
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Infrastructure for Usable Machine Learning
Despite incredible recent advances in machine learning, building machine learning applications remains prohibitively time-consuming and expensive for all but the best-trained, best-funded engineering organizations. This expense comes not from a need for new and improved statistical models but instead from a lack of systems and tools for supporting end-to-end machine learning application development, from data preparation and labeling to productionization and monitoring. In this document, we outline opportunities for infrastructure supporting usable, end-to-end machine learning applications in the context of the nascent DAWN (Data Analytics for What's Next) project at Stanford.
展开查看详情
1 .Research Faculty Summit 2018 Systems | Fueling future disruptions
2 .Infrastructure for Usable Machine Learning Matei Zaharia Stanford DAWN
3 . It’s the Golden Age of ML * Incredible advances in image recognition, natural language, planning, information retrieval Society-scale impact: self-driving cars, real-time translation, personalized medicine *for the best-funded, best-trained engineering teams
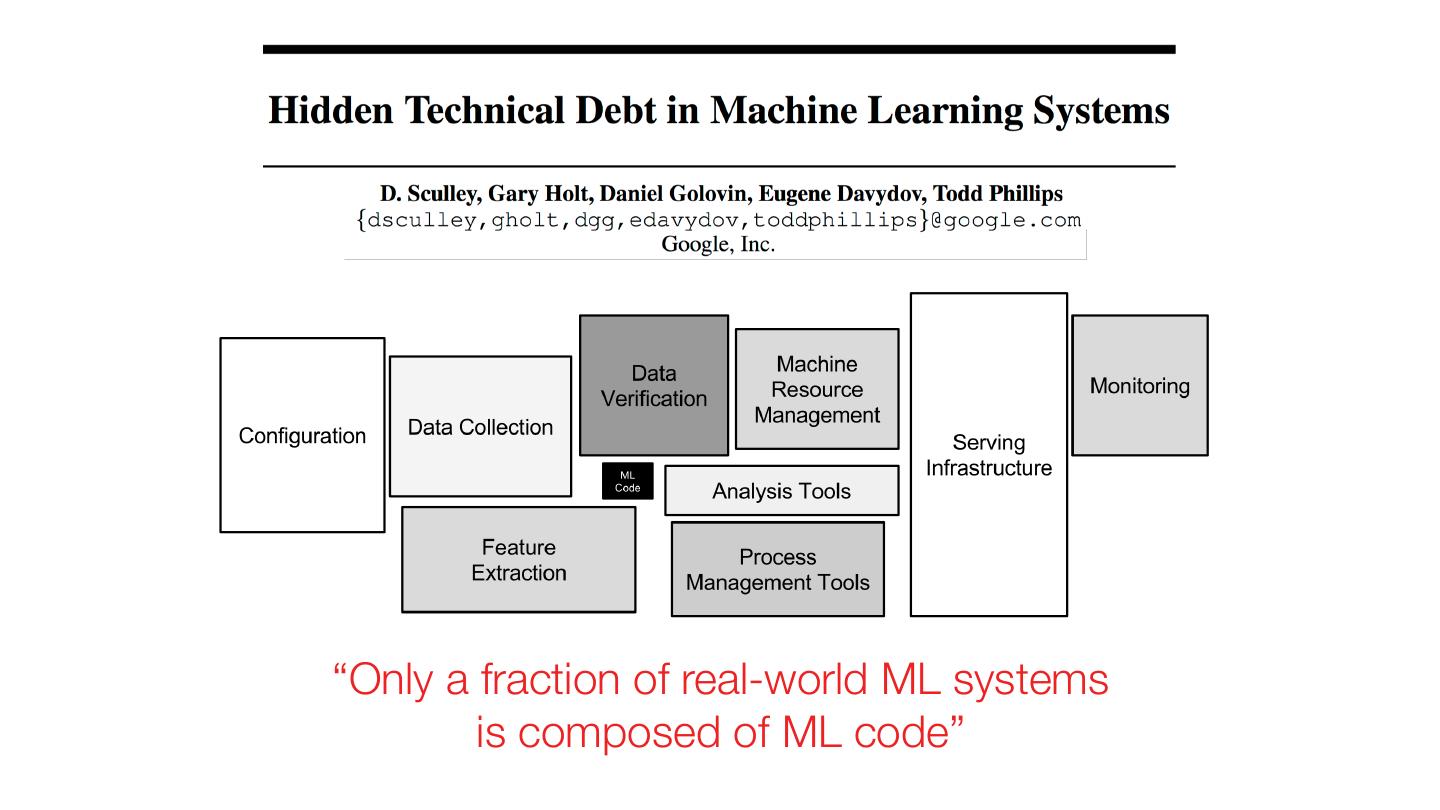
4 . Building ML Products is Too Hard Major successes (e.g., Siri, Alexa, Autopilot) require hundreds to thousands of engineers Most effort in data preparation, QA, debugging, productionization: not modeling! Domain experts can’t easily build ML products
5 .“Only a fraction of real-world ML systems is composed of ML code”
6 . The Stanford DAWN Project How can we enable any domain expert to build production-quality ML applications? • Without a PhD in machine learning • Without being an expert in systems • Without understanding the latest hardware Peter Bailis Chris Ré Kunle Olukotun Matei Zaharia
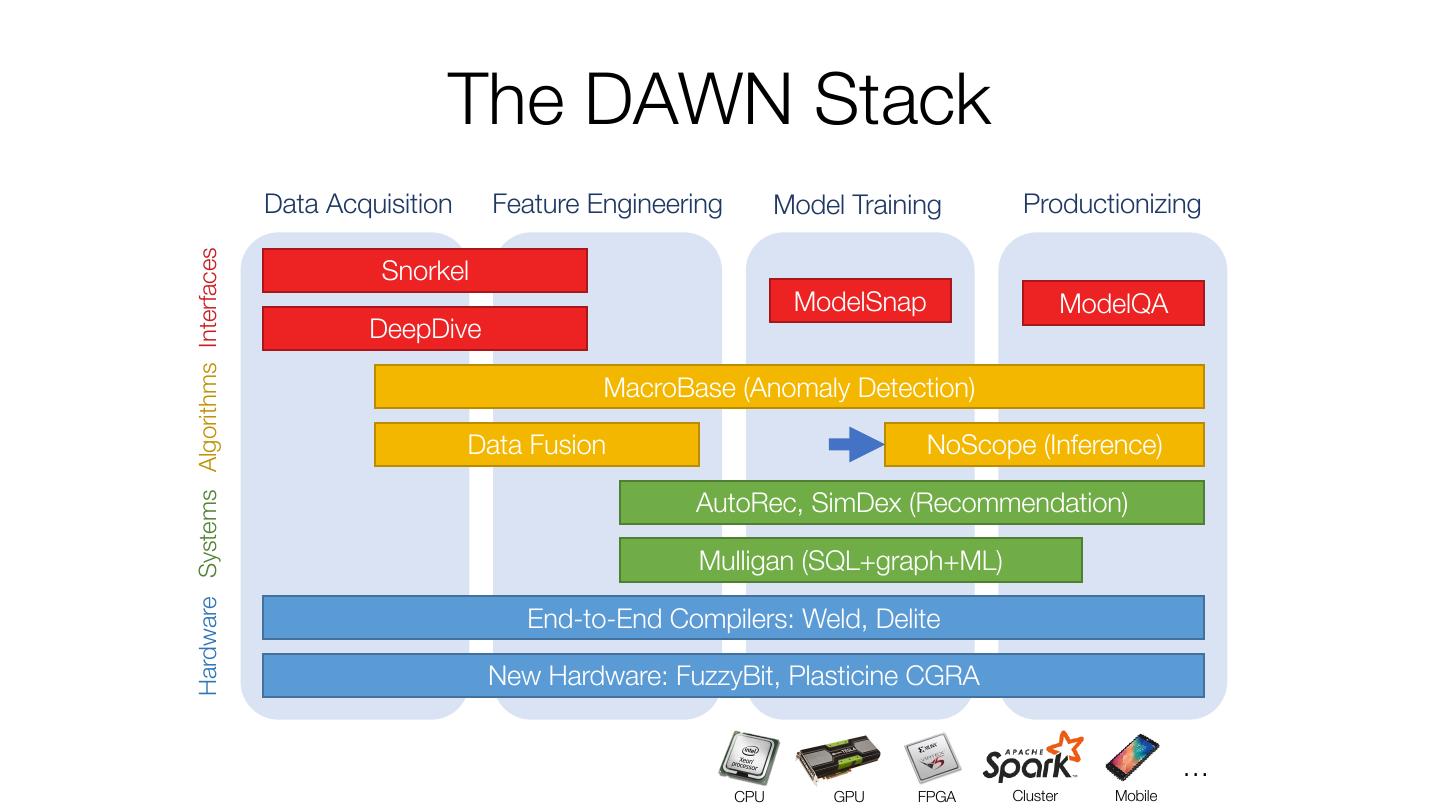
7 . The DAWN Stack Hardware Systems Algorithms Interfaces Data Acquisition Feature Engineering Model Training Productionizing Snorkel ModelSnap ModelQA DeepDive MacroBase (Streaming Data) Data Fusion NoScope (Video) AutoRec, SimDex (Recommendation) Mulligan (SQL+graph+ML) End-to-End Compilers: Weld, Delite New Hardware: FuzzyBit, Plasticine CGRA … CPU GPU FPGA Cluster Mobile
8 . Training Data is the Key to AI Image search, speech, games: labeled training data is cheap & easy to obtain Medicine, document understanding, fraud: labeled data requires expensive human experts! How can we leverage data that’s expensive to label at scale?
9 . Snorkel Project (Chris Ré): Labeling Functions, not Labels 1) User writes labeling functions: short programs that may not always give right label • E.g. regex to search in text 2) Snorkel simultaneously learns noise in LFs and a noise-aware target model (e.g. LSTM) System NCBI Disease CDR Disease CDR Chem. (F1) (F1) (F1) 4TaggerOne hours LF(Dogan, coding2012)* with bio experts: 81.5 match months 79.6 of hand-labeling 88.4 Snorkel: Logisticmodels high-quality Regression 79.1 from low-quality, 88.4 79.6 labeling functions scalable Snorkel: LSTM + Embeddings 79.2 80.4 88.2 NIPS ‘16, VLDB ‘18, github.com/HazyResearch/snorkel
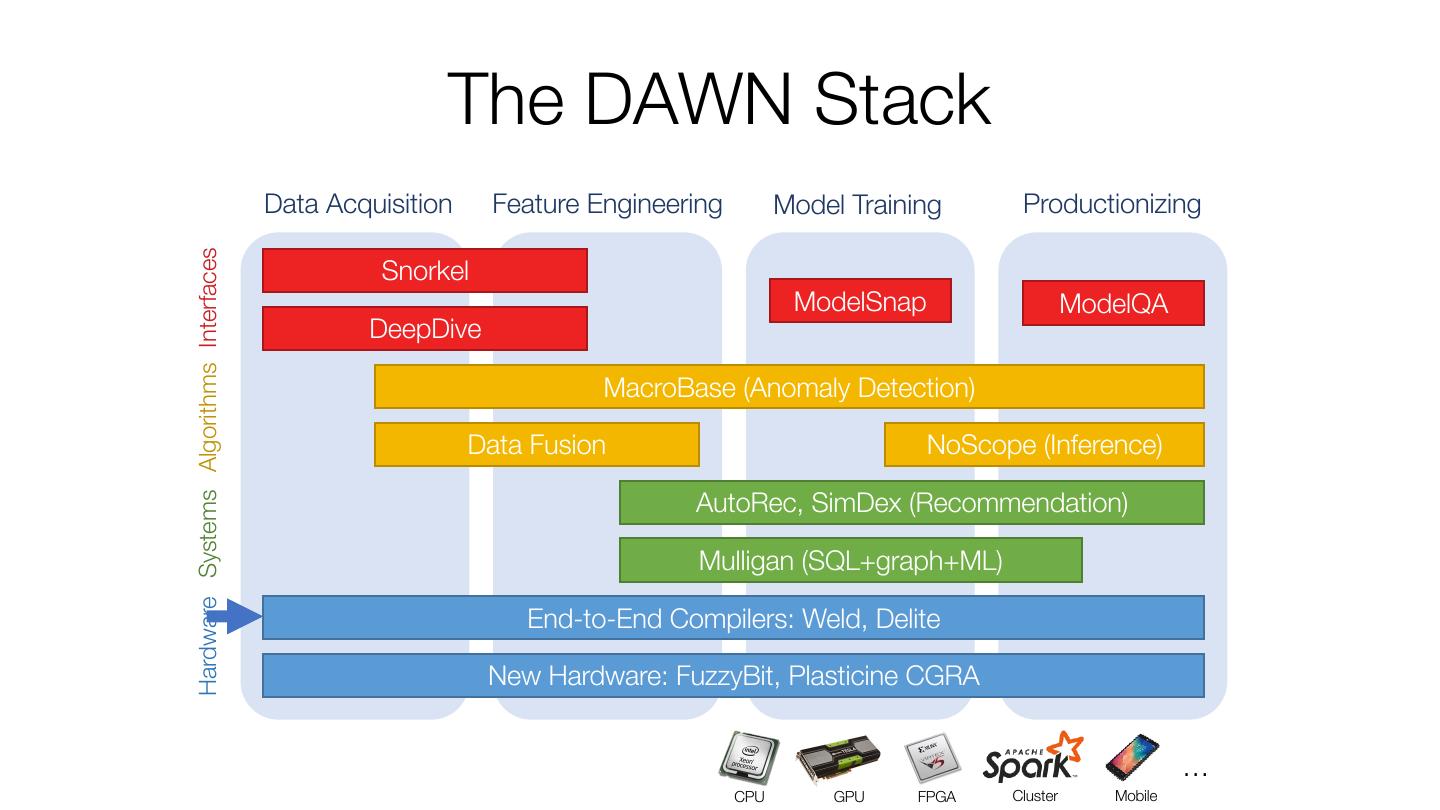
10 . The DAWN Stack Hardware Systems Algorithms Interfaces Data Acquisition Feature Engineering Model Training Productionizing Snorkel ModelSnap ModelQA DeepDive MacroBase (Anomaly Detection) Data Fusion NoScope (Inference) AutoRec, SimDex (Recommendation) Mulligan (SQL+graph+ML) End-to-End Compilers: Weld, Delite New Hardware: FuzzyBit, Plasticine CGRA … CPU GPU FPGA Cluster Mobile
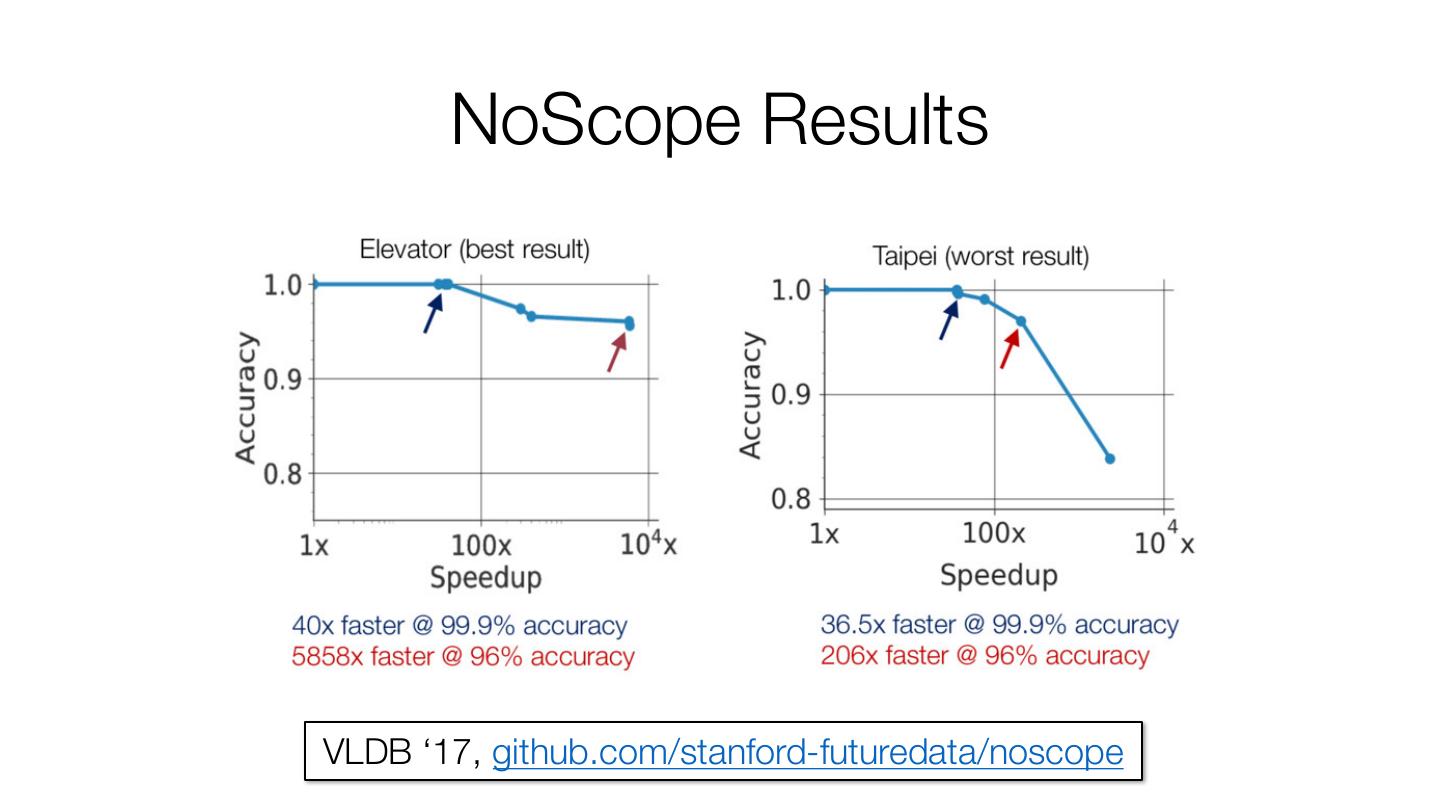
11 . NoScope: Fast CNN-Based Queries on Video Opportunity: CNNs allow more accurate queries on visual data than ever Challenge: processing 1 video stream in real time requires a $1000 GPU Result: 100-1000x faster with <1% loss in accuracy
12 . Key Idea: Model Specialization Given a target model and a query, train a Target Model much smaller specialized model Video When this model is unsure, call original Specific Frames Specialized Model + Cost-based optimizer to select an efficient model cascade
13 . NoScope Results VLDB ‘17, github.com/stanford-futuredata/noscope
14 . New Work: BlazeIt Query Engine Accelerates complex, SQL-like queries using model specialization + statistical techniques https://arxiv.org/abs/1805.01046
15 . The DAWN Stack Hardware Systems Algorithms Interfaces Data Acquisition Feature Engineering Model Training Productionizing Snorkel ModelSnap ModelQA DeepDive MacroBase (Anomaly Detection) Data Fusion NoScope (Inference) AutoRec, SimDex (Recommendation) Mulligan (SQL+graph+ML) End-to-End Compilers: Weld, Delite New Hardware: FuzzyBit, Plasticine CGRA … CPU GPU FPGA Cluster Mobile
16 . Composition in Data Apps ML app developers compose functions from dozens of high-level libraries • Python packages, Spark packages, R, …
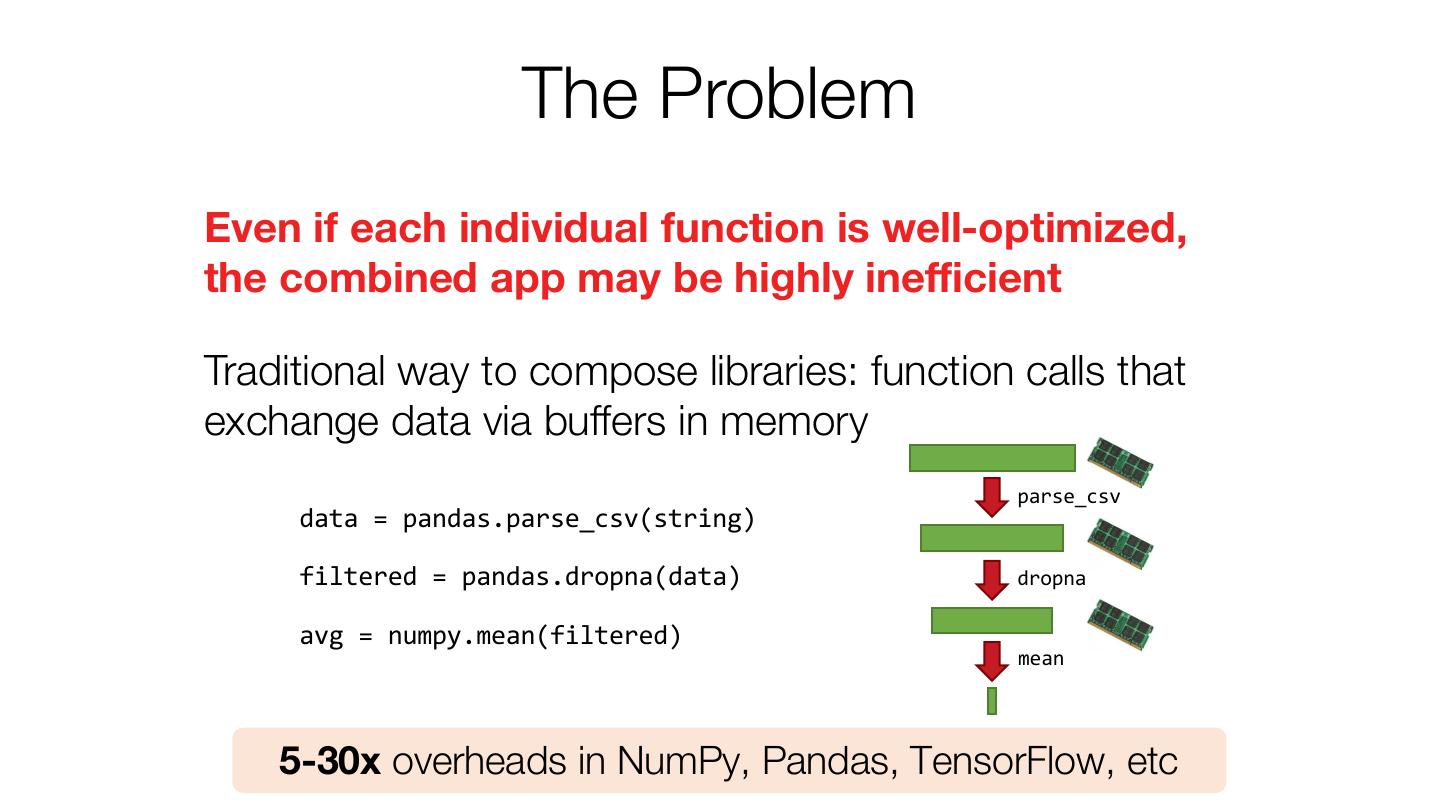
17 . The Problem Even if each individual function is well-optimized, the combined app may be highly inefficient Traditional way to compose libraries: function calls that exchange data via buffers in memory parse_csv data = pandas.parse_csv(string) filtered = pandas.dropna(data) dropna avg = numpy.mean(filtered) mean 5-30x overheads in NumPy, Pandas, TensorFlow, etc
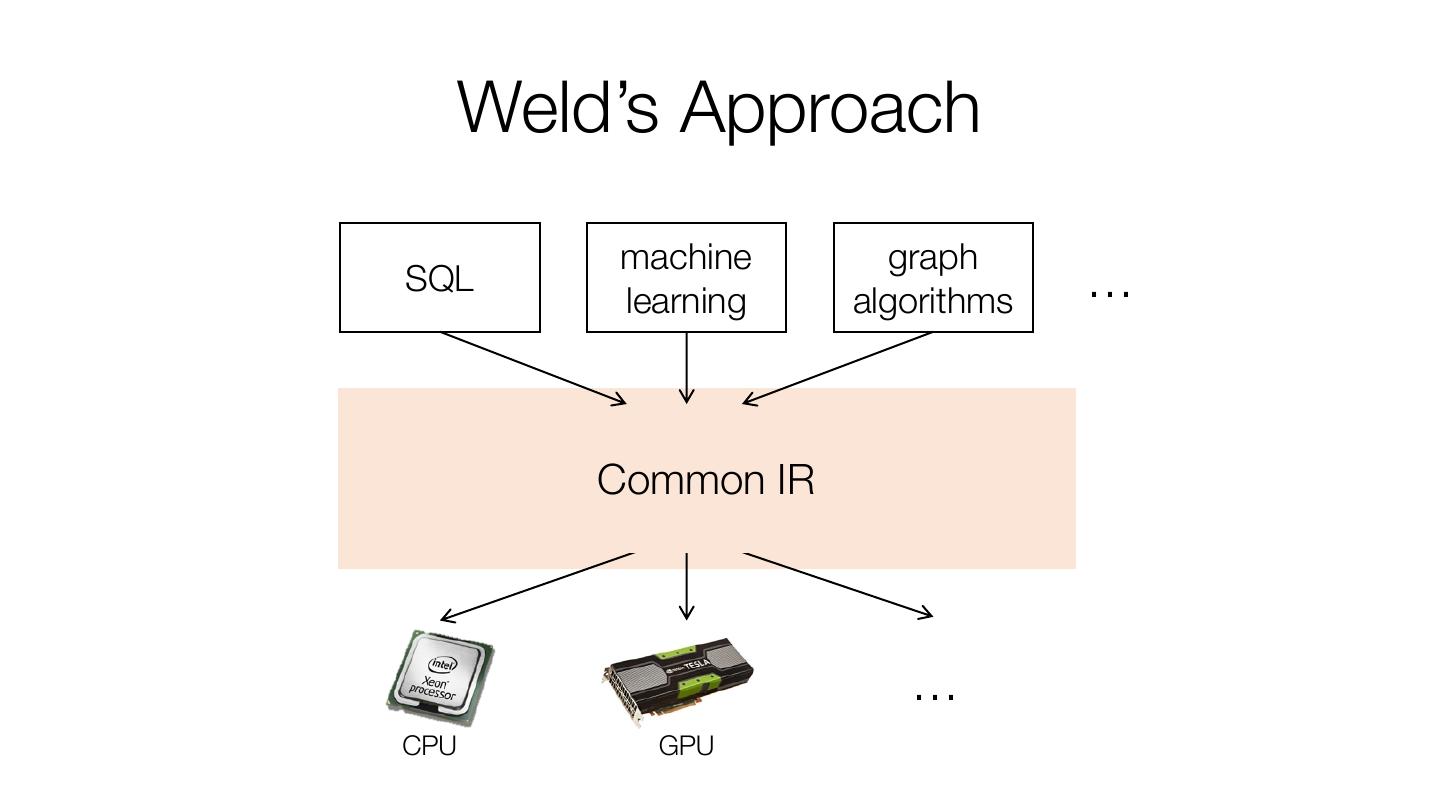
18 . Weld’s Approach machine graph SQL learning algorithms … Common IR … CPU GPU
19 . Results: Individual Libraries 45 0.2 1000 SparkSQL 0.18 TF Runtime [secs; log10] 40 Runtime [secs] Runtime [secs] Weld 0.16 Hand-opt 35 0.14 100 30 0.12 Weld 25 0.1 0.08 10 20 0.06 15 0.04 10 0.02 1 5 0 0 0.1 TPC-H Q1 TPC-H Q6 NP Weld 1 Core LR (1T) 12 Cores LR (12T) Workload NExpr Workload TPC-H Vector Sum Logistic Regression Porting ~10 common functions per library
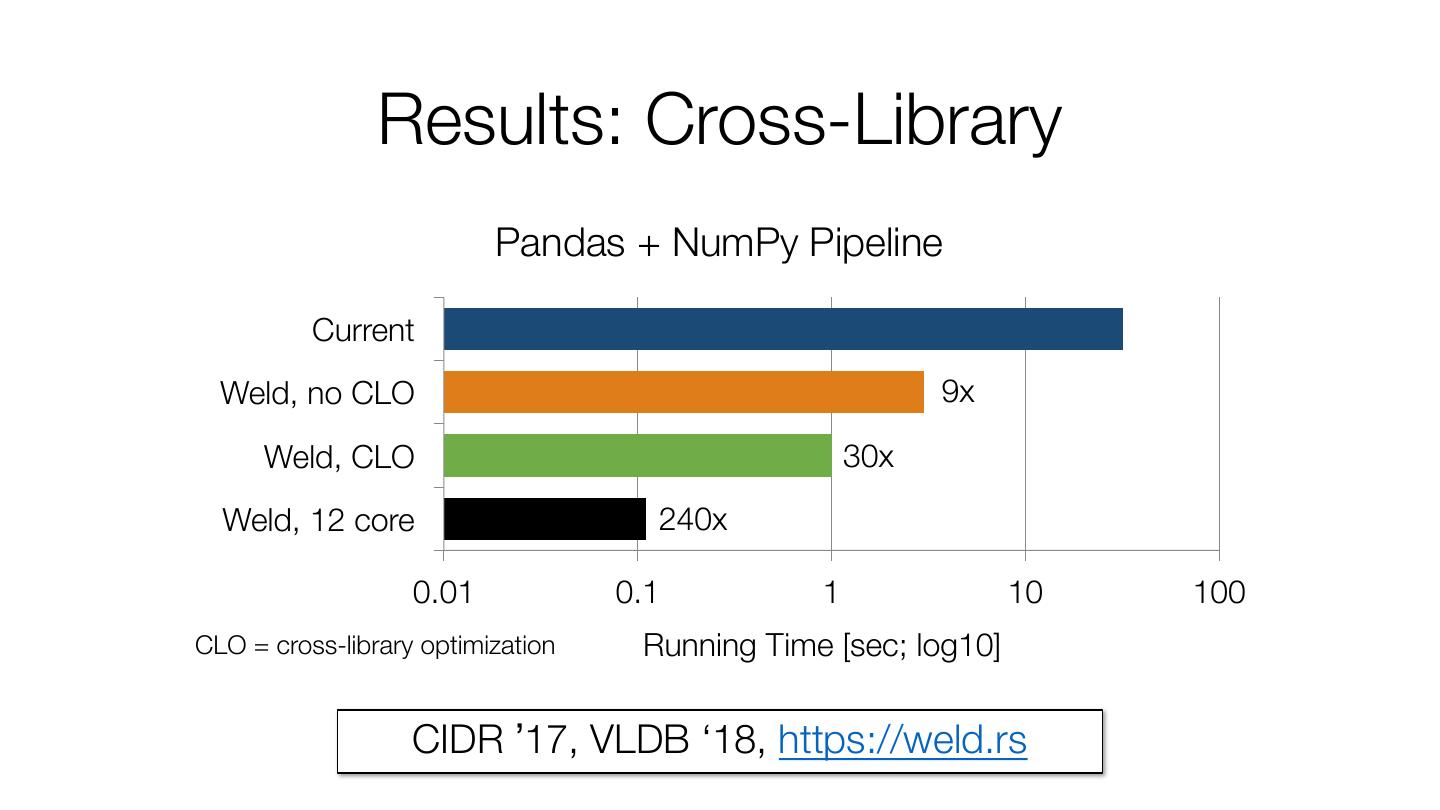
20 . Results: Cross-Library Pandas + NumPy Pipeline Current Weld, no CLO 9x Weld, CLO 30x Weld, 12 core 240x 0.01 0.1 1 10 100 CLO = cross-library optimization Running Time [sec; log10] CIDR ’17, VLDB ‘18, https://weld.rs
21 .“Weld without Weld”: Splittability Annotations Data movement optimization and auto parallelization for unmodified, black-box functions // @splittable MKL w/o SAs MKL w/SAs // (a: S, b: S, res: mut S) Runtime (sec, log10) void vdAdd(vec_t *a, 10 vdAdd(res, v1, res); vec_t *b, vdAdd(res, v2, res); vec_t *res); 1 vdAdd(res, v3, res); vdAdd(res, v4, res); 0.1 ... S: “split arrays the same way” 1 2 4 8 16 32 Threads 8x speedup Competitive performance to Weld without rewriting libraries!
22 .Machine Learning at Industrial Scale: ML Platforms
23 . ML at Industrial Scale: ML Platforms If you believe ML will be a key part of future products, what should be the development process for it? Today, ML development is ad-hoc: • Hard to track experiments: every data scientist has their own way • Hard to reproduce results: won’t happen by default • Difficult to share & manage models Need the equivalent of software dev platforms
24 . ML Platforms A new class of systems to manage the ML lifecycle Pioneered by company-specific platforms: Facebook FBLearner, Uber Michelangelo, Google TFX, etc + Standardize the data prep / training / deploy loop: if you work with the platform, you get these! – Limited to a few algorithms or frameworks – Tied to one company’s infrastructure
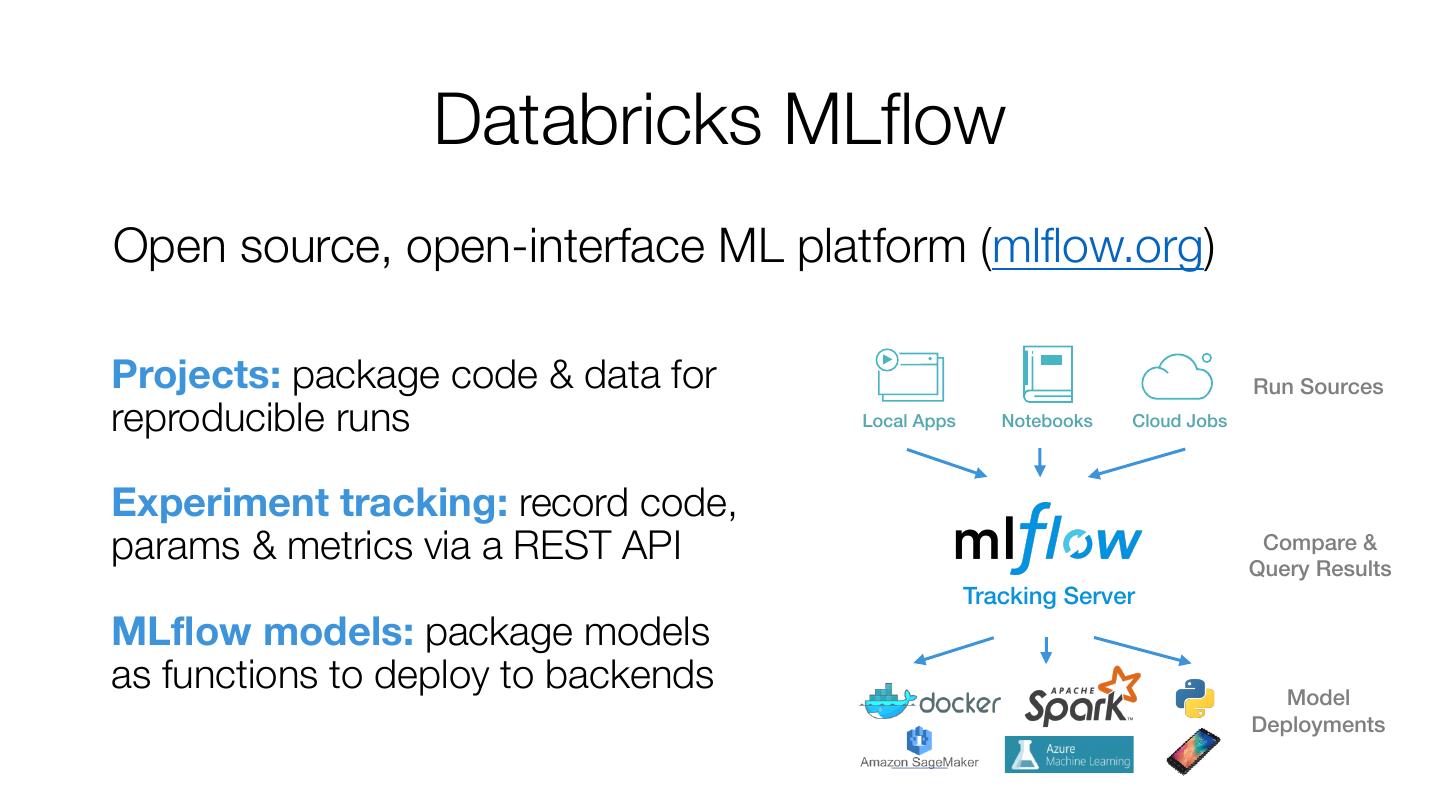
25 . Databricks MLflow Open source, open-interface ML platform (mlflow.org) Projects: package code & data for Run Sources reproducible runs Local Apps Notebooks Cloud Jobs Experiment tracking: record code, params & metrics via a REST API Compare & Query Results Tracking Server MLflow models: package models as functions to deploy to backends Model Deployments
26 . Databricks MLflow Open source, open-interface ML platform (mlflow.org) Projects: package code & data for Run Sources reproducible runs Local Apps Notebooks Cloud Jobs Experiment tracking: record code, params & metrics via a REST API Compare & Query Results Tracking Server MLflow models: package models as functions to deploy to backends Many open questions left in designing such platforms! Model Deployments
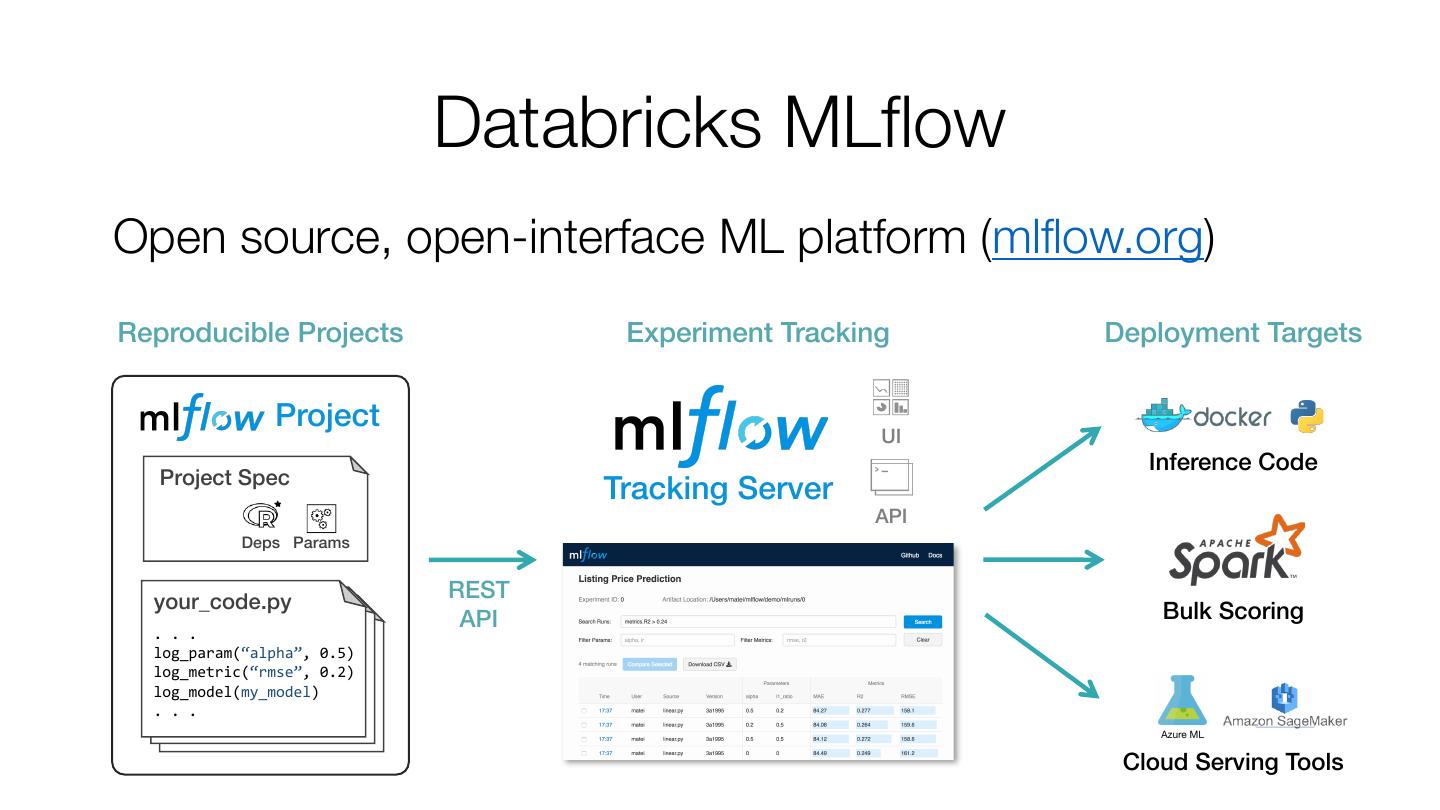
27 . Databricks MLflow Open source, open-interface ML platform (mlflow.org) Reproducible Projects Experiment Tracking Deployment Targets Project UI Inference Code Project Spec Tracking Server API Deps Params your_code.py REST API Bulk Scoring . . . log_param(“alpha”, 0.5) log_metric(“rmse”, 0.2) log_model(my_model) . . . Cloud Serving Tools
28 . Databricks MLflow Open source, open-interface ML platform (mlflow.org) Reproducible Projects Experiment Tracking Deployment Targets Project UI Inference Code Project Spec Tracking Server API Deps Params your_code.py REST API Bulk Scoring . . . Many open questions left in designing such platforms! log_param(“alpha”, 0.5) log_metric(“rmse”, 0.2) log_model(my_model) . . . Cloud Serving Tools
29 . Conclusion The limiting factors for ML adoption are in dev and productionization tools, not training algorithms Many of these are still very unexplored in research! Follow DAWN for our research in this area: dawn.cs.stanford.edu
3秒后跳转登录页面
去登陆

