展开查看详情
2 .++ +. . +0 3 +0
3 +3 . .3
�
5 . Delta Lake
• ACID Transactions Coming soon:
• Scalable Metadata • Audit History
Handling
• Full DML Support
• Time Travel (data
versioning) • Expectations
• Open Format
• Unified Batch and
Streaming Source and
Sink
• Schema Enforcement
�
6 . Data Source V2
• Unified API for batch and streaming
• Flexible API for high performance
implementation
• Flexible API for metadata management
• Target 3.0
�
7 . Runtime Optimization
Adaptive Execution EMR Runtime Filter
Dynamic optimize the execution • Filter big table with runtime
plan at runtime based on the statistic of join key.
statistic of previous stage.
• Support both partitioned
• Self tuning the number of table and normal table.
reducers
• Adaptive join strategy
• Automatic skew join handling
�
8 . EMR Spark Relational Cache
User may analyze data in Data Organization:
certain access pattern • partition, bucket, sort
• Regularly join 2 tables? • file index, zorder
• Regularly aggregate by certain Data pre-computation:
fields?
• pre-filter
• Regularly filter by certain
fields? • denormalization
• …… • pre-aggregation
• ……
Make data adaptive to compute, so spark
compute faster.
�
9 .Easy to build and maintain Transparent to user
P
P
CREATE VIEW emp_flat AS -- User Query --
SELECT * FROM employee, address SELECT * FROM F
F
WHERE e_addrId = a_addrId; employee,
address WHERE C
Spark
J
CACHE TABLE emp_flat
e_addrId =
USING parquet
Optimizer
optimized plan
PARTITIONED BY (e_ob_date)
a_addrId and E A
a_cityName
= ’ShangHai’
P
-- Cached Mata --
emp_flat J
E A
�
11 .Storage and Computing Disaggregation
Why disaggregate storage and computing:
• Pay as you go.
• Scale independently of each other.
• More reliable storage.
The challenge of disaggregation:
• Object store metadata management.
• Limited network resource.
�
12 . Storage and Computing Disaggregation
EMR JindoFS fill the gap between
object store and compute framework:
• File System API and meta
management.
• Local replication support. Remote
reliable storage and fast local access.
• Automatic and transparent cold data
separation and migration
• Optimized for machine learning and
Spark AI
�
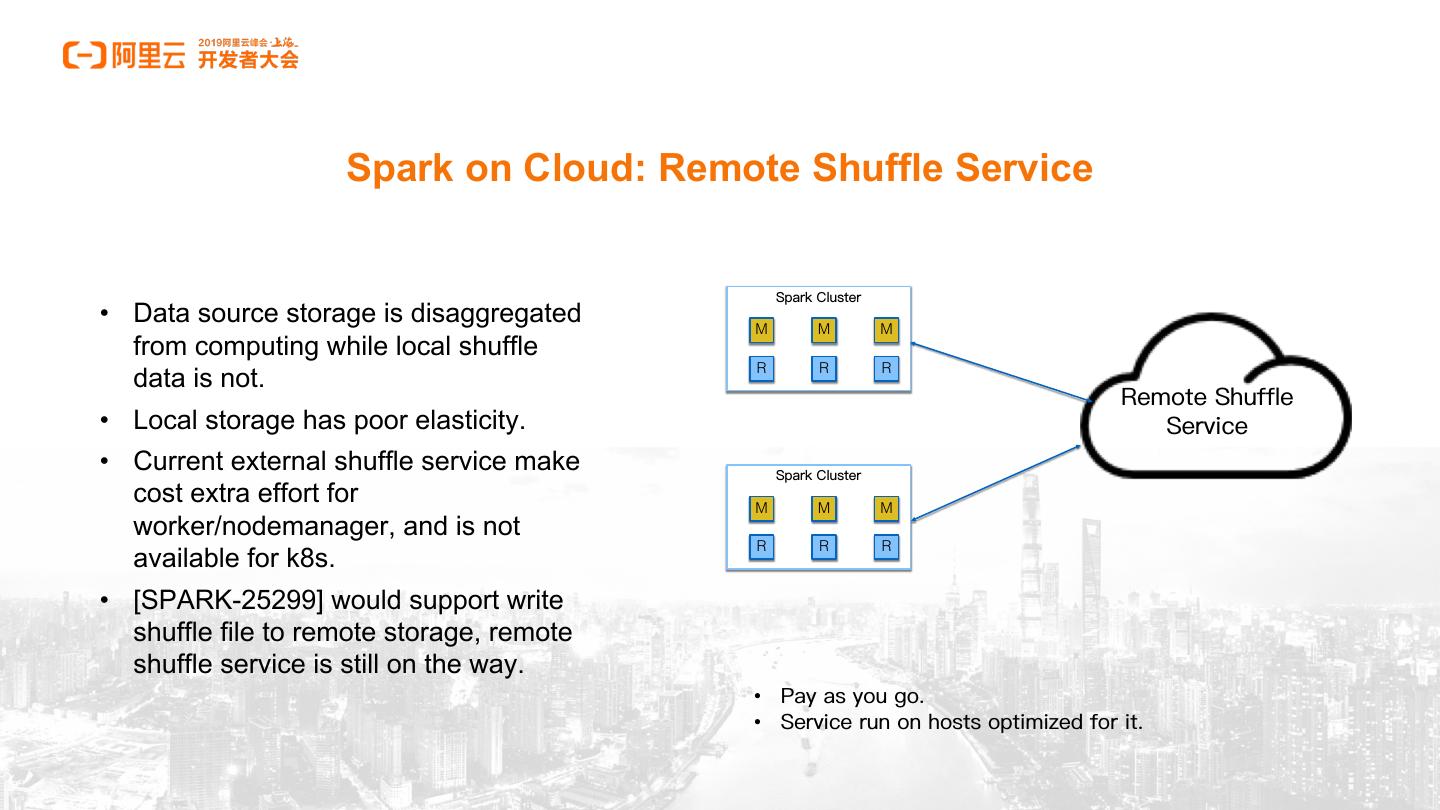
13 . Spark on Cloud: Remote Shuffle Service
• Data source storage is disaggregated M M M
from computing while local shuffle
R R R
data is not.
• Local storage has poor elasticity.
• Current external shuffle service make
cost extra effort for M M M
worker/nodemanager, and is not
R R R
available for k8s.
• [SPARK-25299] would support write
shuffle file to remote storage, remote
shuffle service is still on the way.
•
•
�
14 . Spark on Kubernetes
Natively support since 2.3
Pyspark/R binding and client mode supported
since 2.4
Spark 3.0+
• Dynamic allocation support
• Kerberos support
• …
�
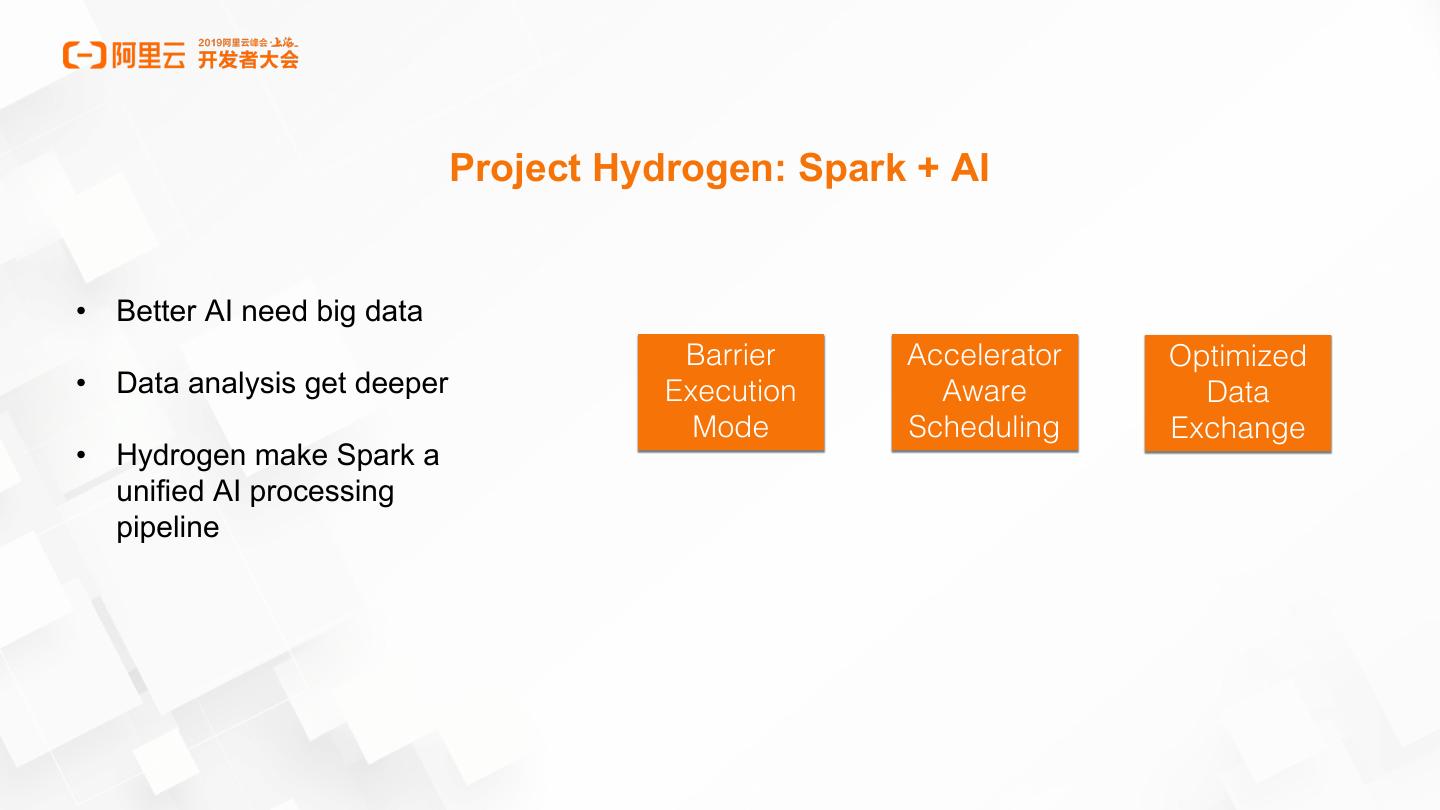
16 . Project Hydrogen: Spark + AI
• Better AI need big data
Barrier Accelerator Optimized
• Data analysis get deeper Execution Aware Data
Mode Scheduling Exchange
• Hydrogen make Spark a
unified AI processing
pipeline
�
17 .Project Hydrogen: Barrier Execution
• Gang scheduling enabled to run
DL job as Spark stage.
• Specific recovery strategy
supported for gang scheduled
stage.
• Available since 2.4
�
18 . Project Hydrogen: Accelerator Aware Scheduling
• GPUs are applied at application level.
• User can retrieve assigned GPUs from
task context.
• Can extend to other accelerator, such
as: FPGA
• Available at 3.0, see [SPARK-27362],
[SPARK-27363]
�
19 . Project Hydrogen: Optimized Data Exchange
• Spark loads/saves data from/to
persistent storage in a data
format used by a DL/AI
framework.
• Spark feeds data into DL/AI data
frameworks for training.
• Prefer to use Apache Arrow as
exchange data format.
• [SPARK-24615] WIP
�
21 . 3.0 Targets
• Spark on K8s
• Project Hydrogen
• Dynamic resource allocation
• GPU-Aware scheduling
• Kerberos support
• Optimized data exchange
• Hadoop 3.x support
• Adaptive Execution
• Self tuning the number of reducers
• Hive 2.3 support
• Adaptive join strategy • Scala 2.12 GA
• Data Source V2 • Better ANSI SQL compliance
This presentation may contain projections or other forward-looking statements regarding the upcoming
release (Apache Spark 3.0). The statements are intended to outline our general direction. They are
intended for information purposes only. They are not a commitment to deliver code or functionality. The
development, release and timing of any feature or functionality described for Apache Spark remains at the
sole discretion of ASF and the Apache Spark PMC.
�