
























































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Scala and the JVM for Big Data
Scala在虚拟机上执行分布式大数据
展开查看详情
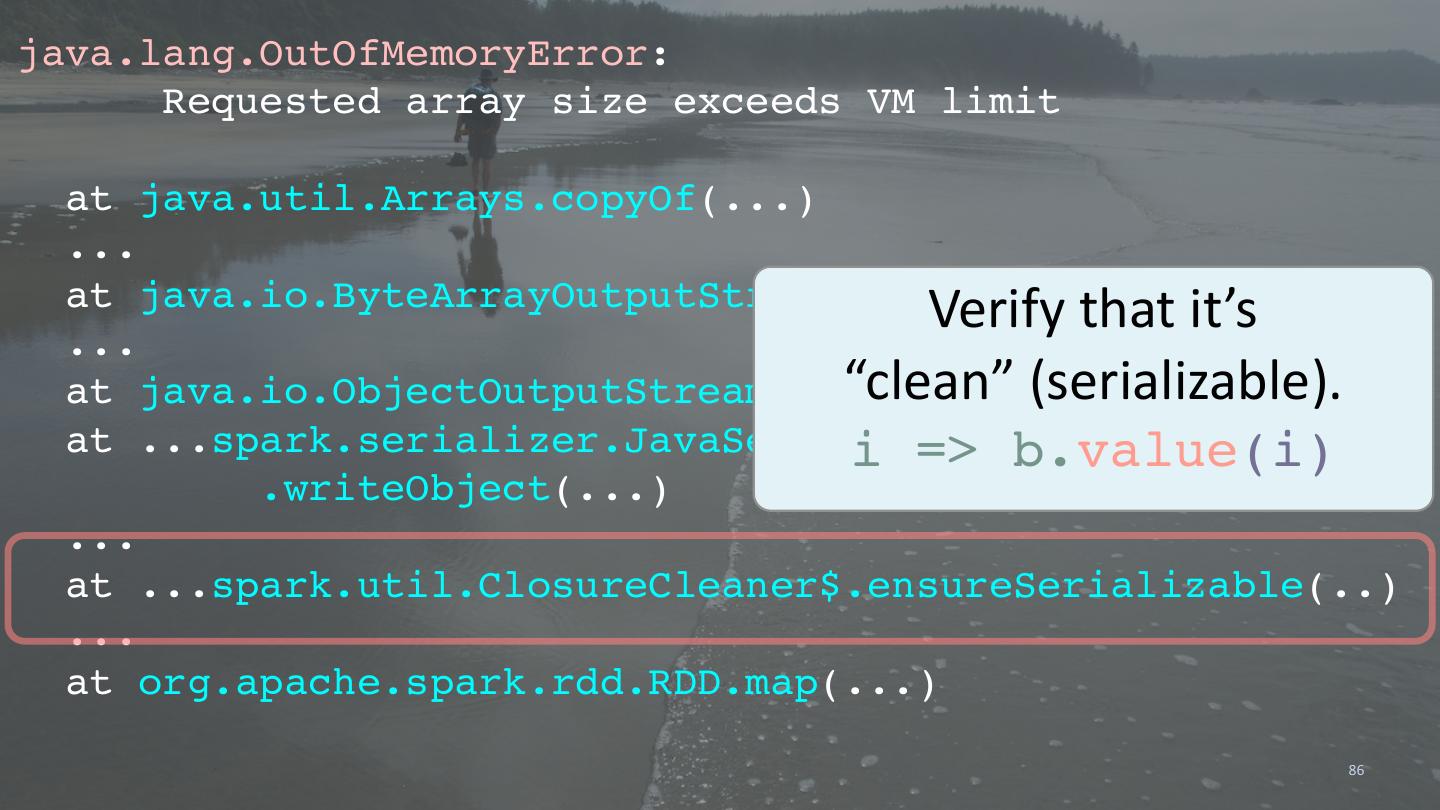
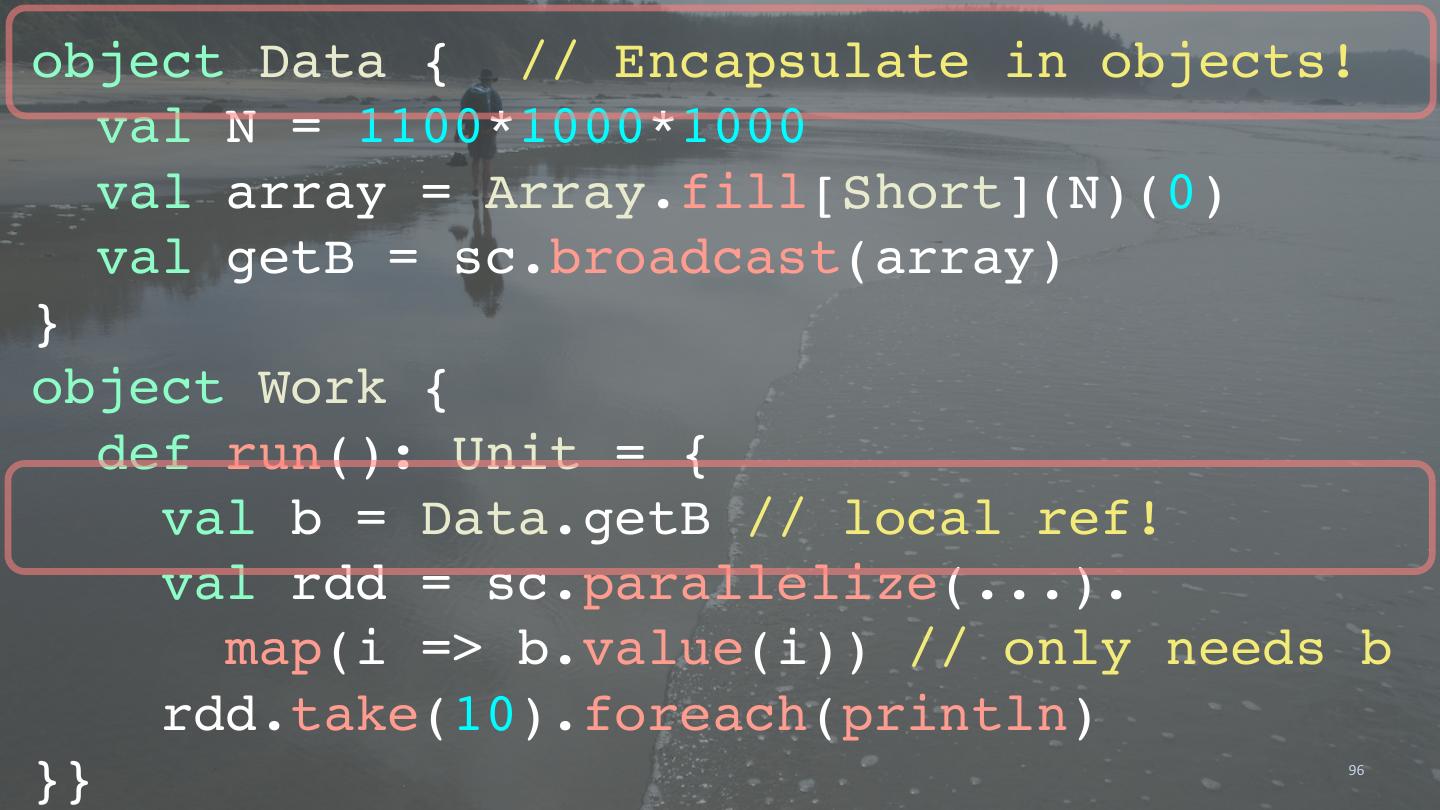
1 . Scala and the JVM for Big Data: Lessons from Spark polyglotprogramming.com/talks dean.wampler@lightbend.com @deanwampler 1 ©Dean Wampler 2014-2019, All Rights Reserved
2 .Spark 2
3 . A Distributed Computing Engine on the JVM 3
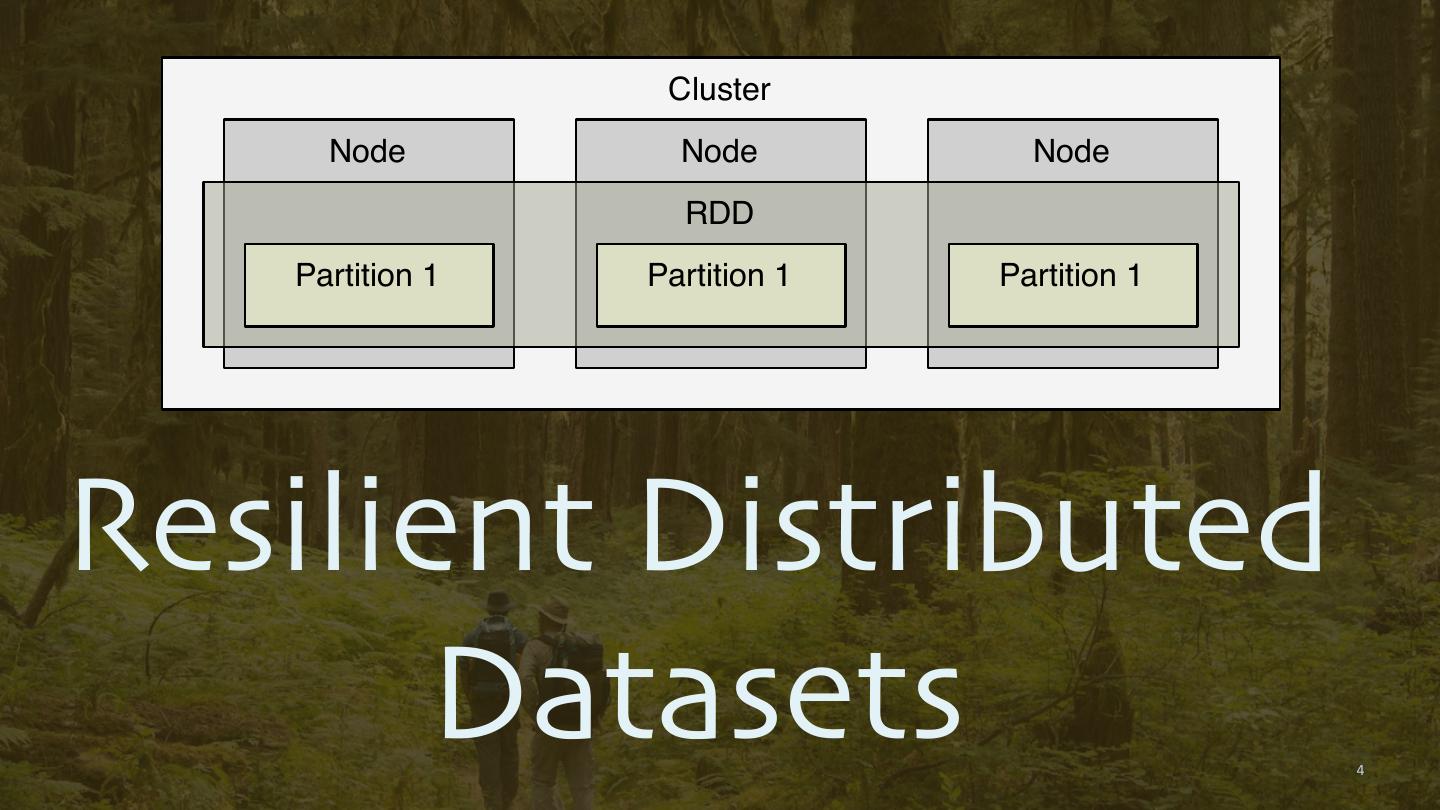
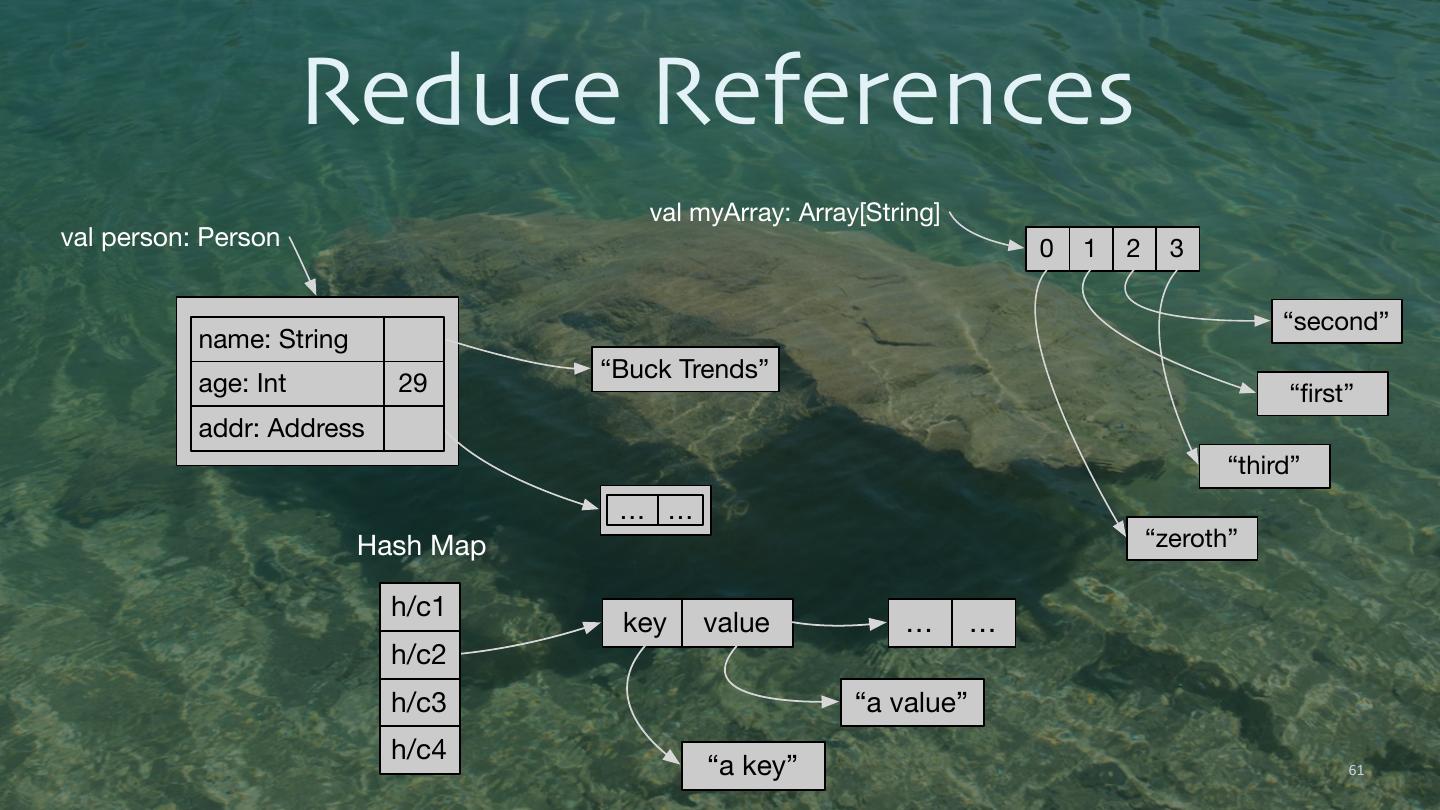
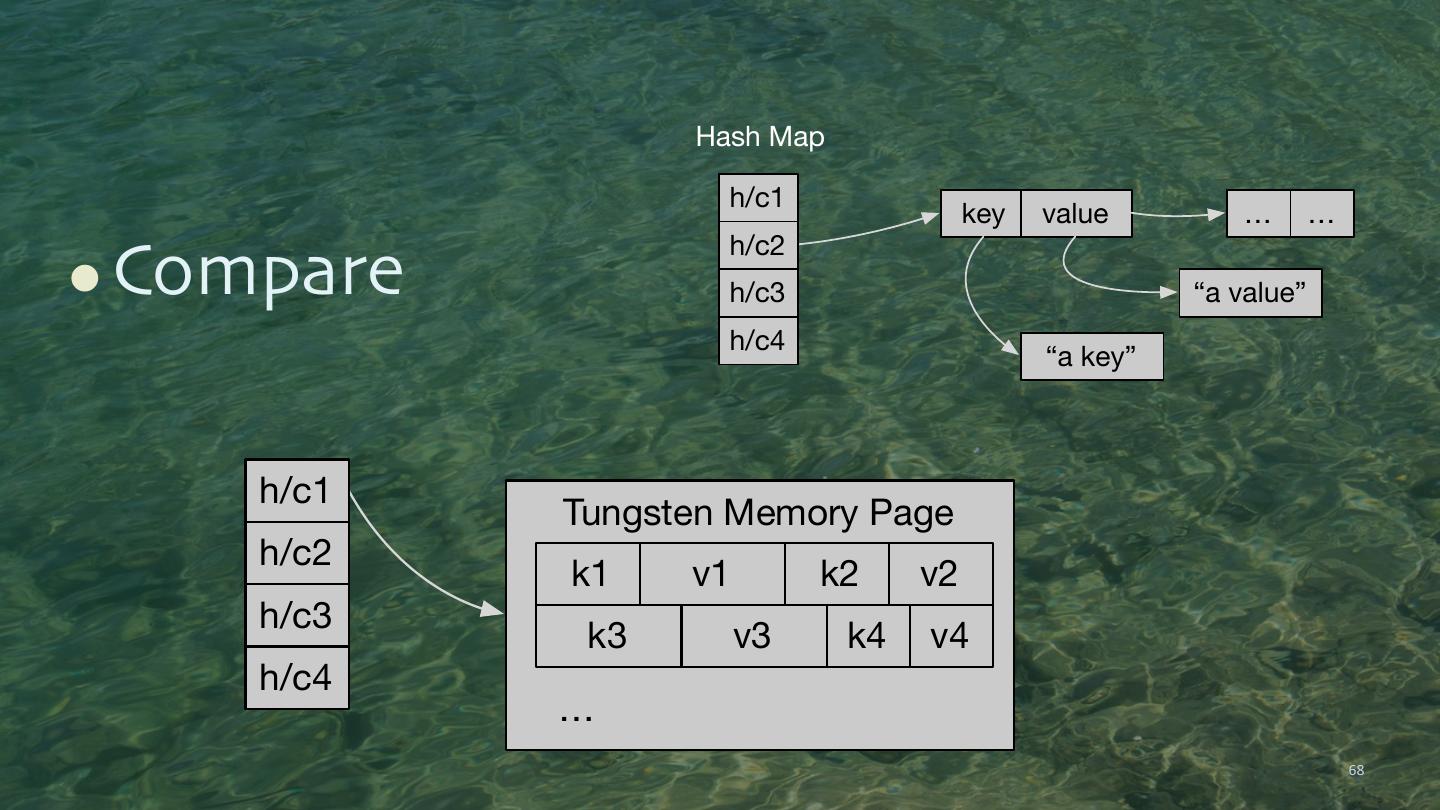
4 . Cluster Node Node Node RDD Partition 1 Partition 1 Partition 1 Resilient Distributed Datasets 4
5 . Productivity? Very concise, elegant, functional APIs. •Scala, Java •Python, R •... and SQL! 5
6 . Productivity? Interactive shell (REPL) •Scala, Python, R, and SQL 6
7 .Notebooks •Jupyter •Spark Notebook •Zeppelin •Beaker •Databricks 7
8 .8
9 . Example: Inverted Index 9
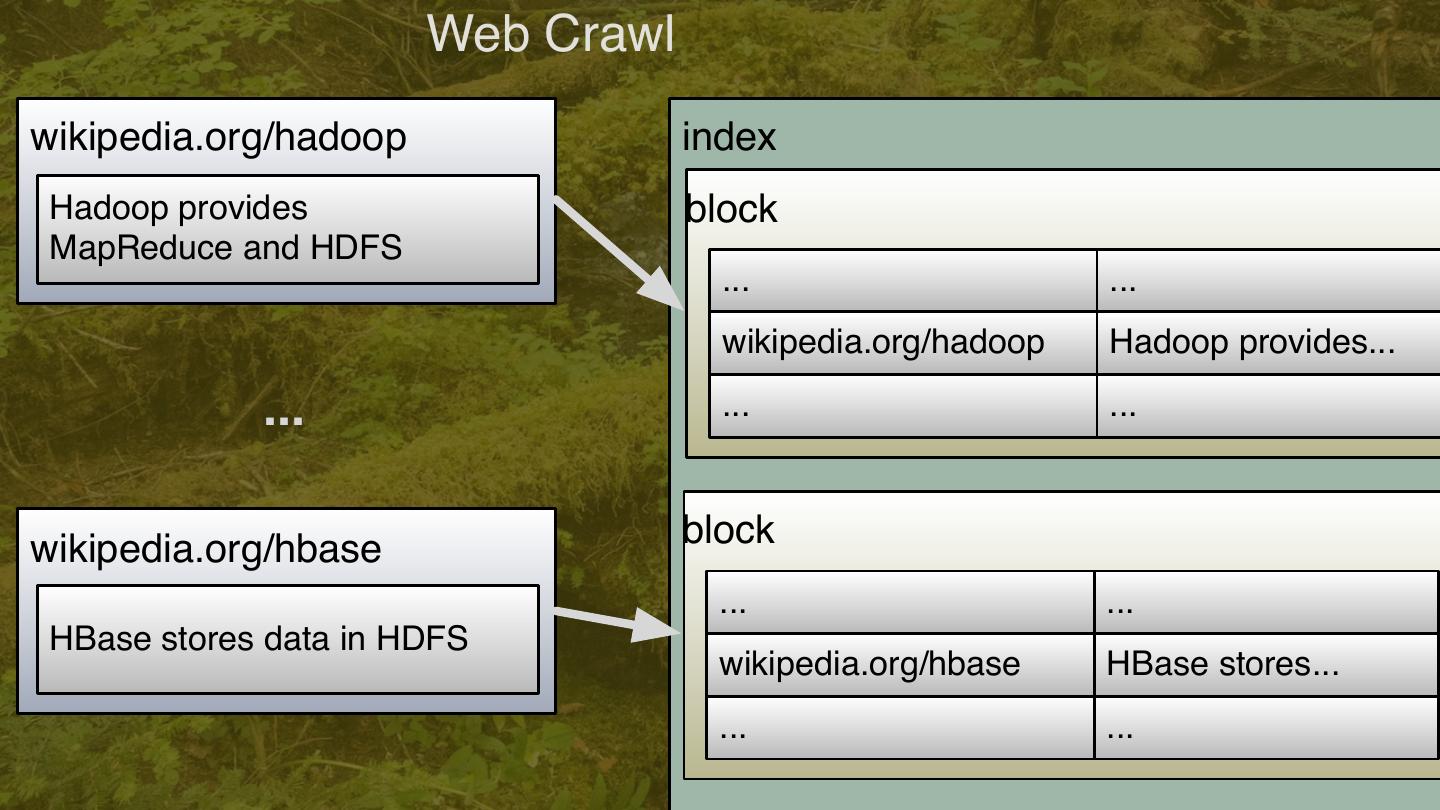
10 . Web Crawl wikipedia.org/hadoop index Hadoop provides block MapReduce and HDFS ... ... wikipedia.org/hadoop Hadoop provides... ... ... ... wikipedia.org/hbase block ... ... HBase stores data in HDFS wikipedia.org/hbase HBase stores... ... ... 10
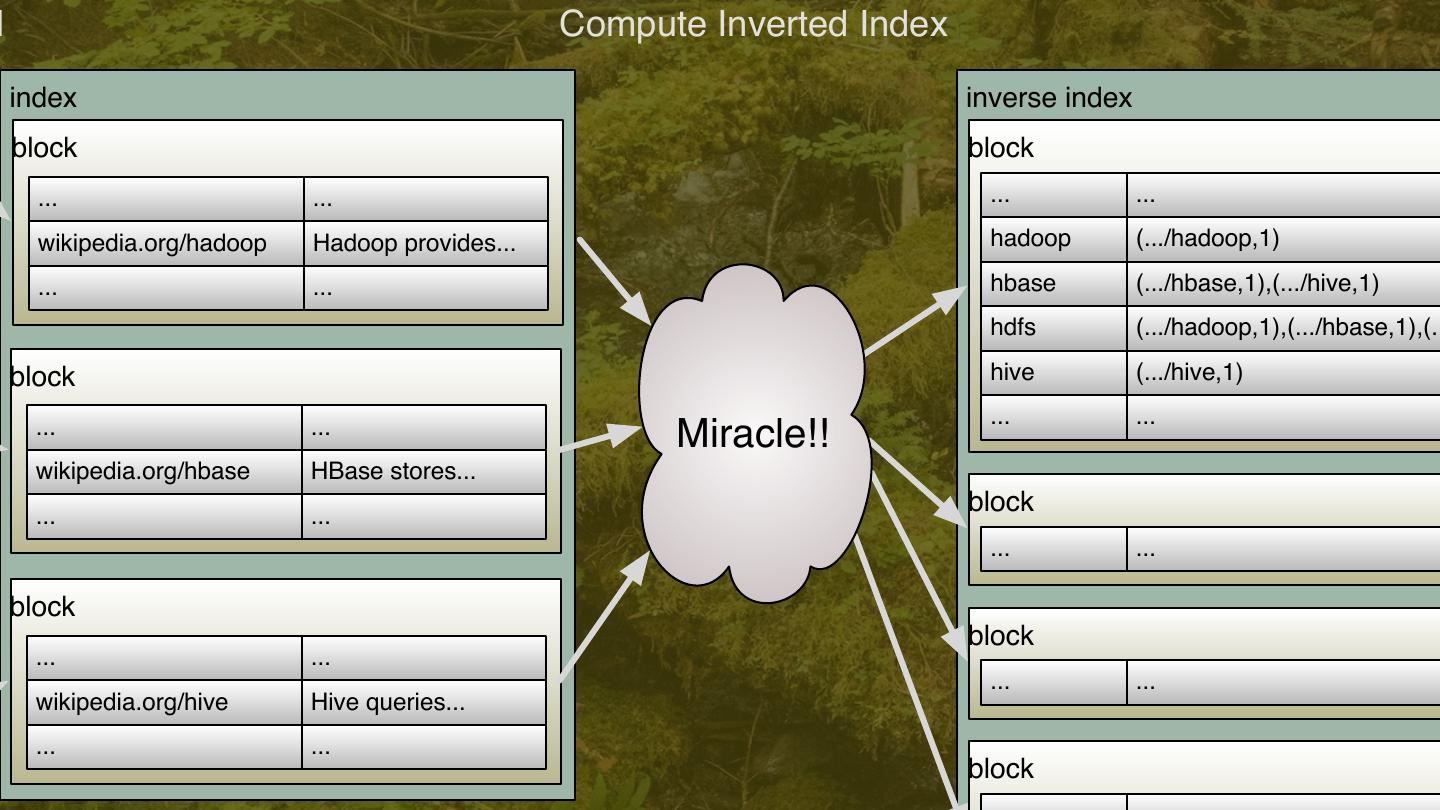
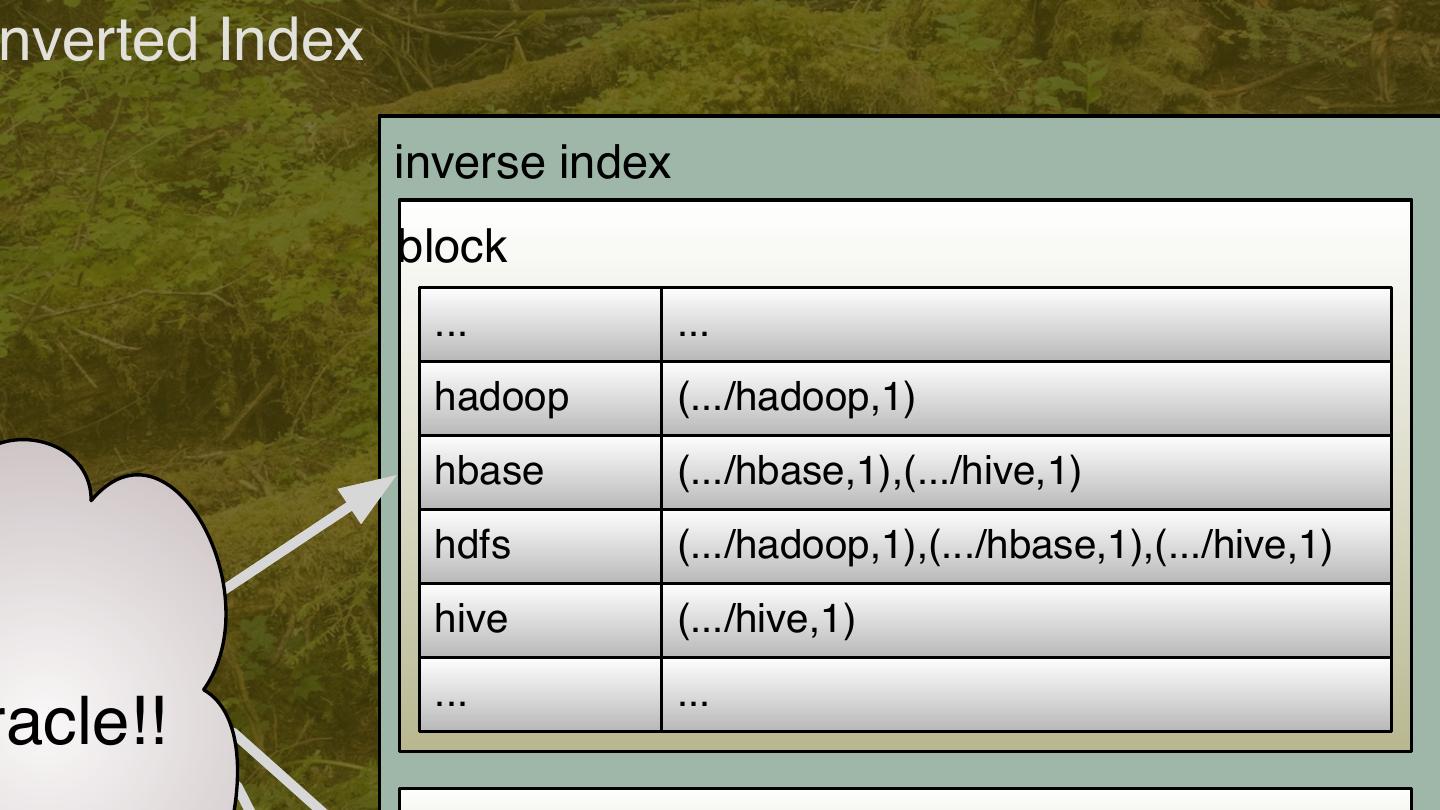
11 .l Compute Inverted Index index inverse index block block ... ... ... ... wikipedia.org/hadoop Hadoop provides... hadoop (.../hadoop,1) ... ... hbase (.../hbase,1),(.../hive,1) hdfs (.../hadoop,1),(.../hbase,1),(.. block hive (.../hive,1) ... ... ... ... Miracle!! wikipedia.org/hbase HBase stores... ... ... block ... ... block block ... ... ... ... wikipedia.org/hive Hive queries... ... ... block 11
12 .nverted Index inverse index block ... ... hadoop (.../hadoop,1) hbase (.../hbase,1),(.../hive,1) hdfs (.../hadoop,1),(.../hbase,1),(.../hive,1) hive (.../hive,1) ... ... racle!! 12
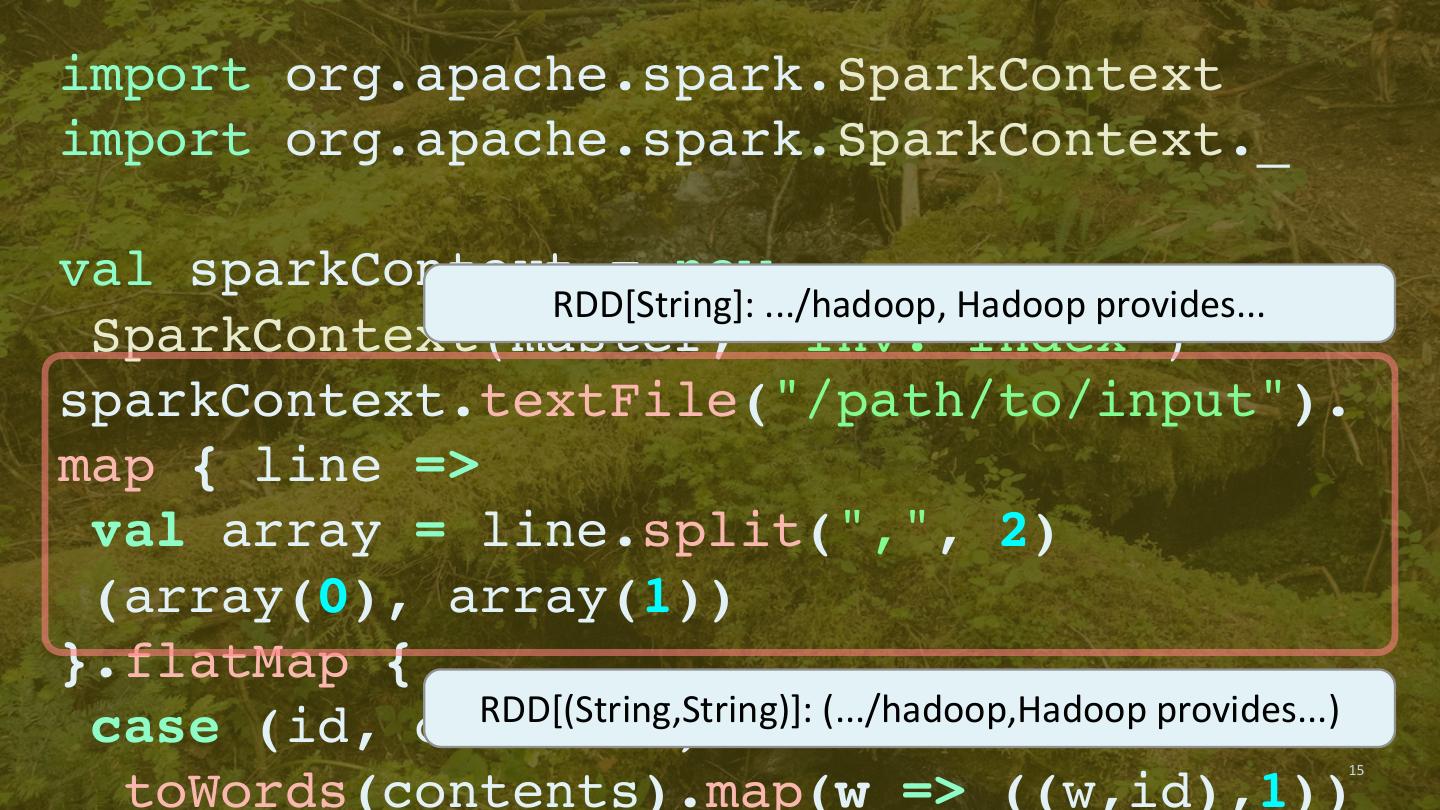
13 .import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ val sparkContext = new SparkContext(master, “Inv. Index”) sparkContext.textFile("/path/to/input"). map { line => val array = line.split(",", 2) (array(0), array(1)) // (id, content) }.flatMap { case (id, content) => toWords(content).map(word => ((word,id),1)) // toWords not shown }.reduceByKey(_ + _). map { case ((word,id),n) => (word,(id,n)) }.groupByKey. mapValues { seq => sortByCount(seq) // Sort the value seq by count, desc. }.saveAsTextFile("/path/to/output") 13
14 .import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ val sparkContext = new SparkContext(master, “Inv. Index”) sparkContext.textFile("/path/to/input"). map { line => val array = line.split(",", 2) (array(0), array(1)) }.flatMap { case (id, contents) => 14 toWords(contents).map(w => ((w,id),1))
15 .import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ val sparkContext = new RDD[String]: .../hadoop, Hadoop provides... SparkContext(master, “Inv. Index”) sparkContext.textFile("/path/to/input"). map { line => val array = line.split(",", 2) (array(0), array(1)) }.flatMap { RDD[(String,String)]: (.../hadoop,Hadoop provides...) case (id, contents) => 15 toWords(contents).map(w => ((w,id),1))
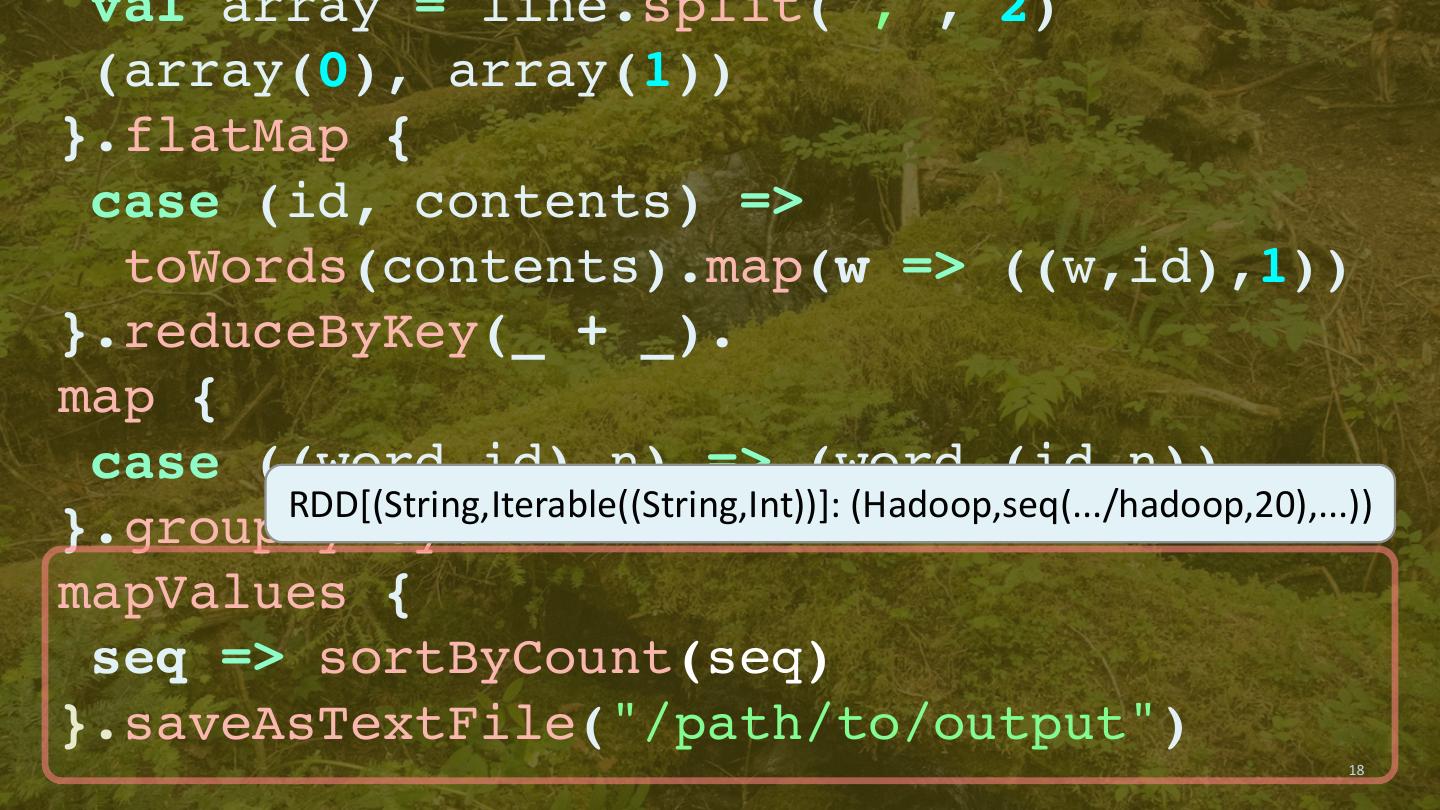
16 . val array = line.split(",", 2) (array(0), array(1)) }.flatMap { case (id, contents) => toWords(contents).map(w => ((w,id),1)) }.reduceByKey(_ + _). map { RDD[((String,String),Int)]: ((Hadoop,.../hadoop),20) case ((word,id),n) => (word,(id,n)) }.groupByKey. mapValues { seq => sortByCount(seq) }.saveAsTextFile("/path/to/output") 16
17 . val array = line.split(",", 2) (array(0), array(1)) }.flatMap { case (id, contents) => toWords(contents).map(w => ((w,id),1)) }.reduceByKey(_ + _). map { case ((word,id),n) => (word,(id,n)) }.groupByKey. mapValues { RDD[(String,Iterable((String,Int))]: (Hadoop,seq(.../hadoop,20),...)) seq => sortByCount(seq) }.saveAsTextFile("/path/to/output") 17
18 . val array = line.split(",", 2) (array(0), array(1)) }.flatMap { case (id, contents) => toWords(contents).map(w => ((w,id),1)) }.reduceByKey(_ + _). map { case ((word,id),n) => (word,(id,n)) RDD[(String,Iterable((String,Int))]: (Hadoop,seq(.../hadoop,20),...)) }.groupByKey. mapValues { seq => sortByCount(seq) }.saveAsTextFile("/path/to/output") 18
19 . Productivity? textFile map Intuitive API: flatMap •Dataflow of steps. reduceByKey map •Inspired by Scala collections groupByKey and functional programming. map saveAsTextFile 19
20 . Performance? textFile map Lazy API: flatMap •Combines steps into “stages”. reduceByKey map •Cache intermediate data in groupByKey memory. map saveAsTextFile 20
21 .21
22 .Higher-Level APIs 22
23 .SQL: Datasets/ DataFrames 23
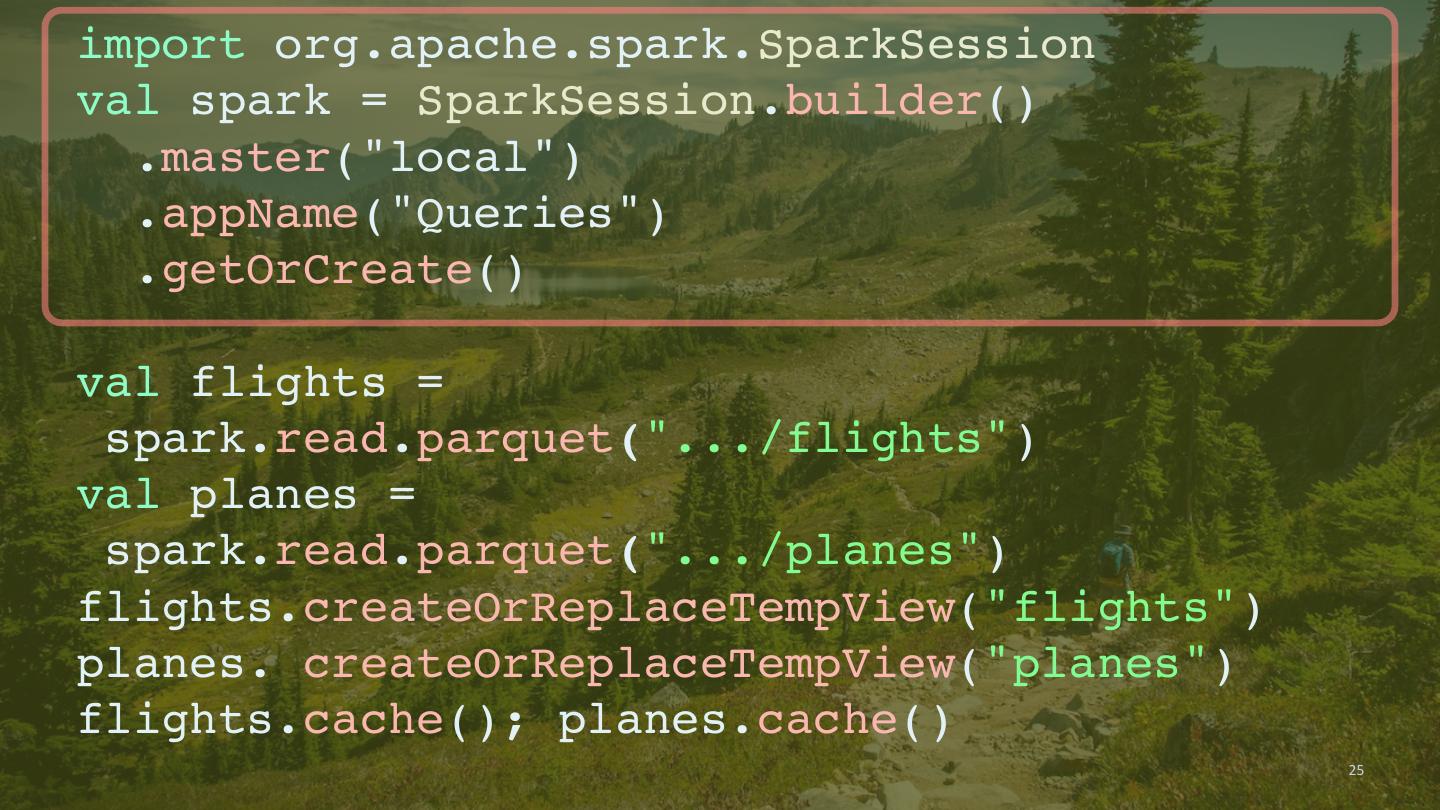
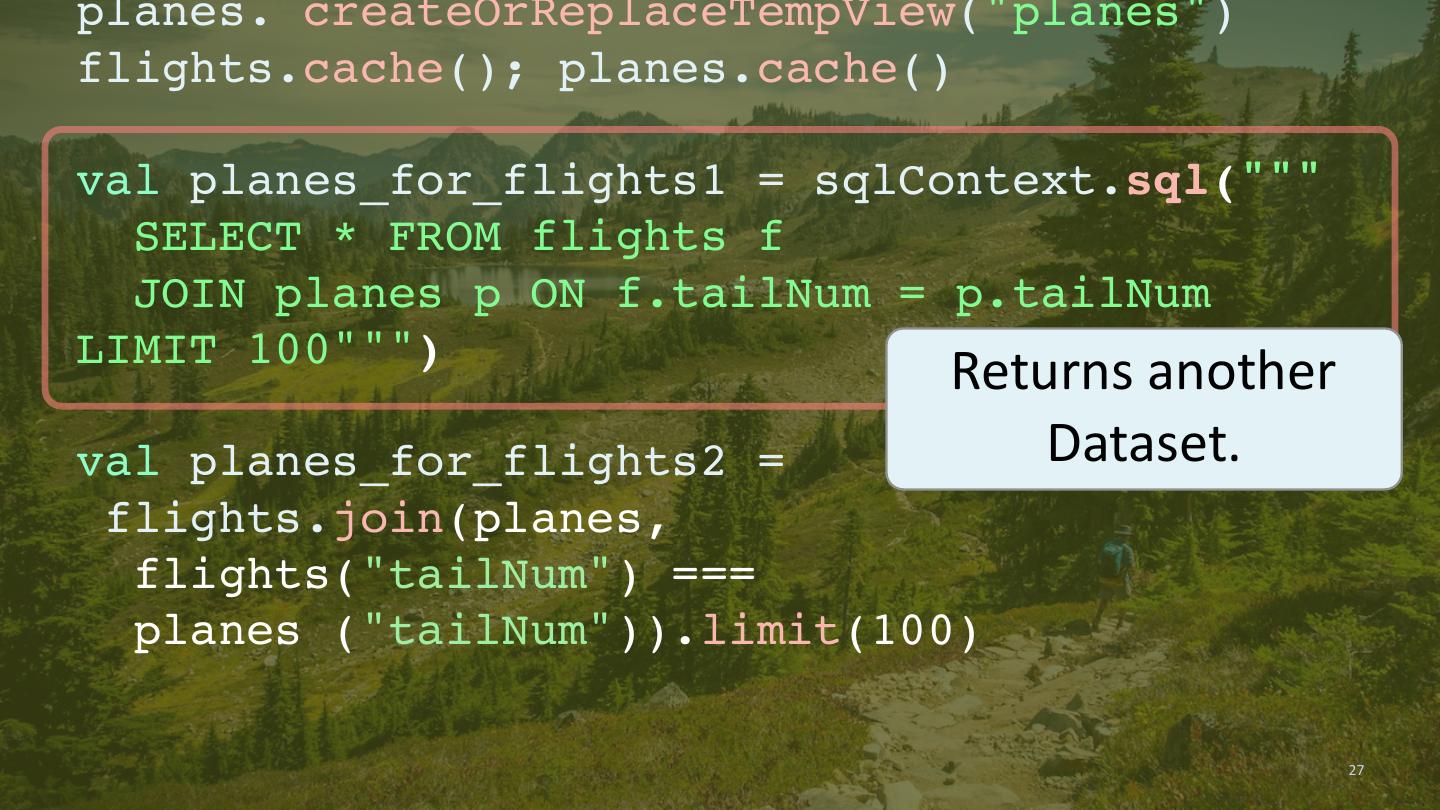
24 .import org.apache.spark.SparkSession val spark = SparkSession.builder() .master("local") Example .appName("Queries") .getOrCreate() val flights = spark.read.parquet(".../flights") val planes = spark.read.parquet(".../planes") flights.createOrReplaceTempView("flights") planes. createOrReplaceTempView("planes") flights.cache(); planes.cache() val planes_for_flights1 = sqlContext.sql(""" SELECT * FROM flights f JOIN planes p ON f.tailNum = p.tailNum LIMIT 100""") val planes_for_flights2 = flights.join(planes, flights("tailNum") === planes ("tailNum")).limit(100) 24
25 .import org.apache.spark.SparkSession val spark = SparkSession.builder() .master("local") .appName("Queries") .getOrCreate() val flights = spark.read.parquet(".../flights") val planes = spark.read.parquet(".../planes") flights.createOrReplaceTempView("flights") planes. createOrReplaceTempView("planes") flights.cache(); planes.cache() 25
26 .import org.apache.spark.SparkSession val spark = SparkSession.builder() .master("local") .appName("Queries") .getOrCreate() val flights = spark.read.parquet(".../flights") val planes = spark.read.parquet(".../planes") flights.createOrReplaceTempView("flights") planes. createOrReplaceTempView("planes") flights.cache(); planes.cache() 26
27 .planes. createOrReplaceTempView("planes") flights.cache(); planes.cache() val planes_for_flights1 = sqlContext.sql(""" SELECT * FROM flights f JOIN planes p ON f.tailNum = p.tailNum LIMIT 100""") Returns another val planes_for_flights2 = Dataset. flights.join(planes, flights("tailNum") === planes ("tailNum")).limit(100) 27
28 .planes. createOrReplaceTempView("planes") flights.cache(); planes.cache() val planes_for_flights1 = sqlContext.sql(""" SELECT * FROM flights f JOIN planes p ON f.tailNum = p.tailNum LIMIT 100""") Returns another val planes_for_flights2 = Dataset. flights.join(planes, flights("tailNum") === planes ("tailNum")).limit(100) 28
29 .val planes_for_flights2 = flights.join(planes, flights("tailNum") === planes ("tailNum")).limit(100) Not an “arbitrary” anonymous funcRon, but a “Column” instance. 29
相关推荐
3秒后跳转登录页面
去登陆

