
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Vectorized Execution Explained
向量化是随着列存数据库一起成熟的新查询执行模型,诸如Hive,Vertica,Vectorwise,Clickhouse等都使用了该技术。向量化也是 TiDB 正在进行的优化之一。本次分享将从为何进行向量化,块执行,SIMD和晚期物化等多个方面阐述向量化引擎的设计和实现。
展开查看详情
1 .Vectorized Execution Explained Xiaoyu Ma / Wenxuan Shi Special thanks for 社区小伙伴一起 讨论解惑
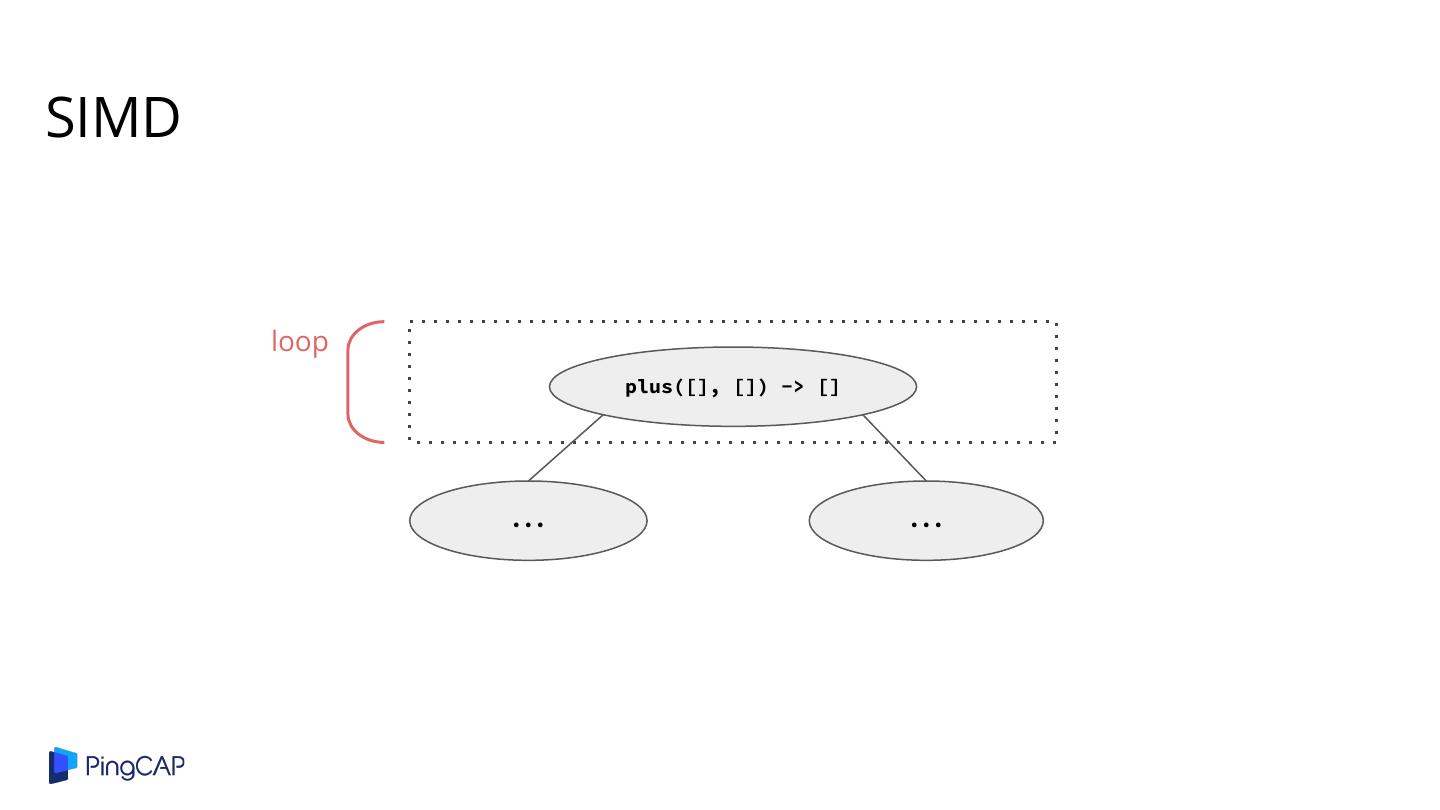
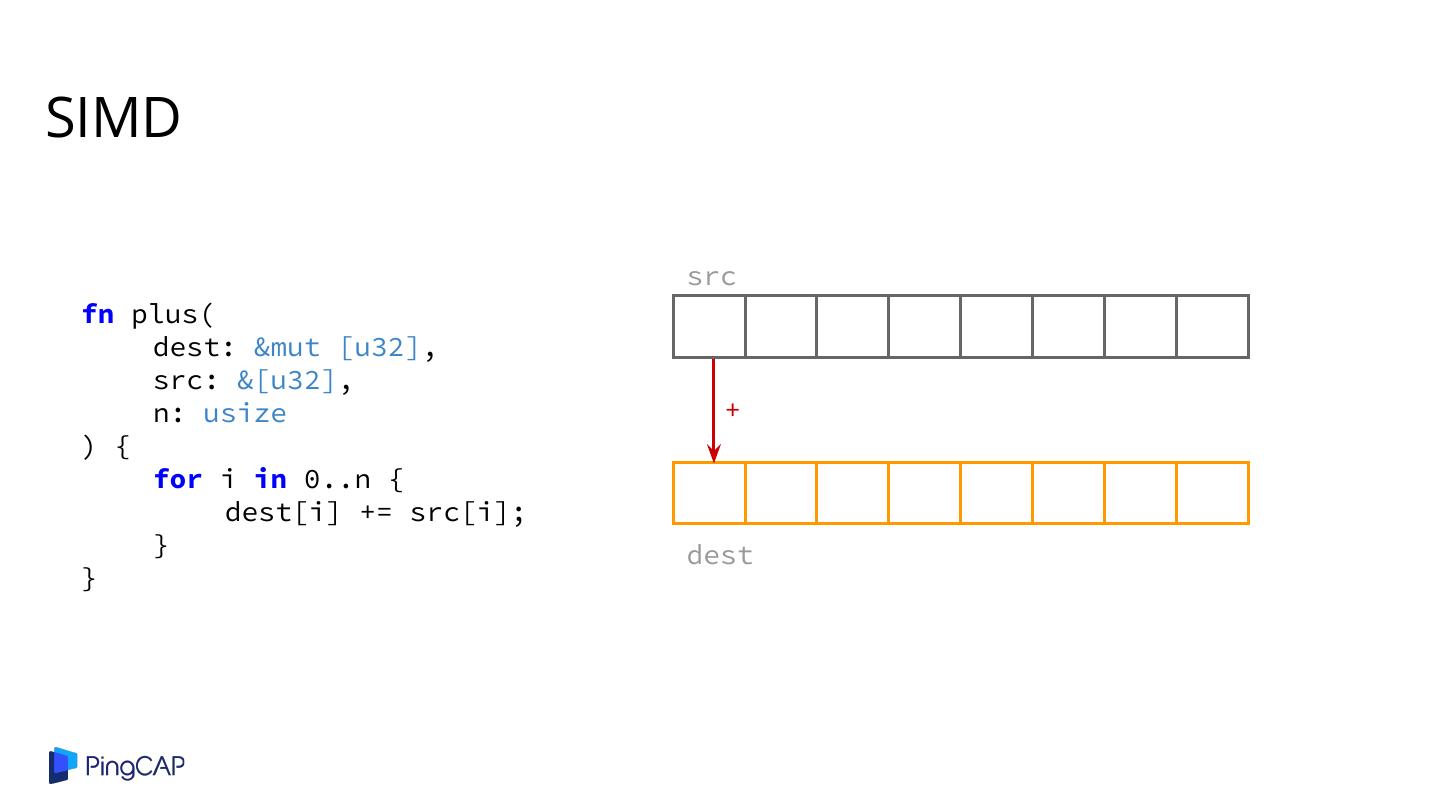
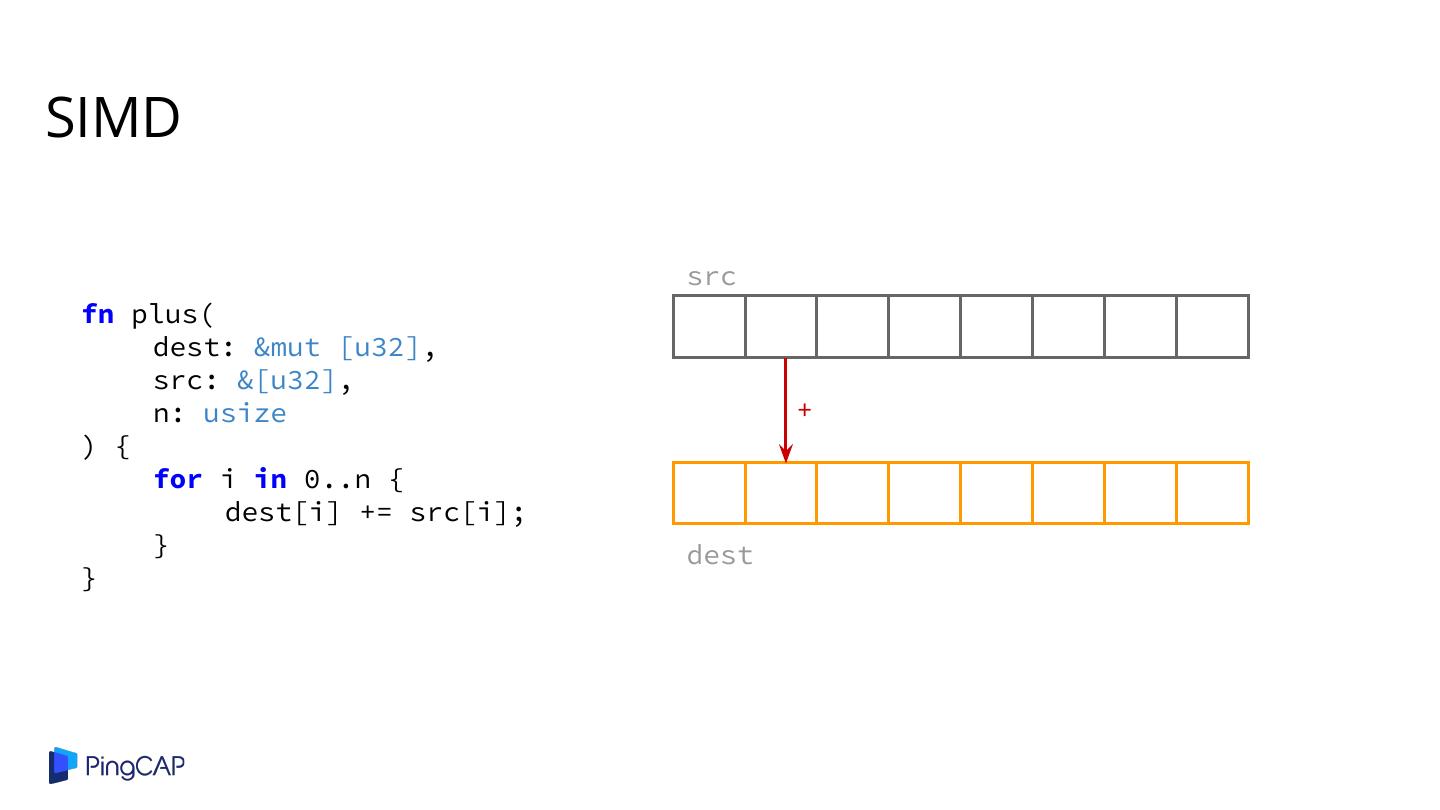
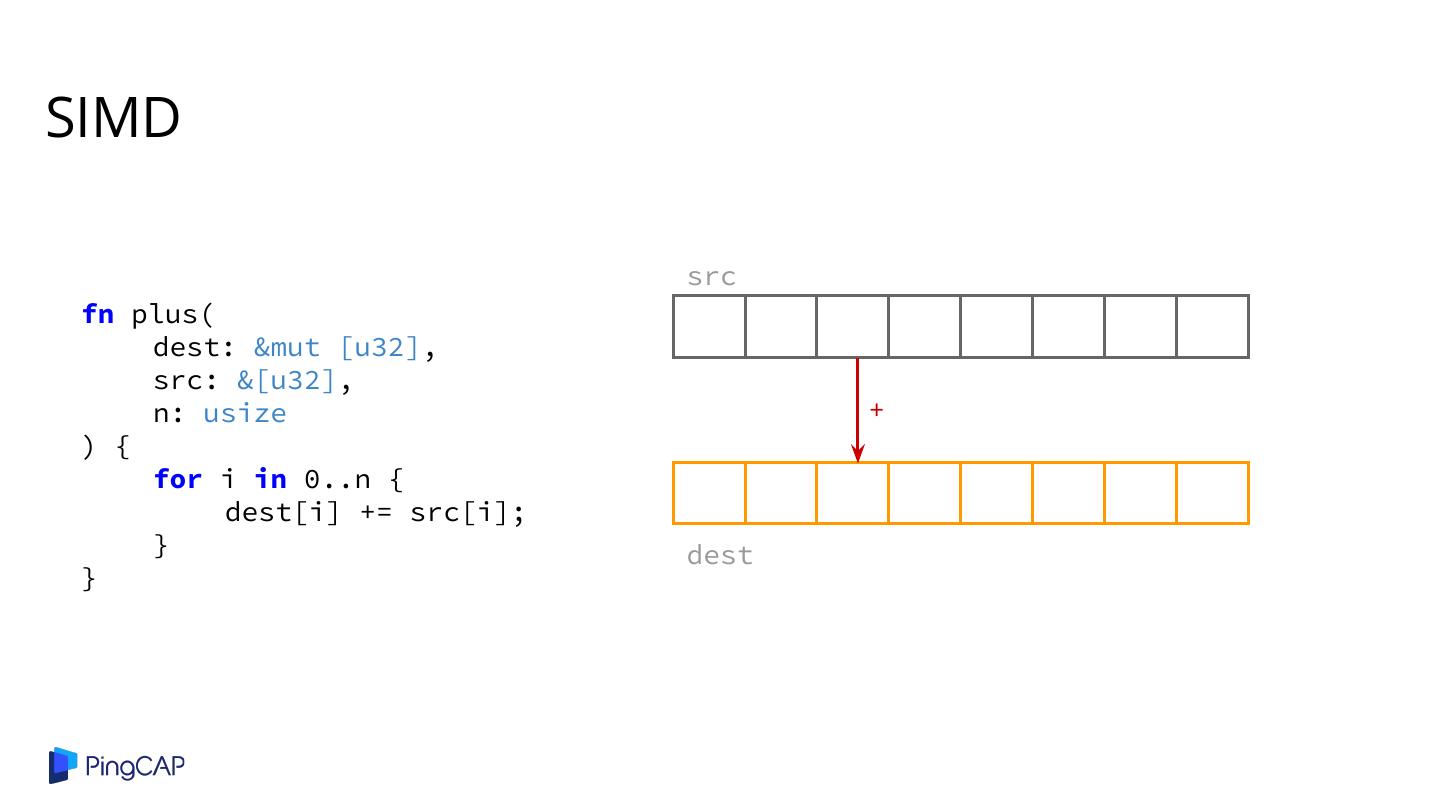
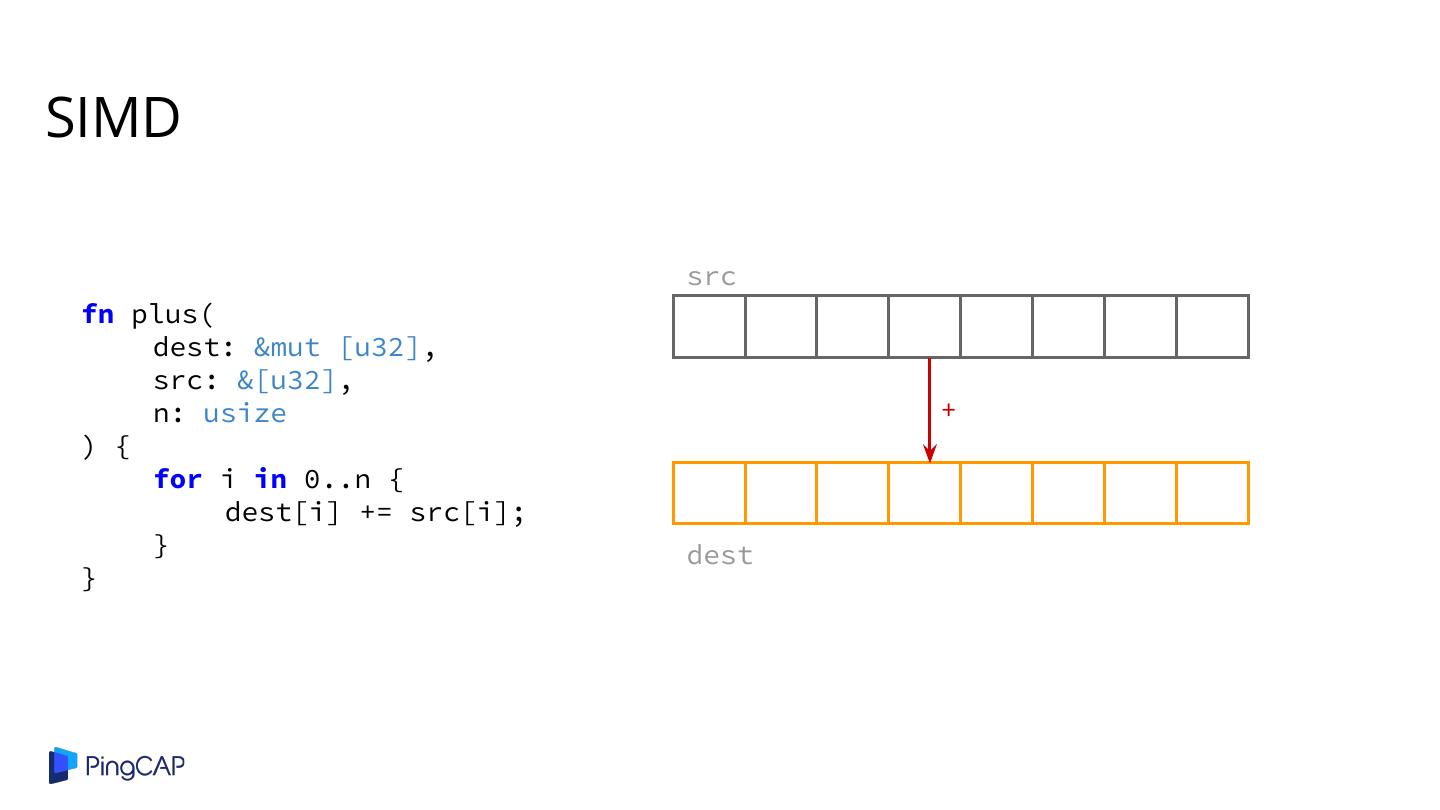
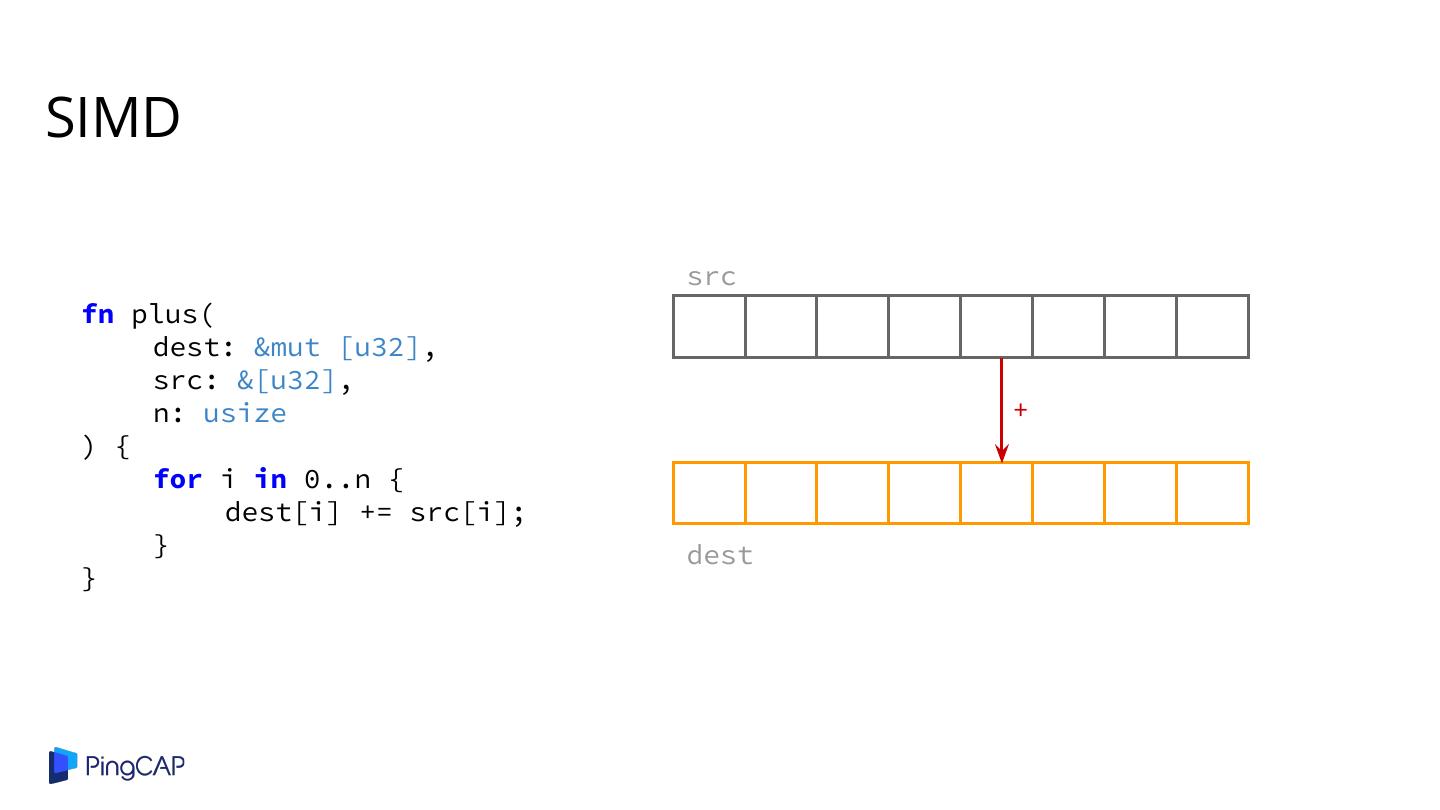
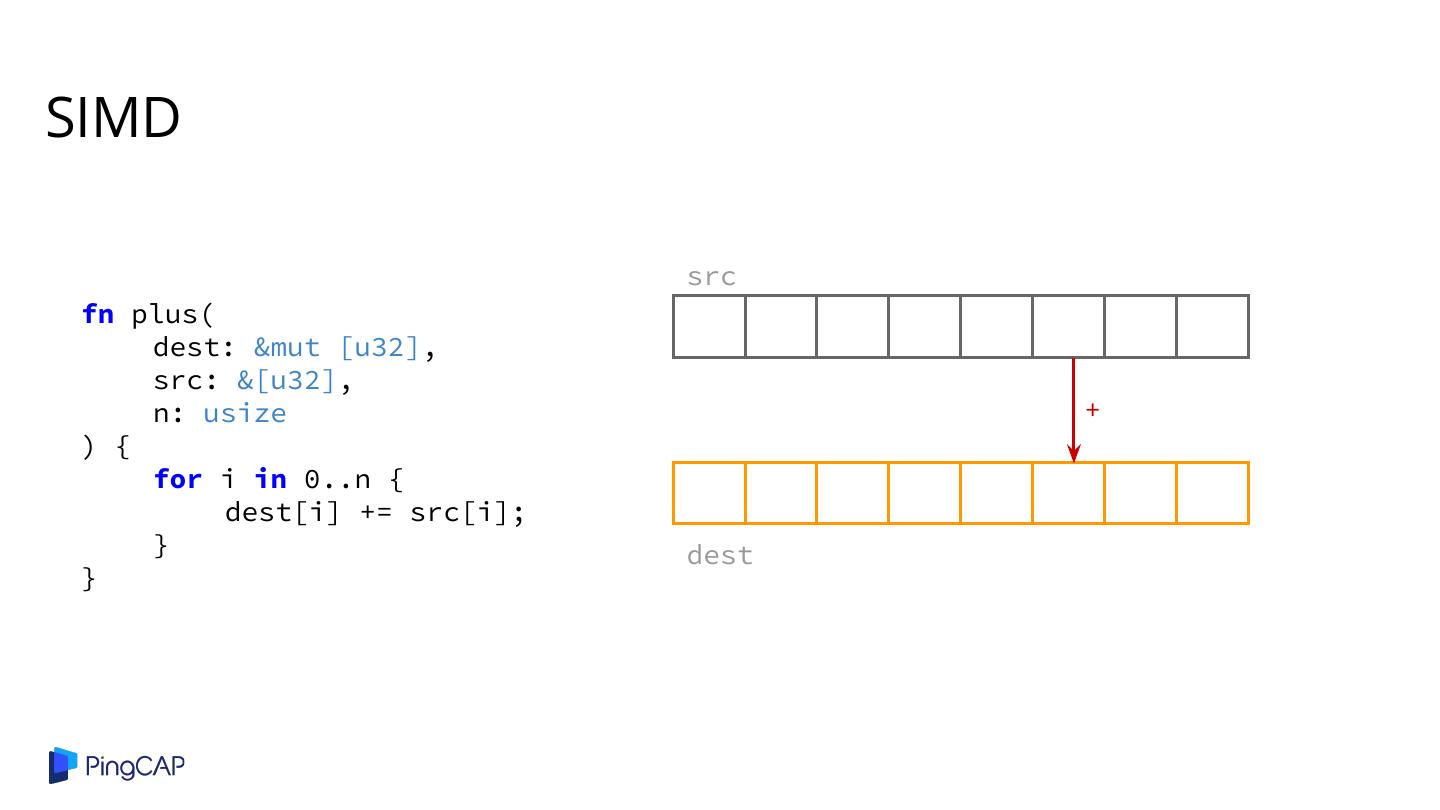
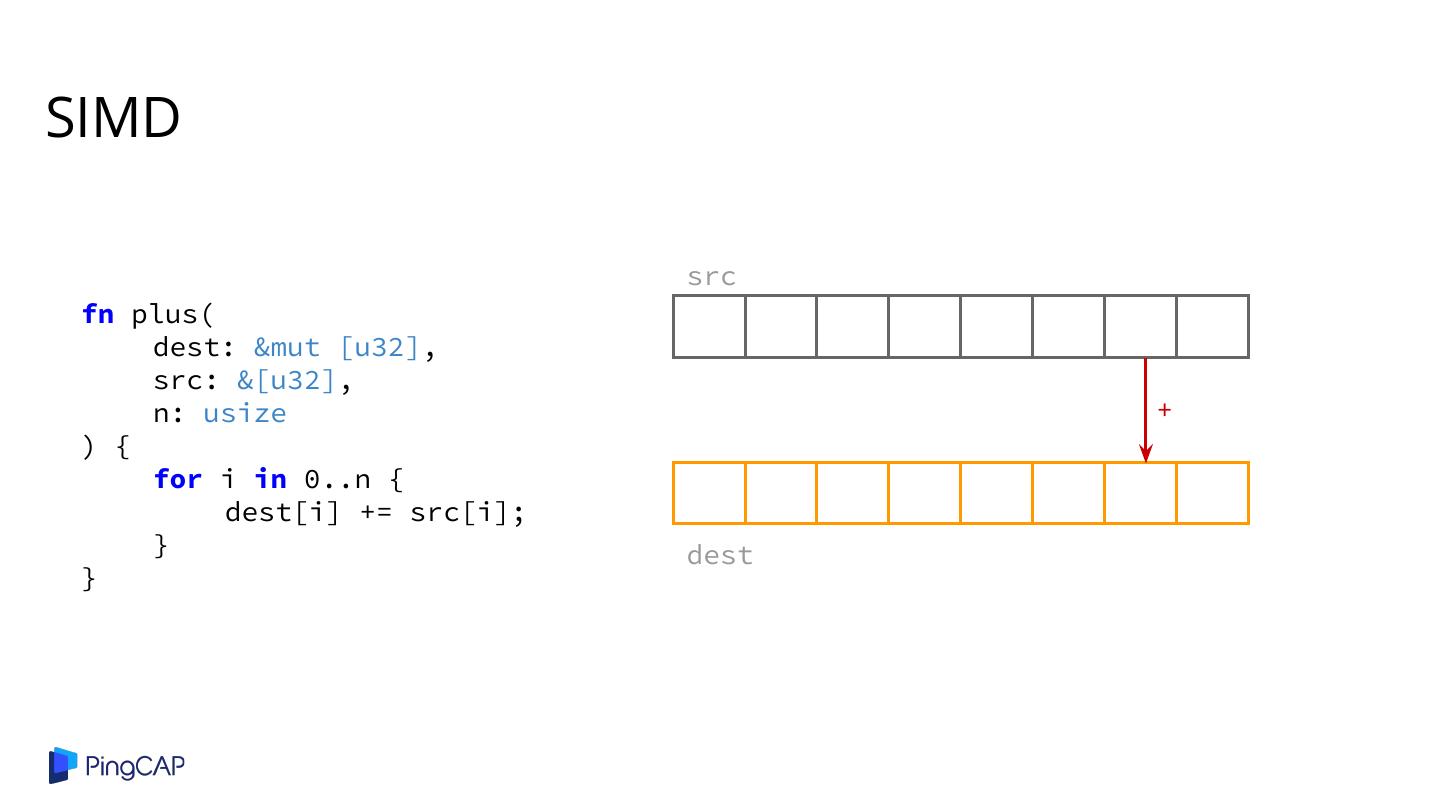
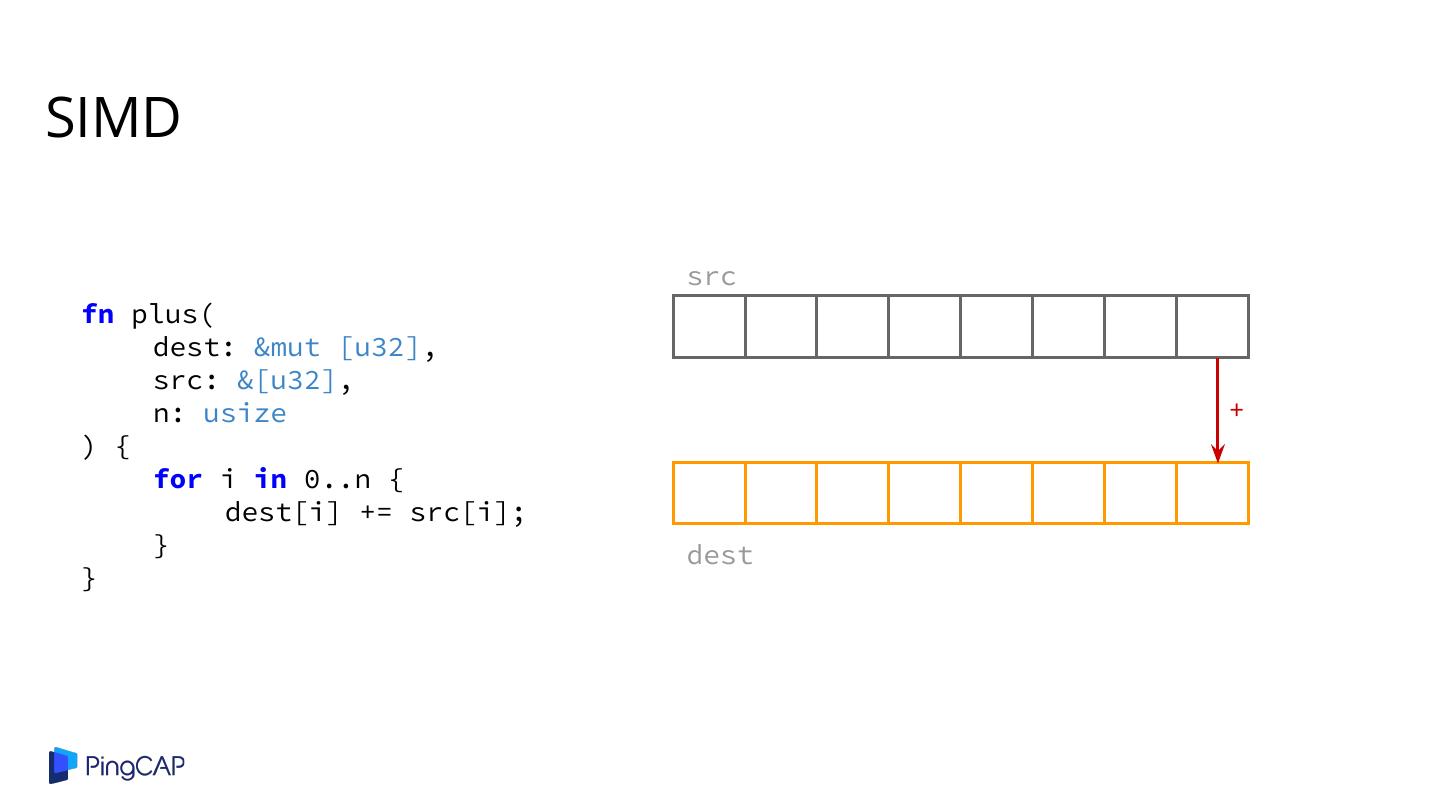
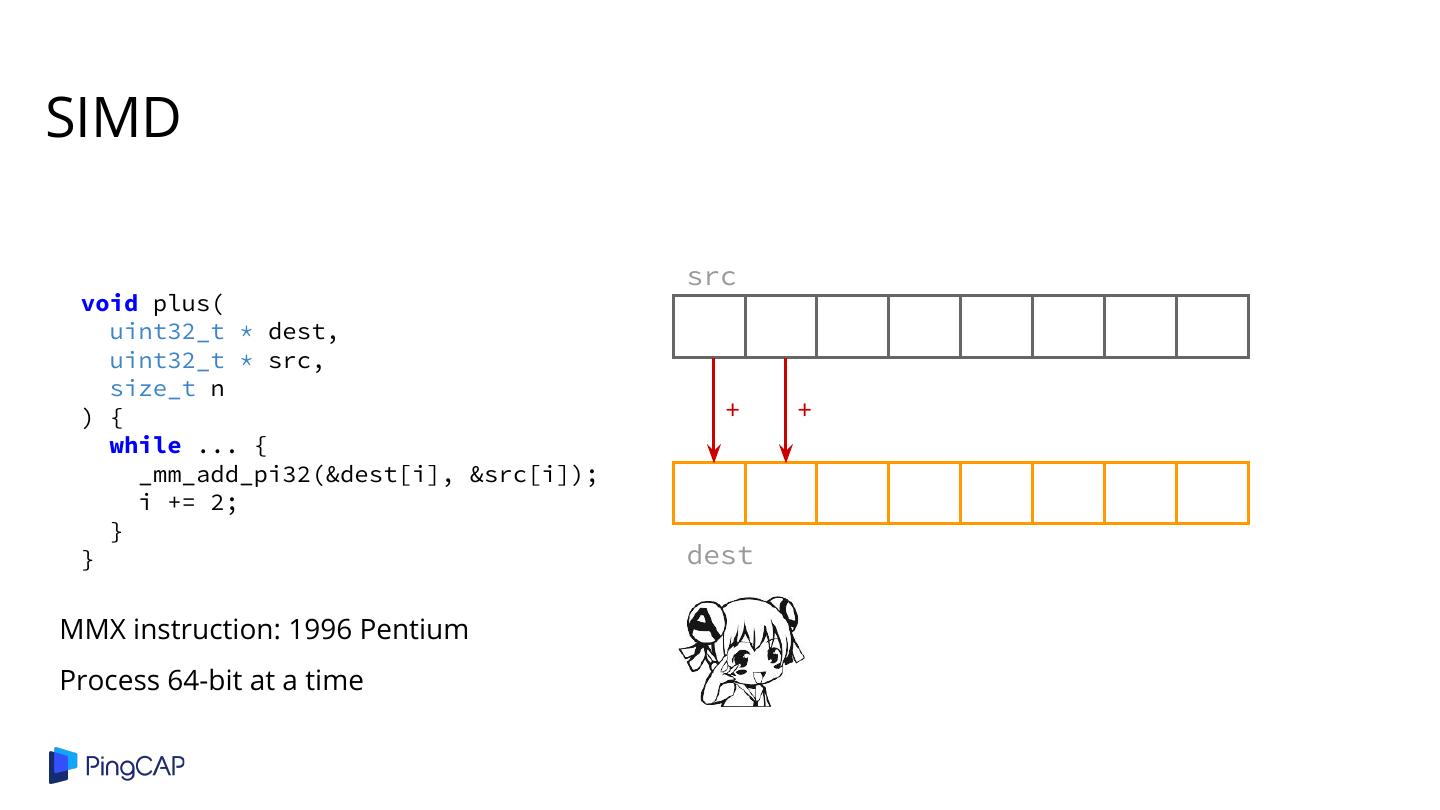
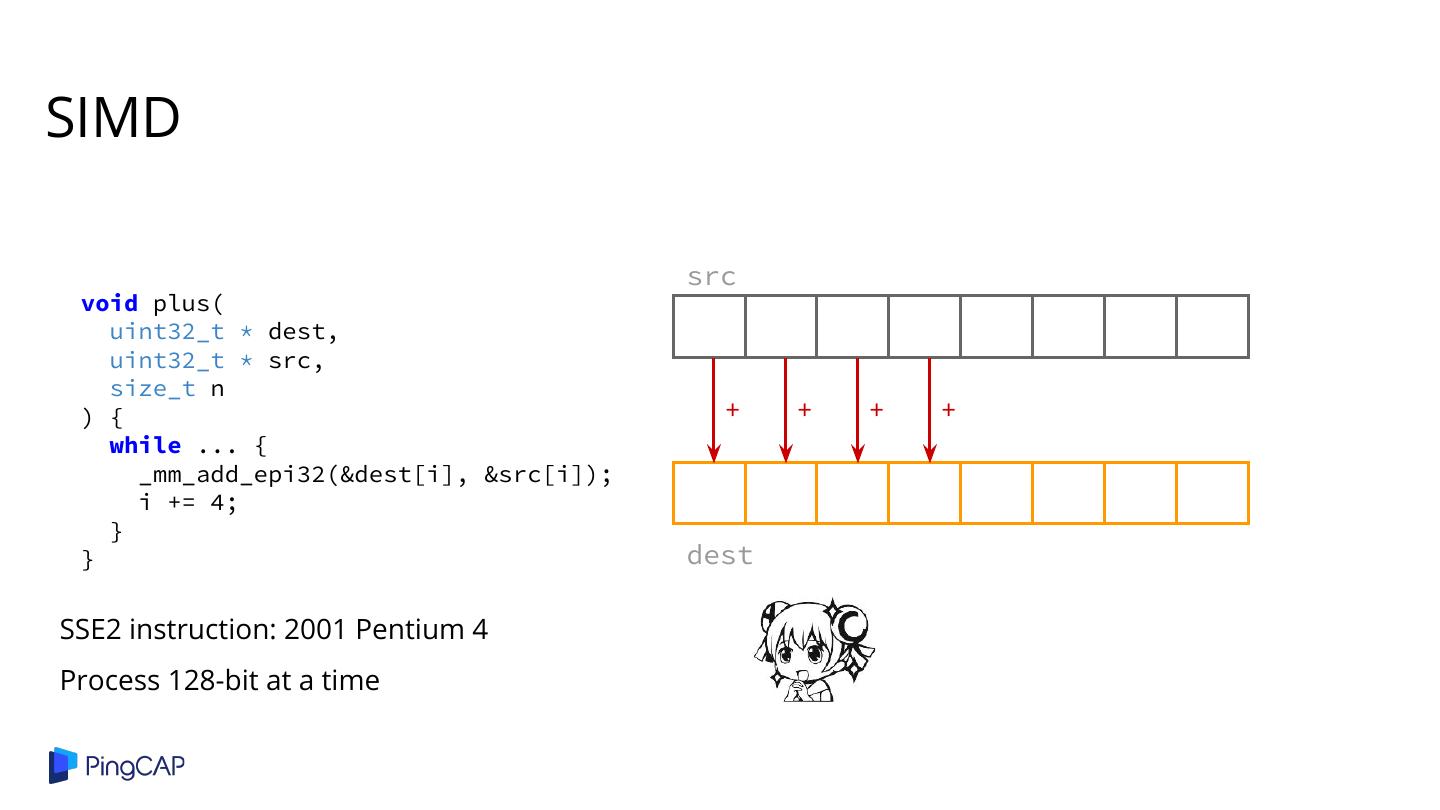
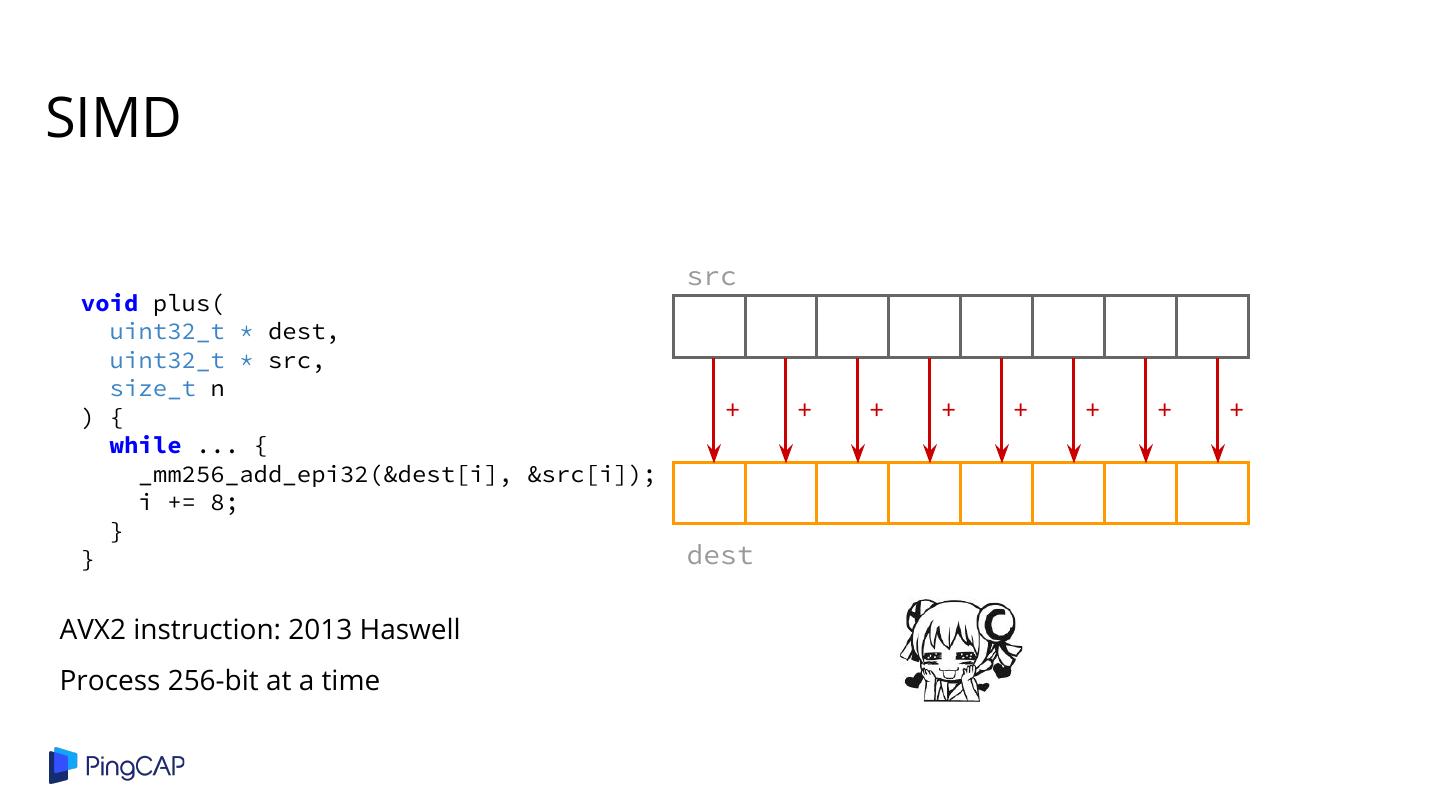
2 .Agenda ● Columnar Database History ● Classic Volcano-style Model ● Column-at-a-time Execution ● Vectorized Execution ● Adaptive Execution ● SIMD ● Materialization
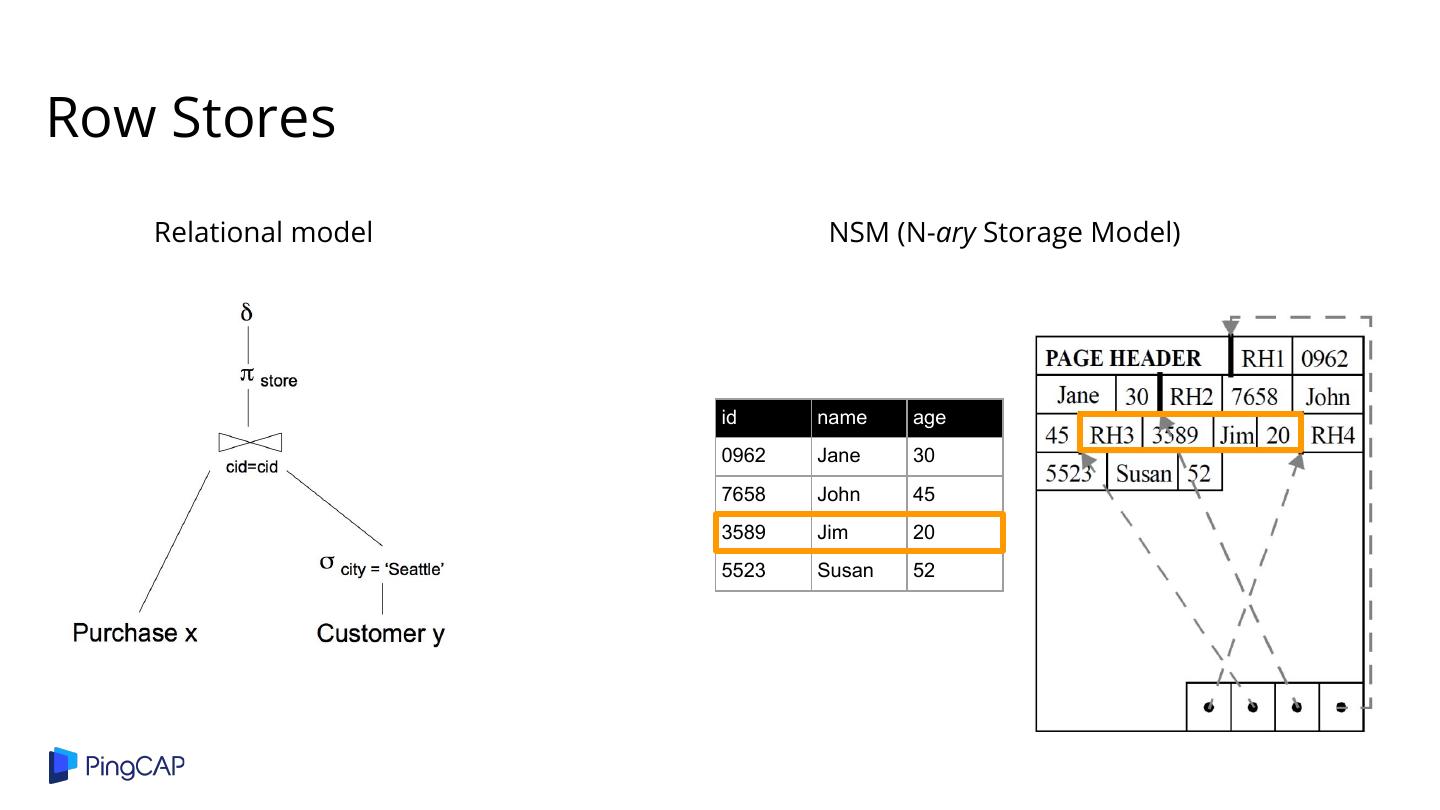
3 .Row Stores Relational model NSM (N-ary Storage Model) id name age 0962 Jane 30 7658 John 45 3589 Jim 20 5523 Susan 52
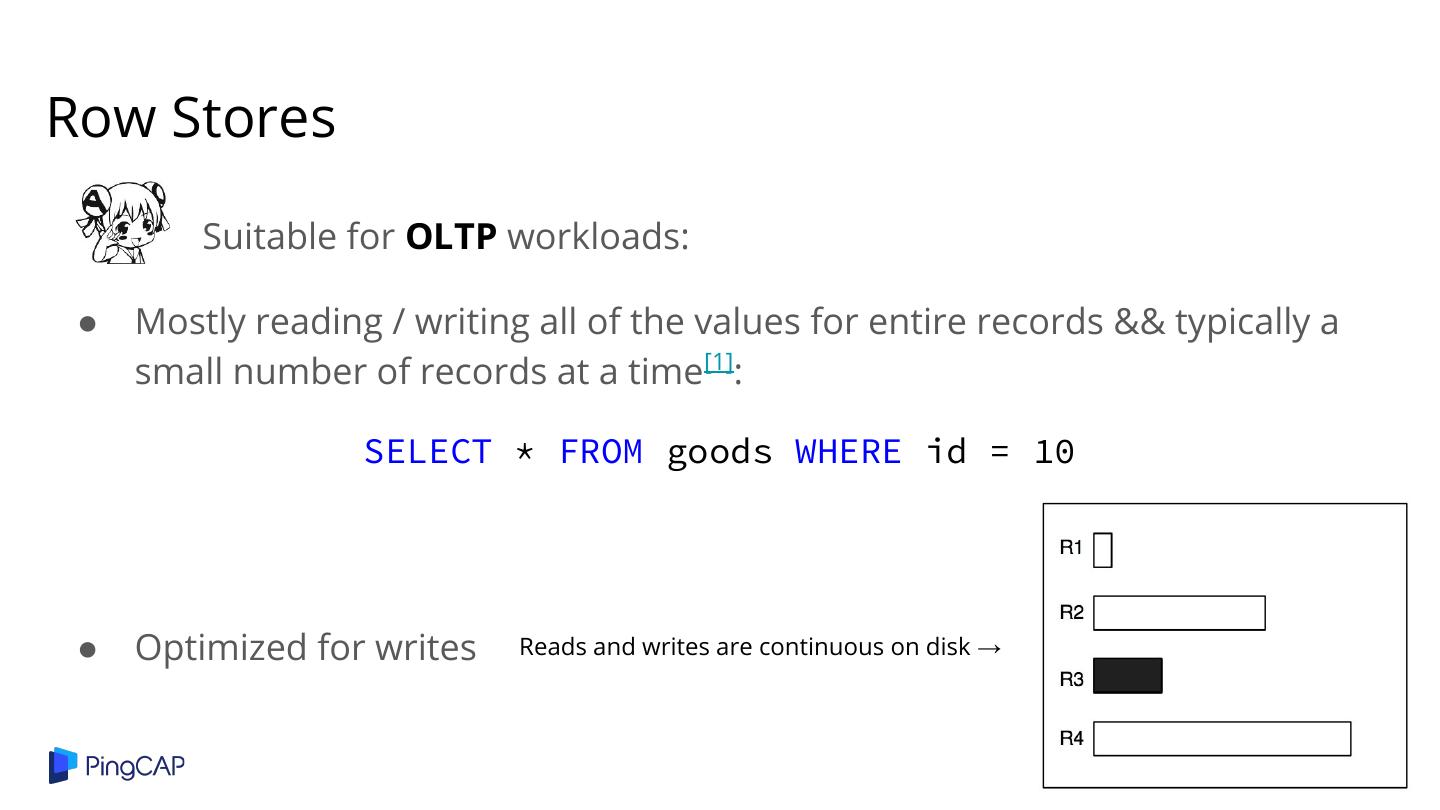
4 .Row Stores Suitable for OLTP workloads: ● Mostly reading / writing all of the values for entire records && typically a small number of records at a time[1]: SELECT * FROM goods WHERE id = 10 ● Optimized for writes Reads and writes are continuous on disk →
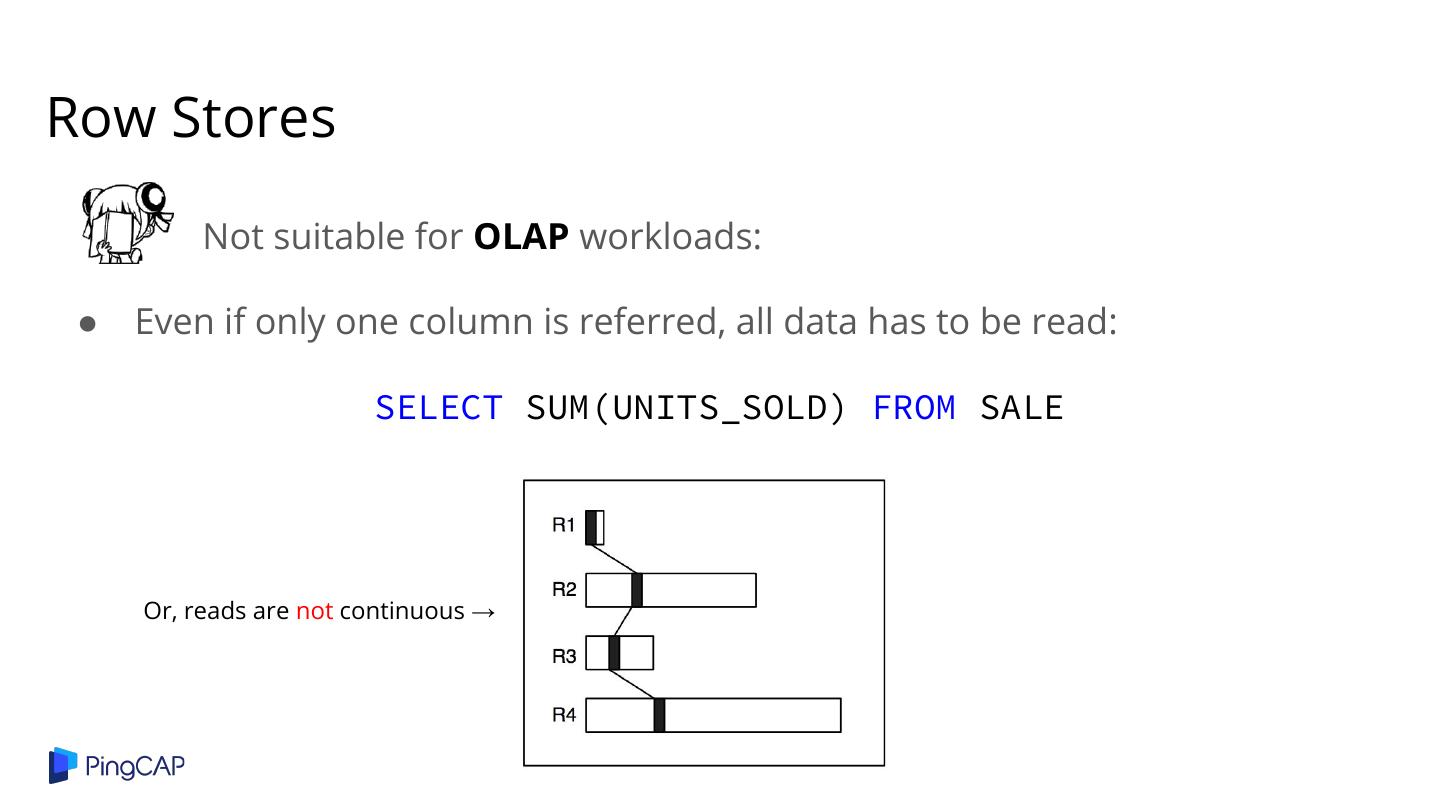
5 .Row Stores Not suitable for OLAP workloads: ● Even if only one column is referred, all data has to be read: SELECT SUM(UNITS_SOLD) FROM SALE Or, reads are not continuous →
6 .Let’s fix it over NSM? ● Split table into (primary key, column) ● Materialized view ● …. and more Or..
7 .Column Stores ● Store columns instead of rows, e.g. DSM (Decomposed Storage Model) id name age 0962 Jane 30 7658 John 45 3589 Jim 20 5523 Susan 52 ● MonetDB/MIL -> MonetDB/X100 -> Vectorwise ● C-Store -> Vertica
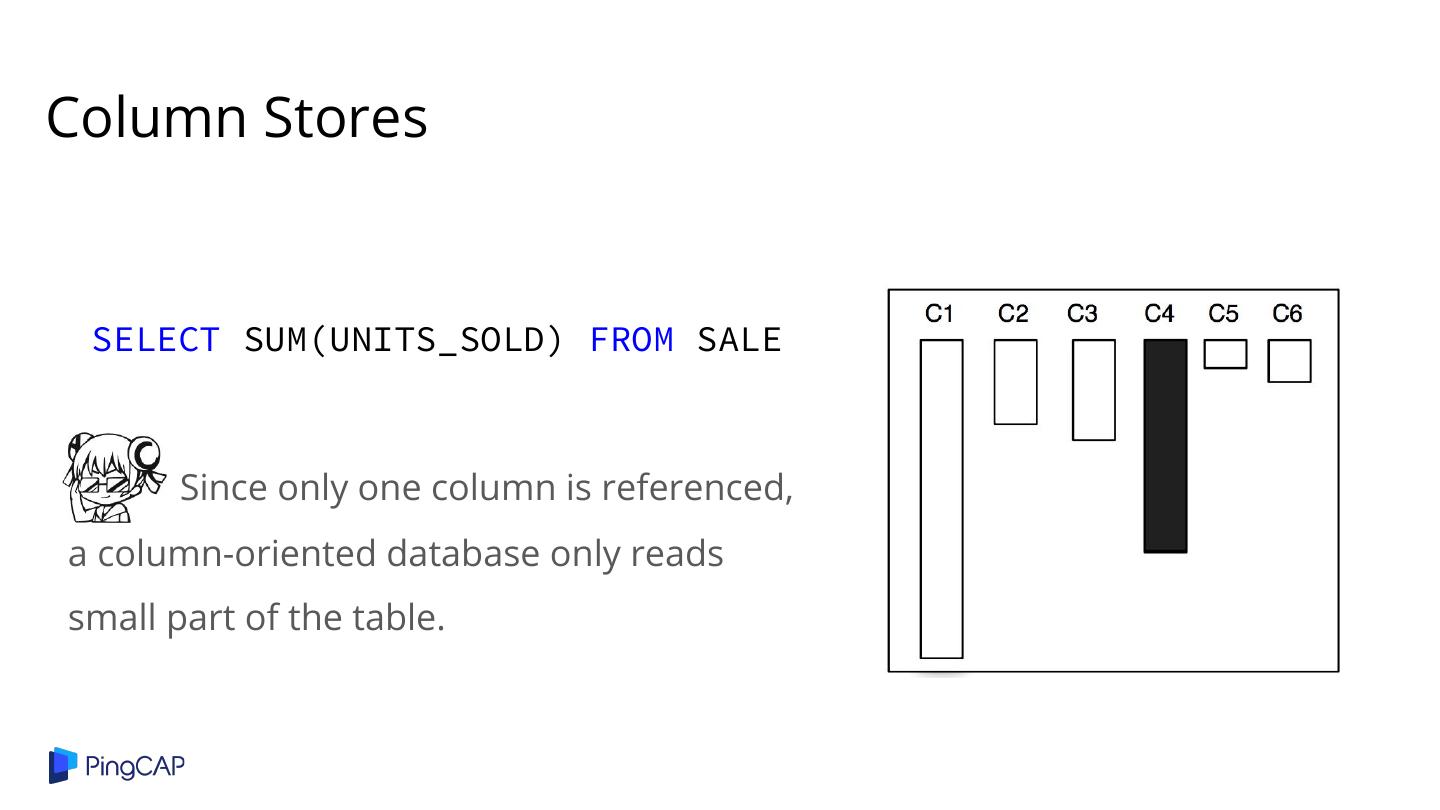
8 .Column Stores SELECT SUM(UNITS_SOLD) FROM SALE Since only one column is referenced, a column-oriented database only reads small part of the table.
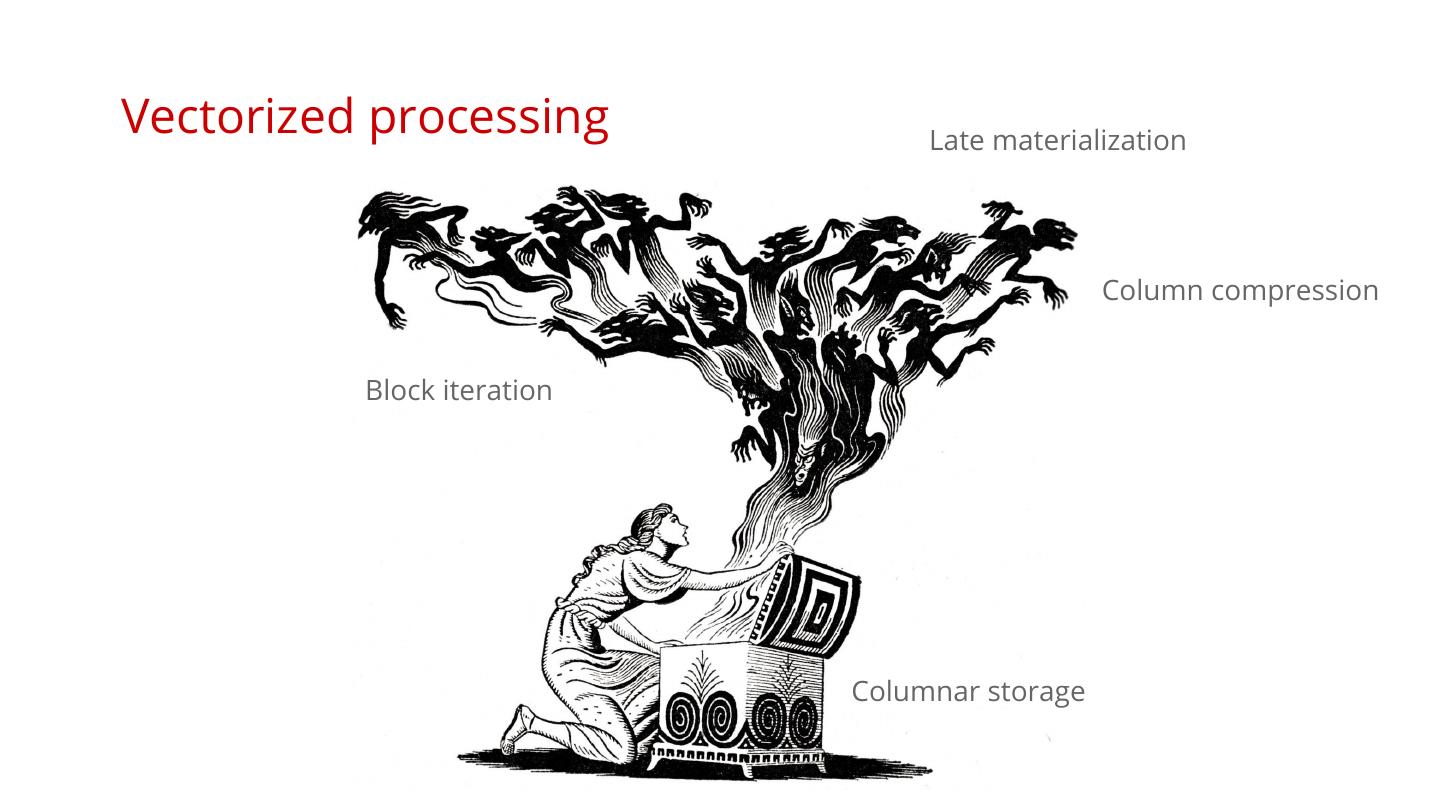
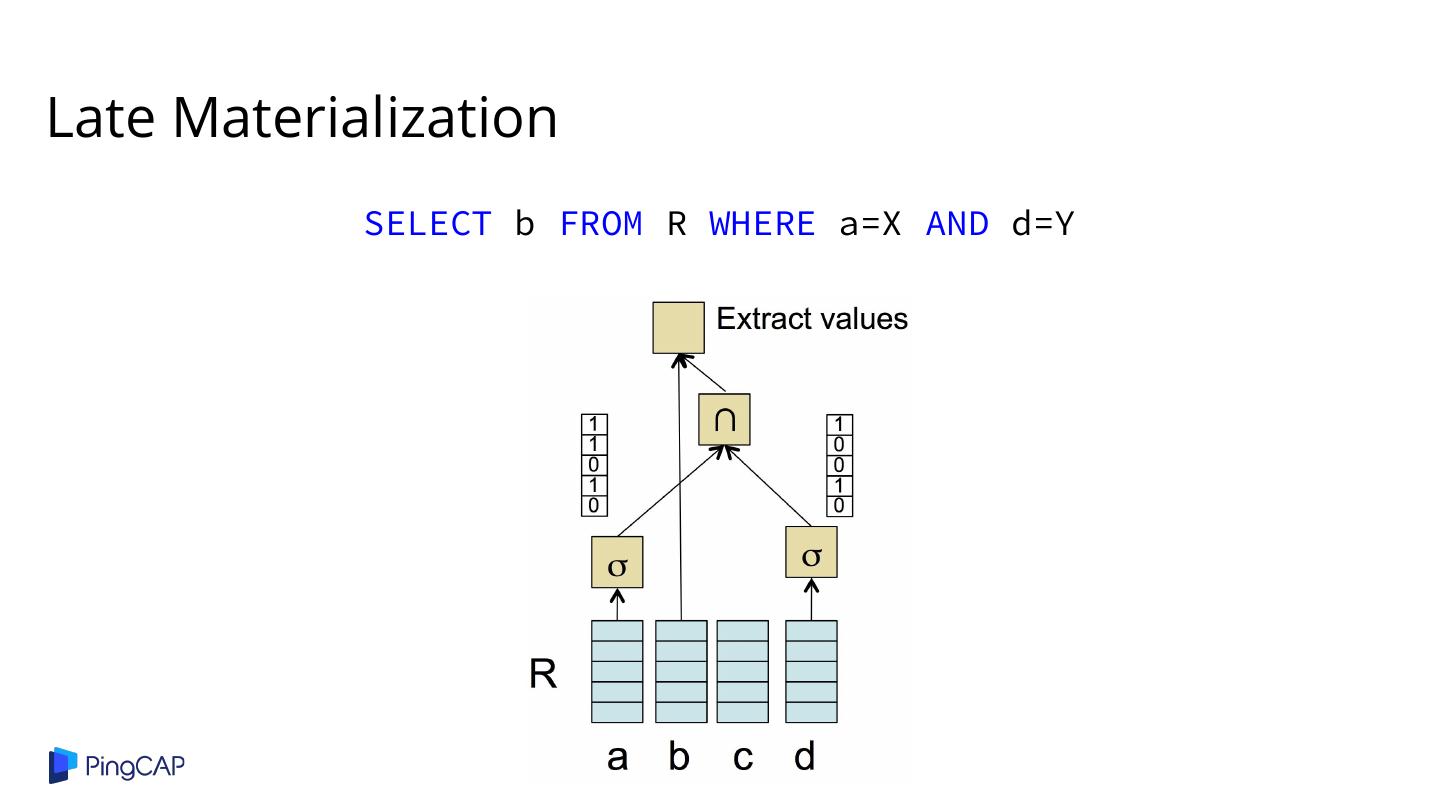
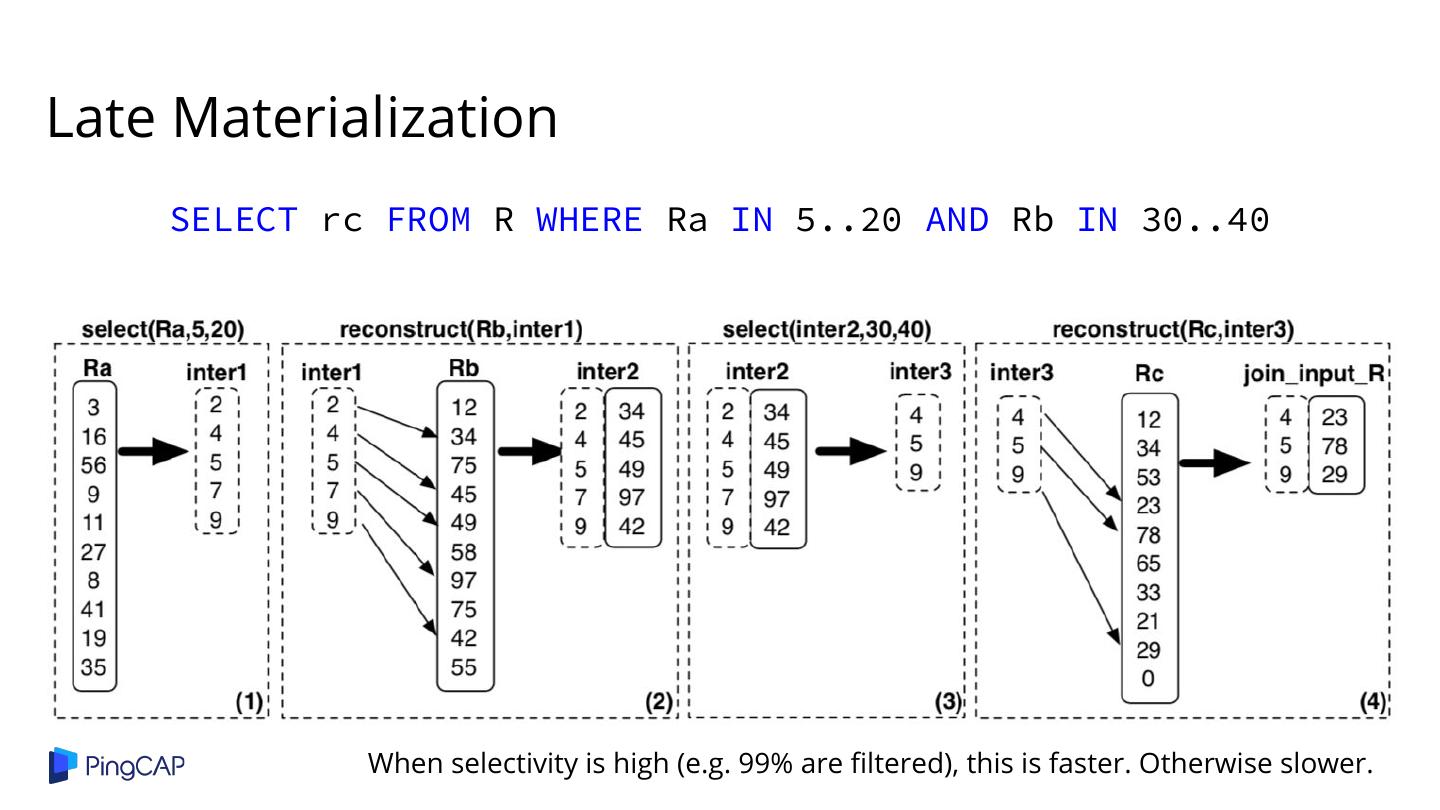
9 .Vectorized processing Late materialization Column compression Block iteration Columnar storage
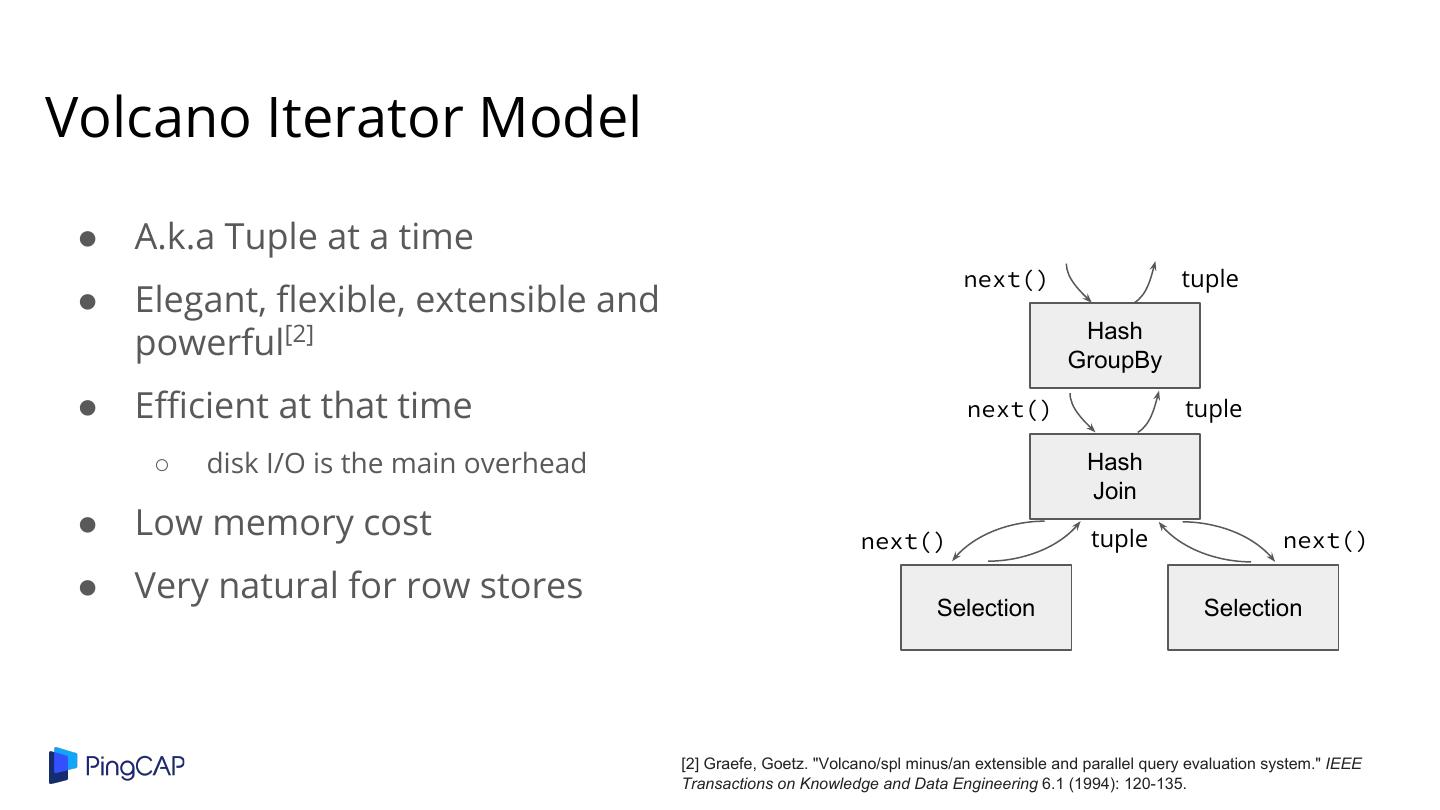
10 .Volcano Iterator Model ● A.k.a Tuple at a time next() tuple ● Elegant, flexible, extensible and Hash powerful[2] GroupBy ● Efficient at that time next() tuple ○ disk I/O is the main overhead Hash Join ● Low memory cost next() tuple next() ● Very natural for row stores Selection Selection [2] Graefe, Goetz. "Volcano/spl minus/an extensible and parallel query evaluation system." IEEE Transactions on Knowledge and Data Engineering 6.1 (1994): 120-135.
11 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
12 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
13 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
14 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
15 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price) id shop_id price 1 5 10.5
16 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
17 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
18 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price) id shop_id price 2 10 1.2
19 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price) id shop_id price 2 10 1.2
20 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
21 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
22 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price)
23 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price) id shop_id price 3 10 13.7
24 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price) id shop_id price 3 10 13.7
25 .Volcano Iterator Model SELECT SUM(price) FROM goods WHERE shop_id = 10 id shop_id price 1 5 10.5 2 10 1.2 3 10 13.7 next() Scan: goods Selection: shop_id = 10 Aggregation: sum(price) sum(price) 14.9
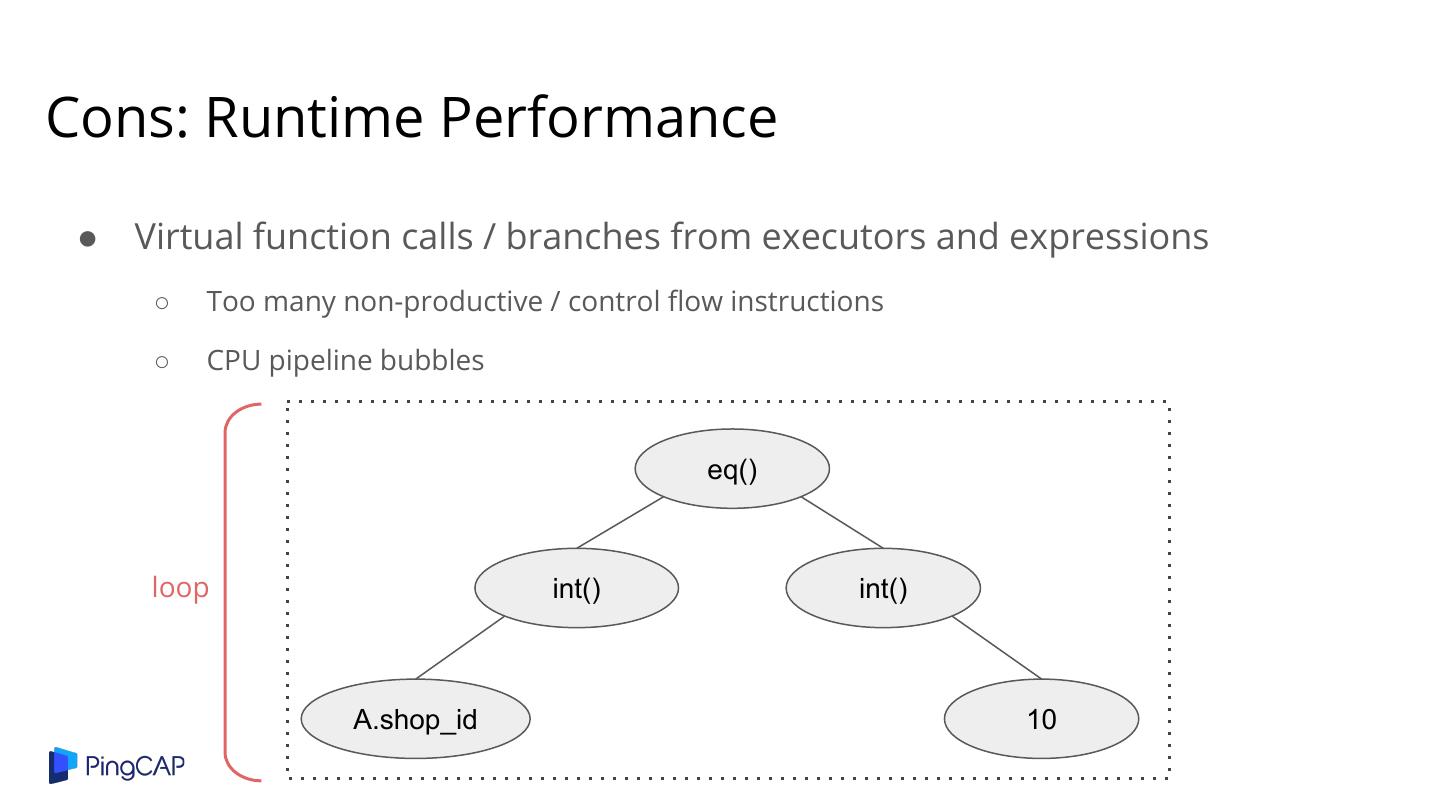
26 .Cons: Runtime Performance ● Virtual function calls / branches from executors and expressions ○ Too many non-productive / control flow instructions ○ CPU pipeline bubbles eq() loop int() int() A.shop_id 10
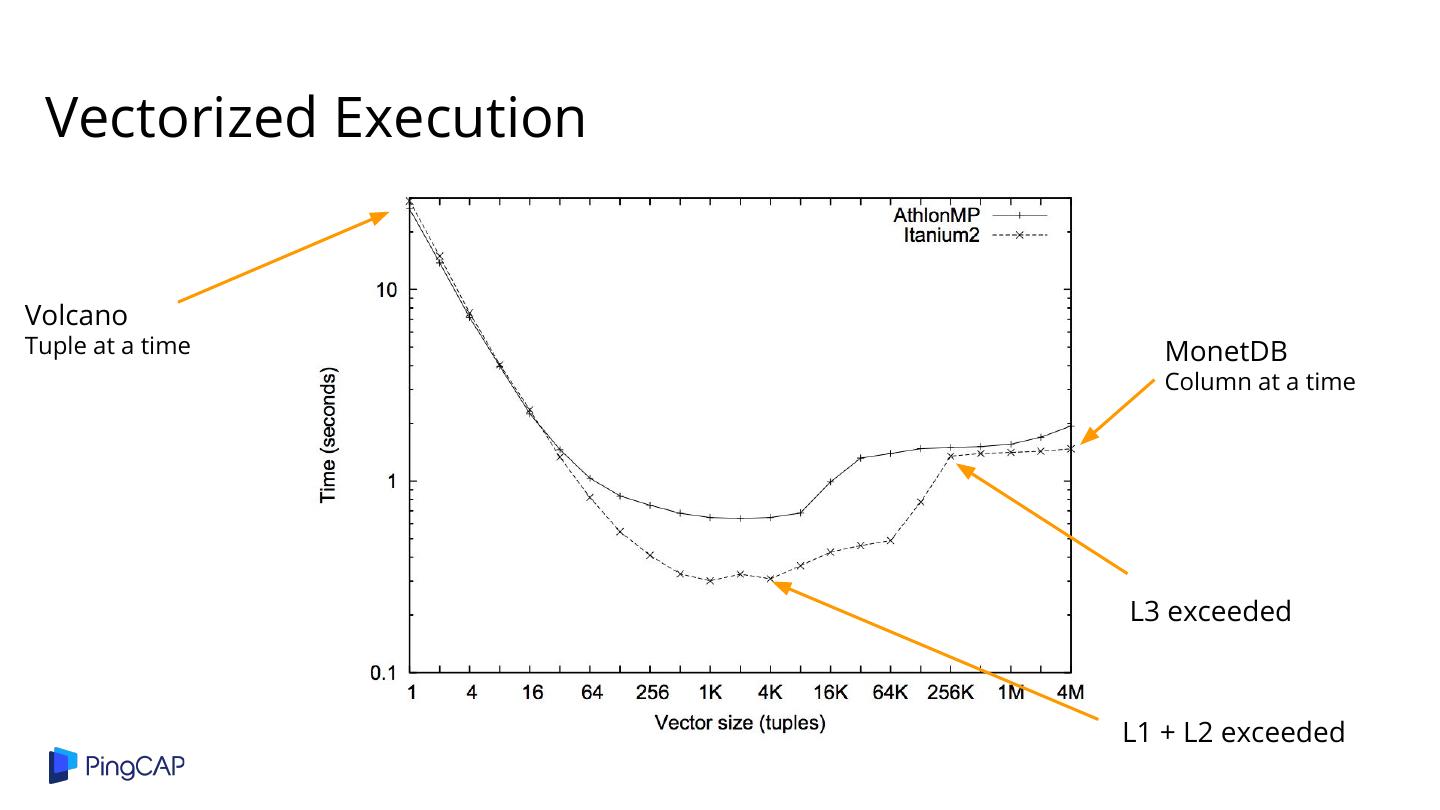
27 .Cons: Runtime Performance ● Example: MySQL runtime takes > 90% in TPC-H Q1[3] ● Function call overhead for each next() ● Poor cache utilization[4] [3] Boncz, Peter A., Marcin Zukowski, and Niels Nes. "MonetDB/X100: Hyper-Pipelining Query Execution." Cidr. Vol. 5. 2005. [4] Klonatos, Yannis, et al. "Building efficient query engines in a high-level language." Proceedings of the VLDB Endowment7.10 (2014): 853-864.
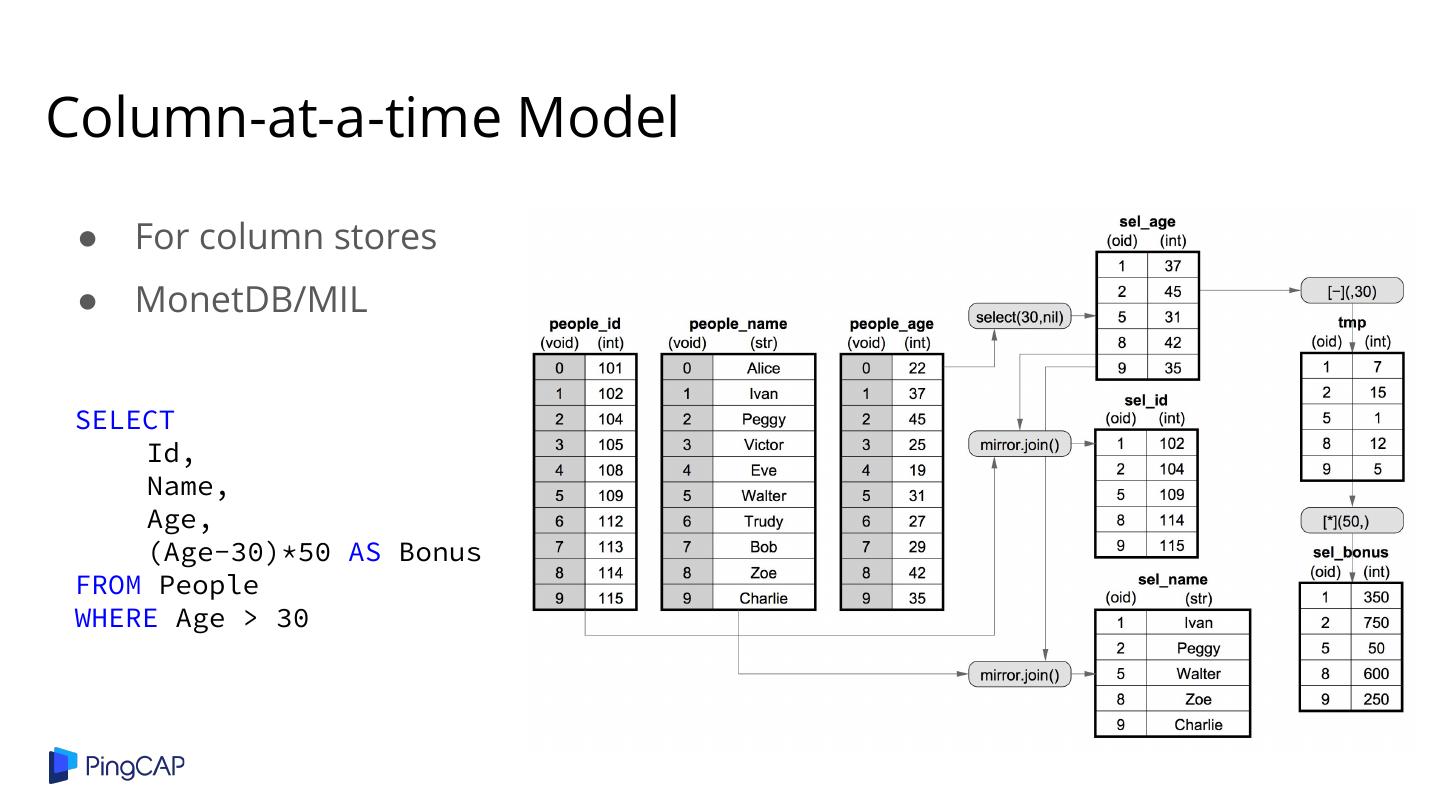
28 .Column-at-a-time Model ● For column stores ● MonetDB/MIL SELECT Id, Name, Age, (Age-30)*50 AS Bonus FROM People WHERE Age > 30
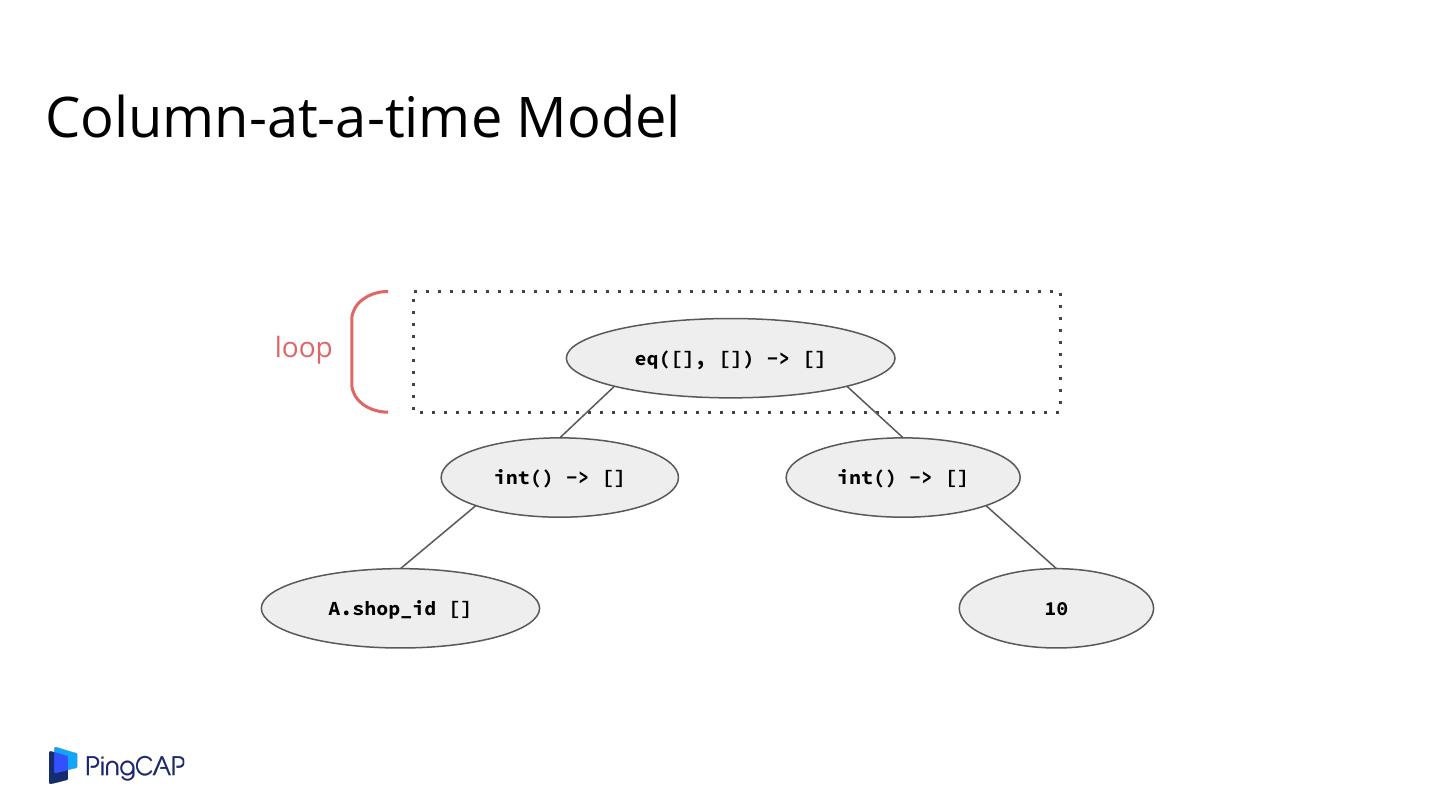
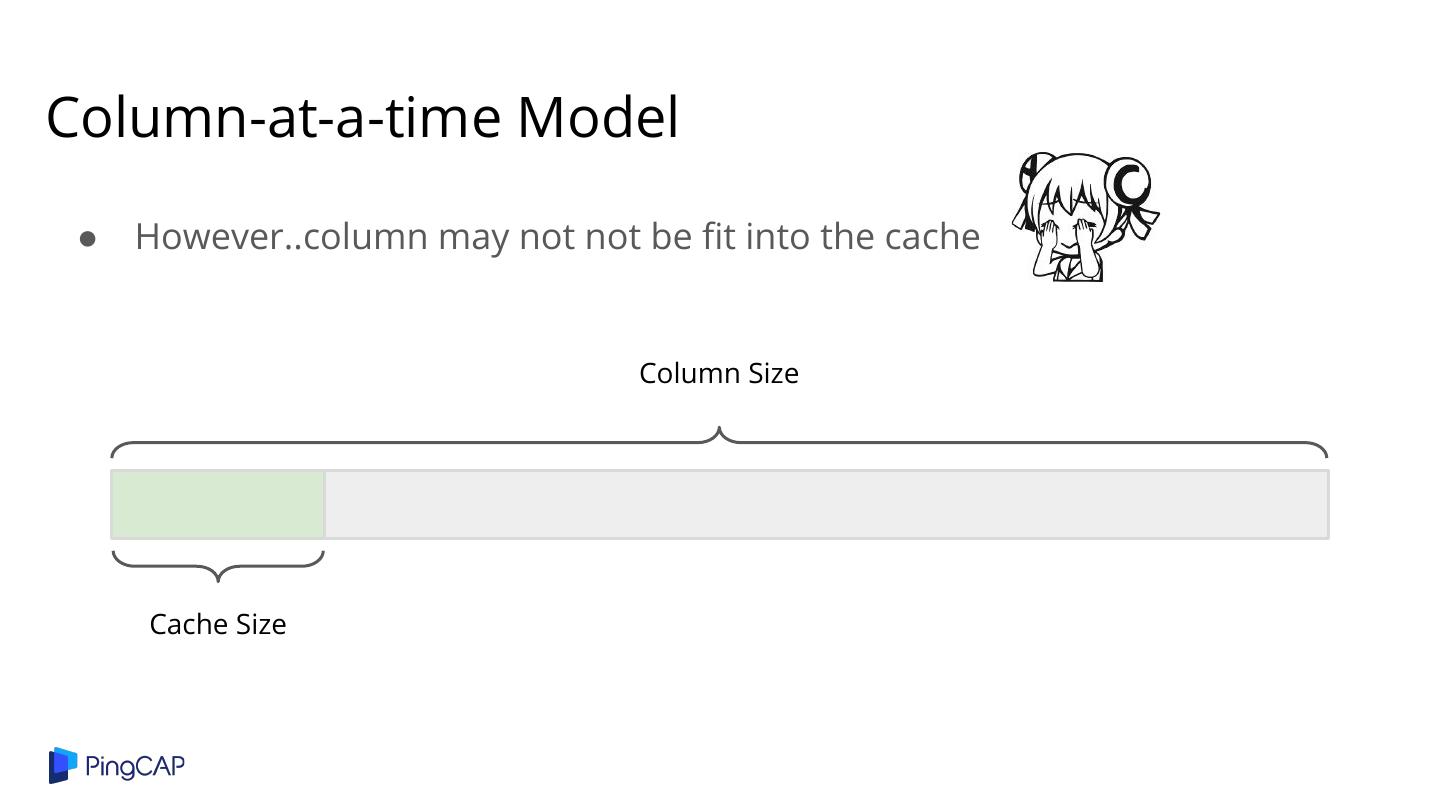
29 .Column-at-a-time Model loop eq([], []) -> [] int() -> [] int() -> [] A.shop_id [] 10
3秒后跳转登录页面
去登陆

