PingCAP-Infra-Meetup-108-同盾大数据平台
分享
点赞
0
收藏
3
下载 6
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
 TiDB
TiDB
/
发布于
/
4577
人观看
李霞老师本次分享的主要内容包括:
•F1 online asynchronous DDL 的原理。
•TiDB DDL 的基本框架,详细讲述其实现。
•Add index 的具体流程,并简介了其他几种 DDL 语句实现特性。
•DDL 的一些辅助功能。
最后结合之前介绍的原理和实现,讲解了常见的几个问题以及解决方式。
展开查看详情
5 . JobServer
1. Spark JobServer
① ⽀支持SQL、Jar、Python 作业运⾏行行,包含流批作业运⾏行行。
② 表权限校验(Aspectj 拦截SparkSession.sql⽅方法),列列权限在Spark和TiSpark 代码中校验
③ 扩展Spark SQL语法(load, compress,merge,druid等)
④ 集成TiSpark(spark.sql.extensions)
⑤ 构建数据⾎血缘
2. Flink JobServer
① ⽀支持SQL、Jar 作业运⾏行行
② 扩展Flink DDL语法(antlr 解析定义的ddl语法,转为table API)
③ 扩展Flink Sink
�
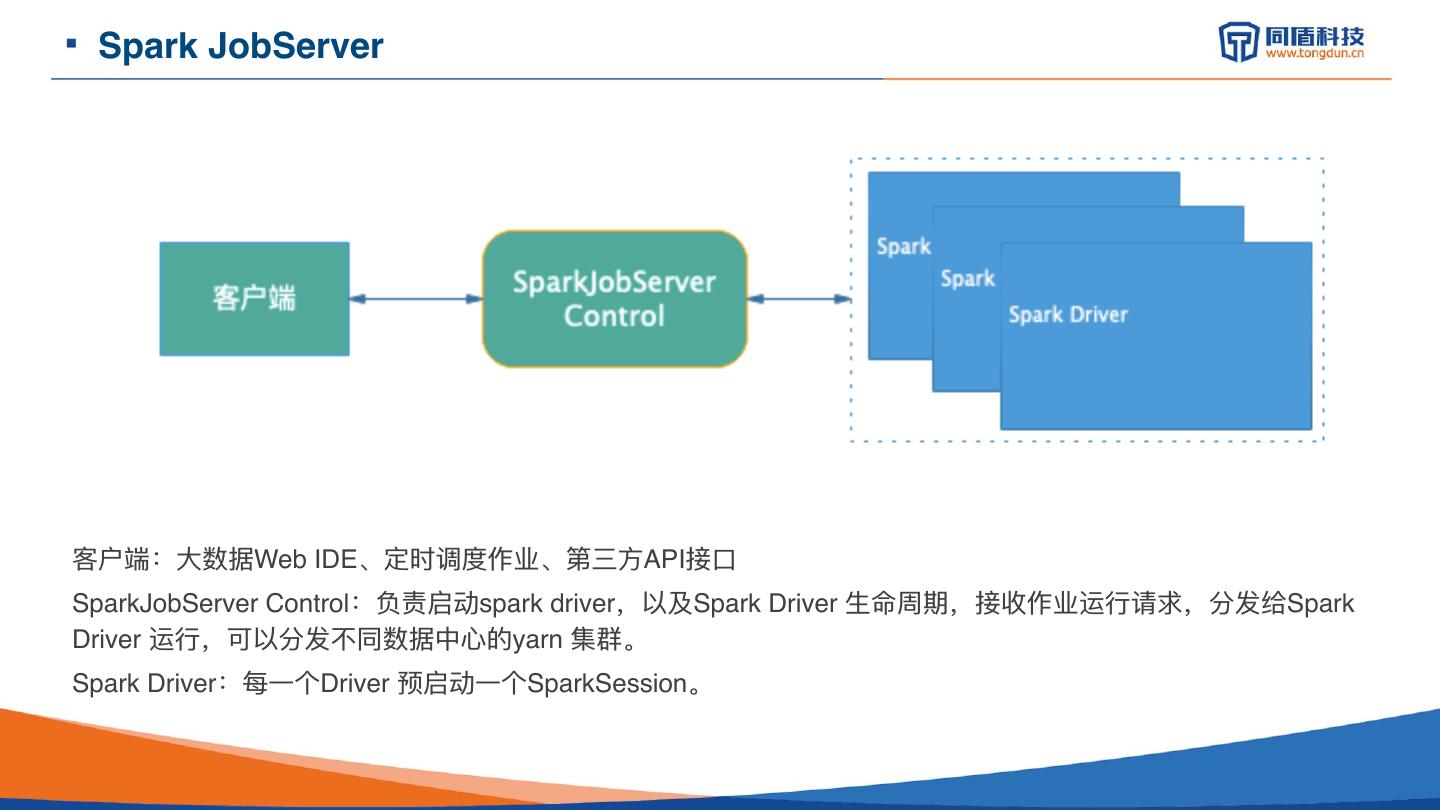
6 . Spark JobServer
客户端:⼤大数据Web IDE、定时调度作业、第三⽅方API接⼝口
SparkJobServer Control:负责启动spark driver,以及Spark Driver ⽣生命周期,接收作业运⾏行行请求,分发给Spark
Driver 运⾏行行,可以分发不不同数据中⼼心的yarn 集群。
Spark Driver:每⼀一个Driver 预启动⼀一个SparkSession。
�
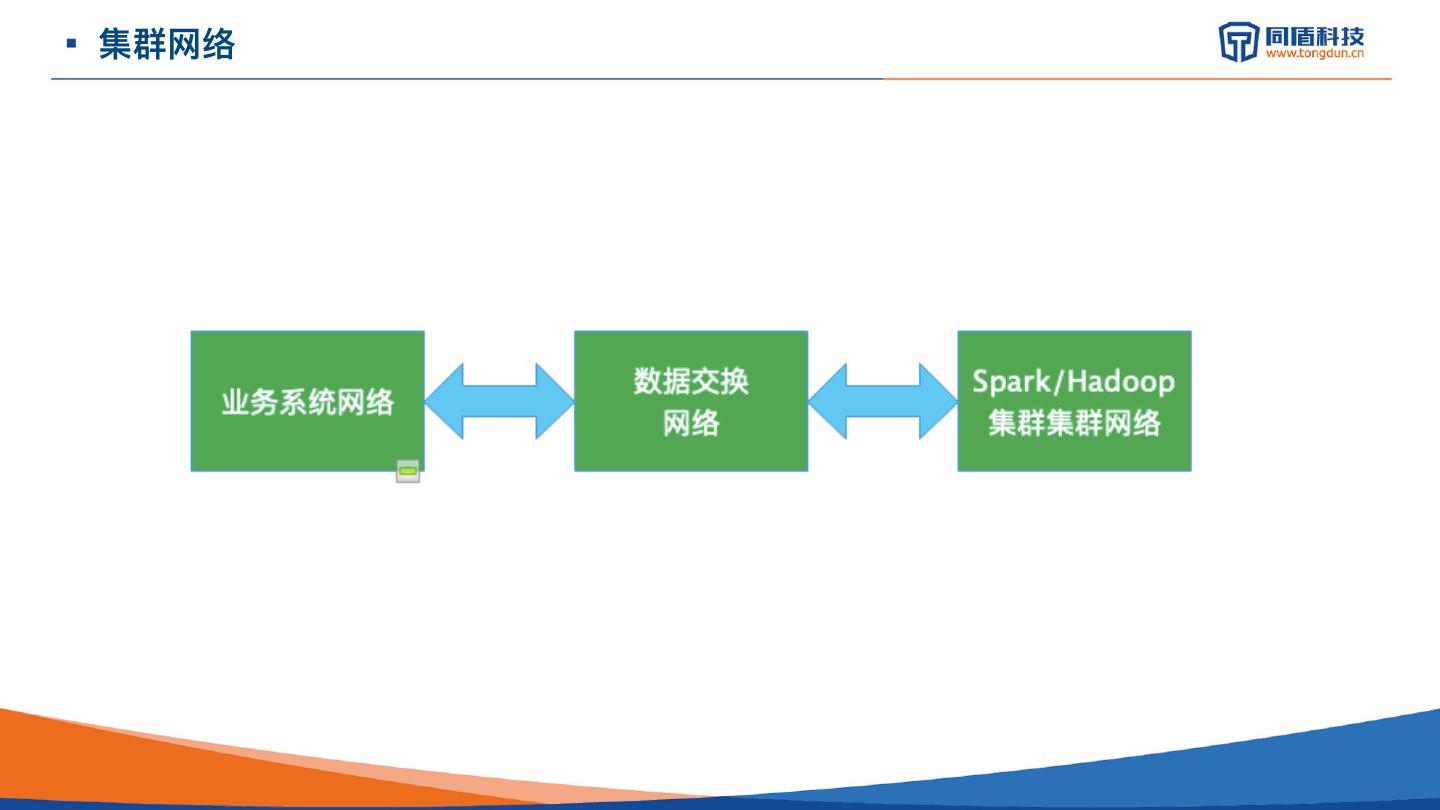
7 . 数据采集平台
1. Agent 标准化部署在所有线上机器器(虚拟机+物理理机),基于filebeat改造;
2. 采集数据写⼊入Kafka,多个不不同业务写⼊入相同topic;
3. Dclog 实时从Kafka 消费数据写⼊入不不同表;
4. 按批次⽣生成parquet,考虑⽂文件碎⽚片问题,15分合并⼀一次,合并之前对⽤用户不不可⻅见
�
9 . 数据交换/同步
● 数据交换流⼊数据源:mysql、mycat、oracle、sqlserver、hive、hbase、kafka等;
● 数据交换流出数据源: mysql 、mycat、hive、hbase、snappydata、codis、redis、elastic、aerospik、
cassandra等;
● 插件化⽀持多数据源,满⾜不同业务场景定制化开发需求;
● ⽀持多数据中⼼双线数据同步;
● ⽀持海量数据同步;
● ⽀持动态流控,避免⺴络带宽被独占;
● ⽀持分布运⾏;
● ⽀持⾃定义交换任务并⾏度;
�
10 . TiSpark
• TIDB 集群 20+
• Otter 集群 20+
• Mysql数据库200+,表6000+
• 数据同步延迟在3秒以内
• 解决数仓数据时效性问题,⽤用户通过Spark 可以在同⼀一个
sql中可以访问tidb表和hive 表;
�
11 . 数据管理理
平台强制数据表存储管理理,规范化数据元数据信息,数据ACL 细粒度权限控制
● 所有表存储使⽤parquet⽂件格式,
● ⽀持表字段和分区信息管理;
● ⽀持表安全等级和数据等级安全分类;
● ⽀持数据⽣命周期,超过⽣命周期清理数据放⼊回收站7天,之后再物理删除。
● ⽀持表上下游⾎缘关系;
● ⽀持表DDL 修改变更记录;
● ⽀持表记录、审计;
● ⽀持表访问权限回收;
�
16 . 表权限控制
1. 平台层⾯面,解析执⾏行行的SQL,获取访问的表和列列信息校验权限。
• 拦截Spark、Hadoop 所有可能读取hdfs file的API
2. HDFS ACL 权限控制
• 扩展org.apache.hadoop.security.GroupMappingServiceProvider
�
17 . 项⽬目
逻辑概念,⽤用于组织作业、表、资源、函数
1. 项⽬目类型:hive,druid,stream
2. 作业类型关联
�
18 . 计算集群
物理理集群+计算引擎两个维度组合。
�
19 . 作业开发
● WebIDE开发运⾏作业,简化开发、数据分析、算法、运营、产品等不同⼈员对⼤数据使⽤的要求。
● WebIDE ⽀持调试、语法检测、代码辅助、代码格式化、多版本、⾃动保存等功能;
● ⽀持开发类型作业:sql、java/scala、python、数据交换/同步
● ⽀持资源管理,上传各种资源⽂件。
● ⽀持⾃定义UDF、UDAF和UDTF 函数
● ⽀持回收站,作业、资源、函数删除先进⼊回收站;
�
21 . 作业调度/作业运维
● 满⾜作业定时运⾏需求,⽀持不同定时运⾏周期:分钟、⼩时、天、周、⽉;
● ⽀持作业调度有效时间;
● ⽀持作业调度运⾏失败重试;
● ⽀持作业调度运⾏失败告警;
● ⽀持作业运⾏流,通过作业产出表和输⼊表,⾃动形成作业流,上游作业运⾏结束,才能运⾏下游作业
● ⽀持作业流可视化图形展现;
● ⽀持作业测试和补数据运⾏;
● ⽀持作业运⾏历史记录监控,查看运⾏时间、运⾏⽇志、⼿动重跑作业等;
�