







- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
李弘博-OS2ATC_TencentOS服务器QoS技术的演进 李弘博
展开查看详情
1 .TencentOS 服务器QoS技术的演进 腾讯 TencentOS团队 李弘博 1
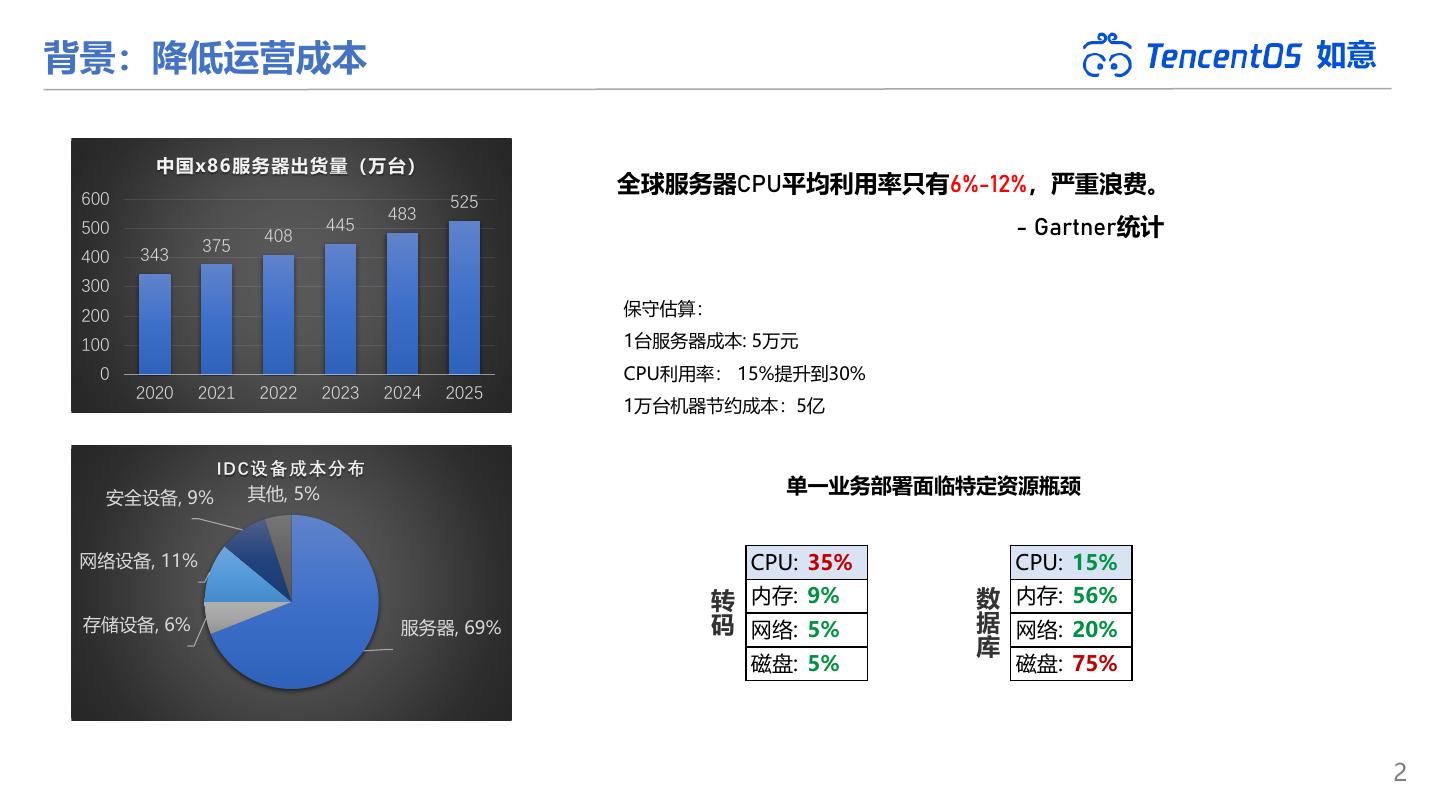
2 .背景:降低运营成本 如意 中国x86服务器出货量(万台) 600 全球服务器CPU平均利用率只有6%-12%,严重浪费。 525 483 500 408 445 - Gartner统计 375 400 343 300 200 保守估算: 100 1台服务器成本: 5万元 0 CPU利用率: 15%提升到30% 2020 2021 2022 2023 2024 2025 1万台机器节约成本:5亿 IDC设备成本分布 其他, 5% 单一业务部署面临特定资源瓶颈 安全设备, 9% 网络设备, 11% CPU: 35% CPU: 15% 转 内存: 9% 数 内存: 56% 存储设备, 6% 服务器, 69% 码 网络: 5% 据 网络: 20% 库 磁盘: 5% 磁盘: 75% 2
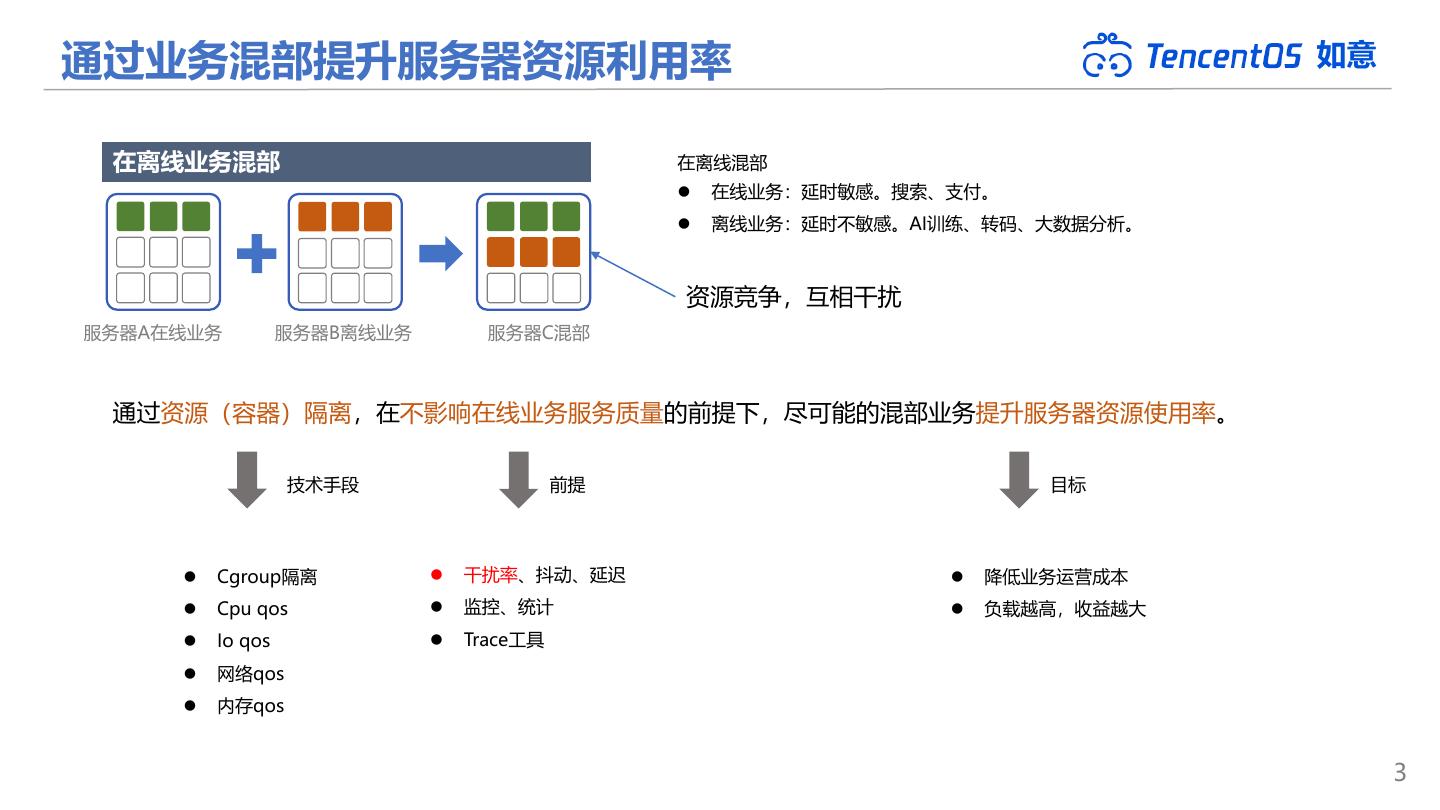
3 .通过业务混部提升服务器资源利用率 如意 在离线业务混部 在离线混部 ⚫ 在线业务:延时敏感。搜索、支付。 ⚫ 离线业务:延时不敏感。AI训练、转码、大数据分析。 资源竞争,互相干扰 服务器A在线业务 服务器B离线业务 服务器C混部 通过资源(容器)隔离,在不影响在线业务服务质量的前提下,尽可能的混部业务提升服务器资源使用率。 技术手段 前提 目标 ⚫ Cgroup隔离 ⚫ 干扰率、抖动、延迟 ⚫ 降低业务运营成本 ⚫ Cpu qos ⚫ 监控、统计 ⚫ 负载越高,收益越大 ⚫ Io qos ⚫ Trace工具 ⚫ 网络qos ⚫ 内存qos 3
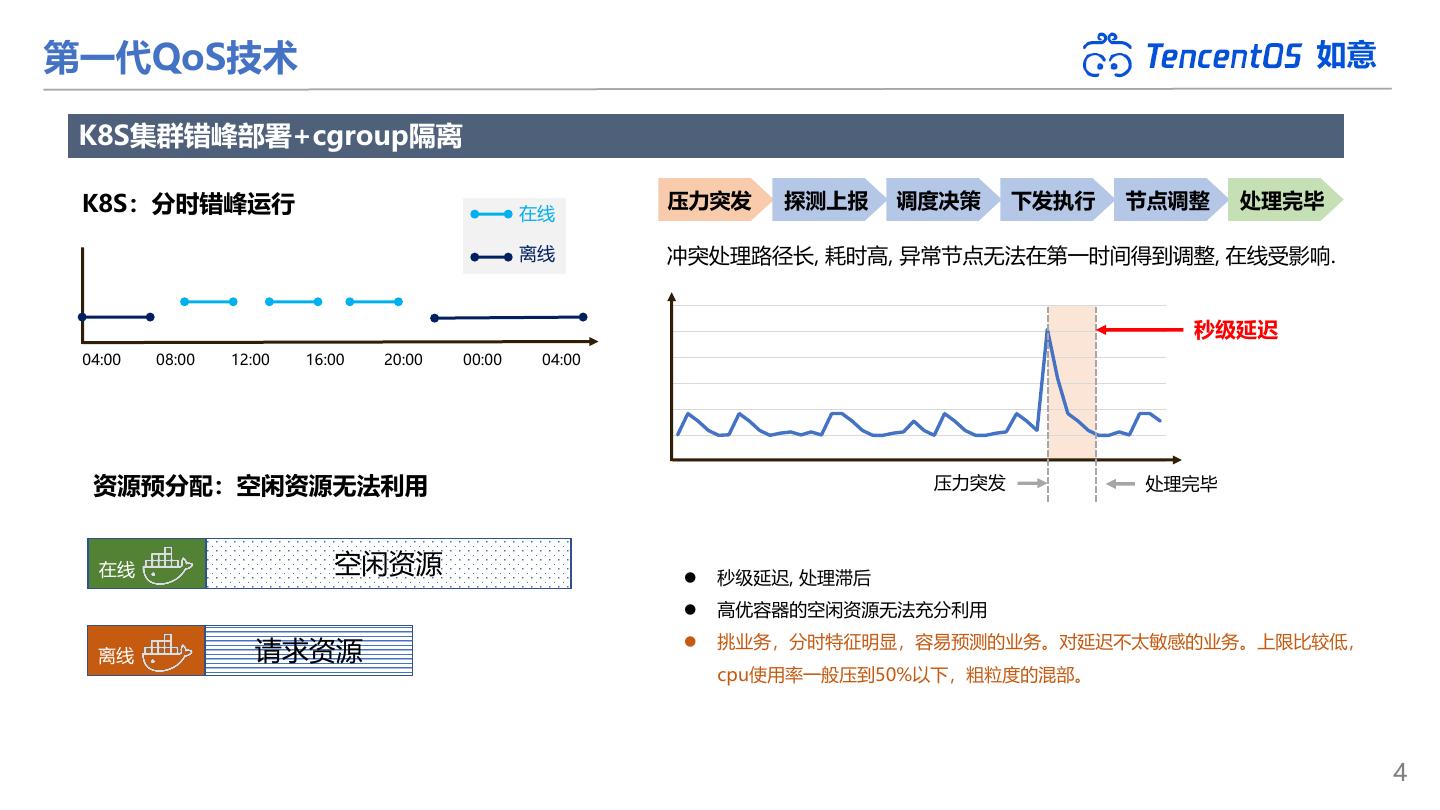
4 .第一代QoS技术 如意 K8S集群错峰部署+cgroup隔离 K8S:分时错峰运行 压力突发 探测上报 上报数据 调度决策 下发执行 节点调整 处理完毕 在线 离线 冲突处理路径长, 耗时高, 异常节点无法在第一时间得到调整, 在线受影响. 秒级延迟 04:00 08:00 12:00 16:00 20:00 00:00 04:00 资源预分配:空闲资源无法利用 压力突发 处理完毕 在线 空闲资源 ⚫ 秒级延迟, 处理滞后 ⚫ 高优容器的空闲资源无法充分利用 挑业务,分时特征明显,容易预测的业务。对延迟不太敏感的业务。上限比较低, 离线 请求资源 ⚫ cpu使用率一般压到50%以下,粗粒度的混部。 4
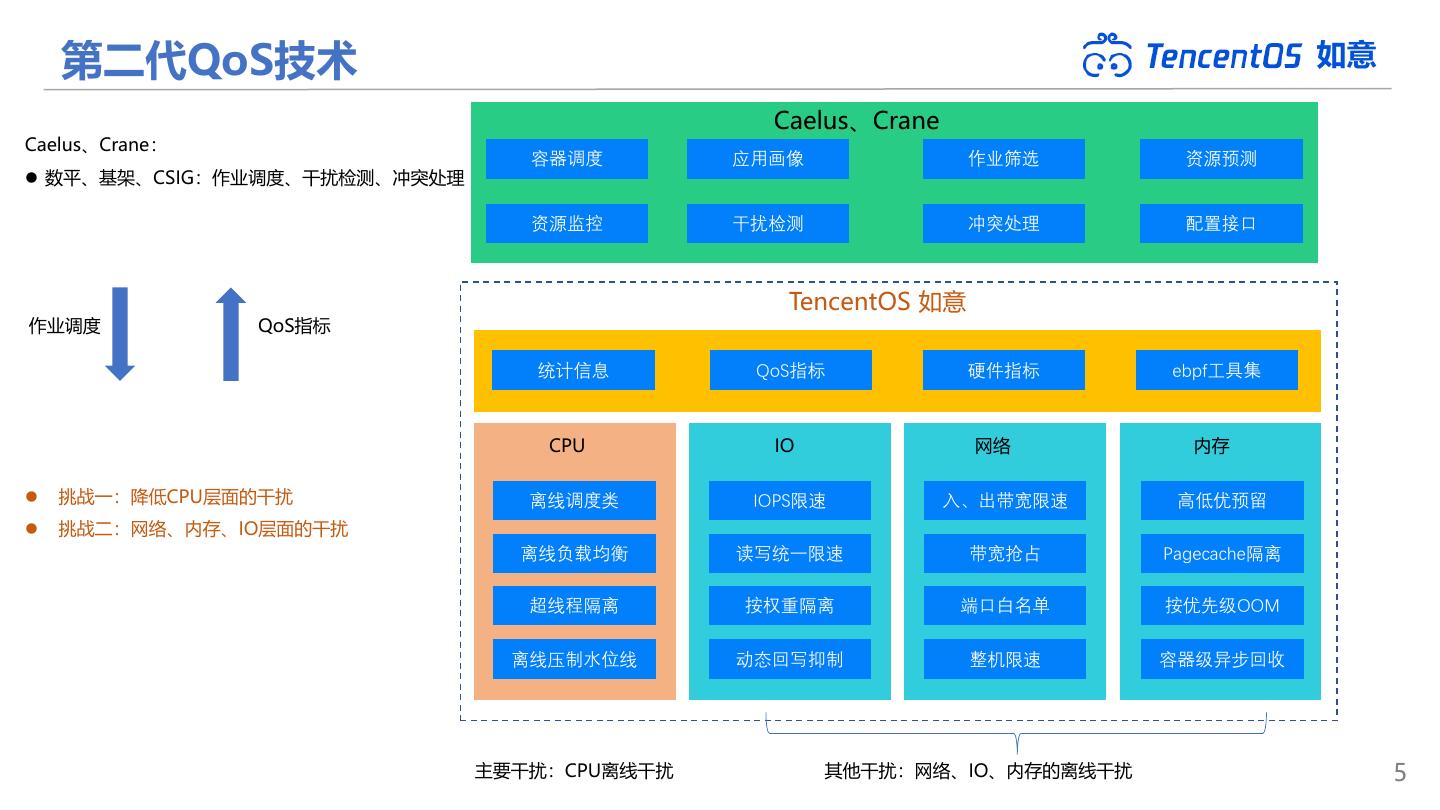
5 . 第二代QoS技术 如意 Caelus、Crane Caelus、Crane: 容器调度 应用画像 作业筛选 资源预测 ⚫ 数平、基架、CSIG:作业调度、干扰检测、冲突处理 资源监控 干扰检测 冲突处理 配置接口 TencentOS 如意 作业调度 QoS指标 统计信息 QoS指标 硬件指标 ebpf工具集 CPU IO 网络 内存 ⚫ 挑战一:降低CPU层面的干扰 离线调度类 IOPS限速 入、出带宽限速 高低优预留 ⚫ 挑战二:网络、内存、IO层面的干扰 离线负载均衡 读写统一限速 带宽抢占 Pagecache隔离 超线程隔离 按权重隔离 端口白名单 按优先级OOM 离线压制水位线 动态回写抑制 整机限速 容器级异步回收 主要干扰:CPU离线干扰 其他干扰:网络、IO、内存的离线干扰 5
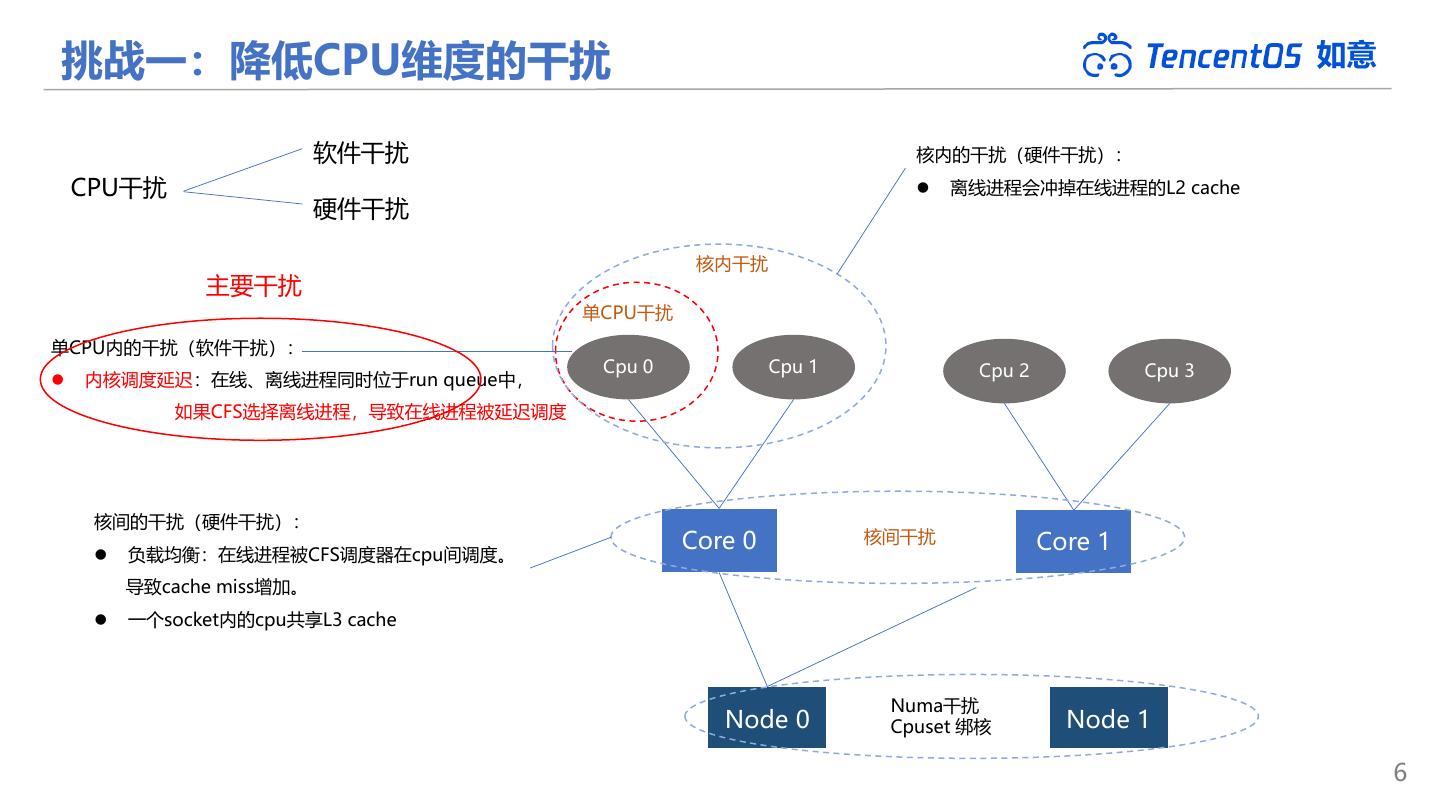
6 .挑战一:降低CPU维度的干扰 如意 软件干扰 核内的干扰(硬件干扰): CPU干扰 ⚫ 离线进程会冲掉在线进程的L2 cache 硬件干扰 核内干扰 主要干扰 单CPU干扰 单CPU内的干扰(软件干扰): Cpu 0 Cpu 1 Cpu 2 Cpu 3 ⚫ 内核调度延迟:在线、离线进程同时位于run queue中, 如果CFS选择离线进程,导致在线进程被延迟调度 核间的干扰(硬件干扰): Core 0 核间干扰 Core 1 ⚫ 负载均衡:在线进程被CFS调度器在cpu间调度。 导致cache miss增加。 ⚫ 一个socket内的cpu共享L3 cache Numa干扰 Node 0 Cpuset 绑核 Node 1 6
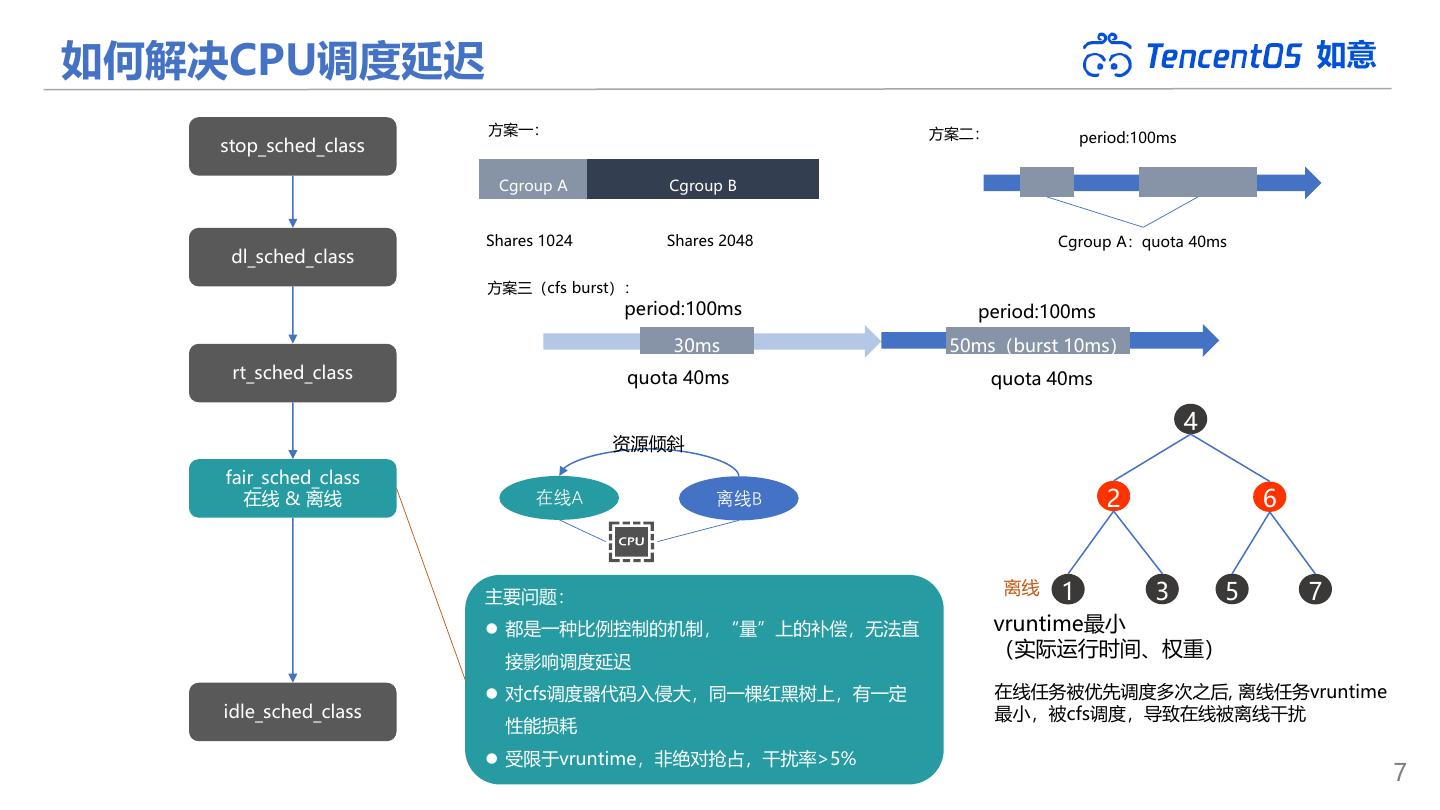
7 .如何解决CPU调度延迟 如意 方案一: 方案二: period:100ms stop_sched_class Cgroup A Cgroup B Shares 1024 Shares 2048 Cgroup A:quota 40ms dl_sched_class 方案三(cfs burst): period:100ms period:100ms 30ms 50ms(burst 10ms) rt_sched_class quota 40ms quota 40ms 4 资源倾斜 fair_sched_class 在线 & 离线 在线A 离线B 2 6 主要问题: 离线 1 3 5 7 ⚫ 都是一种比例控制的机制,“量”上的补偿,无法直 vruntime最小 (实际运行时间、权重) 接影响调度延迟 ⚫ 对cfs调度器代码入侵大,同一棵红黑树上,有一定 在线任务被优先调度多次之后, 离线任务vruntime idle_sched_class 最小,被cfs调度,导致在线被离线干扰 性能损耗 ⚫ 受限于vruntime,非绝对抢占,干扰率>5% 7
8 . 如何解决CPU调度延迟 如意 stop_sched_class 新建、唤醒、迁移在线进程 中断 否 dl_sched_class 当前运行进程是 在线加入run queue 否离线 是 rt_sched_class 无视vruntime 在线A 在线抢占离线得到cpu 按优先级 离线B 绝对抢占 fair_sched_class 在线运行直到结束 在线 如意 ⚫ 独立于CFS,业界首创离线调度类BT 是 ⚫ 复杂度提升,但与在线红黑树解耦 ⚫ 绝对抢占,干扰率 < 1% 是否有在线 bt_sched_class 需要运行 离线 离线 1 2 3 否 没有在线进程需要运行时, 离线 1 2 3 才会调度离线进程运行 调度离线 idle_sched_class 单独的fifo,简化调度策略,减少损耗 更新离线运行统计 8
9 .社区动态 如意 9
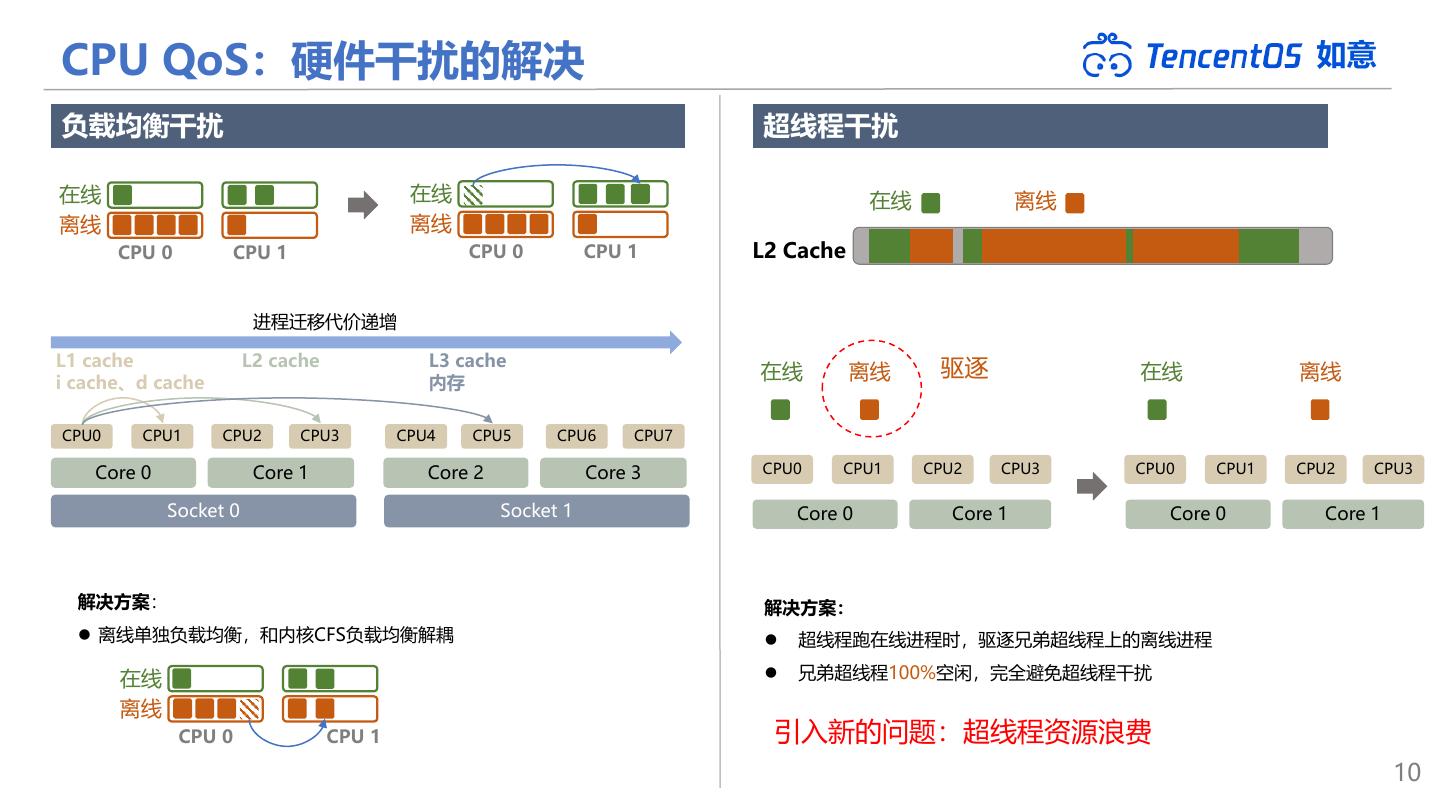
10 .CPU QoS:硬件干扰的解决 如意 负载均衡干扰 超线程干扰 在线 在线 在线 离线 离线 离线 CPU 0 CPU 1 CPU 0 CPU 1 L2 Cache 进程迁移代价递增 L1 cache L2 cache L3 cache 驱逐 i cache、d cache 内存 在线 离线 在线 离线 CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 Core 0 Core 1 Core 2 Core 3 CPU0 CPU1 CPU2 CPU3 CPU0 CPU1 CPU2 CPU3 Socket 0 Socket 1 Core 0 Core 1 Core 0 Core 1 解决方案: 解决方案: ⚫ 离线单独负载均衡,和内核CFS负载均衡解耦 ⚫ 超线程跑在线进程时,驱逐兄弟超线程上的离线进程 在线 ⚫ 兄弟超线程100%空闲,完全避免超线程干扰 离线 CPU 0 CPU 1 引入新的问题:超线程资源浪费 10
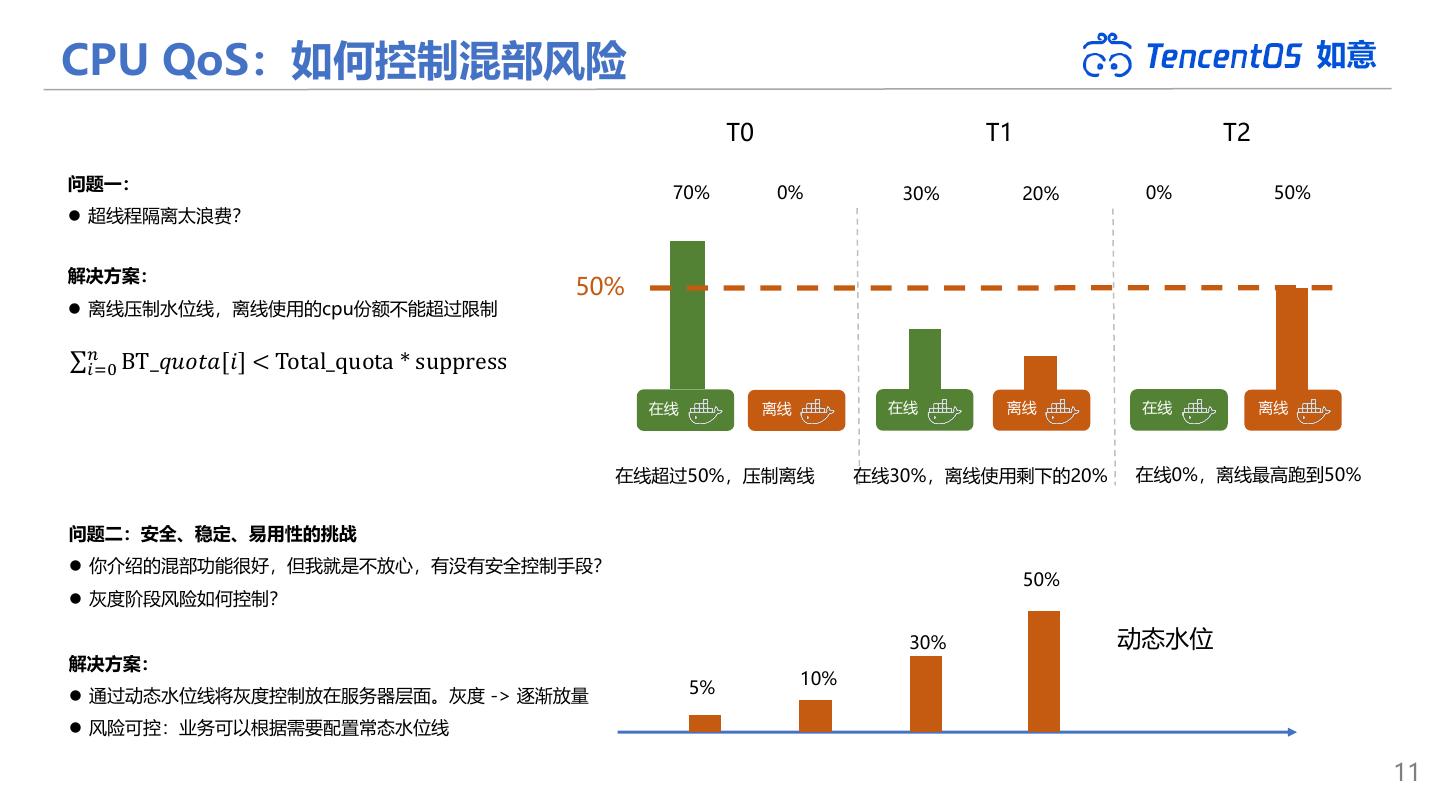
11 .CPU QoS:如何控制混部风险 如意 T0 T1 T2 问题一: 70% 0% 30% 20% 0% 50% ⚫ 超线程隔离太浪费? 解决方案: 50% ⚫ 离线压制水位线,离线使用的cpu份额不能超过限制 σ𝑛𝑖=0 BT_𝑞𝑢𝑜𝑡𝑎[𝑖] < Total_quota * suppress 在线 离线 在线 离线 在线 离线 在线超过50%,压制离线 在线30%,离线使用剩下的20% 在线0%,离线最高跑到50% 问题二:安全、稳定、易用性的挑战 ⚫ 你介绍的混部功能很好,但我就是不放心,有没有安全控制手段? 50% ⚫ 灰度阶段风险如何控制? 30% 动态水位 解决方案: 10% ⚫ 通过动态水位线将灰度控制放在服务器层面。灰度 -> 逐渐放量 5% ⚫ 风险可控:业务可以根据需要配置常态水位线 11
12 .挑战二:如何解决其他资源带来的干扰 如意 其他干扰源:IO带宽、网络带宽、内存侵占。 CPU QoS 内存 QoS 网络 QoS IO QoS ⚫ 各资源QoS之间是割裂的 K8S 如意 ⚫ 非云原生:网络QoS IP端口级别 ⚫ 如何和调度层对接? 解决方案: ◆ 通过统一的“优先级”策略将不同资源的QoS串联起来。 ◆ 与K8S guarantee、burstable、best effort对应。 ◆ 以优先级为纽带进行资源抢占和共享。 12
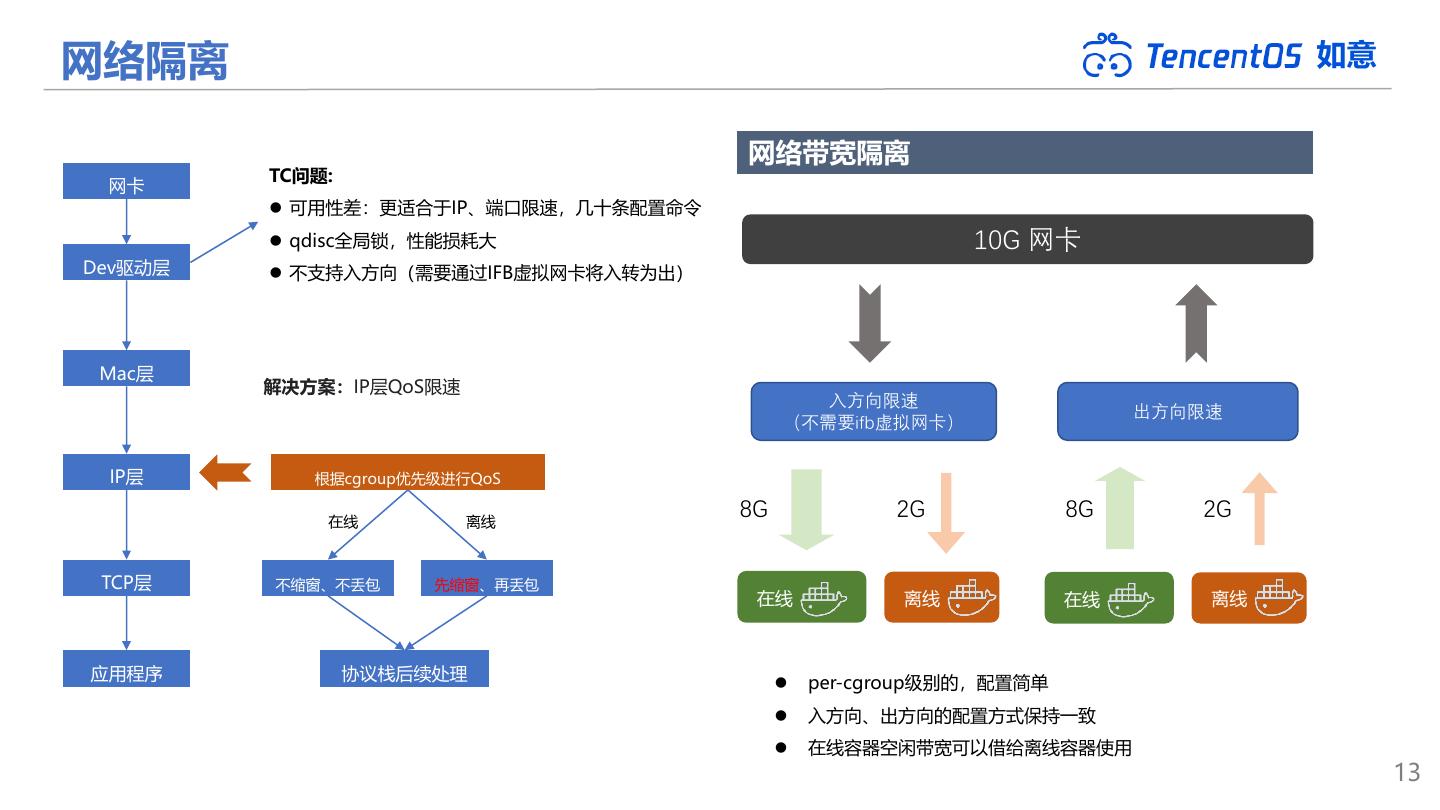
13 .网络隔离 如意 网络带宽隔离 TC问题: 网卡 ⚫ 可用性差:更适合于IP、端口限速,几十条配置命令 ⚫ qdisc全局锁,性能损耗大 10G 网卡 Dev驱动层 ⚫ 不支持入方向(需要通过IFB虚拟网卡将入转为出) Mac层 解决方案:IP层QoS限速 入方向限速 出方向限速 (不需要ifb虚拟网卡) IP层 根据cgroup优先级进行QoS 在线 离线 8G 2G 8G 2G TCP层 不缩窗、不丢包 先缩窗、再丢包 在线 离线 在线 离线 应用程序 协议栈后续处理 ⚫ per-cgroup级别的,配置简单 ⚫ 入方向、出方向的配置方式保持一致 ⚫ 在线容器空闲带宽可以借给离线容器使用 13
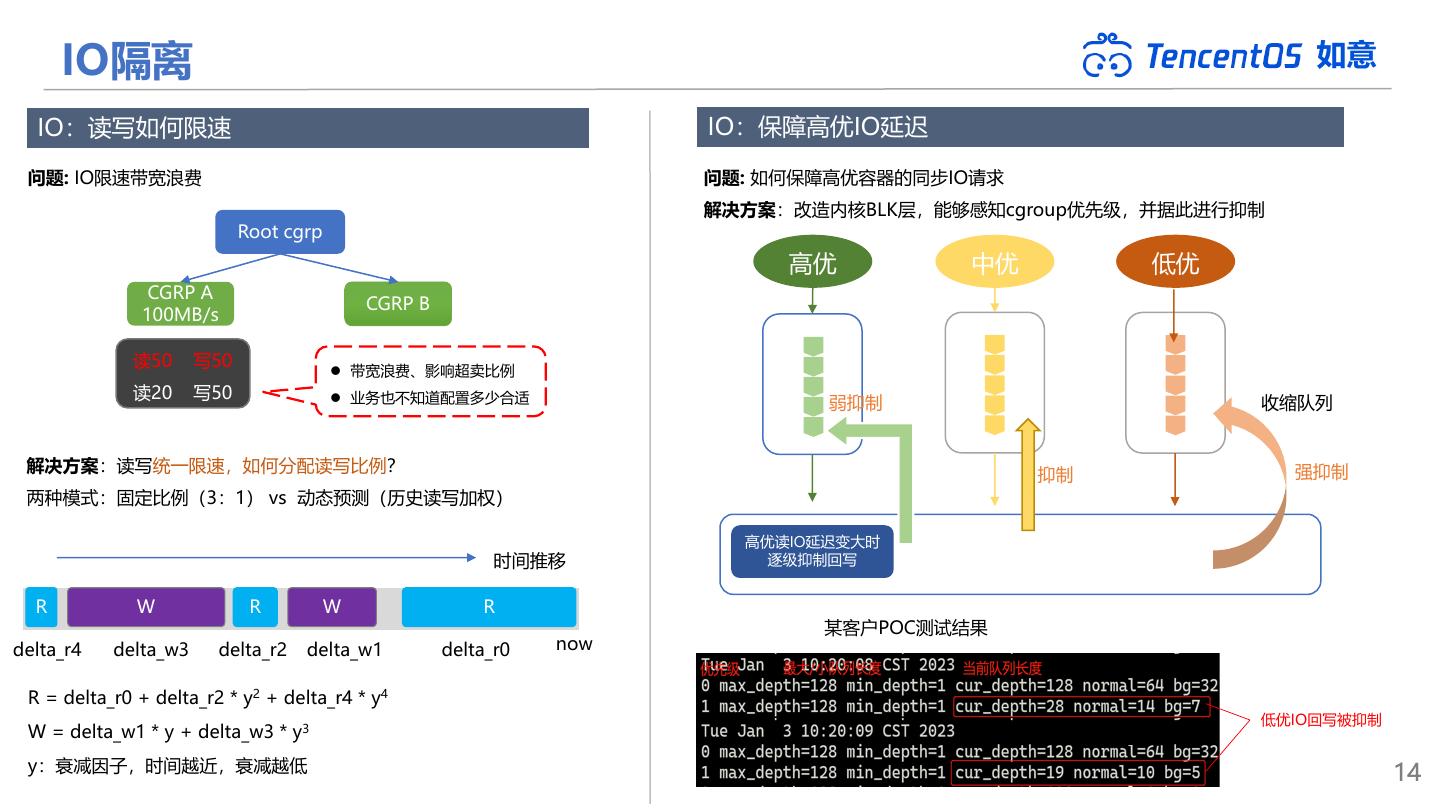
14 . IO隔离 如意 IO:读写如何限速 IO:保障高优IO延迟 问题: IO限速带宽浪费 问题: 如何保障高优容器的同步IO请求 解决方案:改造内核BLK层,能够感知cgroup优先级,并据此进行抑制 Root cgrp 高优 中优 低优 CGRP A CGRP B 100MB/s 读50 写50 ⚫ 带宽浪费、影响超卖比例 读20 写50 ⚫ 业务也不知道配置多少合适 弱抑制 收缩队列 解决方案:读写统一限速,如何分配读写比例? 抑制 强抑制 两种模式:固定比例(3:1) vs 动态预测(历史读写加权) 高优读IO延迟变大时 时间推移 逐级抑制回写 R W R W R 某客户POC测试结果 delta_r4 delta_w3 delta_r2 delta_w1 delta_r0 now R = delta_r0 + delta_r2 * y2 + delta_r4 * y4 低优IO回写被抑制 W = delta_w1 * y + delta_w3 * y3 y:衰减因子,时间越近,衰减越低 14
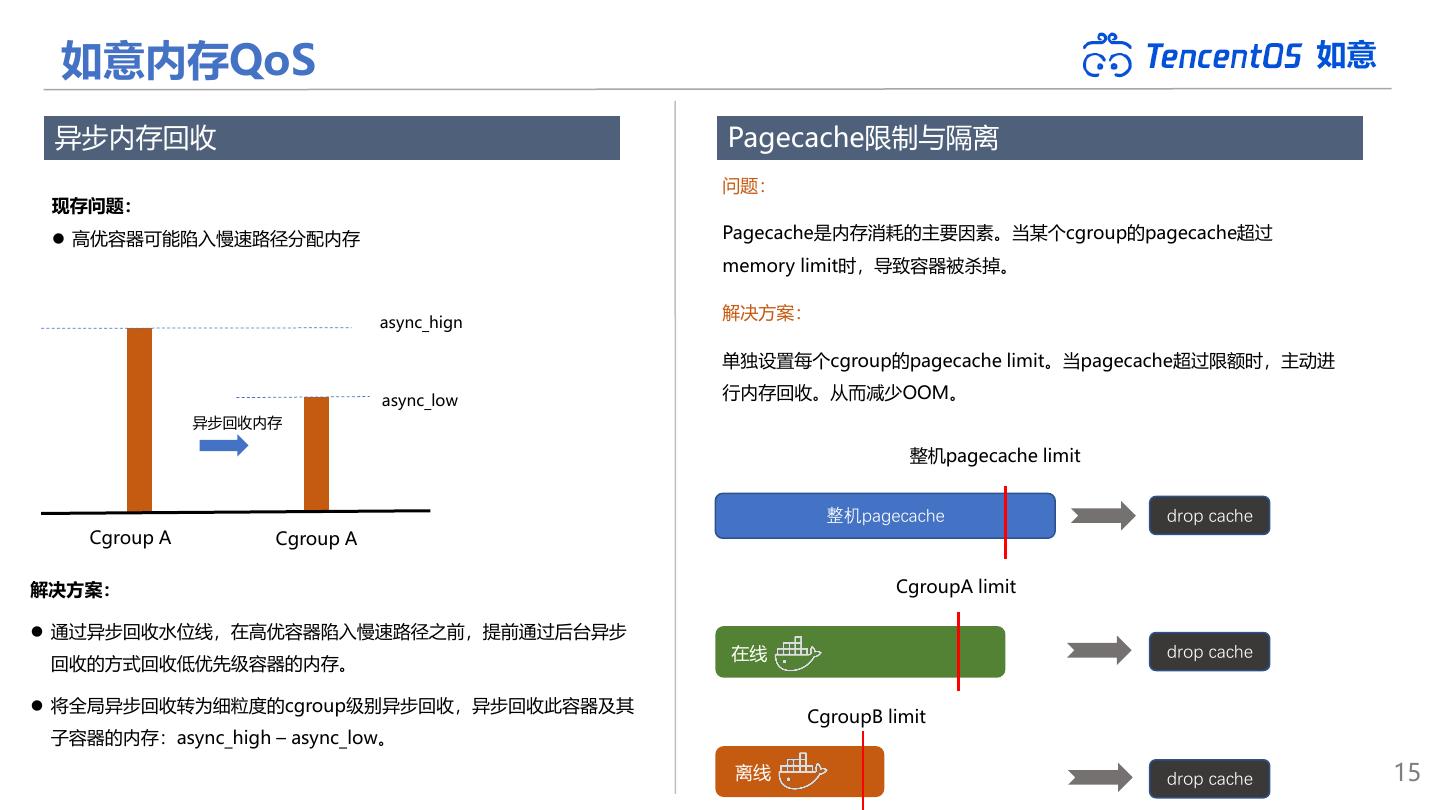
15 . 如意内存QoS 如意 异步内存回收 Pagecache限制与隔离 问题: 现存问题: ⚫ 高优容器可能陷入慢速路径分配内存 Pagecache是内存消耗的主要因素。当某个cgroup的pagecache超过 memory limit时,导致容器被杀掉。 解决方案: async_hign 单独设置每个cgroup的pagecache limit。当pagecache超过限额时,主动进 async_low 行内存回收。从而减少OOM。 异步回收内存 整机pagecache limit 整机pagecache drop cache Cgroup A Cgroup A 解决方案: CgroupA limit ⚫ 通过异步回收水位线,在高优容器陷入慢速路径之前,提前通过后台异步 在线 drop cache 回收的方式回收低优先级容器的内存。 ⚫ 将全局异步回收转为细粒度的cgroup级别异步回收,异步回收此容器及其 CgroupB limit 子容器的内存:async_high – async_low。 离线 drop cache 15
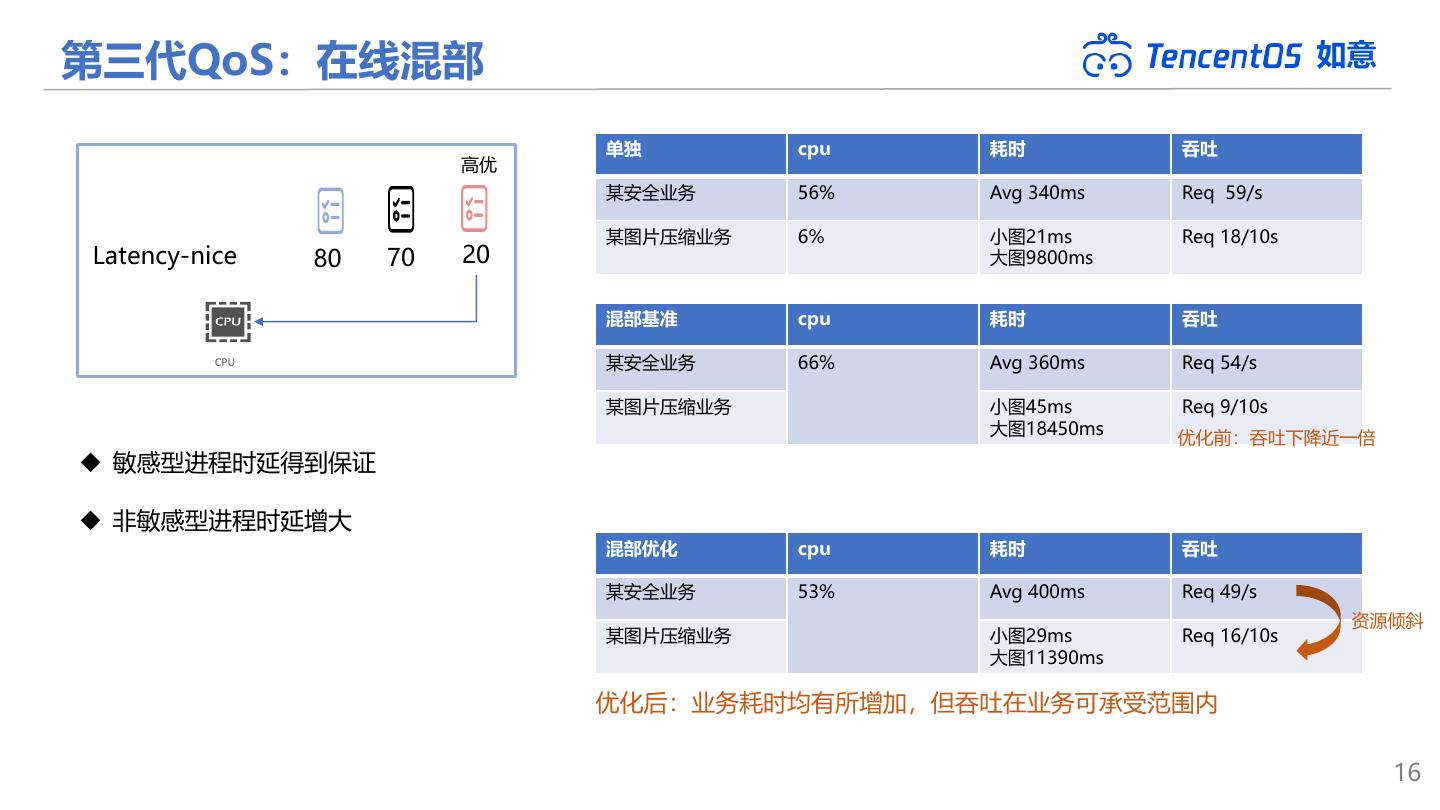
16 .第三代QoS:在线混部 如意 单独 cpu 耗时 吞吐 高优 某安全业务 56% Avg 340ms Req 59/s 某图片压缩业务 6% 小图21ms Req 18/10s Latency-nice 80 70 20 大图9800ms 混部基准 cpu 耗时 吞吐 CPU 某安全业务 66% Avg 360ms Req 54/s 某图片压缩业务 小图45ms Req 9/10s 大图18450ms 优化前:吞吐下降近一倍 ◆ 敏感型进程时延得到保证 ◆ 非敏感型进程时延增大 混部优化 cpu 耗时 吞吐 某安全业务 53% Avg 400ms Req 49/s 资源倾斜 某图片压缩业务 小图29ms Req 16/10s 大图11390ms 优化后:业务耗时均有所增加,但吞吐在业务可承受范围内 16
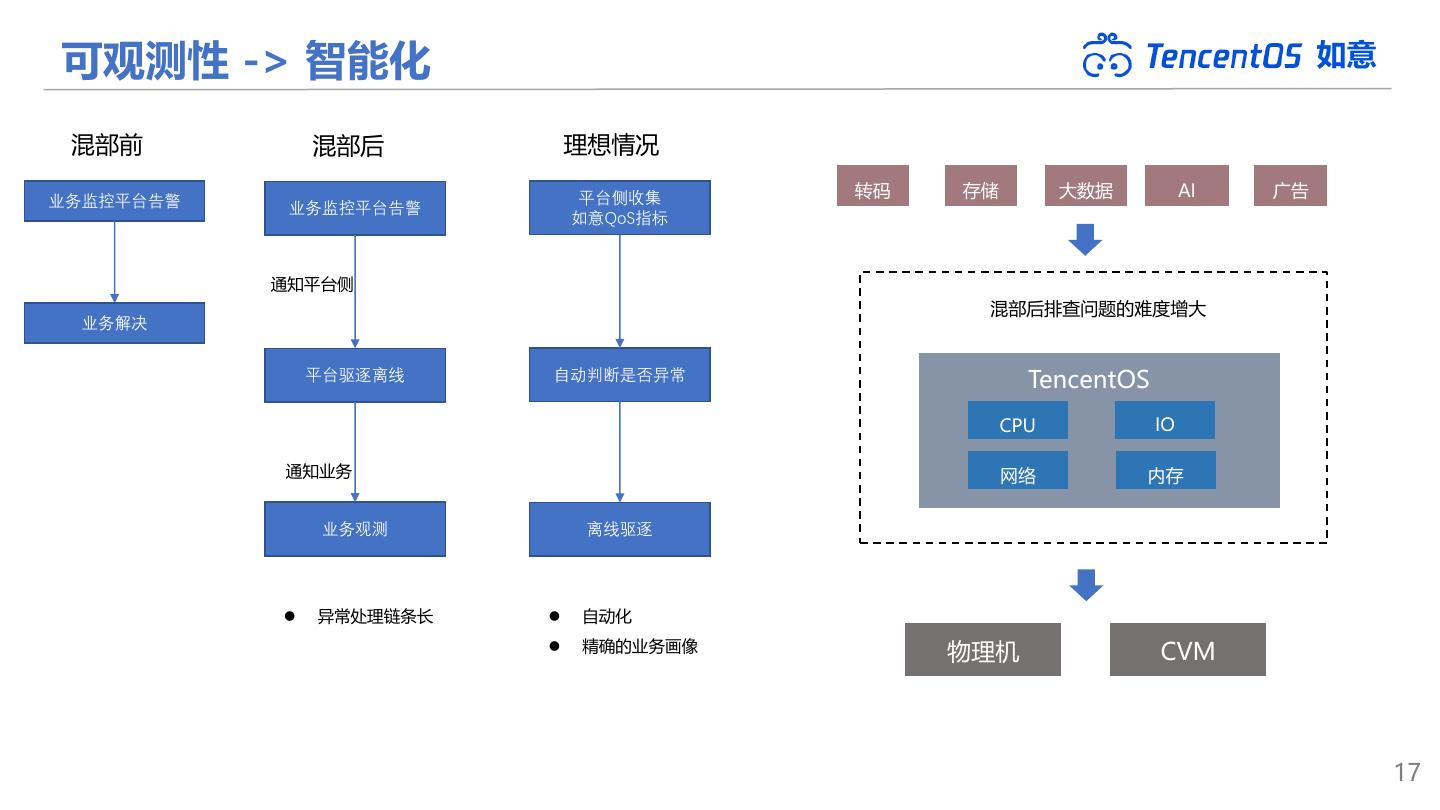
17 .可观测性 -> 智能化 如意 混部前 混部后 理想情况 平台侧收集 转码 存储 大数据 AI 广告 业务监控平台告警 业务监控平台告警 如意QoS指标 通知平台侧 混部后排查问题的难度增大 业务解决 平台驱逐离线 自动判断是否异常 TencentOS CPU IO 通知业务 网络 内存 业务观测 离线驱逐 ⚫ 异常处理链条长 ⚫ 自动化 ⚫ 精确的业务画像 物理机 CVM 17
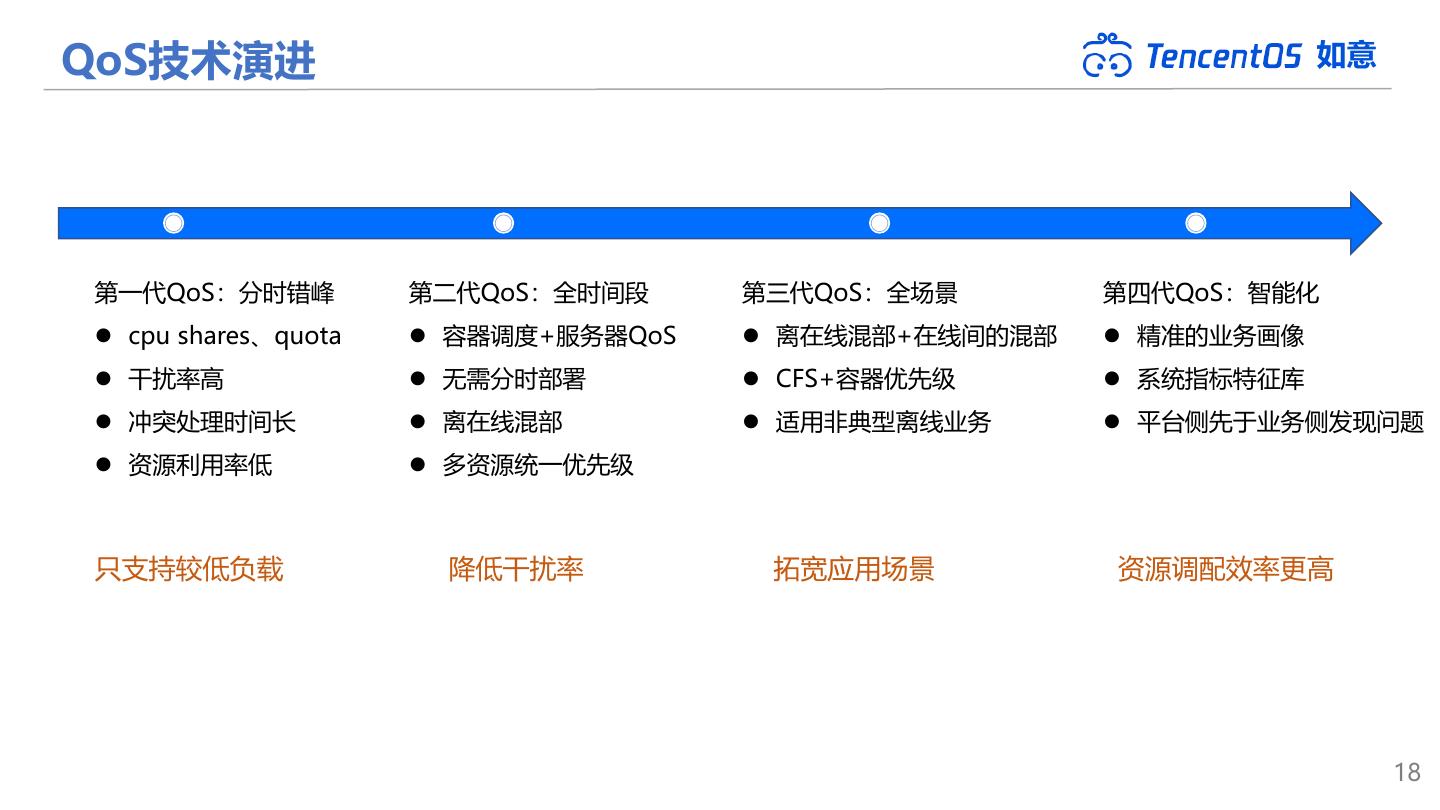
18 .QoS技术演进 如意 第一代QoS:分时错峰 第二代QoS:全时间段 第三代QoS:全场景 第四代QoS:智能化 ⚫ cpu shares、quota ⚫ 容器调度+服务器QoS ⚫ 离在线混部+在线间的混部 ⚫ 精准的业务画像 ⚫ 干扰率高 ⚫ 无需分时部署 ⚫ CFS+容器优先级 ⚫ 系统指标特征库 ⚫ 冲突处理时间长 ⚫ 离在线混部 ⚫ 适用非典型离线业务 ⚫ 平台侧先于业务侧发现问题 ⚫ 资源利用率低 ⚫ 多资源统一优先级 只支持较低负载 降低干扰率 拓宽应用场景 资源调配效率更高 18
19 . 如意 THANK YOU herberthbli@tencent.com 19
3秒后跳转登录页面
去登陆

