























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark SQL优化实践
Spark SQL是Spark生态系统中非常重要的组件,主要用于分布式进行结构化数据的处理,在很多领域有成功的生产实践。在本次分析中首先会简单介绍Intel大数据团队推出的SparkSQL自适应执行引擎(https://github.com/Intel-bigdata/spark-adaptive),在运行过程中通过实时收集到的信息,动态地调整后续的执行计划,包括运行时调整Join的策略,根据shuffle数据量自适应调节shuffle partition的个数,自动优化数据倾斜等优化。然后还会介绍未来我们准备在Spark SQL上实现“智能”Spark SQL引擎,在很多客户场景中,用户经常会在不同规模的数据集中重复运行同一个或类似的SQL,通过收集历史运行时的一些统计数据如join的输入输出数据量去优化下一次运行的执行,来实现如join reordering等的优化。
展开查看详情
1 .Intel Spark SQL Optimizations and The Future Jiajia Li (jiajia.li@intel.com )
2 .Agenda • Challenges in Spark SQL High Performance • Adaptive Execution • Spark Light 2
3 .Shuffle Partition Challenge • Partition Num Too Small:Spill, GC, OOM • Partition Num Too Large:Scheduling overhead. More IO requests. Too many small output files • Partition Num P = spark.sql.shuffle.partition (200 by default) • The same Shuffle Partition number doesn’t fit for each query • The same Shuffle Partition number doesn’t fit for all Stages 3
4 .BroadcastJoin vs. SortMergeJoin • spark.sql.autoBroadcastJoinThreshold is 10 MB by default • For complex queries, a Join may takes intermediate results as inputs. At planning phase, Spark SQL doesn’t know the exact size and plans it to SortMergeJoin. 4
5 .Data Skew in Join • Data in some partitions are extremely larger than other partitions. • Data skew is a common source of slowness for Shuffle Joins. • Ways to Handle Skewed Join with limitation: • Increase shuffle partition number => Rows share the same key? • Increase BroadcastJoin threashold to change Shuffle Join to Broadcast Join => Network overhead • Add prefix to the skewed keys => Require many manual efforts 5
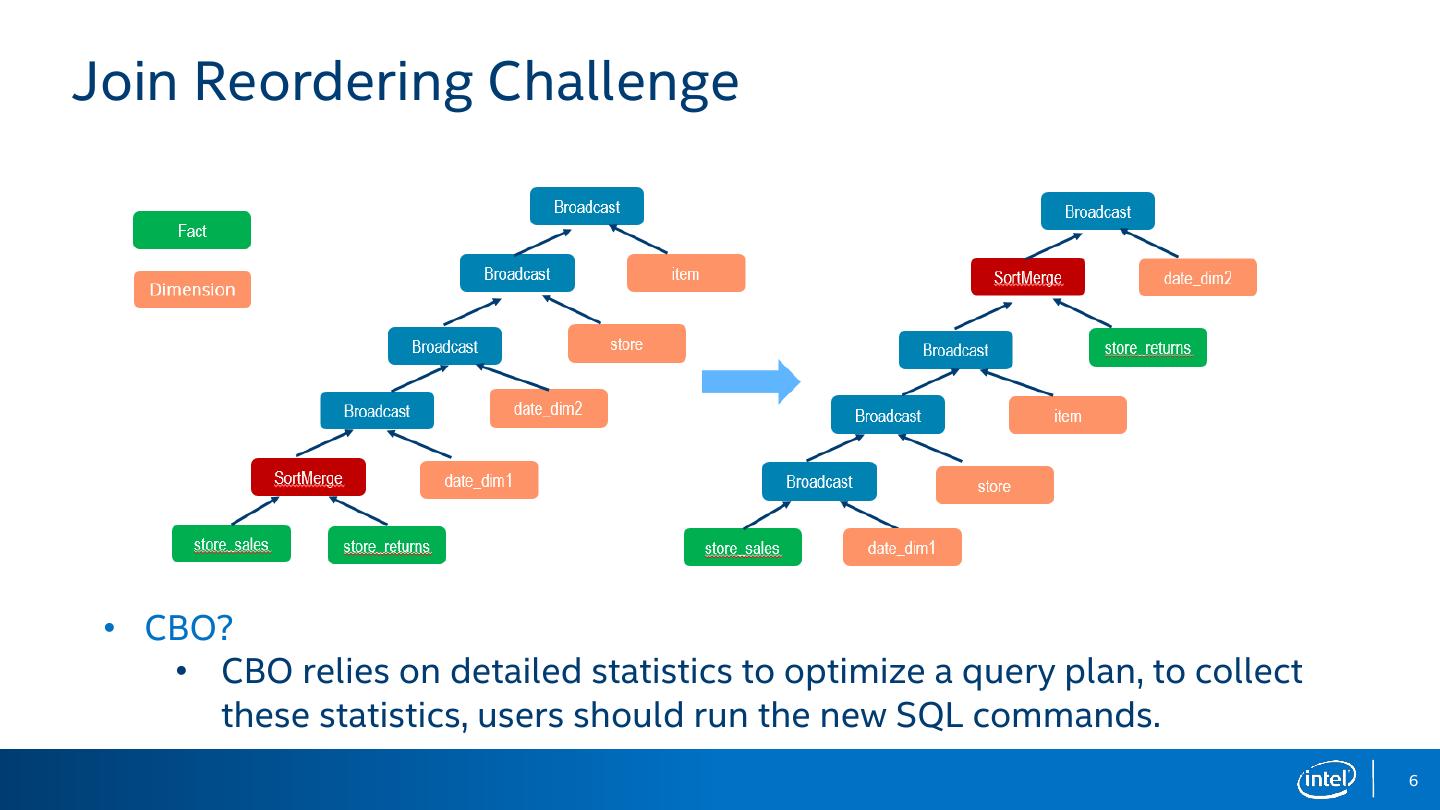
6 .Join Reordering Challenge • CBO? • CBO relies on detailed statistics to optimize a query plan, to collect these statistics, users should run the new SQL commands. 6
7 .Agenda • Challenges in Spark SQL High Performance • Adaptive Execution • Spark Light 7
8 . Adaptive Execution Architecture DAG of RDDs Execution Plan FileScan Shuffled RDD Execute the Stages RDD RowRDD Stage RDD SortMerge Join FileScan Shuffled RDD RDD RowRDD Stage Stage Sort Sort QueryStage QueryStage Exchange Exchange Divide the plan into (a) Execute ChildStages DAG of RDDs multiple QueryStages SortMerge (b) Optimize the plan Broadcast Join (c) Determine Reducer num LocalShu Join ffledRDD RDD … … Stage Sort Sort QueryStage Broadcast Input Exchange Size=100GB Execute the Stage QueryStage QueryStage QueryStage Input Input Input ChildStage ChildStage Size=5MB 8
9 .Auto Setting the Number of Reducers • 5 initial reducer partitions with size [70 MB, 30 MB, 20 MB, 10 MB, 50 MB] • Set target size per reducer = 64 MB. At runtime, we use 3 actual reducers. • Also support setting target row count per reducer. Map Map Reduce Reduce Reduce Task 1 Task 2 Task 1 Task 2 Task 3 Partition 0 Partition 0 Partition 1 (30MB) Partition 1 Partition 1 Partition 0 Partition 2 Parition 4 Partition 2 Partition 2 (70MB) (20 MB) (50 MB) Partition 3 Partition 3 Partition 3 Partition 4 Partition 4 (10 MB) 9
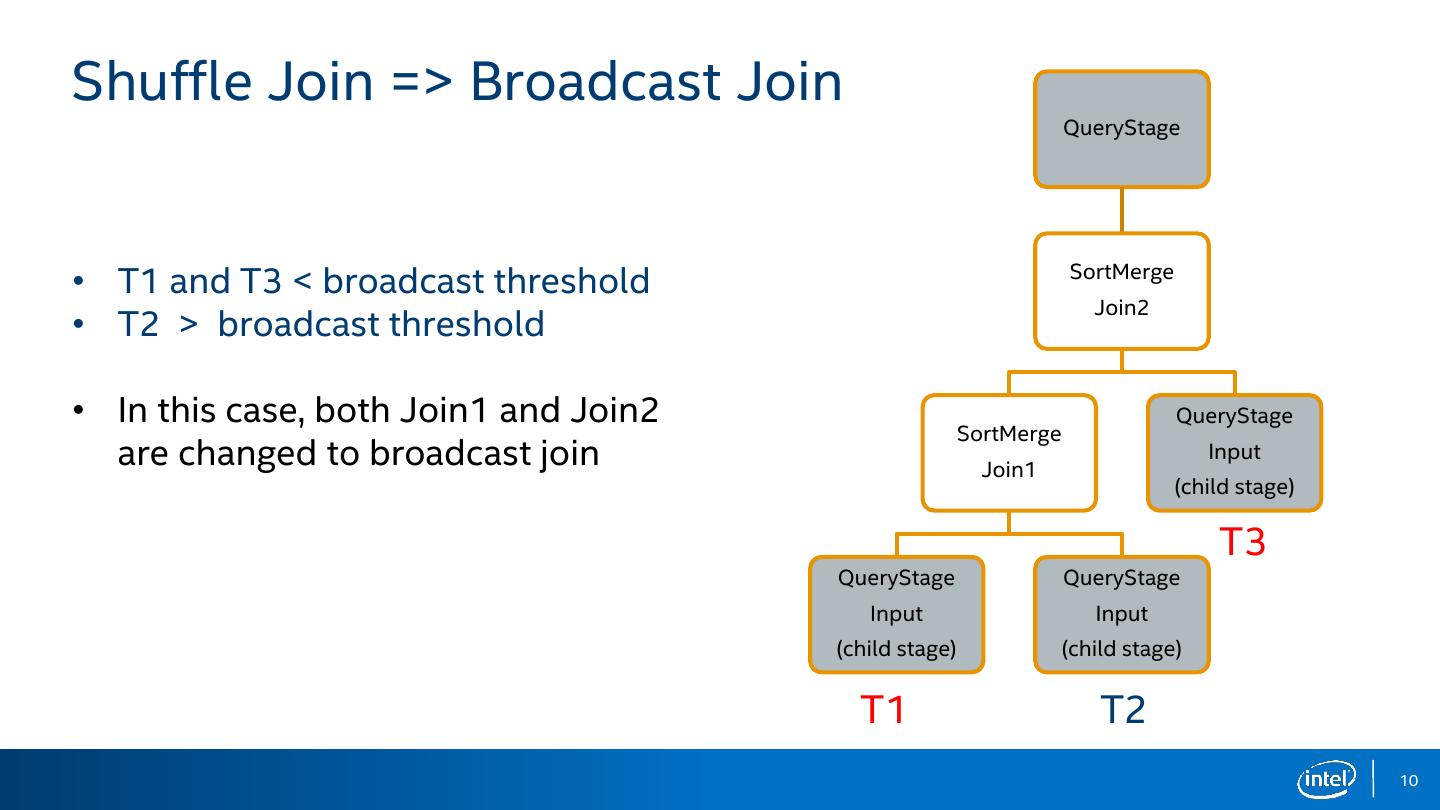
10 .Shuffle Join => Broadcast Join QueryStage • T1 and T3 < broadcast threshold SortMerge Join2 • T2 > broadcast threshold • In this case, both Join1 and Join2 QueryStage SortMerge are changed to broadcast join Join1 Input (child stage) T3 QueryStage QueryStage Input Input (child stage) (child stage) T1 T2 10
11 .Remote Shuffle Read => Local Shuffle Read task1 Task2 Task3 A0 B0 Task4 Task5 Reduce tasks on Node 1 Reduce tasks on Node 2 Map output on Node 1 Remote Shuffle Read A1 B1 task 1 task 2 Map output on Node 2 Reduce tasks on Node 1 Reduce tasks on Node 2 Local Shuffle Read 11
12 .Skewed Partition Detection at Runtime • After executing child stages, we calculate the data size and row count of each partition from MapStaus. • A partition is skewed if its data size or row count is N times larger than the median, and also larger than a pre-defined threshold. 12
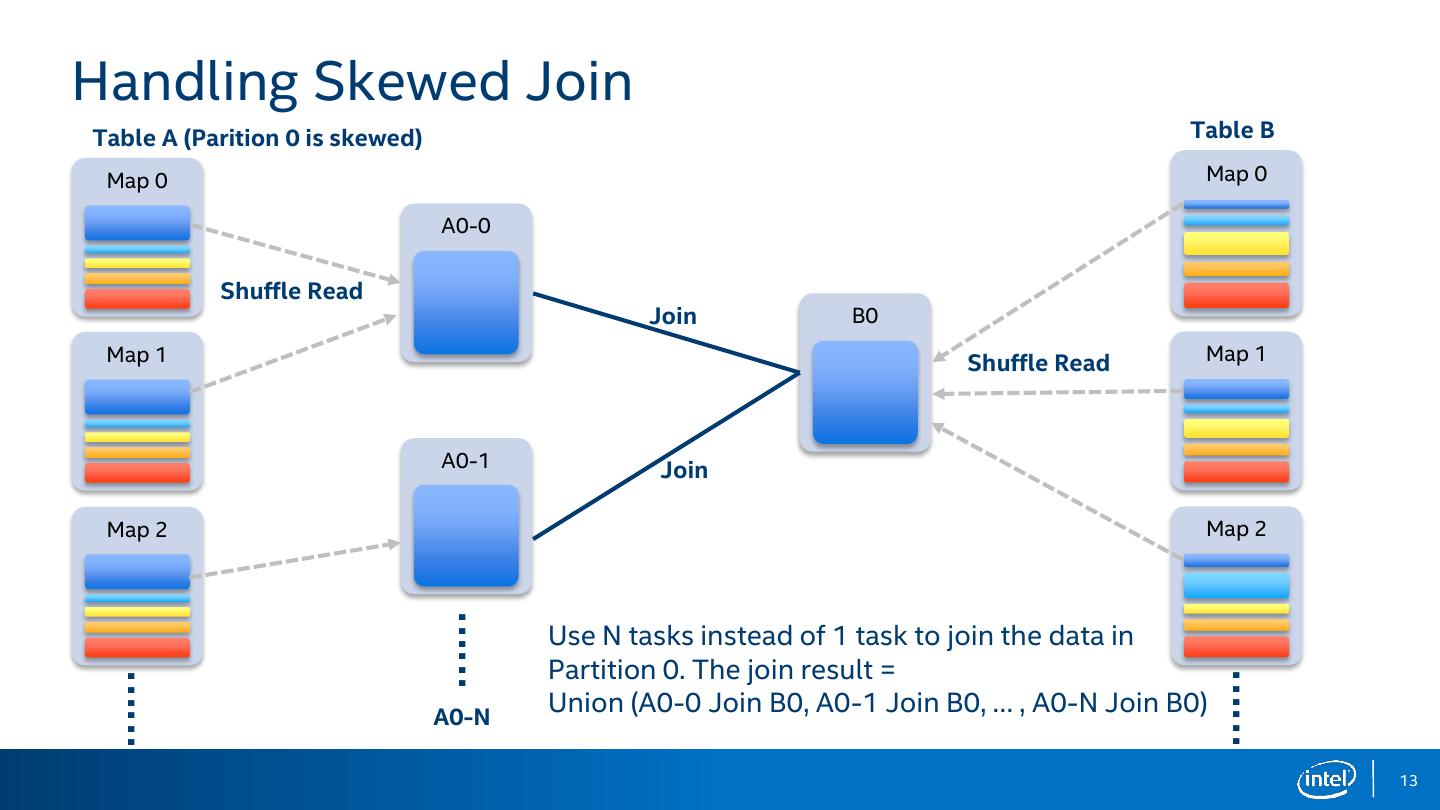
13 .Handling Skewed Join Table A (Parition 0 is skewed) Table B Map 0 Map 0 A0-0 Shuffle Read Join B0 Map 1 Shuffle Read Map 1 A0-1 Join Map 2 Map 2 …… Use N tasks instead of 1 task to join the data in Partition 0. The join result = …… …… A0-N Union (A0-0 Join B0, A0-1 Join B0, … , A0-N Join B0) 13
14 .Auto Setting the Shuffle Partition Number • Less scheduler overhead and task startup time. • Less disk IO requests. • Less data are written to disk because more data are aggregatd. Partition Number 10976 (q30) Partition Number changed to 1084 and 1079 at runtime. (q30) 14
15 .SortMergeJoin -> BroadcastJoin at Runtime • Eliminate the data skew and straggler in SortMergeJoin • Remote shuffle read -> local shuffle read. • Random IO read -> Sequence IO read SortMergeJoin (q8): BroadcastJoin (q8 Adaptive Execution): 15
16 .Summary • Adaptively determine reducer number • Join strategy selection at runtime • Handle skewed Join at runtime • https://github.com/Intel-bigdata/spark-adaptive 16
17 .Agenda • Challenges in Spark SQL High Performance • Adaptive Execution • Spark Light 17
18 .Background • Handle shuffle parallelism on map(shuffle write) + reducer(shuffle read) side ? • Join Reorder? • SMJ => BHJ in planning phase? • Can we optimize the execution plan based on the historical runtime statistics ? 18
19 . History Statistics Collection Framework • Collects table level statistics Number of rows, size in bytes Table Type: Fact/Dimension … • Collects shuffle operation statistics Shuffle ID Inputs Outputs Cost time … 19
20 .BroadcastJoin vs. SortMergeJoin • Broadcast Criterion: whether one join side’s size is small than threshold. JOIN 0.01 million SCAN t1 FILTER 1 billion SCAN t2 10 billion Left Input Right Input SMJ ➔ BHJ 20
21 .Determine Shuffle Parallelism reduced I/O… Reduce shuffle write and read time Map Task 1 Map Task 2 Map Task 3 Partition 0 Partition 0 Partition 0 Partition 1 Partition 1 Partition 1 Partition 2 Partition 2 Partition 2 Partition 3 Partition 3 Partition 3 Partition 4 Partition 4 Partition 4 Reduce Task 1 Reduce Task 2 Reduce Task 3 Reduce Task 4 Reduce Task 5 Partition 0 Partition 1 Partition 2 Partition 3 Partition 4 21
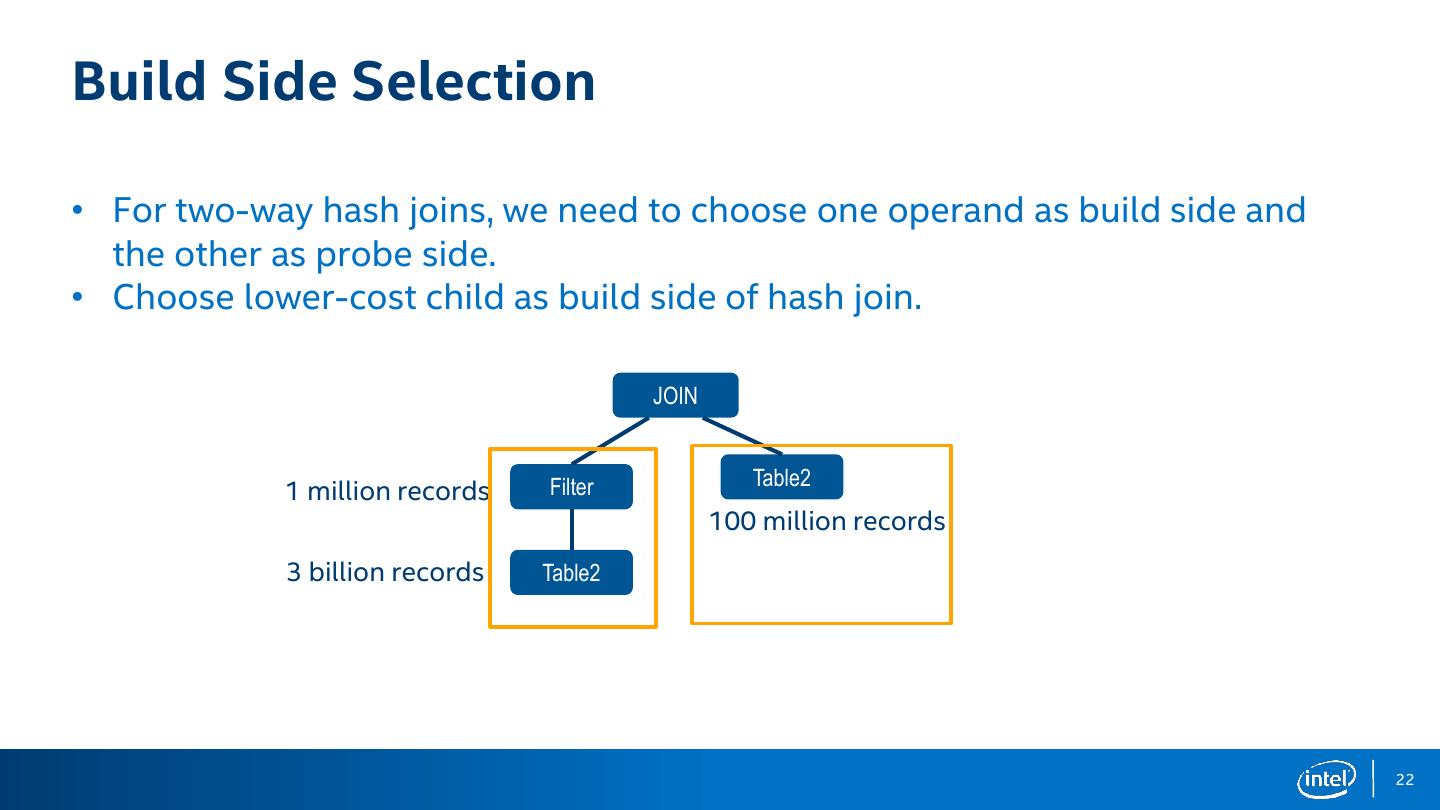
22 .Build Side Selection • For two-way hash joins, we need to choose one operand as build side and the other as probe side. • Choose lower-cost child as build side of hash join. JOIN Filter Table2 1 million records 100 million records 3 billion records Table2 22
23 . Join Reordering 500 million 500 million JOIN JOIN 2.5 billion 0.1 million 2.5 billion 500 million 10 million JOIN SCAN: date_dim 80% less data JOIN FILTER 12 million 10 million FILTER SCAN: customer 3 billion 12 million 3 billion 0.1 million SCAN: store_sales SCAN: customer SCAN: store_sales SCAN: date_dim 23
24 .Data Distribution Rows Rows Rows Time Time Time Ratio Distribution Fixed Distribution Unknow Distribution 24
25 .Thank YOU
26 .Legal Disclaimer No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps. The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm. Intel does not control or audit third-party benchmark data or the web sites referenced in this document. You should visit the referenced web site and confirm whether referenced data are accurate. Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others Copyright © 2017 Intel Corporation. 26
3秒后跳转登录页面
去登陆

