展开查看详情
1 .An Introduction to Titan
Presented by Bokang Zhang
�
4 .Write Amplification
S0
S1=S0*R0
S2=S1*R1
S3=S2*R2
S4=S3*R3
�
5 .Write Amplification
Write performance is optimized when the size ratios are the same.
�
7 .Separate values from LSM-Tree
● Separate large values to blob files to reduce write amplification
○ key: 16B, value: 1KB
○ (40 * 16 + 1024) / (16 + 1024) = 1.6
● An addition I/O may be required for each query
○ LSM-Tree is more small so that can be cached in memory easily
● Range queries require random I/O
○ leverage the parallel I/O characteristic of SSD
○ The difference between random IO and sequential IO is cut down
�
10 .Titan Design Goals
● Separate large values outside of the LSM-Tree to reduce write amplification,and
selective inline small values to get better read performance
● Seamless upgrade from existing RocksDB instances
- Don’t need extra steps to upgrade
- Don’t affect the online service
● Should work well with the features using in TiKV
- IngestExternalFile
�
12 .Why not use vLog instead of WAL ?
● Minimize intrusion changes in RocksDB
● IngestExternalFile may not work well for vLog
�
13 .Implementation
● TitanDBImpl is a warpper of RocksDBImpl
● TitanTableBuilder
● TitanVersion
● TitanGC
○ TableProperties
○ EventListener
�
15 .What We Get
● Large values from different places can be moved to blob files in background
automatically
● Key-values in each blob file are already sorted on flush or compaction, which is
good for sequential scan (prefetch)
● May generate some small files in some scenarios
�
16 .What is Version ?
v1(current)
f1 f2 f3
�
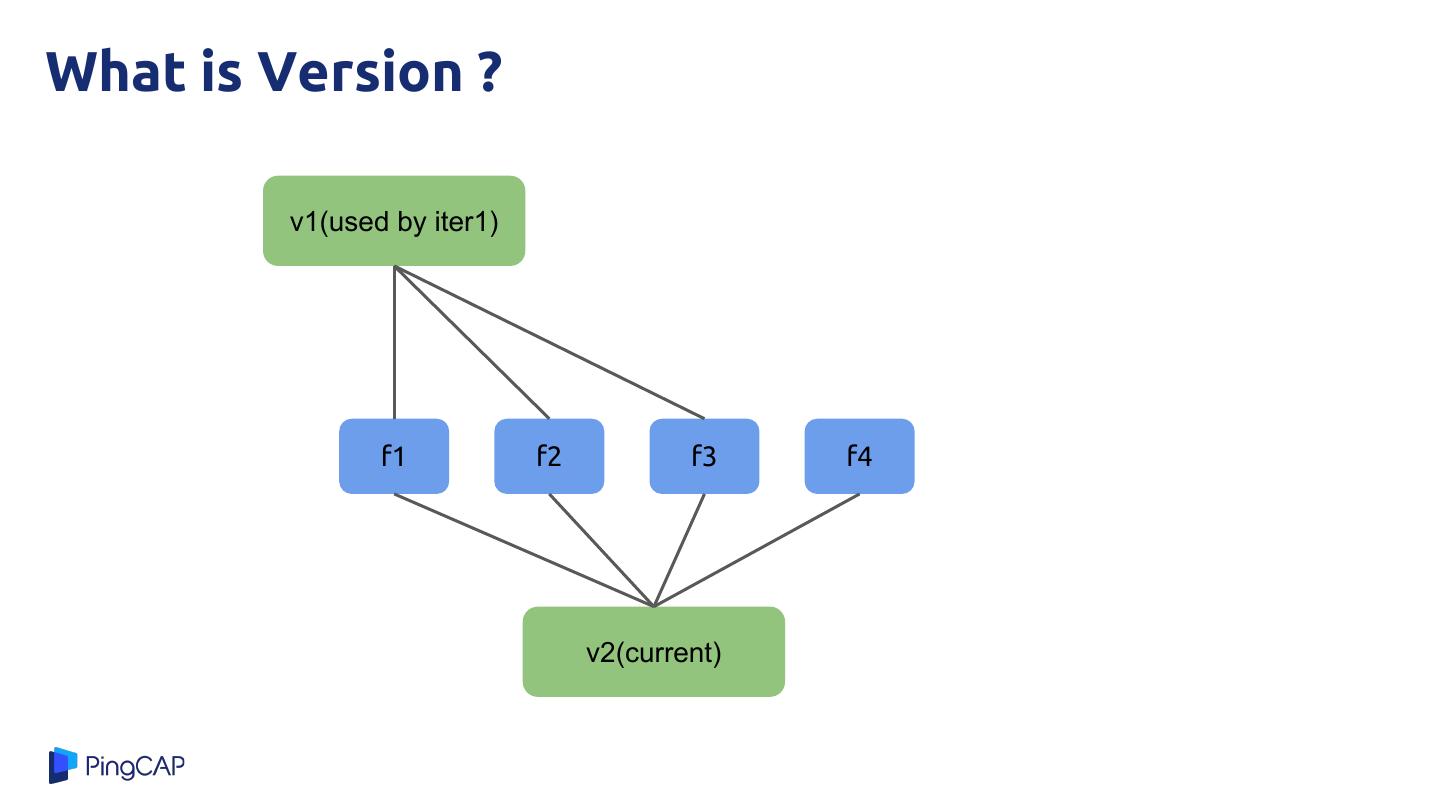
17 .What is Version ?
v1(used by iter1)
f1 f2 f3 f4
v2(current)
�
18 .What is Version ?
v1(used by iter1) v3(current)
f1 f2 f3 f4 f5
v2
�
19 .What is Version ?
v1(used by iter1) v3(current)
f1 f2 f3 f4 f5
�
20 .What is Version ?
v1(usedv1by iter1) v3(current)
f1 f2 f3 f5
�
21 .What is Version ?
v1 v3(current)
f1 f2 f3 f5
�
22 .What is Version ?
v3(current)
f1 f2 f3 f5
�
23 .Titan Version
get a version before every read, and then no need to lock while
adding or deleting blob files
�
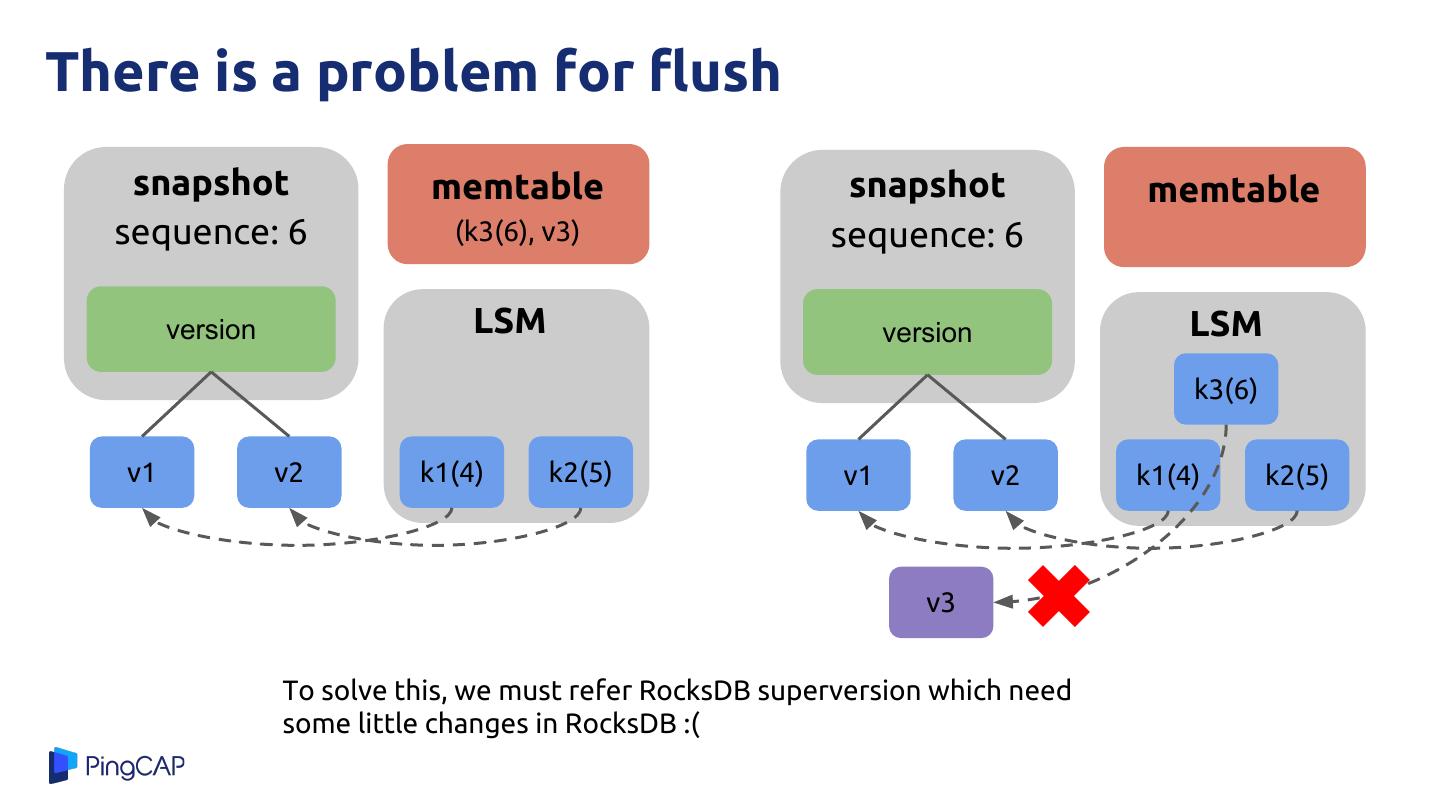
24 .There is a problem for flush
snapshot memtable snapshot memtable
sequence: 6 (k3(6), v3) sequence: 6
version LSM version LSM
k3(6)
v1 v2 k1(4) k2(5) v1 v2 k1(4) k2(5)
v3
To solve this, we must refer RocksDB superversion which need
some little changes in RocksDB :(
�
27 .Titan GC
● How to choose blob files to GC?
○ Use TableProperties to record the size of each blob file indexed in a SST file
○ Use EventListener to listen to the compaction events to calculate how many
bytes have been dropped for each blob file
● How to prevent GC from being deleting blob files for read?
○ Version
● How to update blob index with concurrent writes?
○ WriteCallback
�
28 .GC Process
1. On compaction completed, update discardable size and calculate gc score
2. Select multiple blob files from the largest score to smallest score as candidate files
3. Sample each blob file from candidate files, if the amount of discardable data doesn’t
exceed the DISCARD_RATIO (configurable), remove it from candidate files
4. Iterate all KV pairs in the candidate blob files, merge and sort all active values to a new
blob file
5. Writing new records of adding new blob files to MANIFEST log
6. Rewrite all valid key-index pairs to LSM-Tree
7. Writing new records of deleting old blob files to MANIFEST log
�