






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
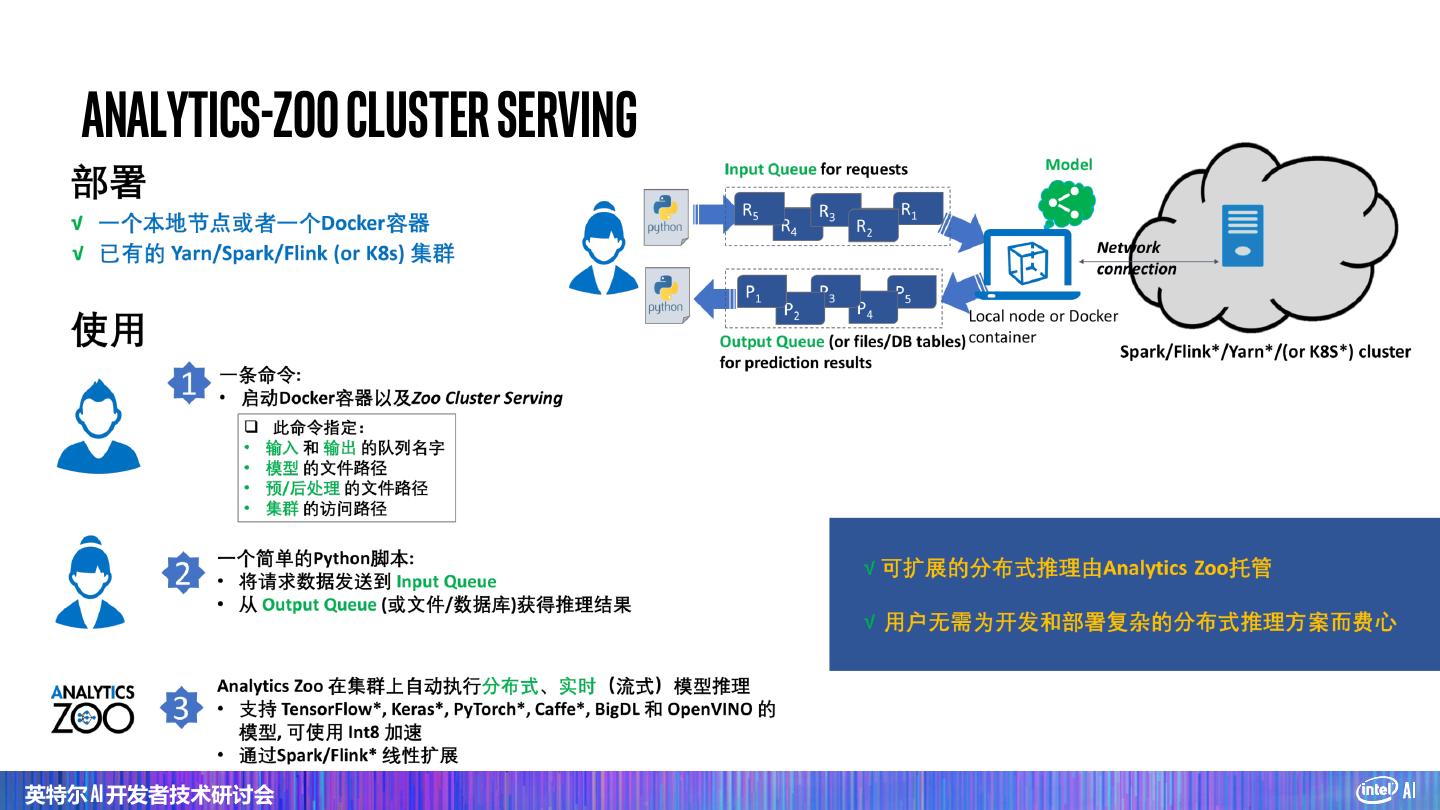
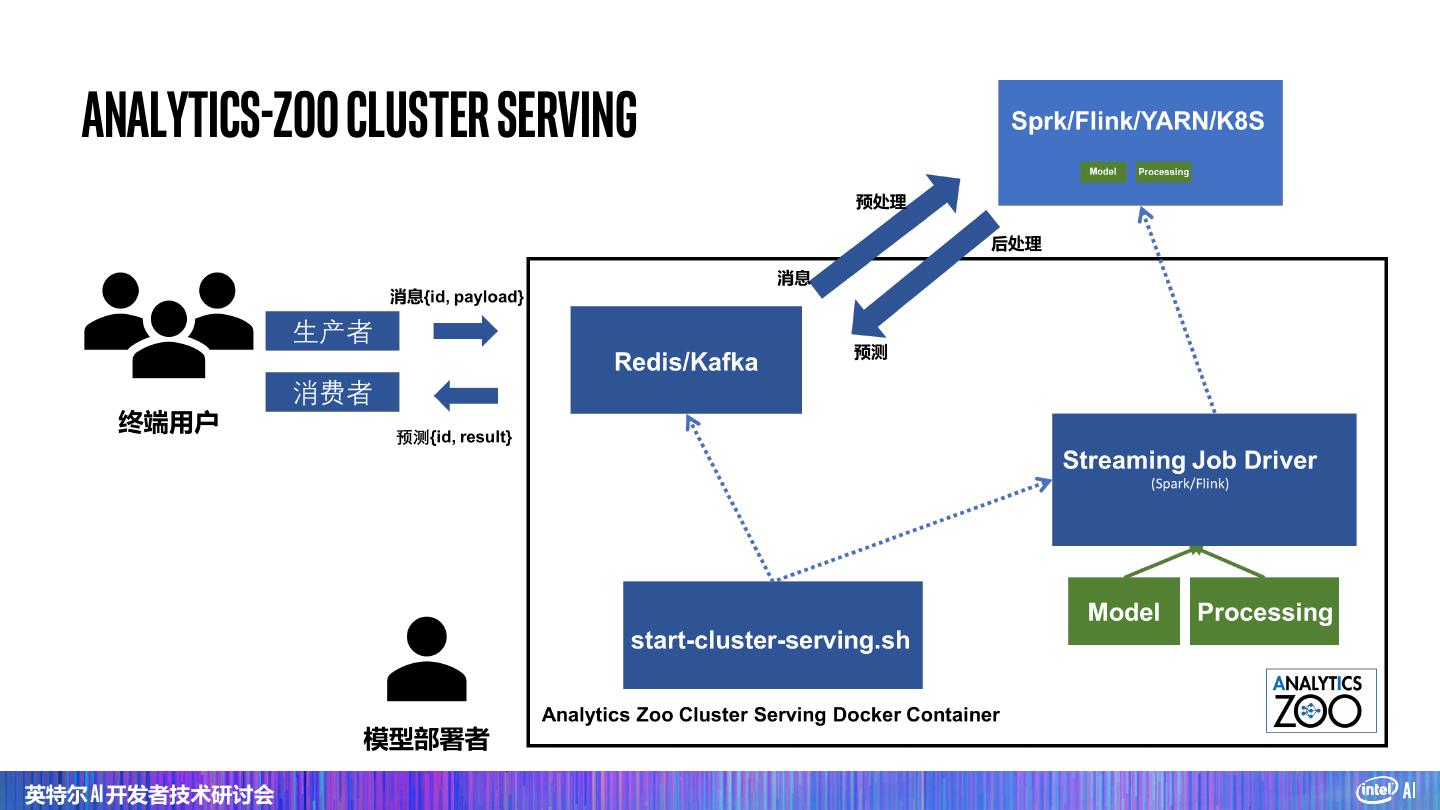
Analytics Zoo Cluster Serving
Analytics-Zoo 是由 Intel 开源的,基于 Apache Spark、Tensorflow、Keras 和 BigDL 的大数据分析 + AI 平台。它能够无缝整合Spark和各类深度学习框架,方便企业在已有的大型 Apache Hadoop/Spark 集群上进行大规模分布式训练及推理。在深度学习的整个生命周期中,模型Serving是最贴近生产环境的一环,也是AI应用落地的最关键一环。其效果直接决定了深度学习模型在实际应用中的最终表现。本次讲座将为大家介绍:如何通过Analytics-Zoo和Flink/Spark Streaming实现统一高效的Cluster Serving。我们还会分享Analytics-Zoo Cluster Serving在垃圾分类和医疗影像分析中的应用、遇到的问题和相应的解决方案。
展开查看详情
1 . Analytics Zoo & Cluster Serving 数据分析+AI平台技术及案例研究
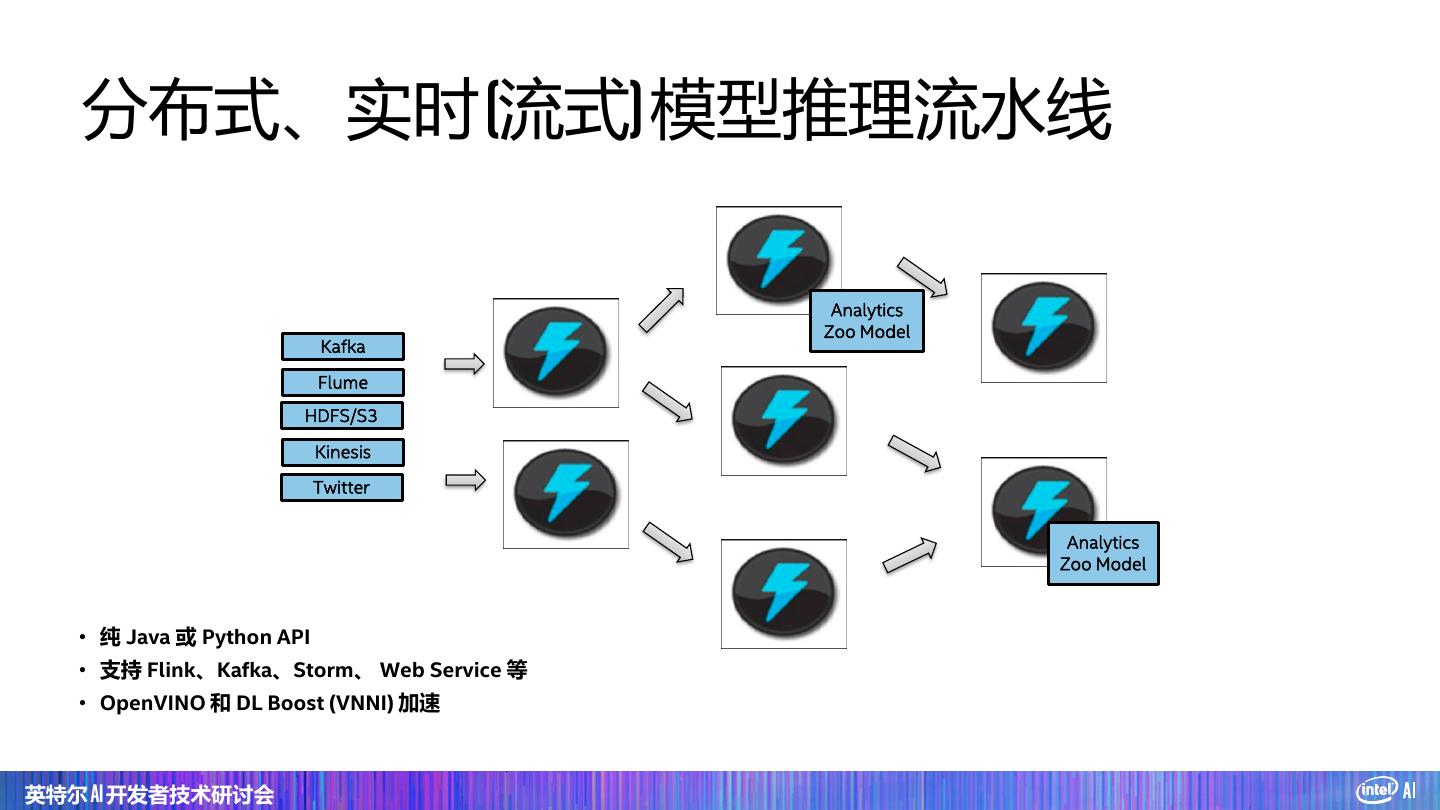
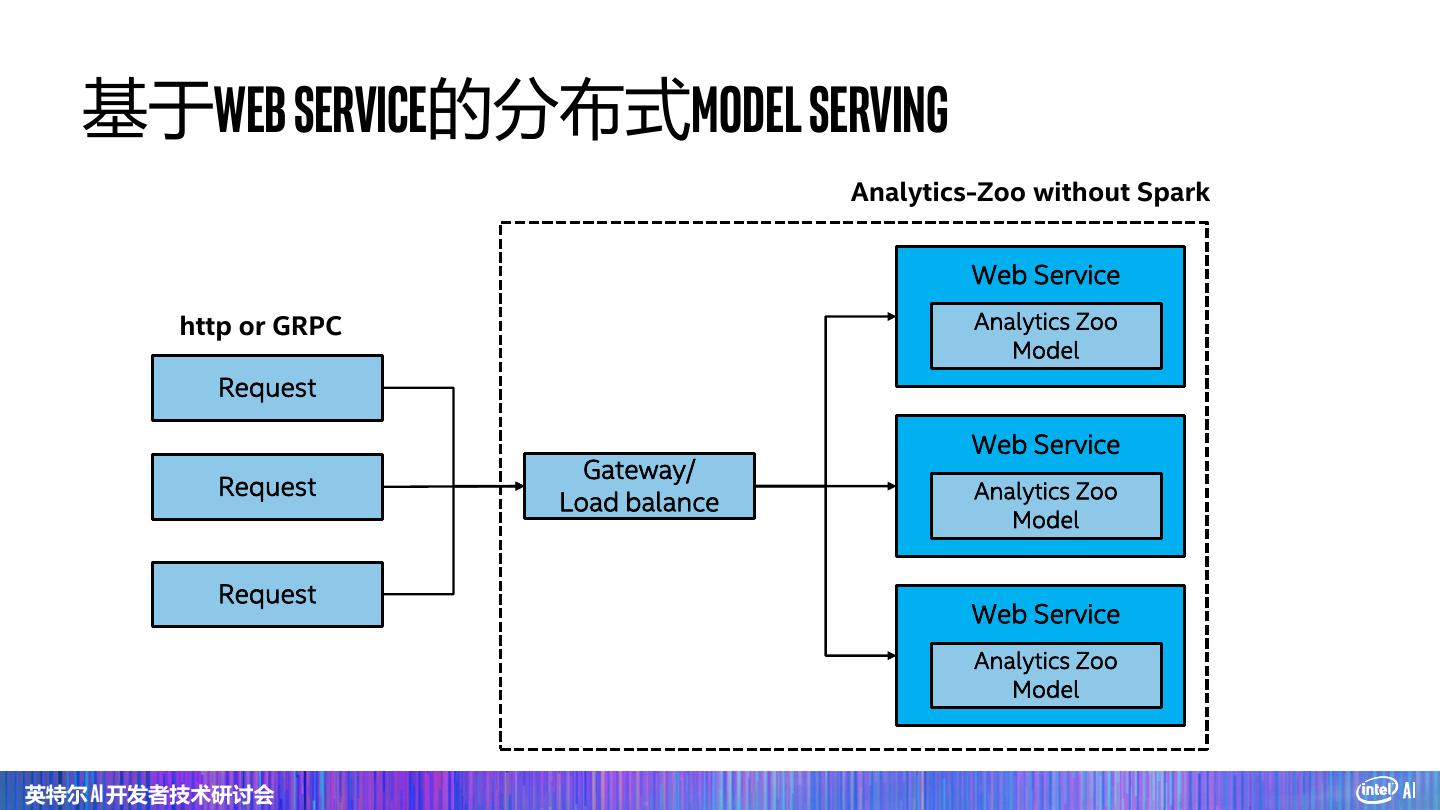
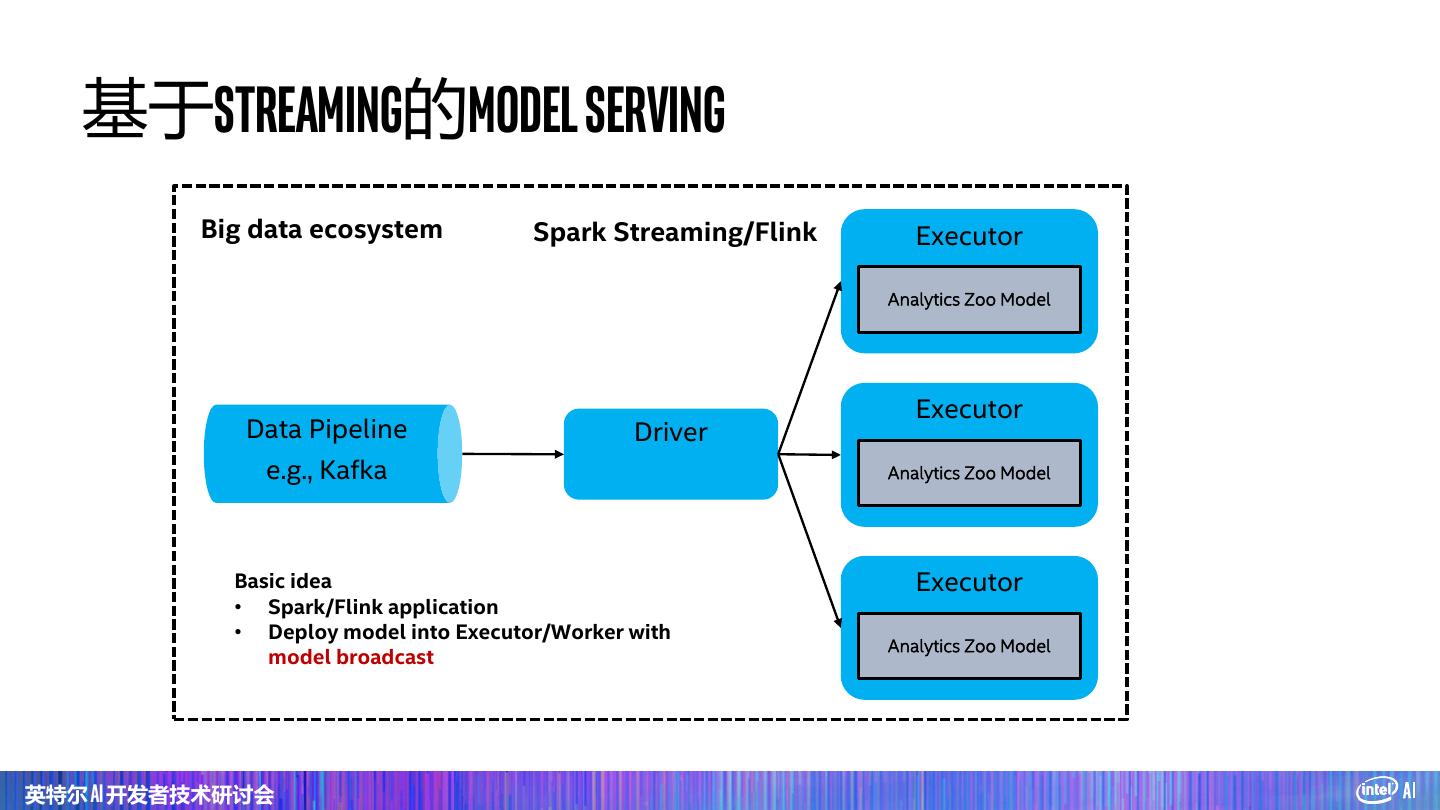
2 . Agenda Part 1: Intel Analytics-Zoo & Use cases Part 2: Cluster Serving with Analytics Zoo 英特尔 AI 开发者技术研讨会
3 .Intel Analytics-zoo & USE CASES
4 . 深度学习 https://www.quora.com/What-is-the-difference-between-deep-learning-and-usual-machine-learning 英特尔 AI 开发者技术研讨会
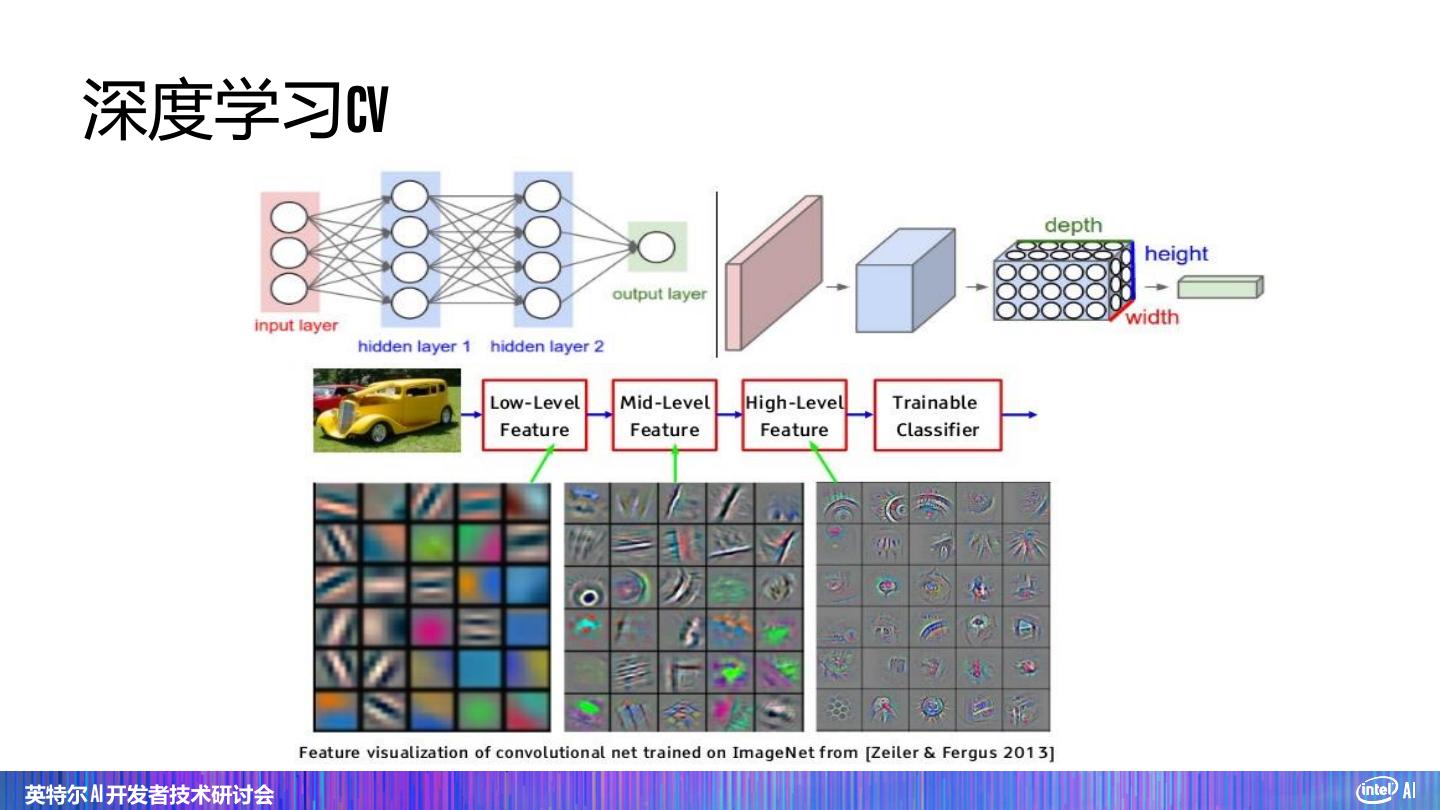
5 . 深度学习CV 英特尔 AI 开发者技术研讨会
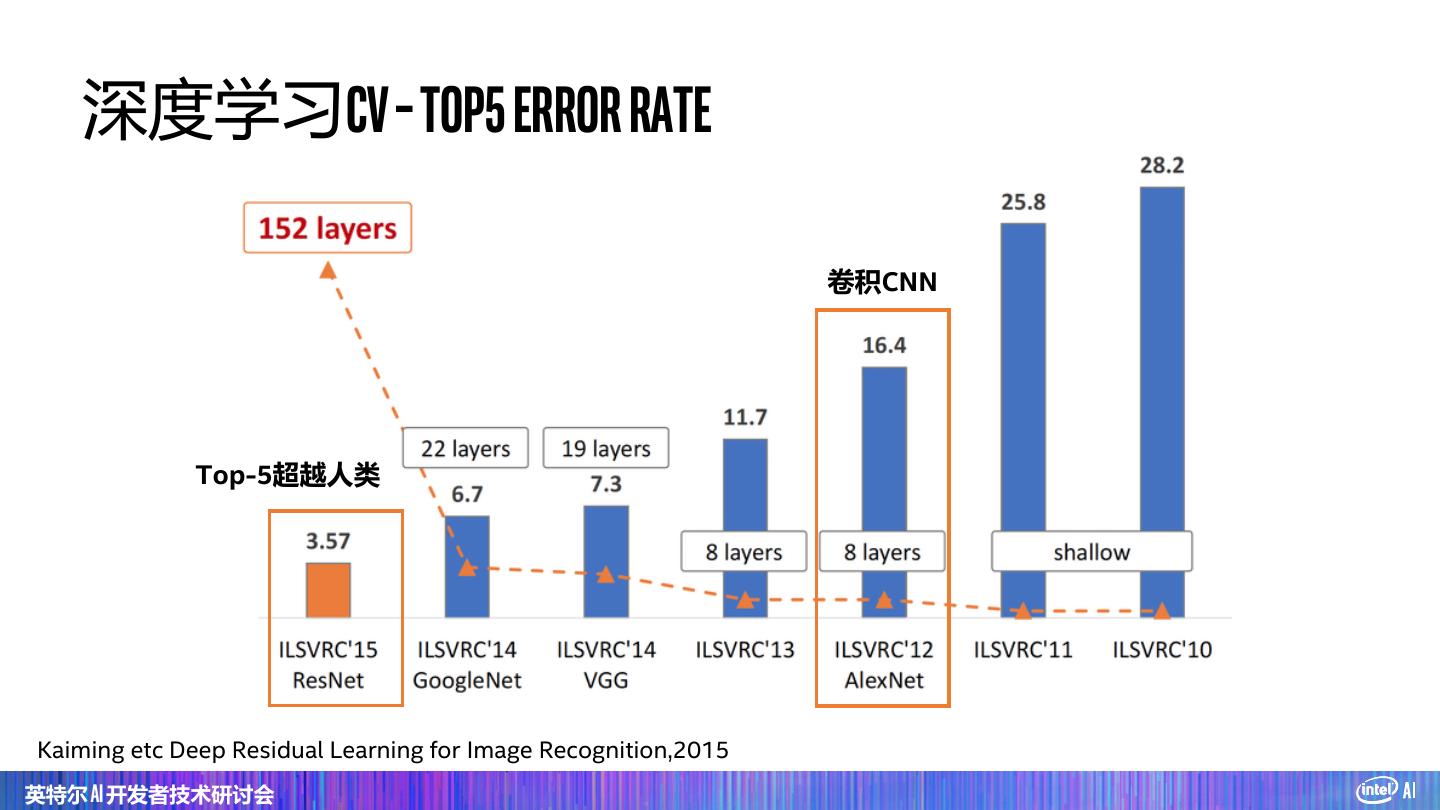
6 . 深度学习CV – Top5 error rate 卷积CNN Top-5超越人类 Kaiming etc Deep Residual Learning for Image Recognition,2015 英特尔 AI 开发者技术研讨会
7 . 深度学习 2016年 Google Alpha Go 击败前世界冠军李世石 In “Nature” 27 January 2016: “DeepMind’s program AlphaGo beat Fan Hui, the European Go champion, five times out of five in tournament conditions...” “…AlphaGo program applied deep learning in neural networks (convolutional NN) — brain-inspired programs in which connections between layers of simulated neurons are strengthened through examples and experience.” 2017年 Google Alpha Go Master 击败世界冠军柯洁 https://www.nature.com/nature/volumes/529/issues/7587 英特尔 AI 开发者技术研讨会
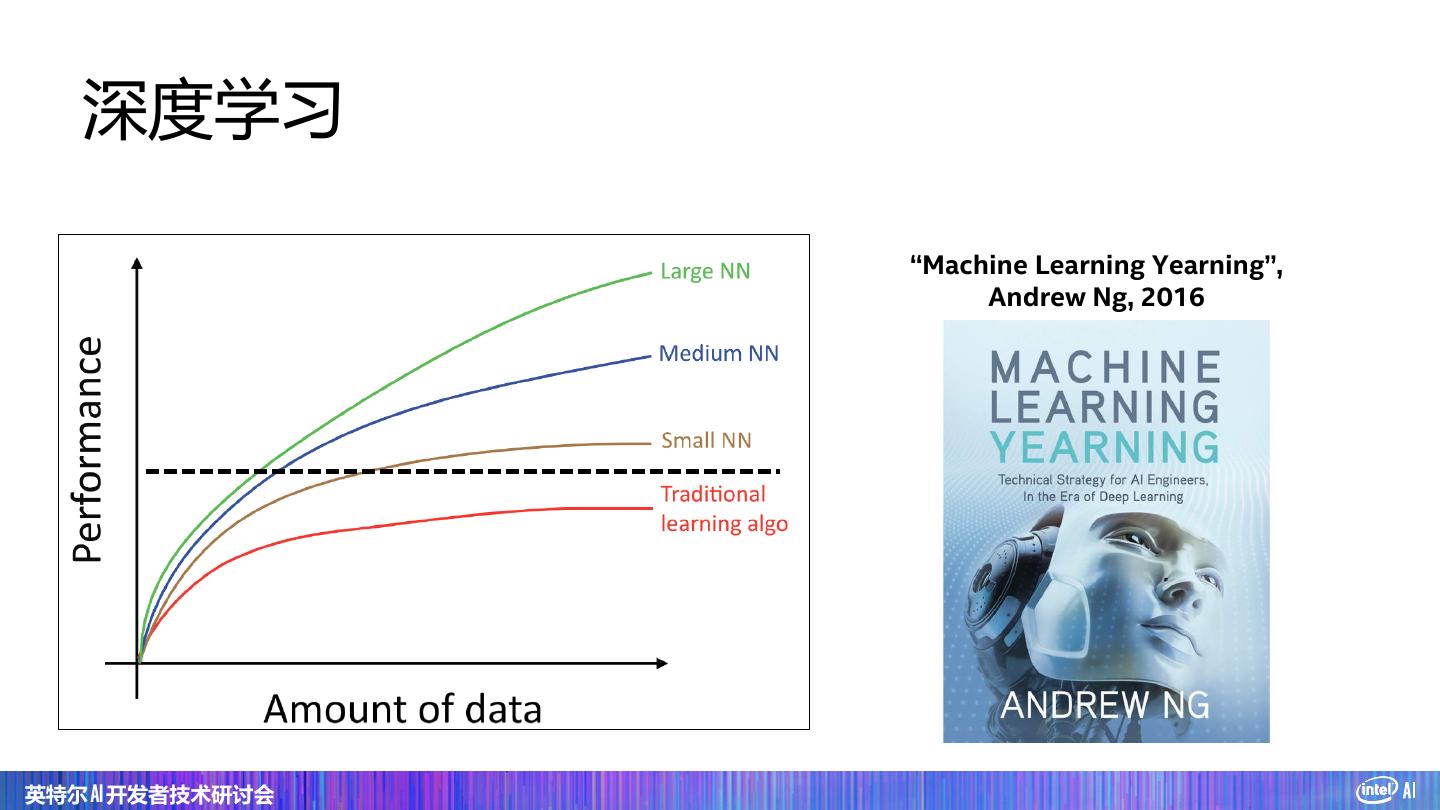
8 . 深度学习 “Machine Learning Yearning”, Andrew Ng, 2016 英特尔 AI 开发者技术研讨会
9 . 深度学习面临的问题 但天下没有免费的午餐 (no free launch) • Deep Learning需要大量算力 (计算密集) • Deep Learning需要大量数据 (data hungry) 足够的存储和算力 “人工”智能 https://medium.com/syncedreview/data-annotation-the-billion-dollar-business- behind-ai-breakthroughs-d929b0a50d23 英特尔 AI 开发者技术研讨会
10 . 深度学习 2016年 Google Alpha Go 击败李世石 • 现场的Alpha Go所使用的计算资源 • 48 CPU, 8 GPU ≈ 24 Servers • 其实还有一个Distributed Alpha Go • 1202 CPU, 176 GPU ≈ 601 Servers https://www.nature.com/articles/nature16961 https://newsroom.intel.com/editorials/re-architecting-data- center-intel-xeon-processor-scalable-family/#gs.hi35lo 英特尔 AI 开发者技术研讨会
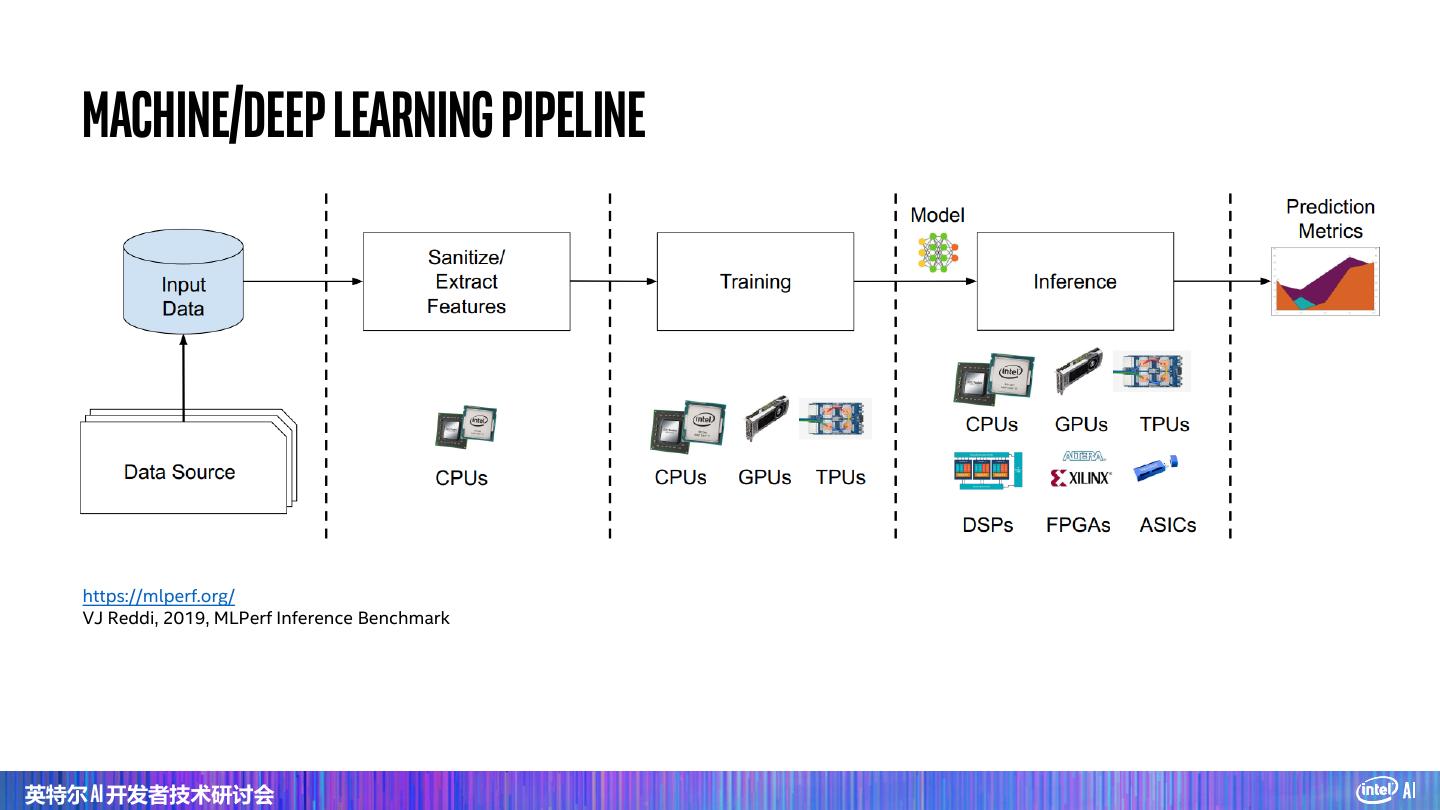
11 . 深度学习 https://mlperf.org/ VJ Reddi, 2019, MLPerf Inference Benchmark 英特尔 AI 开发者技术研讨会
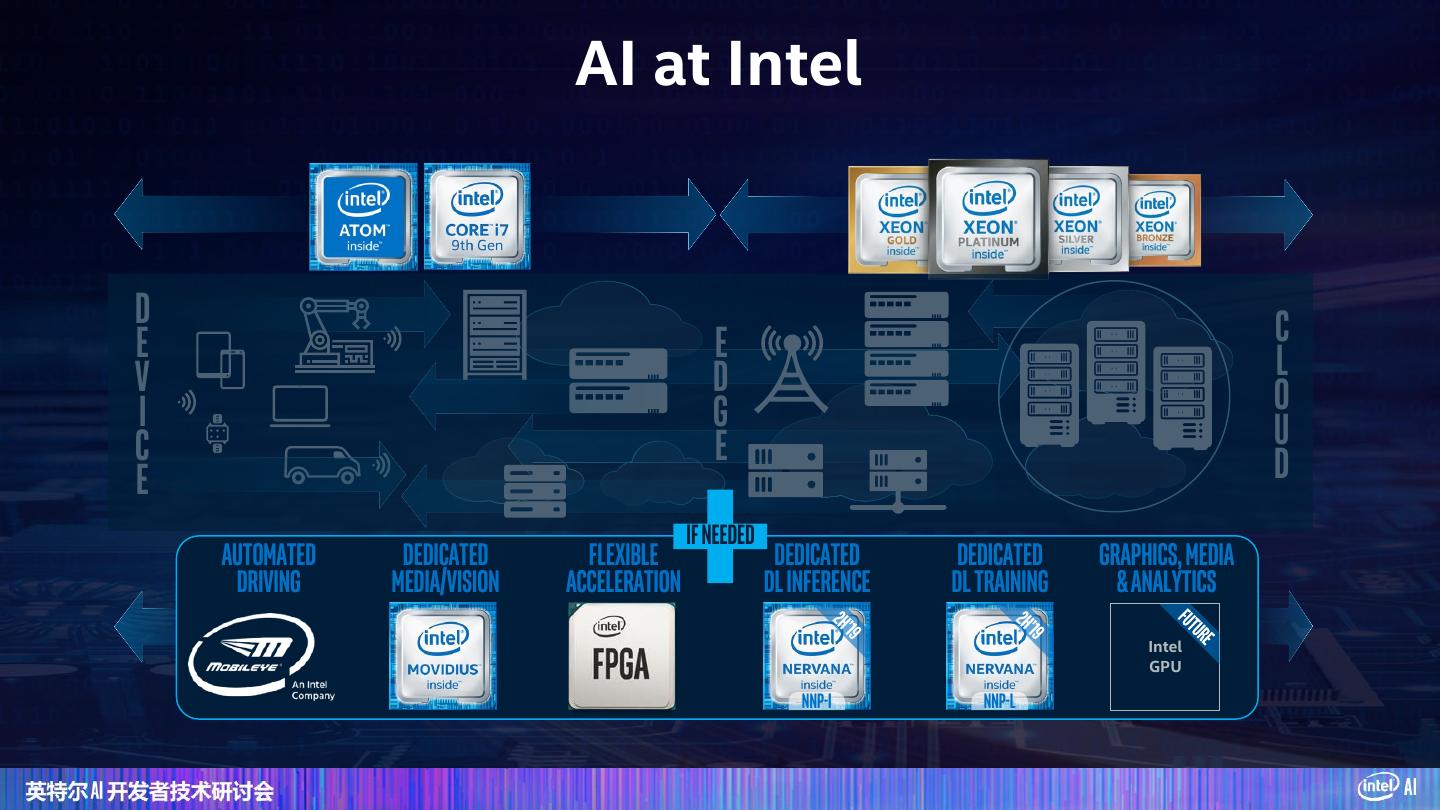
12 . AI at Intel D C e e l v d o I g u c e d e If needed Automated Dedicated Flexible Dedicated Dedicated Graphics, Media Driving Media/Vision Acceleration DL Inference DL Training & Analytics Intel GPU NNP-I NNP-L 12
13 . Speed Up Development Using Open AI Software Machine learning Deep learning TOOLKITS App Open source platform for building E2E Analytics Deep learning inference deployment Open source, scalable, and developers & AI applications on Apache Spark* with on CPU/GPU/FPGA/VPU for Caffe*, extensible distributed deep distributed TensorFlow*, Keras*, BigDL TensorFlow*, MXNet*, ONNX*, Kaldi* learning platform built on Kubernetes (BETA) libraries Python •Scikit- R •Cart Distributed •MlLib (on Spark) * Intel-optimized Frameworks * * And more framework Data learn •Random •Mahout optimizations underway scientists •Pandas Forest * * including PaddlePaddle*, Chainer*, CNTK* & others •NumPy •e1071 Kernels Intel® Distribution Intel® Data Analytics Intel® Math Kernel Library for Deep Library for Python* Acceleration Neural Networks developers Library (DAAL) (MKL-DNN) Open source compiler for deep learning model Intel distribution High performance machine computations optimized for multiple devices (CPU, optimized for learning & data analytics Open source DNN functions for GPU, NNP) from multiple frameworks (TF, MXNet, machine learning library CPU / integrated graphics ONNX) 13
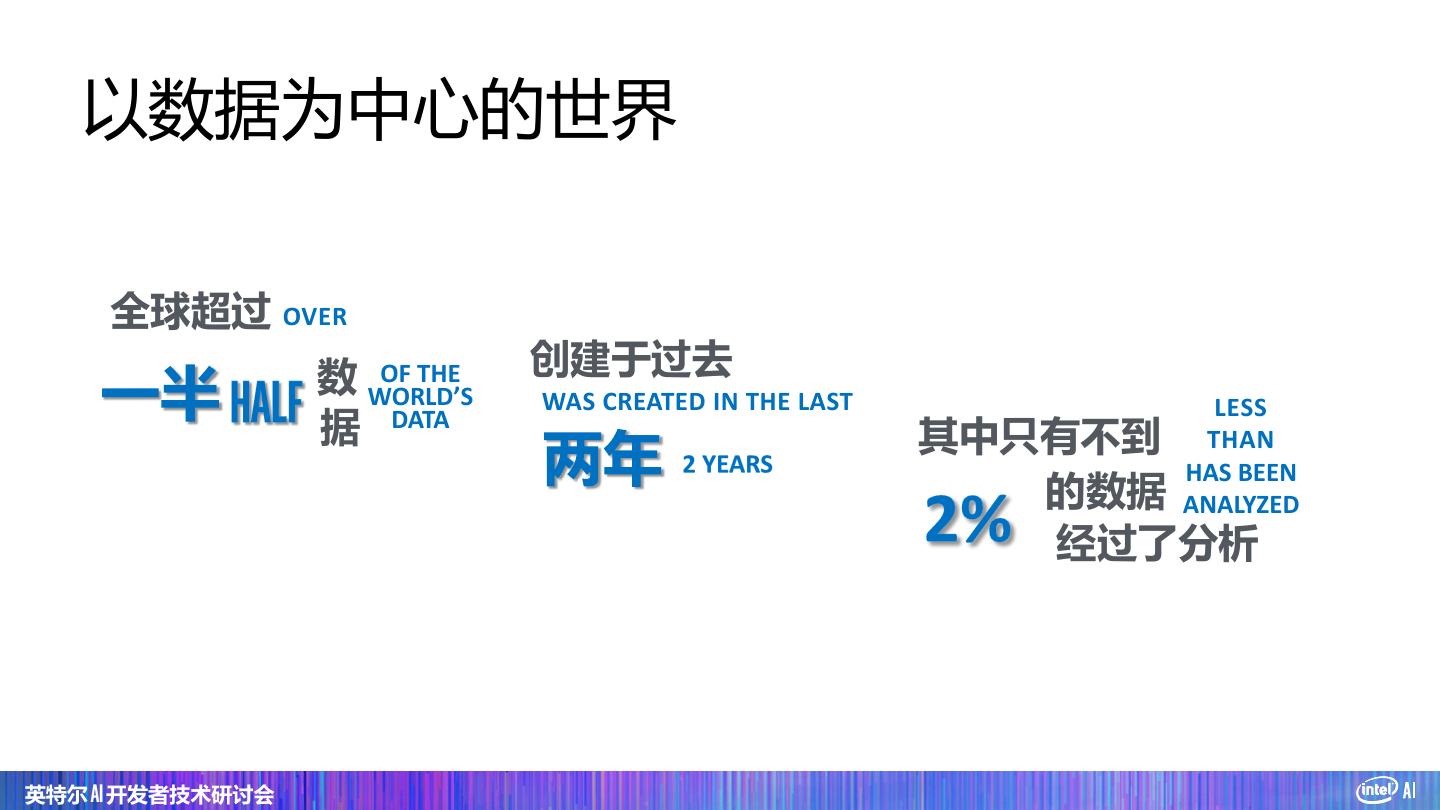
14 . 以数据为中心的世界 全球超过 OVER 数 WORLD’S OF THE 创建于过去 WAS CREATED IN THE LAST LESS 据 DATA 其中只有不到 THAN HAS BEEN 的数据ANALYZED 经过了分析 英特尔 AI 开发者技术研讨会
15 .正面临巨大的挑战 复杂性 成本 可扩展性 专有接口 数据隐私
16 . “Hidden Technical Debt in Machine Learning Systems”, Sculley et al., Google, NIPS 2015 英特尔 AI 开发者技术研讨会
17 .统一的数据分析及AI 获取 / 存储 清洗 / 准备 分析 / 建模 部署 / 可视化 集成的数据流水线 数据管理 数据分析 数据科学及人工智能
18 .Analytics Zoo 统一的大数据分析+人工智能平台
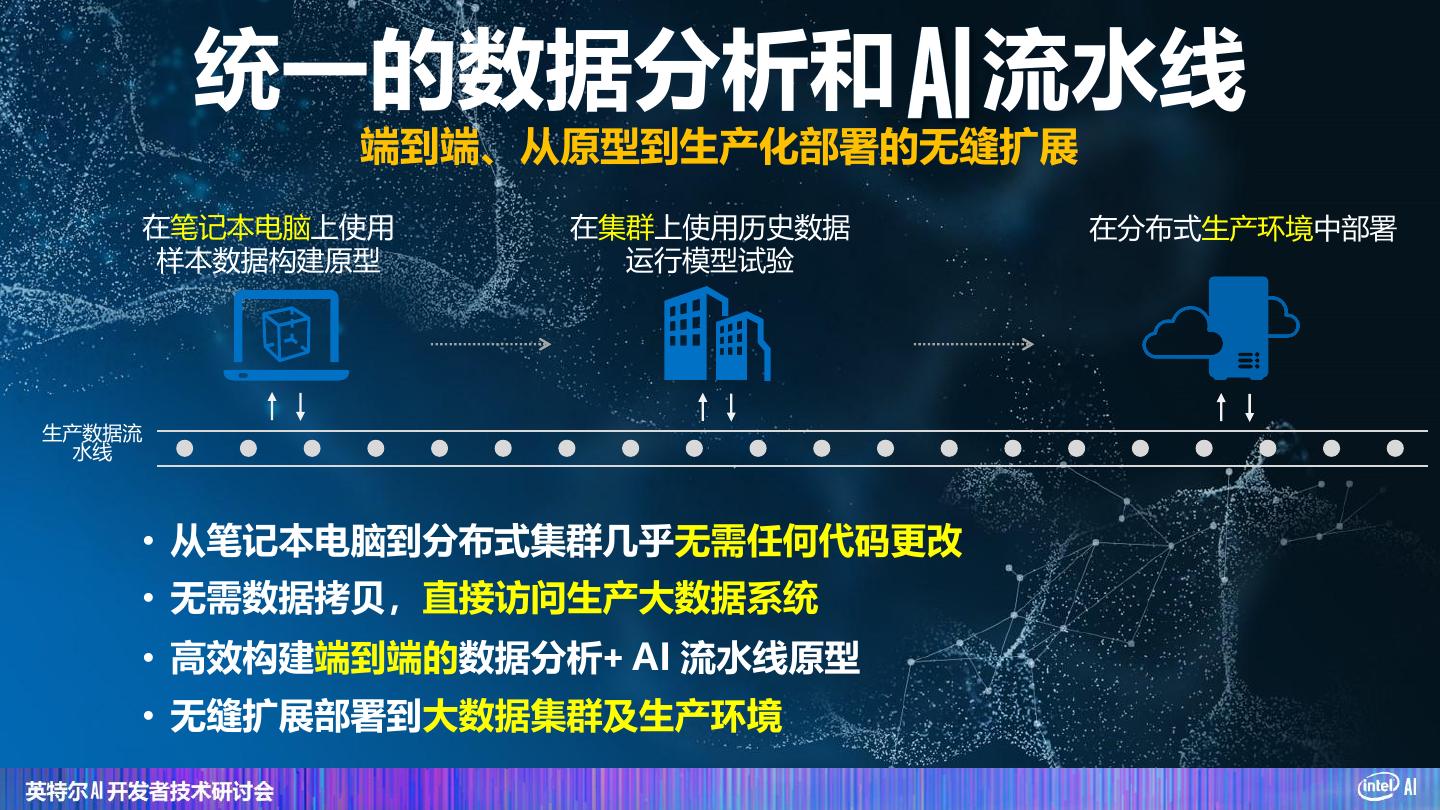
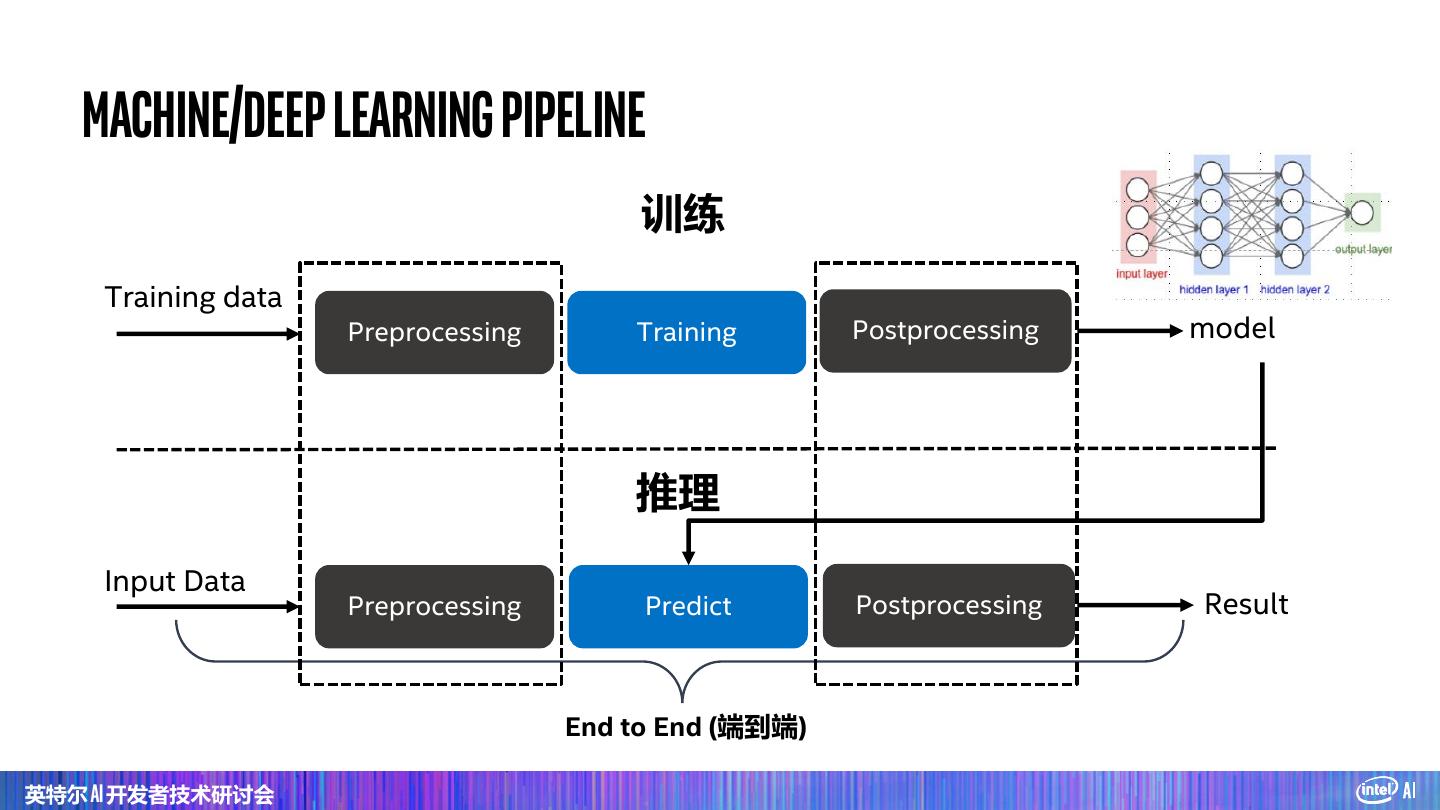
19 . 统一的数据分析和 流水线 端到端、从原型到生产化部署的无缝扩展 在笔记本电脑上使用 在集群上使用历史数据 在分布式生产环境中部署 样本数据构建原型 运行模型试验 生产数据流 水线 • 从笔记本电脑到分布式集群几乎无需任何代码更改 • 无需数据拷贝,直接访问生产大数据系统 • 高效构建端到端的数据分析+ AI 流水线原型 • 无缝扩展部署到大数据集群及生产环境
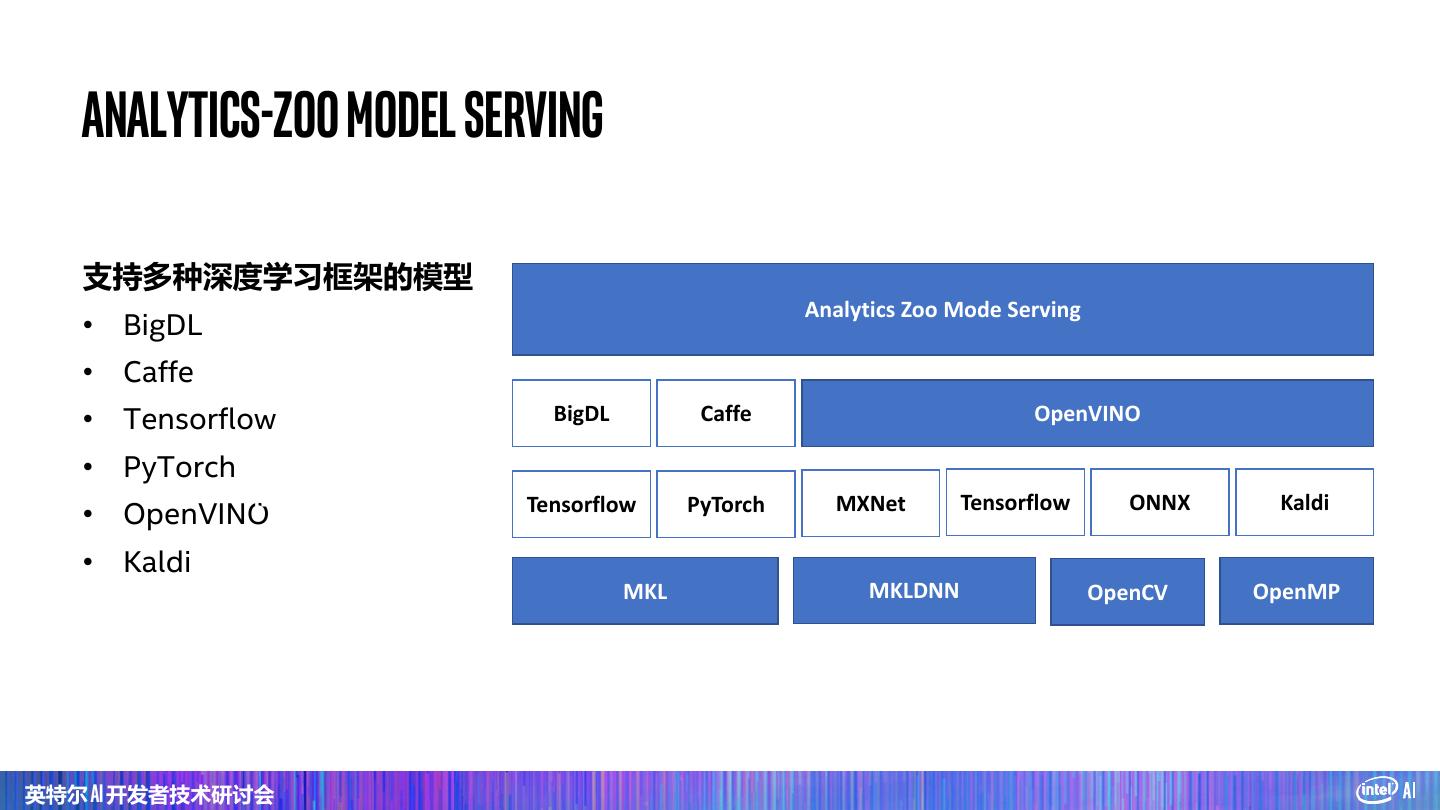
20 . Analytics Zoo 统一的大数据分析+人工智能平台 用户案例 Recommendation Anomaly Detection Text Classification Text Matching 模型 Image Classification Object Detection Seq2Seq Transformer BERT 特征工程 image 3D image text time series tfpark: Distributed TensorFlow on Spark Distributed Keras w/ autograd on Spark 高级 流水线 nnframes: Spark Dataframes & ML Distributed Model Inference Pipelines for Deep Learning (batch, streaming & online) TensorFlow* Keras* PyTorch* BigDL NLP Architect Apache Spark* Apache Flink* 后端 Ray* MKLDNN OpenVINO Intel® Optane™ DCPMM DL Boost (VNNI)
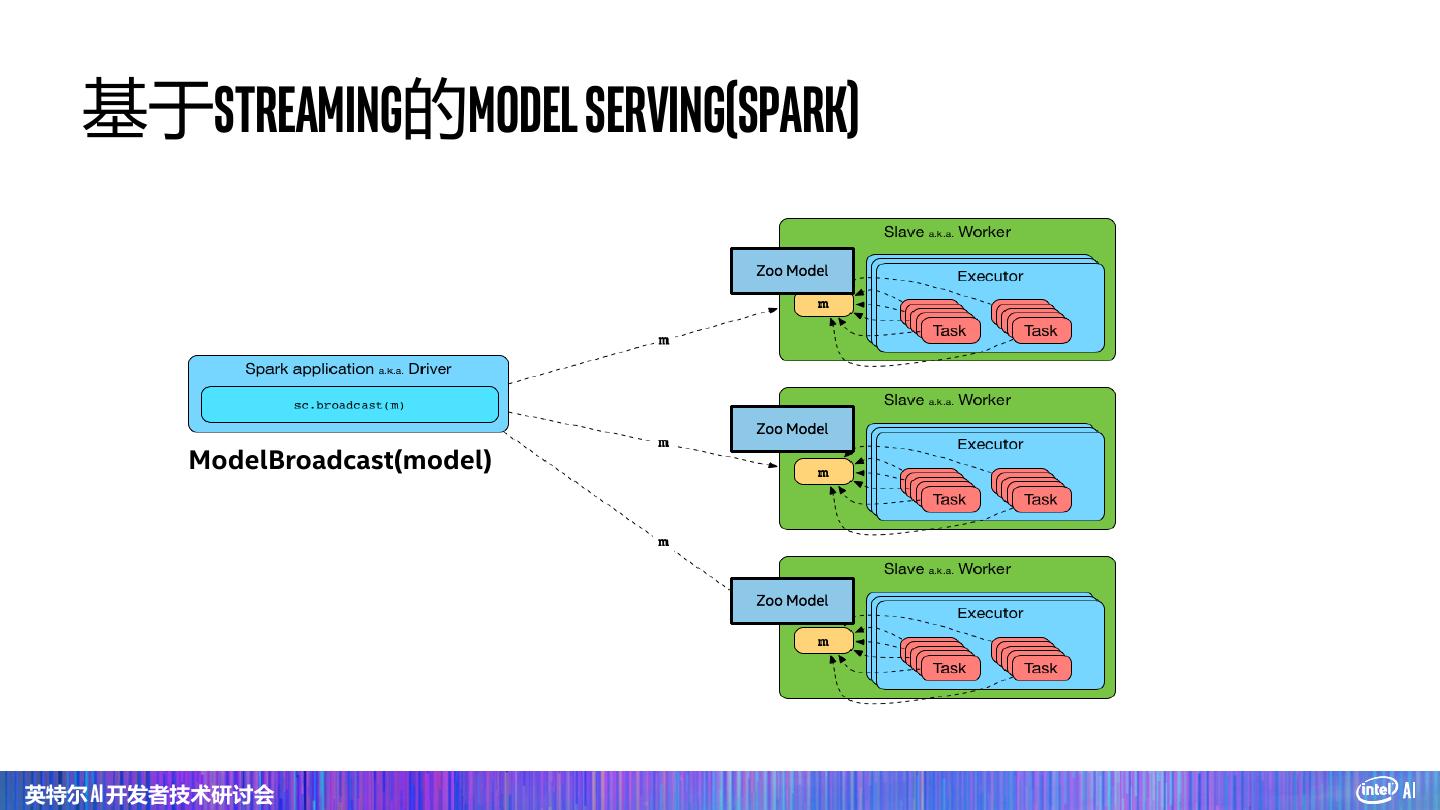
21 . 基于 Spark 的分布式 TensorFlow 流水线 #pyspark code • Data wrangling and train_rdd = spark.hadoopFile(…).map(…) analysis using PySpark dataset = TFDataset.from_rdd(train_rdd,…) #tensorflow code import tensorflow as tf • Deep learning model slim = tf.contrib.slim images, labels = dataset.tensors development using with slim.arg_scope(lenet.lenet_arg_scope()): TensorFlow or Keras logits, end_points = lenet.lenet(images, …) loss = tf.reduce_mean( \ tf.losses.sparse_softmax_cross_entropy( \ logits=logits, labels=labels)) • Distributed training / #distributed training on Spark optimizer = TFOptimizer.from_loss(loss, Adam(…)) inference on Spark optimizer.optimize(end_trigger=MaxEpoch(5)) 在 PySpark 程序内嵌 TensorFlow 代码 英特尔 AI 开发者技术研讨会
22 . 基于Spark Dataframe & ML 流水线的深度学习 #Spark dataframe transformations parquetfile = spark.read.parquet(…) train_df = parquetfile.withColumn(…) #Keras API model = Sequential() .add(Convolution2D(32, 3, 3, activation='relu', input_shape=…)) \ .add(MaxPooling2D(pool_size=(2, 2))) \ .add(Flatten()).add(Dense(10, activation='softmax'))) #Spark ML pipeline Estimater = NNEstimater(model, CrossEntropyCriterion()) \ .setLearningRate(0.003).setBatchSize(40).setMaxEpoch(5) \ .setFeaturesCol("image") nnModel = estimater.fit(train_df) 在 Spark Dataframe 和 ML 流水线中,直接支持深度神经网络模型 英特尔 AI 开发者技术研讨会
23 .* 文中涉及的其它名称及商标属于各自所有者资产 。
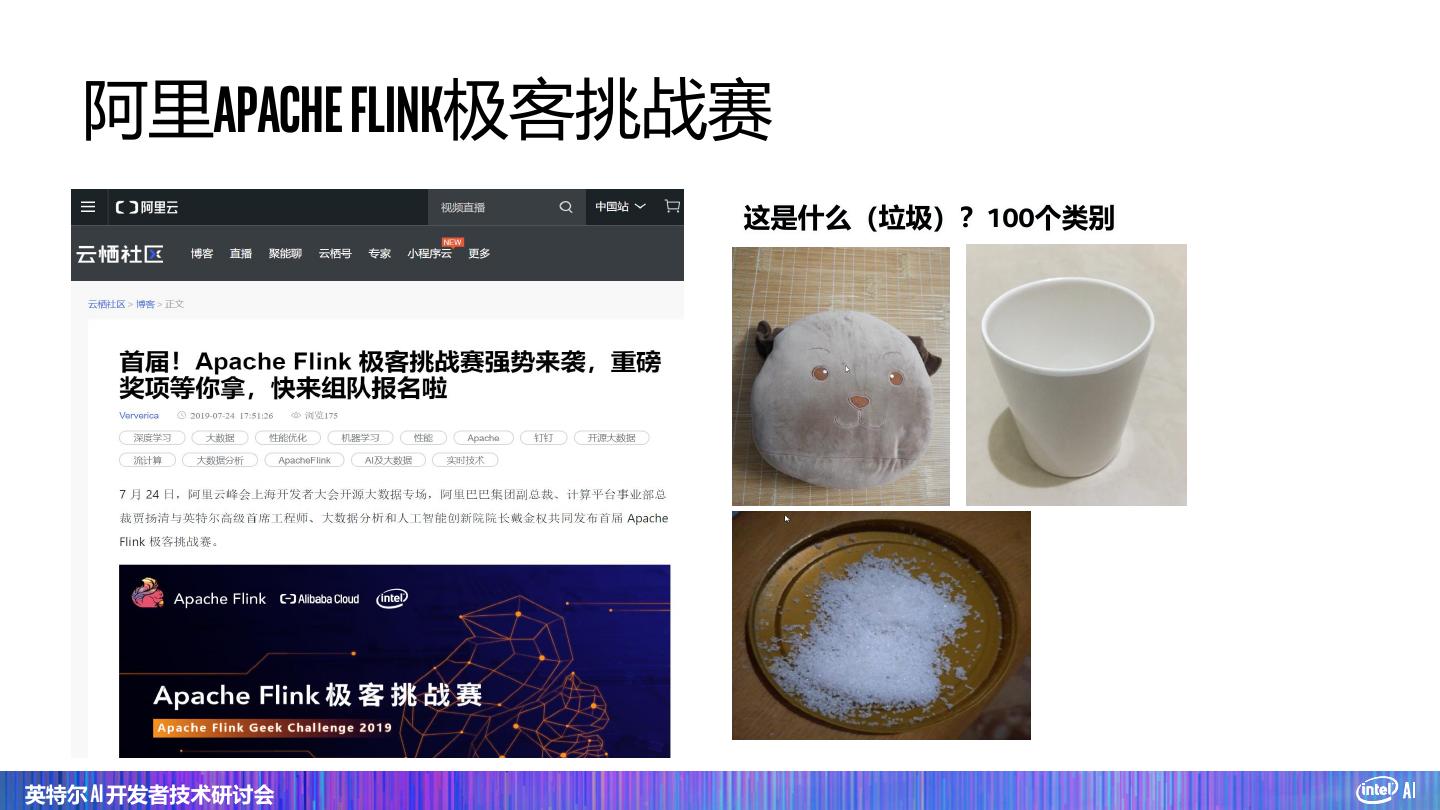
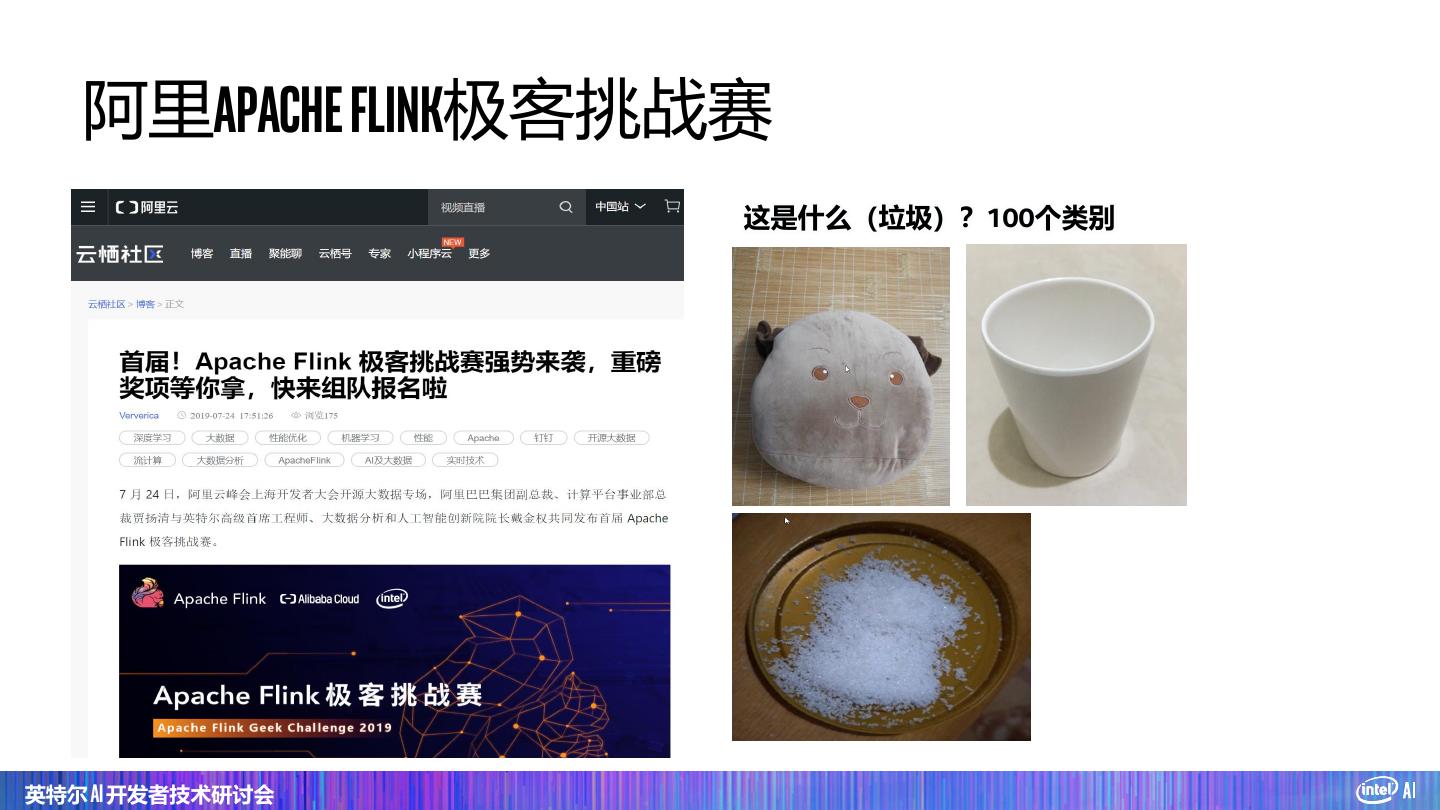
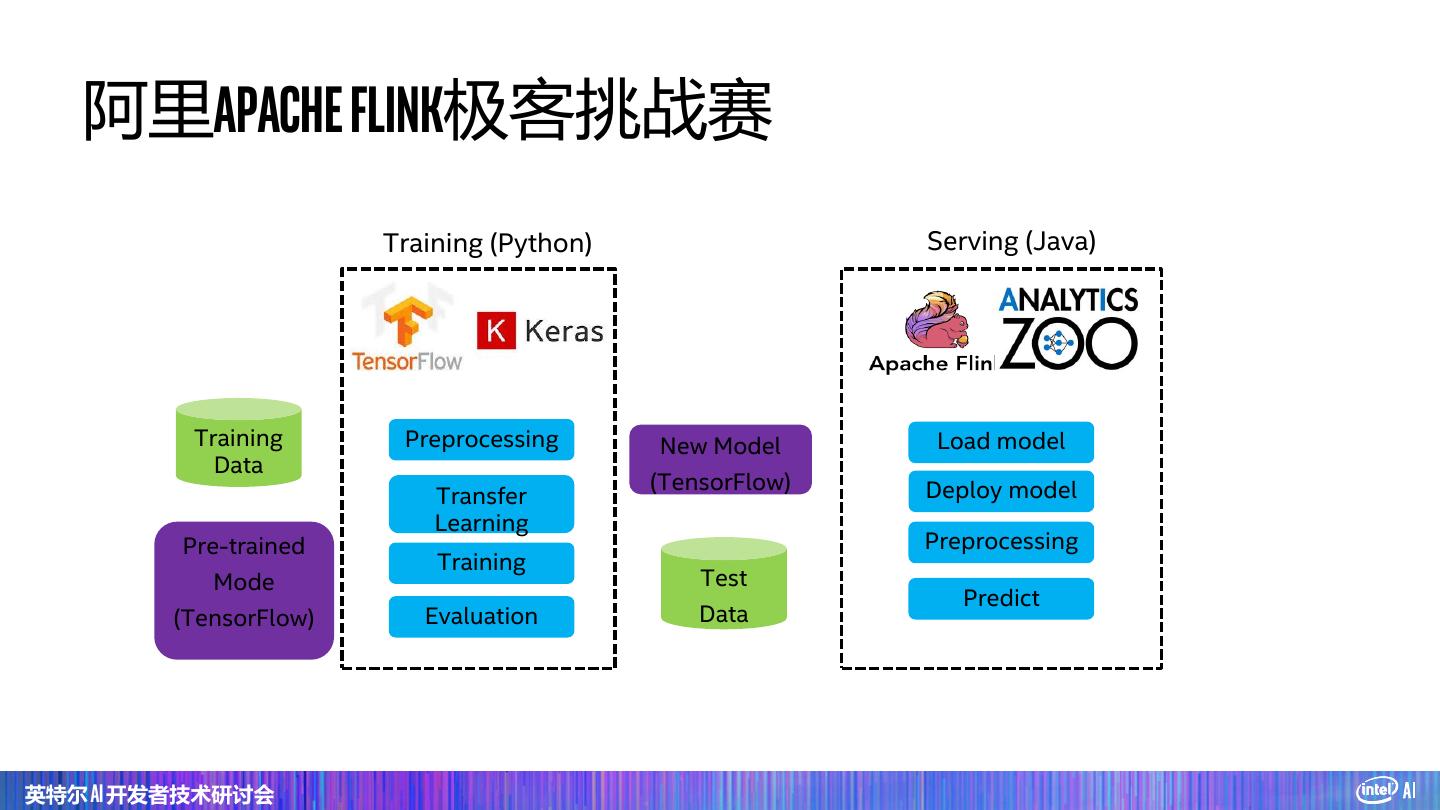
24 . 阿里Apache Flink极客挑战赛 这是什么(垃圾)?100个类别 英特尔 AI 开发者技术研讨会
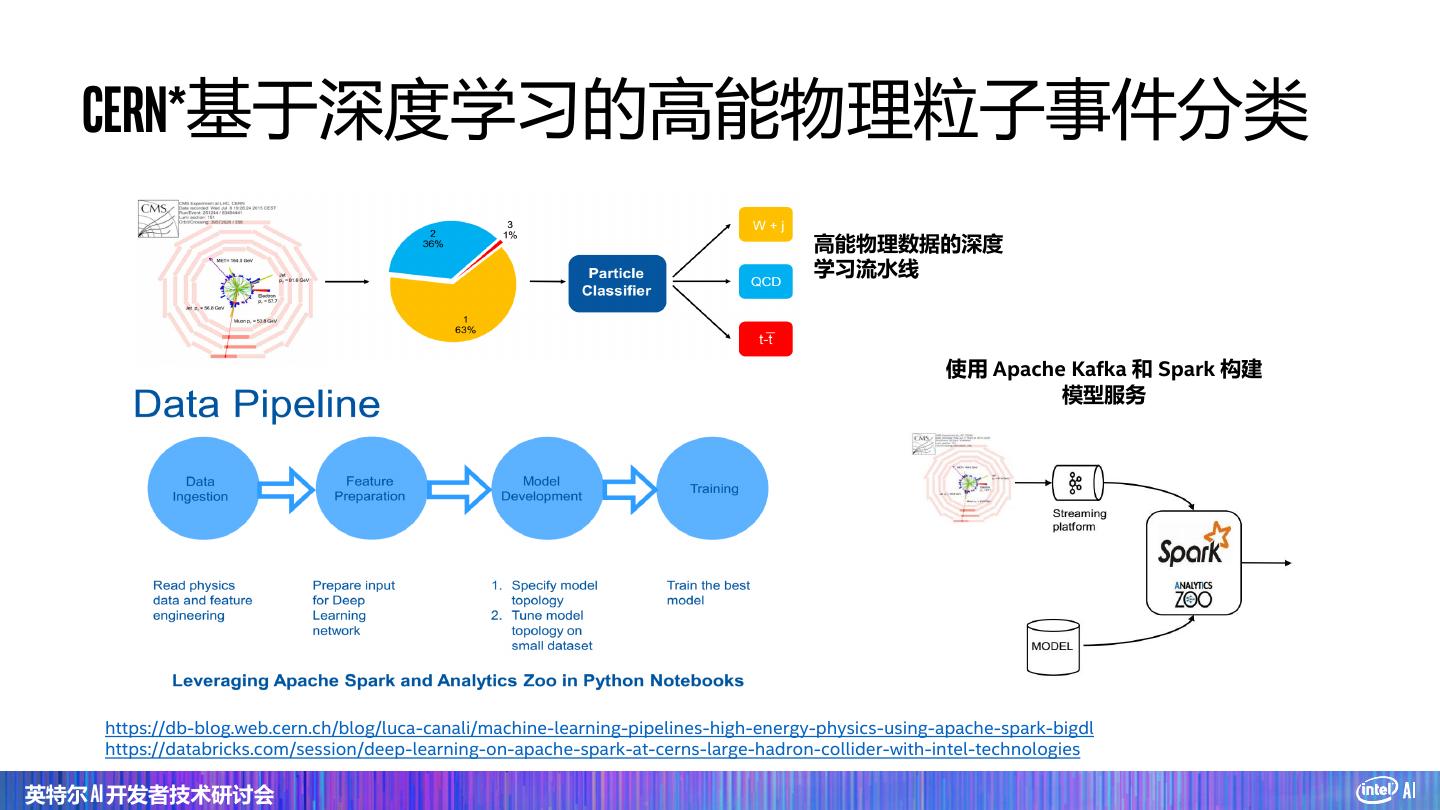
25 . CERN*基于深度学习的高能物理粒子事件分类 高能物理数据的深度 学习流水线 使用 Apache Kafka 和 Spark 构建 模型服务 https://db-blog.web.cern.ch/blog/luca-canali/machine-learning-pipelines-high-energy-physics-using-apache-spark-bigdl https://databricks.com/session/deep-learning-on-apache-spark-at-cerns-large-hadron-collider-with-intel-technologies 英特尔 AI 开发者技术研讨会
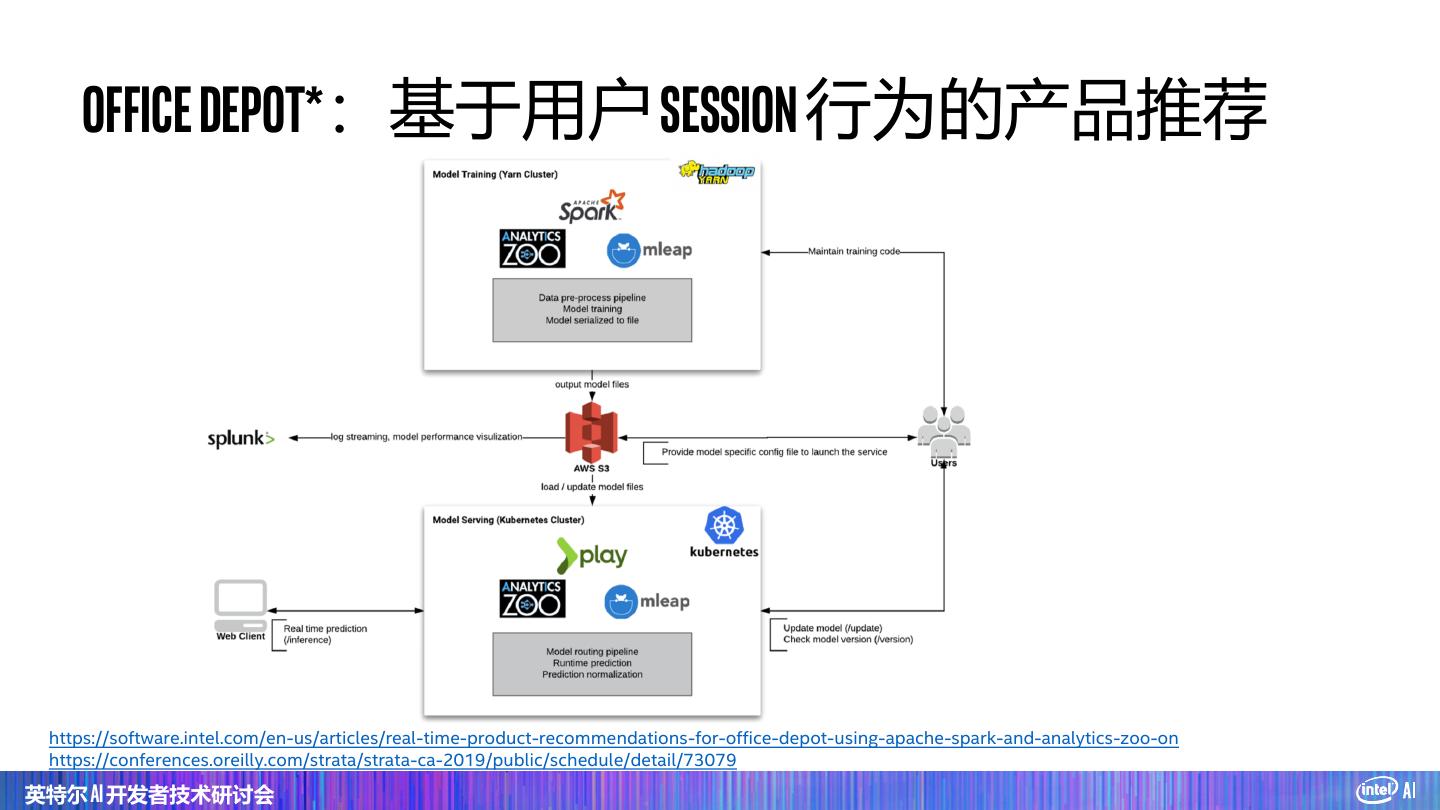
26 . Office Depot*:基于用户 Session 行为的产品推荐 https://software.intel.com/en-us/articles/real-time-product-recommendations-for-office-depot-using-apache-spark-and-analytics-zoo-on https://conferences.oreilly.com/strata/strata-ca-2019/public/schedule/detail/73079 英特尔 AI 开发者技术研讨会
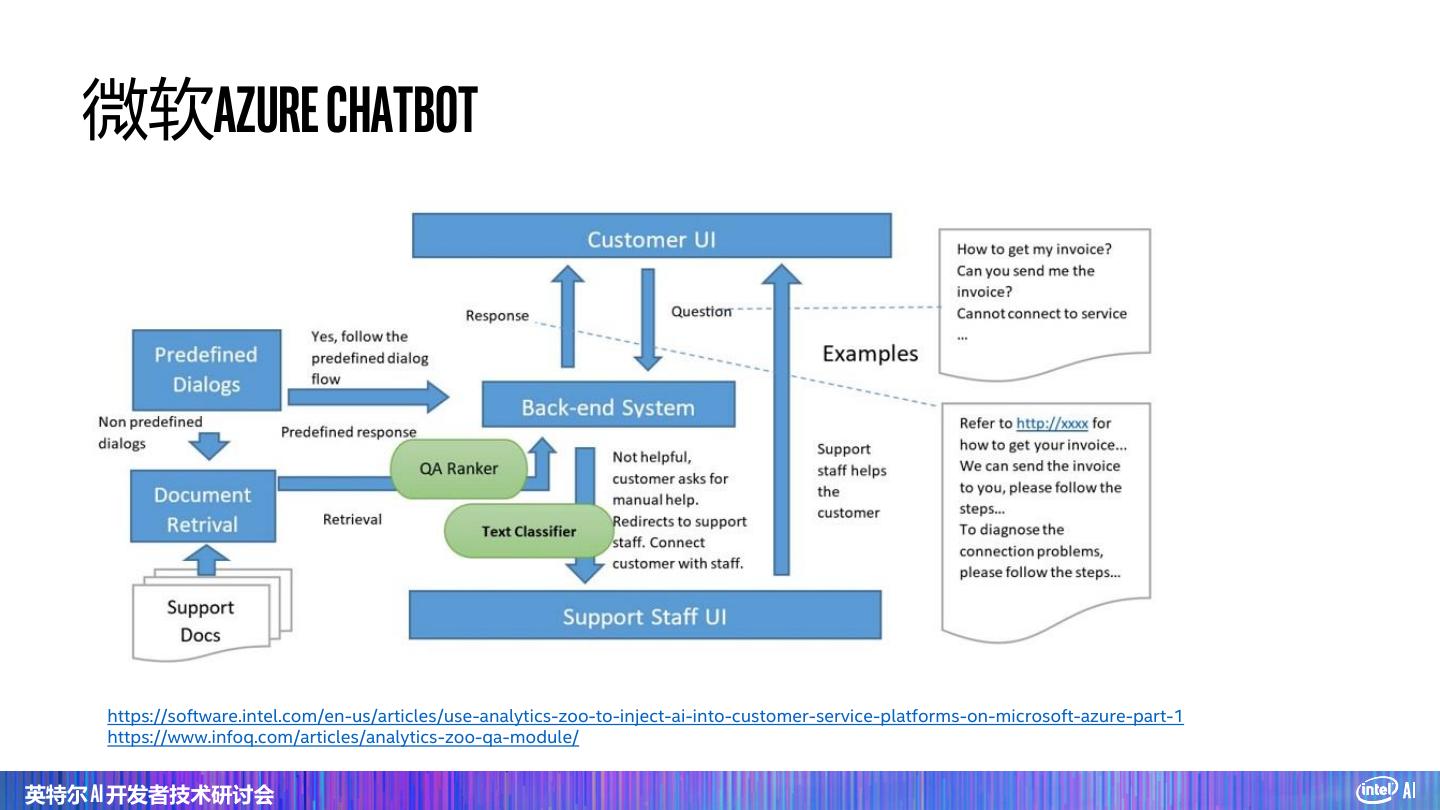
27 . 微软Azure Chatbot https://software.intel.com/en-us/articles/use-analytics-zoo-to-inject-ai-into-customer-service-platforms-on-microsoft-azure-part-1 https://www.infoq.com/articles/analytics-zoo-qa-module/ 英特尔 AI 开发者技术研讨会
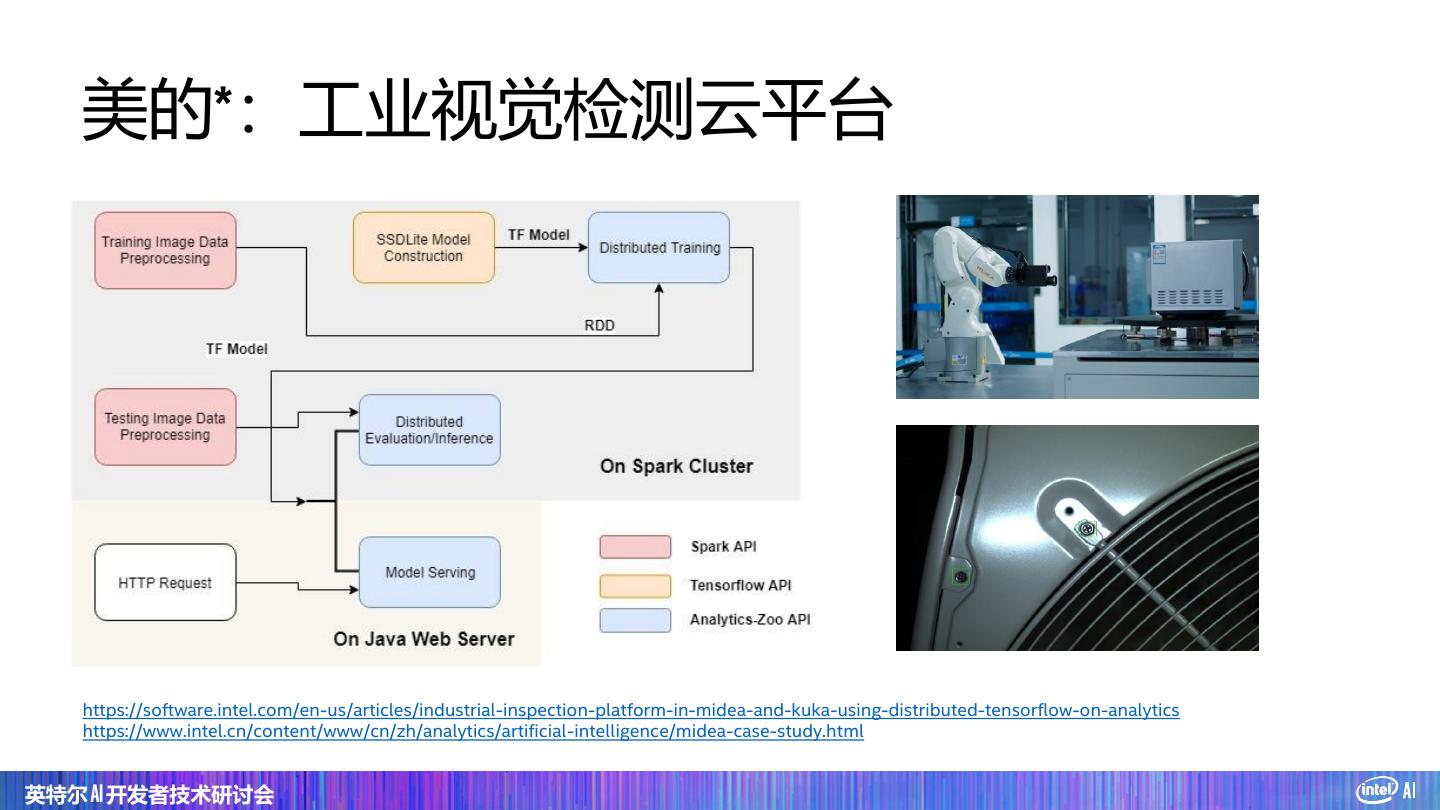
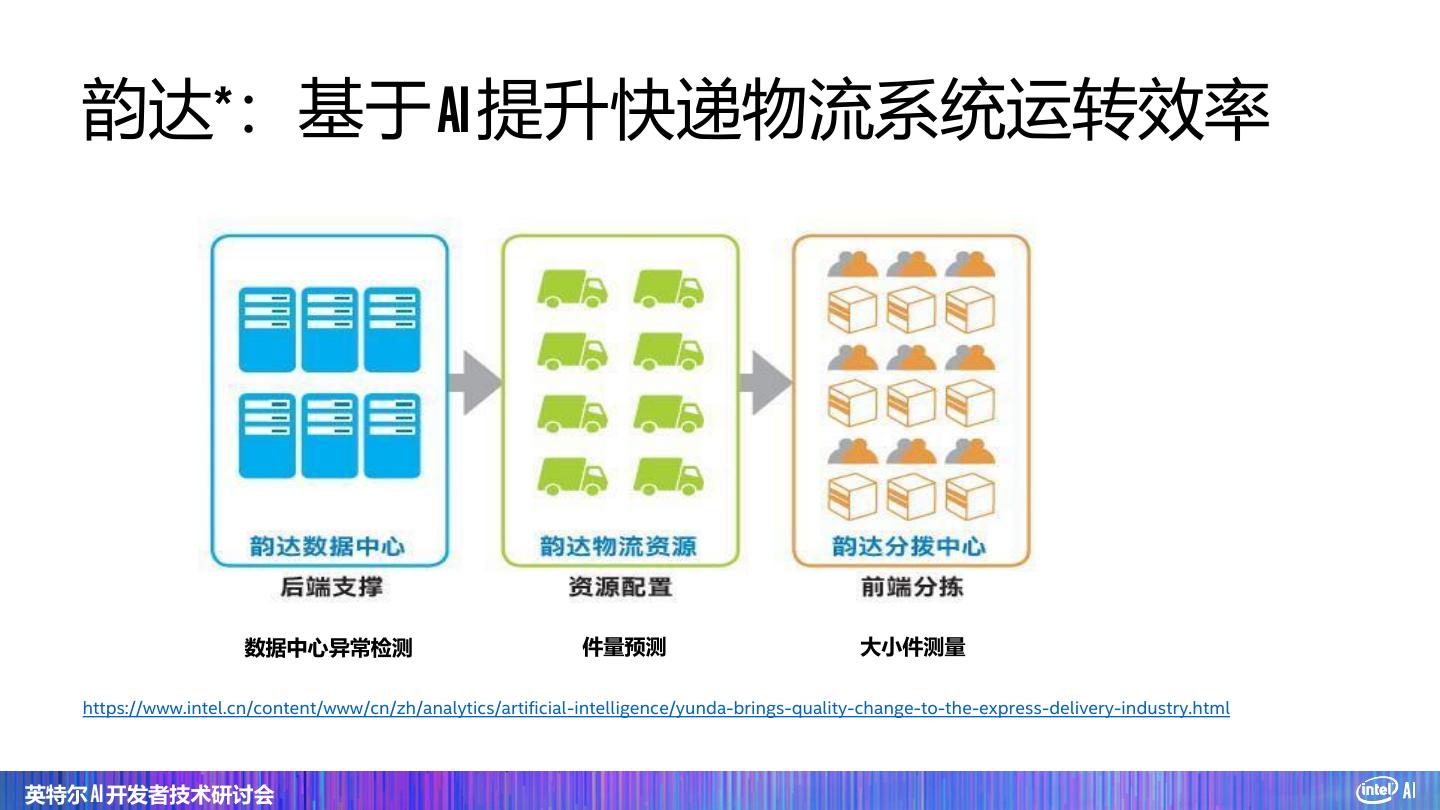
28 . 美的*:工业视觉检测云平台 https://software.intel.com/en-us/articles/industrial-inspection-platform-in-midea-and-kuka-using-distributed-tensorflow-on-analytics https://www.intel.cn/content/www/cn/zh/analytics/artificial-intelligence/midea-case-study.html 英特尔 AI 开发者技术研讨会
29 .美的*:工业视觉检测云平台
3秒后跳转登录页面
去登陆

