






















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
JIT In Databases
JIT(Just-In-Time)是在计算机程序运行期间而不是执行之前编译代码的一种计算机代码运行方式,在Java中,JIT技术比较流行,JVM在运行期间对程序热点进行分析,然后把对应的ByteCode序列编译成计算机本地代码,极大提高了热点代码的执行效率。本篇介绍现代数据库系统中的火山迭代模型(Volcano Iterator Model),查询算子的编译(Operator Compilation - HIQUE),流水线的编译(Pipeline Compilation - Hyper),表达式的编译(Expression Compilation)进行了代码示例说明,同时也对代码生成技术包括ByteCode和LLVM的代码生成技术进行了简要介绍,并对Spark SQL的codegen技术进行了分析。最后对向量化(vectorization)计算,预取(Prefetching)机制以及JIT技术的集成在一起进行优化的可能性进行探讨。
展开查看详情
1 . Welcome! 加入 Infra Meetup No.99 交流群 和大家一起讨论吧~ 我们将分享本期 Meetup 资料
2 .JIT In Databases Presented by Yifei Wu 2019-04-20
3 .Part I - Introduction
4 .What is JIT ● Just-in-time(JIT) compilation ● A way of executing computer code that involves compilation during execution of a program at run time rather than prior to execution ● Java JIT Compiler ● Interact with the JVM at run time and compile appropriate bytecode sequences into native machine code. ● Optimize trace tree at run time ● “Write once, run everywhere.” (WORA)
5 .JIT in Database ● Generate intermediate representation (IR) of queries to be compiled into native code ● Byte code, LLVM IR, etc…. ● SQL: WHERE t.c1 = 2 ● Generate a function that is specific to that expression and can be natively executed by the CPU
6 .Why JIT in databases ● To avoid the overhead of traditional interpretation systems ● Capable to organize the code around register usage in order to minimize memory traffic ● A database engineer optimizing queries between user and database system. ● Optimize specializes underlying schema and data types
7 .Part II - Query Compilation
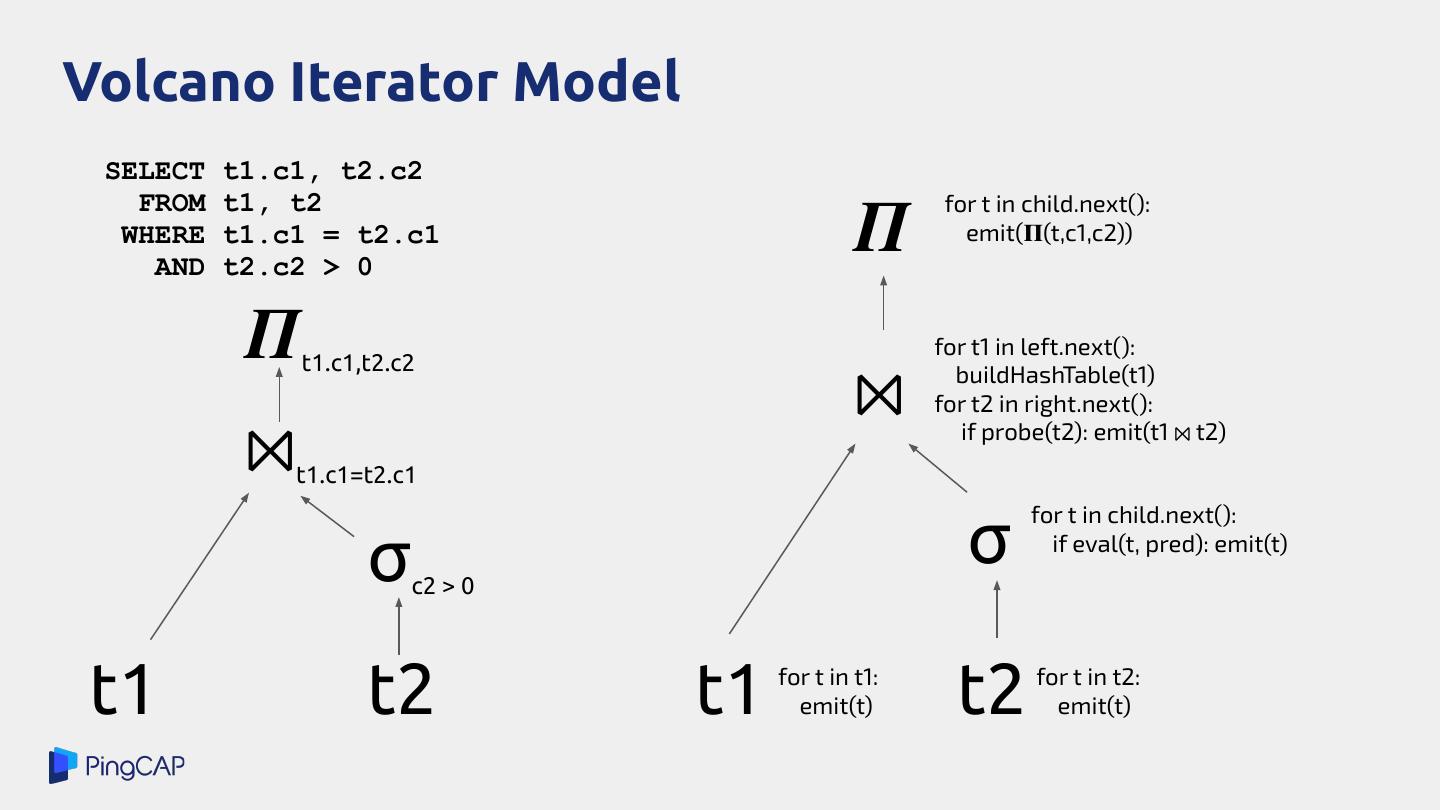
8 .Volcano Iterator Model ● Each database operator (relational algebra) implements a common interface: ● Evaluation is driven by the top-most operator which receives open(), next(), next(), ... calls and propagates. ● pull-based
9 .Volcano Iterator Model SELECT t1.c1, t2.c2 𝜫 FROM t1, t2 for t in child.next(): WHERE t1.c1 = t2.c1 emit(𝚷(t,c1,c2)) AND t2.c2 > 0 𝜫 t1.c1,t2.c2 for t1 in left.next(): ⨝ buildHashTable(t1) for t2 in right.next(): ⨝ t1.c1=t2.c1 if probe(t2): emit(t1 ⨝ t2) for t in child.next(): σ c2 > 0 σ if eval(t, pred): emit(t) t1 t2 t1 for t in t1: emit(t) t2 for t in t2: emit(t)
10 . Volcano Iterator Model SELECT t1.c1, t2.c2 FROM t1, t2 Tuple-at-a-time WHERE t1.c1 = t2.c1 AND t2.c2 > 0 ● Iterator overhead 𝜫 t1.c1,t2.c2 (Item*) operations invoked by projection.next() separately for each tuple ● Operator-centric next() ⨝ t1.c1=t2.c1 Cache inefficiency, tuples pulled into memory cannot be presisted in cache/registery next() σ c2 > 0 ● CPU inefficiency Branching in iterator model reduce preformance next() t1 next() t2
11 .Operator Compilation - HIQUE University of Edinburgh. Generating code for holistic query evaluation, 2010
12 .Operator Compilation - HIQUE ● Code templates σ s>?+1 for i in range(T.num_tuple): for i in range(T.num_tuple): tuple = T.data + i * tuple_size tuple = getTuple(T, i) val = *(tuple + predicate_offset) + 1 if eval(tuple, pred, s): if val == parameter_value : emit(tuple) emit(tuple) T
13 .Operator Compilation - HIQUE ● Code templates Selection Operator Template: tuple_size = $1 predicate_offset = $2 - Generate source code for each operator. parameter_value = $3 - Calculate offset with table schema from catalog for i in range(T.num_tuple): tuple = T.data + i * tuple_size val = *(tuple + predicate_offset) + 1 if val == parameter_value : emit(tuple)
14 .Operator Compilation - HIQUE ● Data-staging All input tables are scanned, all selection predicates are applied, and any unnecessary fields are dropped from the input. Reduce tuple size and increase cache locality on subsequent processing. Any pre-processing needed by the following operator, e.g., sorting or partitioning, is performed by interleaving the pre-processing code with the scanning code. The output is then materialized (though not on disk, if the staged input is small enough to fit in main memory).
15 .Operator Compilation - HIQUE ● Overhead for emitting and compiling query-specific source code ● Depend on Optimization level (-O0/-O2) ● Reduce instructions
16 .Pipeline Compilation - Hyper Hyper. Efficiently Compiling Efficient Query Plans for Modern Hardware, 2011 ● pipeline-breaker Operator that takes an incoming tuple out of the CPU registers for a given input. ● full-pipeline-breaker Operator that materializes all incoming tuples from this side before continuing processing. ● pipeline boundaries
17 .Pipeline Compilation - Hyper ● Push-based model No data flow in pipeline ● Data-centric keep data in cache/registers
18 .
19 .Pipeline Compilation - Hyper ● Code generation comsume() Use C++ code for operators LLVM for portable assembler code (overflow flag, etc….)
20 .Expression Compilation Cloudera Impala. Runtime Code Generation in Cloudera Impala, 2014 ● Specialize generated code using runtime information ● Codegen for MaterializeTuple() differs for different queries
21 .Expression Compilation ● Remove conditionals ● Remove loads ● Inline virtual function calls
22 .Part III - Code Generation
23 .Languages ● Multiple choices for today’s database systems C/C++, LLVM, byte code, etc…. ● Compile and run fast! Time matters. Reduce complexity in develpment & execution ● Low-level / High-level? Speed vs. Safety
24 .Machine Code ● System R - IBM (1970s) Compile SQL query directly into machine code. Abandoned in favor of query interpretation quickly since query compiler code was hard to maintain
25 .Byte Code ● Janino ○ Present JIT Compiler in JVM to optimize code at runtime ○ Take advantage of Java’s continued popularity ○ Java is a dynamic language ● JVM overhead
26 .LLVM IR declare double @putchard(double) define double @printstar(double %n) { entry: ; initial value = 1.0 (inlined into phi) ● Most widely used in industry br label %loop loop: ; preds = %loop, %entry %i = phi double [ 1.000000e+00, %entry ], [ %nextvar, %loop ] ; body ● Global & Typed variables %calltmp = call double @putchard(double 4.200000e+01) ; increment ● Standard runtime %nextvar = fadd double %i, 1.000000e+00 ● Memory management ; termination test ● Exception handling support %cmptmp = fcmp ult double %i, %n %booltmp = uitofp i1 %cmptmp to double ● etc…. %loopcond = fcmp one double %booltmp, 0.000000e+00 br i1 %loopcond, label %loop, label %afterloop afterloop: ; preds = %loop ; loop always returns 0.0 ● Still a bit complex to implement ret double 0.000000e+00 }
27 .High-Level Language /** * Generates code for equal expression in Java. ● Apache Spark */ def genEqual(dataType: DataType, c1: String, c2: String): String = dataType match { case BinaryType => s"java.util.Arrays.equals($c1, $c2)" Generate Java code and case FloatType => compile with Janino s"((java.lang.Float.isNaN($c1) && java.lang.Float.isNaN($c2)) || $c1 == $c2)" case DoubleType => s"((java.lang.Double.isNaN($c1) && java.lang.Double.isNaN($c2)) || $c1 == $c2)" case dt: DataType if isPrimitiveType(dt) => s"$c1 == $c2" case dt: DataType if dt.isInstanceOf[AtomicType] => s"$c1.equals($c2)" case array: ArrayType => genComp(array, c1, c2) + " == 0" case struct: StructType => genComp(struct, c1, c2) + " == 0" case udt: UserDefinedType[_] => genEqual(udt.sqlType, c1, c2) case NullType => "false" case _ => throw new IllegalArgumentException( "cannot generate equality code for un-comparable type: " + dataType.catalogString) }
28 .Generative Programming A Shaikhha, How to Architect a Query Compiler, 2016
29 .Generative Programming RY Tahboub, Purdue University. How to Architect a Query Compiler, Revisited, 2018
3秒后跳转登录页面
去登陆

