














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
eurosys delay scheduling
A Simple Technique for Achieving Locality and in Cluster Scheduling
展开查看详情
1 . Delay Scheduling: A Simple Technique for Achieving Locality and Fairness in Cluster Scheduling Matei Zaharia Dhruba Borthakur Joydeep Sen Sarma University of California, Berkeley Facebook Inc Facebook Inc matei@berkeley.edu dhruba@facebook.com jssarma@facebook.com Khaled Elmeleegy Scott Shenker Ion Stoica Yahoo! Research University of California, Berkeley University of California, Berkeley khaled@yahoo-inc.com shenker@cs.berkeley.edu istoica@cs.berkeley.edu Abstract long batch jobs and short interactive queries over a common data set. Sharing enables statistical multiplexing, leading to As organizations start to use data-intensive cluster comput- lower costs over building separate clusters for each group. ing systems like Hadoop and Dryad for more applications, Sharing also leads to data consolidation (colocation of dis- there is a growing need to share clusters between users. parate data sets), avoiding costly replication of data across However, there is a conflict between fairness in schedul- clusters and letting users run queries across disjoint data sets ing and data locality (placing tasks on nodes that contain efficiently. In this paper, we explore the problem of shar- their input data). We illustrate this problem through our ex- ing a cluster between users while preserving the efficiency perience designing a fair scheduler for a 600-node Hadoop of systems like MapReduce – specifically, preserving data cluster at Facebook. To address the conflict between local- locality, the placement of computation near its input data. ity and fairness, we propose a simple algorithm called delay Locality is crucial for performance in large clusters because scheduling: when the job that should be scheduled next ac- network bisection bandwidth becomes a bottleneck [18]. cording to fairness cannot launch a local task, it waits for a Our work was originally motivated by the MapReduce small amount of time, letting other jobs launch tasks instead. workload at Facebook. Event logs from Facebook’s website We find that delay scheduling achieves nearly optimal data are imported into a 600-node Hadoop [2] data warehouse, locality in a variety of workloads and can increase through- where they are used for a variety of applications, including put by up to 2x while preserving fairness. In addition, the business intelligence, spam detection, and ad optimization. simplicity of delay scheduling makes it applicable under a The warehouse stores 2 PB of data, and grows by 15 TB per wide variety of scheduling policies beyond fair sharing. day. In addition to “production” jobs that run periodically, Categories and Subject Descriptors D.4.1 [Operating Sys- the cluster is used for many experimental jobs, ranging from tems]: Process Management—Scheduling. multi-hour machine learning computations to 1-2 minute ad- hoc queries submitted through an SQL interface to Hadoop General Terms Algorithms, Performance, Design. called Hive [3]. The system runs 7500 MapReduce jobs per 1. Introduction day and is used by 200 analysts and engineers. As Facebook began building its data warehouse, it found Cluster computing systems like MapReduce [18] and Dryad the data consolidation provided by a shared cluster highly [23] were originally optimized for batch jobs such as web beneficial. However, when enough groups began using indexing. However, another use case has recently emerged: Hadoop, job response times started to suffer due to Hadoop’s sharing a cluster between multiple users, which run a mix of FIFO scheduler. This was unacceptable for production jobs and made interactive queries impossible. To address this problem, we have designed the Hadoop Fair Scheduler, re- Permission to make digital or hard copies of all or part of this work for personal or ferred to in this paper as HFS.1 HFS has two main goals: classroom use is granted without fee provided that copies are not made or distributed • Fair sharing: divide resources using max-min fair shar- for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute ing [7] to achieve statistical multiplexing. For example, if to lists, requires prior specific permission and/or a fee. EuroSys’10, April 13–16, 2010, Paris, France. Copyright c 2010 ACM 978-1-60558-577-2/10/04. . . $10.00 1 HFS is open source and available as part of Apache Hadoop.
2 . two jobs are running, each should get half the resources; This paper is organized as follows. Section 2 provides if a third job is launched, each job’s share should be 33%. background on Hadoop. Section 3 analyzes a simple model • Data locality: place computations near their input data, of fair sharing to identify when fairness conflicts with local- to maximize system throughput. ity, and explains why delay scheduling can be expected to To achieve the first goal (fair sharing), a scheduler must perform well. Section 4 describes the design of HFS and our reallocate resources between jobs when the number of jobs implementation of delay scheduling. We evaluate HFS and changes. A key design question is what to do with tasks delay scheduling in Section 5. Section 6 discusses limita- (units of work that make up a job) from running jobs when tions and extensions of delay scheduling. Section 7 surveys a new job is submitted, in order to give resources to the new related work. We conclude in Section 8. job. At a high level, two approaches can be taken: 2. Background 1. Kill running tasks to make room for the new job. 2. Wait for running tasks to finish. Hadoop’s implementation of MapReduce resembles that of Killing reallocates resources instantly and gives control Google [18]. Hadoop runs over a distributed file system over locality for the new jobs, but it has the serious disad- called HDFS, which stores three replicas of each block like vantage of wasting the work of killed tasks. Waiting, on the GFS [21]. Users submit jobs consisting of a map function other hand, does not have this problem, but can negatively and a reduce function. Hadoop breaks each job into tasks. impact fairness, as a new job needs to wait for tasks to fin- First, map tasks process each input block (typically 64 MB) ish to achieve its share, and locality, as the new job may not and produce intermediate results, which are key-value pairs. have any input data on the nodes that free up. There is one map task per input block. Next, reduce tasks Our principal result in this paper is that, counterintu- pass the list of intermediate values for each key and through itively, an algorithm based on waiting can achieve both high the user’s reduce function, producing the job’s final output. fairness and high data locality. We show first that in large Job scheduling in Hadoop is performed by a master, clusters, tasks finish at such a high rate that resources can be which manages a number of slaves. Each slave has a fixed reassigned to new jobs on a timescale much smaller than job number of map slots and reduce slots in which it can run durations. However, a strict implementation of fair sharing tasks. Typically, administrators set the number of slots to compromises locality, because the job to be scheduled next one or two per core. The master assigns tasks in response to according to fairness might not have data on the nodes that heartbeats sent by slaves every few seconds, which report are currently free. To resolve this problem, we relax fairness the number of free map and reduce slots on the slave. slightly through a simple algorithm called delay schedul- Hadoop’s default scheduler runs jobs in FIFO order, with ing, in which a job waits for a limited amount of time for five priority levels. When the scheduler receives a heartbeat a scheduling opportunity on a node that has data for it. We indicating that a map or reduce slot is free, it scans through show that a very small amount of waiting is enough to bring jobs in order of priority and submit time to find one with a locality close to 100%. Delay scheduling performs well in task of the required type. For maps, Hadoop uses a locality typical Hadoop workloads because Hadoop tasks are short optimization as in Google’s MapReduce [18]: after selecting relative to jobs, and because there are multiple locations a job, the scheduler greedily picks the map task in the job where a task can run to access each data block. with data closest to the slave (on the same node if possible, Delay scheduling is applicable beyond fair sharing. In otherwise on the same rack, or finally on a remote rack). general, any scheduling policy defines an order in which 3. Delay Scheduling jobs should be given resources. Delay scheduling only asks that we sometimes give resources to jobs out of order to im- Recall that our goal is to statistically multiplex clusters while prove data locality. We have taken advantage of the gener- having a minimal impact on fairness (i.e. giving new jobs ality of delay scheduling in HFS to implement a hierarchi- their fair share of resources quickly) and achieving high data cal scheduling policy motivated by the needs of Facebook’s locality. In this section, we analyze a simple fair sharing users: a top-level scheduler divides slots between users ac- algorithm to answer two questions: cording to weighted fair sharing, but users can schedule their 1. How should resources be reassigned to new jobs? own jobs using either FIFO or fair sharing. 2. How should data locality be achieved? Although we motivate our work with the data warehous- To answer the first question, we consider two approaches ing workload at Facebook, it is applicable in other settings. to reassigning resources: killing tasks from existing jobs to Our Yahoo! contacts also report job queueing delays to be make room for new jobs, and waiting for tasks to finish to a big frustration. Our work is also relevant to shared aca- assign slots to new jobs. Killing has the advantage that it demic Hadoop clusters [8, 10, 14], and to systems other than is instantaneous, but the disadvantage that work performed Hadoop. Finally, one consequence of the simplicity of de- by the killed tasks is wasted. We show that waiting imposes lay scheduling is that it can be implemented in a distributed little impact on job response times when jobs are longer than fashion; we discuss the implications of this in Section 6. the average task length and when a cluster is shared between
3 .many users. These conditions hold in workloads at Facebook 1 and Yahoo!, so we have based HFS on waiting. Jobs Having chosen to use waiting, we turn our attention to Map Tasks 0.8 Reduce Tasks locality. We identify two locality problems that arise when fair sharing is followed strictly – head-of-line scheduling and 0.6 CDF sticky slots. In both cases, a scheduler is forced to launch a 0.4 task from a job without local data on a node to maintain fairness. We propose an algorithm called delay scheduling 0.2 that temporarily relaxes fairness to improve locality by ask- 0 ing jobs to wait for a scheduling opportunity on a node with 1 10 100 1000 10000 100000 1e+06 local data. We analyze how the amount of waiting impacts Duration (s) locality and job response times. Figure 1: CDF of running times for MapReduce jobs, map tasks For simplicity, we initially focus on one “level” of local- and reduce tasks in production at Facebook in October 2009. ity: placing tasks on the same node as their input data. We start taking into account rack locality in Section 3.6. seconds on average, so j is expected to wait FT /S seconds 3.1 Na¨ıve Fair Sharing Algorithm to acquire all of its slots. This wait time will be negligible compared to j’s running time as long as:2 A simple way to share a cluster fairly between jobs is to always assign free slots to the job that has the fewest running F J T (1) tasks. As long as slots become free quickly enough, the S resulting allocation will satisfy max-min fairness [7]. To Waiting will therefore not impact job response times sig- achieve locality, we can greedily search for a local task nificantly if at least one of the following conditions holds: in this head-of-line job, as in Hadoop’s FIFO scheduler. 1. Many jobs: When there are many jobs running, each Pseudocode for this algorithm is shown below: job’s fractional share of the cluster, f = FS , is small. Algorithm 1 Na¨ıve Fair Sharing 2. Small jobs: Jobs with a small number of tasks (we call these “small jobs”) will also have a small values of f . when a heartbeat is received from node n: if n has a free slot then 3. Long jobs: Jobs where J > T incur little overhead. sort jobs in increasing order of number of running tasks In workload traces from Facebook, we have found that for j in jobs do most tasks are short and most jobs are small, so slots can be if j has unlaunched task t with data on n then reassigned quickly even when the cluster is loaded. Figure 1 launch t on n shows CDFs of map task lengths, job lengths and reduce task else if j has unlaunched task t then lengths over one week in October 2009. The median map launch t on n task is 19s long, which is significantly less than the median end if job length of 84s. Reduces are longer (the median is 231s), end for but this happens because most of jobs do not have many end if reduce tasks, so a few jobs with long reduces contribute a large portion of the CDF. We implemented this algorithm in our first version of We have also calculated the rate at which slots became HFS. We applied the algorithm independently for map slots free during “periods of load” when most slots of a particular and reduce slots. In addition, we only used the locality check type were full. Map slots were more than 95% full 21% of for map tasks, because reduce tasks normally need to read the time, and on average, during these periods of load, 27.1 roughly equal amounts of data from all nodes. slots (out of 3100 total) freed up per second. Reduce slots 3.2 Scheduling Responsiveness were more than 95% full only 4% of the time, and during The first question we consider is how to reassign tasks when these periods, 3.0 slots out of 3100 freed up per second. new jobs are submitted to a cluster. Ideally, we would like Based on the trace, these rates are high enough to let 83% a job j whose fair share is F slots to have a response time of jobs launch within 10 seconds, because 83% of jobs have similar to what it would get if it ran alone on a smaller, fewer than 271 map tasks and 30 reduce tasks. private cluster with F slots. Suppose that j would take J Finally, we have seen similar task and job lengths to those seconds to run on the private cluster. We calculate how long j at Facebook in a 3000-node Yahoo! cluster used for data takes to receive its share of slots if it is submitted to a shared analytics and ad-hoc queries: the median job was 78s long, cluster that uses waiting. If all slots in the cluster are full, the the median map was 26s, and the median reduce was 76s. rate at which j is given slots will be the rate at which tasks 2 Itis also necessary that task finish times be roughly uniformly distributed finish. Suppose that the average task length is T , and that the in time. This is likely to happen in a large multi-user cluster because task cluster contains S slots. Then one slot will free up every T /S durations are variable and jobs are submitted at variable times.
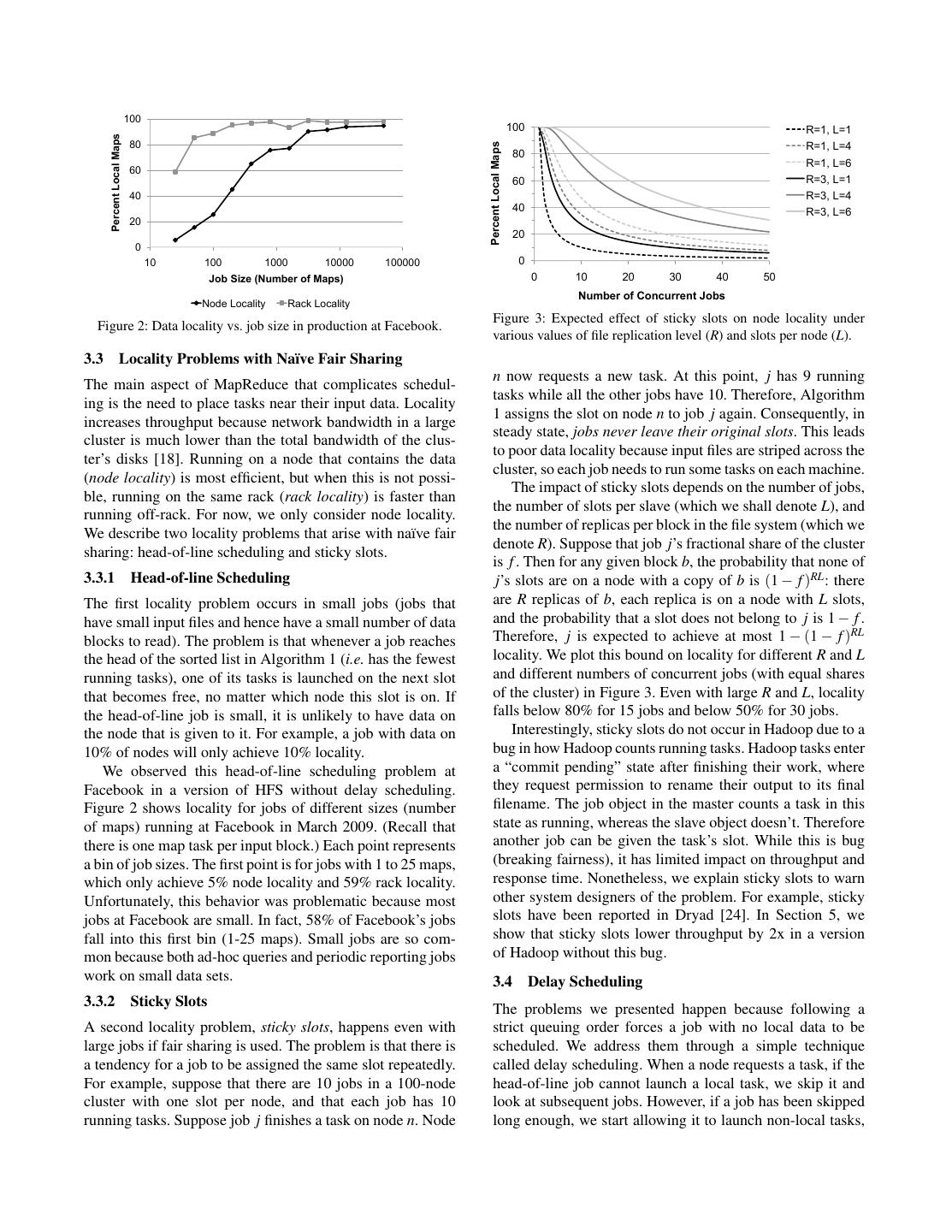
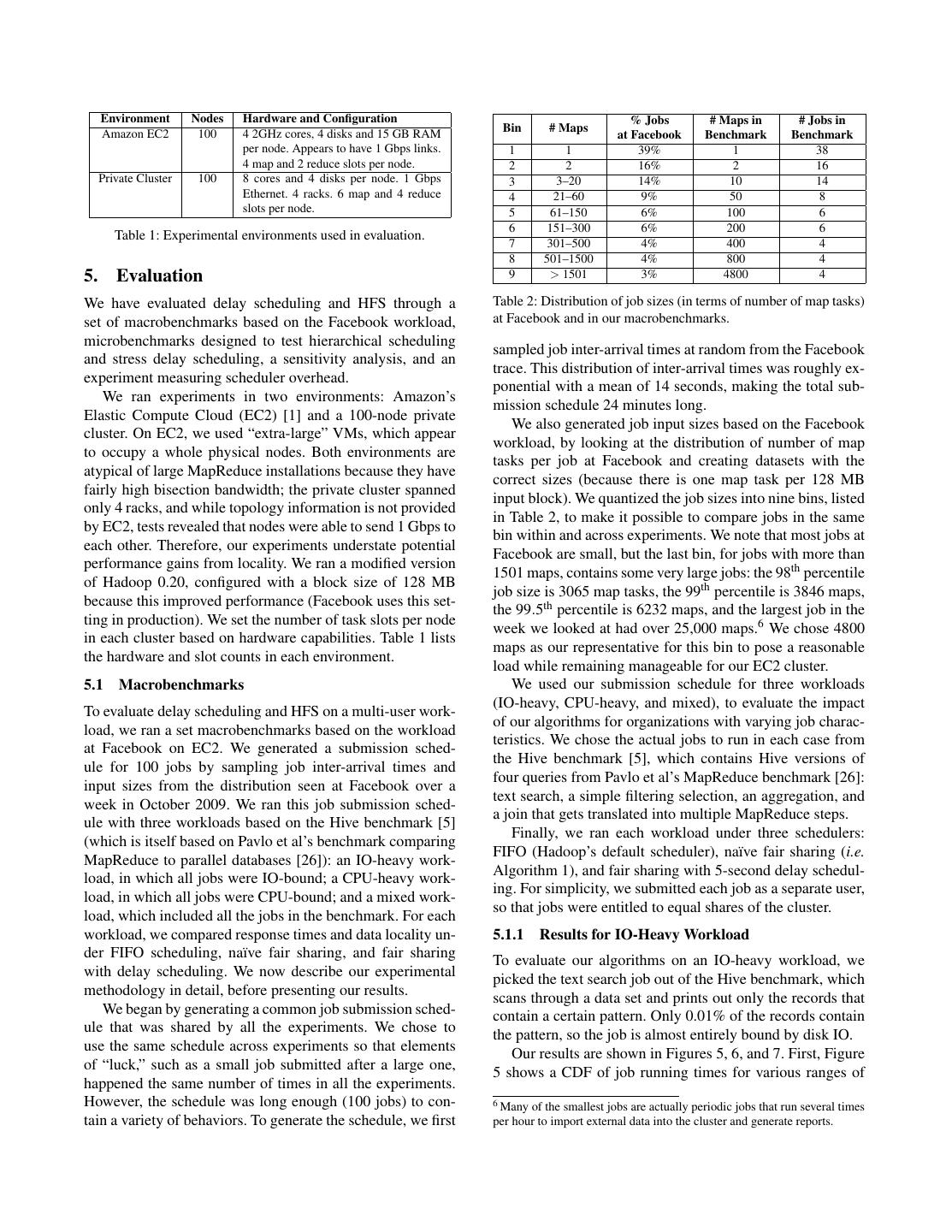
4 . 100 100 R=1, L=1 Percent Local Maps 80 R=1, L=4 Percent Local Maps 80 R=1, L=6 60 60 R=3, L=1 40 R=3, L=4 40 R=3, L=6 20 20 0 10 100 1000 10000 100000 0 Job Size (Number of Maps) 0 10 20 30 40 50 Number of Concurrent Jobs Node Locality Rack Locality Figure 3: Expected effect of sticky slots on node locality under Figure 2: Data locality vs. job size in production at Facebook. various values of file replication level (R) and slots per node (L). 3.3 Locality Problems with Na¨ıve Fair Sharing n now requests a new task. At this point, j has 9 running The main aspect of MapReduce that complicates schedul- tasks while all the other jobs have 10. Therefore, Algorithm ing is the need to place tasks near their input data. Locality 1 assigns the slot on node n to job j again. Consequently, in increases throughput because network bandwidth in a large steady state, jobs never leave their original slots. This leads cluster is much lower than the total bandwidth of the clus- to poor data locality because input files are striped across the ter’s disks [18]. Running on a node that contains the data cluster, so each job needs to run some tasks on each machine. (node locality) is most efficient, but when this is not possi- The impact of sticky slots depends on the number of jobs, ble, running on the same rack (rack locality) is faster than the number of slots per slave (which we shall denote L), and running off-rack. For now, we only consider node locality. the number of replicas per block in the file system (which we We describe two locality problems that arise with na¨ıve fair denote R). Suppose that job j’s fractional share of the cluster sharing: head-of-line scheduling and sticky slots. is f . Then for any given block b, the probability that none of 3.3.1 Head-of-line Scheduling j’s slots are on a node with a copy of b is (1 − f )RL : there The first locality problem occurs in small jobs (jobs that are R replicas of b, each replica is on a node with L slots, have small input files and hence have a small number of data and the probability that a slot does not belong to j is 1 − f . blocks to read). The problem is that whenever a job reaches Therefore, j is expected to achieve at most 1 − (1 − f )RL the head of the sorted list in Algorithm 1 (i.e. has the fewest locality. We plot this bound on locality for different R and L running tasks), one of its tasks is launched on the next slot and different numbers of concurrent jobs (with equal shares that becomes free, no matter which node this slot is on. If of the cluster) in Figure 3. Even with large R and L, locality the head-of-line job is small, it is unlikely to have data on falls below 80% for 15 jobs and below 50% for 30 jobs. the node that is given to it. For example, a job with data on Interestingly, sticky slots do not occur in Hadoop due to a 10% of nodes will only achieve 10% locality. bug in how Hadoop counts running tasks. Hadoop tasks enter We observed this head-of-line scheduling problem at a “commit pending” state after finishing their work, where Facebook in a version of HFS without delay scheduling. they request permission to rename their output to its final Figure 2 shows locality for jobs of different sizes (number filename. The job object in the master counts a task in this of maps) running at Facebook in March 2009. (Recall that state as running, whereas the slave object doesn’t. Therefore there is one map task per input block.) Each point represents another job can be given the task’s slot. While this is bug a bin of job sizes. The first point is for jobs with 1 to 25 maps, (breaking fairness), it has limited impact on throughput and which only achieve 5% node locality and 59% rack locality. response time. Nonetheless, we explain sticky slots to warn Unfortunately, this behavior was problematic because most other system designers of the problem. For example, sticky jobs at Facebook are small. In fact, 58% of Facebook’s jobs slots have been reported in Dryad [24]. In Section 5, we fall into this first bin (1-25 maps). Small jobs are so com- show that sticky slots lower throughput by 2x in a version mon because both ad-hoc queries and periodic reporting jobs of Hadoop without this bug. work on small data sets. 3.4 Delay Scheduling 3.3.2 Sticky Slots The problems we presented happen because following a A second locality problem, sticky slots, happens even with strict queuing order forces a job with no local data to be large jobs if fair sharing is used. The problem is that there is scheduled. We address them through a simple technique a tendency for a job to be assigned the same slot repeatedly. called delay scheduling. When a node requests a task, if the For example, suppose that there are 10 jobs in a 100-node head-of-line job cannot launch a local task, we skip it and cluster with one slot per node, and that each job has 10 look at subsequent jobs. However, if a job has been skipped running tasks. Suppose job j finishes a task on node n. Node long enough, we start allowing it to launch non-local tasks,
5 .to avoid starvation. The key insight behind delay scheduling exponentially with D. For example, a job with data on 10% is that although the first slot we consider giving to a job is of nodes (p j = 0.1) has a 65% chance of launching a local unlikely to have data for it, tasks finish so quickly that some task with D = 10, and a 99% chance with D = 40. slot with data for it will free up in the next few seconds. A second question is how long a job waits below its fair In this section, we consider a simple version of delay share to launch a local task. Because there are S slots in scheduling where we allow a job to be skipped up to D times. the cluster, a slot becomes free every TS seconds on average. Pseudocode for this algorithm is shown below: Therefore, once a job j reaches the head of the queue, it will wait at most DS T seconds before being allowed to launch Algorithm 2 Fair Sharing with Simple Delay Scheduling non-local tasks, provided that it stays at the head of the Initialize j.skipcount to 0 for all jobs j. queue.3 This wait will be much less than the average task when a heartbeat is received from node n: length if S is large. In particular, waiting for a local task if n has a free slot then may cost less time than running a non-local task: in our sort jobs in increasing order of number of running tasks experiments, local tasks ran up to 2x faster than non-local for j in jobs do tasks. Note also that for a fixed number of nodes, the wait if j has unlaunched task t with data on n then time decreases linearly with the number of slots per node. launch t on n We conclude with an approximate analysis of how to set set j.skipcount = 0 else if j has unlaunched task t then D to achieve a desired level of locality.4 Suppose that we if j.skipcount ≥ D then wish to achieve locality greater than λ for jobs with N tasks launch t on n on a cluster with M nodes, L slots per node and replication else factor R. We will compute the expected locality for an N-task set j.skipcount = j.skipcount + 1 job j over its lifetime by averaging up the probabilities that it end if launches a local task when it has N, N − 1, . . . , 1 tasks left to end if K R launch. When j has K tasks left to launch, p j = 1−(1− M ) , end for because the probability that a given node does not have a end if replica of one of j’s input blocks is (1 − M K R ) . Therefore, the probability that j launches a local task at this point is Note that once a job has been skipped D times, we let 1 − (1 − p j )D = 1 − (1 − M ) ≥ 1 − e−RDK/M . Averaging K RD it launch arbitrarily many non-local tasks without resetting this quantity over K = 1 to N, the expected locality for job its skipcount. However, if it ever manages to launch a local j, given a skip count D, is at least: task again, we set its skipcount back to 0. We explain the rationale for this design in our analysis of delay scheduling. 1 N l(D) = ∑ 1 − e−RDK/M N K=1 3.5 Analysis of Delay Scheduling In this section, we explore how the maximum skip count D 1 N −RDK/M = 1− ∑e in Algorithm 2 affects locality and response times, and how N K=1 to set D to achieve a target level of locality. We find that: 1 ∞ −RDK/M 1. Non-locality decreases exponentially with D. ≥ 1− ∑e N K=1 2. The amount of waiting required to achieve a given level e−RD/M of locality is a fraction of the average task length and ≥ 1− decreases linearly with the number of slots per node L. N(1 − e−RD/M ) We assume that we have an M-node cluster with L slots Solving for l(D) ≥ λ, we find that we need to set: per node, for a total of S = ML slots. Also, at each time, let M (1 − λ)N Pj denote the set of nodes on which job j has data left to D≥− ln (2) R 1 + (1 − λ)N process, which we call “preferred” nodes for job j, and let |P | For example, for λ = 0.95, N = 20, and R = 3, we need p j = Mj be the fraction of nodes that j prefers. To simplify the analysis, we assume that all tasks are of the same length D ≥ 0.23M. Also, the maximum time a job waits for a local T and that the sets Pj are uncorrelated (for example, either task is DS T = LM D T = 0.23 L T . For example, if we have L = 8 every job has a large input file and therefore has data on slots per node, this wait is 2.8% of the average task length. every node, or every job has a different input file). 3 Once a job reaches the head of the queue, it is likely to stay there, because We first consider how much locality improves depending the head-of-queue job is the one that has the smallest number of running on D. Suppose that job j is farthest below its fair share. Then tasks. The slots that the job lost to fall below its share must have been given to other jobs, so the other jobs are likely above their fair share. j has probability p j of having data on each slot that becomes 4 This analysis does not consider that a job can launch non-local tasks free. If j waits for up to D slots before being allowed to without waiting after it launches its first one. However, this only happens launch non-local tasks, then the probability that it does not towards the end of a job, so it does not matter much in large jobs. On the find a local task is (1 − p j )D . This probability decreases flip side, the inequalities we use underestimate the locality for a given D.
6 .3.5.1 Long Tasks and Hotspots gation switches connects the racks [24]. Usually, bandwidth The preceding analysis assumed that all tasks were of the per node within a rack is much higher than bandwidth per same length and that job’s preferred location sets, Pj , were node between racks. Therefore, when a task cannot be placed uncorrelated. Two factors can break these assumptions: on a node that contains its data, it is preferable to place it on a rack that contains the data. 1. Some jobs may have long tasks. If all the slots on a This can be accomplished by extending Algorithm 2 to node are filled with long tasks, the node may not free give each job two waiting periods. First, if the head-of-line up quickly enough for other jobs to achieve locality. job has been skipped at most D1 times, it is only allowed 2. Some nodes may be of interest to many jobs. We call to launch node-local tasks. Once a job has been skipped D1 these nodes hotspots. For example, multiple jobs may times, it enters a second “level” of delay scheduling, where be trying to read the same small input file. it is only allowed to launch rack-local tasks. If the job is We note that both hotspots and nodes filled with long skipped D2 times while at this level, it is allowed to launch tasks are relatively long-lasting conditions. This is why, in non-local tasks. A nice consequence of our analysis is that Algorithm 2, we allow jobs to launch arbitrarily many non- D2 can be much smaller than D1 : because there are much local tasks if they have been skipped D times, until they fewer racks than nodes, a job will not be skipped many times launch a local task again. If D is set high enough that a until it finds a slot in a rack that contains its data. job has a good chance of launching a local task on one of We have implemented this algorithm in HFS, and de- its preferred nodes when these nodes are not “blocked” by scribe it in detail in Section 4.1. A similar algorithm can be hotspots or long tasks, then once a job has been skipped D used for networks with more than 2 levels of hierarchy. times, it is likely that the job’s preferred nodes are indeed blocked, so we should not continue waiting. 4. Hadoop Fair Scheduler Design How much long tasks and hotspots impact locality de- The simple fair scheduler described in Section 3, which pends on the workload, the file replication level R, and the gives each job an equal share of the cluster, is adequate for number of slots per node L. In general, unless long tasks and clusters with small numbers of users. However, to handle the hotspots are very common, they will have little impact on lo- needs of a larger organization such as Facebook, we wanted cality. For example, if the fraction of slots running long tasks to address several shortcomings of this model: is ϕ, then the probability that all the nodes with replicas of a given block are filled with long tasks is ϕRL . On a cluster 1. Some users may be running more jobs than others; we with R = 3 and L = 6, this is less than 2% as long as ϕ < 0.8. want fair sharing at the level of users, not jobs. We have not seen significant problems with long tasks and 2. Users want control over the scheduling of their own hotspots in practice. Nonetheless, for workloads where these jobs. For example, a user who submits several batch conditions are common, we propose two solutions: jobs may want them to run in FIFO order to get their results sequentially. Long Task Balancing: To lower the chance that a node 3. Production jobs need to perform predictably even if the fills with long tasks, we can spread long tasks throughout cluster is loaded with many long user tasks. the cluster by changing the locality test in Algorithm 2 to prevent jobs with long tasks from launching tasks on nodes We address these problems in our design of the Hadoop that are running a higher-than-average number of long tasks. Fair Scheduler (HFS). HFS uses a two-level scheduling hi- Although we do not know which jobs have long tasks in erarchy. At the top level, HFS allocates task slots across advance, we can treat new jobs as long-task jobs, and mark pools using weighted fair sharing. There is one pool per user, them as short-task jobs if their tasks finish quickly.5 but organizations can also create special pools for particular workloads (e.g. production jobs). At the second level, each Hotspot Replication: Because distributed file systems like pool allocates its slots among jobs in the pool, using either HDFS place blocks on random nodes, hotspots are only FIFO with priorities or a second level of fair sharing. Fig- likely to occur if multiple jobs need to read the same data ure 4 shows an example pool hierarchy. HFS can easily be file, and that file is small enough that copies of its blocks generalized to support multi-level pool hierarchies, or poli- are only present on a small fraction of nodes. In this case, cies other than FIFO and fair sharing within a pool. no scheduling algorithm can achieve high locality without We provide one feature beyond standard weighted fair excessive queueing delays. Instead, it would be better to sharing to support production jobs. Each pool can be given dynamically increase the replication level of small hot files. a minimum share, representing a minimum number of slots 3.6 Rack Locality that the pool is guaranteed to be given as long as it contains Networks in large clusters are typically organized in a multi- jobs, even if the pool’s fair share is less than this amount level hierarchy, where nodes are grouped into racks of 20-80 (e.g. because many users are running jobs). HFS always nodes at the lowest level, and one or more levels of aggre- prioritizes meeting minimum shares over fair shares, and may kill tasks to meet minimum shares. Administrators are 5 Tasks within a job have similar lengths because they run the same function. expected to set minimum shares for production jobs based
7 . Hadoop cluster count some practical considerations. First, rather than using total slots: 100 a maximum skip count D to determine how long a job waits 60 slots 0 slots for a local task, we set a maximum wait time in seconds. This 40 slots allows jobs to launch within a predictable time when a large Pool 1 (production) Pool 2 (user X) Pool 3 (user Y) number of slots in the cluster are filled with long tasks and min share: 60 min share: 0 min share: 10 internal policy: fair internal policy: FIFO internal policy: fair slots free up at a slow rate. Second, to achieve rack local- ity when a job is unable to launch node-local tasks, we use 30 30 40 0 0 two levels of delay scheduling – jobs wait W1 seconds to find Job 1 Job 2 Job 3 Job 4 Job 5 a node-local task, and then W2 seconds to find a rack-local task. This algorithm is shown below: Figure 4: Example of allocations in HFS. Pools 1 and 3 have minimum shares of 60 and 10 slots. Because Pool 3 is not using its Algorithm 3 Delay Scheduling in HFS share, its slots are given to Pool 2. Each pool’s internal scheduling policy (FIFO or fair sharing) splits up its slots among its jobs. Maintain three variables for each job j, initialized as j.level = 0, j.wait = 0, and j.skipped = f alse. on the number of slots a job needs to meet a certain SLO when a heartbeat is received from node n: (e.g. import logs every 15 minutes, or delete spam messages for each job j with j.skipped = true, increase j.wait by the time since the last heartbeat and set j.skipped = f alse every hour). If the sum of all pools’ minimum shares exceeds if n has a free slot then the number of slots in the cluster, HFS logs a warning and sort jobs using hierarchical scheduling policy scales down the minimum shares equally until their sum is for j in jobs do less than the total number of slots. if j has a node-local task t on n then Finally, although HFS uses waiting to reassign resources set j.wait = 0 and j.level = 0 most of the time, it also supports task killing. We added this return t to n support to prevent a buggy job with long tasks, or a greedy else if j has a rack-local task t on n and ( j.level ≥ 1 or user, from holding onto a large share of the cluster. HFS uses j.wait ≥ W1 ) then two task killing timeouts. First, each pool has a minimum set j.wait = 0 and j.level = 1 share timeout, Tmin . If the pool does not receive its minimum return t to n share within Tmin seconds of a job being submitted to it, else if j.level = 2 or ( j.level = 1 and j.wait ≥ W2 ) or ( j.level = 0 and j.wait ≥ W1 +W2 ) then we kill tasks to meet the pool’s share. Second, there is a set j.wait = 0 and j.level = 2 global fair share timeout, T f air , used to kill tasks if a pool return any unlaunched task t in j to n is being starved of its fair share. We expect administrators else to set Tmin for each production pool based on its SLO, and set j.skipped = true to set a larger value for T f air based on the level of delay end if users can tolerate. When selecting tasks to kill, we pick the end for most recently launched tasks in pools that are above their end if fair share to minimize wasted work. Each job begins at a “locality level” of 0, where it can 4.1 Task Assignment in HFS only launch node-local tasks. If it waits at least W1 seconds, Whenever a slot is free, HFS assigns a task to it through it goes to locality level 1 and may launch rack-local tasks. a two-step process: First, we create a sorted list of jobs If it waits a further W2 seconds, it goes to level 2 and may according to our hierarchical scheduling policy. Second, we launch off-rack tasks. Finally, if a job ever launches a “more scan down this list to find a job to launch a task from, local” task than the level it is on, it goes back down to a applying delay scheduling to skip jobs that do not have data previous level, as motivated in Section 3.5.1. The algorithm on the node being assigned for a limited time. The same is straightforward to generalize to more locality levels for algorithm is applied independently for map slots and reduce clusters with more than a two-level network hierarchy. slots, although we do not use delay scheduling for reduces We expect administrators to set the wait times W1 and W2 because they usually need to read data from all nodes. based on the rate at which slots free up in their cluster and To create a sorted list of jobs, we use a recursive algo- the desired level of locality, using the analysis in Section 3.5. rithm. First, we sort the pools, placing pools that are below For example, at Facebook, we see 27 map slots freeing per their minimum share at the head of the list (breaking ties second when the cluster is under load, files are replicated based on how far each pool is below its minimum share), R = 3 ways, and there are M = 620 machines. Therefore, and sorting the other pools by current share weight to achieve weighted setting W1 = 10s would give each job roughly D = 270 fair sharing. Then, within each pool, we sort jobs based on scheduling opportunities before it is allowed to launch non- the pool’s internal policy (FIFO or fair sharing). local tasks. This is enough to let jobs with K = 1 task achieve Our implementation of delay scheduling differs slightly at least 1 − e−RDK/M = 1 − e−3·270·1/620 = 73% locality, and from the simplified algorithm in Section 3.4 to take into ac- to let jobs with 10 tasks achieve 90% locality.
8 . Environment Nodes Hardware and Configuration % Jobs # Maps in # Jobs in Bin # Maps Amazon EC2 100 4 2GHz cores, 4 disks and 15 GB RAM at Facebook Benchmark Benchmark per node. Appears to have 1 Gbps links. 1 1 39% 1 38 4 map and 2 reduce slots per node. 2 2 16% 2 16 Private Cluster 100 8 cores and 4 disks per node. 1 Gbps 3 3–20 14% 10 14 Ethernet. 4 racks. 6 map and 4 reduce 4 21–60 9% 50 8 slots per node. 5 61–150 6% 100 6 6 151–300 6% 200 6 Table 1: Experimental environments used in evaluation. 7 301–500 4% 400 4 8 501–1500 4% 800 4 5. Evaluation 9 > 1501 3% 4800 4 We have evaluated delay scheduling and HFS through a Table 2: Distribution of job sizes (in terms of number of map tasks) set of macrobenchmarks based on the Facebook workload, at Facebook and in our macrobenchmarks. microbenchmarks designed to test hierarchical scheduling sampled job inter-arrival times at random from the Facebook and stress delay scheduling, a sensitivity analysis, and an trace. This distribution of inter-arrival times was roughly ex- experiment measuring scheduler overhead. ponential with a mean of 14 seconds, making the total sub- We ran experiments in two environments: Amazon’s mission schedule 24 minutes long. Elastic Compute Cloud (EC2) [1] and a 100-node private We also generated job input sizes based on the Facebook cluster. On EC2, we used “extra-large” VMs, which appear workload, by looking at the distribution of number of map to occupy a whole physical nodes. Both environments are tasks per job at Facebook and creating datasets with the atypical of large MapReduce installations because they have correct sizes (because there is one map task per 128 MB fairly high bisection bandwidth; the private cluster spanned input block). We quantized the job sizes into nine bins, listed only 4 racks, and while topology information is not provided in Table 2, to make it possible to compare jobs in the same by EC2, tests revealed that nodes were able to send 1 Gbps to bin within and across experiments. We note that most jobs at each other. Therefore, our experiments understate potential Facebook are small, but the last bin, for jobs with more than performance gains from locality. We ran a modified version 1501 maps, contains some very large jobs: the 98th percentile of Hadoop 0.20, configured with a block size of 128 MB job size is 3065 map tasks, the 99th percentile is 3846 maps, because this improved performance (Facebook uses this set- the 99.5th percentile is 6232 maps, and the largest job in the ting in production). We set the number of task slots per node week we looked at had over 25,000 maps.6 We chose 4800 in each cluster based on hardware capabilities. Table 1 lists maps as our representative for this bin to pose a reasonable the hardware and slot counts in each environment. load while remaining manageable for our EC2 cluster. 5.1 Macrobenchmarks We used our submission schedule for three workloads (IO-heavy, CPU-heavy, and mixed), to evaluate the impact To evaluate delay scheduling and HFS on a multi-user work- of our algorithms for organizations with varying job charac- load, we ran a set macrobenchmarks based on the workload teristics. We chose the actual jobs to run in each case from at Facebook on EC2. We generated a submission sched- the Hive benchmark [5], which contains Hive versions of ule for 100 jobs by sampling job inter-arrival times and four queries from Pavlo et al’s MapReduce benchmark [26]: input sizes from the distribution seen at Facebook over a text search, a simple filtering selection, an aggregation, and week in October 2009. We ran this job submission sched- a join that gets translated into multiple MapReduce steps. ule with three workloads based on the Hive benchmark [5] Finally, we ran each workload under three schedulers: (which is itself based on Pavlo et al’s benchmark comparing FIFO (Hadoop’s default scheduler), na¨ıve fair sharing (i.e. MapReduce to parallel databases [26]): an IO-heavy work- Algorithm 1), and fair sharing with 5-second delay schedul- load, in which all jobs were IO-bound; a CPU-heavy work- ing. For simplicity, we submitted each job as a separate user, load, in which all jobs were CPU-bound; and a mixed work- so that jobs were entitled to equal shares of the cluster. load, which included all the jobs in the benchmark. For each workload, we compared response times and data locality un- 5.1.1 Results for IO-Heavy Workload der FIFO scheduling, na¨ıve fair sharing, and fair sharing To evaluate our algorithms on an IO-heavy workload, we with delay scheduling. We now describe our experimental picked the text search job out of the Hive benchmark, which methodology in detail, before presenting our results. scans through a data set and prints out only the records that We began by generating a common job submission sched- contain a certain pattern. Only 0.01% of the records contain ule that was shared by all the experiments. We chose to the pattern, so the job is almost entirely bound by disk IO. use the same schedule across experiments so that elements Our results are shown in Figures 5, 6, and 7. First, Figure of “luck,” such as a small job submitted after a large one, 5 shows a CDF of job running times for various ranges of happened the same number of times in all the experiments. However, the schedule was long enough (100 jobs) to con- 6 Many of the smallest jobs are actually periodic jobs that run several times tain a variety of behaviors. To generate the schedule, we first per hour to import external data into the cluster and generate reports.
9 . 1 1 1 1 1 1 0.8 0.8 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.6 0.6 0.6 CDF CDF CDF CDF CDF CDF 0.4 0.4 0.4 0.4 0.4 0.4 FIFO FIFO FIFO FIFO FIFO FIFO 0.2 Naive Fair 0.2 Naive Fair 0.2 Naive Fair 0.2 Naive Fair 0.2 Naive Fair 0.2 Naive Fair Fair + DS Fair + DS Fair + DS Fair + DS Fair + DS Fair + DS 0 0 0 0 0 0 0 50 100 150 200 0 50 100 150 200 0 100 200 300 400 500 0 400 800 1200 1600 0 400 800 1200 1600 0 1000 2000 3000 4000 Time (s) Time (s) Time (s) Time (s) Time (s) Time (s) (a) Bins 1-3 (b) Bins 4-8 (c) Bin 9 (a) Bins 1-3 (b) Bins 4-8 (c) Bin 9 Figure 5: CDFs of running times of jobs in various bin ranges in the Figure 8: CDFs of running times of jobs in various bin ranges in the IO-heavy workload. Fair sharing greatly improves performance for CPU-heavy workload. Fair sharing speeds up smaller jobs while small jobs, at the cost of slowing the largest jobs. Delay scheduling slowing down the largest ones, but delay scheduling has little effect further improves performance, especially for medium-sized jobs. because the workload is CPU-bound. FIFO Naïve Fair Fair + Delay Sched. ing from na¨ıve fair sharing to delay scheduling. We see that delay scheduling has a negligible effect on the smallest jobs; Percent Local Maps 100% 80% this is partly because much of the lifetime of small jobs is 60% setup, and partly because the cluster is actually underloaded 40% most of the time, and small jobs are launched roughly uni- 20% 0% formly throughout time, so most of them do not face network 1 2 3 4 5 6 7 8 9 contention. Delay scheduling also has less of an effect on the Bin largest jobs; these have many input blocks on every node, so Figure 6: Data locality for each bin in the IO-heavy workload. they achieve high locality even with Hadoop’s greedy de- fault algorithm. However, significant speedups are seen for medium-sized jobs, with jobs in bin 5 (100 maps) running 1.75 on average 44% faster with delay scheduling. Avg. Speedup from 1.50 Delay Scheduling 1.25 1.00 5.1.2 Results for CPU-Heavy Workload 0.75 0.50 0.25 To create a CPU-heavy workload, we modified the text 0.00 1 2 3 4 5 6 7 8 9 search job in the Hive benchmark to run a compute-intensive Bin user defined function (UDF) on each input record, but still output only 0.01% of records. This made the jobs 2-7 times Figure 7: Average speedup of delay scheduling over na¨ıve fair slower (the effect was more pronounced for large jobs, be- sharing for jobs in each bin in the IO-heavy workload. The black cause much of the lifetime of smaller jobs is Hadoop job lines show standard deviations. setup overhead). We observed data locality levels very close bins. We see that about 30% of the smaller jobs are signif- to those in the IO-heavy workload, so we do not plot them icantly slowed down under FIFO scheduling, because they here. However, we have plotted job response time CDFs must wait for a larger job to finish. Switching to fair shar- in Figure 8. We note two behaviors: First, fair sharing im- ing resolves this problem, letting all the small jobs perform proves response times of small jobs as before, but its effect nearly equally well no matter when they are launched. The is much larger (speeding some jobs as much as 20x), be- job with the greatest improvement runs 5x faster under fair cause the cluster is more heavily loaded (we are running on sharing than FIFO. On the other hand, fair sharing slows the same data but with more expensive jobs). Second, delay down the largest jobs (in bin 9), because it lets other jobs scheduling has a negligible effect, because the workload is run while they are active. The greatest slowdown, of about CPU-bound, but it also does not hurt performance. 1.7x, happens to two jobs from bin 9 that overlap in time. 5.1.3 Results for Mixed Workload This is expected behavior for fair sharing: predictability and We generated a mixed workload by running all four of the response times for small jobs are improved at the expense of jobs in the Hive benchmark. Apart from the text search job moderately slowing down larger jobs. used in the IO-heavy workload, this includes: Second, we observe that adding delay scheduling to fair • A simple select that is also IO-intensive (selecting pages sharing improves performance overall. As shown in Figure 6, delay scheduling brings the data locality to 99-100% for with a certain PageRank). all bins, whereas bins with small jobs have low data locality • An aggregation job that is communication-intensive under both Hadoop’s default scheduler and na¨ıve fair shar- (computing ad revenue for each IP address in a dataset). ing. The effect on response time is more nuanced, and to il- • A complex join query that translates into a series of four lustrate it clearly, we have plotted Figure 7, which shows the jobs (identifying the user that generated the most revenue average speedup experienced by jobs in each bin when mov- and the average PageRank of their pages).
10 . Bin Job Type Map Tasks Reduce Tasks # Jobs Run Naive Fair over FIFO Fair + DS over FIFO 1 select 1 NA 38 6.0 2 text search 2 NA 16 5.0 Average Speedup 3 aggregation 10 3 14 4 select 50 NA 8 4.0 5 text search 100 NA 6 3.0 6 aggregation 200 50 6 2.0 7 select 400 NA 4 8 aggregation 800 180 4 1.0 9 join 2400 360 2 0.0 10 text search 4800 NA 2 1 2 3 4 5 6 7 8 9 10 Bin Table 3: Job types and sizes for each bin in our mixed workload. Figure 10: Average speedup of na¨ıve fair sharing and fair sharing 1 1 1 with delay scheduling over FIFO for jobs in each bin in the mixed 0.8 0.8 0.8 workload. The black lines show standard deviations. 0.6 0.6 0.6 ations where locality is difficult to achieve. For these ex- CDF CDF CDF 0.4 0.4 0.4 periments, we used a “scan” included in Hadoop’s GridMix FIFO FIFO FIFO 0.2 Naive Fair Fair + DS 0.2 Naive Fair Fair + DS 0.2 Naive Fair Fair + DS benchmark. This is a synthetic job in which each map out- 0 0 100 200 300 400 500 600 0 0 100 200 300 400 500 0 0 200 400 600 800 1000 puts 0.5% of its input records, similar to the text search job in Time (s) Time (s) Time (s) the macrobenchmarks. As such, it is a suitable workload for (a) Bins 1-3 (b) Bins 4-8 (c) Bins 9-10 stress-testing data locality because it is IO-bound. The scan Figure 9: CDFs of running times of jobs in various bin ranges in job normally has one reduce task that counts the results, but the mixed workload. we also ran some experiments with no reduces (saving map outputs as the job’s output) to emulate pure filtering jobs. For this experiment, we split bin 9 into two smaller bins, 5.2.1 Hierarchical Scheduling one of which contained 2 join jobs (which translate into a large 2400-map job followed by three smaller jobs each) and To evaluate the hierarchical scheduling policy in HFS and another of which contained two 4800-map jobs as before. measure how quickly resources are given to new jobs, we We list the job we used as a representative in each bin in set up three pools on the EC2 cluster. Pools 1 and 2 used Table 3. Unlike our first two workloads, which had map-only fair sharing as their internal policy, while pool 3 used FIFO. jobs, this workload also contained jobs with reduce tasks, so We then submitted a sequence of jobs to test both sharing be- we also list the number of reduce tasks per job. tween pools and scheduling within a pool. Figure 11 shows a We plot CDFs of job response times in each bin in Figure timeline of the experiment. Delay scheduling (with W1 = 5s) 9. As in the previous experiments, fair sharing significantly was also enabled, and all jobs achieved 99-100% locality. improves the response time for smaller jobs, while slightly We used two types of filter jobs: two long jobs with long slowing larger jobs. Because the aggregation jobs take tasks (12000 map tasks that each took 25s on average) and longer than map-only jobs (due to having a communication- four jobs with short tasks (800 map tasks that each took 12s heavy reduce phase), we have also plotted the speedups on average). To make the first type of jobs have longer tasks, achieved by each bin separately in Figure 10. The dark bars we set their filtering rate to 50% instead of 0.5%. show speedups for na¨ıve fair sharing over FIFO, while the We began by submitting a long-task job to pool 1 at time light bars show speedups for fair sharing with delay schedul- 0. This job was given tasks on all the nodes in the cluster. ing over FIFO. The smaller map-only jobs (bins 1 and 2) Then, at time 57s, we submitted a second long-task job in achieve significant speedups from fair sharing. Bin 3 does pool 2. This job reached its fair share (half the cluster) in not achieve a speedup as high as in other experiments be- 17 seconds. Then, at time 118s, we submitted three short- cause the jobs are longer (the median one is about 100 sec- task jobs to pool 3. The pool ran acquired 33% of the slots onds, while the median in bins 1 and 2 is 32 seconds with in the cluster in 12 seconds and scheduled its jobs in FIFO delay scheduling). However, in all but the largest bins, jobs order, so that as soon as the first job finished tasks, slots benefit from both fair sharing and delay scheduling. We also were given to the second job. Once pool 3’s jobs finished, the see that the benefits from delay scheduling are larger for the cluster returned to being shared equally between pools 1 and bins with IO-intensive jobs (1, 2, 4, 5, 7 and 10) than for 2. Finally, at time 494s, we submitted a second job in pool bins where there are also reduce tasks (and hence a smaller 1. Because pool 1 was configured to perform fair sharing, it fraction of the job running time is spent reading input). split up its slots between its jobs, giving them 25% of the slots each, while pool 2’s share remained 50%. 5.2 Microbenchmarks Note that the graph in Figure 11 shows a “bump” in the We ran several microbenchmarks to test HFS in a more con- share of pool 2 twenty seconds after it starts running jobs, trolled manner, and to stress-test delay scheduling in situ- and a smaller bump when pool 3 starts. These bumps occur
11 . pool 1 job 2 100% Share of Cluster (%) 80% 60% 40% 20% 0% 1 61 121 181 241 301 361 421 481 541 601 661 721 781 pool 1 job 1 Time (s) pool 2 job 1 pool 3 jobs 1-3 Figure 11: Stacked chart showing the percent of map slots in the cluster given to each job as a function of time in our hierarchical scheduling experiment. Pools 1 and 2 use fair sharing internally, while pool 3 uses FIFO. The job submission scheduled is explained in the text. Job Size Node / Rack Locality Node / Rack Locality 1 Time to Run Benchmark Without Delay Sched. With Delay Sched. Without 0.8 3 maps 2% / 50% 75% / 96% Delay (Normalized) 10 maps 37% / 98% 99% / 100% 0.6 Scheduling 100 maps 84% / 99% 94% / 99% 0.4 With Delay Scheduling Table 4: Node and rack locality in small-jobs stress test workload. 0.2 Results were similar for FIFO and fair sharing. 0 3 Maps 10 Maps 100 Maps because of the “commit pending” bug in Hadoop discussed Job Size in Section 3.3.2. Hadoop tasks enter a “commit pending” Figure 12: Performance of small-jobs stress test with and without delay scheduling. Results were similar for FIFO and fair sharing. phase after they finish running the user’s map function when they are still reported as running but a second task can be 3-map jobs was low because, at small job sizes, job initial- launched in their slot. However, during this time, the job ization becomes a bottleneck in Hadoop. Interestingly, the object in the Hadoop master counts the task as running, gains with 10 and 100 maps were due to moving from rack- while the slave object doesn’t. Normally, a small percent local to node-local tasks; rack locality was good even with- of tasks from each jobs are in the “commit pending” state, out delay scheduling because our cluster had only 4 racks. so the bug doesn’t affect fairness. However, when pool 2’s first job is submitted, none of its tasks finish until about 20 5.2.3 Delay Scheduling with Sticky Slots seconds pass, so it holds onto a greater share of the cluster As explained in Section 3.3, sticky slots do not normally than 50%. (We calculated each job’s share as the percent of occur in Hadoop due to an accounting bug. We tested a running tasks that belong to it when we plotted Figure 11.) version of Hadoop with this bug fixed to quantify the effect 5.2.2 Delay Scheduling with Small Jobs of sticky slots. We ran this test on EC2. We generated a large 180-GB data set (2 GB per node), submitted between To test the effect of delay scheduling on locality and through- 5 and 50 concurrent scan jobs on it, and measured the time put in a small job workload where head-of-line scheduling to finish all jobs and the locality achieved. Figures 14 and poses a problem, we ran workloads consisting of filter jobs 13 show the results with and without delay scheduling (with with 3, 10 or 100 map tasks on the private cluster. For each W1 = 10s). Without delay scheduling, locality was lower the workload, we picked the number of jobs based on the job more concurrent jobs there were – from 92% with 5 jobs size so as to have the experiment take 10-20 minutes. We down to 27% for 50 jobs. Delay scheduling raised locality to compared fair sharing and FIFO with and without delay 99-100% in all cases. This led to an increase in throughput scheduling (W1 = W2 = 15s). FIFO performed the same as of 1.1x for 10 jobs, 1.6x for 20 jobs, and 2x for 50 jobs. fair sharing, so we only show one set of numbers for both. Figure 12 shows normalized running times of the work- 5.3 Sensitivity Analysis load, while Table 4 shows locality achieved by each sched- We measured the effect of the wait time in delay scheduling uler. Delay scheduling increased throughput by 1.2x for 3- on data locality through a series of experiments in the EC2 map jobs, 1.7x for 10-map jobs, and 1.3x for 100-map jobs, environment. We ran experiments with two small job sizes: and raised data locality to at least 75% and rack locality to 4 maps and 12 maps, to measure how well delay schedul- at least 94%. The throughput gain is higher for 10-map jobs ing mitigates head-of-line scheduling. We ran 200 jobs in than for 100-map jobs because locality with 100-map jobs is each experiment, with 50 jobs active at any time. We var- fairly good even without delay scheduling. The gain for the ied the node locality wait time, W1 , from 0 seconds to 10
12 . 100% 98% 99% 100% 100% 100% Percent Local Maps Percent Local Maps 80% 80% 80% 68% 60% 60% 40% 40% 20% 11% 5% 20% 0% 0% No Delay 1s Delay 5s Delay 10s Delay 5 Jobs 10 Jobs 20 Jobs 50 Jobs 4-Map Jobs 12-Map Jobs Without Delay Scheduling With Delay Scheduling Figure 15: Effect of delay scheduling’s wait time W1 on node Figure 13: Node locality in sticky slots stress test. As the number locality for small jobs with 4 and 12 map tasks. Even delays as of concurrent jobs grows, locality falls because of sticky slots. low as 1 second raise locality from 5% to 68% for 4-map jobs. 50 lization but no fairness. Our work enables a sweet spot on Time to Run Benchmark 40 this spectrum – multiplexing a cluster efficiently while giv- 30 ing each user response times comparable to a private cluster (minutes) through fair sharing. 20 To implement fair sharing, we had to consider two other 10 tradeoffs between utilization and fairness: first, whether to 0 kill tasks or wait for them to finish when new jobs are 5 Jobs 10 Jobs 20 Jobs 50 Jobs submitted, and second, how to achieve data locality. We Without Delay Scheduling With Delay Scheduling have proposed a simple strategy called delay scheduling that Figure 14: Finish times in sticky slots stress test. When delay achieves both fairness and locality by waiting for tasks to scheduling is not used, performance decreases as the number of finish. Two key aspects of the cluster environment enable jobs increases because data locality decreases. In contrast, finish delay scheduling to perform well: first, most tasks are short times with delay scheduling grow linearly with the number of jobs. compared to jobs, and second, there are multiple locations in which a task can run to read a given data block, because seconds. There was no rack locality because we do not have systems like Hadoop support multiple task slots per node. information about racks on EC2; however, rack locality will Delay scheduling performs well in environments where generally be much higher than node locality because there these two conditions hold, which include the Hadoop envi- are more slots per rack. Figure 15 shows the results. We see ronments at Yahoo! and Facebook. Delay scheduling will not that without delay scheduling, both 4-map jobs and 12-map be effective if a large fraction of tasks is much longer than jobs have poor locality (5% and 11%). Setting W1 as low as the average job, or if there are few slots per node. However, 1 second improves locality to 68% and 80% respectively. In- as cluster technology evolves, we believe that both of these creasing the delay to 5s achieves nearly perfect locality. Fi- factors will improve. First, making tasks short improves fault nally, with a 10s delay, we got 100% locality for the 4-map tolerance [18], so as clusters grow, we expect more develop- jobs and 99.8% locality for the 12-map jobs. ers to split their work into short tasks. Second, due to multi- 5.4 Scheduler Overhead core, cluster nodes are becoming “bigger” and can thus sup- In our 100-node experiments, HFS did not add any notice- port more tasks at once. In the same spirit, organizations are able scheduling overhead. To measure the performance of putting more disks per node – for example, Google used 12 HFS under a much heavier load, we used mock objects to disks per node in its petabyte sort benchmark [9]. Lastly, simulate a cluster with 2500 nodes and 4 slots per node (2 10 Gbps Ethernet will greatly increase network bandwidth map and 2 reduce), running a 100 jobs with 1000 map and within a rack, and may allow rack-local tasks to perform as 1000 reduce tasks each that were placed into 20 pools. Un- well as node-local tasks. This would increase the number of der this workload, HFS was able to schedule 3200 tasks per locations from which a task can efficiently access its input second on a 2.66 GHz Intel Core 2 Duo. This is several times block by an order of magnitude. more than is needed to manage cluster of this size running Because delay scheduling only involves being able to reasonably-sized tasks (e.g., if the average task length is 10s, skip jobs in a sorted order that captures “who should be there will only be 1000 tasks finishing per second). scheduled next,” we believe that it can be used in a variety of environments beyond Hadoop and HFS. We now discuss 6. Discussion several ways in which delay scheduling can be generalized. Underlying our work is a classic tradeoff between utilization Scheduling Policies other than Fair Sharing: Delay schedul- and fairness. In provisioning a cluster computing infrastruc- ing can be applied to any queuing policy that produces a ture, there is a spectrum between having a separate cluster sorted list of jobs. For example, in Section 5.2.2, we showed per user, which provides great fairness but poor utilization, that it can also double throughput under FIFO. and having a single FIFO cluster, which provides great uti-
13 .Scheduling Preferences other than Data Locality: Some While killing tasks may be the most effective way to jobs may prefer to run multiple tasks in the same location reassign resources in some situations, it wastes computation. rather than running each task near its input block. For exam- Our work shows that waiting for suitable slots to free up can ple, some Hadoop jobs have a large data file that is shared also be effective in a diverse real-world workload. One of by all tasks and is dynamically copied onto nodes that run the main differences between our environment and Quincy’s the job’s tasks using a feature called the distributed cache is that Hadoop has multiple task slots per node, while the [4, 12]. In this situation, the locality test in our algorithm system in [24] only ran one task per node. The probability can be changed to prefer running tasks on nodes that have that all slots with local copies of a data block are filled the cached file. To allow a cluster to be shared between jobs by long tasks (necessitating killing) decreases exponentially that want to reuse their slots and jobs that want to read data with the number of slots per node, as shown in Section 3.5.1. spread throughout the cluster, we can distribute tasks from Another important difference is that task lengths are much the former throughout the cluster using the load balancing shorter than job lengths in typical Hadoop workloads. mechanism proposed for long tasks in Section 3.5.1. At first sight, it may appear that Quincy uses more infor- mation about the cluster than HFS, and hence should make Load Management Mechanisms other than Slots: Tasks better scheduling decisions. However, HFS also uses infor- in a cluster may have heterogeneous resource requirements. mation that is not used by Quincy: delay scheduling is based To improve utilization, the number of tasks supported on a on knowledge about the rate at which slots free up. Instead node could be varied dynamically based on its load rather of making scheduling decisions based on point snapshots of than being fixed as in Hadoop. As long as each job has the state of the cluster, we take into account the fact that a roughly equal chance of being scheduled on each node, many tasks will finish in the near future. delay scheduling will be able to achieve data locality. Finally, delay scheduling is simpler than the optimiza- tion approach in Quincy, which makes it easy to use with Distributed Scheduling Decisions: We have also imple- scheduling policies other than fair sharing, as we do in HFS. mented delay scheduling in Nexus [22], a two-level cluster scheduler that allows multiple instances of Hadoop, or of High Performance Computing (HPC): Batch schedulers other cluster computing frameworks, to coexist on a shared for HPC clusters, like Torque [13], support job priority and cluster. In Nexus, a master process from each framework resource-consumption-aware scheduling. However, HPC registers with the Nexus master to receive slots on the clus- jobs run on a fixed number of machines, so it is not possible ter. The Nexus master schedules slots by making “slot of- to change jobs’ allocations over time as we do in Hadoop fers” to the appropriate framework (using fair sharing), but to achieve fair sharing. HPC jobs are also usually CPU or frameworks are allowed to reject an offer to wait for a slot communication bound, so there is less need for data locality. with better data locality. We have seen locality improve- Grids: Grid schedulers like Condor [28] support locality ments similar to those in Section 5 when running multiple constraints, but usually at the level of geographic sites, be- instances of Hadoop on Nexus with delay scheduling. The cause the jobs are more compute-intensive than MapReduce. fact that high data locality can be achieved in a distributed Recent work also proposes replicating data across sites on fashion provides significant practical benefits: first, multiple demand [17]. Similarly, in BAD-FS [16], a workload sched- isolated instances of Hadoop can be run to ensure that ex- uler manages distribution of data across a wide-area network perimental jobs do not crash the instance that runs produc- to dedicated storage servers in each cluster. Our work instead tion jobs; second, multiple versions of Hadoop can coexist; focuses on task placement in a local-area cluster where data and lastly, organizations can use multiple cluster computing is stored on the same nodes that run jobs. frameworks and pick the best one for each application. Parallel Databases: Like MapReduce, parallel databases 7. Related Work run data-intensive workloads on a cluster. However, database queries are usually executed as long-running processes Scheduling for Data-Intensive Cluster Applications: The rather than short tasks like Hadoop’s, reducing the opportu- closest work we know of to our own is Quincy [24], a fair nity for fine-grained sharing. Much like in HPC schedulers, scheduler for Dryad. Quincy also tackles the conflict be- queries must wait in a queue to run [6], and a single “mon- tween locality and fairness in scheduling, but uses a very ster query” can take up the entire system [11]. Reservations different mechanism from HFS. Each time a scheduling de- can be used used to avoid starving interactive queries when cision needs to be made, Quincy represents the scheduling a batch query is running [6], but this leads to underutiliza- problem as an optimization problem, in which tasks must be tion when there are no interactive queries. In contrast, our matched to nodes and different assignments have different Hadoop scheduler can assign all resources to a batch job and costs based on locality and fairness. Min-cost flow is used reassign slots rapidly when interactive jobs are launched. to solve this problem. Quincy then kills some of the running tasks and launches new tasks to place the cluster in the con- Fair Sharing: A plethora of fair sharing algorithms have figuration returned by the flow solver. been developed in the networking and OS domains [7, 19,
14 .25, 30]. Many of these schedulers have been extend to the [12] Personal communication with Owen O’Malley of the Yahoo! hierarchical setting [15, 20, 27, 29]. While these algorithms Hadoop team. are sophisticated and scalable, they do not deal with data [13] TORQUE Resource Manager. locality, as they share only one resource. http://www.clusterresources.com/pages/products/ torque-resource-manager.php. 8. Conclusion [14] Yahoo! Launches New Program to Advance Open-Source Software for Internet Computing. http://research. As data-intensive cluster computing systems like MapRe- yahoo.com/node/1879. duce and Dryad grow in popularity, there is a strong need [15] J. Bennett and H. Zhang. WF2 Q: Worst-case fair weighted to share clusters between users. To multiplex clusters ef- fair queueing. In IEEE INFOCOM’96, pages 120–128, 1996. ficiently, a scheduler must take into account both fairness [16] J. Bent, D. Thain, A. C. Arpaci-Dusseau, R. H. Arpaci- Dusseau, and M. Livny. Explicit control in a batch-aware dis- and data locality. We have shown that strictly enforcing fair- tributed file system. In NSDI’04, 2004. ness leads to a loss of locality. However, it is possible to [17] A. Chervenak, E. Deelman, M. Livny, M.-H. Su, R. Schuler, achieve nearly 100% locality by relaxing fairness slightly, S. Bharathi, G. Mehta, and K. Vahi. Data Placement for using a simple algorithm called delay scheduling. We have Scientific Applications in Distributed Environments. In Proc. implemented delay scheduling in HFS, a fair scheduler for 8th IEEE/ACM International Conference on Grid Computing Hadoop, and shown that it can improve response times for (Grid 2007), September 2007. small jobs by 5x in a multi-user workload, and can double [18] J. Dean and S. Ghemawat. MapReduce: Simplified Data throughput in an IO-heavy workload. HFS is open source Processing on Large Clusters. Commun. ACM, and included in Hadoop: an older version without delay 51(1):107–113, 2008. scheduling is in Hadoop 0.20, and a version with all the fea- [19] A. Demers, S. Keshav, and S. Shenker. Analysis and simula- tures described in this paper will appear in Hadoop 0.21. tion of a fair queueing algorithm. In Journal of Internetwork- ing Research and Experience, pages 3–26, 1990. [20] S. Floyd and V. Jacobson. Link-sharing and resource manage- 9. Acknowledgements ment models for packet networks. IEEE/ACM Transactions We thank the Hadoop teams at Yahoo! and Facebook for on Networking, 3(4):365–386, 1995. the many informative discussions that guided this work. We [21] S. Ghemawat, H. Gobioff, and S.-T. Leung. The Google File are also grateful to our shepherd, Jim Larus, whose input System. In Proc. SOSP 2003, pages 29–43, 2003. greatly improved this paper. In addition, Joe Hellerstein and [22] B. Hindman, A. Konwinski, M. Zaharia, and I. Stoica. A common substrate for cluster computing. In Workshop on Hot Hans Zeller referred us to related work in database systems. Topics in Cloud Computing (HotCloud) 2009, 2009. This research was supported by California MICRO, Cali- [23] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: fornia Discovery, the Natural Sciences and Engineering Re- Distributed data-parallel programs from sequential building search Council of Canada, as well as the following Berkeley blocks. In EuroSys 2007, pages 59–72, 2007. RAD Lab sponsors: Sun Microsystems, Google, Microsoft, [24] M. Isard, V. Prabhakaran, J. Currey, U. Wieder, K. Talwar, Amazon, Cisco, Cloudera, eBay, Facebook, Fujitsu, HP, In- and A. Goldberg. Quincy: Fair scheduling for distributed tel, NetApp, SAP, VMware, and Yahoo!. computing clusters. In SOSP 2009, 2009. [25] J. Nieh and M. S. Lam. A SMART scheduler for multimedia References applications. ACM TOCS, 21(2):117–163, 2003. [26] A. Pavlo, E. Paulson, A. Rasin, D. J. Abadi, D. J. DeWitt, [1] Amazon EC2. http://aws.amazon.com/ec2. S. Madden, and M. Stonebraker. A comparison of approaches [2] Apache Hadoop. http://hadoop.apache.org. to large-scale data analysis. In SIGMOD ’09, 2009. [3] Apache Hive. http://hadoop.apache.org/hive. [27] I. Stoica, H. Zhang, and T. Ng. A hierarchical fair service [4] Hadoop Map/Reduce tutorial. http://hadoop.apache. curve algorithm for link-sharing, real-time and priority ser- org/common/docs/current/mapred tutorial.html. vice. In SIGCOMM’97, pages 162–173, Sept. 1997. [5] Hive performance benchmarks. http://issues.apache. [28] D. Thain, T. Tannenbaum, and M. Livny. Distributed com- org/jira/browse/HIVE-396. puting in practice: the Condor experience. Concurrency [6] HP Neoview Workload Management Services Guide. and Computation Practice and Experience, 17(2-4):323–356, http://www.docs.hp.com/en/544806-001/ 2005. Neoview WMS Guide R2.3.pdf. [29] C. A. Waldspurger. Lottery and Stride Scheduling: Flexible [7] Max-Min Fairness (Wikipedia). Proportional-Share Resource Management. PhD thesis, MIT, http://en.wikipedia.org/wiki/Max-min fairness. Laboratory of Computer Science, 1995. MIT/LCS/TR-667. [8] NSF Cluster Exploratory (CluE) Program Solicitation. [30] C. A. Waldspurger and W. E. Weihl. Lottery scheduling: http://nsf.gov/pubs/2008/nsf08560/nsf08560.htm. Flexible proportional-share resource management. In Proc. [9] Official Google Blog: Sorting 1PB with MapReduce. OSDI 94, 1994. http://googleblog.blogspot.com/2008/11/ sorting-1pb-with-mapreduce.html. [10] Open Cirrus. http://www.opencirrus.org. [11] Personal communication with Hans Zeller of HP.
3秒后跳转登录页面
去登陆

