展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .WORKING WITH 1M TIME SERIES A DAY:
how to scale up a predictive analytics model
switching from sequential to parallel computing
Lucrezia Noli, Dataskills
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli
�
3 . LUCREZIA NOLI
§ Previous roles
§ Business Development Manager at Metail, London
§ Education
§ Bocconi University
§ Bachelor in Finance
§ Master in Economics of Innovation & Technology
§ Master Thesis: «Machine Learning Techniques to Investigate
the ALS Disease»
§ Won second prize of PRISLA competition for research on ALS disease
§ Current roles
§ Big Data Scientist and Community Evangelist at Dataskills
§ Fellow at SEDIN, Department of Informatics, Bocconi University
§ Lecturer for Overnet Education
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli
�
4 .I’m here to talk about
A plug & play engine for efficiently analyzing
time series data
A tool to create optimal portfolios of traded
funds, given specific clients’ characteristics
An innovative way to use Spark to
make this all happen
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 4
�
5 . BIG DATA BUSINESS INTELLIGENCE
Who is Dataskills
We are specialized in creating innovative
solutions in the four main areas of Data Science
analytics.
BUSINESS INTELLIGENCE
•How to transform data and information into
knowledge
PREDICTIVE ANALYTICS
•How to extract hidden relations existing within PREDICTIVE ANALYTICS IOT
the data to offer valuable business insights
BIG DATA
•How to analyze and make sense of huge
amounts of data
IOT ANALYTICS
•How to leverage the data coming from
interconnected devices
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 5
�
6 .Who is Dataskills
25 40
Years of Active
experience clients
3 3
DataScience Lecturers at
books Bocconi
published University
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 6
�
7 .MC Advisory
Financial consulting firm, with a main differenciating asset: Robo4Advisor
Ø It’s a tool ideated for constructing an optimal funds’ portfolio.
It helps professional financial advisors to better serve their clients
Ø It has two main traits: Funds’ Selection Filter & Optimal Portfolio Builder
Fund Selection:
§ Optimized selection based on markets
§ Innovative engine based on client’s requirements: stability, yield, etc.
Optimal Portfolio Builder:
§ Based on proprietary solution ideated by Dataskills, which predicts funds’
performances by monitoring various performance metrics. The engine works as a
plug-and-play tool, but is optimized for each and every single fund, as if each of
them had a dedicated model.
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 7
�
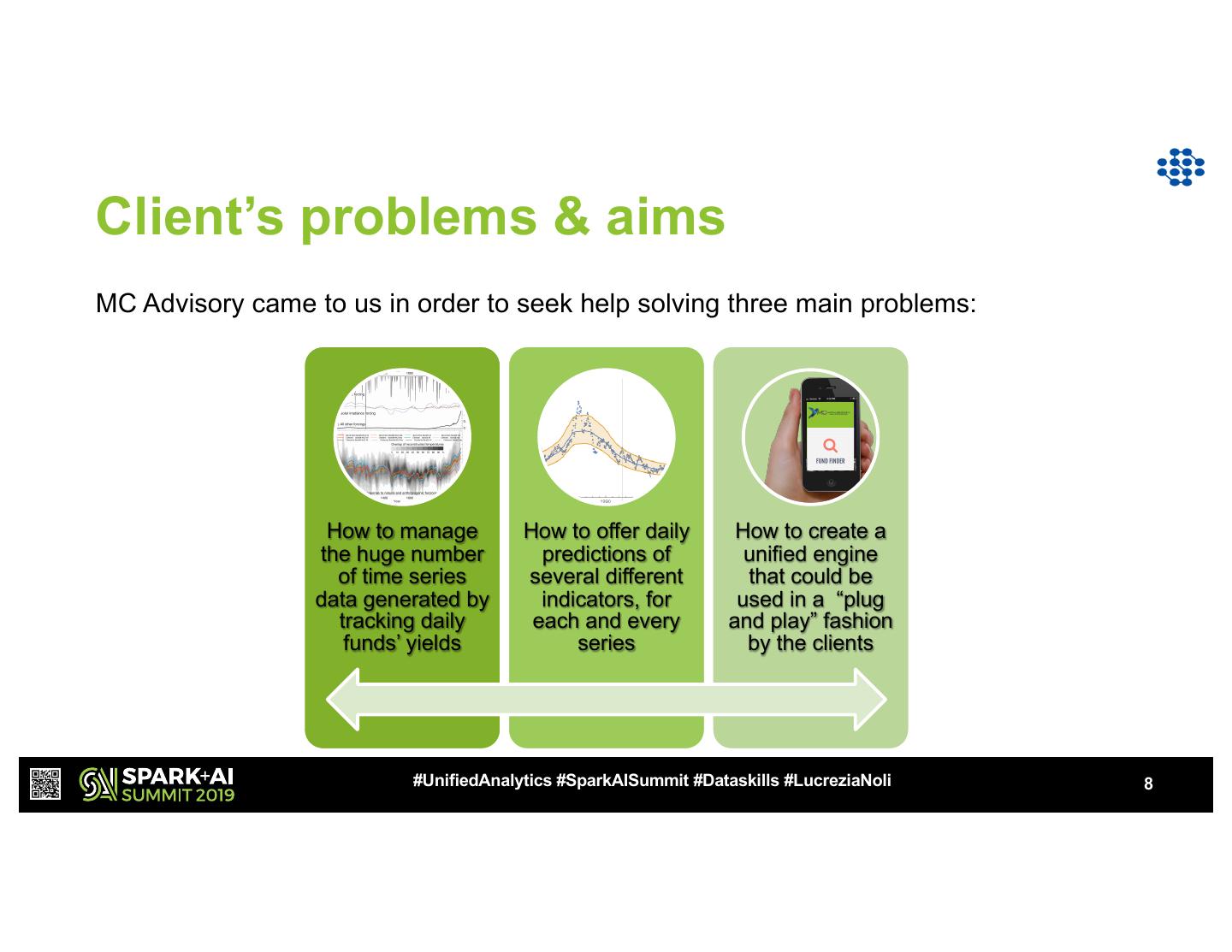
8 .Client’s problems & aims
MC Advisory came to us in order to seek help solving three main problems:
How to manage How to offer daily How to create a
the huge number predictions of unified engine
of time series several different that could be
data generated by indicators, for used in a “plug
tracking daily each and every and play” fashion
funds’ yields series by the clients
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 8
�
9 .The architecture
Collection of funds Prediction of funds’
yields yield increment to create
Time-series predictive
most efficient portfolios
engine composed of
different models
DAILY REASSESMENT OF MODEL PERFORMANCE
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 9
�
10 .The architecture
Performance
DATA:
•Incremental change of funds daily return
25,000 time-series data
on funds’ yields Value at Risk estimation
•Maximum expected loss
5 TARGETS: MODELS:
Expected volatility
• Performance § Deep Neural
• Expected volatility Network SCORING
•Standard deviation of fund’s yield
• VAR § Random Forest METHOD:
• Drawdown § Gradient
Drawdown Boosting PREDICTIONS:
• Efficiency indicator Machine Each day a
§ •Percentage
XG proprietary algorithm
Boosting peak-to-through decline Stock-by-stock
§ Recurrent Neural assesses which predictions permit
Efficiency indicator
Network model is the best- the client to
§ LSTM performing for each create optimal
•Based on proprietary MC Advisory formula
series funds portfolios
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 10
�
11 .Treating time series
Two important aspects of time series analysis:
Ø Predictive variables are the lags of the variable of interest
Ø When splitting between training and test sets, we have to take time into account
Time Return
t-4 v4
t-4 t-3 t-2 t-1 t
t-3 v3
t-2 v2 v4 v3 v2 v1 v
t-1 v1 0
t v 0 t-x
90 T
Training setTraining set window Test
is a 90 days Testsetset
is a 15
days window
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 11
�
12 . Step 1: developing a sequential model
Comparing every model every day, as was
Build our inital aim, is too time-consuming if
sequential computed sequentially
Python models
Pick a single It is not optimal to confine to a single
best model to algorithm to predict so many differently-
make daily behaving funds
predictions
To offer predictions daily we would need to
Use alternative pick a single best-performing model, and
models only in only train other models if the performance
some cases of the best one is not satisfactory enought.
This is still very time-consuming!
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 12
�
13 .Step 2: hand-made parallelization
1 A first possible option was to manually parallelize calculation processes
with python libraries, such as multiprocessing lib
We faced two main problems:
2 • Number of parallelized threads would still be confined to number of
cores
• Have to distribute across multiple machines
\
We finally opted for building the solution with Azure Databricks Spark :
3
• The cloud offers scalability on-demand,
• Quicker & easier than manually creating spark clusters, and very user-friendly
• efficient for massive processing in both data preparation & modelling phases
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 13
�
14 .Step 3: leveraging Spark capabilities
How we use
DATA PREPARATION Spark MODEL IMPLEMENTATION
o Spark SQL is used for data o Spark engine is used fro
preparation & feature engineering distribution, but we don’t use ML
whenever possible libraries
o Not possible when we need o Our need here is different from
data transformations which are not common cases, because rather
natively present in Spark (eg. FFT) than distributing a single model, we
have several different models
o Moreover, since all models
have proprietary tweeks, we need
to be able to implement our custom
functions
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 14
�
15 .Step 3a: hand-made «RDD to pandas»
Main problem
Both for data preparation & modelling, some functions are integrated in Spark, but some
others are not.
We will need to distribute these functions «by-hand» to the Spark context.
We don’t want to give up parallelization & distribution when applying our custom functions
So we manually implemented a way to be able to use our custom functions, without giving
up Spark’s computational efficiency
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 15
�
16 . Step 3a: hand-made «RDD to pandas»
Repartition Spark Dataframe by Series_id 1
THIS IS THE CORE
Don’t use to_pandas function. This will SOLUTION WHICH
compute calculations in the driver node, 2
thus giving up Spark’s parallelization RDD to Pandas MAKES IT POSSIBLE TO
Pandas to RDD
APPLY CUSTOM
Instead, go down one level to RDD, so that
with Map Partition we can apply custom 3 FUNCTIONS TO OUR
function to single partitions
DATA IN A MASSIVE WAY
Data is turned into pandas DF, but is still
processed in worker nodes. 4
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 16
�
17 .Hand-made solution to use custom functions
Apply
Apply Pandas to
Spark DF RDD to custom
DF to RDD custom Spark
repartitioning pandas functions to
prepare data algorithms Dataframe
This logic is used for both data-preparation, when functions are not available in
Spark SQL, and modelling, since we haven’t used Spark ML functions.
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 17
�
18 .Pandas UDFs
Ø Introduced in Spark 2.3 and further developed in Spark 2.4
Ø Vectorized UDFs are a way to work on pandas dataframes without giving up Spark’s ability to distribute
calculations
Ø There are different types of pandas UDFs, we use the «grouped map» implementation, which uses the
split- apply- combine logic
Ø The functioning is the same as the solution we had implemented manually, but being natively included
into Spark it works more efficiently
DATA PREPARATION MODELLING
§ Because we need some functions which § Because we implement proprietary
don’t exist natively in spark models
§ Because we need to parallelize several
different models on small series, rather
than a single model on huge series
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 18
�
19 .Pandas UDFs for data preparation
This is an example of the structure of the code, simply used to convey the main concepts behind the
use of Pandas UDFs
Ø DEFINE OUTPUT SCHEMA
Ø GROUP BY THE SERIES_ID
Ø GROUP_BY HERE IS ANOTHER UNUSUAL
TWEAK.
NOT NECESSARY, BUT USED SO THAT WE
CAN CREATE SLIDING WINDOWS
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 19
�
20 .Pandas UDFs for modelling
This is an example of the structure of the code, simply used to convey the main concepts behind the
use of Pandas UDFs
Ø @pandas_udf is a decorator that
supercharges my function with additional
functionalities, like transforming spark DF
to pandas DF (and vice-versa)
Ø Implement your ad-hoc
model here
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 20
�
21 .Performance comparison
2 computationally
expensive tasks
Data
Modelling
preparation
4 sec per 15 sec per
series model
SEQUENTIAL SPARK-RDD PANDAS UDFs SEQUENTIAL SPARK-RDD PANDAS UDFs
4 secs 4 secs 10 worker nodes 15 secs 15 secs 10 worker nodes
x 5 functions x 5 functions 32 cores x 5 functions x 5 functions 32 cores
x 25K series x 25K series x 25K series x 25K series
1h
28 h 13 min 8.7 min 44 min 520 h 2 h 26 min 1 h 36 min
320x 1.5x 320x 1.5x
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 21
�
22 .Steps forward
This is an ongoing project, for which we envision several future developments:
GROWING COMPLEXITYà more series, more target variables, more models
ANALYSIS OF DIFFERENTIALS à not just analyze a fund’s return by itself, but comparing it to
the average return of all other funds in the same market
TIME-SERIES CLUSTERINGà helpful for both data preparation (fill missing values) and
modelling (additional information)
USE OF SPARKà a further improvement that will likely add efficiency is the identification of
steps requiring same processing time, so as to organize them in a way that doesn’t block worker
nodes
#UnifiedAnalytics #SparkAISummit #Dataskills #LucreziaNoli 22
�
23 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�