



































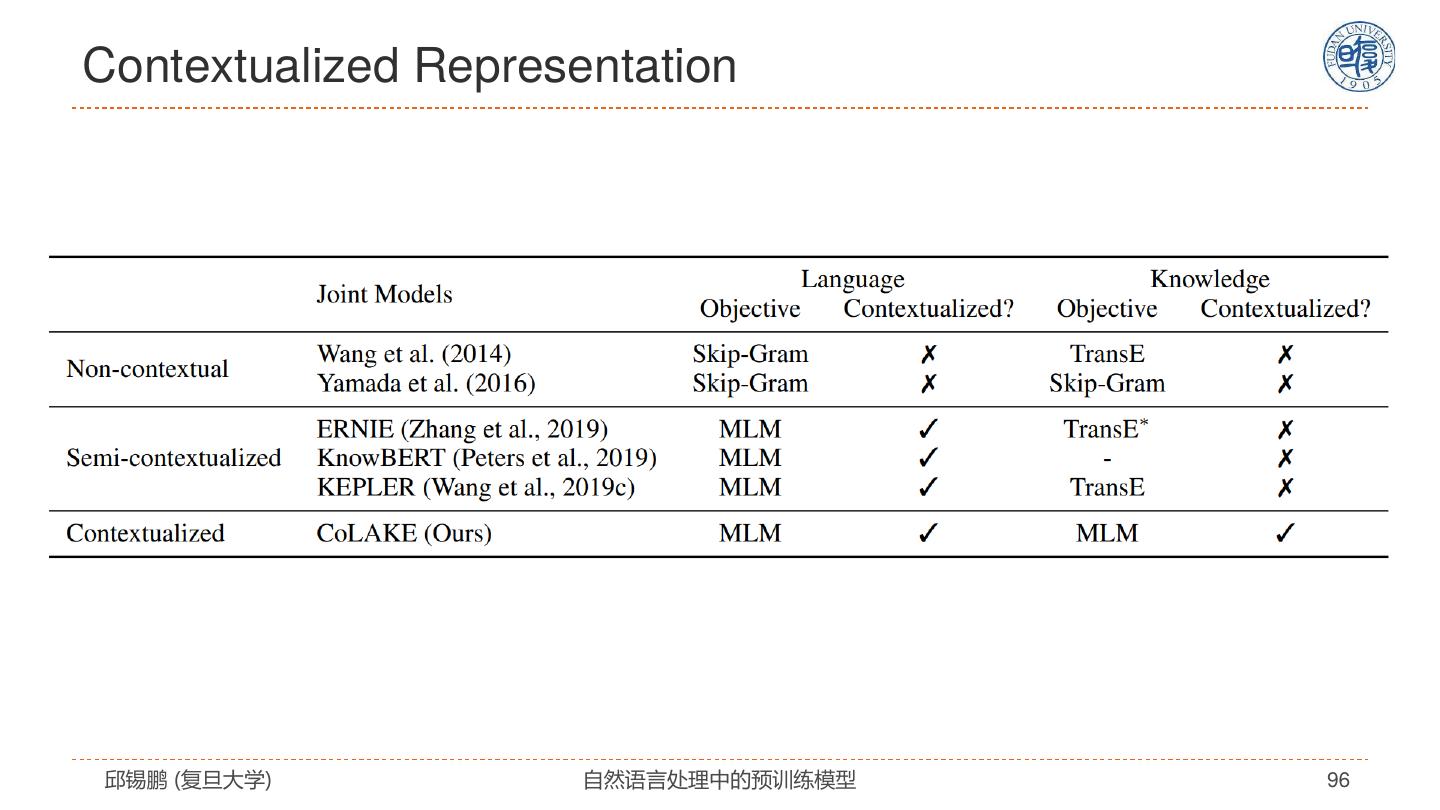

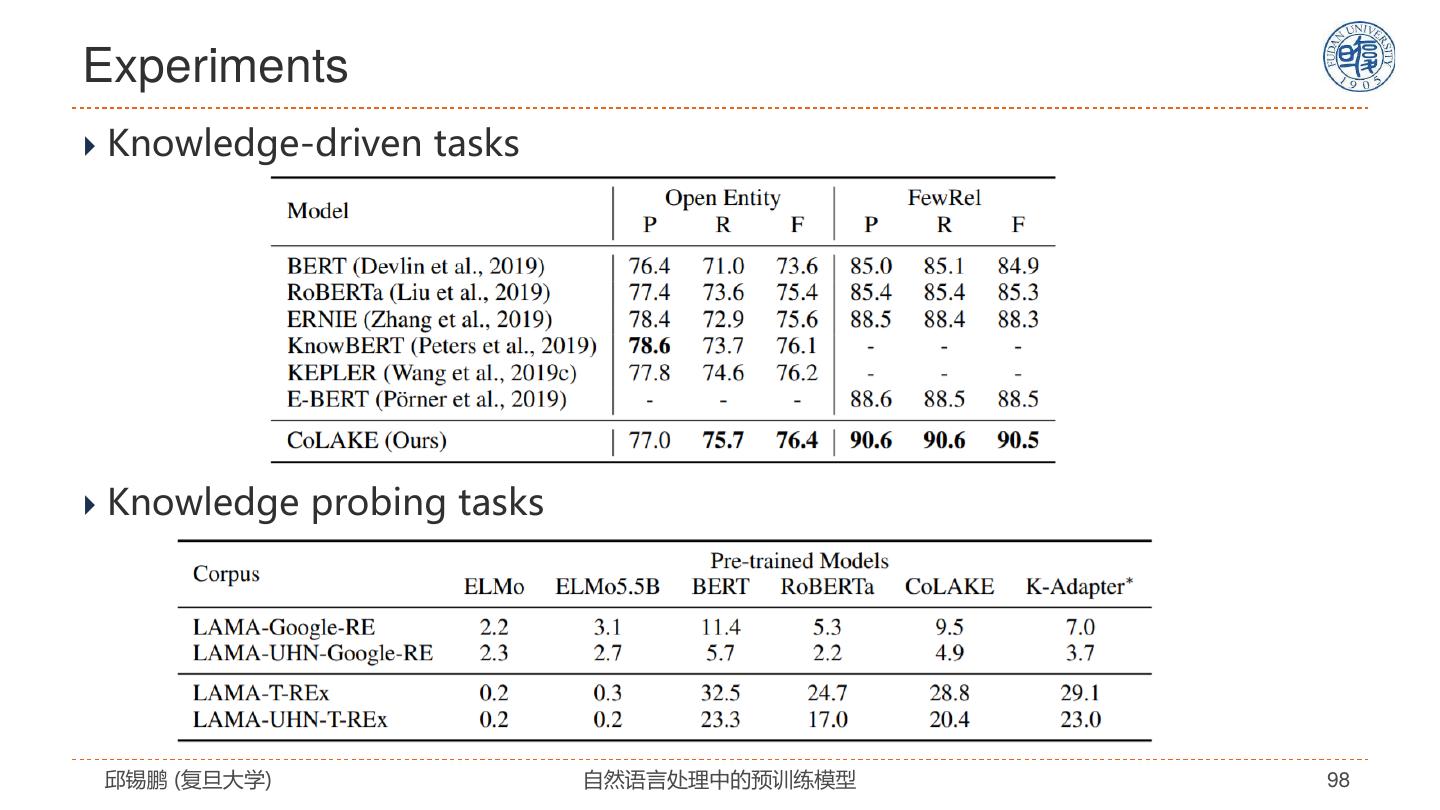
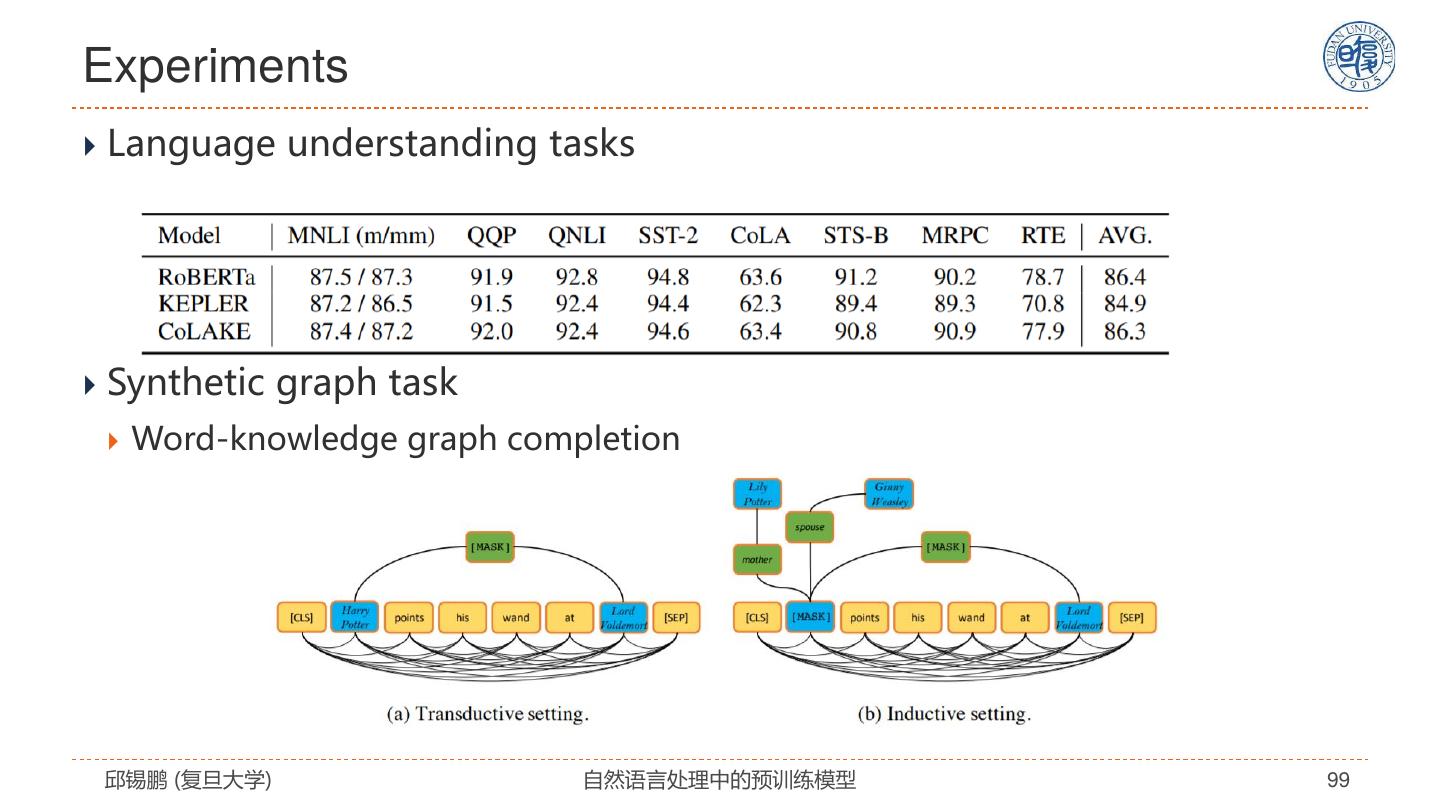


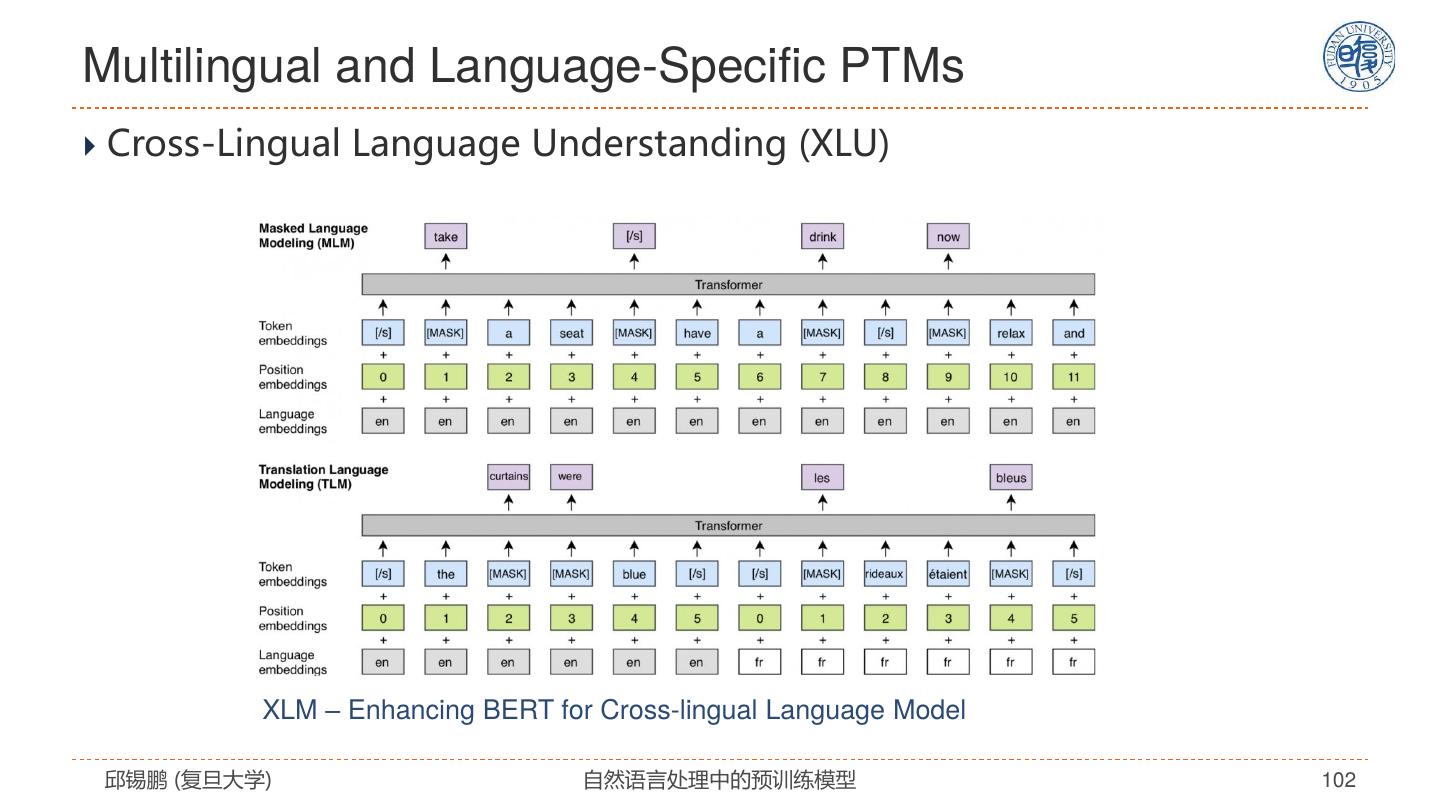























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
202011-CIPS-自然语言处理中的预训练模型
展开查看详情
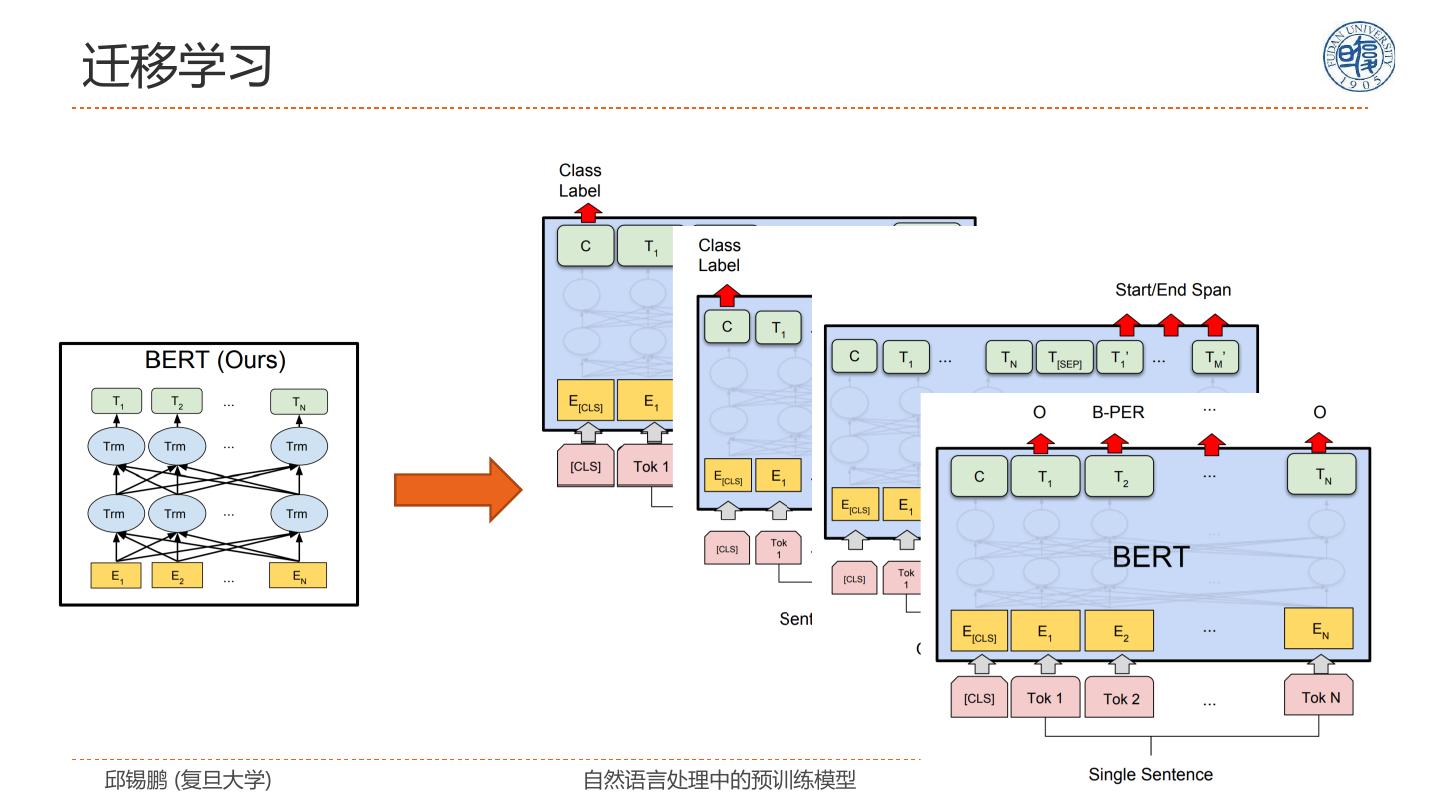
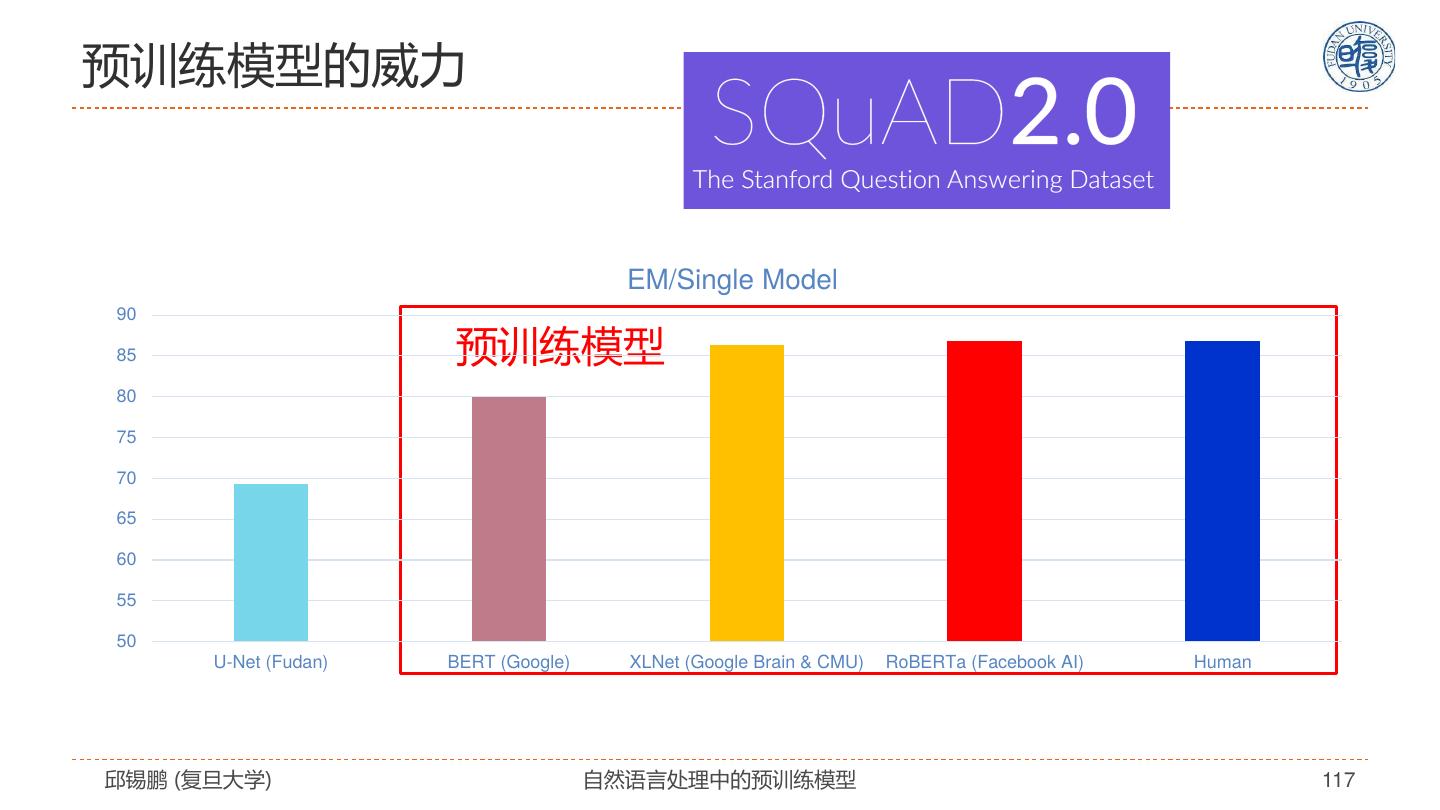
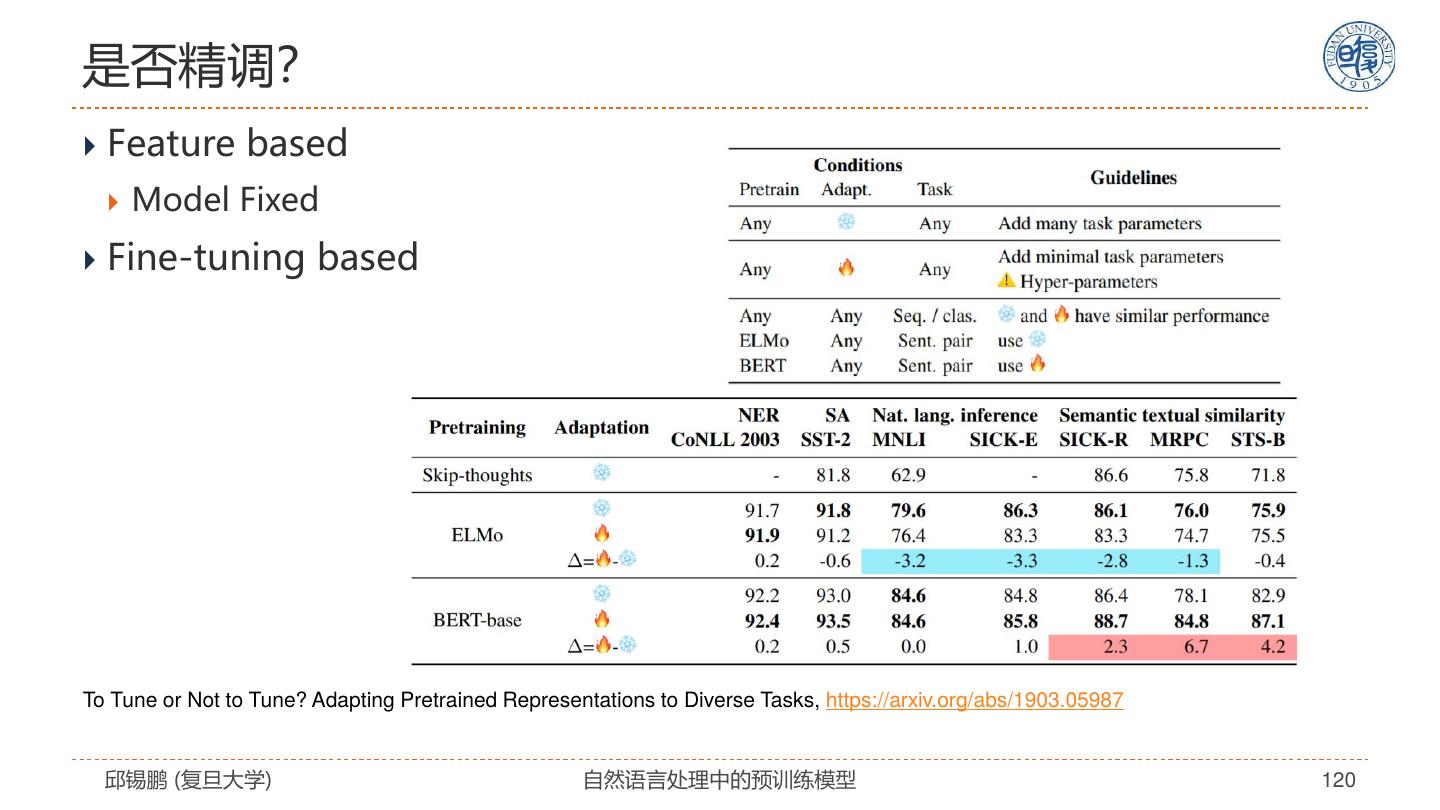
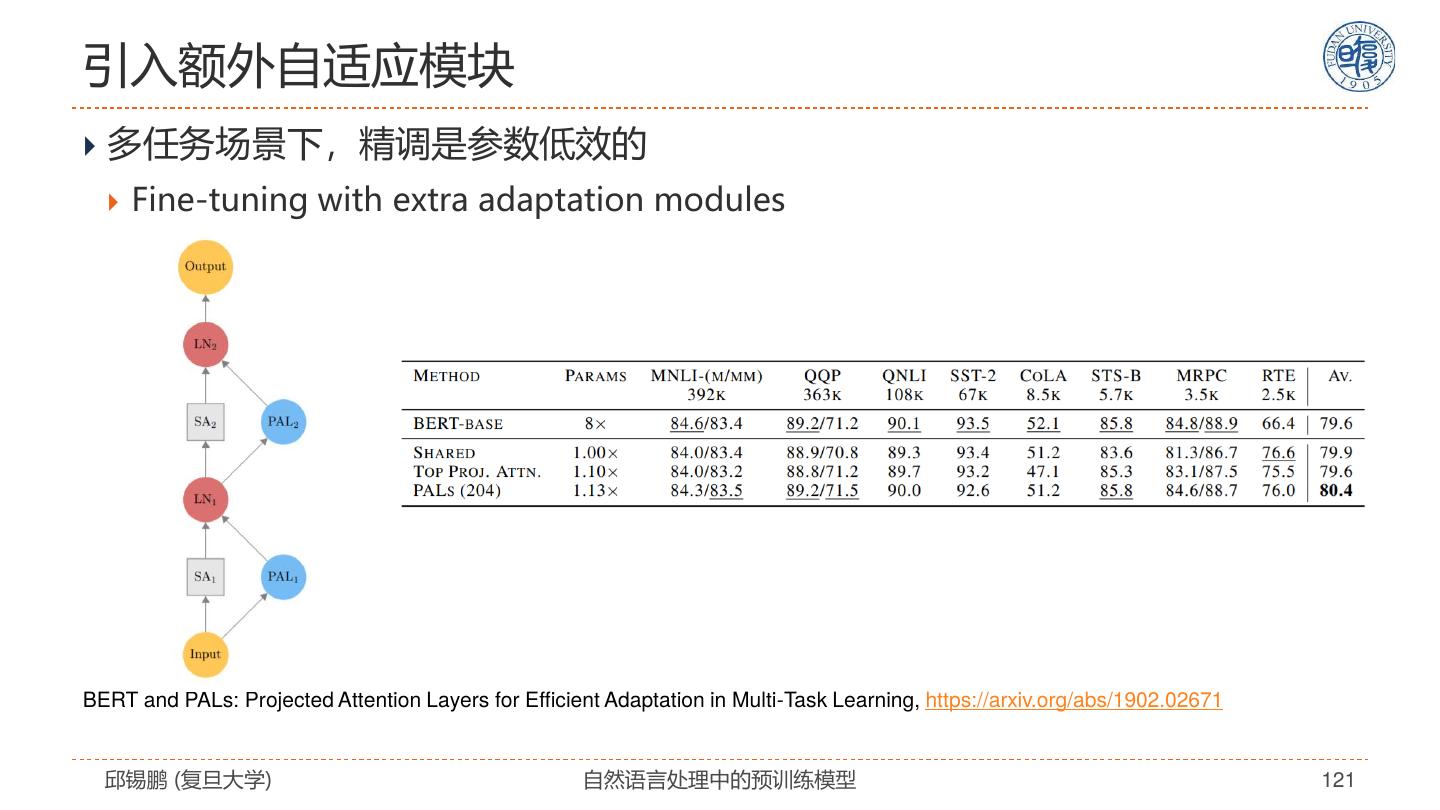
1 . 第十五届中国中文信息学会暑期学校 暨中国中文信息学会《前沿技术讲习班》 自然语言处理中的预训练模型 Pre-trained Models for Natural Language Processing: A Survey, https://arxiv.org/abs/2003.08271 邱锡鹏 复旦大学 2020年11月08日 https://xpqiu.github.io
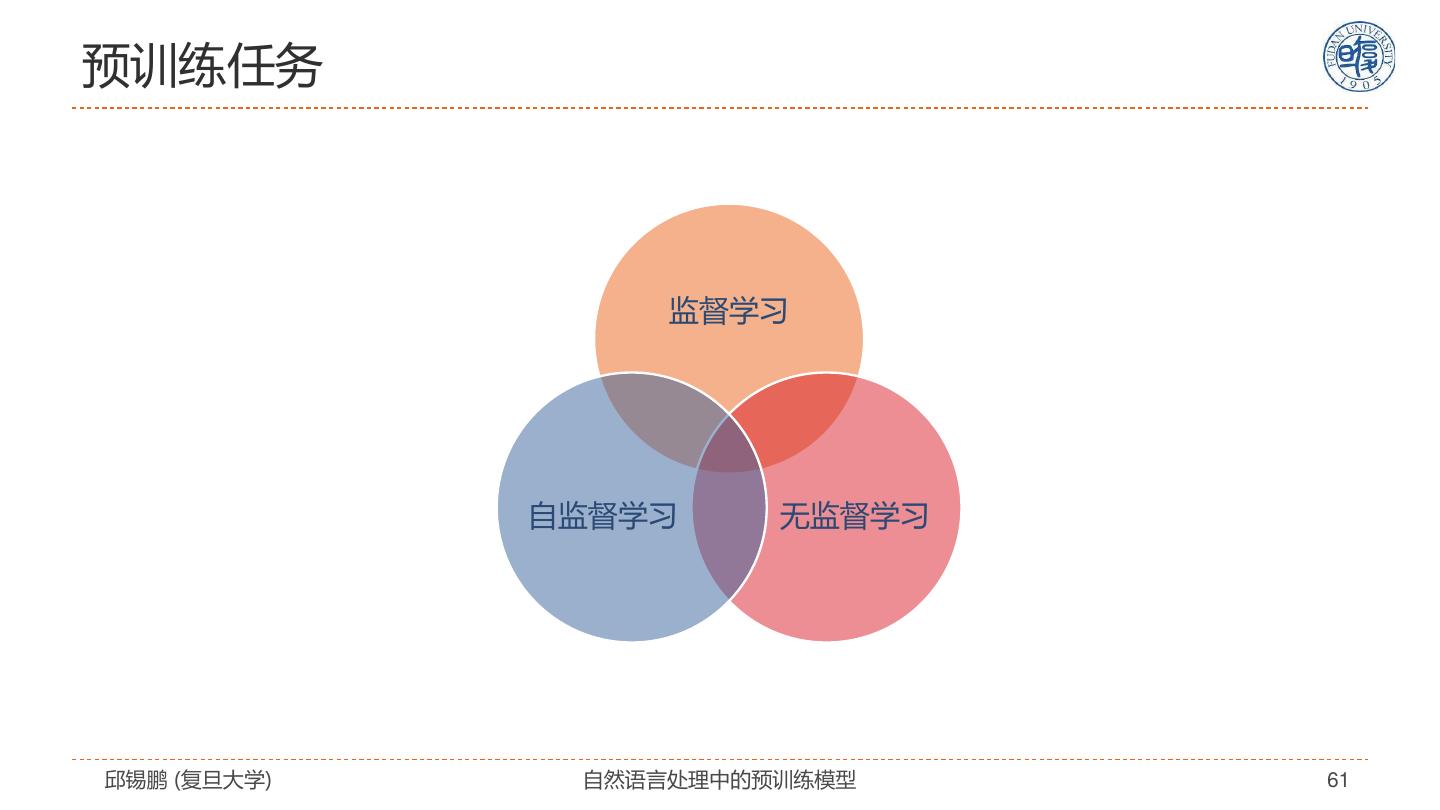
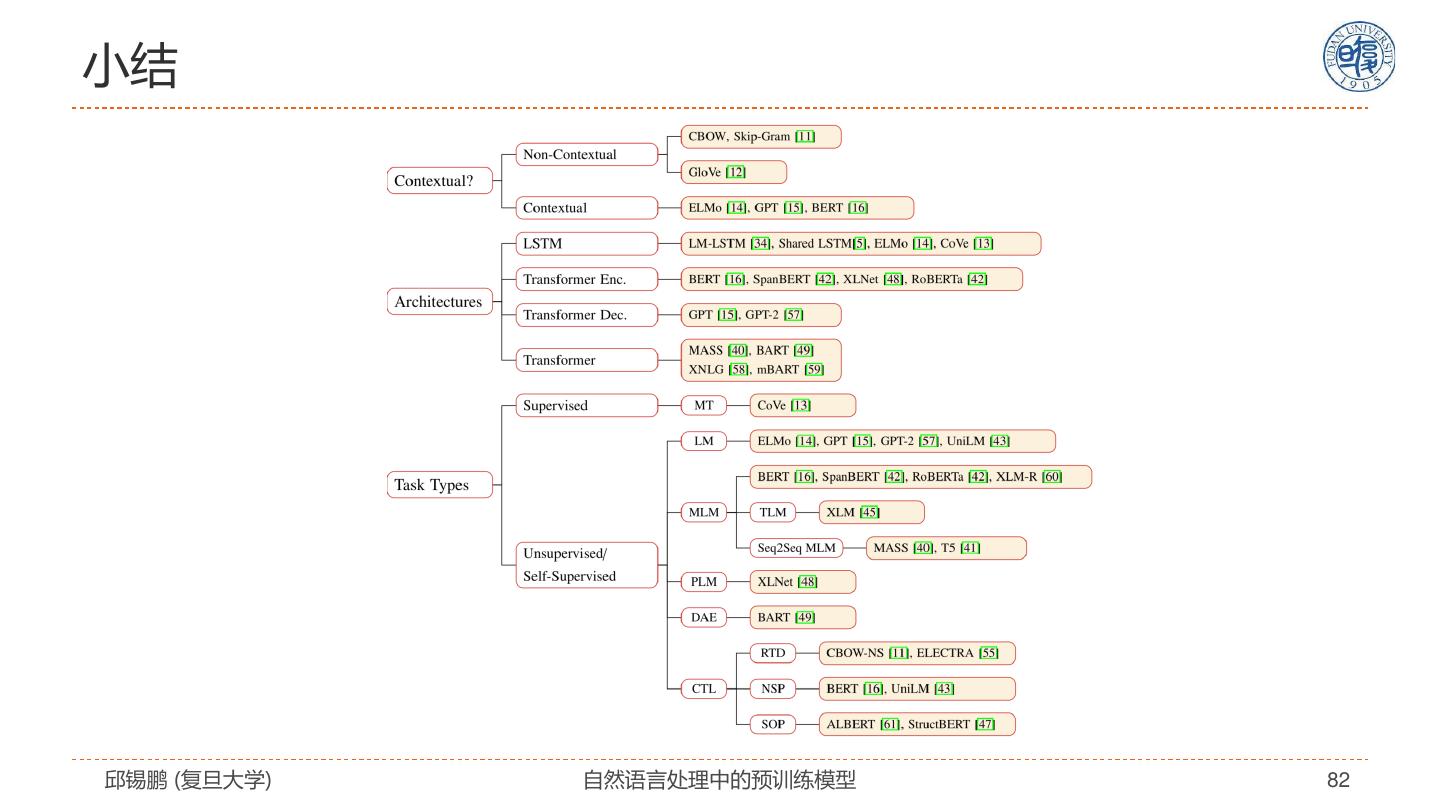
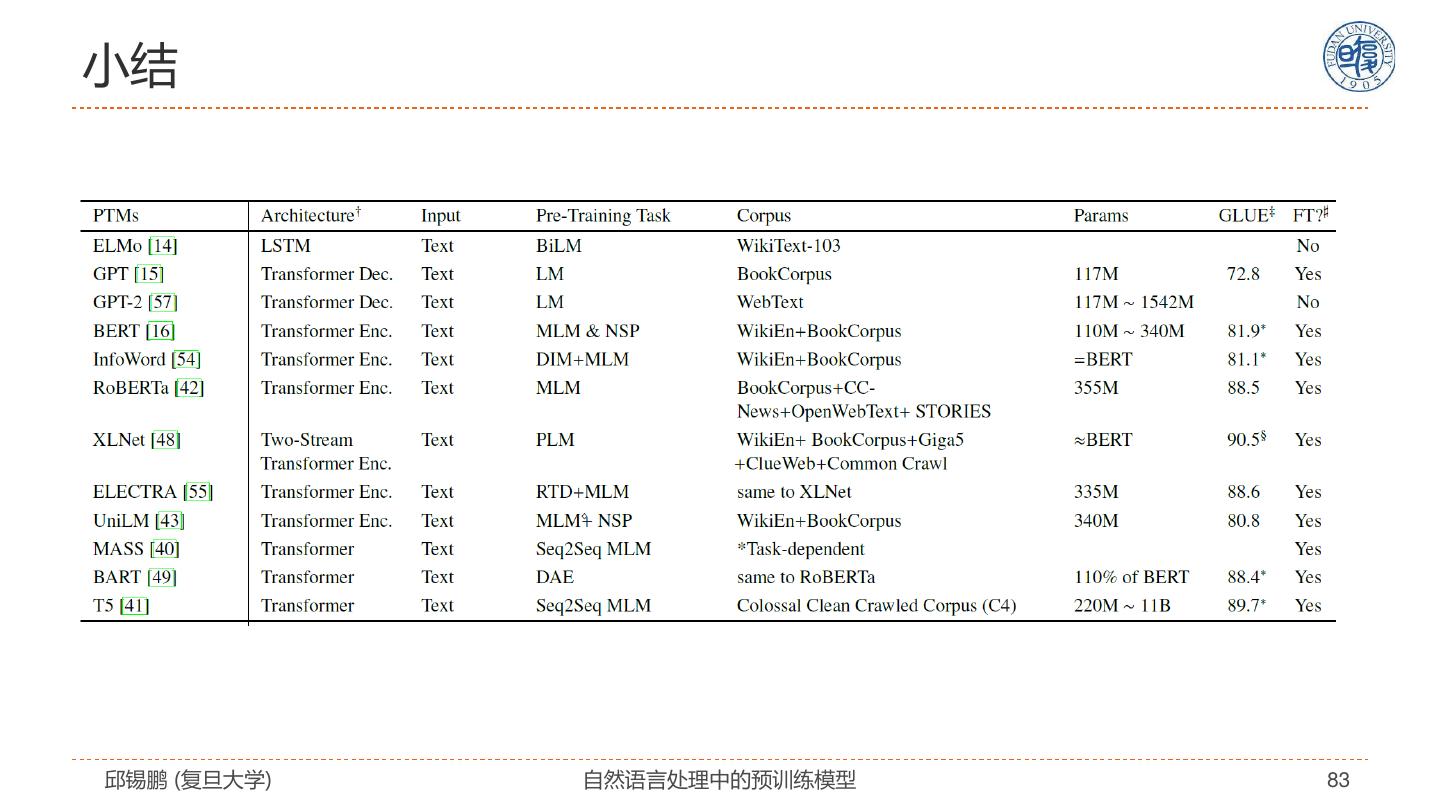
2 .报告概要 自然语言表示学习 • Transformer模型及改进 预训练模型 • 自监督学习、分类体系 预训练模型的扩展 • 跨语言、跨模态、知识嵌入、模型压缩 迁移到下游任务 未来展望 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 2
3 . 自然语言表示学习 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 3
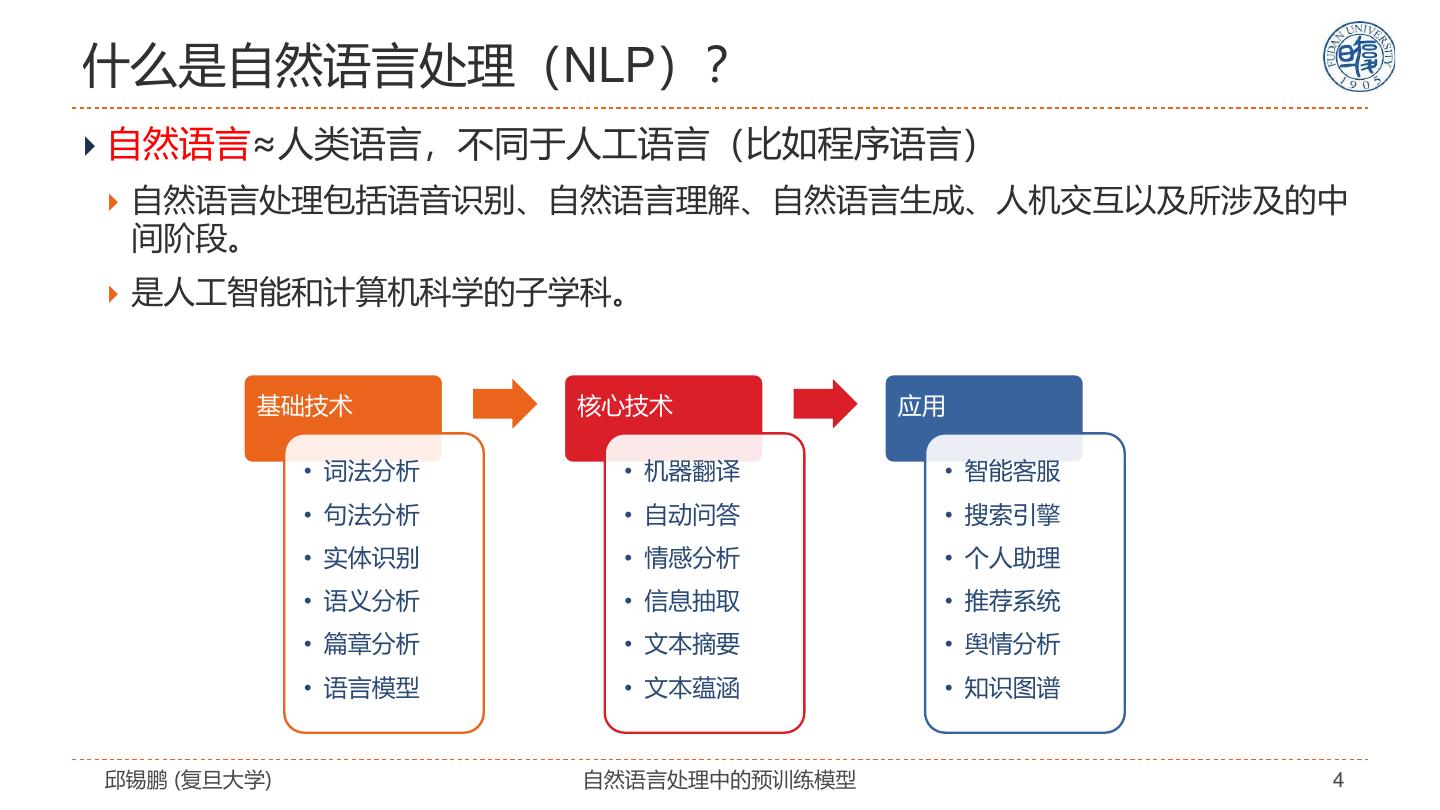
4 .什么是自然语言处理(NLP)? 自然语言≈人类语言,不同于人工语言(比如程序语言) 自然语言处理包括语音识别、自然语言理解、自然语言生成、人机交互以及所涉及的中 间阶段。 是人工智能和计算机科学的子学科。 基础技术 核心技术 应用 • 词法分析 • 机器翻译 • 智能客服 • 句法分析 • 自动问答 • 搜索引擎 • 实体识别 • 情感分析 • 个人助理 • 语义分析 • 信息抽取 • 推荐系统 • 篇章分析 • 文本摘要 • 舆情分析 • 语言模型 • 文本蕴涵 • 知识图谱 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 4
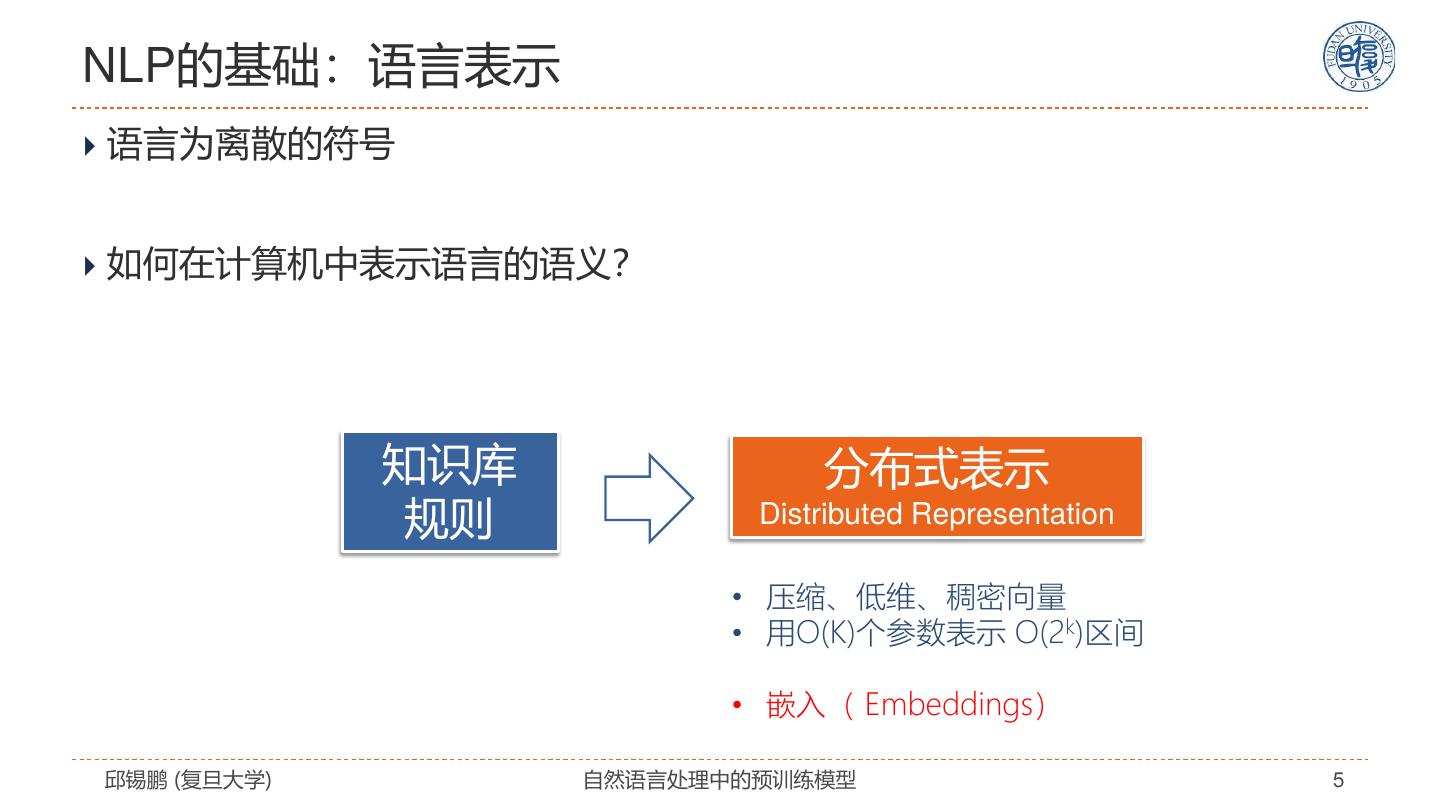
5 .NLP的基础:语言表示 语言为离散的符号 如何在计算机中表示语言的语义? 知识库 分布式表示 规则 Distributed Representation • 压缩、低维、稠密向量 • 用O(K)个参数表示 O(2k)区间 • 嵌入( Embeddings) 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 5
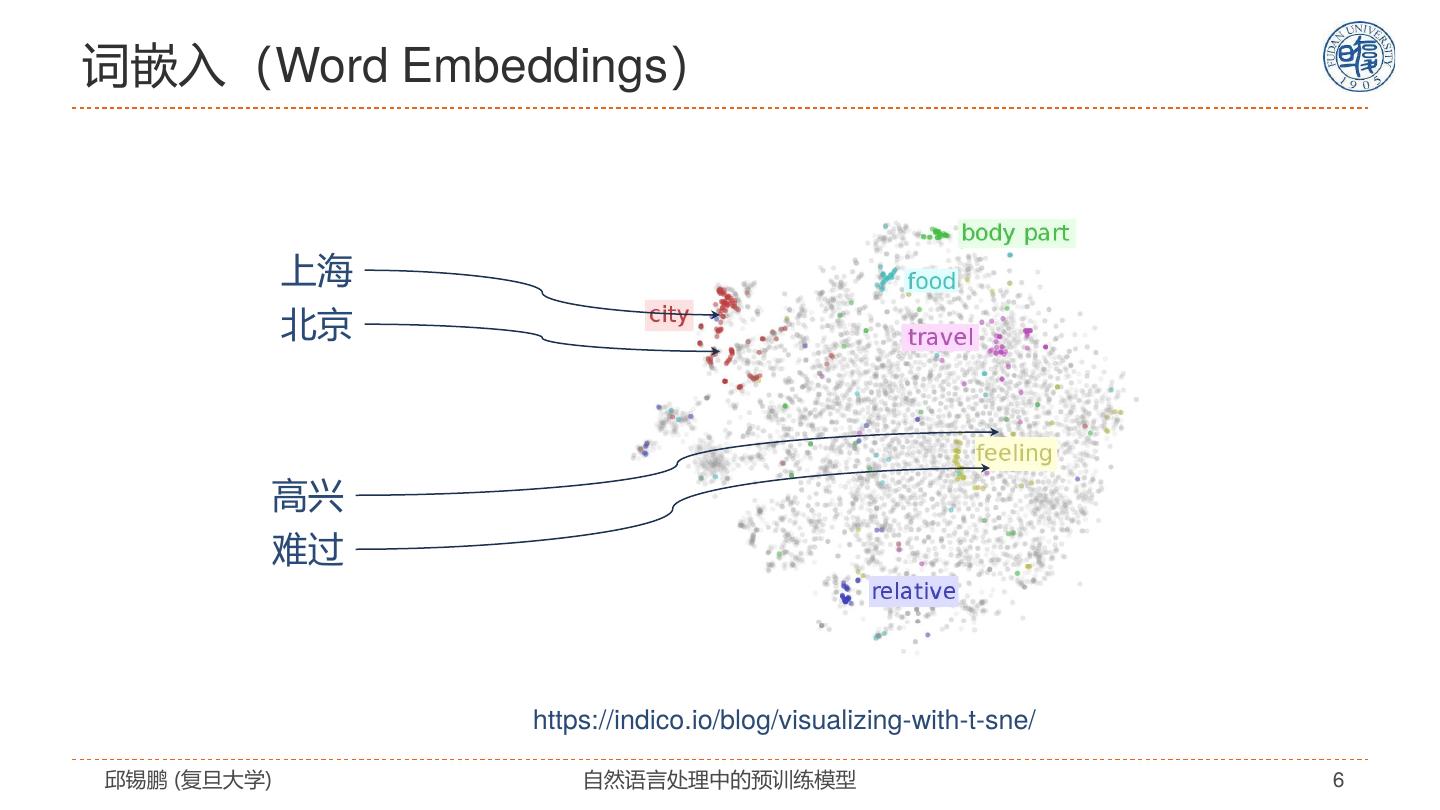
6 .词嵌入(Word Embeddings) 上海 北京 高兴 难过 https://indico.io/blog/visualizing-with-t-sne/ 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 6
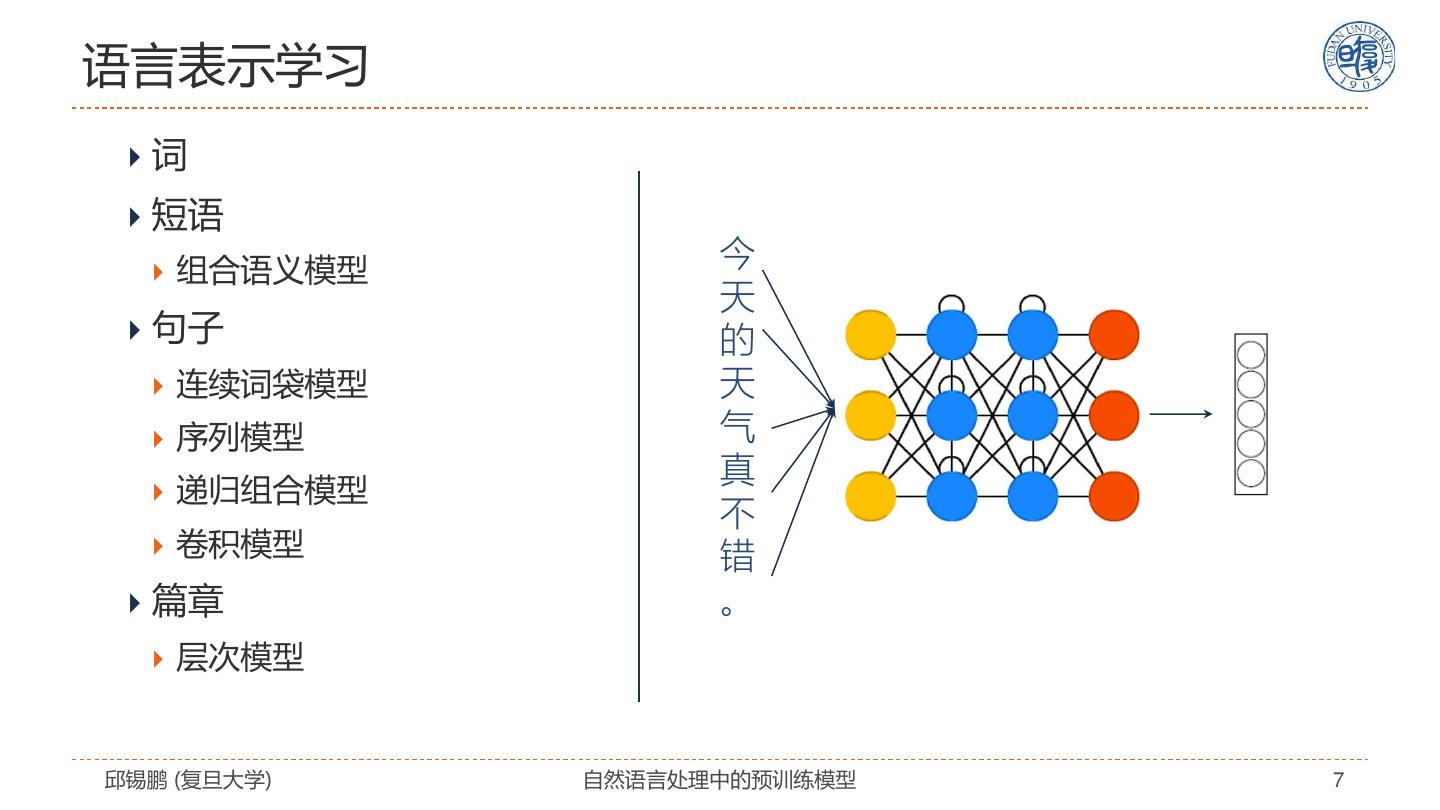
7 .语言表示学习 词 短语 组合语义模型 今 天 句子 的 连续词袋模型 天 序列模型 气 真 递归组合模型 不 卷积模型 错 篇章 。 层次模型 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 7
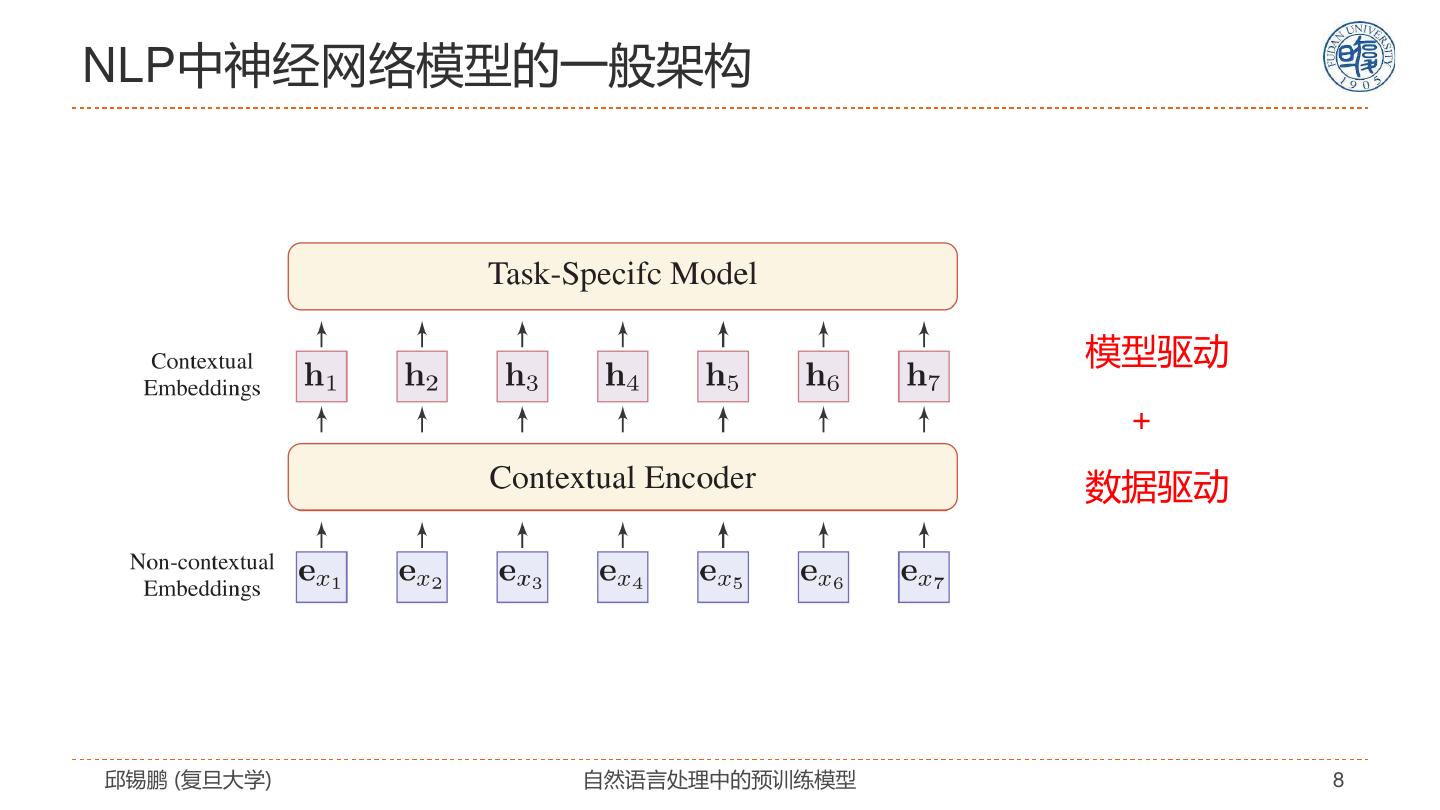
8 .NLP中神经网络模型的一般架构 模型驱动 + 数据驱动 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 8
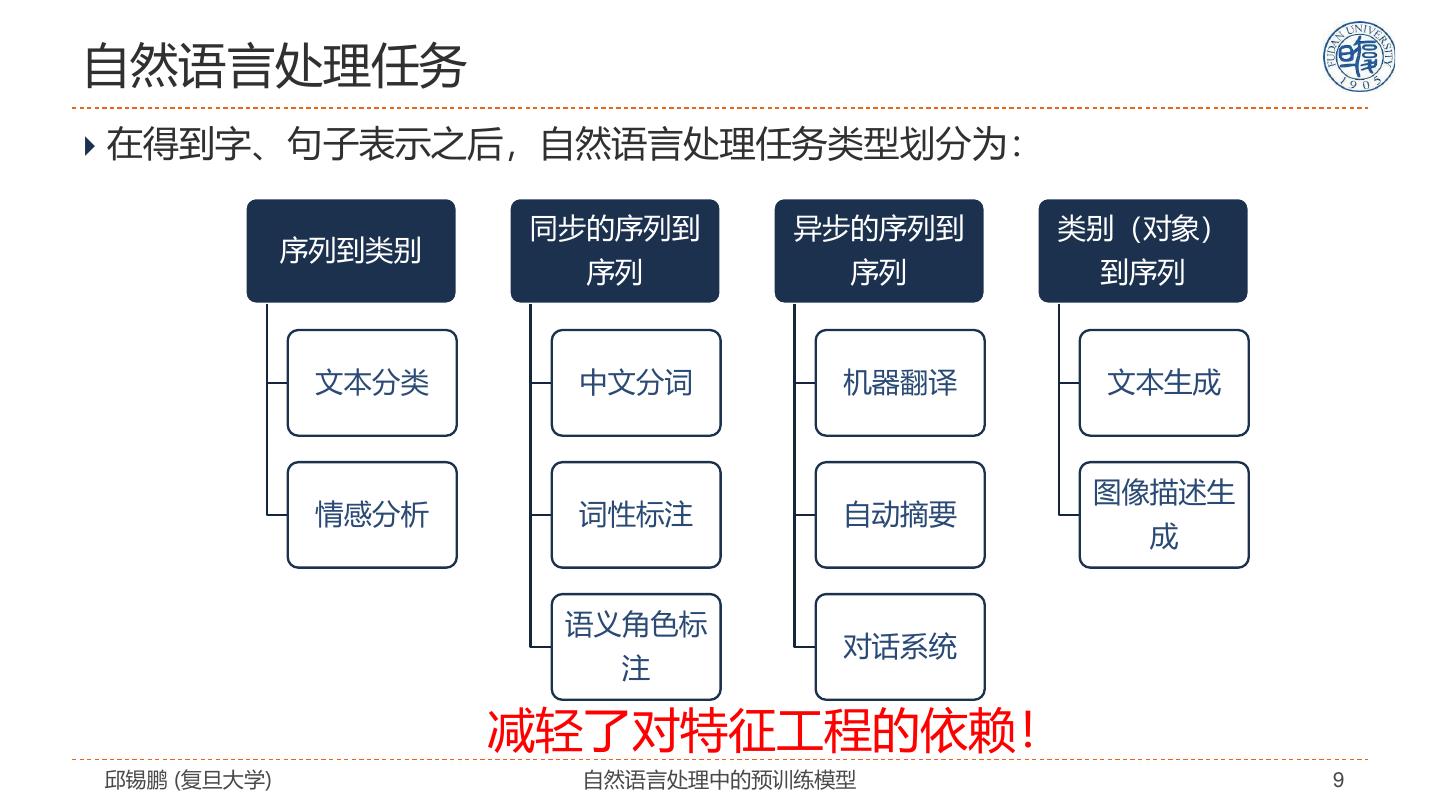
9 .自然语言处理任务 在得到字、句子表示之后,自然语言处理任务类型划分为: 同步的序列到 异步的序列到 类别(对象) 序列到类别 序列 序列 到序列 文本分类 中文分词 机器翻译 文本生成 图像描述生 情感分析 词性标注 自动摘要 成 语义角色标 对话系统 注 减轻了对特征工程的依赖! 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 9
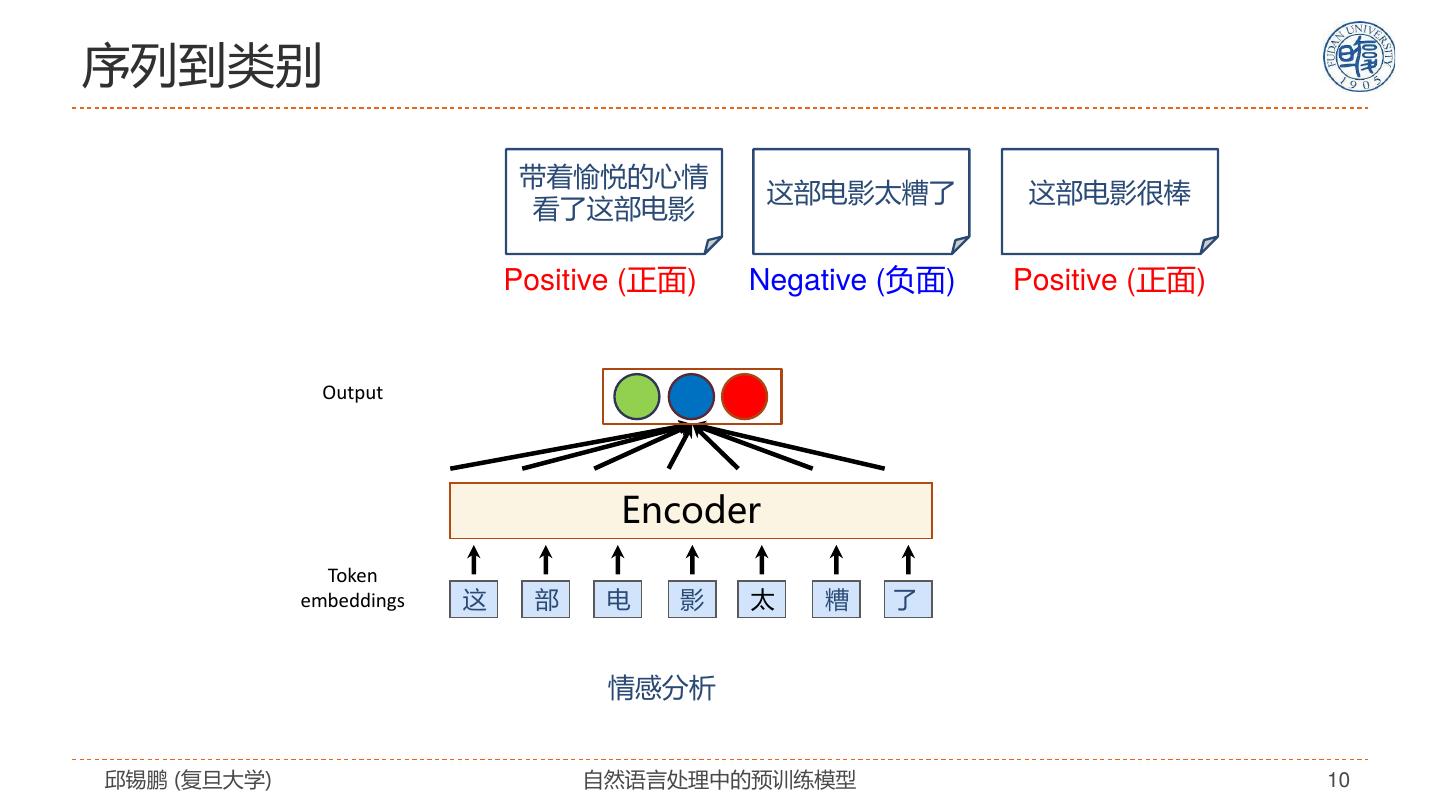
10 .序列到类别 带着愉悦的心情 这部电影太糟了 这部电影很棒 看了这部电影 Positive (正面) Negative (负面) Positive (正面) Output Encoder Token embeddings 这 部 电 影 太 糟 了 情感分析 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 10
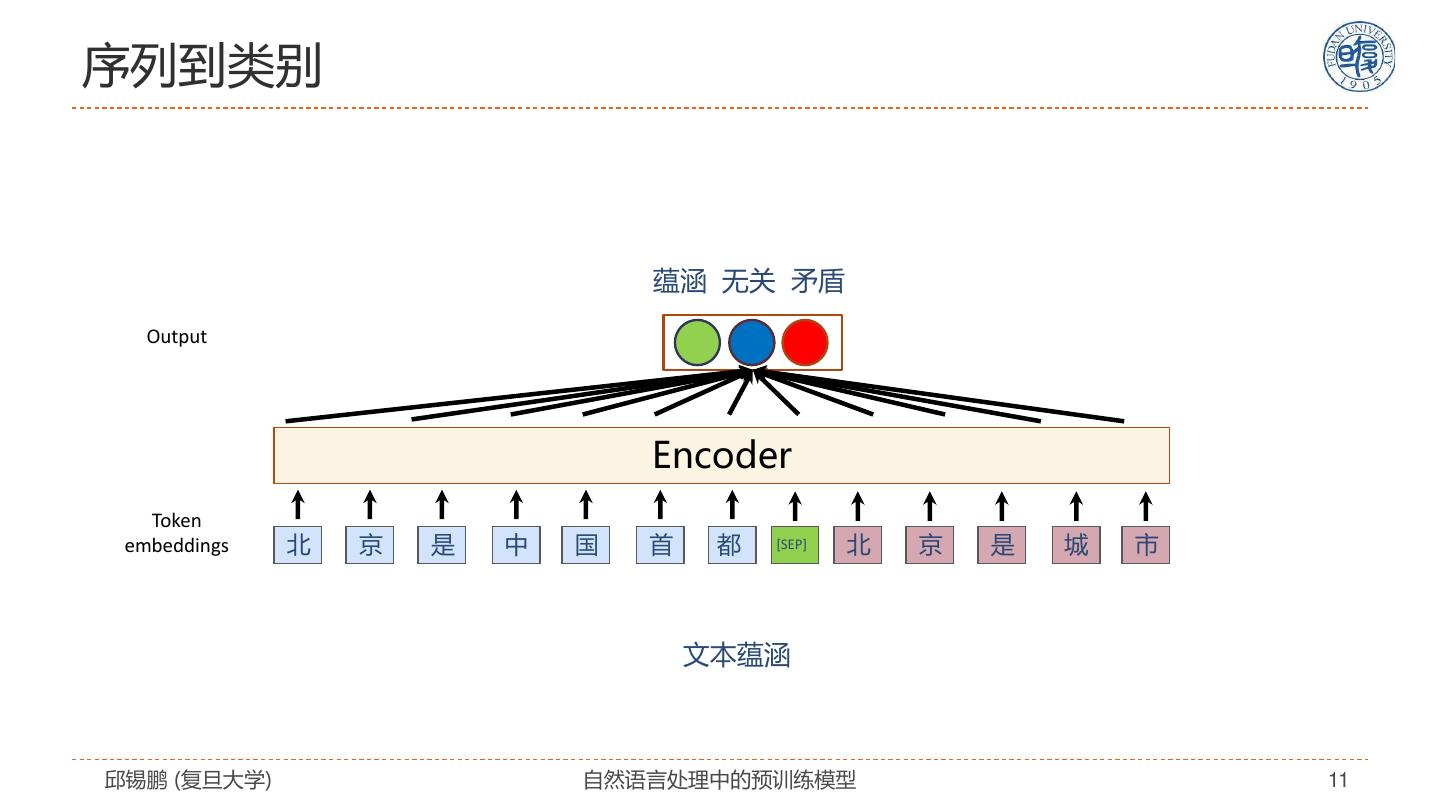
11 .序列到类别 蕴涵 无关 矛盾 Output Encoder Token embeddings 北 京 是 中 国 首 都 [SEP] 北 京 是 城 市 文本蕴涵 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 11
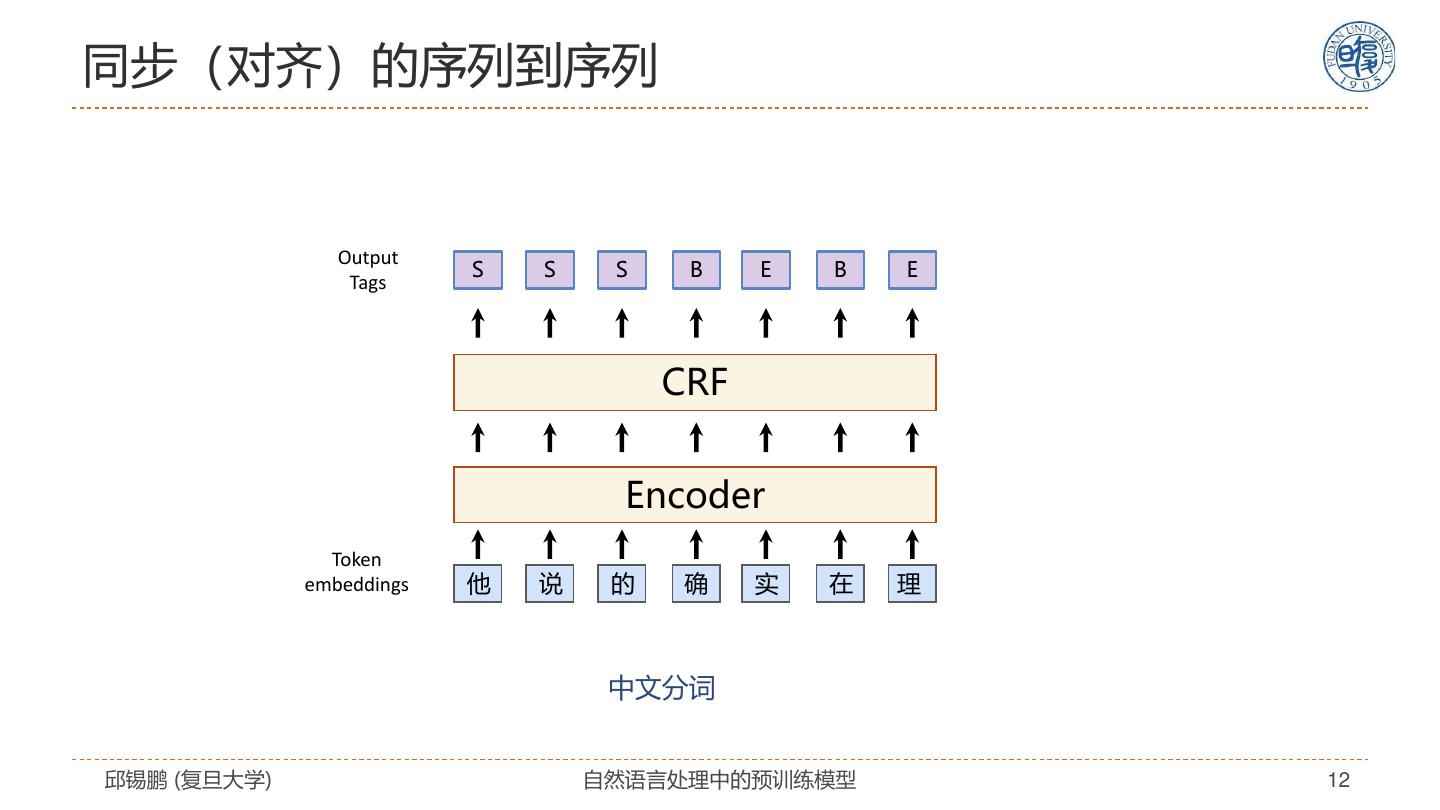
12 .同步(对齐)的序列到序列 Output S S S B E B E Tags CRF Encoder Token embeddings 他 说 的 确 实 在 理 中文分词 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 12
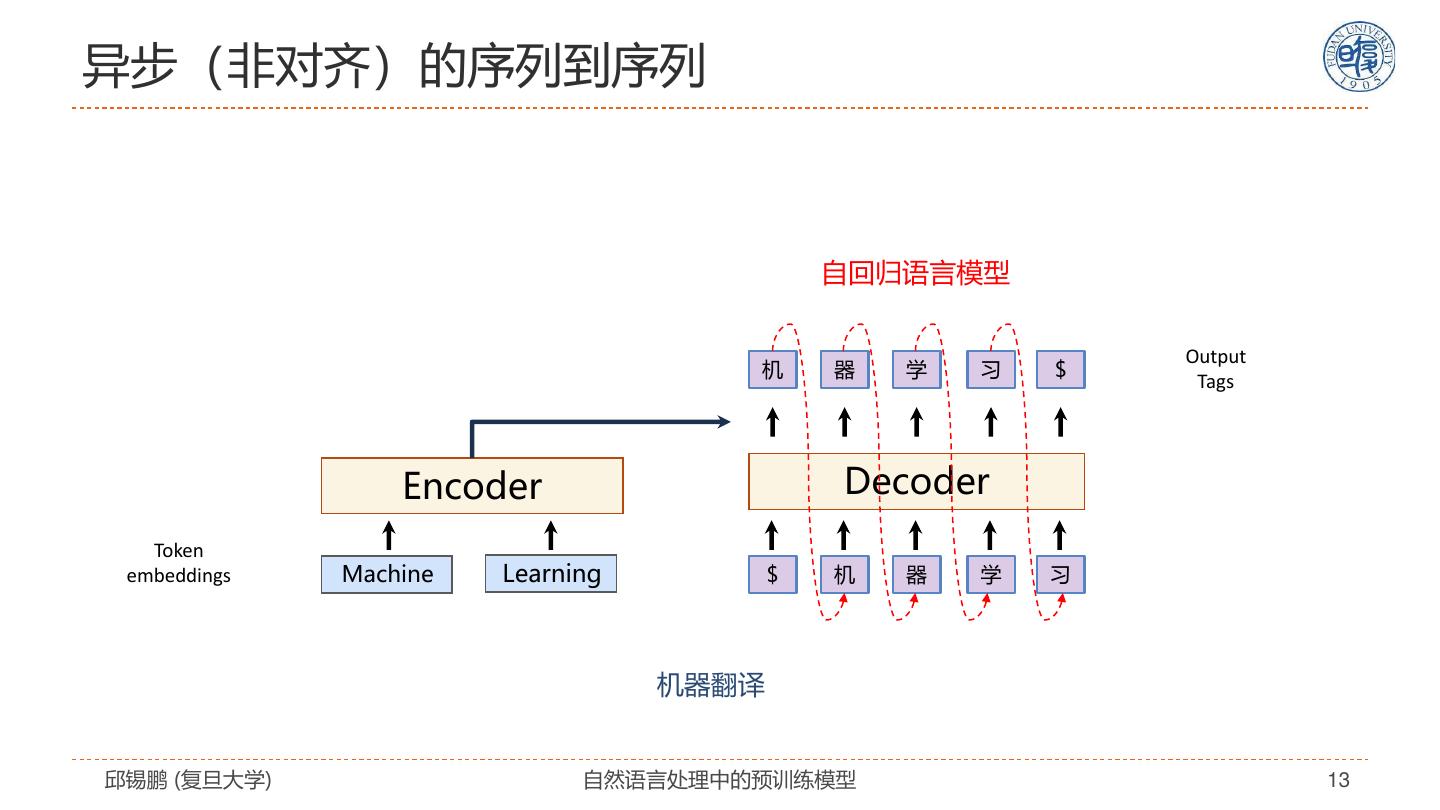
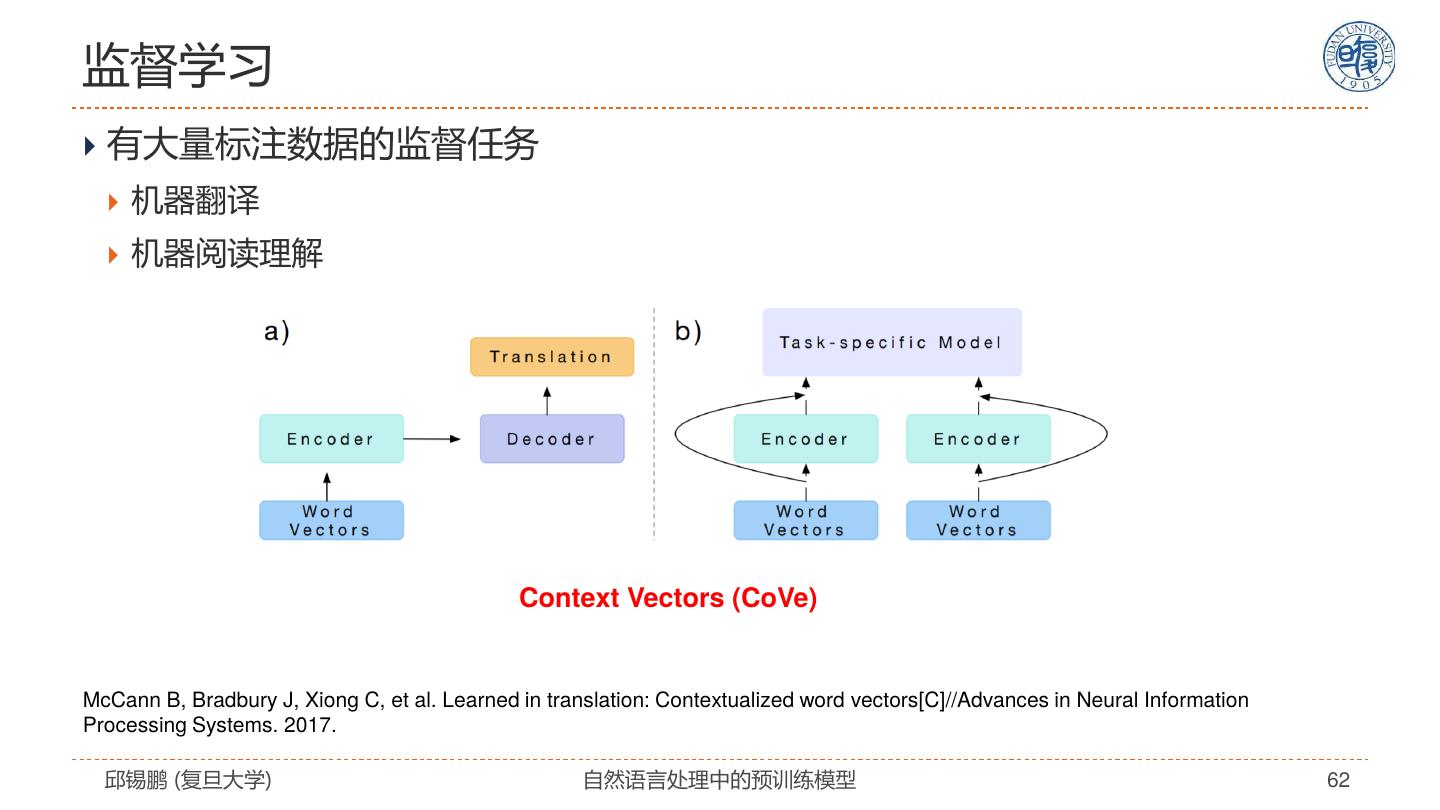
13 .异步(非对齐)的序列到序列 自回归语言模型 Output 机 器 学 习 $ Tags Encoder Decoder Token embeddings Machine Learning $ 机 器 学 习 机器翻译 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 13
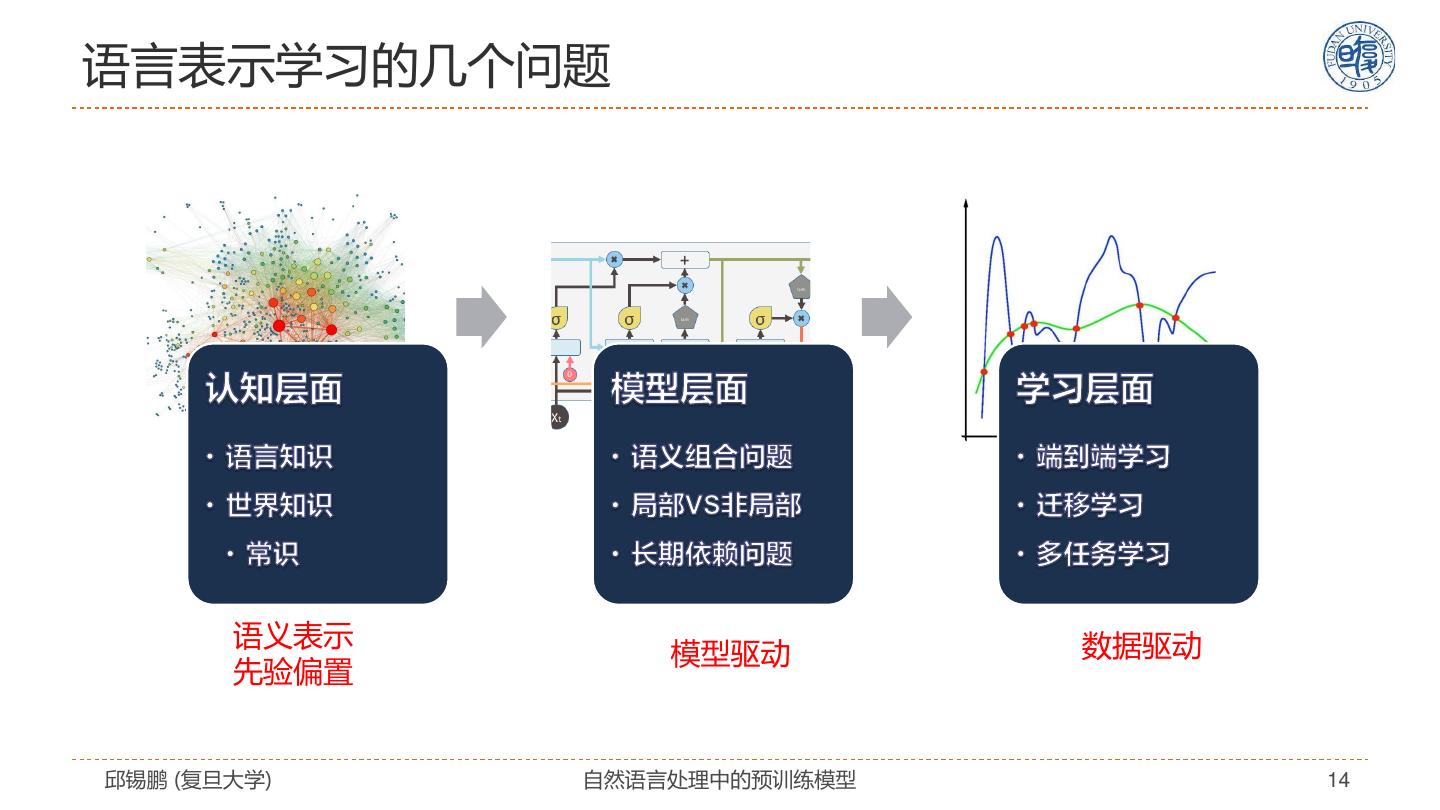
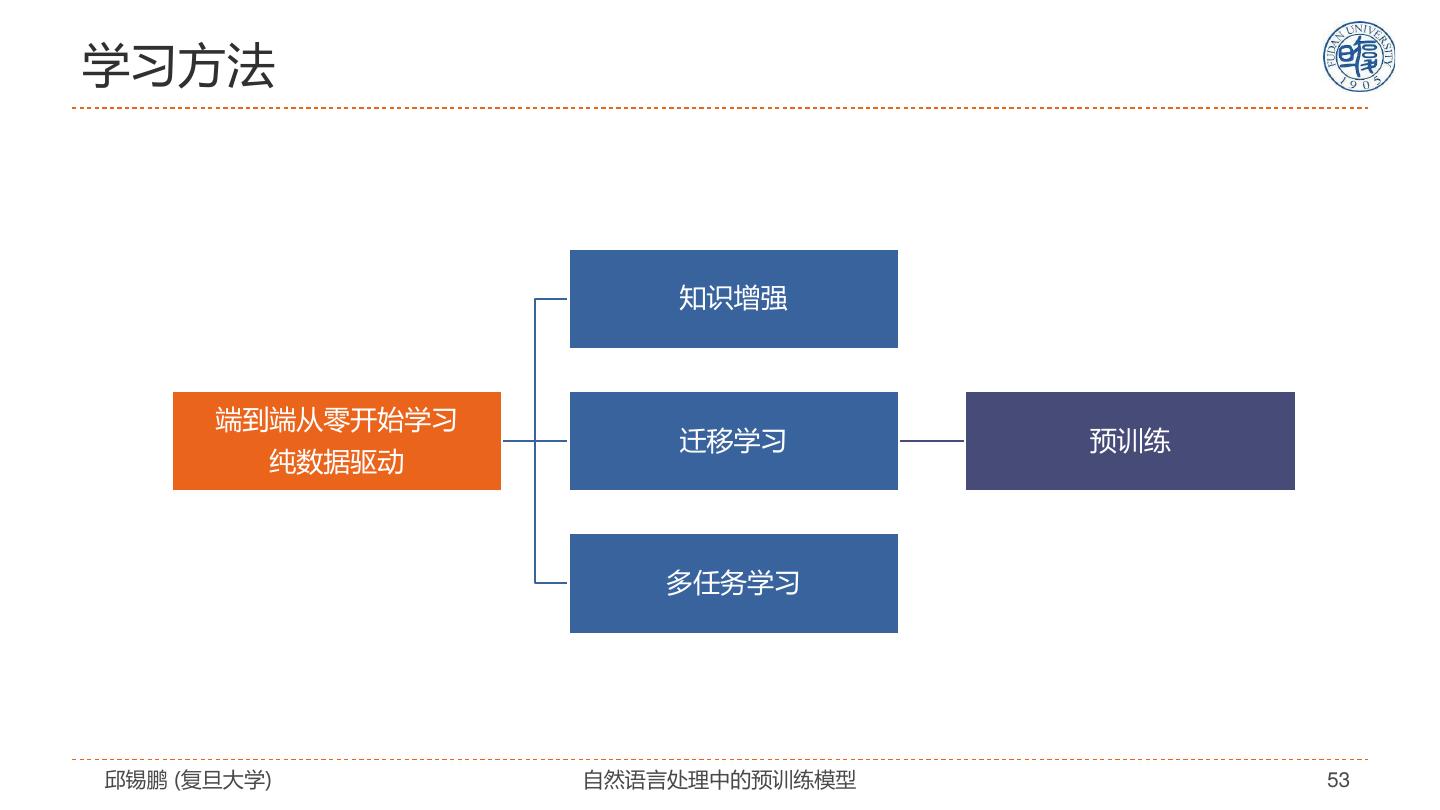
14 .语言表示学习的几个问题 语义表示 数据驱动 模型驱动 先验偏置 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 14
15 .自然语言表示学习 自然语言表 模型驱动 数据驱动 示学习 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 15
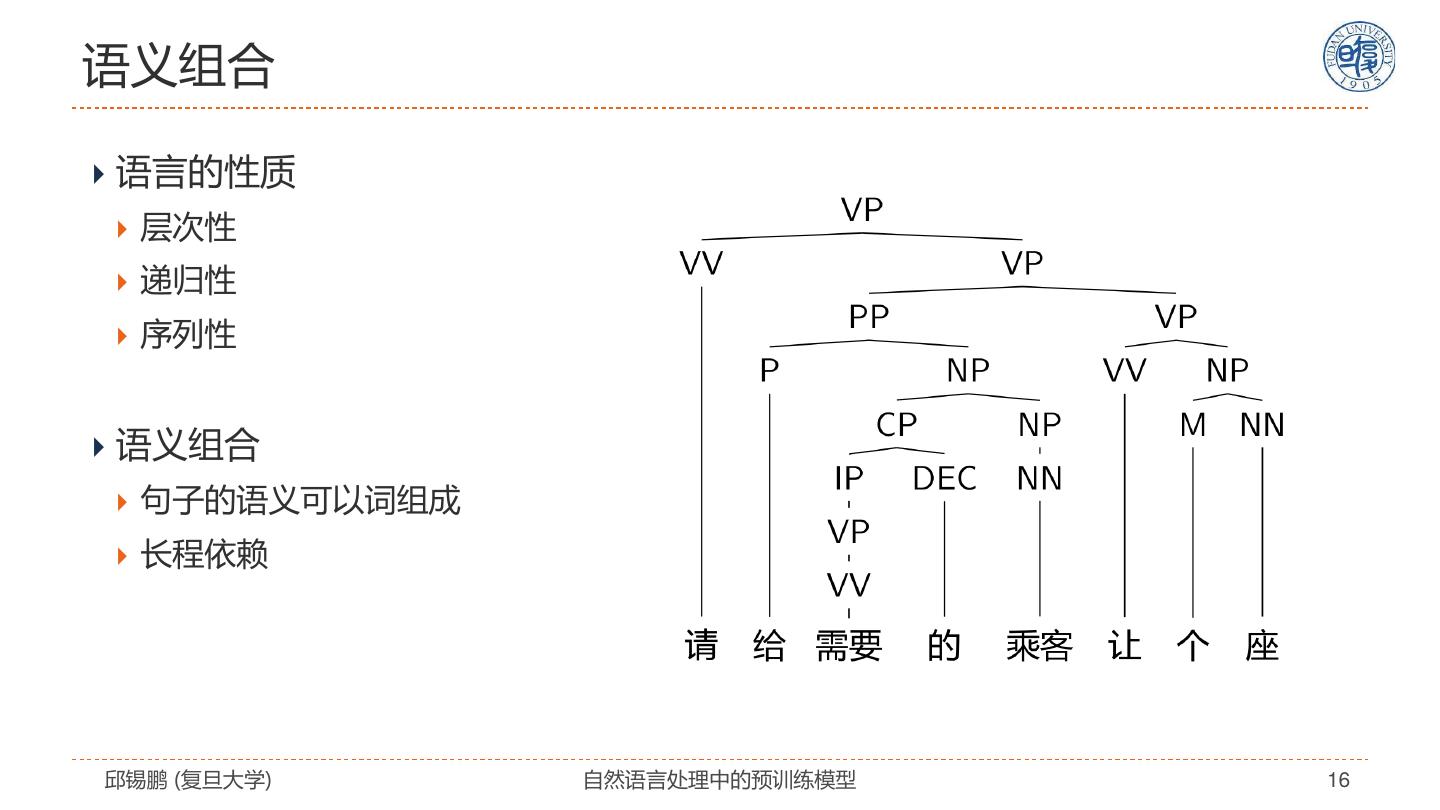
16 .语义组合 语言的性质 层次性 递归性 序列性 语义组合 句子的语义可以词组成 长程依赖 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 16
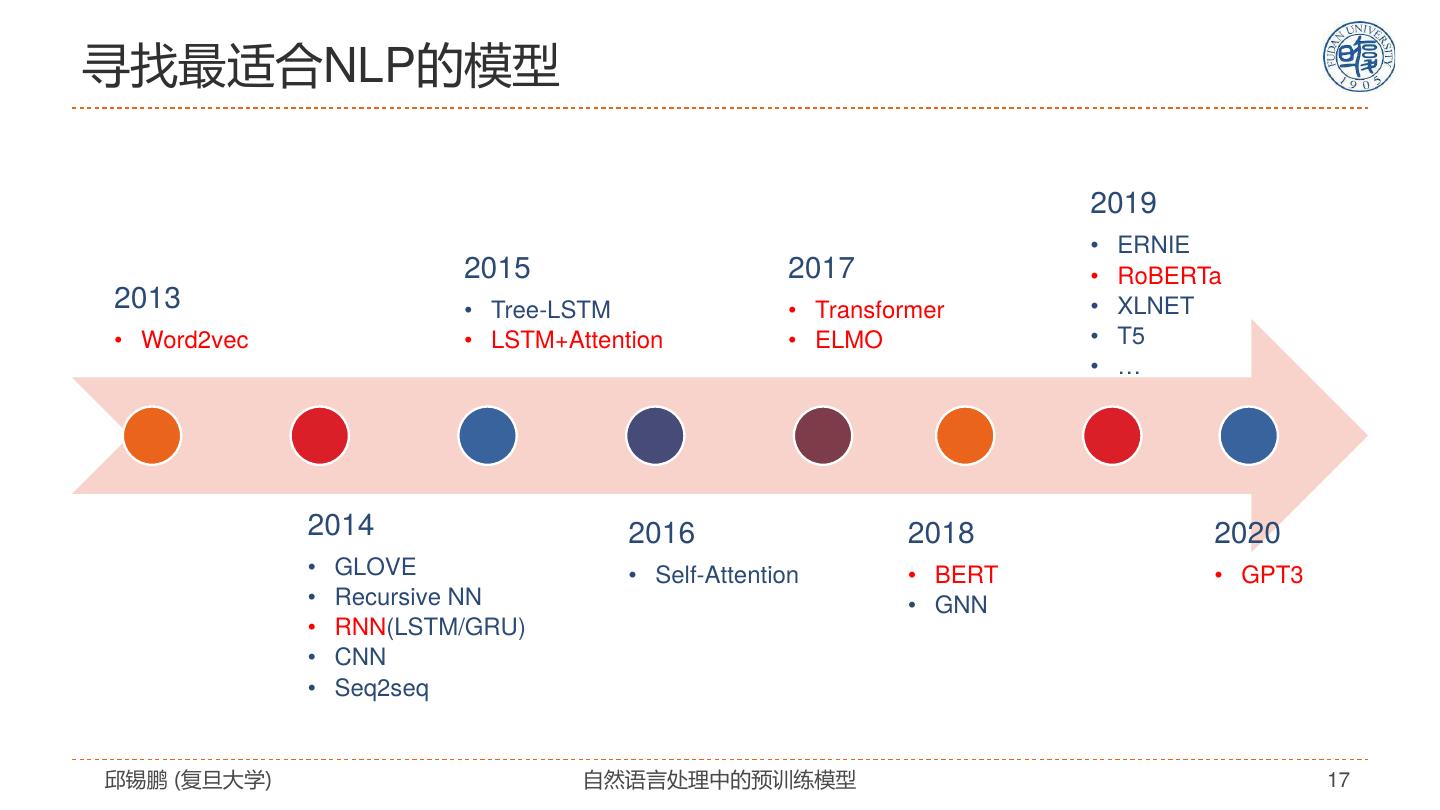
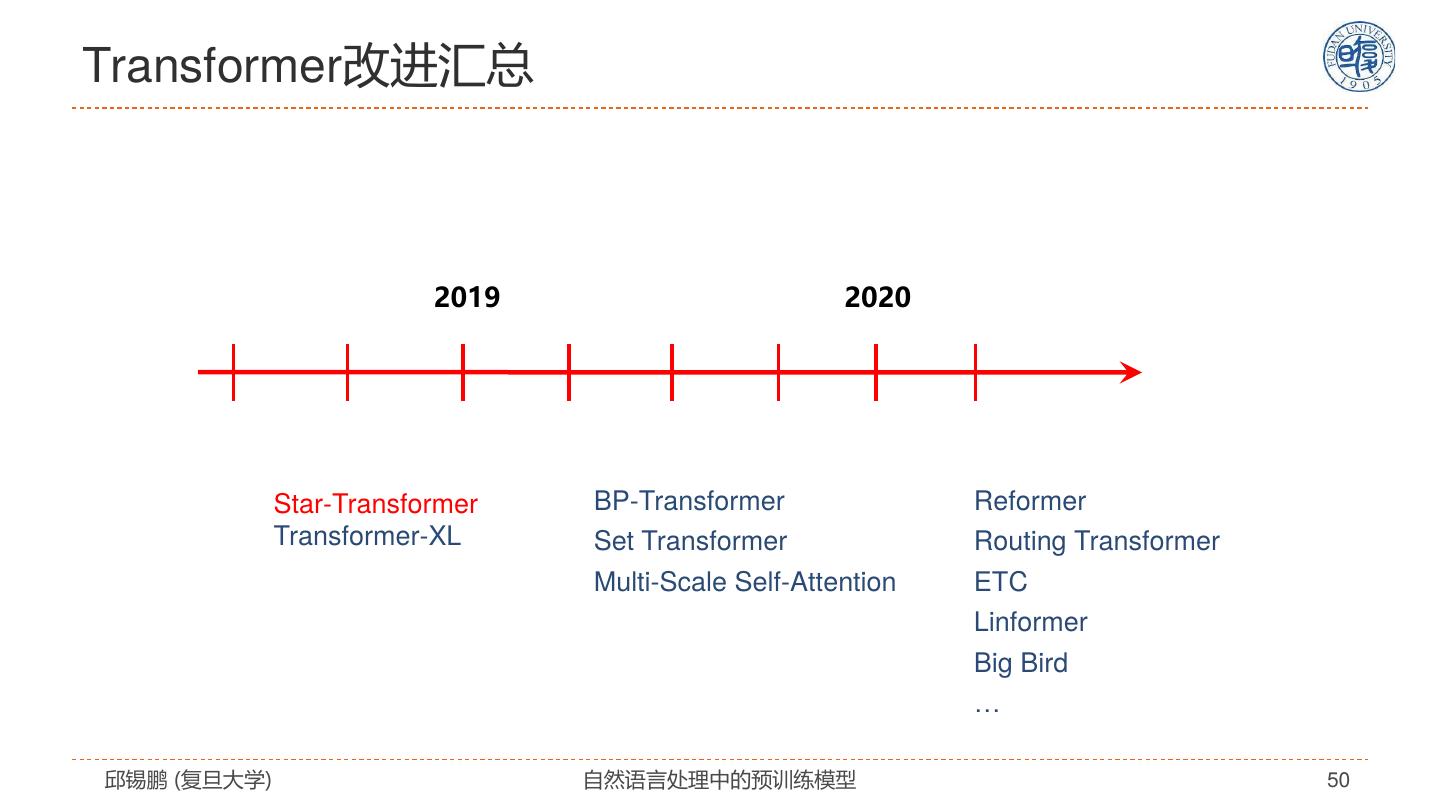
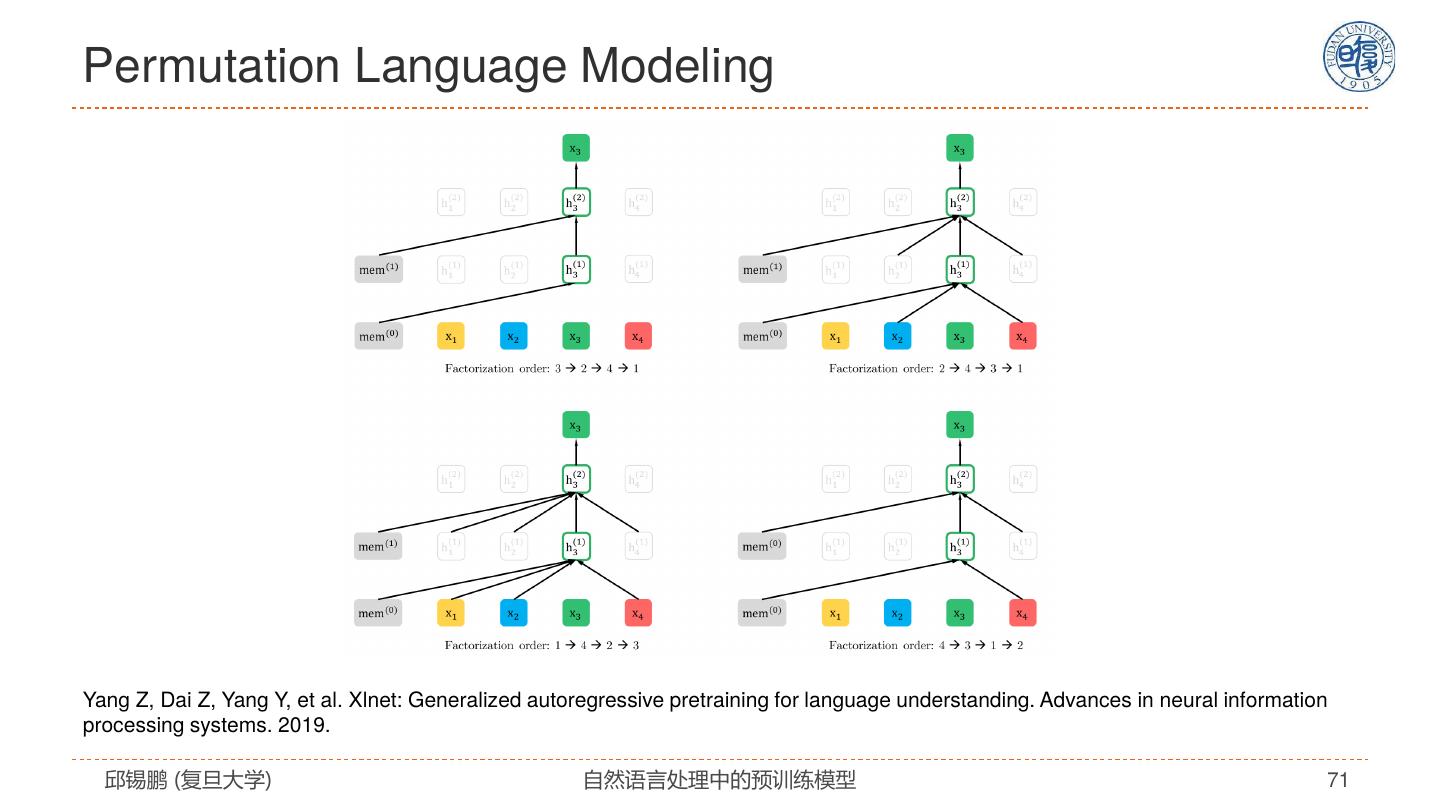
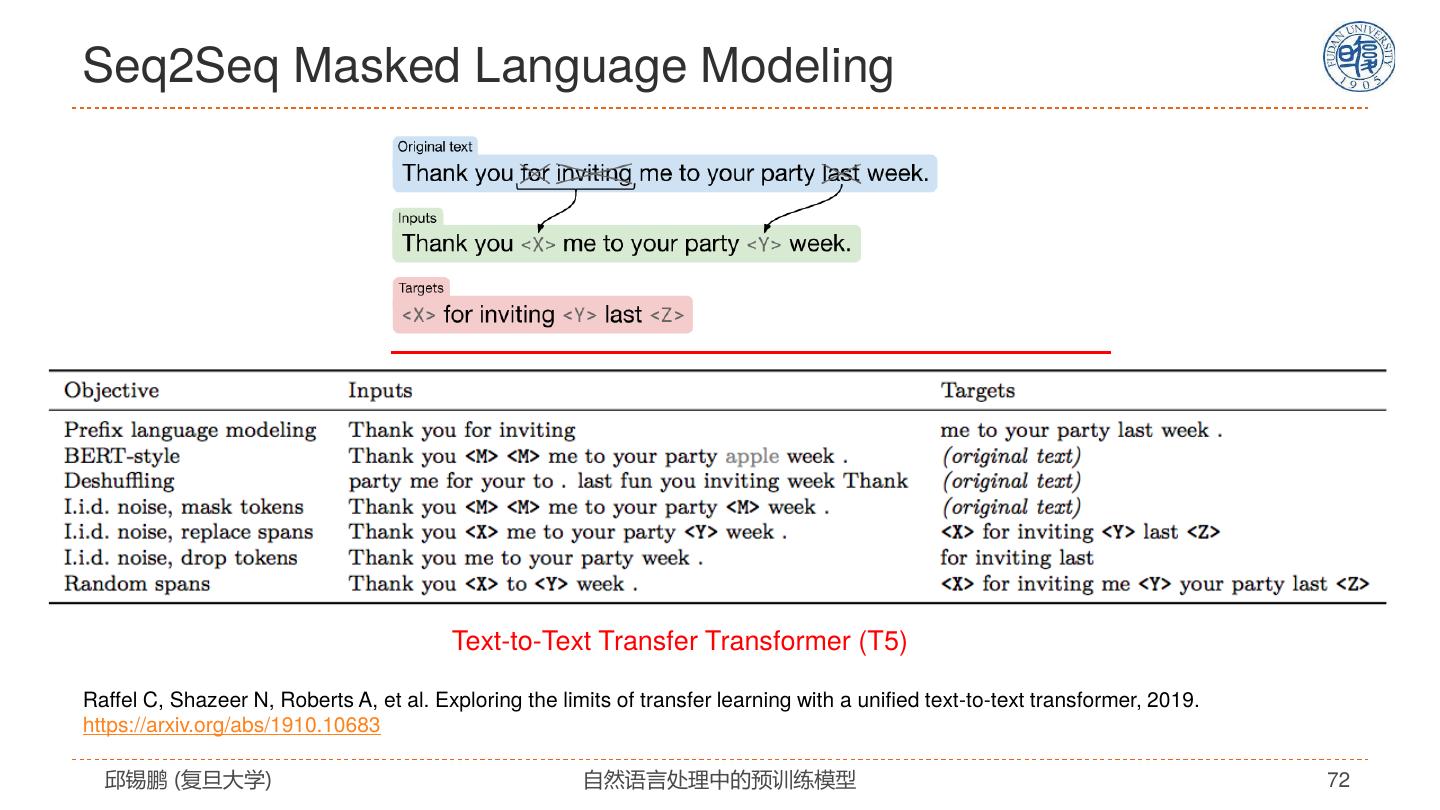
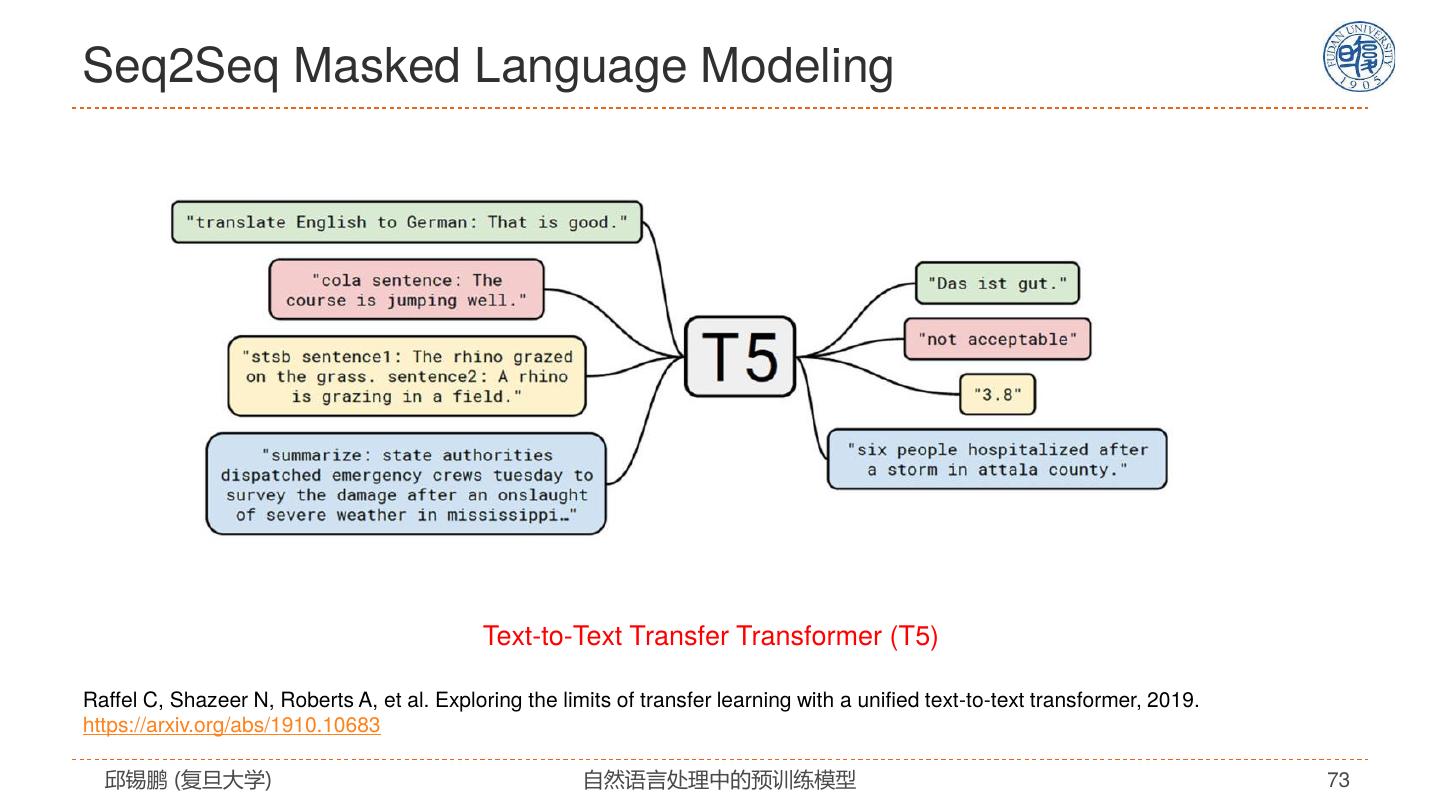
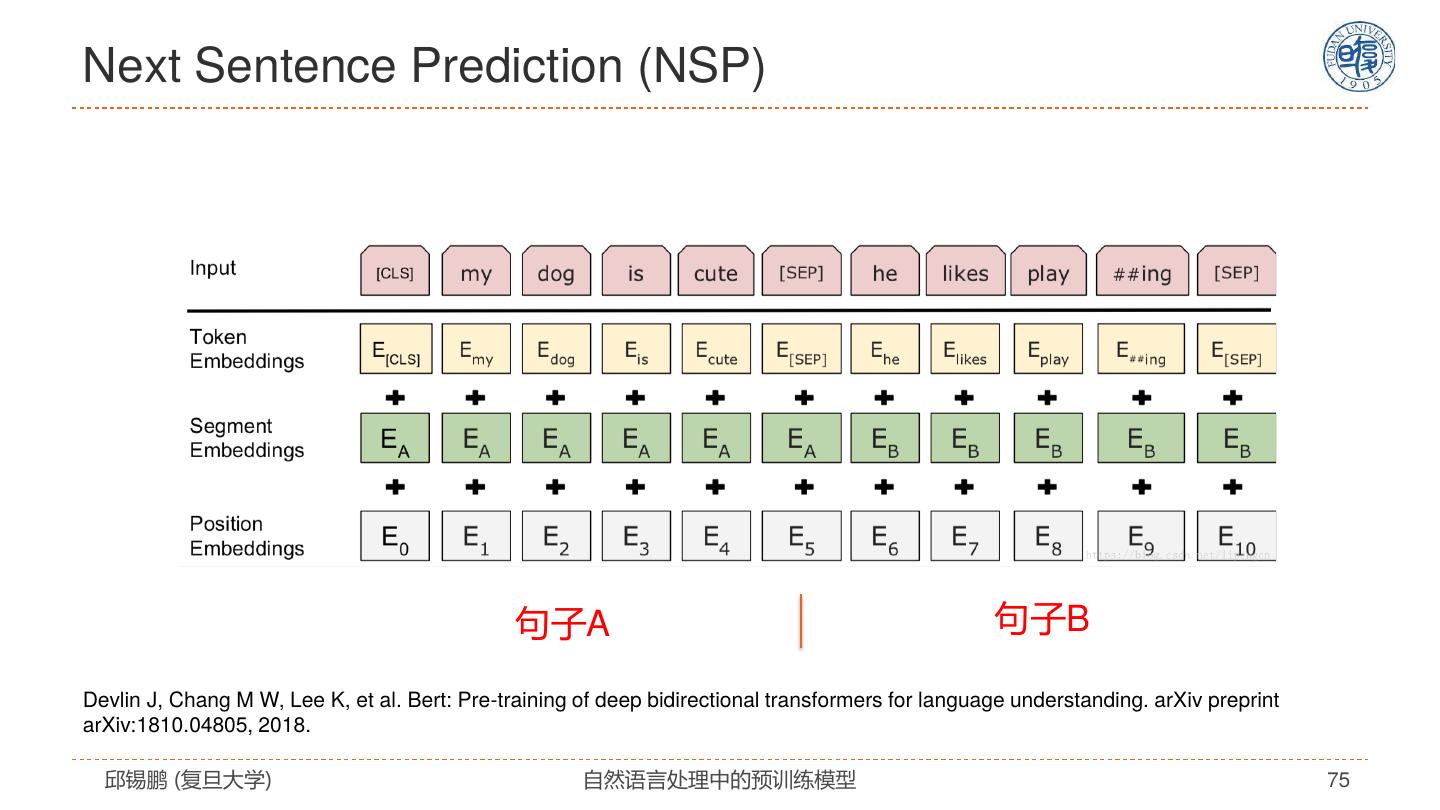
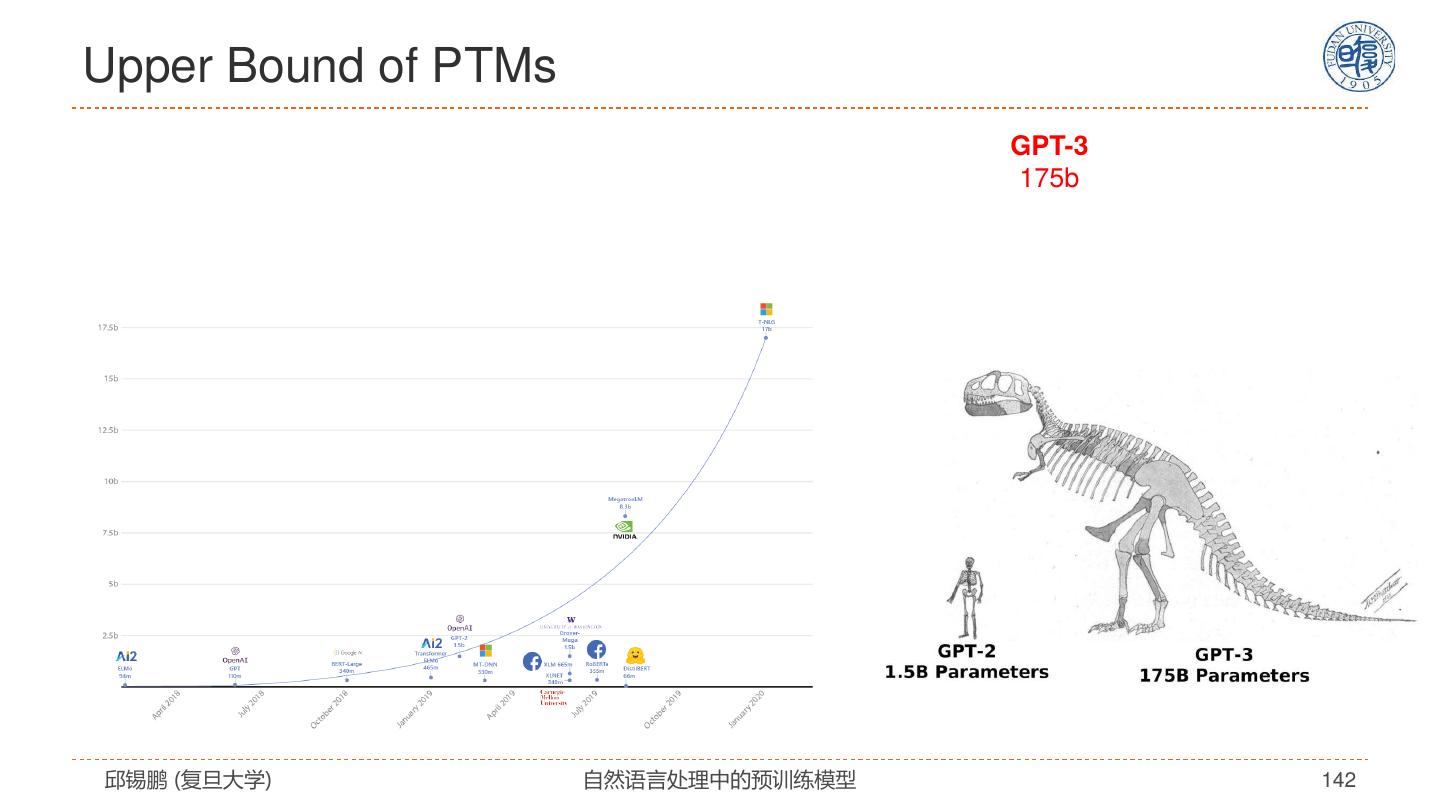
17 .寻找最适合NLP的模型 2019 • ERNIE 2015 2017 • RoBERTa 2013 • Tree-LSTM • Transformer • XLNET • Word2vec • LSTM+Attention • ELMO • T5 • … 2014 2016 2018 2020 • GLOVE • Self-Attention • BERT • GPT3 • Recursive NN • GNN • RNN(LSTM/GRU) • CNN • Seq2seq 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 17
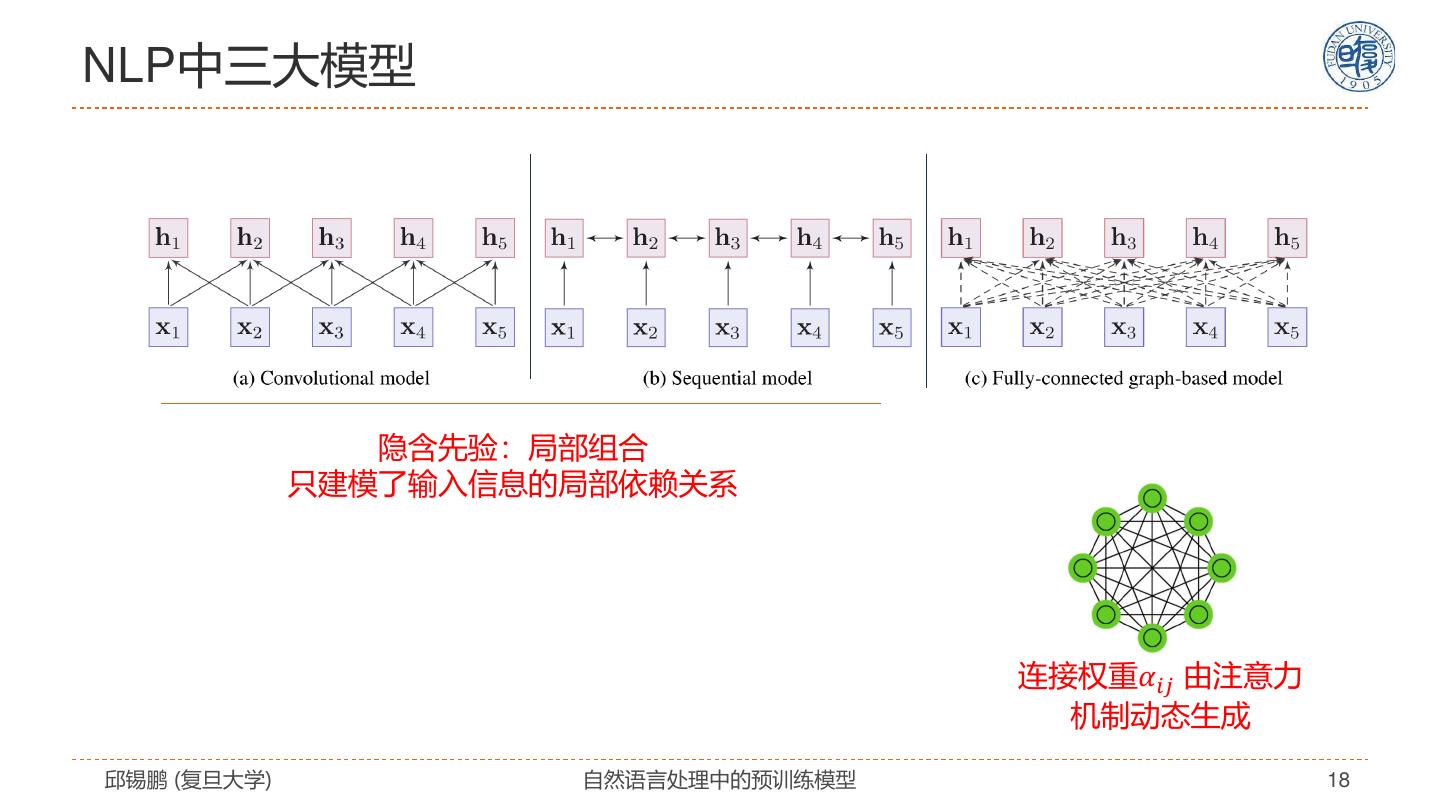
18 .NLP中三大模型 隐含先验:局部组合 只建模了输入信息的局部依赖关系 连接权重𝛼𝑖𝑗 由注意力 机制动态生成 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 18
19 . Transformer模型介绍 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 19
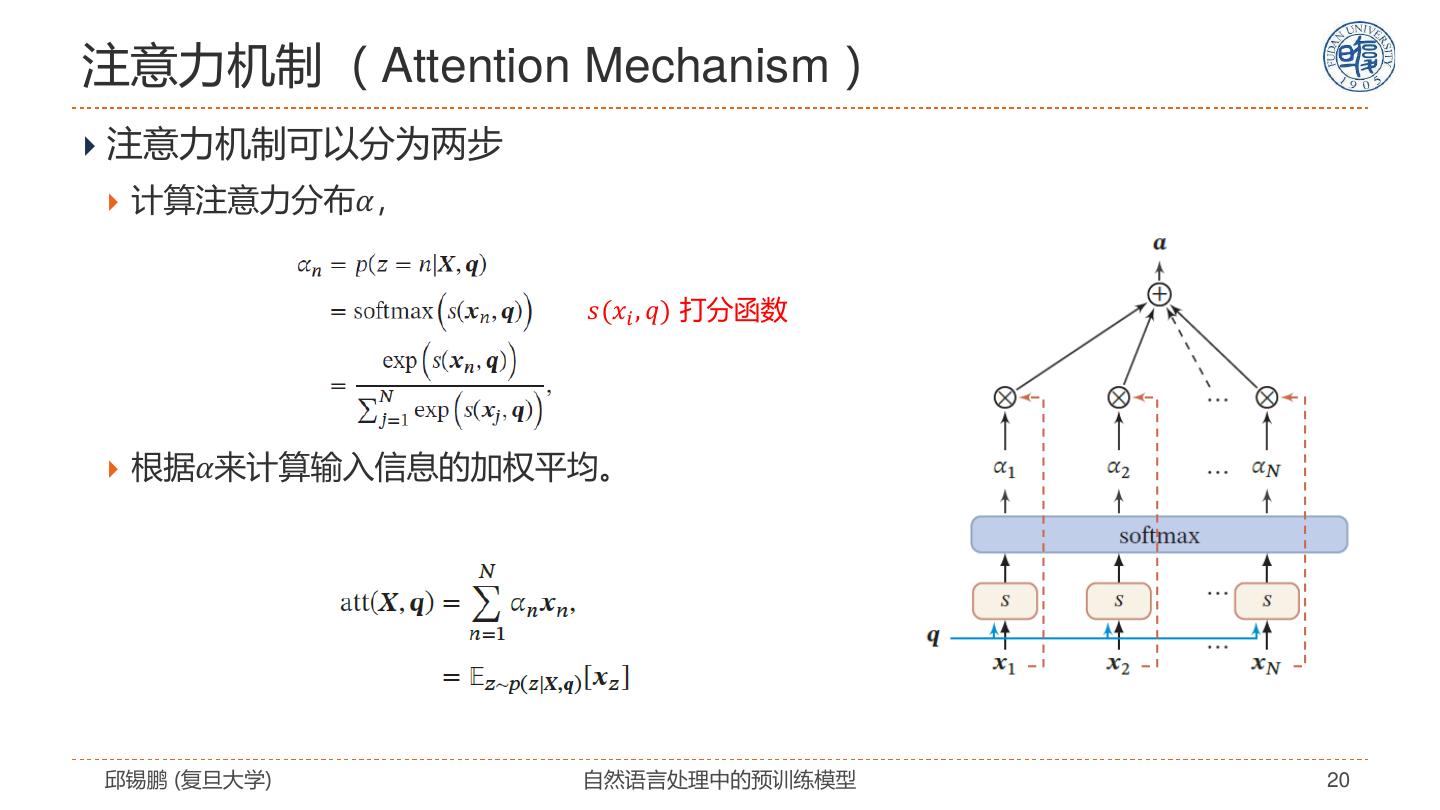
20 .注意力机制( Attention Mechanism ) 注意力机制可以分为两步 计算注意力分布𝛼, 𝑠(𝑥𝑖 , 𝑞) 打分函数 根据𝛼来计算输入信息的加权平均。 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 20
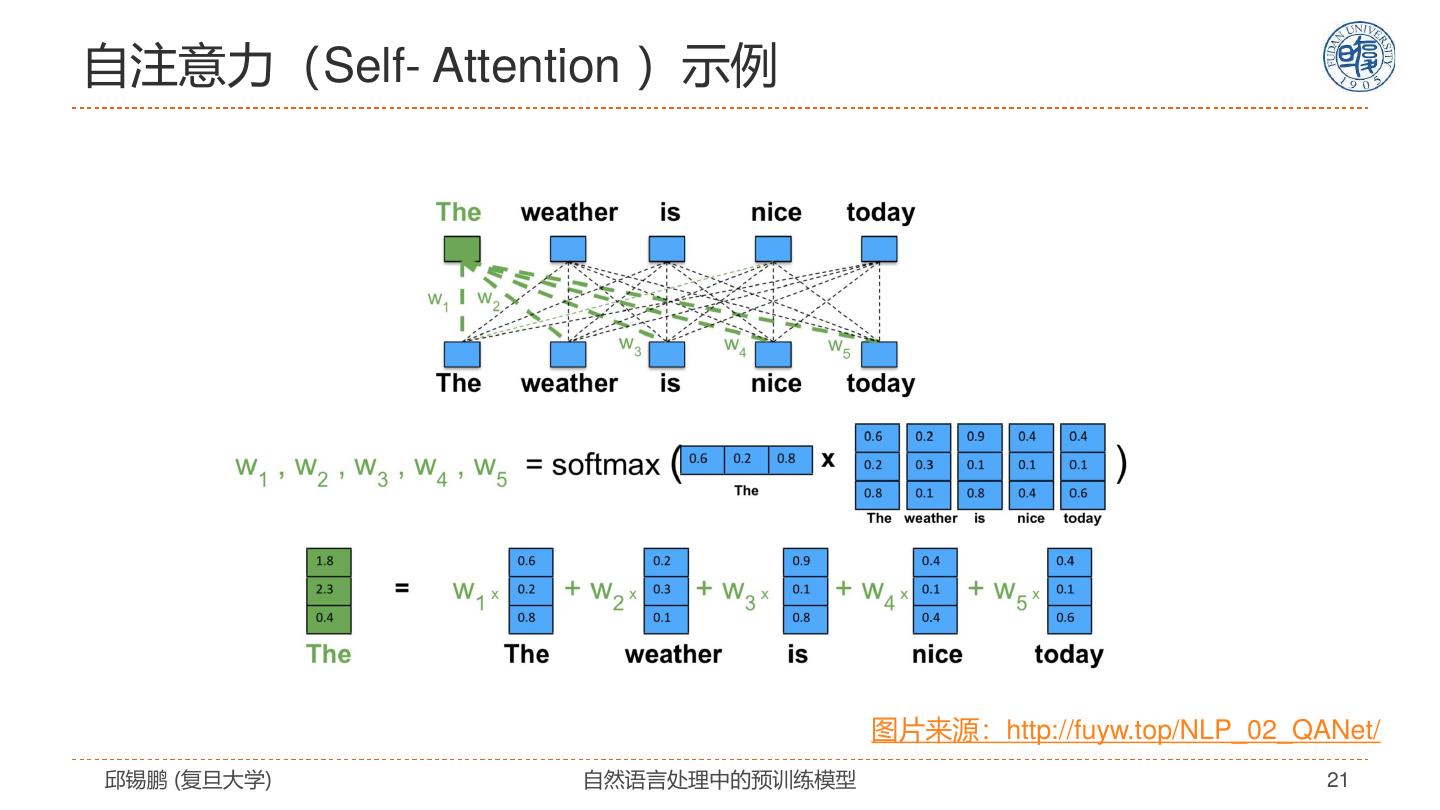
21 .自注意力(Self- Attention )示例 图片来源:http://fuyw.top/NLP_02_QANet/ 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 21
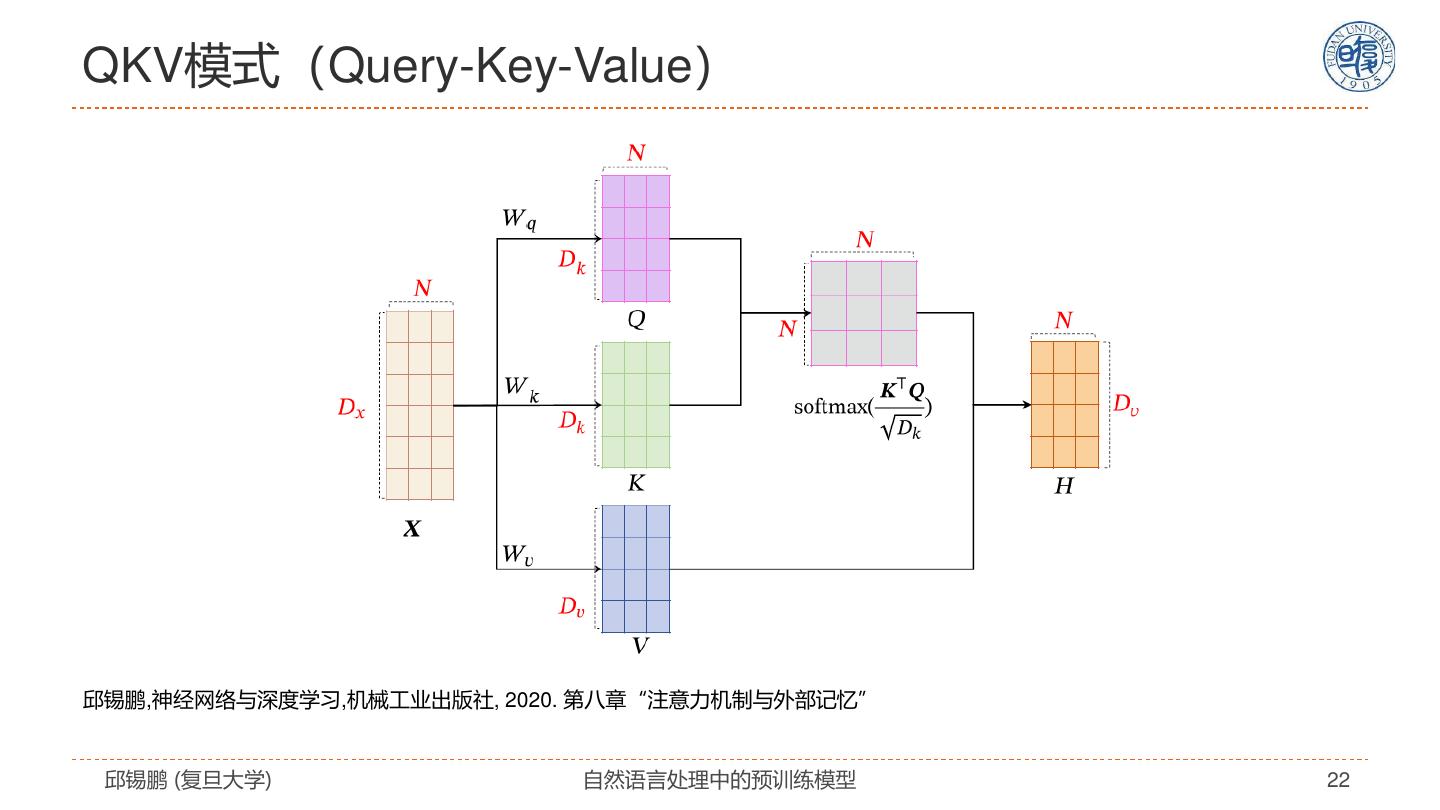
22 .QKV模式(Query-Key-Value) 邱锡鹏,神经网络与深度学习,机械工业出版社, 2020. 第八章“注意力机制与外部记忆” 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 22
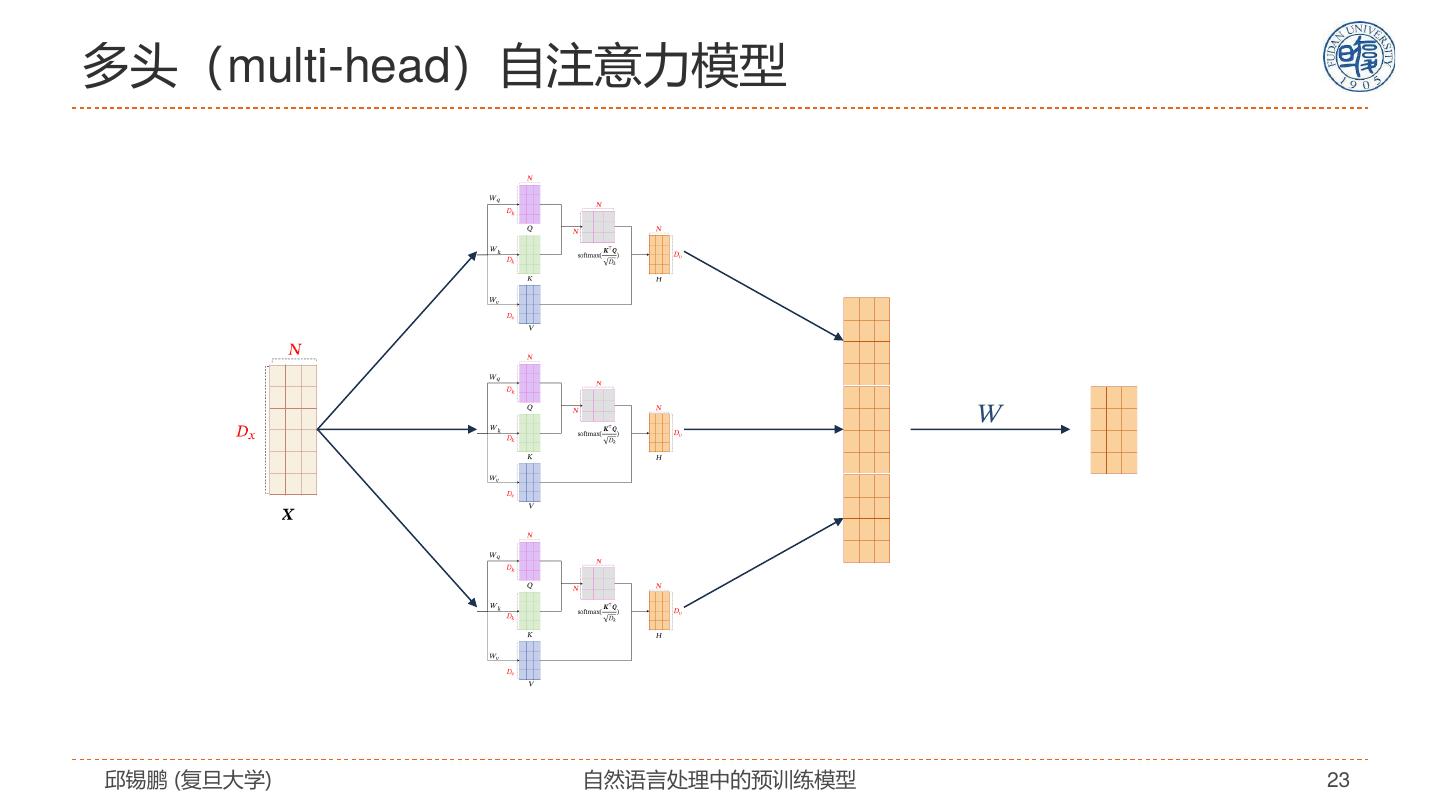
23 .多头(multi-head)自注意力模型 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 23
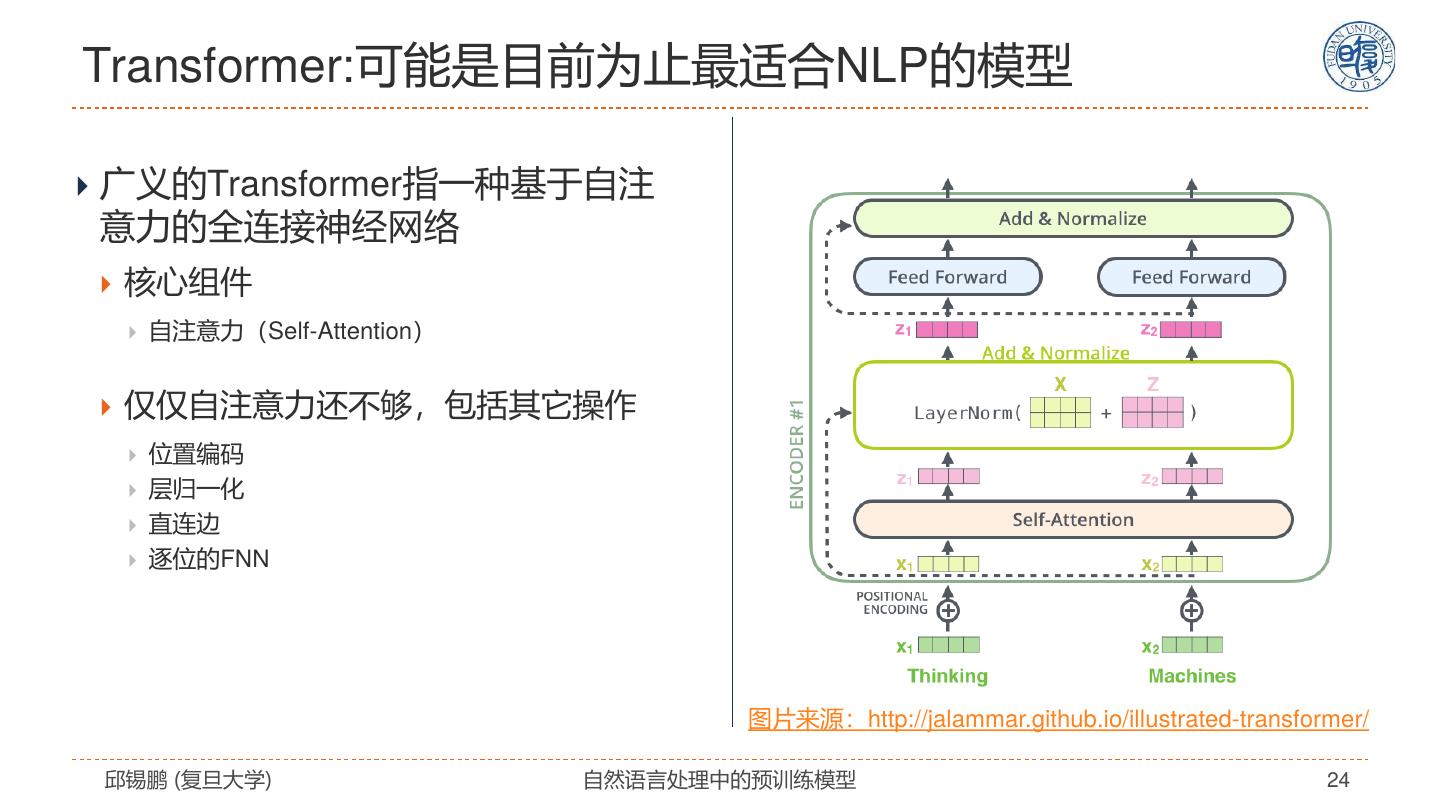
24 .Transformer:可能是目前为止最适合NLP的模型 广义的Transformer指一种基于自注 意力的全连接神经网络 核心组件 自注意力(Self-Attention) 仅仅自注意力还不够,包括其它操作 位置编码 层归一化 直连边 逐位的FNN 图片来源:http://jalammar.github.io/illustrated-transformer/ 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 24
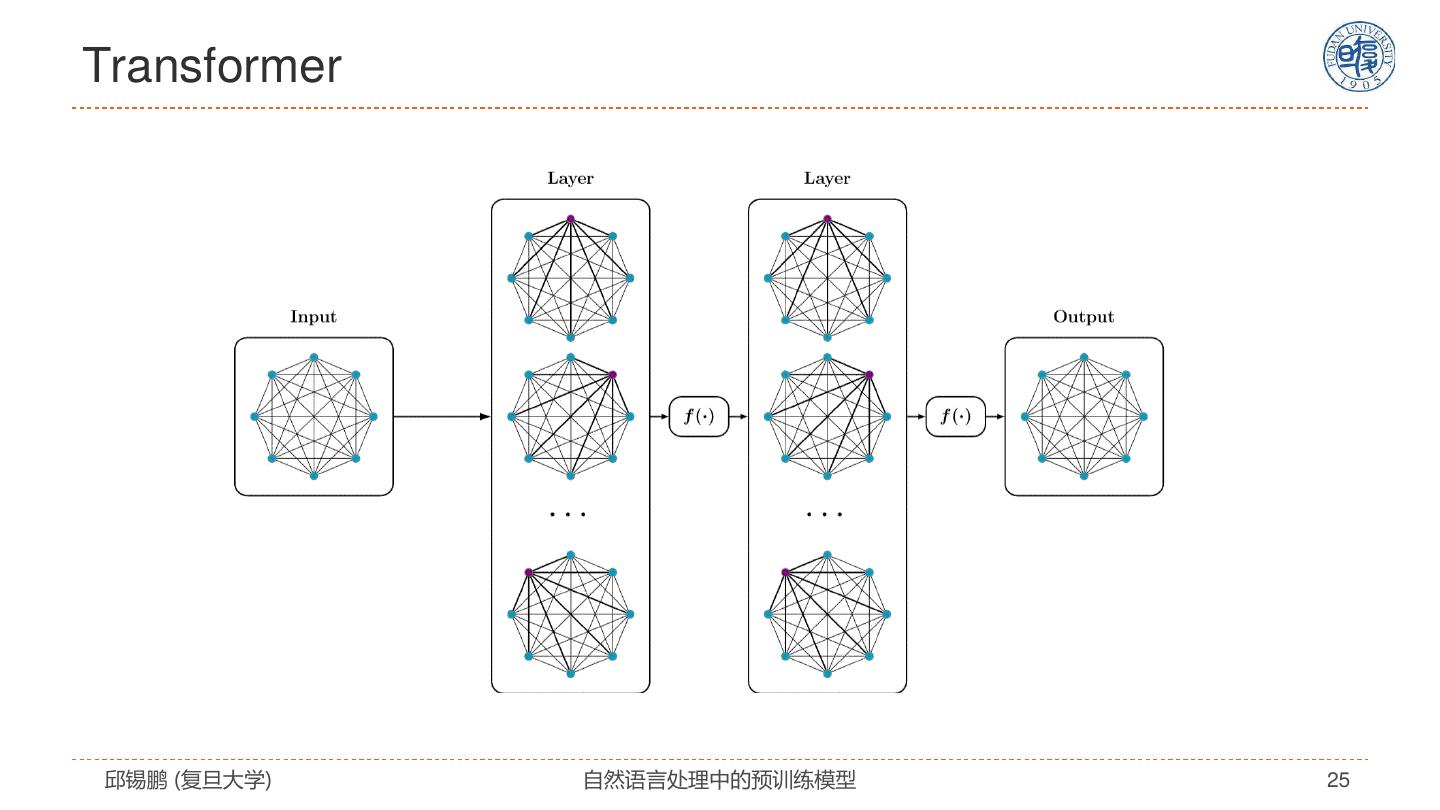
25 .Transformer 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 25
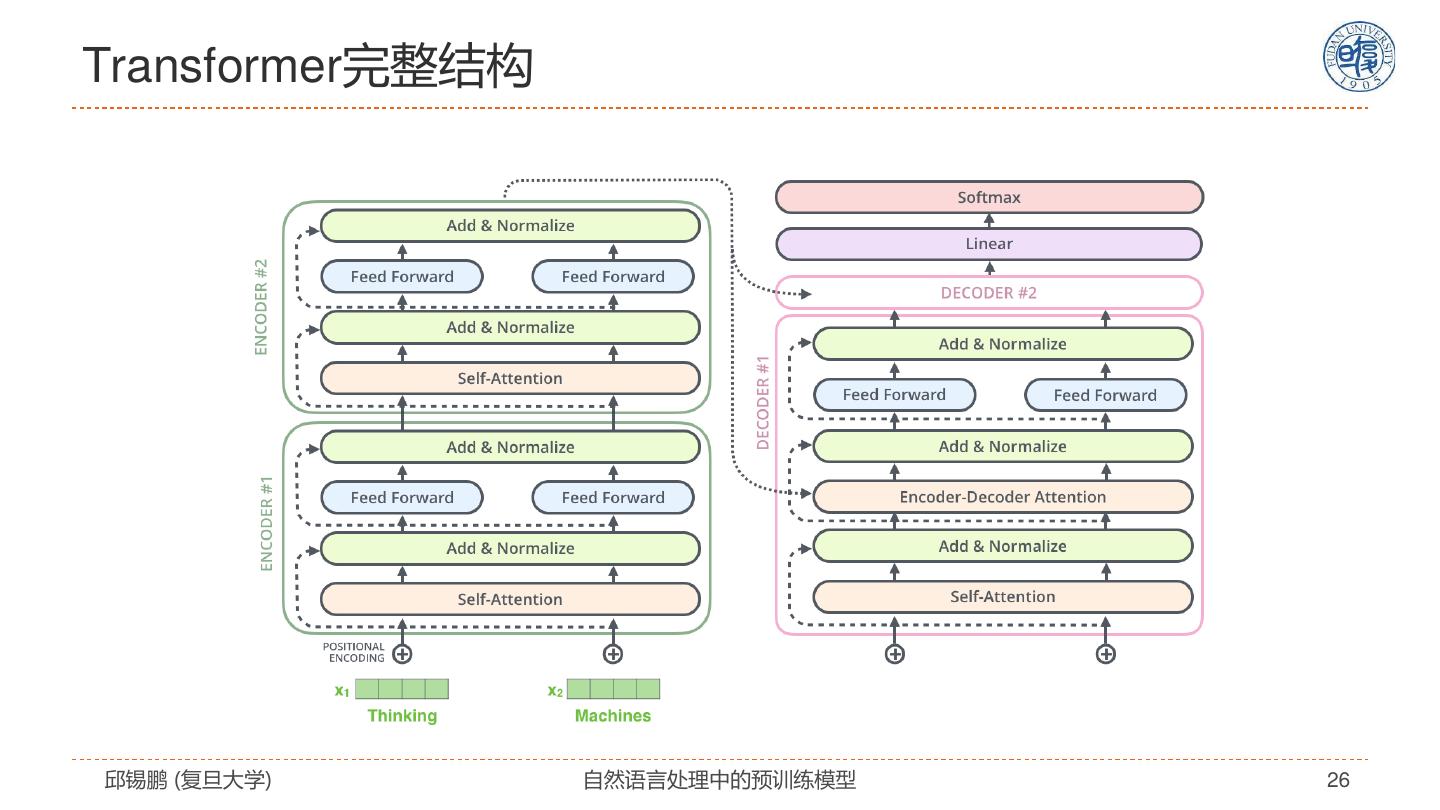
26 .Transformer完整结构 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 26
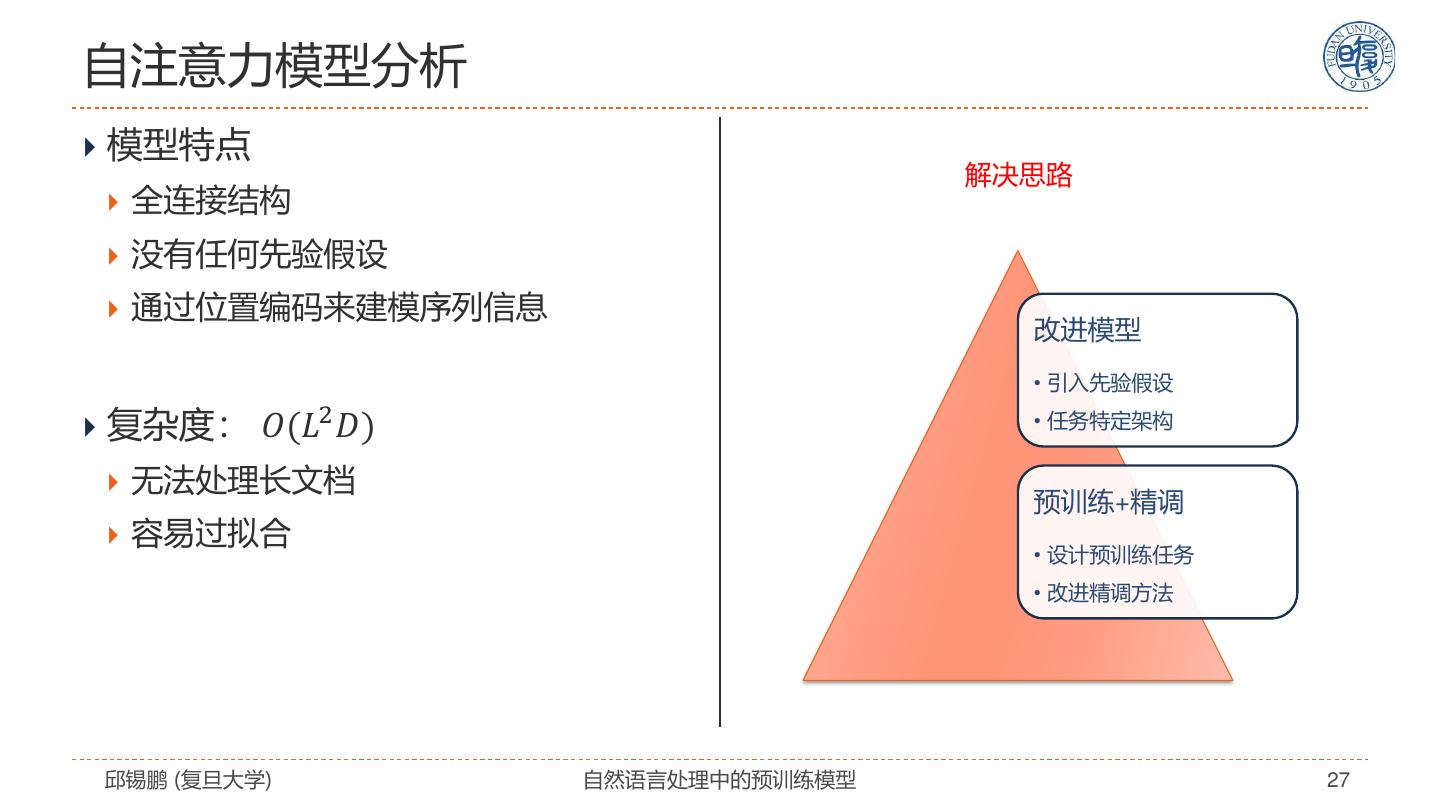
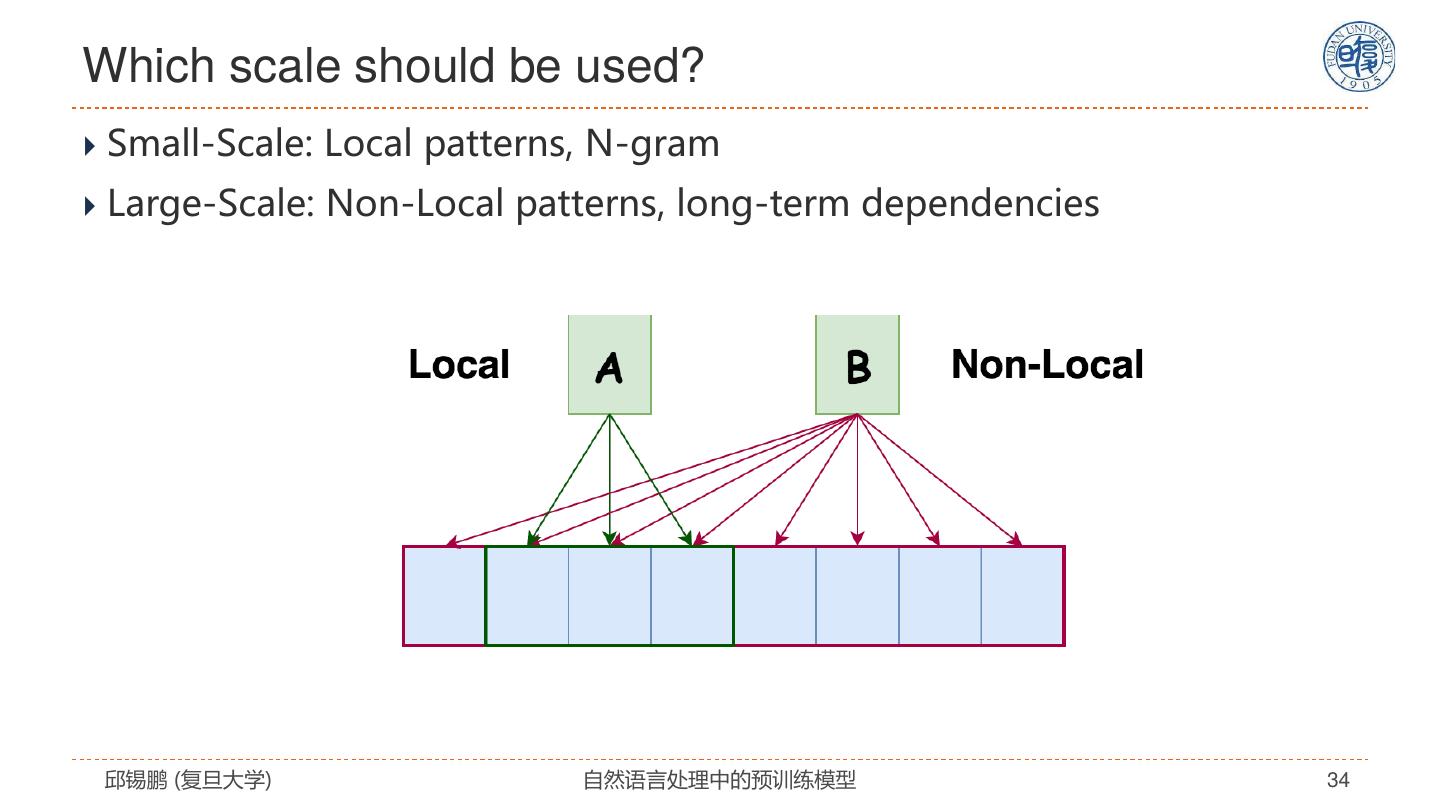
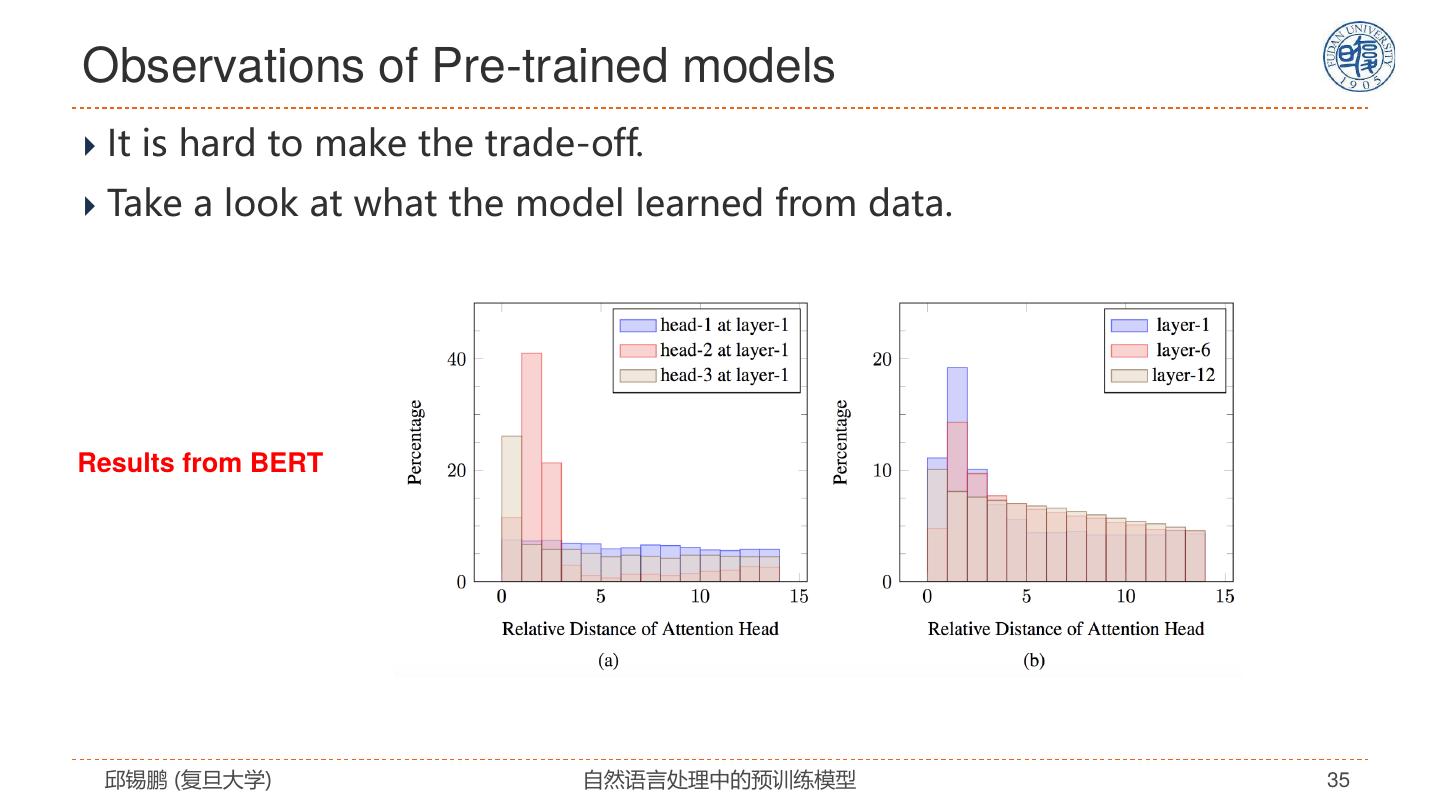
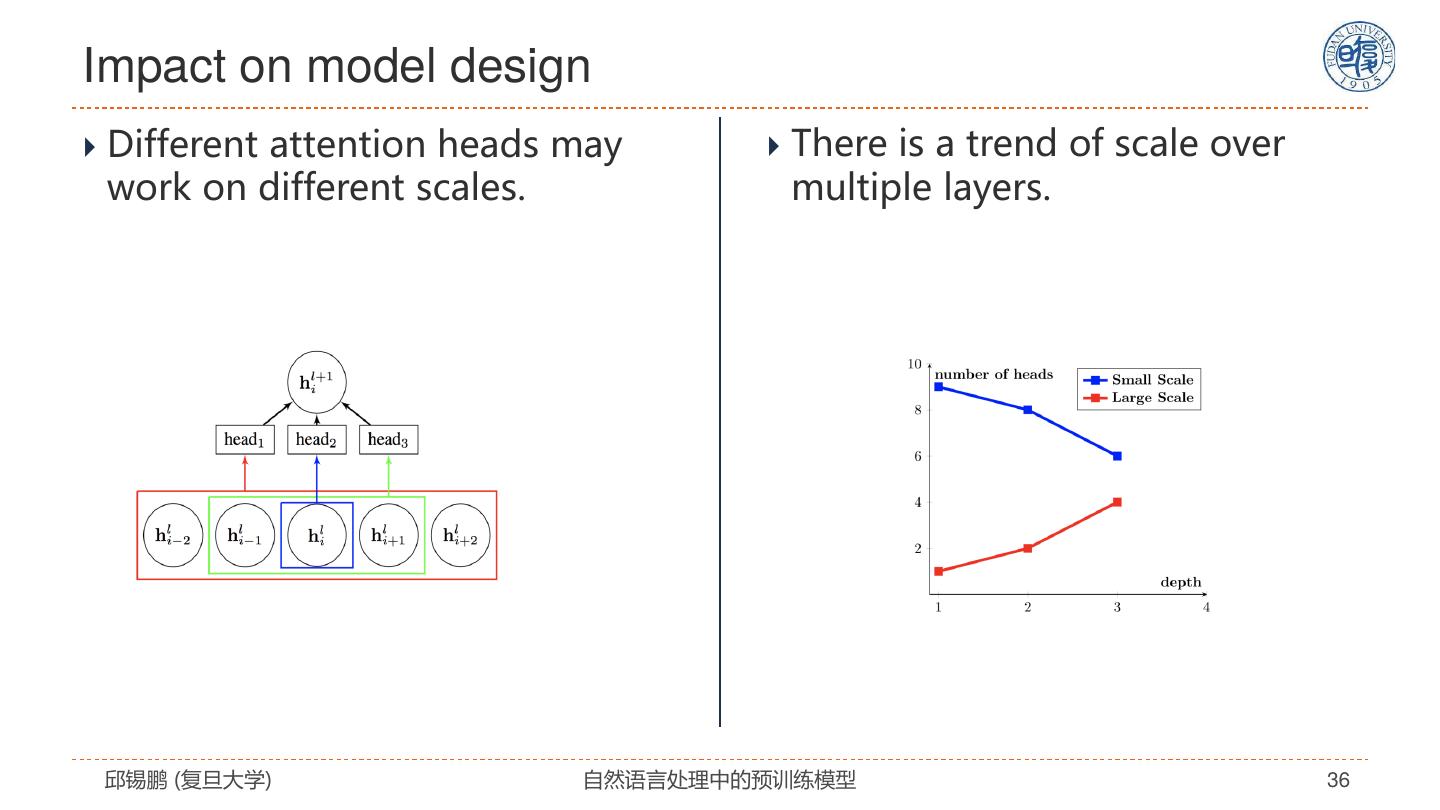
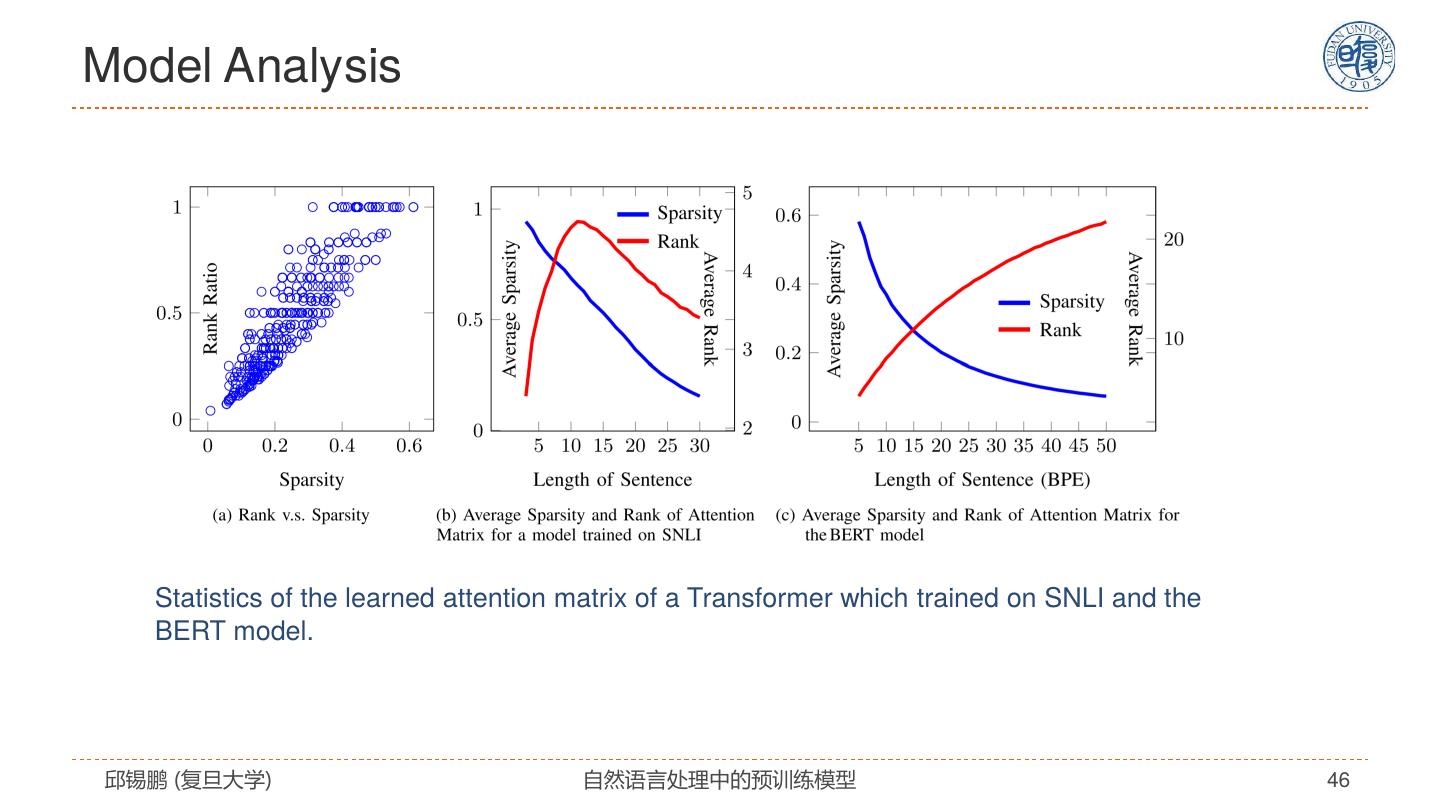
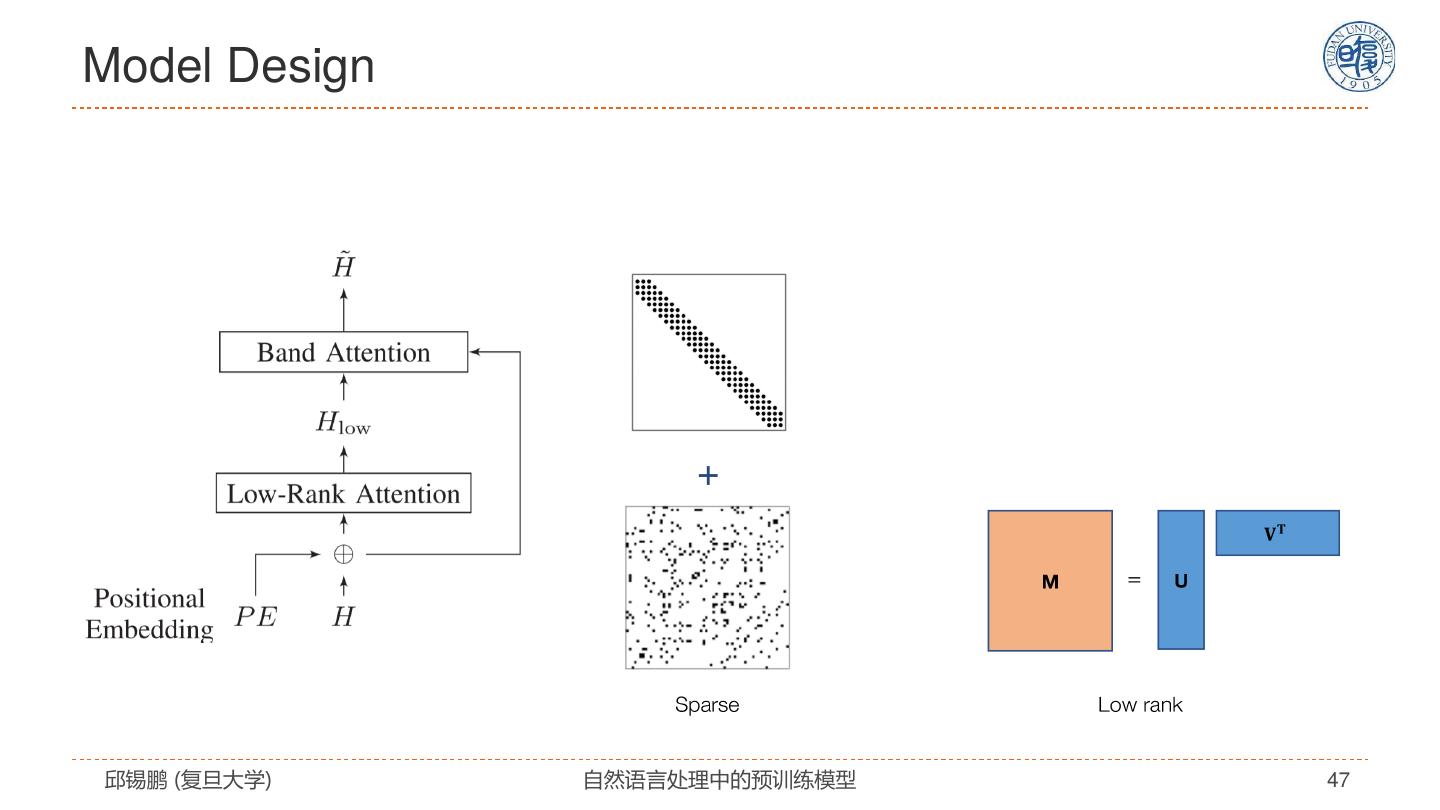
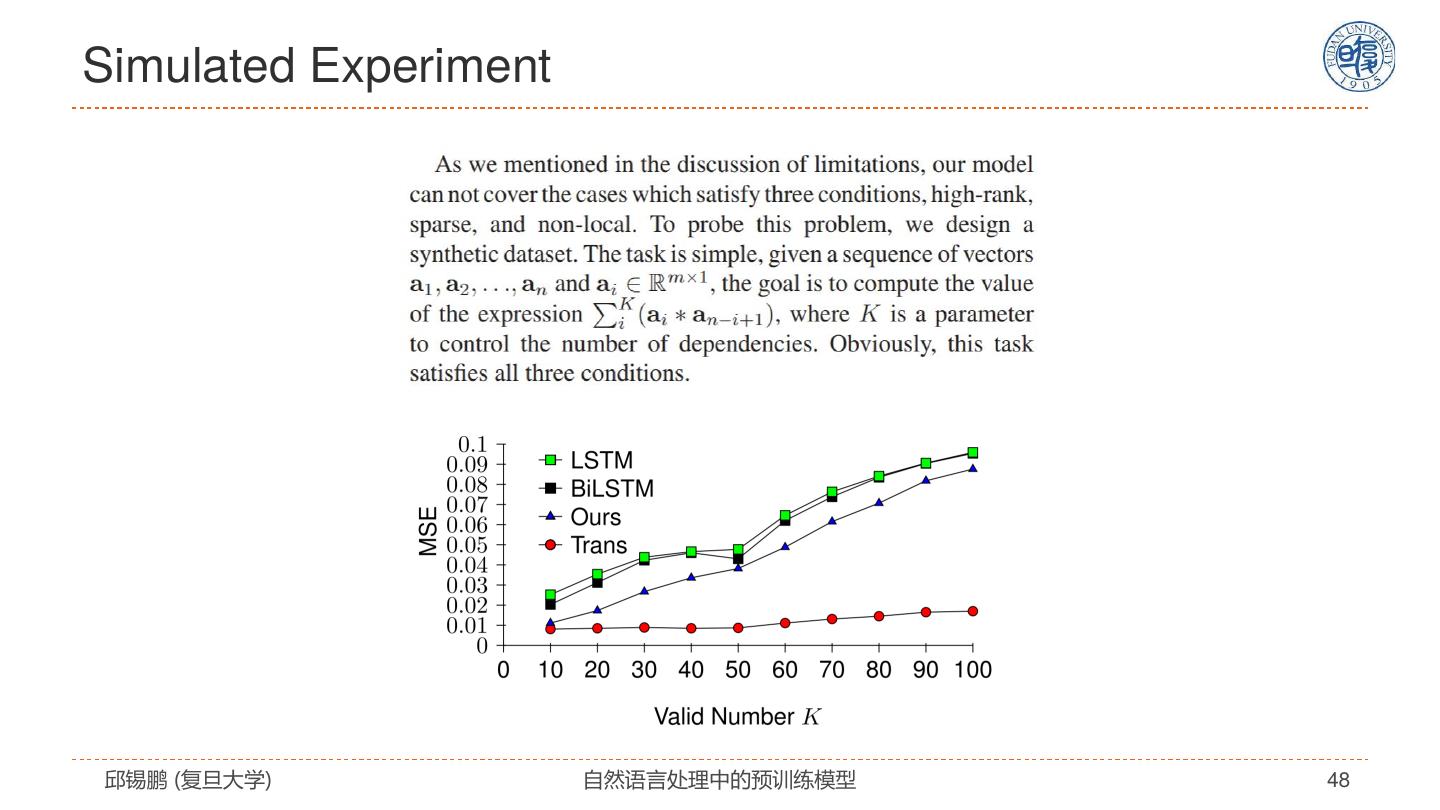
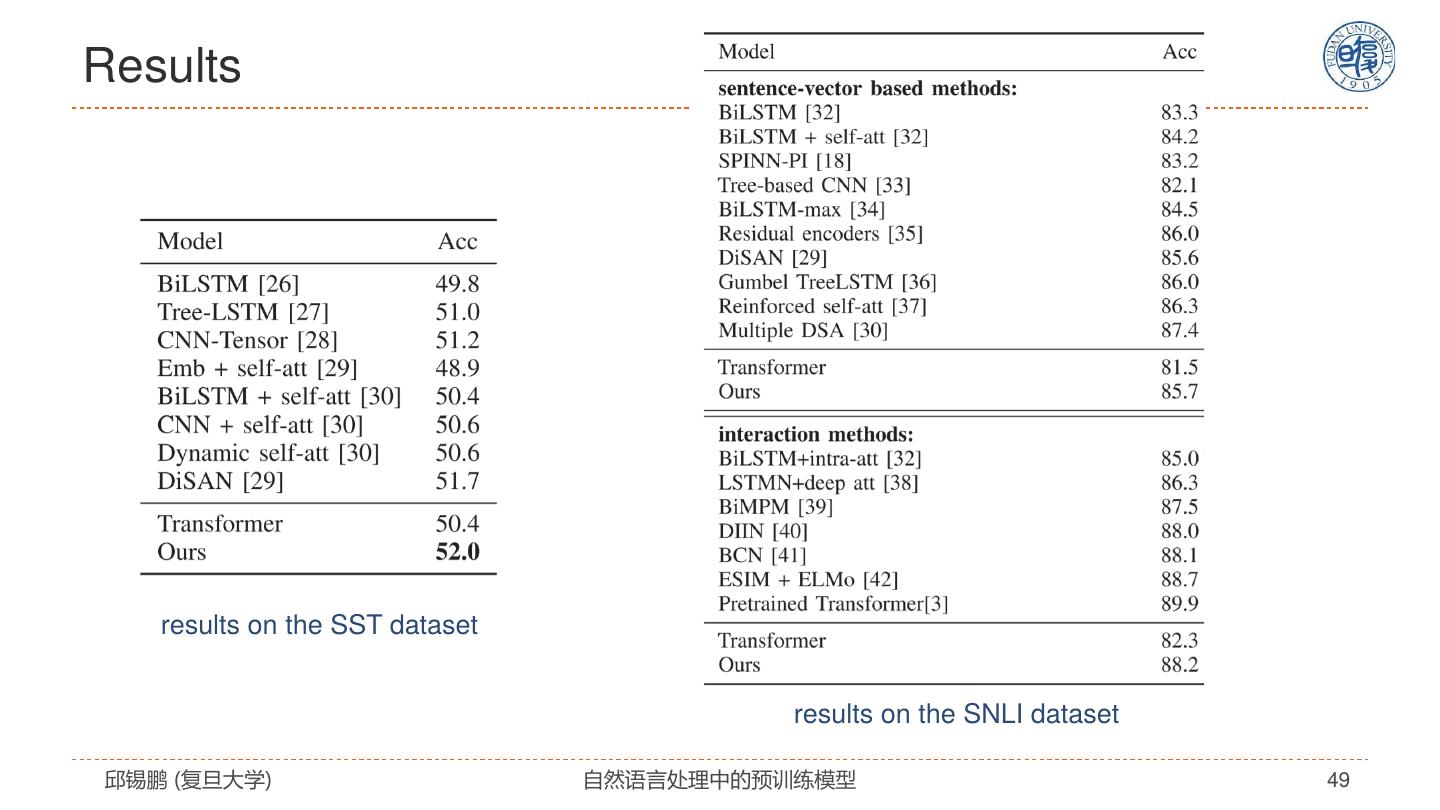
27 .自注意力模型分析 模型特点 解决思路 全连接结构 没有任何先验假设 通过位置编码来建模序列信息 改进模型 • 引入先验假设 复杂度: 𝑂(𝐿2 𝐷) • 任务特定架构 无法处理长文档 预训练+精调 容易过拟合 • 设计预训练任务 • 改进精调方法 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 27
28 . Transformer模型的改进 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 28
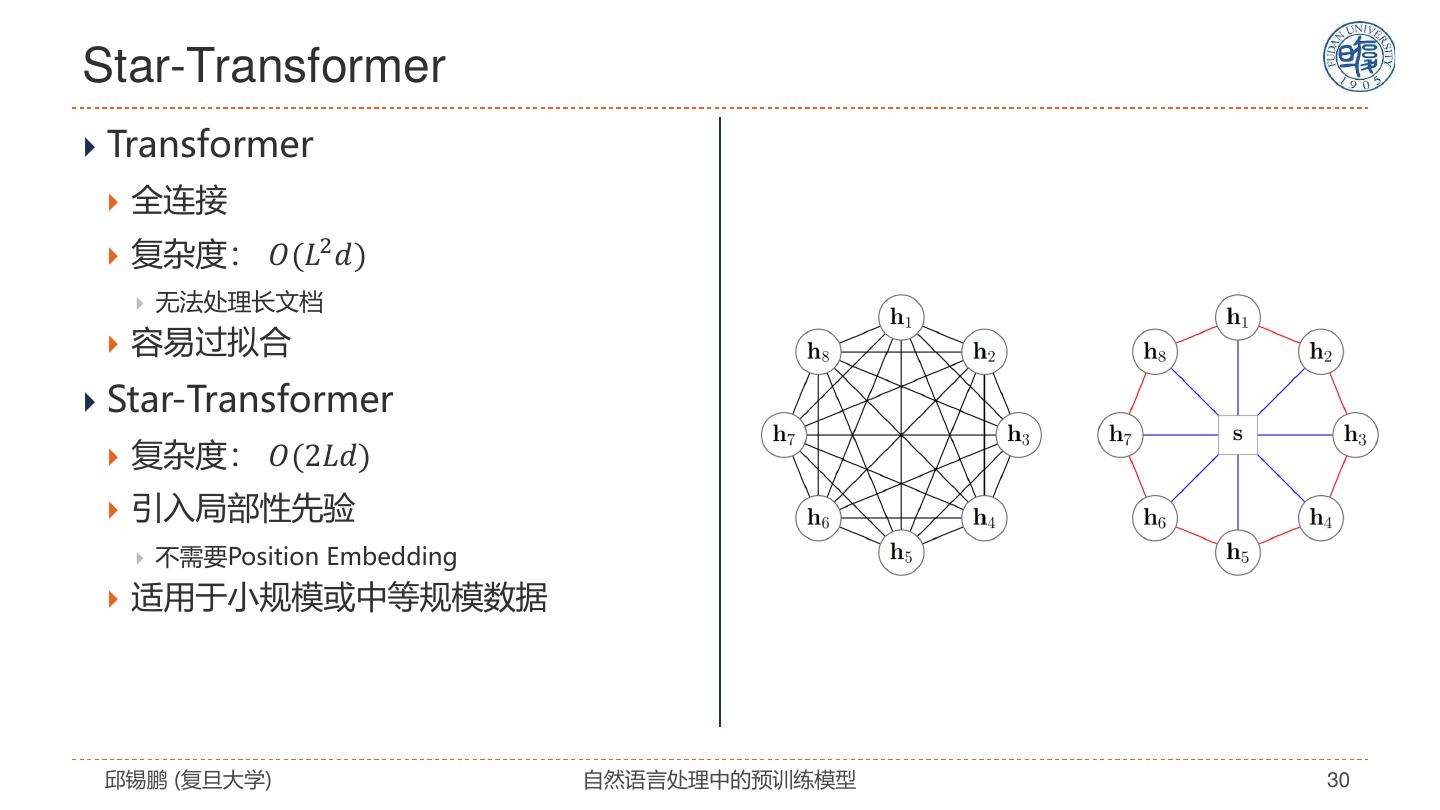
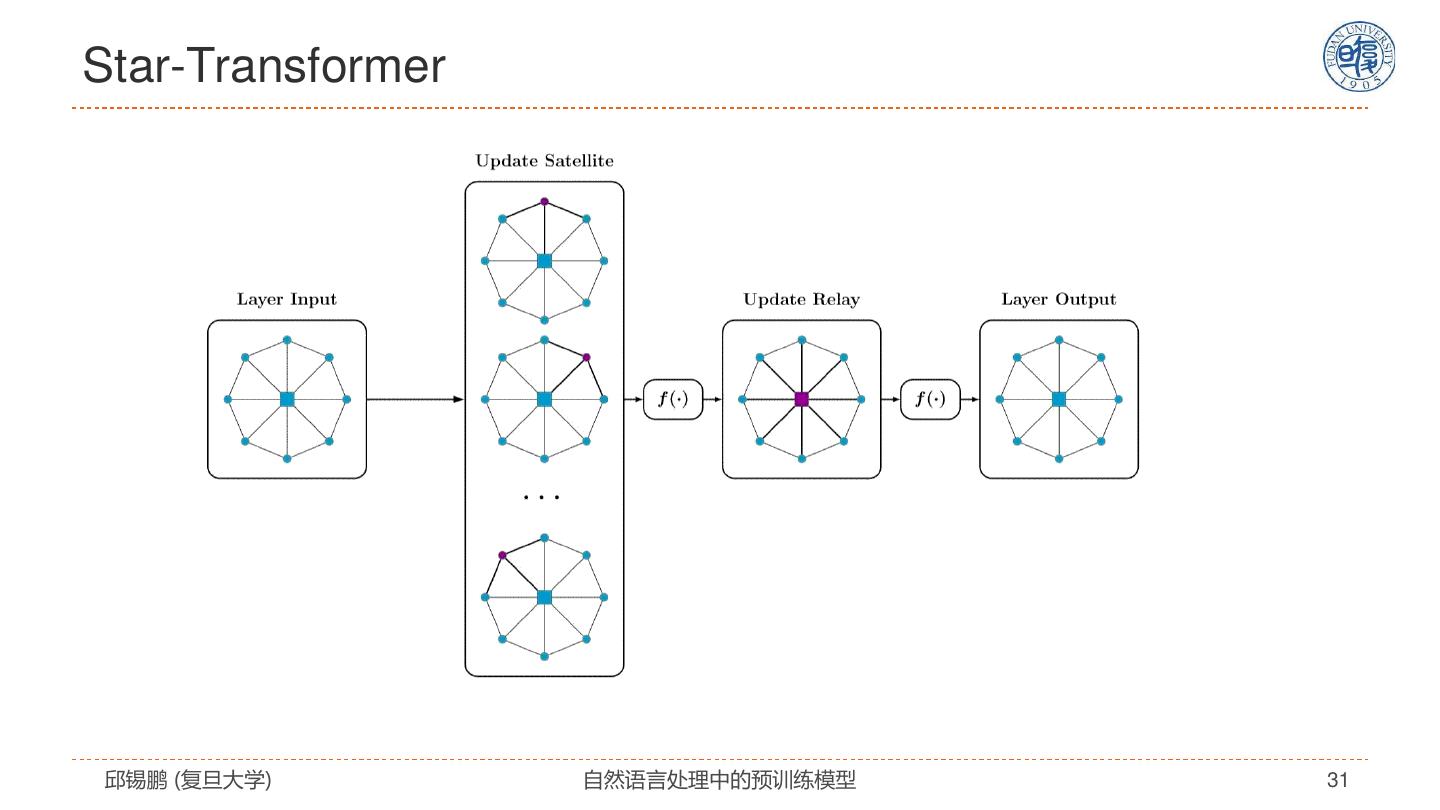
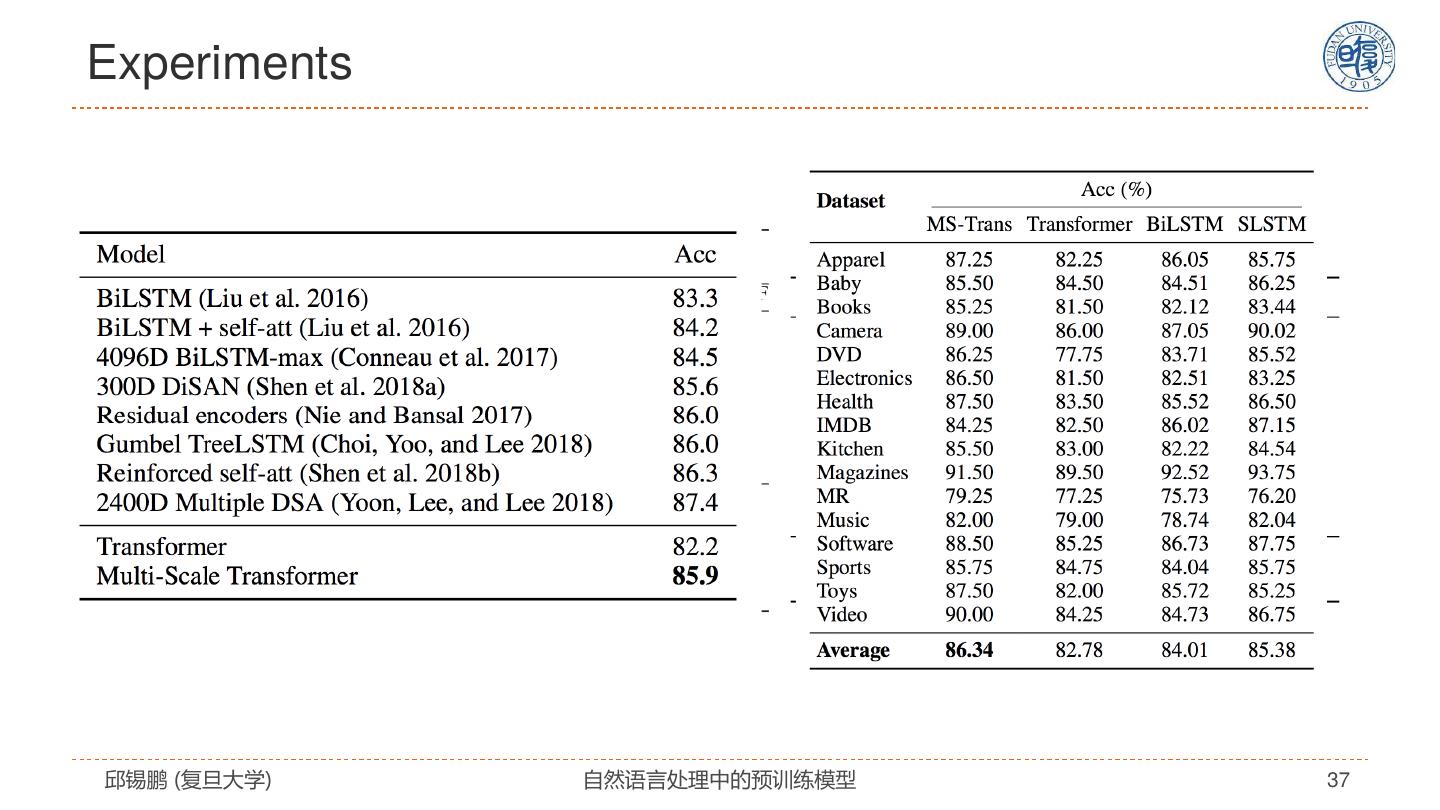
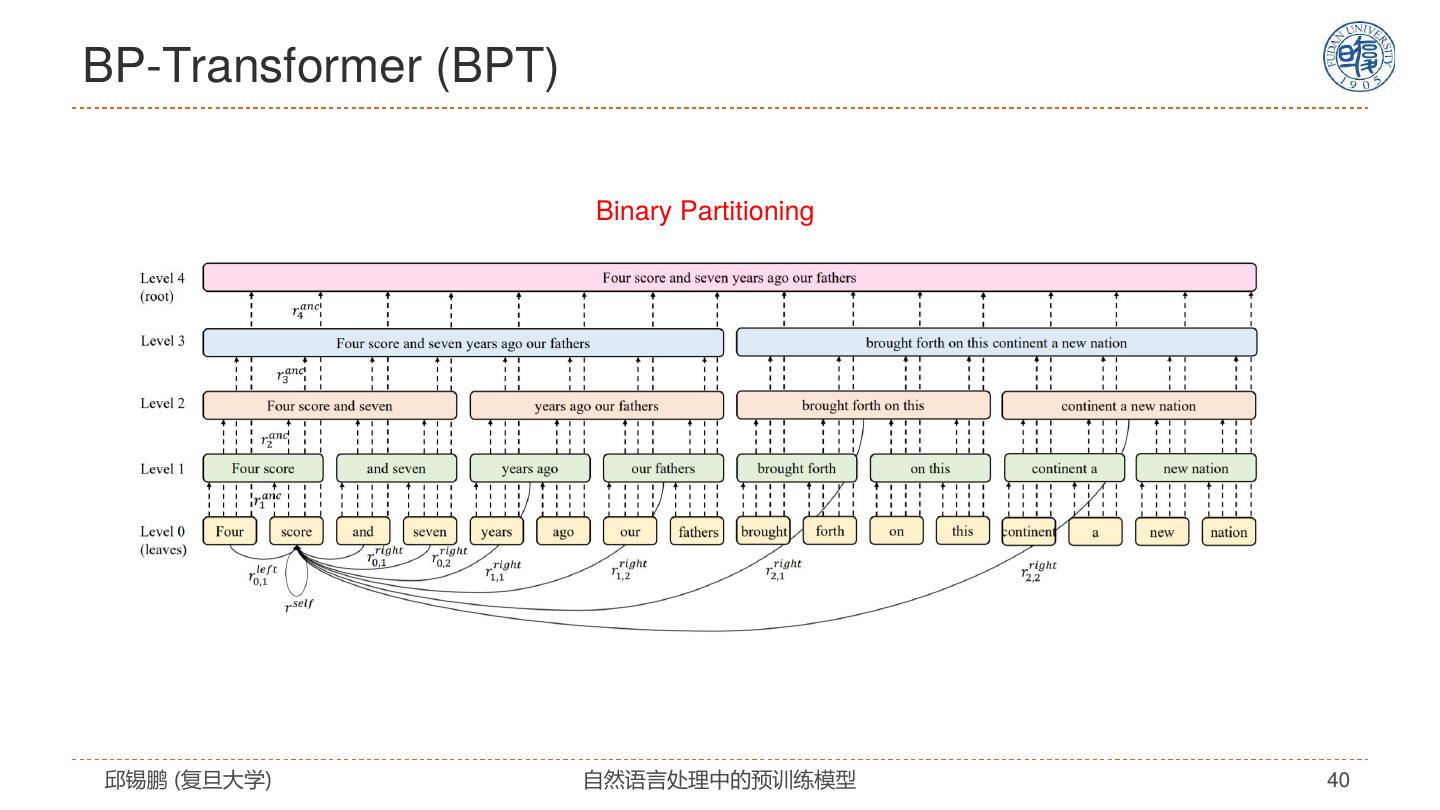
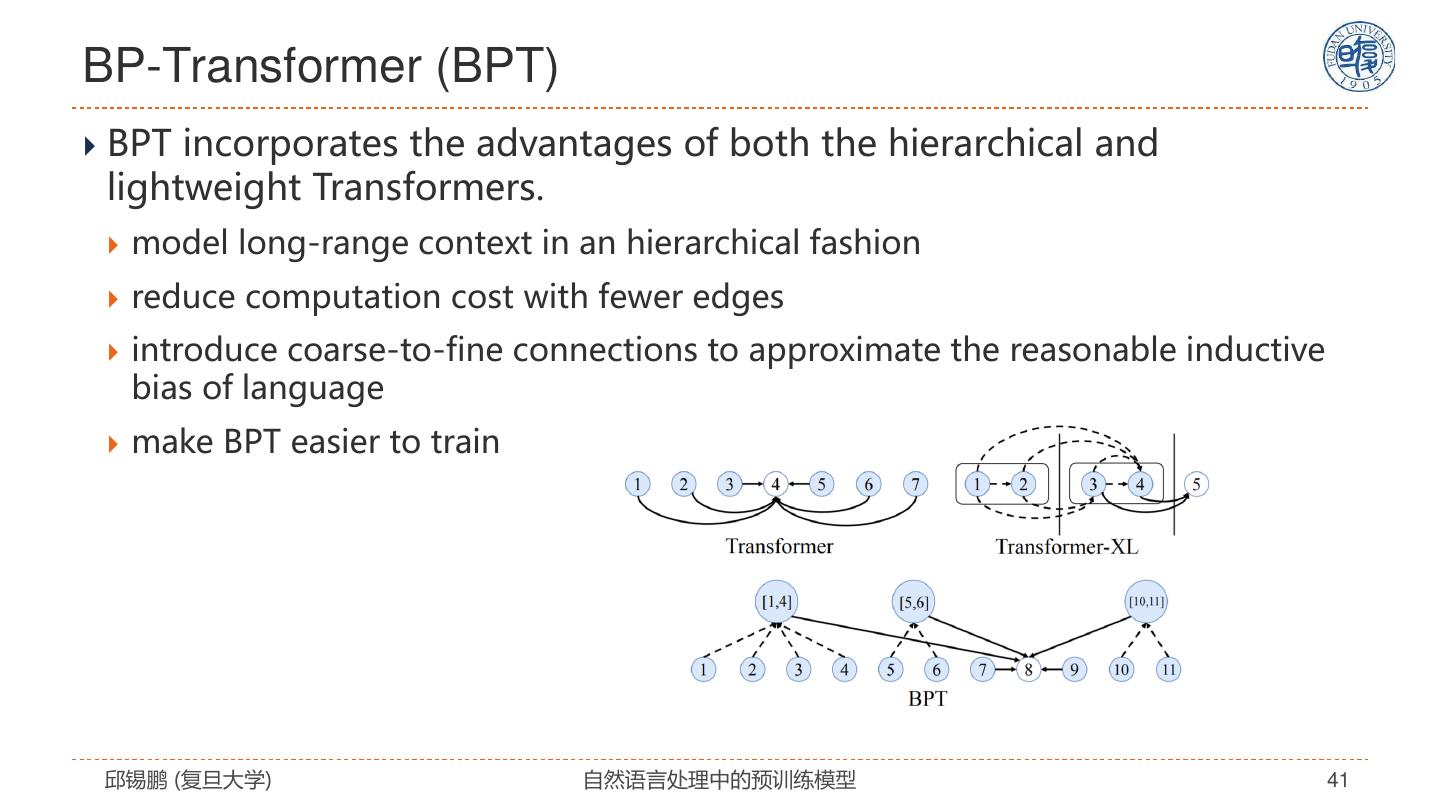
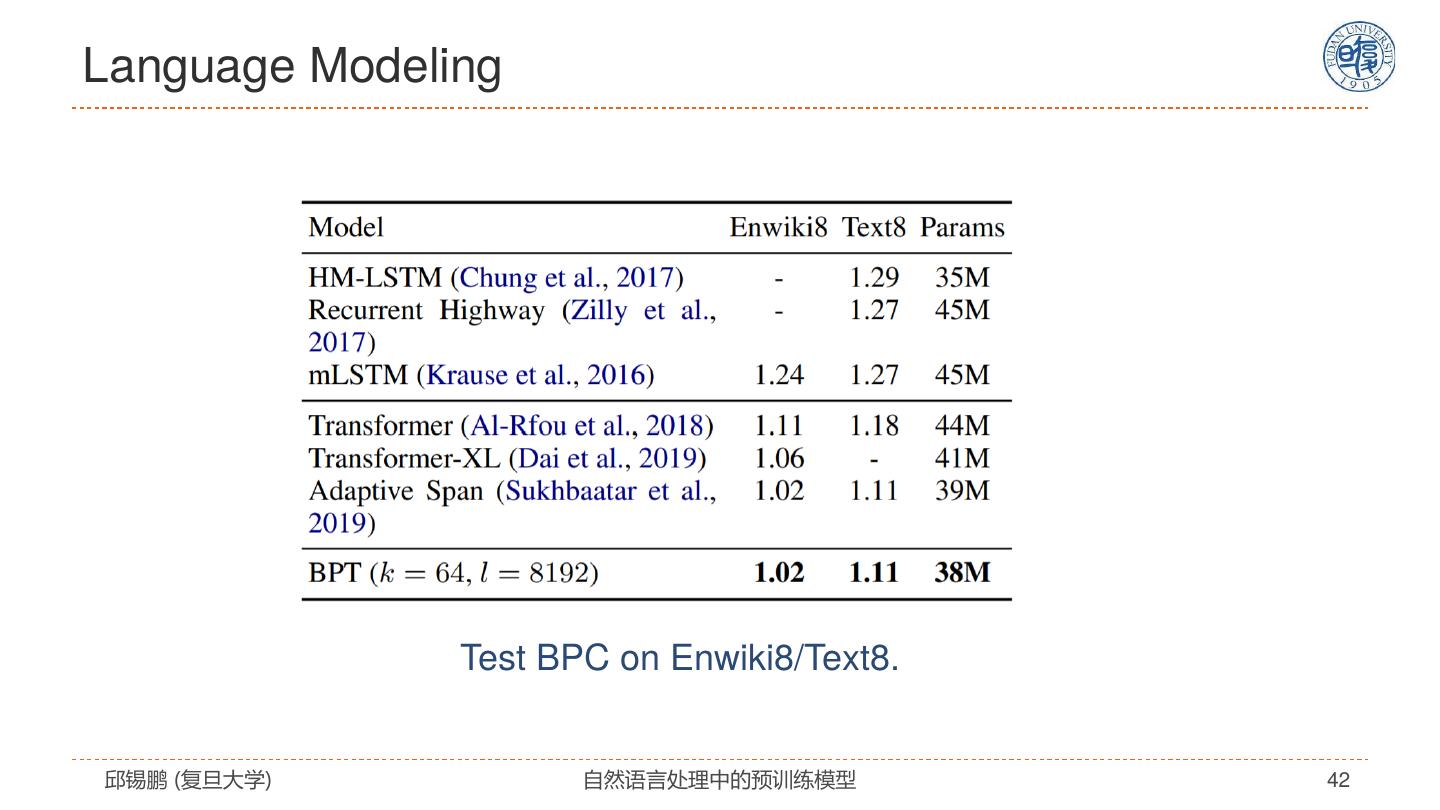
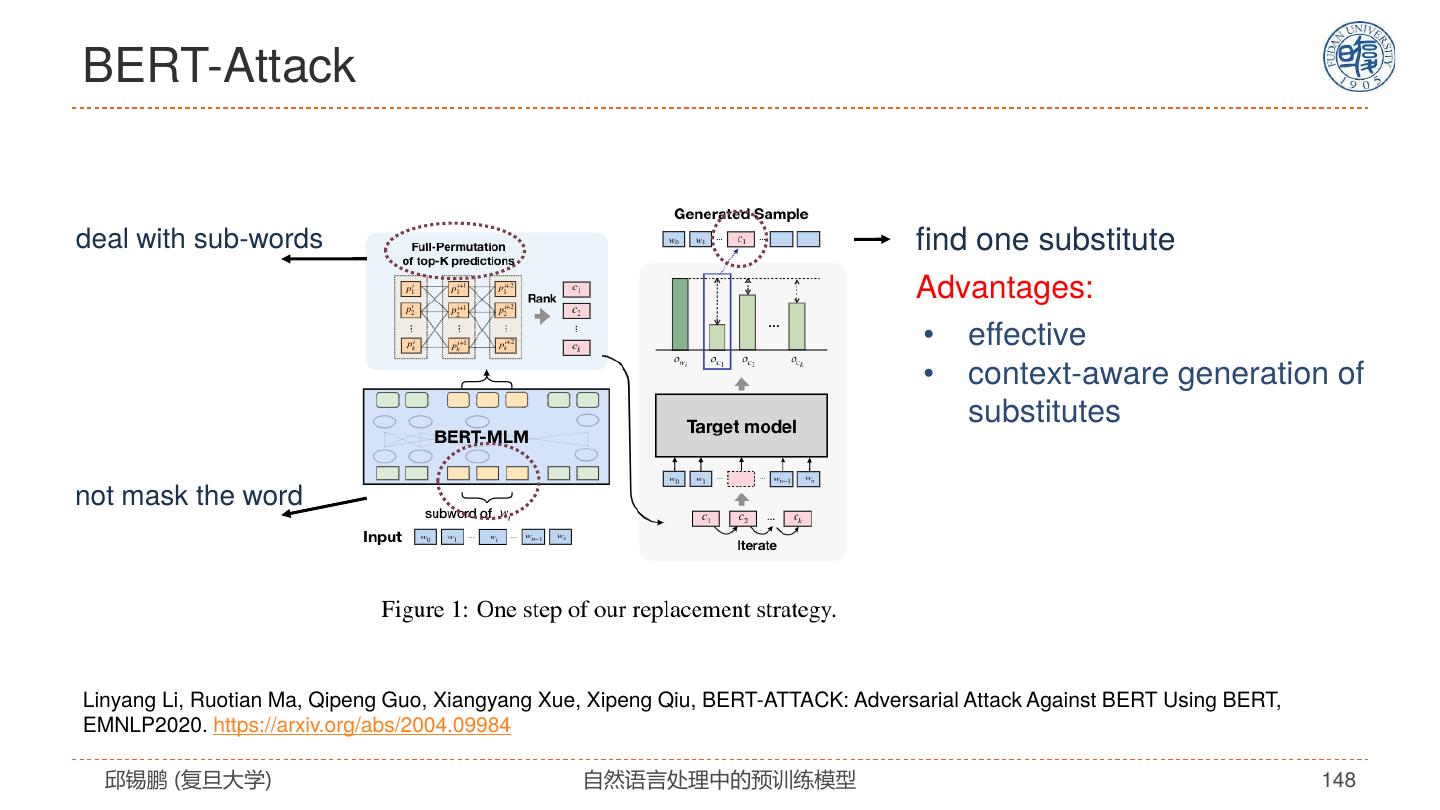
29 . Star-Transformer Qipeng Guo, Xipeng Qiu, Pengfei Liu, Yunfan Shao, Xiangyang Xue, Zheng Zhang. Star-Transformer, NAACL 2019, https://arxiv.org/pdf/1902.09113.pdf 邱锡鹏 (复旦大学) 自然语言处理中的预训练模型 29
3秒后跳转登录页面
去登陆

