展开查看详情
1 .TuneIn: How to get your jobs tuned
while sleeping
Manoj Kumar Arpan Agrawal Pralabh Kumar
Senior Software Engineer Software Engineer Senior Software Engineer
LinkedIn LinkedIn LinkedIn
�
2 . OUR VISION
Create economic opportunity for every
member of the global workforce
2
�
3 . OUR MISSION
Connect the world’s professionals to make them
more productive and successful
3
�
4 .Agenda
• Why TuneIn?
• How does TuneIn work?
• Architecture and framework features
• Road ahead
4
�
5 .Grid Scale at LinkedIn
2008 2018
1 cluster 10+ clusters
20 nodes 1000s of nodes
5 users 1000s of active users
MapReduce Pig, Hive, Spark, etc.
Few workflows 10000s workflows
5
�
6 .Typical Conversations
Hey, this Spark I will tune it to
job is running improve the
slowly. run time.
Manager Developer
6
�
7 .Typical Conversations
We have found
some jobs which I will ask my team
are consuming to tune those jobs
high resources on to reduce the
the cluster. resource usage.
Hadoop Admin Manager
7
�
8 .Typical Conversations
Is there a way
we can get this I will try to tune
daily report 30 it to reduce the
minutes early? run time.
Client Developer
8
�
9 .Why Tuning?
• Optimal parameter configuration:
– leads to better cluster utilization and thus savings
– reduces the execution time
• Default configuration is not always optimal
9
�
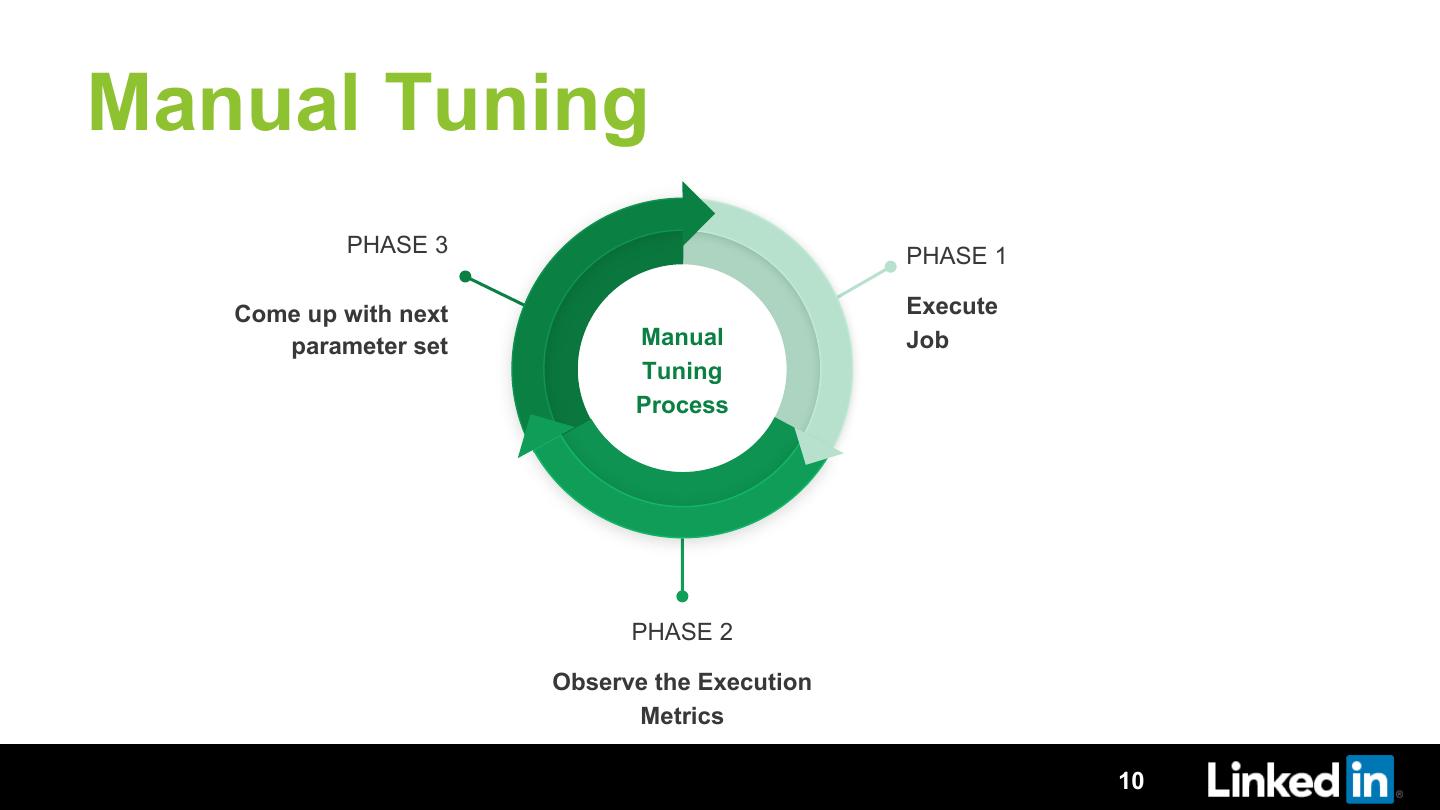
10 .Manual Tuning
PHASE 3 PHASE 1
Come up with next Execute
parameter set Manual Job
Tuning
Process
PHASE 2
Observe the Execution
Metrics
10
�
11 .Dr. Elephant: Heuristic based tuning
• Suggests tuning recommendations
PHASE 3 PHASE 1
based on pre-defined heuristics Come up with next Execute
parameter set Heuristics
Job
• No need to worry about the Based
Manual
hundreds of counters and Tuning
parameters
• Relies on user’s initiative to use the
recommendations
PHASE 2
• Expects some user expertise Look at the Dr. Elephant
recommendations
11
�
14 .Why Auto Tuning?
• 10000s of jobs to tune
• Increases developer productivity
• Tunes without any extra effort
• No expertise is expected
• Option of which objective function to tune for
– resource usage
– execution time etc.
14
�
15 .Let’s auto tune!
Photo: memecreator.org
15
�
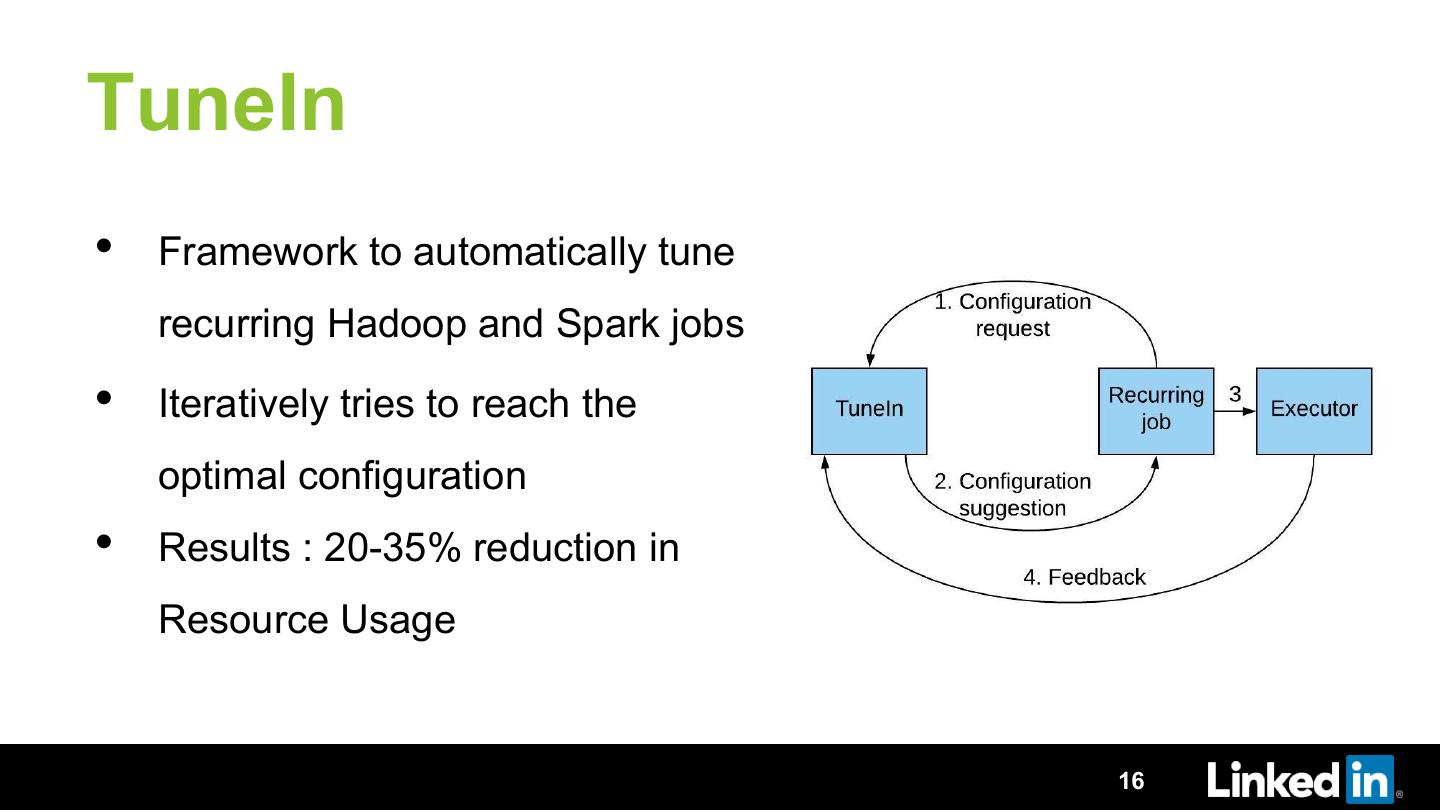
16 .TuneIn
• Framework to automatically tune
recurring Hadoop and Spark jobs
• Iteratively tries to reach the
optimal configuration
• Results : 20-35% reduction in
Resource Usage
16
�
17 .Particle Swarm Optimization (PSO) [1]
• Mimics the behavior of
swarm of birds searching food
• Starts optimization by
introducing particles at random
positions in the search space
Source: Wikipedia
Particle Swarm Optimization by J. Kennedy et al., https://ieeexplore.ieee.org/document/488968/
17
�
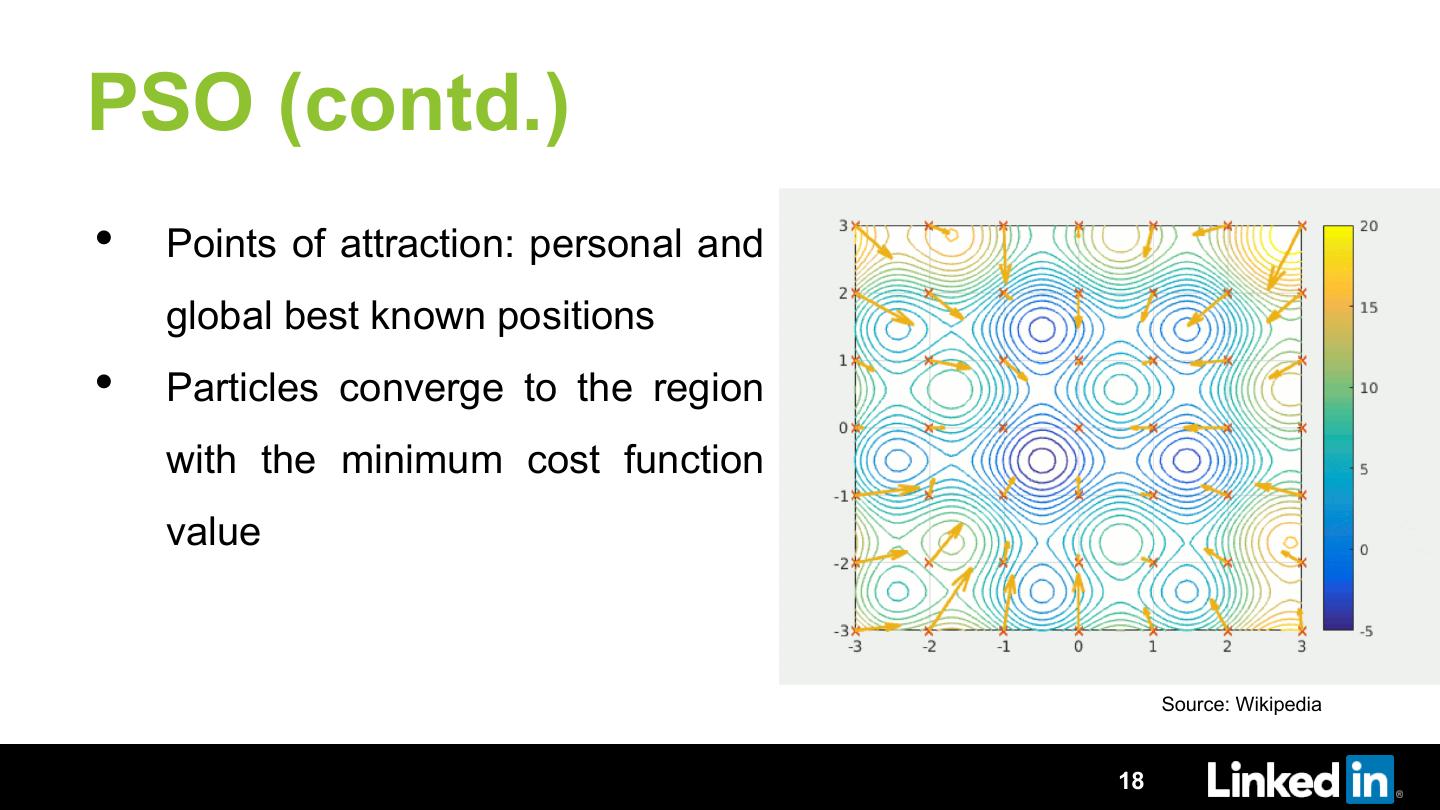
18 .PSO (contd.)
• Points of attraction: personal and
global best known positions
• Particles converge to the region
with the minimum cost function
value
Source: Wikipedia
18
�
19 .Why PSO?
• Cost function is noisy
– PSO is gradient free and robust against noise [3]
• Spark and Hadoop are complex systems
– PSO is a metaheuristic black box optimization algorithm
• Fastest convergence
K. E. Parsopoulos et al., “Particle Swarm Optimizer in Noisy and Continuously Changing Environments,” in Artificial Intelligence and Soft Computing
19
�
20 .PSO Details [2]
• Swarm size of 3 gives the best result
– neither too small to cover the search space
– nor too big to do many first iteration random searches
• Good starting point is important to guide the swarm
Optimizing Hadoop parameter settings with gene expression programming guided PSO by Mukhtaj Khan et al.
20
�
21 .Cost function
• Resource usage per unit input
∑"#$%&'$()* +,-./0-12 314,25 ∗ +,-./0-12 78.041
9,./: ;-8<. =0>1
• Approximately input size invariant
21
�
22 .Search Space
• Parameters being tuned constitutes Param 3
the search space
• Depends on the cost function metric
Param 2
Param 1
22
�
23 .Search Space
Cost function: Resource Usage
Pig Spark
mapreduce.map.memory.mb spark.executor.memory
mapreduce.reduce.memory.mb spark.executor.cores
mapreduce.task.io.sort.mb spark.memory.fraction
mapreduce.task.io.sort.factor spark.yarn.executor.memoryOverhead
23
�
24 .Search Space Reduction
• Important to prevent failures
• Speeds up convergence
• Boundary parameter values
– e.g. !"#$%. '(')*+,$. ),$'! ∈ 1, 10
• Parameter interdependent constraints
– Captures the interdependence among the parameters
– e.g. 1#"$'2*)'. +#!%. 3,. !,$+. 14 < 0.60 ∗ 1#"$'2*)'. 1#". 1'1,$8. 14
24
�
25 .Search Space Reduction
• Different jobs can have different optimal boundary values
• Boundary values are tightened on the basis of previous
job execution counters
25
�
26 . Avoiding over optimization
• Undesirable to squeeze memory
so much that execution time
shoots up significantly
• Updated cost function:
∑"#$%&'$()* +,-./0-12 314,25 ∗ +,-./0-12 78.041
+ @1-/:.5
9,./: ;-8<. =0>1
Photo: Ian Burt
26
�
27 .Convergence
• No theoretical bound on the steps to converge
• Practically converges in 20 job executions
• TuneIn gets turned off for the job automatically on convergence
27
�
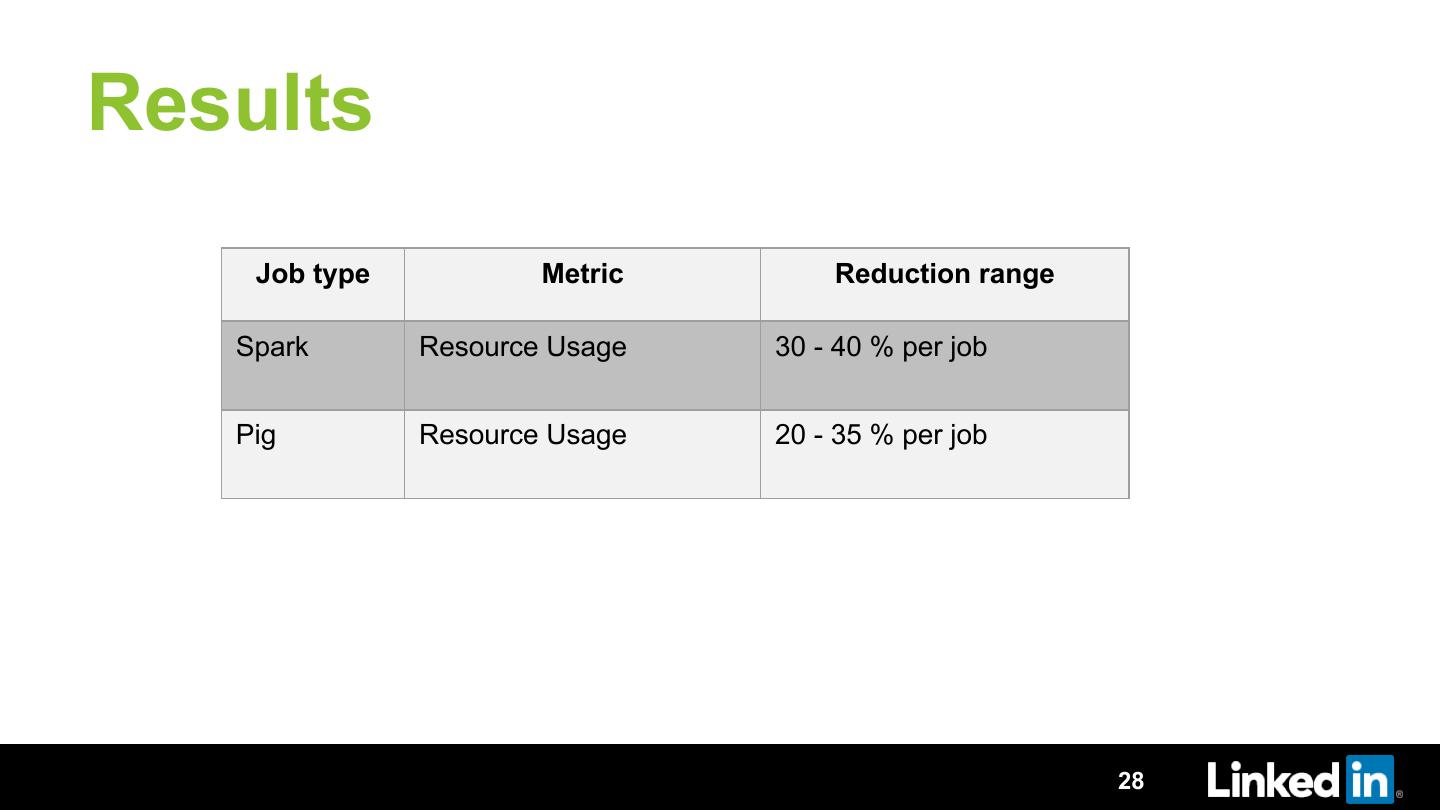
28 .Results
Job type Metric Reduction range
Spark Resource Usage 30 - 40 % per job
Pig Resource Usage 20 - 35 % per job
28
�
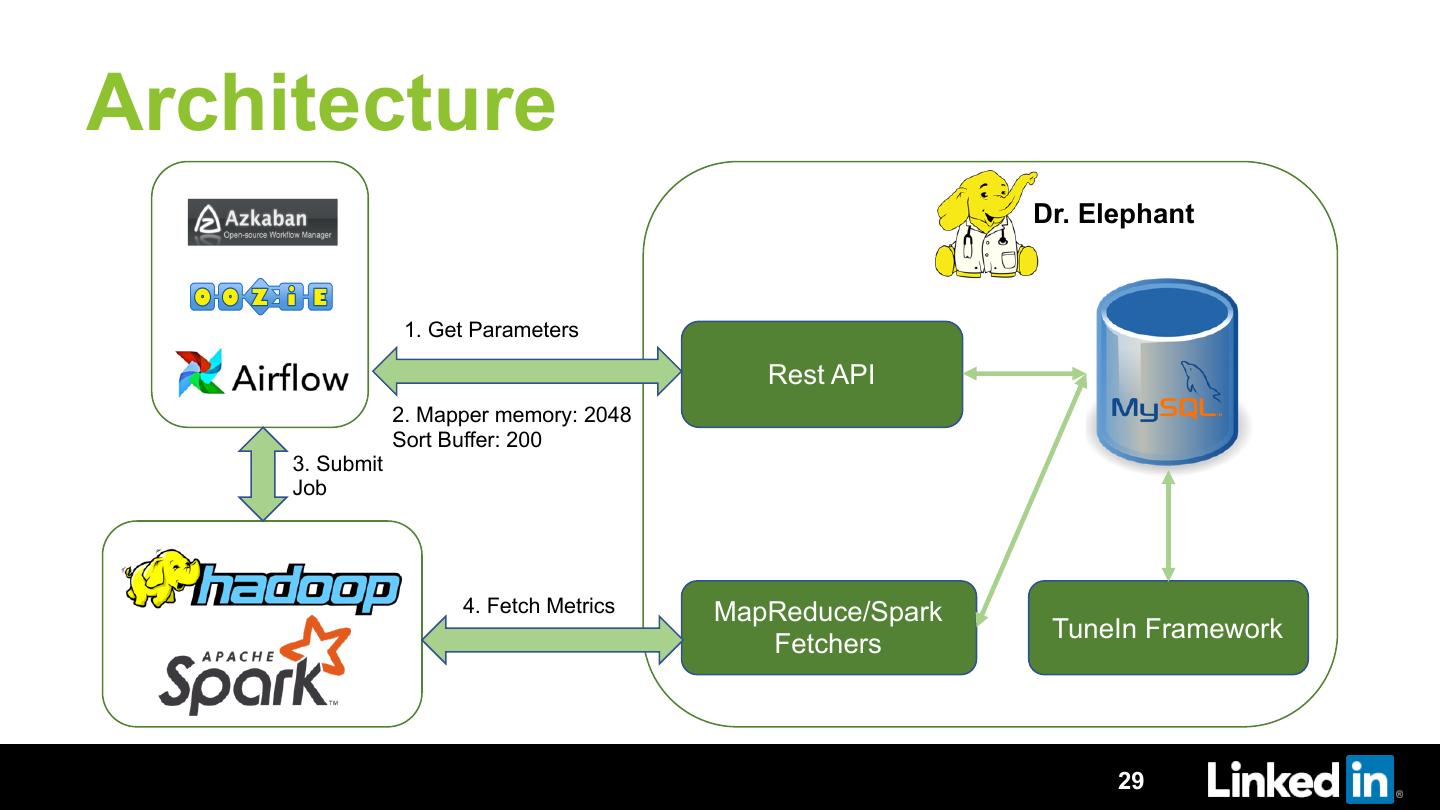
29 .Architecture
Dr. Elephant
1. Get Parameters
Rest API
2. Mapper memory: 2048
Sort Buffer: 200
3. Submit
Job
4. Fetch Metrics MapReduce/Spark
TuneIn Framework
Fetchers
29
�