展开查看详情
1 .Lessons from Large-Scale
Cloud Software at Databricks
Matei Zaharia
@matei_zaharia
�
2 .Outline
The cloud is eating software, but why?
About Databricks
Challenges, solutions and research questions
2
�
3 .Outline
The cloud is eating software, but why?
About Databricks
Challenges, solutions and research questions
3
�
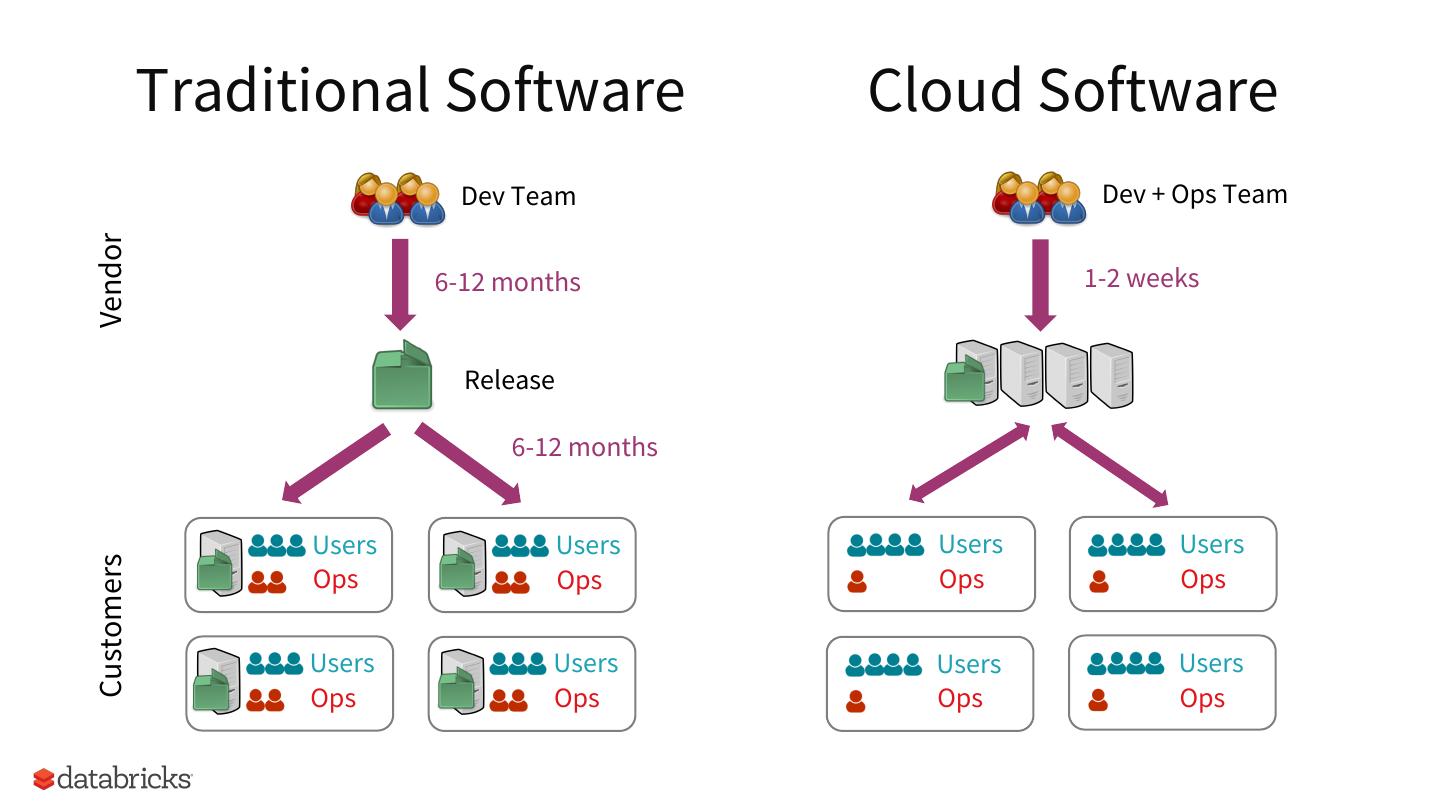
4 . Traditional Software Cloud Software
Dev Team Dev + Ops Team
Vendor
6-12 months 1-2 weeks
Release
6-12 months
Users Users Users Users
Customers
Ops Ops Ops Ops
Users Users Users Users
Ops Ops Ops Ops
4
�
5 .Why Use Cloud Software?
1 Management built-in: much more value than the software
bits alone (security, availability, etc)
2 Elasticity: pay-as-you-go, scale on demand
3 Better features released faster
5
�
6 .Differences in Building Cloud Software
+ Release cycle: send to users faster, get feedback faster
+ Only need to maintain 2 software versions (current & next),
in fewer configurations than you’d have on-prem
– Upgrading without regressions: very hard, but critical for users
to trust your cloud (on-prem apps don’t need this)
§ Includes API, semantics, and performance regressions
6
�
7 .Differences in Building Cloud Software
– Building a multitenant service: significant scaling, security and
performance isolation work that you won’t need on-prem
(customers install separate instances)
– Operating the service: security, availability, monitoring, etc
(but customers would have to do it themselves on-prem)
+ Monitoring: see usage live for ops & product analytics
Many of these challenges aren’t studied in research
7
�
8 .About Databricks
Founded in 2013 by the Apache Spark team at UC Berkeley
Data and ML platform on AWS and Azure for >5000 customers
§ Millions of VMs launched/day, processing exabytes of data
§ 100,000s of users
1000 employees, 200 engineers, >$200M ARR
8
�
10 .Some of Our Customers
Financial Services Healthcare & Pharma Media & Entertainment Data & Analytics Services Technology
Public Sector Retail & CPG Consumer Services Marketing & AdTech Energy & Industrial IoT
10
�
11 .Some of Our Customers
Financial Services Healthcare & Pharma Media & Entertainment Data & Analytics Services Technology
Identify fraud using machine
learning on 30 PB of trade data
Public Sector Retail & CPG Consumer Services Marketing & AdTech Energy & Industrial IoT
11
�
12 .Some of Our Customers
Financial Services Healthcare & Pharma Media & Entertainment Data & Analytics Services Technology
Correlate 500,000 patients’ records
with their DNA to design therapies
Public Sector Retail & CPG Consumer Services Marketing & AdTech Energy & Industrial IoT
12
�
13 .Some of Our Customers
Financial Services Healthcare & Pharma Media & Entertainment Data & Analytics Services Technology
Curb abusive behavior in the
world’s largest online game
Public Sector Retail & CPG Consumer Services Marketing & AdTech Energy & Industrial IoT
13
�
14 .Our Product
Databricks Service Customer’s Cloud Account
Interactive Compute Clusters
data science
Data scientists Databricks Runtime
Scheduled jobs
Data engineers SQL frontend
ML platform Data catalog
Cloud Storage
Security policies
Business users
Built around
open source:
14
�
15 .Our Specific Challenges
All the usual challenges of SaaS:
§ Availability, security, multitenancy, updates, etc
Plus, the workloads themselves are large-scale!
§ One user job could easily overload control services
§ Millions of VMs ⇒ many weird failures
15
�
16 .Four Lessons
1 What goes wrong in cloud systems?
2 Testing for scalability & stability
3 Developing control planes
4 Evolving big data systems for the cloud
16
�
17 .Four Lessons
1 What goes wrong in cloud systems?
2 Testing for scalability & stability
3 Developing control planes
4 Evolving big data systems for the cloud
17
�
18 .What Goes Wrong in the Cloud?
Academic research studies many kinds of failures:
§ Software bugs, network config, crash failures, etc
These matter, but other problems often have larger impact:
§ Scaling and resource limits
§ Workload isolation
§ Updates & regressions
18
�
19 .Causes of Significant Outages
Other
Scaling problem
20% in our services
30%
Deployment
misconfiguration 10%
Insufficient 20% 20% Scaling problem in
user isolation underlying cloud services
19
�
20 .Causes of Significant Outages
Other
Scaling problem
20% in our services
30%
Deployment
misconfiguration 10% 70% scale
related
Insufficient 20% 20% Scaling problem in
user isolation underlying cloud services
20
�
21 .Some Issues We Experienced
Cloud networks: limits, partitions, slow DHCP, hung connections
Automated apps creating large load
Very large requests, results, etc
Slow VM launches/shutdowns, lack of VM capacity
Data corruption writing to cloud storage
21
�
22 .Example Outage: Aborted Jobs
Jobs
Jobs Service launches & tracks jobs on clusters Service
Cloud
1 customer running many jobs/sec on same cluster Network Customer
Clusters
Cloud’s network reaches a limit of 1000 connections/VM
between Jobs Service & clusters
§ After this limit, new connections hang in state SYN_SENT
Resource usage from hanging connections causes
memory pressure and GC
Health checks to some jobs time out, so we abort them
22
�
23 .Surprisingly Rare Issues
1 cloud-wide VM restart on AWS (Xen patch)
1 misreported security scan on customer VM
1 significant S3 outage
1 kernel bug (hung TCP connections due to SACK fix)
23
�
24 .Lessons
Cloud services must handle load that varies on many dimensions,
and rely on other services with varying limits & failure modes
§ Problems likely to get worse in a “cloud service economy”
End-to-end issues remain hard to prevent
The usual factors of MTTR, monitoring, testing, etc help
24
�
25 .Four Lessons
1 What goes wrong in cloud systems?
2 Testing for scalability & stability
3 Developing control planes
4 Evolving big data systems for the cloud
25
�
26 .Testing for Scalability & Stability
Software correctness is a Boolean property: does your software
give the right output on a given input?
Scalability and stability are a matter of degree
§ What load will your system fail at? (any system with limited resources will)
§ What failure behavior will you have? (crash all clients, drop some, etc)
26
�
27 .Example Scalability Problems
Large result: can crash browser,
notebook service, driver or Spark
User Browser Notebook
Service
Large record in file
Large # of tasks
Driver Workers
App Code that freezes a worker
??
+ All these affect other users!
Other Users
27
�
28 .Databricks Stress Test Infrastructure
1. Identify dimensions for a system to scale in (e.g. # of users, number
of output rows, size of each output row, etc)
2. Grow load in each dimension until a failure occurs
3. Record failure type and impact on system
§ Error message, timeout, wrong result?
§ Are other clients affected?
§ Does the system auto-recover? How fast?
4. Compare over time and on changes
28
�