
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Uncovering an Apache Spark 2 Benchmark - Configuration, Tuning and Test Results
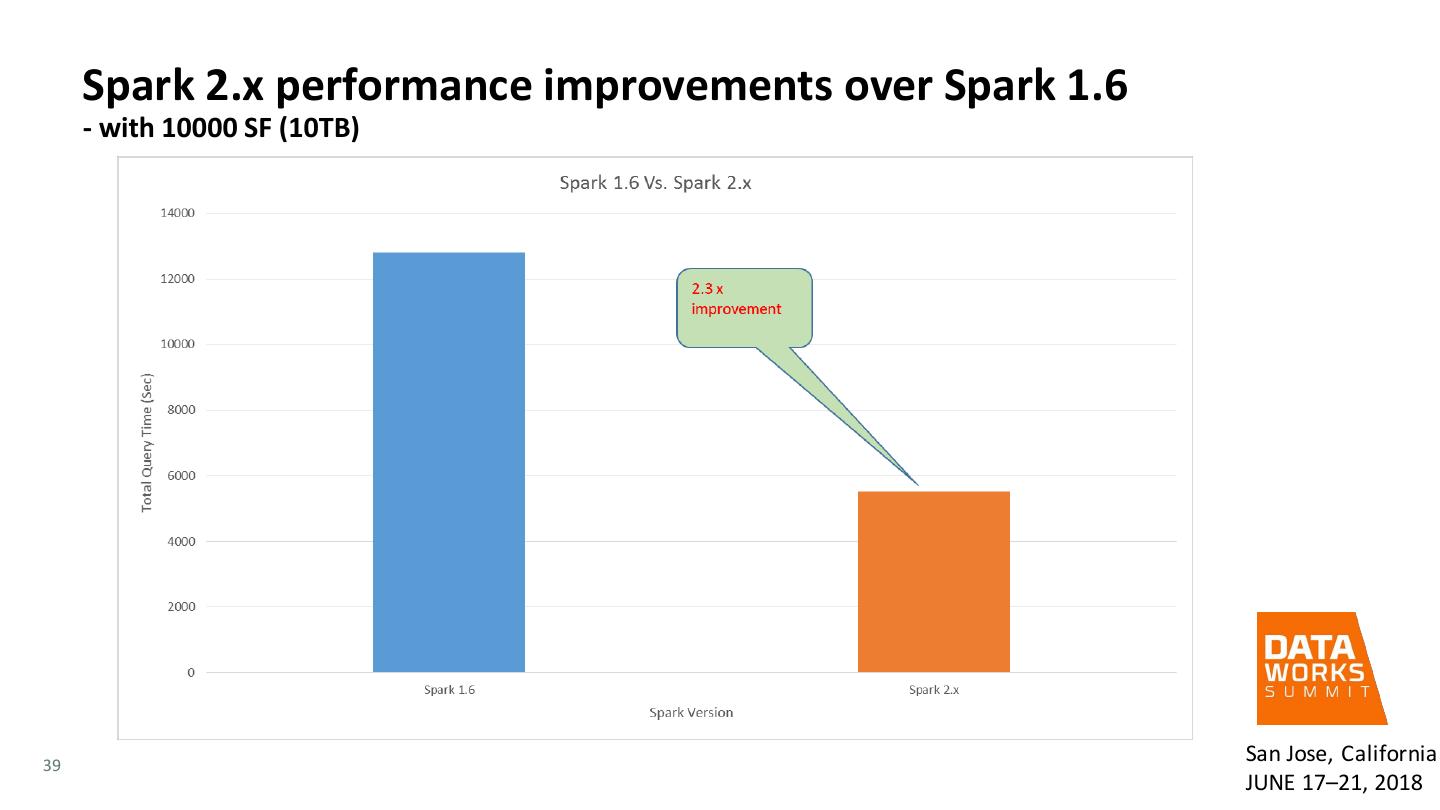
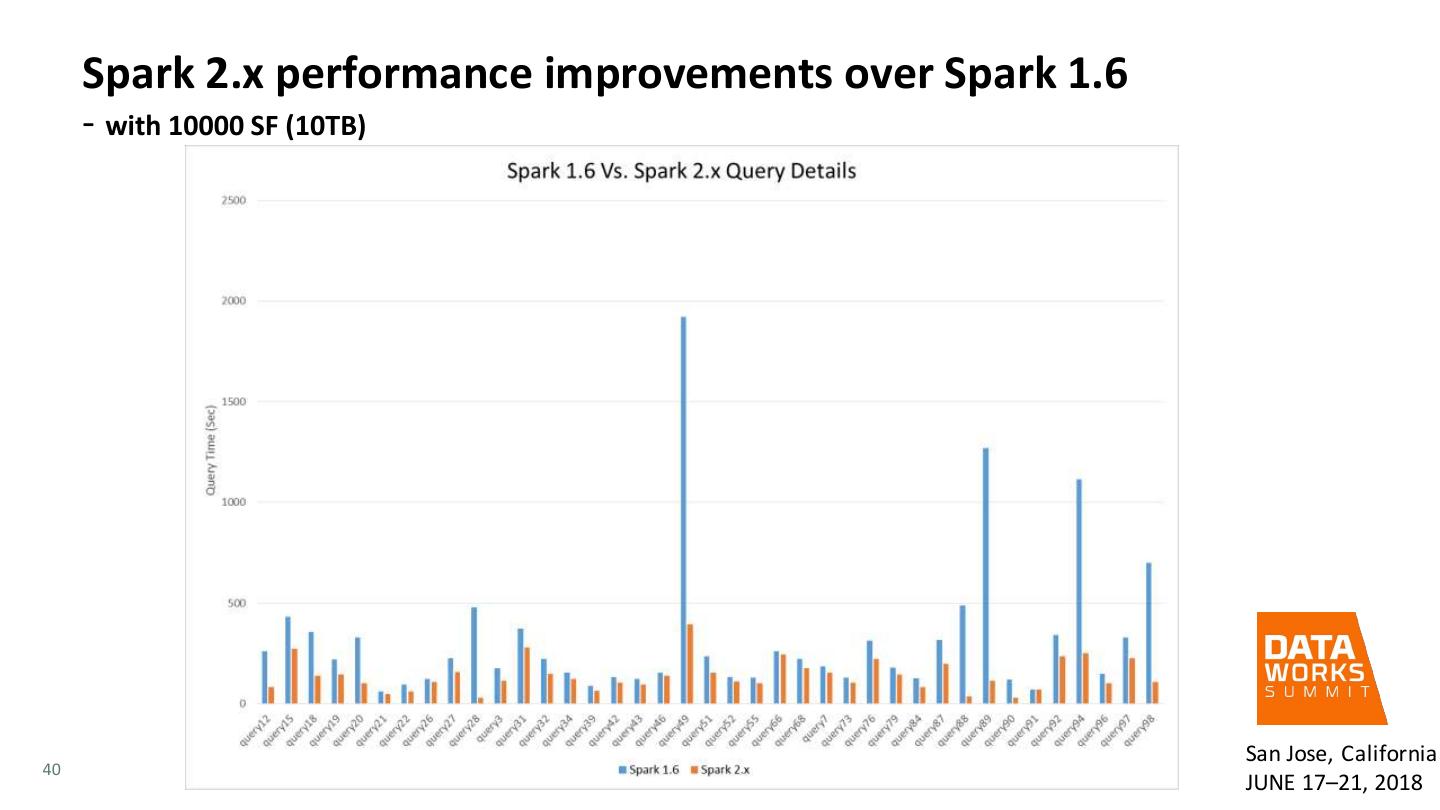
Apache Spark is increasingly adopted as an alternate processing framework to MapReduce, due to its ability to speed up batch, interactive and streaming analytics. Spark enables new analytics use cases like machine learning and graph analysis with its rich and easy to use programming libraries. And, it offers the flexibility to run analytics on data stored in Hadoop, across data across object stores and within traditional databases. This makes Spark an ideal platform for accelerating cross-platform analytics on-premises and in the cloud. Building on the success of Spark 1.x release, Spark 2.x delivers major improvements in the areas of API, Performance, and Structured Streaming. In this paper, we will cover a high-level view of the Apache Spark framework, and then focus on what we consider to be very important improvements made in Apache Spark 2.x. We will then share the results of a real-world benchmark effort and share details on Spark and environment configuration changes made to our lab, discuss the results of the benchmark, and provide a reference architecture example for those interested in taking Spark 2.x for their own test drive. This presentation stresses the value of refreshing the Spark 1 with Spark 2 as performance testing results show 2.3x improvement with SparkSQL workloads similar to TPC Benchmark™ DS (TPC-DS).
展开查看详情
1 .San Jose, California JUNE 17–21, 2018 Uncovering an Apache Spark 2 Benchmark - Configuration, Tuning and Test Results • Mark Lochbihler, Hortonworks - Principal Architect Tuesday, June 19 • Viplava Madasu, HPE - Big Data Systems Engineer 4:00 PM - 4:40 PM Executive Ballroom 210C/D/G/H 1
2 . Today’s Agenda • What’s New with Spark 2.x – Mark • Spark Architecture • Spark on YARN • What’s New • Spark 2.x Benchmark - Viplava • What was Benchmarked • Configuration and Tuning • Infrastructure Used • Results • Questions / More Info – Mark and Viplava San Jose, California 2 JUNE 17–21, 2018
3 .Apache Spark Apache Spark is a fast general-purpose engine for large-scale data processing. Spark was developed in response to limitations in Hadoop’s two-stage disk-based MapReduce processing framework. Orchestration: Spark’s standalone cluster manager, Apache Mesos, 3 or Hadoop YARN San Jose, California JUNE 17–21, 2018
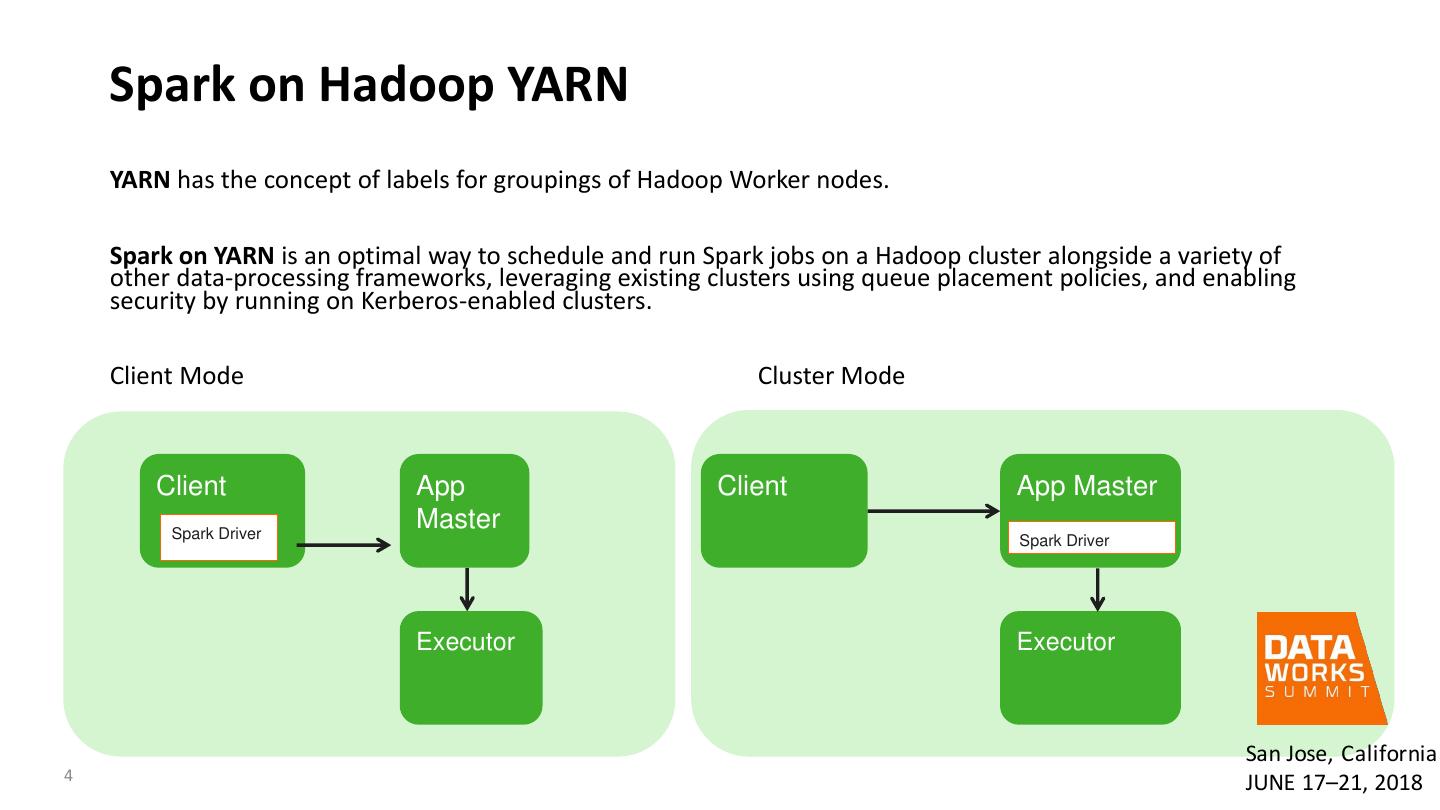
4 . Spark on Hadoop YARN YARN has the concept of labels for groupings of Hadoop Worker nodes. Spark on YARN is an optimal way to schedule and run Spark jobs on a Hadoop cluster alongside a variety of other data-processing frameworks, leveraging existing clusters using queue placement policies, and enabling security by running on Kerberos-enabled clusters. Client Mode Cluster Mode Client App Client App Master Spark Driver Master Spark Driver Executor Executor San Jose, California 4 JUNE 17–21, 2018
5 . Spark 2.x vs Spark 1.x Apache Spark 2.x is a major release update of Spark 1.x and includes significant updates in the following areas: • API usability • SQL 2003 support • Performance improvements • Structured streaming • R UDF support • Operational improvements 5 San Jose, California JUNE 17–21, 2018
6 . Spark 2.x – New and Updated APIs Including: • Unifying DataFrame and Dataset APIs providing type safety for DataFrames • New SparkSession API with a new entry point that replaces the old SQLContext and HiveContext for DataFrame and Dataset APIs • New streamlined configuration API for SparkSession • New improved Aggregator API for typed aggregation in Datasets 6 San Jose, California JUNE 17–21, 2018
7 . Spark 2.x – Improved SQL Functionality • ANSI SQL 2003 support • Enables running all 99 TPC-DS queries • A native SQL parser that supports both ANSI-SQL as well as Hive QL • Native DDL command implementations • Subquery support • Native CSV data source • Off-heap memory management for both caching and runtime execution • Hive-style bucketing support San Jose, California 7 JUNE 17–21, 2018
8 . Spark 2.x – Performance Improvements • By implementing a new technique called “whole stage code generation”, Spark 2.x improves the performance 2-10 times for common operators in SQL and DataFrames. • Other performance improvements include: • Improved Parquet scan throughput through vectorization • Improved ORC performance • Many improvements in the Catalyst query optimizer for common workloads • Improved window function performance via native implementations for all window functions. 8 San Jose, California JUNE 17–21, 2018
9 . Spark 2.x – Spark Machine Learning API • Spark 2.x replaces the RDD-based APIs in the spark.mllib package (put in maintenance mode) with the DataFrame-based API in the spark.ml package. • New features in the Spark 2.x Machine Learning API include: • ML persistence to support saving and loading ML models and Pipelines • New MLlib APIs in R for generalized linear models • Naive Bayes • K-Means Clustering • Survival regression • New MLlib APIs in Python for • LDA, Gaussian Mixture Model, Generalized Linear Regression, etc. 9 San Jose, California JUNE 17–21, 2018
10 . Spark 2.x – Spark Streaming • Spark 2.x introduced a new high-level streaming API, called Structured Streaming, built on top of Spark SQL and the Catalyst optimizer. • Structured Streaming enables users to program against streaming sources and sinks using the same DataFrame/Dataset API as in static data sources, leveraging the Catalyst optimizer to automatically incrementalize the query plans. San Jose, California 10 JUNE 17–21, 2018
11 .Hortonworks Data Platform 2.6.5 – Just Released HDP 2.6.5 / 3.0 includes Apache Spark 2.3 San Jose, California JUNE 17–21, 2018 ORC/Parquet Feature Parity – Spark extends its vectorized read capability to ORC data sources. – Structured streaming officially supports ORC data source with API and documentation Python Pandas UDF, with good performance and easy to use for Pandas users. This feature supports financial analysis use cases. Structured streaming now supports stream-stream joins. Structured streaming that goes to millisecond latency (Alpha). New continuous processing mode provides the best performance by minimizing the latency without waiting in idle status. 11
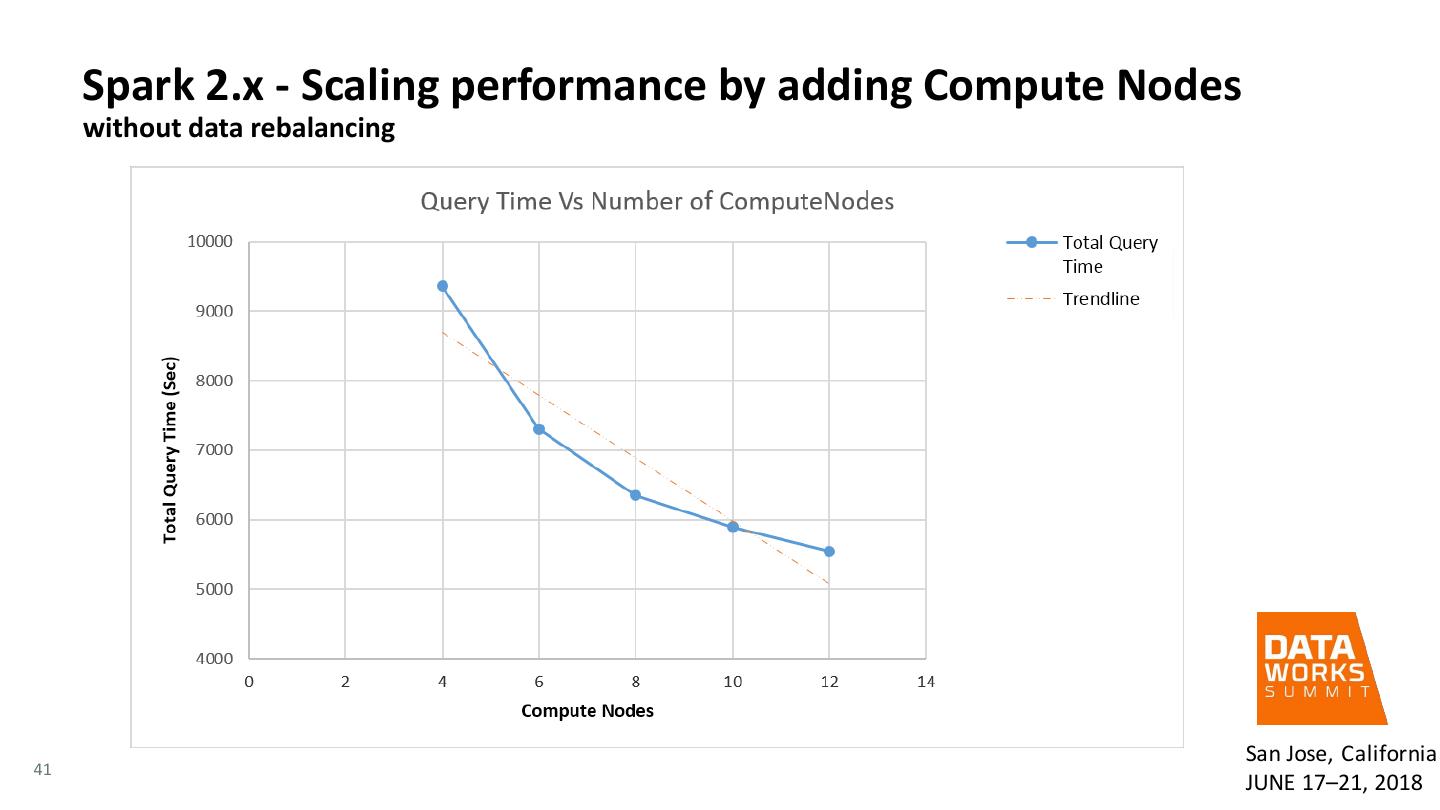
12 . Evaluation of Spark SQL with Spark 2.x versus Spark 1.6 • Benchmark Performed • Hive testbench, which is similar to TPC-DS benchmark • Tuning for the benchmark San Jose, California 12 JUNE 17–21, 2018
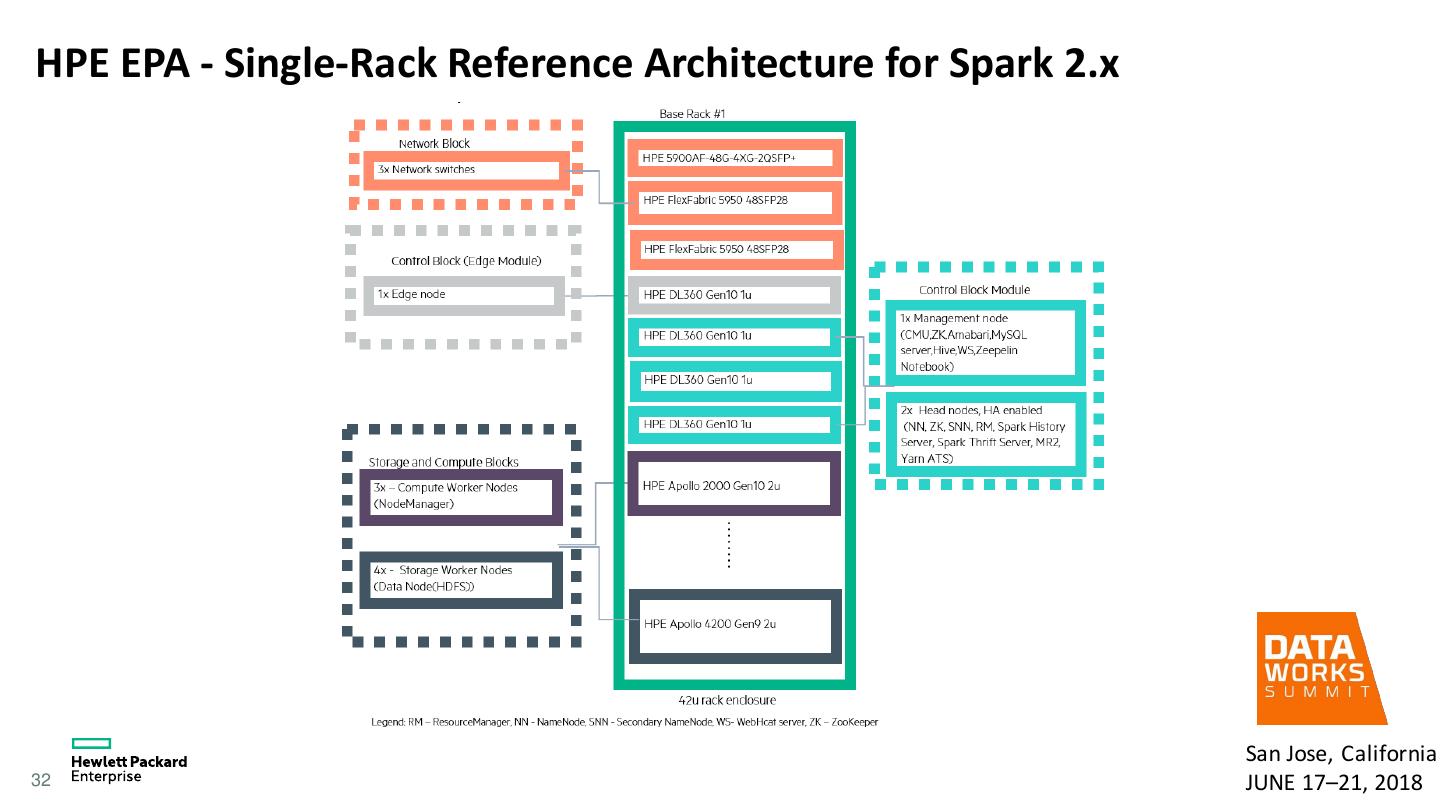
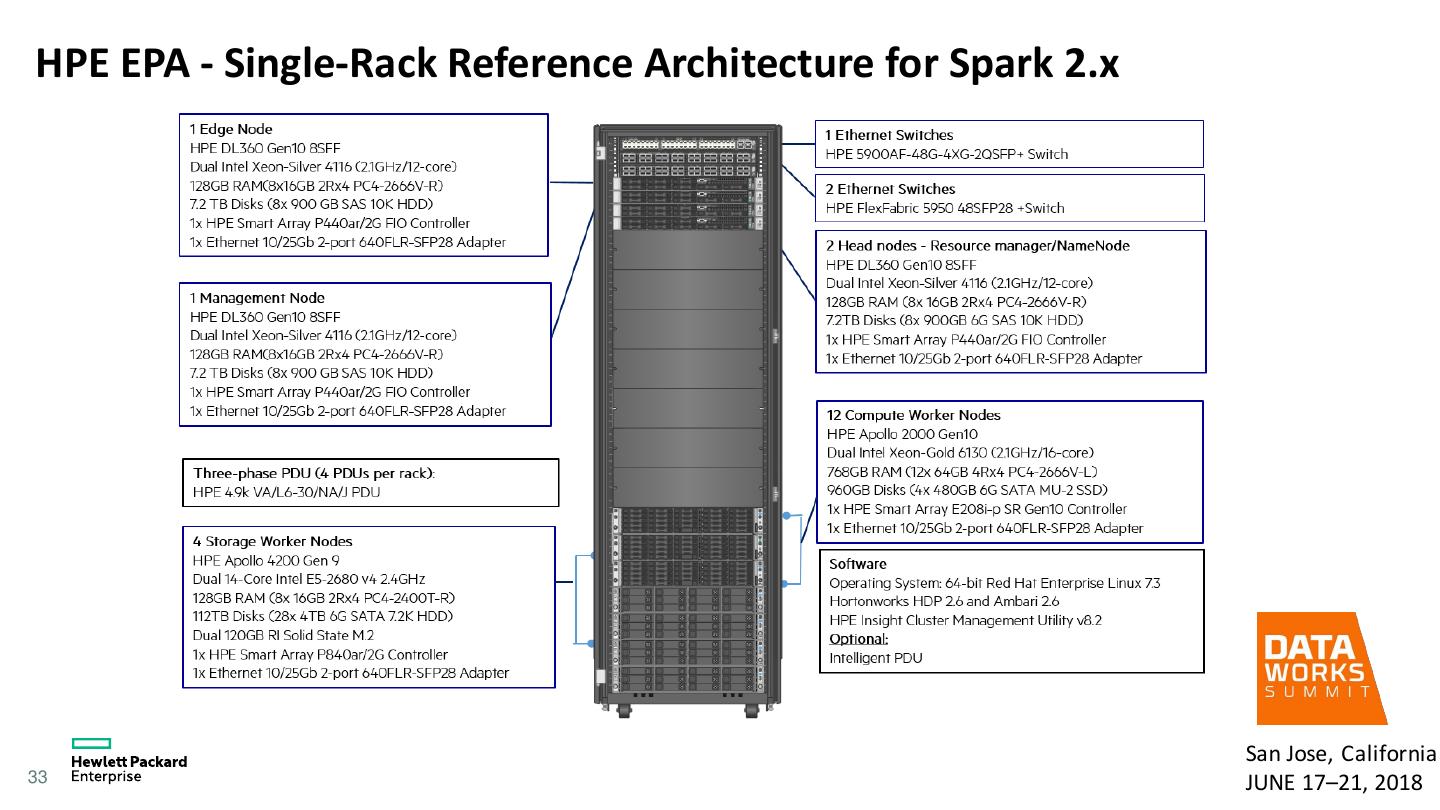
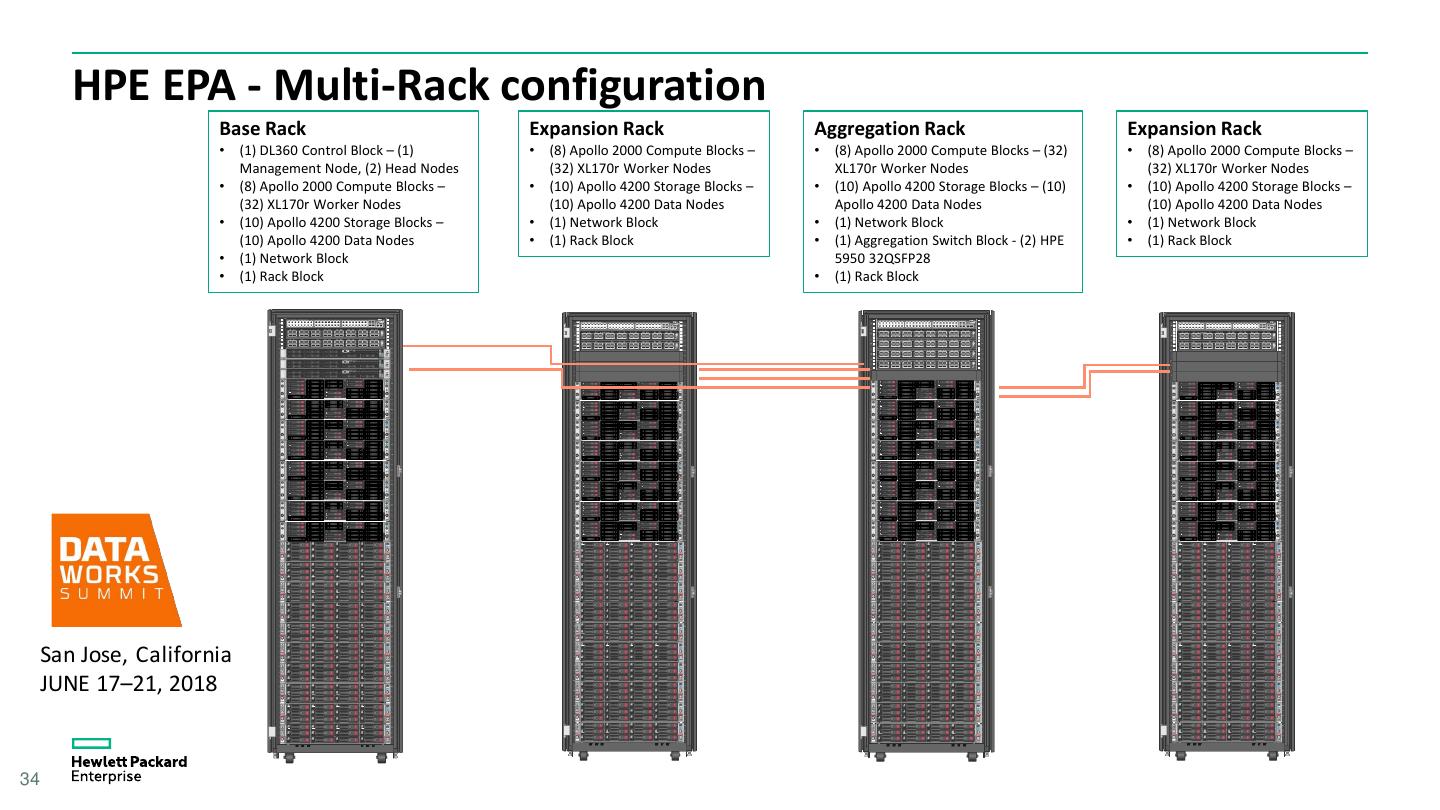
13 . Why Cluster tuning matters • Spark/Hadoop default configurations are not optimal for most enterprise applications • Large number of configuration parameters • Tuning cluster will benefit all the applications • Can further tune job level configuration • More important if using disaggregated compute/storage layers as in HPE Reference Architecture • Useful for cloud too 13 San Jose, California JUNE 17–21, 2018
14 . Factors to consider for Spark performance tuning • Hardware • CPU, Memory, Storage systems, Local disks, Network • Hadoop configuration • HDFS • YARN • Spark configuration • Executor cores, Executor memory, Shuffle partitions, Compression etc. 14 San Jose, California JUNE 17–21, 2018
15 . General Hardware Guidelines • Sizing hardware for Spark depends on the use case, but Spark benefits from • More CPU cores • More memory • Flash storage for temporary storage • Faster network fabric • CPU Cores • Spark scales well to tens of CPU cores per machine • Most Spark applications are CPU bound, so at least 8-16 cores per machine. • Memory • Spark can make use of hundreds of gigabytes of memory per machine • Allocate only at most 75% of the memory for Spark; leave the rest for the operating system and buffer cache. • Storage tab of Spark’s monitoring UI will help. • Max 200GB per executor. 15 San Jose, California JUNE 17–21, 2018
16 .General Hardware Guidelines … • Network • For Group-By, Reduce-By, and SQL join operations, network performance becomes important due to the Shuffles involved • 10 Gigabit network is the recommended choice • Local Disks • Spark uses local disks to store data that doesn’t fit in RAM, as well as to preserve intermediate output between stages • SSDs are recommended • Mount disks with noatime option to reduce unnecessary writes 16 San Jose, California JUNE 17–21, 2018
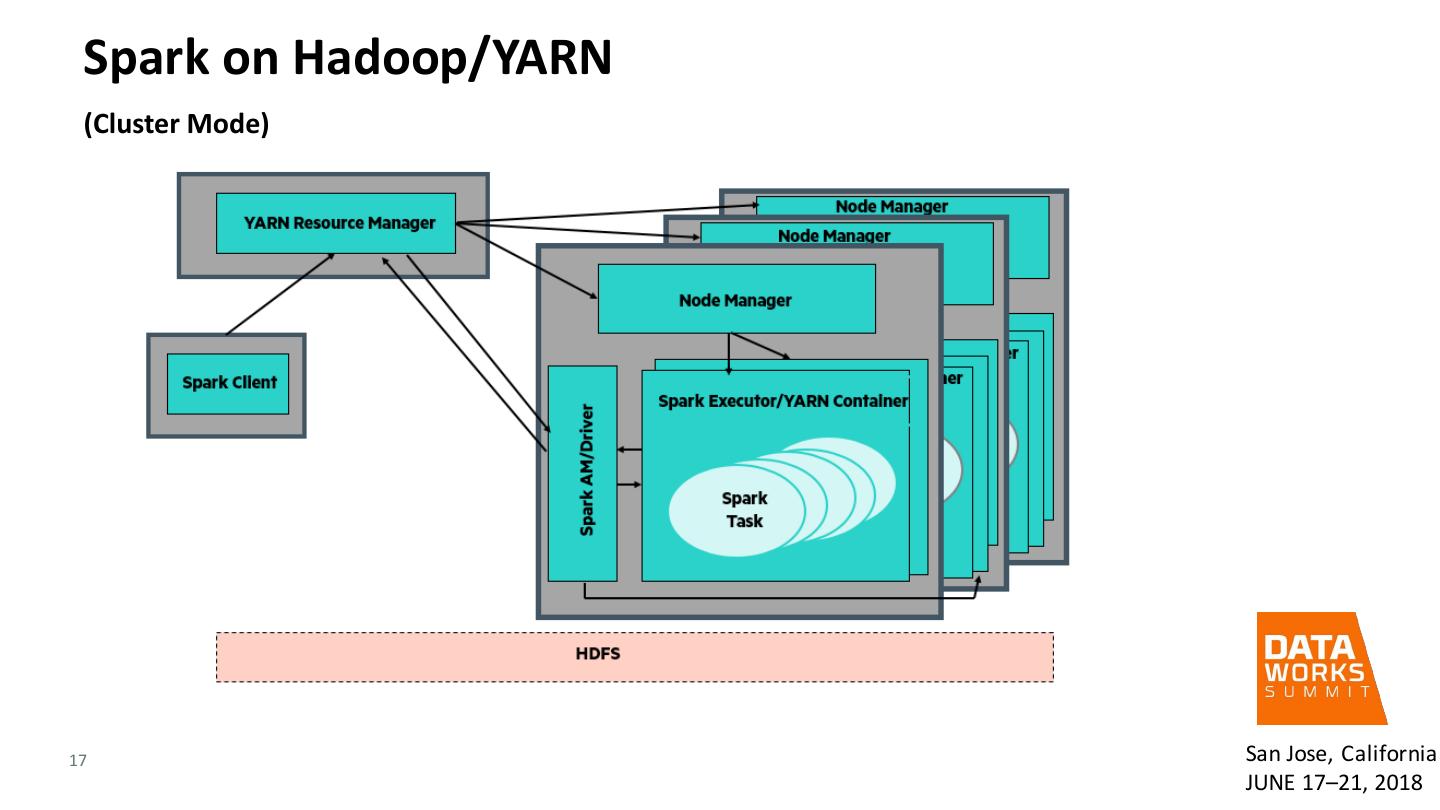
17 . Spark on Hadoop/YARN (Cluster Mode) 17 San Jose, California JUNE 17–21, 2018
18 .Useful HDFS configuration settings • Increase the dfs.blocksize value to allow more data to be processed by each map task • Also reduces NameNode memory consumption • dfs.blocksize 256/512MB • Increase the dfs.namenode.handler.count value to better manage multiple HDFS operations from multiple clients • dfs.namenode.handler.count 100 • To eliminate timeout exceptions (java.io.IOException: Unable to close file close file because the last block does not have enough number of replicas), 18 San Jose, California JUNE 17–21, 2018
19 . Useful YARN configuration settings • YARN is the popular cluster manager for Spark on Hadoop, so it is important that YARN and Spark configurations are tuned in tandem. • Settings of Spark executor memory and executor cores result in allocation requests to YARN with the same values and YARN should be configured to accommodate the desired Spark settings • Amount of physical memory that can be allocated for containers per node • yarn.nodemanager.resource.memory-mb 384 GiB • Amount of vcores available on a compute node that can be allocated for containers • yarn.nodemanager.resource.cpu-vcores 48 19 San Jose, California JUNE 17–21, 2018
20 . YARN tuning … • Number of YARN containers depends on the nature of the workload • Assuming total of 384 GiB on each node, a workload that needs 24 GiB containers will result in 16 total containers • Assuming 12 worker nodes, number of 24 GiB containers = 16 * 12 – 1 = 191 • One container per YARN application master • General guideline is to configure containers in a way that maximizes the utilization of the memory and vcores on each node in the cluster 20 San Jose, California JUNE 17–21, 2018
21 . YARN tuning … • Location of YARN intermediate files on the compute nodes • yarn.nodemanager.local-dirs /data1/hadoop/yarn/local, /data2/hadoop/yarn/local, /data3/hadoop/yarn/local, /data4/hadoop/yarn/local • Setting of spark.local.dir is ignored for YARN cluster mode • The node-locality-delay specifies how many scheduling intervals to let pass attempting to find a node local slot to run on prior to searching for a rack local slot • Important for small jobs that do not have a large number of tasks as it will better utilize the compute nodes • yarn.scheduler.capacity.node-locality-delay 1 21 San Jose, California JUNE 17–21, 2018
22 . Tuning Spark – Executor cores • Unlike Hadoop MapReduce where each map or reduce task is always started in a new process, Spark can efficiently use process threads (cores) to distribute task processing • Results in a need to tune Spark executors with respect to the amount of memory and number of cores each executor can use • Has to work within the configuration boundaries of YARN • Number of cores per executor can be controlled by • the configuration setting spark.executor.cores • the --executor-cores option of the spark-submit command • The default is 1 for Spark on YARN 22 San Jose, California JUNE 17–21, 2018
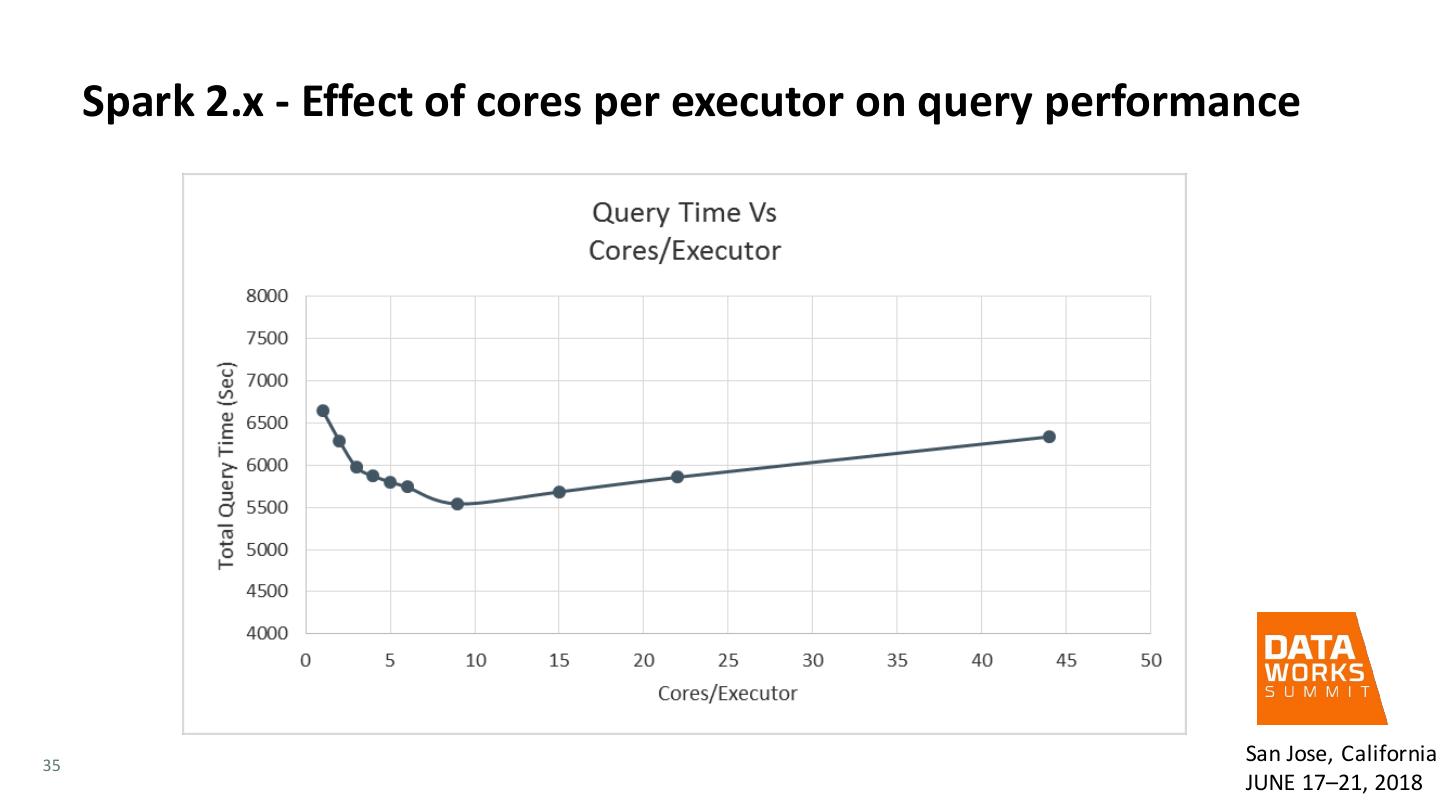
23 . Tuning Spark – Executor cores • Simplest but inefficient approach would be to configure one executor per core and divide the memory equally among the number of executors • Since each partition cannot be computed on more than one executor, the size of each partition is limited and causes memory problems, or spilling to disk for shuffles • If the executors have only one core, then at most one task can run in each executor, which throws away the benefits of broadcast variables, which have to be sent to each executor once. • Each executor has some memory overhead (minimum of 384MB) – so, if we have many small executors, results in lot of memory overhead • Giving many cores to each executor also has issues • GC issues - since a larger JVM heap will delay the time until a GC event is triggered resulting in larger GC pauses • Results in poor HDSF throughput issues because of handling many concurrent threads • spark.executor.cores – experiment and set this based on your workloads. We found 9 was was the right setting for this configuration and bench test in our lab. 23 San Jose, California JUNE 17–21, 2018
24 . Tuning Spark – Memory • Memory for each Spark job is application specific • Configure Executor memory in proportion to the number of partitions and cores per executor • Divide the total amount of memory on each node by the number of executors on the node • Should be less than the maximum YARN container size - so YARN maximum container size may need to be adjusted accordingly • Configuration setting spark.executor.memory or the --executor-memory option of the spark- submit command • JVM runs into issues with very large heaps (above 80GB). • Spark Driver memory • If driver collects too much data, the job may run into OOM errors. • Increase the driver memory using spark.driver.maxResultSize 24 San Jose, California JUNE 17–21, 2018
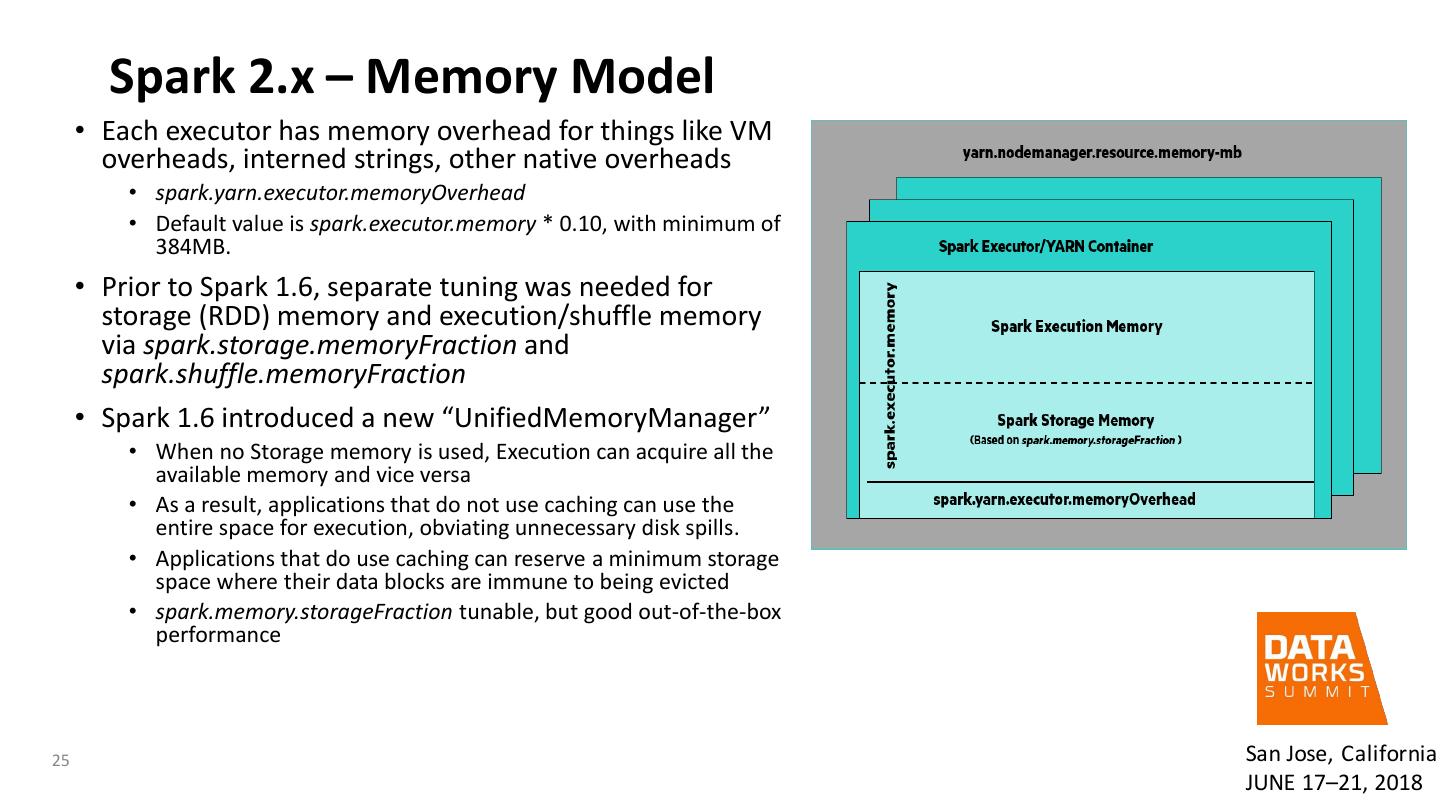
25 . Spark 2.x – Memory Model • Each executor has memory overhead for things like VM overheads, interned strings, other native overheads • spark.yarn.executor.memoryOverhead • Default value is spark.executor.memory * 0.10, with minimum of 384MB. • Prior to Spark 1.6, separate tuning was needed for storage (RDD) memory and execution/shuffle memory via spark.storage.memoryFraction and spark.shuffle.memoryFraction • Spark 1.6 introduced a new “UnifiedMemoryManager” • When no Storage memory is used, Execution can acquire all the available memory and vice versa • As a result, applications that do not use caching can use the entire space for execution, obviating unnecessary disk spills. • Applications that do use caching can reserve a minimum storage space where their data blocks are immune to being evicted • spark.memory.storageFraction tunable, but good out-of-the-box performance 25 San Jose, California JUNE 17–21, 2018
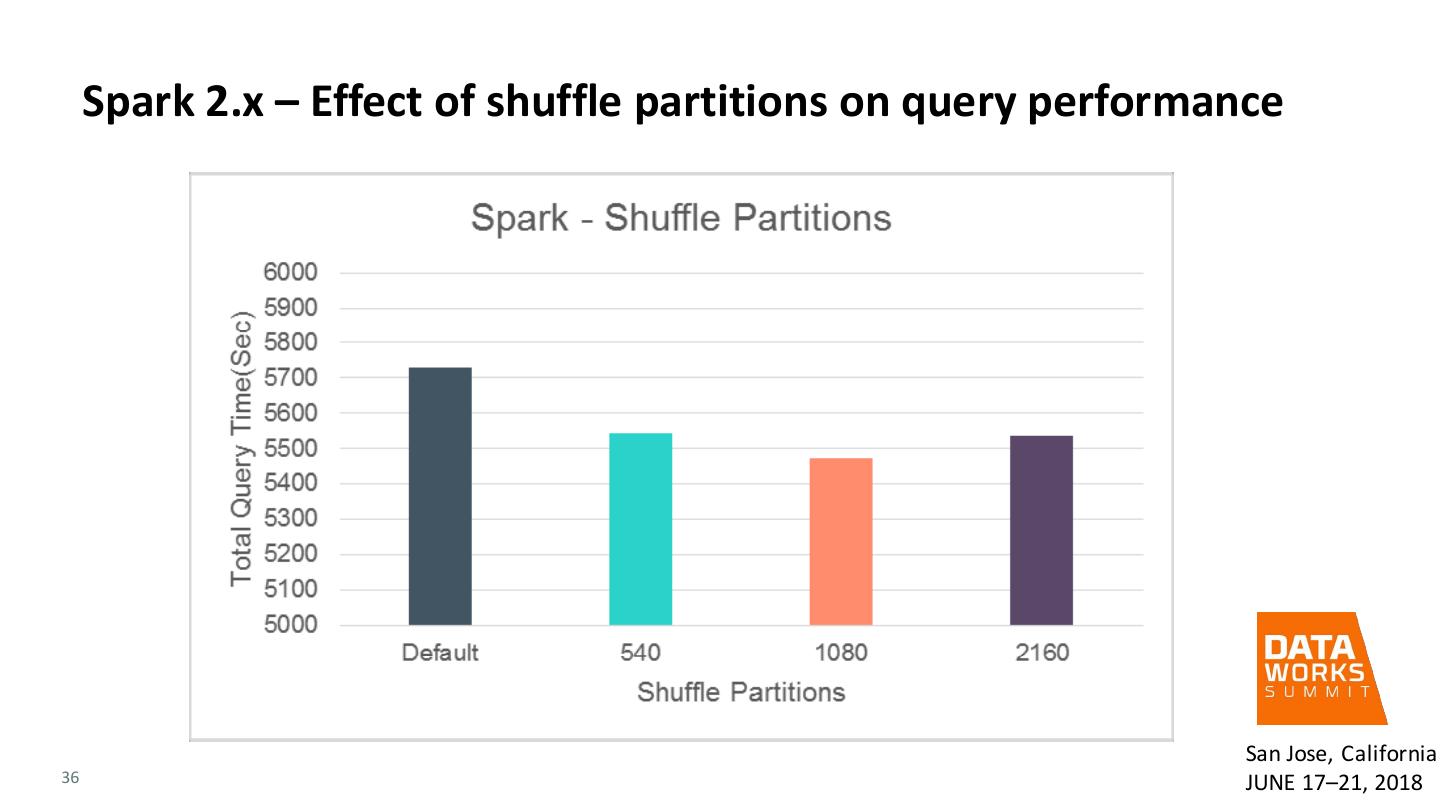
26 . Tuning Spark – Shuffle partitions • Spark SQL, by default, sets the number of reduce side partitions to 200 when doing a shuffle for wide transformations, e.g., groupByKey, reduceByKey, sortByKey etc. • Not optimal for many cases as it will use only 200 cores for processing tasks after the shuffle • For large datasets, this might result in shuffle block overflow resulting in job failures • The number of shuffle partitions should be at least equal to the number of total executor cores or a multiple of it in case of large data sets. • spark.sql.shuffle.partitions setting • Also – helps to partition in prime numbers in terms of hash effectiveness. 26 San Jose, California JUNE 17–21, 2018
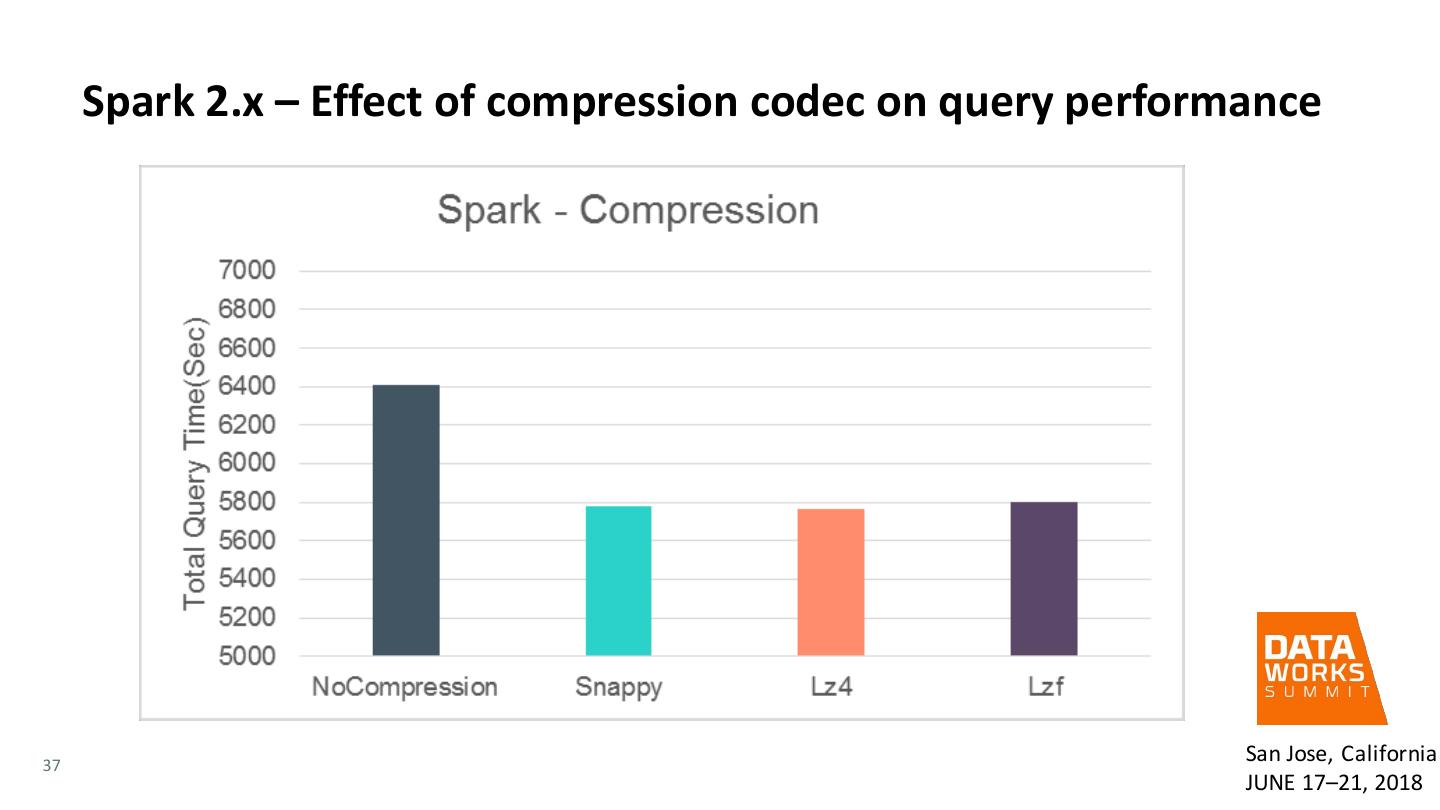
27 . Tuning Spark – Compression • Using compression in Spark can improve performance in a meaningful way as compression results in less disk I/O and network I/O • Even though compressing the data results in some CPU cycles being used, the performance improvements with compression outweigh the CPU overhead when a large amount of data is involved • Also compression results in reduced storage requirements for storing data on disk, e.g., intermediate shuffle files 27 San Jose, California JUNE 17–21, 2018
28 . Tuning Spark – Compression • spark.io.compression.codec setting to decide the codec • three codecs provided: lz4, lzf, and snappy • default codec is lz4 • Four main places where Spark makes use of compression • Compress map output files during a shuffle operation using spark.shuffle.compress setting (Default true) • Compress data spilled during shuffles using spark.shuffle.spill.compress setting (Default true) • Compress broadcast variables before sending them using spark.broadcast.compress setting (Default true) • Compress serialized RDD partitions using spark.rdd.compress setting (Default false) 28 San Jose, California JUNE 17–21, 2018
29 . Tuning Spark – Serialization type • Serialization plays an important role in the performance of any distributed application • Spark memory usage is greatly affected by storage level and serialization format • By default, Spark serializes objects using Java Serializer which can work with any class that implements java.io.Serializable interface • For custom data types, Kryo Serialization is more compact and efficient than Java Serialization • but user classes need to be explicitly registered with the Kryo Serializer • spark.serializer org.apache.spark.serializer.KryoSerializer • Spark SQL automatically uses Kryo serialization for DataFrames internally in Spark 2.x • For customer applications that still use RDDs, Kryo Serialization should result in a significant performance boost 29 San Jose, California JUNE 17–21, 2018
3秒后跳转登录页面
去登陆

