























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase 2.0 在360的技术改进与应用实践
HBase在360的使用现状和发展历程,以及在升级HBase2.0的过程中发现的问题与改进。
展开查看详情
1 .HBase在360的实践及改进 360 / 系统部 / 王小勇
2 . 0x01 HBase在360的使用情况 0x02 功能与改进 0x03 HBase2.0应用实践 0x04 问题与解决 中国 HBase 技术社区网站:http://hbase.group
3 . 0x01 HBase在360的使用情况 中国 HBase 技术社区网站:http://hbase.group
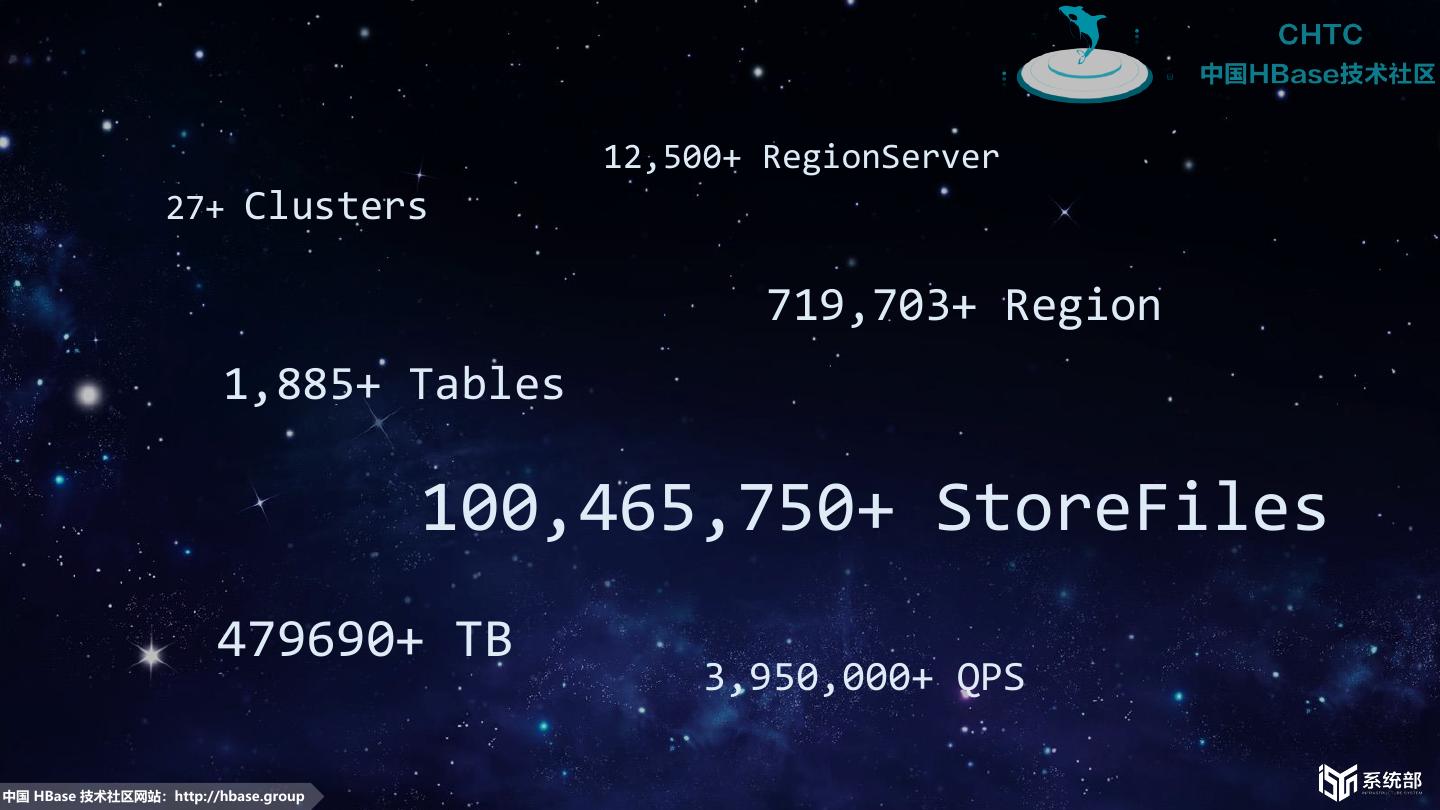
4 . 12,500+ RegionServer 27+ Clusters 719,703+ Region 1,885+ Tables 100,465,750+ StoreFiles 479690+ TB 3,950,000+ QPS 中国 HBase 技术社区网站:http://hbase.group
5 . 发展历程 12000 12500 10000 9000 7000 5000 500 50 2010 2011 2012 2013 2014 2015 2016 2017 中国 HBase 技术社区网站:http://hbase.group
6 . 业务规划与集群选择 Online Cluster Offline Cluster Online & Offline Cluster Application Application Application Thrift HBase YARN HBase YARN Thrift HBase HDFS HDFS HDFS • 优点:使用符合业务特点的硬件,相互隔离,服务可以得到保障 • 优点:扬长避短,资源利用率高 • 缺点:资源利用率不高 • 缺点:资源竞争,相互影响 中国 HBase 技术社区网站:http://hbase.group
7 . 0x02 功能和改进 中国 HBase 技术社区网站:http://hbase.group
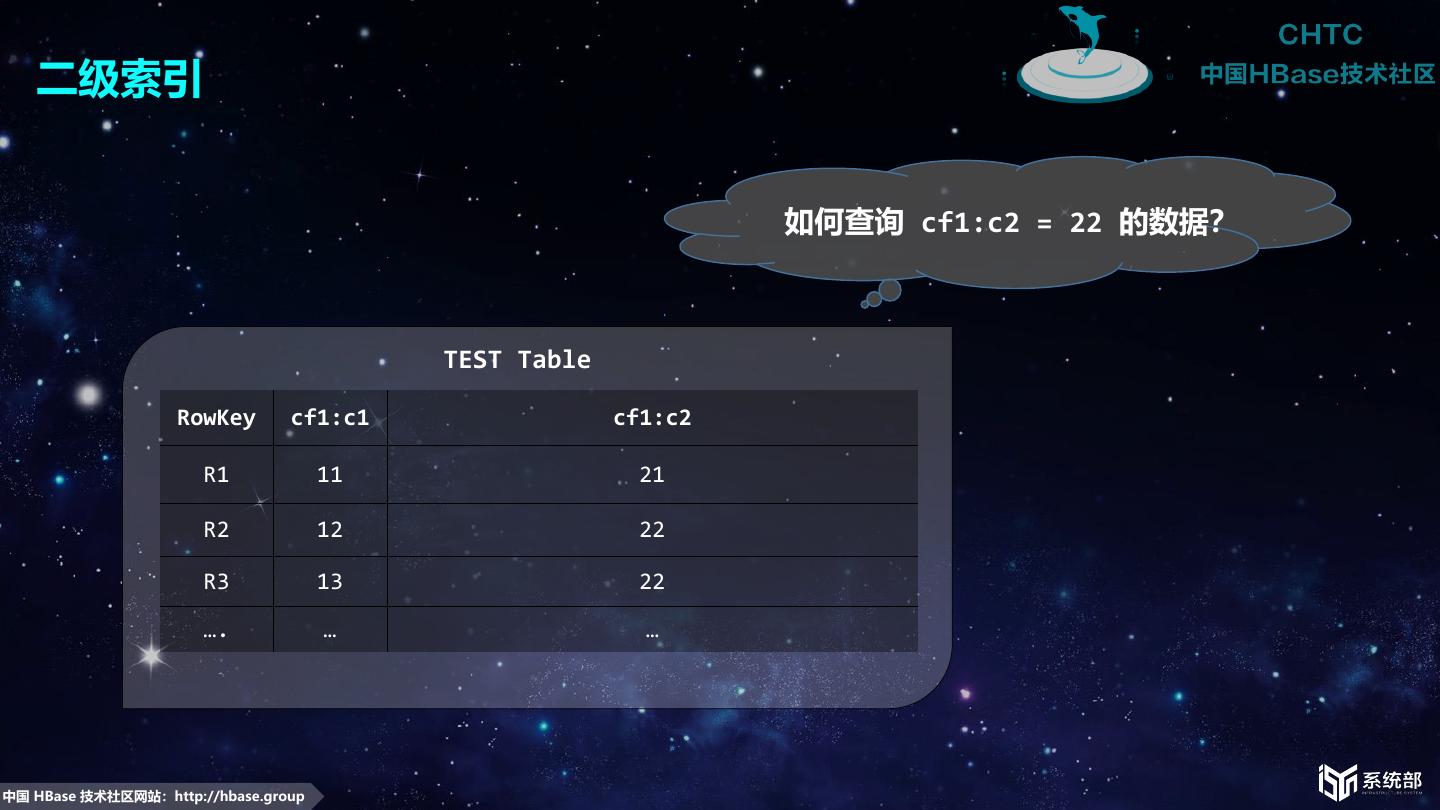
8 . 二级索引 如何查询 cf1:c2 = 22 的数据? TEST Table RowKey cf1:c1 cf1:c2 R1 11 21 R2 12 22 R3 13 22 …. … … 中国 HBase 技术社区网站:http://hbase.group
9 . 二级索引 Test Table RowKey cf1:c1 cf1:c2 为cf1:c2列构建二级索引 R1 11 21 R2 12 22 R3 13 22 …. … … Test Table二级索引Column Family RowKey INDEX:V StartKey+INDEX+21+R1 StartKey.len, R1.len, 21.len StartKey+INDEX+22+R2 StartKey.len, R2.len, 22.len StartKey+INDEX+22+R3 StartKey.len, R3.len, 22.len 中国 HBase 技术社区网站:http://hbase.group
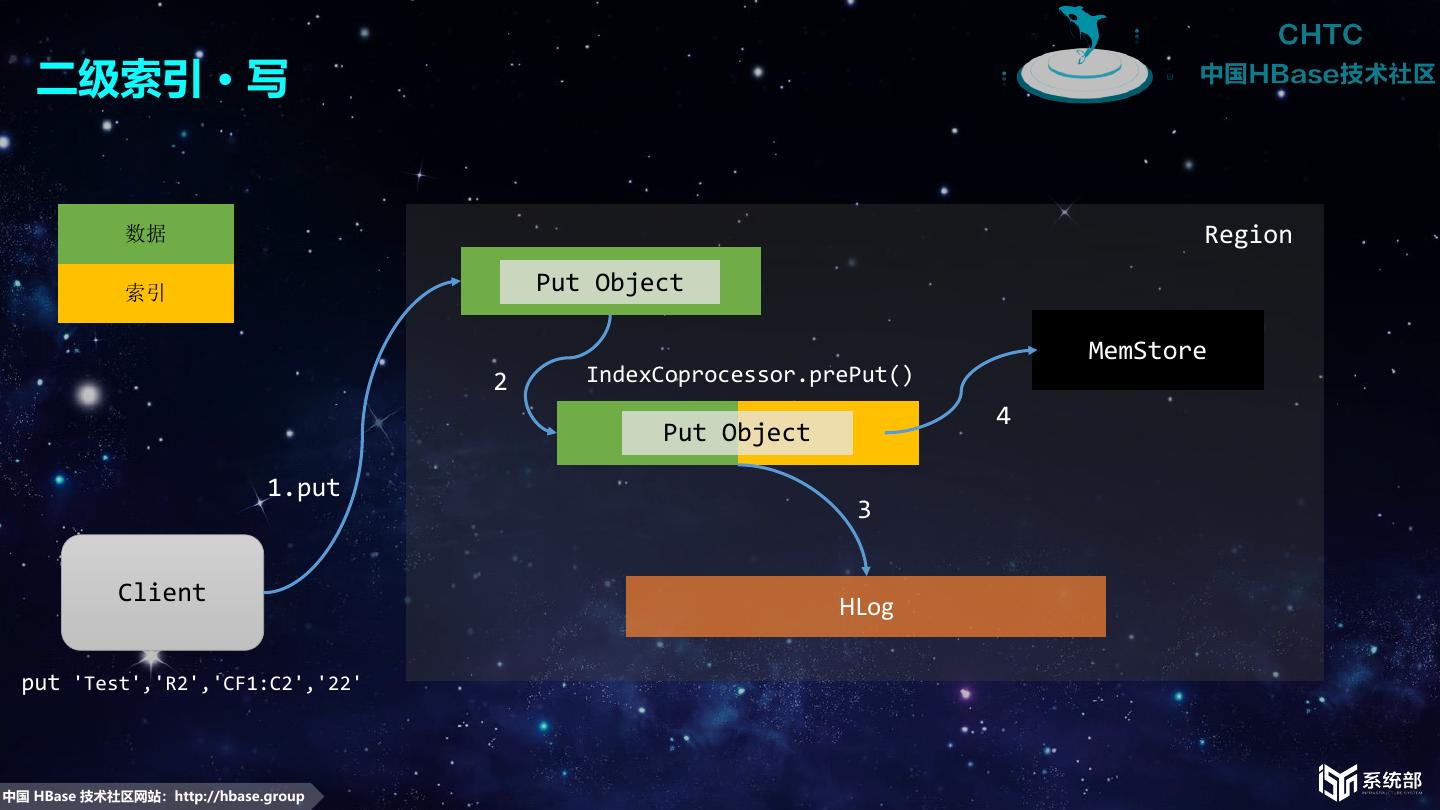
10 . 二级索引 · 写 数据 Region 索引 Put Object MemStore 2 IndexCoprocessor.prePut() 4 Put Object 1.put 3 Client HLog put 'Test','R2','CF1:C2','22' 中国 HBase 技术社区网站:http://hbase.group
11 . 二级索引 · 读 Region IndexCoprocessor.preScannerOpen() Index IndexFamily Scanner OR Leaf Leaf createScanner Scanner Scanner Client Store Store Scanner Scanner get col1 where col2=21 || col3=31 startKey: SK+IDX1+21 startKey: SK+IDX2+31 endKey: SK+IDX1+21’ endKey: SK+IDX2+31’ 中国 HBase 技术社区网站:http://hbase.group
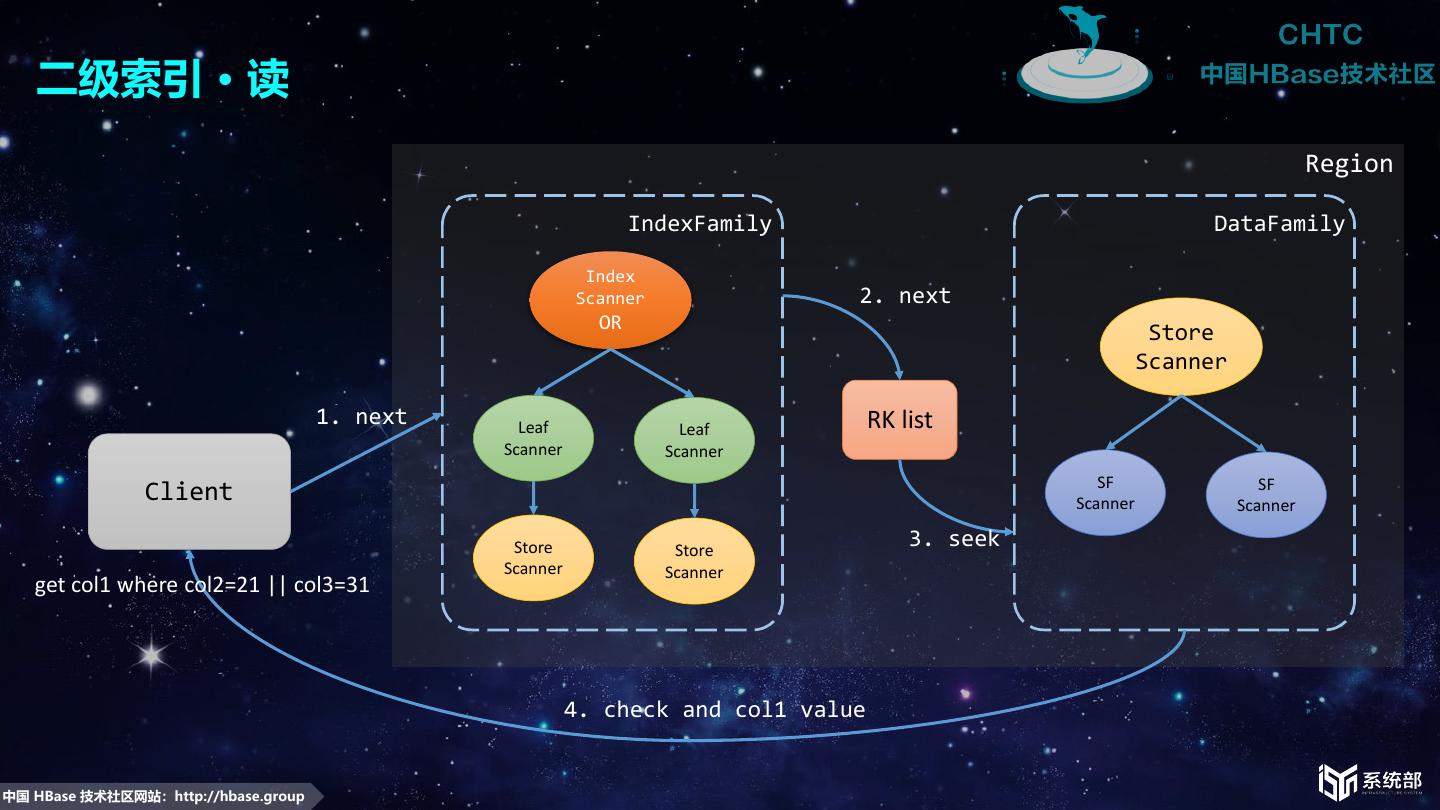
12 . 二级索引 · 读 Region IndexFamily DataFamily Index Scanner 2. next OR Store Scanner 1. next Leaf Leaf RK list Scanner Scanner SF SF Client Scanner Scanner Store Store 3. seek Scanner Scanner get col1 where col2=21 || col3=31 4. check and col1 value 中国 HBase 技术社区网站:http://hbase.group
13 . 二级索引 · 功能 功能项 描述 单列索引 只对某一列创建索引 联合索引 可对多个列创建联合索引 精确查询 如:CF1:C2 = 22 范围查询 如:CF1:C2 > 20 && CF1:C2 > 25 模糊查询 可通过某Text列中的子短语查询整行 索引修改 建表之后,可以通过命令修改索引,但只会对新数据产生效果 索引重建 重新生成索引数据 中国 HBase 技术社区网站:http://hbase.group
14 . 二级索引 · 性能 项目 详情 表结构 10列 + 10个索引 数据规模 4000亿行(8万亿KV) CPU:2路6核; 容量 200+TB MEM: 64GB; DISK::12*4TB; 查询方式 单列精确查询 NodeNum:70台 时延 平均6s 返回记录数 3000+ 查询次数 2400+ 中国 HBase 技术社区网站:http://hbase.group
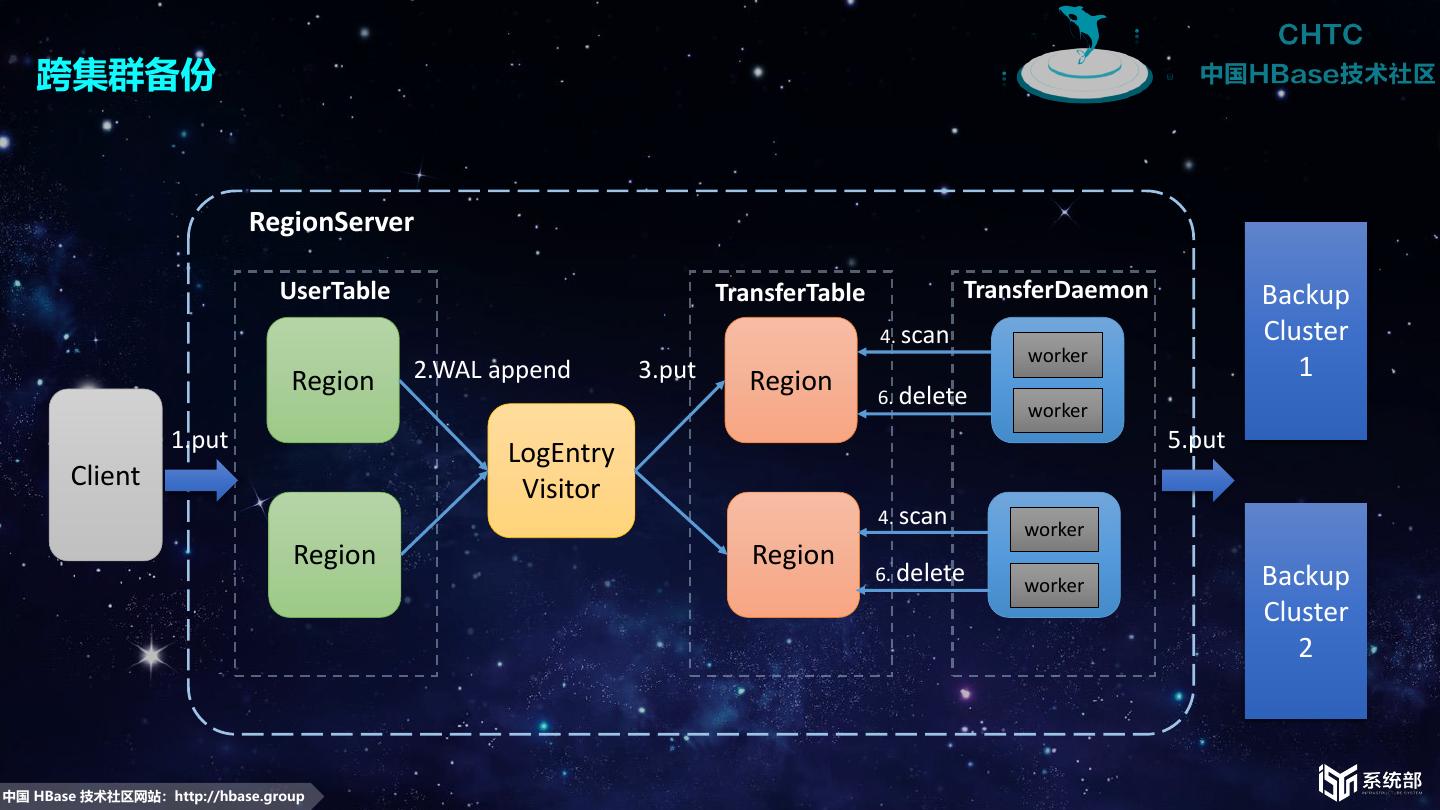
15 . 跨集群备份 RegionServer UserTable TransferTable TransferDaemon Backup 4. scan Cluster worker Region 2.WAL append 3.put Region 1 6. delete worker 1.put 5.put LogEntry Client Visitor 4. scan worker Region Region 6. delete Backup worker Cluster 2 中国 HBase 技术社区网站:http://hbase.group
16 . 0x03 HBase2.0 应用实践 中国 HBase 技术社区网站:http://hbase.group
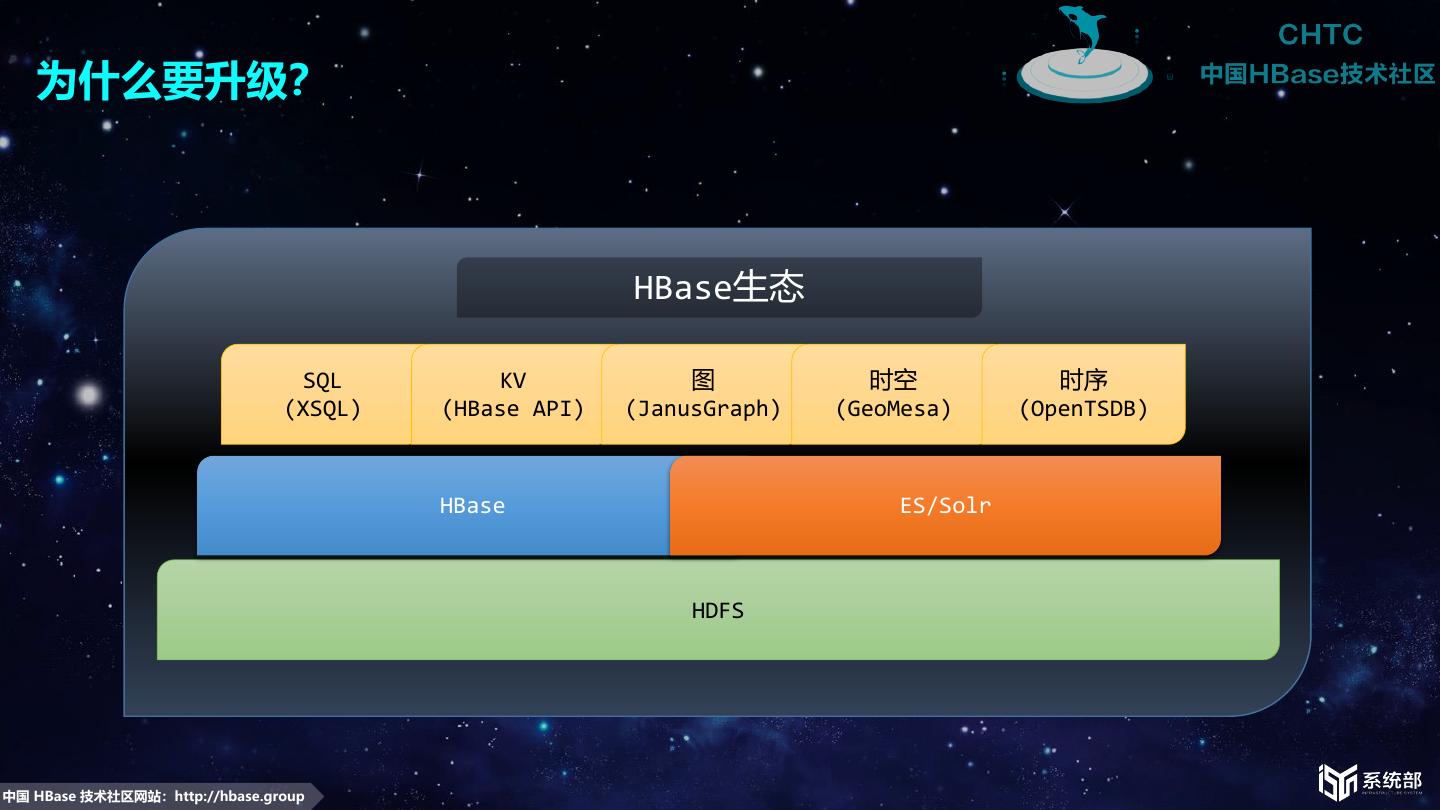
17 . 为什么要升级? HBase生态 SQL KV 图 时空 时序 (XSQL) (HBase API) (JanusGraph) (GeoMesa) (OpenTSDB) HBase ES/Solr HDFS 中国 HBase 技术社区网站:http://hbase.group
18 . 应用场景 Object Storage Service Time Serie Service AWS S3 API Admin 指标采集 指标展示 LVS LVS S3 S3 S3 OpenTSDB OpenTSDB OpenTSDB HBase Cassandra HBase 中国 HBase 技术社区网站:http://hbase.group
19 . 0x04 问题与解决 中国 HBase 技术社区网站:http://hbase.group
20 . MOB · 简述 ROW TS F2:b(MOB) REF FILE r1 t1 MOB_value1_length1,filePath,tag Memstore MOB cells r2 t2 MOB_value2_length1,filePath,tag … … … Flush ROW TS F2:b(MOB) MOB FILE 不同于常规的 HBase CF,当 MOB CF 由 Memstore 向 r1 t1 MOB_value1 R2 t2 MOB_value2 HDFS Flush 时,不仅会生成数据文件 MOB Files,还会生 … … … 成 REF Files,用于记录 MOB Files 的信息,从而在读数 据时,可以确切定位所需的 MOB Flie. 中国 HBase 技术社区网站:http://hbase.group
21 . MOB · 问题 MOB文件过于集中 目前相同 cf 的 mob Files 全部存在同一目录下,在写入 量过大、compaction 不及时等情况时,极易达到HDFS 单点Compaction 目录文件上限 目前的mob Compaction机制完全在master上进行, 且没有限速,会造成compaction不及时、master 负载过大等问题 文件过大不便释放空间 目前的mob compaction机制,除了周期性的按天、周、月合并文件, 还会通过del 文件计算出哪些mob files需要参与Compaction,如果 选中以周、月为维度的大文件,则IO放大问题依旧严重 中国 HBase 技术社区网站:http://hbase.group
22 . MOB · 解决 MOB Compaction MR 作业 1.List mob fileStatus 2.Split mobFiles by startkey 根据条件(时间、大小等)选则合适的mob files,进行分布式Compaction CLIENT 根据startKey打散目录存放 MOB Files 8.Move mobfile from tmp path to MOBDIR/STARTKEY/XXXXX 3.Select mobFiles according 避免全部保存在一个目录,达到目录文件数上限 4.Merge del files Has next? to date or other condition 性价比更高的Compaction策略Need compaction? 9.Bulkload new ref files 5.Create scanner by mob files 6.Write new mob files in tmp path ref file:记录了rowkey保存在哪个mob file中,以及value的大小 del file:记录了哪些rowkey被删除 7.Write new ref file according to new mob files 通过ref file和del file我们可以计算出一个mob file过期数据的比例,然后选取过期 数据比例大(可配置)的文件进行compaction END 中国 HBase 技术社区网站:http://hbase.group
23 . 一些“问题”… # Meta无法分配 # 当一个 RSGroup 中的 Node 全部 Down 掉,在重启之后,此 RSGroup 中的 Table 依然无法分配!!! 使用 RSGroupBasedLoadBalancer.retainAssignment() 方法执行分配计划时,会选择表所属RSGroup中在线 的节点,如果选不出应该怎么处理呢? 很不幸,我们当前使用的代码(hbase 2.0.2)中,它什么都不做,所以table将一直在RIT队列中,而且除了重启 master,没有办法触发重新分配。 # 解决方案 # 1. 分配到一个不存在的节点(localhost,1,1),触发重新分配逻辑 2. 为System表增加降级方案,如果system rsgroup中的机器都挂了,将选择一个负载较低的节点进行分配 中国 HBase 技术社区网站:http://hbase.group
24 . # 部分 region 不分配 # master和几台regionserver挂了,重启之后,有部分region不分配!!! master有一个online rs列表(来自于ZK),还有一个dead rs列表(SCP、WAL全量不在ZK上的),master启动 时,会把 dead rs 中的region进行重新分配;而这次分不掉的region,既不在online列表,也不再dead列表。 这个问题比较奇怪,因为WAL目录中没有此 server,说明此 server 的 hlog 已被 split,而 split hlog 只有在 ServerCrashProcedure 中才会被触发; 也就是说,dead rs要不在HDFS WAL目录中,要不在ServerCrashProcedure procedure store中? 嗯,我们临时解决办法是判断 region 所在的 server,若既不在 online 列表也不再 dead 列表,则重新分配 此region. 中国 HBase 技术社区网站:http://hbase.group
25 . # READ 请求堆积 # block missing 引起的读请求堆积!!! 这个问题不算是HBase的问题,但对HBase的影响很大, 当hbase访问到missing block时,hadoop客户端最多会重试7次,而且重试时间会越来越长,会长达十几二十秒。 而且,当请求量稍微多一点就容易把 HBase 读线程占满,这时就会阻塞其他正常的读请求。 # 解决方案 # 给hadoop客户端添加一个配置,如果是hbase的请求,而且block的副本数为0,则快速失败,不再重试. 中国 HBase 技术社区网站:http://hbase.group
26 . 0x05 未来 中国 HBase 技术社区网站:http://hbase.group
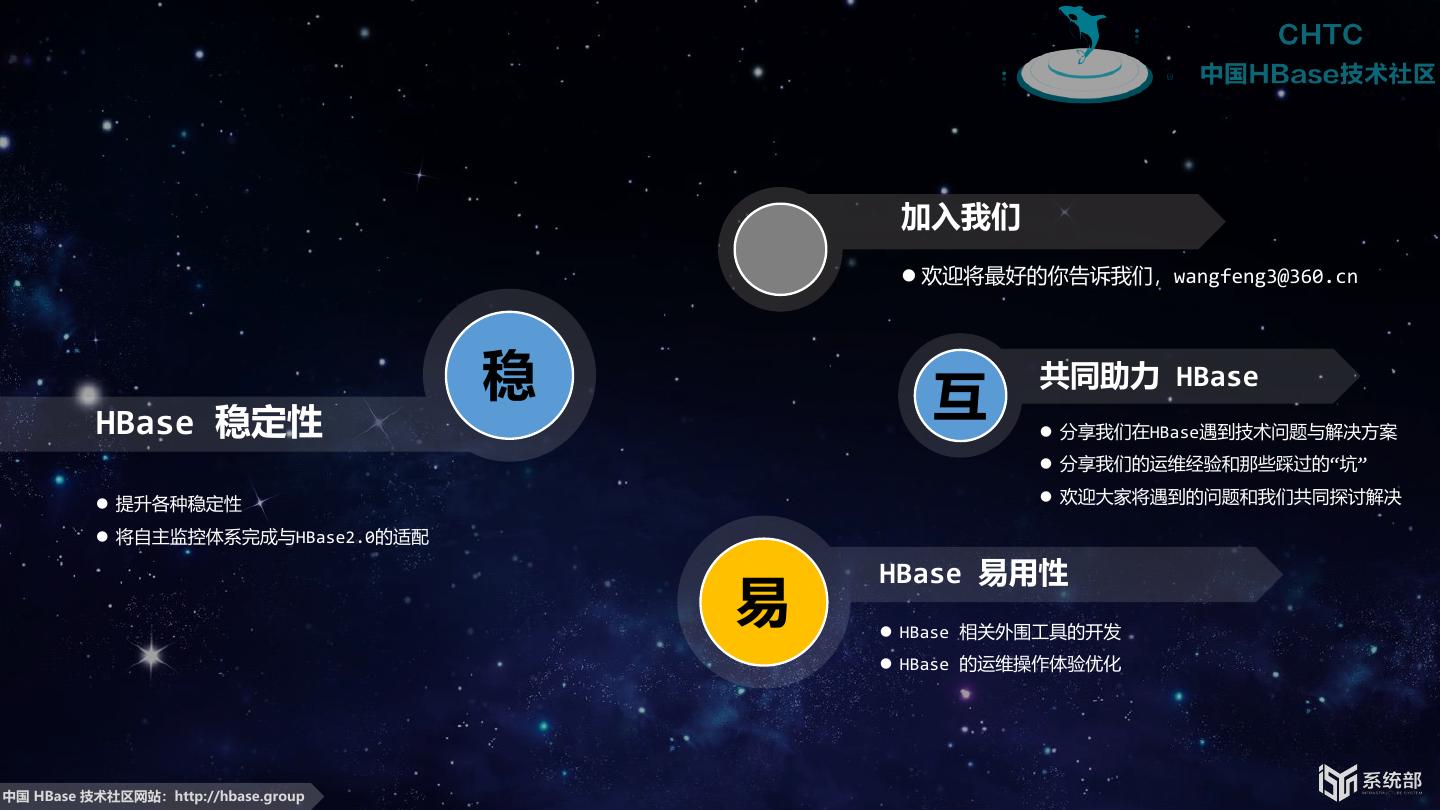
27 . 加入我们 欢迎将最好的你告诉我们,wangfeng3@360.cn 稳 互 共同助力 HBase HBase 稳定性 分享我们在HBase遇到技术问题与解决方案 分享我们的运维经验和那些踩过的“坑” 提升各种稳定性 欢迎大家将遇到的问题和我们共同探讨解决 将自主监控体系完成与HBase2.0的适配 HBase 易用性 易 HBase 相关外围工具的开发 HBase 的运维操作体验优化 中国 HBase 技术社区网站:http://hbase.group
28 .
3秒后跳转登录页面
去登陆

