Unifying Streaming and Historical Telemetry Data For Real-time Performance Repor
分享
点赞
0
收藏
0
下载 1
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
In the oil and gas industry, utilizing vast amounts of data has long been identified as an important indicator of operational performance. The measurement of key performance indicators is a routine practice in well construction, but a systematic way of statistically analyzing performance against a large data bank of offset wells is not a common practice. The performance of statistical analysis in real-time is even less common. With the adoption of distributed computing platforms, like Apache Spark, new analysis opportunities become available to leverage large-scale time-series data sets to optimize performance. Two case studies are presented in this talk: the rate of penetration (ROP) and the amount of vibration per run.
By collecting real-time, telemetry data and comparing it with historic sample datasets within the Databricks Unified Analytics Platform, the optimization team was able to quickly determine whether the performance being delivered matched or exceeded past performance with statistical certainty. This is extremely important while trying new techniques with data that is highly variable. By substituting anecdotal evidence with statistical analysis, decision making is more precise and better informed. In this talk we’ll share how we accomplished this and the lessons learned along the way.
展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Unifying Streaming and
Historical Data for Real-
Time Performance
Reporting
Daniel Antonio, Halliburton
#UnifiedAnalytics #SparkAISummit
© 2019 Halliburton. All Rights Reserved.
�
3 . Performance
Data
Expectations
�
4 . Performance
Data
Expectations
Evidence Utilized to Make Decisions
�
5 .Oil and Gas Data
Highly variable time-series data
Large data sets per well
Millions of rows
Thousands of columns
Difficult to normalize and compare
Geological factors
Equipment factors
Operational factors
�
6 .Business Need: Quickly Compare Current
Operations with Historic Data
?
Historic Operational Data Real-Time Sample Data
�
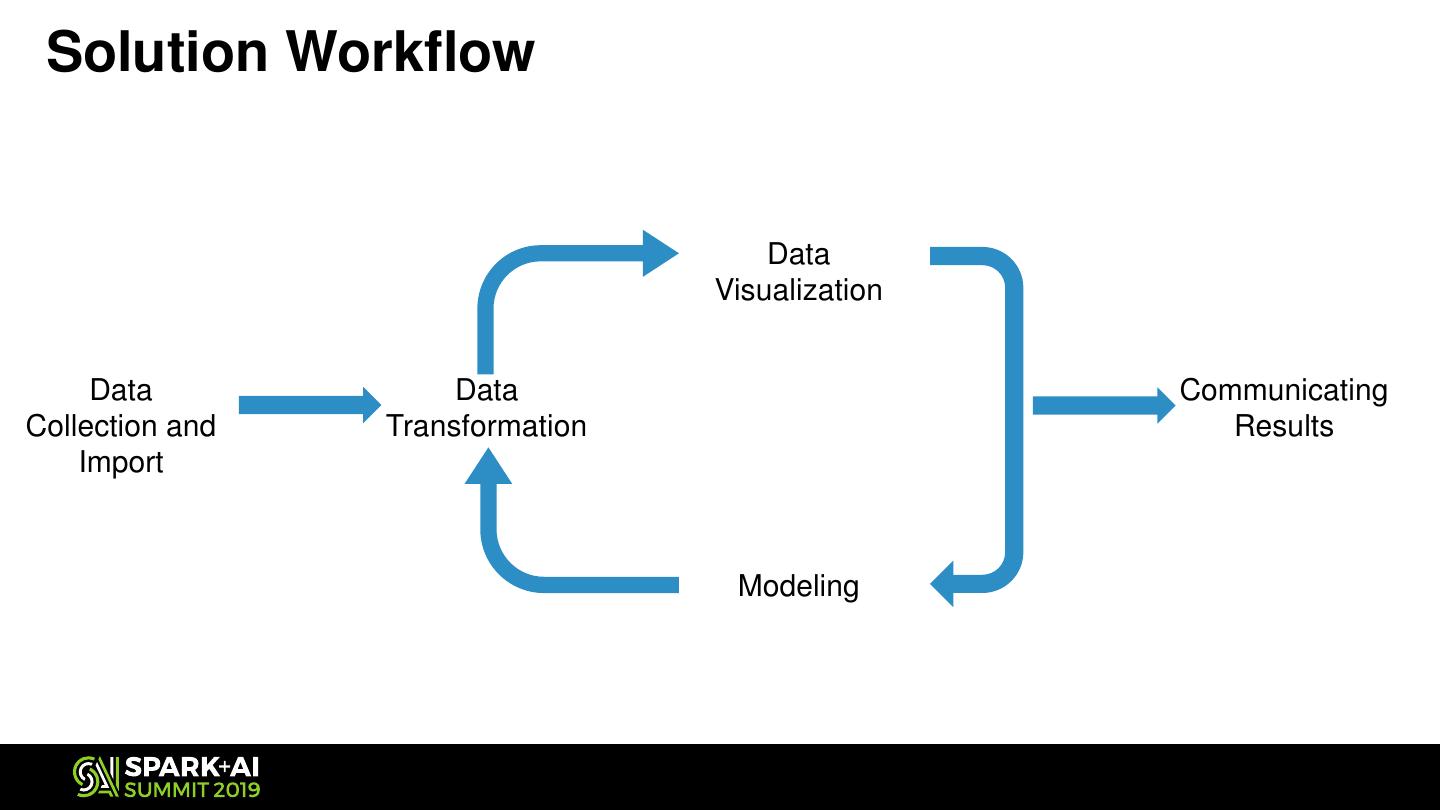
7 . Solution Workflow
Data
Visualization
Data Data Communicating
Collection and Transformation Results
Import
Modeling
SPE-195023-MS • Using Hypothesis Testing to Evaluate Key Performance Indicators in Real Time: an Edge Computing Use Case • P. Kowalchuk
�
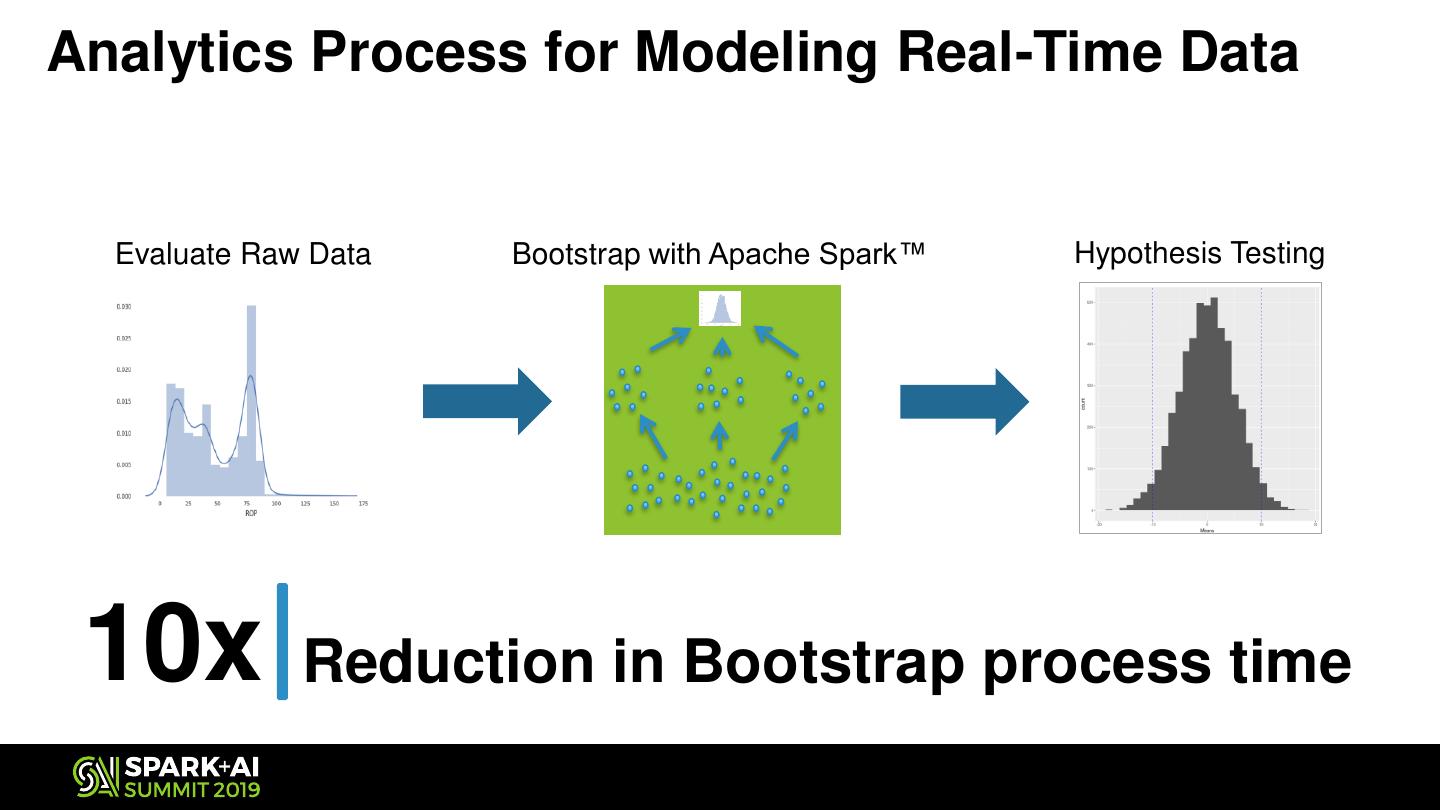
8 .Analytics Process for Modeling Real-Time Data
Evaluate Raw Data Bootstrap with Apache Spark™ Hypothesis Testing
10x Reduction in Bootstrap process time
�
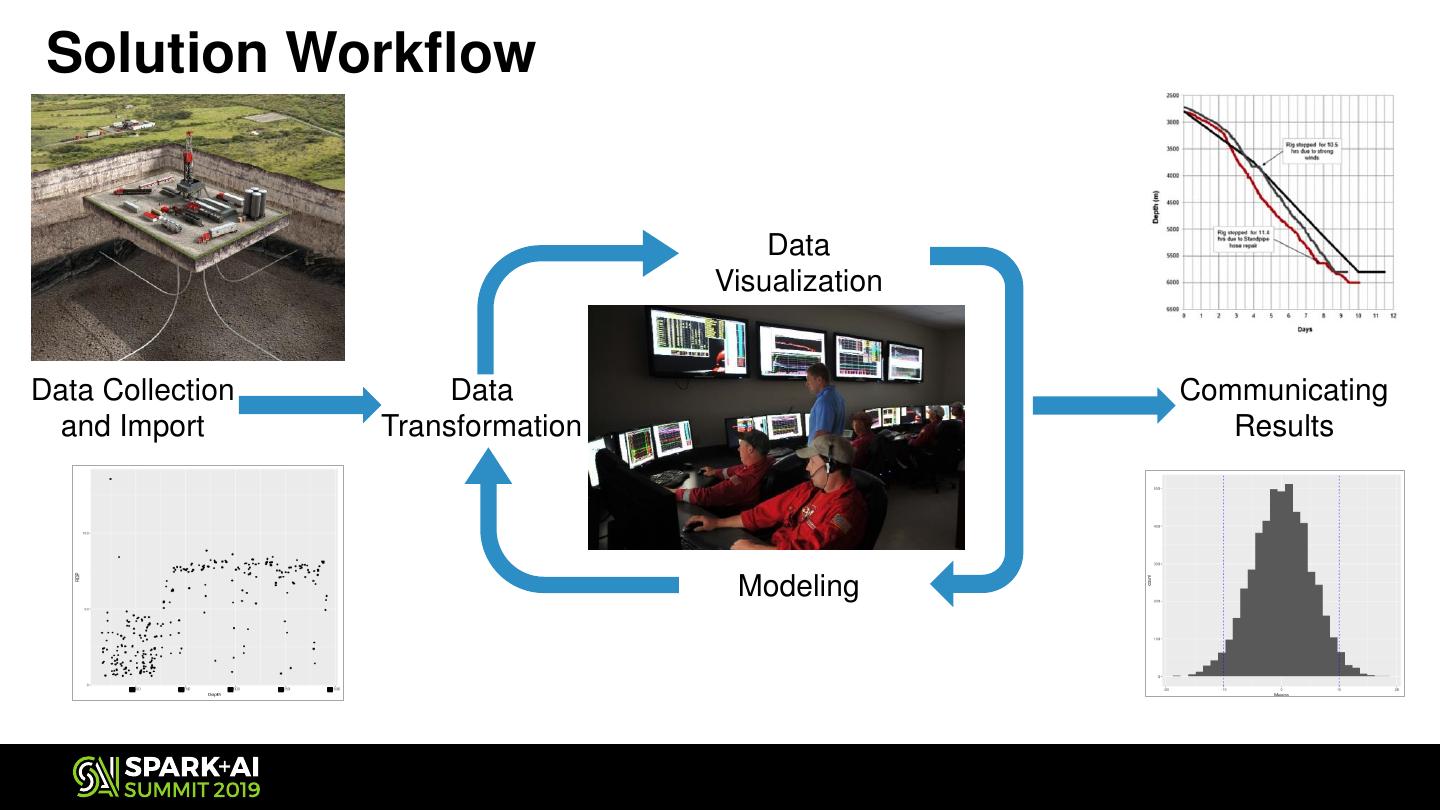
9 . Solution Workflow
Data
Visualization
Data Collection Data Communicating
and Import Transformation Results
Modeling
SPE-195023-MS • Using Hypothesis Testing to Evaluate Key Performance Indicators in Real Time: an Edge Computing Use Case • P. Kowalchuk
�
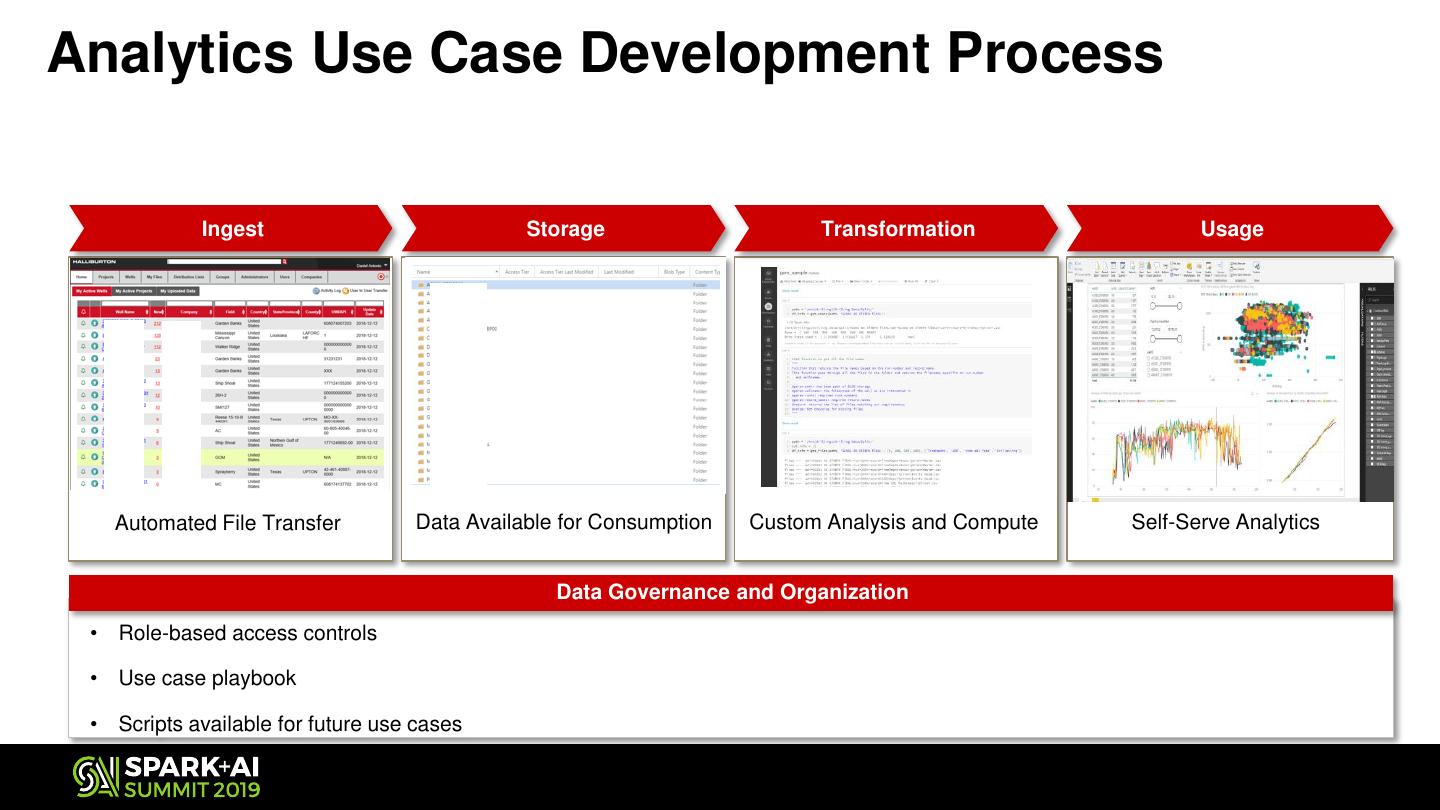
10 .Analytics Use Case Development Process
Ingest Storage Transformation Usage
Automated File Transfer Data Available for Consumption Custom Analysis and Compute Self-Serve Analytics
Data Governance and Organization
• Role-based access controls
• Use case playbook
• Scripts available for future use cases
�
11 .Results
Proven viability for bringing distributed computing resources into a real-time environment
Once models are generated, usage at the edge empowers decision makers
Provides unbiased view of data
Project details available in Society of Petroleum Engineers paper SPE-195023-MS
�
12 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�