









- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Serverless Computing: One Step Forward, Two Steps Back
Serverless computing offers the potential to program the cloud in an autoscaling, pay-as-you go manner. In this paper we address critical gaps in first-generation serverless computing, which place its autoscaling potential at odds with dominant trends in modern computing: notably data-centric and distributed computing, but also open source and custom hardware. Put together, these gaps make current serverless offerings a bad fit for cloud innovation and particularly bad for data systems innovation. In addition to pinpointing some of the main shortfalls of current serverless architectures, we raise a set of challenges we believe must be met to unlock the radical potential that the cloud—with its exabytes of storage and millions of cores—should offer to innovative developers.
展开查看详情
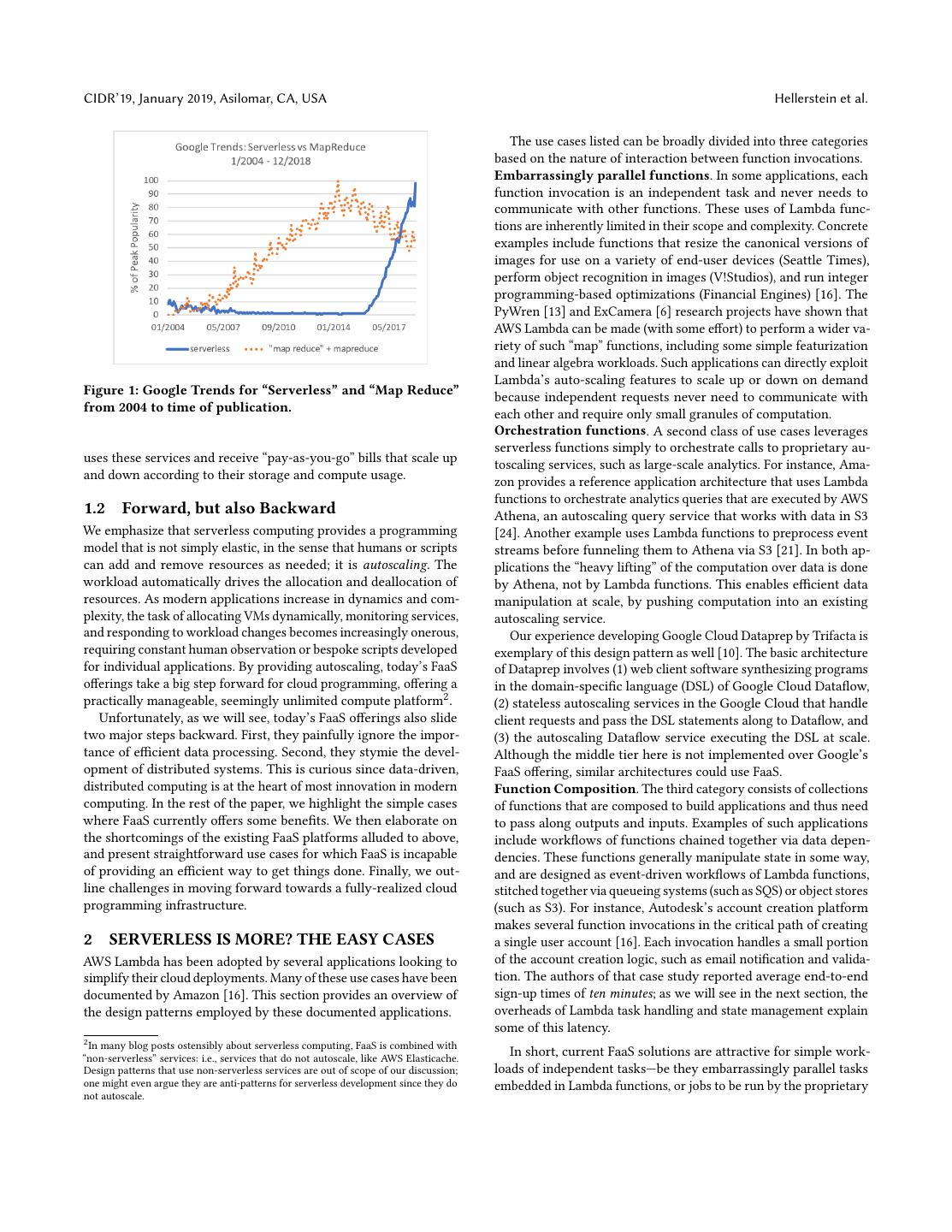
1 . Serverless Computing: One Step Forward, Two Steps Back Joseph M. Hellerstein, Jose Faleiro, Joseph E. Gonzalez, Johann Schleier-Smith, Vikram Sreekanti, Alexey Tumanov and Chenggang Wu UC Berkeley {hellerstein,jmfaleiro,jegonzal,jssmith,vikrams,atumanov,cgwu}@berkeley.edu ABSTRACT offers the attractive notion of a platform in the cloud where devel- Serverless computing offers the potential to program the cloud in opers simply upload their code, and the platform executes it on an autoscaling, pay-as-you go manner. In this paper we address their behalf as needed at any scale. Developers need not concern critical gaps in first-generation serverless computing, which place themselves with provisioning or operating servers, and they pay its autoscaling potential at odds with dominant trends in modern only for the compute resources used when their code is invoked. computing: notably data-centric and distributed computing, but The notion of serverless computing is vague enough to allow also open source and custom hardware. Put together, these gaps optimists to project any number of possible broad interpretations make current serverless offerings a bad fit for cloud innovation on what it might mean. Our goal here is not to quibble about the and particularly bad for data systems innovation. In addition to terminology. Concretely, each of the cloud vendors has already pinpointing some of the main shortfalls of current serverless ar- launched serverless computing infrastructure and is spending a chitectures, we raise a set of challenges we believe must be met significant marketing budget promoting it. In this paper, we assess to unlock the radical potential that the cloud—with its exabytes of the field based on the serverless computing services that vendors storage and millions of cores—should offer to innovative developers. are actually offering today and see why they are a disappointment when viewed in light of the cloud’s potential. 1 INTRODUCTION Amazon Web Services recently celebrated its 12th anniversary, 1.1 “Serverless” goes FaaS marking over a decade of public cloud availability. While the cloud To begin, we provide a quick introduction to Functions-as-a-Service began as a place to timeshare machines, it was clear from the begin- (FaaS), the commonly used and more descriptive name for the core ning that it presented a radical new computing platform: the biggest of serverless offerings from the public cloud providers. Because assemblage of data capacity and distributed computing power ever AWS was the first public cloud—and remains the largest—we focus available to the general public, managed as a service. our discussion on the AWS FaaS framework, Lambda; offerings Despite that potential, we have yet to harness cloud resources from Azure and GCP differ in detail but not in spirit. in radical ways. The cloud today is largely used as an outsourcing The idea behind FaaS is simple and straight out of a programming platform for standard enterprise data services. For this to change, textbook. Traditional programming is based on writing functions, creative developers need programming frameworks that enable which are mappings from inputs to outputs. Programs consist of them to leverage the cloud’s power. compositions of these functions. Hence, one simple way to program New computing platforms have typically fostered innovation in the cloud is to allow developers to register functions in the cloud, programming languages and environments. Yet a decade later, it and compose those functions into programs. is difficult to identify the new programming environments for the Typical FaaS offerings today support a variety of languages (e.g., cloud. And whether cause or effect, the results are clearly visible Python, Java, Javascript, Go), allow programmers to register func- in practice: the majority of cloud services are simply multi-tenant, tions with the cloud provider, and enable users to declare events easier-to-administer clones of legacy enterprise data services like that trigger each function. The FaaS infrastructure monitors the object storage, databases, queueing systems, and web/app servers. triggering events, allocates a runtime for the function, executes it, Multitenancy and administrative simplicity are admirable and desir- and persists the results. The user is billed only for the computing able goals, and some of the new services have interesting internals resources used during function invocation. in their own right. But this is, at best, only a hint of the potential A FaaS offering by itself is of little value, since each function offered by millions of cores and exabytes of data. execution is isolated and ephemeral. Building applications on FaaS Recently, public cloud vendors have begun offering new pro- requires data management in both persistent and temporary storage, gramming interfaces under the banner of serverless computing, and in addition to mechanisms to trigger and scale function execution. interest is growing. Google search trends show that queries for the As a result, cloud providers are quick to emphasize that serverless term “serverless” recently matched the historic peak of popularity is not only FaaS. It is FaaS supported by a “standard library”: the of the phrase “Map Reduce” or “MapReduce” (Figure 1). There has various multitenanted, autoscaling services provided by the ven- also been a significant uptick in attention to the topic more recently dor1 . In the case of AWS, this includes S3 (large object storage), from the research community [13, 6, 27, 14]. Serverless computing DynamoDB (key-value storage), SQS (queuing services), SNS (noti- fication services), and more. This entire infrastructure is managed This article is published under a Creative Commons Attribution License and operated by AWS; developers simply register FaaS code that (http://creativecommons.org/licenses/by/3.0/), which permits distribution and repro- duction in any medium as well as allowing derivative works, provided that you attribute the original work to the author(s) and CIDR 2019. 1 This might be better termed a “proprietary library”, but the analogy to C’s stdlib is apropos: not officially part of the programming model, but integral in practice.
2 .CIDR’19, January 2019, Asilomar, CA, USA Hellerstein et al. The use cases listed can be broadly divided into three categories based on the nature of interaction between function invocations. Embarrassingly parallel functions. In some applications, each function invocation is an independent task and never needs to communicate with other functions. These uses of Lambda func- tions are inherently limited in their scope and complexity. Concrete examples include functions that resize the canonical versions of images for use on a variety of end-user devices (Seattle Times), perform object recognition in images (V!Studios), and run integer programming-based optimizations (Financial Engines) [16]. The PyWren [13] and ExCamera [6] research projects have shown that AWS Lambda can be made (with some effort) to perform a wider va- riety of such “map” functions, including some simple featurization and linear algebra workloads. Such applications can directly exploit Lambda’s auto-scaling features to scale up or down on demand Figure 1: Google Trends for “Serverless” and “Map Reduce” because independent requests never need to communicate with from 2004 to time of publication. each other and require only small granules of computation. Orchestration functions. A second class of use cases leverages serverless functions simply to orchestrate calls to proprietary au- uses these services and receive “pay-as-you-go” bills that scale up toscaling services, such as large-scale analytics. For instance, Ama- and down according to their storage and compute usage. zon provides a reference application architecture that uses Lambda functions to orchestrate analytics queries that are executed by AWS 1.2 Forward, but also Backward Athena, an autoscaling query service that works with data in S3 We emphasize that serverless computing provides a programming [24]. Another example uses Lambda functions to preprocess event model that is not simply elastic, in the sense that humans or scripts streams before funneling them to Athena via S3 [21]. In both ap- can add and remove resources as needed; it is autoscaling. The plications the “heavy lifting” of the computation over data is done workload automatically drives the allocation and deallocation of by Athena, not by Lambda functions. This enables efficient data resources. As modern applications increase in dynamics and com- manipulation at scale, by pushing computation into an existing plexity, the task of allocating VMs dynamically, monitoring services, autoscaling service. and responding to workload changes becomes increasingly onerous, Our experience developing Google Cloud Dataprep by Trifacta is requiring constant human observation or bespoke scripts developed exemplary of this design pattern as well [10]. The basic architecture for individual applications. By providing autoscaling, today’s FaaS of Dataprep involves (1) web client software synthesizing programs offerings take a big step forward for cloud programming, offering a in the domain-specific language (DSL) of Google Cloud Dataflow, practically manageable, seemingly unlimited compute platform2 . (2) stateless autoscaling services in the Google Cloud that handle Unfortunately, as we will see, today’s FaaS offerings also slide client requests and pass the DSL statements along to Dataflow, and two major steps backward. First, they painfully ignore the impor- (3) the autoscaling Dataflow service executing the DSL at scale. tance of efficient data processing. Second, they stymie the devel- Although the middle tier here is not implemented over Google’s opment of distributed systems. This is curious since data-driven, FaaS offering, similar architectures could use FaaS. distributed computing is at the heart of most innovation in modern Function Composition. The third category consists of collections computing. In the rest of the paper, we highlight the simple cases of functions that are composed to build applications and thus need where FaaS currently offers some benefits. We then elaborate on to pass along outputs and inputs. Examples of such applications the shortcomings of the existing FaaS platforms alluded to above, include workflows of functions chained together via data depen- and present straightforward use cases for which FaaS is incapable dencies. These functions generally manipulate state in some way, of providing an efficient way to get things done. Finally, we out- and are designed as event-driven workflows of Lambda functions, line challenges in moving forward towards a fully-realized cloud stitched together via queueing systems (such as SQS) or object stores programming infrastructure. (such as S3). For instance, Autodesk’s account creation platform makes several function invocations in the critical path of creating 2 SERVERLESS IS MORE? THE EASY CASES a single user account [16]. Each invocation handles a small portion AWS Lambda has been adopted by several applications looking to of the account creation logic, such as email notification and valida- simplify their cloud deployments. Many of these use cases have been tion. The authors of that case study reported average end-to-end documented by Amazon [16]. This section provides an overview of sign-up times of ten minutes; as we will see in the next section, the the design patterns employed by these documented applications. overheads of Lambda task handling and state management explain some of this latency. 2 In many blog posts ostensibly about serverless computing, FaaS is combined with “non-serverless” services: i.e., services that do not autoscale, like AWS Elasticache. In short, current FaaS solutions are attractive for simple work- Design patterns that use non-serverless services are out of scope of our discussion; loads of independent tasks—be they embarrassingly parallel tasks one might even argue they are anti-patterns for serverless development since they do embedded in Lambda functions, or jobs to be run by the proprietary not autoscale.
3 .Serverless Computing: One Step Forward, Two Steps Back CIDR’19, January 2019, Asilomar, CA, USA cloud services. Use cases that involve stateful tasks have surpris- while running. As a result, two Lambda functions can only com- ingly high latency: 10 minutes is a long turnaround time for a cloud municate through an autoscaling intermediary service; today, vendor to publicize, even for a sign-up workflow. These realities this means a storage system like S3 that is radically slower and limit the attractive use cases for FaaS today, discouraging new third- more expensive than point-to-point networking. As a corol- party programs that go beyond the proprietary service offerings lary, a client of Lambda cannot address the particular function from the vendors. instance that handled the client’s previous request: there is no “stickiness” for client connections. Hence maintaining state 3 WHY SERVERLESS TODAY IS TOO LESS across client calls requires writing the state out to slow storage, The cloud offers three key features: unlimited data storage, unlim- and reading it back on every subsequent call. ited distributed computing power, and the ability to harness these (4) No Specialized Hardware. FaaS offerings today only allow only as needed—paying only for the resources you consume, rather users to provision a timeslice of a CPU hyperthread and some than buying the resources you might need at peak. amount of RAM; in the case of AWS Lambda, one determines Serverless computing takes one step forward and two steps back the other. There is no API or mechanism to access specialized from this vision. It realizes the potential of pay-as-you-go, fully- hardware. However, as explained by Patterson and Hennessy in managed execution of end-user code via autoscaling. Unfortunately, their recent Turing Lecture [20], hardware specialization will as we will see in this section, current FaaS offerings fatally restrict only accelerate in the coming years. the ability to work efficiently with data or distributed computing resources. As a result, serverless computing today is at best a simple and powerful way to run embarrassingly parallel computations or These constraints, combined with some significant shortcomings harness proprietary services. At worst, it can be viewed as a cynical in the standard library of FaaS offerings, substantially limit the effort to lock users into those services and lock out innovation. scope of feasible serverless applications. A number of corollaries The list of limitations in today’s FaaS offerings is remarkable. follow directly. Our running example, AWS Lambda, has the following constraints FaaS is a Data-Shipping Architecture. This is perhaps the that are typical of the other vendors as well3 : biggest architectural shortcoming of FaaS platforms and their APIs. Serverless functions are run on isolated VMs, separate from data. In (1) Limited Lifetimes. After 15 minutes, function invocations are addition, serverless functions are short-lived and non-addressable, shut down by the Lambda infrastructure. Lambda may keep the so their capacity to cache state internally to service repeated re- function’s state cached in the hosting VM to support “warm quests is limited. Hence FaaS routinely “ships data to code” rather start”, but there is no way to ensure that subsequent invocations than “shipping code to data.” This is a recurring architectural anti- are run on the same VM. Hence functions must be written pattern among system designers, which database aficionados seem assuming that state will not be recoverable across invocations. to need to point out each generation. Memory hierarchy realities— (2) I/O Bottlenecks. Lambdas connect to cloud services—notably, across various storage layers and network delays—make this a bad shared storage—across a network interface. In practice, this design decision for reasons of latency, bandwidth, and cost. typically means moving data across nodes or racks. With FaaS, FaaS Stymies Distributed Computing. Because there is no net- things appear even worse than the network topology would work addressability of serverless functions, two functions can work suggest. Recent studies show that a single Lambda function together serverlessly only by passing data through slow and expen- can achieve on average 538Mbps network bandwidth; numbers sive storage. This stymies basic distributed computing. That field from Google and Azure were in the same ballpark [27]. This is is founded on protocols performing fine-grained communication an order of magnitude slower than a single modern SSD. Worse, between agents, including basics like leader election, membership, AWS appears to attempt to pack Lambda functions from the data consistency, and transaction commit. Many distributed and same user together on a single VM, so the limited bandwidth parallel applications—especially in scientific computing—also rely is shared by multiple functions. The result is that as compute on fine-grained communication. power scales up, per-function bandwidth shrinks proportion- One might argue that FaaS encourages a new, event-driven dis- ately. With 20 Lambda functions, average network bandwidth tributed programming model based on global state. But it is well- was 28.7Mbps—2.5 orders of magnitude slower than a single known that there is a duality between processes passing messages, SSD [27]4 . and event-driven functions on shared data [17]. For FaaS, event (3) Communication Through Slow Storage. While Lambda handling still requires passing pieces of the global state from slow functions can initiate outbound network connections, they storage into and out of stateless functions, incurring time and cost. themselves are not directly network-addressable in any way Meanwhile, the current serverless storage offerings offer weak con- sistency across replicas. Hence in the event-driven pattern, agree- 3 Our discussion in this paper represents the state of AWS Lambda as of Fall 2018. Some ment across ephemeral functions would still need to be “bolted on” new details were announced at the AWS re:Invent conference in late November 2018. as a protocol of additional I/Os akin to classical consensus. We have only had time before publication deadline to comment on them briefly where they may affect our reported results. These announcements do not seem to address In short, with all communication transiting through storage, our main concerns in a substantive way. there is no real way for thousands (much less millions) of cores in 4 AWS announced the availability of 100Gbps networking on 11/26/2018. This moves the needle but leaves the problem unsolved: once you hit the cap, you are constrained. the cloud to work together efficiently using current FaaS platforms Even with 100Gbps/64 cores, under load you get ∼200MBps per core, still an order of other than via largely uncoordinated (embarrassing) parallelism. magnitude slower than a single SSD.
4 .CIDR’19, January 2019, Asilomar, CA, USA Hellerstein et al. FaaS stymies hardware-accelerated software innovation. algorithm on Lambda is 21× slower and 7.3× more expensive than Many of the main Big Data use cases today leverage custom hard- running on EC2. ware. The most prominent example is the pervasive use of GPUs in Low-Latency Prediction Serving via Batching. Our next case deep learning, but there is ongoing innovation in the use of acceler- study focuses on the downstream use of a trained model: making ators for database processing as well. Current FaaS offerings all run live predictions. We have been working for some time on low- on a uniform and fairly mundane virtual machine platform. Not latency prediction serving in Clipper [5]. At first glance, prediction only do these VMs not offer custom processors, the current FaaS of- serving appears to be well-suited to FaaS. Each function is indepen- ferings do not even support main-memory databases that maintain dent, and multiple copies can be deployed to scale the number of large RAM-based data structures—the largest Lambda instance only predictions made with a certain model. allows for 3GB of RAM. The lack of access to such hardware—along In practice, prediction serving relies on access to specialized with appropriate pricing models—significantly limits the utility of hardware like GPUs, which are not available through AWS Lambda. FaaS offerings as a platform for software innovation. Setting that issue aside, we wanted to understand if the key perfor- FaaS discourages Open Source service innovation. Most pop- mance optimizations of a system like Clipper could be achieved in ular open source software cannot not run at scale in current server- a FaaS setting. One optimization in Clipper is to process inputs in less offerings. Arguably this is inherent: that software was not batches; in the traditional case this provides pipeline parallelism designed for serverless execution, and expects human operation. across the handling of input requests (performed by a CPU) with the But given the FaaS limitations on data processing and distributed multi-input vector processing of prediction (performed by a GPU). computing, one should not expect new scalable open source soft- We were curious to see whether Lambda could provide similar ware to emerge. In particular, open-source data systems—an area of benefits for pipelining batch accumulation with prediction. rapid growth and maturity in recent years—would be impossible to To that end, we exercised Lambda’s favored service for batching build on current FaaS offerings. Current serverless infrastructure, inputs: AWS Simple Queueing Service (SQS). We wrote a simple intentionally or otherwise, locks users into either using proprietary application on Lambda that pipelines batching work done by SQS provider services or maintaining their own servers. with a trivial classifier running in Lambda functions. Specifically, our application accepts batches of text documents, uses a model to classify each word in the document as “dirty” or not, and writes the 3.1 Case Studies document out to a storage service with the dirty words replaced To evaluate the severity of these problems, we document three case by punctuation marks. Our model in this experiment is a simple studies from Big Data and distributed computing settings. blacklist of dirty words. SQS only allows batches of 10 messages at Model Training. Our first case study explores AWS Lambda’s a time, so we limited all experiments here to 10-message batches. performance for a common data-intensive application: machine The average latency over 1,000 batch invocations for the Lambda learning model training. As we will see, it suffers dramatically from application was 559ms per batch if the model was retrieved on the data-shipping architecture of Lambda. every invocation and results written back to S3. As an optimization, Using public Amazon product review data [2], we configured Ten- we allowed the model to be compiled into the function itself and sorFlow to train a neural network that predicts average customer results were placed back into an SQS queue; in this implementa- ratings. Each product review is featurized with a bag-of-words tion the average batch latency was 447ms. For comparison, we ran model, resulting in 6,787 features and 90GB total of training data. two experiments using m5.large EC2 instances. The first replaced The model is a multi-layer perceptron with two hidden layers, each Lambda’s role in the application with an EC2 machine to receive with 10 neurons and a Relu activation function. Each Lambda is SQS message batches—this showed a latency of 13ms per batch av- allocated the maximum lifetime (15 min) and 640MB RAM and runs eraged over 1,000 batches—27× faster than our “optimized” Lambda as many training iterations as possible. Our training program uses implementation. The second experiment used ZeroMQ to replace the AdamOptimizer with a learning rate of 0.001 and a batch size SQS’s role in the application, and receive messages directly on the of 100MB. EC2 machine. This “serverful” version had a per batch latency of Each iteration in Lambda took 3.08 seconds: 2.49 to fetch a 2.8ms—127× faster than the optimized Lambda implementation. 100MB batch from S3 and 0.59 seconds to run the AdamOptimizer. A Pricing adds insult to the injury of performance in these services. Lambda function times out of its 15-minute limit after 294 iterations If we wanted to scale this application to 1 million messages a second, of this algorithm. We trained the model over 10 full passes of the the SQS request rate alone would cost $1,584 per hour. Note that this training data, which translates to 31 sequential lambda executions, does not account for the Lambda execution costs. The EC2 instance each of which runs for 15 minutes, or 465 minutes total latency. This on the other hand has a throughput of about 3,500 requests per costs $0.29. second, so 1 million messages per second would require 290 EC2 For comparison, we trained the same model on an m4.large instances, with a total cost of $27.84 per hour—a 57× cost savings. EC2 instance, which has 8GB of RAM and 2vCPUs. In this setting, Distributed Computing. Lambda forbids direct network connec- each iteration is significantly faster (0.14 seconds): 0.04 seconds to tivity between functions, so we are forced to try alternative so- fetch data from an EBS volume and 0.1 seconds to run the optimizer. lutions to achieve distributed computation. As we will see, the The same training process takes about 1300 seconds (just under available solutions are untenably slow. 22 minutes), which translates to a cost of $0.04. Lambda’s limited resources and data-shipping architecture mean that running this
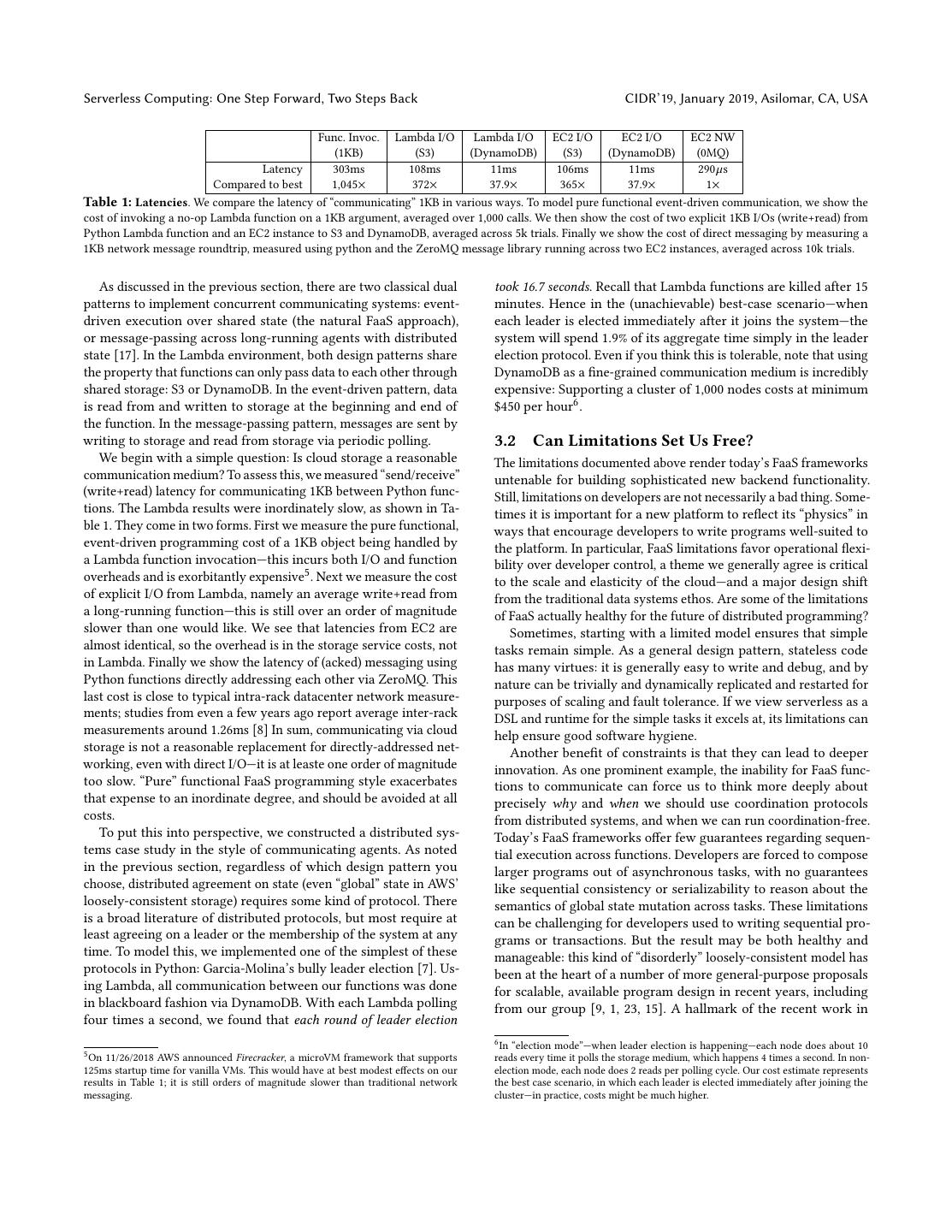
5 .Serverless Computing: One Step Forward, Two Steps Back CIDR’19, January 2019, Asilomar, CA, USA Func. Invoc. Lambda I/O Lambda I/O EC2 I/O EC2 I/O EC2 NW (1KB) (S3) (DynamoDB) (S3) (DynamoDB) (0MQ) Latency 303ms 108ms 11ms 106ms 11ms 290µs Compared to best 1,045× 372× 37.9× 365× 37.9× 1× Table 1: Latencies. We compare the latency of “communicating” 1KB in various ways. To model pure functional event-driven communication, we show the cost of invoking a no-op Lambda function on a 1KB argument, averaged over 1,000 calls. We then show the cost of two explicit 1KB I/Os (write+read) from Python Lambda function and an EC2 instance to S3 and DynamoDB, averaged across 5k trials. Finally we show the cost of direct messaging by measuring a . 1KB network message roundtrip, measured using python and the ZeroMQ message library running across two EC2 instances, averaged across 10k trials. As discussed in the previous section, there are two classical dual took 16.7 seconds. Recall that Lambda functions are killed after 15 patterns to implement concurrent communicating systems: event- minutes. Hence in the (unachievable) best-case scenario—when driven execution over shared state (the natural FaaS approach), each leader is elected immediately after it joins the system—the or message-passing across long-running agents with distributed system will spend 1.9% of its aggregate time simply in the leader state [17]. In the Lambda environment, both design patterns share election protocol. Even if you think this is tolerable, note that using the property that functions can only pass data to each other through DynamoDB as a fine-grained communication medium is incredibly shared storage: S3 or DynamoDB. In the event-driven pattern, data expensive: Supporting a cluster of 1,000 nodes costs at minimum is read from and written to storage at the beginning and end of $450 per hour6 . the function. In the message-passing pattern, messages are sent by writing to storage and read from storage via periodic polling. 3.2 Can Limitations Set Us Free? We begin with a simple question: Is cloud storage a reasonable The limitations documented above render today’s FaaS frameworks communication medium? To assess this, we measured “send/receive” untenable for building sophisticated new backend functionality. (write+read) latency for communicating 1KB between Python func- Still, limitations on developers are not necessarily a bad thing. Some- tions. The Lambda results were inordinately slow, as shown in Ta- times it is important for a new platform to reflect its “physics” in ble 1. They come in two forms. First we measure the pure functional, ways that encourage developers to write programs well-suited to event-driven programming cost of a 1KB object being handled by the platform. In particular, FaaS limitations favor operational flexi- a Lambda function invocation—this incurs both I/O and function bility over developer control, a theme we generally agree is critical overheads and is exorbitantly expensive5 . Next we measure the cost to the scale and elasticity of the cloud—and a major design shift of explicit I/O from Lambda, namely an average write+read from from the traditional data systems ethos. Are some of the limitations a long-running function—this is still over an order of magnitude of FaaS actually healthy for the future of distributed programming? slower than one would like. We see that latencies from EC2 are Sometimes, starting with a limited model ensures that simple almost identical, so the overhead is in the storage service costs, not tasks remain simple. As a general design pattern, stateless code in Lambda. Finally we show the latency of (acked) messaging using has many virtues: it is generally easy to write and debug, and by Python functions directly addressing each other via ZeroMQ. This nature can be trivially and dynamically replicated and restarted for last cost is close to typical intra-rack datacenter network measure- purposes of scaling and fault tolerance. If we view serverless as a ments; studies from even a few years ago report average inter-rack DSL and runtime for the simple tasks it excels at, its limitations can measurements around 1.26ms [8] In sum, communicating via cloud help ensure good software hygiene. storage is not a reasonable replacement for directly-addressed net- Another benefit of constraints is that they can lead to deeper working, even with direct I/O—it is at leaste one order of magnitude innovation. As one prominent example, the inability for FaaS func- too slow. “Pure” functional FaaS programming style exacerbates tions to communicate can force us to think more deeply about that expense to an inordinate degree, and should be avoided at all precisely why and when we should use coordination protocols costs. from distributed systems, and when we can run coordination-free. To put this into perspective, we constructed a distributed sys- Today’s FaaS frameworks offer few guarantees regarding sequen- tems case study in the style of communicating agents. As noted tial execution across functions. Developers are forced to compose in the previous section, regardless of which design pattern you larger programs out of asynchronous tasks, with no guarantees choose, distributed agreement on state (even “global” state in AWS’ like sequential consistency or serializability to reason about the loosely-consistent storage) requires some kind of protocol. There semantics of global state mutation across tasks. These limitations is a broad literature of distributed protocols, but most require at can be challenging for developers used to writing sequential pro- least agreeing on a leader or the membership of the system at any grams or transactions. But the result may be both healthy and time. To model this, we implemented one of the simplest of these manageable: this kind of “disorderly” loosely-consistent model has protocols in Python: Garcia-Molina’s bully leader election [7]. Us- been at the heart of a number of more general-purpose proposals ing Lambda, all communication between our functions was done for scalable, available program design in recent years, including in blackboard fashion via DynamoDB. With each Lambda polling from our group [9, 1, 23, 15]. A hallmark of the recent work in four times a second, we found that each round of leader election 6 In“election mode”—when leader election is happening—each node does about 10 5 On 11/26/2018 AWS announced Firecracker, a microVM framework that supports reads every time it polls the storage medium, which happens 4 times a second. In non- 125ms startup time for vanilla VMs. This would have at best modest effects on our election mode, each node does 2 reads per polling cycle. Our cost estimate represents results in Table 1; it is still orders of magnitude slower than traditional network the best case scenario, in which each leader is elected immediately after joining the messaging. cluster—in practice, costs might be much higher.
6 .CIDR’19, January 2019, Asilomar, CA, USA Hellerstein et al. this area is that it offers programming constructs that are richer programming—one that we believe the public-facing FaaS offerings than black-box function composition; in principle, though, the ideas are trying (and presently failing) to provide. could be layered on top of FaaS. As another example, today’s FaaS frameworks offer no guarantees of physical hardware locality: de- “Just wait for the next network announcement!” velopers cannot control where a function will run, or if its physical Some readers of early drafts commented that datacenter networks address will even remain constant. Again, this may be a manageable are getting faster, and cloud providers are passing those innovations constraint: virtual addressing of dynamically shifting agents was a on to customers. Moreover, it is now conventional wisdom that hallmark of prior work in the peer-to-peer research that presaged scaling needs to be achieved by separating compute and data tiers. cloud services [22, 25]. We have no argument with these points, but they do not address Another benefit of simplicity is that it can foster platform devel- the key problems we raise here beyond matters of tuning. Datacen- opment and community. There is a constructive analogy here to ter networks will surely improve, yet inevitably will continue to MapReduce. While not a success in its own right, MapReduce was play a limiting role in a larger memory hierarchy. Any reasonable simple for developers to start with; as a result it helped change the system design will need the ability to selectively co-locate code mindset of the developer community and eventually led to the rein- and data on the same side of a network boundary, whether that is vigoration of SQL and relational algebra (in the form of “dataframe” done via caching/prefetching data near computation or pushing libraries) as popular, scalable interfaces for programming sophisti- computation closer to data. Neither feature is provided in a mean- cated analytics. Perhaps today’s FaaS offerings will similarly lead ingful way by today’s FaaS offerings. Improvements in network to the reinvigoration of prior ideas for distributed programming at speeds are unlikely architectural game-changers; they can shift the scale. A notable difference is that SQL and relational algebra were parameters of using certain optimizations, but rarely justify the well established, whereas the natural end-state for asynchronous absence of those optimization opportunities. Meanwhile, separat- distributed programming over data in the cloud remains a matter ing compute and storage tiers in a logical design should not prevent of research and debate. co-location in a physical deployment; one can scale compute and Many of the constraints of current FaaS offerings can also be storage independently for flexibility and colocate them as needed overcome, we believe, maintaining autoscaling while unlocking for performance. This is the heart of architectural indirections like the performance potential of data and distributed computing. In “data independence”—they increase flexibility rather than limit it. the next section we outline what we see as the key challenges and At a narrower technical level, current networking progress does opportunities for moving forward on all three fronts. not seem radical. Ultra low-latency networks like Inifiniband are limited in scope; they require an interconnect that supports switch- 3.3 Early Objections ing, which naturally incurs latency. The limit in scope then typically translates into a need for hierarchical routing to scale horizontally, In this paper we purposely focused on the limitations of public FaaS which gives heterogenity of latency. Meanwhile, other technologies APIs, and argued that they are disappointingly far from ready for will improve alongside networks, including direct-attached storage general-purpose, data-rich programming. While many of our early like HBM and NVRAM. readers concurred with the challenges we have raised, we have also heard objections. We try to address the most common ones here. “The main point is simple economics: Serverless is inevitable.” Some have viewed this paper as a negative take on serverless com- “You keep using that word. I do not think it means what you think it puting, and from that perspective see the paper on the wrong side means.” of history. After all, various industry-watchers have described the Some of our colleagues working at the cloud platforms have argued economic inevitability of serverless computing. To quote one such: that our view of the term “serverless” is too narrow: behind the I didn’t have to worry about building a platform and the con- curtain of a cloud provider, they are building “serverless” solutions cept of a server, capacity planning and all that “yak shaving” was for customers that are autoscaling and management-free. We under- far from my mind... However, these changes are not really the stand that use of the term—we talk about Google Cloud Dataprep exciting parts. The killer, the gotcha is the billing by the function... similarly. Perhaps this confusion is a reason why “serverless” is This is like manna from heaven for someone trying to build a not a useful adjective for rallying the technical community around business. Certainly I have the investment in developing the code cloud innovation. Simply put, the delivery of a particular special- but with application being a variable operational cost then I can purpose autoscaling backend service does not solve the problem of make a money printing machine which grows with users... enabling general-purpose cloud programming. Moreover, the work [E]xpect to see the whole world being overtaken by serverless required to deliver these “serverless” backend offerings is done by 2025 [28]. largely with old-fashioned “node-at-a-time” programming and is It is not our intent to pour cold water on this vision. To reiterate, a traditional and expensive endeavor. Indeed, anyone can do this we see autoscaling (and hence pay per use) as a big step forward, but kind of work in the public cloud without “serverless” offerings, by disappointingly limited to applications that can work over today’s using orchestration platforms like Kubernetes7 . Our goal here is hobbled provider infrastructure. We acknowledge that there is an to spark deeper discussion on the grand challenge of cloud-scale enormous market of such “narrow” applications, many of which consist of little more than business logic over a database. Disrupting 7 By these applications by changing their economics will shift significant the same token, the peer-to-peer architectures of the turn of the century were also “serverless”.
7 .Serverless Computing: One Step Forward, Two Steps Back CIDR’19, January 2019, Asilomar, CA, USA spending from traditional enterprise vendors to new, more efficient One can have philosophical debates about whether such co-design cloud-based vendors. is appropriate, or whether “hardware independence” is a paramount However, this business motion will not accelerate the sea concern in the cloud. In either case, recognizing hardware affinity change in computing that the cloud offers. Specifically, it will not does not mean that we advocate tight binding of hardware to ser- encourage—and may even deter—third-party and open source de- vices; the platform should make dynamic physical decisions about velopment of new stateful services, which are the core of modern allocation of code to distinguished resources, based on logical per- computing. Meanwhile, with innovation deterred, the cloud ven- formance requirement specs either provided by programmers or dors increase market dominance for their proprietary solutions. extracted from code. These specs can then be leveraged for the This line of reasoning may suggest that serverless computing could more general, heterogeneity-aware resource space-time division produce a local minimum: yet another setting in which the compute multiplexing [26]. and storage potential of the cloud is lost in the noise of refactoring Long-Running, Addressable Virtual Agents. Affinities be- low-tech and often legacy use cases. tween code, data and/or hardware tend to recur over time. If the The goal of our discussion here—and, we hope, the goal of our platform pays a cost to create an affinity (e.g. moving data), it intended audience—is to push the core technology down the playing should recoup that cost across multiple requests. This motivates field, rather than bet on it from the sidelines. To that end, we hope the ability for programmers to establish software agents—call them this paper shifts the discussion from “What is serverless?” or “Will functions, actors, services, etc.—that persist over time in the cloud, serverless win?” to a rethinking of how we design infrastructure with known identities. Such agents should be addressable with and programming models to spark real innovation in data-rich, performance comparable to standard networks. However, elasticity cloud-scale systems. We see the future of cloud programming as far, requirements dictate that these agents be virtual and dynamically far brighter than the promise of today’s serverless FaaS offerings. remapped across physical resources. Hence we need virtual alter- Getting to that future requires revisiting the designs and limitations natives to traditional operating system constructs like “threads” of what is being called “serverless computing” today. and “ports”: nameable endpoints in the network. Various ideas from the literature have provided aspects of this idea: actors [11], tuplespaces [4] pub/sub [19] and DHTs [22] are all examples. Cho- 4 STEPPING FORWARD TO THE FUTURE sen solutions need to incur minimal overhead on raw network We firmly believe that cloud programmers—whether they are writ- performance. ing simple applications or complex systems—need to be able to Disorderly programming. As discussed above, the requirements harness the compute power and storage capacity of the cloud in an of distributed computing and elastic resizing require changes in pro- autoscaling, cost-efficient manner. Achieving these goals requires a gramming. The sequential metaphor of procedural programming programmable framework that goes beyond FaaS, to dynamically will not scale to the cloud. Developers need languages that encour- manage the allocation of resources in order to meet user-specified age code that works correctly in small, granular units—of both data performance goals for both compute and for data. and computation—that can be easily moved around across time Here we identify some key challenges that remain in achieving and space. There are examples of these patterns in the literature— a truly programmable environment for the cloud. particularly in asynchronous flow-based metaphors like Functional Fluid Code and Data Placement. To achieve good performance, Reactive Programming [12] and Declarative Languages for Net- the infrastructure should be able and willing to physically colocate working [18] and Distributed Computing [1]. A particular chal- certain code and data. This is often best achieved by shipping code to lenge in distributed computing is to couple these programming data, rather than the current FaaS approach of pulling data to code. metaphors with reasoning about semantics of distributed data con- At the same time, elasticity requires that code and data be logically sistency; earlier work offers some answers [9, 1, 23, 3, 15] but more separated, to allow infrastructure to adapt placement: sometimes work is needed to enable full-service applications. data needs to be replicated or repartitioned to match code needs. Flexible Programming, Common IR. Ideally, a variety of new In essence, this is the traditional challenge of data independence, programming languages and DSLs will be explored in this domain. but at extreme and varying scale, with multi-tenanted usage and Still, it is burdensome for each language stack to implement a full fine-grained adaptivity in time. High-level, data-centric DSLs—e.g., set of the relevant optimizations (e.g., fluid code & data, disorderly SQL+UDFs, MapReduce, TensorFlow—can make this more tractable, constructs). As a result, it would be highly beneficial to develop a by exposing at a high level how data flows through computation. common internal Intermediate Representation (IR) for cloud execu- The more declarative the language, the more logical separation (and tion that can serve as a compilation target from many languages. optimization search space) is offered to the infrastructure. This IR must support pluggable code from a variety of languages, Heterogeneous Hardware Support. Cloud providers can attract as is done by UDFs in declarative languages, or functions in FaaS. a critical mass of workloads that make specialized hardware cost- Service-level objectives & guarantees: Today, none of the major effective. Cloud programmers should be able to take advantage of FaaS offerings has APIs for service-level objectives. Price is simply such resources. Ideally, application developers could specify applica- a function of the “size” (RAM, number of cores) and running time tions using high-level DSLs, and the cloud providers would compile used. To support practical use, FaaS offerings should enable up- those applications to the most cost-effective hardware that meets front SLOs that are priced accordingly, with appropriate penalties user specified SLOs. Alternatively, for certain designs it may be use- for mis-estimation. Achieving predictable SLOs requires a smooth ful to allow developers to target code to specific hardware features “cost surface” in optimization—non-linearities are the bane of SLOs. by specification, to foster innovative hardware/software co-design.
8 .CIDR’19, January 2019, Asilomar, CA, USA Hellerstein et al. This reinforces our discussion above regarding small granules of Winstein. “Encoding, Fast and Slow: Low-Latency Video Pro- code and data with fluid placement and disorderly execution. cessing Using Thousands of Tiny Threads”. In: NSDI. Boston, Security concerns: Cloud programming brings up both opportu- MA: USENIX Association, 2017, pp. 363–376. nities and challenges related to security. Cloud-managed software [7] H. Garcia-Molina. “Elections in a distributed computing sys- infrastructure shifts the onus of security onto a small number of tem”. In: IEEE transactions on Computers 1 (1982), pp. 48– well-incentivized operations staff at the cloud provider. This—along 59. with appropriate customer specifications of policy—should in prin- [8] C. Guo et al. “Pingmesh: A large-scale system for data center ciple mitigate many security issues that commonly occur today network latency measurement and analysis”. In: ACM SIG- due to misconfiguration or mismanagement. Furthermore, if cloud COMM Computer Communication Review. Vol. 45. 4. ACM. programming is achieved via higher-level abstractions, it will offer 2015, pp. 139–152. the opportunity for program analysis and constraint enforcement [9] P. Helland and D. Campbell. “Building on Quicksand”. In: that could improve security. However, some of our desired architec- CoRR abs/0909.1788 (2009). arXiv: 0909.1788. tural improvements for performance in this paper make achieving [10] J. M. Hellerstein, J. Heer, and S. Kandel. “Self-Service Data security more difficult for the responsible parties. For example, Preparation: Research to Practice”. In: IEEE Data Eng. Bull. allowing code to move fluidly toward shared data storage is po- 41.2 (2018), pp. 23–34. tentially tricky: it exacerbates security management challenges [11] C. Hewitt. “Viewing control structures as patterns of passing related to multitenancy and the potential for rogue code to gather messages”. In: Artificial intelligence 8.3 (1977), pp. 323–364. signals across customers. But there are new research opportunities [12] P. Hudak. “Functional reactive programming”. In: European for innovation in this space. Technologies like hardware enclaves Symposium on Programming. Springer. 1999, pp. 1–1. can help protect running code, and there has been initial work [13] E. Jonas, S. Venkataraman, I. Stoica, and B. Recht. “Occupy on data processing in those settings (e.g., [29]). Meanwhile, it is the Cloud: Distributed Computing for the 99%”. In: CoRR important for researchers and developers to think not only about abs/1702.04024 (2017). arXiv: 1702.04024. preventative technologies, but also ways to guarantee auditing and [14] A. Klimovic, Y. Wang, C. Kozyrakis, P. Stuedi, J. Pfefferle, and post-hoc security analysis, as well as technologies that enable more A. Trivedi. “Understanding Ephemeral Storage for Serverless fine-grained and easy-to-use end-user control over policy. Analytics”. In: USENIX ATC. Boston, MA: USENIX Associa- tion, 2018, pp. 789–794. Taken together, these challenges seem both interesting and sur- [15] L. Kuper and R. R. Newton. “LVars: lattice-based data struc- mountable. The FaaS platforms from cloud providers are not fully tures for deterministic parallelism”. In: Proceedings of the open source, but the systems issues delineated above can be ex- 2nd ACM SIGPLAN workshop on Functional high-performance plored in new systems by third parties using cloud features like computing. ACM. 2013, pp. 71–84. container orchestration. The program analysis and scheduling is- [16] AWS Lambda Customer Case Studies. https://aws.amazon. sues are likely to open up significant opportunities for more formal com/lambda/resources/customer-case-studies/, retrieved research, especially for data-centric programs. Finally, language 8/24/2018. design issues remain a fascinating challenge, bridging program [17] H. C. Lauer and R. M. Needham. “On the duality of operat- analysis power to programmer productivity and design tastes. In ing system structures”. In: ACM SIGOPS Operating Systems sum, we are optimistic that research can open the cloud’s full poten- Review 13.2 (1979), pp. 3–19. tial to programmers. Whether we call the new results “serverless [18] B. T. Loo, T. Condie, M. Garofalakis, D. E. Gay, J. M. Heller- computing” or something else, the future is fluid. stein, P. Maniatis, R. Ramakrishnan, T. Roscoe, and I. Stoica. “Declarative networking: language, execution and optimiza- REFERENCES tion”. In: ACM SIGMOD. 2006, pp. 97–108. [1] P. Alvaro, N. Conway, J. M. Hellerstein, and W. R. Marczak. [19] B. Oki, M. Pfluegl, A. Siegel, and D. Skeen. “The Information “Consistency Analysis in Bloom: a CALM and Collected Ap- Bus: an architecture for extensible distributed systems”. In: proach”. In: CIDR. 2011, pp. 249–260. ACM SIGOPS Operating Systems Review. Vol. 27. 5. ACM. [2] Amazon product data. http : / / jmcauley . ucsd . edu / data / 1994, pp. 58–68. amazon/, retrieved 8/22/18. [20] D. Patterson and J. L. Hennessy. “A New Golden Age for Com- [3] T. J. Ameloot, F. Neven, and J. Van den Bussche. “Relational puter Architecture: Domain-Specific Hardware/Software Co- transducers for declarative networking”. In: Journal of the Design, Enhanced Security, Open Instruction Sets, and Agile ACM (JACM) 60.2 (2013), p. 15. Chip Development”. 2018. [4] N. Carriero and D. Gelernter. “Linda in context”. In: Commu- [21] U. Ratan. Build a Schema-On-Read Analytics Pipeline Using nications of the ACM 32.4 (1989), pp. 444–458. Amazon Athena. https://goo.gl/FhAqzh, retrieved 8/24/18. [5] D. Crankshaw, X. Wang, G. Zhou, M. J. Franklin, J. E. Gonza- [22] S. Ratnasamy, P. Francis, M. Handley, R. Karp, and S. Shenker. lez, and I. Stoica. “Clipper: A Low-Latency Online Prediction A scalable content-addressable network. Vol. 31. 4. ACM, 2001. Serving System”. In: NSDI. Boston, MA: USENIX Association, [23] M. Shapiro, N. Preguiça, C. Baquero, and M. Zawirski. 2017, pp. 613–627. “Conflict-free replicated data types”. In: Symposium on Self- [6] S. Fouladi, R. S. Wahby, B. Shacklett, K. V. Balasubrama- Stabilizing Systems. Springer. 2011, pp. 386–400. niam, W. Zeng, R. Bhalerao, A. Sivaraman, G. Porter, and K. [24] R. Srinivasan and S. Sriparasa. Build a Serverless Architec- ture to Analyze Amazon CloudFront Access Logs Using AWS
9 .Serverless Computing: One Step Forward, Two Steps Back CIDR’19, January 2019, Asilomar, CA, USA Lambda, Amazon Athena, and Amazon Kinesis Analytics. https://goo.gl/bhjcEV, retrieved 8/24/18. [25] I. Stoica, D. Adkins, S. Zhuang, S. Shenker, and S. Surana. “In- ternet indirection infrastructure”. In: ACM SIGCOMM Com- puter Communication Review. Vol. 32. 4. ACM. 2002, pp. 73– 86. [26] A. Tumanov, T. Zhu, J. W. Park, M. A. Kozuch, M. Harchol- Balter, and G. R. Ganger. “TetriSched: global rescheduling with adaptive plan-ahead in dynamic heterogeneous clus- ters”. In: EuroSys ’16. ACM, Apr. 2016. [27] L. Wang, M. Li, Y. Zhang, T. Ristenpart, and M. Swift. “Peek- ing Behind the Curtains of Serverless Platforms”. In: USENIX ATC. Boston, MA: USENIX Association, 2018, pp. 133–146. [28] S. Wardley. Why the fuss about serverless? https://hackernoon. com/why- the- fuss- about- serverless- 4370b1596da0. Re- trieved December 4, 2018. Nov. 2016. [29] W. Zheng, A. Dave, J. G. Beekman, R. A. Popa, J. E. Gon- zalez, and I. Stoica. “Opaque: An Oblivious and Encrypted Distributed Analytics Platform.” In: NSDI. 2017, pp. 283–298.
3秒后跳转登录页面
去登陆

