

























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
PingCAP-Infra-Meetup-102-yaowei-How-we-build-TiDB
本次分享姚维老师从数据库发展的历程讲起,讲解了 TiDB 的使命。以及从底向上的描述我们是怎么去实现一个 HTAP 数据库的,内容包括如果实现容错性,如果实现扩展性,如何在分布式的事务型 KV 存储之上构建完整的 SQL 系统。
展开查看详情
1 .How we build TiDB YaoWei | PingCAP
2 .About me ● Yao Wei (姚维) ● TiDB Kernel Expert, General Manager of South Region ● 360 Infra team / PingCAP ● Atlas / MySQL-Sniffer ● Infrastructure software engineer
3 .Let’s say we want to build a NewSQL Database ● From the beginning ● What’s wrong with the existing DBs? ○ RDBMS ○ NoSQL & Middleware RDBMS NoSQL NewSQL ● NewSQL: F1 & Spanner 1970s 2010 2015 Present MySQL Redis Google PostgreSQL HBase Spanner Oracle Cassandra Google F1 DB2 MongoDB TiDB ... ...
4 .Google Spanner | F1 - The largest NewSQL database ● Global scale database with external consistency guarantees ○ Spanner - kind of key value database ● Google Adwords、Google Play ● Scalability (millions of machines) ● Auto failover
5 .What to build? ● Scalability ● High Availability ● ACID Transaction ● SQL A Distributed, Consistent, Scalable, SQL Database that supports the best features of both traditional RDBMS and NoSQL Open source, of course
6 .Open Source One of the most famous open-source distributed RDBMS in the world.
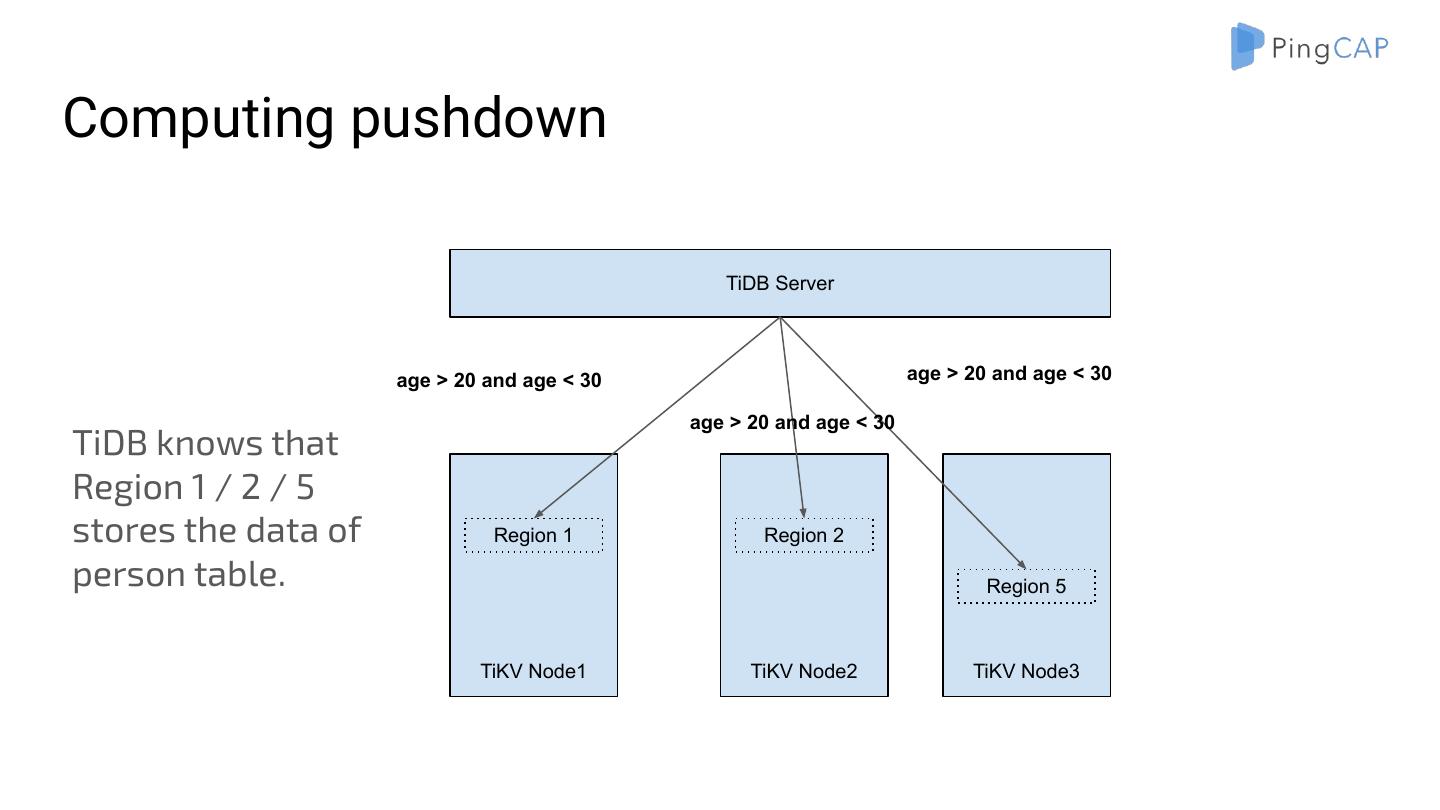
7 . Architecture Applications MySQL Drivers(e.g. JDBC) MySQL Protocol F1 TiDB RPC Spanner TiKV
8 . Architecture Stateless SQL Layer Metadata / Timestamp request TiDB ... TiDB ... TiDB Placement Driver (PD) Raft Raft Raft TiKV ... TiKV TiKV TiKV Control flow: Balance / Failover Distributed Storage Layer
9 .Let’s talk from bottom to top and focus on Key-Value storage first.
10 .We have a key-value store (RocksDB) ● Good start, RocksDB is fast and stable. ○ Atomic batch write ○ Snapshot ● However… It’s a local embedded kv store. ○ Can’t tolerate machine failures ○ Scalability depends on the capacity of the disk
11 .Let’s fix Fault Tolerance ● Use Raft to replicate data ○ Key features of Raft ■ Strong leader: leader does most of the work, issue all log updates ■ Leader election ■ Membership changes ● Implementation: ○ Ported from etcd ● Replicas are distributed across machines/racks/data-centers
12 .Let’s fix Fault Tolerance Raft Raft RocksDB RocksDB RocksDB Machine 1 Machine 2 Machine 3
13 .That’s cool ● Basically we have a lite version of etcd or zookeeper. ○ Does not support watch command, and some other features ● Let’s make it better.
14 .How about Scalability? ● What if we SPLIT data into many regions? ○ We got many Raft groups. ○ Region = Contiguous Keys ● Hash partitioning or Range partitioning ○ Redis: Hash partitioning ○ HBase: Range partitioning
15 .That’s Cool, but... ● But what if we want to scan data? ○ How to support API: scan(startKey, endKey, limit) TiKV Key Space ● So, we need a globally ordered map ○ Can’t use hash partitioning ○ Use range partitioning [ start_key, ■ Region 1 -> [a - d] end_key) ■ Region 2 -> [e - h] ■ … (-∞, +∞) Sorted Map ■ Region n -> [w - z]
16 .How to scale? (1/2) ● That’s simple ● Logical split ● Just Split && Move Region 1 Region 1 Region 2
17 .How to scale? (2/2) ● Raft comes for rescue again ○ Using Raft Membership changes, 2 steps: ■ Add a new replica ■ Destroy old region replica
18 . Scale-out (initial state) Node B Region 1 Region 1 Region 2 Region 3 Region 1* Node D Region 2 Region 2 Region 3 Region 3 Node C Node A
19 . Scale-out (add new node) Node B Region 1^ Region 1 Region 2 Region 3 Region 1* Node D Region 2 Region 2 Region 3 Region 3 Node C Node A Node E 1) Transfer leadership of region 1 from Node A to Node B
20 . Scale-out (balancing) Node B Region 1* Region 1 Region 2 Region 3 Region 1 Node D Region 2 Region 2 Region 3 Region 3 Node C Node A Region 1 Node E 2) Add Replica on Node E
21 . Scale-out (balancing) Node B Region 1* Region 1 Region 2 Region 3 Node D Region 2 Region 2 Region 3 Region 3 Node C Node A Region 1 Node E 3) Remove Replica from Node A
22 .Now we have a distributed key-value store ● We want to keep replicas in different datacenters ○ For HA: any node might crash, even the whole Data center ○ And to balance the workload ● So, we need Placement Driver (PD) to act as cluster manager, for: ○ Replication constraint ○ Data movement
23 .Placement Driver ● The concept comes from Spanner ● Provide the God’s view of the entire cluster ● Store the metadata ○ Clients have cache of placement information. Placement Driver ● Maintain the replication constraint ○ 3 replicas, by default Raft Raft ● Data movement for balancing the workload ● It’s a cluster too, of course. ○ Thanks to Raft. Placement Placement Driver Driver Raft
24 .PD as the Cluster Manager PD Node 1 HeartBeat Region A Cluster Info Region B Scheduling Command Movement Admin Scheduling Config Node 2 Stratege Region C
25 .TiKV: The whole picture Client Placement Driver RPC RPC RPC RPC PD 1 Store 1 Store 2 Store 3 Store 4 PD 2 Region 1 Region 1 Region 2 Region 1 Region 3 Region 5 Region 2 PD 3 Region 2 Raft Region 5 Region 3 Region 5 Region 4 Group Region 4 Region 4 Region 3 TiKV node 1 TiKV node 2 TiKV node 3 TiKV node 4
26 .MVCC (Multi-Version Concurrency Control) ● Each transaction sees a snapshot of database at the beginning time of this transaction, any changes made by this transaction will not seen by other transactions until the transaction is committed ● Data is tagged with versions ○ Key_version: value ● Lock-free snapshot reads
27 .Transaction Model ● Inspired by Google Percolator ● ‘Almost’ decentralized 2-phase commit ○ Timestamp Allocator ● Optimistic transaction model ● Default isolation level: Snapshot Isolation ● Also has Read Committed isolation level ● A blog in detail
28 .TiKV: Architecture overview (Logical) ● Highly layered ● Raft for consistency and scalability Transaction ● No distributed file system ○ For better performance and lower latency MVCC RaftKV Local KV Storage (RocksDB)
29 .That’s really really Cool ● We have A Distributed Key-Value Database with ○ Geo-Replication / Auto Rebalance ○ ACID Transaction support ○ Horizontal Scalability
3秒后跳转登录页面
去登陆

