展开查看详情
1 . - ++
Analytics Zoo: A Unified Data Analytics + AI Platform
�
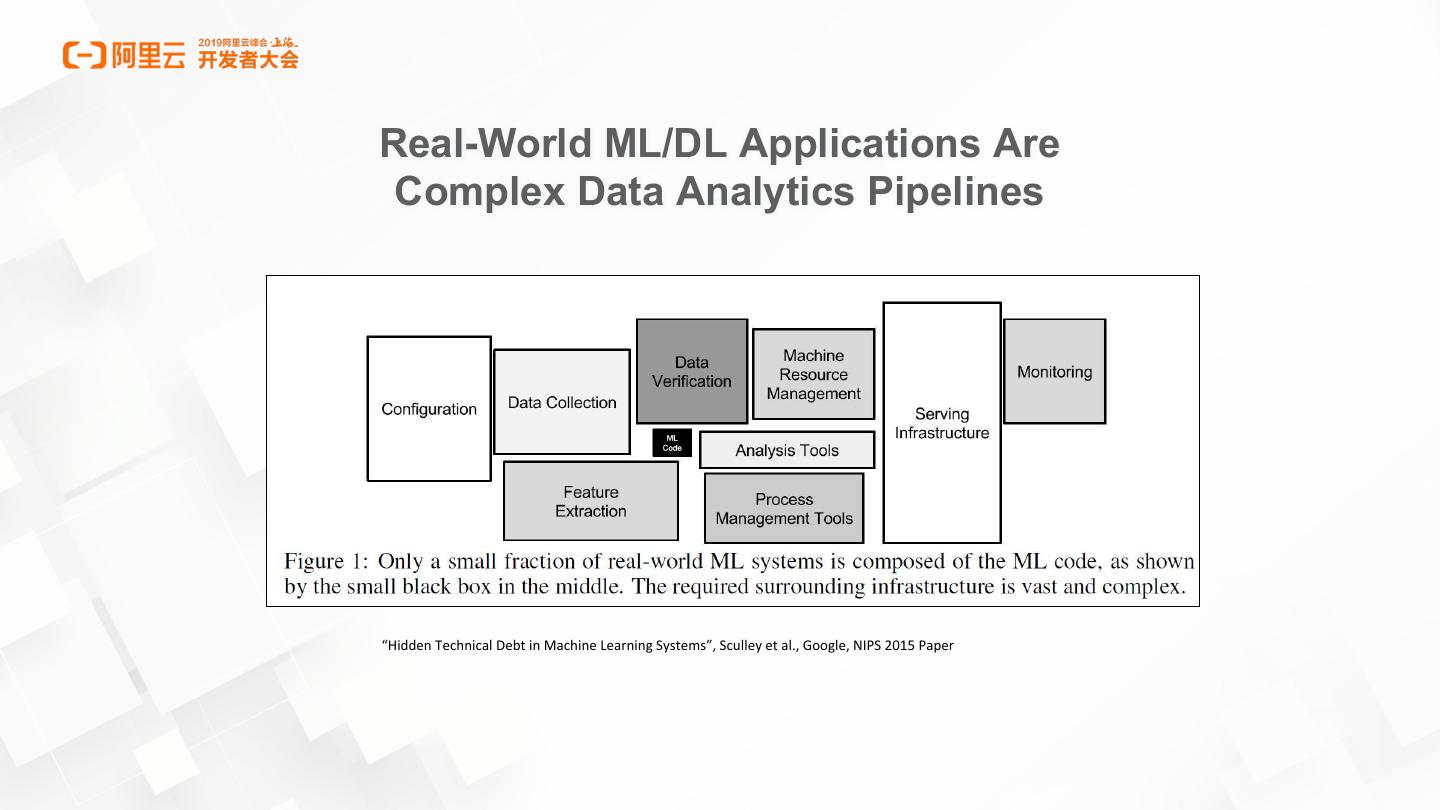
4 .Real-World ML/DL Applications Are
Complex Data Analytics Pipelines
“Hidden Technical Debt in Machine Learning Systems”, Sculley et al., Google, NIPS 2015 Paper
�
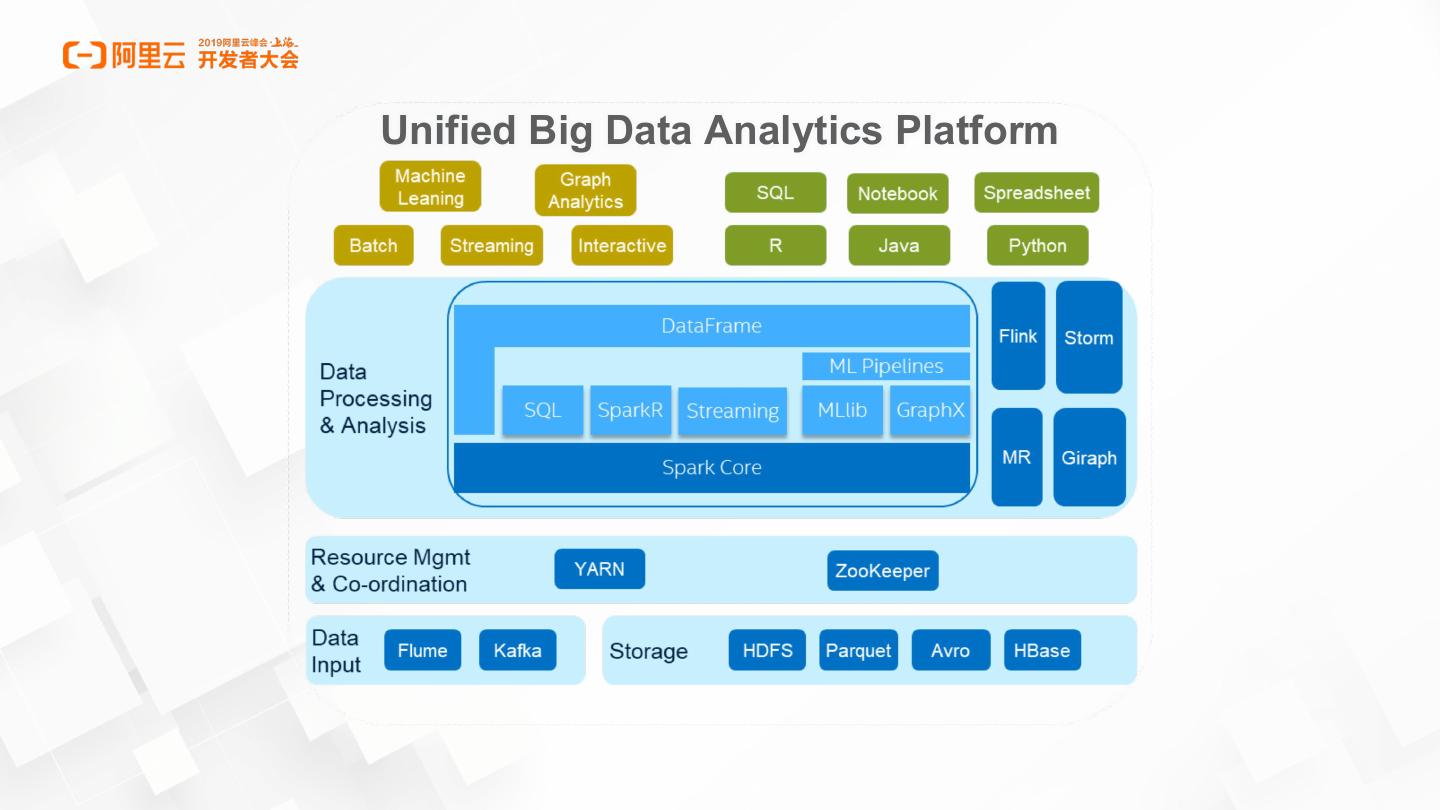
5 .Unified Big Data Analytics Platform
�
6 .Chasm b/w Deep Learning and Big Data Communities
The
Chasm
Deep learning experts Real-world users (big data users, data scientists, analysts, etc.)
�
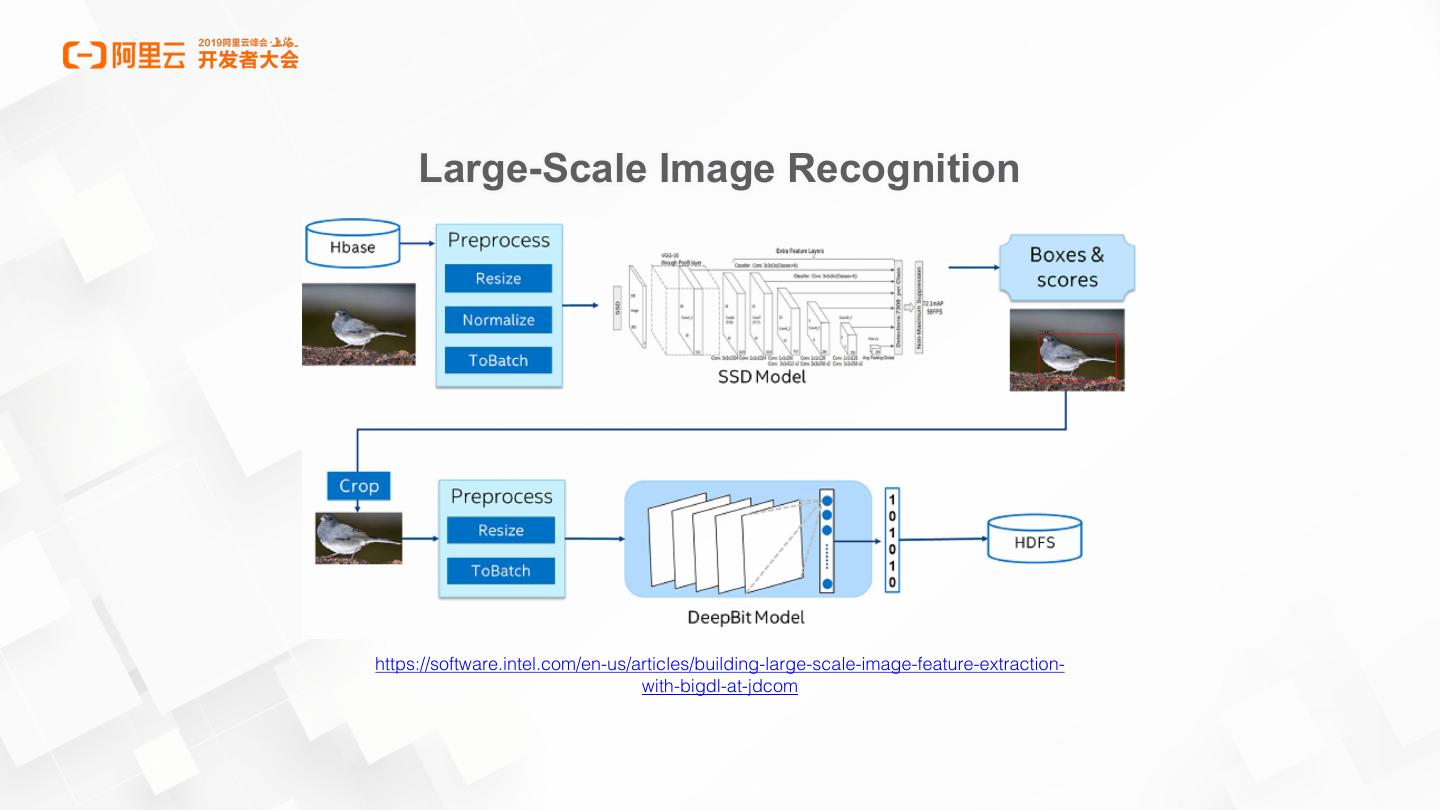
7 . Large-Scale Image Recognition
https://software.intel.com/en-us/articles/building-large-scale-image-feature-extraction-
with-bigdl-at-jdcom
�
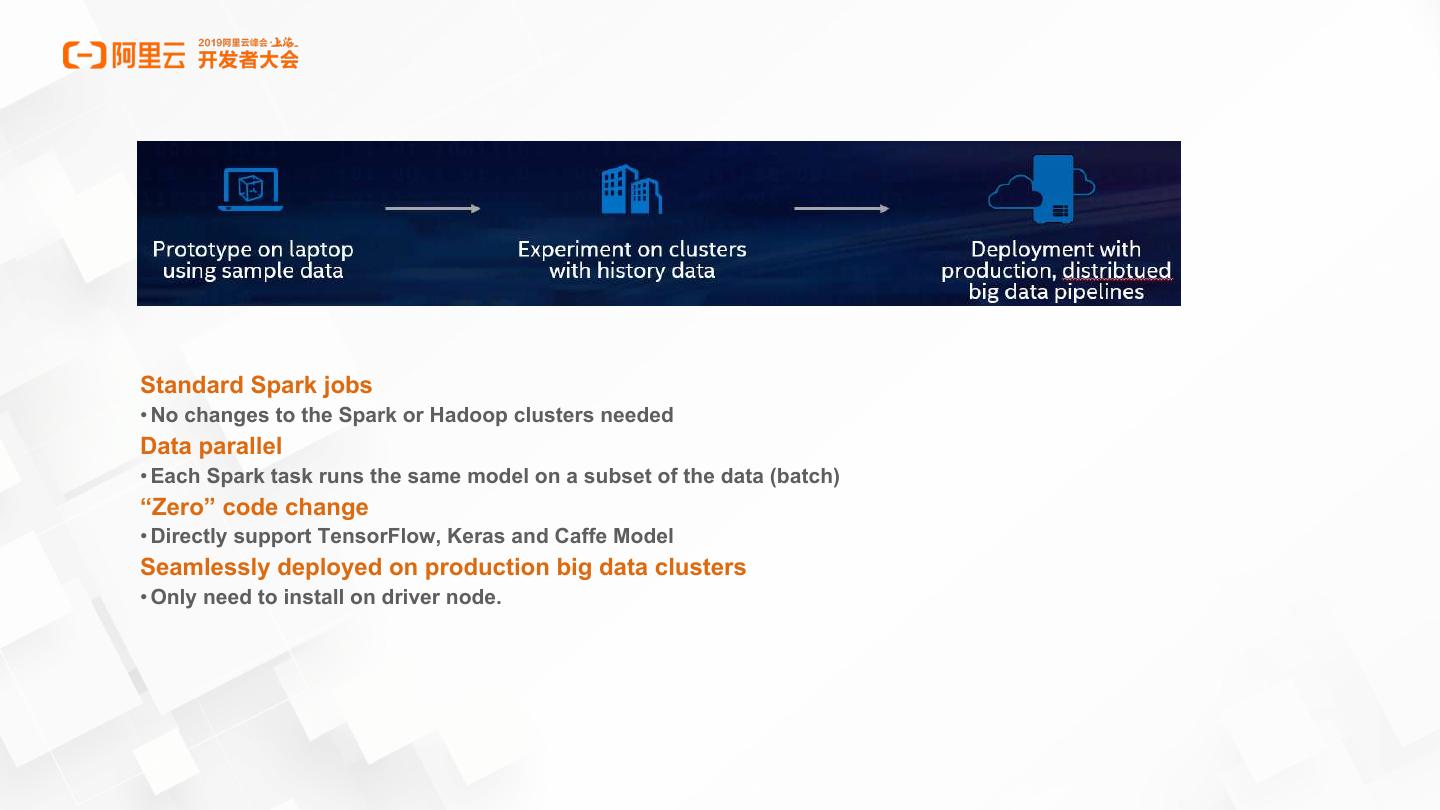
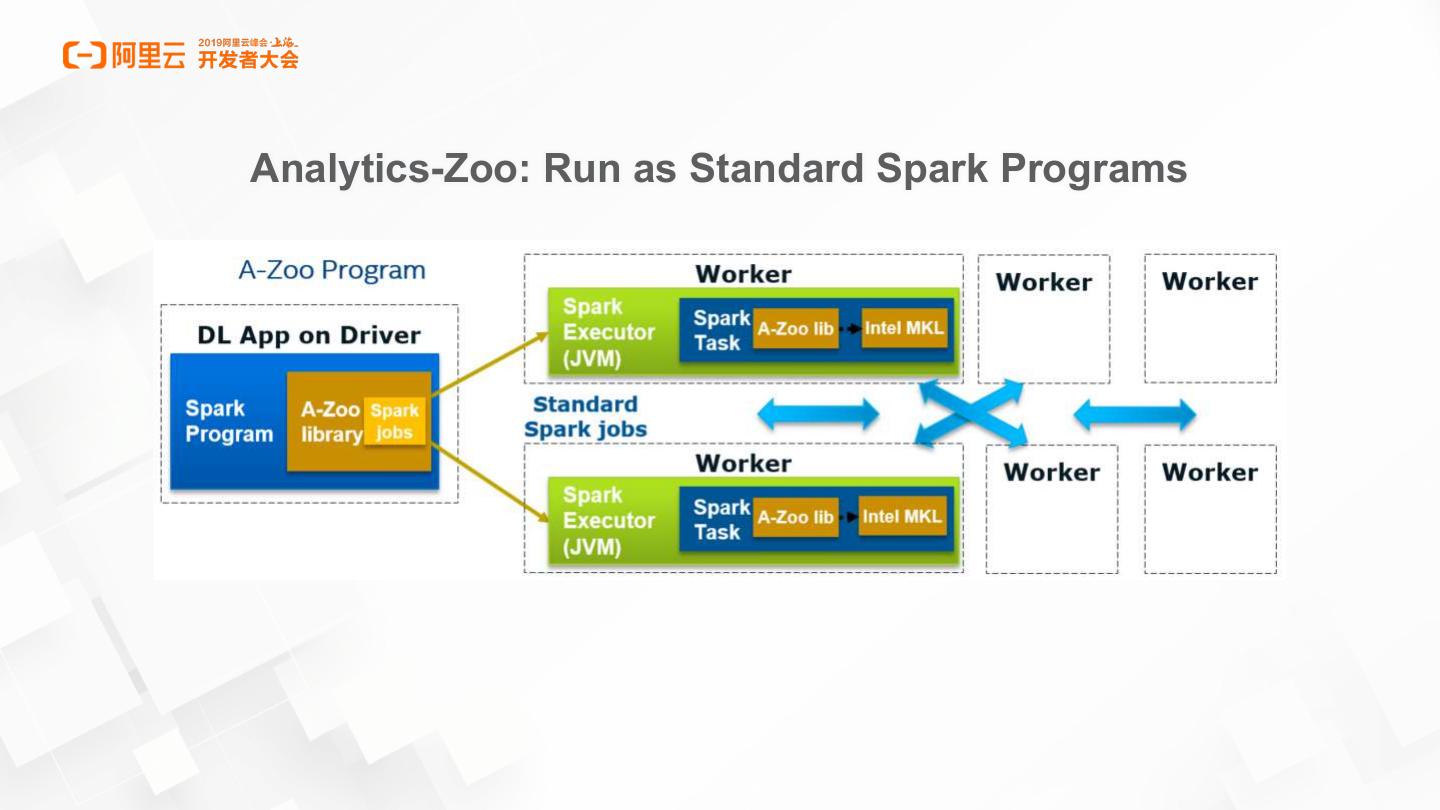
8 .Standard Spark jobs
• No changes to the Spark or Hadoop clusters needed
Data parallel
• Each Spark task runs the same model on a subset of the data (batch)
“Zero” code change
• Directly support TensorFlow, Keras and Caffe Model
Seamlessly deployed on production big data clusters
• Only need to install on driver node.
�
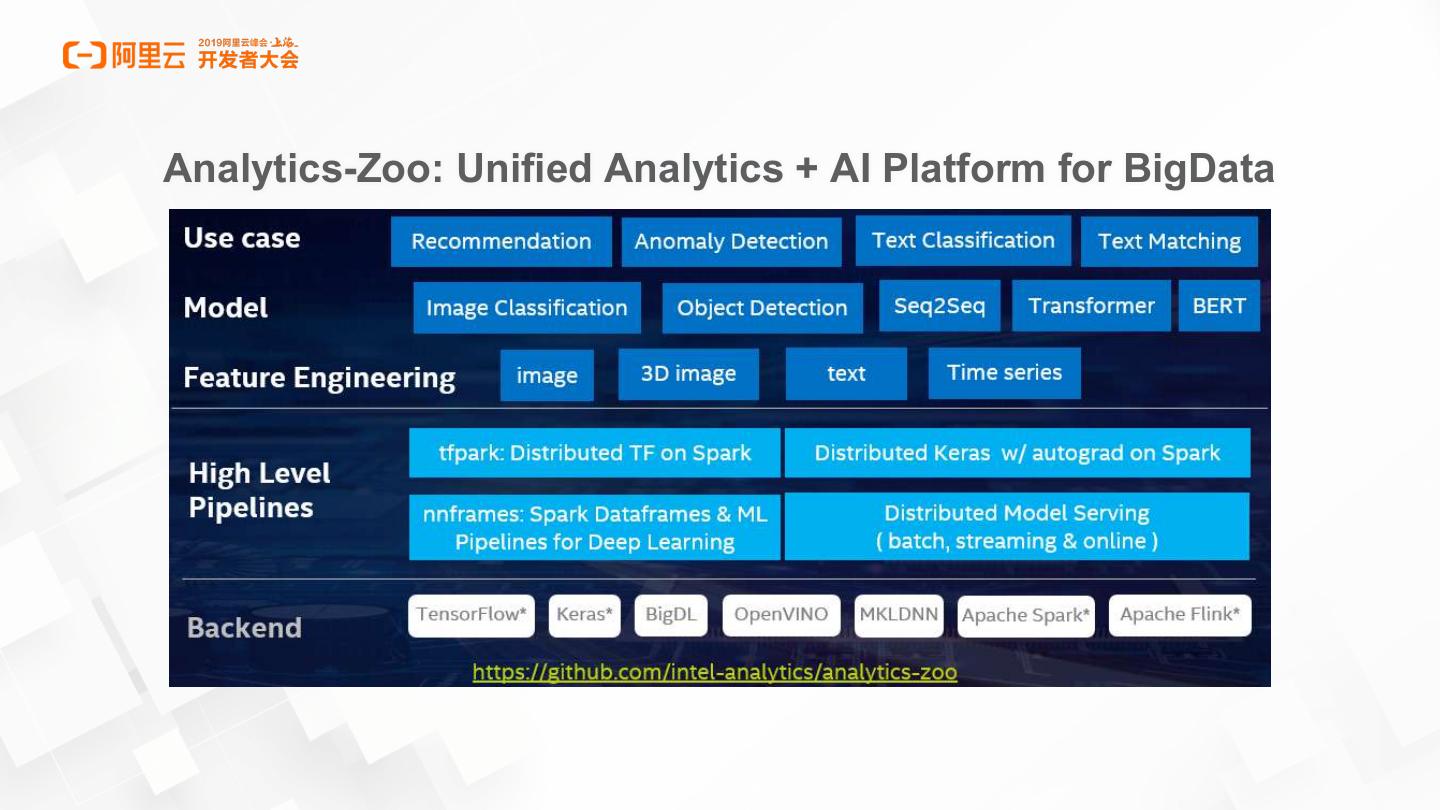
11 .Analytics-Zoo: Unified Analytics + AI Platform for BigData
�
12 .Analytics-Zoo: Run as Standard Spark Programs
�
13 . Training Set
Partition 1
Worker
Training samples Sample
cached in worker
memory 2
1
Partition 2 3
Worker Driver
Sample 1
Broadcast W (>800MB)
Each task computes to each worker in each
2 4
G (>800MB) in each iteration
iteration 3
…
1
Partition n
Worker Each task sends G
Sample (>800MB) for aggregation
in each iteration
3
2
13
�
14 .Distributed Training in Analytics-Zoo
Peer-2-Peer All-Reduce synchronization
�
15 . Distributed TF & Keras on Spark
Write TensorFlow code inline in PySpark program
•Data wrangling and #pyspark code
train_rdd = spark.hadoopFile(…).map(…)
analysis using PySpark dataset = TFDataset.from_rdd(train_rdd,…)
#tensorflow code
•Deep learning model import tensorflow as tf
development using slim = tf.contrib.slim
images, labels = dataset.tensors
TensorFlow or Keras with slim.arg_scope(lenet.lenet_arg_scope()):
logits, end_points = lenet.lenet(images, …)
loss = tf.reduce_mean( \
tf.losses.sparse_softmax_cross_entropy( \
logits=logits, labels=labels))
•Distributed training / #distributed training on Spark
inference on Spark optimizer = TFOptimizer.from_loss(loss, Adam(…)) \
optimizer.optimize(end_trigger=MaxEpoch(5))
�
16 . Spark Dataframe & ML Pipeline for DL
#Spark dataframe transformations
parquetfile = spark.read.parquet(…)
train_df = parquetfile.withColumn(…)
#Keras API
model = Sequential()
.add(Convolution2D(32, 3, 3, activation='relu', input_shape=…)) \
.add(MaxPooling2D(pool_size=(2, 2))) \
.add(Flatten()).add(Dense(10, activation='softmax')))
#Spark ML pipeline
Estimater = NNEstimater(model, CrossEntropyCriterion()) \
.setLearningRate(0.003).setBatchSize(40).setMaxEpoch(5) \
.setFeaturesCol("image")
nnModel = estimater.fit(train_df)
�
17 . Distributed Model Serving
Analytics Zoo
Model
Bolt
Kafka
Flume
Bolt
HDFS/S3
Spout
Kinesis
Twitter
Bolt
Analytics Zoo
Spout Model
Bolt
Bolt
Distributed model serving in Web Service, Flink, Kafka, Storm, etc.
• Plain Java or Python API, with OpenVINO and DL Boost (VNNI) support
�
18 .Analytics-Zoo use cases
�
19 .Computer vision Based Product Defect Detection in Midea
https://software.intel.com/en-us/articles/industrial-inspection-platform-in-midea-and-kuka-using-distributed-tensorflow-on-analytics
�
20 . Recommender AI Service in MasterCard
https://software.intel.com/en-us/articles/deep-learning-with-analytic-zoo-optimizes-mastercard-recommender-ai-service
�
21 .Deep Learning Made Easy for BigData
�
22 . LEGAL DISCLAIMERS
• Intel technologies’ features and benefits depend on system configuration and may require enabled hardware,
software or service activation. Learn more at intel.com, or from the OEM or retailer.
• No computer system can be absolutely secure.
• Tests document performance of components on a particular test, in specific systems. Differences in hardware,
software, or configuration will affect actual performance. Consult other sources of information to evaluate
performance as you consider your purchase. For more complete information about performance and
benchmark results, visit http://www.intel.com/performance.
Intel, the Intel logo, Xeon, Xeon phi, Lake Crest, etc. are trademarks of Intel Corporation in the U.S. and/or other countries.
*Other names and brands may be claimed as the property of others.
© 2019 Intel Corporation
�