

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
TiFlash Intro Shanghai Meetup 2019_03_30
1. HTAP的核心价值:能够解决当前各类数据平台上广泛存在的工具链过于复杂,运维成本高,数据实效性和一致性等问题。
2. HTAP面临的技术挑战:OLTP场景通常使用行存,而OLAP场景通常使用列存;另外,OLAP任务因为对系统资源占用较多,也会严重影响OLTP业务。
3. TiFlash是如何解决这些问题的:
3.1 使用列存及向量化计算来满足OLAP业务;
3.2 数据使用Raft Learner机制同步到列存;
3.3 拥有与TiDB相同的Scalability;
3.4 OLTP与OLAP的物理资源完全隔离,避免互相干扰;
3.5 TiDB/TiSpark能够同时访问行存和列存副本,通过CBO选取最优化的访问方式;
3.6 为TiFlash引入MPP能力。
展开查看详情
1 . Welcome! 加入 Infra Meetup No.XX 交流群 和大家一起讨论吧~ 我们将分享本期 Meetup 资料
2 .TiDB with TiFlash Extension A Venture Towards the True HTAP Platform
3 .About Me ● Sun Ruoxi 孙若曦 ● Senior expert, Analytical Product@PingCAP ● Previously ○ Tech lead, SQL on Hadoop team@Transwarp ○ Tech lead, Arch Infra team@NVIDIA ● Mainly working on Big-data / SQL related things
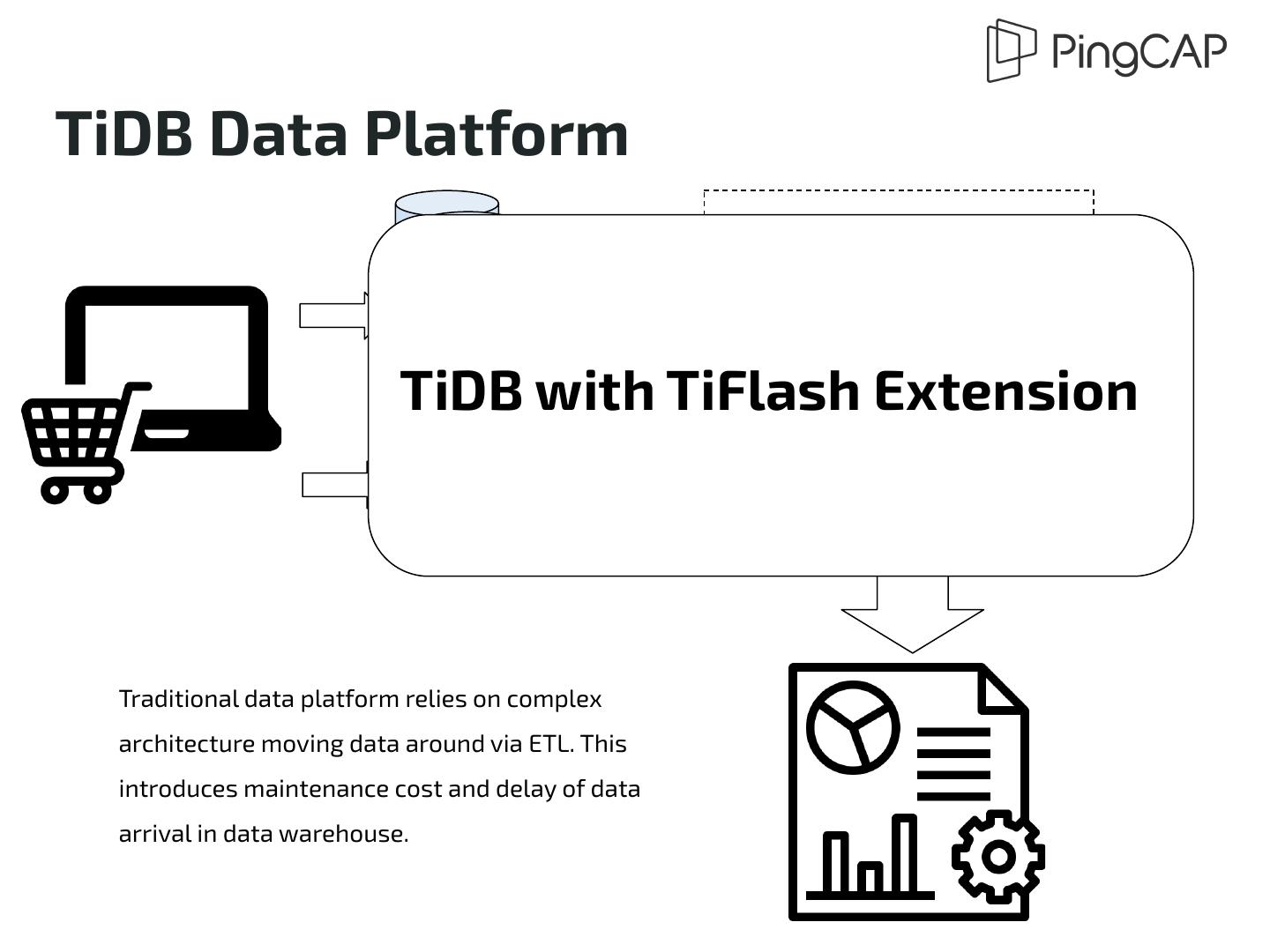
4 .Traditional Data Platform Data Warehouse OLTP OLTP Hadoop OLTP Data Lake Big Data ETL Compute Engine NoSQL Analytical Database Traditional data platform relies on complex architecture moving data around via ETL. This introduces maintenance cost and delay of data arrival in data warehouse.
5 .Why VS
6 .Fundamental Conflicts ● Large / batch process vs point / short access ○ Row format for OLTP ○ Columnar format for OLAP ● Workload Interference ○ A single large analytical query might cause disaster for your OLTP workload
7 .A Popular Solution ● Use different types of databases ○ For live and fast data, use an OLTP specialized database or NoSQL ○ For historical data, use Hadoop / analytical database ● Offload data via the ETL process into your Hadoop cluster or analytical database ○ Maybe per day
8 .Good enough, really?
9 .Complexity or
10 .Freshness or
11 .Consistency
12 .TiFlash Extension
13 .What’s TiFlash Extension ● TiFlash is an extended analytical engine for TiDB ● Powered by columnar storage and vectorized compute engine ○ Speed up OLAP workload for both TiSpark and TiDB ○ Partially based on ClickHouse with tons of proprietary modifications ● Data sync via raft learner ○ Strong consistency ○ Trivial overhead ● Clear Isolation of workload not impacting OLTP ● Tightly integrated with TiDB
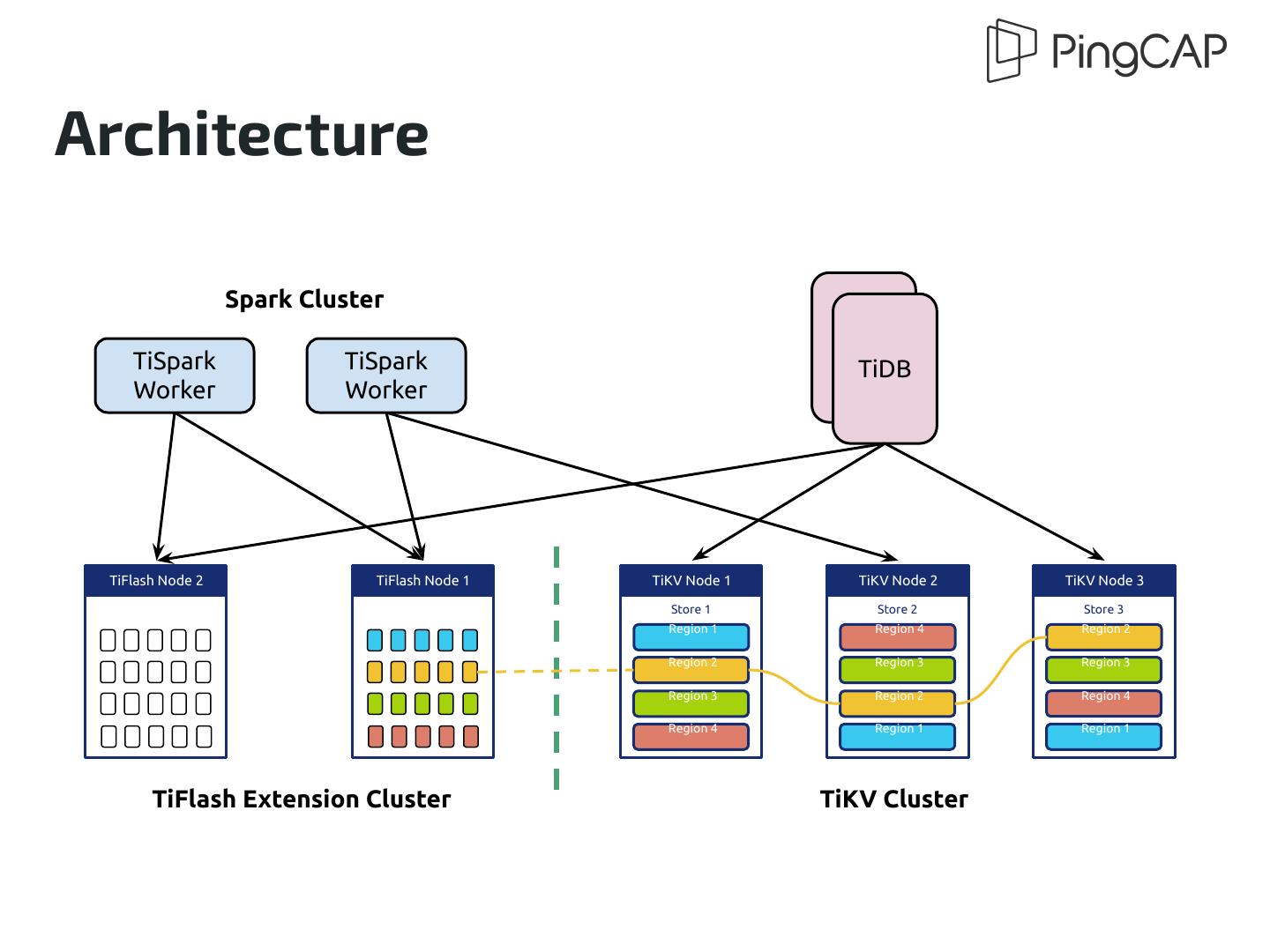
14 .Architecture Spark Cluster TiDB TiSpark TiSpark TiDB Worker Worker TiFlash Node 2 TiFlash Node 1 TiKV Node 1 TiKV Node 2 TiKV Node 3 Store 1 Store 2 Store 3 Region 1 Region 4 Region 2 Region 2 Region 3 Region 3 Region 3 Region 2 Region 4 Region 4 Region 1 Region 1 TiFlash Extension Cluster TiKV Cluster
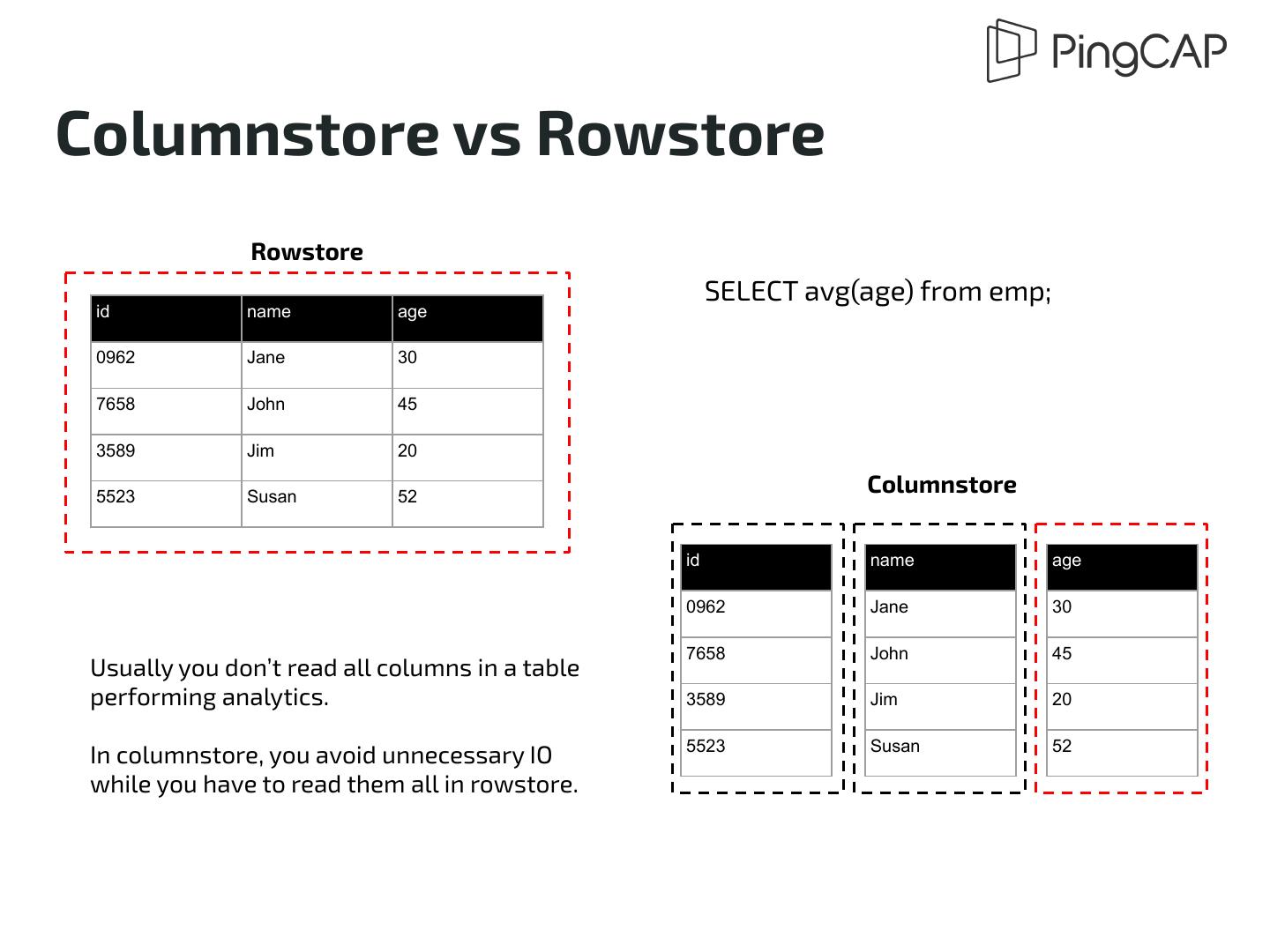
15 .Columnstore vs Rowstore ● Columnar Storage stores data in columns instead of rows ○ Suitable for analytical workload ■ Possible for column pruning ○ Compression made possible and further IO reduction ■ ⅕ on average storage requirement ○ Bad small random read and write ■ Which is the typical workload for OLTP ● Rowstore is the classic format for databases ○ Researched and optimized for OLTP scenario for decades ○ Cumbersome in analytical use cases
16 .Columnstore vs Rowstore Rowstore SELECT avg(age) from emp; id name age 0962 Jane 30 7658 John 45 3589 Jim 20 5523 Susan 52 Columnstore id name age 0962 Jane 30 7658 John 45 Usually you don’t read all columns in a table performing analytics. 3589 Jim 20 5523 Susan 52 In columnstore, you avoid unnecessary IO while you have to read them all in rowstore.
17 .Columnstore vs Rowstore “If your mother and your wife fell into a river at the same time, who would you save?” “Why not both?”
18 .Raft Learner TiFlash synchronizes data in columnstore via Raft Learner ● Strong consistency on read enabled by the Raft protocol ● Introduce almost zero overhead for the OLTP workload ○ Except the network overhead for sending extra replicas ○ Slight overhead on read (check Raft index for each region in 96 MB by default) ○ Possible for multiple learners to speed up hot data read
19 .Raft Learner TiKV TiFlash Region A R e g i o n A Instead of connecting as a Raft Follower, TiKV TiKV regions in TiFlash act as Raft Learner. Region A Region A When data is written, Raft leader does not wait for learner to finish writing. Therefore, TiFlash introduces almost no overhead replicating data.
20 .Raft Learner Raft Leader 4 Raft Learner When being read, Raft Learner sends request to check the Raft log index with 3 Leader to see if its data is up-to-date.
21 .Raft Learner Raft Leader 4 Raft Learner After data catches up via Raft log, Learner serves the read request 4 then.
22 .Scalability ● An HTAP database needs to store huge amount of data ● Scalability is very important ● TiDB relies on multi-raft for scalability ○ One command to add / remove node ○ Scaling is fully automatic ○ Smooth and painless data rebalance ● TiFlash adopts the same design
23 .Isolation ● Perfect Resource Isolation ● Data rebalance based on the “label” mechanism ○ Dedicated nodes for TiFlash / Columnstore ○ Nodes are differentiated by “label” ■ Raft Learner only exists within labeled nodes ■ Rebalance between labeled nodes ● Computation Isolation is possible by nature ○ Use a different set of compute nodes ○ Read only from nodes with AP label
24 .Isolation Region 1 AP label constrained Peer 1 Label: TP TiDB / Peer 2 Label: TP TiSpark Peer 3 Label: TP Peer 4 Label: AP Label: AP Label: TP TiFlash Node 2 TiFlash Node 1 TiKV Node 1 TiKV Node 2 TiKV Node 3 Store 1 Store 2 Store 3 Region 1 Region 4 Region 2 Region 2 Region 3 Region 3 Region 3 Region 2 Region 4 Region 4 Region 1 Region 1 TiFlash Extension Cluster TiKV Cluster
25 .Integration ● Tightly Integrated Interaction ○ TiDB / TiSpark might choose to read from either side ■ Based on cost ○ Upon TiFlash replica failure, read TiKV replica transparently ○ Join data from both sides in a single query
26 . Integration SELECT AVG(s.price) FROM prod p, sales s TiDB WHERE p.pid = s.pid / AND p.batch_id = ‘B1328’; TiSpark Index Scan(batch_id = B1328) TableScan(price,pid) TiFlash Node 2 TiFlash Node 1 TiKV Node 1 TiKV Node 2 TiKV Node 3 Store 1 Store 2 Store 3 Region 1 Region 4 Region 2 Region 2 Region 3 Region 3 Region 3 Region 2 Region 4 Region 4 Region 1 Region 1 TiFlash Extension Cluster TiKV Cluster
27 .MPP Support ● TiFlash nodes form a MPP cluster by themselves ● Full computation support on MPP layer ○ Speed up TiDB since it is not MPP design ○ Speed up TiSpark by avoiding writing disk during shuffle
28 .MPP Support TiDB / Coordinator TiSpark TiFlash nodes exchange data and enable complex operators like distributed join. Plan Segment TiFlash Node 1 TiFlash Node 2 TiFlash Node 3 MPP Worker MPP Worker MPP Worker
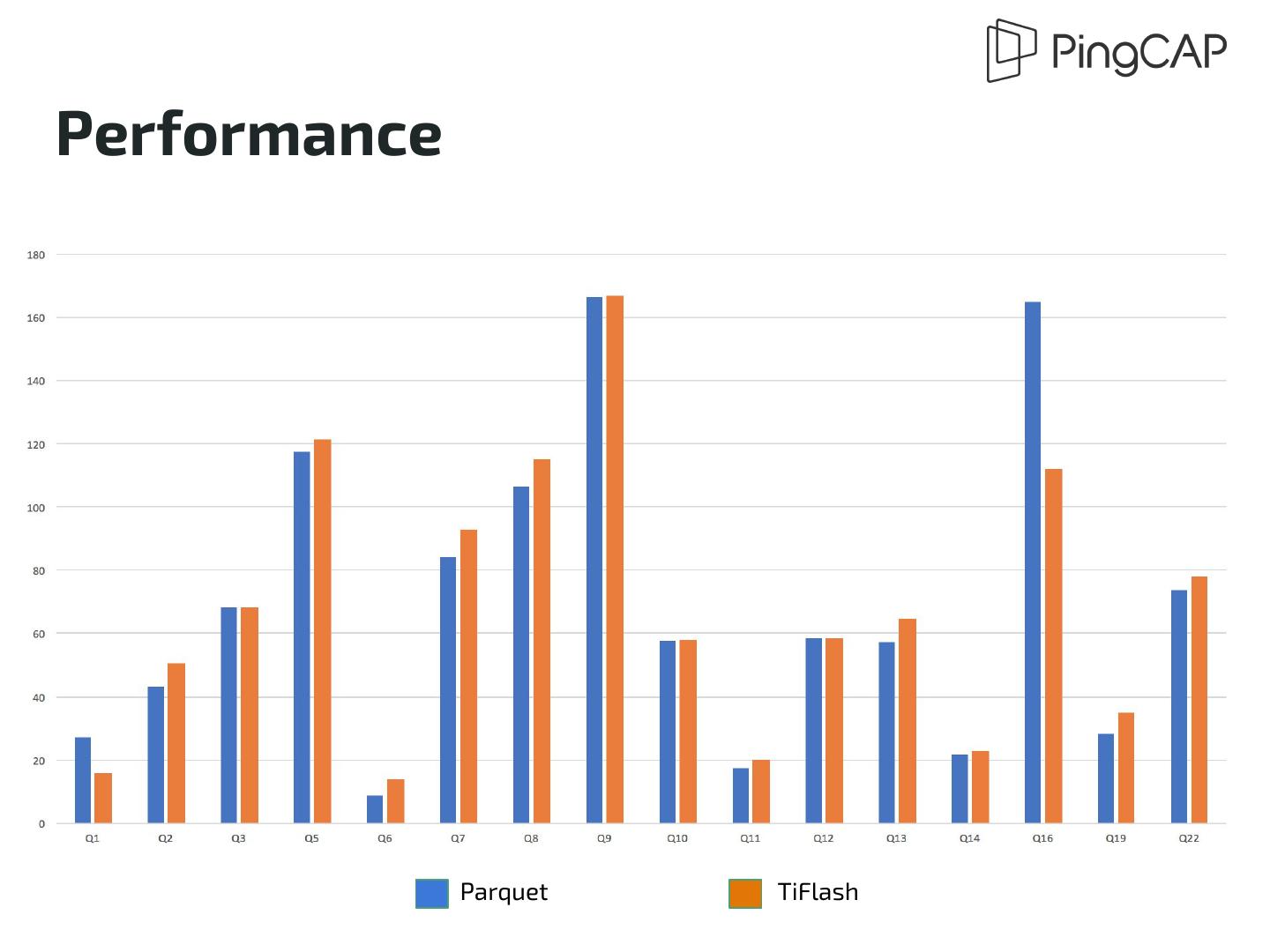
29 .Performance ● Comparable performance against vanilla Spark on Hadoop + Parquet ○ Benchmarked with Pre-Alpha version of TiFlash + Spark (without MPP support) ○ TPC-H 100
3秒后跳转登录页面
去登陆

