase 热点严重
3. 系统稳定性
4. 生产效率
1. 基于 Kafka Client 封装了一个 Broker 与 Thread 绑定的版本,即一个线程负责某一 Broker 的
写入,当某一节点写入有问题,数据自动 Balance 到别的节点
2. 不支持全文检索,有时看起很用的功能,其实不一定是用户真正需要的
3. 从 Pipeline 处理所有数据流,到计算和写存储分离类似 Lambda,计算采用类 SQL
4. 所有的数据都转换成 Metrics, 外加自定义的可视化组件,阶段性的前进,每个阶段只做 1-2 件
重要的事情
全球敏捷运维峰会 广州站
�
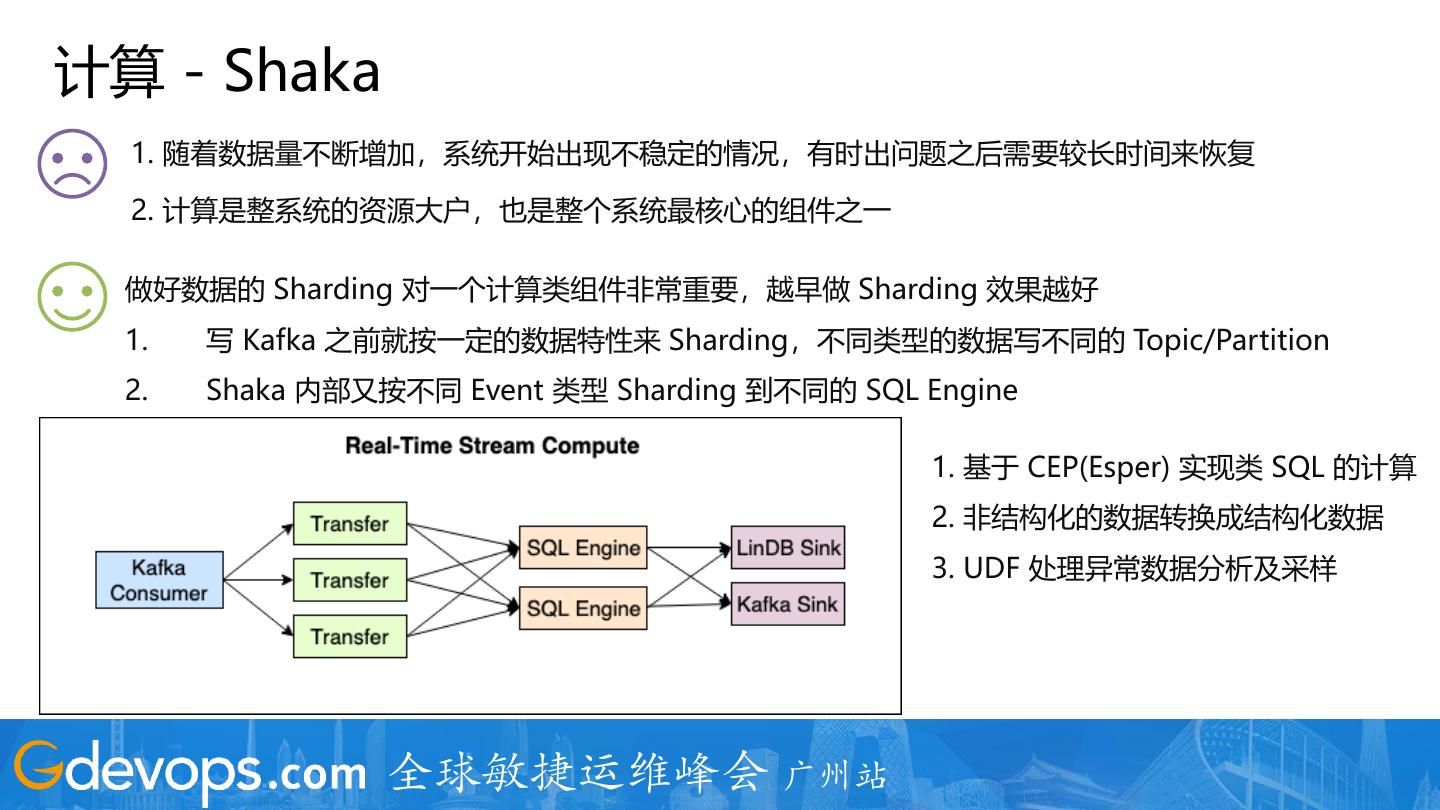
27 .计算 - Shaka
1. 随着数据量不断增加,系统开始出现不稳定的情况,有时出问题之后需要较长时间来恢复
2. 计算是整系统的资源大户,也是整个系统最核心的组件之一
做好数据的 Sharding 对一个计算类组件非常重要,越早做 Sharding 效果越好
1. 写 Kafka 之前就按一定的数据特性来 Sharding,不同类型的数据写不同的 Topic/Partition
2. Shaka 内部又按不同 Event 类型 Sharding 到不同的 SQL Engine
1. 基于 CEP(Esper) 实现类 SQL 的计算
2. 非结构化的数据转换成结构化数据
3. UDF 处理异常数据分析及采样
全球敏捷运维峰会 广州站
�
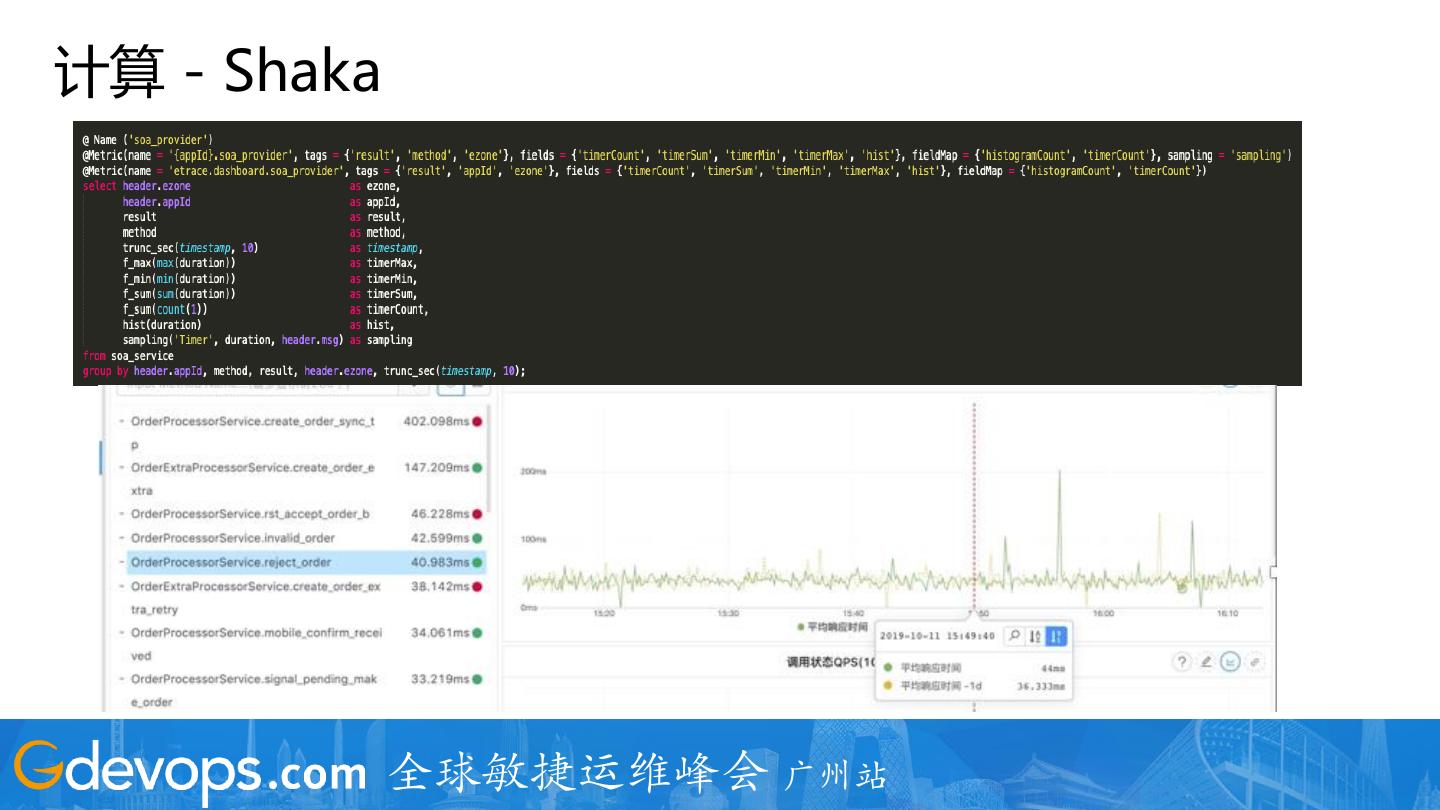
28 .计算 - Shaka
全球敏捷运维峰会 广州站
�
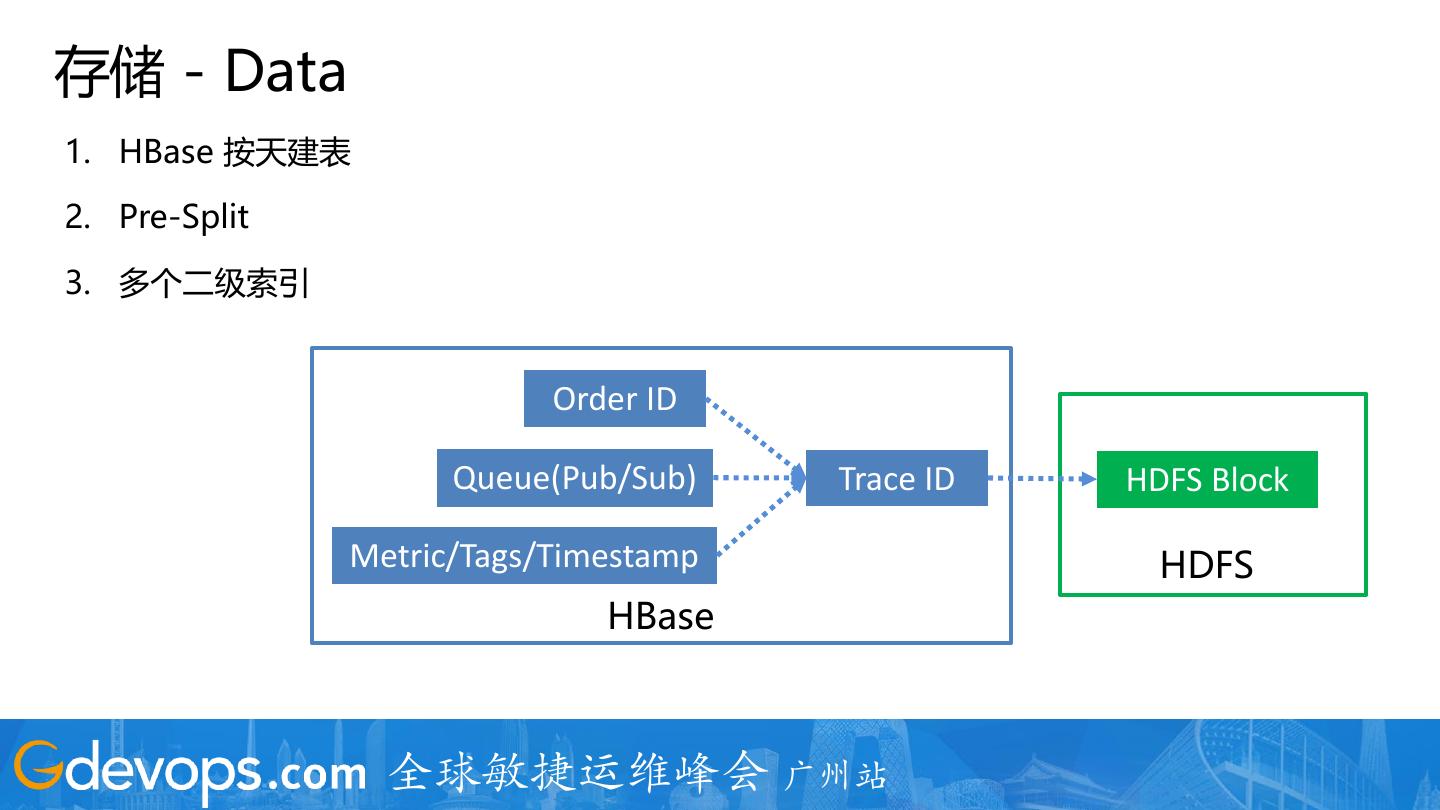
29 .存储 - Data
1. HDFS + HBase 存储所有的 Raw Data,HDFS 存储所有的 Raw Data,HBase 存储简单的
索引 (Request ID/Trace ID + RPC ID => file + block offset + message Offset)
2. 64 KB Block + Snappy
3. Block 压缩前置到 Collector 完成
全球敏捷运维峰会 广州站
�