

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
TiFlash Introduction
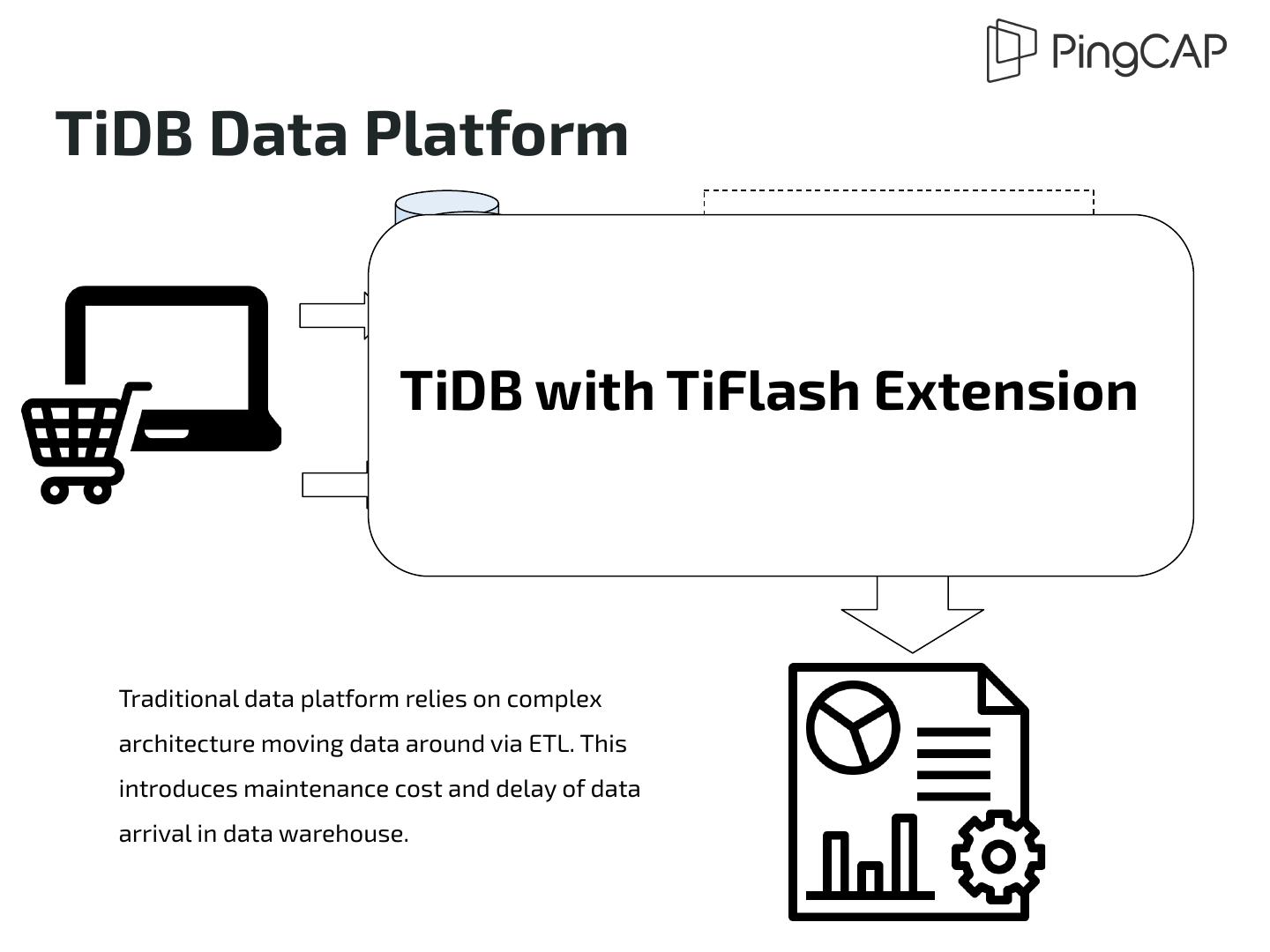
由于分析型与交易型数据库设计上的本质矛盾,使得用户的数据平台变得异常复杂:人们不得不通过各种手段将在线交易数据搬运到分析平台中。这样的架构不但难于维护,而且可能会丢失数据库新鲜度与一致性。HTAP 是一个并不容易的目标。包括 TiDB + TiSpark 本身,以往版本所提出的解决方案并不完善。一个相对完善的 HTAP 数据库,必须良好地解决交易和分析负载隔离;行存和列存的融合且互不影响,避免设计中可能引入的延迟或一致性冲突。
本次演讲将和听众探讨 HTAP 的价值,为何难以实现以及 TiDB 产品线的新组件 TiFlash 如何围绕 Multi-Raft 独创性地解决这些问题,同时为在线交易和大数据分析场景提供助力。
展开查看详情
1 .TiDB with TiFlash Extension A Venture Towards the True HTAP Platform
2 .Traditional Data Platform Data Warehouse OLTP OLTP Hadoop OLTP Data Lake Big Data ETL Compute Engine NoSQL Analytical Database
3 .Why VS
4 .Fundamental Conflicts ● Large / batch process vs point / short access ○ Row format for OLTP ○ Columnar format for OLAP ● Workload Interference ○ A single large analytical query might cause disaster for your OLTP workload
5 .A Popular Solution ● Use different types of databases ○ For live and fast data, use an OLTP specialized database or NoSQL ○ For historical data, use Hadoop / analytical database ● Offload data via the ETL process into your Hadoop cluster or analytical database ○ Per hour or even per day ○ Complex offload procedures
6 .Good enough, really?
7 .Complexity or
8 .Freshness or
9 .Consistency
10 .TiFlash Extension
11 .What’s TiFlash ● An extended analytical engine for TiDB ○ Columnar storage and vectorized processing ○ Based on ClickHouse with tons of proprietary modifications ● Data sync via extended Raft consensus algorithm ○ Strong consistency ○ Trivial overhead ● Clear workload isolation for not impacting OLTP ● Tight integration with TiDB
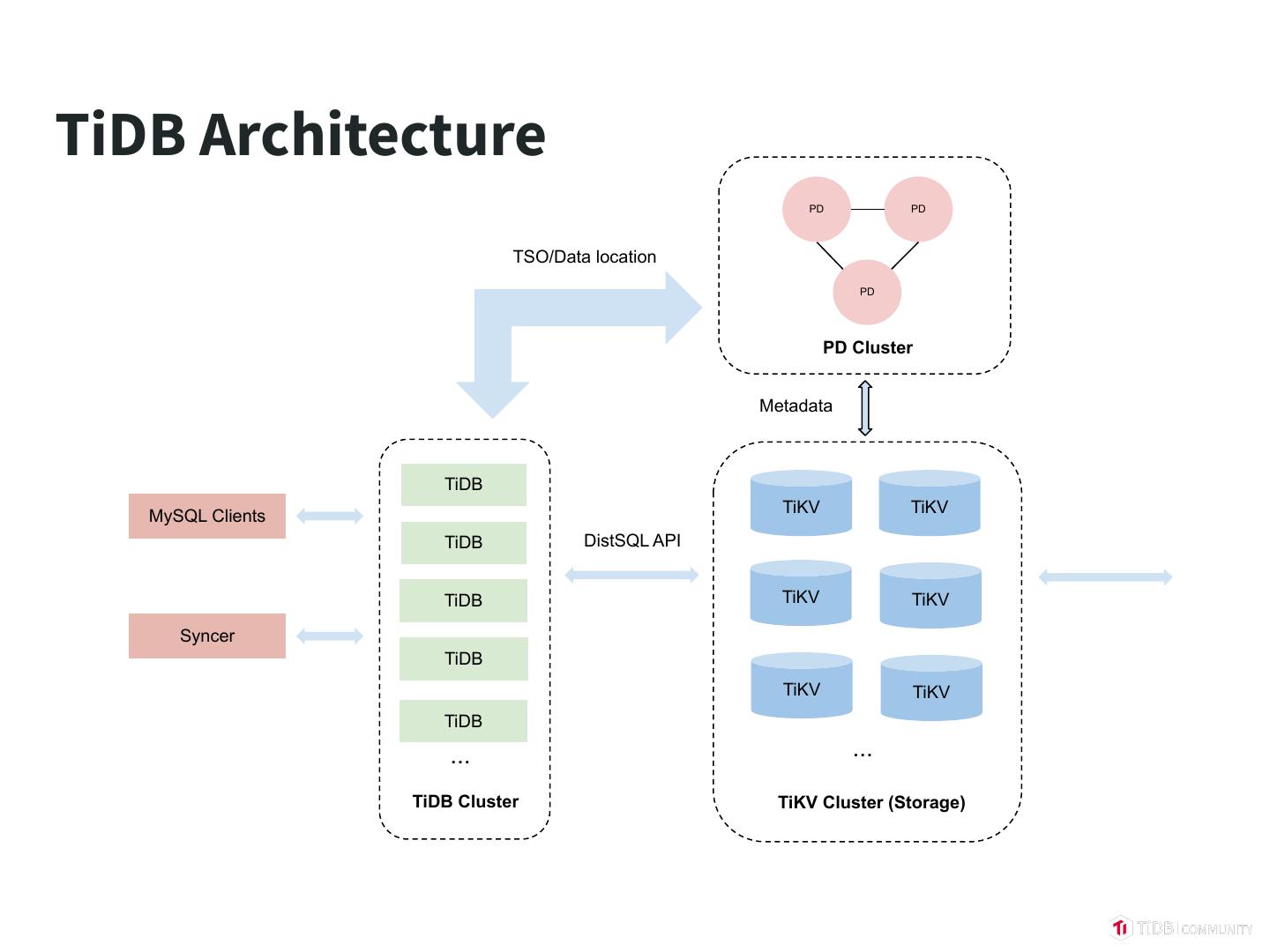
12 .TiDB Architecture PD PD TSO/Data location PD PD Cluster Metadata TiDB TiKV TiKV MySQL Clients TiDB DistSQL API TiDB TiKV TiKV Syncer TiDB TiKV TiKV TiDB ... ... TiDB Cluster TiKV Cluster (Storage)
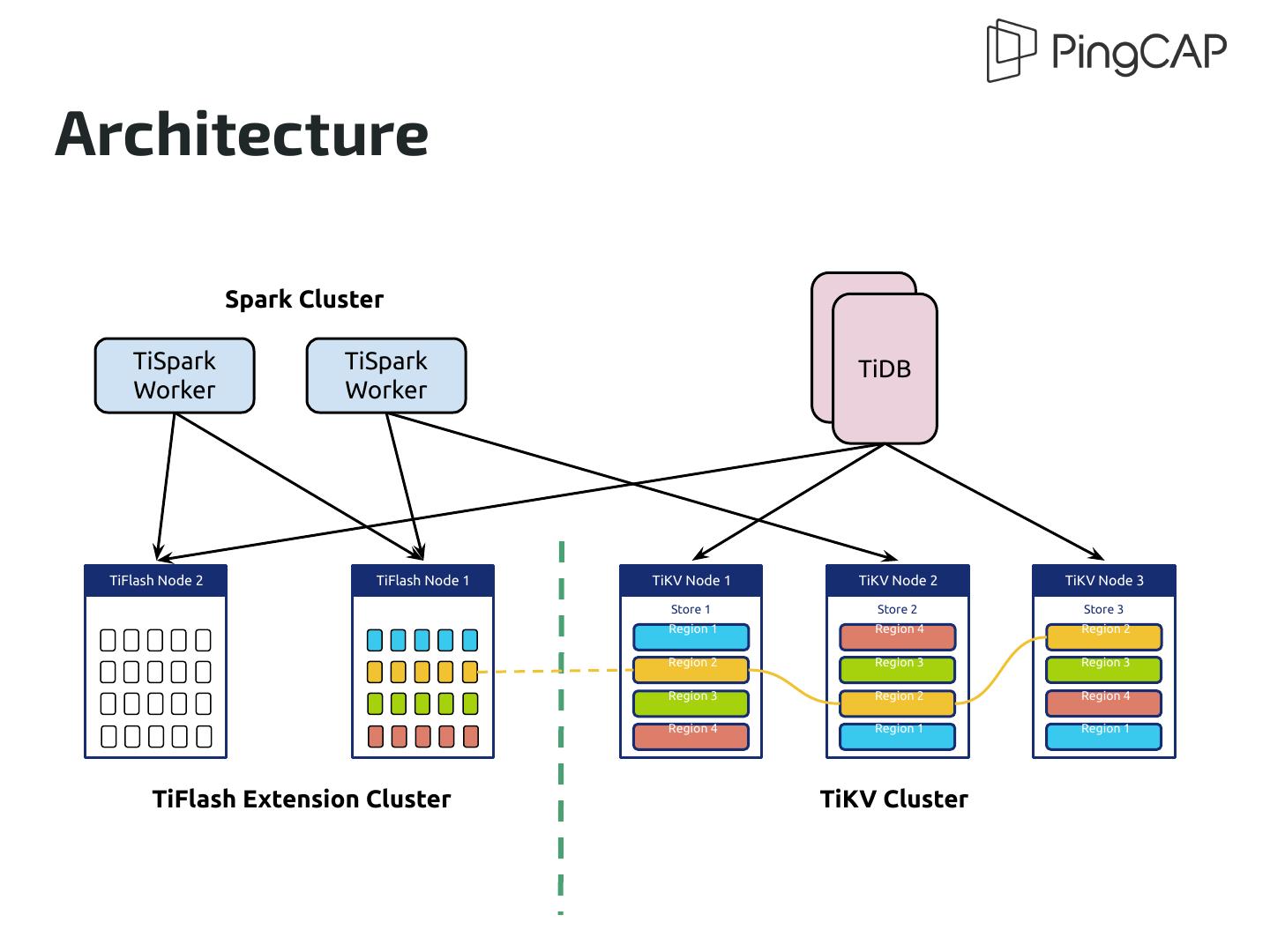
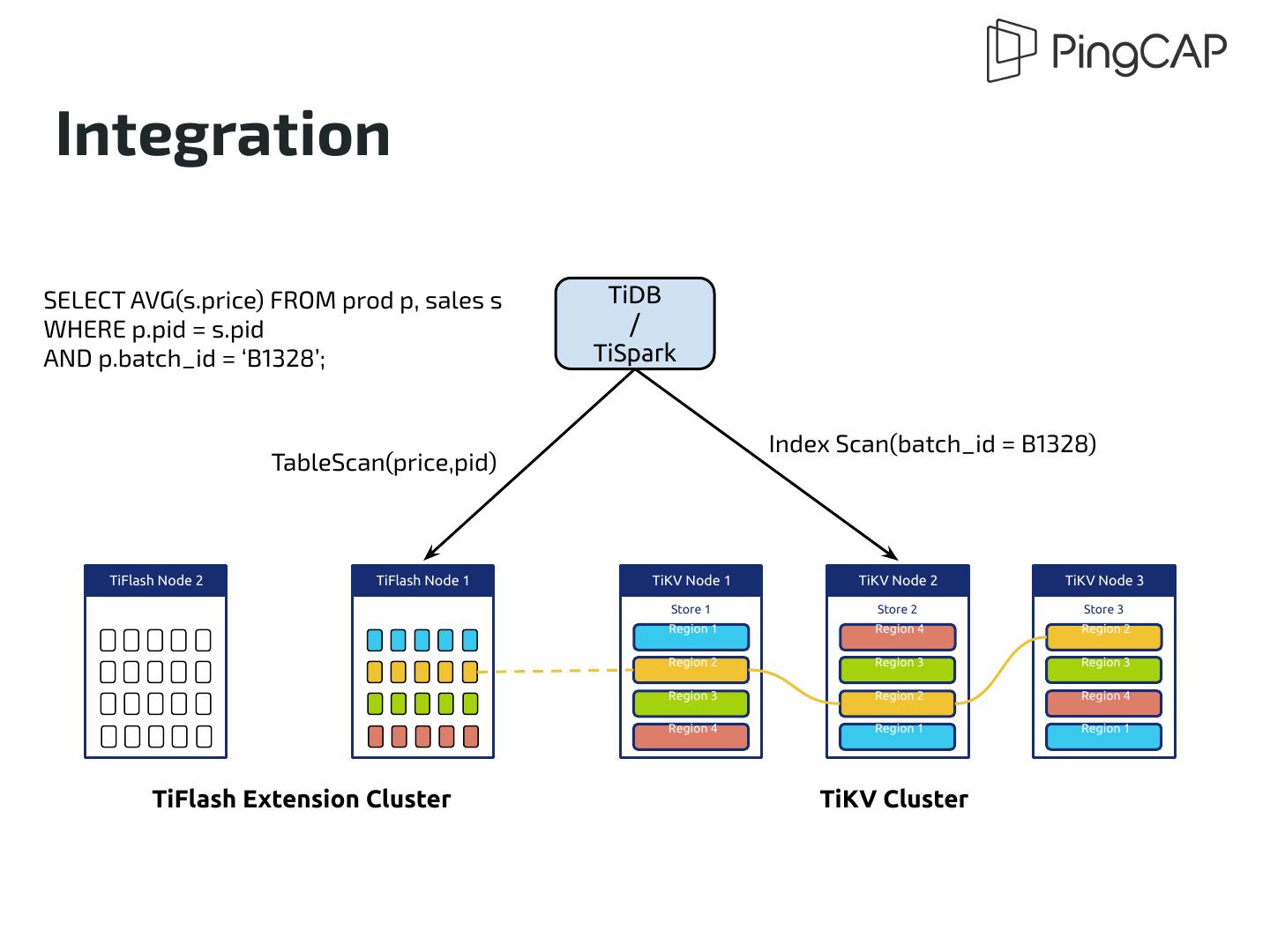
13 .Architecture Spark Cluster TiDB TiSpark TiSpark TiDB Worker Worker TiFlash Node 2 TiFlash Node 1 TiKV Node 1 TiKV Node 2 TiKV Node 3 Store 1 Store 2 Store 3 Region 1 Region 4 Region 2 Region 2 Region 3 Region 3 Region 3 Region 2 Region 4 Region 4 Region 1 Region 1 TiFlash Extension Cluster TiKV Cluster
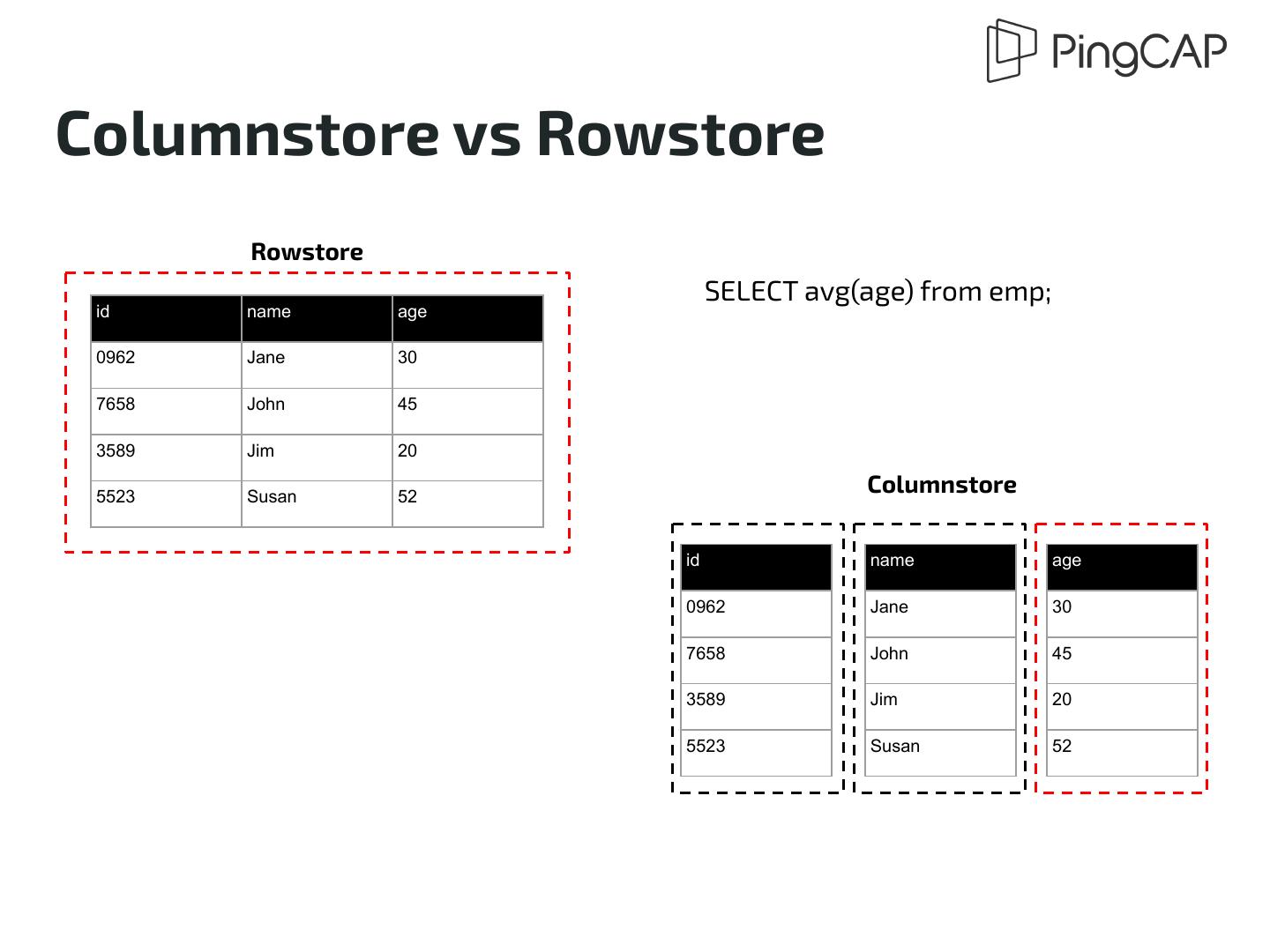
14 .Columnstore vs Rowstore ● Columnar Storage stores data in columns instead of rows ○ Suitable for analytical workload ■ Possible for column pruning ○ Compression made possible and further IO reduction ■ Far less storage requirement ○ Bad small random read ■ Which is the typical workload for OLTP ● Rowstore is the classic format for databases ○ Researched and optimized for OLTP scenario for decades ○ Cumbersome in analytical use cases
15 .Columnstore vs Rowstore Rowstore SELECT avg(age) from emp; id name age 0962 Jane 30 7658 John 45 3589 Jim 20 5523 Susan 52 Columnstore id name age 0962 Jane 30 7658 John 45 3589 Jim 20 5523 Susan 52
16 .Columnstore vs Rowstore “If your mother and your wife fell into a river at the same time, who would you save?” “Why not both?”
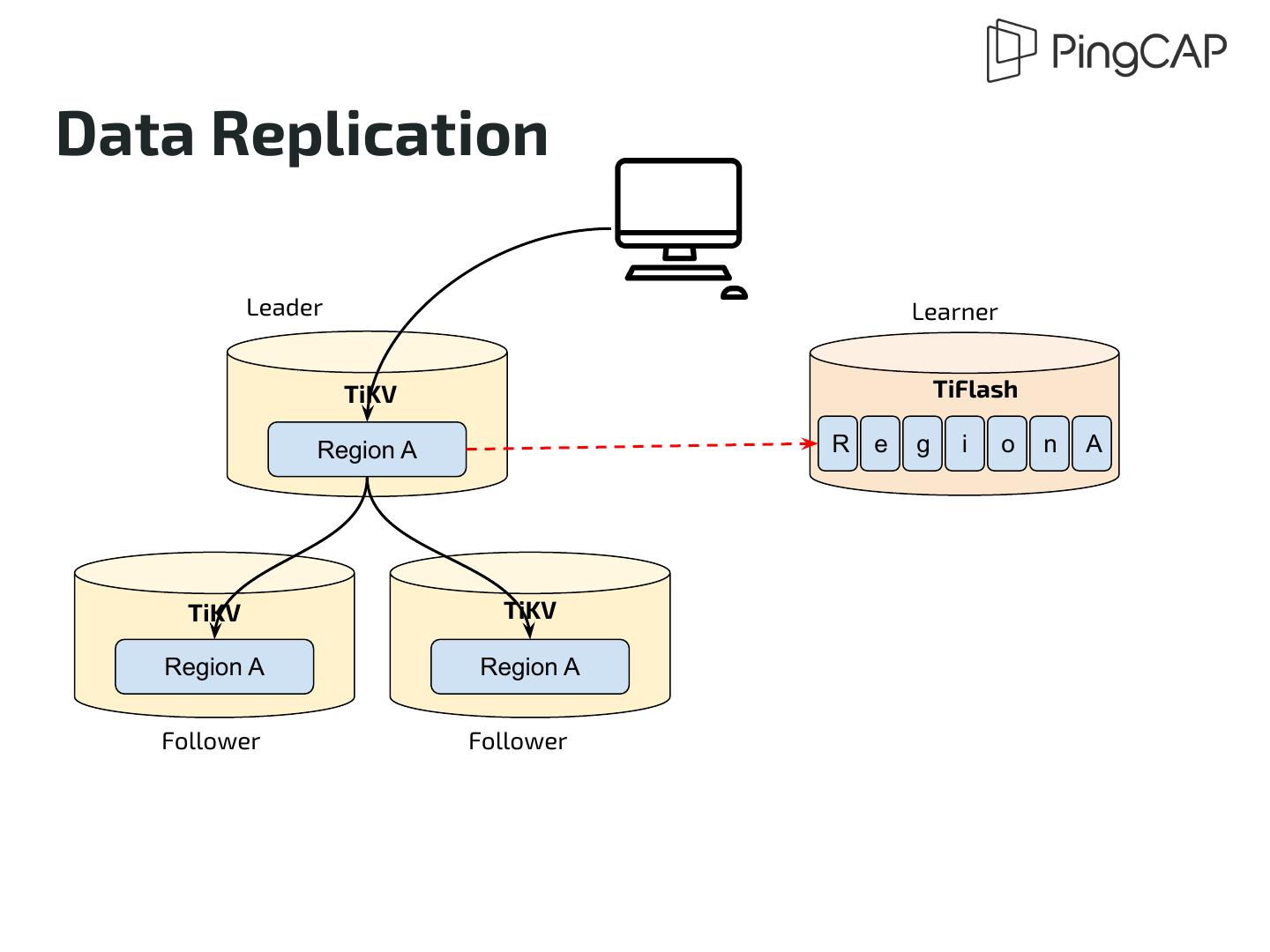
17 .Low-cost Data Replication ● TiDB replicates log via Raft consensus protocol ● TiFlash replicates data in columnstore via Raft Learner ● Learner is a special read-only role in Raft ● Data is replicated to learner asynchronously ○ Write operation does not wait for learner finish replicating data ● Introduce very low latency for the OLTP workload
18 .Data Replication Leader Learner TiKV TiFlash Region A R e g i o n A TiKV TiKV Region A Region A Follower Follower
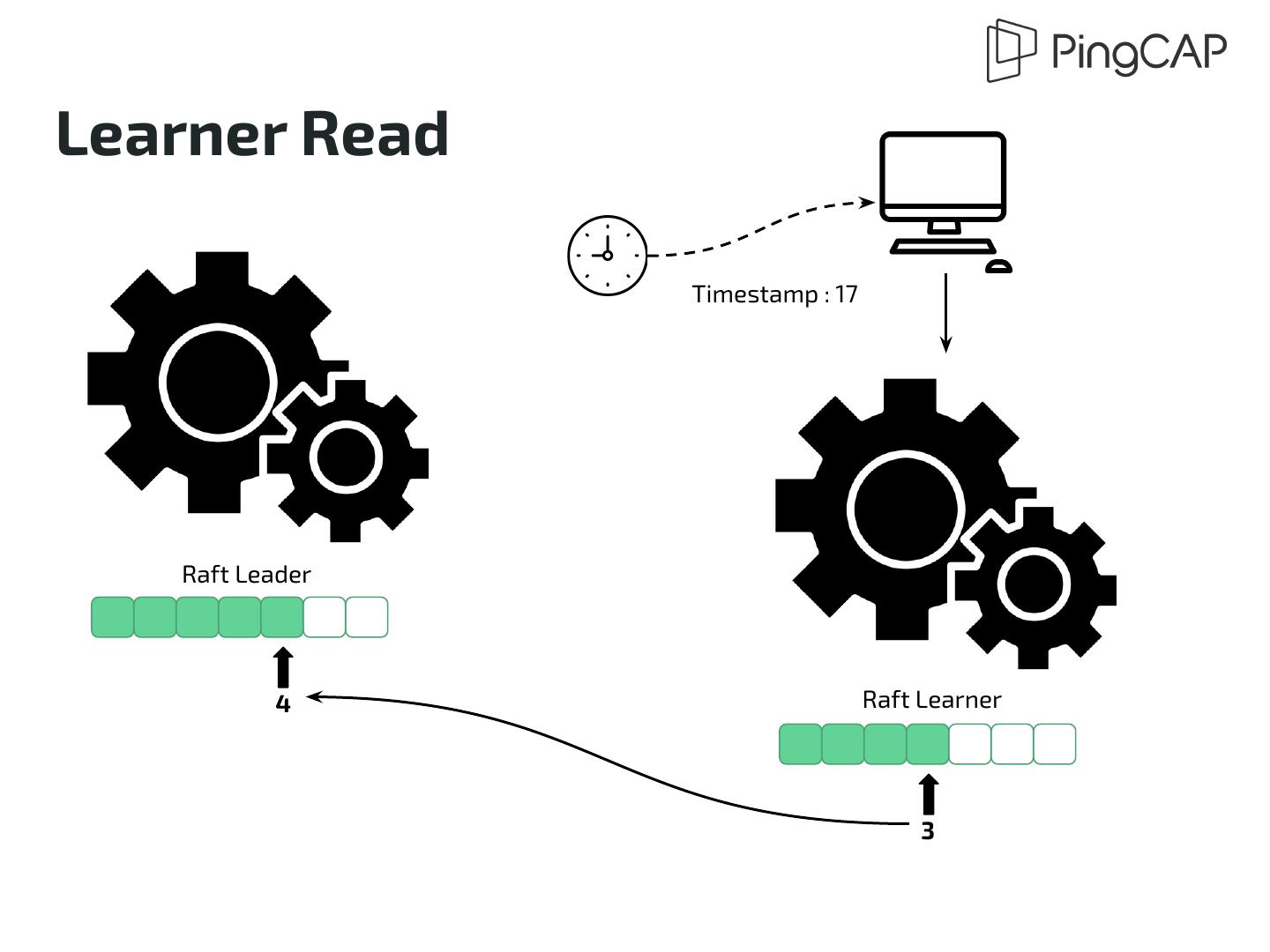
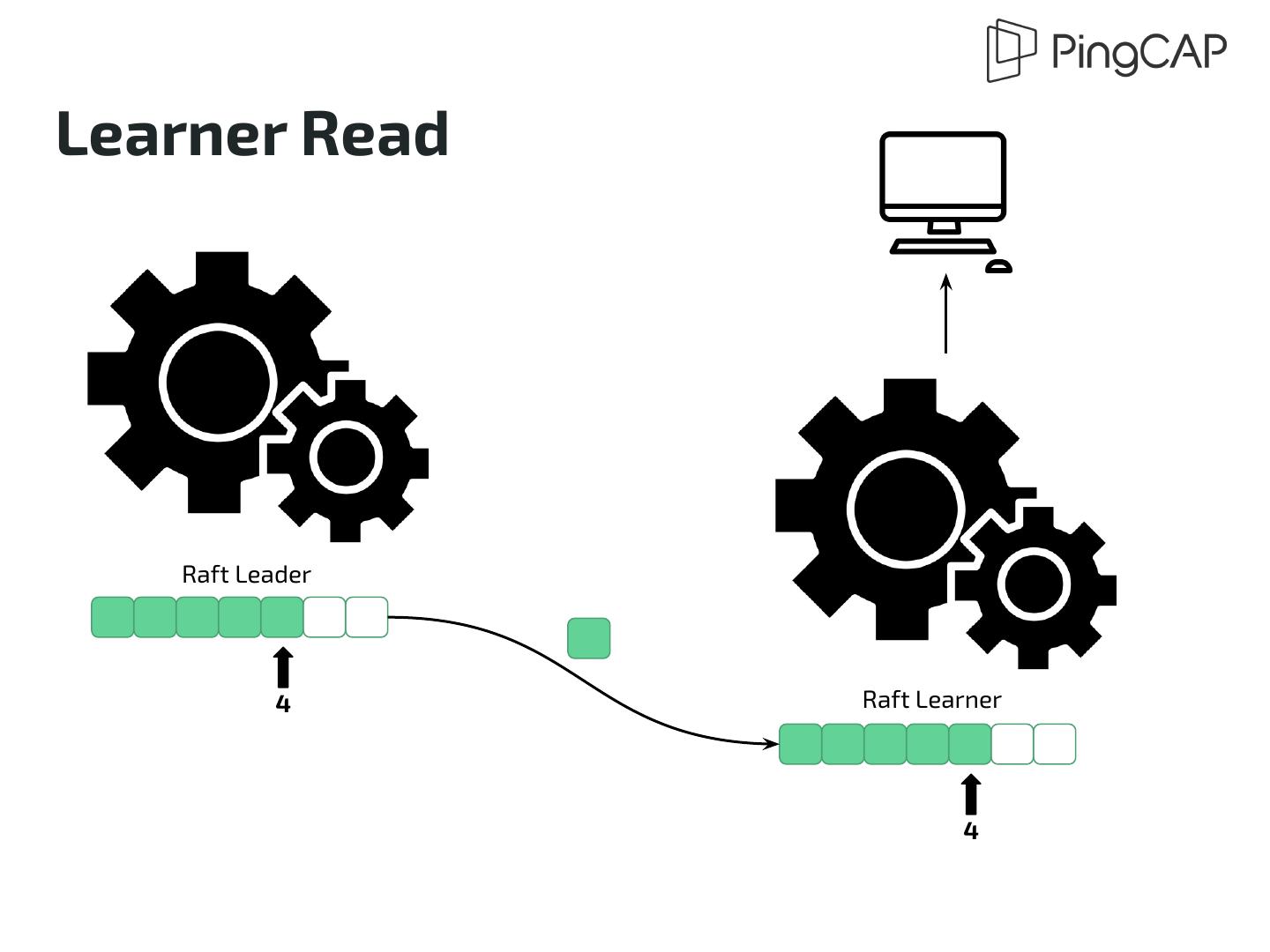
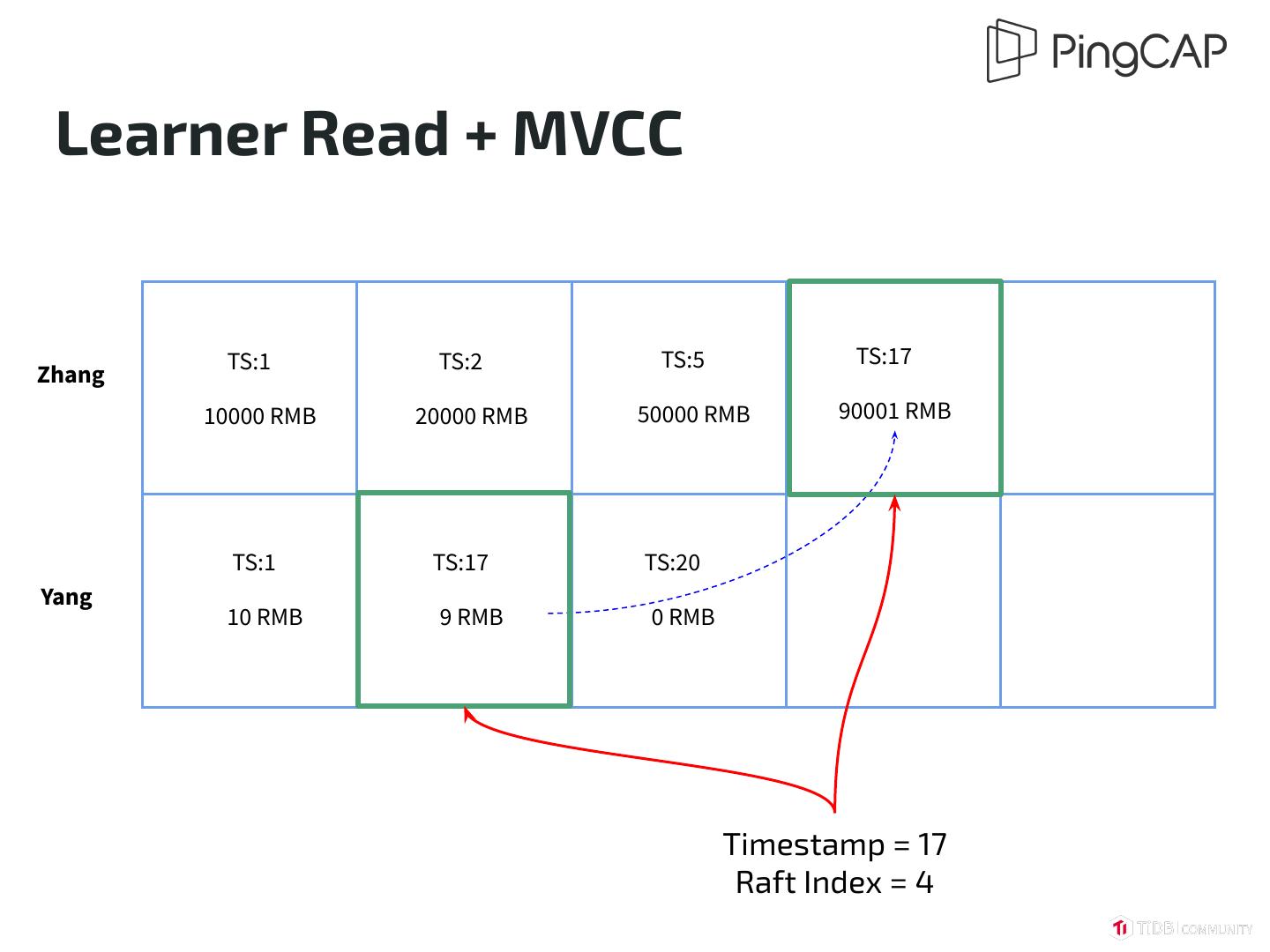
19 .Strong Consistency ● Although data replication is asynchronous ● Read operation guarantees strong consistency ● Raft Learner read protocol + MVCC do the trick ○ Check readIndex on read and wait for necessary log ○ Read according to Timestamp within each log
20 .Learner Read Timestamp : 17 Raft Leader 4 Raft Learner 3
21 .Learner Read Raft Leader 4 Raft Learner 4
22 . Learner Read + MVCC TS:1 TS:2 TS:5 TS:17 Zhang 10000 RMB 20000 RMB 50000 RMB 90001 RMB TS:1 TS:17 TS:20 Yang 10 RMB 9 RMB 0 RMB Timestamp = 17 Raft Index = 4
23 .Write Procedure ● TiKV use 2PC to write data ○ Prepare phase: ■ PUT Data Column Family ■ PUT Lock Column Family ○ Commit phase: ■ PUT Write Column Family (PUT Flag / DEL Flag) ■ DEL Lock Column Family ○ Rollback phase: ■ DEL Lock Column Family ■ DEL Data Column Family ● TiKV use percolator to process txn
24 .Update support In memory, L0 L0 L0 } rowbased (raft, transaction, key ts del value cache) a 102 0 bob a 104 0 alice L1 L1 a b 108 105 1 0 alice kevin L2 } On disk, columnar (MVCC, AP performance) b 107 0 joe Versioned rows MutableMergeTree Storage Engine (MVCC) (Based on MergeTree of ClickHouse, LSM-Tree like design)
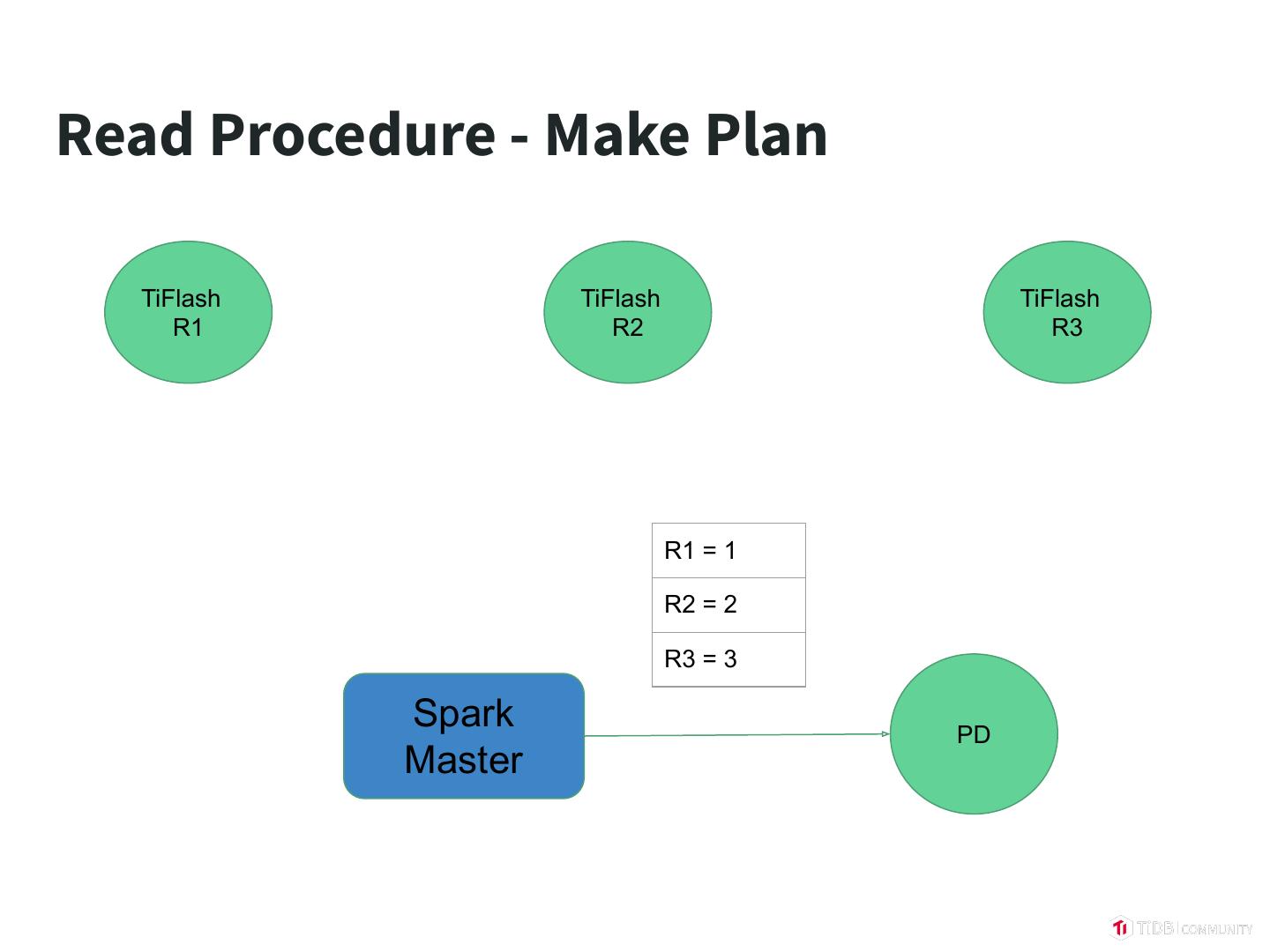
25 .Read Procedure - Make Plan TiFlash TiFlash TiFlash R1 R2 R3 R1 = 1 R2 = 2 R3 = 3 Spark PD Master
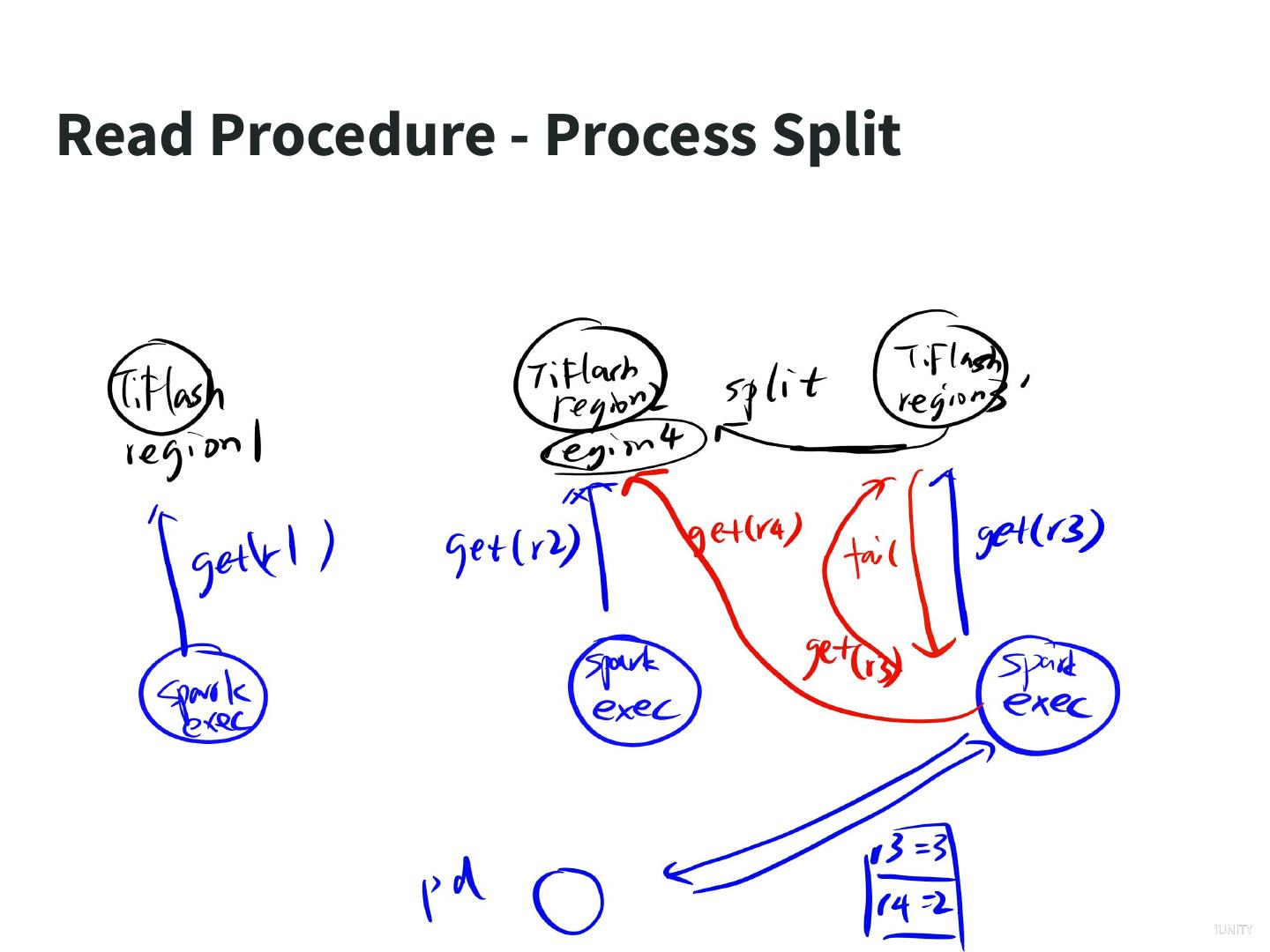
26 .Read Procedure - Process Split
27 .Read Procedure - Process Split
28 .TiFlash is beyond columnar format
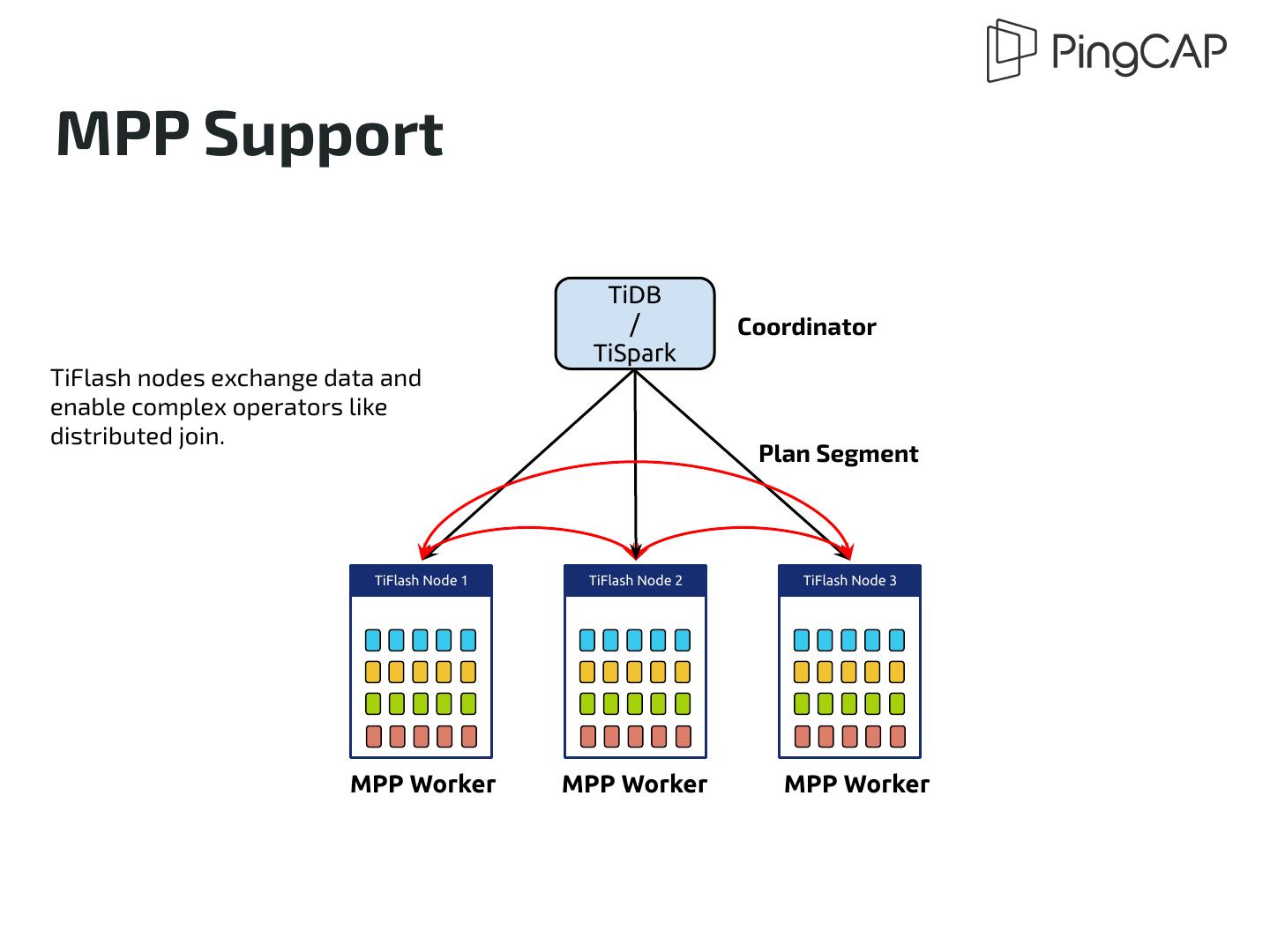
29 .Scalability ● An HTAP database needs to store huge amount of data ● Scalability is very important ● TiDB relies on multi-raft for scalability ○ One command to add / remove node ○ Scaling is fully automatic ○ Smooth and painless data rebalance ● TiFlash adopts the same design
3秒后跳转登录页面
去登陆

