展开查看详情
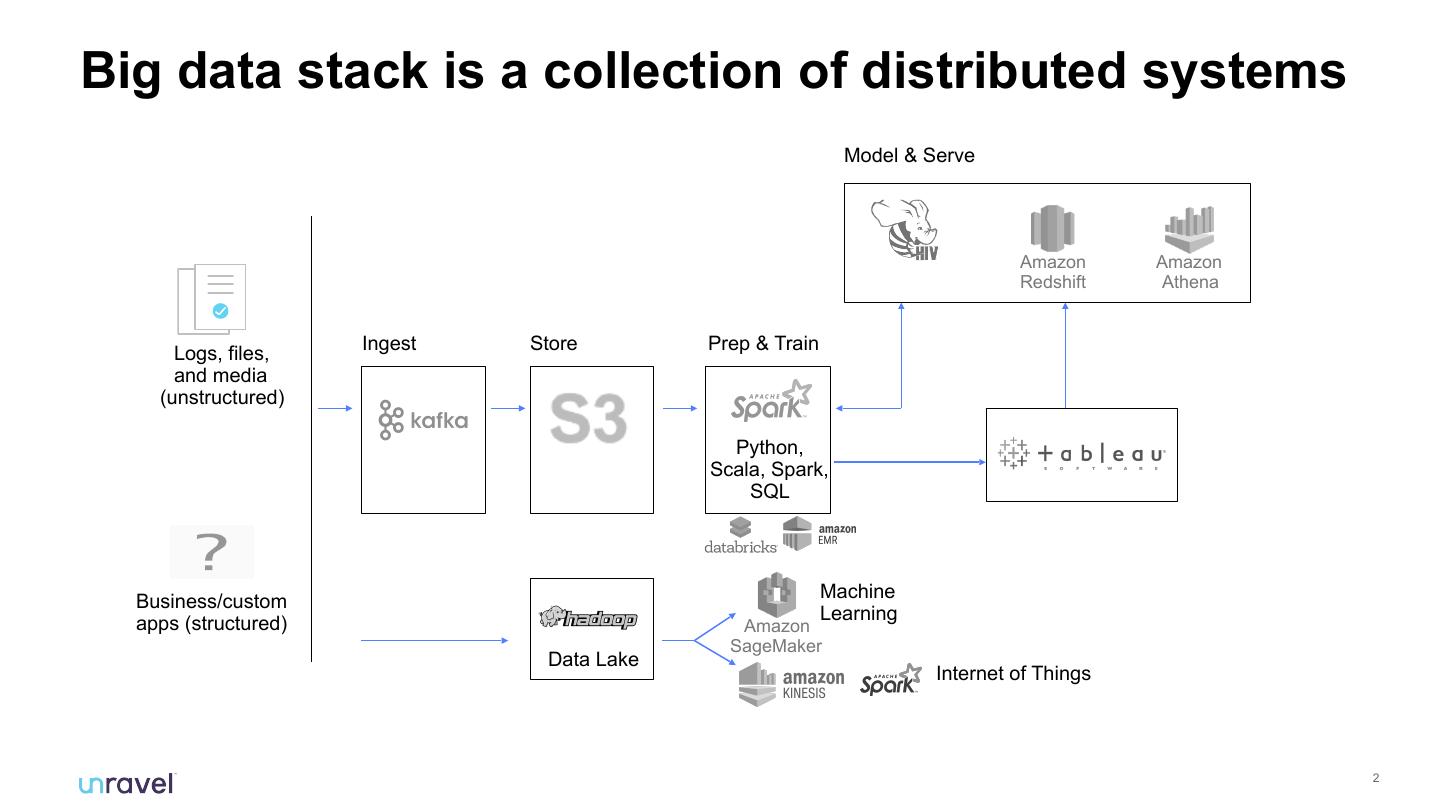
2 .Big data stack is a collection of distributed systems
Model & Serve
Amazon Amazon
Redshift Athena
Ingest Store Prep & Train
Logs, files,
and media
(unstructured)
Python,
Scala, Spark,
SQL
Machine
Business/custom
Learning
apps (structured) Amazon
SageMaker
Data Lake
Internet of Things
!2
�
4 .My data pipeline is missing SLA
!4
�
5 .Our Cloud costs are out of control
!5
�
6 .What is the real root cause?
!6
�
7 .What enterprises are facing: Monitoring Data is Silo’ed
A survey of 6000+ enterprise IT professionals
from Australia, Canada, France, Germany,
UK, & USA reveals that
91% are struggling with silo'ed monitoring data
Published: https://blog.appdynamics.com/aiops/aiops-platforms-transform-performance-monitoring/
!7
�
8 .What enterprises are facing: Reactive Approach
Published: https://blog.appdynamics.com/aiops/aiops-platforms-transform-performance-monitoring/
!8
�
9 .What enterprises are facing: High MTTR
Published: https://blog.appdynamics.com/aiops/aiops-platforms-transform-performance-monitoring/
!9
�
10 .Solving this as a Data + AI problem
1. Lots of data about how the applications run
2. Most root causes are common and recurring
3. Much of the root cause analysis and
recommendations can be automated and improved
via learning
!10
�
11 . AIOps
Using AI/ML to address
distributed application performance &
operations management
!11
�
12 .First: Bring all monitoring data to a single platform
Resource Manager
API
History Server API
Container Metrics
Data Statistics
SQL Query Plans
Logs
Metadata
Configuration
One complete correlated view
!12
�
13 .Then: Apply algorithms to analyze the data &
(whenever possible) take actions automatically
Resource Manager
API
History Server API
Container Metrics
Data Statistics
SQL Query Plans
Logs
Metadata
Configuration
One complete correlated view Built-in intelligence & automation
!13
�
14 .Building such a platform
requires innovation
In data collection & transport
• Non-intrusive, low overhead, transient/elastic clusters
In data storage
• Variety, scale, asynchronous arrival
In algorithms to provide insights
• Real-time, combine expert knowledge with ML
In algorithms to take actions
• Reliable, predictable
!14
�
15 .Innovative
solutions Application autotuning
designed for
production
enterprise
Holistic cluster optimization
environments
!15
�
16 .spark.driver.cores 2
spark.executor.cores 10
PERFORMANCE
…
spark.sql.shuffle.partitions 300
spark.sql.autoBroadcastJoinThreshold 20MB
…
SKEW('orders', 'o_custId') true
spark.catalog.cacheTable(“orders") true
…
We represent this setting as vector X X
Tuning is often by trial-and-error
!16
�
17 .Given: App + Goal
PERFORMANCE
• Goal: Find the setting of X
that best meets the goal
• Challenge: Response
surface y = ƒ(X) is
unknown
X
!17
�
18 .A new world
INPUTS
1. App = Spark Query
2. Goal = Speedup
“I need to make this app faster”
!18
�
19 .A new world
APP DURATION
90%
faster!
TIME
In blink of an eye, user As user finishes User comes back from
gets recommendations to
checking email, she lunch. A verified run that
make the app 30% faster has a verified run that is 90% faster
is 60% faster
!19
�
20 .Autotuning workflow
Recommendation Monitoring
Algorithm Data
App,Goal
Probe Algorithm Historical Data
&
Xnext Probe Data
Orchestrator
Cluster Services On-premises and Cloud
!20
�
21 . Bootstrap
1
Get initial set of
monitoring data
from history or via
probes: <X1,y1>,
PERFORMANCE
<X2,y2>, …, <Xn,yn>
Probe Algorithm
2
Select next probe
Xnext based on all
Until the
stopping history and probe data
condition available so far to
is reached calculate the setting
with maximum expected X
improvement EIP(X)
!21
�
22 . Balance exploration VS exploitation
8
Performance
6
y
EIP(X)
4
2
⌔ ⌔ ⌔
0
4 6 8 10 12
x1
X
Exploration Exploitation
!22
�
23 .Automated tuning of a failed Spark application
Failed due to OOM
Fixed conf setting
More memory-efficient
configuration
!23
�
24 .Challenges and Limitations
• Need to account for data volume changes
• Not applicable to certain root causes
- Small files
- SQL queries that need to be rewritten
- Node/network issues
- Pool resource allocation
Need user input!
!24
�
26 .Innovative
solutions Application autotuning
designed for
production
enterprise
Holistic cluster optimization
environments
!26
�
27 . Holistic cluster optimization
Resource Manager Examples of optimization
API
History Server API
beyond app level
Container Metrics • Scheduler configurations
Data Statistics for queues
SQL Query Plans • Schema/Data insights
Logs
• Cluster default for certain
Metadata
parameters
Configuration
• Cluster cost optimization
One complete correlated view
!27
�
28 . Single-app tuning is not scalable
spark.driver.cores 2
spark.executor.cores 10
PERFORMANCE
…
spark.sql.shuffle.partitions 300
spark.sql.autoBroadcastJoinThreshold 20MB
…
SKEW('orders', 'o_custId') true
spark.catalog.cacheTable(“orders") true
…
• A cluster may run 1000s of apps everyday
• Default is often bad - many apps could use some tuning
!28
�
29 .Better idea: Change the cluster defaults instead!
• Every app uses the new values automatically
• Challenge: new default could be better for some
apps but worse for others
• Data-driven approach: identify the best new default
based on the cluster’s workload
• New default not necessarily the best for a given app,
but the best for the input workload
!29
�