








































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Writing Continuous Applications with Structured Streaming in PyS
PyData的热门讲座,Jules科普如何用PySpark来实现实时应用!PPT通俗易懂,最棒的是他用Jupyter Notebook给的例子,有简单的流处理,有实时智能预测,有事件处理。。。直接就上手,立马简历上就可以放上新技能!!!流处理,就是这么简单!https://github.com/dmatrix/spark-saturday/tree/master/dbcs/pydata_miami/jupyter
展开查看详情
1 . https://dbricks.co/tutorial-pydata-miami WiFi: CIC or CIC-A Enter your cluster name Use DBR 5.0 and Apache Spark 2.4, Scala 2.11 Choose Python 3 1
2 .Writing Continuous Applications with Structured Streaming in PySpark Jules S. Damji PyData, Miami, FL Jan 11, 2019
3 .I have used Apache Spark 2.x Before…
4 .Apache Spark Community & Developer Advocate @ Databricks Developer Advocate @ Hortonworks Software engineering @ Sun Microsystems, Netscape, @Home, VeriSign, Scalix, Centrify, LoudCloud/Opsware, ProQuest Program Chair Spark + AI Summit https://www.linkedin.com/in/dmatrix @2twitme
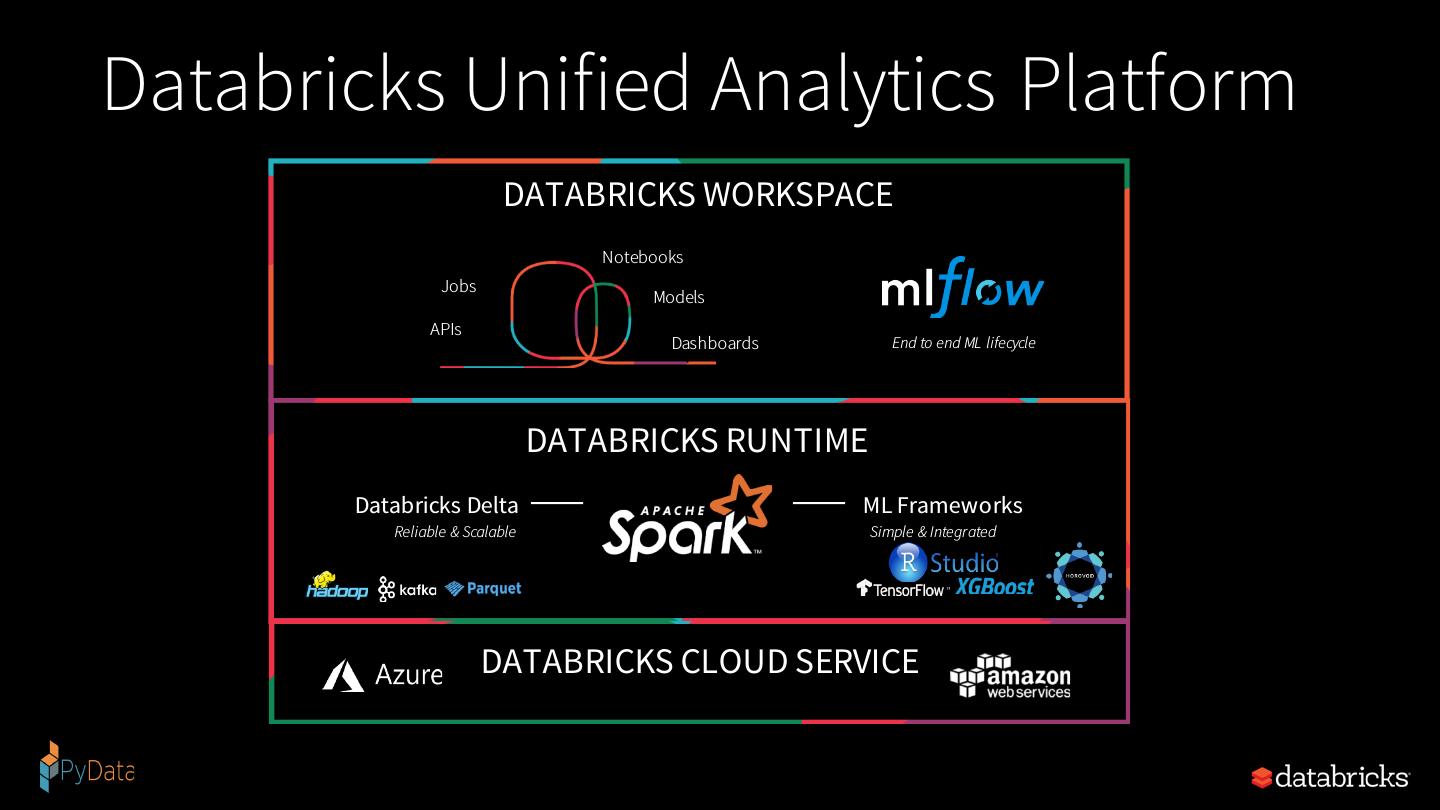
5 .Databricks Unified Analytics Platform DATABRICKS WORKSPACE Notebooks Jobs Models APIs Dashboards End to end ML lifecycle DATABRICKS RUNTIME Databricks Delta ML Frameworks Reliable & Scalable Simple & Integrated DATABRICKS CLOUD SERVICE
6 .Agenda for Today’s Talk • What and Why Apache Spark • Why Streaming Applications are Difficult • What’s Structured Streaming • Anatomy of a Continunous Application • Tutorials & Demo •Q&A
7 .How to think about data in 2019 - 2020 “Data is the new oil"
8 .What’s Apache Spark & Why
9 .What is Apache Spark? • General cluster computing engine Streaming SQL ML Graph DL that extends MapReduce • Rich set of APIs and libraries • Unified Engine • Large community: 1000+ orgs, clusters up to 8000 nodes … Apache Spark, Spark and Apache are trademarks of the Apache Software Foundation
10 .Unique Thing about Spark • Unification: same engine and same API for diverse use cases • Streaming, batch, or interactive • ETL, SQL, machine learning, or graph
11 .Why Unification?
12 .Why Unification? • MapReduce: a general engine for batch processing
13 .Big Data Systems Yesterday Pregel Giraph Dremel Millwheel MapReduce Storm Impala Drill S4 . . . General batch Specialized systems processing for new workloads Hard Hardto tomanage, combine tune, deploy in pipelines
14 .Big Data Systems Today Pregel Giraph MapReduce Dremel Millwheel Storm Impala Drill S4 . . . ? General batch Specialized systems Unified engine processing for new workloads
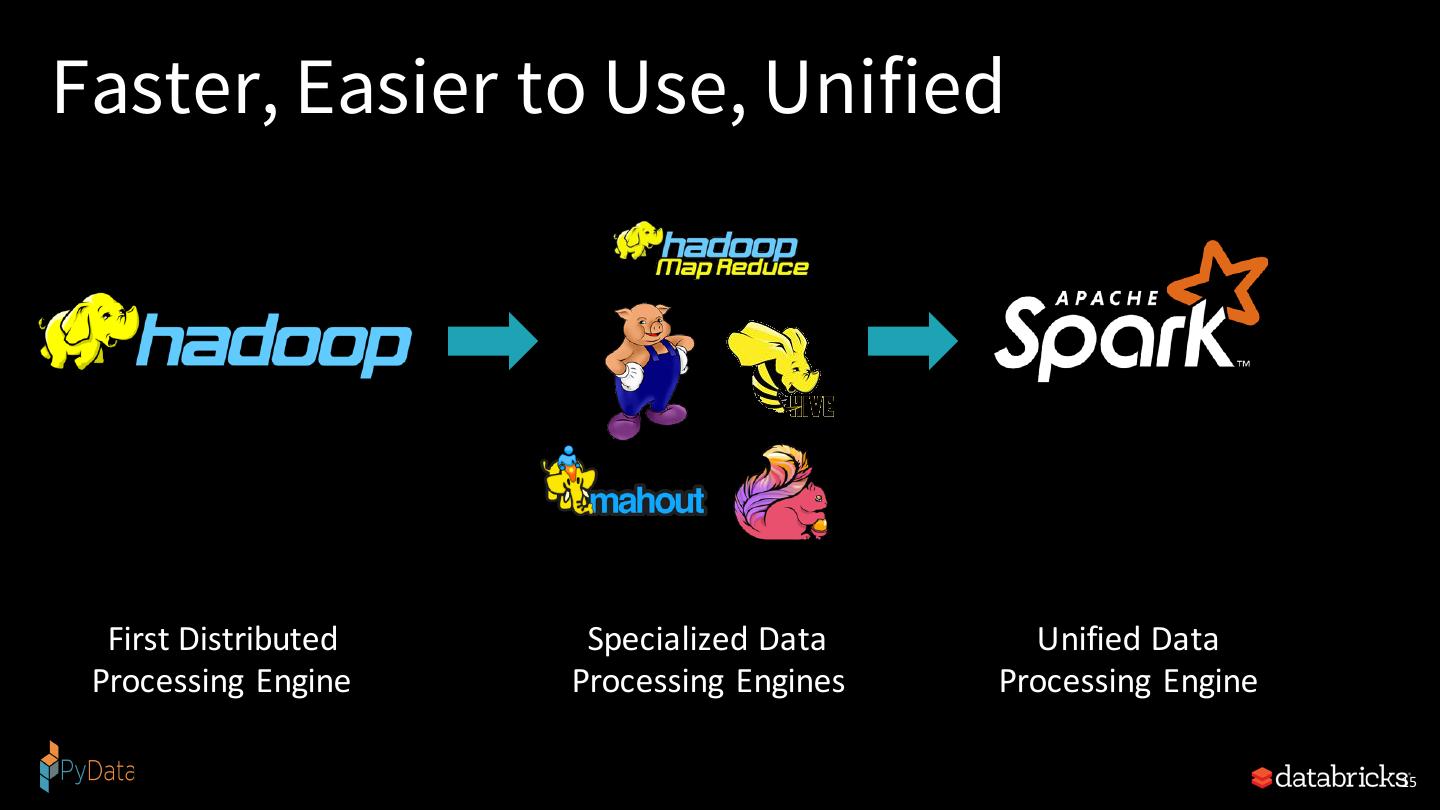
15 .Faster, Easier to Use, Unified First Distributed Specialized Data Unified Data Processing Engine Processing Engines Processing Engine 15
16 .Benefits of Unification 1. Simpler to use and operate 2. Code reuse: e.g. only write monitoring, FT, etc once 3. New apps that span processing types: e.g. interactive queries on a stream, online machine learning
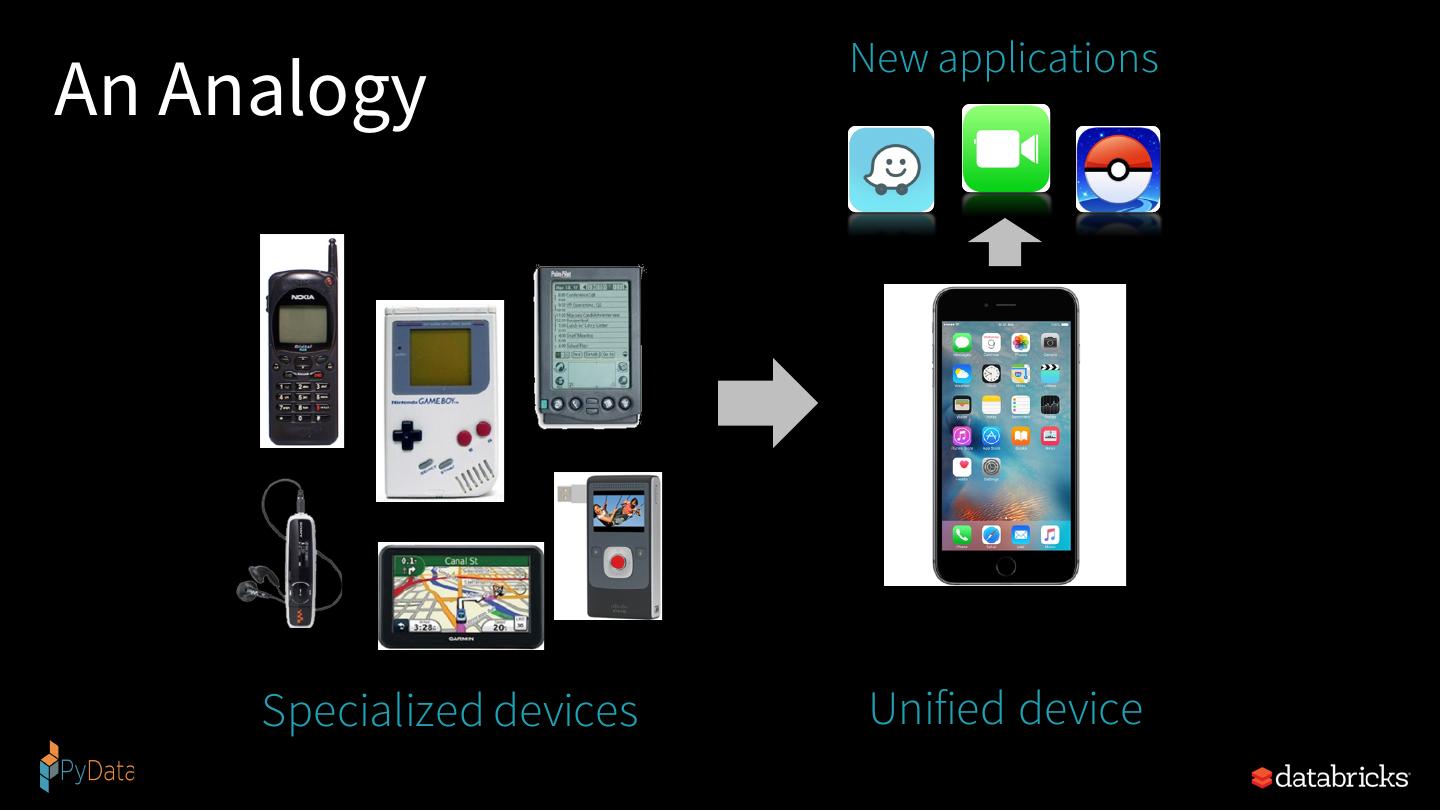
17 . New applications An Analogy Specialized devices Unified device
18 .Why Streaming Applications are Inherently Difficult?
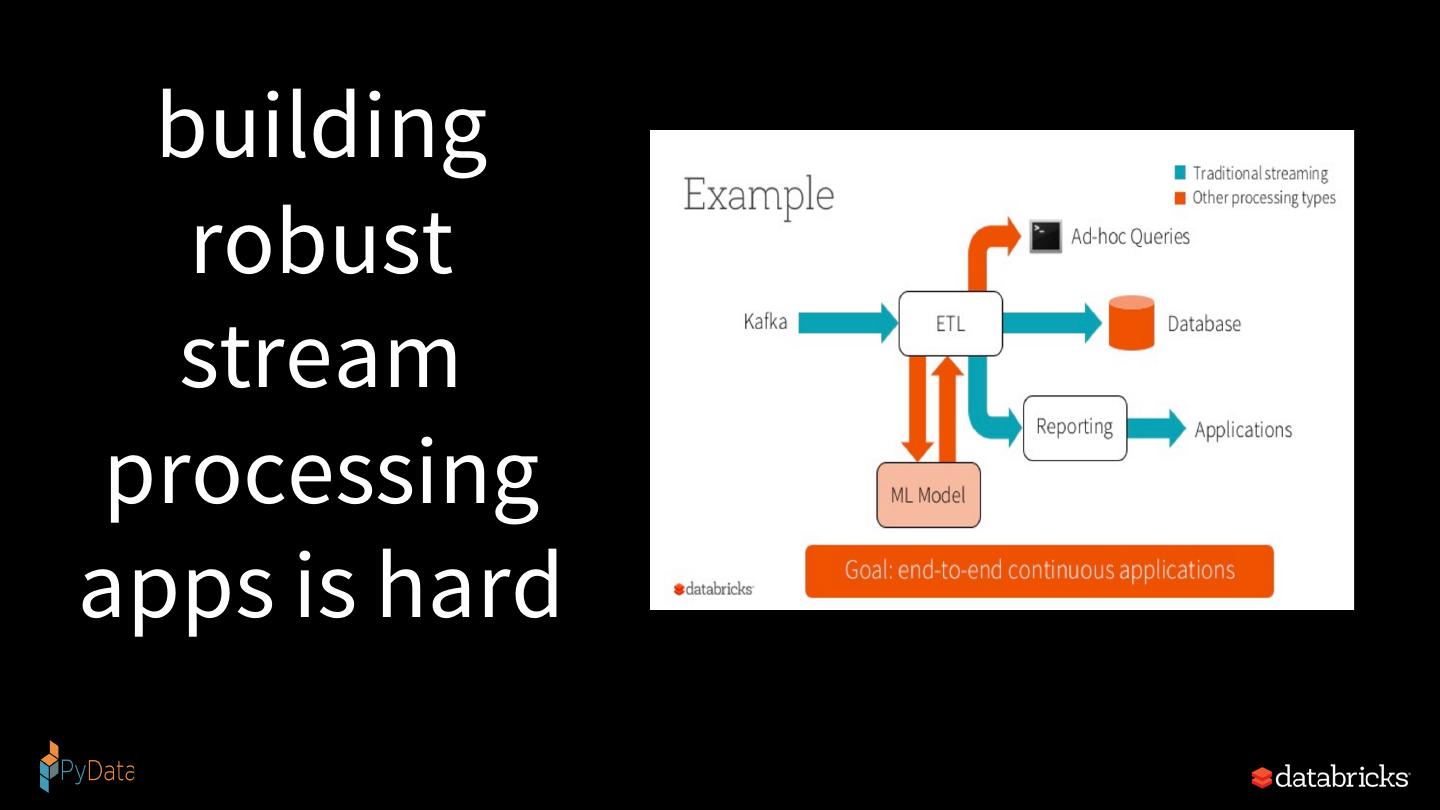
19 . building robust stream processing apps is hard
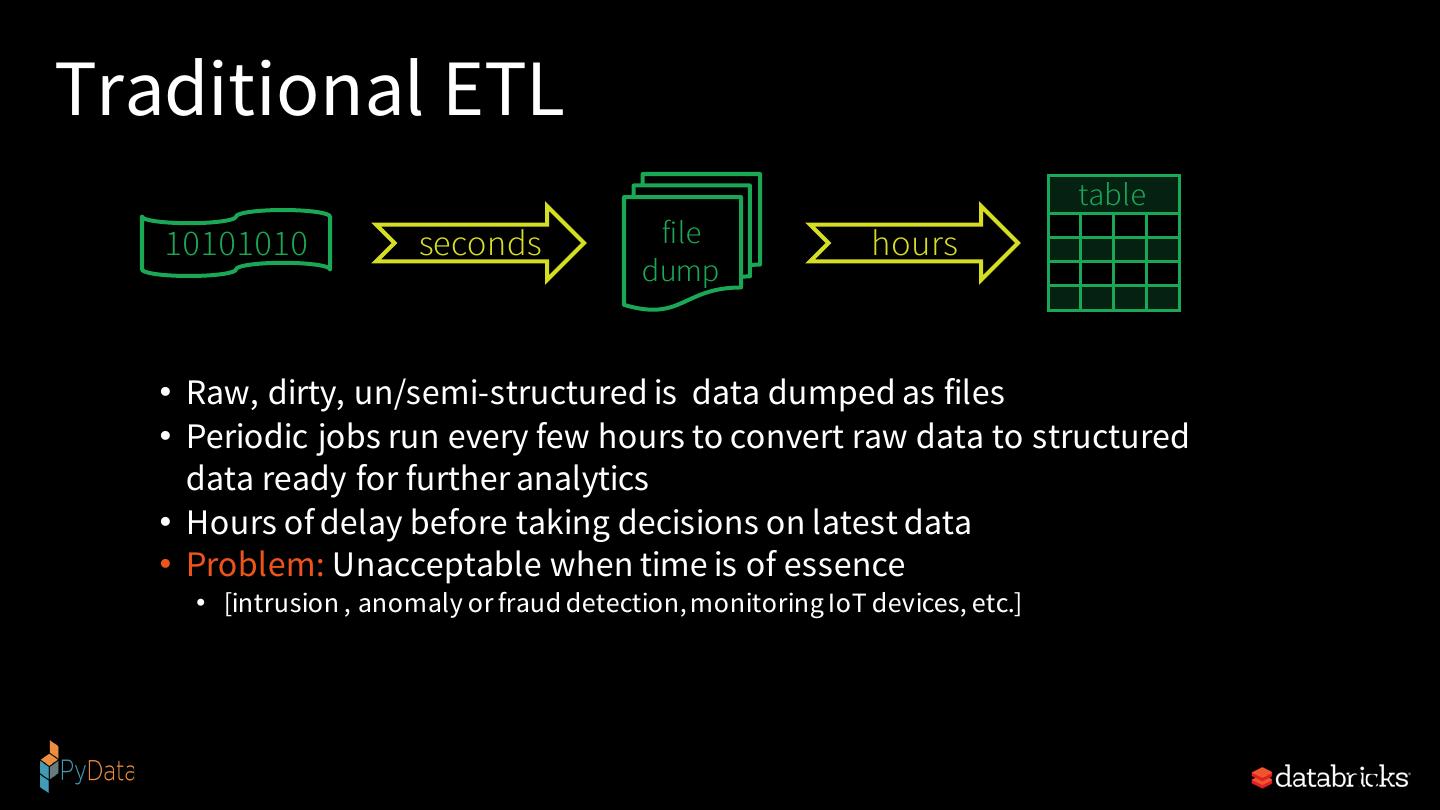
20 .Complexities in stream processing COMPLEX DATA COMPLEX WORKLOADS COMPLEX SYSTEMS Diverse data formats Combining streaming with Diverse storage systems (json, avro, txt, csv, binary, …) interactive queries (Kafka, S3, Kinesis, RDBMS, …) Data can be dirty, Machine learning System failures late, out-of-order
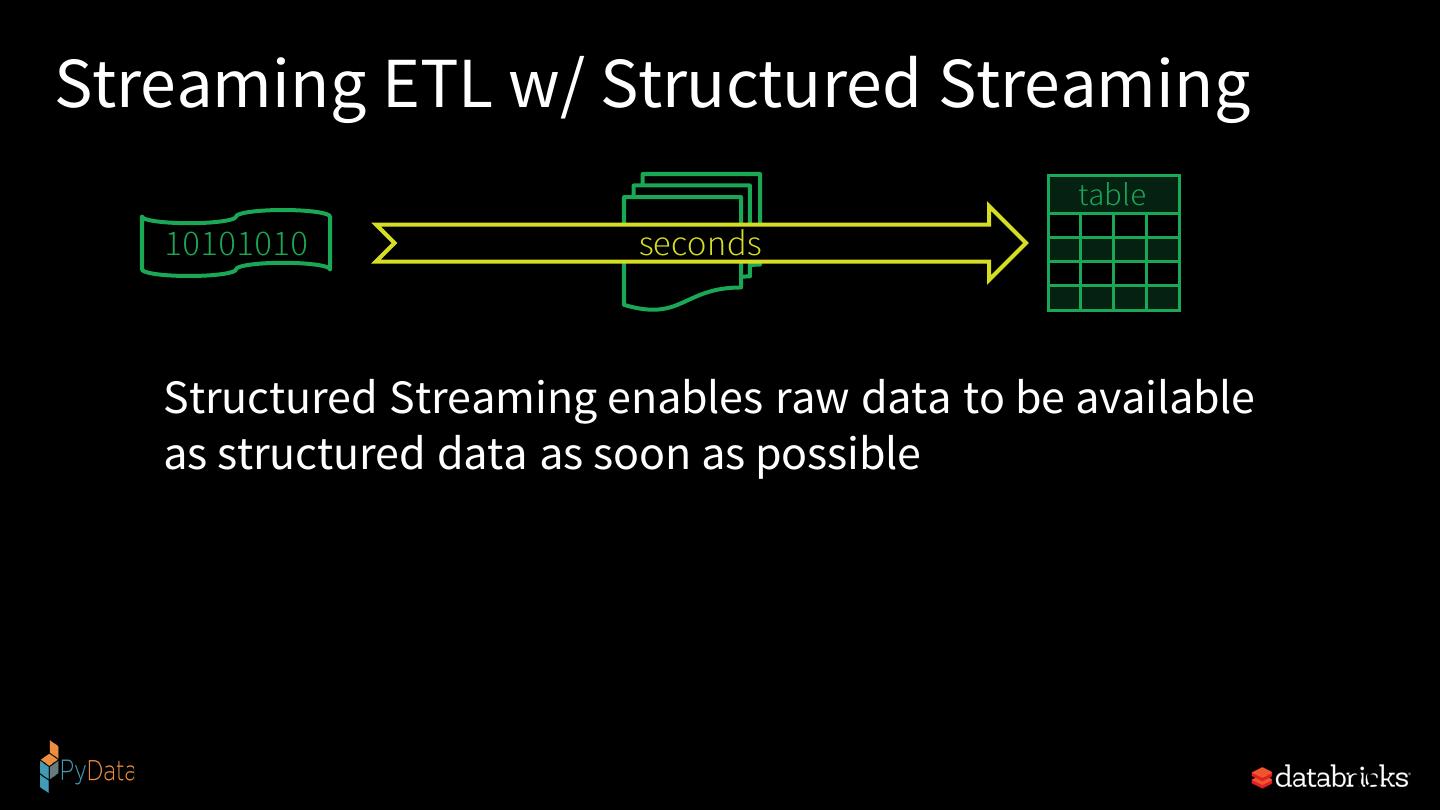
21 . Structured Streaming stream processing on Spark SQL engine fast, scalable, fault-tolerant rich, unified, high level APIs deal with complex data and complex workloads rich ecosystem of data sources integrate with many storage systems
22 . you should not have to reason about streaming
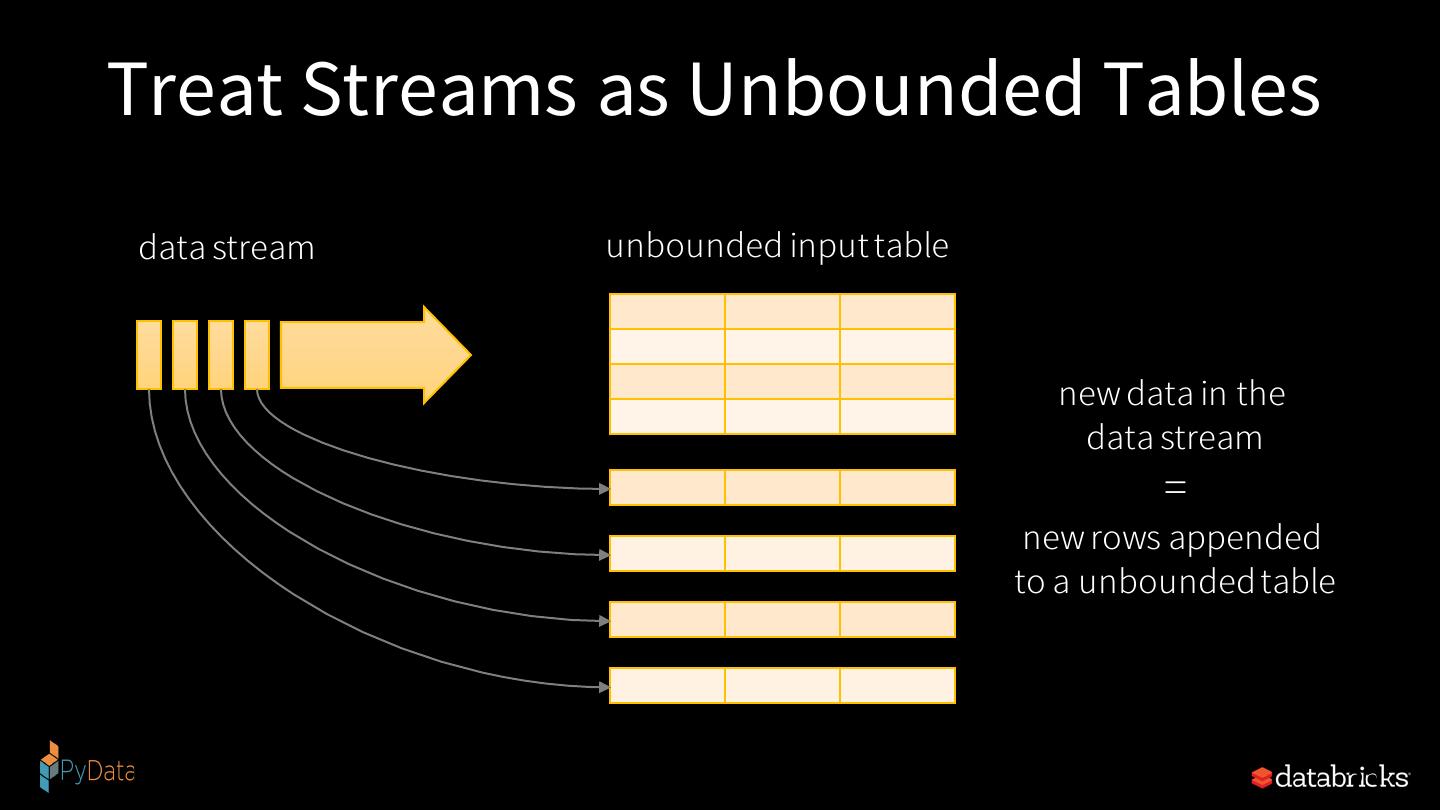
23 .Treat Streams as Unbounded Tables data stream unbounded input table new data in the data stream = new rows appended to a unbounded table 23
24 . you should write queries & Apache Spark should continuously update the answer
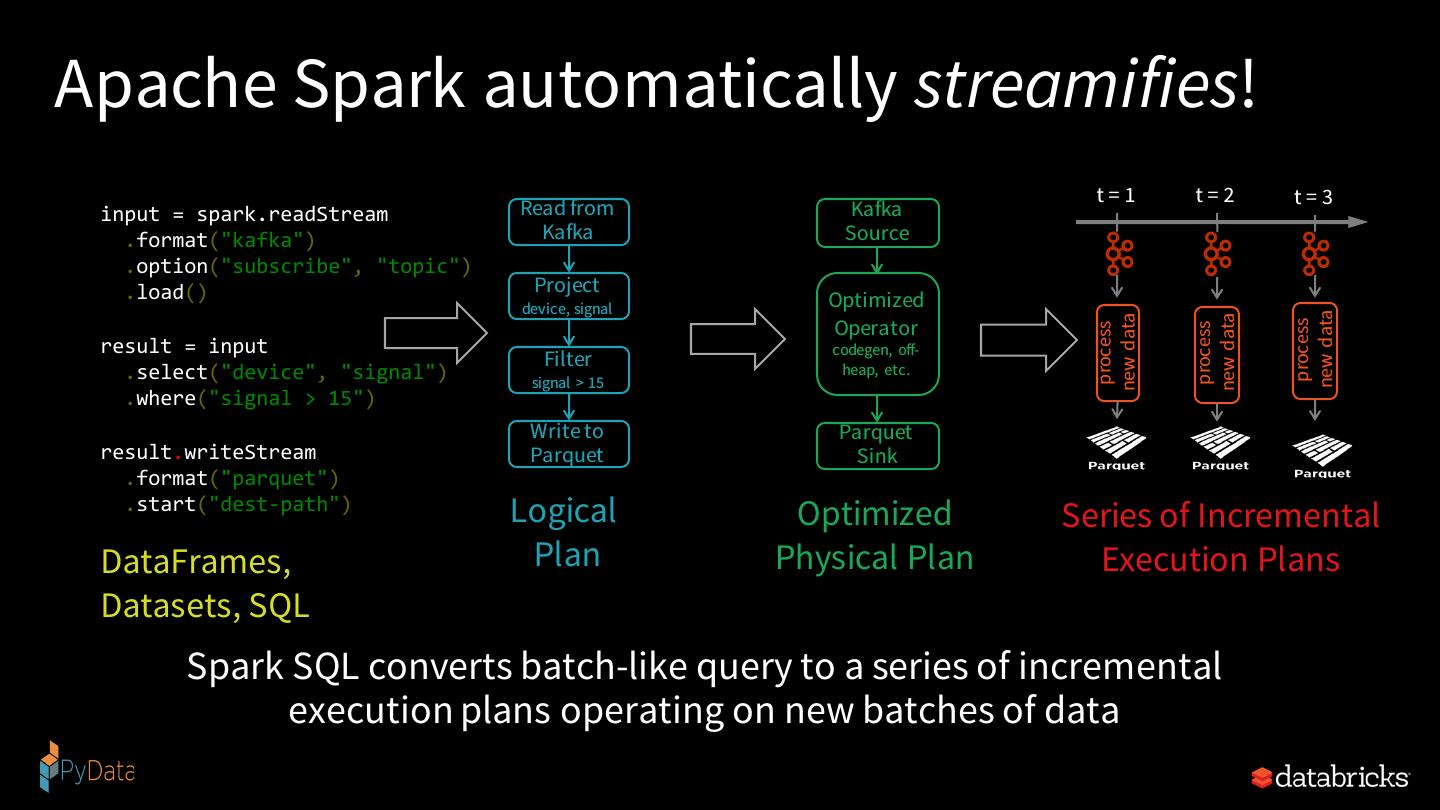
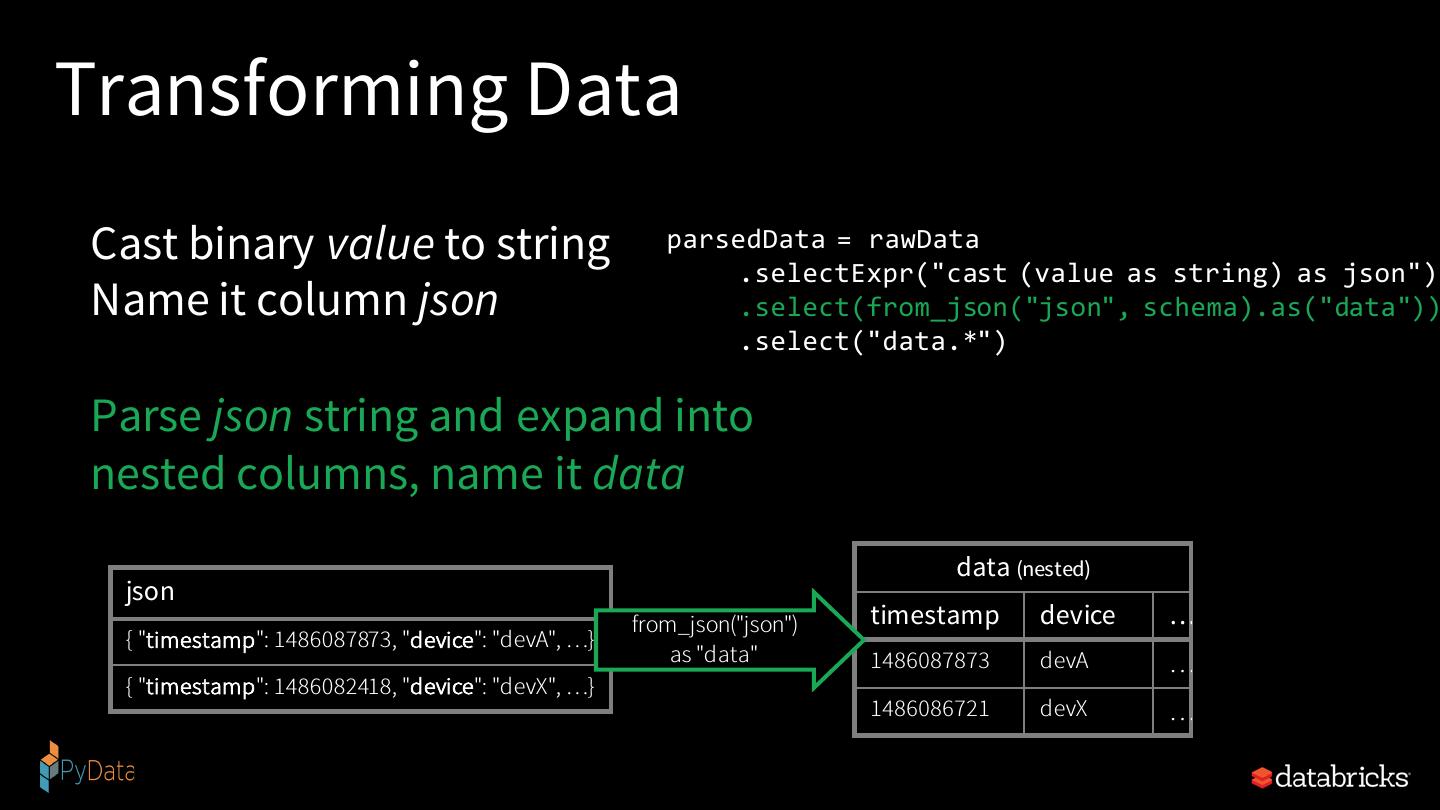
25 .Apache Spark automatically streamifies! t=1 t=2 t=3 input = spark.readStream Read from Kafka .format("kafka") Kafka Source .option("subscribe", "topic") .load() Project device, signal Optimized new data new data new data Operator process process process result = input codegen, off- Filter heap, etc. .select("device", "signal") signal > 15 .where("signal > 15") Write to Parquet result.writeStream Parquet Sink .format("parquet") .start("dest-path") Logical Optimized Series of Incremental DataFrames, Plan Physical Plan Execution Plans Datasets, SQL Spark SQL converts batch-like query to a series of incremental execution plans operating on new batches of data
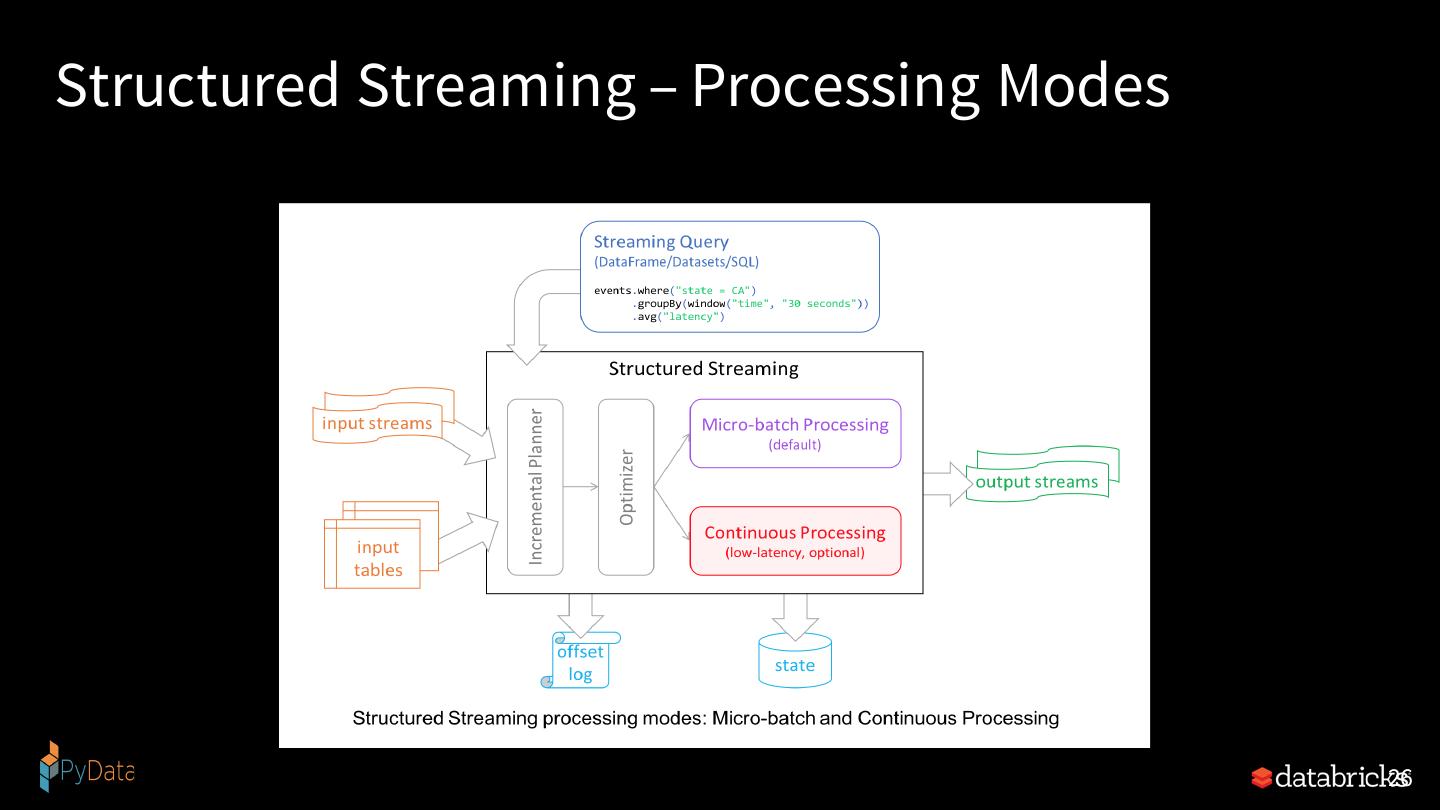
26 .Structured Streaming – Processing Modes 26
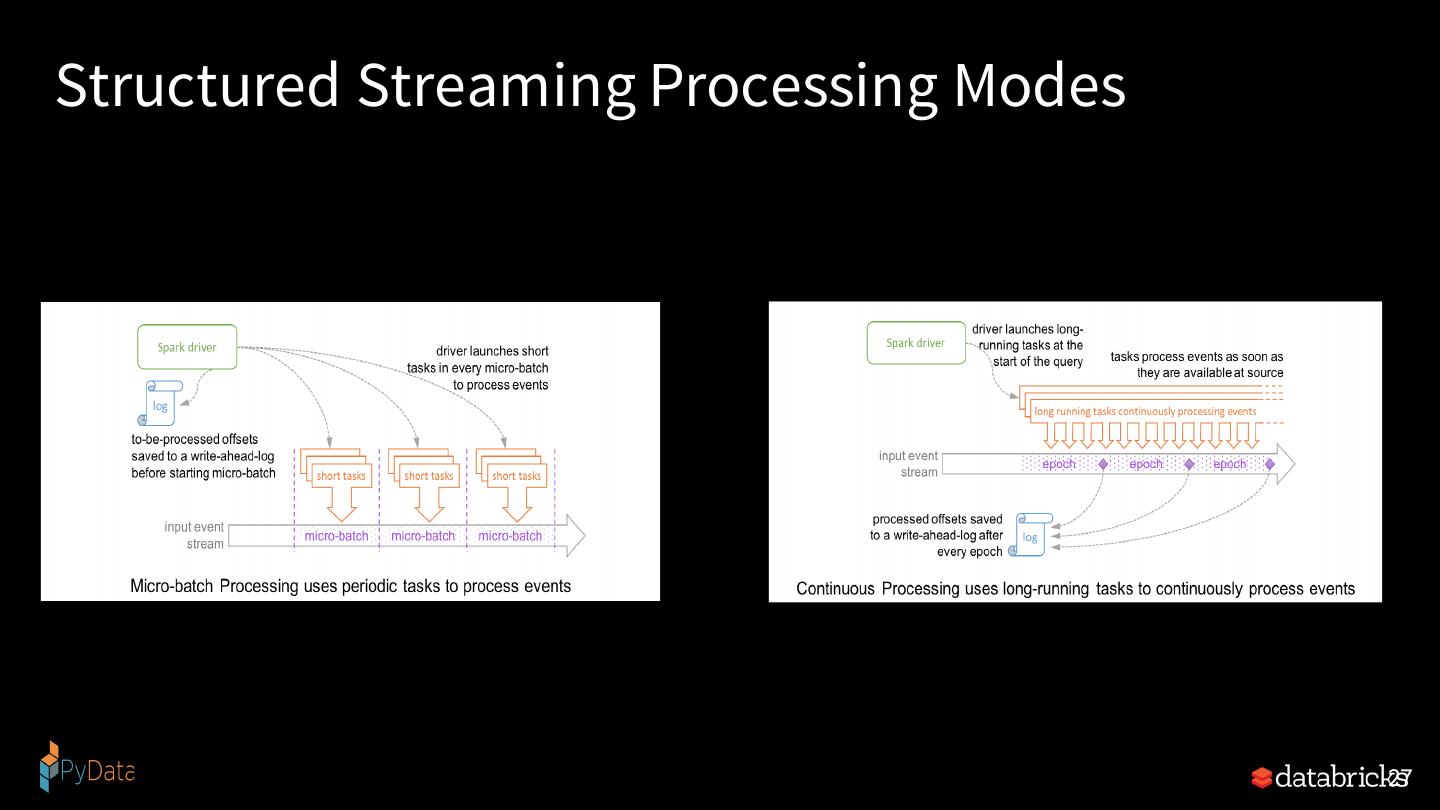
27 .Structured Streaming Processing Modes 27
28 .Simple Streaming ETL
29 .Anatomy of a Streaming Query Streaming word count
3秒后跳转登录页面
去登陆

