展开查看详情
1 .A Study of LSM-Tree
林金河
�
2 .Applications of LSM-Tree
❏ NoSQL
❏ Bigtable
❏ HBase
❏ Cassandra
❏ Scylla
❏ MongoDB
❏ Storage Engine
❏ LevelDB
❏ RocksDB
❏ MyRocks
❏ NewSQL
❏ TiDB(TiKV)
❏ CockroachDB
�
3 .Beginning of LSM-Tree
❏ 1996: The Log-Structured Merge-Tree (LSM-Tree)
❏ Memory is small
❏ Disk is slow for random access(r/w)
❏ Originally designed for fast-growing History table
❏ Data and indexes
❏ Write heavy
❏ Read sparse
�
4 .Beginning of LSM-Tree
❏ Out-of-place update
❏ Optimized for write
❏ Sacrifice read
❏ Not optimized for space
❏ Require data reorganization (merge/compaction)
�
5 .Modern Structure of LSM-Tree
❏ Read
❏ Point Query
❏ Range Query
❏ Write(Insert/Delete/Update)
❏ Compaction
❏ Leveled
❏ Tired
�
6 .Point Query
❏ Returns immediately when
something found
❏ Read amplification, worst-case
I/O: 2 * (N - 1 + files num of level-0)
❏ Optimization
❏ Page cache/Block cache
❏ Bloom filter
�
7 .Bloom Filter
❏ Simple
❏ Space-efficient
❏ False positive is possible, buf false negative is impossible
❏ Range query is not supported
�
8 .Range Query
SELECT * FROM t WHERE key >= 23 AND
key < 40;
for (itr->Seek(23); itr->Valid(); itr->Next()) {
if (itr->key() < 40) {
...
} else ...
}
❏ Must seek every sorted run
❏ Bloom filter not support range
query
❏ Optimization
❏ Parallel Seeks
❏ Prefix bloom filter(RocksDB)
❏ SuRF (SIGMOD 2018)
�
9 .SuRF: Succinct Range Filter
❏ SuRF: Practical Range Query Filtering with Fast Succinct Tries
❏ Fast Succinct Tries
❏ Level-Ordered Unary Degree Sequence
❏ LOUDS-Dense
❏ The upper levels using a fast bitmap-based encoding scheme.
❏ Choosing performance over space.
❏ LOUDS-Sparse
❏ The lower levels using the space-efficient encoding scheme.
❏ Choosing space over performance.
❏ LOUDS-DS
�
10 .SuRF: Succinct Range Filter
❏ Trie => SuRF-Base => SuRF-Hash/SuRF-Real
❏ Example: (“SIGAI”, “SIGMOD”, “SIGOPS”)
�
11 .SuRF: Succinct Range Filter
�
12 .Read Operation Summary
❏ Read amplification ⇒ Use filters to reduce unnecessary I/O
❏ Space-efficient
❏ Lookup performance
❏ Low false positive, no false negative
❏ Bloom filter/Prefix bloom filter
❏ SuRF
❏ Others: Cuckoo Filter...
�
13 .Compaction - Tiered vs Leveled
❏ Each level has N sorted runs (overlapped).
❏ Compaction merges all sorted runs in one
level to create a new sorted run in the
next level.
❏ Minimizes write amplification at the cost
of read and space amplification.
❏ Each level is one sorted run.
❏ Compaction into Ln merges data from Ln-1
into Ln.
❏ Compaction into Ln rewrites data that was
previously merged into Ln.
❏ Minimizes space amplification and read
amplification at the cost of write
amplification.
�
14 .Tiered + Leveled
❏ Less write amplification than leveled and less space amplification than tiered.
❏ More read amplification than leveled and more write amplification than tired.
❏ It is flexible about the level at which the LSM tree switches from tiered to leveled.
�
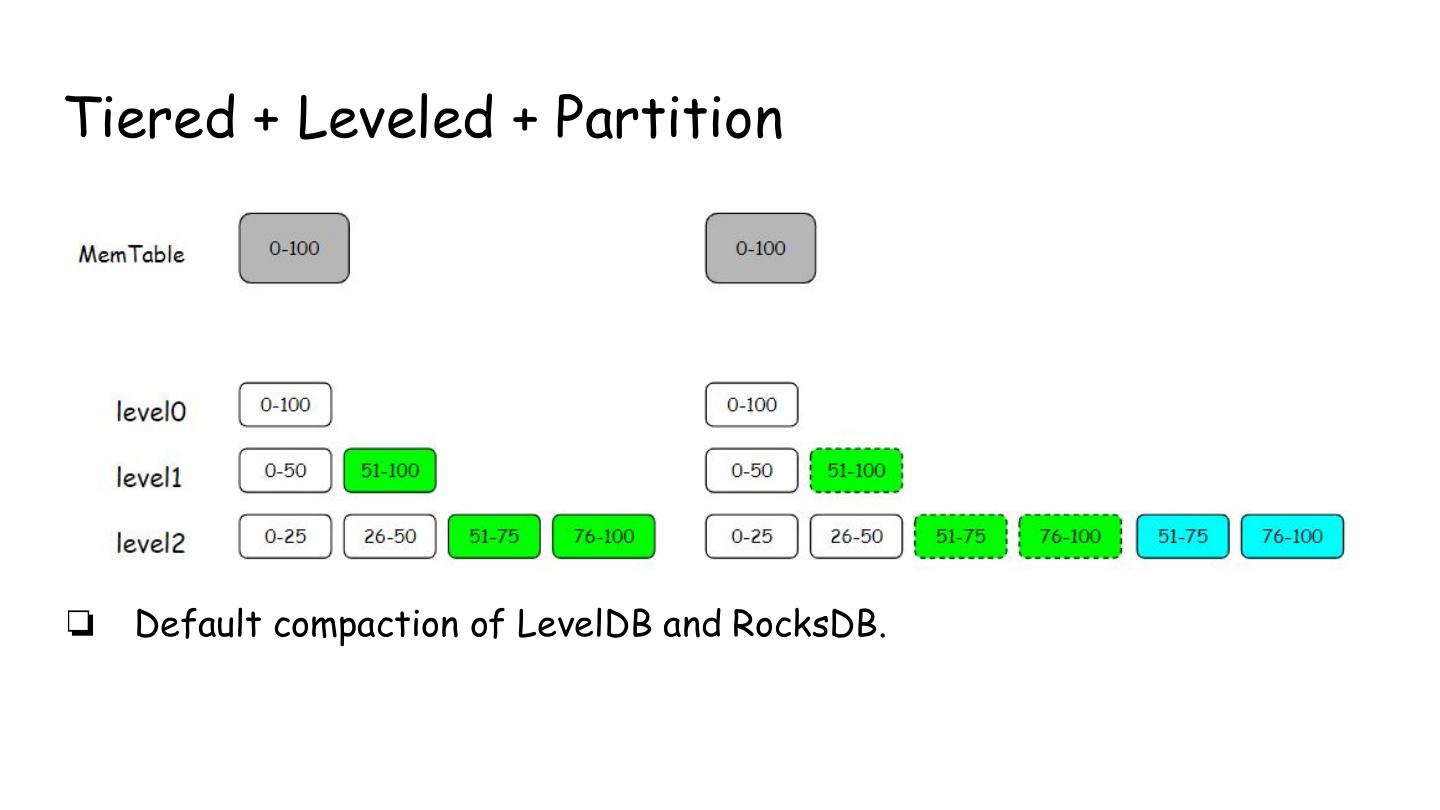
15 .Tiered + Leveled + Partition
❏ Default compaction of LevelDB and RocksDB.
�
16 .Problems of compaction
❏ Write amplification
❏ System jitter(CPU、I/O)
❏ SSD wear out
❏ Invalid block cache/page cache
❏ Compaction rate is a problem
❏ Too fast - write amplification
❏ Too slow - read amplification and space amplification.
�
17 .Multi-Thread Compaction
�
18 .Pipelined Compaction
❏ Pipelined Compaction for the LSM-tree
❏ The compaction procedure:
❏ Step 1: Read data blocks.
❏ Step2: Checksum.
❏ Step3: Decompress.
❏ Step4: Merge sort.
❏ Step5: Compress.
❏ Step6: Re-checksum.
❏ Step7: Write to the disk.
❏ Read -> Compute -> Write
❏ It is difficult to devide the stages evenly.
❏ If data blocks must flows through multiple processors, it will result in low CPU cache
performance. Let S2~S6 as on stage will be more CPU cache friendly.
�
19 .Compaction Buffer
❏ Re-enabling high-speed caching for LSM-trees
❏ LSbM-tree: Re-enabling Buffer Caching in Data Management for Mixed
Reads and Writes
�
20 .Coprocessor
❏ Co-KV: A Collaborative Key-Value Store Using Near-Data Processing to
Improve Compaction for the LSM-tree
❏ 当数据库遇见FPGA:X-DB异构计算如何实现百万级TPS?
�
21 .PebblesDB
❏ PebblesDB: Building Key-Value Stores using Fragmented Log-Structured
Merge Trees
❏ Guards divide the key space (for that level) into disjoint units
❏ Less write amplification, more read amplification and space amplification.
�
22 .PebblesDB Compaction
❏ Similar to Tired + Partition
�
23 .WiscKey
❏ WiscKey: Separating Keys from Values in SSD-conscious Storage
❏ Compaction = sorting + garbage collection
❏ Only keys are required to be sorted
❏ Keys are usually smaller than values
❏ Key-Value separation ⇒ Decouple sorting and garbage collection
�
24 .WiscKey
❏ Key-Value separation’s challenges and optimizations
❏ An additional I/O may be required for each query
❏ WiscKey’s LSM-Tree is small and can be easily cached in memory
❏ Range queries require random I/O
❏ Prefetch: leverages the parallel I/O characteristic of SSD
❏ Garbage Collection
❏ Invalid keys are reclaimed by compaction
❏ Value log needs a special garbage collector
❏ Crash Consistency
❏ Atomicity of inserted key-value pairs is complicated
❏ Combine value log and WAL
�
25 .Summary
❏ Designing Access Methods: The RUM Conjecture
❏ Read, Update, Memory – Optimize Two at the Expense of the Third
❏ Read Amplification vs Write Amplification vs Space Amplification
�