



















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
EBay - MPP迁移至Spark
本次主要分享关于迁移实际案例与最佳实践更加深入的探讨。在迁移过程中,我们遇到了很多的预料之外的问题,如字符集问题,数字进位问题,各种OOM等等,更加深入地了解了Spark和RDMBS之间的差异。在弥补鸿沟和解决问题的过程中,我们做了很多的实践,贡献给了社区很多的反馈,也解决了很多的bug。即便对于Spark当前不能处理的场景,比如recurisve query,也有了一些可行的探索。此外,我们现在还开发了一套自动化框架来帮助加速迁移工作。在这次分享中,我们会深入迁移的关键步骤,并分享踩过的一些坑,最后会介绍我们的自动化工具,如SQL Converter等。相信对正工作在类似的任务或者即将开展类似工作的工程师们会有所帮助。
展开查看详情
1 .,
2 .About US • DSS(Data Services & Solutions) team in eBay. • Focus on Big data development and optimization on MPP RDBMS, Spark, Hadoop systems, data modeling and data services. • Now , more time on the migration from MPP to Spark.
3 .Talks from our team • Experience Of Optimizing Spark SQL When Migrating from MPP Database , Yucai Yu & Yuming Wang, Spark Summit 2018, London. • Analytical DBMS to Apache Spark Auto Migration Framework Edward Zhang, Spark Summit 2018, London. 3
4 .Agenda Background Use Cases and Best Practices Auto Migration Deep Dive 4
5 .Why Migrate to Spark MORE COMPLEX BIG STREAMING, GRAPH MACHINE LEARNING EXTREME DATA PROCESSING COMPUTATION, USE CASES PERFORMANCE NEEDS OPTIMIZATION NEED 5
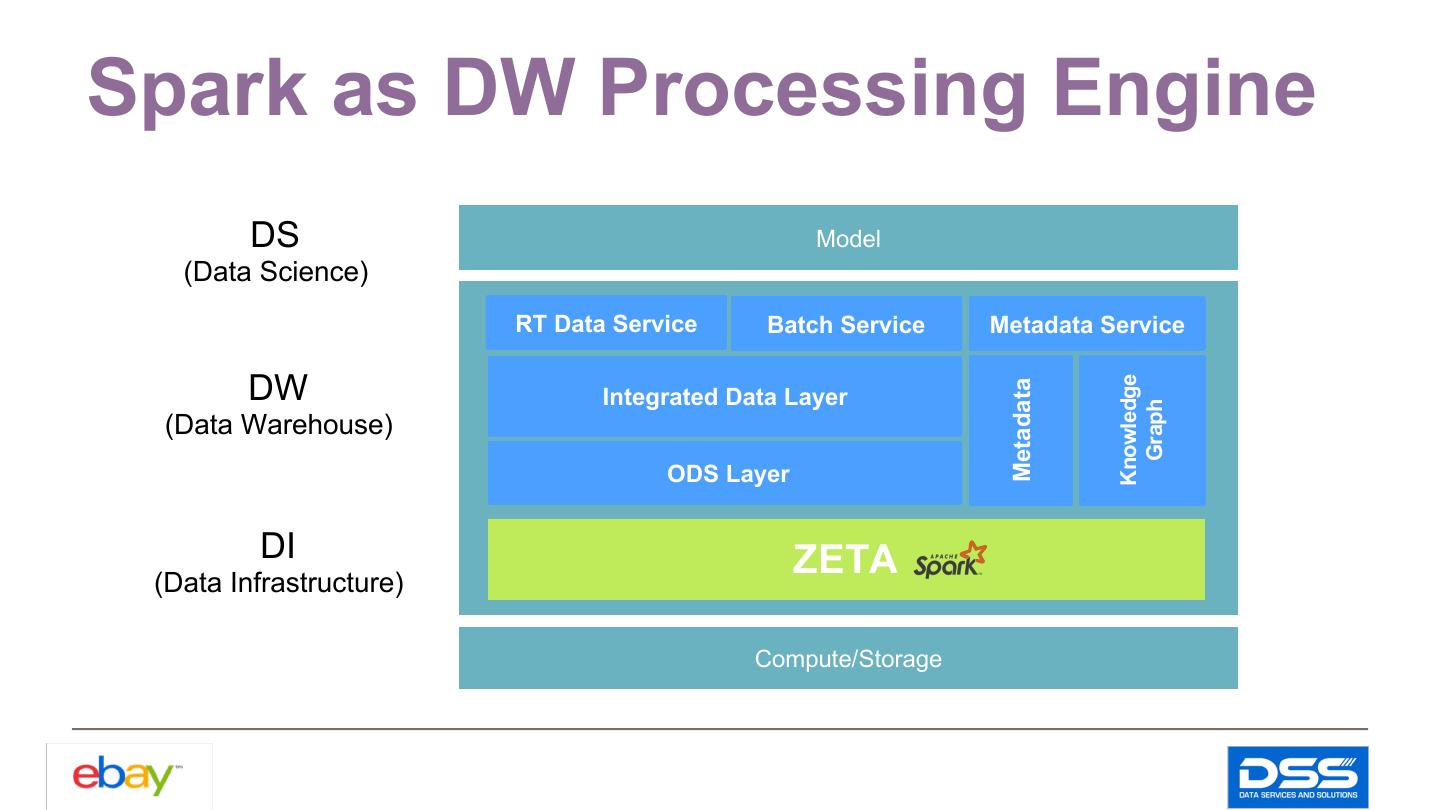
6 .Spark as DW Processing Engine DS Model (Data Science) RT Data Service Batch Service Metadata Service DW Knowledge Metadata Integrated Data Layer Graph (Data Warehouse) ODS Layer DI ZETA (Data Infrastructure) Compute/Storage 6
7 .Spark Cluster Environment Spark Hadoop Hive 2.1.0/2.3.1 2.7.1 1.2.1 1900 460TB Nodes Memory 7
8 .Agenda Background Use Cases and Best Practices Auto Migration Deep Dive 8
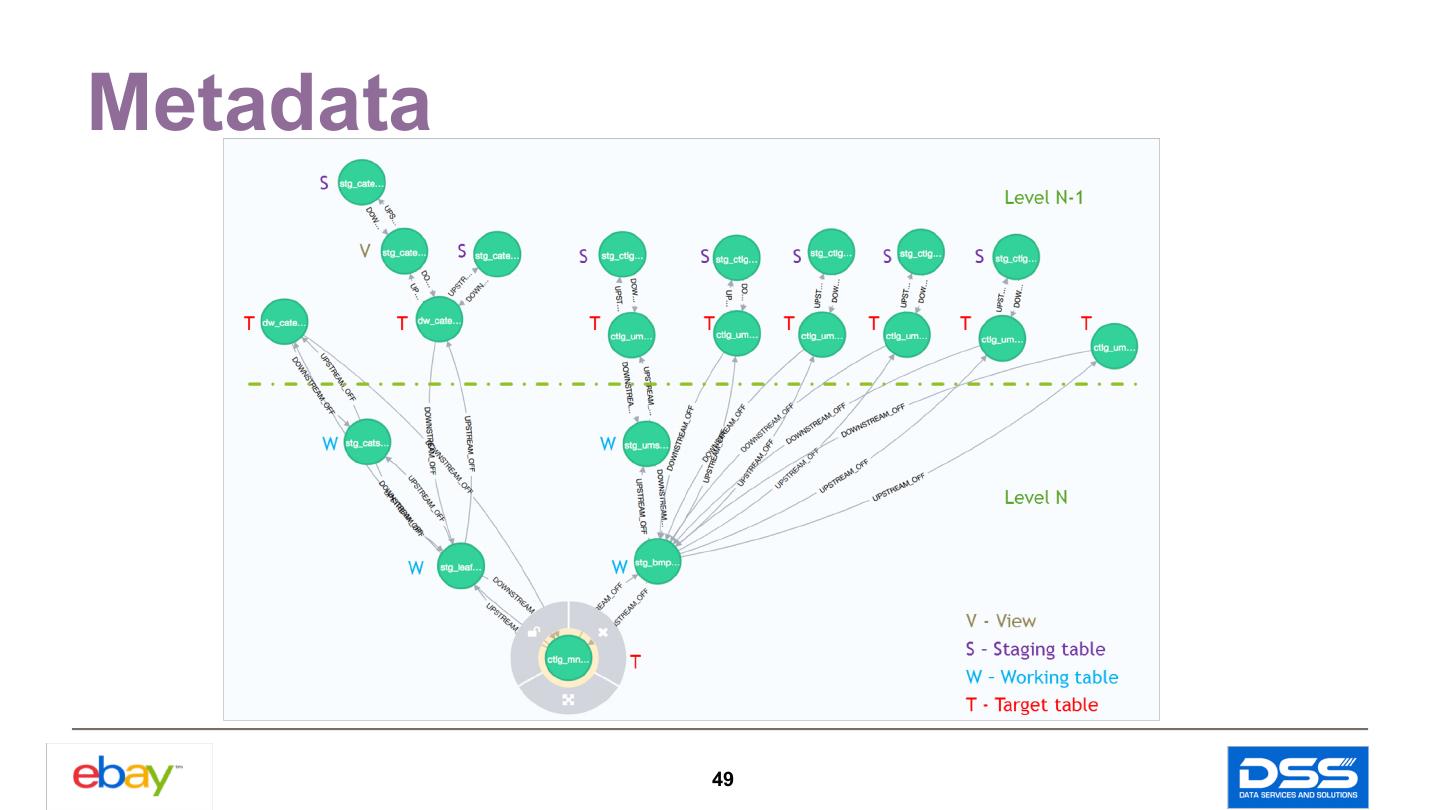
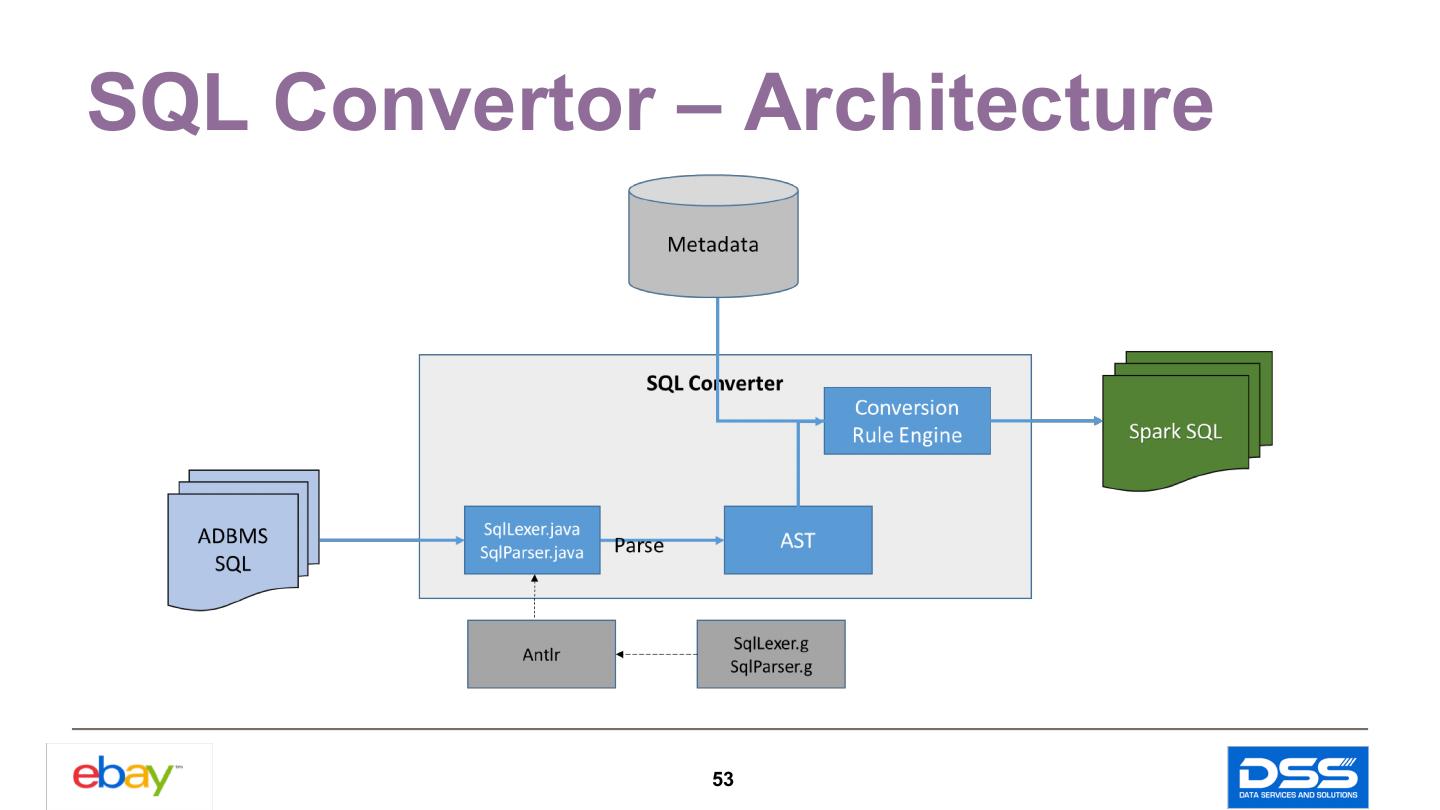
9 . Table Schema Translation SQL Conversion Migration Historical Data Copy Steps SQL run on Yarn cluster Overview Post Data Quality Check Logging and Error Parsing 9
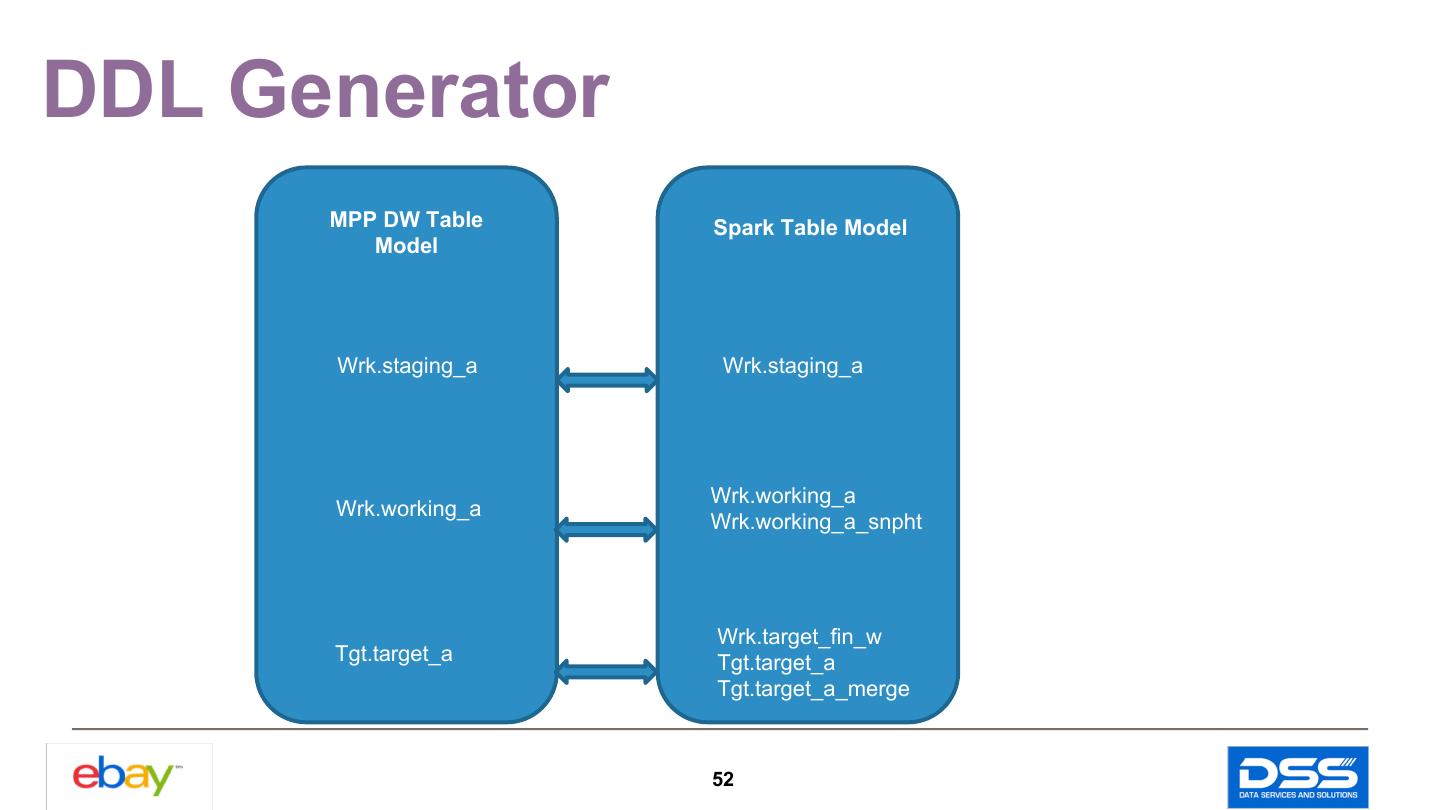
10 .Table Schema Translation Single Partitioned Table Is Not Enough Column Name Is Case Sensitive Column Type Mapping Tips 10
11 .Single Partitioned Table Is Not Enough Ø “Cannot overwrite a path that is also being read from.” regardless of different partitions. See SPARK-18107. Instead , create 2 tables : TableX & TableX_Merge. TableX_Merge is partitioned table and keeps daily snapshots and TableX point to the latest snapshot for downstream reference. 11
12 .Table Design Sample CREATE TABLE Table_X_Merge( CREATE TABLE Table_X ( … ….. dt string ) ) USING parquet USING parquet OPTIONS ( OPTIONS ( path path 'hdfs://hercules/table_x/snapshot/ 'hdfs://hercules/table_x/snapshot/' dt=20190311’ ) ) ---point latest partition PARTITIONED BY (dt) 12
13 .Column Name Is Case Sensitive Ø Lowercase the column name. For Hive/Spark Parquet file interoperation , otherwise you may see “NULL” fields, wrong result or errors . (SPARK-25132) 13
14 .Spark 2.3.1 returns wrong result silently. 14
15 .Spark 2.1.0 throw error : “Caused by: java.lang.IllegalArgumentException: Column [id] was not found in schema!” 15
16 .Column Type Mapping Tips Ø Decimal typed integer map to Integer For Parquet filter push down to accelerate file scan. 16
17 .Sample For Parquet filter push down to accelerate file scan.(SPARK-24549 ) 17
18 .Query Improvements – Predicate Pushdown [SPARK-25419] Improvement parquet predicate pushdown • [SPARK-23727] Support Date type • [SPARK-24549] Support Decimal type • [SPARK-24718] Support Timestamp type • [SPARK-24706] Support Byte type and Short type • [SPARK-24638] Support StringStartsWith predicate • [SPARK-17091] Support IN predicate DATA SERVICES AND SOLUTIONS
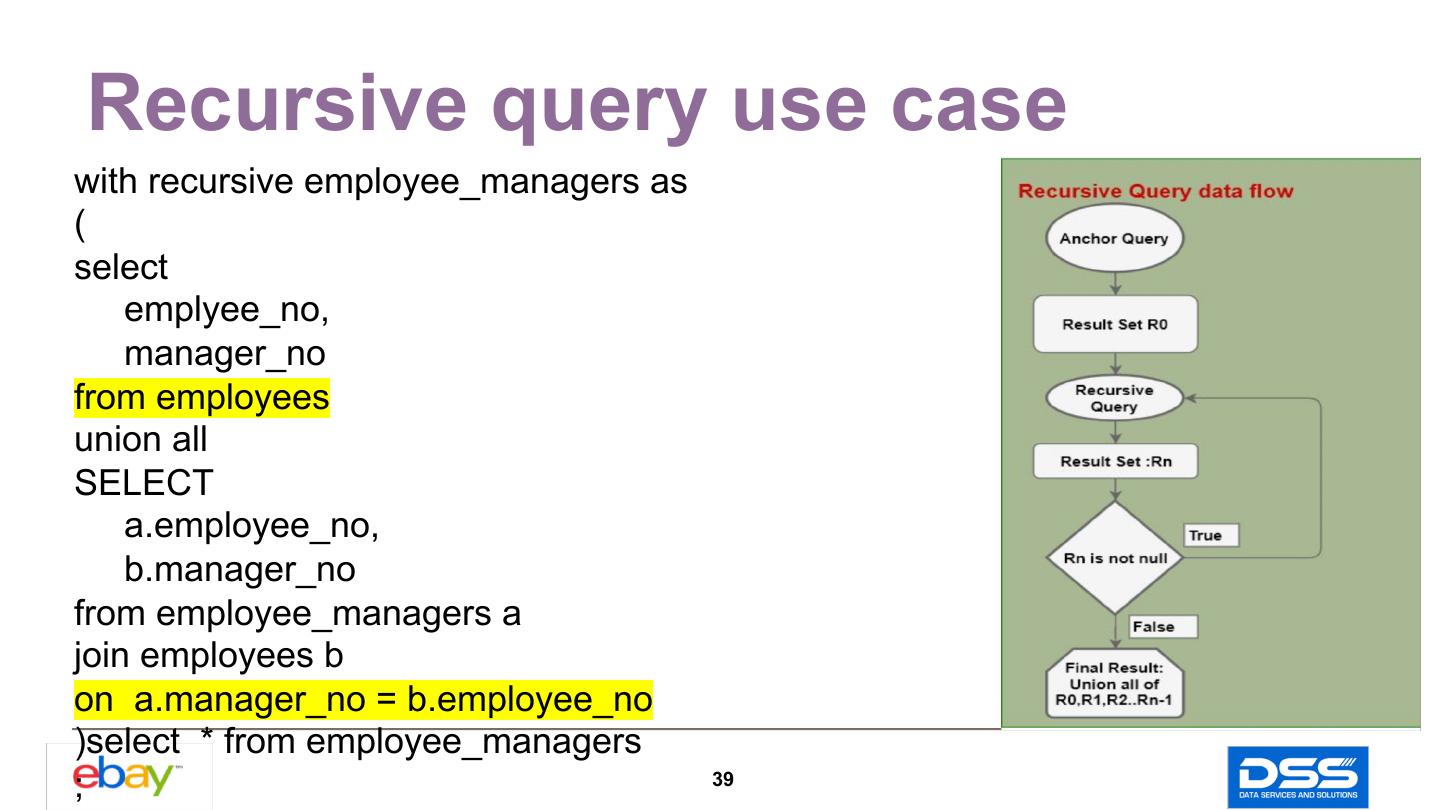
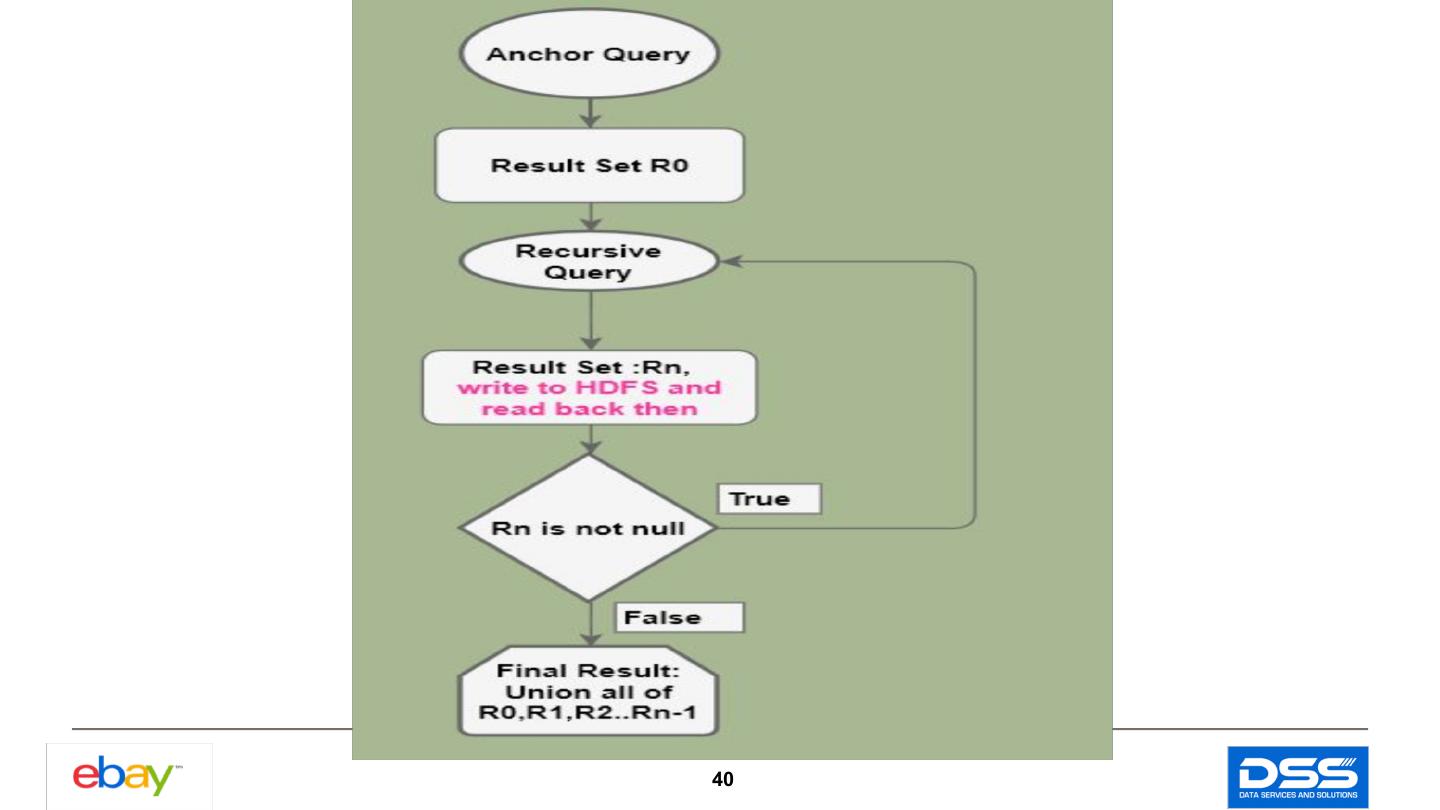
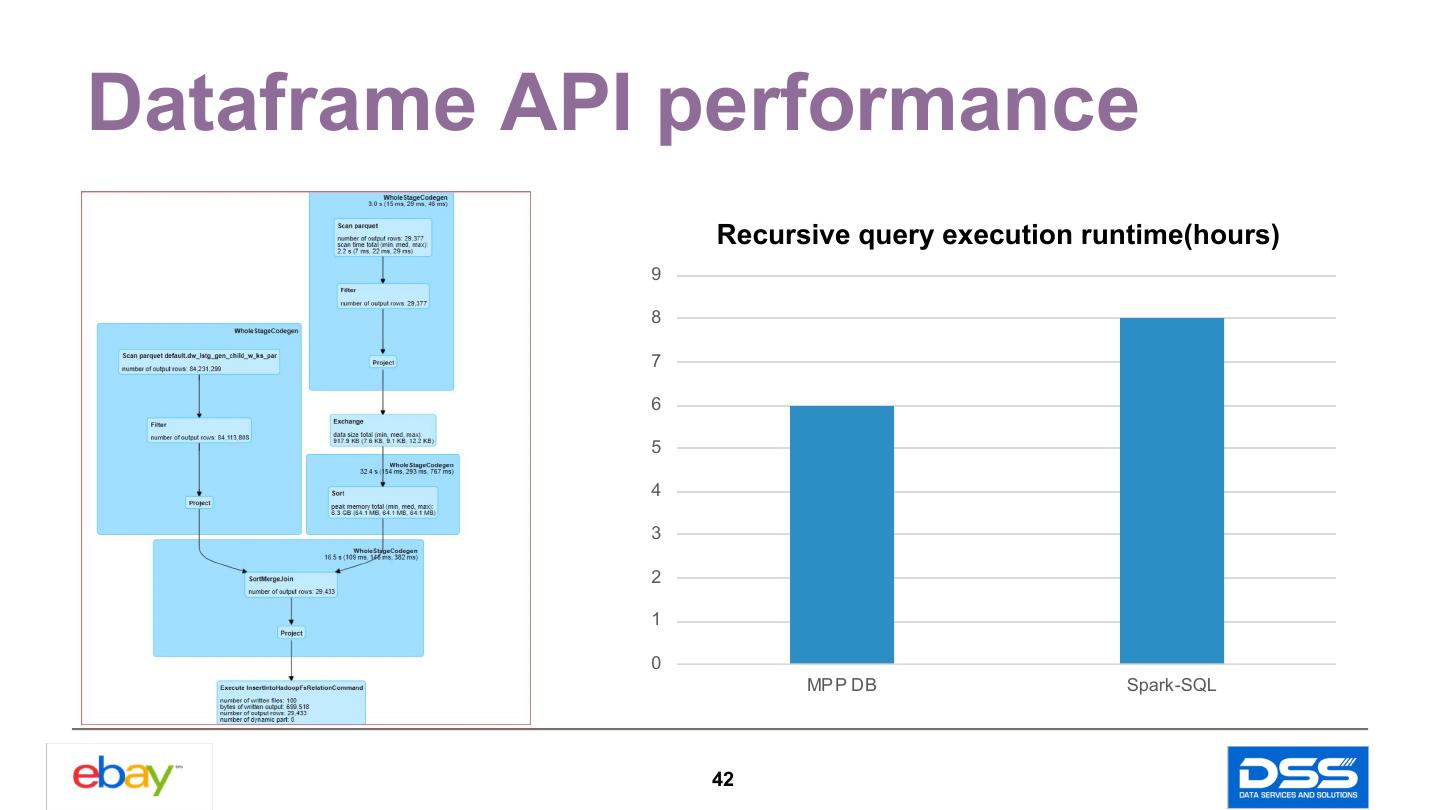
19 .SQL Conversion Update & Delete Conversion Insert Conversion Number Expression String Expression Recursive Query Conversion 19
20 .SQL Conversion- Update/Delete Spark-SQL does not support update/delete yet. Transform the update/delete to insert or insert overwrite. 20
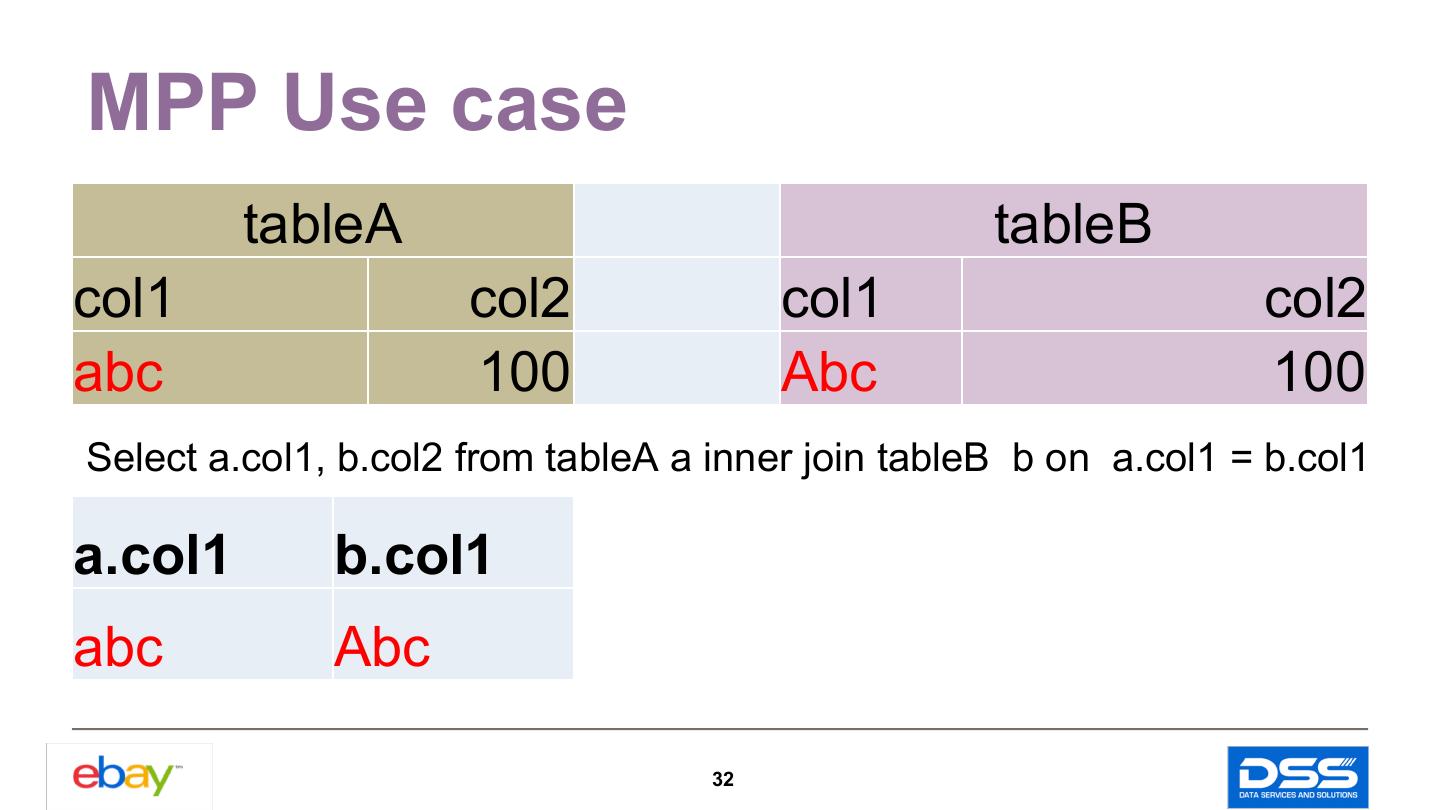
21 .MPP Use case update tgt from database.tableX tgt, database.Delta ods set AUCT_END_DT = ods.AUCT_END_DT where tgt.LSTG_ID = ods.LSTG_ID ; insert into database.tableX( LSTG_ID,AUCT_END_DT) select LSTG_ID ,AUCT_END_DT from database.Delta ods Yesterday left outer join database.tableX tgt Full Data Delta on tgt.LSTG_ID = ods.LSTG_ID where tgt.LSTG_ID is null; 21
22 .Spark-SQL sample insert overwrite table TableX_merge partition(dt='20190312') select coalesce(tgt.LSTG_ID,ods.LSTG_ID) as LSTG_ID ,IF(ods.LSTG_ID is not null, ods.AUCT_END_DT,tgt.AUCT_END_DT) as AUCT_END_DT from TableX as tgt full outer join Delta ods on tgt.LSTG_ID = ods.LSTG_ID ; alter table TableX set location ‘xxxx/dt=20190312’; 22
23 .SQL Conversion- Insert Ø MPP DB will implicitly dedupe data when insert into SET table(the default case for new tables). Then, for such case, a “group by” or “distinct” is necessary. 23
24 .MPP Use case (TableY is defined a SET table ) insert into TableY( LSTG_ID,AUCT_END_DT) select LSTG_ID ,AUCT_END_DT from ods_tableY tgt 24
25 .Spark-SQL sample insert overwrite table TableY_merge partition(dt='20190312') select distinct * from ( select LSTG_ID, AUCT_END_DT FROM TableY tgt UNION ALL select LSTG_ID, AUCT_END_DT FROM ODS_TableY) tmp; 25
26 .SQL Conversion – Number Expression Ø Rounding behavior MPP DW round with “HALF_EVEN” rule by default, but Spark-SQL use “HAFL_UP”. Use bround to replace direct ”cast” 26
27 .MPP Sample select cast(2.5 as decimal(4,0)) as result; 2. select cast(3.5 as decimal(4,0)) as result; 4. 27
28 .Spark-SQL Result spark-sql> select cast(2.5 as decimal(4,0)) 3 spark-sql> select bround(2.5,0) as col1; 2 28
29 .SQL Conversion – Number Expression Ø Number division result MPP return closest Integer for Integer division, while Spark always return double . Explicit cast division result to integer. 29
3秒后跳转登录页面
去登陆

